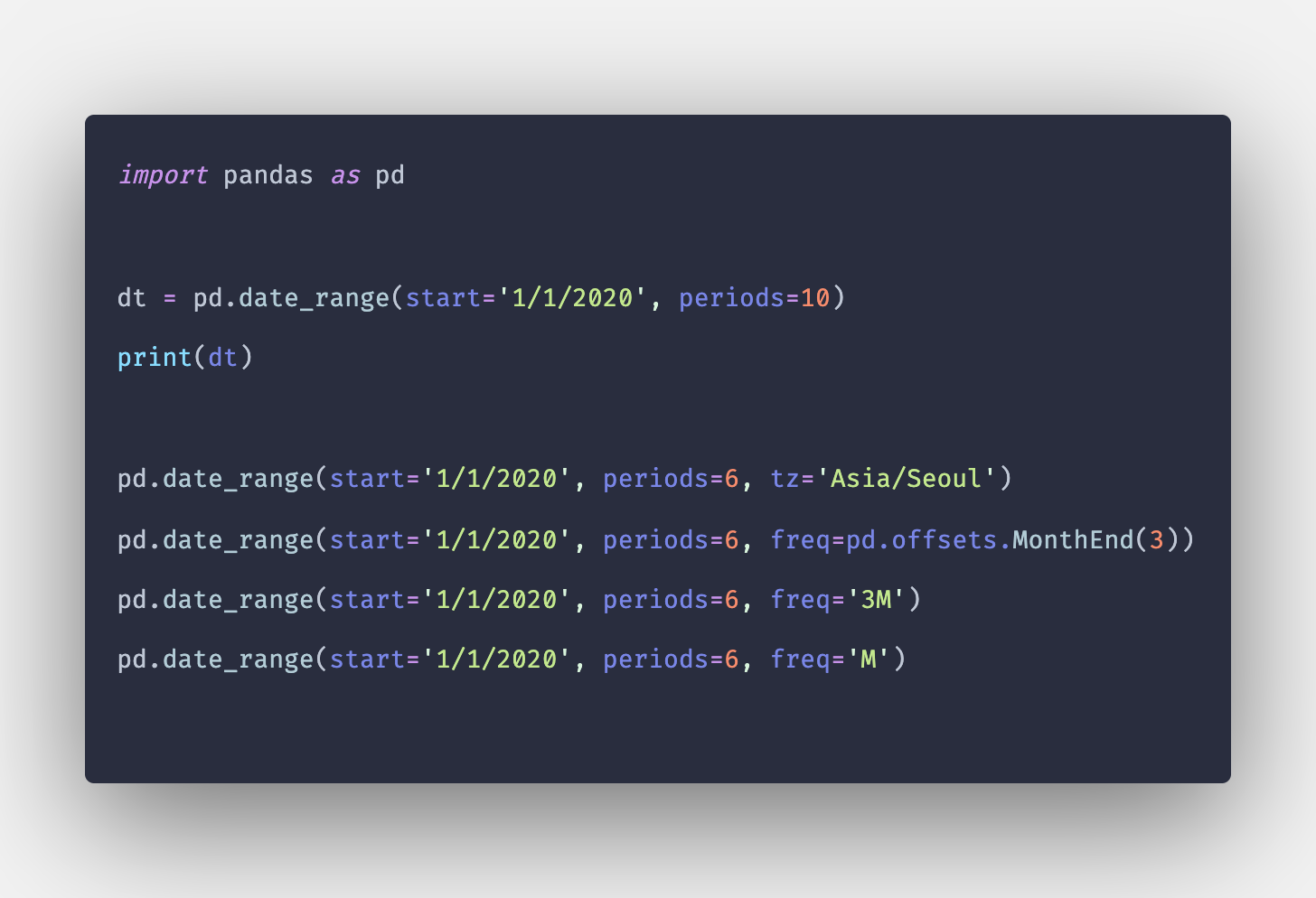
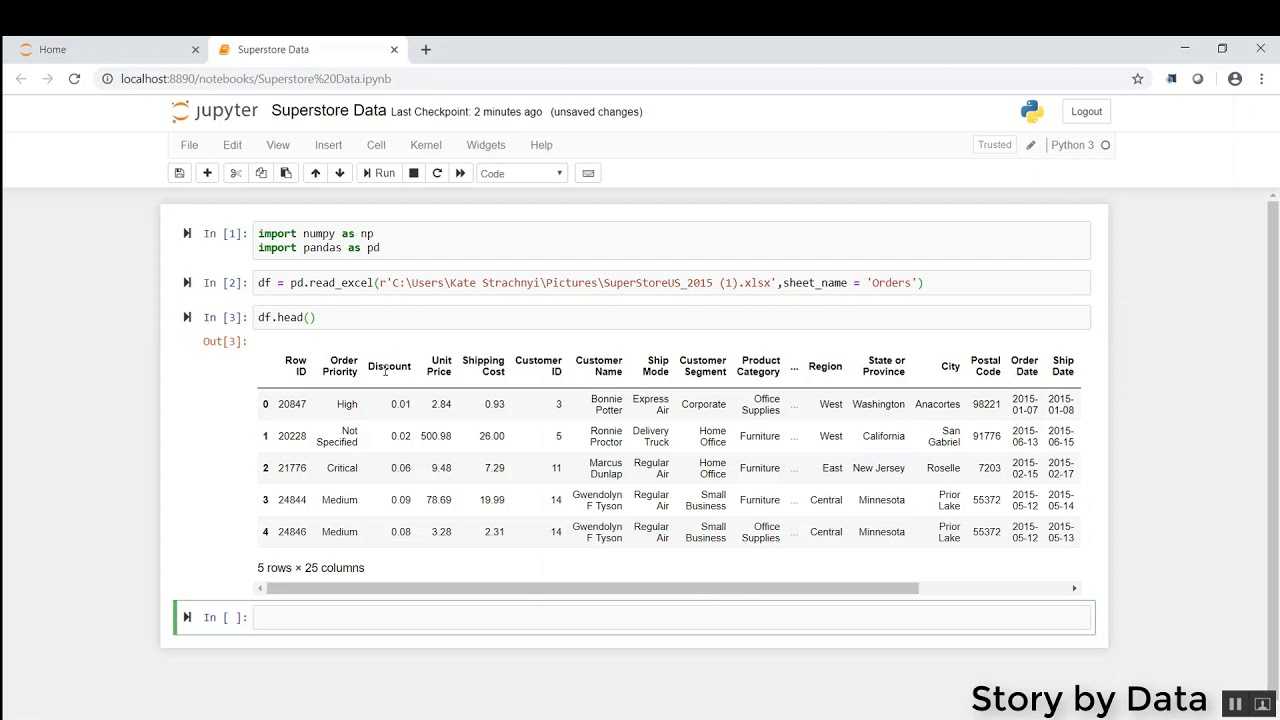
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Практические проекты – это то, как вы обостряете вашу пилу в кодировке!
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Затем станьте питоном независимым разработчиком! Это лучший способ приближения к задаче улучшения ваших навыков Python – даже если вы являетесь полным новичком.
Присоединяйтесь к моему бесплатным вебинаре «Как создать свой навык высокого дохода Python» и посмотреть, как я вырос на моем кодированном бизнесе в Интернете и как вы можете, слишком от комфорта вашего собственного дома.
Присоединяйтесь к свободному вебинару сейчас!
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python одноклассники (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
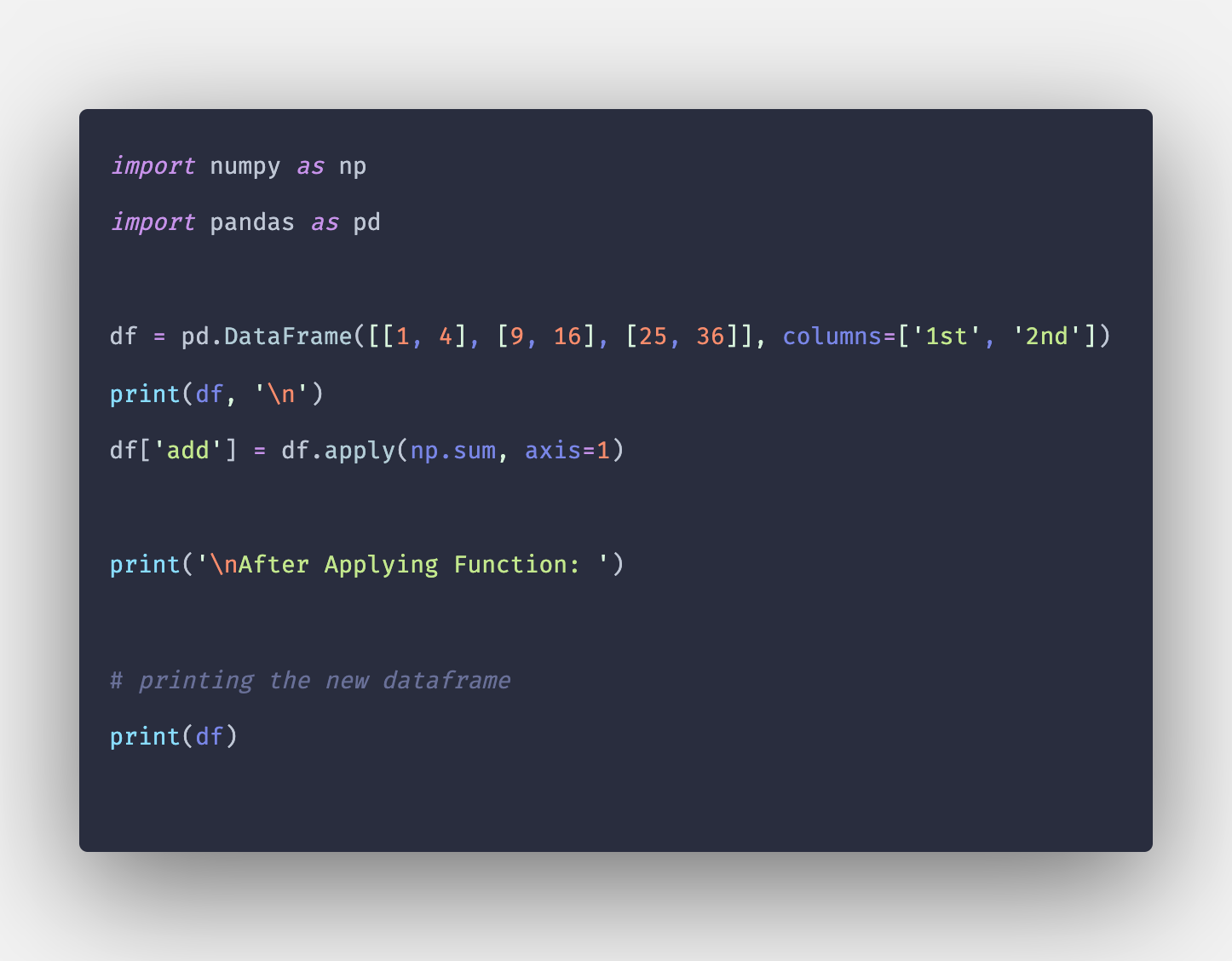
Оригинал: “https://blog.finxter.com/how-to-convert-list-of-lists-to-a-pandas-dataframe/”
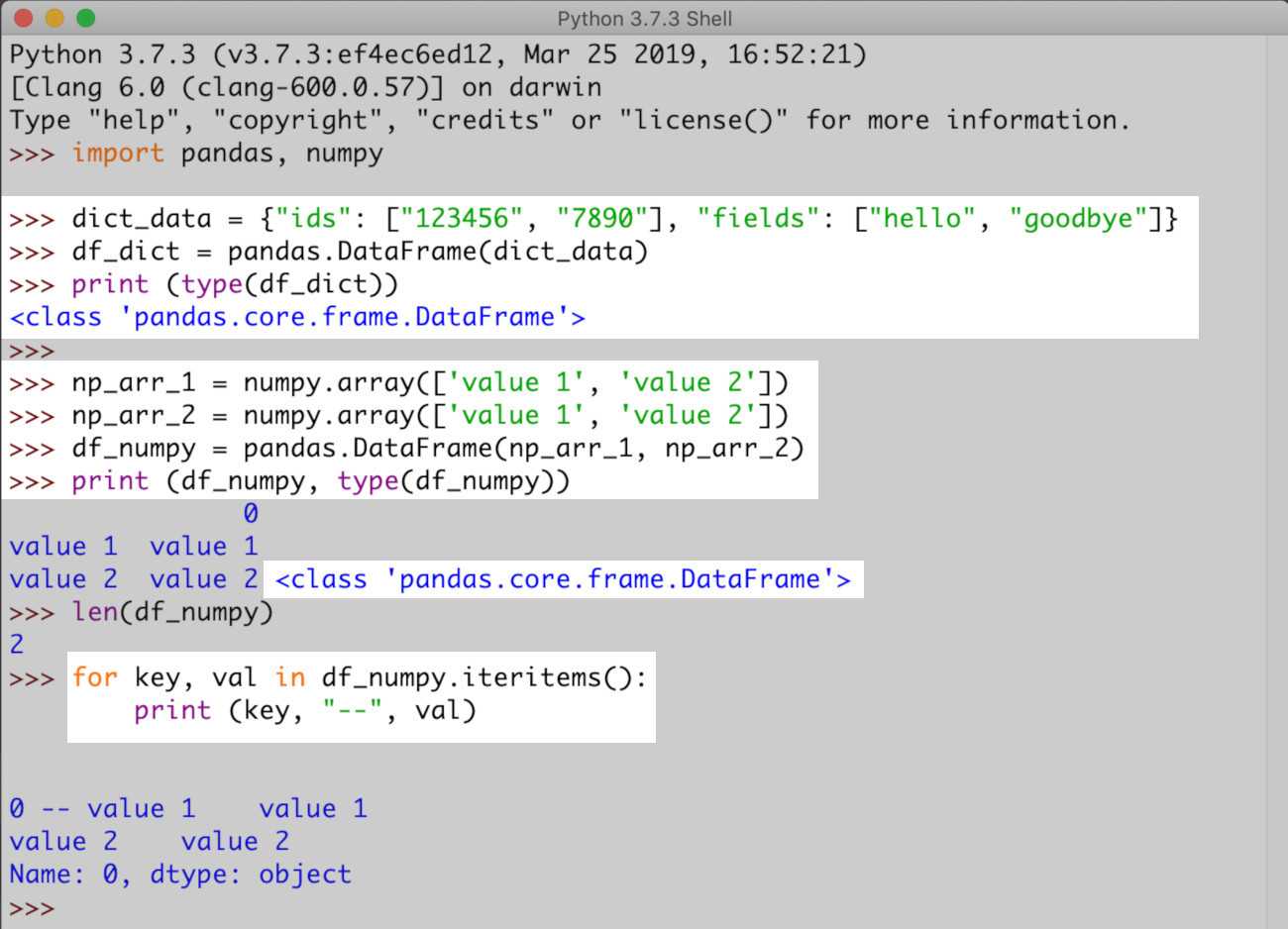
DataFrames
DataFrame — это двумерная структура данных, в которой данные выровнены в табличной форме, то есть в строках и столбцах. DataFrames от Pandas упрощают управление вашими данными. Вы можете выбрать, заменить столбцы и строки и даже изменить ваши данные.
Вот основной синтаксис для создания DataFrame:
pd.DataFrame(data,index)
Давайте создадим DataFrame случайных чисел, имеющий 5 строк и 4 столбца:
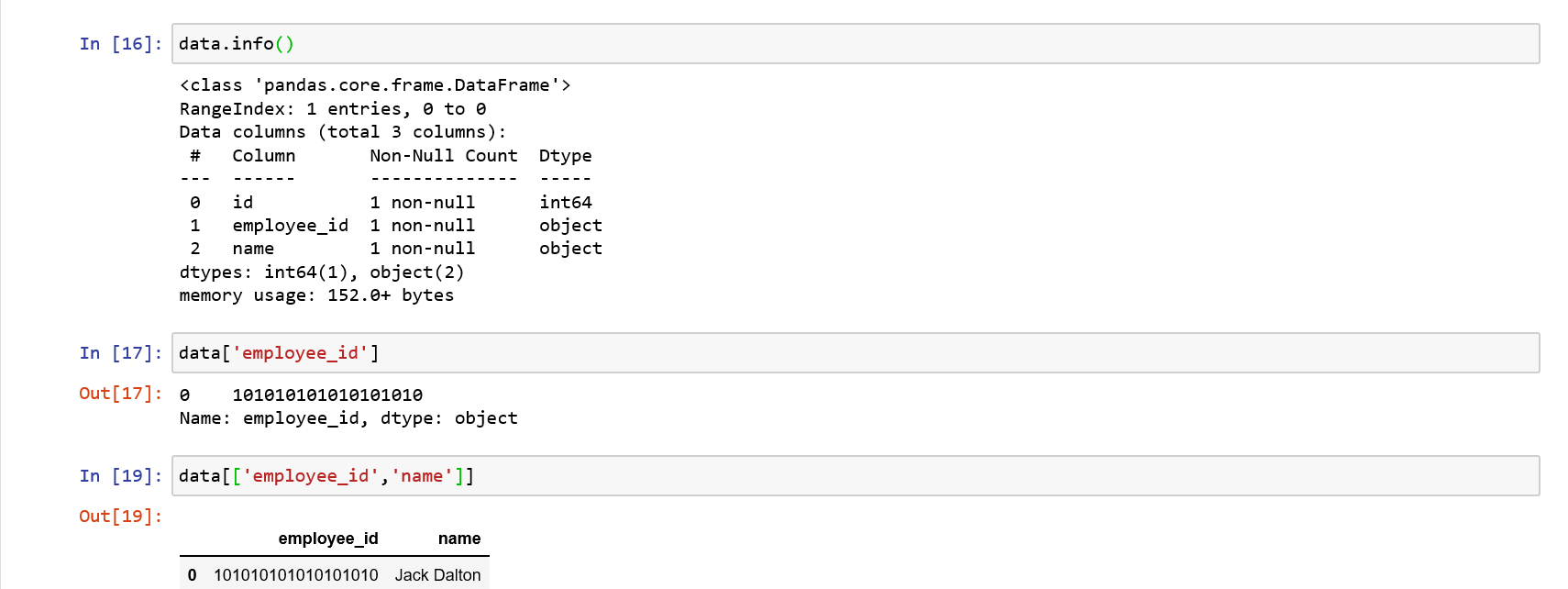
Как мы видим, каждый из приведенных выше столбцов на самом деле является просто серией Pandas, и все они имеют общую, Следовательно, можно с уверенностью сказать, что DataFrame — это коллекция Series, совместно использующая, В приведенном ниже примере мы создадим DataFrame из серии:
Выбор столбцов из фреймов данных
Использование скобочной записимы можем легко получить объекты из DataFrame так же, как это делается в Series. Давайте возьмем колонну:
Поскольку мы взяли один столбец, он возвращает серию. Идите вперед и подтвердите тип данных, возвращаемых с помощью:
Если мы возьмем несколько столбцов, результатом будет DataFrame:
Добавление столбцов в DataFrame
При создании нового столбца вы должны определить его так, как будто он уже существует. Наличие DataFrame:
Мы можем легко добавить новые столбцы, создав их заново или из существующих столбцов, как показано ниже:
Удаление строк / столбцов из DataFrame
Мы можем удалить строку или столбец, используяфункция. При этом мы должны указатьдляряд, а такжедляколонка,
Важно отметить, что Pandas не удаляет строку / столбец навсегда, когда вы используетеметод, если вы не скажете это сделать. Это так, потому что Pandas не хочет, чтобы вы случайно потеряли свои данные
Подтвердите, позвонив, Чтобы окончательно удалить строку / столбец, необходимо установитьвот так:
Выбор строк в фрейме данных
Чтобы выбрать строки, мы должны вызвать расположение строк, используякоторый принимает в имени ярлыка иликоторый занимает в индексной позиции строки.
Мы также можем выбрать подмножество строк и столбцов, используя обозначение столбцауказав строку и столбец, мы хотим, как мы сделали вNumPy, Скажем, мы хотимв ряду
Условный отбор
Pandas позволяет выполнять условный выбор, используя скобки Пример ниже возвращает строки где
Скажем, мы хотим вернуть только значения столбцагде
Идите и попробуйте это:, вы должны получить это:
Вышеупомянутая абстракция в одну строку также может быть достигнута, разбив ее на несколько этапов:
my_series = df>0result = dfmy_cols = result
Используя несколько условий, мы можем получить значения в DataFrame, объединив его с логическими операторами & (AND) и | (ИЛИ). Например, чтобы вернуть значения гдеа также,использовать:
Сброс индекса фрейма данных
Если ваш индекс выглядит не совсем так, как вы хотите, вы можете легко сбросить его, используя, Это сбрасывает наш индекс DataFrame в столбец с именемсо значениями индекса Pandas по умолчаниюбыть нашим новым индексом.
Как и ожидалось,не навсегда сбрасывает индекс, пока вы не укажете, сказав:
Установка индекса для DataFrame
Точно так же мы можем указать, какой столбец мы хотим использовать в качестве метки индекса, используяфункция. Для этого мы создадим новый столбец с именеми установите его как наш новый индекс:
Многоуровневый индекс (мультииндексный)и индексная иерархия
MultiIndex — это просто массив кортежей, каждый из которых уникален. Он может быть создан из списка массивов (используя), массив кортежей (используя) или скрещенный набор итераций (используя).


Давайте создадим MultiIndex из turple:
Мы можем пойти дальше, чтобы получить строки из нашего MultiIndex, используявот так:
Как видим, первые два столбца нашего DataFrameнет имен. Мы можем дать им имена, используявот так:
Поперечное сечение строк и столбцов
ИспользуяМетод, мы можем легко выбрать данные на определенных уровнях MultiIndex. Например, скажем, мы хотим захватить все уровни, где:
Изучение данных с помощью графиков в Python
Следующие графики дадут общий обзор определенного столбца указанного набора данных. Сначала мы рассмотрим распределение собственности с помощью гистограммы. Затем мы познакомимся с некоторыми инструментами для исследования выбросов.
Распределения и гистограммы в Pandas
Вы можете представить каждый столбец из DataFrame как объект Series. Далее дан пример использования столбца из структуры DataFrame, созданной на основе данных специальностей колледжей:
Python
In : median_column = df
In : type(median_column)
Out: pandas.core.series.Series
|
1 2 3 4 |
In12median_column=df»Median» In13type(median_column) Out13pandas.core.series.Series |
При наличии объекта вы можете создать на его основе новый график. Гистограмма является хорошим способом визуализировать, как значения распределяются по набору данных. Гистограммы разбивают значения на интервалы (bins) и отображают количество данных, чьи значения находятся в определенном интервале.
Создадим гистограмму для столбца :
Python
In : median_column.plot(kind=»hist»)
Out: <AxesSubplot:ylabel=’Frequency’>
|
1 2 |
In14median_column.plot(kind=»hist») Out14<AxesSubplotylabel=’Frequency’> |
Мы вызываем метод для и передаем строку параметру . Вот и все!
При вызове метода вы увидите следующую фигуру:
![]()
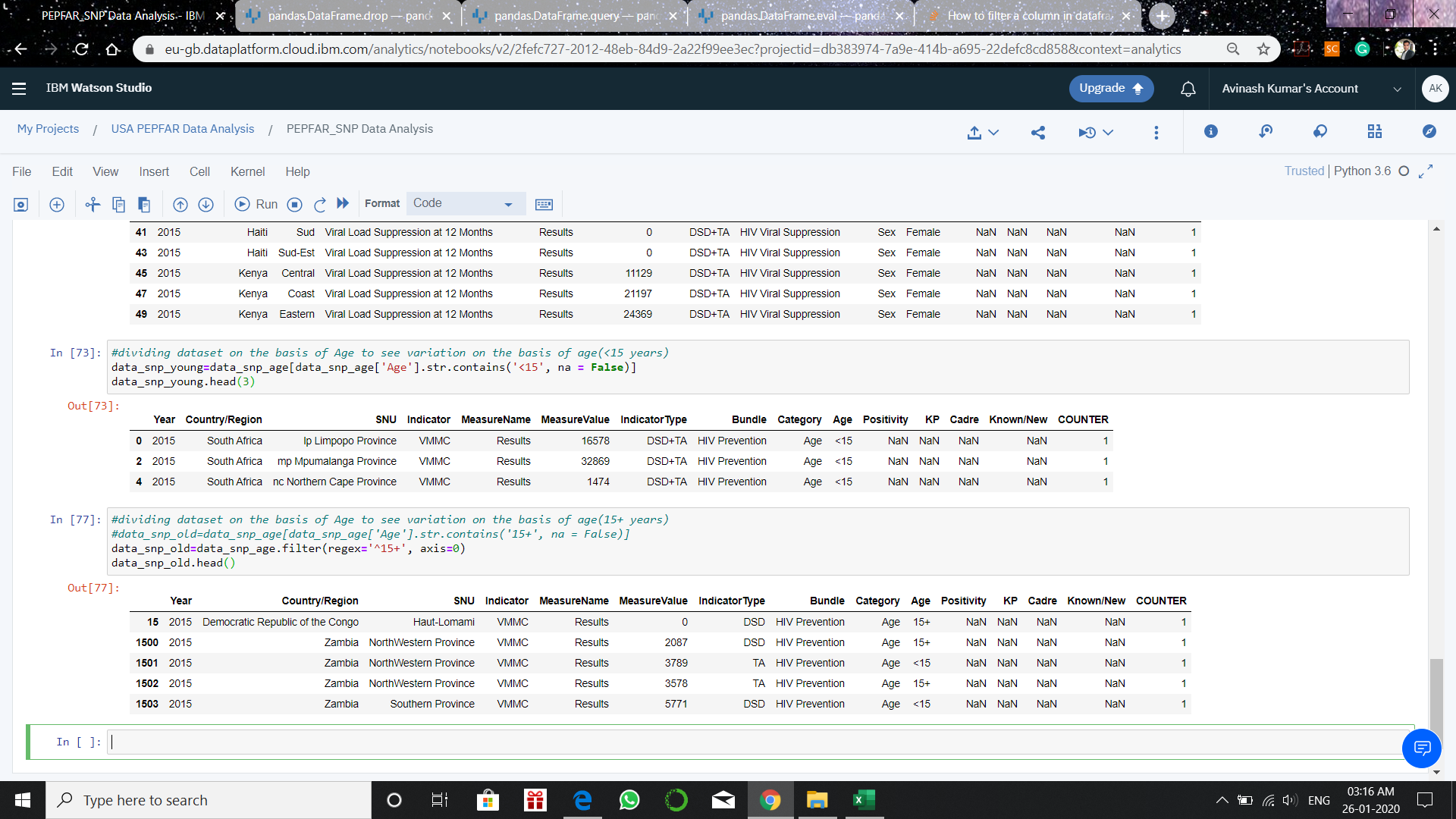
Однако у гистограммы средних данных есть пики слева ниже $40,000. Хвост тянется далеко вправо и сообщает о том, что есть отрасли, в которых определенные специальности могут рассчитывать на более высокие доходы.
Как создать DataFrame из списка словарей
Чтобы создать DataFrame из списка словарей, просто предоставьте список конструктору класса DataFrame следующим образом: DataFrame(list). Этот вызов возвращает объект DataFrame, содержащий данные списка с ключами в виде имен столбцов.
В данном случае пример выглядит следующим образом:
Результатом приведенного выше кода будет:
Основная проблема этого решения заключается в том, что вы должны убедиться, что ключи в каждом словаре корректны и согласованы друг с другом. В целевом DataFrame будет создано столько столбцов, сколько различных ключей в словарях. Если, например, ключ, связанный с именем, в одном словаре – Name, в другом – name, а в третьем – NAME, то в итоге мы получим три разных колонки (с учетом регистра) для данных об имени, что нам не нужно. Кроме того, у нас будет много значений None, потому что если в других словарях нет значений для определенного ключа, то по умолчанию у нас будет именно None.
Как создать DataFrame из базы данных SQL
Давайте рассмотрим немного более сложный пример, использующий возможности баз данных SQL.
Для создания DataFrame из базы данных SQL можно использовать функцию pandas read_sql, которой необходимо предоставить имя таблицы или SQL-запрос и соединение с базой данных. Функция вернет DataFrame с соответствующими данными, готовый к использованию.
Предположим, что на этот раз у нас есть две разные таблицы в базе данных. Одна из сотрудников и одна из отделов. Таблица сотрудников содержит такие столбцы, как код сотрудника, имя, возраст и код отдела, в котором работает сотрудник. Таблица отдела имеет в качестве столбцов код отдела, название и местоположение.
Мы хотим создать DataFrame, в котором будут столбцы обеих таблиц, которые мы должны объединить с помощью операции объединения в столбце кода отдела.
В вашем случае база данных уже создана в определенной системе управления базами данных, такой как MariaDB или PostgreSQL. В этом примере я буду работать с SQLite.
Убедитесь, что у вас установлена библиотека SQLAlchemy, поскольку она необходима pandas для подключения к базе данных. Вы можете установить его с помощью команды pip install sqlalchemy.
Я создал базу данных под названием database_base.db (оригинально, не правда ли?) со структурой, которую я описал выше. Я также вставил некоторые данные в эти две таблицы. Я оставляю здесь SQL-код, позволяющий создать базу данных в точности как у меня, так что вы можете попробовать этот пример, если вам интересно:
После создания базы данных нам остается только создать несколько DataFrames. Начнем с самого прямого варианта, который заключается в загрузке DataFrame с каждой из таблиц.
Для этого нам просто нужно использовать функцию read_sql, которой мы должны передать два параметра. Первое – это имя таблицы, которую мы хотим прочитать. Второй – это строка подключения к базе данных, которая в нашем случае будет в стиле sqlite:///database_name.db. Мы это видим:
Если вы заметили, теперь у нас есть два DataFrames, это df_employees и df_departments. Когда мы выводим их на экран, то получаем следующее:
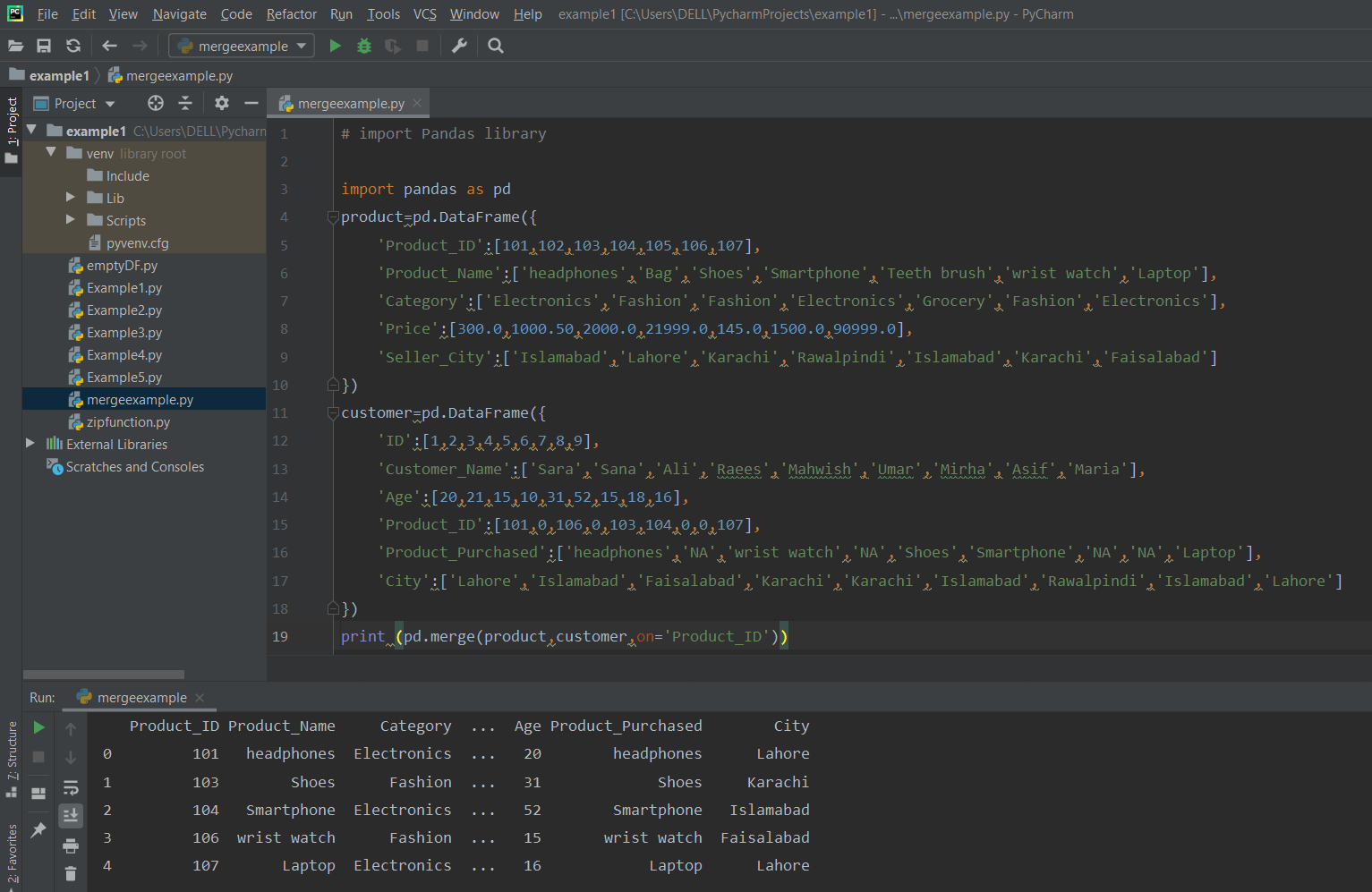
Так просто и так быстро. Но теперь давайте сделаем кое-что более сложное, потому что я хочу получить один DataFrame со всеми полями обеих таблиц, объединенными так, чтобы за каждым сотрудником следовала информация его отдела, а не только его код.
Я могу решить это с помощью простой операции объединения между двумя таблицами, которую можно выполнить следующим образом, где я также выбираю только некоторые поля, потому что меня не интересуют коды. SQL-запрос выглядит следующим образом:
Сила функции read_sql заключается в том, что она позволяет нам задать SQL-запрос для получения нужных нам данных и затем как можно меньше манипулировать DataFrame. Просто введите запрос вместо имени таблицы, и все готово. Код:
Результат следующий:
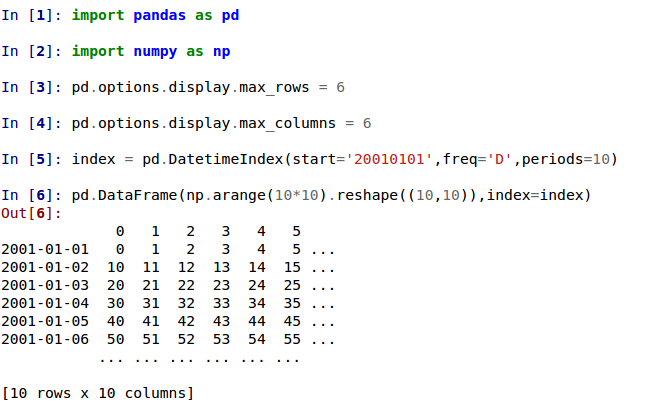
Структуры данных в Pandas: DataFrame
Обычно в работе с данными имеют дело не с единичными значениями, а с целыми группами данных, например, в продажах обычно учитывают множество факторов: цену, количество продаж, количество товаров, наличие скидок, средний чек и так далее.
Для хранения такой информации хорошо подходят датафреймы (DataFrame).
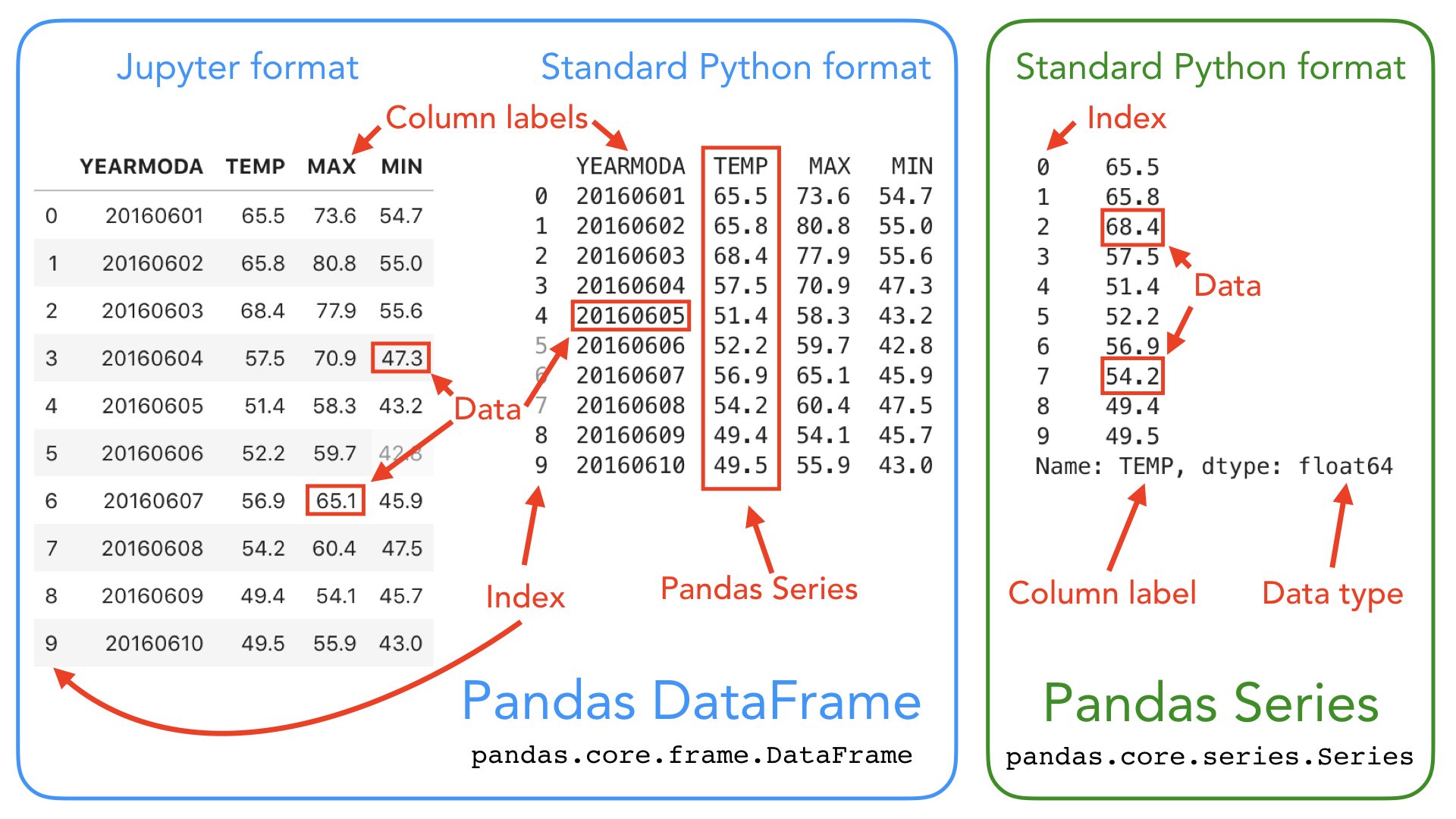
Если Series мы сравнивали с колонкой таблицы, то DataFrame — это уже целая таблица, у которой есть столбцы (колонки), строки и ячейки.
Получается, что колонки датафрейма — это серии.
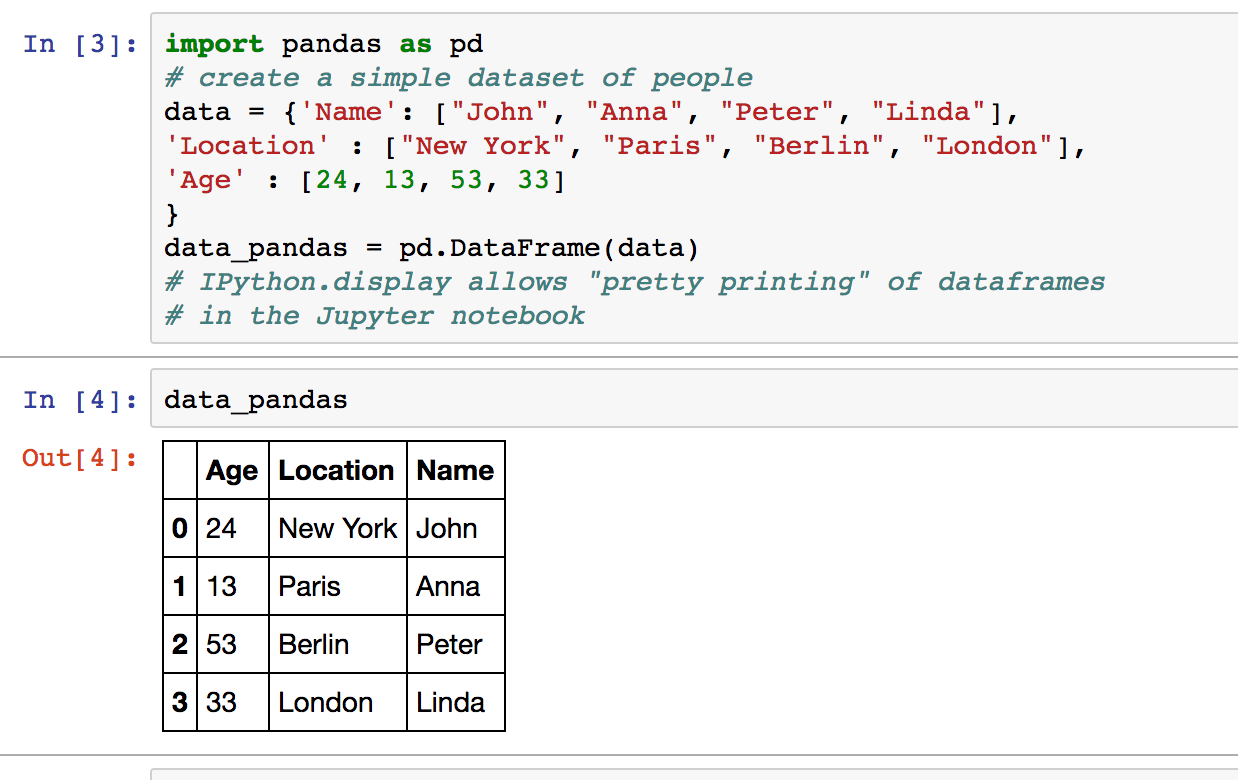
Создаем DataFrame
Обычно в одной колонке таблицы хранятся данные, описывающие одну и ту же характеристику. Давайте рассмотрим простой пример, где мы хотим посмотреть на динамику продаж:
Создать датафрейм можно двумя способами:
- Создать пустой DataFrame и наполнить его данными:
- Создать DataFrame на основе других структур данных стандартного Python, например, из словаря, как мы делали в примере:
Получение информации о датафрейме
Метод .info() позволяет увидеть информацию о датафрейме: названии колонок, количестве элементов, пропусков и типе данных, хранящихся в колонах.
![]()
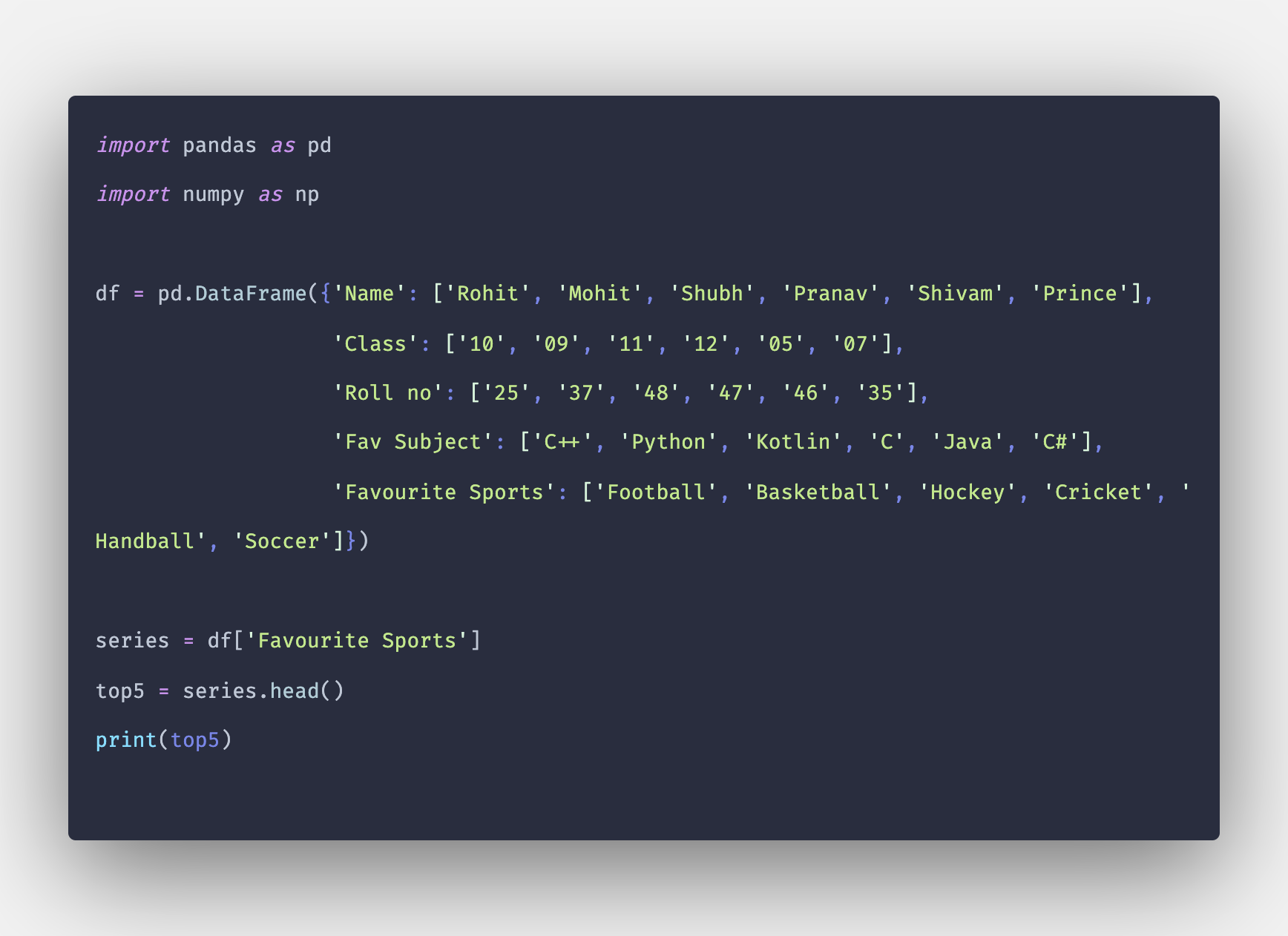
Пустые ячейки в DataFrame Pandas
Иногда в таблицах бывают пропуски. Рассмотрим пример с продажами за 3 месяца: январь, февраль и март. В январе было продано 8 яблок, 9 бананов и 7 апельсинов, а в феврале бананы не продавались совсем, зато было продано 7 лимонов:
![]()
То, что в некоторые месяцы не продавалась определенная группа товаров, не нарушило структуру таблицы: пропуски заполняются значением “NaN”.
В последствии, эти пропуски можно заполнить определенными значениями, удались или сгруппировать.
Подробнее о том как работать с пропусками можно почитать здесь.
Сортировка по ярлыку
Метод sort_index() используется для сортировки данных на основе значений индекса.
Пример:
import pandas
import numpy
input = {'Name':pandas.Series(),
'Marks':pandas.Series(),
'Roll_num':pandas.Series()
}
data_frame = pandas.DataFrame(input, index=)
print("Unsorted data frame:\n")
print(data_frame)
sorted_df=data_frame.sort_index()
print("Sorted data frame:\n")
print(sorted_df)
Выход:
Unsorted data frame:
Name Marks Roll_num
0 John 44 1
2 Caret 75 3
1 Bran 48 2
4 Sam 99 5
3 Joha 33 4
Sorted data frame:
Name Marks Roll_num
0 John 44 1
1 Bran 48 2
2 Caret 75 3
3 Joha 33 4
4 Sam 99 5
Визуализация данных в pandas
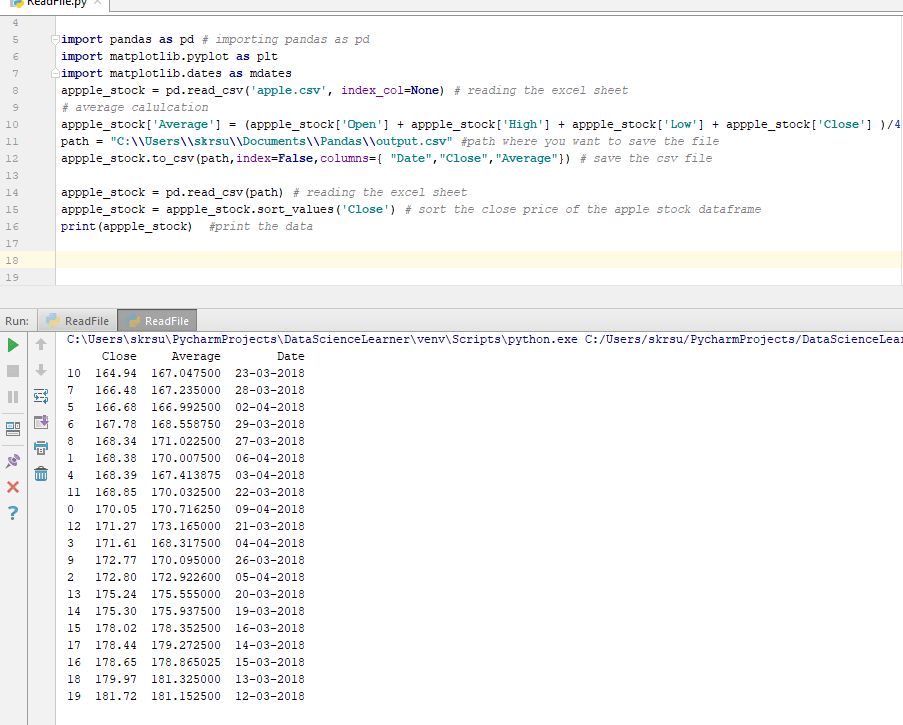
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
И видим вот такую картину:
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ ![]()
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Поиск уникальных значений в DataFrame
Уникальные значения, это просто отдельные значения в DataFrame. Существует три основных полезных метода для поиска уникальных значений в DataFrame.
С помощьюмы можем найти все уникальные значения вDataFrame ниже:
Вместо отображения уникальных значений мы можем выбрать только количество уникальных значений в DataFrame, используя:
Наконец, мы можем решить возвращать только количество раз, когда уникальное значение отображается в столбце, используя:
Метод apply ()
Метод используется для вызова пользовательских функций в DataFrame. Представьте, что у нас есть функция:
В приведенном выше примере мы транслируем функцию каждому элементу в столбце. Мы также можем применять встроенные функции для DataFrames. Допустим, мы хотим получить длину строк в:
Иногда вы можете определить функцию, которую вы используете только один раз. Вместо того, чтобы определять такую функцию в нескольких строках кода, вы можете просто использовать лямбда-выражение, которое является сокращенной версией функции. Например, мы могли бы представить квадратную функцию ввыше лямбда-выражением:
Получение атрибутов DataFrame
Атрибуты — это имена столбцов и индексов DataFrame. Скажем, мы не уверены, что если имена столбцов в нашем DataFrame содержат пробелы, мы можем просто получить их атрибуты:
Сортировка и упорядочивание DataFrame
Представьте, что мы хотим отобразить DataFrame с определенным столбцом, отображаемым в порядке возрастания, мы можем легко отсортировать его, используя
Как видите, значения вотображались от низшего к высшему
Также обратите внимание, какоставался прикрепленным к каждому ряду, чтобы информация не терялась
Нахождение нулевых значений
Скажем, у вас большой набор данных, Pandas упростила поиск нулевых значений с помощью
Сводная таблица
Возможно, вы уже знакомы с сводными таблицами в Excel. Сводная таблица — это таблица, которая суммирует данные в другой таблице. Это позволяет автоматически группировать, нарезать, фильтровать, сортировать, подсчитывать, суммировать или усреднять данные, хранящиеся в одной таблице. Наличие DataFrame:
Мы можем создать сводную таблицу из нее, используя синтаксис:гдепредставляет столбец, из которого мы хотим, чтобы точки данных были составлены,это столбец, по которому вы хотите сгруппировать данные ипредставляет столбцы, по которым должен быть определен DataFrame. Вы можете прочитать больше на сводной таблицеВот,
В приведенном выше примере мы получилизначения, потому что не было значений, соответствующих этим конкретным точкам.
Как создать DataFrame из объектов pickle, parquet или Feather, файлов ORC, HDF, запросов SPSS, SAS, Stata или Google BigQuery.
Существуют и другие менее распространенные или более специализированные объекты или файлы данных, из которых также может быть сгенерирован DataFrame.
Если вы прочитали часть этой статьи, вы уже поняли общий подход к созданию DataFrame. Поэтому я не буду приводить примеры всех этих форматов, потому что статья будет слишком длинной (а я думаю, что она и так слишком длинная), но я хочу дать вам список функций, используемых для чтения этих объектов и файлов, чтобы вы знали об их существовании.
Со всеми этими функциями, а также со всеми теми, о которых я уже рассказал, можно ознакомиться в официальной документации pandas.
| Объект или файл | Функция |
| Pickle | read_pickle |
| PyTables, HDF5 | read_hdf |
| Feather | read_feather |
| Parquet | read_parquet |
| ORC | read_orc |
| SAS | read_sas |
| SPSS | read_spss |
| Google BigQuery | read_gbq |
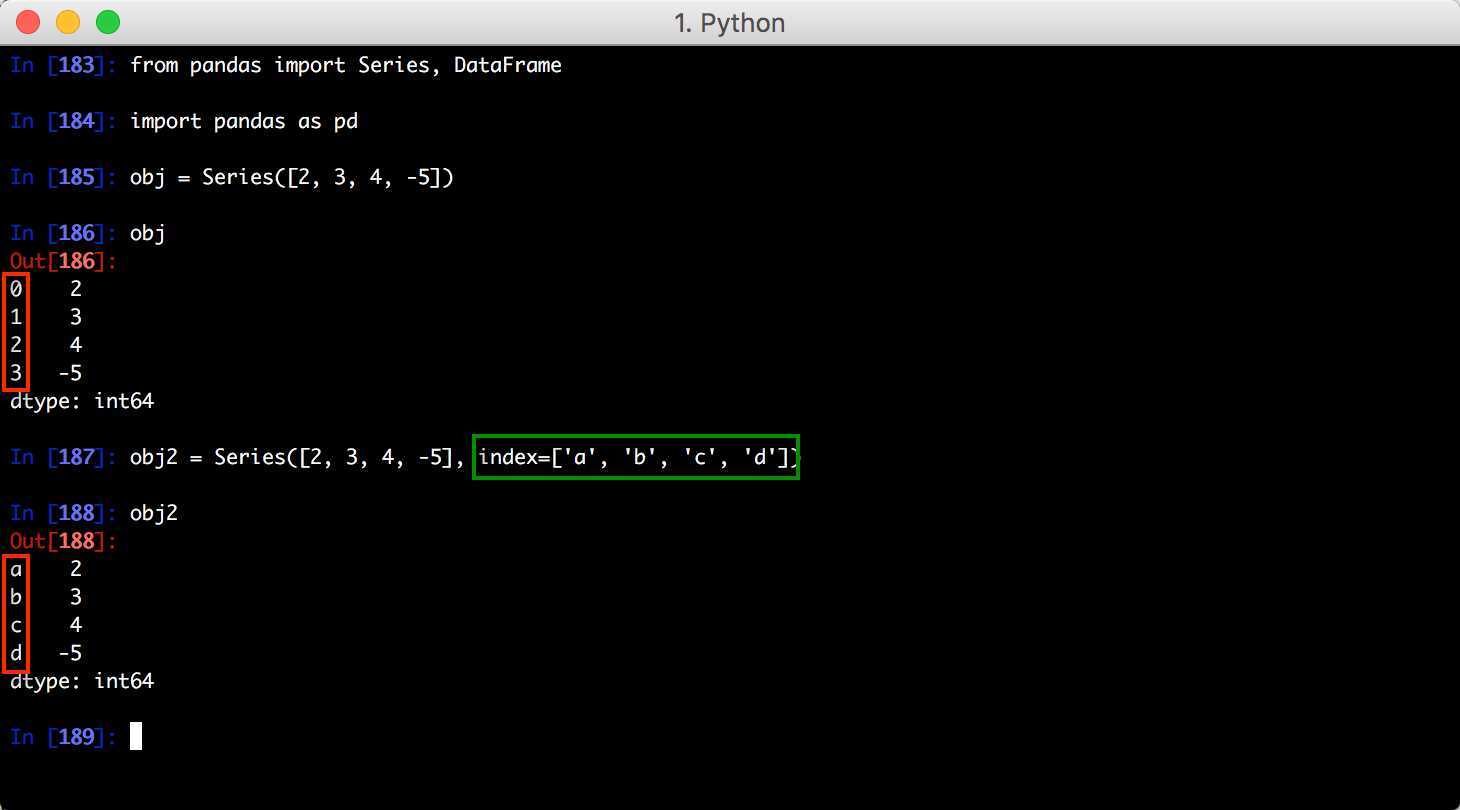
| Stata | read_stata |
Таблица 2: Функции для создания DataFrames из других форматов
Пример 2
Если вы не укажете параметр ignoreIndex = False, вы получите TypeError.
В следующем примере мы попытаемся добавить строку в DataFrame с параметром ignoreIndex = False.
import pandas as pd
data = {'name': ,
'physics': ,
'chemistry': }
#create dataframe
df_marks = pd.DataFrame(data)
print('Original DataFrame\n------------------')
print(df_marks)
new_row = {'name':'Geo', 'physics':87, 'chemistry':92}
#append row to the dataframe
df_marks = df_marks.append(new_row, ignore_index=False)
print('\n\nNew row added to DataFrame\n--------------------------')
print(df_marks)
Вывод:
Original DataFrame
------------------
name physics chemistry
0 Amol 77 73
1 Lini 78 85
Traceback (most recent call last):
File "example1.py", line 14, in <module>
df_marks = df_marks.append(new_row, ignore_index=False)
File "C:\Users\PythonExamples\AppData\Local\Programs\Python\Python37\lib\site-packages\pandas\core\frame.py", line 6658, in append
raise TypeError('Can only append a Series if ignore_index=True'
TypeError: Can only append a Series if ignore_index=True or if the Series has a name
Как говорится в сообщении об ошибке, нам нужно либо предоставить параметр ignore_index = True, либо добавить строку, то есть Series, с именем.
Мы уже видели в примере 1, как добавить строку в DataFrame с ignore_index = True. Теперь посмотрим, как добавить строку с ignore_index = False.
import pandas as pd
data = {'name': ,
'physics': ,
'chemistry': }
#create dataframe
df_marks = pd.DataFrame(data)
print('Original DataFrame\n------------------')
print(df_marks)
new_row = pd.Series(data={'name':'Geo', 'physics':87, 'chemistry':92}, name='x')
#append row to the dataframe
df_marks = df_marks.append(new_row, ignore_index=False)
print('\n\nNew row added to DataFrame\n--------------------------')
print(df_marks)
Мы назвали серию данными. Поэтому ignore_index = False не возвращает TypeError, и строка добавляется к DataFrame.
Вывод:
Original DataFrame ------------------ name physics chemistry 0 Amol 77 73 1 Lini 78 85 New row added to DataFrame -------------------------- name physics chemistry 0 Amol 77 73 1 Lini 78 85 x Geo 87 92
В этом руководстве по Pandas мы использовали функцию append(), чтобы добавить строку в Pandas DataFrame.
Как выбрать строки из Pandas DataFrame по условию
Собираем тестовый набор данных для иллюстрации работы выборки по условию
| Color | Shape | Price |
| Green | Rectangle | 10 |
| Green | Rectangle | 15 |
| Green | Square | 5 |
| Blue | Rectangle | 5 |
| Blue | Square | 10 |
| Red | Square | 15 |
| Red | Square | 15 |
| Red | Rectangle | 5 |
Пишем скрипт:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df)
Результат выполнения:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 2 Green Square 5 3 Blue Rectangle 5 4 Blue Square 10 5 Red Square 15 6 Red Square 15 7 Red Rectangle 5
Синтаксис выборки строк из Pandas DataFrame по условию
Вы можете использовать следующую логику для выбора строк в Pandas DataFrame по условию:
df.loc
Например, если вы хотите получить строки с зеленым цветом , вам нужно применить:
df.loc
Где:
- Color — это название столбца
- Green — это условие (значение колонки)
А вот полный код Python для нашего примера:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df.loc)
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 2 Green Square 5
Выберем строки, где цена равна или больше 10
Чтобы получить все строки, где цена равна или больше 10, Вам нужно применить следующее условие:
df.loc
Полный код Python:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df.loc)
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 4 Blue Square 10 5 Red Square 15 6 Red Square 15
Выберем строки, в которых цвет зеленый, а форма — прямоугольник
Теперь цель состоит в том, чтобы выбрать строки на основе двух условий:
- Color зеленый; а также
- Shape = прямоугольник
Мы будем использовать символ & для применения нескольких условий. В нашем примере код будет выглядеть так:
df.loc
Полный код примера Python для выборки Pandas DataFrame:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df.loc)
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15
Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
Для достижения этой цели будем использовать символ | следующим образом:
df.loc
Полный код Python 3:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df.loc)
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 2 Green Square 5 3 Blue Rectangle 5 7 Red Rectangle 5
Выберем строки, где цена не равна 15
Мы будем использовать комбинацию символов !=, чтобы выбрать строки, цена которых не равна 15:
df.loc
Полный код Pandas DF на питоне:
import pandas as pd
Boxes = {'Color': ,
'Shape': ,
'Price':
}
df = pd.DataFrame(Boxes, columns= )
print (df.loc)
Результат работы скрипта Python:
Color Shape Price 0 Green Rectangle 10 2 Green Square 5 3 Blue Rectangle 5 4 Blue Square 10 7 Red Rectangle 5
1 Серия
Pandas Series — это одномерная структура, напоминающая массивы, содержащие однородные данные. Это линейная структура данных, в которой элементы хранятся в одном измерении.

Синтаксис:
- input_data: принимает ввод в виде списка, константы, массива NumPy, Dict и т. д.
- index: значения индекса, переданные в данные.
- data_type: распознает тип данных.
- copy: Копирует данные. Значение по умолчанию неверно.
Пример:
import pandas import numpy input = numpy.array() series_data = pandas.Series(input,index=) print(series_data)
В приведенном выше фрагменте кода мы предоставили ввод с использованием массивов NumPy и установили значения индекса для входных данных.
Выход:
Как создать DataFrame из данных буфера обмена
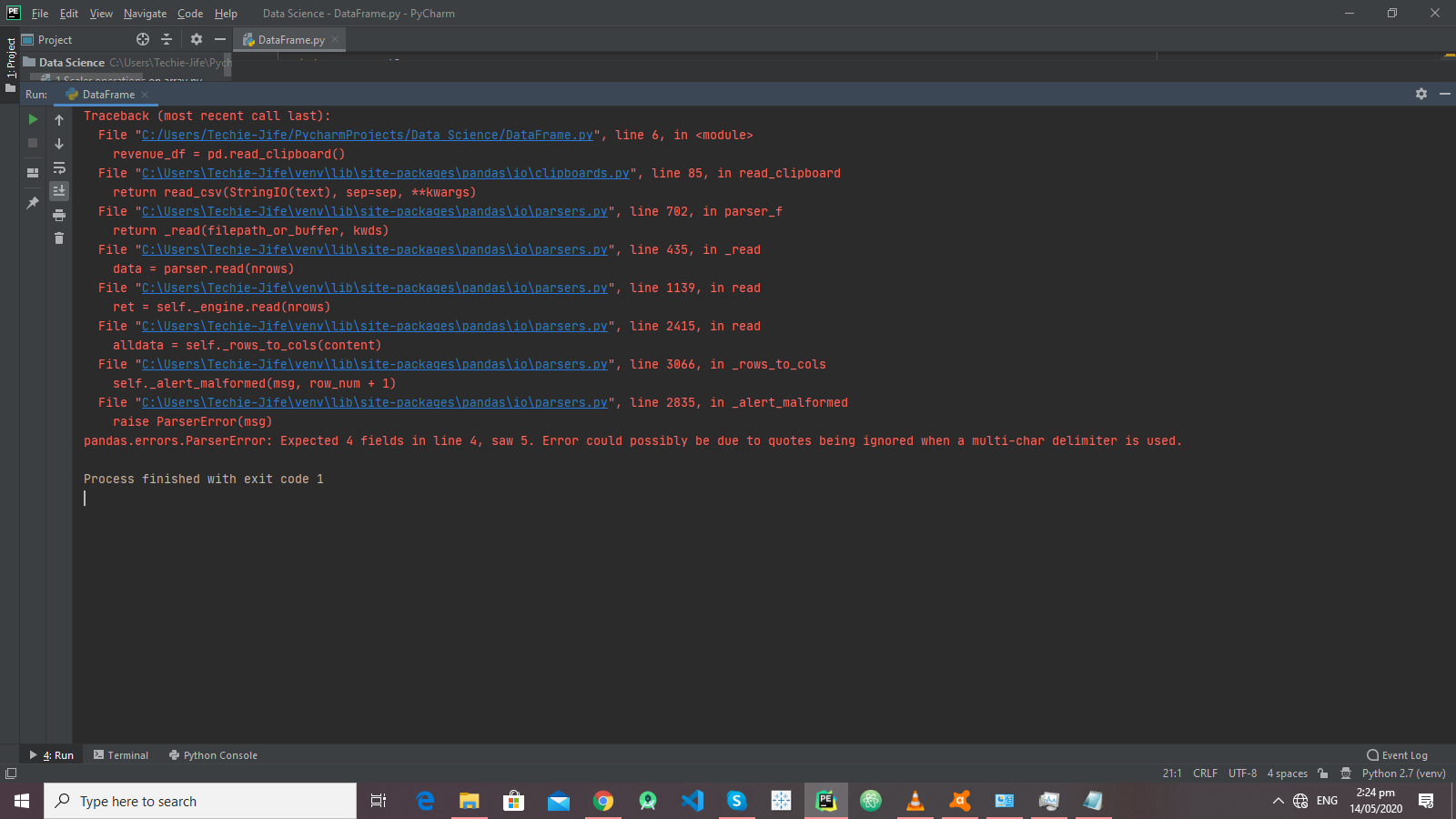
Если у вас есть данные в формате таблицы, подобном предыдущему случаю, разделенные запятыми (или другим разделителем) в системном буфере обмена, pandas позволяет читать их прямо оттуда без необходимости создавать для этого файл. Это интересно, поскольку позволяет нам динамически и очень быстро создавать DataFrame из данных, полученных из различных источников, просто копируя данные в буфер обмена.
Для создания DataFrame из значений, разделенных запятыми, скопированных в системный буфер обмена, можно использовать функцию pandas read_clipboard, указав символ-разделитель. Эта функция создает новый DataFrame с данными, содержащимися в буфере обмена.
Попробуйте это сделать, выбрав данные из следующего примера и скопировав их:
Теперь просто используйте функцию read_clipboard, и у вас есть DataFrame – почти магия!
Результат будет таким же, как и выше.
Если символ-разделитель полей не является одним или несколькими пробелами, вы должны указать нужный символ или строку, передав параметр функции, например, read_clipboard(‘,’). Если вы вызываете функцию без параметров, в качестве разделителей будут использоваться пробелы.
Основные типы данных в Pandas
Тип данных сообщает информацию о том, как Python может манипулировать данными. При анализе данных информация о типе данных позволяет одним образом обрабатывать данные одного типа и избежать ошибок.
В Pandas типы данных еще называются .
- : текстовые (строковые) или смешанные данные, нечисловые величины
- : целые числа
- : булевые значения: true/false
- : числа с плавающей точкой
- : категориальные или определенный конечный список текстовых значений
- : дата и время
- : временная дельта или разница между двумя временными величинами ()
Кроме того, в Pandas есть два, возможно, незнакомых ранее типа структур данных — DataFrame для многомерных массивов и Series для одномерных. Поговорим о них подробнее.
Структуры данных в Pandas: отличия Series и DataFrame
Для того, чтобы сразу увидеть разницу между двумя основными структурами данных в Pandas можно проассоциировать DataFrame с таблицей со строками и колонками. Каждое значение внутри имеет 2 индекса: ряда и колонки.
— одна двухмерная колонка, которая может хранить данные любого типа.
![]()
Pandas DataFrame Groupby () синтаксис
Синтаксис функции Groupby ():
groupby(
self,
by=None,
axis=0,
level=None,
as_index=True,
sort=True,
group_keys=True,
squeeze=False,
observed=False,
**kwargs
)
- По Аргумент определяет путь к элементам группы. Как правило, имена столбцов используются для группы элементов DataFrame.
- Ось Параметр определяет, нужно ли погружать строки или столбцы.
- Уровень используется с Multiindex (иерархическими) для группы по определенному уровню или уровням.
- AS_INDEX Указывает, чтобы вернуть агрегированный объект с помощью меток групп в качестве индекса.
- Сортировать Параметр используется для сортировки групповых ключей. Мы можем пройти его как ложь для лучшей производительности с более крупными объектами DataFrame.
- group_keys : При вызове Apply, добавьте групповые клавиши, чтобы индексировать, чтобы идентифицировать кусочки.
- сжать : Уменьшить размерность типа возврата, если это возможно, в противном случае верните последовательный тип.
- Наблюдается : Если true: только показать наблюдаемые значения для категориальных управляющих. Если false: показать все значения для категориальных управляющих.
- ** kwargs : Принимает только ключевое слово «мутировать» и передается в группу.
Функция groupby () возвращает dataframegroupby или seriesgroupby в зависимости от объекта вызывающего.