
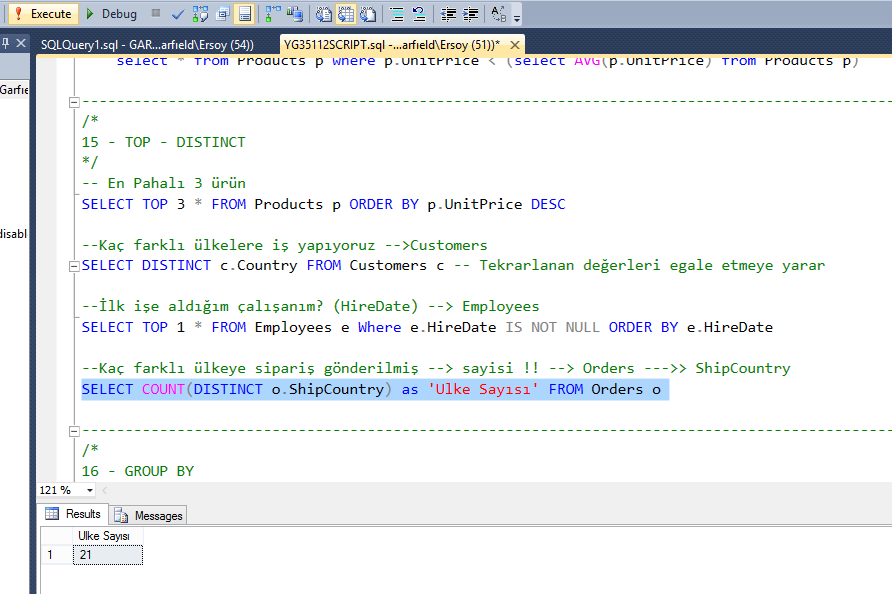
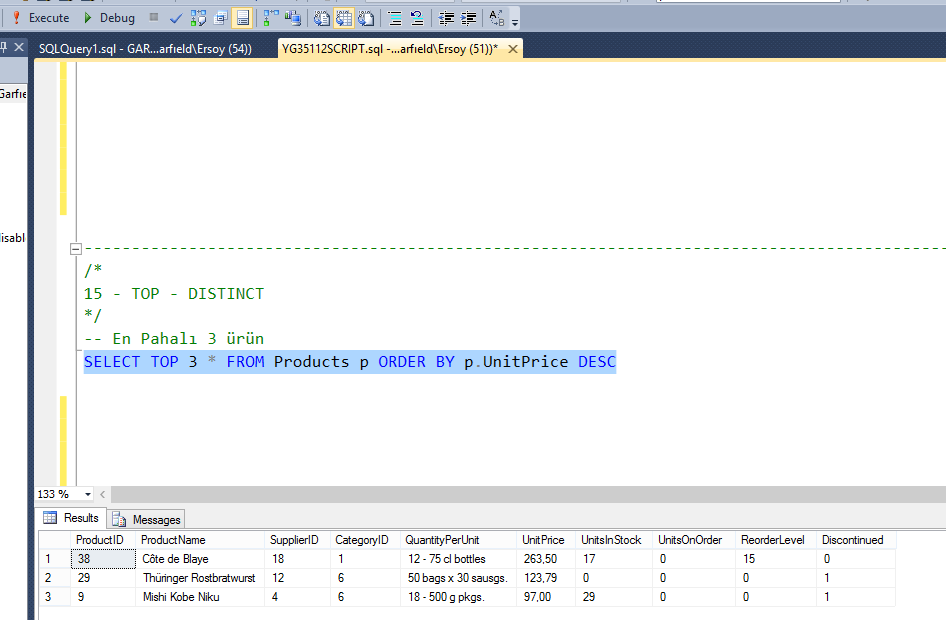
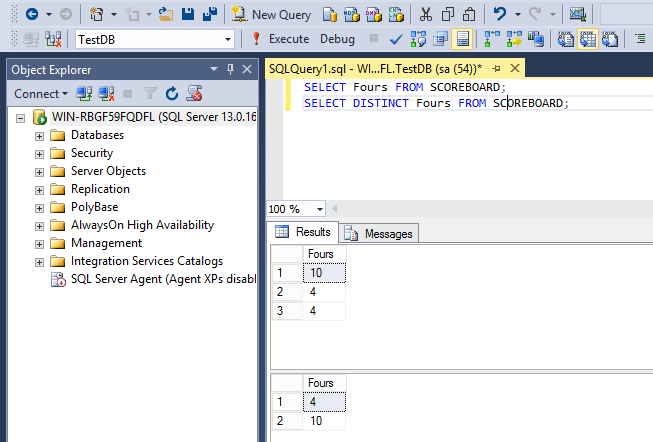
DISTINCT или GROUP BY в MySQL
В MySQL DISTINCT наследует поведение от GROUP BY. Если вы используете выражение GROUP BY без агрегатной функции, то оно будет выполнять роль ключевого слова DISTINCT.
Единственное отличие между ними заключается в следующем:
- GROUP BY сначала сортирует данные, а затем осуществляет группировку;
- Ключевое слово DISTINCTне выполняет сортировки.
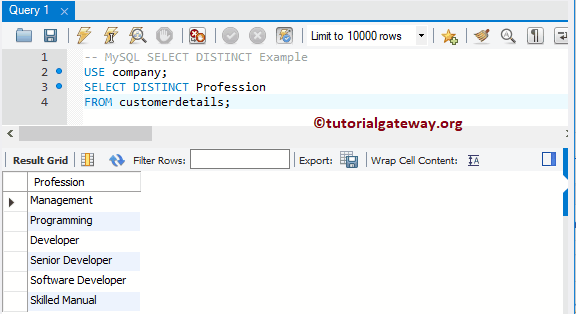
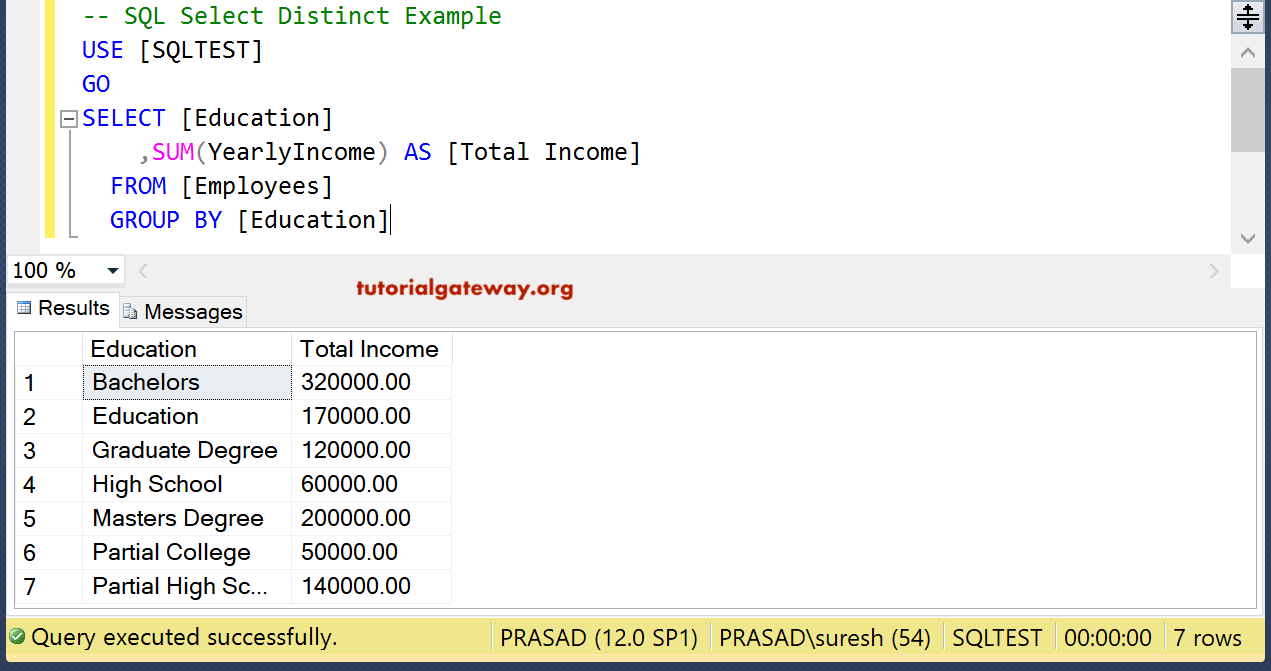
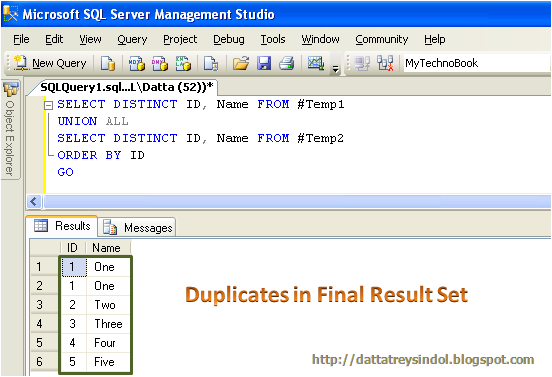
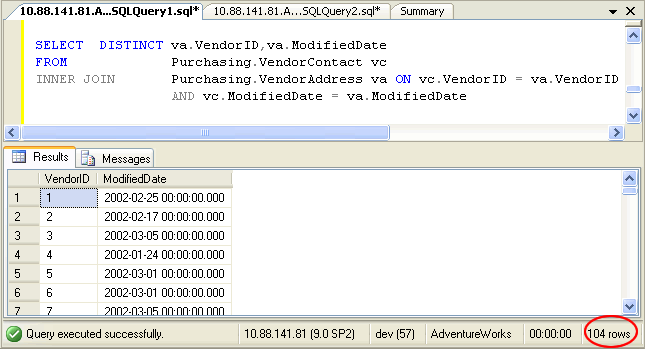
Если вы используете ключевое слово DISTINCT вместе с выражением ORDER BY, то получите тот же результат, что и при применении GROUP BY. Следующий запрос возвращает уникальные значения столбца profession из таблицы customerdetails:
-- MySQL SELECT DISTINCT Example USE company; SELECT DISTINCT Profession FROM customerdetails;
Результат:
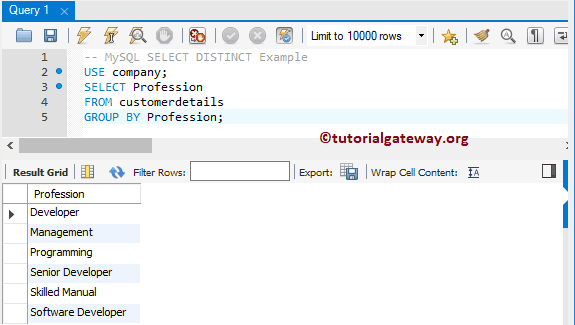
Уберём ключевое слово DISTINCT и используем выражение GROUP BY:
-- MySQL SELECT DISTINCT Example USE company; SELECT Profession FROM customerdetails GROUP BY Profession;
Как видите, запрос возвращает тот же результат, но в другом порядке:
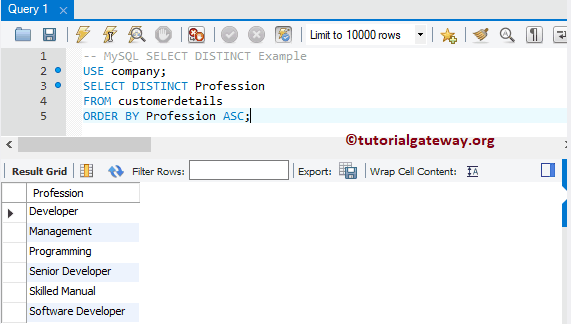
В этом MySQL SELECT DISTINCT примере я использую выражение ORDER BY:
-- MySQL SELECT DISTINCT Example USE company; SELECT DISTINCT Profession FROM customerdetails ORDER BY Profession ASC;
Результат тот же, что и при использовании GROUP BY:
MODIFY COLUMN
Запрос изменяет следующие свойства столбца :
-
Тип
-
Значение по умолчанию
-
Кодеки сжатия
-
TTL
Примеры изменения кодеков сжатия смотрите в разделе .
Примеры изменения TTL столбца смотрите в разделе .
Если указано , запрос не возвращает ошибку при условии, что столбец не существует.
Запрос также может изменять порядок столбцов при помощи , смотрите описание .
При изменении типа, значения преобразуются так, как если бы к ним была применена функция toType. Если изменяется только выражение для умолчания, запрос не делает никакой сложной работы и выполняется мгновенно.
Пример запроса:
Изменение типа столбца — это единственное действие, которое выполняет сложную работу — меняет содержимое файлов с данными. Для больших таблиц, выполнение может занять длительное время.
Выполнение запроса ALTER атомарно.
Запрос на изменение столбцов реплицируется. Соответствующие инструкции сохраняются в ZooKeeper, и затем каждая реплика их применяет. Все запросы выполняются в одном и том же порядке. Запрос ждёт выполнения соответствующих действий на всех репликах. Но при этом, запрос на изменение столбцов в реплицируемой таблице можно прервать, и все действия будут осуществлены асинхронно.
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
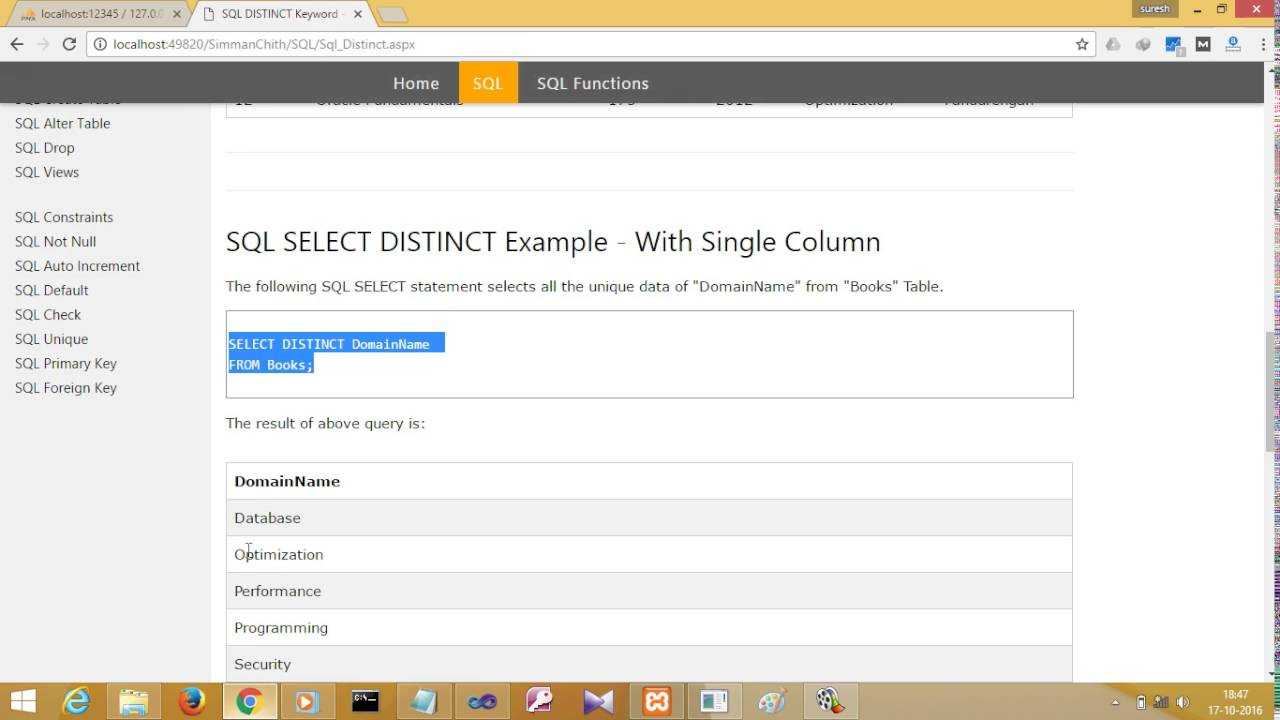
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions:
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions:
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions:
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions:
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions:
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions:
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions:
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions:
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions:
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
Ограничения запроса ALTER
Запрос позволяет создавать и удалять отдельные элементы (столбцы) вложенных структур данных, но не вложенные структуры данных целиком. Для добавления вложенной структуры данных, вы можете добавить столбцы с именем вида и типом — вложенная структура данных полностью эквивалентна нескольким столбцам-массивам с именем, имеющим одинаковый префикс до точки.
Отсутствует возможность удалять столбцы, входящие в первичный ключ или ключ для сэмплирования (в общем, входящие в выражение ). Изменение типа у столбцов, входящих в первичный ключ возможно только в том случае, если это изменение не приводит к изменению данных (например, разрешено добавление значения в Enum или изменение типа с на ).
Если возможностей запроса не хватает для нужного изменения таблицы, вы можете создать новую таблицу, скопировать туда данные с помощью запроса , затем поменять таблицы местами с помощью запроса , и удалить старую таблицу. В качестве альтернативы для запроса , можно использовать инструмент clickhouse-copier.
Запрос блокирует все чтения и записи для таблицы. То есть если на момент запроса выполнялся долгий , то запрос сначала дождётся его выполнения. И в это время все новые запросы к той же таблице будут ждать, пока завершится этот .
Для таблиц, которые не хранят данные самостоятельно (типа Merge и Distributed), всего лишь меняет структуру таблицы, но не меняет структуру подчинённых таблиц. Для примера, при ALTER-е таблицы типа , вам также потребуется выполнить запрос для таблиц на всех удалённых серверах.
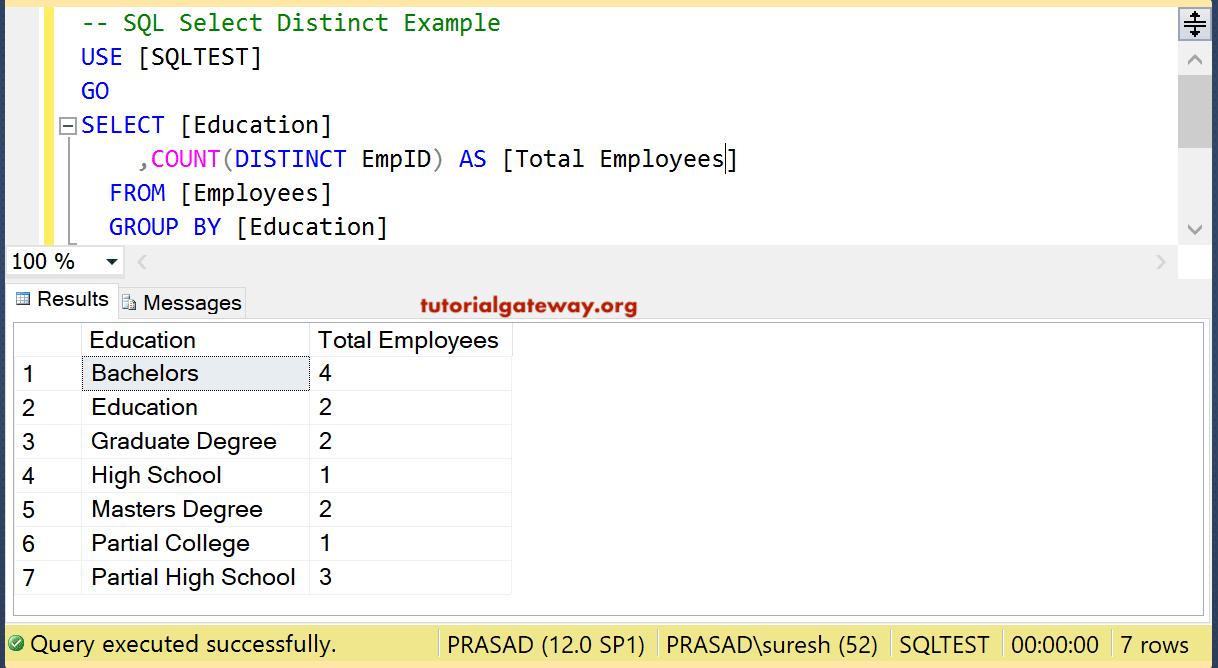
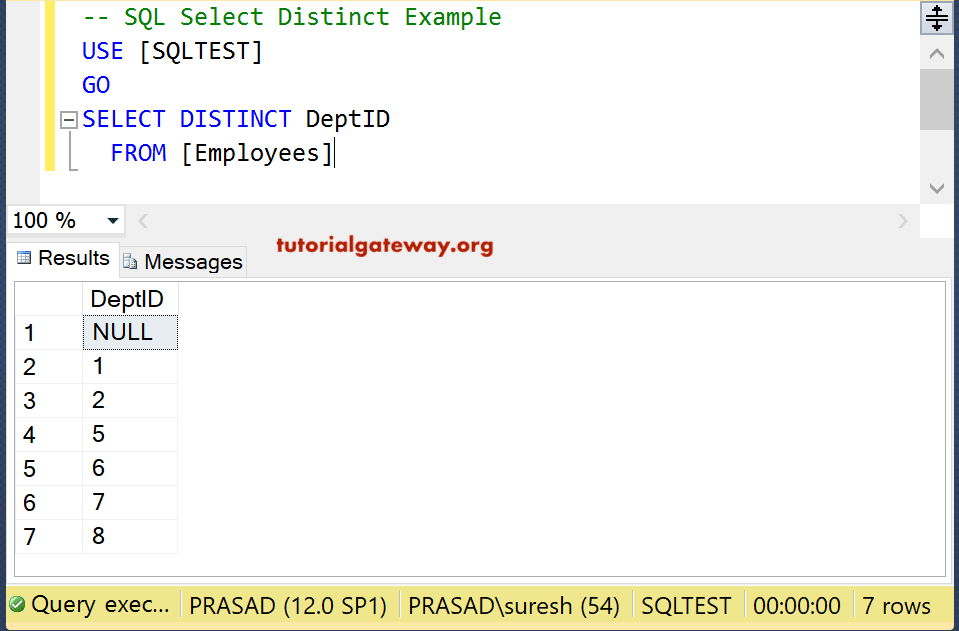
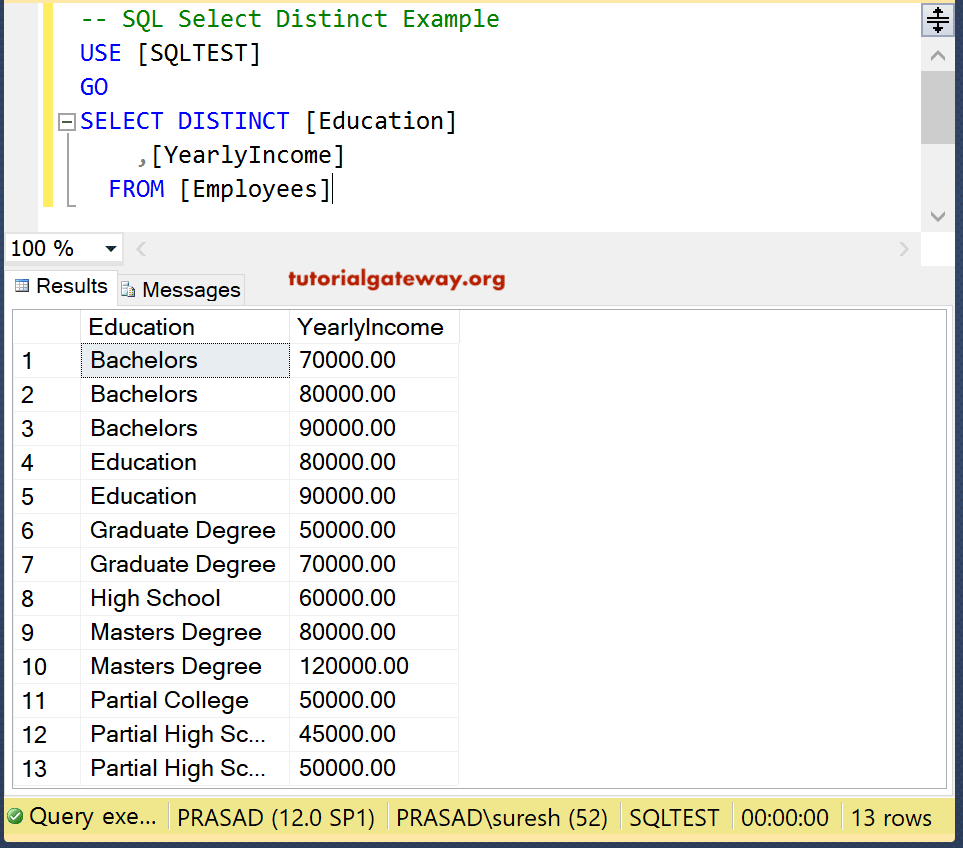
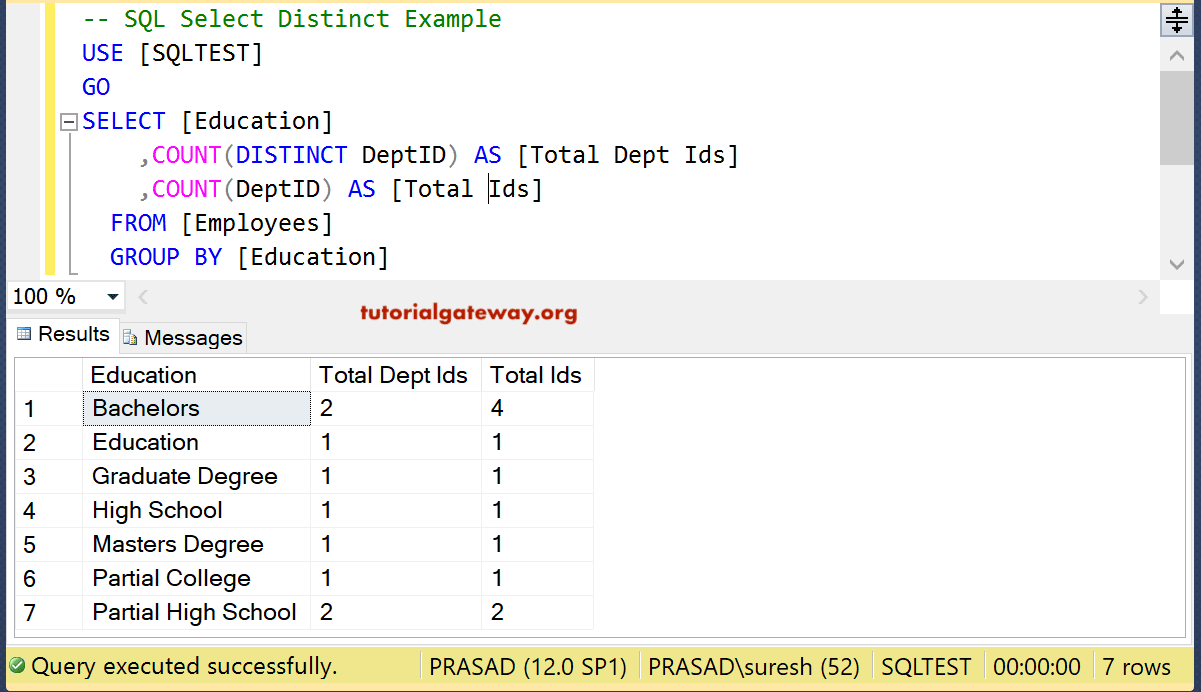
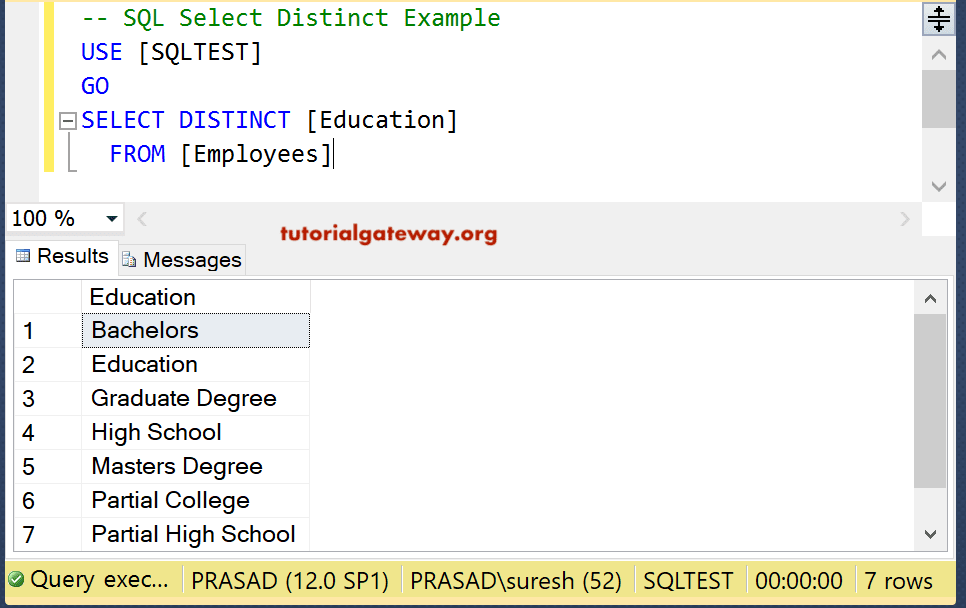


Default LISTAGG Functionality
Here we see a simple example of the function, producing a comma-separated list of employees for each department.
COLUMN employees FORMAT A40
SELECT deptno, LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
GROUP BY deptno
ORDER BY deptno;
DEPTNO EMPLOYEES
---------- ----------------------------------------
10 CLARK,KING,MILLER
20 ADAMS,FORD,JONES,SCOTT,SMITH
30 ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD
SQL>
If the concatenation results in a string longer than the return data type of the function an «ORA-01489» error is produced. In the following example we use a to force a large aggregation.
COLUMN employees FORMAT A40
SELECT deptno, LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 1000)
WHERE deptno = 30
GROUP BY deptno
ORDER BY deptno;
FROM emp
*
ERROR at line 2:
ORA-01489: result of string concatenation is too long
This default behaviour is functionally equivalent to explicitly specifying the overflow clause.
COLUMN employees FORMAT A40
SELECT deptno, LISTAGG(ename, ',' ON OVERFLOW ERROR) WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 1000)
WHERE deptno = 30
GROUP BY deptno
ORDER BY deptno;
FROM emp
*
ERROR at line 2:
ORA-01489: result of string concatenation is too long
SQL>
Setup
The examples in this article rely on the following test table.
--DROP TABLE emp PURGE;
CREATE TABLE emp (
empno NUMBER(4) CONSTRAINT pk_emp PRIMARY KEY,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
);
INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO emp VALUES (7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO emp VALUES (7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO emp VALUES (7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO emp VALUES (7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO emp VALUES (7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO emp VALUES (7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO emp VALUES (7788,'SCOTT','ANALYST',7566,to_date('13-JUL-87','dd-mm-rr')-85,3000,NULL,20);
INSERT INTO emp VALUES (7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO emp VALUES (7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO emp VALUES (7876,'ADAMS','CLERK',7788,to_date('13-JUL-87', 'dd-mm-rr')-51,1100,NULL,20);
INSERT INTO emp VALUES (7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO emp VALUES (7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO emp VALUES (7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);
COMMIT;
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Синтаксис
Синтаксис Oracle/PLSQL функции LEAD:
LEAD ( expression ] )
over ( order_by_clause )
Параметры или аргументы
expression выражение, которое может содержать другие встроенные функции, но не может содержать аналитические функции.
offset — необязательный. Это физические смещение от текущей строки в таблице. Если этот параметр не указан, то по умолчанию 1.
default — необязательный. Это значение, которое возвращается, если offset выходит за границы таблицы. Если этот параметр не указан, то по умолчанию Null.
query_partition_clause — необязательный. Он используется для разделения результатов на группы на основе одного или нескольких выражений.
order_by_clause — необязательный. Он используется для упорядочения данных в каждом разделе.
Функция LEAD возвращает значения из следующей строки таблицы.
Аргументы
order_by_expression
Указывает столбец или выражение, по которому производится сортировка результирующего набора запроса. Столбец сортировки может быть указан с помощью имени или псевдонима столбца или неотрицательного целого числа, представляющего позицию столбца в списке выбора.
Можно указать несколько столбцов сортировки. Имена столбцов должны быть уникальными. Последовательность столбцов сортировки в предложении ORDER BY определяет организацию упорядоченного результирующего набора. Иными словами, результирующий набор сортируется по первому столбцу, затем упорядоченный список сортируется по второму и т. д.
Имена столбцов, на которые содержатся ссылки в предложении ORDER BY, должны однозначно соответствовать столбцу или псевдониму столбца в списке выбора либо столбцу, определенному в таблице, указанной в предложении FROM. Если предложение ORDER BY ссылается на псевдоним столбца в списке выбора, псевдоним должен использоваться отдельно, а не как часть выражения в предложении ORDER BY, например:
COLLATE collation_name
Указывает, что операция ORDER BY должна выполняться в соответствии с параметрами сортировки, указанными в аргументе collation_name, но не в соответствии с параметрами сортировки столбца, определенными в таблице или представлении. Аргументом collation_name может быть либо имя параметров сортировки Windows, либо имя параметров сортировки SQL. Дополнительные сведения см. в статье Collation and Unicode Support. Аргумент COLLATE применяется только к столбцам типа char, varchar, nchar и nvarchar.
ASC | DESC
Указывает порядок сортировки значений в указанном столбце — по возрастанию или по убыванию. Значение ASC сортирует от низких значений к высоким. Значение DESC сортирует от высоких значений к низким. Порядок сортировки по умолчанию — ASC. Значения NULL рассматриваются как минимально возможные значения.
OFFSET { integer_constant | offset_row_count_expression } { ROW | ROWS }
Указывает число сток, которые необходимо пропустить, прежде чем будет начат возврат строк из выражения запроса. Это значение может быть целочисленной константой или выражением, значение которого больше нуля или равно нулю.
Применимо к: SQL Server 2012 (11.x) и выше, База данных SQL Azure.
offset_row_count_expression может быть переменной, параметром или вложенным запросом, возвращающим скалярную константу. При использовании вложенного запроса он не должен ссылаться на какие-либо столбцы, определенные в области внешнего запроса. Иными словами, он не может коррелировать с внешним запросом.
ROW и ROWS являются синонимами и оставлены для совместимости со стандартом ANSI.
В плане выполнения запроса значение смещения строки отображается в атрибуте Offset оператора запроса TOP.
FETCH { FIRST | NEXT } { integer_constant | fetch_row_count_expression } { ROW | ROWS } ONLY
Указывает число строк, возвращаемых после обработки предложения OFFSET. Это значение может быть целочисленной константой или выражением, значение которого больше единицы или равно единице.
Применимо к: SQL Server 2012 (11.x) и выше, а также База данных SQL Azure.
fetch_row_count_expression может быть переменной, параметром или вложенным запросом, возвращающим скалярную константу. При использовании вложенного запроса он не должен ссылаться на какие-либо столбцы, определенные в области внешнего запроса. Иными словами, он не может коррелировать с внешним запросом.
FIRST и NEXT являются синонимами и предусмотрены для совместимости со стандартом ANSI.
ROW и ROWS являются синонимами и оставлены для совместимости со стандартом ANSI.
В плане выполнения запроса значение смещения строки отображается в атрибуте Rows или Top оператора запроса TOP.
Quick Links
The «*» indicates the function supports the full analytic syntax, including the windowing clause.
| * | CHECKSUM * | CLUSTER_DETAILS | CLUSTER_DISTANCE | CLUSTER_ID |
| CLUSTER_SET | * | * | * | * |
| FEATURE_DETAILS | FEATURE_ID | FEATURE_SET | ||
| FEATURE_VALUE | * | * | * | |
| * | ||||
| MATCH_RECOGNIZE | * | * | * | |
| PERCENTILE_CONT | PERCENTILE_DISC | PREDICTION | ||
| PREDICTION_COST | PREDICTION | PREDICTION_COST | PREDICTION_DETAILS | PREDICTION_PROBABILITY |
| PREDICTION_SET | REGR_ (Linear Regression) Functions * | |||
| * | * | * | * | * |
| SUM * | * | * | * | String Aggregation |
| Top-N Queries |
For more information see:
- LISTAGG Analytic Function
- LISTAGG Function Enhancements in Oracle Database 12c Release 2 (12.2)
Hope this helps. Regards Tim…
Модификаторы запроса SELECT
Вы можете использовать следующие модификаторы в запросах .
APPLY
Вызывает указанную функцию для каждой строки, возвращаемой внешним табличным выражением запроса.
Синтаксис:
Пример:
Исключает из результата запроса один или несколько столбцов.
Синтаксис:
Пример:
REPLACE
Определяет одно или несколько . Каждый алиас должен соответствовать имени столбца из запроса . В списке столбцов результата запроса имя столбца, соответствующее алиасу, заменяется выражением в модификаторе .

Этот модификатор не изменяет имена или порядок столбцов. Однако он может изменить значение и тип значения.
Синтаксис:
Пример:
Комбинации модификаторов
Вы можете использовать каждый модификатор отдельно или комбинировать их.
Примеры:
Использование одного и того же модификатора несколько раз.
Использование нескольких модификаторов в одном запросе.
Why should I use a columnstore index?
A columnstore index can provide a very high level of data compression, typically by 10 times, to significantly reduce your data warehouse storage cost. For analytics, a columnstore index offers an order of magnitude better performance than a btree index. Columnstore indexes are the preferred data storage format for data warehousing and analytics workloads. Starting with SQL Server 2016 (13.x), you can use columnstore indexes for real-time analytics on your operational workload.
Reasons why columnstore indexes are so fast:
-
Columns store values from the same domain and commonly have similar values, which result in high compression rates. I/O bottlenecks in your system are minimized or eliminated, and memory footprint is reduced significantly.
-
High compression rates improve query performance by using a smaller in-memory footprint. In turn, query performance can improve because SQL Server can perform more query and data operations in memory.
-
Batch execution improves query performance, typically by two to four times, by processing multiple rows together.
-
Queries often select only a few columns from a table, which reduces total I/O from the physical media.
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions:
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions:
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions:
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions:
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions:
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions:
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions:
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions:
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions:
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
Секция SELECT
указанные в секции анализируются после завершения всех вычислений из секций, описанных выше. Вернее, анализируются выражения, стоящие над агрегатными функциями, если есть агрегатные функции.
Сами агрегатные функции и то, что под ними, вычисляются при агрегации (). Эти выражения работают так, как будто применяются к отдельным строкам результата.
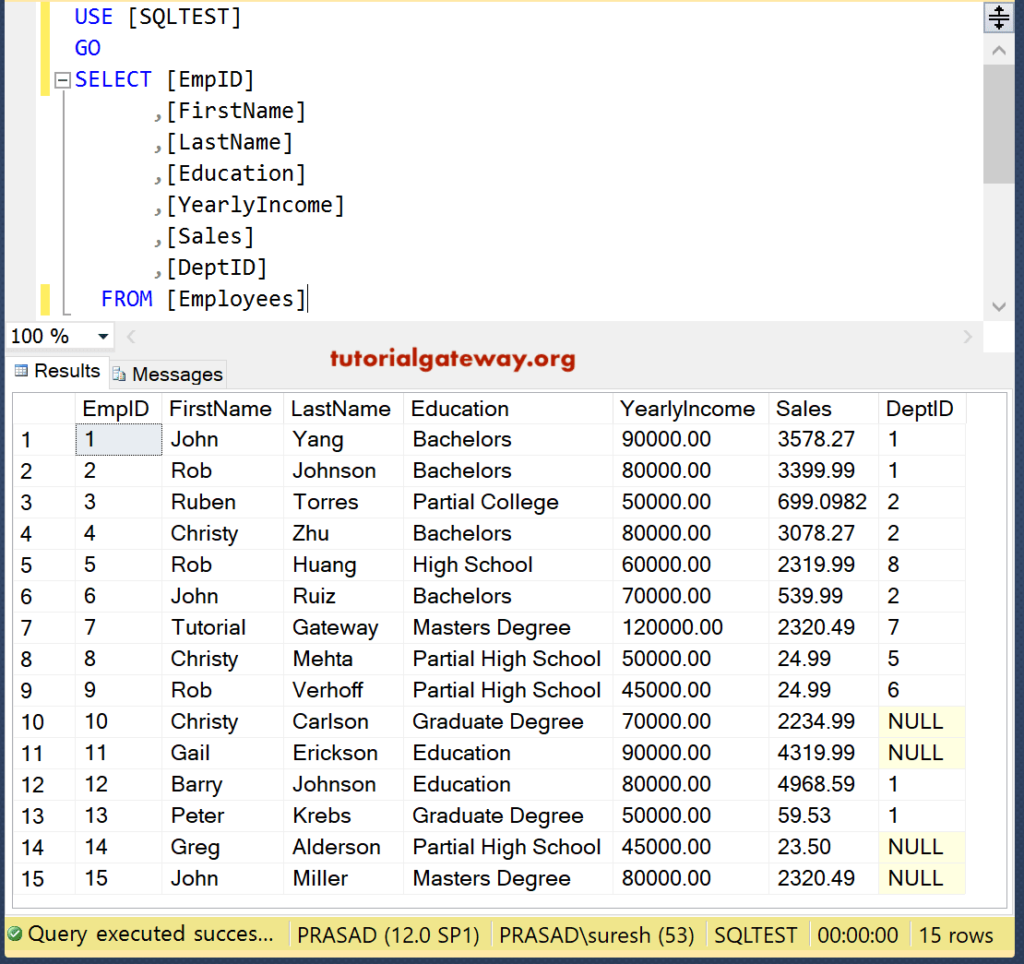
Если в результат необходимо включить все столбцы, используйте символ звёздочка (). Например, .
Чтобы включить в результат несколько столбцов, выбрав их имена с помощью регулярных выражений re2, используйте выражение .
Например, рассмотрим таблицу:
Следующий запрос выбирает данные из всех столбцов, содержащих в имени символ .
Выбранные стоблцы возвращаются не в алфавитном порядке.
В запросе можно использовать несколько выражений , а также вызывать над ними функции.
Например:
Каждый столбец, возвращённый выражением , передаётся в функцию отдельным аргументом. Также можно передавать и другие аргументы, если функция их поддерживаем. Аккуратно используйте функции. Если функция не поддерживает переданное количество аргументов, то ClickHouse генерирует исключение.
Например:
В этом примере, возвращает два столбца: и . возвращает столбец . Оператор не работает с тремя аргументами, поэтому ClickHouse генерирует исключение с соответствущим сообщением.
Столбцы, которые возвращаются выражением могут быть разных типов. Если не возвращает ни одного столбца и это единственное выражение в запросе , то ClickHouse генерирует исключение.
Звёздочка
В любом месте запроса, вместо выражения, может стоять звёздочка. При анализе запроса звёздочка раскрывается в список всех столбцов таблицы (за исключением и столбцов). Есть лишь немного случаев, когда оправдано использовать звёздочку:
- при создании дампа таблицы;
- для таблиц, содержащих всего несколько столбцов — например, системных таблиц;
- для получения информации о том, какие столбцы есть в таблице; в этом случае, укажите . Но лучше используйте запрос ;
- при наличии сильной фильтрации по небольшому количеству столбцов с помощью ;
- в подзапросах (так как из подзапросов выкидываются столбцы, не нужные для внешнего запроса).
В других случаях использование звёздочки является издевательством над системой, так как вместо преимуществ столбцовой СУБД вы получаете недостатки. То есть использовать звёздочку не рекомендуется.
Экстремальные значения
Вы можете получить в дополнение к результату также минимальные и максимальные значения по столбцам результата. Для этого выставите настройку extremes в 1. Минимумы и максимумы считаются для числовых типов, дат, дат-с-временем. Для остальных столбцов будут выведены значения по умолчанию.
Вычисляются дополнительные две строчки — минимумы и максимумы, соответственно. Эти две дополнительные строки выводятся в форматах , , и отдельно от остальных строчек. В остальных форматах они не выводится.
Во форматах , экстремальные значения выводятся отдельным полем ‘extremes’. В форматах , строка выводится после основного результата и после ‘totals’ если есть. Перед ней (после остальных данных) вставляется пустая строка. В форматах , строка выводится отдельной таблицей после основного результата и после если есть.

Экстремальные значения вычисляются для строк перед , но после . Однако при использовании , строки перед включаются в . В потоковых запросах, в результате может учитываться также небольшое количество строчек, прошедших .
Замечания
Вы можете использовать синонимы (алиасы ) в любом месте запроса.
В секциях , и можно использовать не названия столбцов, а номера. Для этого нужно включить настройку . Тогда, например, в запросе с будет выполнена сортировка сначала по первому, а затем по второму столбцу.
Пример
Функция LAG может быть использована в Oracle/PLSQL.
Давайте посмотрим на пример. Если у нас есть таблица orders, которая содержит следующие данные:
| ORDER_DATE | PRODUCT_ID | QTY |
|---|---|---|
| 25/09/2007 | 1000 | 20 |
| 26/09/2007 | 2000 | 15 |
| 27/09/2007 | 1000 | 8 |
| 28/09/2007 | 2000 | 12 |
| 29/09/2007 | 2000 | 2 |
| 30/09/2007 | 1000 | 4 |
И мы выполним следующий запрос:
Oracle PL/SQL
select product_id,
order_date,
LAG (order_date,1) over (ORDER BY order_date) AS prev_order_date
from orders;
|
1 |
selectproduct_id, order_date, LAG(order_date,1)over(ORDERBYorder_date)ASprev_order_date fromorders; |
То получим следующий результат:
| ORDER_DATE | PRODUCT_ID | QTY |
|---|---|---|
| 1000 | 25/09/2007 | |
| 2000 | 26/09/2007 | 25/09/2007 |
| 1000 | 27/09/2007 | 26/09/2007 |
| 2000 | 28/09/2007 | 27/09/2007 |
| 2000 | 29/09/2007 | 28/09/2007 |
| 1000 | 30/09/2007 | 29/09/2007 |
Так как мы использовали offset = 1, запрос возвращает предыдущий ORDER_DATE.
Если бы мы использовали offset = 2 вместо 1, то запрос вернул бы ORDER_DATE на 2 позиции ранее. Если бы мы использовали offset = 3, то запрос вернул бы ORDER_DATE на 3 позиции ранне …. и так далее.
Если мы хотим получить только заказы для данного product_id, то мы выполним следующий SQL запрос:
Oracle PL/SQL
SELECT product_id,
order_date,
LAG (order_date,1) over (ORDER BY order_date) AS prev_order_date
FROM orders
WHERE product_id = 2000;
|
1 |
SELECTproduct_id, order_date, LAG(order_date,1)over(ORDERBYorder_date)ASprev_order_date FROMorders WHEREproduct_id=2000; |
Получим результат:
| ORDER_DATE | PRODUCT_ID | QTY |
|---|---|---|
| 2000 | 26/09/2007 | |
| 2000 | 28/09/2007 | 26/09/2007 |
| 2000 | 29/09/2007 | 28/09/2007 |
В этом примере, запрос вернул ORDER_DATE для product_id = 2000 и игнорировал все другие записи.
Использование partition
Теперь давайте рассмотрим более сложный пример, в котором мы используем параметр partition для возврата предыдущей order_date для каждого product_id.
Введите следующий оператор SQL:
Oracle PL/SQL
SELECT product_id,
order_date,
LAG (order_date,1) OVER (PARTITION BY product_id ORDER BY order_date) AS prev_order_date
FROM orders;
|
1 |
SELECTproduct_id, order_date, LAG(order_date,1)OVER(PARTITIONBYproduct_idORDERBYorder_date)ASprev_order_date FROMorders; |
Это вернет следующий результат:
| PRODUCT_ID | ORDER_DATE | PREV_ORDER_DATE |
|---|---|---|
| 1000 | 2007/09/25 | NULL |
| 1000 | 2007/09/27 | 2007/09/25 |
| 1000 | 2007/09/30 | 2007/09/27 |
| 2000 | 2007/09/26 | NULL |
| 2000 | 2007/09/28 | 2007/09/26 |
| 2000 | 2007/09/29 | 2007/09/28 |
В этом примере функция LAG разделит результаты по product_id, а затем отсортирует по order_date, как указано в PARTITION BY product_id ORDER BY order_date. Это означает, что функция LAG будет оценивать значение order_date, только если product_id совпадает с product_id текущей записи. Когда встречается новый product_id, функция LAG перезапускает свои вычисления и использует соответствующий раздел product_id.
Как вы можете видеть, первая запись в наборе результатов имеет значение NULL для prev_order_date, потому что это первая запись для раздела, где product_id равен 1000 (отсортировано по order_date), поэтому нет более низкого значения order_date. Это также верно для 4-й записи, где product_id равен 2000.
Quick Links
The «*» indicates the function supports the full analytic syntax, including the windowing clause.
| * | CHECKSUM * | CLUSTER_DETAILS | CLUSTER_DISTANCE | CLUSTER_ID |
| CLUSTER_SET | * | * | * | * |
| FEATURE_DETAILS | FEATURE_ID | FEATURE_SET | ||
| FEATURE_VALUE | * | * | * | |
| * | ||||
| MATCH_RECOGNIZE | * | * | * | |
| PERCENTILE_CONT | PERCENTILE_DISC | PREDICTION | ||
| PREDICTION_COST | PREDICTION | PREDICTION_COST | PREDICTION_DETAILS | PREDICTION_PROBABILITY |
| PREDICTION_SET | REGR_ (Linear Regression) Functions * | |||
| * | * | * | * | * |
| SUM * | * | * | * | String Aggregation |
| Top-N Queries |
For more information see:
- LISTAGG Analytic Function
- LISTAGG DISTINCT in Oracle Database 19c
Hope this helps. Regards Tim…