
Выполнение кода
Среда CLR предоставляет инфраструктуру, обеспечивающую управляемое выполнение кода, и ряд служб, которые можно использовать при выполнении. Перед выполнением метода его необходимо скомпилировать в код для конкретного процессора. Каждый метод, для которого создан MSIL-код, компилируется с помощью JIT-компилятора при первом вызове и затем запускается. При следующем вызове метода будет выполняться существующий JIT-скомпилированный код. Процесс JIT-компиляции и последующего выполнения кода повторяется до завершения выполнения.
Во время выполнения для управляемого кода доступны такие службы, как сборка мусора, обеспечение безопасности, взаимодействие с неуправляемым кодом, поддержка отладки на нескольких языках, а также поддержка расширенного развертывания и управления версиями.
В Microsoft Windows Vista загрузчик операционной системы выполняет поиск управляемых модулей, анализируя бит в заголовке COFF. Установленный бит обозначает управляемый модуль. При обнаружении управляемых модулей загружается библиотека Mscoree.dll, а подпрограммы и уведомляют загрузчик о загрузке и выгрузке образов управляемых модулей. Подпрограмма выполняет следующие действия:
-
Проверяет, является ли код допустимым управляемым кодом.
-
Заменяет точку входа в образе на точку входа в среде выполнения.
В 64-разрядных системах Windows изменяет образ, находящийся в памяти, путем преобразования его из формата PE32 в формат PE32+.
4.3 Построение цепочки кросс-компиляции с нуля
Это наиболее сложный и трудоемкий процесс. В конце концов, чтобы создать такую цепочку кросс-компиляции, вам необходимо хорошо понимать принцип встроенной компиляции. По крайней мере, вам нужно знать, куда обращаться, чтобы прочитать информацию в случае возникновения проблемы
Кроме того, это также место, где испытывают наибольшее терпение и осторожность.Если вы не соответствуете варианту или шагу, у вас могут возникнуть проблемы, которых вы никогда раньше не видели, и эти проблемы часто не связаны напрямую с этим параметром или шагом
Конечно, если он собран, он, безусловно, будет самым полезным. По крайней мере, процесс компиляции и зависимости относительно ясны. Детали, возможно, должны пройти через соответствующий протокол или стандарт, но, по крайней мере, скелет будет более понятным.
Для подробного процесса строительства, пожалуйста, обратитесь к последующим статьям, в которых есть подробные параметры и шаги:Подробное объяснение кросс-компиляции 2 Создание цепочки кросс-компиляции из нуля
Чтобы помочь каждому построить цепочку кросс-компиляции, я написал сценарий, сгенерированный одним щелчком мыши (включая загрузку исходного кода и автоматическую компиляцию). Если вам не удалось создать его самостоятельно, вы можете попробовать этот сценарий, а затем сравнить, является ли ваш процесс согласованным и отличаются ли параметры. Возможно, это поможет вам преодолеть это препятствие:Подробное объяснение кросс-компиляции 3 Используйте скрипт для автоматической генерации цепочки кросс-компиляции
Что делает компилятор C
Работа компилятора C заключается в конвертировании текста программы на C, понятного человеку, в нечто, что понимает компьютер. На выходе компилятор выдаёт объектный файл.
Содержание объектного файла — в сущности, две вещи:
- код, соответствующий определению функции в C-файле,
- данные, соответствующие определению глобальных переменных в C-файле (для инициализированных глобальных переменных начальное значение переменной тоже должно быть сохранено в объектном файле).
Код и данные будут иметь ассоциированные с ними имена — имена функций или переменных, с которыми они связаны определением.
Объектный код — это последовательность машинных инструкций для процессора, которая соответствует C-коду: if‘ы и while‘ы и пр. Эти инструкции должны манипулировать информацией определённого рода, а информация должна где-нибудь находится — для этого нам и нужны переменные. Код может также ссылаться на другой код (в частности, на другие C-функции в программе).
Где бы код ни ссылался на переменную или функцию, компилятор допускает это, только если он видел раньше объявление этой переменной или функции. Объявление — это обещание, что определение существует где-то в другом месте программы.
Работа компоновщика проверить эти обещания. Однако, что компилятор делает со всеми этими обещаниями, когда он генерирует объектный файл?
По существу компилятор оставляет пустые места. Пустое место (ссылка) имеет имя, но значение, соответствующее этому имени, пока неизвестно.
Учитывая это, мы можем изобразить объектный файл, соответствующей программе, приведённой выше, следующим образом:
![]()
Анализ объектного файла
Полезно посмотреть, как это работает на практике.
$ gcc -c example1.c $ ls example1.c example1.o
Объектный файл, хоть и не может быть запущен напрямую, имеет формат, схожий с форматом исполняемого файла.
На UNIX объектные файлы имеют расширение o. Формат — ELF.
На Windows используется расширение obj. Формат — COFF.
На платформе UNIX основным инструментом для нас будет команда nm, которая выдаёт информацию о символах объектного файла. Для Windows команда dumpbin с опцией /symbols является приблизительным эквивалентом. Также есть портированные под Windows инструменты GNU binutils, которые включают nm.exe.
Давайте посмотрим, что выдаёт nm для объектного файла, полученного из нашего примера выше.
$ nm -S example1.o
U fn_a
0000000000000000 000000000000000f t fn_b
000000000000000f 0000000000000059 T fn_c
0000000000000000 0000000000000004 D x_global_init
0000000000000004 0000000000000004 C x_global_uninit
0000000000000004 0000000000000004 d y_global_init
0000000000000000 0000000000000004 b y_global_uninit
U z_global
Результат может выглядеть немного по разному на разных платформах.
$ nm -f sysv example1.o Symbols from example1.o: Name Value Class Type Size Line Section fn_a | | U | NOTYPE| | |*UND* fn_b |0000000000000000| t | FUNC|000000000000000f| |.text fn_c |000000000000000f| T | FUNC|0000000000000059| |.text x_global_init |0000000000000000| D | OBJECT|0000000000000004| |.data x_global_uninit |0000000000000004| C | OBJECT|0000000000000004| |*COM* y_global_init |0000000000000004| d | OBJECT|0000000000000004| |.data y_global_uninit |0000000000000000| b | OBJECT|0000000000000004| |.bss z_global | | U | NOTYPE| | |*UND*
Ключевыми сведениями являются класс каждого символа и его размер (если присутствует).
- Класс U (от undefined) обозначает неопределённые ссылки, те самые «пустые места», упомянутые выше. Для этого класса существует два объекта: fn_a и z_global.
- Классы t и T (от слова text) указывают на код, который определён; различие между t и T заключается в том, является ли функция статической (t) (локальной в файле) или нет (T), т.е. была ли функция объявлена как static.
- Классы d и D (от слова data) содержат инициализированные глобальные переменные. При этом статические переменные принадлежат классу d.
- Для неинициализированных глобальных переменных мы получаем b, если они статичные, и B или C иначе.
Генерация промежуточного кода
В процессе компиляции, могут создаваться несколько промежуточных представлений, в частности, синтаксическое дерево.
Как правило, после завершения синтаксического и семантического анализа, значительная часть высокоуровневой информации (типы, названия переменных, многие управляющие конструкции и т.п.) далее не требуется, в связи с чем многие компиляторы по достижении этой фазы генерируют более низкоуровневое представление, называемое обычно промежуточным кодом.
Основными требованиями к промежуточному коду являются, с одной стороны, простота его получения из синтаксического дерева, и с другой стороны, простота генерации на его основе машинного кода.
Как следствие, часто в качестве промежуточного кода используется последовательность инструкций для некой абстрактной вычислительной машины.
На этом этапе обычно принимаются решения о распределении памяти для хранения значений переменных.
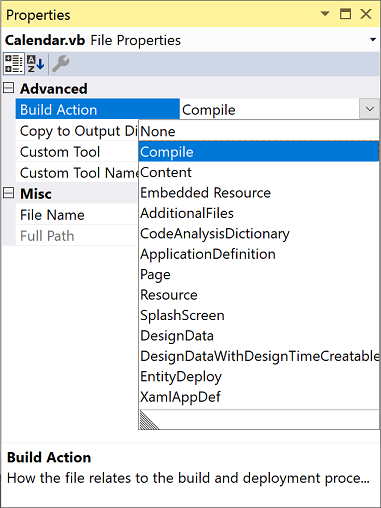
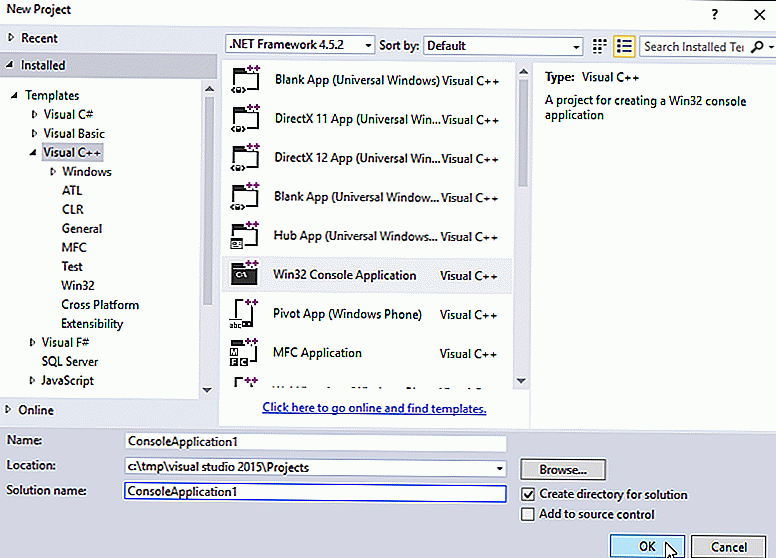
Указание значка приложения
Настоятельно рекомендуется указывать значок приложения для каждого проекта Xamarin.Android. Некоторые магазины приложений не допускают публикацию приложений Android без значков. Указать значок приложения для проекта Xamarin.Android можно с помощью свойства атрибута .
В этих примерах ссылается на файл значка, расположенный в области ресурсы, которые можно (Обратите внимание, что расширение .png не включено в имя ресурса). Этот атрибут также объявляется в файле Properties\AssemblyInfo.cs, как показано в следующем примере:. Как правило, объявляется в верхней части (пространство имен атрибута — ); однако может потребоваться добавить эту инструкцию, если она еще не существует
Как правило, объявляется в верхней части (пространство имен атрибута — ); однако может потребоваться добавить эту инструкцию, если она еще не существует.
Правила целостности для пофайлового использования предкомпилированных заголовков
Параметр компилятора /Yu позволяет указать, какой файл PCH следует использовать.
При использовании файла PCH компилятор предполагает ту же среду компиляции, которая использует последовательные параметры компилятора, прагмы и т. д., которые действуют при создании файла PCH, если не указано иное. Если компилятор обнаруживает несогласованность, он выдает предупреждение и по возможности определяет несогласованность. Такие предупреждения не обязательно указывают на проблему с файлом PCH. Они просто предупреждают о возможных конфликтах. Требования к согласованности для файлов PCH описаны в следующих разделах.
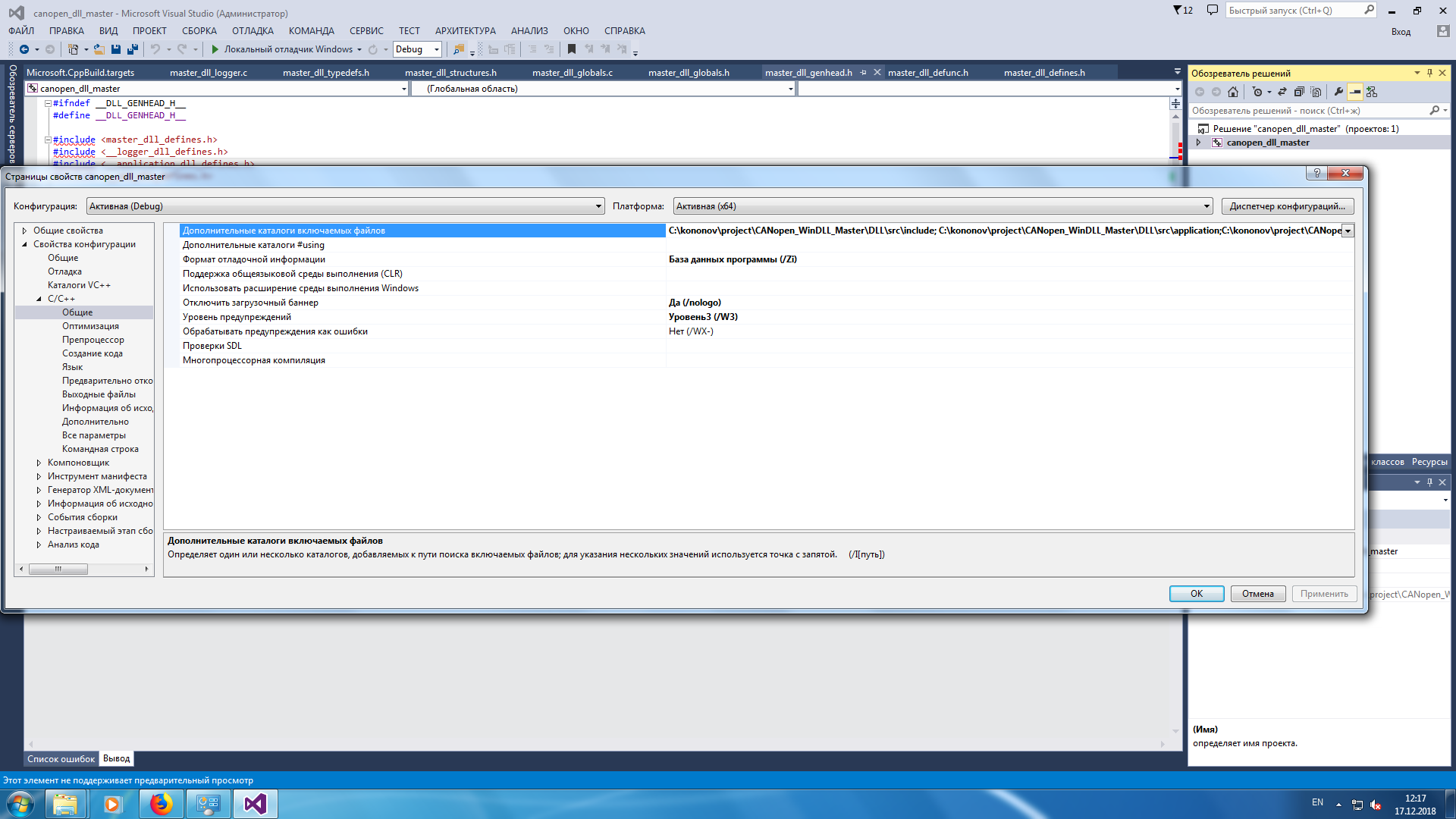
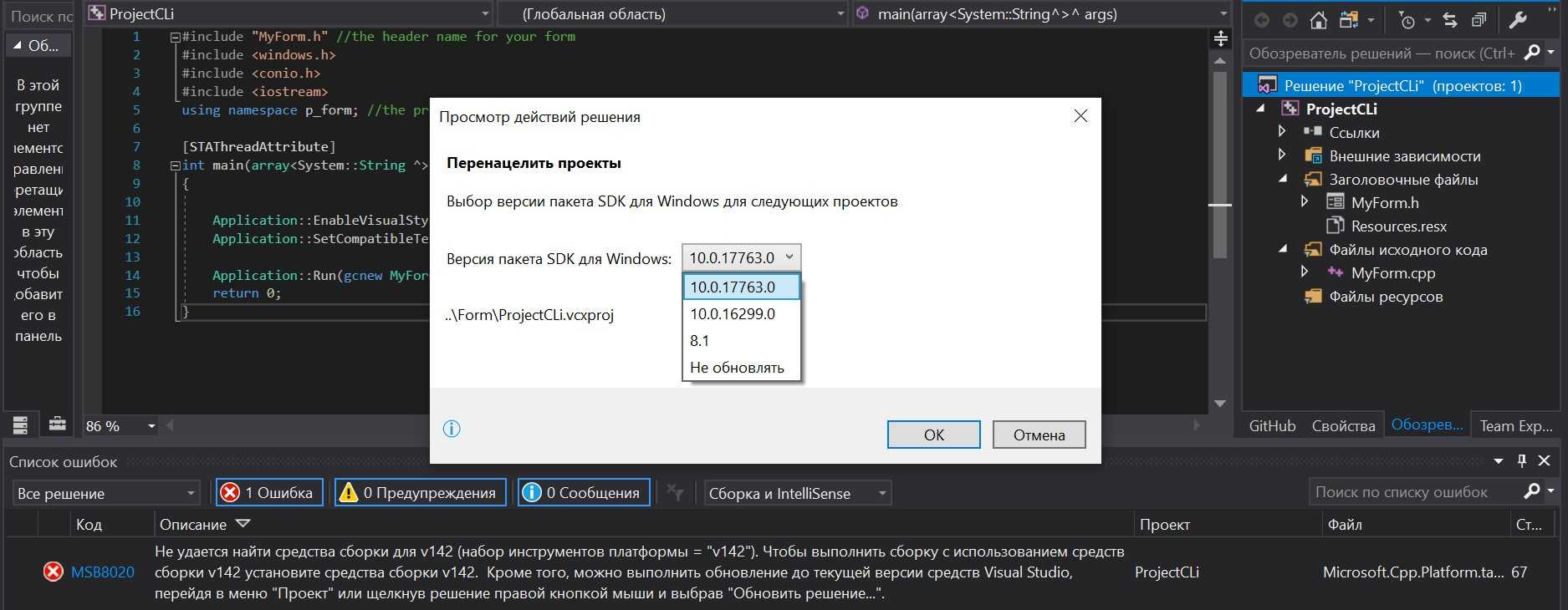
Согласованность параметров компилятора
Следующие параметры компилятора могут вызвать предупреждение о несогласованности при использовании файла PCH:
-
Макросы, созданные с помощью параметра препроцессора (/D), должны быть одинаковыми в компиляциях, создавшими файл PCH, и текущей компиляцией. Состояние определенных констант не проверяется, но при их изменениях могут возникать непредсказуемые результаты.
-
Файлы PCH не работают с параметрами/E и /EP.
-
Файлы PCH должны быть созданы с помощью параметра создания сведений о просмотре (/FR) или исключения локальных переменных (/Fr), прежде чем последующие компиляции, использующие файл PCH, смогут использовать эти параметры.
C7 совместимо (/Z7)
Если при создании файла PCH этот параметр включен, последующие компиляции, использующие файл PCH, могут использовать отладочную информацию.
Если при создании файла PCH параметр «C7 совместимо (/Z7)» отключен, последующие компиляции, использующие файл PCH и/Z7, вызывают предупреждение. Отладочная информация помещается в текущий OBJ-файл, а локальные символы, определенные в файле PCH, недоступны отладчику.
Согласованность пути включаемых файлов
В файле PCH не содержатся сведения о пути включаемых файлов, который применялся при создании. При использовании файла PCH компилятор всегда использует путь включаемых файлов, указанный в текущей компиляции.
Согласованность исходного файла
При указании параметра использования файла предкомпилированного заголовка (/Yu) компилятор игнорирует все директивы препроцессора (включая прагмы), отображаемые в исходном коде, который будет предварительно скомпилирован. Компиляция, указанная такими директивами препроцессора, должна совпадать с компиляцией, используемой для параметра создания файла предкомпилированного заголовка (/Yc).
Согласованность прагмы
Прагмы, обработанные во время создания файла PCH, обычно влияют на файл, с которым впоследствии используется файл PCH. Прагмы и не влияют на оставшуюся часть компиляции.
Они влияют только на код в файле PCH; они не влияют на код, который впоследствии использует файл PCH:
Эти прагмы сохраняются как часть предкомпилированного заголовка и влияют на оставшуюся часть компиляции, использующую предкомпилированный заголовок:
4 ответа
Лучший ответ
При сборке, при компиляции?
Компилятор автоматически перекомпилирует модули только при изменении отметки даты и времени исходных файлов .pas (1,2).
При других изменениях состояния в проекте (директивы, отладка или другие настройки компилятора и т. Д.) Компилятор не будет автоматически перекомпилировать. Вот когда вам нужно форсировать сборку.
Вам также необходимо принудительно выполнить перестройку при изменении .inc или других включенных ($ I) файлов (3), поскольку их отметка даты и времени не проверяется.
Таким образом, если изменяется что-либо, кроме файлов .pas модуля, вам необходимо выполнить сборку.
Бывают странные случаи в строительстве. В большинстве случаев возникает ошибка «не удается найти блок xxx» , хотя он, кажется, есть
- один — когда путь к модулю в проекте неверен или используется относительный путь, а рабочий каталог неверен. (см. Delphi отлаживает неправильный модуль)
- (Я не совсем уверен в этом, это гипотеза) .dcu перекомпилирован из-за CRC (1), но вновь скомпилированный dcu помещается в другой каталог. Это не проблема для текущей компиляции (поскольку правильный dcu уже загружен), но при последующей компиляции (например, в зависимом пакете) старый файл dcu обнаруживается снова, а источник не -> ошибка. в случае сомнений всегда очищайте каталоги сборки, рекурсивно удаляя все DCU
- объект указан с неправильным путем в .dpr
(1) и если Delphi похож на FPC, .dcu содержат CRC раздела интерфейса всех dcu, от которых он зависит. Это можно использовать, чтобы проверить, есть ли дополнительная необходимость в перекомпиляции. Например. из-за манипуляций с файловой системой (перемещение dcu)
(2) для экспертов также обратите внимание на {$ implicitbuild xx}. (3) в отличие от Delphi, FPC перестраивается с изменениями .inc
Проект FPC широко использует файлы .inc внутри, это изменение уже относится к тому времени, когда появилась поддержка Delphi. В результате пакеты, которые копируют файл «define» inc в какой-либо каталог, не будут компилироваться с FPC, потому что они обычно имеют немного другой размер и CRC. Indy (10) — хороший тому пример
(3) в отличие от Delphi, FPC перестраивается с изменениями .inc. Проект FPC широко использует файлы .inc внутри, это изменение уже относится к тому времени, когда появилась поддержка Delphi. В результате пакеты, которые копируют файл «define» inc в какой-либо каталог, не будут компилироваться с FPC, потому что они обычно имеют немного другой размер и CRC. Indy (10) — хороший тому пример.
18
7 revs
23 Май 2017 в 11:46
При подготовке выпуска вам необходимо обязательно выполнить полную сборку. Нет никаких оправданий, ведь компилятор Delphi достаточно быстр.
Разъяснение важности воспроизводимого высвобождения
- При подготовке релиза у вас будет версия вашего продукта, которую будут использовать другие люди.
- Если они сообщают о проблемах, вам может потребоваться вернуться к этой версии, чтобы проверить и исправить проблему.
- Если вы не выполнили полную сборку, а вместо этого полагались на существующие DCU, существует шанс , что один из ваших исходных файлов не был перекомпилирован.
- Даже если эта возможность довольно мала, она может серьезно помешать вашей способности быстро решить проблему.
- Эта проблема усугубляется по мере того, как система становится больше, имеет больше взаимозависимостей и больше версий, «поддерживаемых в дикой природе».
Для вашего собственного здравомыслия я настоятельно рекомендую вам всегда делать полную сборку для готовой к выпуску версии. Я регулярно делаю полные сборки даже для невыпускаемых версий.
3
Disillusioned
13 Июл 2010 в 16:09
При изменении настроек всегда следует выполнять сборку.
Ранее скомпилированные файлы DCU могли быть скомпилированы с другими настройками, такими как определения компилятора. Это может привести к тому, что два модуля в одном проекте будут скомпилированы с разными настройками.
3
Robert Love
13 Июл 2010 в 02:34
@Daisetsu, вот разница между сборкой и компиляцией.
Сборка компилирует все используемые модули в проекте, когда доступен исходный код.
Compile компилирует только измененные используемые единицы.
По моему личному опыту, когда вы вносите изменения в конфигурацию компилятора, вы должны выполнить сборку приложения, чтобы изменения отражались во всех модулях проекта.
26
RRUZ
13 Июл 2010 в 02:38
Типы IL
Типы IL кода описаны в классе ILEmitStyle.
На диаграмме выше показано, что тип генерируемого IL кода C# компилятором зависит от OptimizationLevel.
Аргумент debug не меняет его, за исключение аргумента debug+ когда OptimizationLevel установлен в Release.
![Процесс сборки edkii: процесс настройки и компиляции исходного кода проекта edkii [3] - русские блоги](https://fuzeservers.ru/wp-content/uploads/8/b/7/8b7fbca85fd450a0b46566a527734bd9.png)
![[язык c] подробное объяснение (идентификатор предварительной обработки / макрос и функция / процесс компиляции) - русские блоги](https://fuzeservers.ru/wp-content/uploads/7/1/2/7127b818f94f4d0399e862cfdd83dd30.png)
- ILEmitStyle.Debug — нету оптимизация IL в дополнение к добавлению nop инструкций для сопоставления точекостановки с IL.
- LEmitStyle.Release — полная оптимизация.
- ILEmitStyle.DebugFriendlyRelease — выполняет только те оптимизации, которые не помешаю отладке приложения.
Следующий кусок кода продемонстрирует все это наглядно.
Комментарий в исходном файле Optimizer.cs гласит, что они не опускают никаких определенных пользователем локальных переменных (примеры на 28 строчке) и не переносят значения в стек между операторами.
Я рад, что прочитал это, так как я был немного разочарован своими собственными экспериментами в ildasm с debug +, поскольку все, что я видел, это сохранение локальных переменных.
Нет намеренной «деоптимизации», например, добавления команд nop.
Оптимизация кода
На этом этапе производится попытка сделать объектные программы более эффективными (т.е. быстрее работающими или более компактными).
ДОПОЛНИТЕЛЬНЫЙ МАТЕРИАЛ
Так, для операций, составляющих линейный участок программы, может применяться удаление бесполезных присваиваний, исключение лишних операций, перестановка операций, арифметические преобразования.
Еще одним методом оптимизации кода является оптимизация вычисления логических выражений (не всегда полностью надо выполнять вычисление всего выражения, чтобы знать его результат, иногда по значению одного операнда можно определить значение всего выражения).
Оптимизация передачи параметров в процедуры и функции через стек не является эффективным, если выполняются несложные вычисления над небольшим количеством параметров (всякий раз при вызове процедуры компилятор создает объектный код для размещения фактических параметров в стеке, а при выходе – код для освобождения ячеек). Эффективность результирующей программы повышается при передаче параметров через регистры либо подстановкой кода функции в вызывающий объектный код.
Для оптимизации циклов используются следующие методы: вынесение инвариантных вычислений из циклов (вынесение тех операций, операнды которых не изменяются); замена операций с индуктивными переменными (изменение сложных операций с переменными, значения которых в процессе выполнения цикла образуют арифметическую прогрессию, на более простые операции); слияние и развертывание циклов (слияние двух вложенных циклов в один и замена цикла на линейную последовательность операций).
Генерация объектного кода
Последний заключительный этап. Происходит порождение команд, составляющих предложения выходного языка и в целом текст результирующей программы.
В системе программирования Borland Pascal компиляция запускается с помощью режима меню Compile.
В случае отсутствия синтаксических ошибок (перевод осуществлен успешно) система программирования сообщает об этом пользователю и предлагает нажать любую клавишу для продолжения работы:
Compile successful. Press any key.
Если ошибка обнаружена, система сообщает пользователю название ошибки и указывает курсором ту строку, в которой обнаружена ошибка (иногда следующую строку после ошибочной). В этом случае пользователю необходимо исправить ошибку и снова запустить режим компиляции.
Следующие шаги
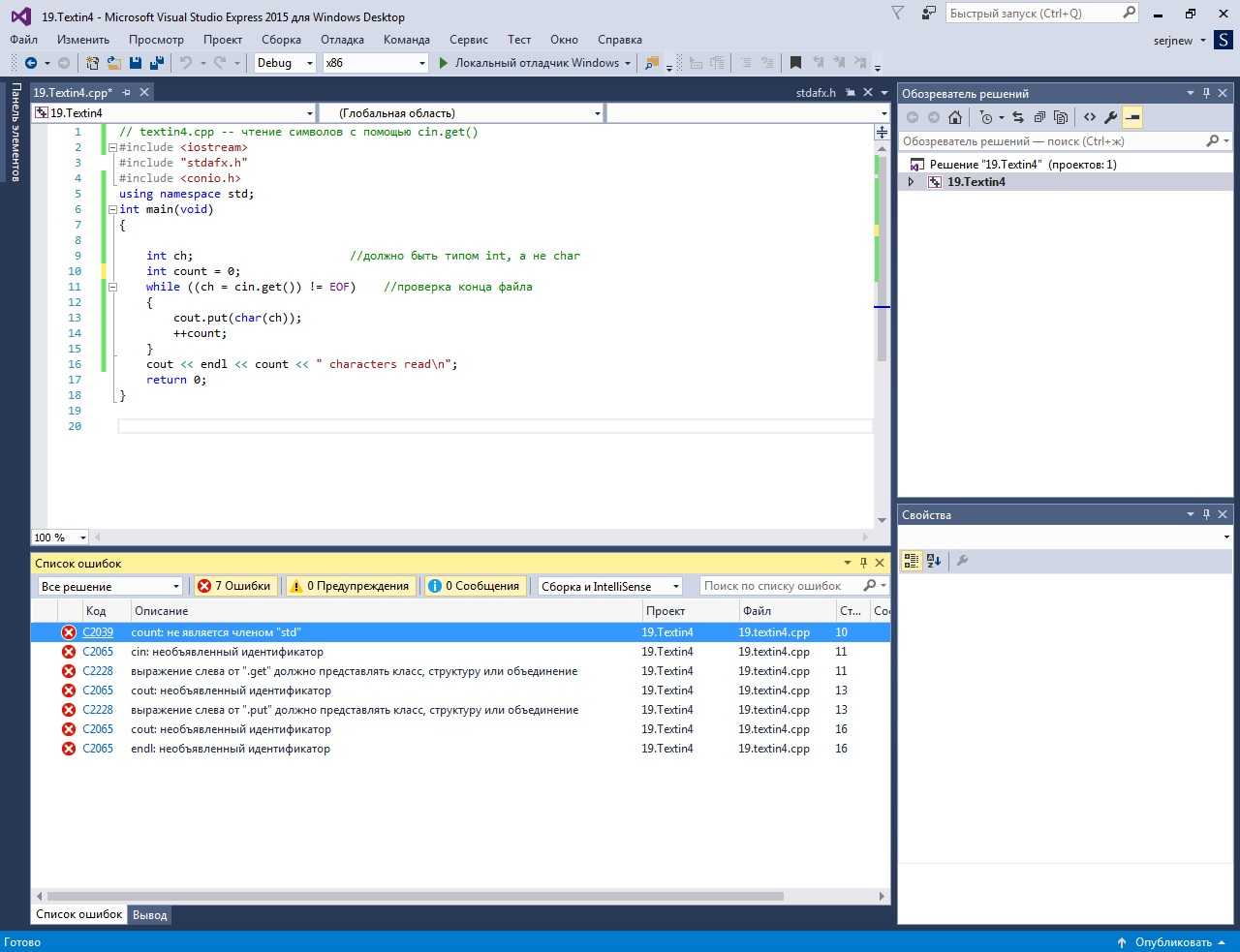
Этот пример Hello, World является самой простой программой C. Реальные программы выполняют полезные действия и имеют файлы заголовков, дополнительные исходные файлы и ссылки на библиотеки.
Вы можете использовать шаги, описанные в этом пошаговом руководстве для C, для создания собственного кода, чтобы не вводить приведенный пример. Вы также можете выполнить сборку различных примеров кода на C, которые можно найти в других местах. Чтобы скомпилировать программу с дополнительными файлами исходного кода, введите их все в командной строке, например:
Компилятор выдает программу с именем file1.exe. Чтобы изменить имя на program1.exe, добавьте параметр компоновщика /out:
Чтобы автоматически перехватывать другие ошибки программирования, рекомендуется выполнить компиляцию с помощью порога предупреждений /W3 или /W4:
Компилятор cl.exe имеет множество других параметров, которые можно применять для создания, оптимизации, отладки и анализа кода. Чтобы просмотреть краткий список, введите в командной строке разработчика. Можно также выполнять компиляцию и компоновку отдельно и применять параметры компоновщика в более сложных сценариях сборки. Дополнительные сведения о параметрах компилятора и компоновщика и использовании см. в разделе Справочник по построению C/C++.
Для настройки и создания более сложных проектов в командной строке можно использовать NMAKE и файлы makefile либо MSBuild и файлы проекта. Дополнительные сведения об использовании этих средств см. в разделах Справочник по NMAKE и MSBuild.
Языки C и C++ похожи, но имеют различия. Компилятор Microsoft C/C++ (MSVC) использует простое правило для определения языка, используемого при компиляции кода. По умолчанию компилятор MSVC рассматривает все файлы с расширением как исходные коды на языке С, а файлы с расширением как исходные коды на языке С++. Если указан параметр компилятора /TC, компилятор будет рассматривать все файлы как исходные коды на языке С вне зависимости от расширения.
Компилятор MSVC совместим со стандартами ANSI C89 и ISO C99, но не полностью. В большинстве случаев переносимый код на языке C будет компилироваться и выполняться должным образом. Компилятор обеспечивает дополнительную поддержку изменений в ISO C11/C17. Чтобы выполнить компиляцию с поддержкой C11/C17, используйте флаг компилятора или . Для поддержки C11 и C17 требуется Windows SDK 10.0.20201.0 или более поздняя версия. Рекомендуется использовать Windows SDK 10.0.22000.0 или более позднюю версию. Последнюю версию пакета можно скачать на странице Windows SDK. Дополнительные сведения и инструкции по установке и использованию этого пакета SDK для разработки на языке C см. в статье Установка поддержки C11 и C17 в Visual Studio.
Некоторые функции библиотеки и имена функций POSIX являются нерекомендуемыми в компиляторе MSVC. Функции поддерживаются, но предпочтительные имена изменились. Дополнительные сведения см. в статьях Функции безопасности в CRT и Предупреждение компилятора (уровень 3) C4996.
За и против
Основным аргументом за использование процесса компиляции является скорость. Возможность компилировать любой программный код в машинный, который может понять процессор ПК, исключает использование промежуточного кода. Можно запускать программы без дополнительных шагов, тем самым увеличивая скорость обработки кода.
Но наибольшим недостатком компиляции является специфичность. Когда компилируете программу для работы на конкретном процессоре, вы создаете объектный код, который будет работать только на этом процессоре. Если хотите, чтобы программа запускалась на другой машине, вам придется перекомпилировать программу под этот процессор. А перекомпиляция может быть довольно сложной, если процессор имеет ограничения или особенности, не присущие первому. А также может вызывать ошибки компиляции.
Основное преимущество интерпретации — гибкость. Можно не только запускать интерпретируемую программу на любом процессоре или платформе, для которых интерпретатор был скомпилирован. Написанный интерпретатор может предложить дополнительную гибкость. В определенном смысле интерпретаторы проще понять и написать, чем компиляторы.
С помощью интерпретатора проще добавить дополнительные функции, реализовать такие элементы, как сборщики мусора, а не расширять язык.
Другим преимуществом интерпретаторов является то, что их проще переписать или перекомпилировать для новых платформ.
Написание компилятора для процессора требует добавления множества функций, или полной переработки. Но как только компилятор написан, можно скомпилировать кучу интерпретаторов и на выходе мы имеем перспективный язык. Не нужно повторно внедрять интерпретатор на базовом уровне для другого процессора.
Самым большим недостатком интерпретаторов является скорость. Для каждой программы выполняется так много переводов, фильтраций, что это приводит к замедлению работы и мешает выполнению программного кода.
Это проблема для конкретных real-time приложений, таких как игры с высоким разрешением и симуляцией. Некоторые интерпретаторы содержат компоненты, которые называются just-in-time компиляторами (JIT). Они компилируют программу непосредственно перед ее исполнением. Это специальные программы, вынесенные за рамки интерпретатора. Но поскольку процессоры становятся все более мощными, данная проблема становится менее актуальной.
Директива #define
Директива #define позволяет вводить в текст программы константы и макроопределения.
Общая форма записи
#define Идентификатор Замена
ИдентификаторЗамена#defineЗаменаИдентификатор
12345678
#include <stdio.h>#define A 3int main(){ printf(«%d + %d = %d», A, A, A+A); // 3 + 3 = 6 getchar(); return 0;}
- U или u представляет целую константу в беззнаковой форме (unsigned);
- F (или f) позволяет описать вещественную константу типа float;
- L (или l) позволяет выделить целой константе 8 байт (long int);
- L (или l) позволяет описать вещественную константу типа long double
#define A 280U // unsigned int#define B 280LU // unsigned long int#define C 280 // int (long int)#define D 280L // long int#define K 28.0 // double#define L 28.0F // float#define M 28.0L // long double
идентификатор(аргумент1, …, агрументn)
заменаПример на Си
12345678910111213141516
#include <stdio.h>#include <stdlib.h>#include <math.h>#define PI 3.14159265#define SIN(x) sin(PI*x/180)int main(){ int c; system(«chcp 1251»); system(«cls»); printf(«Введите угол в градусах: «); scanf(«%d», &c); printf(«sin(%d)=%lf», c, SIN(c)); getchar(); getchar(); return 0;}
Результат выполнения![]()
Отличием таких макроопределений от функций в языке Си является то, что на этапе компиляции каждое вхождение идентификатора замещается соответствующим кодом. Таким образом, программа может иметь несколько копий одного и того же кода, соответствующего идентификатору
В случае работы с функциями программа будет содержать 1 экземпляр кода, реализующий указанную функцию, и каждый раз при обращении к функции ей будет передано управление.
Отменить макроопределение можно с помощью директивы #undef.
Однако при использовании таких макроопределений следует соблюдать осторожность, например
12345678910111213
#include <stdio.h>#define sum(A,B) A+Bint main(){ int a, b, c, d; a = 3; b = 5; c = (a + b) * 2; // c = (a + b)*2 d = sum(a, b) * 2; // d = a + b*2; printf(» a = %d\n b = %d\n», a, b); printf(» c = %d \n d = %d \n», c, d); getchar(); return 0;}
![]() \
\
1234567891011121314
#include <stdio.h>#define sum(A,B) A + \ Bint main(){ int a, b, c, d; a = 3; b = 5; c = (a + b) * 2; // c = (a + b)*2 d = sum(a, b) * 2; // d = a + b*2; printf(» a = %d\n b = %d\n», a, b); printf(» c = %d \n d = %d \n», c, d); getchar(); return 0;}
#define##
123456789
#include <stdio.h>#define SUM(x,y) (a##x + a##y)int main(){ int a1 = 5, a2 = 3; printf(«%d», SUM(1, 2)); // (a1 + a2) getchar(); return 0;}
![]()
Заключение
Всегда июмейте всегда в виду, что некоторые языки программирования специально предназначены для компиляции кода, например, C. В то время как другие языки всегда должны интерпретироваться, например Java.
Для меня не имеет значения, скомпилировано что-то или интерпретировано, если оно может выполнить задачу эффективно.
Некоторые системы не предлагают технические условия для эффективного использования интерпретаторов. Поэтому вы должны запрограммировать их с помощью чего-то, что может быть непосредственно скомпилировано, например C. Иногда нужно выполнить вычисления настолько интенсивно, насколько это возможно. Например, при точном распознавании голоса роботом. В других случаях скорость или вычислительная мощность могут быть не столь критичными, и написать эмулятор на оригинальном языке может быть проще.
Сообщите мне, что бы вы предпочли: интерпретацию или компиляцию? Спасибо за уделенное время!
Пожалуйста, оставьте ваши комментарии по текущей теме статьи. Мы крайне благодарны вам за ваши комментарии, дизлайки, подписки, отклики, лайки!
Пожалуйста, оставляйте свои отзывы по текущей теме статьи. За комментарии, дизлайки, подписки, отклики, лайки огромное вам спасибо!
Вадим Дворниковавтор-переводчик статьи «Interpretation Versus Compilation»





