IntConsumer, LongConsumer, DoubleConsumer
Начиная с Java 8, у нас есть встроенные потребительские интерфейсы для примитивных типов данных: IntConsumer, LongConsumer и DoubleConsumer.
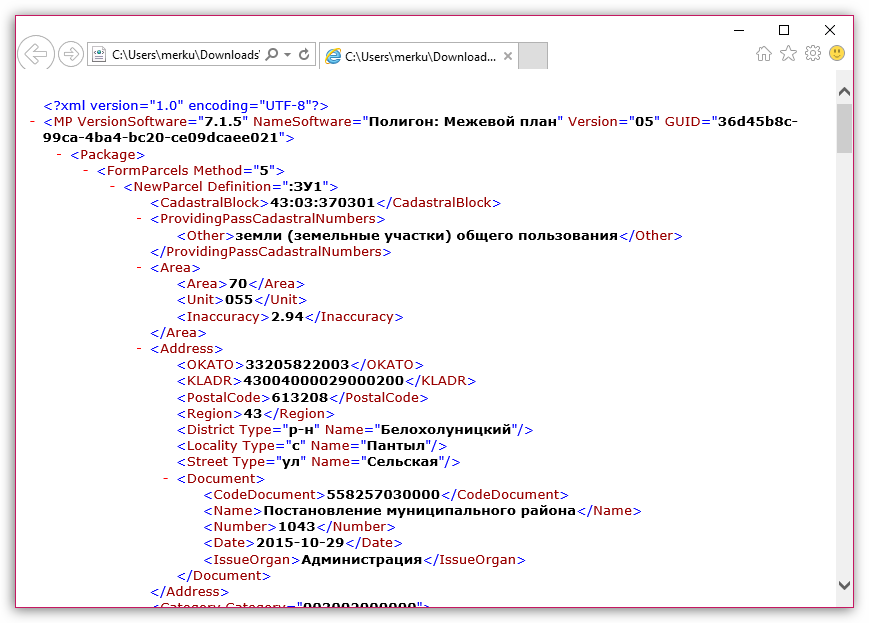
package com.zetcode;
import java.util.Arrays;
import java.util.function.DoubleConsumer;
import java.util.function.IntConsumer;
import java.util.function.LongConsumer;
public class JavaForEachConsSpec {
public static void main(String[] args) {
int[] inums = { 3, 5, 6, 7, 5 };
IntConsumer icons = i -> System.out.print(i + " ");
Arrays.stream(inums).forEach(icons);
System.out.println();
long[] lnums = { 13L, 3L, 6L, 1L, 8L };
LongConsumer lcons = l -> System.out.print(l + " ");
Arrays.stream(lnums).forEach(lcons);
System.out.println();
double[] dnums = { 3.4d, 9d, 6.8d, 10.3d, 2.3d };
DoubleConsumer dcons = d -> System.out.print(d + " ");
Arrays.stream(dnums).forEach(dcons);
System.out.println();
}
}
В этом примере мы создаем три типа потребителей и перебираем их с помощью forEach().
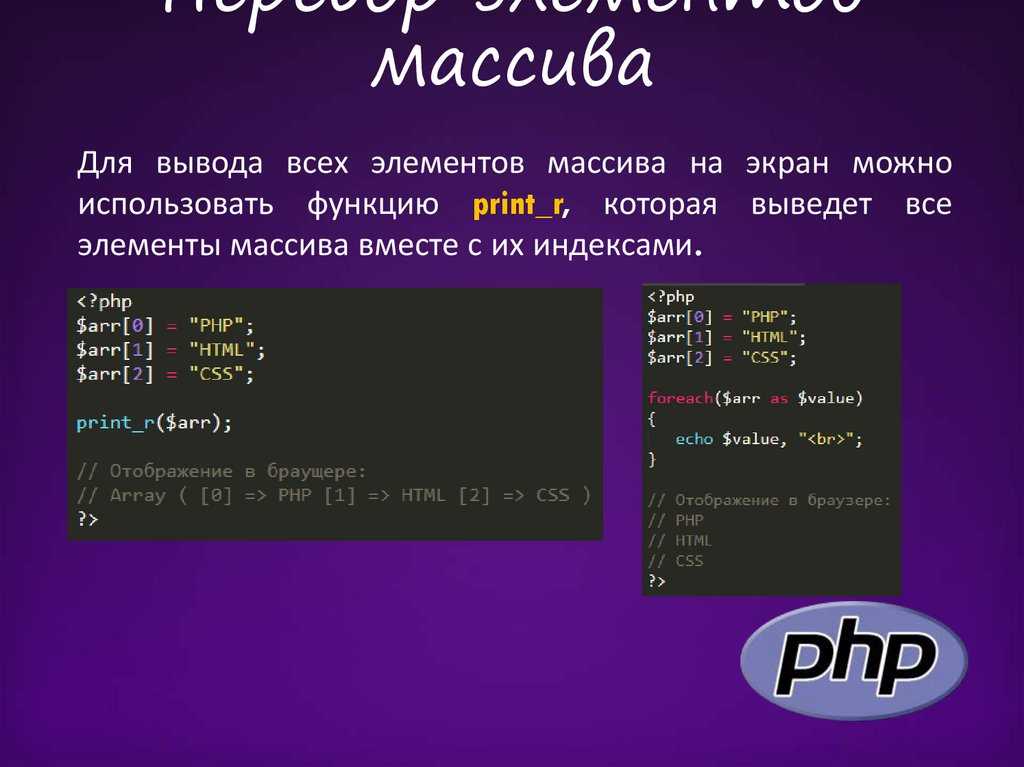
Обычный способ зациклить карту.
Map<String, Integer> items = new HashMap<>();
items.put("A", 10);
items.put("B", 20);
items.put("C", 30);
items.put("D", 40);
items.put("E", 50);
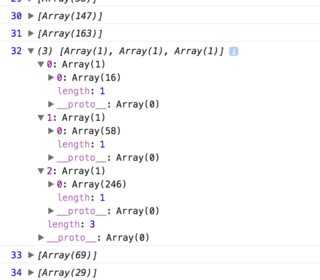
items.put("F", 60);
for (Map.Entry<String, Integer> entry : items.entrySet()) {
System.out.println("Item : " + entry.getKey() + " Count : " + entry.getValue());
}
В Java 8 Вы можете зациклить карту с помощью forEach + лямбда-выражения.
Map<String, Integer> items = new HashMap<>();
items.put("A", 10);
items.put("B", 20);
items.put("C", 30);
items.put("D", 40);
items.put("E", 50);
items.put("F", 60);
items.forEach((k,v)->System.out.println("Item : " + k + " Count : " + v));
items.forEach((k,v)->{
System.out.println("Item : " + k + " Count : " + v);
if("E".equals(k)){
System.out.println("Hello E");
}
});
Нормальный цикл for в цикле список.
List items = new ArrayList<>();
items.add("A");
items.add("B");
items.add("C");
items.add("D");
items.add("E");
for(String item : items){
System.out.println(item);
}
В Java 8 вы можете зациклить список с помощью forEach + лямбда-выражения или ссылки на метод.
List items = new ArrayList<>();
items.add("A");
items.add("B");
items.add("C");
items.add("D");
items.add("E");
//lambda
//Output : A,B,C,D,E
items.forEach(item->System.out.println(item));
//Output : C
items.forEach(item->{
if("C".equals(item)){
System.out.println(item);
}
});
//method reference
//Output : A,B,C,D,E
items.forEach(System.out::println);
//Stream and filter
//Output : B
items.stream()
.filter(s->s.contains("B"))
.forEach(System.out::println);
Оцени статью
Оценить
Средняя оценка / 5. Количество голосов:
Видим, что вы не нашли ответ на свой вопрос.
Помогите улучшить статью.
Спасибо за ваши отзыв!
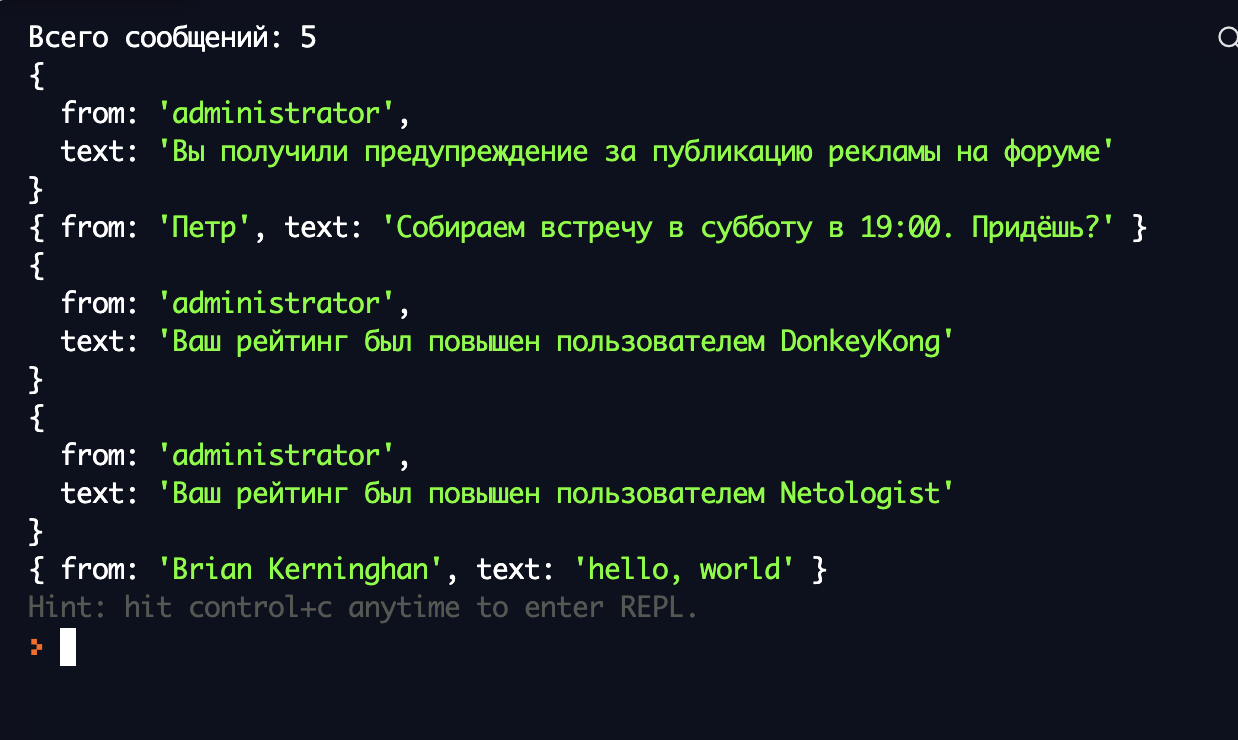
Цикл foreach и не массивы
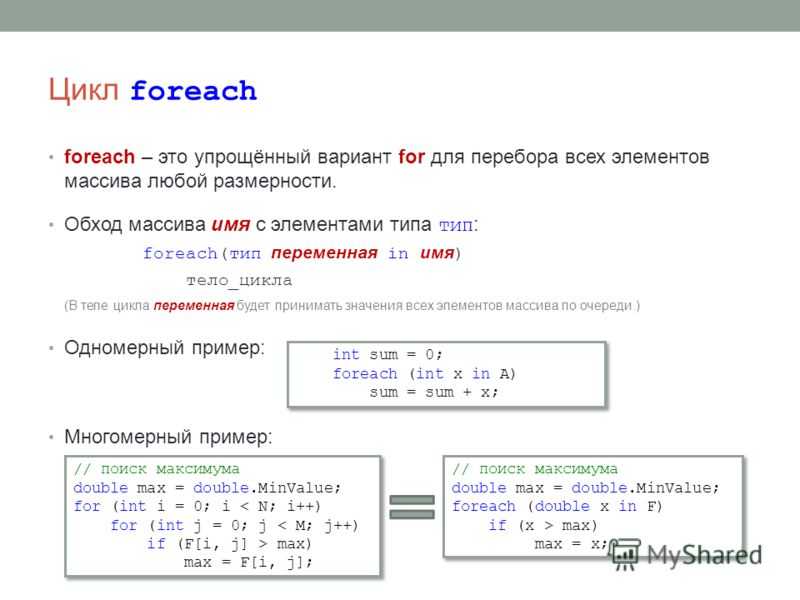
Циклы foreach работают не только с фиксированными массивами, но также и со многими другими структурами типа списка такими, как векторы (например, std::vector), связанные списки, деревья. Не беспокойтесь, если вы не знаете, что это такое (мы всё это рассмотрим чуть позже). Просто помните, что циклы foreach обеспечивают гибкий и удобный способ итерации не только по массивам:
#include
#include
int main()
{
std::vector math = { 0, 1, 4, 5, 7, 8, 10, 12, 15, 17, 30, 41}; // обратите внимание здесь на использование std::vector вместо фиксированного массива
for (const auto &number : math)
std::cout
1
2
3
4
5
6
7
8
9
10
11
#include
#include
intmain()
{
std::vectormath={,1,4,5,7,8,10,12,15,17,30,41};// обратите внимание здесь на использование std::vector вместо фиксированного массива
for(constauto&numbermath)
std::cout
5 последних уроков рубрики «PHP»
Когда речь идёт о безопасности веб-сайта, то фраза «фильтруйте всё, экранируйте всё» всегда будет актуальна. Сегодня поговорим о фильтрации данных.
Обеспечение безопасности веб-сайта — это не только защита от SQL инъекций, но и протекция от межсайтового скриптинга (XSS), межсайтовой подделки запросов (CSRF) и от других видов атак
В частности, вам нужно очень осторожно подходить к формированию HTML, CSS и JavaScript кода.
Expressive 2 поддерживает возможность подключения других ZF компонент по специальной схеме. Не всем нравится данное решение
В этой статье мы расскажем как улучшили процесс подключение нескольких модулей.
Предположим, что вам необходимо отправить какую-то информацию в Google Analytics из серверного скрипта. Как это сделать. Ответ в этой заметке.
Подборка PHP песочниц
Подборка из нескольких видов PHP песочниц. На некоторых вы в режиме online сможете потестить свой код, но есть так же решения, которые можно внедрить на свой сайт.
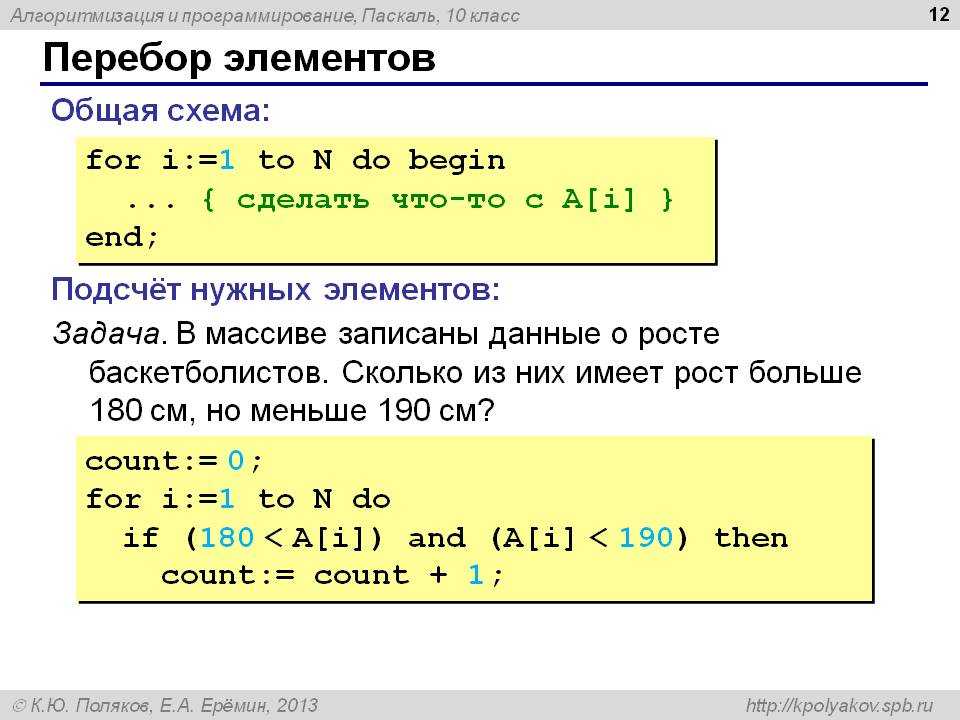
Цикл по значениям элементов
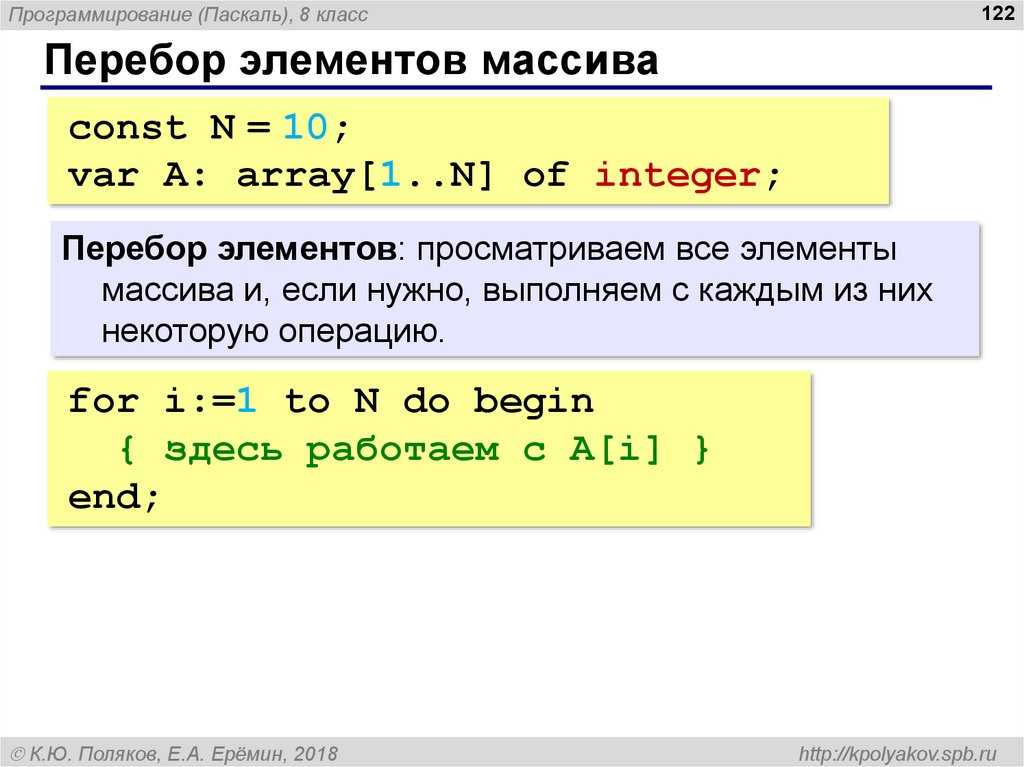
Самый простой случай использования — это организация цикла по значениям в индексированном массиве. Основной синтаксис :
foreach ( $array as $value ) {
// Делаем что-нибудь с $value
}
// Здесь код выполняется после завершения цикла
Например, следующий скрипт проходит по списку режисеров в индексированном массиве и выводит имя каждого:
$directors = array( "Alfred Hitchcock", "Stanley Kubrick", "Martin Scorsese", "Fritz Lang" );
foreach ( $directors as $director ) {
echo $director . "<br />";
}
Выше приведенный код выведет:
Alfred Hitchcock Stanley Kubrick Martin Scorsese Fritz Lang
Powershell — Циклы for и foreach
Начнем с цикла foreach. Цикл foreach позволяет перебирать значения, которые находятся в массиве без условий. Единственное условие на словах выглядит так: выполнить действие для каждого элемента массива.
Весьма просто не так ли? Давайте попробуем написать ваш первый foreach. Создать массив целых чисел и прибавим к каждому из них по единице. Безусловно можно воспользоваться оператором сложения. Но как быть в случае, когда массив динамически формируется при каждом прогоне скрипта? Давайте используем foreach:
$numbers = 1, 2, 103
foreach ($number in $numbers) {
$number + 1
}
2
3
104
|
1 |
array$numbers=1,2,103 foreach($number in$numbers){ $number+1 } |
Давайте разбираться, как это работает все то, что написано после foreach. Первым делом мы объявляем уникальную переменную $number для каждого числа из массива $numbers
Ее можно назвать как угодно, но важно понимать, что в дальнейшем действия арифметические или логические происходят именно для этой переменной. Дальше это показано наглядно
К числу, которое находится в переменной $number, инструкция цикла прибавляет единицу.
Другими словами, если бы мы перебирали элементы массива вручную, то нам бы пришлось делать так:
$numbers + 1
$numbers + 1
$numbers + 1
|
1 |
$numbers+1 $numbers1+1 $numbers2+1 |
Цикл foreach сделал это за нас, занося при каждой итерации следующий элемент массива в переменную $number. Если постараться объяснить еще проще, то выглядит это примерно так:
foreach ($number in $numbers) { #Первая итерация
$numbers + 1
}
foreach ($number in $numbers) { #Вторая итерация
$numbers + 1
}
foreach ($number in $numbers) { #Третья итерация
$numbers + 1
}
|
1 |
foreach($number in$numbers){#Первая итерация $numbers+1 } foreach($number in$numbers){#Вторая итерация $numbers1+1 } foreach($number in$numbers){#Третья итерация $numbers2+1 } |
Думаю с циклом foreach мы разобрались. Парочка примеров, что можно делать с помощью него.
-
Получить содержимое файлов:
$files = (Get-ChildItem «D:\Powershell\текст*»)
foreach ($file in $files) {
Get-Content $file
}
стопицот
двестипяцот
СТОПИСЯТ1
2
3
4
5
6
7
8Array$files=(Get-ChildItem»D:\Powershell\текст*»)
foreach($file in$files){
Get-Content$file
}
стопицот
двестипяцот
СТОПИСЯТ -
Перебрать сервера и проделать ряд операций по копированию файлов извне:
PowerShell
param($Servers, $Source, $Target)
$ServerNames = $Servers
foreach ($serverName in $ServerNames)
{
$TargetPath = «\\$serverName\$Target»
Copy-Item $Source $TargetPath -Recurse -Force
}1
2
3
4
5
6
7
8
9param(String$Servers,String$Source,string$Target)
$ServerNames=$Servers
foreach($serverNamein$ServerNames)
{
$TargetPath=»\\$serverName\$Target»
Copy-Item$Source$TargetPath-Recurse-Force
}
Теперь переходим к циклу for. Он немного сложнее в освоении, но достаточно один раз понять, как правильно его написать, и каждый последующий раз будет даваться легко. Используем тот же массив из чисел. Конструкция цикла for в powershell отличается от foreach и выглядит так:
for ($i=0; $i -lt $numbers.Length; $i++) {
$numbers+10;
}
|
1 |
for($i=;$i-lt$numbers.Length;$i++){ $numbers$i+10; } |
Теперь по порядку. В скобках указана конструкция в которой обозначены: объект; условие; действие. В нашем случае объект — это переменная $i равная нулю. Условие — переменная $i меньше длины массива $numbers. Действие — инкрементировать переменную $i (простыми словами в данном контексте увеличить на 1).
В самом теле цикла мы обращаемся к элементам массива по индексу. Индекс в первой итерации равен нулю потому, что мы используем переменную $i для работы с массивом. Соответственно в каждой итерации индекс становится больше на единицу.
Еще один пример
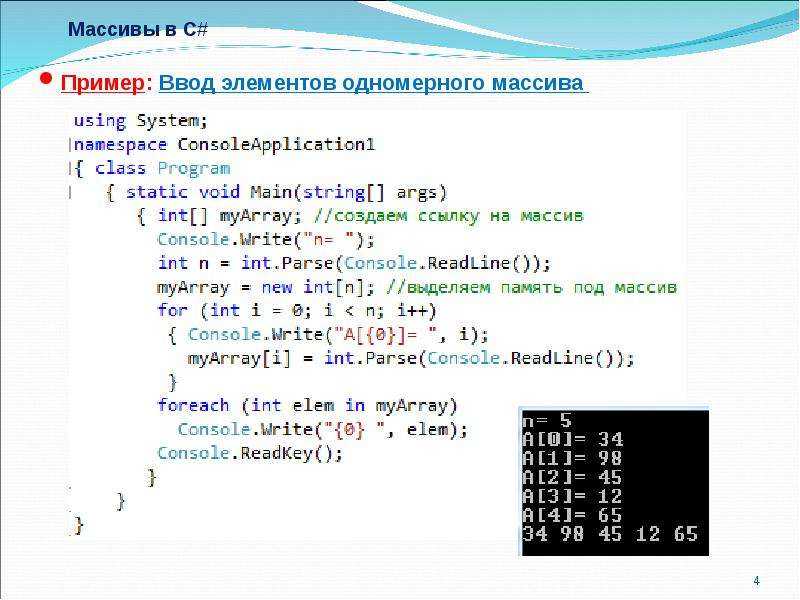
Вот пример первой программы из начала этого урока, но уже с использованием цикла foreach:
#include <iostream>
int main()
{
const int numStudents = 7;
int scores = { 45, 87, 55, 68, 80, 90, 58};
int maxScore = 0; // отслеживаем индекс наибольшего score (значения)
for (const auto &score: scores) // итерация по массиву, присваиваем каждое значение массива поочередно переменной score
if (score > maxScore)
maxScore = score;
std::cout << «The best score was » << maxScore << ‘\n’;
return 0;
}
|
1 |
#include <iostream> intmain() { constintnumStudents=7; intscoresnumStudents={45,87,55,68,80,90,58}; intmaxScore=;// отслеживаем индекс наибольшего score (значения) for(constauto&scorescores)// итерация по массиву, присваиваем каждое значение массива поочередно переменной score if(score>maxScore) maxScore=score; std::cout<<«The best score was «<<maxScore<<‘\n’; return; } |
Обратите внимание, здесь нам уже не нужно вручную прописывать индексацию массива. Мы можем получить доступ к каждому элементу массива непосредственно через переменную
Parallel LINQ (PLINQ)
Пожалуй, самой высокоуровневой абстракцией параллельных вычислений является возможность объявить: «Я хочу, чтобы этот фрагмент кода выполнялся параллельно», — и переложить все хлопоты на используемый фреймворк. Именно это позволяет фреймворк Parallel LINQ. Но сначала вспомним, что такое LINQ.






LINQ (Language Integrated Query — язык интегрированных запросов) — это фреймворк и набор расширений языка, появившийся в версии C# 3.0 и .NET 3.5, стирающий грань между императивным и декларативным программированием там, где требуется выполнять итерации через данные. Например, следующий запрос LINQ извлекает из источника customers — который может быть обычной коллекцией в памяти, таблицей в базе данных или иметь более экзотическое происхождение — имена и возраст клиентов, проживающих в Москве, сделавших не менее трех покупок на сумму более 100 руб. за последние десять месяцев, и выводит эти данные в консоль:
Первое, на что следует обратить внимание, — большая часть запроса определена декларативно, подобно запросу на языке SQL. Здесь не используются циклы для фильтрации объектов или группировки объектов из разных источников
Часто вам не придется даже волноваться о синхронизации итераций, выполняемых запросом, потому что запросы LINQ являются исключительно функциональными и не имеют побочных эффектов — они преобразуют одну коллекцию (IEnumerable) в другую, не изменяя никакие объекты в процессе работы.
Чтобы распараллелить запрос, представленный выше, достаточно лишь изменить тип коллекции источника с обобщенного IEnumerable<T> на ParallelQuery<T>. Для этого можно воспользоваться методом AsParallel() расширения и получить в результате следующий элегантный код:
Параллельная обработка запросов выполняется фреймворком PLINQ в три этапа, как показано на рисунке ниже. Сначала PLINQ решает, сколько потоков следует использовать для выполнения запроса. Затем рабочие потоки извлекают свои фрагменты их исходной коллекции, под защитой блокировок. Все потоки выполняют свои задания независимо и помещают результаты в свои локальные очереди. В заключение, локальные результаты объединяются в единую коллекцию, которая подается в цикл foreach, в примере выше.
![]()
Серые прямоугольники представляют результаты завершенных заданий, помещенные в локальные очереди потоков, откуда они последовательно перемещаются в общий выходной буфер, доступный вызывающей программе. Заштрихованные прямоугольники представляют задания, выполняющиеся в данный момент.
Главное преимущество PLINQ перед методом Parallel.ForEach() заключается в автоматическом объединении результатов, полученных разными потоками. В примере поиска простых чисел с использованием Parallel.ForEach)_ мы были вынуждены вручную добавлять результаты работы каждого потока в глобальную коллекцию. При этом необходимо было использовать механизм синхронизации и тем самым увеличивать накладные расходы. Тот же результат легко можно получить с помощью PLINQ:
Настройка параллельных циклов и PLINQ
Параллельные циклы (Parallel.For и Parallel.ForEach) и PLINQ поддерживают несколько методов для выполнения настройки, которые делают эти инструменты чрезвычайно гибкими и близкими в богатстве и выразительности к механизму параллельных задач, обсуждавшемуся выше. Методы параллельных циклов принимают объект ParallelOptions с различными свойствами, определяющими дополнительные параметры, а фреймворк PLINQ — дополнительные методы объектов ParallelQuery<T>. В число настраиваемых параметров входят:
-
ограничение степени параллелизма (максимально возможное количество задач, выполняемых параллельно);
-
передача признака отмены для остановки параллельных задач;
-
принудительное определение порядка получения результатов параллельных запросов;
-
управление буферизацией вывода (режимом слияния) результатов параллельных запросов.
При использовании параллельных циклов чаще всего ограничивают максимально возможное количество задач, выполняемых одновременно, тогда как при использовании PLINQ обычно настраивают режим слияния результатов и порядок их вывода.
Поиск в массиве
Далее рассмотрим методы, которые помогут найти что-нибудь в массиве.
Методы arr.indexOf, arr.lastIndexOf и arr.includes имеют одинаковый синтаксис и делают по сути то же самое, что и их строковые аналоги, но работают с элементами вместо символов:
- ищет , начиная с индекса , и возвращает индекс, на котором был найден искомый элемент, в противном случае .
- – то же самое, но ищет справа налево.
- – ищет , начиная с индекса , и возвращает , если поиск успешен.
Например:
Обратите внимание, что методы используют строгое сравнение. Таким образом, если мы ищем , он находит именно , а не ноль
Если мы хотим проверить наличие элемента, и нет необходимости знать его точный индекс, тогда предпочтительным является .
Кроме того, очень незначительным отличием является то, что он правильно обрабатывает в отличие от :
Представьте, что у нас есть массив объектов. Как нам найти объект с определённым условием?
Здесь пригодится метод arr.find.
Его синтаксис таков:
Функция вызывается по очереди для каждого элемента массива:
- – очередной элемент.
- – его индекс.
- – сам массив.
Если функция возвращает , поиск прерывается и возвращается . Если ничего не найдено, возвращается .
Например, у нас есть массив пользователей, каждый из которых имеет поля и . Попробуем найти того, кто с :
В реальной жизни массивы объектов – обычное дело, поэтому метод крайне полезен.
Обратите внимание, что в данном примере мы передаём функцию , с одним аргументом. Это типично, дополнительные аргументы этой функции используются редко
Метод arr.findIndex – по сути, то же самое, но возвращает индекс, на котором был найден элемент, а не сам элемент, и , если ничего не найдено.
Метод ищет один (первый попавшийся) элемент, на котором функция-колбэк вернёт .
На тот случай, если найденных элементов может быть много, предусмотрен метод arr.filter(fn).
Синтаксис этого метода схож с , но возвращает массив из всех подходящих элементов:
Например:
Для чего используется цикл foreach PHP?
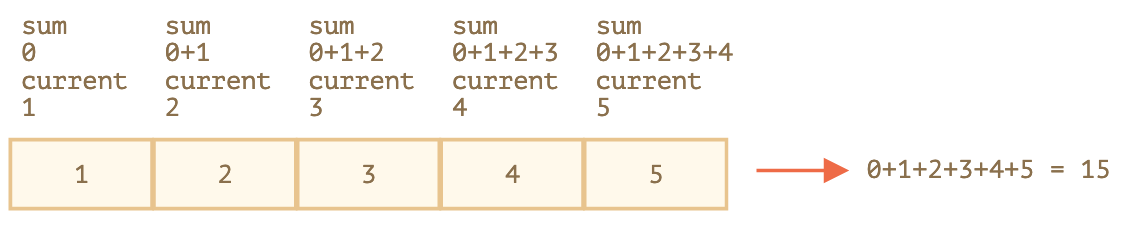
Цикл foreach PHP используется для работы с массивом. Он перебирает каждый его элемент.
Также можно использовать для работы с массивами цикл for. Например, используя свойство length, чтобы получить длину массива, а затем применить его в качестве оператора max. Но foreach делает это проще, так как он предназначен для работы с массивами.
Если вы работаете с MySQL, то для этого данный цикл подходит еще больше. Например, можно выбрать несколько строк из таблицы БД и передать их в массив. После этого, используя цикл foreach, перебрать все элементы массива с выполнением какого-либо действия.
Обратите внимание, что можно использовать цикл foreach с массивом или только с объектом
Дополнительные шаблоны в TPL
До сих пор мы рассматривали довольно простые примеры алгоритмов, легко поддающихся распараллеливанию. В этом разделе мы коротко исследуем несколько дополнительных приемов, которые могут пригодиться вам при решении настоящих проблем; в некоторых случаях мы можем обеспечить прирост производительности в самых неожиданных местах.
Первым приемом оптимизации, который может использоваться при распараллеливании циклов с общим состоянием, является агрегирование (иногда называется сверткой (reduction)). Когда в параллельном цикле используется общее состояние, масштабируемость часто утрачивается из-за необходимости синхронизировать доступ к общим данным; чем больше ядер в процессоре оказывается доступно, тем меньше выигрыш из-за синхронизации (этот эффект является прямым следствием закона Амдала (Amdahl Law), который часто называют законом убывающей отдачи (The Law of Diminishing Returns)). Значительный прирост производительности часто достигается за счет создания локальных состояний потоков или задач, выполняющих параллельные итерации цикла, и их объединения в конце. Методы из библиотеки TPL, используемые для организации циклов, имеют перегруженные версии, обслуживающие такого рода локальные агрегаты.
Вернемся к примеру поиска простых чисел, реализованному ранее в одной из статей. Одной из основных помех масштабированию в нем является необходимость добавления новых обнаруженных простых чисел в совместно используемый список, для чего требуется использовать механизм синхронизации. Вместо этого мы можем использовать в каждом потоке свой, локальный список и объединить их по завершении цикла:
В примере выше количество попыток приобрести блокировку значительно меньше, чем в предыдущих примерах — блокировку требуется приобрести лишь один раз для каждого потока, а не для каждого найденного простого числа. Мы добавили накладные расходы на объединение списков, но эта цена незначительна, в сравнении с увеличившейся масштабируемостью.
Еще одно место, где можно применить оптимизацию, — итерации цикла, слишком короткие, чтобы их эффективно можно было распараллелить. Даже при том, что механизм параллелизма данных объединяет несколько итераций иногда тело цикла может выполняться настолько быстро, по скорости превосходят вызов делегата, необходимый для вызова тела цикла в каждой итерации. В этом случае можно использовать класс Partitioner и с его помощью вручную группировать итерации, уменьшая количество вызовов делегатов:


За дополнительной информацией о разбиении циклов на фрагменты, являющемся важным способом оптимизации, обращайтесь к статье «Пользовательские разделители для PLINQ и TPL» на сайте MSDN.
Наконец, существуют приложения, в которых могут пригодиться собственные планировщики задач. В качестве примеров можно привести планирование заданий в потоке управления пользовательским интерфейсом, назначение приоритетов задачам, планируя их с помощью высокоприоритетного планировщика, и связывание задач с определенным процессором, планируя их с помощью планировщика, использующего потоки, привязанные к определенному процессору. Реализовать собственные планировщики можно путем наследования класса TaskScheduler. Пример такой реализации можно найти в статье «Практическое руководство. Создание планировщика заданий, ограничивающего степень параллелизма» на сайте MSDN.
Description
calls a provided function once
for each element in an array in ascending index order. It is not invoked for index properties
that have been deleted or are uninitialized. (For sparse arrays, .)
is invoked with three arguments:
- the value of the element
- the index of the element
- the Array object being traversed
If a parameter is provided to ,
it will be used as callback’s value. The
value ultimately observable by
is determined according to the usual rules for
determining the seen by a function.
The range of elements processed by is set before the first
invocation of . Elements which are assigned to indexes
already visited, or to indexes outside the range, will not be visited by
. If existing elements of the array are changed or
deleted, their value as passed to will be the value at
the time visits them; elements that are deleted before being
visited are not visited. If elements that are already visited are removed (e.g. using
) during the iteration, later elements
will be skipped. (.)
Warning: Concurrent modification of the kind described in the previous paragraph frequently leads to hard-to-understand code and is generally to be avoided (except in special cases).
executes the function once for
each array element; unlike or
it always returns the value
and is not chainable. The typical use case is to execute side
effects at the end of a chain.
does not mutate the array on which it is called. (However,
may do so)
Note: There is no way to stop or break a loop other than by throwing
an exception. If you need such behavior, the method is the
wrong tool.
Early termination may be accomplished with:
-
A simple for
loop -
A for…of
/ for…in
loops
Array methods: ,
, , and test the
array elements with a predicate returning a truthy value to determine if further
iteration is required.
Note: expects a synchronous function.
does not wait for promises. Make sure you are aware of the
implications while using promises (or async functions) as callback.
Примеры
Примечание: Для отображения содержимого массива в консоли вы можете использовать , который выводит отформатированную версию массива.
Следующий пример иллюстрирует альтернативный подход, использующий .
Следующий код выводит каждый элемент массива на новой строке журнала:
Следующий (надуманный) пример обновляет свойства объекта, когда перебирает записи массива:
Поскольку в передан параметр (), он затем передаётся в при каждом вызове. И callback использует его в качестве собственного значения .
Примечание: Если при передаче callback функции используется , параметр может быть опущен, так как все стрелочные функции лексически привязываются к значению.
Следующий код использует для логирования содержимого массива и останавливается при превышении значением заданного порогового значения .
Следующий код создаёт копию переданного объекта. Существует несколько способов создания копии объекта, и это один из них. Он позволяет понять, каким образом работает , используя функции мета-свойств из ECMAScript 5.
В следующем примере в лог выводится , , .
При достижении записи, содержащей значение , первая запись всего массива удаляется, в результате чего все оставшиеся записи перемещаются на одну позицию вверх. Поскольку элемент теперь находится на более ранней позиции в массиве, будет пропущен.
не делает копию массива перед итерацией.
Следующий пример приведён только для целей обучения. Если вы хотите выравнять массив с помощью встроенных методов, вы можете использовать
Examples
Note: In order to display the content of an array in the console,
you can use , which prints a formatted
version of the array.
The following example illustrates an alternative approach, using
.
The following code logs a line for each element in an array:
The following (contrived) example updates an object’s properties from each entry in the
array:
Since the parameter () is provided to
, it is passed to each time it’s
invoked. The callback uses it as its value.
Note: If passing the callback function used an arrow function
expression, the parameter could be omitted,
since all arrow functions lexically bind the
value.
The following code creates a copy of a given object.
There are different ways to create a copy of an object. The following is just one way
and is presented to explain how works by using
ECMAScript 5 meta property functions.
The following example logs , , .
When the entry containing the value is reached, the first entry of the
whole array is shifted off—resulting in all remaining entries moving up one position.
Because element is now at an earlier position in the array,
will be skipped.
does not make a copy of the array before iterating.
The following example is only here for learning purpose. If you want to flatten an
array using built-in methods you can use .
Новый тип возврата never rfc
Тип never может быть использован для того, чтобы указать, что функция фактически остановит поток приложения. Это можно сделать, выбросив исключение, вызывая exit/die или используя другие подобные функции.
Тип возвращаемого значенияnever аналогичен существующему типу возвращаемого значения void, но тип never гарантирует, что программа завершится или выдаст исключение. Другими словами, объявленная функция/метод never типом вообще не должна вызывать return.
Как видите, если функция/метод с типом never никак не сгенерирует исключение, или прекратит работу, то PHP выдаст исключение TypeError.
А если при never типе вызвать return, то PHP выдаст Fatal Error. Узнать об этом можно будет только во время вызова, а не во время синтаксического анализа.
Исходный RFC предлагал использовать noreturn для этой цели. Впрочем последующее голосование в RFC прошло уже в пользу never и он был избран.
Ключи
Ключи помогают React идентифицировать, какие элементы были изменены, добавлены или удалены. Ключи должны быть заданы элементам внутри массива, чтобы предоставить элементам постоянный идентификатор:
Лучший способ выбрать ключ — использовать строку, которая однозначно идентифицирует элемент списка среди его соседних элементов. Чаще всего в качестве ключей вы будете использовать идентификаторы из ваших данных:
Если у вас нет постоянных идентификаторов для отрисовываемых элементов, в крайнем случае вы можете использовать индекс элемента в качестве ключа:
Мы не рекомендуем использовать индексы для ключей, если порядок элементов может измениться. Это может негативно сказаться на производительности и вызвать проблемы с состоянием компонента. Ознакомтесь со статьёй Робина Покорни (Robin Pokorny) для подробного объяснения негативных последствий использования индекса в качестве ключа. Если вы решите не назначать явный ключ для списка элементов, тогда React по умолчанию будет использовать индексы в качестве ключей.
Также вы можете прочитать , если вам интересно узнать это.
Выделение компонентов с ключами
Ключи имеют смысл только в контексте окружающего массива.
Например, если вы компонент , вам нужно присваивать ключ элементам в массиве, а не элементам в самом .
Пример: неправильное назначение ключа
Пример: Корректное использование ключа
Придерживайтесь хорошему правилу: внутри вызова обязательно указывать ключи для элементов.
Ключи должны быть уникальными только в пределах элементов одного уровня
Ключи, используемые в массивах, должны быть уникальными среди их элементов на одном и том же уровне. Поэтому им не обязательно быть глобально уникальными. Мы можем использовать те же самые ключи при создании двух разных массивов:





Ключи служат подсказкой для React, но они не передаются вашим компонентам. Если вам нужно то же самое значение в вашем компоненте, передайте его явно в виде свойства с другим именем:
В примере выше компонент может получить значение , но не .
Встраивание map() в JSX
В приведённых выше примерах мы объявили отдельную переменную и включили её в JSX:
JSX позволяет в фигурных скобках, поэтому мы могли встроить результат вызова :
Иногда это приводит к более чистому коду, но этим стилем не стоит злоупотреблять. Как и в JavaScript, вам решать, стоит ли извлекать переменную для большей читабельности. Имейте в виду, что если у блока кода в слишком большой уровень вложенности, возможно, наступило подходящее время для .
Другие небольшие изменения
Вот краткое изложение наиболее значительных изменений:
- MYSQLI_STMT_ATTR_UPDATE_MAX_LENGTH больше не действует
- MYSQLI_STORE_RESULT_COPY_DATA больше не действует
- PDO::ATTR_STRINGIFY_FETCHES теперь также работает с логическими значениями
- Целые числа и числа с плавающей запятой в наборах результатов PDO MySQL и Sqlite будут возвращаться с использованием собственных типов PHP вместо строк при использовании эмулированных подготовленных операторов.
- Такие функции, как htmlspecialchars и htmlentities по умолчанию, также переходят ‘в '; неверно сформированный UTF-8 также будет заменен символом Юникода вместо того, чтобы приводить к пустой строке
- У hash, hash_file и hash_init есть дополнительный аргумент $options, по умолчанию он имеет значение [], поэтому не повлияет на ваш код.
- Новая поддержка для MurmurHash3 и xxHash
На данный момент это все, имейте в виду, что я буду регулярно обновлять этот пост в течение года, поэтому можете следить за этим постом.
Новая функция array_is_list rfc
Возможно, время от времени, вам приходится иметь с этим дело: определять, находятся ли ключи массива в числовом порядке, начиная с индекса 0. Точно так же, как json_encode решает, должен ли массив быть закодирован как массив или объект.
PHP 8.1 добавляет встроенную функцию, чтобы определить, является ли массив списком с этой семантикой или нет:
Любой массив с ключами, не начинающимися с нуля, или любой массив, в котором не все ключи являются целыми числами в последовательном порядке, результат будет false:
- array_is_list принимает только параметры типа array. Передача любого другого типа вызовет исключение TypeError.
- array_is_list не принимает iterable или другие объекты класса, подобные массиву, такие как ArrayAccess, SPLFixedArray и т.д.
- array_is_list объявлен в глобальном пространстве имен.
Полифил функции будет выглядеть, как:
Описание
Метод выполняет функцию один раз для каждого элемента, находящегося в массиве в порядке возрастания. Она не будет вызвана для удалённых или пропущенных элементов массива. Однако, она будет вызвана для элементов, которые присутствуют в массиве и имеют значение .
Функция будет вызвана с тремя аргументами:
- значение элемента (value)
- индекс элемента (index)
- массив, по которому осуществляется проход (array)
Если в метод был передан параметр , при вызове он будет использоваться в качестве значения . В противном случае, в качестве значения будет использоваться значение . В конечном итоге, значение , наблюдаемое из функции , определяется согласно .
Диапазон элементов, обрабатываемых методом , устанавливается до первого вызова функции . Элементы, добавленные в массив после начала выполнения метода , не будут посещены функцией . Если существующие элементы массива изменятся, значения, переданные в функцию , будут значениями на тот момент времени, когда метод посетит их; удалённые элементы посещены не будут. Если уже посещённые элементы удаляются во время итерации (например, с помощью ), последующие элементы будут пропущены. ()
Примечание: Не существует способа остановить или прервать цикл кроме как выбрасыванием исключения. Если вам необходимо такое поведение, метод неправильный выбор.
Досрочное прекращение может быть достигнуто с:
- Простой цикл
- Циклы /
Если нужно протестировать элементы массива на условие и нужно вернуть булево значение, вы можете воспользоваться методами , , или .
Метод выполняет функцию один раз для каждого элемента массива; в отличие от методов и , он всегда возвращает значение .
Заключение
Как правило, for/of — это самый надежный способ перебора массива в JavaScript. Он более лаконичен, чем обычный цикл for, и не имеет такого количества граничных случаев, как for/in и forEach(). Основным недостатком for/of является то, что вам нужно проделать дополнительную работу для доступа к индексу массива (см. дополнение), и вы не можете строить цепочки кода, как вы можете это делать с помощью forEach(). Но если вы знаете все особенности forEach(), то во многих случаях его использование делает код более лаконичным.
Дополнение: Чтобы получить доступ к текущему индексу массива в цикле for/of, вы можете использовать функцию .
for (const of arr.entries()) {
console.log(i, v); // Prints "0 a", "1 b", "2 c"
}
Оригинал: For vs forEach() vs for/in vs for/of in JavaScript
Spread the love