
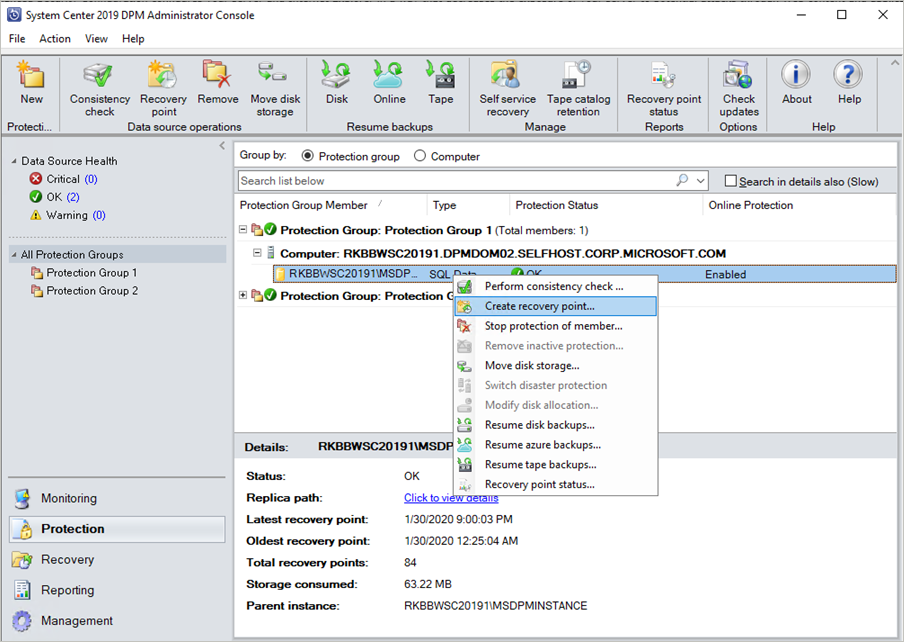
Восстановление работоспособности в VMmanager Cloud
Восстановление виртуальных машин
При отказе узла кластера виртуальные машины, работающие на этом узле, восстанавливаются на другом работоспособном узле кластера. Для этого необходимо, чтобы виртуальные диски виртуальных машин были расположены в сетевых хранилищах. Если для диска виртуальной машины использовалось локальное хранилище, виртуальная машина не будут восстановлена, поскольку ее данные становятся недоступными.
Восстановление виртуальных машин на работоспособных узлах кластера начинается сразу же при отказе узла кластера. Процесс восстановления последовательный, при этом выполняются следующие действия для каждой виртуальной машины:
- выбирается узел кластера, на котором будет создана виртуальная машина. Подробнее об алгоритме см. в статье Настройка распределения виртуальных машин по узлам кластера;
- создаётся виртуальная машина с такими же параметрами, как и на отказавшем узле кластера;
- подключается сетевой диск машины и происходит ее запуск.
Процедура восстановления логируется в общем логе VMmanager — vmmgr.log, запись в логе при восстановлении машины:
Restore vm $id
Пояснения
id — это номер виртуальной машины в базе данных VMmanager (база данных mysql — vmmgr, таблица vm).
Восстановление узла кластера
Узел кластера считается отказавшим и отсоединяется от кластера, если он не отвечает более 1 секунды
Обратите внимание, что перезагрузка сервера длится дольше. В связи с этим необходимо учитывать, что после перезагрузки узел кластера потребуется восстанавливать
Нельзя одновременно перезагружать узлы кластера таким образом, что количество продолжающих работать узлов будет меньше кворума.
После того, как узел кластера оказался недоступным, система corolistener изменяет файлы конфигурации на всех живых узлах кластера. Для последующего восстановления узла кластера:
- убедитесь, что все сервисы на узле функционируют в штатном порядке;
- верните узел в кворум. Для этого нажмите Настройка кластера → Узлы кластера → Присоединить;
- синхронизируйте конфигурационный файл corosync с другими узлами:
/usr/local/mgr5/sbin/mgrctl -m vmmgr cloud.conf.rebuild
запустите систему corosync:
/etc/init.d/corosync start
запустите сервис corolistener:
/usr/local/mgr5/sbin/corolistener -c start
Восстановление кластера после потери кворума
VMmanager Cloud реплицируется на все узлы кластера, чтобы обеспечить отказоустойчивость самой панели. При этом запускается VMmanager только на одном узле кластера. После потери кворума бывают ситуации, когда VMmanager не может запуститься даже на узле кластера с максимальным приоритетом.
Алгоритм восстановления кластера:
- На мастер-сервере:
- Удалите опцию Option ClusterEnabled из конфигурационного файла (по умолчанию /usr/local/mgr5/etc/vmmgr.conf).
-
Убедитесь в наличии файла /tmp/.lock.vmmgr.service. Если файл отсутствует, создайте его:
touch /tmp/.lock.vmmgr.service
-
Добавьте IP-адрес лицензии на интерфейс vmbr0:
ip addr add <IP-адрес> dev vmbr0
- На узлах кластера:
-
Убедитесь в наличии файлов /usr/local/mgr5/var/disabled. Если файл отсутствует, создайте его:
touch /usr/local/mgr5/var/disabled
-
Убедитесь в отсутствии файла /tmp/.lock.vmmgr.service. Если файл присутствует, удалите его:
rm /tmp/.lock.vmmgr.service
- Убедитесь в отсутствии на интерфейсе vmbr0 IP-адреса лицензии.
- Запустите панель управления.
- Включите облачные функции в интерфейсе панели управления.
-
Зачем нужен LVM[править]
Установка системы прямо на разделы диска зачастую приводит к следующей проблеме. Нужно каким-то образом «правильно» разбить жесткий диск. Слово «правильно» стоит в кавычках, потому что «правильного» разбиения диска для всех возможных ситуаций и применений не существует. В сети есть много советов по данному поводу, но они не учитывают потребностей конкретного пользователя (в случае настольной системы) или конкретного администратора (в случае сервера). Обычно рекомендуют разделы /home, /var, /usr, какие-то еще выносить на отдельные разделы диска. Но если разбивающий ошибется в размерах этих разделов, возникает очень нехорошая ситуация — на одних разделах место подходит к концу, в то время как на остальных места еще много. Приехали! Дисковое пространство нужно переразмечать. Для этого есть много способов:
1. Тотальный backup, затем переустановка системы с переразбиением диска.
2. Переразметка с помощью parted с риском потерять данные.
3. Изначальная установка системы на LVM, который позволяет изменять размеры своих разделов прямо на работающей системе.
Создание файловой системы и монтирование тома
Чтобы начать использовать созданный том, необходимо его отформатировать, создав файловую систему и примонтировать раздел в каталог.
Файловая система
Процесс создания файловой системы на томах LVM ничем не отличается от работы с любыми другими разделами.
Например, для создания файловой системы ext4 вводим:
mkfs.ext4 /dev/vg01/lv01
* vg01 — наша группа томов; lv01 — логический том.
Для создания, например, файловой системы xfs вводим:
mkfs.xfs /dev/vg01/lv01
Монтирование
Как и в случае с файловой системой, процесс монтирования не сильно отличается от разделов, созданных другими методами.
Для разового монтирования пользуемся командой:
mount /dev/vg01/lv01 /mnt
* где /dev/vg01/lv01 — созданный нами логический том, /mnt — раздел, в который мы хотим примонтировать раздел.
Для постоянного монтирования раздела добавляем строку в fstab:
vi /etc/fstab
/dev/vg01/lv01 /mnt ext4 defaults 1 2
* в данном примере мы монтируем при загрузке системы том /dev/vg01/lv01 в каталог /mnt; используется файловая система ext4.
Проверяем настройку fstab, смонтировав раздел:
mount -a
Проверяем, что диск примонтирован:
df -hT
Тонкая настройка ежедневного резервного копирования базы данных 1С средствами SQL ver. 2014 (SP3) — 12.0.6024.0 (X64)
Хочу вам предложить небольшой пример, как можно реализовать резервное копирование 1С-ых баз данных средствами SQL. Данный материал не претендует на пулитцеровскую премию. Но возможно кому-то будет интересно узнать, что-то новенькое.
Данный материал для резервного копирования только одной базы данных. А именно, если у вас 20-ть баз, то вам придется создавать 20-ть планов обслуживания для каждой базы индивидуально.
(Слава разработчикам SQL, они разрешили копировать блоки из одного плана в другой, вам остается только произвести небольшую настройку для каждого скопированного блока — некоторые настройки блоков сбрасываются и выставляются значением по умолчанию и остаются неактивными)
Назначение и принцип работы снапшотов
Снапшоты отчасти относятся к системам резервного копирования, но по сути не являются бэкапом, а лишь позволяют возвращать данные в исходное состояние на определенный момент времени. Так, когда необходимо сделать полный бэкап (например, сервера с активной базой данных), понадобится останавливать запись на диск и только потом снимать копию, т.к. в противном случае не все данные попадут в копию. Вариант с наличием slave-базы в счёт не берется, т.к. это частный случай ещё одной возможности для создания резервной копии. При больших объемах копирование может занимать несколько часов и более, что недопустимо для production-систем, работающих 24\7 – ведь никто не останавливает боевую базу для снятия дампа.
В таких случаях при необходимости создания полной копии без остановки на запись (почти) и приходят на помощь снапшоты. При создании снапшота происходит моментальный снимок или “заморозка” данных. Процесс создания снимка происходит, как правило, очень быстро – приложение или операционная система на какое-то непродолжительное время приостанавливает запись, и в этот момент создается моментальный снимок текущего состояния данных. Под приостановкой записи подразумевается, что приложение будет работать, но процессы записи на диск осуществляться не будут. Для клиента это может выглядеть как некая кратковременная задержка. Длительность такой задержки будет зависеть от приложения и его размера.
COW (Copy-On-Write)
Итак, разобравшись, что такое снапшот и когда он применяется, необходимо понимать, что происходит с файлами после создания снимка. Снапшот создан, и все старые файлы, т.е. которые не изменялись на момент создания снимка, остались на месте. А вот новые файлы или изменения для существующих уже будут записаны в новое расположение файловой системы на диске. Даже когда модификация данных завершена, старые данные никогда не перезаписываются. По сути будет создан ещё один файл, в котором содержатся все изменения (дельта), которые происходят с исходными данными. Таким образом достигается экономия дискового пространства засчет хранения лишь изменений на диске, а не полной копии данных. Технически происходит следующее: при необходимости изменения старого файла создается reflink и выделяется место под изменения.
Поэтому есть общие рекомендации и напоминания относительно снапшотов:
- Снапшот – не бэкап!
- Не стоит хранить снапшоты длительное время, особенно в продакшене. Снапшот выполнил свою функцию и должен быть сразу удален.
- Не стоит хранить большое дерево снапшотов (2-3 штуки будет достаточно), в противном случае производительность диска значительно просядет.
Удаление томов
Если необходимо полностью разобрать LVM тома, выполняем следующие действия.
Отмонтируем разделы:
umount /mnt
* где /mnt — точка монтирования для раздела.
Удаляем соответствующую запись из fstab (в противном случае наша система может не загрузиться после перезагрузки):
vi /etc/fstab
#/dev/vg01/lv01 /mnt ext4 defaults 1 2
* в данном примере мы не удалили, а закомментировали строку монтирования диска.
Смотрим информацию о логичеких томах:
lvdisplay
Теперь удаляем логический том:
lvremove /dev/vg01/lv01
На вопрос системы, действительно ли мы хотим удалить логических том, отвечаем да (y):
Do you really want to remove active logical volume vg01/lv01? [y/n]: y
* если система вернет ошибку Logical volume contains a filesystem in use, необходимо убедиться, что мы отмонтировали том.
Смотрим информацию о группах томов:
vgdisplay
Удаляем группу томов:
vgremove vg01
Убираем пометку с дисков на использование их для LVM:
pvremove /dev/sd{b,c,d}
* в данном примере мы деинициализируем диски /dev/sdb, /dev/sdc, /dev/sdd.
В итоге мы получим:
Labels on physical volume «/dev/sdb» successfully wiped.
Labels on physical volume «/dev/sdc» successfully wiped.
Labels on physical volume «/dev/sdd» successfully wiped.
Создание разделов
Рассмотрим пример создания томов из дисков sdb и sdc с помощью LVM.
1. Инициализация
Помечаем диски, что они будут использоваться для LVM:
pvcreate /dev/sdb /dev/sdc
* напомним, что в качестве примера нами используются диски sdb и sdc.
Посмотреть, что диск может использоваться LMV можно командой:
pvdisplay
В нашем случае мы должны увидеть что-то на подобие:
«/dev/sdb» is a new physical volume of «1,00 GiB»
— NEW Physical volume —
PV Name /dev/sdb
VG Name
PV Size 1,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID rR8qya-eJes-7AC5-wuxv-CT7a-o30m-bnUrWa
«/dev/sdc» is a new physical volume of «1,00 GiB»
— NEW Physical volume —
PV Name /dev/sdc
VG Name
PV Size 1,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 2jIgFd-gQvH-cYkf-9K7N-M7cB-WWGE-9dzHIY
* где
- PV Name — имя диска.
- VG Name — группа томов, в которую входит данный диск (в нашем случае пусто, так как мы еще не добавили его в группу).
- PV Size — размер диска.
- Allocatable — распределение по группам. Если NO, то диск еще не задействован и его необходимо для использования включить в группу.
- PE Size — размер физического фрагмента (экстента). Пока диск не добавлен в группу, значение будет 0.
- Total PE — количество физических экстентов.
- Free PE — количество свободных физических экстентов.
- Allocated PE — распределенные экстенты.
- PV UUID — идентификатор физического раздела.
2. Создание групп томов
Инициализированные на первом этапе диски должны быть объединены в группы.
Группа может быть создана:
vgcreate vg01 /dev/sdb /dev/sdc
* где vg01 — произвольное имя создаваемой группы; /dev/sdb, /dev/sdc — наши диски.
Просмотреть информацию о созданных группах можно командой:
vgdisplay
На что мы получим, примерно, следующее:
— Volume group —
VG Name vg01
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 1,99 GiB
PE Size 4,00 MiB
Total PE 510
Alloc PE / Size 0 / 0
Free PE / Size 510 / 1,99 GiB
VG UUID b0FAUz-wlXt-Hzqz-Sxs4-oEgZ-aquZ-jLzfKz
* где:
- VG Name — имя группы.
- Format — версия подсистемы, используемая для создания группы.
- Metadata Areas — область размещения метаданных. Увеличивается на единицу с созданием каждой группы.
- VG Access — уровень доступа к группе томов.
- VG Size — суммарный объем всех дисков, которые входят в группу.
- PE Size — размер физического фрагмента (экстента).
- Total PE — количество физических экстентов.
- Alloc PE / Size — распределенное пространство: колическтво экстентов / объем.
- Free PE / Size — свободное пространство: колическтво экстентов / объем.
- VG UUID — идентификатор группы.
3. Создание логических томов
Последний этап — создание логического раздела их группы томов командой lvcreate. Ее синтаксис:
lvcreate <имя группы томов>
Примеры создания логических томов:
lvcreate -L 1G vg01
* создание тома на 1 Гб из группы vg01.
lvcreate -L50 -n lv01 vg01
* создание тома с именем lv01 на 50 Мб из группы vg01.
lvcreate -l 40%VG vg01
* при создании тома используется 40% от дискового пространства группы vg01.
lvcreate -l 100%FREE -n lv01 vg01
* использовать все свободное пространство группы vg01 при создании логического тома.
* также можно использовать %PVS — процент места от физического тома (PV); %ORIGIN — размер оригинального тома (применяется для снапшотов).
Посмотрим информацию о созданном томе:
lvdisplay
— Logical volume —
LV Path /dev/vg01/lv01
LV Name lv01
VG Name vg01
LV UUID 4nQ2rp-7AcZ-ePEQ-AdUr-qcR7-i4rq-vDISfD
LV Write Access read/write
LV Creation host, time vln.dmosk.local, 2019-03-18 20:01:14 +0300
LV Status available
# open 0
LV Size 52,00 MiB
Current LE 13
Segments 1
Allocation inherit
Read ahead sectors auto
— currently set to 8192
Block device 253:2
* где:
- LV Path — путь к устройству логического тома.
- LV Name — имя логического тома.
- VG Name — имя группы томов.
- LV UUID — идентификатор.
- LV Write Access — уровень доступа.
- LV Creation host, time — имя компьютера и дата, когда был создан том.
- LV Size — объем дискового пространства, доступный для использования.
- Current LE — количество логических экстентов.
Инициализация жестких дисков
Для того чтобы начать работу с LVM, необходимо жесткие диски сделать понятными для LVM, перевести их в LVM — 8E Linux LMV.
Вывод имеющихся жестких дисков в системе:
| 1 | sudo fdisk-l |
|
1 |
Дискdevsdb483.2Гб,483183820800байт 255головок,63секторовтреков,58743цилиндров,всего943718400секторов Units=секторыof1*512=512bytes Размерсектора(логическогофизического)512байт512байт IOsize(minimumoptimal)512bytes512bytes Идентификатордиска0x00000000 Надискеdevsdbотсутствуетвернаятаблицаразделов 255головок,63секторовтреков,58743цилиндров,всего943718400секторов Units=секторыof1*512=512bytes Размерсектора(логическогофизического)512байт512байт IOsize(minimumoptimal)512bytes512bytes Идентификатордиска0x00000000 Надискеdevsdcотсутствуетвернаятаблицаразделов |
Жесткие диски /dev/sdb, /dev/sdc переводим в формат LVM (pvcreate):
|
1 |
sudo pvcreatedevsdb Physical volume»/dev/sdb»successfully created sudo pvcreatedevsdc Physical volume»/dev/sdc»successfully created |
Отобразить физические LVM разделы, можно командой (pvscan):
|
1 |
sudo pvscan PVdevsdb lvm2400,00GiB PVdevsdc lvm2450,00GiB Total2850,00GiBinuseinno VG2850,00GiB |
Отобразить физические LVM разделы с подробными сведениями, можно командой (pvdisplay):
|
1 |
sudo pvdisplay —Physical volume— PV Namedevsda6 VG Name PV Size1.86GBnot usable2.12MB Allocatable yes PE Size(KByte)4096 Total PE476 Free PE456 Allocated PE20 PV UUID m67TXf-EY6w-6LuX-NNB6-kU4L-wnk8-NjjZfv —Physical volume— PV Namedevsda7 VG Name PV Size1.86GBnot usable2.12MB Allocatable yes PE Size(KByte)4096 Total PE476 Free PE476 Allocated PE PV UUID b031x0-6rej-BcBu-bE2C-eCXG-jObu-0Boo0x |
Снапшоты
Одна из важнейших особенностей LVM — это поддержка механизма снапшотов. Снапшоты позволяют сделать мгновенный снимок логического тома и использовать его в дальнейшем для работы с данными.
Примеры использования
LVM активно используется, когда необходим механизм снапшотов. Например, этот механизм крайне важен при бекапе постоянно меняющихся файлов. LVM позволяет заморозить некоторое состояние ФС и скопировать с неё все нужные данные, при этом на оригинальной ФС останавливать запись не нужно.
Также снапшоты можно применить для организации поддержки файловым сервером с Samba механизма архивных копий, об этом в соответствующей статье:
Поддержка архивных копий файлов в Samba
Скрипт для автоматического бэкапа виртуальных машин KVM
По мотивам всего написанного выше я набросал простенький скрипт для автоматического живого бэкапа всех дисков всех работающих в момент выполнения скрипта виртуальных машин
Обращаю внимание, что бэкапятся все диски. Скрипт привожу просто для примера, не используйте его, если вам не нужны полные бэкапы всех дисков
Лично я бэкаплю только небольшие системные диски. Все, что много весит, предпочитаю архивировать другими способами уже изнутри виртуальной машины. Если это базы данных, то делаю , если это файловый сервер, то использую rsync для создания инкрементных бэкапов. Ну и так далее. Каждый выбирает средства на свой вкус.
#!/bin/bash
# Дата год-месяц-день
data=`date +%Y-%m-%d`
# Папка для бэкапов
backup_dir=/backup-vm
# Список работающих VM
vm_list=`virsh list | grep running | awk '{print $2}'`
# Список VM, заданных вручную, через пробел
#vm_list=(vm-1 vm-2)
# Лог файл
logfile="/var/log/kvmbackup.log"
# Использовать это условие, если список VM задается вручную
#for activevm in "${vm_list}";
# Использовать это условие, если список работающих VM берется автоматически
for activevm in $vm_list
do
mkdir -p $backup_dir/$activevm
# Записываем информацию в лог с секундами
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start backup $activevm" >> $logfile
# Бэкапим конфигурацию
virsh dumpxml $activevm > $backup_dir/$activevm/$activevm-$data.xml
echo "`date +"%Y-%m-%d_%H-%M-%S"` Create snapshots $activevm" >> $logfile
# Список дисков VM
disk_list=`virsh domblklist $activevm | grep vd | awk '{print $1}'`
# Адрес дисков VM
disk_path=`virsh domblklist $activevm | grep vd | awk '{print $2}'`
# Делаем снепшот диcков
virsh snapshot-create-as --domain $activevm snapshot --disk-only --atomic --quiesce --no-metadata
sleep 2
for path in $disk_path
do
echo "`date +"%Y-%m-%d_%H-%M-%S"` Create backup $activevm $path" >> $logfile
# Вычленяем имя файла из пути
filename=`basename $path`
# Бэкапим диск
pigz -c $path > $backup_dir/$activevm/$filename.gz
sleep 2
done
for disk in $disk_list
do
# Определяем путь до снепшота
snap_path=`virsh domblklist $activevm | grep $disk | awk '{print $2}'`
echo "`date +"%Y-%m-%d_%H-%M-%S"` Commit snapshot $activevm $snap_path" >> $logfile
# Объединяем снепшот
virsh blockcommit $activevm $disk --active --verbose --pivot
sleep 2
echo "`date +"%Y-%m-%d_%H-%M-%S"` Delete snapshot $activevm $snap_path" >> $logfile
# Удаляем снепшот
rm $snap_path
done
echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup $activevm" >> $logfile
done
Обращаю внимание на несколько моментов:
vm_list может либо автоматически заполняться списком работающих виртуальных машин, либо можно вручную указать список только тех машин, которые нужно бэкапить. Для этого нужно раскомментировать соответствующую строку в начале скрипта при объявлении переменной. Затем выбрать подходящую строку для цикла for. Он будет немного разным, в зависимости от списка.
Снепшоты будут создаваться в той же папке, где хранится основной файл данных. На время отладки советую для начала закомментировать строку с удалением снепшота, на всякий случай. Рекомендую этот крипт прогнать сначала на тестовом сервере. Я его написал на примере одного гипервизора, больше нигде не проверял. Но работает он однозначно, я проверил несколько раз с разными списками VM. В итоге оставил его у себя на сервере в работе.
Для регулярной очистки бэкапов, если они у вас будут храниться где-то в доступном с этого сервера месте, можно добавить в самый конец условие очистки. Для полного бэкапа VM мне видится нормальной схема хранения бэкапов в несколько месяцев, с созданием архивов раз в неделю. Чаще бэкапить системные диски не вижу смысла, там редко бывают ежедневные изменения.
/usr/bin/find /backup-vm/*/ -type f -mtime +90 -exec rm -rf {} \;
Данная команда удалит все файлы старше 90 дней в папках с названиями виртуальных машин, расположенных в /backup-vm.
Резервное копирование виртуальных машин
| Рабочая нагрузка | Версия | Установка Azure Backup Server | Поддерживаемые Azure Backup Server | Защита и восстановление |
|---|---|---|---|---|
| Узел Hyper-V-MABS Protection Agent на сервере узла Hyper-V, кластере или виртуальной машине | Windows Server 2019, 2016, 2012 R2, 2012 | Физический сервер Виртуальная машина Hyper-V Виртуальная машина VMware | V3 UR1 | Защита: компьютеры Hyper-V, общие тома кластера (CSV) Восстановление: виртуальная машина, восстановление файлов и папок на уровне элементов, доступные только для Windows, томов, виртуальных жестких дисков |
| Виртуальные машины VMware | VMware Server 5,5, 6,0 или 6,5, 6,7 (лицензированная версия) | Виртуальная машина Hyper-V Виртуальная машина VMware | V3 UR1 | Защита: виртуальные машины VMware в общих томах кластера (CSV), NFS и хранилище SAN Восстановление: виртуальная машина, восстановление файлов и папок на уровне элементов, доступные только для Windows, томов, виртуальных жестких дисков VMware vApp не поддерживается. |
Создание зеркала
С помощью LVM мы может создать зеркальный том — данные, которые мы будем на нем сохранять, будут отправляться на 2 диска. Таким образом, если один из дисков выходит из строя, мы не потеряем свои данные.
Зеркалирование томов выполняется из группы, где есть, минимум, 2 диска.
1. Сначала инициализируем диски:
pvcreate /dev/sd{d,e}
* в данном примере sdd и sde.
2. Создаем группу:
vgcreate vg02 /dev/sd{d,e}
3. Создаем зеркальный том:
lvcreate -L200 -m1 -n lv-mir vg02
* мы создали том lv-mir на 200 Мб из группы vg02.
В итоге:
lsblk
… мы увидим что-то на подобие:
sdd 8:16 0 1G 0 disk
vg02-lv—mir_rmeta_0 253:2 0 4M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
vg02-lv—mir_rimage_0 253:3 0 200M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
sde 8:32 0 1G 0 disk
vg02-lv—mir_rmeta_1 253:4 0 4M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
vg02-lv—mir_rimage_1 253:5 0 200M 0 lvm
vg02-lv—mir 253:6 0 200M 0 lvm
* как видим, на двух дисках у нас появились разделы по 200 Мб.
Создание и удаление
Большинство команд требуют прав суперпользователя.
Как уже отмечалось, LVM строится на основе разделов жёсткого диска и/или целых жёстких дисков. На каждом из дисков/разделов должен быть создан физический том (physical volume). К примеру, мы используем для LVM диск sda и раздел sdb2:
pvcreate /dev/sda pvcreate /dev/sdb2
На этих физических томах создаём группу томов, которая будет называться, скажем, vg1:
vgcreate -s 32M vg1 /dev/sda /dev/sdb2
Посмотрим информацию о нашей группе томов:
vgdisplay vg1
Групп можно создать несколько, каждая со своим набором томов. Но обычно это не требуется.
Теперь в группе томов можно создать логические тома lv1 и lv2 размером 20 Гбайт и 30 Гбайт соответствено:
lvcreate -n lv1 -L 20G vg1 lvcreate -n lv2 -L 30G vg1
Теперь у нас есть блочные устройства /dev/vg1/lv1 и /dev/vg1/lv2.
Осталось создать на них файловую систему. Тут различий с обычными разделами нет:
mkfs.ext4 /dev/vg1/lv1 mkfs.reiserfs /dev/vg1/lv2
Удаление LVM (или отдельных его частей, например, логических томов или групп томов) происходит в обратном порядке — сначала нужно отмонтировать разделы, затем удалить логические тома (), после этого можно удалить группы томов () и ненужные физические тома ().





