
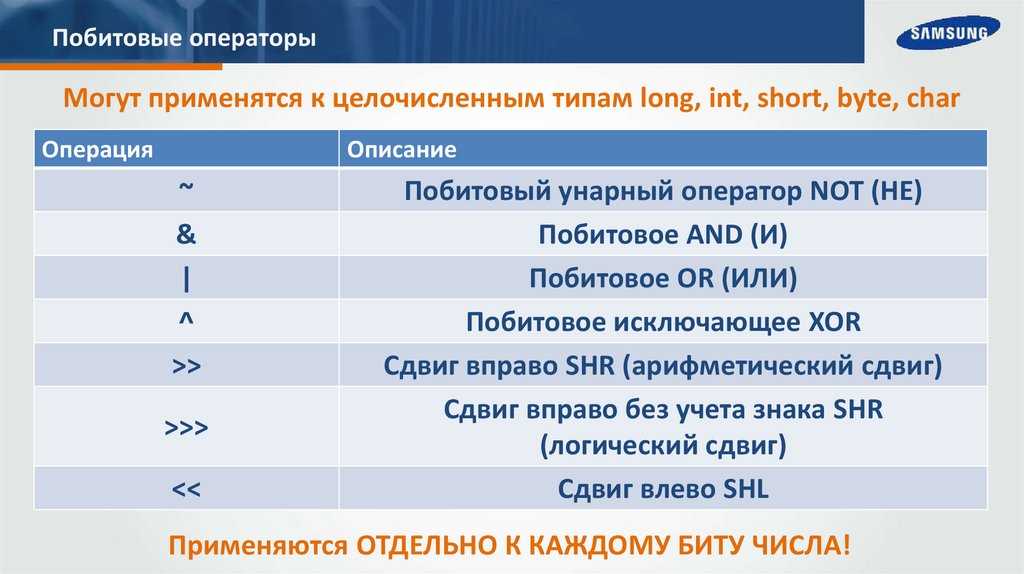
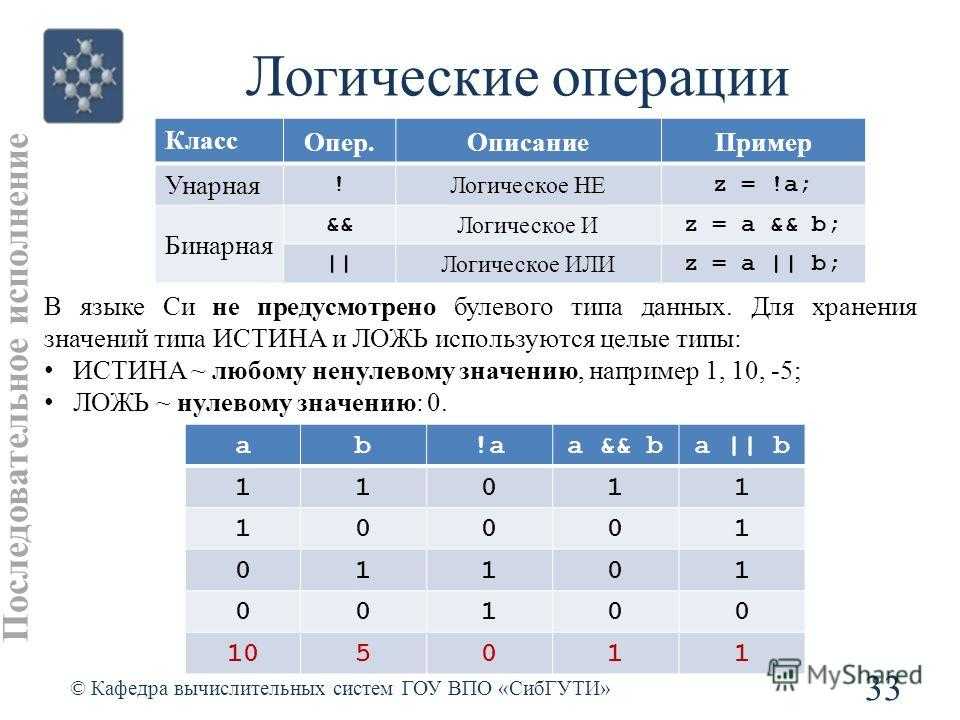
Разница между побитовыми и логическими операторами
Существует несколько различий между побитовыми операторами, которые мы обсуждали здесь, и более известными логическими операторами.
Во-первых, логические операторы работают с логическими выражениями и возвращают логические значения (либо true или false), в то время как побитовые операторы работают с двоичными цифрами целочисленных значений ( long, int, short, char, и byte ) и возвращают целое число.
Кроме того, логические операторы всегда вычисляют первое логическое выражение и, в зависимости от его результата и используемого оператора, могут вычислять или не вычислять второе. С другой стороны, побитовые операторы всегда вычисляют оба операнда .
Наконец, логические операторы используются при принятии решений на основе нескольких условий, в то время как побитовые операторы работают с битами и выполняют побитовые операции.
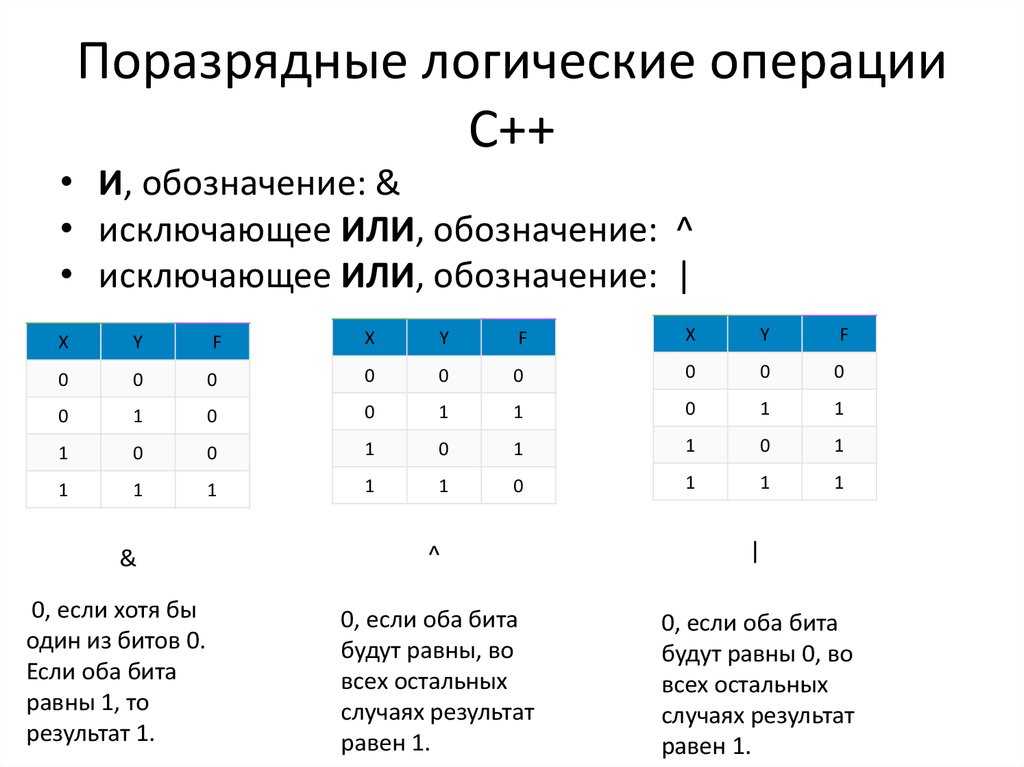
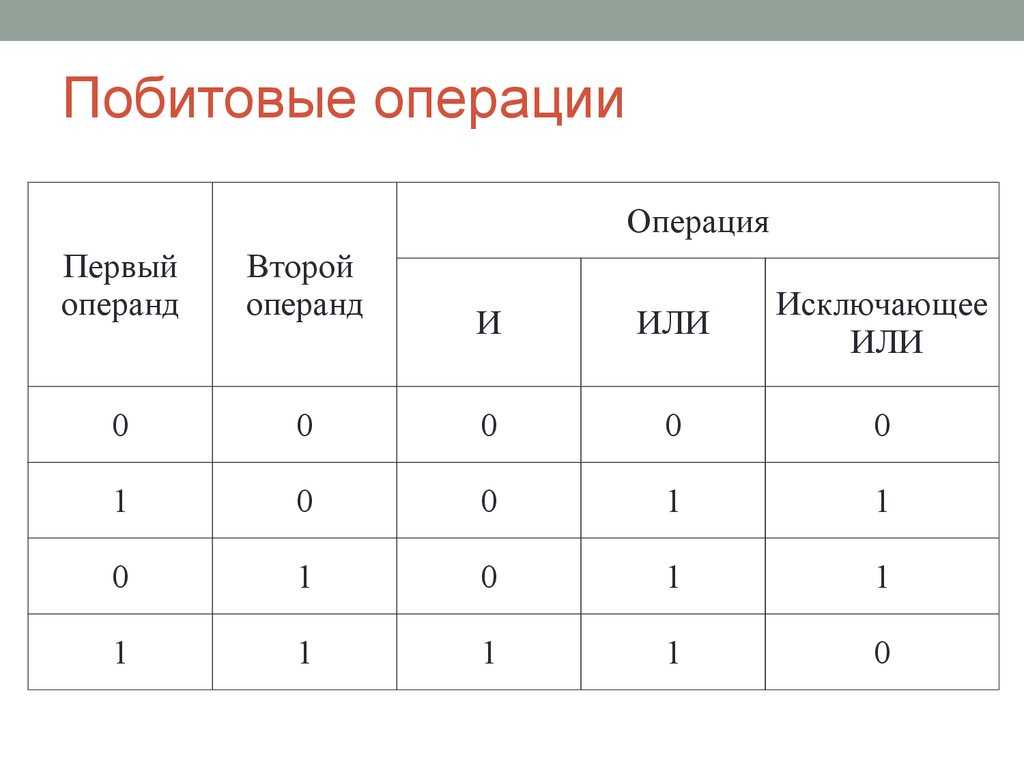
Побитовое И (&)
Побитовое И () выполняет булеву операцию конъюнкции над каждой парой битов, которые стоят на одинаковых позициях в двоичных представлениях операндов. Другими словами, результат равен 1, если оба соответствующих бита операндов равны 1; если же хотя бы один бит из пары равен , результирующий двоичный разряд равен .
Таблица истинности для этой операции выглядит так:
| a | b | a & b |
| 1 | ||
| 1 | ||
| 1 | 1 | 1 |
В следующем примере поразрядное И выполняется для чисел 38 и 3:
Выполнить код »
Скрыть результаты
Как видите, только в одной позиции биты обоих операндов равны 1. Из-за этого
все остальные биты результата обнуляются, что в итоге дает 000010.
Как результат, получаем 0000102, или 210.
Битовая операция ИЛИ
Следующая битовая операция – поразрядное ИЛИ. Она задается оператором | и
ее таблица истинности выглядит следующим образом.
|
x |
y |
ИЛИ |
|
1 |
1 |
|
|
1 |
1 |
|
|
1 |
1 |
1 |
Где обычно
используется эта операция? Обычно ее применяют, когда нужно включить отдельные
биты переменной. Рассмотрим такую программу.
byte flags = 8; //двоичный вид: 00001000 byte mask = 5; //двоичный вид: 00000101 flags = (byte)(flags | mask); //двоичная запись 00001101 (число 13) System.out.println(flags);
Здесь мы имеем
такую картину.
|
flags= |
1 |
||
|
mask= |
1 |
1 |
|
|
flags= |
1 |
1 |
1 |
то есть,
операция поразрядное ИЛИ, как бы собирает все единички из обеих переменных и
получается такое своеобразное сложение. Кстати, в этом случае действительно
получилось 8+5=13. Но это будет не всегда так, например, если
byte flags = 9; //двоичный вид: 00001001
то результат
тоже будет 13, так как операция ИЛИ включает бит вне зависимости был ли он уже
включен или нет, все равно на выходе будет единица. И здесь уже 9+5=13, что
математически неверно.
Формат 32-битного целого числа со знаком
Поразрядные (побитовые) операторы работают с 32-битными целыми числами в их двоичном представлении.
Двоичные числа представляют из себя строки, состоящие из нулей и единиц, в которых значение каждой единицы определяется ее позицией в данной строке.
Вот так, например, выглядият числа, записанные в формате 32-разрядного целого двоичного числа:
Каждый сдвиг влево на одну позицию означает удвоение значения, которое соответствует предыдущей позиции, находящейся справа.
Чтобы не путать, в какой системе счисления записано число, обычно в индексе пишут основание системы счисления, в которой оно записао. Например, число 5 в десятичной системе – 510,а в двоичной – 1012.
Чтобы перевести число в двоичную систему счисления необходимо делить его нацело на 2 пока не получим , затем необходимо записать все остатки от деления в обратном порядке.
Например, число 18, записываемое в двоичной системе счисления, имеет значение:
Теперь записываем полученные остатки от деления в обратном порядке
Получаем, что число 18 в двоичном представлении будет выглядеть как 00000000000000000000000000010010 (обратите внимание, число состоит ровно из 32-битов), или, сокращенно, как 10010. Эти пять значимых битов и определяют фактическое значение числа 18
Для преобразования из двоичной системы в десятичную используют формулу, состоящую из степеней основания 2:
a = a * 2 + a1 * 21 + a2 * 22 + … + an * 2n
где а – число в десятичной системе счисления; a, a1, … an – цифры данного числа в двоичном представлении. Причём a — это последняя или правая цифра, а an – первая.
Например, возьмём двоичное число 1010012. Для перевода в десятичное запишем его как сумму по разрядам следующим образом:
1 * 25 + * 24 + 1 * 23 + * 22 + * 21 + 1 * 2 = 41
Перепишем тоже самое, возведя в степени все основания 2:
1 * 32 + * 16 + 1 * 8 + * 4 + * 2 + 1 * 1 = 41
Можно записать это в виде таблицы следующим образом:
| 512(210) | 256(29) | 128(28) | 64(26) | 32(25) | 16(24) | 8(23) | 4(22) | 2(21) | 1(2) |
| 1 | 1 | 1 | |||||||
| +32 | +0 | +8 | +0 | +0 | +1 |
Положительные числа хранятся в настоящем двоичном формате, в котором все биты, кроме знакового (крайний левый), представляют степени двойки: первый бит (справа) соответствует 2, второй – 21, третий – 22 и т. д. Если какие-либо биты не используются, они считаются равными нулю.
Теперь под каждой двоичной единицей напишите её эквивалент в нижней строчке таблицы и сложите получившиеся десятичные числа. Таким образом, двоичное число 1010012 равнозначно десятичному 4110.
Термин «целые числа со знаком» означает, что в этой форме могут быть представлены как положительные, так и отрицательные целые числа.
Отрицательные числа также хранятся в двоичном коде, но в формате, который называется «дополнителъным кодом» (англ. two’s complement, иногда twos-complement).
Представление в «дополнительном коде» означает, что отрицательное значение числа (например 5 и -5) получается путем инвертирования числа (операция «побитовое НЕ», также известное как «обратный код» или «первое дополнение») и прибавлением к инверсии единицы («второе дополнение»).
К примеру, определим двоичное представление числа -5. Начнём с двоичного представления его абсолютного значения (5):
00000000000000000000000000000101
Инвертируем все разряды числа (заменим на 1, а 1 на ), получая таким образом обратный код (первое дополнение) числа 5:
11111111111111111111111111111010
Дополнительный код (второе дополнение) двоичного числа получается добавлением 1 (обычным двоичным сложением) к младшему значащему разряду его первого дополнения:
11111111111111111111111111111010 +
1 =
11111111111111111111111111111011
Итак, мы получили:
-5 = 11111111111111111111111111111011
В целых числах со знаком все биты, кроме 32-го, представляют само значение, тогда как 32-й бит определяет знак числа: если крайний-левый бит равен – число положительное, если 1 – число отрицательное. Поэтому этот бит называется знаковым битом.
Однако в JavaScript такое двоичное представление чисел скрыто. Например, при выводе отрицательного числа в виде двоичной строки вы получите сокращенный двоичный код абсолютного значения этого числа со знаком «минус»:
При изучении побитовых операторов вам могут пригодиться функции, которые облегчают перевод чисел из десятичного в двоичное представление и наоборот:
Выполнить код »
Скрыть результаты
Зачем нужны побитовые операторы?
В далеком прошлом компьютерной памяти было очень мало и ею сильно дорожили. Это было стимулом максимально разумно использовать каждый доступный бит. Например, в логическом типе данных bool есть всего лишь два возможных значения (true и false), которые могут быть представлены одним битом, но по факту занимают целый байт памяти! А это, в свою очередь, из-за того, что переменные используют уникальные адреса памяти, а они выделяются только в байтах. Переменная bool занимает 1 бит, а другие 7 бит — тратятся впустую.







Используя побитовые операторы, можно создавать функции, которые позволят уместить 8 значений типа bool в переменную размером 1 байт, что значительно сэкономит потребление памяти. В прошлом такой трюк был очень популярен. Но сегодня, по крайней мере, в прикладном программировании, это не так.
Теперь памяти стало существенно больше и программисты обнаружили, что лучше писать код так, чтобы было проще и понятнее его поддерживать, нежели усложнять его ради незначительной экономии памяти. Поэтому спрос на использование побитовых операторов несколько уменьшился, за исключением случаев, когда необходима уж максимальная оптимизация (например, научные программы, которые используют огромное количество данных; игры, где манипуляции с битами могут быть использованы для дополнительной скорости; встроенные программы, где память по-прежнему ограничена).
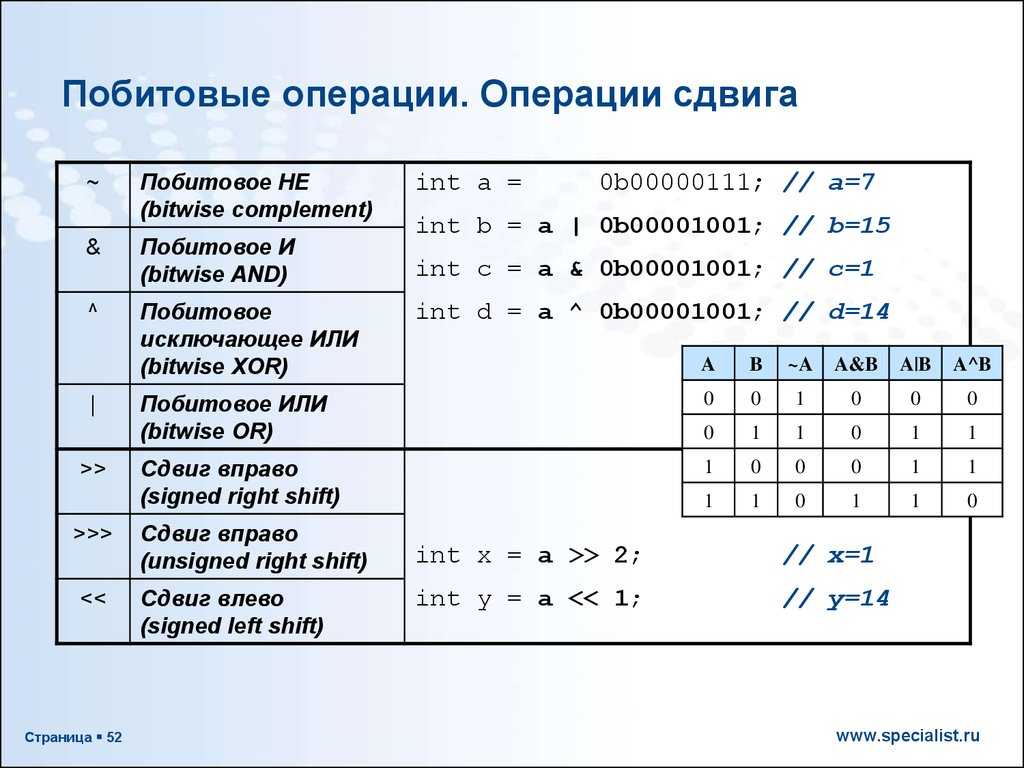
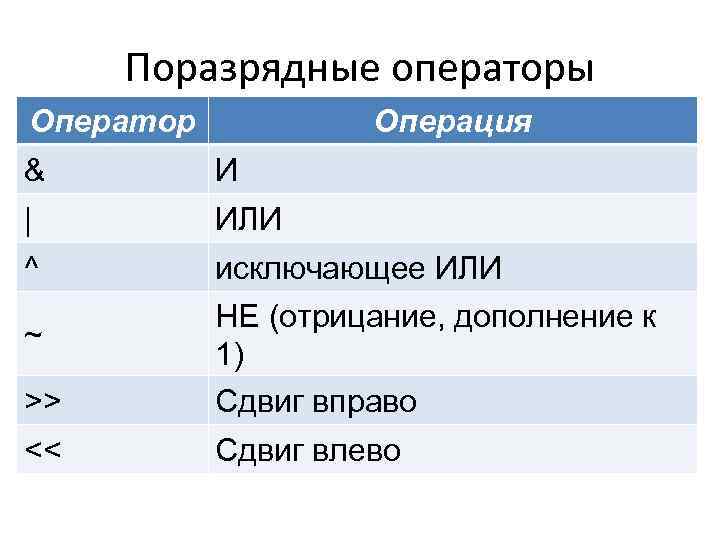
В языке С++ есть 6 побитовых операторов:
| Оператор | Символ | Пример | Операция |
| Побитовый сдвиг влево | << | x << y | Все биты в x смещаются влево на y бит |
| Побитовый сдвиг вправо | >> | x >> y | Все биты в x смещаются вправо на y бит |
| Побитовое НЕ | ~ | ~x | Все биты в x меняются на противоположные |
| Побитовое И | & | x & y | Каждый бит в x И каждый соответствующий ему бит в y |
| Побитовое ИЛИ | | | x | y | Каждый бит в x ИЛИ каждый соответствующий ему бит в y |
| Побитовое исключающее ИЛИ (XOR) | ^ | x ^ y | Каждый бит в x XOR с каждым соответствующим ему битом в y |
В побитовых операциях следует использовать только целочисленные типы данных unsigned, так как C++ не всегда гарантирует корректную работу побитовых операторов с целочисленными типами signed.
Правило: При работе с побитовыми операторами используйте целочисленные типы данных unsigned.
Операторы побитового сдвига влево ()
Оператор побитового сдвига влево () сдвигает биты влево. Левый операнд – это выражение для сдвига битов, а правый операнд – это целое число, представляющее количество бит, на которое нужно выполнить сдвиг.
Поэтому, когда мы говорим , мы говорим «сдвинуть биты в переменной влево на 1 место». Новые биты, сдвинутые с правой стороны, получают значение 0.
Обратите внимание, что в третьем случае мы вытеснили бит с левого конца числа! Биты, сдвинутые с конца двоичного числа, теряются навсегда. Оператор побитового сдвига вправо () сдвигает биты вправо
Оператор побитового сдвига вправо () сдвигает биты вправо.
Обратите внимание, что в третьем случае мы вытеснили бит с правого конца числа, поэтому он потерялся. Вот пример выполнения побитового сдвига:
Вот пример выполнения побитового сдвига:
Эта программа напечатает:
Обратите внимание, что результаты применения операторов побитового сдвига к целому числу со знаком до C++20 зависели от компилятора. Предупреждение
Предупреждение
При использовании стандарта до C++20 не выполняйте сдвиг для значений целочисленных типов со знаком (и даже при новом стандарте, вероятно, всё же лучше использовать беззнаковые типы).
Формат 32-битного целого числа со знаком
Операнды всех побитовых операндов интерпретируются как 32-битные целые числа со знаком и старшим битом слева и дополнением до двойки.
«Старший бит слева» — означает, что самый значимый бит (битовая позиция с самым большим значением) находится на крайнем левом месте.
«Дополнение до двойки» означает, что двоичный вид числа, обратного данному (например, 5 и -5) получается путем обращения(двоичного НЕ) всех битов с добавлением 1.
Например, вот число 314:
00000000000000000000000100111010
Чтобы получить -314, первый шаг — обратить биты числа:
11111111111111111111111011000101
Второй шаг — прибавить единицу:
11111111111111111111111011000110
Принцип дополнения до двойки делит все двоичные представления на два множества: если крайний-левый бит равен 0 — число положительное, если 1 — число отрицательное. Поэтому этот бит называется знаковым битом.
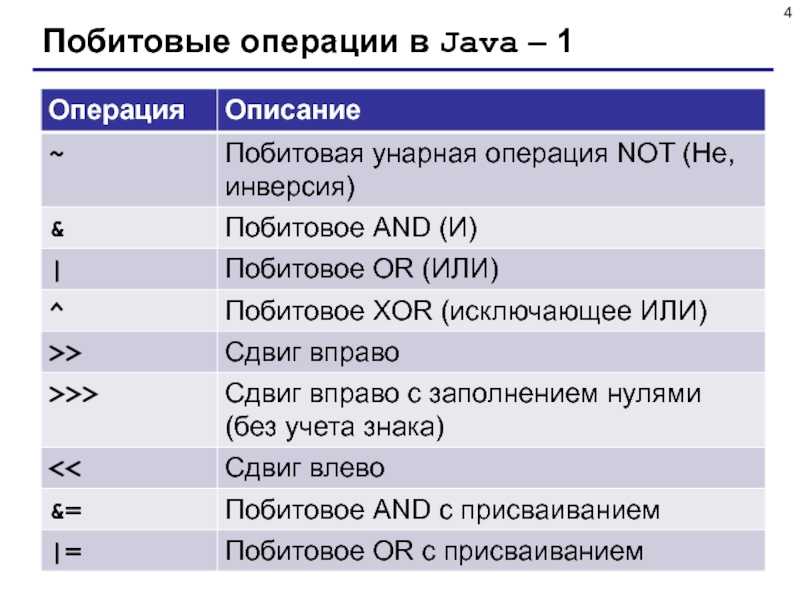
Битовые сдвиги в Java
Операция Описание
>> Сдвиг вправо (арифметический сдвиг)
>>> Сдвиг вправо с заполнением нулями (беззнаковый сдвиг)
<< Сдвиг влево
Битовые сдвиги смещают все двоичные разряды значения на указанное количество позиций.
Общая форма:
Например:
Для того чтобы понять, как происходит сдвиг, лучше рассмотреть его на примере двоичных чисел:
При сдвиге отрицательных чисел имеется разница в использовании операторов и . Операция распространяет знаковый (левый) бит направо до конца, заполняет нулями. У положительных чисел результат будет одинаков.
Типы и продвигаются к типу при вычислении выражения.
Пример битовых сдвигов:
Целые числа и дополнение до 10
Хранение целых чисел на компьютере в десятичном мире
Для начала представим себе, что данные в компьютерах хранятся в ячейках-«битах», каждое из которых может принимать 10 разных значений.
В таком случае очень легко хранить положительные целые числа: каждое число по цифрам записывается в ячейки памяти.
Реальный процессор может выполнять арифметические с такими числами, но есть проблема:
чем больше цифр в числах, которые он сможет складывать за одну операцию (такт), тем сложнее его проектировать, тем больше тепла он выделяет и энергии потребляет.
Поэтому необходимо выбрать некоторое фиксированную «стандартную» длину чисел так, чтобы с одной стороны для большей части основных задач числа туда помещались, с другой стороны были наиболее короткими.
Например, можно выбрать длину в 10 цифр для «обычных» чисел и длину 20 для «длинных» (операций с длинными целыми числами за один такт процессора будет выполняться меньше).
Кстати, нам потребуется хранить ещё и знак числа.
Как лучше всего это сделать — вопрос очень хороший.
В реальности используется несколько подходов к хранению знака числа, вернее даже к хранению просто целых чисел.
Самый «популярный» в данный момент называется «дополнение до двойки» (two’s complement), что для нашего воображаемого десятичного процессора превращается в «дополнение до десятки».
Основная идея подхода состоит в следующем.
Так как наши числа ограничены 10-ю цифрами, то если в результате арифметической операции возникнет перенос через разряд в 11-ю цифру, то он будет потерян.
В таких случаях говорят, что вычисления производятся по модулю $10^{10}$.
Пусть у нас есть два числа: отрицательное $x$ и положительное $y$, и нам нужно вычислить $x+y$.
Заметим, что по замечанию выше $x+y\equiv (10^{10}+x) + y$ (ведь добавление лишнего $10^{10}$ ничего не меняет, у нас нет «места», чтобы хранить эту цифру).
Но число $(10^{10}+x)$ уже заведомо положительное.
Итак, ровно в этом состоит идея: для хранения отрицательного числа $x$ используется положительное число $(10^{10}+x)$.
Неотрицательные числа от до хранятся как есть.
А числа от до отдаются отрицательным числам,
причём $-1$ превращается в $10^{10}-1 = 9999999999$, $-2$ превращается в $10^{10}-2 = 9999999998$, и так далее,
$-5000000000$ превращается в… в $-5000000000$.
Заметим, что отрицательных чисел «поместилось» на одно больше, чем положительных.
Вот примеры:
сложим $8\,512$ и $-3\,628$.
$$10^{10}-3628 = 9\,999\,996\,372.$$
Далее $$8\,512 + (-3\,628) \equiv 8\,512 + 9\,999\,996\,372 = 10\,000\,004\,884 \equiv 4\,884.$$
Сложим $-6\,460$ и $-9\,290$.
$$(-6\,460) + (-9\,290) \equiv (10^{10}-6\,460) + (10^{10}-9\,290) = 9\,999\,993\,540 + 9\,999\,990\,710 = $$
$$= 19\,999\,984\,250 \equiv 9\,999\,984\,250 \equiv 9\,999\,984\,250 — 10^{10} = (-15\,750).$$
В чём выгода такого подхода? Во-первых, используются все возможные значения (если знак хранить в первой цифре, то будут «потеряны» 80% чисел).
Во-вторых, с таким подходом отрицательные числа ничем не отличаются от положительных и не требуется усложнения схем для организации арифметических операций с ними. По модулю $10^{10}$ отлично работают все арифметические операции, поэтому работать будут и вычитание, и умножение.
Tilde Python Table
Вот таблица, показывающая результаты различных операций Tilde на положительных целочисленных целях.
| -1 | ~ 0. | ~ 00000000 -> 11111111 |
| -2 | ~ 1. | ~ 00000001 -> 11111110 |
| -3 | ~ 2. | ~ 00000010 -> 11111101 |
| -4 | ~ 3. | ~ 00000011 -> 11111100 |
| -5 | ~ 4. | ~ 00000100 -> 11111011 |
| -6 | ~ 5. | ~ 00000101 -> 11111010 |
| -7 | ~ 6. | ~ 00000110 -> 11111001 |
| -8 | ~ 7. | ~ 00000111 -> 11111000 |
| -9 | ~ 8. | ~ 00001000 -> 11110111 |
| -10 | ~ 9. | ~ 00001001 -> 11110110 |
| -11 | ~ 10. | ~ 00001010 -> 11110101 |
| -12 | ~ 11. | ~ 00001011 -> 11110100 |
Вот таблица, показывающая результаты различных операций Tilde на отрицательных целочисленных значениях.
| -1 | ~ 0. | ~ 00000000 -> 11111111 |
| ~ -1. | ~ 11111111 -> 00000000 | |
| 1 | ~ -2 | ~ 11111110 -> 00000001 |
| 2 | ~ -3. | ~ 11111101 -> 00000010 |
| 3 | ~ -4. | ~ 11111100 -> 00000011 |
| 4 | ~ -5. | ~ 11111011 -> 00000100 |
| 5 | ~ -6. | ~ 11111010 -> 00000101 |
| 6 | ~ -7 | ~ 11111001 -> 00000110 |
| 7 | ~ -8 | ~ 11111000 -> 00000111 |
| 8 | ~ -9 | ~ 11110111 -> 00001000 |
| 9 | ~ -10 | ~ 11110110 -> 00001001 |
| 10 | ~ -11 | ~ 11110101 -> 00001010 |
Общая формула для расчета операции Tilde это Отказ
Так что же использование оператора Tilde?
Тонкости битового представления целых чисел в Python
Как вам уже известно, целые числа в питоне ограничены лишь объёмом оперативной памяти, то есть могут быть весьма и весьма большими.
В этом случае можно представлять себе битовую запись целых чисел так.
Если число положительно, то слева от записи числа идёт бесконечное количество 0.
А если число отрицательно, то слева идёт бесконечное количество 1.
Число -1 записывается как последовательность из одних лишь единиц: ,
а число 0 — из одних лишь нулей .
То есть 21, это не просто , а .
Таким образом, — это число вида , то есть бесконечное количество 1, а затем .
Как понять, какому целому числу соответствует такая запись?
Если слева нули, то число положительно, и всё просто: отбрасываем ведущие нули, получаем число в двоичной записи.
А если слева единицы?
Для этого найдём самую правую 1, после которой слева идут только 1.
В нашем примере получится вот такая единица: .
Очевидно, что в двоичной записи после такой единицы сразу идёт 0 (кроме случая, когда в двоичной записи вообще только 1, то есть кроме числа -1).
Таким образом, число разбивается на бесконечную «голову» единиц и хвост после первого нуля (возможно пустой) — .
Итоговое число равно их разности: .
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Практические проекты – это то, как вы обостряете вашу пилу в кодировке!
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Затем станьте питоном независимым разработчиком! Это лучший способ приближения к задаче улучшения ваших навыков Python – даже если вы являетесь полным новичком.
Присоединяйтесь к моему бесплатным вебинаре «Как создать свой навык высокого дохода Python» и посмотреть, как я вырос на моем кодированном бизнесе в Интернете и как вы можете, слишком от комфорта вашего собственного дома.
Присоединяйтесь к свободному вебинару сейчас!
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python One-listers (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
Делаем битовые маски более осмысленными
Присвоение нашим битовым маскам имен «» или «» говорит нам, какой бит обрабатывается, но не дает нам никакой индикации, для чего на самом деле используется этот битовый флаг.
Лучше всего давать вашим битовым маскам полезные имена, чтобы документировать значение ваших битовых флагов. Вот пример из игры, которую мы могли бы написать:
Вот тот же пример, реализованный с использованием :
Два примечания: во-первых, не имеет удобной функции, позволяющей запрашивать биты с использованием битовой маски. Поэтому, если вы хотите использовать битовые маски, а не индексы позиций, для запроса битов вам придется использовать побитовое И. Во-вторых, чтобы увидеть, остался ли запрошенный нами бит установленным или сброшенным, мы используем функцию , которая возвращает , если какие-либо биты установлены в 1, и в противном случае.






>> (Правый сдвиг, переносящий знак)
Этот оператор сдвигает биты вправо, отбрасывая лишние. Копии крайнего-левого бита добавляются слева. Так как итоговый крайний-левый бит имеет то же значение, что и исходный, знак числа (представленный крайним-левым битом) не изменяется.
Поэтому он назван «переносящим знак».
Например, даст :
9 (по осн.10)
= 00000000000000000000000000001001 (по осн.2)
--------------------------------
9 >> 2 (по осн.10)
= 00000000000000000000000000000010 (по осн.2)
= 2 (по осн.10)
Аналогично, даст , так как знак сохранен:
-9 (по осн.10)
= 11111111111111111111111111110111 (по осн.2)
--------------------------------
-9 >> 2 (по осн.10)
= 11111111111111111111111111111101 (по осн.2) = -3 (по осн.10)
>>> (Правый сдвиг с заполнением нулями)
Этот оператор сдвигает биты первого операнда вправо. Лишние биты справа отбрасываются. Слева добавляются нулевые биты.
Знаковый бит становится равным 0, поэтому результат всегда положителен.
Для неотрицательных чисел правый сдвиг с заполнением нулями и правый сдвиг с переносом знака дадут одинаковый результат, т.к в обоих случаях слева добавятся нули.
Для отрицательных чисел — результат работы разный. Например, даст , отличное от (дает -3):
Как настроить интеграцию: на примере Tilda и Google Sheets
Для работы с коннектором не нужны навыки программирования. Чтобы создать интеграцию, достаточно подключить аккаунты Tilda и другого сервиса к сайту ApiX-Drive и настроить между ними связь. На это потребуется около 15 минут.
Для наглядности разберем процесс по шагам. В качестве примера подключим к Tilda Google Sheets, чтобы данные из форм автоматически попадали в таблицу. Это позволит нам вести учет всех заказов в одной удобной системе.
Итак, регистрируемся на сайте ApiX-Drive. Заходим в личный кабинет и кликаем «Создать связь».
![]()
После этого приступаем к подключению.
Подключение формы Tilda
Выбираем Tilda в качестве системы-источника данных.
![]()
Выбираем действие, которое должен совершать коннектор: «Получить данные из форм».
![]()
Кликаем «Подключить аккаунт «Tilda».
![]()
Копируем URL для приема данных — он поможет подключить нужную форму.
![]()
Открываем в новой вкладке личный кабинет Tilda. Заходим в настройки сайта, который хотим подключить к Google Sheets, открываем раздел «Формы» и выбираем Webhook. Затем вставляем только что скопированный URL и нажимаем «Добавить».
![]()
Добавляем приемщик данных ко всем формам.
![]()
Нажимаем «Опубликовать все страницы», чтобы изменения вступили в силу.
![]()
![]()
Возвращаемся к настройке ApiX-Drive. При необходимости добавляем условия фильтрации. С их помощью коннектор способен передавать только те заказы, которые содержат нужные ключевые слова или другие параметры. Например, таким образом можно настроить фильтр на передачу заказов только определенной товарной категории.
![]()
На экране появятся данные, которые мы отправили в качестве тестового заказа. Переходим к следующему этапу.
![]()
Подключение таблицы Google Sheets
Кликаем «Начать настройку Приема Данных».
![]()
Выбираем Google Sheets в качестве приемника данных.
![]()
Выбираем действие, которое должен выполнять коннектор с загруженными данными: «Добавить строчку».
![]()
Подключаем аккаунт Google Sheets.
![]()
Выбираем таблицу (файл) и лист, в которые ApiX-Drive будет вставлять заказы. Затем выбираем, какие именно данные по каждому заказу будут попадать в Google Sheets. Для этого кликаем по нужным полям и выбираем подходящие типы данных. Каждое поле соответствует колонке в нашей таблице. Лишние поля оставляем пустыми.
![]()
Проверяем пример данных, которые будут передаваться по каждому заказу. Если надо что-то изменить, кликаем «Редактировать» и вносим правки. Если все правильно, нажимаем «Далее».
![]()
![]()
Включаем обновление, чтобы разрешить передачу данных.
![]()
Кликаем по шестеренке и выбираем подходящий интервал передачи данных. Чем он меньше, тем быстрее данные из форм будут попадать в таблицу.
![]()
Примерно так переданные заказы будут отображаться в Google Sheets:
![]()
На этом все. ApiX-Drive начнет передавать данные в соответствии с заданными параметрами.
Небольшой тест
Вопрос 1
a) Что дает выражение 0110 >> 2 в двоичном формате?
Ответ
0110 >> 2 вычисляется как 0001
b) Чему в двоичном формате равно следующее выражение: 0011 | 0101?
Ответ
c) Чему в двоичном формате равно следующее выражение: 0011 & 0101?
Ответ
d) Чему в двоичном формате равно следующее выражение: (0011 | 0101) & 1001?
Ответ
Вопрос 2
Побитовое вращение похоже на побитовый сдвиг, за исключением того, что любые биты, сдвинутые с одного конца, добавляются обратно в другой конец. Например, 0b1001 << 1 будет равно 0b0010, но вращение влево на 1 бит приведет в результате к 0b0011. Реализуйте функцию, которая выполняет вращение влево на . Для этого можно использовать функции и .





Должен выполняться следующий код:
и печататься следующее:
Ответ
Мы назвали функцию «», а не «», потому что «» – это хорошо известное в информатике имя, а также имя стандартной функции .
Вопрос 3
Дополнительное задание: повторите задание 2, но не используйте функции и .
Ответ
Битовые маски, включающие несколько битов
Хотя битовые маски часто используются для выбора одного бита, их также можно использовать для выбора нескольких битов. Давайте посмотрим на немного более сложный пример, в котором мы это делаем.
Цветные дисплеи, такие как телевизоры и мониторы, состоят из миллионов пикселей, каждый из которых может отображать точку цвета. Точка цвета состоит из трех световых лучей: красного, зеленого и синего (RGB – red, green, blue). Изменяя интенсивность этих цветов, можно получить любой цвет в цветовом спектре. Обычно яркость R, G и B для пикселя представлена 8-битовым целочисленным типом без знака. Например, красный пиксель будет иметь R = 255, G = 0, B = 0. У фиолетового пикселя R = 255, G = 0, B = 255. Средне-серый пиксель будет иметь R = 127, G = 127, B = 127.
При присвоении значений цвета пикселю, помимо R, G и B, часто используется 4-е значение, называемое A. «A» означает «альфа», и оно определяет, насколько прозрачным будет цвет. Если A = 0, цвет полностью прозрачный. Если A = 255, цвет непрозрачный.
R, G, B и A обычно хранятся как одно 32-битное целое число, в котором для каждого компонента используется 8 бит:
| биты 31-24 | биты 23-16 | биты 15-8 | биты 7-0 |
|---|---|---|---|
| RRRRRRRR | GGGGGGGG | BBBBBBBB | AAAAAAAA |
| красный | зеленый | синий | альфа |
Следующая программа просит пользователя ввести 32-битное шестнадцатеричное значение, а затем извлекает из него 8-битные цветовые значения для R, G, B и A.
Эта программа дает следующий результат:
В приведенной выше программе мы используем побитовое И для запроса интересующего нас набора из 8 бит, а затем сдвигаем их вправо в 8-битное значение, чтобы мы могли распечатать его как шестнадцатеричное значение.
Список побитовых операторов
| Оператор | Использование | Описание |
|---|---|---|
| Побитовое И (AND) | Возвращает 1 в тех позициях результата, в которых биты каждого из операндов равны 1. | |
| Побитовое ИЛИ (OR) | Возвращает 1 в тех позициях результата, в которых бит хотя бы одного из операндов равен 1. | |
| Побитовое исключающее ИЛИ (XOR) | Возвращает 1 в тех позициях результата, в которых бит только одного из операндов равен 1. | |
| Побитовое НЕ (NOT) | Заменяет каждый бит операнда на противоположный. | |
| Сдвиг влево | Сдвигает двоичное представление числа a на b разрядов влево заполняя освободившиеся справа разряды нулями. | |
| Правый сдвиг, переносящий знак | Сдвигает двоичное представление а на b разрядов вправо, отбрасывая уходящие биты. | |
| Правый сдвиг с заполнением нулями | Сдвигает двоичное представление числа a на b разрядов вправо. Освобождающиеся разряды заполняются нулями. |
Побитовые операторы, подобно логическим операторам, выполняют логические операции , но с каждым отдельным битом целого числа. Cреди побитовых операторов есть также операторы сдвига позволяющие переместить все биты числа влево или вправо на нужно количество разрядов.
Побитовые операторы преобразуют свои операнды в 32-битные целые числа, представленные последовательностью битов. Дробная часть, если она есть, отбрасывается. Получившаяся в результате выполнения последовательность бит интерпретируется как обычное число.
Операторы эквивалентности
Пользовательские классы и структуры не получают дефолтной реализации эквивалентных операторов, известных как “равен чему-то” оператор (==) или “не равен чему-то” (!=).
Чтобы использовать операторы эквивалентности для проверки эквивалентности вашего собственного пользовательского типа, предоставьте реализацию для этих операторов тем же самым способом, что и для инфиксных операторов и добавьте соответствие протоколу стандартной библиотеки Equatable:
Пример выше реализует оператор “равен чему-то” (==) для проверки эквивалентности значений двух экземпляров Vector2D. В контексте Vector2D имеет смысл считать, что “равно чему-то” означает, что “оба экземпляра имеют одни и те же значения x и y”, таким образом это является той логикой, которая используется при реализации оператора. Пример так же реализует оператор “не равен чему-то” (!=), который просто возвращает обратный результат оператора “равен чему-то”.
Теперь вы можете использовать эти операторы для проверки того, эквивалентны ли экземпляры Vector2D друг другу или нет:
Swift предоставляет синтезированные реализации операторов эквивалентности для следующих пользовательских типов:
- Структур, имеющих только свойства хранения, соответствующие протоколу Equatable
- Перечислений, имеющих только ассоциированные типы, соответствующие протоколу Equatable
- Перечислений, не имеющих связанных типов
Объявите о соответствии протоколу Equatable в исходной реализации для получения этих дефолтных реализаций.
Приведенный ниже пример определяет структуру Vector3D для трехмерного вектора положения (x, y, z), аналогичную структуре Vector2D. Поскольку свойства x, y и z являются эквивалентными, Vector3D принимает стандартные реализации операторов эквивалентности.
Пользовательские операторы
Вы можете объявить и реализовать ваши собственные пользовательские операторы в дополнение к стандартным операторам Swift. Список символов, которые можно использовать для определения пользовательских операторов, см. в разделе «».
Новые операторы объявляются на глобальном уровне при помощи ключевого слова operator и отмечаются модификатором prefix, infix, postfix:
Пример выше определяет новый префиксный оператор +++. Этот оператор не имеет никакого значения в Swift, таким образом мы даем ему собственное назначение, которое описано чуть ниже, которое имеет специфический контекст работы с экземплярами Vector2D. Для целей этого примера, оператор +++ рассматривается как новый “префиксный двойной” оператор. Он удваивает значения x и y экземпляра Vector2D, путем добавления вектора самому себе при помощи оператора сложения-присваивания, который мы определили ранее. Для реализации +++ оператора мы добавим метод типа Vector2D с именем +++ как показано ниже:
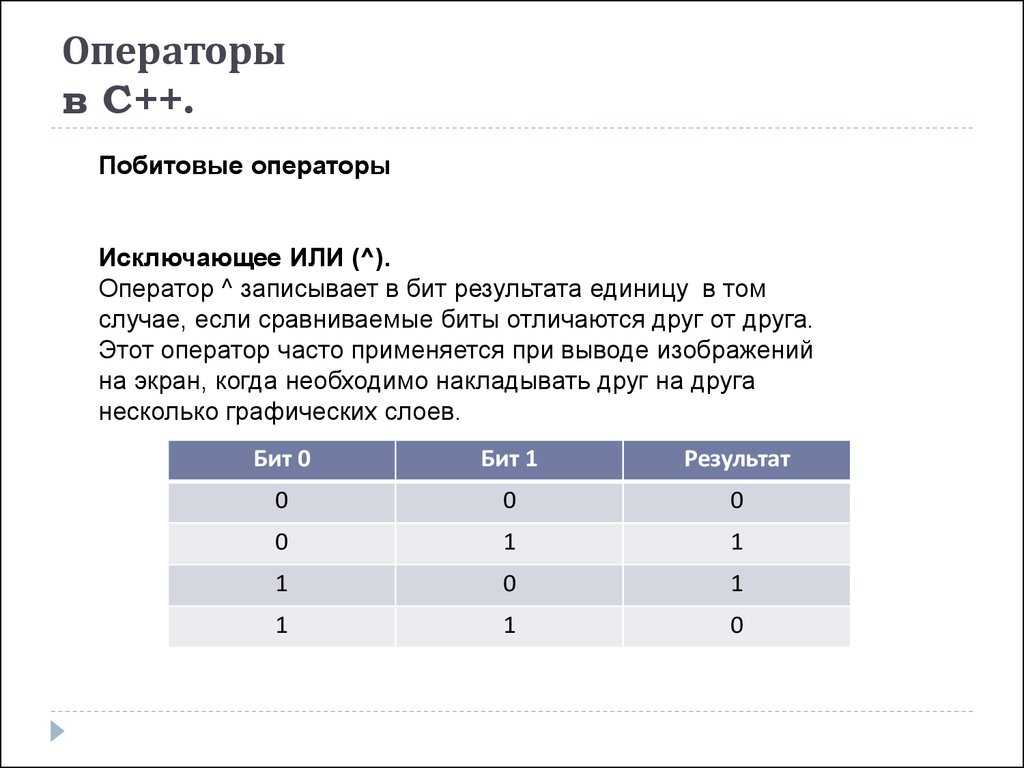
Побитовое НЕ (NOT)
Оператор побитовое НЕ (), пожалуй, самый простой для понимания из всех побитовых операторов. Он просто инвертирует каждый бит с 0 на 1, или наоборот
Обратите внимание, что результат побитового НЕ зависит от размера вашего типа данных
Инвертирование 4-битного значения:
Инвертирование 8-битного значения:
И в 4-битном, и в 8-битном случаях мы начинаем с одного и того же числа (двоичное 0100 соответствует 0000 0100 точно так же, как десятичное 7 соответствует 07), но в конечном итоге мы получаем другой результат.
Мы можем увидеть это в действии в следующей программе:
Эта программа напечатает:
Побитовые операторы присваивания
Подобно арифметическим операторам присваивания, C++, чтобы упростить изменение переменных, предоставляет побитовые операторы присваивания.
| Оператор | Обозначение | Пример использования | Операция |
|---|---|---|---|
| Присваивание со сдвигом влево | Сдвигает влево на количество бит, представленное значением | ||
| Присваивание со сдвигом вправо | Сдвигает вправо на количество бит, представленное значением | ||
| Присваивание с побитовым И (AND) | Присваивает результат выполнения переменной | ||
| Присваивание с побитовым ИЛИ (OR) | Присваивает результат выполнения переменной | ||
| Присваивание с побитовым исключающее ИЛИ (XOR) | Присваивает результат выполнения переменной |
Например, вместо записи вы можете написать .
Эта программа напечатает:





