DateTime Тип данных
Тип данных DATETIME используется для указания даты и времени.
DATETIME задается в следующем виде «YYYY-MM-DDThh:mm:ss» , где:
- YYYY указывает год
- ММ указывает месяц
- DD означает день
- T указывает на начало требуемого времени раздела
- чч указывает на час
- мм указывает на минуту
- сс указывает второй
Note: Все компоненты необходимы!
Ниже приведен пример декларации DATETIME в схеме:
<xs:element name=»startdate» type=»xs:dateTime»/>
Элемент в документе может выглядеть следующим образом:
<startdate>2002-05-30T09:00:00</startdate>
Или это может выглядеть следующим образом:
<startdate>2002-05-30T09:30:10.5</startdate>
Часовые пояса
Чтобы указать часовой пояс, вы можете либо ввести DATETIME во времени UTC, добавив «Z» за время — как это:
<startdate>2002-05-30T09:30:10Z</startdate>
или вы можете задать смещение от времени UTC путем добавления положительного или отрицательного времени за время — как это:
<startdate>2002-05-30T09:30:10-06:00</startdate>
or
<startdate>2002-05-30T09:30:10+06:00</startdate>
Тип дата-время
Тип дата-время определяется стандартным идентификатором TDateTime и предназначен для одновременного хранения и даты, и времени. Во внутреннем представлении он занимает 8 байт и подобно Currency представляет собой вещественное число с фиксированной дробной частью: в целой части числа хранится дата, в дробной — время.
Дата определяется как количество суток, прошедших с 30 декабря 1899 года, а время — как часть суток, прошедших с 0 часов, так что значение 36444,837 соответствует дате 11.10.1999 и времени 20:05. Количество суток может быть и отрицательным, однако значения меньшие -693594 (соответствует дате 00.00.0000 от Рождества Христова) игнорируются функциями преобразования даты к строковому типу.
Над данными типа TDateTime определены те же операции, что и над вещественными числами, а в выражениях этого типа могут участвовать константы и переменные целого и вещественного типов. Например, можно без труда определить дату, отстоящую от заданной на сколько-то дней вперед или назад: для этого достаточно соответственно прибавить к заданной дате или отнять от нее нужное целое число. Например, оператор:
IbOutput.Caption = DateToStr(Date + 21);
поместит в метку IbOutput дату, соответствующую текущей дате плюс 3 недели. Чуть сложнее с исчислением времени. Например, чтобы добавить к текущему времени полтора часа, следует использовать выражение:
Time + StrToTime('1:30')
или
Time+1.524
Другие решения
ответ от ThW в целом вдумчивый и путь. Это хорошо объясняет, как интерфейс в PHP предназначен для использования.
Кредиты также идут ему за большую часть работы, проделанной для этого дифференцированного ответа, поскольку мы обсуждали этот вопрос вчера в чате.
Есть некоторые ограничения с CDATA в XML, однако, это также относится к намеченным двум способам использования XMLWriter для CDATA:
От: Раздел CDATA — сравнить
Обычно XMLWriter принимает строковые данные, которые не закодированы для использования. Например. если вы передадите какой-нибудь текст, он будет написан в правильном кодировании (если ).
Но если вы начнете раздел CDATA, а затем напишите текст или же вы пишете CDATA напрямую, передаваемая строка не должна заканчиваться или содержать другой раздел CDATA. Это означает, что он не может содержать последовательность символовmsgstr «так как это преждевременно завершит раздел CDATA.
Таким образом, ответственность за передачу действительных данных в XMLWriter остается за пользователем этих методов.
Обычно это тривиально (одиночные октеты, двоичные кодировки набора символов на основе US-ASCII и Unicode UTF-8), вот пример кода:
И пример использования:
Примерный вывод:
DOMDocument Кстати. делает что-то очень похожее под капотом уже:
Выход:
Технически понять почему XMLWriter в PHP ведет себя так, вы должны знать, что XMLWriter основан на библиотека libxml2. Расширение в PHP для большей части проделанной работы передает вызовы libxml:
РНР делегаты в libxml который делает из , а также ,
используется во многих подпрограммах (например, написание PI), но только для некоторых случаев написания текста строка параметра содержимого является кодируются:
- Название,
- Текст и
- Атрибут.
Для всех остальных это передается как есть. Это включает в себя CDATA, поэтому данные передаются должен соответствовать требованиям для XML CData (потому что это написано этим методом):
CData ::= (Char* — (Char* ‘]]>’ Char*))
Что технически говорит: любая строка не содержит».
Это может быть легко упущено, я сам подозревал, что это могло быть ошибкой вчера. И я не единственный, связанный отчет об ошибках на PHP.net: https://bugs.php.net/bug.php?id=44619 с лет назад.
Смотри также Что значит <! ]> в XML значит?
Вещественные типы
В отличие от порядковых типов, значения которых всегда сопоставляются с рядом целых чисел и, следовательно, представляются в ПК абсолютно точно, значения вещественных типов определяют произвольное число лишь с некоторой конечной точностью, зависящей от внутреннего формата вещественного числа. Pascal Script поддерживает следующие вещественные типы:
| Тип данных | Длина, байт | Количество значащих цифр | Диапазон допустимых значений |
| Single | 4 | 7-8 | 1.5*10e-45 .. 3.4*10e38 |
| Double | 8 | 15-16 | 5.0*10e324 .. 1.7*10e308 |
| Extended | 10 | 19-20 | 3.4*10-4951 .. 1.1*10e4932 |
| Currency | 8 | 19-20 | +/-922 337 203 685 477,5807 |
В DataExpress числовые поля имеют тип Double.
1.6 Прерывание программы
В процессе выполнения программы могут возникнуть ситуации, при которых дальнейшее выполнение программы невозможно или недопустимо. Например, пользователь вместо числа ввёл в консоли букву. Хорошим тоном разработчика в данном случае будет не пускать ситуацию на самотёк и ждать пока программа сама споткнется и выдаст системное сообщение об ошибке, а обработать некорректный ввод сразу, сообщить об этом пользователю и остановить программу явным образом.
Прервать выполнение программы можно разными способами. Рассмотрим две часто используемые для этого функции:
- выводит на экран объекты, перечисленные через запятую в и завершает выполнение программы. При ручном вызове этой функции в целесообразно передать текстовую строку с сообщением о причине остановки программы. Вызов происходит обычно после проверки некоторого условия оператором .
- вызывает , если хотя бы одно из выражений, перечисленных через запятую в имеет значение . При этом в передается первое выражение, которое было оценено в .
Реализуем вышеописанный пример с контролем пользовательского ввода:
Если пользователь введет , программа остановит выполнение:
Обратите внимание, что R напечатал также и само выражение, которое было оценено как. Вышеприведенный код можно сделать более дружелюбным для пользователя, если воспользоваться непосредственно функцией :. Вывод программы в случае ввода строки будет следующим:
Вывод программы в случае ввода строки будет следующим:
Свойства
|
Возвращает класс XmlAttributeCollection, содержащий атрибуты данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает базовый URI текущего узла. (Унаследовано от XmlNode) |
|
|
Возвращает все дочерние узлы данного узла. (Унаследовано от XmlNode) |
|
|
Содержит данные узла. (Унаследовано от XmlCharacterData) |
|
|
Возвращает первый дочерний узел данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает значение, свидетельствующее о наличии дочерних узлов у текущего узла. (Унаследовано от XmlNode) |
|
|
Возвращает или задает последовательно соединенные значения узла и его дочерних узлов. (Унаследовано от XmlCharacterData) |
|
|
Возвращает или задает разметку, отражающую только дочерние узлы данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает значение, определяющее, доступен ли узел только для чтения. (Унаследовано от XmlNode) |
|
|
Возвращает первый дочерний элемент с помощью указанного свойства и . (Унаследовано от XmlNode) |
|
|
Возвращает первый дочерний элемент с помощью указанного свойства . (Унаследовано от XmlNode) |
|
|
Возвращает последний дочерний узел данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает длину данных в знаках. (Унаследовано от XmlCharacterData) |
|
|
Возвращает локальное имя узла. |
|
|
Возвращает полное имя узла. |
|
|
Возвращает URI пространства имен данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает узел, следующий сразу за данным узелом. (Унаследовано от XmlLinkedNode) |
|
|
Возвращает тип текущего узла. |
|
|
Возвращает разметку, содержащую данный узел и все его дочерние узлы. (Унаследовано от XmlNode) |
|
|
Возвращает класс XmlDocument, которому принадлежит данный узел. (Унаследовано от XmlNode) |
|
|
Возвращает родительский узел для данного узла (только для тех узлов, которые могут иметь родительские узлы). |
|
|
Возвращает родительский узел для данного узла (только для тех узлов, которые могут иметь родительские узлы). (Унаследовано от XmlNode) |
|
|
Возвращает или задает префикс пространства имен данного узла. (Унаследовано от XmlNode) |
|
|
Возвращает узел, непосредственно предшествующий данному узлу. (Унаследовано от XmlLinkedNode) |
|
|
Возвращает текстовый узел, непосредственно предшествующий данному. |
|
|
Возвращает текстовый узел, непосредственно предшествующий данному. (Унаследовано от XmlNode) |
|
|
Возвращает информационный набор после проверки схемы (назначенный этому узлу в результате проверки схемы). (Унаследовано от XmlNode) |
|
|
Возвращает или задает значение узла. (Унаследовано от XmlCharacterData) |
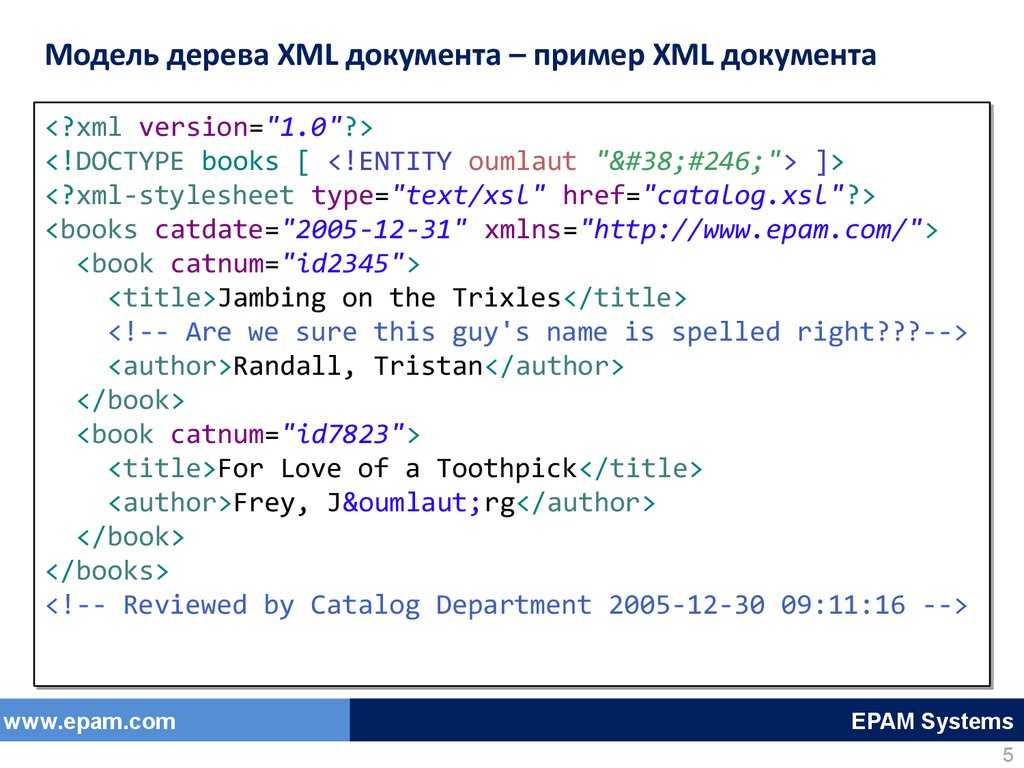
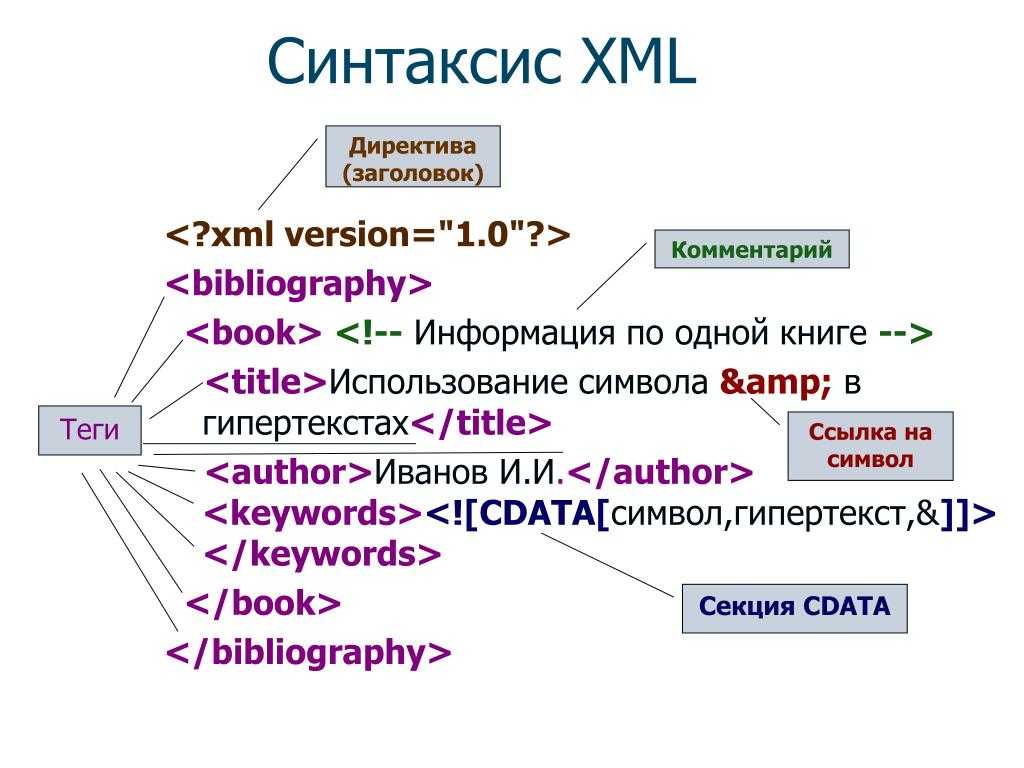
Разделы CDATA в XML [ править ]
В XML-документе или внешнем объекте раздел CDATA — это часть содержимого элемента, размеченная для интерпретации буквально как текстовые данные, а не как размеченное содержимое. Раздел CDATA — это просто альтернативный синтаксис для выражения символьных данных; нет семантической разницы между символьными данными в разделе CDATA и символьными данными в стандартном синтаксисе, где, например, » » и » » представлены как » » и » » соответственно.









Синтаксис и интерпретация
Раздел CDATA начинается со следующей последовательности:
< ! [CDATA [
и заканчивается следующим появлением последовательности:
]]>
Все символы, заключенные между этими двумя последовательностями, интерпретируются как символы, а не как разметка или ссылки на объекты. Каждый символ воспринимается буквально, за исключением последовательности символов. В:
<sender> Джон Смит </sender>
начальный и конечный теги «отправитель» интерпретируются как разметка. Однако код:
<! [CDATA [<sender> Джон Смит </sender>]]>
эквивалентно:
& lt; отправитель & gt; Джон Смит & lt; / отправитель & gt;
Таким образом, «теги» будут иметь тот же статус, что и «Джон Смит»; они будут рассматриваться как текст.
Точно так же, если числовая ссылка на символ появляется в содержимом элемента, она будет интерпретироваться как единственный символ Unicode 00F0 (строчная буква eth ). Но если то же самое появляется в разделе CDATA, он будет проанализирован как шесть символов: амперсанд, решетка, цифра 2, цифра 4, цифра 0, точка с запятой.
Использование разделов CDATA
Новые авторы XML-документов часто неправильно понимают назначение раздела CDATA, ошибочно полагая, что его цель — «защитить» данные от обработки как обычные символьные данные во время обработки. Некоторые API-интерфейсы для работы с XML-документами действительно предлагают варианты независимого доступа к разделам CDATA, но такие возможности существуют сверх обычных требований систем обработки XML и по-прежнему не изменяют неявное значение данных. Символьные данные — это символьные данные, независимо от того, выражены ли они через раздел CDATA или обычную разметку. Разделы CDATA полезны для записи кода XML в виде текстовых данных в документе XML. Например, если кто-то хочет набрать книгу с помощью XSL поясняя использование приложения XML, разметка XML, которая появится в самой книге, будет записана в исходном файле в разделе CDATA.
Вложенность
Раздел CDATA не может содержать строку » «, и поэтому раздел CDATA не может содержать вложенные разделы CDATA. Предпочтительный подход к использованию секций CDATA для кодирования текста, содержащего триаду » «, заключается в использовании нескольких секций CDATA путем разделения каждого вхождения триады непосредственно перед » «. Например, чтобы закодировать » » , нужно написать:
<! ]]]> <! ]>
Это означает, что для кодирования » » в середине раздела CDATA замените все вхождения » » следующим:
]]]]> <! [CDATA [>
Это эффективно останавливает и перезапускает раздел CDATA.
Проблемы с кодировкой
В текстовых данных любой символ Юникода, недоступный в кодировке, объявленной в заголовке, может быть представлен с помощью числовой ссылки на символы . Но текст в разделе CDATA строго ограничен символами, доступными в кодировке.
Из-за этого программное использование раздела CDATA для цитирования данных, которые потенциально могут содержать символы «или» , может вызвать проблемы, когда данные содержат символы, которые не могут быть представлены в кодировке. В зависимости от реализации кодировщика эти символы могут быть потеряны, могут быть преобразованы в символы ссылки на символ или могут вызвать сбой кодирования. Но они не будут поддерживаться.
Другая проблема заключается в том, что XML- документ можно перекодировать из одной кодировки в другую во время транспортировки. Когда XML- документ преобразуется в более ограниченный набор символов, такой как ASCII, символы, которые больше не могут быть представлены, преобразуются в ссылки на символы для преобразования без потерь. Но в разделе CDATA эти символы вообще не могут быть представлены, и их необходимо удалить или преобразовать в какой-либо эквивалент, изменяя содержимое раздела CDATA.
Какие типы данных есть в Java
В Java типы данных делят на две большие группы: примитивные и ссылочные. В состав примитивных типов (или просто примитивов) входят четыре подвида и восемь типов данных:
1) целые числа (byte, short, int, long);
2) числа с плавающей точкой (float, double);
3) логический (boolean);
4) символьный (char).
Ссылочные типы данных ещё называют ссылками. К ним относятся все классы, интерфейсы, массивы, а также тип данных String.
Хотя у примитивов и ссылок много общего, между ними есть существенные различия. И главное различие — в том, что именно в них хранится.
| Примитивные переменные | Ссылочные переменные |
|---|---|
| Хранят значение | Хранят адрес объекта в памяти, на который ссылаются (отсюда и название).Используются для доступа к объектам (его нельзя получить, если на объект нет ссылки) |
| Создаются присваиванием значения | Создаются через конструкторы классов (присваивание только создаёт вторую ссылку на существующий объект) |
| Имеют строго заданный диапазон допустимых значений | По умолчанию их значение — null |
| В аргументы методов попадают копии значения переменной (это передача по значению) | В методы передаётся значение ссылки — операция выполняется над оригинальным объектом, на который ссылается переменная |
| Могут использоваться для ссылки на любой объект объявленного или совместимого типа |
Вот пример использования примитивных и ссылочных типов данных:
CDATA в DTD
Значение атрибута типа CDATA
В Определение типа документа (DTD) для SGML и XML значение атрибута может быть обозначено как имеющее тип CDATA: произвольные символьные данные. В атрибуте типа CDATA разрешена разметка символов и ссылок на объекты, которые будут обрабатываться при чтении документа.
Например, если XML DTD содержит
фу а CDATA # ПРЕДПОЛАГАЕТСЯ>
это означает, что элементы с именем foo могут дополнительно иметь атрибут с именем «а«который имеет тип CDATA. В XML-документе, который действителен согласно этому DTD, может появиться такой элемент:
а ="1 и 2 равны & lt; & # 51; & # x0A;" />
а синтаксический анализатор XML интерпретирует «а«значение атрибута как символьные данные»1 и 2 «.
Сущность типа CDATA
SGML или XML DTD может также включать в себя объявления объектов, в которых используется токен CDATA, чтобы указать, что объект состоит из символьных данных. Символьные данные могут появляться в самом объявлении или могут быть доступны извне, на которые ссылается URI. В любом случае в сущности разрешены ссылки на символы и разметки ссылок на сущности параметров, которые будут обрабатываться как таковые при чтении.
Атрибут ="Y"><!]></DISPLAY_NAME>имя ="" val ="" ЦЕЛОЕ имя ="" val ="" ДЛИННЫЙ имя ="" val =""/>
1.4 Условный оператор
Проверка условий позволяет осуществлять так называемое ветвление в программе. Ветвление означает, что при определенных условиях (значениях переменных) будет выполнен один программный код, а при других условиях — другой. В R для проверки условий используется условный оператор if — else if — else следующего вида:
Сначала проверяется условие в выражении , и если оно истинно, то выполнится вложенный в фигурные скобки программный код , после чего оставшиеся условия не будут проверяться. Если первое условие ложно, программа перейдет к проверке следующего условия . Далее, если оно истинно, то выполнится вложенный код , если нет — проверка переключится на следующее условие и так далее. Заключительный код , следующий за словом , выполнится только если ложными окажутся все предыдущие условия.
Например, сгенерируем случайное число, округлим его до одного знака после запятой и проверим относительно нуля:
Условия можно использовать, в частности, для того чтобы обрабатывать пользовательский ввод в программе. Например, охарактеризуем положение точки относительно Полярного круга:
Пользователь вводит , а мы оцениваем результат:
Логический и символьный типы данных
Чтобы работать с логическими значениями, используют тип данных boolean — это его единственное применение. У такой переменной может быть только два значения: false (ложь) и true (истина).
В Java boolean — отдельная переменная. Это не аналог 1 или , как, например, в JavaScript и PHP.
Тип данных char используют, чтобы хранить в переменных любые 16-разрядные символы Unicode. Но их нужно записывать строго в одинарные кавычки ‘ ‘, и только по одному.
Не стоит путать символьные и строковые переменные — ‘ж’ не равно «ж», потому что в двойных кавычках хранится тип данных String. А это уже не примитив.
6 ответов
Лучший ответ
Из WIKI:
24
Ólafur Waage
13 Май 2009 в 13:21
Анализируются как PCDATA, так и CDATA. Оба они являются символьными данными.
Оба они должны включать только допустимые символы. Например, если кодировка вашего документа — UTF-8, содержимое разделов CDATA должно по-прежнему содержать допустимые символы UTF-8. Таким образом, случайные двоичные данные, вероятно, помешают правильно сформировать документ. Также разделы CDATA по-прежнему анализируются, хотя бы для того, чтобы найти тег конечного раздела. Но другие подобные разметке символы, такие как и &, игнорируются и передаются синтаксическим анализатором как есть.
OTOH в PCDATA litteral
Так что да, разделы CDATA действительно разбираются. Я не уверен, почему вам сказали, что PCDATA не анализируется.
9
Thanatos
30 Май 2013 в 18:57
PCDATA — проанализированные символьные данные
CDATA — (неразборчивые) символьные данные
7
SoyChai
25 Мар 2021 в 17:37
- PCDATA — это текст, который будет проанализирован парсером. Теги внутри текста будут рассматриваться как разметка, а объекты будут расширены.
- CDATA — это текст, который не анализируется парсером. Теги внутри текста будут не рассматриваться как разметка, и объекты не будут разворачиваться.
По умолчанию все — PCDATA. В следующем примере, игнорируя корень, будет проанализирован, и у него не будет содержимого, кроме одного дочернего элемента.
Когда мы хотим указать, что элемент будет содержать только текст, а не дочерние элементы, мы используем ключевое слово PCDATA, потому что это ключевое слово указывает, что элемент должен содержать анализируемые символьные данные, то есть любой текст, кроме символов, меньших чем (), амперсанд (&), кавычки (‘) и двойные кавычки («).
В следующем примере панель — это CDATA, она не анализируется и имеет содержимое .
В SGML есть несколько моделей содержимого. Модель содержимого #PCDATA говорит, что элемент может содержать простой текст. Его «проанализированная» часть означает, что разметка (включая PI, комментарии и директивы SGML) в нем анализируется, а не отображается как необработанный текст. Это также означает, что ссылки на сущности заменяются.
Другой тип модели содержимого, допускающий использование обычного текстового содержимого, — это CDATA. В XML для модели содержимого элемента не может быть неявно установлено значение CDATA, но в SGML это означает, что разметка и ссылки на сущности игнорируются в содержимом элемента. Однако в атрибутах типа CDATA ссылки на сущности заменяются.
В XML #PCDATA — единственная модель текстового содержимого. Вы используете его, если хотите разрешить текстовое содержимое в элементе. Модель содержимого CDATA может использоваться явно через разметку блока CDATA в #PCDATA, но содержимое элемента не может быть определено как CDATA по умолчанию.
В DTD тип атрибута, который содержит текст, должен быть CDATA. Ключевое слово CDATA в объявлении атрибута имеет другое значение, чем раздел CDATA в документе XML. В разделе CDATA допустимы все символы (включая символы , &, ’и«), кроме конечного тега «]]>».
#PCDATA не соответствует типу атрибута. Используется для типа «листового» текста.



Перед #PCDATA стоит хэш (также известный как «хэштег» или octothorp) просто по историческим причинам.
3
Mr Lister
26 Сен 2019 в 12:01
Ваше первое определение верно.
PCDATA анализируется, что означает, что объекты раскрываются и этот текст обрабатывается как разметка. CDATA не анализируется анализатором XML.
1
Ronald Wildenberg
13 Май 2009 в 13:21
Если бы только элементы были установлены на CDATA по умолчанию в XHTML DTD, это избавило бы от множества уродливых ручных переопределений … Почему блоки сценария должны содержать другие элементы? Если такие элементы есть, они обрабатываются интерпретатором JS в действиях по манипулированию DOM — и в этом случае они все равно должны полностью игнорироваться анализатором XML перед вставкой и рендерингом документа. Я полагаю, это могло быть разработано для принудительного использования внешних файлов ресурсов скрипта, что в конечном итоге хорошо.
trojjer
12 Мар 2013 в 09:38
Варианты
Переменная вариантного типа может принимать хранить значение следующих типов: целый, вещественный, логический, строка, дата-время, OLE-объект. Вариант представляет собой структуру, в которой хранятся сведения о типе и значении переменной. В выражениях и при передаче параметров в процедуры происходит попытка преобразования варианта к нужному типу. Если это не удается, будет ошибка “invalid variant type cast”. Вариант может хранить специальное значение Null (пусто, неизвестно).
Любая арифметическая операция с null даст в результате null. Попытка автоматического преобразования null к какому-либо типу (кроме Variant) приведет к ошибке ‘could not convert variant of type (Null) into type (…)’.
var V1, V2, V3, V4, V5 Variant; begin V1 = 1; V2 = ‘4’; V3 = V + V2; // Результат 5 или ‘5’ V4 = V3 + Null; // V4 = Null V5 = V1 + ‘sdfsdf’; // invalid variant type cast MsgBox(‘Сообщение’, V4); // Could not convert variant of type (Null) into type (String) end;
Варианты широко используются при работе с OLE-объектами. С помощью специальных функций можно узнать значение какого типа хранится в варианте или преобразовать значение к нужному типу.
Порядковые типы
К порядковым типам относятся целые, логические, символьный и перечисляемый. К любому из них применима функция Ord(x), которая возвращает порядковый номер значения выражения X.
Для целых типов функция Ord(x) возвращает само значение х, т. е. Ord(X) = х для х, принадлежащего любому целому типу. Применение Ord(x) к логическому, символьному и перечисляемому типам дает положительное целое число в диапазоне от 0 до 1 (логический тип), от 0 до 255 (символьный), от 0 до 65535 (перечисляемый).
К порядковым типам можно также применять функции:
- — возвращает предыдущее значение порядкового типа, которое соответствует порядковому номеру ord (X) -1, т. е. ;
- — возвращает следующее значение порядкового типа, которое соответствует порядковому номеру ord (X) +1, т. е. .
Например, если в программе определена переменная:
var с Char; begin с = '5'; end;
то функция вернет символ ‘4’, а функция — символ ‘6’.
Если представить себе любой порядковый тип как упорядоченное множество значений, возрастающих слева направо и занимающих на числовой оси некоторый отрезок, то функция не определена для левого, a – для правого конца этого отрезка.
Значения переменных по умолчанию
Как мы уже отмечали, в зависимости от типа данных у каждой переменной есть значение по умолчанию. Оно присваивается при её создании.
В этом примере значения по умолчанию получат все переменные:
А в этом примере значения получают только переменные класса: когда мы создадим класс Cat, по умолчанию weight будет равен 0.0.
Но локальные переменные нужно инициировать сразу при создании. Если написать просто int sum; , компилятор выдаст ошибку: java: variable a might not have been initialized.
У примитивов есть строгие рамки допустимых значений по умолчанию и диапазоны значений — для удобства мы собрали их в таблицу.
Основы работы с ODBC API
Прежде чем перейти к проблеме организации эффективного ввода-вывода, давайте рассмотрим основные этапы работы с ODBC API. Для доступа к данным при помощи ODBC любая программа вызывает API-функции, причем в определённой последовательности:
- подключение к источнику данных;
- инициализация и настройка параметров SQL-запроса/оператора;
- формирование и выполнение запроса/оператора;
- получение результатов;
- отключение от источника данных.
Для соединения с источником данных с помощью функции SQLAllocHandle следует создать «хэндлы» для среды (environment) и соединения (connection).
|
ПРИМЕЧАНИЕ
Объявления ODBC-функций и констант находятся в файлах sql.h и sqlext.h, библиотечный файл – odbc32.lib. |
Необходимо также указать, что работать мы будем с третьей версией ODBC API. Затем можно подключиться к источнику данных функцией SQLConnect. Этой функции передаются имя источника данных (Data Source Name, DSN), имя пользователя (login), пароль (password) и длины этих строк.
|
Для строк языка С, которые заканчиваются нулём, можно передавать константу SQL_NTS (Null-Terminated String). |
DSN – обязательный параметр, без которого дальнейшая работа программы невозможна. Обычно DSN создают при установке приложения. Например, инсталлятор InstallShield легко справляется с этой задачей, также он устанавливает необходимые ODBC-драйверы.
|
В этом месте стоит упомянуть о возможности создания «на лету» имени для источника данных (DSN). Функция SQLConfigDataSource позволяет программным путём создать DSN и избавляет конечного пользователя от процесса настройки DSN. |
Все последующие этапы связаны с подготовкой и выполнением SQL-запросов. Для выполнения запроса требуется хэндл, который можно получить с помощью функции SQLAllocHandle. Далее может следовать так называемый прямой запрос, который выполняет функция SQLExecDirect, а может – сложный. В последнем случае запрос сначала подготавливается с помощью SQLPrepare, затем для передачи исходных данных или установки связи между переменными и параметрами SQL-оператора применяется функция SQLBindParameter. Когда всё готово для выполнения запроса, вызывают функцию SQLExecute. Для чтения данных обычно используют пару функций SQLFetch и SQLGetData, хотя существуют и другие способы. Например, для быстрого чтения данных из таблиц используют SQLBindCol. По окончании работы с запросом ресурсы следует освободить функцией SQLFreeHandle. Нужно не забыть отключиться от источника данных (функция SQLDisconnect) и освободить все ресурсы (функция SQLFreeHandle).
Всегда следует проверять значения, которые возвращают функции ODBC API. Функции в случае успешного выполнения возвращают значения SQL_SUCCESS или SQL_SUCCESS_WITH_INFO. Для того чтобы не выполнять две операции сравнения, существует удобный макрос SQL_SUCCEEDED.
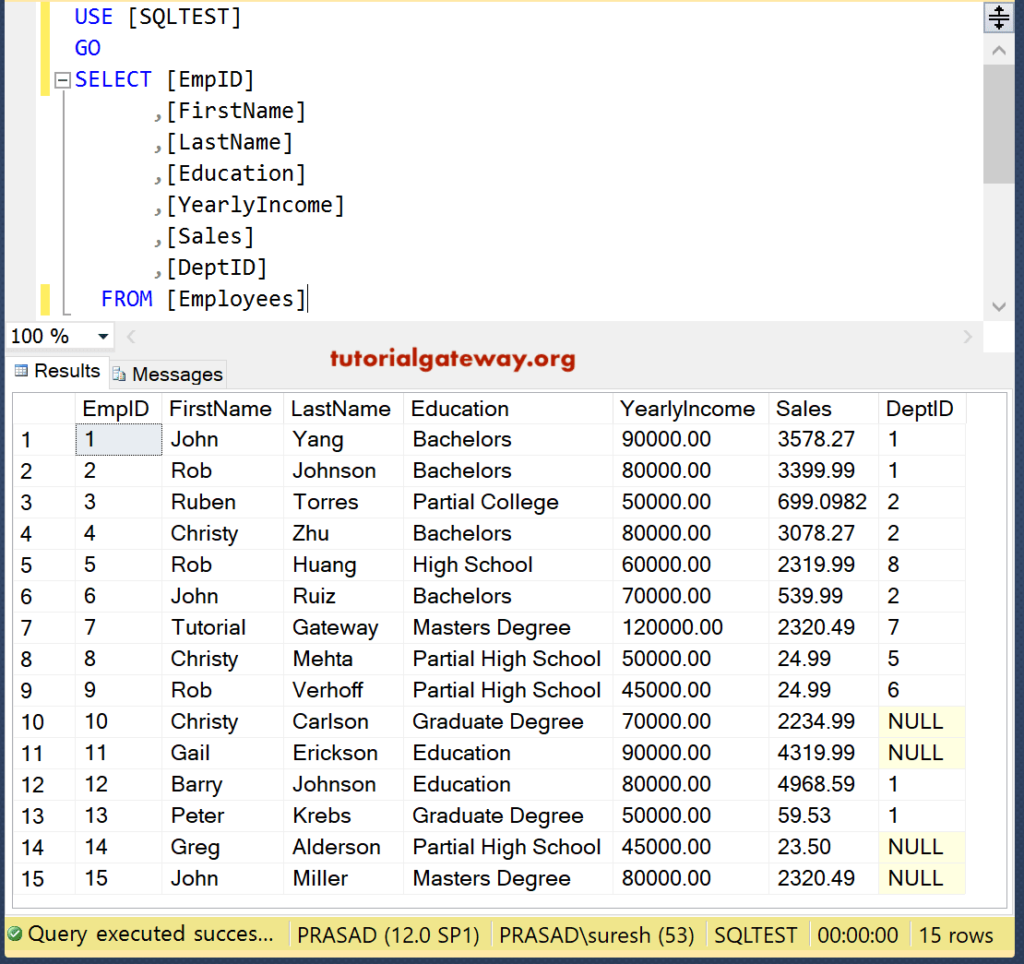
Рисунок 1. Таблица users в базе данных
Проиллюстрируем работу с ODBC API на примере добавления записи в таблицу. Пусть у нас имеется таблица users. Эту таблицу мы будем использовать и для других примеров. В таблице три поля – идентификатор (номер) пользователя, его имя (name) и величина зарплаты (salary). В таблице используются поля трёх наиболее часто используемых типов – целое число, строка символов и число с плавающей точкой.
SQLHANDLE hEnv, hDbc;
SQLRETURN res;
// --== ИНИЦИАЛИЗАЦИЯ СОЕДИНЕНИЯ С БД ЧЕРЕЗ ODBC ==--
// Получаем хэндл ODBC-среды.
res = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &hEnv);
if( !SQL_SUCCEEDED(res) ) return -1;
// Запрашиваем третью версию.
SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
// Получаем хэндл для соединения.
SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDbc);
// Подключаемся к источнику данных.
res = SQLConnect(hDbc, "Sample_DB", SQL_NTS, "", SQL_NTS, "", SQL_NTS);
if( SQL_SUCCEEDED(res) )
{
// --== ВЫПОЛНЕНИЕ SQL-ЗАПРОСА ==--
SQLHSTMT hStmt;
// SQL-оператор для добавления записи в БД.
SQLCHAR szSQL[]="INSERT INTO users (id, name, salary) VALUES (1, 'Bill', 100);";
// Получаем хэндл для SQL-запроса/оператора.
SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt);
// Простейший прямой SQL-запрос/оператор.
SQLExecDirect(hStmt, szSQL, SQL_NTS);
// Освобождаем ресурсы.
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
}
// --== ЗАВЕРШЕНИЕ РАБОТЫ С ODBC ==--
// Отключаемся от источника данных.
SQLDisconnect(hDbc);
// Освобождаем ресурсы.
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
SQLFreeHandle(SQL_HANDLE_ENV, hEnv);
|
Использование CDATA в выводе программы
Разделы CDATA в XHTML документы могут анализироваться веб-браузерами по-разному, если они отображают документ как HTML, поскольку анализаторы HTML не распознают маркеры начала и конца CDATA, а также не распознают ссылки на объекты HTML, такие как & lt; внутри тегов
Поскольку полезно иметь возможность использовать знаки «меньше» ( и
<сценарий тип="текст / javascript">// документ.записывать("<");//]]></сценарий>
или это CSS пример:
<стиль тип="текст / CSS">/ * тело { фоновая картинка url("мрамор.png? width = 300 & height = 300") } /*]]>*/</стиль>
Этот метод необходим только при использовании встроенных скриптов и таблиц стилей и зависит от языка. Таблицы стилей CSS, например, поддерживают только второй стиль комментирования (/* … */), но CSS также меньше нуждается в символах
Использование CDATA в выводе программы
Разделы CDATA в документах XHTML могут анализироваться веб-браузерами по-разному, если они отображают документ как HTML, поскольку анализаторы HTML не распознают маркеры начала и конца CDATA, а также не распознают ссылки на объекты HTML, такие как & lt; внутри тегов <script>. Это может вызвать проблемы с рендерингом в веб-браузерах и может привести к уязвимостям межсайтового скриптинга, если они используются для отображения данных из ненадежных источников, поскольку два вида парсеров не будут согласовывать, где заканчивается раздел CDATA.
Поскольку полезно иметь возможность использовать знаки «меньше» (<) и амперсанды (&) в сценариях веб-страниц и, в меньшей степени, стили, без необходимости помнить об их экранировании, маркеры CDATA обычно используются вокруг текст встроенных элементов <script> и <style> в XHTML-документах. Но чтобы документ мог быть проанализирован парсерами HTML, которые не распознают маркеры CDATA, маркеры CDATA обычно закомментированы, как в этом примере JavaScript :
<script type="text/javascript"> //<![CDATA[ document.write("<"); //]]> </script>
или этот пример CSS :
<style type="text/css"> /*<![CDATA[*/ body { background-image url("marble.png?width=300&height=300") } /*]]>*/ </style>
Этот метод необходим только при использовании встроенных скриптов и таблиц стилей и зависит от языка. Таблицы стилей CSS, например, поддерживают только второй стиль комментирования ( / * … * / ), но CSS также меньше нуждается в символах <и &, чем JavaScript, и поэтому меньше нуждается в явных маркерах CDATA.
Использование CDATA в выводе программы [ править ]
Разделы CDATA в документах XHTML могут анализироваться веб-браузерами по-разному, если они отображают документ как HTML, поскольку анализаторы HTML не распознают маркеры начала и конца CDATA, а также не распознают ссылки на объекты HTML, такие как & lt; внутри тегов <script>. Это может вызвать проблемы с рендерингом в веб-браузерах и может привести к уязвимостям межсайтового скриптинга, если они используются для отображения данных из ненадежных источников, поскольку два вида парсеров не будут согласовывать, где заканчивается раздел CDATA.
Поскольку полезно иметь возможность использовать знаки «меньше» (<) и амперсанды (&) в скриптах веб-страниц и, в меньшей степени, стили, без необходимости помнить их экранирование, то маркеры CDATA обычно используются вокруг текст встроенных элементов <script> и <style> в документах XHTML. Но чтобы документ мог быть проанализирован парсерами HTML, которые не распознают маркеры CDATA, маркеры CDATA обычно закомментированы, как в этом примере JavaScript :
< script type = "text / javascript" > // <! [CDATA [ document . написать ( "<" ); //]]> </ script >
или этот пример CSS :
< style type = "text / css" > / * <! [CDATA [* / body { background-image url ( "marble.png? width = 300 & height = 300" ) } / *]]> * / </ style >
Этот метод необходим только при использовании встроенных скриптов и таблиц стилей и зависит от языка. Таблицы стилей CSS, например, поддерживают только второй стиль комментирования ( / * … * / ), но CSS также меньше нуждается в символах <и &, чем JavaScript, и поэтому меньше нуждается в явных маркерах CDATA.
![Cdata содержание а также разделы cdata в xml [ править ]](https://fuzeservers.ru/wp-content/uploads/a/c/f/acf17f251918ca6b06d22533ff1a5e69.jpeg)