
Введение в XML¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки,
предназначенный для хранения и передачи данных.
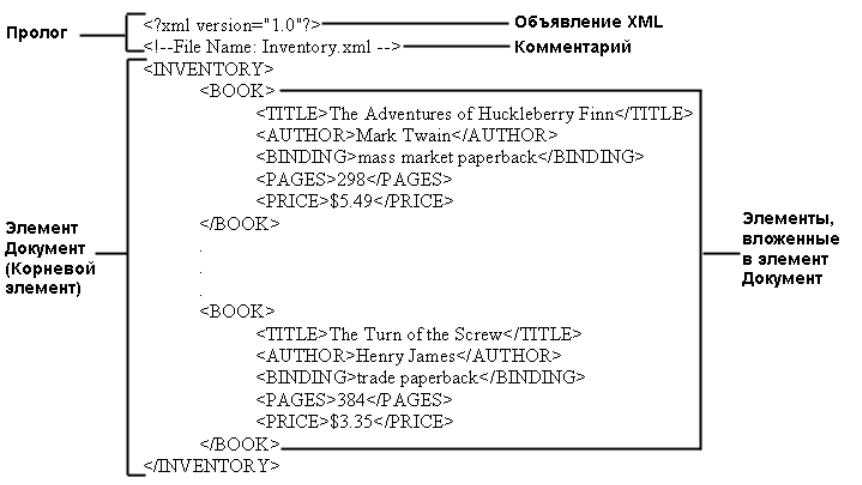
Простейший XML-документ выглядит следующим образом:
<?xml version="1.0" encoding="windows-1251"?> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price></price> </book>
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( , , , ). Последняя строка определяет конец корневого элемента (закрывающий тег).
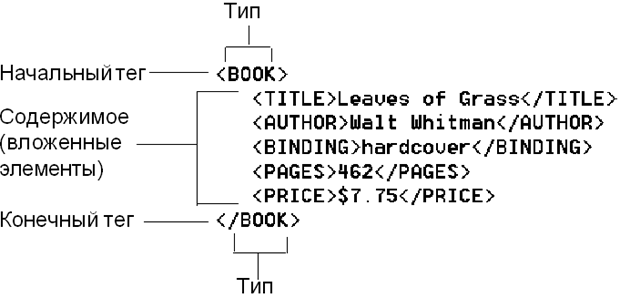
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: . Т.е. элемент принимает значение . Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег имеет атрибут , который принимает значение . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ ставится в конце открывающего тега:
Метод Application.MacroOptions
Метод Application.MacroOptions позволяет добавить пользовательской функции описание, назначить сочетание клавиш, указать категорию, добавить описания аргументов и добавить или изменить другие параметры. Давайте рассмотрим возможности этого метода, используемые чаще всего.
Пример кода с методом Application.MacroOptions:
|
1 |
SubИмяПодпрограммы() Application.MacroOptions_ Macro=»ИмяФункции»,_ Description=»Описание функции»,_ Category=»Название категории»,_ ArgumentDescriptions=Array(«Описание 1″,»Описание 2″,»Описание 3»,…) EndSub |
- ИмяПодпрограммы — любое уникальное имя, подходящее для наименования процедур.
- ИмяФункции — имя функции, параметры которой добавляются или изменяются.
- Описание функции — описание функции, которое добавляется или изменяется.
- Название категории — название категории в которую будет помещена функция. Если параметр Category отсутствует, пользовательская функция будет записана в раздел по умолчанию — «Определенные пользователем». Если указанное Название категории соответствует одному из названий стандартного списка, функция будет записана в него. Если такого Названия категории нет в списке, будет создан новый раздел с этим названием и функция будет помещена в него.
- «Описание 1», «Описание 2», «Описание 3», … — описания аргументов в том порядке, как они расположены в объявлении пользовательской функции.
Эта подпрограмма запускается один раз, после чего ее можно удалить или использовать как шаблон для корректировки параметров других пользовательских функций.
Сейчас с помощью метода Application.MacroOptions попробуем изменить описание пользовательской функции «Деление» и добавить описания аргументов.
|
1 |
SubИзменениеОписания() Application.MacroOptions_ Macro=»Деление»,_ Description=»Описание функции Деление изменено методом Application.MacroOptions»,_ ArgumentDescriptions=Array(«- любое числовое значение»,»- числовое значение, кроме нуля») EndSub |
После однократного запуска этой подпрограммы получаем следующий результат:
Новое описание пользовательской функции и ее второго аргумента
Метод Application.MacroOptions не работает в Личной книге макросов, но и здесь можно найти решение. Добавьте описания к пользовательским функциям и их аргументам в обычной книге Excel, затем экспортируйте модуль с функциями в любой каталог на жестком диске и оттуда импортируйте в Личную книгу макросов. Все описания сохранятся.
Обязательные (позиционные) аргументы
Обязательные аргументы — это аргументы, переданные функции в правильном позиционном порядке. Здесь количество аргументов и их порядок в вызове функции должно точно соответствовать определению функции.
Чтобы вызвать функцию printme() , вам обязательно нужно передать один аргумент, иначе она выдаст следующую синтаксическую ошибку:
# Определение функции def printme( str ): """This prints a passed string into this function""" print(str) return # Теперь вы можете вызвать функцию printme printme()
Ошибка (в функции Printme не указан аргумент):
Traceback (most recent call last):
File "C:/Users/User/Desktop/CodePythonFunc.py", line 8, in <module>
printme()
TypeError: printme() missing 1 required positional argument: 'str'
Правильно указать аргумент так:
# Определение функции
def printme( str ):
"""This prints a passed string into this function"""
print(str)
return
# Теперь вы можете вызвать функцию printme
printme("Текстовая переменная")
Стрелочные функции (arrow function)
Стрелочная функция (arrow function) — это современный синтаксис для создания функций, который появился с приходом ES6 (ES 2015). Он позволяет записать её более кратко по сравнению с синтаксисом Function Expression.
Базовый синтаксис стрелочной функции:
(argument1, argument2, ... argumentN) => {
// тело функции
}
Например, функция возвращающая среднее арифметическое двух чисел:
// Function Expression
const average = function(num1, num2) {
return (num1 + num2) / 2;
}
// Стрелочная функция
const average = (num1, num2) => {
return (num1 + num2) / 2;
}
В этом примере мы создали стрелочную функцию с двумя параметрами и , которая вычисляет выражение и возвращает его результат.
Если стрелочная функция простая, т.е. она просто вычисляет выражение как в предыдущем примере, то её можно записать ещё короче:
const average = (num1, num2) => (num1 + num2) / 2;
Пример, в котором создадим стрелочную функцию, возвращающую массив определённой длины, заполненный случайными числами от 0 до 9.
const fillArr = (numElements) => {
const arr = [];
for (let i = 0; i < numElements; i++) {
arr.push(parseInt(Math.random() * 10));
}
return arr;
};
// вызов функции fillArr
console.log(fillArr(5)); //
При создании стрелочной функции с одним параметром круглые скобки можно не указывать:
const fillArr = numElements => {
...
};
Если стрелочная функция не имеет параметров, или их два и более, то круглые скобки в этом случае нужно писать обязательно:
// () - необходимо указывать при отсутствии параметров
const result = numElements = () => {
console.log('Привет, мир!');
};
result(); // 'Привет, мир!'
До появления стрелочных функций каждая функция имела свой (контекст в котором она выполнялась).
Например, в функции-конструкторе в контекст указывал не на этот объект, а на , т.к. данная функция является его методом:






const Timer = function () {
// здесь this - это ссылка на этот объект
this.counter = 0;
setInterval(function () {
// здесь this - это window
console.log(this.counter++);
}, 1000);
};
const timer1 = new Timer();
Чтобы в нам получить ссылку на этот объект, нам приходилось сохранять её в другую переменную, например :
const Timer = function () {
this.counter = 0;
// сохраняем текущий контекст в that
const that = this;
setInterval(function () {
// используем that, которая указывает на этот объект
console.log(that.counter++);
}, 1000);
};
const timer1 = new Timer();
Стрелочная функция не содержит собственный контекст . Значение в стрелочной функции определяется снаружи, т.е. из окружающего её контекста.
const Timer = function () {
// здесь this - это ссылка на этот объект
this.counter = 0;
setInterval(() => {
// здесь this тоже указывает на этот контекст, т.к. берётся снаружи
console.log(this.counter++);
}, 1000);
};
const timer1 = new Timer();
Стрелочные функции не имеет собственного объекта . В этом случае получить аргументы для которых не заведены параметры можно с помощью rest параметров:
// ...otherNums - rest парамтеры
const sum = (...otherNums) => {
let result = 0;
for (let num of otherNums) {
if (typeof num === 'number') {
result += num;
}
}
return result;
};
console.log(sum(2, 5, -7, 11)); // 11
Не спеша, эффективно и правильно – путь разработки. Часть 3. Практика
Черновой вариант книги Никиты Зайцева, a.k.a.WildHare. Разработкой на платформе 1С автор занимается с 1996-го года, специализация — большие и по-хорошему страшные системы. Квалификация “Эксперт”, несколько успешных проектов класса “сверхтяжелая”. Успешные проекты ЦКТП. Четыре года работал в самой “1С”, из них два с половиной архитектором и ведущим разработчиком облачной Технологии 1cFresh. Ну — и так далее. Не хвастовства ради, а понимания для. Текст написан не фантазером-теоретиком, а экспертом, у которого за плечами почти двадцать три года инженерной практики на больших проектах.
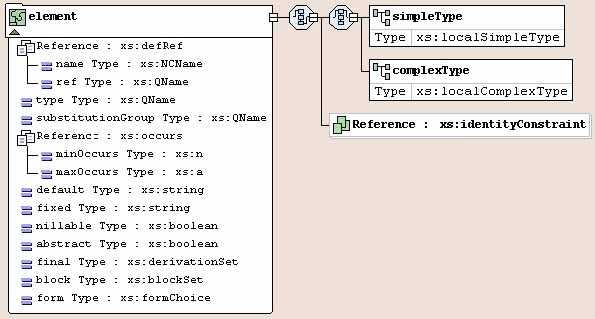
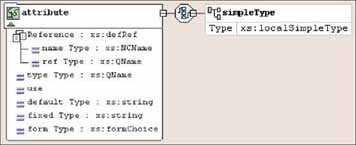
Объявления атрибутов
Объявление списка атрибутов определяет имена атрибутов, устанавливает тип для каждого атрибута и задаёт
востребованность для каждого атрибута, в частности, может задавать значение атрибута по умолчанию. Объявление
списка атрибутов имеет следующую форму записи:
<!ATTLIST Имя ОпрАтр>
Здесь «Имя» — имя элемента, для которого задаются атрибуты. «ОпрАтр» — это одно или несколько определений атрибутов.
Определение атрибута имеет следующую форму записи:
Имя ОпрАтр ОбъявУмолч
Здесь «Имя» — имя атрибута. ОпрАтр представляет собой тип атрибута. ОбъявУмолч — это объявление значения по
умолчанию, которое указывает на востребованность атрибута и содержит некоторую дополнительную информацию. Пример
объявления:
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
Вышеприведённое объявление означает, что вы можете присвоить атрибуту Retail любую строку в кавычках (ключевое
слово CDATA); если этот атрибут опущен, ему будет присвоено значение по умолчанию «retail». Вы можете присвоить
атрибуту Title любую строку в кавычках; этот атрибут должен быть обязательно задан для каждого элемента PRODUCT
(ключевое слово #REQUIRED) и не имеет значения по умолчанию.
Объявления атрибутов просто включаются в DTD наряду с объявлениями типов элементов, например:
…
<!ELEMENT PRODUCT (#PCDATA)>
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
…
Вы можете задавать тип атрибута тремя различными способами:
- Строковый тип (ключевое слово CDATA, что означает символьные данные, Character Data).
- Маркерный тип.
- Нумерованный тип.
Вот список ключевых слов, которые вы можете использовать в определении маркерных типов атрибутов:
| ID | Для каждого элемента атрибут должен иметь уникальное значение. Элемент может иметь только один атрибут типа ID. В объявлении значения по умолчанию такого атрибута должно фигурировать #REQUIRED или #IMPLIED. |
| IDREF | Значение такого атрибута является ссылкой на атрибут типа ID другого элемента . |
| IDREFS | Этот тип атрибута похож на IDREF, но его значение может включать ссылки на несколько идентификаторов — разделённых пробелами — внутри строки в кавычках. |
| ENTITY | Значение атрибута должно совпадать с именем примитива, объявленного в DTD. Такой примитив ссылается на внешний файл, обычно содержащий не XML-данные. Таким способом, например, определяют путь к файлу, содержащему графические данные (рисунок). |
| ENTITIES | Этот тип атрибута похож на ENTITY, но его значение может включать ссылки на несколько идентификаторов, разделённых пробелами — внутри строки в кавычках. Таким способом, например, определяют пути к файлам, содержащим графические данные (рисунки) в альтернативных форматах. |
| NMTOKEN | Элементарное имя. |
| NMTOKENS | Этот тип атрибута похож на NMTOKEN, но его значение может включать несколько элементарных имён, разделённых пробелами — внутри строки в кавычках.. |
Два способа, которые вы можете использовать в определении нумерованных типов атрибутов:
-
Если вы хотите ограничить значение атрибута «Mass» словами «net» и «gross», вы можете написать следующее:
<!ATTLIST PRODUCT Mass (net | gross) «net»>
-
Нумерованный тип можно определить с помощью ключевого слова NOTATION. Каждая из указанных нотаций должна точно
соответствовать имени нотации, объявленному в DTD. Нотация описывает формат данных или идентифицирует программу,
применяемую для обработки определённого формата данных:<!ATTLIST PRODUCT Description NOTATION (HTML | SGML | RTF) #REQUIRED>
Объявление значения атрибута по умолчанию может иметь четыре формы:
| #REQUIRED | Вы должны задать значение атрибута для каждого элемента. |
| #IMPLIED | Вы можете опустить атрибут, но никакое значение по умолчанию назначено не будет. |
| AttValue | Собственно значение по умолчанию. Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию. |
| #FIXED AttValue | Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию (AttValue). Если вы не опускаете атрибут, вы обязаны назначить ему это значение по умолчанию. При таком объявлении указывать атрибут в элементе имеет смысл только для того, чтобы сделать документ более понятным для восприятия. |
Использование примитивов
Термин «примитив» в широком смысле относится к любому из следующих типов единиц хранения информации для
XML-документов:
- Собственно XML-документ как единое целое (файл).
- Внешнее подмножество DTD (файл).
- Внешний файл, определённый как внешний примитив в DTD и допускающий использование посредством ссылки (файл).
- Строка в кавычках, определённая как внутренний примитив в DTD и допускающая использование посредством ссылки
(не файл).
Однако чаще термин «примитив» используется в узком смысле, а именно — в двух последних смыслах.
Механизм примитивов может оказаться удобным для сокращения времени набора документа, а также может облегчить
внесение изменений в документ. Кроме того, механизм примитивов необходим при включении не XML-данных в XML-документ.
В принципе, механизм примитивов сходен с определением констант в различных языках программирования.
Примитивы классифицируются по трём признакам:
- Общие и параметрические. Общий примитив включает текстовые или нетекстовые данные, которые вы можете
использовать внутри корневого элемента. Параметрический примитив содержит XML-текст, который может быть помещён в
DTD. - Внутренние и внешние. Внутренний примитив содержится внутри строки в кавычках. Внешний примитив содержится в
отдельном файле. - Разбираемые и неразбираемые. Разбираемый примитив содержит XML-текст (символьные данные, разметка или и то, и
другое). Когда вы вставляете ссылку на разбираемый примитив в документ, ссылка замещается содержимым примитива.
Синтаксический анализатор разбирает содержимое примитива точно так же, как он сканирует текст, непосредственно
введённый в документ. Неразбираемый примитив может содержать как XML-данные, так и не XML-данные. Его содержимое
нельзя непосредственно вставить в документ посредством ссылки.
Реально в XML поддерживается пять типов примитивов:
- Общие внутренние разбираемые.
- Общие внешние разбираемые.
- Общие внешние неразбираемые.
- Параметрические внутренние разбираемые.
- Параметрические внешние разбираемые.
Примитив создаётся путём объявления его в DTD документа.
Используйте класс Objects и библиотеку StringUtils
Ошибки нередко прокрадываются в базу кода, когда у нас нет ясного понимания того, что код делает или почему он это делает
Здесь важно удобство в обслуживании. Я часто сталкиваюсь с запутанным кодом создания строки
По какой-то причине люди склонны увлекаться тернарными выражениями, помещая их в другие выражения или вкладывая друг в друга. Это очень эффективно усложняет чтение и понимание простой логики.
Тернарный оператор часто используется для возвращения предустановленного значения, когда переменная содержит . Ниже приведен пример этого, взятый прямо из нашей базы кода Columna:
String s = (form != null ? form : "-") + " " + (nameAndStrength != null ? nameAndStrength: "");
Примечательно, что это не самый сложный для анализа код, но я думаю, что его можно написать гораздо лучше. В C# существует так называемый оператор объединения с неопределенным значением, относящийся к тернарному оператору, явно проверяющему значение на . Вот пример:
String s = form ?? "-" + " " + nameAndStrength ?? "-";
Здесь левое значение оператора присваивается, если оно не , в противном случае используется правая сторона. Несмотря на то, что в Java недостает подобного оператора, с той же целью можно использовать встроенный класс , описанный выше. Метод класса возвращает значение первого объекта, если этот объект не , в противном случае он возвращает указанное строковое значение.
String hyphen = "";String s = Objects.toString(form, hyphen) + " " + Objects.toString(nameAndStrength, hyphen);
Не так складно, как в примере с C#, но, на мой взгляд, намного надежнее, чем исходный пример, а значит и шанс появления ошибок при работе с кодом уже существенно меньше.
Рекурсивные функции
Функция, которая вызывает сама себя, называется рекурсивной функцией.Рекурсия — вызов функции из самой функции.Пример рекурсивной функции — функция вычисления факториала.








123456789101112131415161718
#define _CRT_SECURE_NO_WARNINGS // для возможности использования scanf#include <stdio.h>int fact(int num) // вычисление факториала числа num{ if (num <= 1) return 1; // если число не больше 1, возвращаем 1 else return num*fact(num — 1); // рекурсивный вызов для числа на 1 меньше}// Главная функцияint main() { int a, r; printf(«a= «); scanf(«%d», &a); r = fact(a); // вызов функции: num=a printf(«%d! = %d», a, r); getchar(); getchar(); return 0;}
этой статье
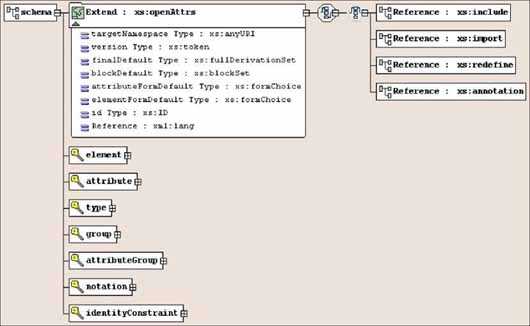
Понятие о языке XML
XML — это расширяемый язык разметки (Extensible Markup Language), разработанный специально для размещения информации
в World Wide Web, наряду с HTML, который давно стал стандартным языком создания Web-страниц. В отличие от HTML,
вместо использования ограниченного набора определённых элементов вы имеете возможность создавать ваши собственные
элементы и присваивать им любые имена по вашему выбору. Примечание: подразумевается, что читатель данной статьи хотя
бы очень поверхностно знаком с языком HTML.
XML решает ряд проблем, которые не решает HTML, например:
- Представление документов любого (не только текстового) типа, например, музыки, математических уравнений и
т.д. - Сортировка, фильтрация и поиск информации.
- Представление информации в структурированном (иерархическом) виде.
В зависимости от уровня соответствия стандартам документ может быть «верно сформированным» («well-formed»), либо
«валидным» («valid»). Вот несколько основных правил создания верно сформированного документа:
- Каждый элемент XML должен содержать начальный и конечный тэг (либо пустой тэг типа <TAG />, который может
нести информацию посредством своих атрибутов). - Любой вложенный элемент должен быть полностью определён внутри элемента, в состав которого он входит.
- Документ должен иметь только один элемент верхнего уровня.
- Имена элементов чувствительны к регистру.
Есть три основных способа сообщить браузеру, как отображать каждый из созданных вами XML-элементов:
- Каскадная таблица стилей (Cascading Style Sheet — CSS) или расширяемая таблица в формате языка стилевых
таблиц (Extensible Stylesheet Language — XSL). - Связывание данных. Этот метод требует создания HTML-страницы, связывания с ней XML-документа и установления
взаимодействий HTML-элементов с элементами XML. В дальнейшем HTML-элементы автоматически отображают информацию
из связанных с ними XML-элементов. - Написание сценария. Этот метод требует создания HTML-страницы, связывания с ней XML-документа и получение
доступа к XML-элементам с помощью кода сценария JavaScript или VBScript.
Индивидуальный пользователь, компания или комитет по стандартам может определить необходимый набор элементов XML
и структуру документа, которые будут применяться для особого класса документов. Подобный набор элементов и описание
структуры документа называют XML-приложением или XML-словарём.
XML-приложение обычно определяется созданием описателя типа документа (DTD), который является допустимым
компонентом XML-документа. DTD устанавливает и определяет имена элементов, которые могут быть использованы в
документе, порядок, в котором элементы могут появляться, и доступные к применению атрибуты элементов. DTD обычно
включается в XML-документ и ограничивает круг элементов и структур, которые будут использоваться. Примечание:
приложение XML Schema позволяет разрабатывать подробные схемы для ваших XML-документов с использованием стандартного
синтаксиса XML и является альтернативой DTD.
Выгрузка и загрузка XML для управляемых форм 8.3 (с отбором)
В работе постоянно приходится разделять в различные базы или объединять несколько организаций в одну базу, долгое время пользовался стандартной обработкой выгрузка-загрузка из UNIREPS 8.2, в режиме обычного приложения, но, к сожалению, для управляемого приложения стандартная обработка из UNIREPS 8.3 (Диск ИТС) не позволяет нормально сделать выгрузку с отбором, поэтому ей никогда не воспользовался. Решил что напишу обработку, которая позволит делать отборы в различных вариациях, кроме того, в обработках из UNIREPS (8.2 и 8.3) существенно отличается процесс загрузки предопределенных, что не всегда удобно при больших объемах данных. Обработка написана на базе UNIREPS 8.3, но есть существенные изменения.
Но интерфейс доработан так, чтобы обработка была похожа на старую добрую обработку из UNIREPS 8.2, к которой все так привыкли.
1 стартмани
Область действия переменной — область видимости переменных
Переменные в программе могут быть доступны или недоступны в разных местах этой программы. Это зависит от того, где вы объявили переменную.
Область действия переменной определяет ту часть программы, в которой вы можете получить доступ к определенному идентификатору (т.е. к значению переменной и возможности эту переменную поменять). В Python есть две основные области видимости переменных:
- Глобальные переменные
- Локальные переменные
Область видимости переменной в Python называют также пространством имен. Любая переменная, которой присвоено значение внутри функции, по умолчанию попадает в локальное пространство имен.
Локальное пространство имен создается при вызове функции, и в него сразу же заносятся аргументы функции. По завершении функции локальное пространство имен уничтожается (хотя бывают и исключения, см. ниже раздел о замыканиях).
Переменные внутри функции – локальные. Поиск переменных: сперва среди локальных, потом среди глобальных.
Рассмотрим следующую функцию:
def func():
a = []
for i in range(5):
a.append(i)
При вызове func() создается пустой список a, в него добавляется 5 элементов, а затем, когда функция завершается, список a уничтожается. Но допустим, что мы объявили a следующим образом:
a = []
def func():
for i in range(5):
a.append(i)
Присваивать значение глобальной переменной внутри функции допустимо, но такие переменные должны быть объявлены глобальными с помощью ключевого слова global:
a = None
def bind_a_variable():
global a
a = []
bind_a_variable()
print a
Результат:
[]
Функции можно объявлять в любом месте, в том числе допустимы локальные функции, которые динамически создаются внутри другой функции при ее вызове:
def outer_function(x, y, z):
def inner_function(a, b, c):
pass
pass
Здесь функция inner_function не существует, пока не вызвана функция outer_function. Как только outer_function завершает выполнение, inner_function уничтожается.
Вложенные функции могут обращаться к локальному пространству имен объемлющей функции, но не могут связывать в нем переменные. Подробнее смотрите в разделе о замыканиях.
Строго говоря, любая функция локальна в какой-то области видимости, хотя это может быть и область видимости на уровне модуля.
Альтернативное получение значения из хранилища значения. Свой ХранилищеЗначения.Получить();
Данная публикация не претендует на использование в продакшене, но когда «Нельзя, но очень хочется» в отношении получения ооочень больших данных из ХранилищаЗначения и когда сама платформа не может получить значение и падает, при этом, перед падением съедает почти всю память. Это своего рода костыль, в безвыходной ситуации. Речь пойдет про получение больших данных из хранилища значения в файловых базах на 32-х битной платформе. Данное не касается 64-х битных клиентов/серверов где нет ограничения на размер потребляемой памяти (верней есть, но доступно памяти гораздо больше, чем 32-х битному приложению без PAE).
1 стартмани
Функция CallByName
Рассмотрим, например, клиентское приложение, которое оценивает выражения, вводимых пользователем, передавая оператор в COM-компонент. Предположим, что вы постоянно добавляете новые функции в компонент, требующий новых операторов. При использовании методов доступа к стандартным объектам необходимо перекомпилировать и повторно распространить клиентское приложение, прежде чем оно сможет использовать новые операторы. Чтобы избежать этого, можно использовать функцию для передачи новых операторов в виде строк без изменения приложения.
Функция позволяет использовать строку для указания свойства или метода во время выполнения. Сигнатура для функции выглядит следующим образом:
= Результат (Object, ProcedureName, каллтипе, arguments())
Первый аргумент, объект, принимает имя объекта, с которым вы хотите работать. Аргумент ProcedureName принимает строку, содержащую имя метода или процедуры свойства, которые необходимо вызвать. Аргумент каллтипе принимает константу, представляющую тип вызываемой процедуры: метод ( ), свойство Read ( ) или набор свойств ( ). Аргумент arguments , который является необязательным, принимает массив типа , который содержит любые аргументы для процедуры.








в текущем решении можно использовать с классами, но чаще всего они используются для доступа к COM-объектам или объектам из платформа .NET Framework сборок.
Предположим, что вы добавили ссылку на сборку, содержащую класс с именем , который содержит новую функцию с именем , как показано в следующем коде:
Приложение может использовать элементы управления «текстовое поле» для управления тем, какой метод будет вызываться, и его аргументы. Например, если содержит выражение для вычисления и используется для ввода имени функции, можно использовать следующий код для вызова функции в выражении в :
Если ввести «64» в , «SquareRoot» в , а затем вызвать процедуру, вычисляется квадратный корень числа в . Код в примере вызывает функцию (которая принимает строку, содержащую выражение, которое должно быть оценено как обязательный аргумент) и возвращает «8» в (квадратный корень из 64). Конечно, если пользователь вводит недопустимую строку в , если строка содержит имя свойства вместо метода или если метод имел дополнительный обязательный аргумент, возникает ошибка времени выполнения. Необходимо добавить надежный код обработки ошибок, если вы используете , чтобы предвидеть эти или любые другие ошибки.
Примечание
Хотя функция может быть полезной в некоторых случаях, необходимо взвесить ее полезность относительно влияния на производительность . использование для вызова процедуры немного медленнее, чем вызов с поздним связыванием. При вызове функции, которая вызывается многократно, например внутри цикла, может серьезно повлиять на производительность.
В заключение
В моем редакторе получается 8 страниц. По-моему, для одной статьи даже много и нужно прерваться.
В этой статье мы рассмотрели то, как создаются XML схемы с помощью Liquid и как они отображаются в объекты XDTO. В других редакторах схем они создаются практически так же. Были рассмотрены разные способы задания объектов в XML, определились с терминами “Атрибут”, “Элемент”, “Текстовый узел”. Кроме того, в приведенном примере рассмотрен один нюанс, который с непривычки сложно понять. При присваивании объекта XDTO куда-либо в другом объекте, первый объект удаляется из своего старого места (если он имел таковое), и помещается в новое место. Нельзя один раз создать маленький повторяющийся объект (вроде «Должности»), а потом помещать его в несколько разных других объектов.
На этом предлагаю остановиться. Более подробно копать XDTO будем в одной из следующих статей.
В следующей серии:
Создание собственных Фабрик
Тонкости сериализации
Стандартная XDTO сериализация, с чем едят «СериализаторXDTO» и чем он отличается от «Фабрики».





