
Запись файлов данных JSON с помощью Pandas
Чтобы преобразовать фрейм данных Pandas в файл JSON, используем функцию to_json() и передадим ей в качестве параметра путь к файлу, который будет создан.
Создадим файл JSON из набора данных tips, который включен в библиотеку Seaborn. Но сначала установим ее:
$ pip install seaborn
Затем импортируем ее и загрузим подсказки в набор данных:
import seaborn as sns
dataset = sns.load_dataset('tips')
dataset.head()
Ниже показано как выглядит набор данных:
![]()
Функция Seaborn load_dataset() возвращает DataFrame, поэтому загрузка набора данных позволяет вызвать функцию to_json() для ее преобразования.
После получения доступа к набору данных, сохраним его содержимое в файле JSON. Мы создали для этого каталог datasets:
dataset.to_json('E:/datasets/tips.json')
Перейдя в каталог E:/datasets, вы должны увидеть там файл tips.json, JSON-данные которого соответствует записям во фрейме данных Pandas tips:
{
"total_bill":{
"0":16.99,
"1":10.34,
"2":21.01,
"3":23.68,
"4":24.59,
"5":25.29,
...
}
"tip":{
"0":1.01,
"1":1.66,
"2":3.5,
"3":3.31,
"4":3.61,
"5":4.71,
...
}
"sex":{
"0":"Female",
"1":"Male",
"2":"Male",
"3":"Male",
"4":"Female",
"5":"Male",
...
}
"smoker":{
"0":"No",
"1":"No",
"2":"No",
"3":"No",
"4":"No",
"5":"No",
...
}
...
Использование методов Writelines и Readlines
Как упоминалось в начале этой статьи, Python также содержит два метода Writelines() и readlines() для записи и чтения нескольких строк за один шаг соответственно. Чтобы записать весь список в файл на диске, код Python выглядит следующим образом:
# define list of places
places_list =
with open('listfile.txt', 'w') as filehandle:
filehandle.writelines("%s\n" % place for place in places_list)
Чтобы прочитать весь список из файла на диске, код Python выглядит следующим образом:
# define empty list
places = []
# open file and read the content in a list
with open('listfile.txt', 'r') as filehandle:
filecontents = filehandle.readlines()
for line in filecontents:
# remove linebreak which is the last character of the string
current_place = line
# add item to the list
places.append(current_place)
Приведенный выше пример следует более традиционному подходу, заимствованному из других языков программирования. Чтобы написать его более питоническим способом, взгляните на приведенный ниже код:
# define empty list
places = []
# open file and read the content in a list
with open('listfile.txt', 'r') as filehandle:
places =
После открытия файла listfile.txt в строке 5, восстановление списка происходит полностью в строке 6. Во-первых, содержимое файла считывается с помощью readlines(). Во-вторых, в цикле for из каждой строки удаляется символ переноса строки с помощью метода rstrip(). В-третьих, строка добавляется в список мест, как новый элемент списка. По сравнению с приведенным выше листингом код намного компактнее, но может быть более трудным для чтения для начинающих программистов Python.
Строки
Строка – это последовательность символов. Чаще всего строки – это просто некоторые наборы слов. Слова могут быть как на английском языке, так и почти на любом языке мира.
Операции со строками
string извлекает символ в позиции i
string извлекает последний символ
string извлекает символы в диапазоне от i до j
Методы работы сос строками
string.upper() преобразует строку в верхний регистр
String.lower() преобразует в строку в нижний регистр
string.count(x) подсчитывает, сколько раз появляется x
string.find(x) позиция первой строки вхождения x
string.replace(x, y) заменяет x на y
string.strip(x) удаляет как начальные, так и конечные символы x
string.join (List) объединяет список строк
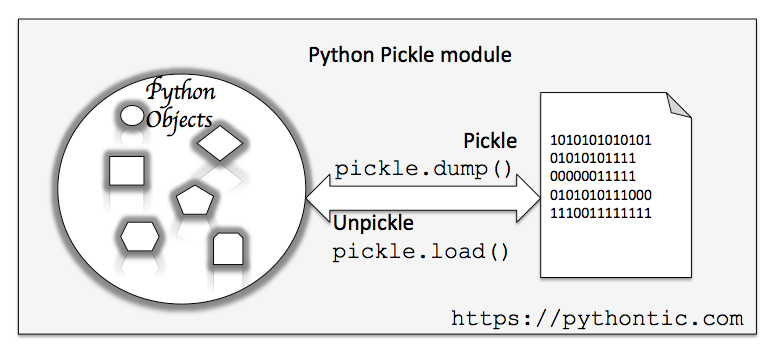
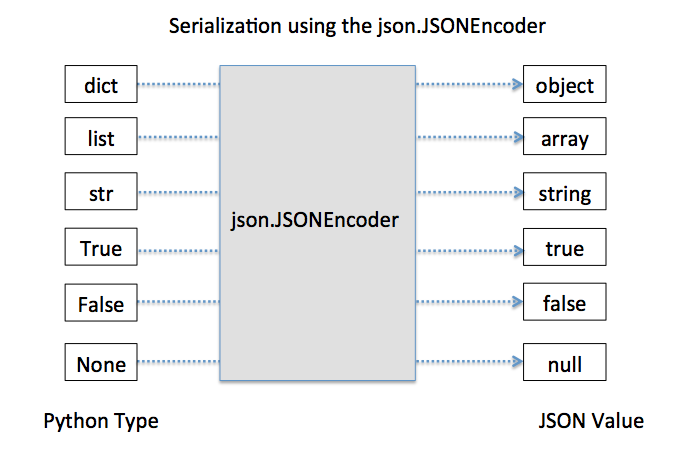
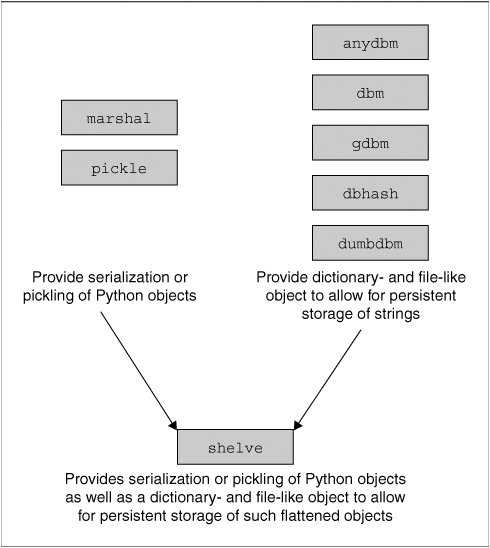
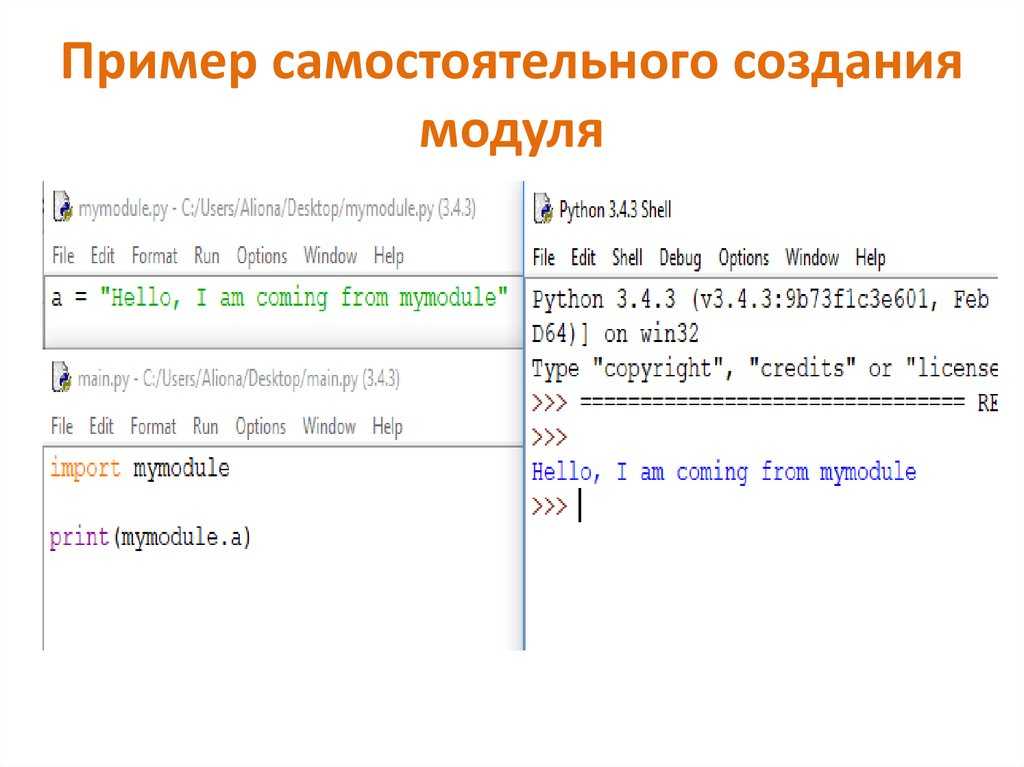
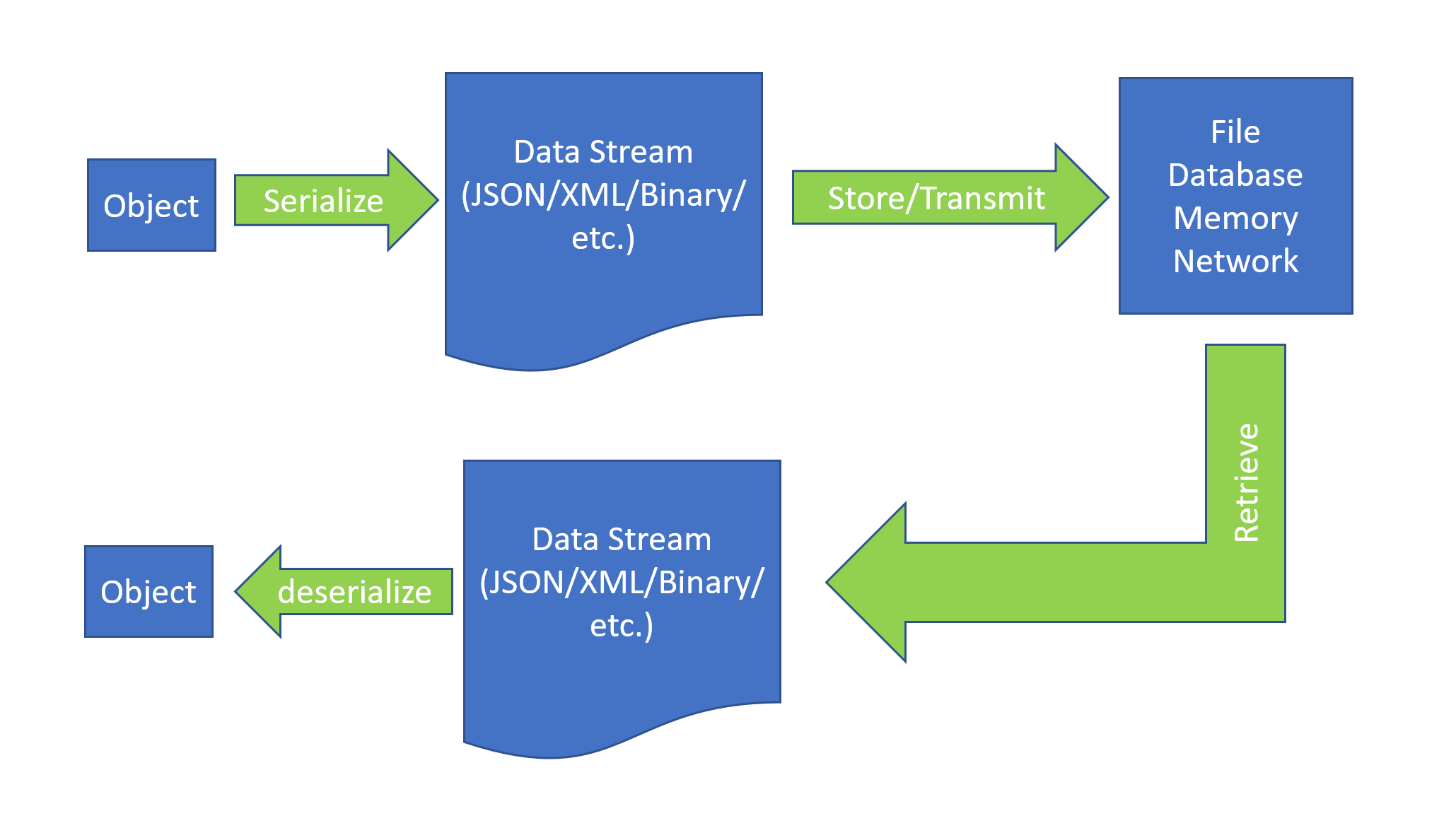
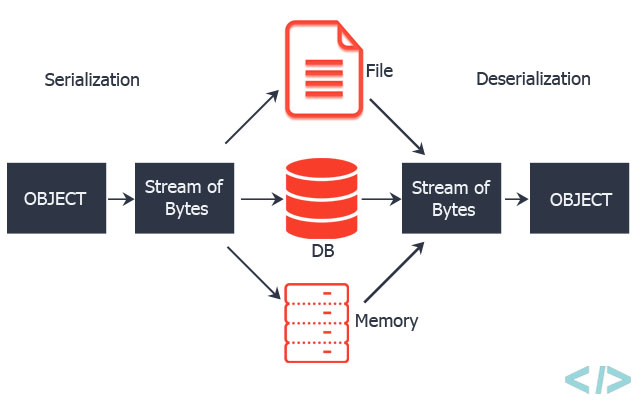
Что такое сериализация в Python?
Сериализация в Python – это процесс преобразования объектов или структур данных в байтовые потоки или строки. Поток байтов – это один байт состоит из 8 бит нулей и единиц. Эти байтовые потоки затем можно легко сохранить или передать. Это позволяет разработчикам сохранять, например, данные конфигурации или прогресс пользователя, а затем сохранять их (на диске или в базе данных) или отправлять в другое место.
Объекты в Python также можно сериализовать с помощью модуля под названием Pickle.
Одним из основных отличий маринования объектов в Python от маринования овощей является неизбежное и необратимое изменение вкуса и текстуры маринованной пищи. Между тем, маринованные объекты можно легко вернуть в их первоначальную форму. Кстати, этот процесс широко известен, как десериализация.
Pickling (или сериализацию в целом) не следует путать со сжатием. Целью Pickling является перевод данных в формат, который может быть перенесен из ОЗУ на диск. С другой стороны, сжатие – это процесс кодирования данных с использованием меньшего количества бит (для экономии места на диске).
Сериализация особенно полезна в любом программном обеспечении, где важно иметь возможность сохранить некоторый прогресс на диске, выйти из программы, а затем загрузить прогресс обратно после повторного открытия программы. Видеоигры могут быть наиболее интуитивным примером полезности сериализации, но есть много других программ, в которых сохранение и загрузка данных или прогресса пользователя имеет решающее значение.
Область видимости переменной
Как и в других языках программирования, в JavaScript существуют локальные и глобальные переменные. Ключевую роль здесь играет понятие области видимости переменной. Область видимости (scope) переменной — это та часть программы, для которой эта переменная определена.
В JavaScript существует два типа области видимости:
- Глобальные переменные имеют глобальную область видимости – они могут использоваться в любом месте программы, а также в вызываемых программах из других файлов.
- Локальные переменные имеют локальную область видимости — это переменные, определенные только в коде функции с помощью ключевого слова либо только в рамках блока {…}, в котором объявлена переменная с помощью ключевого слова .
Внутри тела функции локальная переменная имеет преимущество перед глобальной переменной с тем же именем:
Выполнить код »
Скрыть результаты
Объявляя переменные с глобальной областью видимости, инструкцию можно опустить, но при объявлении локальных переменных всегда следует использовать инструкцию .
В строгом режиме «use strict» так делать уже не допускается:
Примечание: Подробнее об области видимости переменной мы поговорим, когда будем рассматривать функции.
В ES-2015 предусмотрен новый способ объявления переменных: через .
Областью видимости переменных, объявленных ключевым словом , является блок, в котором они объявлены. В этом работа оператора схожа с работой оператора . Основным отличием является то, что переменная, объявленная через , видна везде в функции. Переменная, объявленная через , видна только в рамках блока {…}, в котором объявлена:
Выполнить код »
Скрыть результаты
В коде лучше использовать локальные переменные, а не глобальные потому, что ограничение области видимости снижает вероятность того, что значение такой переменной будет случайно заменено значением другой переменной с тем же именем.
Открытие файла с помощью функции open()
Первый шаг к работе с файлами в Python – научиться открывать файл. Вы можете открывать файлы с помощью метода open().
Функция open() в Python принимает два аргумента. Первый – это имя файла с полным путем, а второй – режим открытия файла.
Ниже перечислены некоторые из распространенных режимов чтения файлов:
- ‘r’ – этот режим указывает, что файл будет открыт только для чтения;
- ‘w’ – этот режим указывает, что файл будет открыт только для записи. Если файл, содержащий это имя, не существует, он создаст новый;
- ‘a’ – этот режим указывает, что вывод этой программы будет добавлен к предыдущему выводу этого файла;
- ‘r +’ – этот режим указывает, что файл будет открыт как для чтения, так и для записи.
Кроме того, для операционной системы Windows вы можете добавить «b» для доступа к файлу в двоичном формате. Это связано с тем, что Windows различает двоичный текстовый файл и обычный текстовый файл.
Предположим, мы помещаем текстовый файл с именем file.txt в тот же каталог, где находится наш код. Теперь мы хотим открыть этот файл.
Однако функция open (filename, mode) возвращает файловый объект. С этим файловым объектом вы можете продолжить свою дальнейшую работу.
#directory: /home/imtiaz/code.py
text_file = open('file.txt','r')
#Another method using full location
text_file2 = open('/home/imtiaz/file.txt','r')
print('First Method')
print(text_file)
print('Second Method')
print(text_file2)
Результатом следующего кода будет:
================== RESTART: /home/imtiaz/code.py ================== First Method Second Method >>>
Возврат нескольких значений из одной функции
В Python существует возможность возвращать из функции несколько значений.
Вот простой пример:
def f():
a = 5
b = 6
c = 7
return a, b, c
var1, var2, var3 = f()
print("var1={0} var2={1} var3={2}".format(var1, var2, var3))
Результат:
var1=5 var2=6 var3=7
В анализе данных и других научных приложениях это встречается сплошь и рядом, потому что многие функции вычисляют несколько результатов.
На самом деле, функция возвращает только один объект, кортеж, который затем распаковывается в результирующие переменные.
Этот пример можно было бы записать и так:
def f():
a = 5
b = 6
c = 7
return a, b, c
return_value = f()
print(return_value)
Результат:
(5, 6, 7)
В таком случае return_value было бы кортежем, содержащим все три возвращенные переменные.
Иногда разумнее возвращать несколько значений не в виде кортежа, а в виде словаря:
def f():
a = 5
b = 6
c = 7
return {'a' : a, 'b' : b, 'c' : c}
return_value = f()
print(return_value)
Результат:
{'a': 5, 'b': 6, 'c': 7}
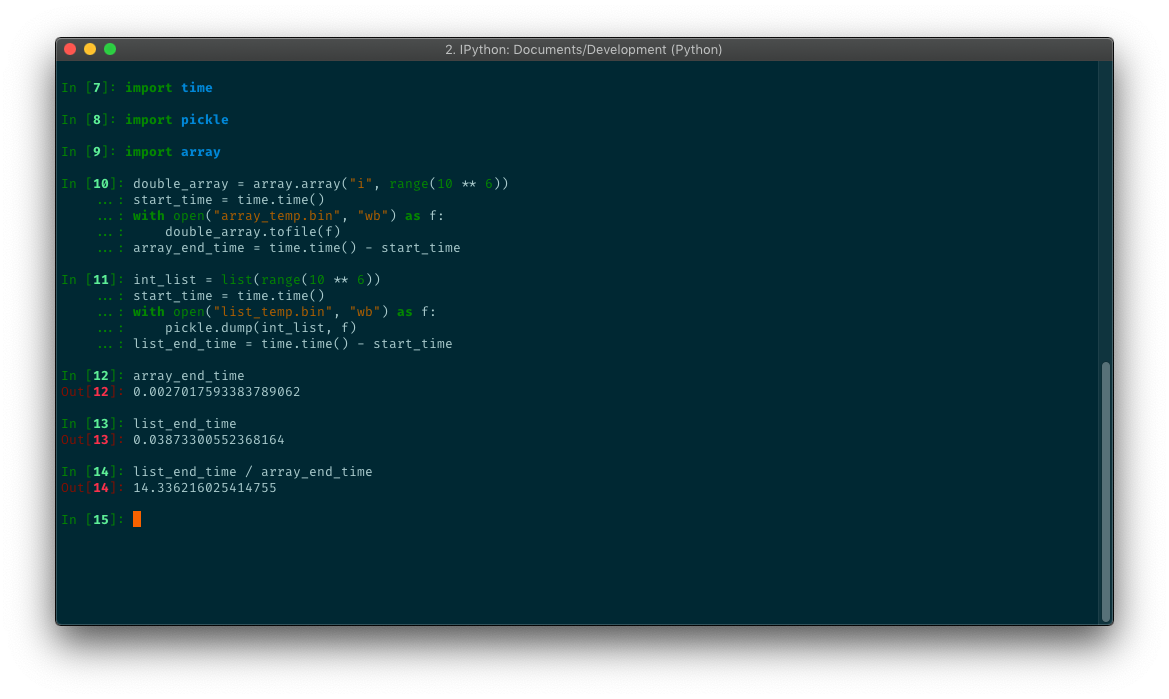
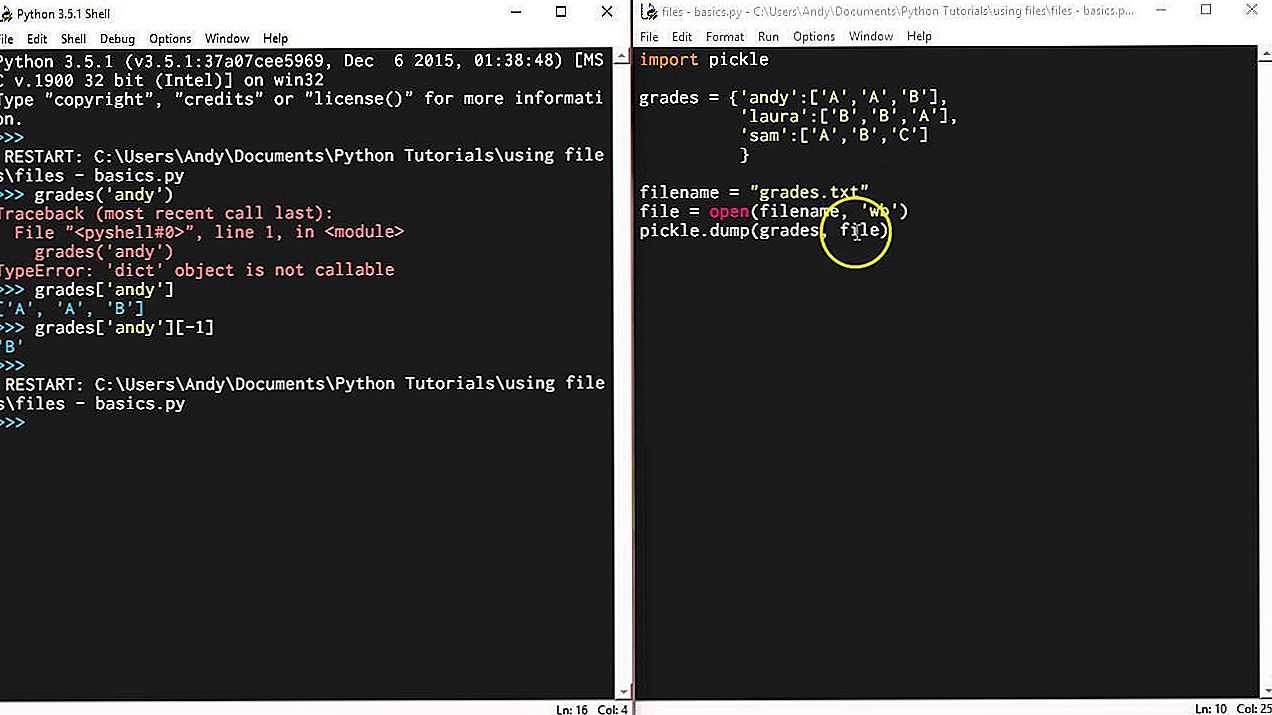
Работа с потоками
В дополнение к и , предоставляет удобные функции для работы с файловыми потоками. Можно записать несколько объектов в поток, а затем прочитать их из потока, не зная заранее, сколько объектов записано или насколько они велики.


pickle_stream.py
import io
import pickle
import pprint
class SimpleObject:
def __init__(self, name):
self.name name
self.name_backwards name
return
data []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('preserve'))
data.append(SimpleObject('last'))
# Simulate a file.
out_s io.BytesIO()
# Write to the stream
for o in data:
print('WRITING : {} ({})'.format(o.name, o.name_backwards))
pickle.dump(o, out_s)
out_s.flush()
# Set up a read-able stream
in_s io.BytesIO(out_s.getvalue())
# Read the data
while True:
try:
o pickle.load(in_s)
except EOFError:
break
else:
print('READ : {} ({})'.format(
o.name, o.name_backwards))
В этом примере моделируются потоки с использованием двух буферов . Первый получает маринованные объекты, а его значение передается второму, откуда выполняется чтение . В простом формате базы данных можно также использовать соленые огурцы для хранения объектов. Модуль полки – одна из таких реализаций.
$ python3 pickle_stream.py WRITING : pickle (elkcip) WRITING : preserve (evreserp) WRITING : last (tsal) READ : pickle (elkcip) READ : preserve (evreserp) READ : last (tsal)
Помимо хранения данных, соленья удобны для межпроцессного взаимодействия. Например, и можно использовать для создания рабочих процессов, которые читают инструкции задания из одного канала и записывают результаты в другой канал. Основной код для управления пулом рабочих и отправки заданий и получения ответов можно использовать повторно, поскольку объекты задания и ответа не обязательно должны основываться на конкретном классе. При использовании каналов или сокетов не забывайте промывать после сброса каждого объекта, чтобы протолкнуть данные через соединение на другой конец. См. Модуль multiprocessing для многоразового диспетчера пула рабочих.
Классы DictReader и DictWriter
DictReader и DictWriter — это классы, доступные в Python для чтения и записи в CSV. Хотя они и похожи на функции чтения и записи, эти классы используют объекты словаря для чтения и записи в CSV-файлы.
DictReader
Он создает объект, который отображает прочитанную информацию в словарь, ключи которого задаются параметром . Этот параметр является необязательным, но если он не указан в файле, данные первой строки становятся ключами словаря.
Пример:
DictWriter
Этот класс аналогичен классу DictWriter и выполняет противоположную функцию: запись данных в файл CSV. Класс определяется
Параметр определяет последовательность ключей, которые определяют порядок, в котором значения в словаре записываются в файл CSV. В отличие от DictReader, этот ключ не является обязательным и должен быть определен во избежание ошибок при записи в CSV.
Переменные (ключевые слова var, let и const)
Переменная – это именованный участок памяти для хранения данных.
Представить себе переменную можно как некоторую область памяти, в которую вы можете как записать некоторую информацию, так и прочитать её из неё. Доступ к этому месту в памяти выполняется по имени, которое вы установили переменной при её создании.
Данные, хранящиеся в переменной, называются её значением.
В процессе выполнения программы значения переменной могут меняться. Но в определённый момент времени переменная всегда имеет какое-то одно значение.
В JavaScript до ES6 (ECMAScript 2015) объявление (создание) переменных осуществлялось с использованием только ключевого слова .
// объеявление переменной message (message - это имя переменной) var message;
При создании переменной ей сразу же можно присвоить некоторое значение. Эту операцию называют инициализацией переменной.
Присвоение переменной значения выполняется через оператор .
// например, создадим переменную email и присвоим ей в качестве значения строку "no-reply@astr.org" var email = 'no-reply@astr.org'; // установим переменной email новое значение email = 'support@astr.org';
Для того чтобы получить значение переменной к ней нужно просто обратиться по имени.
// например, выведем в консоль браузера значение переменной email console.log(email);
Переменная, которая объявлена без инициализации имеет по умолчанию значение .
var phone; // например, выведем в консоль браузера значение переменной phone console.log(phone); // undefined
Для того чтобы объявить не одну, а сразу несколько переменных с помощью одного ключевого слова , их необходимо просто отделить друг от друга с помощью запятой.
// например, объявим с помощью одного ключевого слова var сразу три переменные, и двум из них сразу присвоим значения var price = 78.55, quantity = 10, message;
Объявление переменных с помощью let и const
Сейчас ключевое слово практически не используется, вместо него новый стандарт (ES6) рекомендует использовать и .
В чем отличия от ?
1. Переменная объявленная посредством имеет область видимости, ограниченную блоком. Т.е. она видна только внутри фигурных скобок, в которых она создана, а также в любых других скобках, вложенных в эти. Вне них она не существует.
{
let name = 'John';
console.log(name); // "John"
{
console.log(name); // "John"
}
}
console.log(name); // Uncaught ReferenceError: name is not defined
Переменная, объявленная через ключевое слово имеет функциональную область видимости. Т.е. она ограничена только пределами функции.
Такая переменная будет видна за пределами блока, в котором она создана.
{
var name = 'John';
console.log(name); // "John"
{
console.log(name); // "John"
}
}
console.log(name); // "John"
2. Переменные, созданные с помощью не поднимаются к началу текущего контекста, т.е. hoisting для них не выполняется. Другими словами, к такой переменной нельзя обратиться до её объявления.
age = 10; // ReferenceError: Cannot access 'age' before initialization let age = 28;
Переменные, созданные с помощью поднимаются к началу текущего контекста. Это означает что к таким переменным вы можете обратиться до их объявления.
age = 10; var age = 28;
Константы (const)
Мы разобрали отличия от . А что же насчёт ? Переменные, созданные с помощью ведут себя также как с . Единственное отличие между ними заключается в том, что непосредственное значение переменной созданной через вы не можете изменить. Таким образом, – это ключевое слово, предназначенное для создания своего рода констант.
const COLOR_RED = '#ff0000';
Именование констант рекомендуется выполнять прописными буквами. Если константа состоит из несколько слов, то их между собой желательно отделять с помощью нижнего подчёркивания.
При попытке изменить значение константы вам будет брошена ошибка.
const COLOR_RED = '#ff0000'; COLOR_RED = '#f44336'; // Uncaught TypeError: Assignment to constant variable.
Когда переменной вы присваиваете значение, имеющее объектный тип данных, в ней уже будет храниться не сам этот объект, а ссылка на него. Это необходимо учитвать при работе с переменными в JavaScipt.
В этом случае когда вы константе присваиваете некий объект, то вы не можете изменить ссылку, хранящуюся в самой константе. Но сам объект доступен для изменения.
const COLORS = ;
// присвоить другой объект или значение константе нельзя
COLORS = []; // Uncaught TypeError: Assignment to constant variable.
COLORS = { red: '#ff0000', green: '#00ff00', blue: '#00ff00' }; // Uncaught TypeError: Assignment to constant variable.
COLORS = '#00ff00'; // Uncaught TypeError: Assignment to constant variable
// но имзменить сам объект можно
COLORS.push('#4caf50');
console.log(COLORS); //
Чтение значений из частных методов
Чтобы прочитать значение из частных методов, мы должны использовать метод получения. Без использования метода получения мы не можем использовать метод свойств для доступа к значениям частных атрибутов. Давайте рассмотрим пример, чтобы понять этот метод.
Пример:
# A program to read the value from private method
class Javatpoint:
def __init__(self, year=27):
self._year = year
@property
def Aboutyear(self):
return self.__year
@Aboutyear.setter
def Aboutyear(self, x):
self.__year = x
grad_obj = Javatpoint()
print(grad_obj._year)
grad_obj.year = 2020
print(grad_obj.year)
Вывод:
27 2020
Пример:
Возьмем еще один пример создания класса со свойствами. Из этого класса мы возьмем несколько объектов.
class Javatpoint:
def __init__(self):
self.emp = "None"
Mark = Friend()
John = Friend()
Для этих объектов свойство (Emp) не задано. Мы могли бы установить его напрямую, но это не лучший метод. Вместо этого мы создаем два метода: getEmp() и setEmp().
class Javatpoint:
def __init__(self):
self.emp = "None"
def getEmp(self):
return self.emp
def setEmp(self, emp):
self.emp = emp
Mark = Javatpoint()
John = Javatpoint()
Mark.setEmp("Developer")
John.setEmp("Designer")
print(John.emp)
print(Mark.emp)
Вывод:
Designer Developer
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Как сохранить словарь в файл?
У меня проблема с изменением значения dict и сохранением dict в текстовый файл (формат должен быть таким же), я только хочу изменить member_phone поле.
Мой текстовый файл имеет следующий формат:
и я разделил текстовый файл с помощью:
Когда я пытаюсь изменить member_phone сохраненный в d , значение изменилось не поток по ключу,
а как сохранить dict в текстовый файл с таким же форматом?
Python имеет модуль pickle только для такого рода вещей.
Эти функции — все, что вам нужно для сохранения и загрузки практически любого объекта:
Эти функции предполагают, что у вас есть obj папка в вашем текущем рабочем каталоге, которая будет использоваться для хранения объектов.
Похожие публикации:
Зачем и как использовать аннотации типов
Полезной особенностью языков со статической типизацией является то, что тип значения переменной всегда известен. Например, мы знаем, что строковые переменные могут быть только строками, может быть только целым числом и т. д. С динамически типизированными языками можно только догадываться, каким является или должно быть значение переменной.
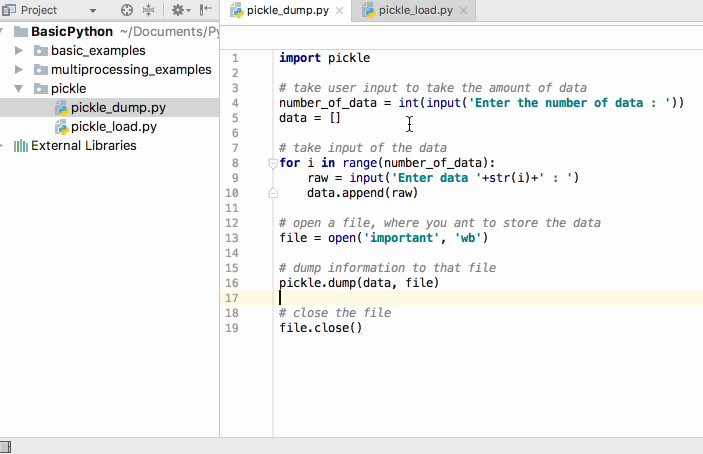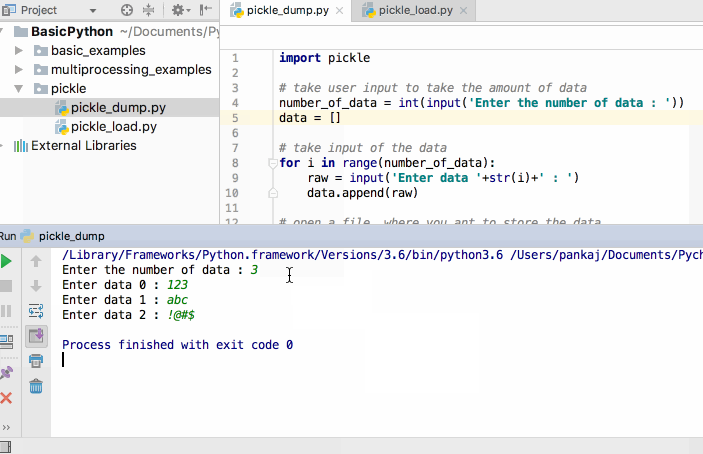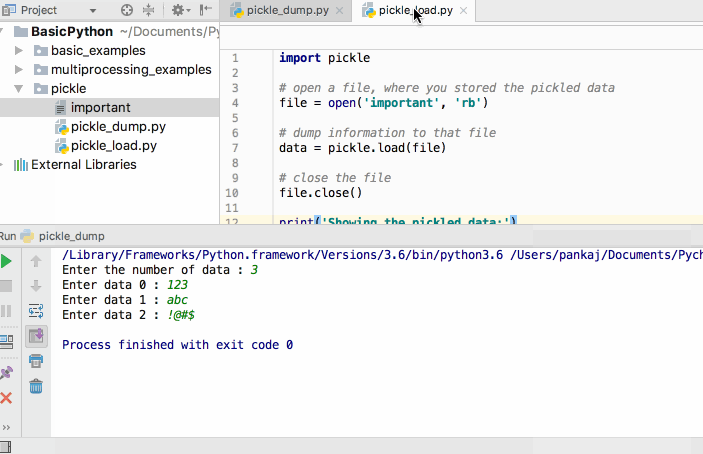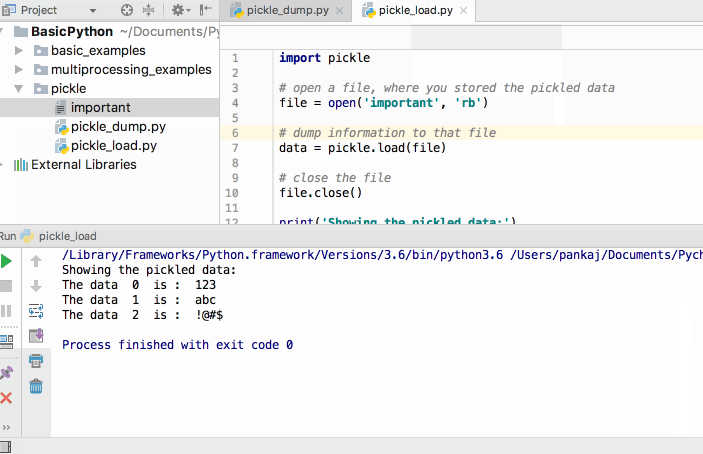


Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Скачать
×
Мы можем использовать ожидаемый тип переменной при написании и вызове функций, чтобы обеспечить правильную передачу и использование параметров. Если мы передадим , когда функция ожидает , то, скорее всего, она не будет работать так, как мы ожидали.
Рассмотрим следующий код:
def mystery_combine(a, b, times):
return (a + b) * times
# Исходная функция
def mystery_combine(a, b, times):
return (a + b) * times
print(mystery_combine(2, 3, 4))
# 20
print(mystery_combine('Hello ', 'World! ', 4))
# Hello World! Hello World! Hello World! Hello World!
Странно: в зависимости от того, что мы передаем функции, мы получаем два совершенно разных результата. С целыми числами мы получаем вычисления, но когда мы передаем в функцию строки, первые два аргумента объединяются, и эта результирующая строка умножается на .
Оказывается, написавший функцию разработчик ожидал, что именно вторая версия станет вариантом использования ! Используя аннотации типов, мы можем устранить эту путаницу.
def mystery_combine(a: str, b: str, times: int) -> str:
return (a + b) * times
К параметрам функции добавились , и , чтобы показать, какого типа они должны быть. Это должно сделать код более понятным для чтения и лучше раскрыть его предназначение.
Мы также добавили , чтобы показать, что эта функция вернет . Используя , мы можем более легко показать типы возвращаемых значений любой функции или метода, чтобы избавить от возможной путаницы будущих разработчиков!
Функцию все еще можно вызвать неправильно, но, присмотревшись, программист должен понять, как следует ее использовать. Аннотации типов и подсказки невероятно полезны для приложений Python, над которыми работают нескольких разработчиков. Это устраняет большую часть догадок при чтении кода!
Обязательные (позиционные) аргументы
Обязательные аргументы — это аргументы, переданные функции в правильном позиционном порядке. Здесь количество аргументов и их порядок в вызове функции должно точно соответствовать определению функции.
Чтобы вызвать функцию printme() , вам обязательно нужно передать один аргумент, иначе она выдаст следующую синтаксическую ошибку:
# Определение функции def printme( str ): """This prints a passed string into this function""" print(str) return # Теперь вы можете вызвать функцию printme printme()
Ошибка (в функции Printme не указан аргумент):
Traceback (most recent call last):
File "C:/Users/User/Desktop/CodePythonFunc.py", line 8, in <module>
printme()
TypeError: printme() missing 1 required positional argument: 'str'
Правильно указать аргумент так:
# Определение функции
def printme( str ):
"""This prints a passed string into this function"""
print(str)
return
# Теперь вы можете вызвать функцию printme
printme("Текстовая переменная")
Закрытие открытого файла с помощью метода close()
Когда вы открываете файл в Python, чрезвычайно важно закрыть файл после внесения изменений. Это сохраняет любые изменения, которые вы сделали ранее, удаляет файл из памяти и предотвращает дальнейшее чтение или запись в программе
Синтаксис для закрытия открытого файла в Python:
fileobject.close()
Если мы продолжим наши предыдущие примеры, где мы читаем файлы, вот как вы закроете файл:
text_file = open('/Users/pankaj/abc.txt','r')
# some file operations here
text_file.close()
Кроме того, вы можете избежать закрытия файлов вручную, если используете блок with. Как только блок with выполняется, файлы закрываются и становятся недоступными для чтения и записи.
Как открыть CSV в Excel
Перейдем к примеру, в котором рассмотрим, как открыть CSV файл в Excel. Пусть у нас есть файл CSV формата, который будет выглядеть следующим образом, если его просто открыть с помощью Excel или другого текстового редактора.
Как открыть CSV в Excel – Неформатированный файл CSV в Excel
Для того чтобы представить данные из CSV файла в удобном виде, в виде таблицы, необходимо импортировать файл CSV в Excel. Разберем как вставить данные из CSV файла в открытую рабочую книгу Excel.
- Перейдите во вкладку « Данные », и в группе « Получение внешних данных » выберите пункт « Из текста ».
Как открыть CSV в Excel – Получение внешних данных из текста в Excel
- В открывшемся окне найдите в вашем компьютере CSV файл, который хотите открыть в Excel. Выберите его и нажмите кнопку «Импорт» либо дважды кликните по файлу.
Как открыть CSV в Excel – Импорт CSV файла в Excel
- Далее появится окно мастера импорта текстов.
Шаг 1. В поле « Формат исходных данных » у нас должен быть выбран пункт «с разделителями», так как в текстовом файле CSV элементы разделены запятыми.
В поле « Начать импорт со строки » мы указываем номер первой строки импортируемых данных. В нашем случае начнем с первой строки. И нажимаем кнопку « Далее ».
Как открыть CSV в Excel – Импорт CSV файла. Шаг 1
- Шаг 2. На втором этапе мы выбираем разделители и ограничители строк.
В поле « Символом-разделителем является :» мы выбираем символ, который разделяет значения в текстовом файле CSV. В нашем случае это запятая. Если в вашем CSV файле разделителями выступают другие символы, или он отсутствует в списке, то выбирайте пункт « другой :» и введите его в поле.
В поле « Ограничитель строк » мы выбираем “ . Нажимаем кнопку « Далее ».
Как открыть CSV в Excel – Импорт CSV файла. Шаг 2
Разберемся в каких случаях нужно выбирать определенный вид ограничителя строк.
Когда разделителем выступает запятая (,), а ограничитель строк – кавычки («), текст «Иванов, бухгалтер» будет импортирован в Excel в одну ячейку как Иванов, бухгалтер. Если ограничителем строк выступает одинарная кавычка или он не задан, то текст «Иванов, бухгалтер», импортированный в Excel будет разбит на две ячейки как «Иванов», «бухгалтер «.
- Шаг 3. В группе « Формат данных столбца » задаем формат данных для каждого столбца в предпросмотре « Образец разбора данных ».
Как открыть CSV в Excel – Импорт CSV файла. Шаг 3
В случае, если какой-то столбец не нужно импортировать из CSV файла выберите пункт пропустить .
Как открыть CSV в Excel – Пропустить столбец при импорте CSV в Excel
Нажимаем кнопку « Готово ».
- После мастера импорта текста появится окно «Импорт данных»:
Как открыть CSV в Excel – Окно «Импорт данных»
В группе « Куда следует поместить данные » выбираем расположение наших импортируемых данных из CSV в Excel. Если выбираем поле « Имеющийся лист », то указываем адрес ячейки. А если хотим расположить на новом листе, то – пункт « Новый лист ». Мы выберем « Имеющийся лист ». Нажимаем кнопку « ОК ».
В итоге мы получили вот такую таблицу:
Как открыть CSV в Excel – CSV файл в Excel
Ну вот и все, теперь вы с легкостью можете открыть CSV в Excel, и далее работать с полученными табличными данными привычными инструментами MS Excel.
Установка
Процесс установки YAML довольно прост. Это можно сделать двумя способами, начнем с простого.


Метод 1: через точку
Самый простой способ установить библиотеку YAML в Python – через диспетчер пакетов pip. Если в вашей системе установлен pip, выполните следующую команду, чтобы загрузить и установить YAML:
$ pip install pyyaml
Метод 2: через источник
Если у вас не установлен pip или у вас возникли проблемы с описанным выше методом, вы можете перейти на исходную страницу библиотеки. Загрузите репозиторий в виде zip-файла, откройте терминал или командную строку и перейдите в каталог, в который загружен файл. Когда вы окажетесь там, выполните следующую команду:
$ python setup.py install
Запись файлов CSV
Мы также можем не только читать, но и писать любые новые и существующие файлы CSV. Запись файлов на Python осуществляется с помощью модуля csv.writer(). Он похож на модуль csv.reader() и также имеет два метода, то есть функцию записи или класс Dict Writer.
Он представляет две функции: writerow() и writerows(). Функция writerow() записывает только одну строку, а функция writerows() записывает более одной строки.
Диалекты
Они определяются как конструкция, которая позволяет создавать, хранить и повторно использовать различные параметры форматирования. Диалект поддерживает несколько атрибутов; наиболее часто используются:
- Dialect.delimiter: этот атрибут используется как разделительный символ между полями. Значение по умолчанию – запятая(,).
- Dialect.quotechar: этот атрибут используется для выделения полей, содержащих специальные символы, в кавычки.
- Dialect.lineterminator: используется для создания новых строк, значение по умолчанию – ‘\r\n’.
Запишем следующие данные в файл CSV.
data =
Пример –
import csv
with open('Python.csv', 'w') as csvfile:
fieldnames =
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Rank': 'B', 'first_name': 'Parker', 'last_name': 'Brian'})
writer.writerow({'Rank': 'A', 'first_name': 'Smith',
'last_name': 'Rodriguez'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Loive'})
print("Writing complete")
Выход:
Writing complete
Он возвращает файл с именем Python.csv, который содержит следующие данные:
first_name,last_name,Rank Parker,Brian,B Smith,Rodriguez,A Jane,Oscar,B Jane,Loive,B





