
UTF-32
Почему UTF-8 обычно используется, каковы преимущества?
Прежде всего, UTF-8 — это реализация юникода, адаптирующаяся ко всем персонажам в мире.
Во-вторых, UTF-8 имеет переменную длину, вы можете использовать 1-3 байта в соответствии с различными символами, Unicode2 составляет 1-8 байтов для хранения относительного UTF-16, UTF-32 для экономии места для хранения.
Что касается вопроса, что Блокнот не может сохранить «Unicom» в одиночку (воспроизведенный)
Когда вы создаете новый текстовый документ, введите в него слово «Unicom» и сохраните его. Когда вы откроете его снова, первоначально введенный «Unicom» станет двумя искаженными символами.
Эта проблема вызвана конфликтом между кодировкой GB2312 и UTF8. Правило преобразования из UNICODE в UTF8 вводится из Интернета:
Например, кодировкой Unicode китайского символа является 6C49. 6C49 находится между 0800-FFFF, поэтому используется 3-байтовый шаблон: 1110xxxx 10xxxxxx 10xxxxxx. Запись 6C49 в двоичную форму: 0110 1100 0100 1001, битовый поток делится на 0110 110001 001001 в соответствии с методом сегментации трехбайтового шаблона, и, в свою очередь, заменяя x в шаблоне, мы получаем: 1110-0110 10-110001 10-001001, то есть E6 B1 89, это его кодировка UTF8.
Когда вы создаете новый текстовый файл, кодировкой по умолчанию для Блокнота является ANSI. Если вы вводите китайские символы в кодировке ANSI, это фактически метод кодирования серии GB. Под этой кодировкой внутренний код «Unicom»:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
Вы заметили? Первые два байта, а также начало третьего и четвертого байтов — это «110» и «10», что в точности совпадает с двухбайтовым шаблоном в правиле UTF8, поэтому при повторном открытии Блокнота заметка Я ошибочно подумал, что это был файл в кодировке UTF8. Давайте удалим первый байт из 110 и второй байт из 10, и мы получим «00001 101010», а затем выровняем всех, чтобы они заняли лидирующие позиции. 0, вы получите «0000 0000 0110 1010», извините, это 006A UNICODE, который является строчной буквой «j», а следующие два байта — 0368 после декодирования UTF8, этот символ — ничто. По этой причине файлы с одним словом «Unicom» не могут нормально отображаться в Блокноте.
Из-за этой проблемы может возникнуть много проблем. Более распространенный вопрос: я сохранил файл в кодировке XX, почему он является исходной кодировкой YY при каждом открытии? ! Причина в том, что хотя вы сохранили код XX, когда система распознала, он был ошибочно распознан как код YY, поэтому он все еще отображается как код YY. Чтобы избежать этой проблемы, Microsoft сделалаBOMВо-первых.
Вопрос о заголовке файла спецификации
При использовании программного обеспечения, такого как Блокнот, который поставляется вместе с WINDOWS, при сохранении файла в кодировке UTF-8 в начале файла вставляются три невидимых символа (0xEF 0xBB 0xBF или BOM). Это строка скрытых символов, используемая для того, чтобы редакторы, такие как Блокнот, могли распознать, кодируется ли этот файл в UTF-8. Это может избежать этой проблемы. Для общих файлов это не вызовет никаких проблем.
Определите, какой текст UTF используется
Чтобы узнать, какой метод кодирования является конкретным, вы можете посмотреть начало текста (BOM), ниже находится начальная отметка, соответствующая всем кодировкам.
EF BB BF UTF-8FE FF UTF-16/UCS-2, little endianFF FE UTF-16/UCS-2, big endianFF FE 00 00 UTF-32/UCS-4, little endian.00 00 FE FF UTF-32/UCS-4, big-endian.
UCS — это стандарт, установленный упомянутым выше ISO, который в точности совпадает с Unicode, но имя другое. Ucs-2 соответствует utf-16, ucs-4 соответствует UTF-32. UTF-8 не имеет соответствующей UCS
Создаём файл конфигурации
Создадим файл send.php с таким содержанием
Здесь вам нужно отредактировать эти поля под себя:
// Формирование самого письма$title = "Заголовок письма";$body = "Само письмо"// Настройки вашей почты$mail->Host = 'smtp.yandex.ru'; // SMTP сервера вашей почты$mail->Username = 'your_login'; // Логин на почте$mail->Password = 'password'; // Пароль на почте$mail->SMTPSecure = 'ssl';$mail->Port = 465;// Адрес самой почты и имя отправителя$mail->setFrom('mail@yandex.ru', 'Имя отправителя');// Получатель письма$mail->addAddress('youremail@yandex.ru'); $mail->addAddress('youremail@gmail.com'); // Ещё один, если нужен
Кодировки и Юникод¶
Простейшая кодировка текста (называемая или )
сопоставляет кодовые точки 0–255 с байтами — , что означает,
что строковый объект, содержащий кодовые точки выше , не может быть
закодирован с помощью этой кодировки. Вызовет ,
который выглядит следующим образом (хотя подробности сообщения об ошибке могут
отличаться): .
Есть ещё одна группа кодировок (так называемые кодировки charmap), которые
выбирают другое подмножество всех кодовых точек Юникод и то, как эти кодовые
точки отображаются в байты — . Чтобы увидеть, как это
делается, просто откройте, например, (кодировка,
которая используется в основном в Windows). Существует строковая константа из
256 символов, которая показывает, какой символ сопоставлен с каким значением
байта.
Все эти кодировки могут кодировать только 256 из 1114112 кодовых точек,
определенных в Юникоде. Простой и понятный способ сохранить каждую кодовую Юникод
точку — это сохранить каждую кодовую точку как четыре последовательных
байта. Есть две возможности: хранить байты в прямом или обратном порядке. Эти
две кодировки называются и соответственно. Их
недостаток в том, что если, например, вы используете на машине с
прямым порядком байтов, вам всегда придется менять байты местами при
кодировании и декодировании. позволяет избежать этой проблемы: у байтов
всегда будет естественный порядок следования байтов. Когда эти байты
читаются ЦПУ с другим порядком байтов, тогда байты необходимо поменять местами.
Чтобы была возможность определять порядок байтов последовательности байтов
или , существует так называемая BOM («Метка порядка
байтов»). Это символ Юникода . Этот символ может быть добавлен к
каждой последовательности байтов или . Версия этого
символа с перестановкой байтов () является недопустимым символом,
который может отсутствовать в тексте Юникод. Поэтому, когда первый символ в
байтовой последовательности или оказывается ,
байты должны быть поменяны местами при декодировании. К сожалению, у символа
была вторая цель как : символ, у которого
нет ширины и не позволяет разделить слово. Это может, например,
использоваться для подсказки алгоритма лигатуры. В Юникод 4.0 использование
в качестве устарело (с
(), принимающим на себя эту роль). Тем не менее, Юникод
программное обеспечение всё ещё должно уметь обрабатывать в обеих ролях:
как спецификация это устройство для определения структуры хранения
закодированных байтов и исчезает после того, как последовательность байтов была
декодирована в строку; как это обычный символ,
который будет декодирован, как и любой другой.
Есть ещё одна кодировка, которая может кодировать весь диапазон символов
Юникод: UTF-8. UTF-8 — это 8-битная кодировка, что означает, что в UTF-8 нет
проблем с порядком байтов. Каждый байт в байтовой последовательности UTF-8
состоит из двух частей: битов маркера (старшие биты) и битов полезной нагрузки.
Биты маркера представляют собой последовательность от нуля до четырех битов
, за которыми следует бит . Символы Юникод кодируются следующим
образом (где x — это биты полезной нагрузки, которые при объединении дают
символ Юникод):
| Диапазон | Кодировка |
|---|---|
| … | 0xxxxxxx |
| … | 110xxxxx 10xxxxxx |
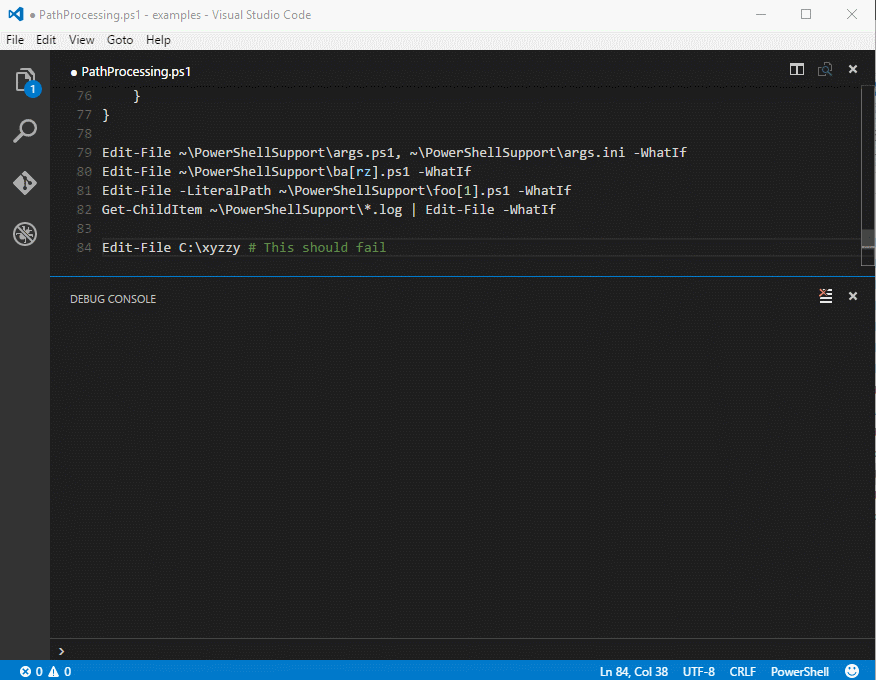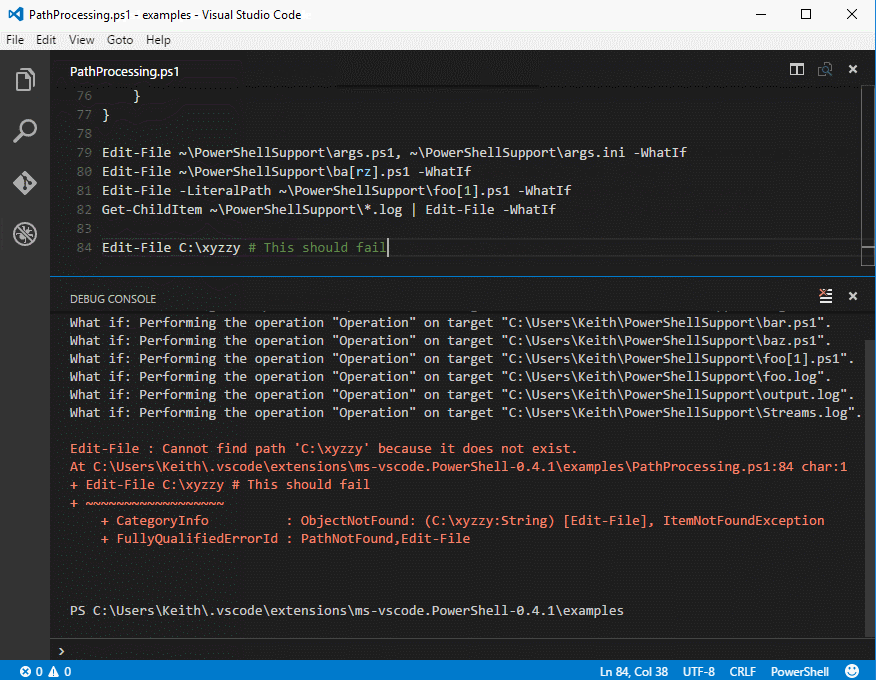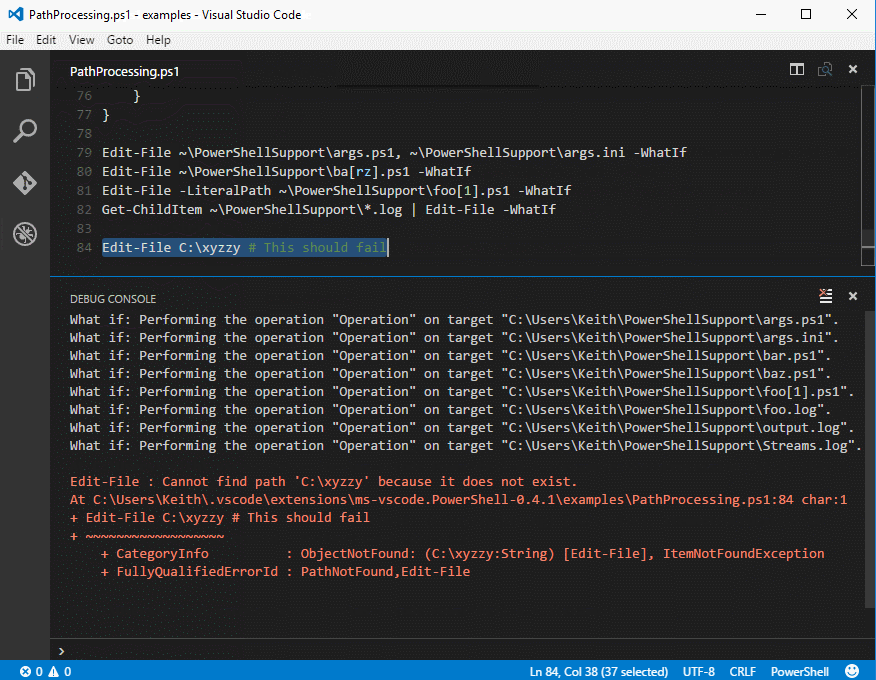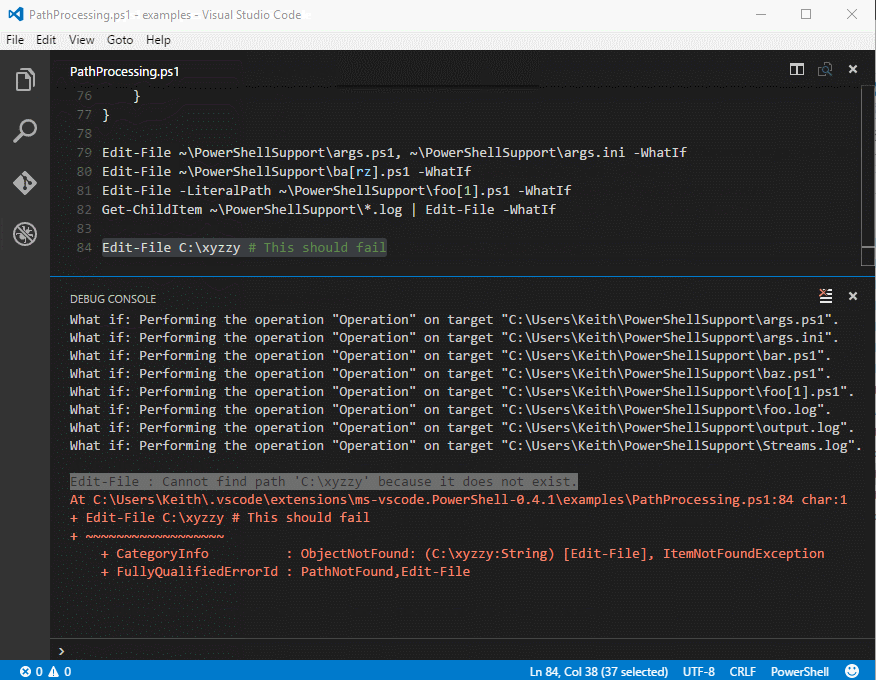
| … | 1110xxxx 10xxxxxx 10xxxxxx |
| … | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Наименьший значащий бит символа Юникода — это крайний правый бит x.
Поскольку UTF-8 представляет собой 8-битную кодировку, спецификация не
требуется, и любой символ в декодированной строке (даже если это
первый символ) обрабатывается как .
Без внешней информации невозможно достоверно определить, какая кодировка
использовалась для кодирования строки. Каждая кодировка charmap может
декодировать любую случайную последовательность байтов. Однако это невозможно с
UTF-8, поскольку у байтовых последовательностей UTF-8 структура, которая не
допускает произвольных байтовых последовательностей. Чтобы повысить надежность,
с которой может быть обнаружена кодировка UTF-8, Microsoft изобрела вариант
UTF-8 (который Python 2.5 называет ) для своей программы
Notepad: перед тем, как любой из символов Юникод будет записан в файл, UTF-
записывается 8 закодированная BOM (которая выглядит как последовательность
байтов: , , ). Поскольку маловероятно, что какой-либо
файл с кодировкой charmap начинается с этих байтовых значений (которые,
например, сопоставляются с
GB2312、GBK、GB18030
Кривые орехи кажутся идеальными, этого достаточно! !
Но когда дело дошло до Китая, китайцы увидели достаточно шаров. В Великом Китае около 80 000 человек. Эти 255 находятся далеко.
Поэтому китайцы изобрели свой собственный набор символов GB2312, который был выпущен Национальным управлением стандартов Китая в 1980 году и начал применяться 1 мая 1981 года. Стандартный номер — GB2312-1980. Это код, который может быть распознан компьютером и подходит для обмена информацией между системой обработки китайских символов и системами связи китайских символов. Стандарт GB 2312 содержит в общей сложности 6763 китайских иероглифа, в том числе 3755 китайских символов первого уровня и 3008 китайских символов второго уровня. В то же время GB 2312 включает латинские буквы, греческие буквы, японские буквы хирагана и катакана и русские буквы кириллицы. 682 символа полной ширины. Появление GB 2312 в основном отвечает потребностям китайских иероглифов в компьютерной обработке. Содержащиеся в нем китайские иероглифы покрывают 99,75% частоты использования в материковом Китае.
Таким образом, китайский народ самостоятельно исследовал и разработал и отменил странные символы после 127-го. Правило: значение символа меньше 127 совпадает с оригиналом, но когда два символа больше 127 объединены, это означает китайский символ. Первый байт (он назвал его старшим байтом) используется от 0xA1 до 0xF7, за которым следует Один байт (младший байт) имеет значение от 0xA1 до 0xFE, поэтому мы можем комбинировать более 7000 упрощенных китайских символов. В этих кодах мы также скомпилировали математические символы, латинские греческие буквы и японские псевдонимы. Даже исходные числа, знаки препинания и буквы в ASCII были перекодированы с помощью двухбайтовых кодов. Это то, что часто называют символом «полной ширины», а символы ниже 127 называются символами «полуширины».
Однако GB 2312 не может обрабатывать редкие символы, встречающиеся в именах древних китайцев и т. Д., Что привело к появлению китайского набора символов GBK и GB 18030.
GBK — это стандарт расширения внутреннего кода китайского иероглифа, K — начальная часть «расширения» в расширенном китайском пиньине. Английское полное название — китайская спецификация внутреннего кода. Стандарт кодирования GBK совместим с GB2312, который содержит в общей сложности 21 003 китайских и 883 символов и обеспечивает 1894 кодовых пункта для создания символов. Упрощенные и традиционные символы объединяются в одну библиотеку.
GBK больше не требует, чтобы младший байт был кодом после 127. Пока первый байт больше 127, он фиксируется, чтобы указывать, что это начало китайского символа, независимо от того, следует ли за ним содержимое расширенного набора символов.
Набор символовКомпьютерная системаМинистерство информационной индустрииГосударственное бюро качества и технического надзораИнформационные технологиихарактерМонголияКореяУйгурскийхарактерОбязательные стандарты
Вышеуказанные кодыСовместим с существующими кодами ANSI (не включая коды расширения)В противном случае китайцы используют GBK, американцы используют ANSI, а китайцы вынуждены переключаться назад на коды ANSI, чтобы увидеть американские вещи.
Применение в Lazarus
Новый режим включается автоматически при компиляции FPC 3.0+.
Это поведение может быть отключено директивой компиляции -dDisableUTF8RTL, детали см. на странице Lazarus with FPC3.0 without UTF-8 mode.
Если вы используете строковые литералы в новом режиме, ваши исходники всегда должны быть в кодировке UTF-8.
Однако, ключ -FcUTF8 на самом деле обычно не требуется. Дополнительные сведения приведены ниже, в разделе «Строковые литералы».
Что же на самом деле происходит в новом режиме? В секции предварительной инициализации вызываются две FPC функции, устанавливающие кодировку строк по умолчанию в исполняющих библиотеках FPC в UTF-8 :
SetMultiByteConversionCodePage(CP_UTF8); SetMultiByteRTLFileSystemCodePage(CP_UTF8);
Кроме того, функции UTF8…() из LazUTF8 (LazUtils) устанавливаются в качестве функций обратного вызова для функций RTL, имена которых начинаются с Ansi…().
Почему бы не использовать UTF8String в Lazarus?
Кратко: потому что FCL не использует его.
Исчерпывающе:
UTF8String определен в модуле system как
UTF8String = type AnsiString(CP_UTF8);
Компилятор всегда предполагает, что он имеет кодировку UTF-8 (CP_UTF8), которая является многобайтовой кодировкой (то есть 1-4 байта на кодовую точку)
Обратите внимание, что оператор [] обращается к байтам, а не к символам или кодовым точкам. То же самое для UnicodeString, но только слова вместо байтов.
С другой стороны, предполагается, что String во время компиляции имеет DefaultSystemCodePage (CP_ACP)
DefaultSystemCodePage определяется во время выполнения, поэтому компилятор консервативно полагает, что String и UTF8String имеют разные кодировки. Когда вы присваиваете или комбинируете String и UTF8String, компилятор вставляет код преобразования. То же самое для ShortString и UTF8String.
Lazarus использует FCL, который использует String, поэтому использование UTF8String добавит конверсии. Если DefaultSystemCodePage не UTF-8, вы теряете символы. Если это UTF-8, то нет смысла использовать UTF8String.
UTF8String станет полезным, когда в конце концов появится FCL UTF-16.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
iconv опция iconv опции -f из-кодировки -t в-кодировку файл(ы) ввода -o файлы вывода
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:
iconv -l
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
������� � �������� ������ ����...
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
enca -i mypoem_draft.txt cat mypoem_draft.txt iconv -f CP1251 -t UTF-8//TRANSLIT mypoem_draft.txt -o poem.txt cat poem.txt enca -i poem.txt
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
![[передача] о кодировке символов java: кодировка unicode, iso-8859-1, gbk, utf-8 и взаимное преобразование - русские блоги](https://fuzeservers.ru/wp-content/uploads/0/0/c/00c867ed099d571e4ec30fcd2447bc1e.png)
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
enca -x UTF-8 mypoem_draft.txt
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
echo $'СТРОКА_ДЛЯ_ИЗМЕНЕНИЯ_КОДИРОВКИ' | iconv -f 'ЖЕЛАЕМАЯ_КОДИРОВКА'
Пример:
echo $'\xed\xe5 \xed\xe0\xe9\xe4\xe5\xed \xf3\xea\xe0\xe7\xe0\xed\xed\xfb\xe9 \xec\xee\xe4\xf3\xeb\xfc' | iconv -f 'Windows-1251' не найден указанный модуль
Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)





