
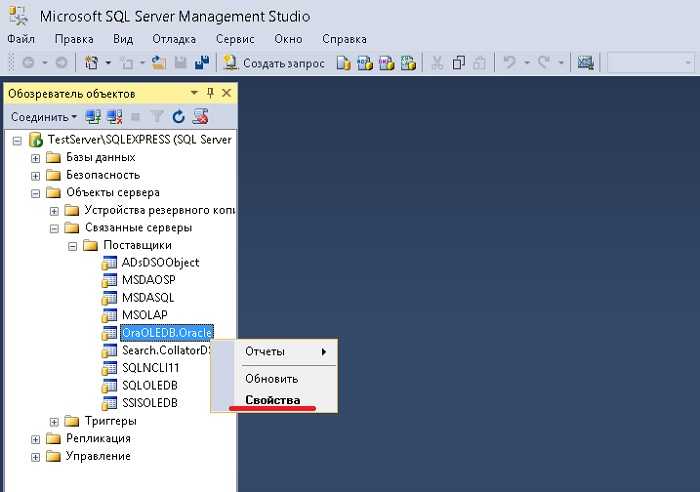
Использование SELECT и предикатов IN, OR, BETWEEN, LIKE
Предикаты — слова IN, OR, BETWEEN, LIKE в секции WHERE — также позволяют выбрать определённые диапазоны значений (IN, OR, BETWEEN) или
значения в строках (LIKE), которые требуется выбрать из таблицы. Запросы с предикатами IN, OR, BETWEEN имеют
следующий синтаксис:
SELECT ИМЯ_СТОЛБЦА FROM ИМЯ_ТАБЛИЦЫ
WHERE ЗНАЧЕНИЕ
ПРЕДИКАТ (IN, OR, BETWEEN) (ЗНАЧЕНИЯ, УКАЗЫВАЮЩИЕ ДИАПАЗОН)
Запросы с предикатом LIKE имеют следующий синтаксис:
SELECT ИМЯ_СТОЛБЦА FROM ИМЯ_ТАБЛИЦЫ
WHERE ИМЯ_СТОЛБЦА LIKE
ВЫРАЖЕНИЕ
Пример 7. Пусть требуется выбрать из таблицы Staff имена, должности
и число отработанных лет сотрудников, работающих в отделах с номерами 20 или 84.
Это можно сделать следующим запросом (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Dept IN (20, 84)
Результат выполнения запроса:
На сайте есть подробный урок об использовании предиката IN.
Пример 8. Пусть теперь требуется выбрать из таблицы Staff те же данные,
что и в предыдущем примере. Запрос со словом OR аналогичен запросу со словом IN и перечислением интересующих
значений в скобках. Запрос будет следующим (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Dept=20 OR Dept=84
Пример 9. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, зарплата которых между 15000 и 17000 включительно (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Salary BETWEEN 15000 AND 17000
Результат выполнения запроса:
На сайте есть подробный урок об использовании предиката BETWEEN.
Предикат LIKE используется для выборки тех строк, в значениях которых встречаются символы, указанные
после предиката между апострофами (‘).
Пример 10. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, имена которых начинаются с буквы S и состоят из 7 символов
(на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Name LIKE ‘S_ _ _ _ _ _’
Символ подчёркивания (_) означает любой символ. Результат выполнения запроса:
Пример 11. Выберем из той же таблицы имена, должности
и число отработанных лет сотрудников, имена которых начинаются с буквы S и содержат любые другие буквы
в любом количестве (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Name, Job, Years
FROM Staff
WHERE Name LIKE ‘S%’
Символ процентов (%) означает любое количество символов. Результат выполнения запроса:
На сайте есть подробный урок об использовании предиката LIKE.
Значения, указанные с использованием предикатов IN, OR, BETWEEN, LIKE можно инвертировать при помощи
слова NOT. Тогда запрашиваемые данные будут иметь противоположный смысл. Если мы используем NOT IN (20, 84),
то будут выведены данные сотрудников, которые работают во всех отделах, кроме имеющих номера 20 и 84.
С использованием NOT BETWEEN 15000 AND 17000 можно получить данные сотрудников, зарплата которых не
входит в интервал от 15000 до 17000. Запрос с NOT LIKE выведет данные сотрудников, чьи имена не начинаются
или не содержат символов, указанных с NOT LIKE.
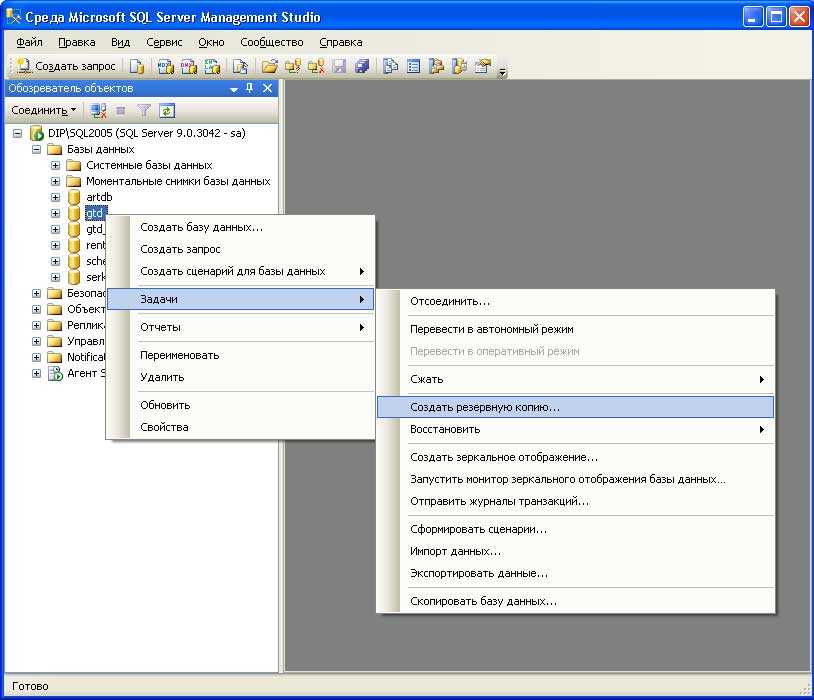
Преимущества использования отслеживания измененных данных или отслеживания изменений
Возможность выполнять запросы к измененным данным в базе данных — важное условие для эффективной работы некоторых приложений. Обычно для определения изменений данных разработчикам приложений приходилось реализовывать в своих приложениях специальный метод отслеживания, использующий сочетание триггеров, столбцов отметок времени и дополнительных таблиц
Создание таких приложений обычно связано с большими трудозатратами, требует обновлений схемы и часто вызывает серьезное снижение производительности.
Использование функций отслеживания измененных данных или отслеживания изменений в приложениях для отслеживания изменений в базах данных, вместо разработки специализированного решения, имеет следующие преимущества.
-
Сокращение времени проектирования. Поскольку функции реализованы в SQL Server 2019 (15.x), не нужно разрабатывать собственное решение.
-
Изменения схемы не нужны. Не требуется добавлять столбцы, триггеры или создавать дополнительные таблицы, в которых будут отслеживаться удаленные строки или храниться информация об отслеживании изменений, если столбцы невозможно добавить в пользовательские таблицы.
-
Имеется встроенный механизм очистки. Очистка для отслеживания изменений выполняется автоматически в режиме в сети. Специальная очистка для данных, хранимых в побочной таблице, не требуется.
-
Для получения сведений об изменениях предоставляются функции.
-
Накладные затраты при операциях DML невелики. Синхронному отслеживанию изменений всегда сопутствуют некоторые затраты. Однако отслеживание изменений может помочь снизить затраты. Затраты часто оказываются меньше, чем при использовании альтернативных решений, особенно решений с использованием триггеров.
-
-
Отслеживание изменений основано на зафиксированных транзакциях. Порядок изменений основан на времени фиксации транзакции. Это позволяет получить надежные результаты при наличии долго выполняемых и перекрывающихся транзакций. Пользовательские решения, в которых используются значения timestamp , должны проектироваться специально для обработки таких ситуаций.
-
Доступны стандартные средства, которые вы можете использовать для настройки и управления. SQL Server 2019 (15.x) предоставляет стандартные инструкции DDL, среду SQL Server Management Studio, представления каталогов и разрешения безопасности.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Ректальное администрирование: Основы для практикующих системных АДминистраторов
Одной из самых популярных и зарекомендовавших себя методологий системного администрирования является так называемое ректальное. Редкий случай сопровождения и обслуживания информационных систем, инфраструктуры организации обходится без его использования. Зачастую без знания данной методологии сисадминам даже бывает сложно найти работу в сфере ИТ, потому что работодатели, особенно всякие аутсорсинговые ИТ фирмы, в основном отдают предпочтение классическим, зарекомендовавшим себя методикам, а не новомодным заграничным веяниям: практикам ITIL, нормальным ITSM и прочей ерунде.
Предикат SQL IN и набор значений, возвращаемых подзапросом
Часто требуется выбрать строки, значения столбцов в которых соответствуют большому набору данных и этот
набор не всегда известен специалисту по работе с базой данных. Тогда составляются сложные запросы, в
которых в скобках после предиката IN пишется подзапрос (вложенный запрос). По набору значений,
возвращаемому этим подзапросом и происходит отбор строк в основном запросе. Иногда такие сложные запросы
могут иметь несколько уровней вложения. Синтаксис запроса с подзапросами следующий:
SELECT ИМЕНА_СТОЛБЦОВ FROM ИМЯ_ТАБЛИЦЫ
WHERE ИМЯ_СТОЛБЦА
IN (SELECT ИМЕНА_СТОЛБЦОВ FROM ИМЯ_ТАБЛИЦЫ )
Далее будем работать с базой данных библиотеки. Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными —
в файле по этой ссылке.
Пример 4. Итак, есть база данных библиотеки и её таблица «Книга в
пользовании» (Bookinuse). Столбец Customer_ID содержит идентификационный номер пользователя.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т.1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Определить ID пользователей, которым выданы книги
авторов, книги которых выданы пользователю с ID 31. Запрос будет следующим:
SELECT DISTINCT Customer_ID
FROM Bookinuse WHERE Author IN (SELECT
Author FROM Bookinuse
WHERE Customer_ID=31)
Результатом выполнения запроса будет следующая таблица:
| Customer_ID |
| 31 |
| 120 |
| 65 |
| 205 |
Внутренний запрос (после IN) выбирает авторов: Чехов; Ильф и Петров. Внешний запрос
выбирает всех пользователей, которым выданы книги этих авторов. Видим, что, в отличие от предиката EXISTS,
предикат IN предваряется именем столбца, в данном случае — Author.
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору GROUP BY,
предикату EXISTS и функциям
CONCAT, COALESCE.
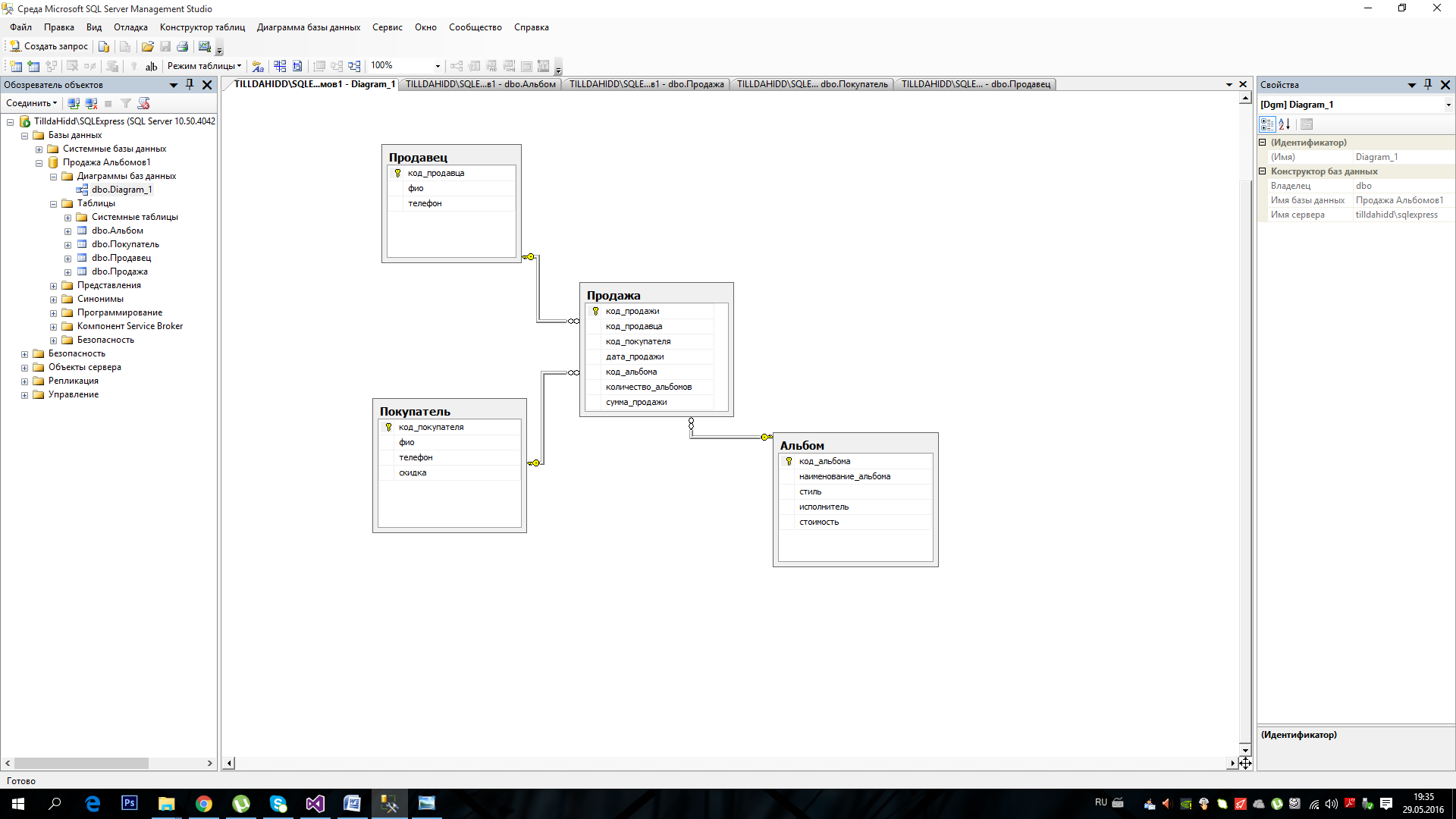
В следующих примерах работаем с базой данных «Театр». Таблица Play содержит данные о постановках. Таблица Team —
о ролях актёров. Таблица Actor — об актёрах. Таблица Director — о режиссёрах. Поля таблиц, первичные
и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).
![]()
Пример 5. Вывести актёрский состав спектакля «War of the Roses».
Пишем следующий запрос с двумя подзапросами:
SELECT FName, LName
FROM ACTOR WHERE Actor_ID IN (SELECT
Actor_ID FROM Team
WHERE Play_ID=(SELECT
Play_ID FROM Play
WHERE Name=’War of the Roses’))
Второй по уровню вложенности запрос возвращает идентификаторы актёров. Они и
принимаются предикатом IN и по этому набору происходит отбор строк во внешнем запросе.
Написать запросы с предикатом IN самостоятельно, а затем посмотреть решения
Пример 6. Вывести список актёров, которые не разу не были
утверждены на главную роль. В таблице team данные о главных ролях содержатся в столбце mainteam.
Если роль — главная, то в соответствующей строке отмечено ‘Y’.
Пример 7. Вывести список актеров, которые играли во всех
спектаклях WilliamShakespeare. Данные об авторах содержается в таблице play в столбце author.
Пишем вместе ещё один запрос с предикатом IN
Пример 8. Вывести список актёров, которые не задействованы
в постановках последних 3 лет.
Пишем следующий запрос с двумя подзапросами:
SELECT FName, LName
FROM ACTOR WHERE Actor_ID NOT IN (SELECT
Actor_ID FROM Team
WHERE Play_ID IN (SELECT
Play_ID FROM Play
WHERE Premieredate > (CURDATE() — 3 YEAR)))
Предикат IN используется два раза. Первый раз (причём с отрицанием NOT) — со вторым по уровню вложенности
запросом, который возвращает идентификаторы актёров. Второй раз — с третьим по уровню вложенности запросом,
котрый возвращает идентификаторы постановок.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Запросы с предикатом EXISTS к двум таблицам
Запросы с предикатом EXISTS могут извлекать данные из более чем одной таблицы. Многие задачи можно с
тем же результатом решить с помощью оператора JOIN,
но в ряде случаев использование EXISTS позволяет составить менее громоздкий запрос. Использовать EXISTS
предпочительнее в тех случаях, когда в результирующую таблицу попадут столбцы лишь из одной таблицы.
В следующем примере из той же базы данных помимо таблицы BOOKINUSE потребуется также таблица
«Пользователь» (CUSTOMER).
| Customer_ID | Surname |
| 18 | Зотов |
| 31 | Перов |
| 47 | Васин |
| 65 | Тихонов |
| 120 | Краснов |
| 205 | Климов |
Пример 6. Определить авторов, книги которых выданы пользователю
по фамилии Краснов. Пишем следующий запрос, в котором предикатом EXISTS задано единственное условие:
SELECT DISTINCT Author
FROM Bookinuse bk
WHERE EXISTS (SELECT *
FROM Customer cs
WHERE cs.Customer_ID=bk.Customer_ID
AND Surname=’Краснов’)
Результатом выполнения запроса будет следующая таблица:
| Author |
| Чехов |
| Маяковский |
| Пастернак |
Как и в случае использования оператора JOIN, в случаях более одной таблицы следует
использовать псевдонимы таблиц для проверки соответствия значений ключей, соединяющих таблицы.
В нашем примере псевдонимы таблиц — bk и us, а ключ, соединяющий таблицы — User_ID.
Примеры запросов к базе данных «Библиотека» есть также в уроках по операторам GROUP BY,
IN и функциям
CONCAT, COALESCE.
Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Основы вложенных запросов
Вложенный запрос по-другому называют внутренним запросом или внутренней операцией выбора, в то время как инструкцию, содержащую вложенный запрос, называют внешним запросом или внешней операцией выбора.
Многие инструкции языка Transact-SQL, включающие подзапросы, можно записать в виде соединений. Другие запросы могут быть осуществлены только с помощью подзапросов. В языке Transact-SQL обычно не бывает разницы в производительности между инструкцией, включающей вложенный запрос, и семантически эквивалентной версией без вложенного запроса. Дополнительные сведения о том, как SQL Server обрабатывает запросы, см. в разделе . Однако в некоторых случаях, когда проверяется существование, соединения показывают лучшую производительность. В противном случае для устранения дубликатов вложенный запрос должен обрабатываться для получения каждого результата внешнего запроса. В таких случаях метод работы соединений дает лучшие результаты.
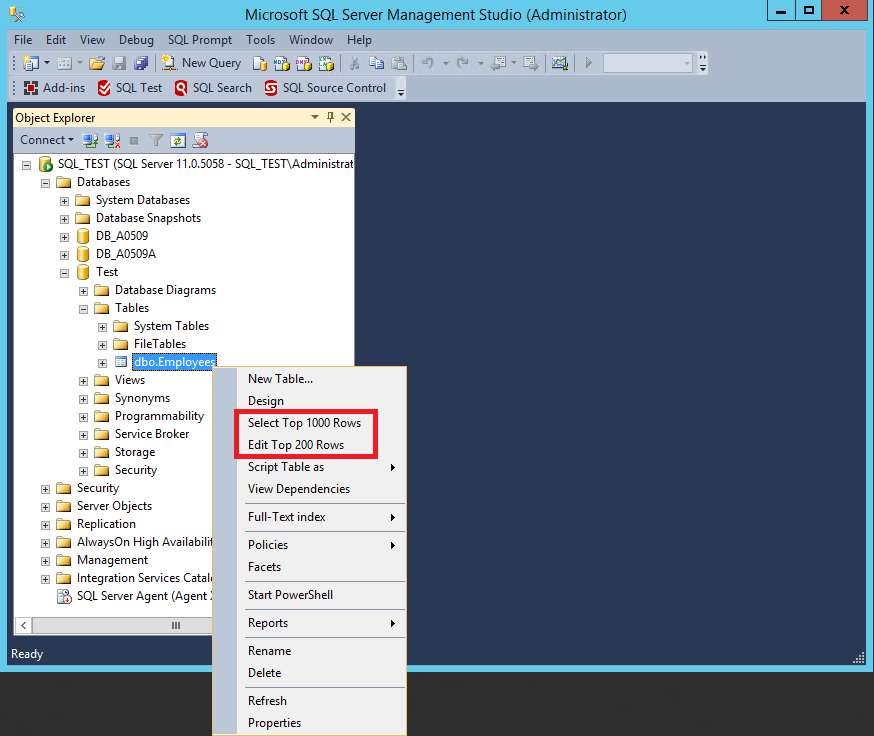
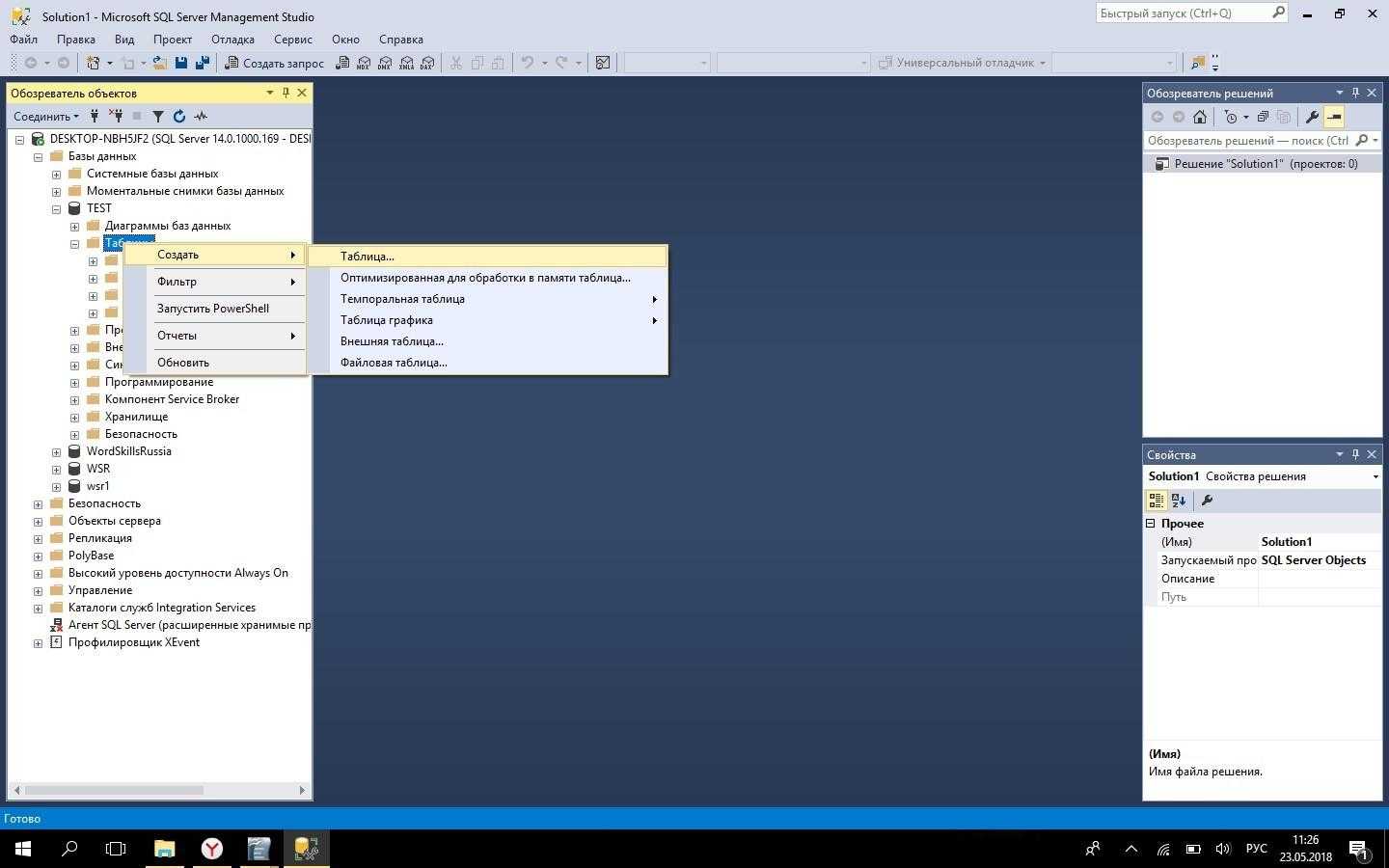
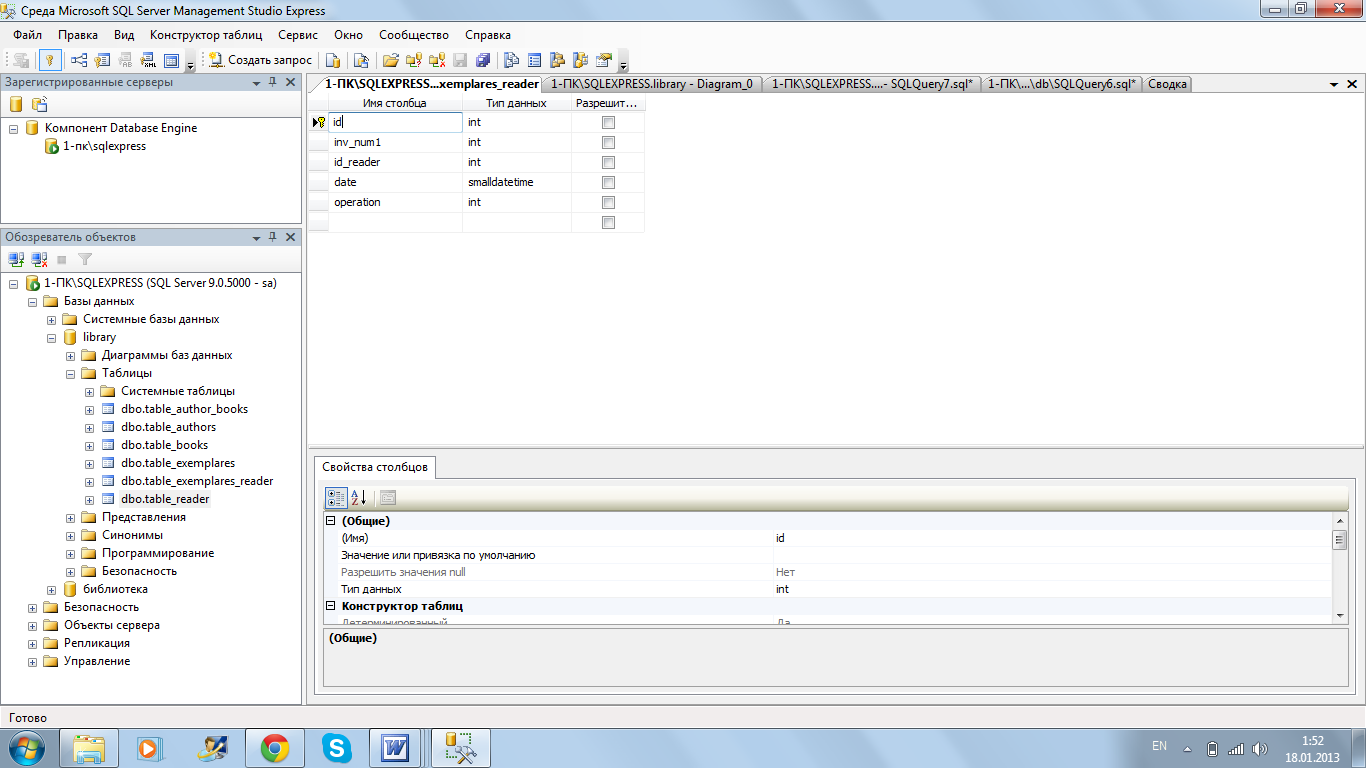
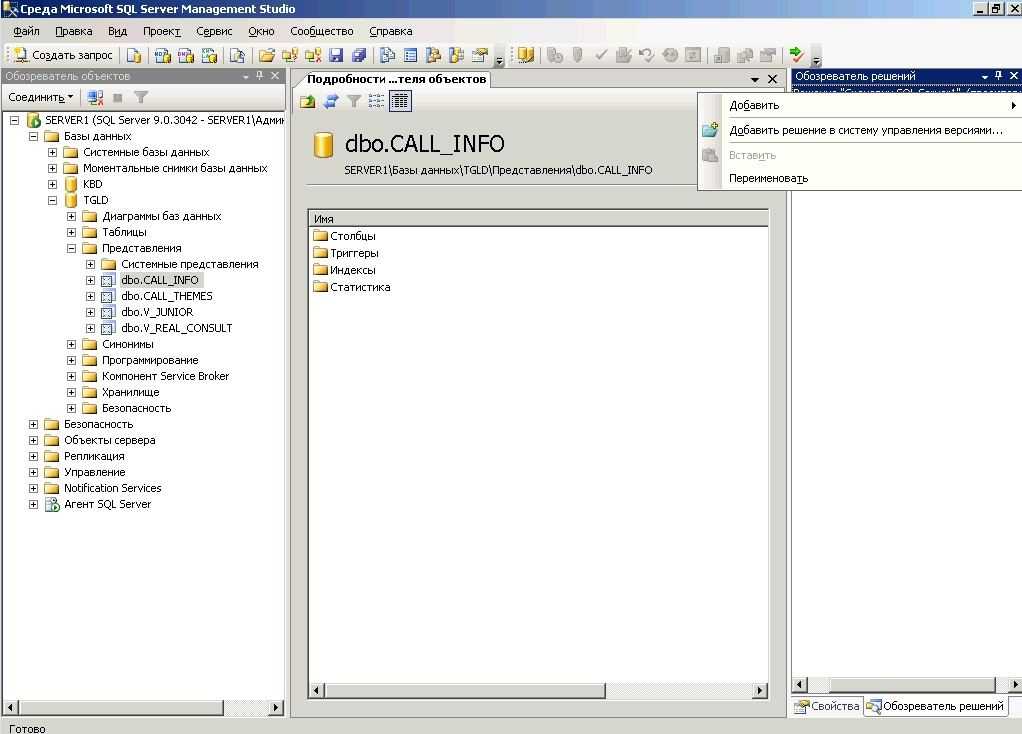
В следующем примере используются вложенный запрос и соединение , которые возвращают один и тот же результирующий набор и план выполнения:
Вложенный во внешнюю инструкцию SELECT запрос, имеет следующие компоненты:
- обычный запрос , включающий обычные компоненты списка выборки;
- обычное предложение , включающее одно или несколько имен таблиц или представлений.
- Необязательное предложение .
- Необязательное предложение .
- Необязательное предложение .
Запрос SELECT вложенного запроса всегда заключен в скобки. Он не может включать предложения или и может включать предложение только вместе с предложением TOP.
Вложенный запрос может быть включен в предложение или внешней инструкции , , или или в другой вложенный запрос. Возможно создавать вложенность до 32-го уровня, хотя ограничения меняются в зависимости от объема доступной памяти и сложности других выражений в запросе. Отдельные запросы могут не поддерживать вложенность до 32-го уровня. Подзапрос может появляться везде, где может использоваться выражение, если он возвращает одно значение.
Если таблица появляется только во вложенном запросе, а не во внешнем запросе, в этом случае столбцы данной таблицы не могут быть включены в выходные данные (список выборки внешнего запроса).
Инструкции, включающие вложенные запросы, обычно имеют один из следующих форматов:
В некоторых инструкциях языка Transact-SQL вложенный запрос может рассматриваться как отдельный запрос. Обычно результаты вложенного запроса подставляются во внешний запрос (хотя SQL Server может обрабатывать инструкции Transact-SQL с вложенными запросами и по-другому).
Существуют три основных типа подзапросов, которые:
- работают в списках, указанных с помощью ключевого слова , или тех, которые оператор сравнения изменил с помощью ключевого слова или ;
- вставлены оператором немодифицированных сравнений и должны возвращать одно значение;
- являются проверками на существование, начинающимися с ключевого слова .
Ограничения типа данных hierarchyid
Тип данных hierarchyid имеет следующие ограничения.
-
Столбец типа hierarchyid не принимает древовидную структуру автоматически. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.
-
Иерархические связи, представленные значениями типа hierarchyid , не обеспечиваются и не проверяются, как связи по внешнему ключу. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.
Аргументы
table_type_definition
То же подмножество данных, которое используется для определения таблицы с помощью инструкции CREATE TABLE. Декларация таблицы включает определения столбцов, имен, типов данных и ограничений. К допустимым типам ограничений относятся только PRIMARY KEY, UNIQUE KEY и NULL.
Дополнительные сведения о синтаксисе см. в статьях CREATE TABLE (Transact-SQL), CREATE FUNCTION (Transact-SQL) и DECLARE @local_variable (Transact-SQL).
collation_definition
Параметры сортировки столбцов, состоящие из поддерживаемых Microsoft Windows языкового стандарта и стиля сопоставления, языкового стандарта Windows и двоичной записи или параметров сортировки Microsoft SQL Server. Если значение аргумента collation_definition не задано, столбец наследует параметры сортировки текущей базы данных. Либо, если столбец определен как имеющий определяемый пользователем тип данных среды CLR, он унаследует параметры сортировки этого определяемого пользователем типа.
ограничения
Для переменных Table не предусмотрена статистика распределения. Они не будут вызывать перекомпиляцию. Во многих случаях оптимизатор строит план запроса на предположении, что у табличной переменной нет строк
По этой причине следует проявлять осторожность относительно использования табличной переменной, если ожидается большое число строк (больше 100). В этом случае временные таблицы могут быть предпочтительным решением
Для запросов, которые объединяют табличную переменную с другими таблицами, используйте указание RECOMPILE, чтобы оптимизатор использовал правильную кратность для табличной переменной.
Переменные table не поддерживаются в модели выбора на основе затрат оптимизатора SQL Server. Поэтому их не нужно использовать, если требуется принять решение на основе затрат, чтобы получить эффективный план запроса. Временные таблицы являются предпочтительными при необходимости осуществления выбора с учетом затрат. Этот план обычно включает запросы с соединениями, решения в отношении параллелизма и варианты выбора индекса.
Запросы, изменяющие переменные table, не создают параллельных планов выполнения запроса. При изменении больших переменных table или переменных table в сложных запросах может снизиться производительность. В ситуациях с изменением переменных table мы рекомендуем использовать временные таблицы. Дополнительные сведения см. в разделе CREATE TABLE (Transact-SQL). Запросы, которые считывают переменные table, не изменяя их, могут выполняться параллельно.
Важно!
Уровень совместимости базы данных 150 повышает производительность табличных переменных с введением отложенной компиляции табличных переменных. См. дополнительные сведения об .
Для переменных table нельзя явно создавать индексы, при этом статистика для переменных table не сохраняется. Начиная с SQL Server 2014 (12.x), реализован новый синтаксис, который позволяет создавать определенные встроенные типы индекса с использованием определения таблицы. С помощью этого нового синтаксиса можно создавать индексы в переменной table как часть определения таблицы. В некоторых случаях можно добиться повышения производительности за счет использования временных таблиц, которые позволяют работать с индексами и статистикой. Дополнительные сведения о временных таблицах и создании встроенных индексов см. в руководстве по использованию CREATE TABLE (Transact-SQL).
Ограничения CHECK, значения DEFAULT и вычисляемые столбцы в объявлении типа table не могут вызывать определяемые пользователем функции.
Операция присвоения между переменными table не поддерживается.
Так как переменные table имеют ограниченную область действия и не являются частью постоянной базы данных, они не изменяются при откатах транзакций.
Табличные переменные нельзя изменить после их создания.
Предикат EXISTS в соединениях более двух таблиц
Сейчас мы увидим более предметно, почему использовать EXISTS
предпочительнее в тех случаях, когда в результирующую таблицу попадут столбцы лишь из одной таблицы.
Работаем с базой данных «Недвижимость». Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными —
в файле по этой ссылке.
Таблица Deal содержит данные о сделках. Для наших
заданий в этой таблице будет важен столбец Type с данными о типе сделки — продажа или аренда. Таблица
Object содержит данные об объектах. В этой таблице нам понадобятся значения столбцов Rooms (число комнат) и LogBalc, содержащего
данные о наличии лоджии или балкона в булевом формате: 1 (да) или 0 (нет). Таблицы Client, Manager и Owner
содержат данные соответственно о клиентах, менеджерах фирмы и собственниках объектов недвижимости. В этих
таблицах FName и LName соответственно имя и фамилия.
![]()
Пример 7. Определить клиентов, купивших или взявших в аренду
объекты, у которых нет лоджии или балкона. Пишем следующий запрос, в котором предикатом EXISTS
задано обращение к результату соединения двух таблиц:
SELECT cl.* FROM Client cl
WHERE EXISTS (SELECT 1
FROM Deal de JOIN Object ob
ON ob.Obj_ID=de.Object_ID
WHERE de.Client_ID=cl.Client_ID
AND ob.LogBalc=0)
Так как из таблицы Client столбцы выбираются при помощи оператора «звёздочка», то
будут выведены все столбцы этой таблицы, в которой будет столько строк, сколько насчитывается клиентов,
соответствующих условию, заданному предикатом EXISTS. Из таблиц, к соединению которых обращается вложенный
запрос, нам не требуется выводить ни одного столбца. Поэтому для экономии машинного времени извлекается
лишь один столбец. Для этого после слова SELECT прописана единица. Этот же приём применён и в запросах
в следующих примерах.
Продолжаем писать вместе запросы SQL с предикатом EXISTS
Пример 9. Определить собственников объектов, которые были
взяты в аренду. Пишем следующий запрос, в котором предикатом EXISTS также
задано обращение к результату соединения двух таблиц:
SELECT ow.* FROM Owner ow
WHERE EXISTS (SELECT 1
FROM Object ob JOIN Deal de
ON de.Object_ID=ob.Obj_ID
WHERE ow.Owner_ID=ob.Owner_ID
AND de.Type=’rent’)
Как и в предыдущем примере, из таблицы, к которой обращён внешний запрос, будут
выведены все поля.
Пример 10. Определить число собственников, с объектами которых
провёл менеджер Савельев. Пишем запрос, в котором внешний запрос обращается к соединению трёх таблиц, а
предикатом EXISTS задано обращение лишь к одной таблице:
SELECT COUNT(*) FROM Object ob
JOIN Deal de ON
de.Object_ID=ob.Obj_ID
JOIN Owner ow ON
ob.Owner_ID=ow.Owner_ID
WHERE EXISTS (SELECT 1
FROM Manager ma WHERE
de.Manager_ID=ma.Manager_ID
AND ma.LName=’Савельев’)
Все запросы проверены на существующей базе данных. Успешного использования!
Примеры запросов к базе данных «Недвижимость» есть также в уроках по операторам GROUP BY и IN.
Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Основные свойства типа hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии. Значения hierarchyid обладают следующими свойствами.
-
Исключительная компактность
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла. Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.
-
Сравнение проводится в порядке приоритета глубины
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом. Например, потомки некоторой записи хранятся рядом с этой записью.
-
Поддержка произвольных вставок и удалений
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее. Большинство операций вставки и удаления сохраняют свойство компактности. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.
Версии CE
В 1998 г. основное обновление CE входило в состав SQL Server 7.0. Уровень совместимости компонента был равен 70. Эта версия модели CE основана на четырех допущениях.
- Независимость: предполагается, что данные, распределенные по разным столбцам, независимы друг от друга, если нет доступных или используемых сведений о корреляции.
- Единообразие: отдельные значения равномерно распределены и имеют одинаковую частоту. Говоря точнее, отдельные значения равномерно распределены на каждом шаге и все значения имеют одинаковую частоту.
- Автономность (простая) : пользователи запрашивают существующие данные. Например, в случае соединения по равенству между двумя таблицами учитывайте избирательность предикатов 1 в каждой входной гистограмме перед соединением гистограмм для оценки избирательности соединения.
- Включение: для предикатов фильтра, где , предполагается, что константа фактически существует для связанного столбца. Если соответствующий шаг гистограммы не пуст, предполагается, что одно из конкретных значений шага совпадает со значением из предиката.
1 Число строк, удовлетворяющее предикат.
Последующие обновления выпущены вместе с SQL Server 2014 (12.x) с уровнем совместимости 120 и выше. Обновления CE для уровней 120 и выше включают обновленные допущения и алгоритмы, которые хорошо сочетаются с современными хранилищами данных и рабочими нагрузками OLTP. Из допущений CE 70 были изменены следующие допущения моделей, начиная с CE 120:
- Независимость стала корреляцией: комбинация разных значений столбцов, которые необязательно будут независимы. Это может напоминать более реальные запросы данных.
- Простая автономность стала базовой автономностью: пользователи могут запрашивать несуществующие данные. Например, в случае соединения по равенству между двумя таблицами используются гистограммы базовых таблиц для оценки избирательности соединений, а затем учитывается избирательность предикатов.





