
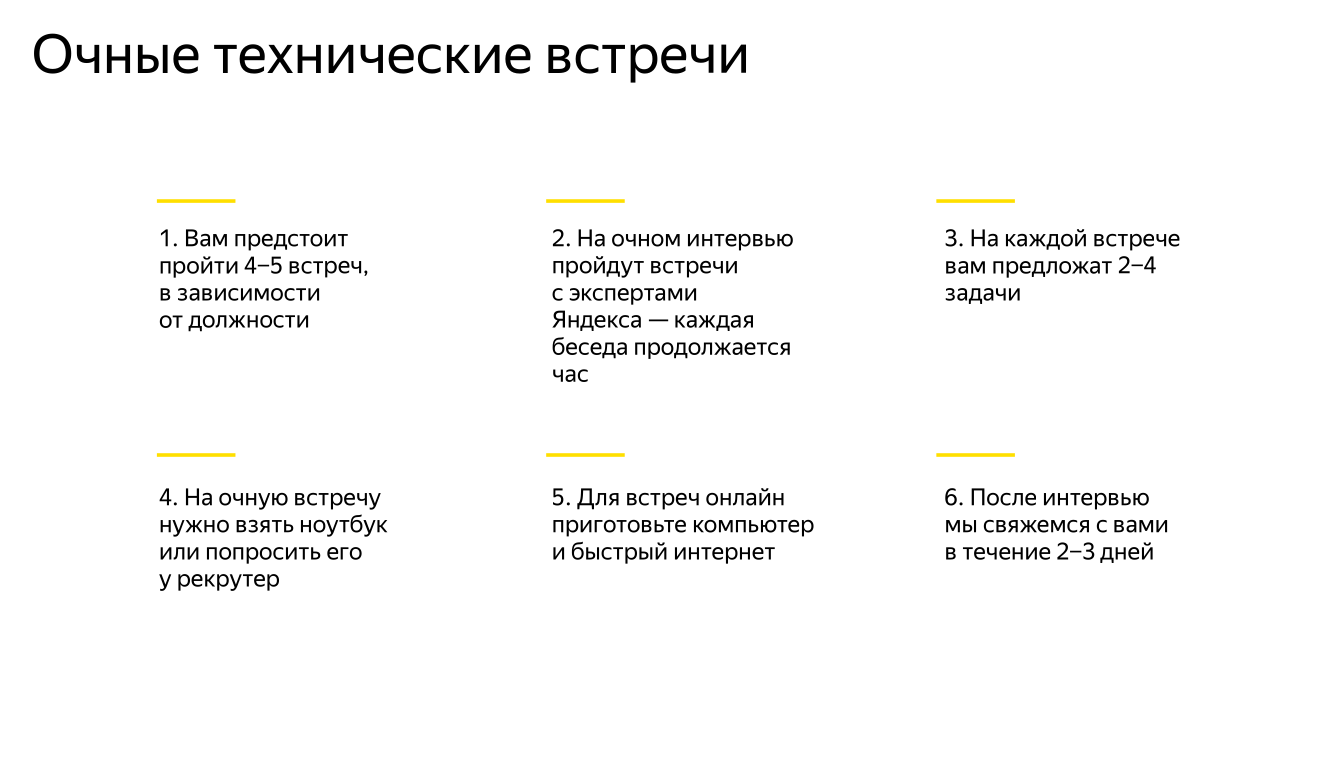
6-дюймовый e-ink экран — нечто
Только если совсем близко приглядеться можно заметить пиксели. При обычном использовании изображение гладкое. Самое главное — не режет глаза.
Электронные чернила ничем не отличаются от чернил обычных. Текст на экране выглядит потрясающе, высокое, по меркам ридеров, разрешение даёт гладкую и чёткую картинку.
У моего девайса используется самое последнее поколение матрицы e-ink Carta, она имеет высокую контрастность (буквы легко читаются при любом свете), а поверхность имеет матовую текстуру. За счёт этого прямой свет рассеивается и не оставляет никаких бликов. Так что глаза не устают совсем.
На случай, если вы окажетесь где-то в темноте, производитель предусмотрел наличие светодиодной подсветки. Она регулируется, для чтения перед сном или в поезде — самое то. Яркость не бьёт по глазам и создаётся ощущение, как будто экран подсвечен светильником с мягким светом.
Ещё можно менять размер шрифта у книги и подобрать наиболее удобный.
Сам экран слегка утоплен под рамки, и это тоже плюс к эргономике. Во-первых, пальцы редко касаются экрана, и на нём практически нет никаких отпечатков. Во-вторых, за счёт наличия рамок книгу удобно держать в руке, большой палец идеально ложится на них и не закрывает «рабочую область». Экран, кстати, здесь не сенсорный, управление осуществляется при помощи кнопок навигации снизу.
Правая кнопка отвечает за пролистывания вперёд, левая – за пролистывание назад. Есть ещё джойстик для навигации по интерфейсу. Обычно я держу ридер в правой руке, скажу честно, возвращаться к предыдущим страницам неудобно, пальцем до левой части не дотянуться. Джойстик для навигации тоже неудобный. У меня большие пальцы, и я постоянно попадаю на центральную клавишу, которая выполняет функцию подтверждения выбора.
Может быть для девочек с аккуратными пальчиками подойдет, но для брутальных парней с «работящими» руками точно нет. Но тут отмечу, что пользоваться центральными клавишами для навигациями приходится только тогда, когда приходит время выбирать новую книгу в библиотеке. При чтении они не задействуются.
Что такое модуль?
Вы когда-нибудь поставьте код в файл «yourfile.py» и выполнили этот код через ‘python yourfile.py’? Поздравляю, вы уже создали и выполнили свой собственный модуль!
Давайте сделаем концепцию модулей на 100%. Скажем, вы хотите реализовать свой собственный модуль. Как ты делаешь это? Просто создайте два файла (только в голове): «Main.py», который содержит вашу основную программу и «Module.py», которая содержит ваш минимальный модуль.
Головоломка 1: каков результат выполнения «Python Main.py» в вашей оболочке? (Найдите решение в конце этой статьи.)
# file module.py
print("2+2")
# file main.py
import module
(Alert Spoiler: решить головоломку сначала до продолжения чтения.)
Оператор импорта в Python – это просто удобный способ «скопировать и вставлять» содержимое модуля в ваш файл (не делая это)
Обратите внимание, что вы должны пропустить суффикс «.py» при импорте модуля. (Не спрашивайте меня, почему.)
Puzzle 2: Каков результат выполнения «Main.py»?
# file italian_greetings.py
def hi():
print("Ciao bella!")
def bye():
print("Ciao bella!!")
# file main.py
import italian_greetings
italian_greetings.hi()
Понятно, что мы не видим результата функции BYE (). Причина в том, что мы определили только, но еще не выполненные BYE ().
Отлично, теперь вы можете импортировать модули из библиотеки модулей), и вы даже можете создавать свои собственные модули и библиотеки! Не слишком потрепанный.
Тем не менее, вы быстро будете раздражены, всегда пишенные название модуля, как в Italian_GreeTings.hi ().
Вот где появляется новая команда: Импортируйте x как y. Замените заполнителю X с вашим (короче) модулем Y.
Puzzle 3: Каков результат выполнения «Main.py»?
# file italian_greetings.py
def hi():
print("Ciao bella!")
# file german_greetings.py
def hi():
print("Guten Tag!")
# file main.py
import german_greetings as de
import italian_greetings as it
de.hi()
it.hi()
Но как мы полностью избавимся от этих префиксов?
Пришло время ввести третью команду (после импорта X, и импортировать X как Y): из X Import Z. Заполнитель X все еще модуль, но Z – это определенная функция в этом модуле. Это позволяет нам делать мелкозернистые импортные функции, которые нам нужны. Это полезно, если у нас есть огромные модули с сотнями функций или если мы хотим лазер-фокусировать наш импорт.
Puzzle 4: Каков результат выполнения Main.py?
# file main.py from german_greetings import hi from italian_greetings import bye hi() bye()
Далее вы узнаете о очень важной теме в Python: Pip. При установке Python самые полезные пакеты уже предустановлены
Эти пакеты образуют «Библиотека Python Standard»
При установке Python самые полезные пакеты уже предустановлены. Эти пакеты образуют «Библиотека Python Standard».
Хотя стандартная библиотека огромен, она содержит только долю всех пакетов Python. Если вы создаете свой собственный пакет Python, он не включен в стандартную библиотеку по умолчанию
Так как же люди могут выиграть от вашей тяжелой работы, создавая свой собственный пакет Python? И, что более важно, как вы можете использовать работу других людей? Ответ – pypi
9 ответов
Лучший ответ
Чтобы сделать это с помощью «простого цикла for», используя ваши ограничения на использование методов dict:
Если вы должны избегать диктовых методов, очевидно, это академическое упражнение.
Без этого ограничения:
Модуль в стандартной библиотеке имеет метод , что было бы моей первой мыслью (поскольку стандартная библиотека не требует сторонних пакетов.):
У сторонних пакетов, таких как numpy и pandas, есть объекты с методом :
Если мы позволим себе использовать метод , это станет немного проще с повторяемой распаковкой. По некоторым причинам другие ответы нарушают это условие, поэтому я полагаю, что должен показать более эффективный способ сделать это:
7
Aaron Hall
23 Сен 2019 в 12:31
Итерация по словарю повторяется по его ключам. Попробуйте просто использовать , а затем использовать надлежащим образом вместо .
В качестве альтернативы используйте метод словаря для получения пар из G, т.е.
(Кстати, ваш реальный метод вычисления среднего значения мне не подходит, но вы также можете сначала решить проблему с итерациями).
4
Gian
14 Мар 2014 в 21:58
Вместо текущих ответов я предлагаю принять функциональную парадигму программирования, которая может быть многократно используемой и гибкой. Например, создание функции для вычисления любой статистики по значениям, содержащимся в простом :
Тестирование:
Урожайность :
1
Adam Erickson
23 Мар 2018 в 19:16
Используйте , чтобы получить все значения из словаря.
Это печатает .
Обратите внимание, что здесь есть разница между Python 2 и Python 3. В Python 2 является вновь созданным списком значений
В Python 3 это генератор, который можно рассматривать как «ленивый список». То же самое называется в Python 2.







3
Gassa
14 Мар 2014 в 22:03
Еще один цикл, для которого не нужен счетчик предметов.
Результаты к:
На самом деле, учитывая ваши данные, нет необходимости использовать . С моей стороны, удаление и просто выход из по-прежнему выдает то же самое, поскольку значения в любом случае не являются строками.
Jerome Montino
14 Мар 2014 в 22:13
Если вы используете NumPy:
7
Sergio R
13 Дек 2018 в 19:47
Вы хотите:
Ваш оригинальный код также даст:
Когда вы пытаетесь суммировать значения.
1
ebarr
14 Мар 2014 в 22:10
В Python 3.4 и выше существует очень понятный путь:
4
barrios
14 Мар 2014 в 22:13
1
insanely_sin
30 Май 2019 в 04:39
«Вы тут поехавшие все? Какой вондерленд? Что вы несёте? Какая визуализация?» или «Я дерево едва представить могу, а вы о воображаемых мирах говорите. Как вы это делаете?».
Об этом мало кто знает, но в силе воображения меж людьми есть колоссальная разница. У других людей воображение не такое, как у вас. Эта разница доходит впредь до того, что один человек имеет воображение, а другой нет. Если вы с закрытыми глазами не можете представить дерево либо вам это удаётся с немалым трудом, то это явный индикатор вашей «несчастливости» в плане врождённого воображения. Ваше воображение может быть от природы ригидным, и вы изменить его толком не сможете. Если вы тот самый человек, который читает книги и не представляет её события в воображении, то являетесь ярким номинантом на звание человека без воображения. Для таких «счастливчиков» дорога вондерленд, как правило, закрыта.
Обычно такие случаи крайне редки, поэтому не торопитесь сваливать все свои неудачи на нюанс выше. Однако, несмотря на это, в тульповодстве встречалось много людей с этими недостатками, из-за чего рождалось настолько же много вопросов.
Ссылки
архаичное написание, на данный момент принято писать «тульпОфорсинг», «тульпОводство», но «TulpaWiki»
старая, ныне забытая система классификации
Понимание проблемы суммирования
Суммирование числовых значений – довольно распространенная задача в программировании. Например, предположим, что у вас есть список чисел и вы хотите сложить элементы и получить сумму. Используя стандартную арифметику, вы сделаете что-то вроде этого:
Что касается математики, это выражение довольно простое.
Можно выполнить этот конкретный расчет вручную, но представьте себе другие ситуации, в которых это может быть невозможно. Если у вас очень длинный список чисел, добавление вручную будет неэффективным и, скорее всего, вы допустите ошибку. А если вы даже не знаете, сколько элементов в списке? Наконец, представьте сценарий, в котором количество элементов, которые вам нужно добавить, изменяется динамически или вообще непредсказуемо.
В подобных ситуациях, независимо от того, есть ли у вас длинный или короткий список чисел, Python может быть весьма полезен для решения задач суммирования.
Использование цикла for
Если вы хотите суммировать числа, создав собственное решение с нуля, вы можете использовать цикл :
numbers =
total = 0
for number in numbers:
total += number
print(total)
# 15
Здесь вы сначала инициализируете сумму и приравниваете её к 0. Эта переменная работает как аккумулятор, в котором вы сохраняете промежуточные результаты, пока не получите окончательный. Цикл перебирает числа и обновляет общее количество.
Цикл можно заключить в функцию. Благодаря этому вы сможете повторно использовать код для разных списков:
def sum_numbers(numbers):
total = 0
for number in numbers:
total += number
return total
sum_numbers()
# 15
sum_numbers([])
# 0
В вы берете итерируемый объект в качестве аргумента и возвращаете общую сумму значений элементов списка.
Использование рекурсии
Вы также можете использовать рекурсию вместо итерации. Рекурсия – это метод функционального программирования, при котором функция вызывается в пределах ее собственного определения. Другими словами, рекурсивная функция вызывает сама себя в цикле:
def sum_numbers(numbers):
if len(numbers) == 0:
return 0
return numbers + sum_numbers(numbers)
sum_numbers()
# 15
Когда вы определяете рекурсивную функцию, вы рискуете попасть в бесконечный цикл. Чтобы предотвратить это, нужно определить как базовый случай, останавливающий рекурсию, так и рекурсивный случай для вызова функции и запуска неявного цикла.
В приведенном выше примере базовый случай подразумевает, что сумма списка нулевой длины равна 0. Рекурсивный случай подразумевает, что общая сумма – это первый элемент плюс сумма остальных элементов. Поскольку рекурсивный случай использует более короткую последовательность на каждой итерации, вы ожидаете столкнуться с базовым случаем, когда числа представляют собой список нулевой длины.
Скачивайте книгу у нас в телеграм
Скачать
×
Использование reduce()
Другой вариант суммирования списка чисел в Python – использовать из functools. Чтобы получить сумму списка чисел, вы можете передать либо оператор , либо соответствующую лямбда-функцию в качестве первого аргумента функции :
from functools import reduce from operator import add reduce(add, ) # 15 reduce(add, []) # Traceback (most recent call last): # ... # TypeError: reduce() of empty sequence with no initial value reduce(lambda x, y: x + y, ) # 15
Вы можете вызвать с folding-функцией и итерируемым объектом в качестве аргументов. использует переданную функцию для обработки итерируемого объекта и вернет единственное кумулятивное значение.
В первом примере folding-функция – это , которая берет два числа и складывает их. Конечный результат – это сумма чисел во входном итерируемом объекте. Но если вы вызовете с пустым итерируемым объектом, получите .
Во втором примере folding-функция – это лямбда-функция, которая возвращает сложение двух чисел.
Поскольку суммирование является обычным явлением в программировании, писать новую функцию каждый раз, когда нам нужно сложить какие-нибудь числа, — бессмысленная работа. Кроме того, использование – далеко не самое удобочитаемое решение.
Python предоставляет специальную встроенную функцию для решения этой проблемы. Это функция . Поскольку это встроенная функция, вы можете использовать ее в коде напрямую, ничего не импортируя.
Рассчитать среднее арифметическое на C
Чтобы вычислить среднее арифметическое чисел в программировании на С, вы должны попросить пользователя ввести размер числа, затем попросить ввести числа этого размера для выполнения сложения, затем назначить переменную, отвечающую за среднее и поместить сложение / размер в среднем, затем отобразить результат
Программный код на С для расчета среднего арифметического
Следуя программе на C, попросите пользователя ввести «Сколько цифр он / она хочет ввести», затем попросить ввести все числа для вычисления и отображения среднего арифметического:
Когда вышеупомянутая программа c скомпилирована и выполнена, она выдаст следующий результат:
![]()
Пример 1
В этом примере мы рассчитаем среднее значение по столбцам. Мы узнаем средние оценки, полученные студентами по предметам.
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n----------')
print(df_marks)
# calculate mean
mean = df_marks.mean()
print('\nMean\n------')
print(mean)
Вывод:
DataFrame ---------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 Mean ------ physics 74.25 chemistry 70.50 algebra 83.75 dtype: float64
Функция mean() возвращает Pandas, это поведение функции mean() по умолчанию. Следовательно, в этом конкретном случае вам не нужно передавать какие-либо аргументы функции mean(). Или, если вы хотите явно указать функцию для вычисления по столбцам, передайте axis = 0, как показано ниже.
df_marks.mean(axis=0)
Пример 2
В этом примере мы создадим DataFrame с числами, присутствующими во всех столбцах, и вычислим среднее значение.
Из предыдущего примера мы видели, что функция mean() по умолчанию возвращает среднее значение, вычисленное среди столбцов.
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n----------')
print(df_marks)
# calculate mean of the whole DataFrame
mean = df_marks.mean().mean()
print('\nMean\n------')
print(mean)
Вывод:
DataFrame ---------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 Mean ------ 76.16666666666667
Примеры использования sum() в Python
До сих пор мы говорили про основы работы с . В этом разделе вы увидите еще несколько примеров того, когда и как использовать в вашем коде. Из этих практических примеров вы узнаете, что эта встроенная функция очень удобна, когда вы выполняете вычисления, требующие на промежуточном этапе нахождения суммы ряда чисел.
Кроме того, мы разберем, как применять при работе со списками и кортежами. Мы также рассмотрим особый пример, когда нужно объединить несколько списков.
Расчет среднего значения выборки
Один из практических вариантов применения – использовать ее в качестве промежуточного вычисления перед дальнейшими вычислениями. Например, вам нужно вычислить среднее арифметическое для выборки числовых значений. Среднее арифметическое, также известное как среднее значение, представляет собой общую сумму значений, деленную на количество значений в выборке.
Если у вас есть выборка и вы хотите вычислить среднее арифметическое вручную, вы можете решить эту операцию так:
Если вы хотите ускорить это с помощью Python, вы можете разбить решение на две части. Первая часть – вы складываете все числа – это задача для . В следующей части, где вы делите на 8, используется количество чисел в вашей выборке. Чтобы определить свой делитель, вы можете использовать :








data_points = sum(data_points) / len(data_points) # 3.25
Здесь вычисляет общую сумму в нашей выборке. Затем мы используем , чтобы получить общее количество. Наконец, выполняем деление, чтобы вычислить среднее арифметическое значение выборки.
Нахождение скалярного произведения двух последовательностей
Другая проблема, которую мы можем решить с помощью , – это нахождение скалярного произведения двух числовых последовательностей равной длины. Скалярное произведение – это алгебраическая сумма произведений каждой пары значений во входных последовательностях. Например, если у вас есть последовательности и , вы можете вычислить их скалярное произведение вручную, используя сложение и умножение:
Чтобы извлечь последовательные пары значений, мы можем использовать zip(). Затем воспользуемся генератором для умножения каждой пары значений. Наконец, поможет суммировать произведения:
x_vector = (1, 2, 3) y_vector = (4, 5, 6) sum(x * y for x, y in zip(x_vector, y_vector)) # 32
Объединение списков
Объединение списков – обычная задача в Python. Предположим, у вас есть список списков, и вам нужно объединить его в единый список, содержащий все элементы из исходных вложенных списков. Вы можете использовать любой из нескольких подходов к объединению списков в Python. Например, можно воспользоваться циклом , как в следующем коде:
def flatten_list(a_list):
flat = []
for sublist in a_list:
flat += sublist
return flat
matrix = ,
,
,
]
flatten_list(matrix)
#
Внутри цикл перебирает все вложенные списки, содержащиеся в . Затем он объединяет их в один. В результате вы получаете единый список со всеми элементами из исходных вложенных списков.
Но можно ли использовать функцию для объединения списков, как в примере выше? Да! Вот как:
matrix = ,
,
,
]
sum(matrix, [])
#
Это было быстро! Одна строка кода — и мы получили единый список. Однако использование не кажется самым быстрым решением.
Важным недостатком любого решения, предполагающего конкатенацию, является то, что за кулисами каждый промежуточный шаг создает новый список. Это может быть довольно расточительным с точки зрения использования памяти.
Список, который в итоге возвращается, является самым последним созданным списком из всех, которые создавались на каждом этапе конкатенации. Использование генератора списка вместо этого гарантирует, что вы создадите и вернете только один список:
def flatten_list(a_list):
return
matrix = ,
,
,
]
flatten_list(matrix)
#
Эта новая версия более эффективна и менее расточительна с точки зрения использования памяти. Однако вложенные генераторы могут быть сложными для чтения и понимания.
Использование , вероятно, является наиболее читаемым и питоничным способом объединить списки:
def flatten_list(a_list):
flat = []
for sublist in a_list:
for item in sublist:
flat.append(item)
return flat
matrix = ,
,
,
]
flatten_list(matrix)
#
В этой версии функция выполняет итерацию по каждому подсписку в . Внутри внутреннего цикла она перебирает каждый элемент подсписка, чтобы заполнить новый список с помощью . Как и в предыдущем случае, это решение создает только один список в процессе. Преимущество его в том, что оно хорошо читается.
Вычислить среднее арифметическое в C++
Чтобы вычислить среднее арифметическое чисел в программировании на C++ , вы должны попросить пользователя ввести размер числа, а затем попросить ввести числа этого размера.
Чтобы вычислить среднее арифметическое для всех чисел, сначала выполните сложение всех чисел, затем возьмите переменную, отвечающую за среднее арифметическое, и поместите добавление / размер в переменную, скажем armean (среднее арифметическое), а затем отобразите результат на экране вывода, как показано здесь в следующей программе.
Программа на C++ определяющая среднее арифметическое значение
После программы на C++ попросите пользователя ввести размер числа (скажем, n ), затем попросите ввести n чисел для вычисления и отображения среднего арифметического всех чисел:
/ * Программа C ++ — Вычислить среднее арифметическое * /
Когда вышеупомянутая программа C++ компилируется и выполняется, она даст следующий результат:
iPhone с iPad неплохие варианты, но…
iPhone 11 один из лучших смартфонов, который у меня только был.
В 2019-м на самом старте продаж я купил себе iPhone 11. У него уже был IPS-экран, и после AMOLED с ШИМ это был огромный плюс. Читать с него оказалось намного комфортнее, глаза почти не уставали. Он идеален для чтения в кровати или такси, если бы снова не пара «но».
Экран у него был большой, но недостаточно, чтобы вместить весь текст. Приходилось периодически увеличивать и уменьшать размер текста. Золотой середины я не нашёл. К тому же смартфон весит прилично, и постоянно держать его в руке со временем становится неудобно — ты просто устаёшь.
Экран iPhone один из лучших. Читать и смотреть кино с него всё равно одно удовольствие по сравнению с другими смартфонами.
Такие моменты, увы, как я говорил выше отвлекают от процесса чтения. Зато на iPhone можно читать в ванной, потому что у него есть защита от воды. С бумажной книгой лежать в ванной на мой взгляд кощунственно. Бумага и переплёт вряд ли выдержат влагу.
iPad у меня появился чуть раньше, в 2018 году, и он сравним с большими книгами. Планшет идеален для чтения в помещении. В остальном, это большой и тяжёлый гаджет, который куда угодно с собой не возьмёшь. Исключение из правил — iPad mini. Он, как и электронная книга, спокойно помещается в поясную сумку. Правда, от экрана iPad у меня глаза уставали почему-то даже больше, чем от iPhone.
На чтение с «таблетки» я тоже забил и вернулся к обычным книгам, пока не решился на одну из своих лучших покупок.
Что лучше выбрать
Итак, существенная разница между планшетом и электронной книгой с чернилами – во времени работы и воздействии на глаза.
Совет! Если покупатель не может решить, что ему нужно, электронная книга или планшет, при этом гаджет нужен исключительно для чтения, то следует купить читалку на основе чернил.
Время автономной работы в зависимости от емкости батареи может достигать месяца, то есть даже длительные поездки не вызовут потребности искать зарядку. Второй момент – проведя с таким устройством несколько часов, владелец не почувствует усталости. Считается, что подобные модели безопасны для зрения, а ученые установили, что глаз не понимает разницу между дисплеем E-Ink и текстом, напечатанным на бумаге.
Подобные устройства рекомендуются для школы. Здесь есть сразу несколько плюсов. В устройство можно скачать любые учебники и дополнительную литературу. Для школьника это способ избавиться от тяжелых книжек в сумке, глаза не устают от мерцания. Кроме того, за счет ограниченного количества функций, девайс на чернилах не даст ученику лишний раз отвлечься, так как игры, интернет и прочие развлекательные функции здесь вторичны и носят скорее характер присутствия, нежели действительно удобны для пользования.
![]()
Гаджеты на основе чернил, как и планшеты, бывают самых разных размеров – от карманных вариантов 6 дюймов до моделей с диагональю 10 дюймов. По отзывам, на последних удобно читать журналы, скачанные в формате PDF. Чаще всего подобные девайсы имеют кнопочное управление, сенсоры встречаются, но редко и в дорогих моделях.
Стоимость гаджетов с чернилами достаточно высокая. Они дороже обычных электронных книг, а самые достойные модели могут соперничать по стоимости с планшетами среднего ценового сегмента. Но стоит понимать, что покупая дорогую читалку на чернилах, пользователь получает сразу несколько плюсов.
- Эргономичная поверхность с покрытием Soft Touch, то есть гаджет не выскользнет из руки.
- У аппарата будет хорошая скорость отзыва — странички перелистываются очень быстро, это оценят заядлые читатели, которые буквально проглатывают страницы.
- Нередко в дорогих читалках встречается защита от влаги и подсветка, упомянутая выше.
![]()
Выборочная дисперсия от числовой последовательности.
Описание:
Функция модуля возвращает выборочную дисперсию данных , которые представляют готовую выборку элементов из всей числовой последовательности.
- Аргумент может быть последовательностью или итерацией и должна иметь по крайней мере два действительных числа..
- Если входные данные пусты, то возникает ошибка .
Дисперсия является мерой изменчивости (разброса) элементов числовой последовательности. Большая дисперсия указывает на то, что данные распределены относительно среднего значения. Небольшая дисперсия указывает на то, что они тесно сгруппированы вокруг среднего значения числовой последовательности.
Если указан необязательный второй аргумент , то это должно быть среднее значение данных . Если аргумент отсутствует или None (по умолчанию), то среднее арифметическое значение рассчитывается автоматически.
Используйте функцию , когда данные являются выборкой из элементов числовой последовательности. Смотрите функцию , чтобы вычислить дисперсию всей совокупности числовой последовательности.
Примеры использования функции :
>>> import statistics >>> data = 2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5 >>> statistics.variance(data) # 1.3720238095238095 # дисперсию всей числовой последовательности >>> statistics.pvariance(data) # 0.9739583333333334
Если есть рассчитанное среднее значение данных, то можно передать его как необязательный второй аргумент , чтобы избежать пересчета:
>>> data = 2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5 >>> m = statistics.mean(data) >>> statistics.variance(data, m) # 1.3720238095238095
Функция не проверяет переданное значение аргумента на фактическое среднее значение числовой последовательности. Использование произвольных значений для может привести к недействительным или невозможным результатам.
Функция поддерживает десятичные и дробные значения:
>>> from decimal import Decimal as D
>>> statistics.variance()
# Decimal('31.01875')
>>> from fractions import Fraction as F
>>> statistics.variance()
# Fraction(67, 108)
Примечание. Значение этой функции представляет собой выборочную дисперсию из элементов числовой последовательности с поправкой Бесселя, также известную как дисперсия с N-1 степенями свободы. При условии, что элементы данных репрезентативны (например, независимы и одинаково распределены), то результатом должна быть объективная оценка истинной дисперсии всей числовой последовательности.
Если каким-то образом известно фактическое среднее значение всей числовой последовательности , то это значение необходимо передать функции в качестве параметра , чтобы получить дисперсию выборки из числовой последовательности.
Вычислить среднее арифметическое в C++
Чтобы вычислить среднее арифметическое чисел в программировании на C++ , вы должны попросить пользователя ввести размер числа, а затем попросить ввести числа этого размера.
Чтобы вычислить среднее арифметическое для всех чисел, сначала выполните сложение всех чисел, затем возьмите переменную, отвечающую за среднее арифметическое, и поместите добавление / размер в переменную, скажем armean (среднее арифметическое), а затем отобразите результат на экране вывода, как показано здесь в следующей программе.
Программа на C++ определяющая среднее арифметическое значение
После программы на C++ попросите пользователя ввести размер числа (скажем, n ), затем попросите ввести n чисел для вычисления и отображения среднего арифметического всех чисел:
Когда вышеупомянутая программа C++ компилируется и выполняется, она даст следующий результат:
![]()
Продажи смартфонов просто смыли продажи компьютеров
![]() Квартальная выручка Apple с 2007 по 2020 годы в разрезе категорий гаджетов.
Квартальная выручка Apple с 2007 по 2020 годы в разрезе категорий гаджетов.
Компания Apple уже более 10 лет зарабатывает на iPhone больше, чем на продажах Mac. Последние 5 лет смартфоны приносят купертиновцам в несколько раза больше, чем компьютеры и планшеты вместе взятые.
Мировые продажи смартфонов обогнали компьютеры еще 10 лет назад. С каждым годом разрыв между данными категориями все больше. При этом планшеты продаются ненамного лучше стационарных ПК. Всплеск в данной нише наблюдался во время появления первых iPad и их конкурентов, но сейчас ежегодные продаже планшетов все равно ниже, чем количество продаваемых компьютеров.
Вряд ли планшеты смогут составить конкуренцию рынку ПК в ближайшие годы. И тех и других беспощадно побеждают смартфоны.
От сухих цифр к реальным примерам. Многие пользователи, у которых компьютер есть на работе, не покупают стационарный комп домой. Интернет, новости и социальные сети есть в смартфоне, а дома остальные потребности перекрывают игровая консоль, умная колонка или телевизор.








Несколько методов для поиска среднего и стандартного отклонения в Python
Давайте напишем код Python для расчета среднего и стандартного отклонения. Вы получаете несколько вариантов для расчета среднего и стандартного отклонения в Python. Давайте посмотрим на встроенный статистический модуль, а затем попробуйте написать нашу собственную реализацию.
1. Использование модуля статистики
Этот модуль предоставляет вам возможность вычисления среднего и стандартного отклонения напрямую.
Давайте начнем, импортируя модуль.
import statistics
Давайте объявим массив с фиктивными данными.
data =
Теперь, чтобы рассчитать среднее значение образца данных, используйте:
statistics.mean(data)
Это утверждение вернет среднее значение данных. Мы можем напечатать среднее значение в выходе, используя:
print("Mean of the sample is % s " %(statistics.mean(data)))
Мы получаем вывод как:
Mean of the sample is 13.666666666666666
Если вы используете IDE для кодирования, вы сможете наведите следующее заявление и получить дополнительную информацию о статистике. МЕС ().
В качестве альтернативы вы можете прочитать документацию здесь Отказ
Для расчета стандартного отклонения использования образцов использования:
print("Standard Deviation of the sample is % s "%(statistics.stdev(data)))
Мы получаем вывод как:
Standard Deviation of the sample is 15.61623087261029
Вот краткая документация статистики .Stev ().
Полный код, чтобы найти стандартное отклонение и среднее значение
Полный код для фрагментов выше выглядит следующим образом:
import statistics
import numpy as np
data = np.array()
print("Standard Deviation of the sample is % s "% (statistics.stdev(data)))
print("Mean of the sample is % s " % (statistics.mean(data)))
2. Напишите свою собственную функцию
Давайте напишем нашу функцию для расчета среднего.
def mean(data): n = len(data) mean = sum(data) / n return mean
Эта функция рассчитает среднее значение.
Теперь давайте напишем функцию для расчета стандартного отклонения.
Это может быть немного сложно, поэтому давайте пойдем на это шаг за шагом.
Стандартное отклонение – Квадратный корень дисперсии Отказ Таким образом, мы можем написать две функции:
- тот, который рассчитает отклонение
- тот, который рассчитает квадратный корень дисперсии.
Функция для расчетной дисперсии заключается в следующем:
def variance(data): n = len(data) mean = sum(data) / n deviations = variance = sum(deviations) / n return variance
Вы можете обратиться к шагам, указанным в начале учебника, чтобы понять код.
Теперь мы можем написать функцию, которая рассчитывает квадратный корень дисперсии.
def stdev(data): import math var = variance(data) std_dev = math.sqrt(var) return std_dev
Полный код
Полный код выглядит следующим образом:
import numpy as np #for declaring an array
def mean(data):
n = len(data)
mean = sum(data) / n
return mean
def variance(data):
n = len(data)
mean = sum(data) / n
deviations =
variance = sum(deviations) / n
return variance
def stdev(data):
import math
var = variance(data)
std_dev = math.sqrt(var)
return std_dev
data = np.array()
print("Standard Deviation of the sample is % s "% (stdev(data)))
print("Mean of the sample is % s " % (mean(data)))
Как попасть в вондер?
Копипаста из абсолютного гайда:
Вот порядок действий для создания страны чудес:
Шаг 1: Решите для себя, на что она будет похожа. Сделайте её план на бумаге, если хотите. Вам вовсе не нужно определять в ней абсолютно всё, перед тем как пойти туда. Вы можете прорабатывать её по мере того как Вы будете идти по ней, но будет мудро, по крайней мере представлять на что она должна быть похожа.
Шаг 2: Вообразите себя на том месте, которое Вы запланировали.
Шаг 3: ???
Шаг 4: Profit!
Серьезно, это очень просто.
Либо ещё проще объяснение: закройте глаза и представьте чашку. Представили? Вы уже в вондере
Обратите внимание на пространство, в котором находится чашка. Оно чёрное? Пока что это ваш вондер
Заполняйте его, создавайте, творите.
Важно! Для кого-то глупо прозвучит, но многие не понимали вондерленд, так как думали, что не должны его воображать. Это ошибочно
Смотрите вондер не глазами, а воображением/мыслевзором. Не смотрите в свои тёмные веки и не ждите неких самостоятельно всплывающих образов. Также, как вы не сможете прочитать книгу, не переворачивая страницы, вы не сможете вондерить, если просто закроете глаза и будете смотреть в темноту. Нужно представлять.
Вообще для входа в вондерленд используется в 95% случаев лестница, поэтому настоятельно рекомендуем ознакомиться с ней в тульпавики (Метод лестницы. EnTrance). Зачем вам лестница, если всё так просто? Об этом немного ниже.





