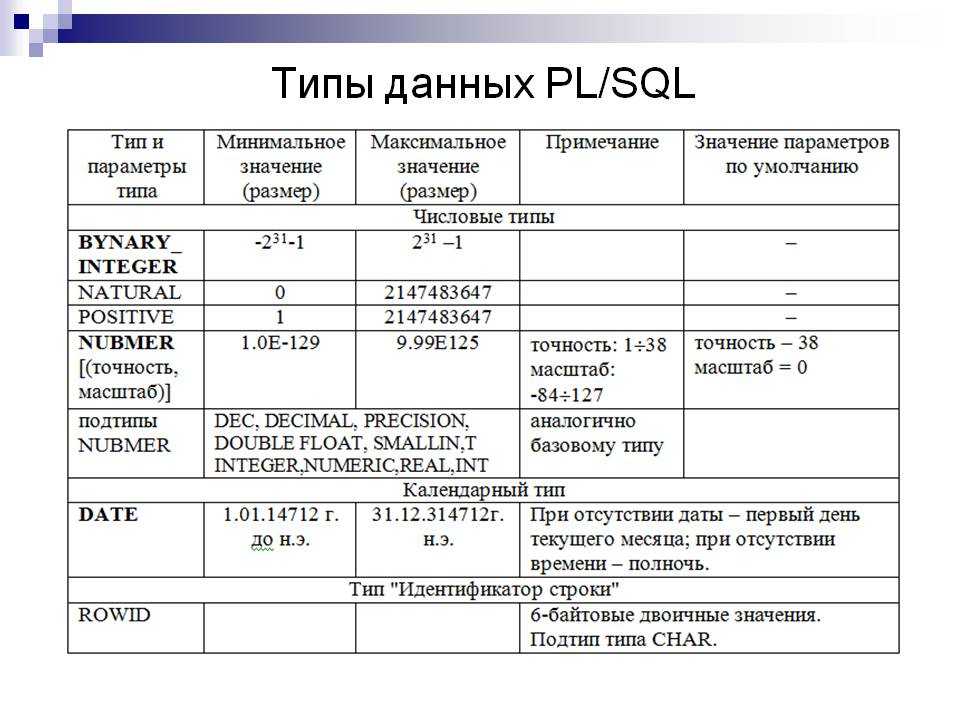
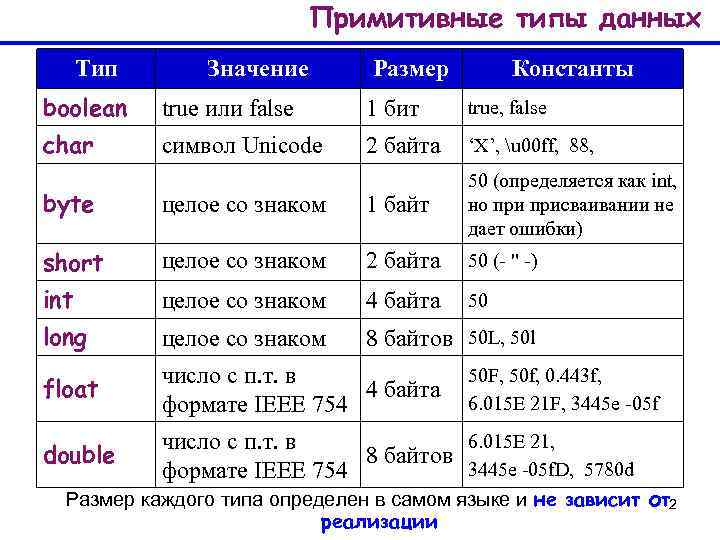
Преобразование между байтом и шестнадцатеричным
Прежде всего, давайте рассмотрим логику преобразования между байтовыми и шестнадцатеричными числами.
2.1. Байт в шестнадцатеричном формате
Байты-это 8-битные целые числа со знаком в Java. Поэтому нам нужно преобразовать каждый 4-битный сегмент в шестнадцатеричный отдельно и объединить их . Следовательно, после преобразования мы получим два шестнадцатеричных символа.
Например, мы можем записать 45 как 0010 1101 в двоичном формате, а шестнадцатеричный эквивалент будет “2d”:
0010 = 2 (base 10) = 2 (base 16) 1101 = 13 (base 10) = d (base 16) Therefore: 45 = 0010 1101 = 0x2d
Давайте реализуем эту простую логику в Java:
public String byteToHex(byte num) {
char[] hexDigits = new char;
hexDigits = Character.forDigit((num >> 4) & 0xF, 16);
hexDigits = Character.forDigit((num & 0xF), 16);
return new String(hexDigits);
}
Теперь давайте разберемся в приведенном выше коде, проанализировав каждую операцию. Прежде всего, мы создали массив символов длиной 2 для хранения выходных данных:
char[] hexDigits = new char;
Затем мы выделили биты более высокого порядка, сдвинув вправо 4 бита. А затем мы применили маску, чтобы изолировать 4 бита более низкого порядка. Маскировка необходима, потому что отрицательные числа внутренне представлены как дополнение двойки к положительному числу:
hexDigits = Character.forDigit((num >> 4) & 0xF, 16);
Затем мы преобразуем оставшиеся 4 бита в шестнадцатеричные:
hexDigits = Character.forDigit((num & 0xF), 16);
Наконец, мы создаем объект String из массива char. А затем вернул этот объект в виде преобразованного шестнадцатеричного массива.
Теперь давайте разберемся, как это будет работать для отрицательного байта -4:
hexDigits: 1111 1100 >> 4 = 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 & 0xF = 0000 0000 0000 0000 0000 0000 0000 1111 = 0xf hexDigits: 1111 1100 & 0xF = 0000 1100 = 0xc Therefore: -4 (base 10) = 1111 1100 (base 2) = fc (base 16)
Также стоит отметить, что символ . forDigit () метод всегда возвращает строчные символы.
2.2. От шестнадцатеричного до байтового
Теперь давайте преобразуем шестнадцатеричную цифру в байт. Как мы знаем, байт содержит 8 бит. Поэтому нам нужны две шестнадцатеричные цифры, чтобы создать один байт .
Прежде всего, мы преобразуем каждую шестнадцатеричную цифру в двоичный эквивалент отдельно.
А затем нам нужно объединить два четырехбитовых сегмента, чтобы получить байтовый эквивалент:
Hexadecimal: 2d 2 = 0010 (base 2) d = 1101 (base 2) Therefore: 2d = 0010 1101 (base 2) = 45
Теперь давайте напишем операцию на Java:
public byte hexToByte(String hexString) {
int firstDigit = toDigit(hexString.charAt(0));
int secondDigit = toDigit(hexString.charAt(1));
return (byte) ((firstDigit << 4) + secondDigit);
}
private int toDigit(char hexChar) {
int digit = Character.digit(hexChar, 16);
if(digit == -1) {
throw new IllegalArgumentException(
"Invalid Hexadecimal Character: "+ hexChar);
}
return digit;
}
Давайте разберемся в этом, по одной операции за раз.
Прежде всего, мы преобразовали шестнадцатеричные символы в целые числа:
int firstDigit = toDigit(hexString.charAt(0)); int secondDigit = toDigit(hexString.charAt(1));
Затем мы оставили самую значимую цифру сдвинутой на 4 бита. Следовательно, двоичное представление имеет нули в четырех младших значащих битах.
Затем мы добавили к нему наименее значимую цифру:
return (byte) ((firstDigit << 4) + secondDigit);
Теперь давайте внимательно рассмотрим метод two digit () . Мы используем метод Character.digit() для преобразования. Если значение символа, переданное этому методу, не является допустимой цифрой в указанном радиксе, возвращается значение -1.
Мы проверяем возвращаемое значение и создаем исключение, если было передано недопустимое значение.
Git Essentials
Ознакомьтесь с этим практическим руководством по изучению Git, содержащим лучшие практики и принятые в отрасли стандарты. Прекратите гуглить команды Git и на самом деле изучите это!
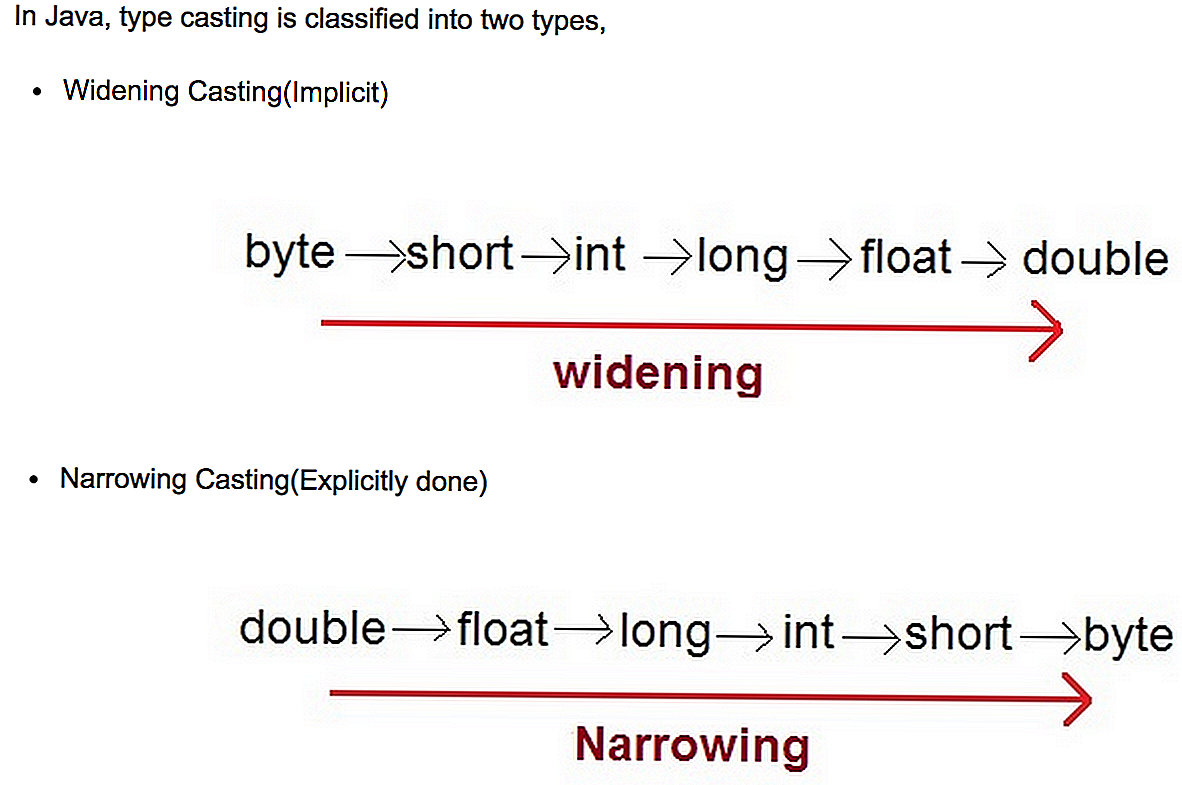
Начиная с Java 7 , мы познакомились с классом , в котором доступно несколько , таких как , , и среди прочих.
Каждая имеет и метод, который принимает (который , такую же, как ). С практической точки зрения – это означает, что мы можем вставить строку в методы .
Метод возвращает , который мы можем легко снова превратить в строку.
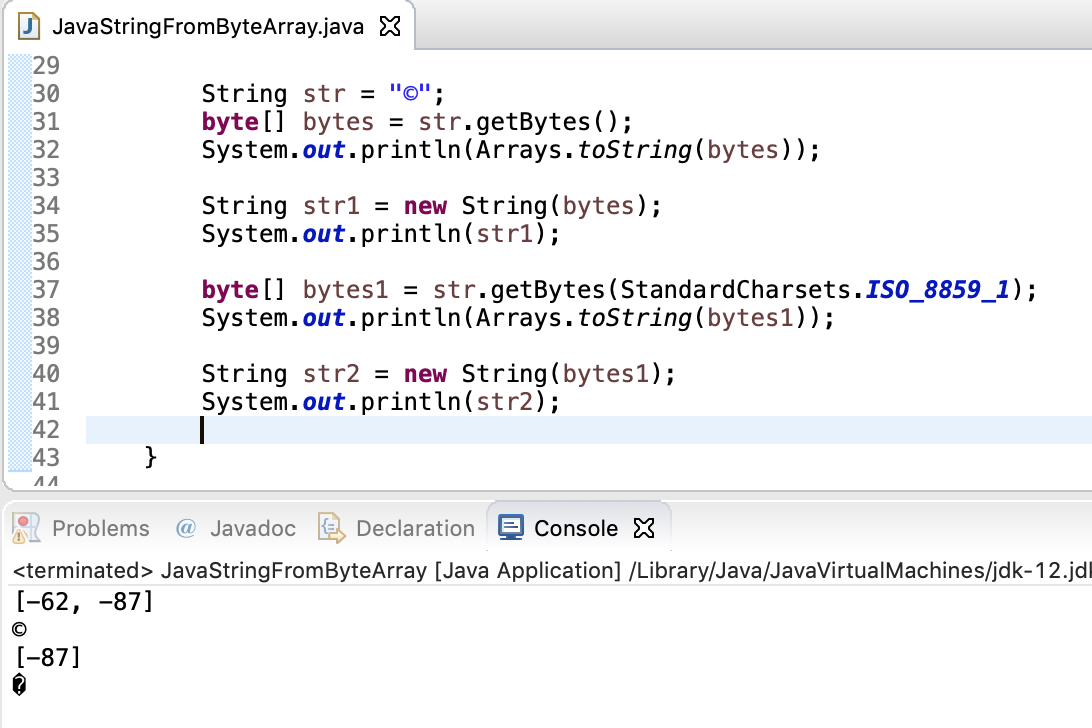
Ранее, когда мы использовали наш метод , мы сохраняли полученные байты в массиве байтов, но при использовании класса все немного по-другому. Сначала нам нужно использовать класс для хранения наших байтов. Затем нам нужно как кодировать , так и декодировать обратно наши недавно выделенные байты. Давайте посмотрим, как это работает в коде:
String japaneseString = "よろしくお願いします"; // Pleased to meet you. ByteBuffer byteBuffer = StandardCharsets.UTF_8.encode(japaneseString); String utf8String = new String(byteBuffer.array(), StandardCharsets.UTF_8); System.out.println(utf8String);
Выполнение этого кода приводит к:
よろしくお願いします
Закодируйте строку в UTF-8 с помощью Apache Commons
Пакет кодеков Apache Commons содержит простые кодеры и декодеры для различных форматов, таких как Base64 и Шестнадцатеричный . В дополнение к этим широко используемым кодерам и декодерам, пакет кодеков также поддерживает набор утилит фонетического кодирования .
Чтобы мы могли использовать кодек Apache Commons, нам нужно добавить его в наш проект в качестве внешней зависимости.
Используя Maven, давайте добавим зависимость в ваш файл:
commons-codeccommons-codec1.15
В качестве альтернативы, если вы используете Gradle:
compile 'commons-codec:commons-codec:1.15'
Теперь мы можем использовать служебные классы Apache Commons – и, как обычно, мы будем использовать класс .
Это позволяет нам преобразовывать строки в байты и из байтов, используя различные кодировки, требуемые спецификацией Java. Этот класс является нулевым и потокобезопасным, поэтому у нас есть дополнительный уровень защиты при работе со строками.
Для кодирования строки в UTF-8 с помощью класса Apache Common мы можем использовать метод , который работает так же, как метод с указанной :
String germanString = "Wie heißen Sie?"; // What's your name? byte[] bytes = StringUtils.getBytesUtf8(germanString); String utf8String = StringUtils.newStringUtf8(bytes); System.out.println(utf8String);
Это приводит к:
Wie heißen Sie?
Или , вы можете использовать обычный класс из зависимости:
org.apache.commonscommons-lang3
Если вы используете Gradle:
implementation group: 'org.apache.commons', name: 'commons-lang3', version: ${version}
И теперь мы можем использовать почти тот же подход, что и с обычными строками:
String germanString = "Wie heißen Sie?"; // What's your name? byte[] bytes = StringUtils.getBytes(germanString, StandardCharsets.UTF_8); String utf8String = StringUtils.toEncodedString(bytes, StandardCharsets.UTF_8); System.out.println(utf8String);
Благодаря этому подход является потокобезопасным и нулевым:
Wie heißen Sie?
Вывод
В этом уроке мы рассмотрели как кодировать строку Java в UTF-8 . Мы рассмотрели несколько подходов – ручное создание строки с использованием и управление ими, класс Java 7 , а также Apache Commons.
Использование BCEL
Инженерная библиотека байт-кода, известная в народе как Apache Commons BCEL , предоставляет удобный способ создания/управления файлами классов Java.
Как обычно, давайте добавим последнюю зависимость bcel Maven в ваш pom.xml :
org.apache.bcelbcel6.5.0
5.2. Разберите класс и просмотрите байт-код
Затем мы можем использовать класс Repository для создания объекта Java-класса :
try {
JavaClass objectClazz = Repository.lookupClass("java.lang.Object");
System.out.println(objectClazz.toString());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Здесь мы использовали метод toString для объекта object Clazz , чтобы увидеть байт-код в сжатом формате:
public class java.lang.Object
file name java.lang.Object
compiled from Object.java
compiler version 52.0
access flags 33
constant pool 78 entries
ACC_SUPER flag true
Attribute(s):
SourceFile: Object.java
14 methods:
public void ()
private static native void registerNatives()
public final native Class getClass() [Signature: ()Ljava/lang/Class<*>;]
public native int hashCode()
public boolean equals(Object arg1)
protected native Object clone()
throws Exceptions: java.lang.CloneNotSupportedException
public String toString()
public final native void notify()
// ...
Кроме того, класс Java предоставляет такие методы, как getConstantPool , GetFields и GetMethods для просмотра сведений о разобранном классе .
assertEquals(objectClazz.getFileName(), "java.lang.Object");
assertEquals(objectClazz.getMethods().length, 14);
assertTrue(objectClazz.toString().contains("public class java.lang.Object"));
Аналогично, методы set* доступны для манипулирования байт-кодом.
Списки символов
Списки символов – не что иное, как списки из кодовых обозначений. Списки символов можно создать с помощью литералов в одиночных кавычках:
Вы можете увидеть, что список символов хранит не последовательность байт, а кодовые обозначения символов, указанных в одинарных кавычках (помните, что по умолчанию будет выводить только коды, если хотя бы один из них не входит в диапазон ). Таким образом двойные кавычки используются для строк (внутри это бинарная последовательность), одиночные – для списков символов (внутри список).



На практике, списки символов чаще всего используются для взаимодействия с Эрлангом, в частности со старыми библиотеками, которые не принимают бинарные последовательности в качестве аргументов. Вы можете конвертировать список символов в строку и обратно, используя функции: и :
Обратите внимание, что эти функции полиморфичны. Они могут конвертировать в строки не только списки символов, но и числа, атомы и т. д
На это всё с бинарными последовательностями, строками и списками символов. Самое время поговорить о структурах данных, основанных на парах ключ-значение.
Языки и утилиты, ориентированные на символьные строки
Символьные строки являются настолько полезным типом данных, что было разработано несколько языков, чтобы упростить написание приложений для обработки строк. Примеры включают следующие языки:
- awk
- Значок
- Швабры
- Perl
- Rexx
- Рубин
- sed
- СНОБОЛ
- Tcl
- ТТМ
Многие утилиты Unix выполняют простые операции со строками и могут использоваться для простого программирования некоторых мощных алгоритмов обработки строк. Файлы и конечные потоки можно рассматривать как строки.
Некоторые API, такие как интерфейс управления мультимедиа , встроенный SQL или printf, используют строки для хранения команд, которые будут интерпретироваться.
Последние языки программирования сценариев , включая Perl, Python , Ruby и Tcl, используют регулярные выражения для облегчения текстовых операций. Perl особенно известен использованием регулярных выражений, и многие другие языки и приложения реализуют совместимые с Perl регулярные выражения .
Некоторые языки, такие как Perl и Ruby, поддерживают строковую интерполяцию , которая позволяет вычислять произвольные выражения и включать их в строковые литералы.
Классы ByteArrayInputStream и ByteArrayOutputStream
Последнее обновление: 26.04.2018
Для работы с массивами байтов — их чтения и записи используются классы ByteArrayInputStream и ByteArrayOutputStream.
Чтение массива байтов и класс ByteArrayInputStream
Класс ByteArrayInputStream представляет входной поток, использующий в качестве источника данных массив байтов. Он имеет следующие конструкторы:
ByteArrayInputStream(byte[] buf) ByteArrayInputStream(byte[] buf, int offset, int length)
В качестве параметров конструкторы используют массив байтов , из которого производится считывание, смещение относительно начала массива
и количество считываемых символов .
Считаем массив байтов и выведем его на экран:
import java.io.*;
public class Program {
public static void main(String[] args) {
byte[] array1 = new byte[]{1, 3, 5, 7};
ByteArrayInputStream byteStream1 = new ByteArrayInputStream(array1);
int b;
while((b=byteStream1.read())!=-1){
System.out.println(b);
}
String text = "Hello world!";
byte[] array2 = text.getBytes();
// считываем 5 символов
ByteArrayInputStream byteStream2 = new ByteArrayInputStream(array2, 0, 5);
int c;
while((c=byteStream2.read())!=-1){
System.out.println((char)c);
}
}
}
В отличие от других классов потоков для закрытия объекта не требуется вызывать метод .
Запись массива байт и класс ByteArrayOutputStream
Класс ByteArrayOutputStream представляет поток вывода, использующий массив байтов в качестве места вывода.
Чтобы создать объект данного класса, мы можем использовать один из его конструкторов:
ByteArrayOutputStream() ByteArrayOutputStream(int size)
Первая версия создает массив для хранения байтов длиной в 32 байта, а вторая версия создает массив длиной .
Рассмотрим применение класса:
import java.io.*;
public class Program {
public static void main(String[] args) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
String text = "Hello Wolrd!";
byte[] buffer = text.getBytes();
try{
baos.write(buffer);
}
catch(Exception ex){
System.out.println(ex.getMessage());
}
// превращаем массив байтов в строку
System.out.println(baos.toString());
// получаем массив байтов и выводим по символьно
byte[] array = baos.toByteArray();
for(byte b: array){
System.out.print((char)b);
}
System.out.println();
}
}
Как и в других потоках вывода в классе определен метод , который записывает в поток некоторые данные.
В данном случае мы записываем в поток массив байтов. Этот массив байтов записывается в объекте ByteArrayOutputStream в защищенное поле ,
которое представляет также массив байтов ().
Так как метод может сгенерировать исключение, то вызов этого метода помещается в блок try..catch.
Используя методы и , можно получить массив байтов buf в виде текста или непосредственно в виде массива байт.
С помощью метода мы можем вывести массив байт в другой поток. Данный метод в качестве параметра принимает объект ,
в который производится запись массива байт:
ByteArrayOutputStream baos = new ByteArrayOutputStream();
String text = "Hello Wolrd!";
byte[] buffer = text.getBytes();
try{
baos.write(buffer);
}
catch(Exception ex){
System.out.println(ex.getMessage());
}
try(FileOutputStream fos = new FileOutputStream("hello.txt")){
baos.writeTo(fos);
}
catch(IOException e){
System.out.println(e.getMessage());
}
После выполнения этой программы в папке с программой появится файл hello.txt, который будет содержать строку «Hello Wolrd!».
И в заключении также надо сказать, что как и для объектов ByteArrayInputStream, для ByteArrayOutputStream не надо явным образом закрывать поток с помощью метода
.
НазадВперед
Алгоритмы обработки строк
Существует множество алгоритмов обработки строк, каждый из которых имеет различные компромиссы. Конкурирующие алгоритмы можно анализировать с точки зрения времени выполнения, требований к хранилищу и т. Д.
Некоторые категории алгоритмов включают:
- Алгоритмы поиска по строке для поиска заданной подстроки или шаблона
- Алгоритмы обработки строк
- Алгоритмы сортировки
- Алгоритмы регулярных выражений
- Разбор строки
- Последовательный майнинг
В продвинутых строковых алгоритмах часто используются сложные механизмы и структуры данных, в том числе деревья суффиксов и конечные автоматы .
Название стрингология было придумано в 1984 году компьютерным ученым Цви Галилом для проблемы алгоритмов и структур данных, используемых для обработки строк.
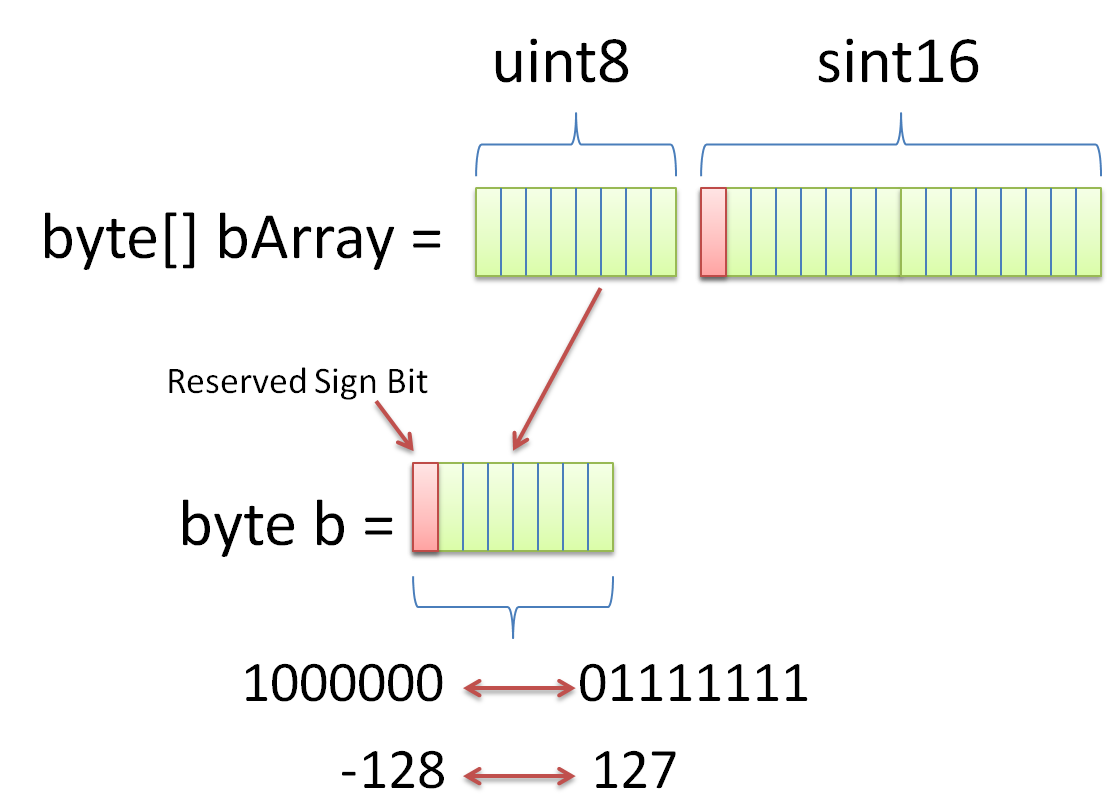
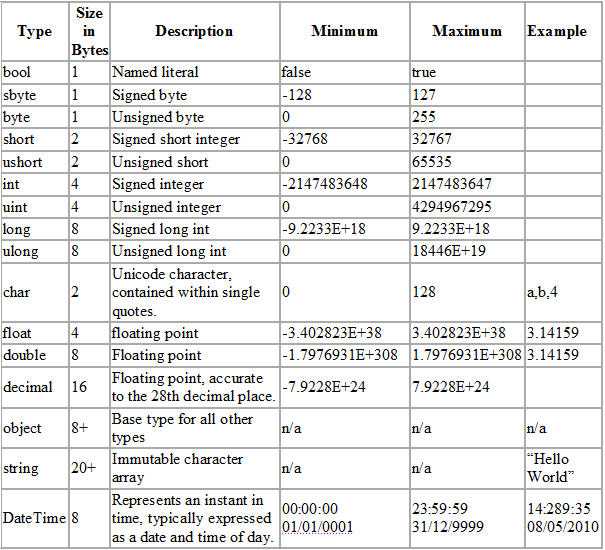
Массив битов
Для хранения и манипулирования массивами битов можно утверждать, что мы должны использовать boolean[] в качестве структуры данных. На первый взгляд это может показаться разумным предложением.
Однако каждый член boolean в boolean[] обычно потребляет один байт вместо одного бита . Поэтому, когда у нас жесткие требования к памяти или мы просто стремимся к сокращению объема памяти, boolean[] далеки от идеала.
Чтобы сделать вопрос более конкретным, давайте посмотрим, сколько места занимает boolean[] с 1024 элементами:
boolean[] bits = new boolean; System.out.println(ClassLayout.parseInstance(bits).toPrintable());
В идеале мы ожидаем 1024-битный объем памяти от этого массива. Однако Макет объекта Java (JOL) показывает совершенно иную реальность:
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 7b 12 07 00 (01111011 00010010 00000111 00000000) (463483)
12 4 (object header) 00 04 00 00 (00000000 00000100 00000000 00000000) (1024)
16 1024 boolean [Z. N/A
Instance size: 1040 bytes
Если мы проигнорируем накладные расходы заголовка объекта, элементы массива потребляют 1024 байта вместо ожидаемых 1024 бит. Это на 700% больше памяти, чем мы ожидали.
Проблемы адресуемости и разрыв слов являются основными причинами, по которым boolean s-это больше, чем просто один бит.
Для решения этой проблемы мы можем использовать комбинацию числовых типов данных (например, long ) и побитовых операций. Вот тут-то и появляется набор битов
Функции и процедуры
Функция Copy(S, Poz, N) выделяет из строки S подстроку длиной N символов, начиная с позиции Роz. N и Роz — целочисленные выражения.
Пример
![]()
Функция Concat (S1, S2, . . ., SN) выполняет сцепление (конкатенацию) строк S1,…, SN в одну строку.
Пример
![]()
Функция Length (S) определяет текущую длину строки S. Результат — значение целочисленного типа.



Пример
![]()
Функция Pos(S1, S2) обнаруживает первое появление в строке S2 подстроки S1. Результат — целое число, равное номеру позиции, где находится первый символ подстроки S1. Если в S2 не обнаружена подстрока S1, то результат равен 0.
Пример
![]()
Процедура Delete (S, Poz, N) удаляет N символов из строки S, начиная с позиции Poz.
Пример
![]()
В результате выполнения процедуры уменьшается текущая длина строки в переменной S.
Процедура Insert (S1,S2, Poz) выполняет вставку строки S1 в строку S2, начиная с позиции Poz.
Пример
![]()
RandomAccessFile – Чтение файлов в режиме только для чтения
Класс RandomAccessFile позволяет нам читать файл в разных режимах. Это хороший вариант, если вы хотите убедиться, что в файле не выполняется случайная операция записи.
package com.journaldev.io.readfile;
import java.io.IOException;
import java.io.RandomAccessFile;
public class ReadFileUsingRandomAccessFile {
public static void main(String[] args) {
try {
RandomAccessFile file = new RandomAccessFile("/Users/pankaj/Downloads/myfile.txt", "r");
String str;
while ((str = file.readLine()) != null) {
System.out.println(str);
}
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Это все для чтения файла на Java с использованием различных классов из Java IO API.
Рекомендации:
FileInputStream – Считывание двоичных файлов в байты
Мы всегда должны использовать поток для чтения файлов, не основанных на символах, таких как изображения, видео и т.д.
package com.journaldev.io.readfile;
import java.io.FileInputStream;
import java.io.IOException;
public class ReadFileUsingFileInputStream {
public static void main(String[] args) {
FileInputStream fis;
byte[] buffer = new byte;
try {
fis = new FileInputStream("/Users/pankaj/Downloads/myfile.txt");
while (fis.read(buffer) != -1) {
System.out.print(new String(buffer));
buffer = new byte;
}
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Операция чтения FileInputStream используется с массивом байтов, в то время как операция чтения BufferedReader использует массив символов.
Преобразуйте строку в двоично–разрядную маскировку.
2.1 В этом примере Java будет использоваться метод битовой маскировки для генерации двоичного формата из 8-битного байта.
package com.mkyong.crypto.bytes;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class StringToBinaryExample2 {
public static void main(String[] args) {
String input = "a";
String result = convertByteArraysToBinary(input.getBytes(StandardCharsets.UTF_8));
System.out.println(prettyBinary(result, 8, " "));
}
public static String convertByteArraysToBinary(byte[] input) {
StringBuilder result = new StringBuilder();
for (byte b : input) {
int val = b;
for (int i = 0; i < 8; i++) {
result.append((val & 128) == 0 ? 0 : 1); // 128 = 1000 0000
val <<= 1;
}
}
return result.toString();
}
public static String prettyBinary(String binary, int blockSize, String separator) {
//... same with 1.1
}
}
Выход
01100001
Самое сложное – это этот код. Идея похожа на эту Java – Преобразование целого числа в двоичное с помощью битовой маскировки . В Java/|байт int 128 1000 0000
for (byte b : input) {
int val = b; // byte -> int
for (int i = 0; i < 8; i++) {
result.append((val & 128) == 0 ? 0 : 1); // 128 = 1000 0000
val <<= 1; // val = val << 1
}
}
Это является , только является , другие комбинации – это все .
1 & 1 = 1 1 & 0 = 0 0 & 1 = 0 0 & 0 = 0
Это на самом деле , это оператор сдвига влево на бит, он перемещает биты влево на 1 бит.
Просмотрите следующий проект: давайте предположим, что – это , или представляет символ .
00000000 | 00000000 | 00000000 | 01100001 # val = a in binary 00000000 | 00000000 | 00000000 | 10000000 # 128 & # bitwise AND 00000000 | 00000000 | 00000000 | 00000000 # (val & 128) == 0 ? 0 : 1, result = 0 00000000 | 00000000 | 00000000 | 11000010 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & # bitwise AND 00000000 | 00000000 | 00000000 | 10000000 # (val & 128) == 0 ? 0 : 1, result = 1 00000000 | 00000000 | 00000001 | 10000100 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 10000000 # result = 1 00000000 | 00000000 | 00000011 | 00001000 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 00000000 # result = 0 00000000 | 00000000 | 00000110 | 00010000 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 00000000 # result = 0 00000000 | 00000000 | 00001100 | 00100000 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 00000000 # result = 0 00000000 | 00000000 | 00011000 | 01000000 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 00000000 # result = 0 00000000 | 00000000 | 00110000 | 10000000 # val << 1 00000000 | 00000000 | 00000000 | 10000000 # 128 & 00000000 | 00000000 | 00000000 | 10000000 # result = 1 # collect all bits # 01100001
Для строки двоичная строка – это .
Использование Javassist
Кроме того, мы можем использовать библиотеку Javassist ( Помощник по программированию Java) , которая предоставляет высокоуровневые API для просмотра/управления байт-кодом Java.
Во-первых, мы добавим последнюю зависимость javassist Maven в ваш pom.xml :
org.javassistjavassist3.27.0-GA
6.2. Создание файла класса
Затем мы можем использовать Пул классов и Файл класса классы для создания класса Java :
try {
ClassPool cp = ClassPool.getDefault();
ClassFile cf = cp.get("java.lang.Object").getClassFile();
cf.write(new DataOutputStream(new FileOutputStream("Object.class")));
} catch (NotFoundException e) {
e.printStackTrace();
}
Здесь мы использовали метод write , который позволяет нам записать файл класса с помощью объекта DataOutputStream :
// Compiled from Object.java (version 1.8 : 52.0, super bit)
public class java.lang.Object {
// Method descriptor #19 ()V
// Stack: 0, Locals: 1
public Object();
0 return
Line numbers:
// Method descriptor #19 ()V
private static native void registerNatives();
// Method descriptor #24 ()Ljava/lang/Class;
// Signature: ()Ljava/lang/Class<*>;
public final native java.lang.Class getClass();
// Method descriptor #28 ()I
public native int hashCode();
// ...
Кроме того, объект файла Class class предоставляет доступ к пулу констант, полям и методам:
assertEquals(cf.getName(), "java.lang.Object"); assertEquals(cf.getMethods().size(), 14);
UTF-8 и Юникод
Строка в представляет собой бинарную последовательность. Для понимания, что мы подразумеваем, следует понять разницу между байтами и кодовыми обозначениями.
Стандарт Юникод связывает кодовые обозначения со многими известными символами. Например, латинская буква имеет кодовое обозначение , тогда как буква имеет код . Чтобы записать строку на диск, нужно конвертировать эти коды в байты. Если мы примем за правило, что один байт соответствует одному кодовому обозначению, мы не сможем записать строку , потому что она использует код для , а один байт может представлять число от до . Но, раз мы можем прочитать на экране, есть какой-то способ записать такую строку. Это место, где начинает работать кодировка.
Для представления кодовых обозначений в виде байт, нужно как-то их закодировать. Эликсир выбрал кодировку своей главной и стандартной кодировкой. Когда мы говорим, что закодирован в двоичном виде, мы имеем в виду, что строка – это набор байт, представляющих некоторые кодовые обозначения, в соответствии с правилами кодировки .
Т. к. у нас есть символы вроде , соответствующий коду , нам нужно больше одного байта для их представления. Поэтому мы видим разницу при вычислении в сравнении с результатом :
Так, считает количество байт, необходимых для представления строки, а считает символы.
нужен один байт для представления символов , , и , но два байта для представления . В Эликсире вы можете узнать код символа с помощью :
Вы можете также использовать функции из модуля для разделения строки на индивидуальные символы, каждый из которых будет строкой длины 1:
Вы увидите, что Эликсир имеет отличную поддержку работы со строками. Он также поддерживает многие операции Юникода. Фактически, Эликсир успешно проходит все тесты, показанные в статье «The string type is broken».
Однако, строки – это только часть истории. Раз строки являются бинарными, и мы использовали функцию , Эликсир должен иметь более мощный тип, лежащий в основе строк. И он есть! Поговорим о бинарных данных.
Использование класса BigInteger
Мы можем создать объект типа BigInteger , передав сигнум и массив байтов .
Теперь мы можем сгенерировать шестнадцатеричный String с помощью статического формата метода, определенного в классе String :
public String encodeUsingBigIntegerStringFormat(byte[] bytes) {
BigInteger bigInteger = new BigInteger(1, bytes);
return String.format(
"%0" + (bytes.length << 1) + "x", bigInteger);
}
Предоставленный формат будет генерировать шестнадцатеричную строку с нулевым заполнением в нижнем регистре . Мы также можем сгенерировать строку в верхнем регистре, заменив “x” на “X”.
В качестве альтернативы мы могли бы использовать метод toString() из BigInteger . Тонкое отличие использования метода toString() заключается в том, что выходные данные не заполняются начальными нулями :
public String encodeUsingBigIntegerToString(byte[] bytes) {
BigInteger bigInteger = new BigInteger(1, bytes);
return bigInteger.toString(16);
}
Теперь давайте посмотрим на шестнадцатеричное преобразование String в byte Array:
public byte[] decodeUsingBigInteger(String hexString) {
byte[] byteArray = new BigInteger(hexString, 16)
.toByteArray();
if (byteArray == 0) {
byte[] output = new byte;
System.arraycopy(
byteArray, 1, output,
0, output.length);
return output;
}
return byteArray;
}
Метод toByteArray() создает дополнительный знаковый бит . Мы написали специальный код для обработки этого дополнительного бита.
Следовательно, мы должны знать об этих деталях, прежде чем использовать класс BigInteger для преобразования.
sprintf
int sprintf( char* dest, const char* fmt, ... );
Записывает в буфер по адресу dest строку,
сформированную на основании форматирующей строки fmt
и произвольного количества необязательных аргументов. Строка
fmt, помимо обычных символов, может содержать так
называемые форматирующие последовательности. Каждая такая
последовательность соответствует одному необязательному аргументу; она начинается с
символа «%» и имеет в общем случае форму

![Как преобразовать массив байтов[] в строку в java - javascopes.com](https://fuzeservers.ru/wp-content/uploads/7/b/1/7b11c3140b5af3b5f4d16541befa8bdc.png)

%fw.pst
Здесь t — это один символ, определяющий тип аргумента, строковое
представление которого должно быть подставлено на место данной форматирующей
последовательности, и вид выполняемого преобразования. Это обязательная составляющая
форматирующей последовательности; допустимо использование следующих символов:
| t | ожидаемыйтип аргумента | вид преобразования |
|---|---|---|
| c | char | — |
| di | int или long | в десятичной системе |
| u | unsigned int | в десятичной системе |
| o | unsigned int | в восьмеричной системе |
| x | unsigned int | в шестнадцатеричной системе, буквы a…f строчные |
| X | unsigned int | в шестнадцатеричной системе, буквы A…F заглавные |
| e | double | в экспоненциальной форме, буква e строчная |
| E | double | в экспоненциальной форме, буква E заглавная |
| f | double | в десятичной форме |
| g | double | в наиболее компактной форме, буква e строчная |
| G | double | в наиболее компактной форме, буква E заглавная |
| p | void* | в шестнадцатеричной системе, буквы A…F заглавные |
| s | char* | параметр интерпретируется как строка C/C++ |
Необязательная часть f форматирующей последовательности определяет выравнивание
преобразованного аргумента, необходимость отображения его знака, etc, и может состоять
из одного или нескольких символов, перечисленных ниже:
| символ | значение | |
|---|---|---|
| — | преобразованный аргумент выравнивается по левому краю (по умолчанию — по правому) |
|
| + | знак отображается при любом значении аргумента (по умолчанию — только при отрицательном) |
|
| «лишние» позиции заполняются символом «0» (по умолчанию — пробелом) |
||
| пробел | при положительном значении аргумента на месте знака выводится пробел |
|
| # | o | к преобразованному аргументу добавляется префикс «0» |
| x | к преобразованному аргументу добавляется префикс «0x» | |
| X | к преобразованному аргументу добавляется префикс «0X» | |
| eEf | преобразованный аргумент будет содержать десятичную точку даже при отсутствии дробной части |
|
| gG | преобразованный аргумент будет содержать десятичную точку даже при отсутствии дробной части; при необходимости дробная часть дополняется незначащими нулями |
Необязательная составляющая w задает требуемую минимальную ширину преобразованного
аргумента; заметим, что аргумент будет выведен полностью, даже если заданное значение
окажется недостаточным.
Необязательная составляющая p определяет точность представления аргумента; ее
интерпретация зависит от типа этого аргумента:
| тип | p |
|---|---|
| eEf | требуемое количество знаков после десятичной точки; при необходимости выполняется округление аргумента или дополнение его дробной части незначащими нулями |
| gG | максимальное количество значащих цифр |
| s | максимальное количество символов аргумента, которое следует использовать |
Необязательная составляющая s «уточняет» размер целочисленного
аргумента и может быть одним из следующих символов:
| символ | размер аргумента |
|---|---|
| l | long |
| h | short |
Если в формируемую строку необходимо вставить символ «%», то его следует
написать два раза подряд. Ниже приведен пример использования функции
sprintf:
Массив локальных переменных
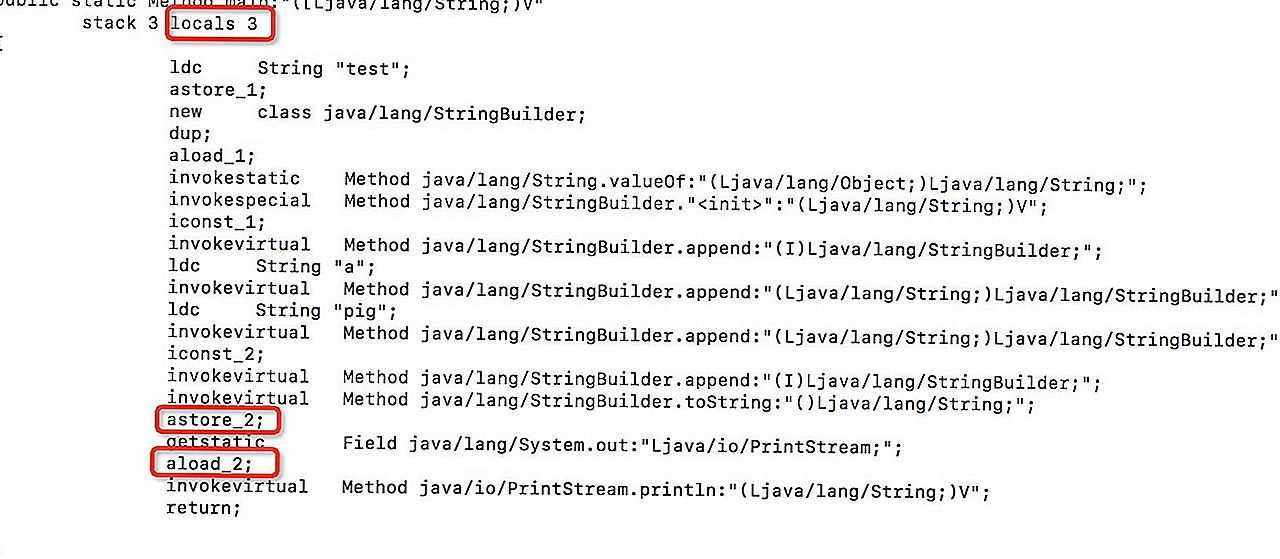
Массив локальных переменных, как следует из названия, нужен для хранения локальных переменных в методе. Также он хранит аргументы, которые принимает метод.
В массиве локальных переменных с индексацией от нуля первые индексы используются для хранения аргументов метода. После того, как они будут сохранены, в массив сохранятся другие локальные переменные. Если метод — не статический, а создаёт экземпляры, нулевой индекс будет зарезервирован для хранения ссылки , которая указывает на экземпляр объекта для вызова метода.
Определим два метода: один статический и один метод экземпляра, но схожие во всем остальном.
public String sayHello(int num, String name){ String hello = "Hello, " + name; return hello;}public static String sayHello(int num, String name){ String hello = "Hello, " + name; return hello;}
Локальные массивы переменных для этих методов будут выглядеть следующим образом:
Локальные массивы переменных во фреймах метода JVM
Apache Commons Lang
В этом решении мы будем использовать библиотеку Apache Commons Lang3 для выполнения наших преобразований. Apache Commons Lang3 предоставляет несколько вспомогательных функций для управления основными классами Java.
Сначала мы разделим нашу строку на массив строк с помощью StringUtils.splitPreserveAllTokens . Затем мы преобразуем наш новый строковый массив в список, используя метод Arrays.asList :
List convertedCountriesList = Arrays.asList(StringUtils.splitPreserveAllTokens(countries, ","));
Теперь давайте преобразуем нашу строку чисел в список целых чисел.
Мы снова будем использовать метод StringUtils.split для создания массива строк из нашей строки. Затем мы преобразуем каждую строку в нашем новом массиве в целое число с помощью Integer.parseInt и добавим преобразованное целое число в наш список:
String[] convertedRankArray = StringUtils.split(ranks, ",");
List convertedRankList = new ArrayList();
for (String number : convertedRankArray) {
convertedRankList.add(Integer.parseInt(number.trim()));
}
В этом примере мы использовали метод splitPreserveAllTokens для разделения нашей строки стран , в то время как мы использовали метод split для разделения нашей строки рангов .
Несмотря на то, что обе эти функции разбивают строку на массив, splitPreserveAllTokens сохраняет все токены, включая пустые строки, созданные соседними разделителями, в то время как метод split игнорирует пустые строки .
Итак, если у нас есть пустые строки, которые мы хотим включить в наш список, то мы должны использовать splitPreserveAllTokens вместо split .
Заключение
На этом первая часть, посвященная С-строкам заканчивается. В качестве домашнего задания рекомендую реализовать упоминавшиеся здесь стандартные функции, за исключением sprintf и sscanf самостоятельно. Это нетрудно, и если вы справитесь, значит, вы отлично овладели материалом. Тем не менее, всегда используйте стандартные функции, а не ваши собственные. Это общее правило – реализовать стандартные функции имеет смысл только в качестве учебного задания.
Для использования строковых функций вам потребуется подключить к программе соответствующие стандартные заголовки. Это string.h для всех функций, кроме sprintf и sscanf, определенных в stdio.h и функций преобразования, определенных в stdlib.h.
В С++ вместо вышеупомянутых заголовочных файлов следует подключать cstring, cstdio и cstdlib соответственно.
Во второй части статьи я рассмотрю возможности C++, позволяющее значительно упростить работу со строками и сделать ее более удобной.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.