
Формальное определение
Совместное вероятностное право
Есть несколько способов определить байесовскую сеть. Самый простой выражает совместный вероятностный закон на множестве случайных величин, моделируемых в сети. Байесовская сеть — это ациклический ориентированный граф G = (V, E), где V — множество узлов в сети, а E — множество дуг. С каждым узлом x, принадлежащим V графа, связано следующее условное распределение вероятностей:
- п(Икс|па(Икс)){\ Displaystyle Р (х \, {\ большой |} \, \ OperatorName {pa} (х)) \,} где pa (x) представляет непосредственных родителей x в V
Таким образом, множество V представляет собой дискретный набор случайных величин. Каждый узел V условно независим от своих не-потомков, учитывая его непосредственных родителей. Таким образом, можно факторизовать условные распределения вероятностей для всех переменных, производя их произведение:
- п(V)знак равно∏Икс∈Vп(Икс|па(Икс)){\ Displaystyle P (V) = \ prod _ {x \ in V} P {\ big (} x \, {\ big |} \, \ operatorname {pa} (x) {\ big)}}
Этот результат иногда обозначается JPD для совместного распределения вероятностей. Это определение можно найти в статье « Байесовские сети: модель самоактивируемой памяти для доказательных рассуждений» , где Джудея Перл вводит термин «байесовская сеть».
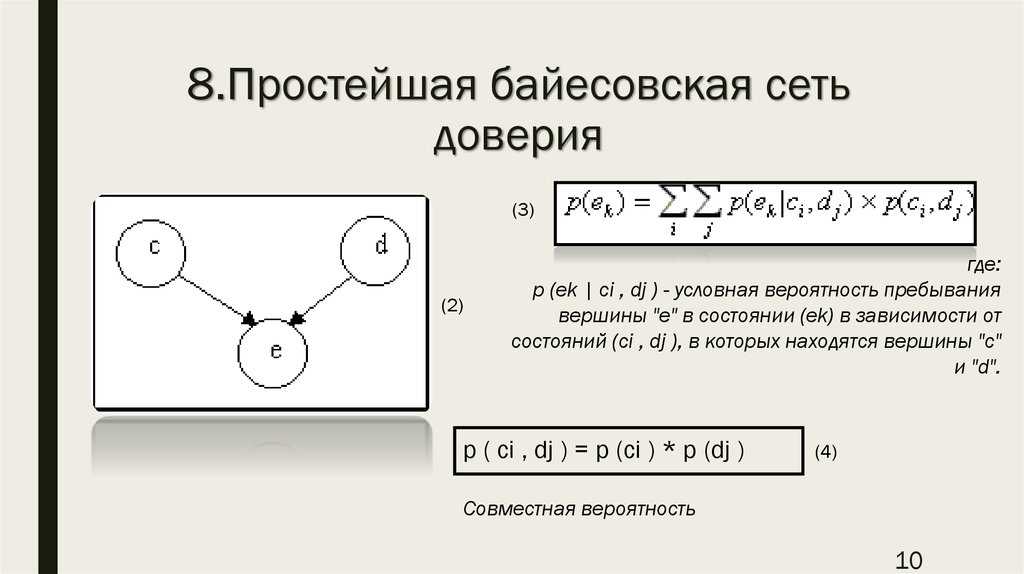
В примере, приведенном на рисунке 1, совместная вероятность равна:
- п(еИксперяенетпротивеопервтетыр)×п(противомплеИксятемвпротивчасянете)×п(впротивпротивяdенетт|еИксперяенетпротивеопервтетыр,противомплеИксятемвпротивчасянете){\ Displaystyle P (опыт \, оператор) \ раз P (сложность \, машина) \ раз P (авария \, {\ большой |} \, опыт \, оператор, сложность \, машина)}.
Глобальная марковская собственность
Другой способ определить байесовскую сеть — оценить, удовлетворяет ли ациклический ориентированный граф G = (V, E) глобальному марковскому свойству (называемому здесь направленным из-за природы G) с учетом вероятностного закона P на множестве переменных V .Пусть X, Y, S — три подмножества V, такие, что X и Y d-разделены символом S, обозначенное (X | S | Y): глобальное марковское свойство выражает условную независимость между X и Y, т. Е. X не зависит от Y при условии на S. Формально свойство ориентированного графа выглядит следующим образом:
- ∀Икс,Y,S⊂Vdяsjоянеттs,(Икс|S|Y)⇒Икс⊥⊥Y|S{\ Displaystyle \ forall \, X, Y, S \ подмножество Vdisjoints, (X | S | Y) \ Rightarrow X \ perp \! \! \! \ perp Y \, {\ big |} \, S}
Уместно определить d-разделение для «направленного разделения» или «ориентированного разделения» в ориентированном графе. Подмножества X и Y d-разделены S тогда и только тогда, когда любая цепочка узлов от X до Y «заблокирована» S. Для трех узлов x, принадлежащих X, y, принадлежащих Y, и s, принадлежащих S, канал блокируется в следующих двух случаях:
- либо строка содержит последовательность, либо ;Икс→s→y{\ displaystyle x \ rightarrow s \ rightarrow y}Икс←s→y{\ displaystyle x \ leftarrow s \ rightarrow y}
- либо цепочка содержит последовательность, в которой z не принадлежит S и ни один потомок z не принадлежит S.Икс→z←y{\ displaystyle x \ rightarrow z \ leftarrow y}
Интуиция подсказывает, что S «блокирует» информацию между X и Y.
Наконец, условная независимость, отмеченная выше , выражает, что X условно не зависит от Y при данном S. Формально:
Икс⊥⊥Y|S{\ Displaystyle X \ перп \! \! \! \ перп Y \, {\ большой |} \, S}
- Икс⊥⊥Y|S{\ Displaystyle X \ перп \! \! \! \ перп Y \, {\ большой |} \, S}тогда и только тогда, когда ип(Икс|Y,S)знак равноп(Икс|S){\ Displaystyle P (Икс \, {\ большой |} \, Y, S) = P (X \, {\ big |} \, S)}п(Y|Икс,S)знак равноп(Y|S){\ Displaystyle P (Y \, {\ big |} \, X, S) = P (Y \, {\ big |} \, S)}
- Или тогда и только тогда, когдаИкс⊥⊥Y|S{\ Displaystyle X \ перп \! \! \! \ перп Y \, {\ большой |} \, S}п(Икс,Y|S)знак равноп(Икс|S)×п(Y|S){\ Displaystyle P (X, Y \, {\ big |} \, S) = P (X \, {\ big |} \, S) \ times P (Y \, {\ big |} \, S) }
В приведенном выше примере (рис. 1) мы можем написать, что опыт оператора не зависит от сложности машины, но что он условно зависит от сложности машины с учетом риска «аварии».
В заключение, ациклический ориентированный граф G = (V, E) является байесовской сетью тогда и только тогда, когда он удовлетворяет направленному глобальному марковскому свойству с учетом вероятностного закона P по множеству переменных V.
Приложения
Библиография
- Патрик Наим , Пьер-Анри Вуйлемен , Филипп Лере , Оливье Пурре и Анна Беккер , байесовские сети , Eyrolles ,2011 г., 3 е изд. , 424 с.
- (ru) Аднан Дарвиче , Моделирование и рассуждение с помощью байесовских сетей , Cambridge University Press ,2009 г., 548 с.
- (ru) Уффе Б. Кьерулфф и Андерс Л. Мэдсен , Байесовские сети и диаграммы влияния: руководство по построению и анализу , Нью-Йорк, Springer ,2007 г., 318 с.
- (ru) Тимо Коски и Джон Ноубл , Байесовские сети: введение , John Wiley & Sons ,2011 г., 2- е изд. , 366 с.
- (ru) Ричард Э. Неаполитан , Изучение байесовских сетей , Пирсон Прентис Холл,2004 г.
- (ru) Джудея Перл , Вероятностное рассуждение в интеллектуальных системах: сети правдоподобных выводов , Морган Кауфманн ,1988 г., 552 с.
- Стюарт Джонатан Рассел и Питер Норвиг ( перевод с английского Фабриса Попино), Искусственный интеллект , Париж, Pearson Education France,2010 г., 3 е изд. , 1198 с.
Рекомендации
- ↑ и Лепаж, Э., Фиески, М., Трейно, Р., Гуверне, Дж., И Частанг, К. (1992). Система поддержки принятия решений, основанная на применении байесовской сетевой модели для наблюдения за переливанием крови . Новые методы обработки информации в медицине, 5, 76-87.
- Жан-Жак Боре , Эрик Родитель и Жак Бернье , Практика байесовского исчисления , Париж / Берлин / Гейдельберг и т. Д., Springer ,2009 г., 333 с. , стр. 38–39
- , стр. 90-91
- (in) Джудея Перл , « Байесовские сети: модель самоактивированной памяти для доказательных рассуждений » , Труды 7-й конференции Общества когнитивных наук ,1985 г., стр. 329–334
- , стр. 86-87
- Дэвид Беллот , Объединение данных с байесовскими сетями для моделирования динамических систем и его применения в телемедицине , Университет Нанси-I ,2002 г. , стр. 68 (Тезис)
- , стр. 354-356
- ↑ и , стр. 532
- , стр. 93–94
- (in) Невин Лианвен Чжан , « Односторонний подход к вычислениям байесовской сети » , Труды 10-й Канадской конференции — искусственный интеллект ,1994 г.
- ↑ and (ru) Грегори Ф. Купер , « Вероятностный вывод с использованием сетей верований является NP-трудным » , Лаборатория систем знаний (отчет) ,1987 г. ; (en) Грегори Ф. Купер , « Вычислительная сложность вероятностного вывода с использованием байесовских сетей доверия » , Искусственный интеллект , т. 42, п кость 2-3,Март 1990 г., стр. 393-405
- , стр. 9
- (in) Томас Дин и Кейджи Канадзава , « Модель рассуждений о причинно-следственных связях и устойчивости » , Computational Intelligence , Vol. 5, п о 21989 г., стр. 142-150
- ↑ и (in) Кевин Патрик Мерфи , Динамические байесовские сети: представление, вывод и обучение , Калифорнийский университет в Беркли , стр. 14-15 (Тезис)
- ↑ и Ролан Донат , Филипп Лере , Лоран Буйло и Патрис Акнин , « Динамические байесовские сети для представления моделей длительности в дискретном времени », Франкоязычные дни в байесовских сетях ,2008 г.
- ↑ и (ru) Нир Фридман и Мойзес Гольдшмидт , « Построение классификаторов с использованием байесовских сетей » , Труды тринадцатой национальной конференции по искусственному интеллекту ,1996 г.
- (in) Иудейская жемчужина , Книга почему: Новая наука о причине и следствии , Penguin Books ,2019 г., 432 с. ( ISBN 978-0-14-198241-0 и ).
- Портал вероятностей и статистики
- Портал теоретических вычислений
Пример[править]
![]()
Рис. 1: Байесовская сеть «Студент».
Байесовская сеть, представленная на рисунке 1, отображает следующие зависимости. Оценка студента зависит от его интеллекта и сложности курса. Студент просит у преподавателя рекомендацию, предположим, что преподаватель может написать плохую или хорошую рекомендацию в зависимости от оценки студента. Также студент сдаёт госэкзамен, результаты экзамена не зависят от рекомендации преподавателя, оценки за его курс и сложности курса. Представление этой модели в Байесовской сети представлено на рисунке ниже.
С помощью цепного правила рассчитаем вероятность того, что умный студент получает B по лёгкому курсу, высокий балл за госэкзамен и плохую рекомендацию:
Байесовская сеть представляет корректное вероятностное распределение:
- Вероятность исхода в Байесовской сети неотрицательна, так как вычисляется как произведение условных вероятностей событий, которые неотрицательны.
- Сумма вероятностей исходов в Байесовской сети равна единице:
Почему парадокс Симпсона имеет значение
Парадокс Симпсона важен, потому что он напоминает нам, чтоданные, которые нам показывают, это не все данные, которые есть.Мы не можем быть удовлетворены только цифрами или цифрами, мы должны учитыватьпроцесс генерации данных- причинно-следственная модель — отвечает заданные.Как только мы поймем механизм получения данных, мы сможем найти другие факторы, влияющие на результат, которых нет на графике.Думая причинноэто не навык, которому учат большинство ученых, работающих с данными, но очень важно помешать нам сделать ошибочные выводы из цифр. Мы можем использовать наш опыт и знания предметной области — или опыт экспертов в этой области — в дополнение к данным, чтобы принимать лучшие решения
Более того, хотя наша интуиция обычно служит нам довольно хорошо, в некоторых случаях она может потерпеть неудачугде не вся информация доступна сразу. Мы склонны зацикливаться на том, что перед нами — все, что мы видим, — это все, что есть — вместо того, чтобы копать глубже и использовать наширациональный, медленный способ мышления, Особенно, когда у кого-то есть продукт для продажи или программа для реализации, мы должны скептически относиться к цифрам. Данные — это мощное оружие, но им могут пользоваться как те, кто хочет нам помочь, так и гнусные актеры.
Что делать
В анализе данных необходимо понимать, какая история за ними лежит: что происходит в реальном мире, как его измерили и перевели в вид данных. Поэтому исследователь данных в отделе маркетинга должен знать основы маркетинга, а в нефтегазовой отрасли — что-то о добыче полезных ископаемых. Это поможет избежать большого количества потенциальных ошибок, не последней из которых является ошибка агрегации, вызываемая парадоксом Симпсона.
К возникновению парадокса Симпсона обычно приводят следующие характеристики данных:
- Наличие значимых когорт, которые могут влиять на значения зависимой (Y) и независимой (X) переменных;
- Несбалансированность когорт.
В каждом случае нужен индивидуальный подход. Считать, что все данные всегда необходимо разбивать на когорты — тоже неверный подход, ведь зачастую именно агрегированные данные позволяют построить самую точную модель. Кроме того, любые данные можно разбить так, чтобы получить взаимосвязь, которую нам бы хотелось получить. Правда, это не будет иметь никакого практического применения — когорты должны быть обоснованы.
Для интернет-маркетинга один из самых важных выводов — это необходимость проверять правильную работу сплиттера в A/B экспериментах. Группы пользователей в каждом тестовом варианте должны быть примерно одинаковыми. Речь не только об общем количестве пользователей, но и об их структуре. При подозрении на проблемы в первую очередь следует проверить когорты по следующим характеристикам:
- Демографические характеристики;
- Географическое распределение;
- Источник траффика;
- Тип устройства;
- Время посещения.
Условная независимость[править]
| Определение: |
| Маргинальная вероятность — это безусловная вероятность события ; то есть, вероятность события , независимо от того, наступает ли какое-то другое событие или нет. |
Если о можно думать как о некоторой случайной величине, принявшей данное значение, маргинальная вероятность может быть получена суммированием (или более широко интегрированием) совместных вероятностей по всем значениям этой случайной величины. Эту процедуру иногда называют маргинализацией вероятности. На рисунке 1 вероятность того, что студент умный (), является маргинальной, так как у вершины нет родителей, с помощью маргинализации эту же вероятность можно получить, сложив вероятности того, что студент умный и он получит высокий балл за госэкзамен, и того, что студент умный и получит низкий балл за госэкзамен.
| Определение: |
| и являются -разделёнными (англ. -separated), если в графе при означивании не существует активного пути между и . Обозначение: . |
| Определение: |
| факторизуется над , если |
Знак следует читать как «удовлетворяет», — «пропорционально».
| Определение: |
| — в вероятностном пространстве переменная не зависима от переменной при условии означивания переменной . |
| Утверждение: |
| , если , где — факторы. |
| Теорема: |
| Если факторизуется над и , то . |
Проверим утверждение теоремы:
,
— цепное правило, факторизуется над ,
Значит, .
| Утверждение: |
| Если факторизуется над , то в каждая переменная -отделена (независима) от вершин, не являющихся её потомками, при означивании родителей. |
Рис. 2: Иллюстрация к утверждению про независимость переменной от вершин, не являющихся её потомками. Красным цветом обозначена проверочная вершина, жёлтым — её родители, синим — потомки, зелёным — вершины, не являющиеся её потомками.










Рассмотрим пример на рисунке 2: вершина -отделена от всех вершин, не являющихся её потомками: в вершину можно попасть из вершин или , все пути к ней от вершин, не являющихся её потомками, проходящие через , неактивны, так как получила означивание, а пути, проходящие через , также не являются активными, так как не получила означивания и образует -образную структуру с и и и .
| Определение: |
| , если , является картой независимостей (англ. Independency map (I-map)) для . — множество независимостей. |
| Теорема: |
| Если факторизуется над , то является картой независимостей для . |
| Теорема: |
| Если является картой независимостей для , то факторизуется над . |
| Доказательство: |
|
— цепное правило для вероятностей, Значит факторизуется над . |
Машинное обучение
Машинное обучение относится к способам с целью извлечения информации , содержащуюся в данных. Это процессы искусственного интеллекта, потому что они позволяют системе развиваться автономно на основе эмпирических данных. В байесовских сетях машинное обучение можно использовать двумя способами: для оценки структуры сети или для оценки таблиц вероятностей сети в обоих случаях на основе данных.
Изучение структуры
Существует два основных семейства подходов к изучению структуры байесовской сети на основе данных:
Подходы, основанные на ограничениях. Принцип состоит в том, чтобы проверить условную независимость и найти сетевую структуру, совместимую с наблюдаемыми зависимостями и независимостью.
Подходы с использованием функции оценки. В этих подходах оценка связана с каждой сетью-кандидатом, измеряя адекватность (не) зависимостей, закодированных в сети с данными. Затем мы ищем сеть, максимизирующую этот показатель.
Пример 1: половая дискриминация в Беркли
Самый известный пример парадокса Симпсона в реальном мире — это неразбериха с половой дискриминацией при приеме в университет Беркли в 1973 году. Среди исследователей ходит байка о том, что университет даже судили, однако в интернете не найти убедительных свидетельств судебного разбирательства.
Так выглядит статистика приема университета за 1973 год:
| Пол | Заявки | Принято |
| Мужчины | 8442 | 3738 (44%) |
| Женщины | 4321 | 1494 (35%) |
Разница значительная. Слишком большая, чтобы быть случайной.
Однако если разбить данные по факультетам, картина меняется. Исследователи выяснили, что причина разницы в том, что женщины подавали заявки на направления с более жестким конкурсом. К тому же было обнаружено, что 6 из 85 факультетов имели дискриминацию в пользу женщин, и только 4 — против.
Разница возникает исключительно из-за разницы в размерах выборок и размере конкурса между факультетами . Об этом говорит сайт https://intellect.icu . Покажу на примере двух факультетов.
| Фаультет | Пол | Заявки | Принято |
| A | Мужчины | 400 | 200 (50%) |
| A | Женщины | 200 | 100 (50%) |
| B | Мужчины | 150 | 50 (33%) |
| B | Женщины | 450 | 150 (33%) |
| Итого | Мужчины | 550 | 250 (45%) |
| Итого | Женщины | 650 | 250 (38%) |
Оба факультета принимают одинаковые доли женщин и мужчин. Однако поскольку абсолютное количество мужчин было больше на факультете с более высоким процентом принятых, если объединить данные, получится, что в целом процент поступления мужчин выше.
Варианты
Динамическая байесовская сеть
Динамическая или временная байесовская сеть (часто называемая RBN или DBN для динамической байесовской сети ) — это расширение байесовской сети, которое позволяет представить эволюцию случайных величин как функцию дискретной последовательности, например временных шагов. Термин динамический характеризует смоделированную систему, а не сеть, которая не изменяется. Например, исходя из сети, представленной на фиг.1, систему можно сделать динамической, указав, что будущий риск аварии зависит от риска прошлой и настоящей аварии. Интуиция подсказывает, что чем больше неопытных пользователей сменяют друг друга, тем больше возрастает риск несчастного случая; Напротив, череда опытных пользователей со временем снижает этот риск. В этом примере переменная «авария» называется динамической, временной или постоянной.
Формально динамическая байесовская сеть определяется как пара . — классическая байесовская сеть, представляющая априорное (или начальное) распределение случайных величин; говоря более интуитивно, это время 0. — это динамическая байесовская сеть с двумя временными шагами, описывающими переход от временного шага t-1 к временному шагу t , то есть для любого узла, принадлежащего , в ориентированном ациклическом графе, как представлено выше. Затем записывается совместная вероятность временного шага:
(B1,B2d){\ displaystyle (B_ {1}, B_ {2d})}B1{\ displaystyle B_ {1}}B2d{\ displaystyle B_ {2d}}п(Икст|Икст-1){\ Displaystyle Р (х_ {т} \, {\ большой |} \, х_ {т-1})}Икс{\ displaystyle x}V{\ displaystyle V}граммзнак равно(V,E){\ Displaystyle G = (V, E)}
- п(Vт|Vт-1)знак равно∏Икс∈Vп(Икст|па(Икст)){\ Displaystyle P (V_ {t} \, {\ big |} \, V_ {t-1}) = \ prod _ {x \ in V} P (x_ {t} \, {\ big |} \, \ OperatorName {pa} (x_ {t})) \,}
Родители узла, отмеченные для записи , могут, таким образом, быть либо прямым родителем в сети в момент времени t , либо прямым родителем в момент времени t-1 .
па(Икст){\ displaystyle \ operatorname {pa} (x_ {t})}
Факторизованный закон совместной вероятности вычисляется путем «раскручивания» сети по временной последовательности при условии, что ее длина известна, что будет здесь отмечено . Формально, если — совместная вероятность исходной сети , поэтому на временном шаге 0 мы можем написать:
Т{\ displaystyle T}п(V){\ displaystyle P (V_ {0})}B1{\ displaystyle B_ {1}}
- п(VТ)знак равноп(V)×п(V1Т)знак равно∏Икс∈Vп(Икс|па(Икс))×∏тзнак равно1Т∏Икс∈Vп(Икст|па(Икст)){\ Displaystyle P (V_ {0: T}) = P (V_ {0}) \ times P (V_ {1: T}) = \ prod _ {x \ in V} P (x_ {0} \, { \ big |} \, \ operatorname {pa} (x_ {0})) \ times \ prod _ {t = 1} ^ {T} \ prod _ {x \ in V} P (x_ {t} \, { \ big |} \, \ operatorname {pa} (x_ {t}))}
Таким образом, динамическая байесовская сеть соблюдает марковское свойство , которое выражает, что условные распределения в момент времени t зависят только от состояния в момент времени t-1 в случайном процессе . Динамические байесовские сети являются обобщением вероятностных моделей временных рядов, таких как скрытая марковская модель , фильтр Калмана …
Наивный байесовский классификатор
Наивный байесовский классификатор — это тип линейного классификатора, который вместо этого можно определить как упрощение байесовских сетей. Их структура фактически состоит только из двух уровней: первый содержит только один узел, например , отмеченный , а второй — несколько узлов, имеющих только одного родителя . Эти модели называются наивными, потому что они предполагают, что все потоки независимы друг от друга. С учетом детей отмеченного , совместный вероятностный закон байесовского классификатора записывается:
ПРОТИВ{\ displaystyle C}ПРОТИВ{\ displaystyle C}ПРОТИВ{\ displaystyle C}F1…Fнет{\ displaystyle F_ {1} … F_ {n}}
- п(ПРОТИВ|F1…Fнет){\ Displaystyle P (C | F_ {1} … F_ {n})}
Эти модели особенно подходят для задач автоматической классификации , где представлены возможные ненаблюдаемые классы домена и наблюдаемые переменные, характеризующие каждый класс . Примером может служить разделение людей в популяции на две группы или класса, «здоровые» и «больные», в соответствии с наблюдаемыми симптомами, такими как наличие лихорадки и т. Д.
ПРОТИВ{\ displaystyle C}F1…Fнет{\ displaystyle F_ {1} … F_ {n}}ПРОТИВ{\ displaystyle C}
Причинно-следственная диаграмма
Причинно — следственная диаграмма , представляет собой сеть , в которой байесовская связи между узлами представляют причинно — следственные связи. Причинно-следственные диаграммы используются для причинно-следственных выводов .
Что такого прекрасного в этой аппроксимации (свойстве условной независимости)?
Это сильно сокращает объём вычислений, ведь теперь нам нужно считать только родительский элемент, остальное можно проигнорировать.
Давайте посмотрим на числа.
Скажем, у вас есть n двоичных переменных (= n ребер).
Неограниченное совместное распределение требует O(2^n) вероятностей.
Для байесовской сети с максимумом k родителей для каждого узла нам нужна только O(n * 2^k) вероятностей (что может быть выполнено в линейное время для определенного числа классов).
n = 30 двоичных переменных, k = 4 максимальное число родителей для узла• Неограниченное совместное распределение: нужно 2^30 (около 1 миллиона) вероятностей -> Трудно обрабатывать!• Байесовская сеть: нужно только 480 вероятностей
Обращение корреляции
Другая интригующая версия парадокса Симпсона возникает, когда корреляция, которая указывает в одном направлении в стратифицированных группах, становится корреляцией впротивоположное направлениекогда агрегировано для населения. Давайте посмотрим на упрощенный пример. Скажем, у нас есть данные о количестве часов физических упражнений в неделю в зависимости от риска развития заболевания для двух групп пациентов, тех, кто моложе 50 лет и старше 50 лет. Вот отдельные графики, показывающие взаимосвязь между физической нагрузкой и вероятность заболевания.









![]()
Графики вероятности заболевания в зависимости от часов еженедельных упражнений, стратифицированных по возрасту.
(Пример может быть воссоздан в этомJupyter Notebook).
Мы ясно видимотрицательная корреляцияЭто указывает на то, что повышение уровня физической активности в неделю коррелирует с более низким риском развития заболевания в обеих группах. Теперь давайте объединим данные на одном графике:
![]()
Совокупный график зависимости вероятности заболевания от физической нагрузки.
Корреляция полностьюобратная!Если показано только это число, мы бы пришли к выводу, что упражнениеувеличиваетсяриск заболевания, противоположный тому, что мы бы сказали на отдельных участках. Как физические упражнения могут уменьшить и увеличить риск заболевания? Ответ заключается в том, что это не так, и чтобы понять, как разрешить этот парадокс, нам нужно смотреть за пределы данных, которые нам показывают, и анализировать процесс генерации данных — что послужило причиной результатов.
Разрешение Парадокса
Чтобы избежать парадокса Симпсона, приводящего нас к двум противоположным выводам, нам нужно выбрать разделение данных в группы или объединение их вместе. Это кажется достаточно простым, но как мы решаем, что делать? Ответ надумать причинно: как были получены данные и на основании этого,какие факторы влияют на результаты, которые мыне показаны?
В примере «упражнение против болезни» мы интуитивно знаем, что физические упражнения не являются единственным фактором, влияющим на вероятность развития заболевания. Существуют и другие факторы, такие как диета, окружающая среда, наследственность и так далее. Тем не менее, на графиках выше, мы видимтольковероятность против часов упражнений В нашем вымышленном примере давайте предположим, что болезнь вызвана как физическими упражнениями, так и возрастом. Это представлено в следующей причинно-следственной модели вероятности заболевания.
![]()
Причинно-следственная модель вероятности заболевания с двумя причинами.
В данных есть две различные причины заболевания, но, объединяя данные и рассматривая только вероятность против физической нагрузки, мы полностью игнорируем вторую причину — возраст. Если мы продолжим и построим график зависимости вероятности от возраста, мы увидим, что возраст пациента сильно положительно коррелирует с вероятностью заболевания.
![]()
Графики вероятности заболевания в зависимости от возраста стратифицированы по возрастной группе.
По мере того, как возраст пациента увеличивается, его / ее риск заболевания увеличивается, что означает, что у пожилых пациентов вероятность развития заболевания выше, чем у более молодых пациентов, даже при одинаковом количестве упражнений. Поэтому для оценки эффектатолько чтоупражнения на болезнь, мы хотели бы держать возрастпостояннаяа такжеменятьколичество еженедельных упражнений.
A. Условная независимость в байесовской сети (графовые модели)
Байесовская сеть представляет совместное распределение с использованием направленного ациклического графа, в котором каждое ребро является условной зависимостью, а каждый узел — отдельной случайной величиной. Существует множество других названий: сеть доверия, сеть решений, причинная сеть, Байесова модель, вероятностная направленная ациклическая графическая модель и т.д.
Выглядит это так:
![]()
Простая байесовская сеть с таблицей условной вероятности
Чтобы байесовская сеть моделировала распределение вероятностей, она опирается на важное условие: каждая переменная условно независима от своих не-потомков, включая родителей. К примеру, мы можем упростить P(Мокрая трава|Дождевальная установка, Дождь) до P(Мокрая трава|Дождевальная установка), поскольку Мокрая трава условно не зависит от своего не-потомка, Дождя, влияющего также на Дождевальную установку
К примеру, мы можем упростить P(Мокрая трава|Дождевальная установка, Дождь) до P(Мокрая трава|Дождевальная установка), поскольку Мокрая трава условно не зависит от своего не-потомка, Дождя, влияющего также на Дождевальную установку.
Используя это свойство, мы можем упростить совместное распределение в формулу ниже:
![]()
Вывод
Определение и сложность
Умозаключение в байесовской сети является вычисление апостериорных вероятностей в сети, с учетом новой информации наблюдается. Это вычислительная проблема, потому что благодаря вероятностным операциям и теореме Байеса все возможные апостериорные вероятности в сети могут быть вычислены. Таким образом, учитывая набор свидетельств (экземпляров переменных) Y, проблема вывода в G = (V, E) состоит в вычислении с помощью . Если Y пусто (нет доказательств), это равносильно вычислению P (X). Интуитивно это вопрос ответа на вопрос о вероятности в сети.
п(Икс|Y){\ Displaystyle P (X | Y)}Икс⊂V,Y⊂V{\ Displaystyle X \ подмножество V, Y \ подмножество V}
Хотя проблема вывода зависит от сложности сети (чем проще топология сети, тем проще вывод), в 1987 г. Г. Ф. Купер показал, что в общем случае это « NP-сложная проблема . Более того, Дагум и Луби также показали в 1993 году, что найти приближение задачи вывода в байесовской сети также NP-сложно. В результате этих результатов естественно возникают две основные категории алгоритмов вывода: алгоритмы точного вывода, которые вычисляют апостериорные вероятности, как правило, за экспоненциальное время, и эвристики, которые скорее обеспечивают аппроксимацию апостериорных распределений, но с меньшей вычислительной сложностью. Более строго, алгоритмы точного вывода обеспечивают результат и доказательство того, что результат является точным, в то время как эвристика предоставляет результат без доказательства его качества (то есть в зависимости от случаев эвристика также может найти точное решение, чем очень грубое приближение).





Классификация проблемы вывода как NP-трудная, таким образом, является важным результатом. Чтобы установить свое доказательство, Купер рассматривает общую проблему P (X = x)> 0: является ли вероятность того, что переменная X принимает значение x больше нуля в байесовской сети? Это проблема решения (ответ — да или нет). Купер сначала показывает, что если проблема P (X = x)> 0 является NP-полной, то P (X = x) является NP-сложной, и, следовательно, проблема вывода в байесовских сетях является NP-сложной. Для доказательства NP-полноты р (х = х)> 0, он Полиномиально уменьшает на 3-SAT задачу (классическая NP-полной задачи) задачи P (X = X)> 0: во- первых, он показывает , что построение байесовской сети из экземпляра 3-SAT, обозначенного C, может быть выполнено с полиномиальной сложностью; тогда это показывает, что C удовлетворяется тогда и только тогда, когда P (X = x)> 0 истинно. Отсюда следует, что P (X = x)> 0 NP-полно.
Пропагация вывода (англ. Flow of Probabilistic Influence)[править]
Обобщим наблюдения из прошлой секции.
Свидетельства — утверждения вида «событие в узле x произошло».
влияет на , когда свидетельство может изменить распределение вероятностей .
Рассмотрим случаи, когда влияет на при имеющихся свидетельствах :
- : всегда влияет на .
- : всегда влияет на .
- : влияет на , если не принадлежит .
- : влияет на , если не принадлежит .
- : влияет на , если не принадлежит .
- (-образная структура): влияет на , если или кто-либо из потомков принадлежит , и, соответственно, не влияет на , если или хотя бы кто-либо из потомков не принадлежит .
| Определение: |
Активные пути (англ. Active Trails) — путь активен при свидетельствах , если:
|





