
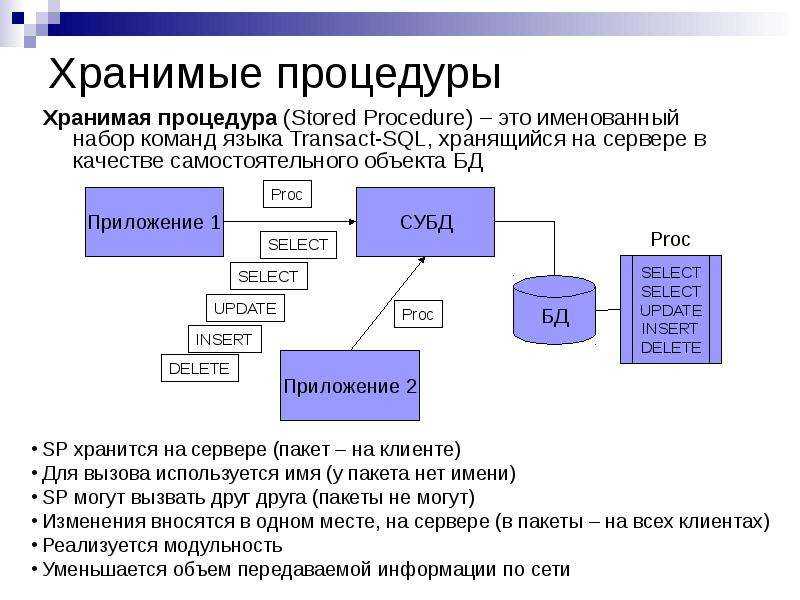
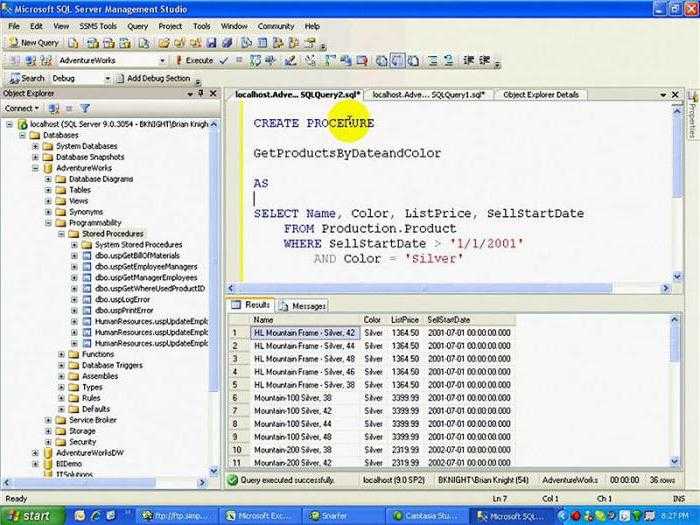
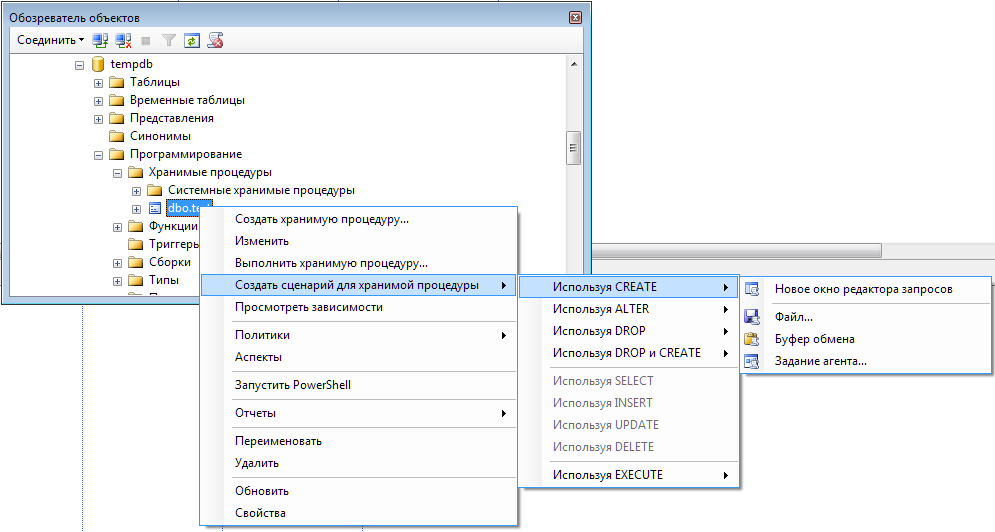
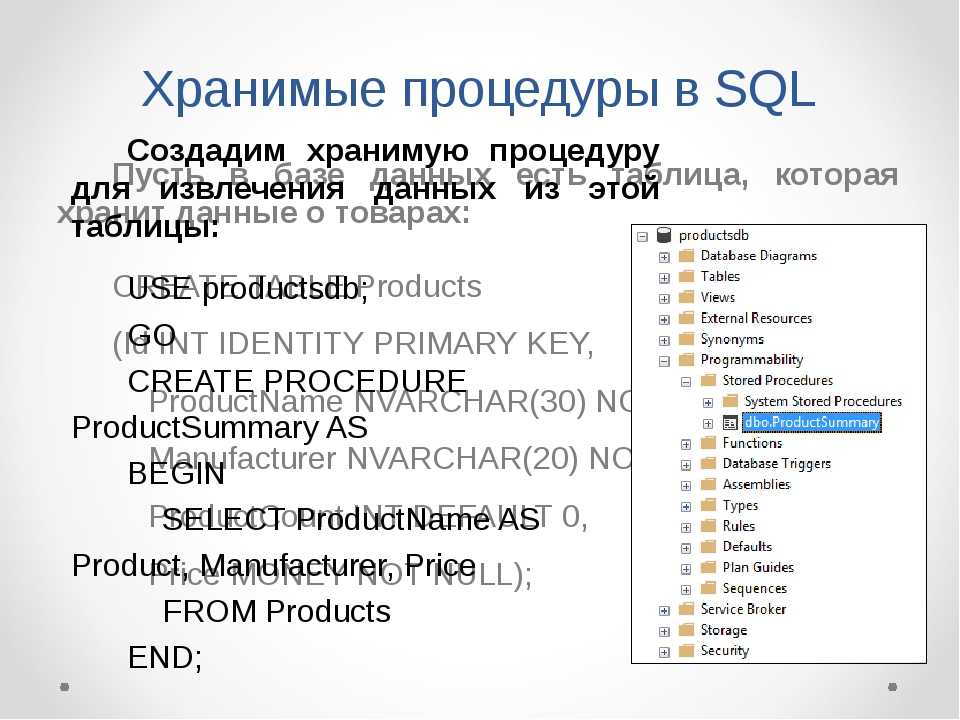
Факторы, влияющие на принятие решений
На самом деле объем темы факторов, влияющих на процесс принятия решений, очень велик, поэтому мы осветим только наиболее важные на наш взгляд тонкости, самым прямым образом воздействующие на совершение выбора и его эффективность.
В первую очередь это личностные факторы. К ним относятся психические свойства, состояния и процессы. Далее идут факторы ситуационные: внешние и внутренние. Внешняя среда – это экономические и политические условия, правовые нормы, социокультурные факторы и технологии, природно-географические факторы. Деловая сфера здесь также дополняется потребителями, поставщиками, конкурентами, инфраструктурой – все это имеет значение. Внутренняя среда – это цели и структура организации, корпоративная культура, организационные процессы и имеющиеся ресурсы
Говоря о среде принятия решений, не менее важно упомянуть о рисках, определенности и неопределенности, времени и изменениях самой среды
Есть также и неопределенные факторы (они различаются по источнику неопределенности (неопределенность среды или личная неопределенность), по природе (случайные или неслучайные)), информационные и поведенческие факторы, а также отрицательные последствия и взаимосвязанность решений.
Как вы и сами видите, тема факторов, влияющих на принятие решений, не только очень интересна, но и широка
Чтобы лучше разобраться в ней, а также вообще в том, как люди принимают решения, можно (настоятельно рекомендуется тем, кто хочет стать специалистом в этой области), обратить внимание на теорию принятия решений. Она способна дать ответы на многие вопросы
Отличия PBL от других подходов
Нередко программы обучения строятся на формировании отдельных знаний, умений или компетенций, которые в сочетании должны привести к появлению определённой «базы» для использования полученных знаний на практике. Но студентам бывает трудно понять, как объединить полученные знания и по-настоящему эффективно перенести их в свою работу, выполнять с их помощью реальные задачи.
Здесь-то и кроется преимущество проблемно-ориентированного обучения: в его основе уже лежит аутентичная задача, с которой учащиеся столкнутся в профессиональной жизни.
Она, в свою очередь, подразделяется на множество других задач, выполнение которых приведёт студентов к некому финальному результату. Например, на курсе по журналистике таким результатом может быть создание собственного медиа. В этом случае в задачи будет входить написание статьи, подбор иллюстраций, вёрстка и так далее. А вот в рамках «обычного» курса учащиеся отдельно изучат теорию журналистики, жанры, основы стилистики и далеко не всегда смогут применить полученные знания в комплексе, чтобы написать правильно структурированный и грамотный текст.
Стоит отметить, что в чистом PBL, то есть подходе, предложенном Барроузом, студенты должны были не только найти ответ или верное решение, но и определить область своего незнания. То есть им необходимо было понять, каких знаний или умений не хватает в процессе, и, соответственно, закрыть существующие пробелы
Для врачей это было особенно важно, ведь им приходится продолжать обучение на протяжении всей жизни, — и, вероятно, этот фактор в дальнейшем и стал одной из причин популярности PBL во всем мире
![]()
Фото: BoxerX / Shutterstock
В связи с этим большую роль в обучении по PBL играет сам процесс: он должен быть построен таким образом, чтобы в итоге учащиеся получили комплексное представление об изучаемом предмете.
Обычно в вузах, где обучение строится на основе проблемы, информацию по тому или иному кейсу студентам выдают порционно, чтобы они могли самостоятельно исследовать проблему, найти информацию и представить финальное решение. Когда очередной этап работы выполнен и ответы на поставленные вопросы найдены — открывается следующий блок материалов.
Это работает так же, как и в реальной жизни. Приведём простой пример: к врачу обращается пациент с жалобой — и у специалиста нет никакой дополнительной информации. Ему предстоит определить, чем может быть вызвано недомогание, какие анализы помогут прояснить ситуацию и какие лекарства могут хотя бы временно решить проблему. После получения первых результатов специалист может скорректировать лечение, выбрать другой подход или продолжить исследования.
Однако в учебных условиях с формулировкой проблемы или кейса не всё так просто. Например, в некоторых случаях их разрабатывает целая команда преподавателей — и пересматривает каждый год. Причём один кейс будет по-разному выглядеть для студентов и для педагогов, которые им преподают: учащиеся получат меньше информации, чтобы найти «недостающие» кусочки пазла. Кроме того, проблема должна быть подходящей для обучения, то есть посильной для студентов, но при этом достаточно интересной, чтобы вовлечь их в процесс.
Ещё одна важная особенность проблемно-ориентированного обучения — занятия в малых группах. Обычно в группу входят не больше 10-15 студентов, так проще организовать обсуждение задачи и вырабатывать совместные её решения.
Функции разбиения строк в MS SQL
STRING_SPLIT
SELECT *
FROM string_split('Value 1,Value 2,Value 3,Value 4,Value 5',',' );
![]() Estimated Number of Rows Per Execution
Estimated Number of Rows Per Execution
USE AdventureWorks2019; DECLARE @Persons NVARCHAR(4000) = 'Miller,Margheim,Galvin,Duffy,Khanna'; SELECT PersonType, FirstName, MiddleName, LastName FROM PErson.Person WHERE LastName IN ( SELECT value FROM string_split(@Persons,',') );
![]()
- Принимается только односимвольный разделитель. Если вам требуется больше символов, придется использовать пользовательскую функцию.
- Один выходной столбец — на выходе всегда получается одностолбцовая таблица без позиции элемента строки в строке с разделителями. Это позволяет сортировать только по имени элемента.
- Строковый тип данных — вы используете эту функцию для разделения строки чисел (хотя все значения в выходном столбце являются числами, их типом данных является строка). При соединении из с числовыми столбцами в других таблицах требуется выполнить преобразование типа данных. Если вы забудете выполнить явное преобразование, то можете получить неожиданные результаты.
Плюсы
- Их легко понять. В каждом узле мы можем точно увидеть, какое решение принимает наша модель. На практике мы сможем точно узнать, откуда исходят точности и ошибки, с какими видами данных модель будет справляться и как значения признаков влияют на выход. Опция визуализация в Scikit-learn является удобным инструментом, способствующим хорошему пониманию деревьев решений.
- Не требует объемной подготовки данных. Многие модели машинного обучения требуют предварительной обработки данных (например, нормализации) и нуждаются в сложных схемах регуляризации. С другой стороны, деревья решений эффективны после настройки некоторых параметров.
- Стоимость использования дерева для вывода является логарифмической от числа точек данных, используемых для обучения дерева. Это является большим преимуществом, так как большое количество данных не сильно повлияет на скорость вывода.
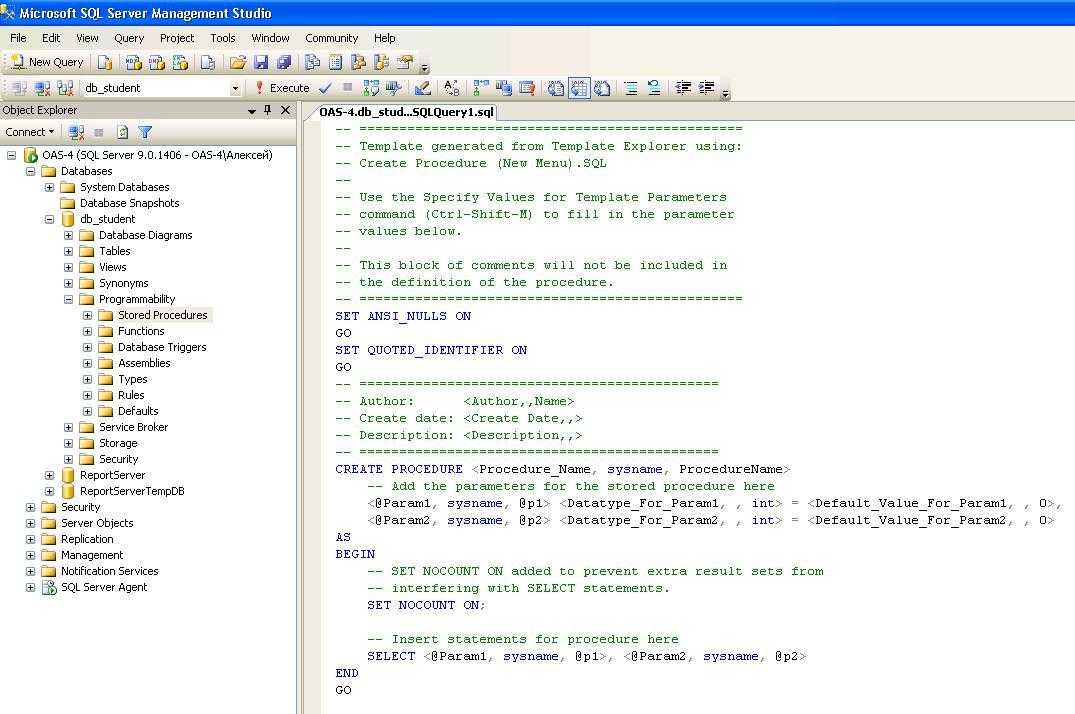
Как написать курсор в SQL Server
Объявите ваши переменные (для имен файлов, имен баз данных, номеров счетов и т.д.), которые вам нужны для реализации логики, и присвойте им начальные значения. Эта логика будет меняться в зависимости от задачи.
Объявите курсор с конкретным именем (как db_cursor в этом примере), которое вы будете использовать на протяжении всей логики вместе с бизнес-логикой (оператор SELECT) для наполнения курсора требуемыми записями. Имя курсора может быть осмысленным. Сразу после этого следует открытие курсора. Эта логика будет меняться в зависимости от задачи.
Извлеките запись из курсора, чтобы начать обработку.Замечание. Число переменных, объявленных для курсора, число столбцов в операторе SELECT и число переменных в операторе FETCH одинаково. В рассматриваемом примере имеется только одна переменная для извлечения данных из единственного столбца. Однако если должно быть пять элементов данных в курсоре, то необходимо также указать пять переменных в операторе FETCH.
Обработка данных уникальна для каждого набора логики. Это может быть вставка, обновление, удаление и т.д. для каждой извлекаемой строки данных. Это самый важный набор логики в данном процессе, который выполняется для каждой строки. Эта логика будет меняться в зависимости от задачи
Извлечение следующей записи из курсора, как это делалось на шаге 3, а затем шаг 4 снова повторяется при обработке выбранных данных.
По завершению обработки всех данных курсор закрывается.
На последнем и важном шаге вам необходимо освободить курсор, т.е. освободить все удерживаемые внутренние ресурсы SQL Server.
-- 1 - Объявление переменных
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
DECLARE @name VARCHAR(50) -- имя базы данных
DECLARE @path VARCHAR(256) -- путь в файлам резервных копий
DECLARE @fileName VARCHAR(256) -- имя файла бэкапа
DECLARE @fileDate VARCHAR(20) -- используется для имени файла
-- Инициализация переменных
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SET @path = 'C:\Backup\'
SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112)
-- 2 - Объявление курсора
DECLARE db_cursor CURSOR FOR
-- Наполнить курсор вашей логикой
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SELECT name
FROM MASTER.dbo.sysdatabases
WHERE name NOT IN ('master','model','msdb','tempdb')
-- Открыть курсор
OPEN db_cursor
-- 3 - Извлечь следующую запись из курсора
FETCH NEXT FROM db_cursor INTO @name
-- Проверить состояние курсора
WHILE @@FETCH_STATUS = 0
BEGIN
-- 4 - Начало настраиваемой бизнес-логики
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SET @fileName = @path + @name + '_' + @fileDate + '.BAK'
BACKUP DATABASE @name TO DISK = @fileName
-- 5 - Извлечь следующую запись из курсора
FETCH NEXT FROM db_cursor INTO @name
END
-- 6 - Закрыть курсор
CLOSE db_cursor
-- 7 - Освободить ресурсы
DEALLOCATE db_cursor
Что не является трендом в области ГосТех?[править]
вариант 1править
Адаптивная безопасность
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Создание множества независимых систем по учету трудовых ресурсов в каждом регионе
Цифровая идентификация граждан +
вариант 2править
Адаптивная безопасность
Мультиканальное вовлечение граждан
Рабочая сила в цифровом формате
Уменьшение количества использования аналитических отчетах на всех этапах государственного управления
Цифровая идентификация граждан +
вариант 3править
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Рабочая сила в цифровом формате
Создание неизменяющегося подхода для противодействия киберугрозам
Цифровая идентификация граждан +
Конкретные примеры использования
Закончив с виртуальным примером, который помог разобраться с особенностями построения таблицы и задачи условий перейдём к более приземлённым и конкретным примерам. С их помощью в задаче будет разобраться немного проще.



Изготовление йогурта
Попробуем рассчитать какой из видов йогурта при разной концентрации компонентов производить лучше, чем остальные. Для этого определим компоненты, их соотношение и стоимость конечного продукта, при условии ограниченности запасов:
В раздел «Расход сырья» внесены формулы, которые опираются на «количество» и нормы расхода. Прибыль является произведением стоимости и количества. Количество и будет переменной, которая будет изменяться в пределах «запасы». Для этого формируется следующий набор условий:
В результате вычислений (с учётом дробного остатка, поскольку условие работы только с целыми числами добавлено не было), получилось, что эффективнее всего производить 1 и 3 йогурты, а второй полностью игнорировать.
Затраты на рекламу
Другим вопросом, с которым поможет эта функция будет «оптимизация расходов на рекламу». В этом случае перед пользователем стоит задача: повысить возможную прибыль посредством изменения рекламных вложений в определённые месяцы.
Итак, прибыль является целевой ячейкой (выделена изумрудным цветом). Зелёным выделены расходы на рекламу, а красным максимальные затраты. При поиске решения ограничиваем подстановку переменных в значениях рекламы максимумом, а в качестве цели ставим максимизацию прибыли.
В результате получаем максимизированную прибыль в указанном месяце, посредством грамотного распределения рекламного бюджета между остальными месяцами.
Отсюда и вытекает главный недостаток «поиска решений». Он оперирует лишь конечной (одной) ячейкой. Чтобы максимизировать прибыль требуется работать с последней ячейкой (прибыль – всего), что сопряжено с вероятностью появления ошибки в программе, если формулы настроены неверно.
Что такое «тест Тьюринга»?[править]
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, обладает ли компьютер сознанием человека.
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, может ли компьютер вести диалог с человеком.
Тест, в ходе которого, через анонимную коммуникацию, компьютер должен определить, общается ли с ним человек или другая программа.
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, с кем общаются – с компьютером или человеком. +
Тест, в ходе которого, через анонимную коммуникацию, компьютер должен определить, каким уровнем интеллекта обладает человек.
Присвоение значения переменной в языке Transact-SQL
При объявлении переменной присваивается значение NULL. Чтобы изменить значение переменной, применяется инструкция SET. Этот способ присвоения значений переменным является предпочтительным. Кроме того, переменной можно присвоить значение, указав ее в списке выбора инструкции SELECT.
Чтобы присвоить значение переменной при помощи инструкции SET, необходимо указать ее имя и присваиваемое значение. Этот способ присвоения значений переменным является предпочтительным. Например, следующий пакет объявляет две переменные, присваивает им значения и использует их в предложении инструкции :
Переменной можно присвоить значение, указав ее в списке выбора. Если список выбора ссылается на переменную, то ей должно быть присвоено скалярное значение, или инструкция SELECT должна возвращать только одну строку. Пример:
Предупреждение
Когда при выполнении инструкции SELECT переменной присваивается несколько значений, сервер SQL Server не гарантирует порядок вычисления выражений
Обратите внимание, что этот эффект проявляется, только если инструкция присваивает значение переменной
Если инструкция SELECT возвращает более одной строки и переменная ссылается на нескалярное выражение, ей присваивается значение, которое возвращается для выражения в последней строке результирующего набора. Например, в следующем пакете переменной @EmpIDVariable присваивается значение идентификатора BusinessEntityID последней возвращенной строки, равное 1:
Сравнение производительности в худшем и среднем случае
Анализ производительности наихудшего случая и анализ производительности среднего случая имеют некоторое сходство, но на практике обычно требуют разных инструментов и подходов.
Определить, что означает типичный ввод, сложно, и часто этот средний ввод имеет свойства, которые затрудняют математическую характеристику (рассмотрим, например, алгоритмы, которые предназначены для работы со строками текста). Точно так же, даже когда разумное описание конкретного «среднего случая» (которое, вероятно, будет применимо только для некоторых применений алгоритма) возможно, они, как правило, приводят к более сложному анализу уравнений.
Анализ наихудшего случая дает надежный анализ (наихудший случай никогда нельзя недооценивать), но такой анализ может быть излишне пессимистичным , поскольку может не быть (реалистичных) исходных данных, которые потребовали бы такого количества шагов.
В некоторых ситуациях может потребоваться пессимистический анализ, чтобы гарантировать безопасность. Однако часто пессимистический анализ может быть слишком пессимистичным, поэтому анализ, который приближается к реальному значению, но может быть оптимистичным (возможно, с известной низкой вероятностью отказа), может быть гораздо более практичным подходом. Один из современных подходов в академической теории к преодолению разрыва между анализом наихудшего и среднего случая называется сглаженным анализом .
При анализе алгоритмов, выполнение которых часто занимает мало времени, но периодически требует гораздо большего времени, можно использовать амортизированный анализ для определения наихудшего времени выполнения по (возможно, бесконечной) серии операций . Эта амортизированная стоимость наихудшего случая может быть намного ближе к средней стоимости, при этом обеспечивая гарантированный верхний предел времени работы.
Анализ наихудшего случая связан со сложностью наихудшего случая .
Подходы к принятию решений
Всего есть четыре пары подходов к принятию решений:
- Централизованный и децентрализованный
- Групповой и индивидуальный
- Участия и неучастия
- Демократичный и совещательный
Давайте разберемся, в чем их особенности.
1
Централизованный и децентрализованный подходы
Централизованный подход берет за основу то, что максимальное количество решений принимается какой-либо высшей инстанцией, например, советом директоров в компании. А в децентрализованном ответственность за принятие решений распространяется на все уровни, включая самые низкие. Величина и характер децентрализации в каждом конкретном случае определяются отдельно.
2
Групповой и индивидуальный подходы
В групповом подходе к принятию решения привлекается несколько сторон, сообща работающих над проблемой. Индивидуальный подход допускает только единоличный выбор. Первый вариант целесообразнее, т.к. коллективное решение реализовать проще. Но второй вариант более предпочтителен, если есть ограниченность во времени или другая вовлеченная сторона не может принимать участие в принятии решения физически.
3
Подходы участия и неучастия
Если ориентироваться на подход участия, нужно узнать мнение по поводу принимаемого решения всех сторон. Если выбор делается с учетом мнений заинтересованных лиц, вероятность его успеха повышается. Не следует путать этот подход с групповым, т.к. в нем решение принимается коллективно, а в подходе участия идет лишь опрос – окончательное решение принимает ответственное лицо. Когда же речь идет о подходе неучастия, только один человек производит сбор информации и анализ альтернатив, а затем сам делает выбор.
4
Демократичный и совещательный подходы
Демократичный подход предполагает принятие решения в сторону большинства. Он не очень эффективен для организаций, т.к. зачастую делит людей на два лагеря – «победителей» и «проигравших», что может привести к конфликтным ситуациям и сбоям в управлении и работе. Совещательный же подход приобщает к принятию решений все стороны, что позволяет найти компромисс, устраивающий всех.
Совещательный подход, как правило, служит одной из форм группового подхода, но внимание фокусируется на том, чтобы выяснить точки зрения максимального количества заинтересованных лиц (с помощью совещаний, собеседований, собраний и т.п.), и после это сделать выбор. Интересно то, что на практике применения группового подхода было замечено следующее:
Интересно то, что на практике применения группового подхода было замечено следующее:
- Активизируется групповое мышление, при котором большинство оказывает социальное давление на меньшинство, вследствие чего отдельные люди соглашаются с тем, что выгодно массе, даже если их интересы никак не учитываются.
- Групповой подход служит почвой для столкновения личных мнений участников в гораздо большей степени, чем все остальные подходы.
Одновременно с этим нужно учитывать, что применение группового подхода обладает рядом серьезных преимуществ:
- Группа эффективнее решает проблемы, имея более широкой взгляд на нее и ее причины
- Группа намного шире видит перспективы, а значит и способна найти лучшее решение
- Групповой энтузиазм (особенно поощряемый) гораздо сильнее индивидуального
- Группа менее склонна к неуверенности и недоверию к новым решениям
Руководствуясь всем, сказанным выше, можно сделать вывод, что если разрешаемая проблема касается нескольких сторон, принимать решения эффективнее всего коллективно и с учетом мнений каждого. Если же проблема касается одного человека, он может принимать решения сам, но при этом свободен использовать любые другие подходы и средства поиска решений.









Все, о чем мы успели поговорить, носит более рекомендательный характер, нежели является системой. Однако эта информация универсальна – она поможет вам принимать эффективные решения в любых простых и сложных ситуациях. Но всегда следует оглядываться на особенности проблемных ситуаций, интересы вовлеченных сторон и другие факторы, воздействующие на принятие решений. Именно об этих факторах и пойдет речь далее.
Основные принципы работы с курсорами
Курсор проще всего представить себе как указатель на таблицу в базе данных. Например, следующее объявление связывает всю таблицу employee с курсором :
Объявленный курсор можно открыть:
Далее из него можно выбирать строки:
Завершив работу с курсором, его следует закрыть:
В этом случае каждая выбранная из курсора запись представляет строку таблицы employee. Однако с курсором можно связать любую допустимую команду . В следующем примере в объявлении курсора объединяются три таблицы:
В данном случае курсор действует не как указатель на конкретную таблицу базы данных — он указывает на виртуальную таблицу или неявное представление, определяемое командой . (Такая таблица называется виртуальной, потому что команда генерирует данные с табличной структурой, но эта таблица существует только временно, пока программа работает с возвращенными командой данными.) Если тройное объединение возвращает таблицу из 20 строк и 3 столбцов, то курсор действует как указатель на эти 20 строк.
Решения на основе суждений
Решения, принятые на основе суждений, могут на первый взгляд показаться интуитивными. Причиной тому – неочевидность логики. Но в действительности такие решения – продукт знаний и накопленного опыта. Люди применяют знания о том, что происходило в подобных случаях в прошлом, для поиска альтернативных выборов в настоящем и прогнозирования их результатов в будущем. Беря за основу здравый смысл, человек принимает решение, успешное ранее. Суждение выступает основой решения, и это полезно, ведь многие жизненные ситуации зачастую повторяются. Поэтому то, что принесло пользу тогда, может принести ее и сейчас.
Учитывая то, что решение на основе суждения принимается в сознании человека, оно всегда будет отличаться быстротой и невысокой «ценой». Однако здравый смысл в чистом виде – явление очень редкое, т.к. у каждого есть свои потребности, задачи, убеждения и т.д. Так что одних суждений для принятия решений маловато в уникальных и сложных ситуациях, где проблемы лишь кажутся очевидными.
Если ситуация новая и у человека еще нет опыта, он не может обосновать свой выбор логически. Суждения здесь могут оказаться плохими, т.к. факторов, которые нужно учитывать, очень много, и разум не способен обработать их все сразу в силу ограниченности своих возможностей. Исходя из того, что суждение берет за основу опыт, слишком большая ориентация на последний может смещать решения в стороны, знакомые человеку по действиям в прошлом. В такой ситуации очень просто не заметить хороших альтернатив. Но еще важнее то, что человек, слишком уповающий на суждения и опыт, может осознанно или неосознанно избегать нового. А это в свою очередь может стать причиной больших проблем в будущем, ведь актуальность практически любой информации со временем снижается.
Адаптироваться к новому и тем более сложному никогда не бывает слишком просто, ведь всегда существует вероятность принятия неверного решения. Но во множестве ситуаций человек вполне может повысить свои шансы на правильный выбор – если только он попробует принять решение рационально.
Основные параметры поиска решений
Найти решение задачи можно тремя способами. Во-первых, вручную перебирать параметры, пока не найдется оптимальное соотношение. Во-вторых, составить уравнение с большим количеством неизвестных. В-третьих, вбить данные в Excel и использовать «Поиск решений». Последний способ самый быстрый и покажет максимально точное решение, если знать, как использовать функцию.
Итак, мы решаем задачу с помощью поиска решений в Excel и начинаем с математической модели. В ней четыре типа данных: константы, изменяемые ячейки, целевая функция и ограничения. К поиску решения вернемся чуть позже, а сейчас разберемся, что входит в каждый из этих типов:
Константы — исходная информация. К ней относится удельная маржинальная прибыль, стоимость каждой перевозки, нормы расхода товарно-материальных ценностей. В нашем случае — производительность работников, их оплата и норма в 1000 изделий. Также константа отражает ограничения и условия математической модели: например, только неотрицательные или целые значения. Мы вносим константы в таблицу цифрами или с помощью элементарных формул (СУММ, СРЗНАЧ).
Изменяемые ячейки — переменные, которые в итоге нужно найти. В задаче это распределение 1000 изделий между работниками с минимальными затратами. В разных случаях бывает одна изменяемая ячейка или диапазон
При заполнении функции «Поиск решений» важно оставить ячейки пустыми — программа сама найдет значения
Целевая функция — результирующий показатель, для которого Excel подбирает наилучшие показатели. Чтобы программа понимала, какие данные наилучшие, мы задаем функцию в виде формулы. Эту формулу мы отображаем в отдельной ячейке. Результирующий показатель может принимать максимальное или минимальное значения, а также быть конкретным числом.
Ограничения — условия, которые необходимо учесть при оптимизации функции, называющейся целевой. К ним относятся размеры инвестирования, срок реализации проекта или объем покупательского спроса. В нашем случае — количество дней и число работников.
1.10.7. Математическая постановка
Данные обучающие векторы $x_i \in R^n$, i = 1,…, l и вектор-метка $y \in R^l$ дерево решений рекурсивно разбивает пространство признаков таким образом, что образцы с одинаковыми метками или аналогичными целевыми значениями группируются вместе.
Пусть данные в узле m быть представлен $Q_m$ с участием $N_m$ образцы. Для каждого раскола кандидатов $\theta = (j, t_m)$ состоящий из функции $j$ и порог $t_m$, разделите данные на $Q_m^{left}(\theta)$ а также $Q_m^{right}(\theta)$ подмножества$$Q_m^{left}(\theta) = {(x, y) | x_j <= t_m}$$$$Q_m^{right}(\theta) = Q_m \setminus Q_m^{left}(\theta)$$
Качество кандидата разделения узла $m$ затем вычисляется с использованием функции примеси или функции потерь $H()$, выбор которых зависит от решаемой задачи (классификация или регрессия)$$G(Q_m, \theta) = \frac{N_m^{left}}{N_m} H(Q_m^{left}(\theta)) + \frac{N_m^{right}}{N_m} H(Q_m^{right}(\theta))$$
Выберите параметры, которые минимизируют примеси$$\theta^* = \operatorname{argmin}_\theta G(Q_m, \theta)$$
Рекурсия для подмножеств $Q_m^{left}(\theta^*)$ а также $Q_m^{right}(\theta^*)$ пока не будет достигнута максимально допустимая глубина, $N_m < \min_{samples}$ или же $N_m = 1$.
1.10.7.1. Критерии классификации
Если целью является результат классификации, принимающий значения 0,1,…, K-1, для узла m, позволять$$p_{mk} = 1/ N_m \sum_{y \in Q_m} I(y = k)$$
быть пропорцией наблюдений класса k в узле m. Еслиmявляется конечным узлом, для этого региона установлено значение $p_{mk}$. Общие меры примеси следующие.
Джини:$$H(Q_m) = \sum_k p_{mk} (1 — p_{mk})$$
Энтропия:$$H(Q_m) = — \sum_k p_{mk} \log(p_{mk})$$
Неверная классификация:$$H(Q_m) = 1 — \max(p_{mk})$$
1.10.7.2. Критерии регрессии
Если целью является непрерывное значение, то для узла m, общими критериями, которые необходимо минимизировать для определения местоположений будущих разделений, являются среднеквадратичная ошибка (ошибка MSE или L2), отклонение Пуассона, а также средняя абсолютная ошибка (ошибка MAE или L1). MSE и отклонение Пуассона устанавливают прогнозируемое значение терминальных узлов равным изученному среднему значению $\bar{y}_m$ узла, тогда как MAE устанавливает прогнозируемое значение терминальных узлов равным медиане $median(y)_m$.
Среднеквадратичная ошибка:$$\bar{y}m = \frac{1}{N_m} \sum{y \in Q_m} y$$$$H(Q_m) = \frac{1}{N_m} \sum_{y \in Q_m} (y — \bar{y}_m)^2$$
Половинное отклонение Пуассона:$$H(Q_m) = \frac{1}{N_m} \sum_{y \in Q_m} (y \log\frac{y}{\bar{y}_m} — y + \bar{y}_m)$$
Настройка может быть хорошим выбором, если ваша цель — счетчик или частота (количество на какую-то единицу). В любом случае, y>=0 является необходимым условием для использования этого критерия. Обратите внимание, что он подходит намного медленнее, чем критерий MSE. Средняя абсолютная ошибка:$$median(y)m = \underset{y \in Q_m}{\mathrm{median}}(y)$$$$H(Q_m) = \frac{1}{N_m} \sum{y \in Q_m} |y — median(y)_m|$$
Средняя абсолютная ошибка:$$median(y)m = \underset{y \in Q_m}{\mathrm{median}}(y)$$$$H(Q_m) = \frac{1}{N_m} \sum{y \in Q_m} |y — median(y)_m|$$
Обратите внимание, что он подходит намного медленнее, чем критерий MSE
Практические последствия
Многие алгоритмы с плохой производительностью в наихудшем случае имеют хорошую производительность в среднем случае. Для проблем, которые мы хотим решить, это хорошо: мы можем надеяться, что конкретные экземпляры, которые нам интересны, являются средними. Для криптографии это очень плохо: мы хотим, чтобы типичные примеры криптографической проблемы были сложными. Здесь для некоторых конкретных задач можно использовать такие методы, как случайная самовосстановление, чтобы показать, что худший случай не сложнее среднего или, что то же самое, что средний случай не легче худшего.





С другой стороны, некоторые структуры данных, такие как хеш-таблицы, имеют очень плохое поведение в худшем случае, но хорошо написанная хеш-таблица достаточного размера статистически никогда не даст худшего случая; среднее количество выполняемых операций следует экспоненциальной кривой спада, поэтому время выполнения операции статистически ограничено.
Что важно при обработке данных при цифровой трансформации?[править]
вариант 1править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Сильная внутренняя экспертиза команды в области подхода управления с помощью данных +
Хранить данные в бумажном виде в архиве
вариант 2править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Понимать, какой информацией располагает компания, а чего не хватает +
Хранить данные в бумажном виде в архиве
вариант 3править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Определить методы сбора, анализа и интерпретации результатов +
Хранить данные в бумажном виде в архиве





