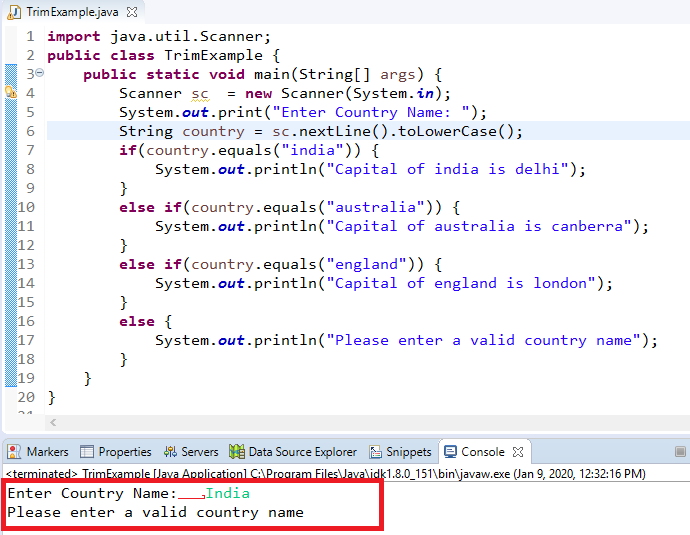
Удалите разрывы строк с помощью формул Excel.
Плюсы: вы можете использовать вложенные формулы для более сложной обработки текста в ячейках. Например, можно удалить символы перевода строки, а затем удалить лишние начальные и конечные пробелы, а также пробелы между словами.
Или вам может потребоваться удалить перевод строки, чтобы использовать ваш текст в качестве аргумента другой функции без изменения исходных ячеек. Например, если вы хотите использовать результат в качестве аргумента функции ВПР.
Минусы: вам нужно создать вспомогательный столбец и выполнить некоторое количество дополнительных действий.
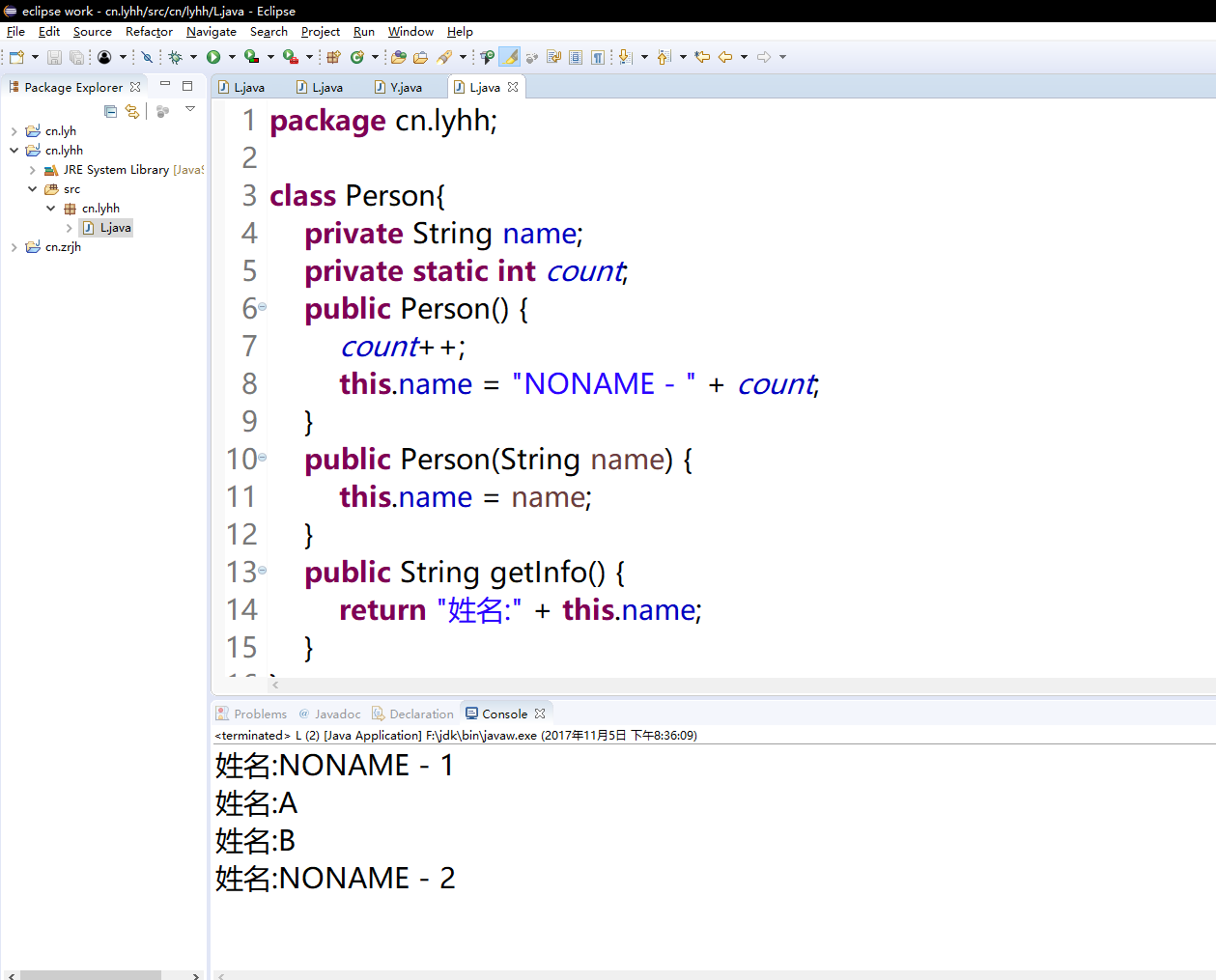
- Добавьте вспомогательный столбец в конец ваших данных. Вы можете назвать его «В одну строку».
- В первой его позиции (C2) введите формулу для удаления или замены переносов строк. Здесь мы представим вам несколько полезных формул для разных случаев:
Удаление возврата каретки и перевода строки как в Windows, так и в UNIX.
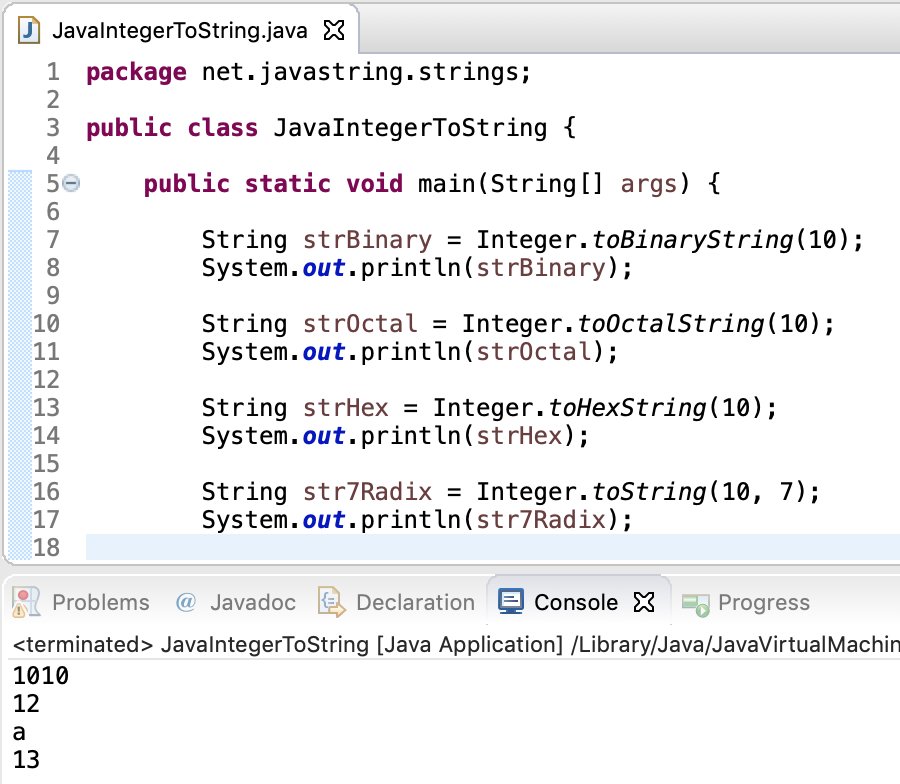
Заменяем перенос строки любым другим символом (например, запятая + пробел). В этом случае строки не будут «слипаться» и лишние пробелы не появятся.
Или же можно обойтись и без запятой, просто заменив пробелом:
Если вы хотите удалить из текста все непечатаемые символы, включая в том числе и переносы строк:
Как видите, не всегда результат выглядит красиво и аккуратно. В зависимости от исходных данных выбирайте наиболее подходящий для вас вариант.
При желании вы можете заменить исходный столбец на тот, в котором были удалены переносы строк:
- Выделите все данные в столбце В и нажмите , чтобы скопировать данные в буфер обмена.
- Теперь выберите А2 и нажмите .
- Удалите вспомогательный столбец В.
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string LTRIM(str string)
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string RTRIM(str string)
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.
Пример:
SELECT LTRIM (‘ текст ‘);
Результат: ‘текст ‘
SELECT RTRIM (‘ текст ‘);
Результат: ‘ текст’
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string TRIM( string FROM] str string)
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.
Пример:
SELECT TRIM (‘ текст ‘);
Результат: ‘текст’
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
Пример:
SELECT TRIM (BOTH ‘а’ FROM ‘текст’);
Результат: ‘текст’
SELECT TRIM (LEADING ‘а’ FROM ‘текстааа’);
Результат: ‘текстааа’
SELECT TRIM (TRAILING ‘а’ FROM ‘ааатекст’);
Результат: ‘ааатекст’
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string SPACE(n integer)
Возвращает строку, которая состоит из n пробелов.
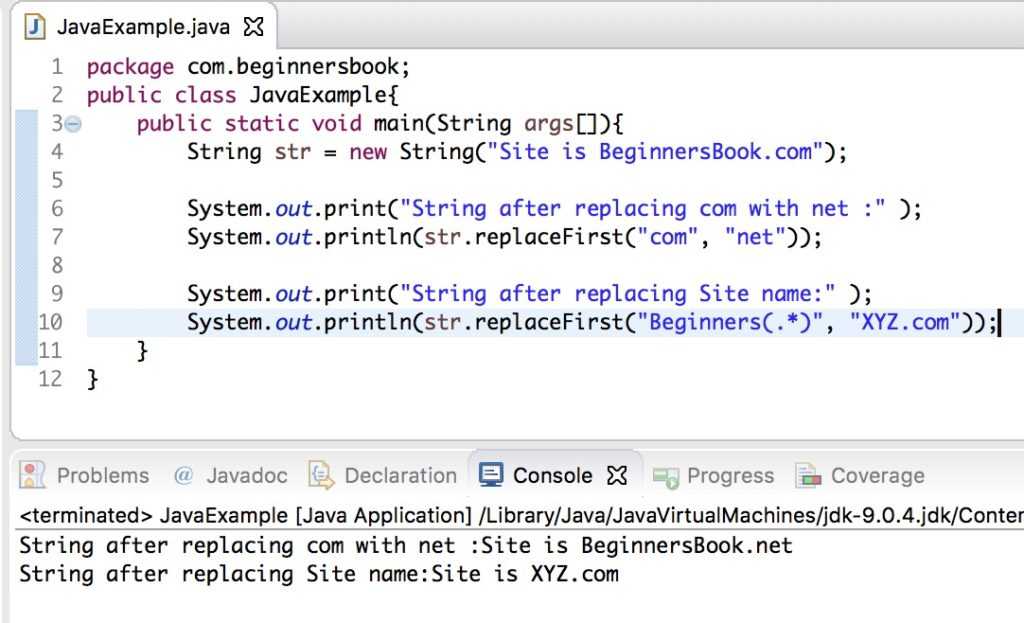
Функция REPLACE нужна для замены заданных символов в строке:
string REPLACE(str string, from_str string, to_str string)
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.
Пример:
SELECT REPLACE ( ‘замена подстроки’, ‘подстроки’, ‘текста’ )
Результат: ‘замена текста’
Функция REPEAT:
string REPEAT(str string, count integer)
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
Пример:
SELECT REPEAT (‘w’, 3);
Результат: ‘www’
Функция REVERSE переворачивает строку:
string REVERSE(str string)
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
Пример:
SELECT REVERSE (‘текст’);
Результат: ‘тскет’
Функция INSERT для вставки подстроки в строку:
string INSERT(str string, pos integer, len integer, newstr string)
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
Пример:
SELECT INSERT (‘text’, 2, 5, ‘MySQL’);
Результат: ‘tMySQL’
‘SELECT INSERT (‘text’, 2, 0, ‘MySQL’);
Результат: ‘tMySQLext’
SELECT INSERT (‘вставка текста’, 2, 7, ‘MySQL’);
Результат: ‘SELECT INSERT (‘вставка текста’, 2, 7, ‘MySQL’);’
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string LCASE(str string) и string LOWER(str string)
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
Пример:
SELCET LOWER (‘АБВГДеЖЗиКЛ’);
Результат:’абвгдежзикл’
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string UCASE(str string) и string UPPER (str string)
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:

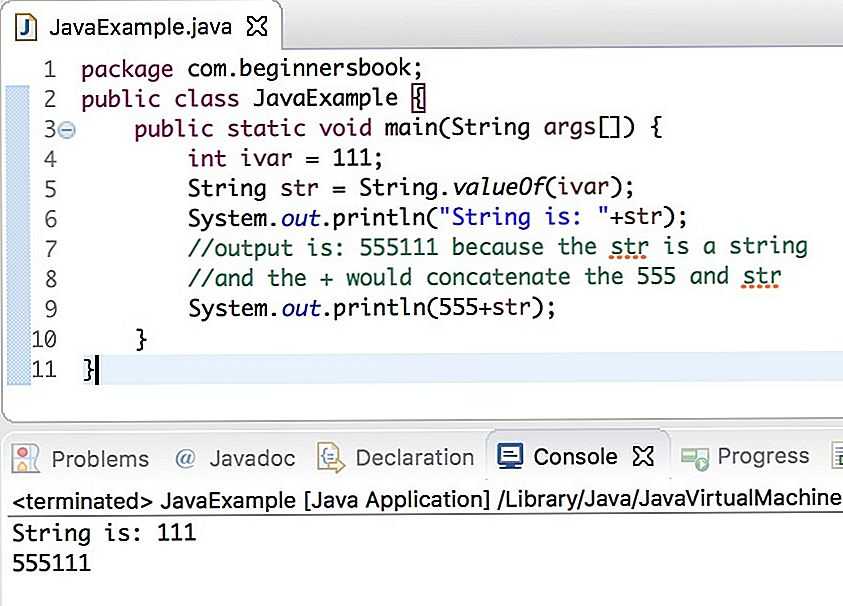


SELECT UPPER (‘Абвгдежз’);
Результат: ‘АБВГДЕЖЗ’
Меню Правка – Редактор Notepad++
Отмена – Позволяет отменить внесенные изменения в документ, комбинация «Ctrl + Z».
Повтор – Позволяет повторить действия, отмененные с помощью пункта Отмена, комбинация «Ctrl + Y».
Вырезать – Вырезать выделенный фрагмент, вырезанный фрагмент будет храниться в памяти, комбинация «Ctrl + X»
Копировать – Скопировать выделенный фрагмент в буфер обмена, комбинация «Ctrl + C».
Вставить – Вставить данные, которые хранятся в буфере обмена, комбинация «Ctrl + V».
Удалить – Позволяет удалить выделенный фрагмент, клавиша «DEL».
Выделить все – Выделяет весь текст, содержащийся в активном документе, комбинация «Ctrl + A».
Копирование в буфер обмена – Позволяет скопировать в буфер обмена данные про файл.
- Копировать Путь и Имя файла
- Копировать Имя файла
- Копировать Путь к файлу
Отступы(табуляция) – Работа с табуляцией.
- Вставить табуляцию – Клавиша «Tab».
- Удалить табуляцию – Просто перемещает курсор влево на число символов, равных табуляции, комбинация «Shift + Tab».
Преобразовать регистр – Позволяет изменить регистр выделенных символов.
- Прописные – Комбинация «Ctrl + Shift + U».
- Строчные – Комбинация «Ctrl + U».
Операции со строками – Данный пункт редактора Notepad++ и его подпункты позволяют производить различные манипуляции со строками текста.
- Дублировать текущую строку – Вставляет с новой строки содержимое текущей строки (строки, в которой находится курсор), комбинация «Ctrl + D».
- Разбить строки — Комбинация «Ctrl + I».
- Объединить строки – Позволяет объединить выбранные строки в одну строку, комбинация «Ctrl + J».
- Переместить строку вверх – Комбинация «Shift + Ctrl + Up».
- Переместить строку вниз – Комбинация «Shift + Ctrl + Down».
- Удалить пустые строки – Удаляет все пустые строки в редакторе кода Notepad++, однако, если в строке содержится знак табуляции или пробел, то она не будет считаться пустой.
- Удалить пустые строки(содержащие символы Пробел) – В данном случае, будут удаляться все строки, даже те, которые содержат пробелы и символы табуляции.
Комментарии – Данный пункт содержит несколько подпунктов, которые позволяют управлять комментариями в программном коде.
- Вкл./Выкл. Комментарий строки – Комбинация «Ctrl + Q»
- Закомментировать строку — Комбинация «Ctrl + K»
- Раскомментировать строку — Комбинация «Ctrl + Shift + K»
- Закомментировать выделение — Комбинация «Ctrl + Shift + Q»
Автозавершение – Данный пункт меню содержит несколько подпунктов, которые позволяют сократить время при вводе текста:
- Завершение функций – Позволяет включить отображение выпадающего списка, в котором будут отображаться возможные варианты для вводимой функции, или любой другой программной конструкции, комбинация «Ctrl + SpaceBar»
- Завершение слов – Тут также отображается список возможных слов, которые вы хотите ввести, список формируется из слов, которые уже содержаться в документе, комбинация «Ctrl + Enter»
- Подсказка по функциям — Комбинация «Ctrl + Shift + SpaceBar»
Формат конца строки – Меню позволяет задать код-символ, которым будет завершаться строка.
- Преобразовать в Win-формат – Символ CRLF
- Преобразовать в UNIX-формат – Символ LF
- Преобразовать в MAC-формат – Символ CR
Операции с пробелами – Возможность удалить пробелы в нужных местах.
- Убрать замыкающие пробела – Пробелы, которые находятся в конце строки.
- Убрать начальные пробела – Пробелы, которые находятся вначале строки
- Убрать замыкающие пробела – Пробелы, которые находятся вначале и в конце строки.
- Символ Конец строки в Пробел – Фактически, размещает все строки в одну, так как вместо символа перевода строки мы получим пробел.
- Убрать лишние пробелы и концы строк – Тут, фактически объединены два предыдущих пункта.
- Табуляцию в пробел – Символ табуляции преобразуется в пробел
- Пробел в табуляцию (Все) – Преобразует все пробелы в символ табуляции.
- Пробел в табуляцию (Заглавные) – Преобразует только пробелы в начале строк в символ табуляции.
Редактор столбцов…. – Данный пункт меню открывает диалоговое окно Редактор столбцов, в котором можно задать текст или нумерацию, которые будут вставлены в документ в виде столбика. Вставка произойдет с того места, где находится курсор и до конца последней строки с текстом.
Панель символов – Очень полезный пункт, так как он выводит панель, в которой содержатся символы и их ASCII коды.
Только чтение – Включает или отключает режим, в котором можно только просматривать выбранный документ.
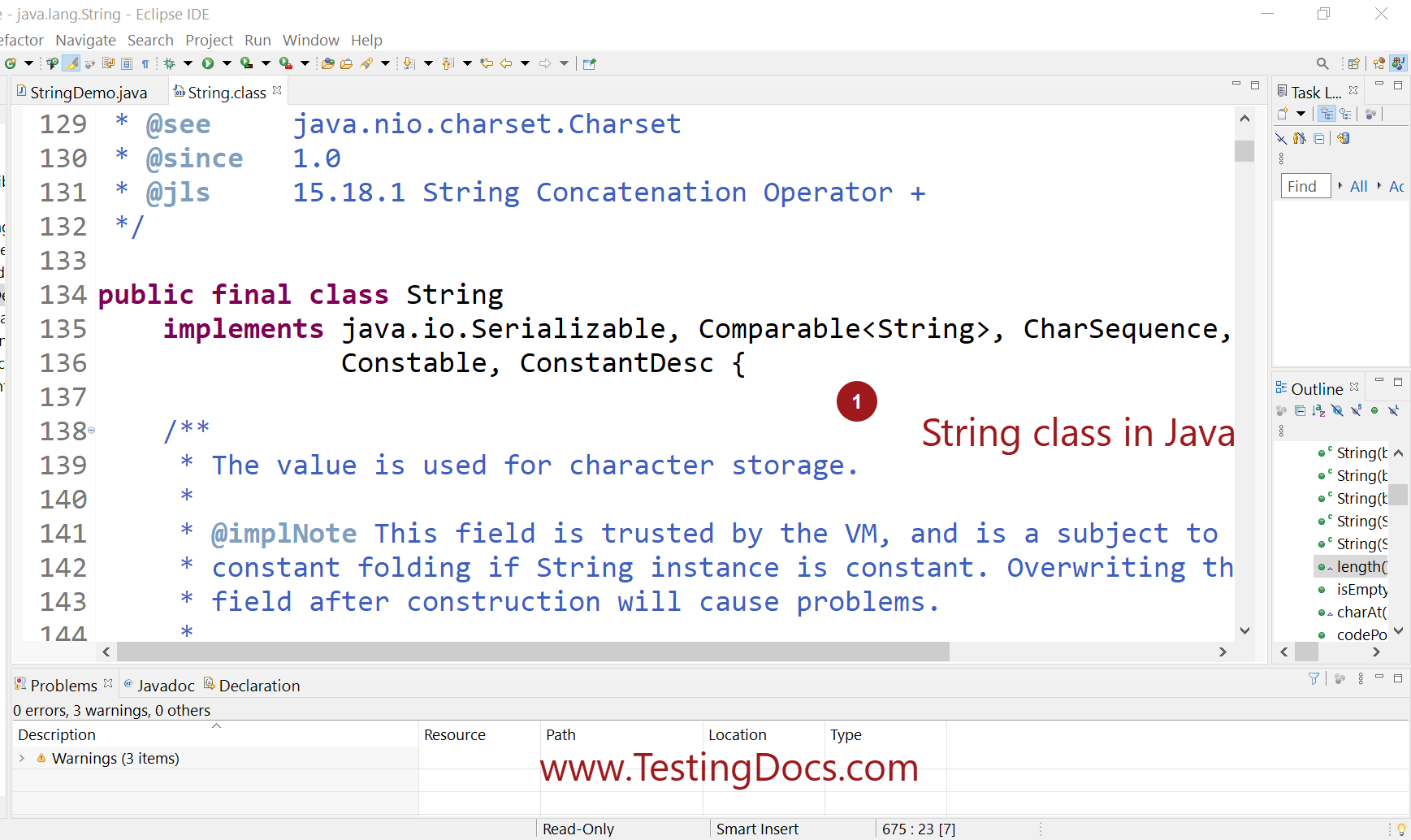
Notepad ++: удалить пробелы в текстовом документе
Используя любую версию программного обеспечения Notepad ++, вы сможете легко выполнить расширенную операцию удаления пробелов в блокноте, которая может применяться к любому тексту, файлу, выделенному тексту или группе файлов, всего несколькими щелчками мыши.
Если вы еще не сделали этого, начните с загрузки и установки последней версии замечательного приложения Notepad ++ бесплатно с их веб-сайта:
Затем либо откройте файл как текст, в котором вы хотите удалить пробелы или другие нежелательные символы, и перейдите в поле «Заменить» с помощью сочетания клавиш CTRL + H.
В окне «Заменить» введите пробел в поле «Найти» и убедитесь, что поле «Заменить на» остается пустым.
Затем вы можете выполнить расширенный Notepad ++ для удаления пробелов или другую операцию с символами:
- Замените следующее вхождение пробела в целевом отображаемом тексте, нажав кнопку «Заменить»,
- Замените все пробелы в целевом видимом текстовом файле, нажав кнопку «Заменить все»,
- Заменить только следующее или все вхождения в выделенном тексте, установив флажок «В выделенном» и выбрав функцию «Заменить» или «Заменить все»,
- Удалите пробелы во всех файлах Notepad ++, открытых в данный момент, нажав кнопку «Заменить все во всех открытых документах» — будьте осторожны, эту мощную операцию можно выполнить по ошибке, если вы нажмете эту кнопку вместо другой!
- Замените пробелы только от текущей позиции курсора до конца текста, сняв отметку с опции «Обтекать», что позволяет в противном случае применить операцию ко всему файлу.
После выбора операции, которая лучше всего работает в вашей ситуации, количество успешных операций удаления пробелов будет отображаться в поле состояния окна поиска и замены.
Идем дальше: используйте NotePad ++ для замены табуляции пробелами
В Notepad ++ можно выполнить замену вкладок пробелами таким образом: выберите вкладку с помощью мыши в тексте и скопируйте ее.
Затем откройте окно поиска и замены с помощью комбинации клавиш CTRL-H и вставьте вкладку, чтобы заменить ее пробелами в поле поиска, и введите пробел в поле замены.
Операция копирования и вставки необходима для копирования одной из вкладок для замены пробелов в Notepad ++, потому что, если вы попытаетесь ввести табуляцию, программа интерпретирует ее как сочетание клавиш для выделения следующего доступного поля в форме поиска. Поэтому, чтобы использовать Notepad ++ для замены табуляции пробелами, просто скопируйте табуляцию из текста и вставьте ее в поле поиска!
Часто задаваемые вопросы и ответы об удалении пробелов в Блокноте
- Как мне удалить блокнот по умолчанию?
- Измените ассоциацию файлов Windows10 для приложения Notepad, например, чтобы переключить его на отличный Notepad ++.
- Как изменить масштаб по умолчанию в блокноте?
- Используйте просмотр функций меню и масштабирование для увеличения или уменьшения масштаба.
- Какой шрифт используется в блокноте?
- В Блокноте используется шрифт «Lucida Console».
- Что означают цвета в Notepad ++ сравнить?
- Красный цвет в Notepad ++ compare означает, что строка отсутствует в другом файле, а зеленый цвет означает, что строка была добавлена в файл.
- Как заменить в блокноте?
- Заменить в Блокноте с помощью сочетания клавиш CTRL + H.
- Что такое символ LF в блокноте?
- Символ LF в Блокноте — это разрыв строки.
- Какой символ новой строки в блокноте?
- Символ новой строки в Блокноте — \ n.
- Как удалить Notepad ++?
- Вы можете удалить Notepad ++ с помощью приложения Windows10 «Установка и удаление программ».
- Как мне отсортировать в блокноте?
- Вам нужно скопировать и вставить текст из Блокнота, чтобы отсортировать его. Вы можете сортировать в Notepad ++, используя функции упорядочивания списка плагина TextFX Tools.
- Как выровнять текст в Notepad ++?
- Вы можете выровнять текст в Notepad ++, выделив текст для выравнивания и используя клавишу Tab на клавиатуре для выравнивания по правому краю и сочетание клавиш Shift + Tab для выравнивания выделенного текста по левому краю.
- Как удалить неотмеченные строки в Notepad ++?
- Используйте функцию поиска в меню, создания закладок, удаления отмеченных строк.
- Как заменить текст в Блокноте?
- Замените текст в Блокноте, используя функцию поиска и замены, доступную с помощью сочетания клавиш CTRL + H.
- Как мне найти Блокнот?
- Блокнот можно найти с помощью функции поиска Windows в левом нижнем углу экрана, справа от логотипа Windows.
- Как удалить текст после Notepad ++?
- Удалите определенный текст после заданной позиции символа в Notepad ++, выполнив поиск и заменив его с помощью CTRL + H в выделении, выделив текст после заданного символа и введя текст для удаления в поле поиска.
- Как мне перейти с Wordpad на Блокнот?
- Чтобы перейти с WordPad на Notepad, сохраните файл в Wordpad, закройте программу и откройте файл в Notepad. Если вы хотите, чтобы файлы по умолчанию открывались в Блокноте, подумайте об изменении ассоциации файлов.
 Кодируем символы с помошью ROT
Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор (это значит abcdefghijklmnopqrstuvwxyz). Второй набор (который содержит pqrstuvwxyzabcdefghijklmn).
tr 'a-z' 'p-za-n'
Простая команда для демонстрации вышеуказанной теории:
$ echo 'abg' | tr 'ab' 'ef' efg
Полезно при шифровании электронных адресов:
$ echo 'cryptography@example.com' | tr 'A-Za-z' 'N-ZA-Mn-za-m pelcgbtencul@rknzcyr.pbz
LEFT
Задачу обрезание лишних символов из начала строки можно было бы решить и с использованием функции LEFT, которая возвращает указанное количество символов, начиная с 1-го. Функции нужно передать следующие два параметра:
- Поле, подстроку которого нужно получить;
- Количество символов.
Следующий пример формирует ФИО, в котором имя и отчество сокращены:
SELECT vcFamil+' '+left(vcName, 1)+'. '+left(vcSurName, 1)+'.' FROM tbPeoples
Поле «vcFamil» выводится полностью, а вот от имени и отчества выводится только один левый (первый) символ.
Теперь посмотрим, как можно было использовать LEFT для обрезания префикса ‘mr.’:
UPDATE tbPeoples
SET vcFamil=(case LEFT(vcFamil, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
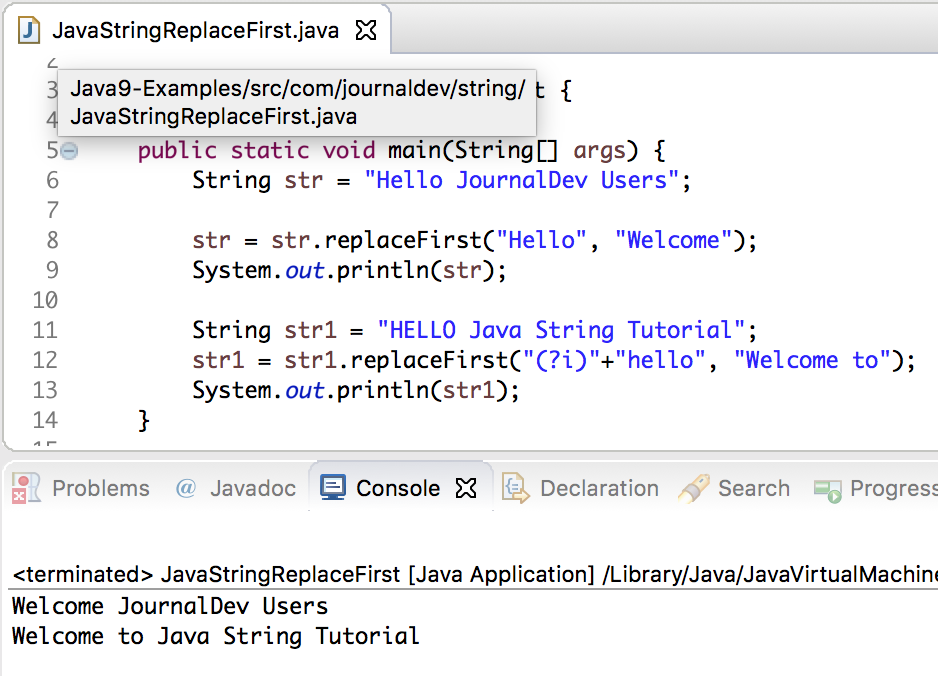
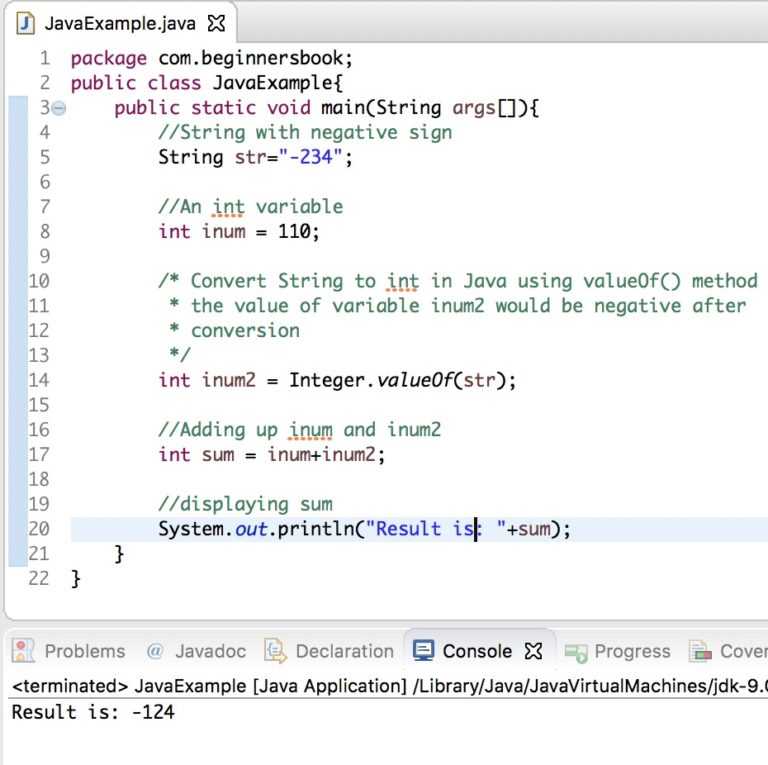
Как удалить разрыв строки и непечатаемые символы
В ходе переноса информации с других программ нередко появляются непечатаемые символы, которые выглядят, как пробел или же немного по-другому, но они занимают место в ячейке. Это разнообразные возвраты каретки, переводы строк, табуляция и так далее.
Описанная ранее функция СЖПРОБЕЛЫ прекрасно справляется с тем, чтобы убрать из ячейки пробелы, но она не подходит для очистки ее от непечатаемых символов. Фактически она нужна только для того, чтобы убирать символ с кодом 32 в ASCII таблице 7-битного разряда. Именно так кодируется этот символ. Но есть и значения с другими кодами, для которых нужно использовать функцию ПЕЧСИМВ. В английской локализации программы она называется CLEAN. Как мы можем понять из названия, с помощью этого оператора можно очистить ячейку от всевозможного хлама и удалять первые 32 непечатаемые символы.
Допустим, нам нужно убрать и пробелы, и непечатаемые символы в ячейке A2. В этом случае наша задача – использовать сначала формулу ПЕЧСИМВ для того, чтобы убрать непечатные знаки, после чего передать эту строку функции СЖПРОБЕЛЫ, которая убирает оставшиеся пробелы. Результат использования этой комбинации экселевских операторов мы видим на скриншоте.
По сути, каждый раз, когда с использованием описанного выше метода вы убираете разрывы строки, слова, разделенные ими, склеиваются. Как же исправить эту ситуацию?
- Открываем диалоговое окно «Найти и заменить» методом, описанным выше. В поле «Найти» указываем символ возврата каретки. Для этого вводим комбинацию клавиш Ctrl + J. В свою очередь, в поле «Заменить» используем символ пробела. Когда мы нажимаем кнопку «Заменить все» все разрывы автоматически заменяются на пробелы.
- Также можно заменять возврат каретки на пробелы с помощью этой формулы: =СЖПРОБЕЛЫ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(A2; СИМВОЛ(13);» «); СИМВОЛ(10); » «)) . Естественно, надо адрес ячейки в функции ПОДСТАВИТЬ заменить на тот, который нужен конкретно в вашей ситуации.
Как видим, теперь проблема с почтовым адресом оказалась успешно решенной.
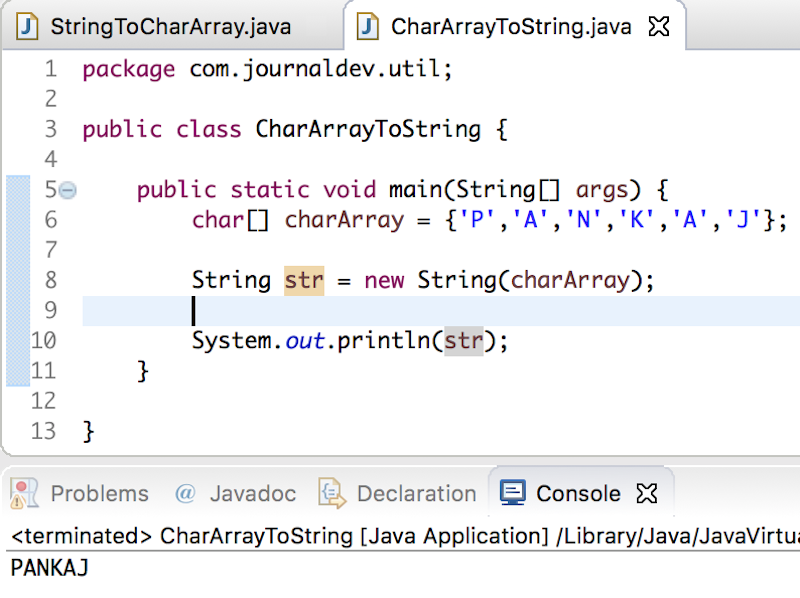
Использование различных
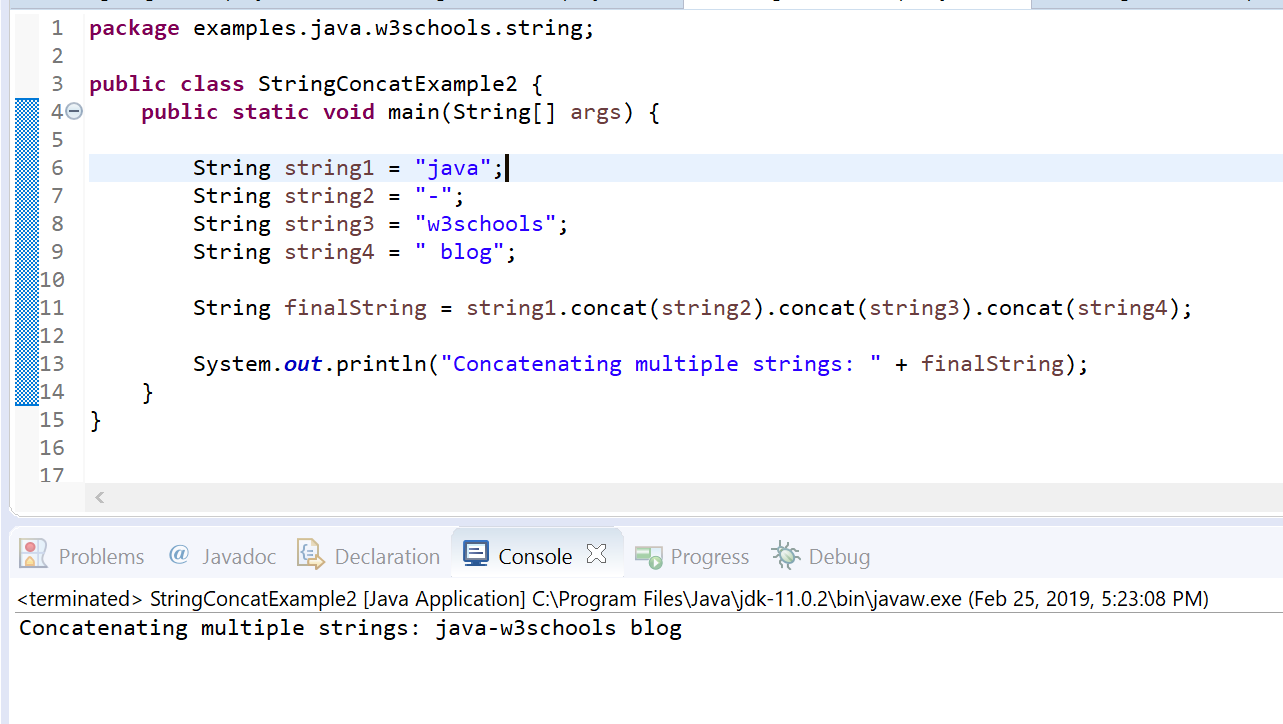
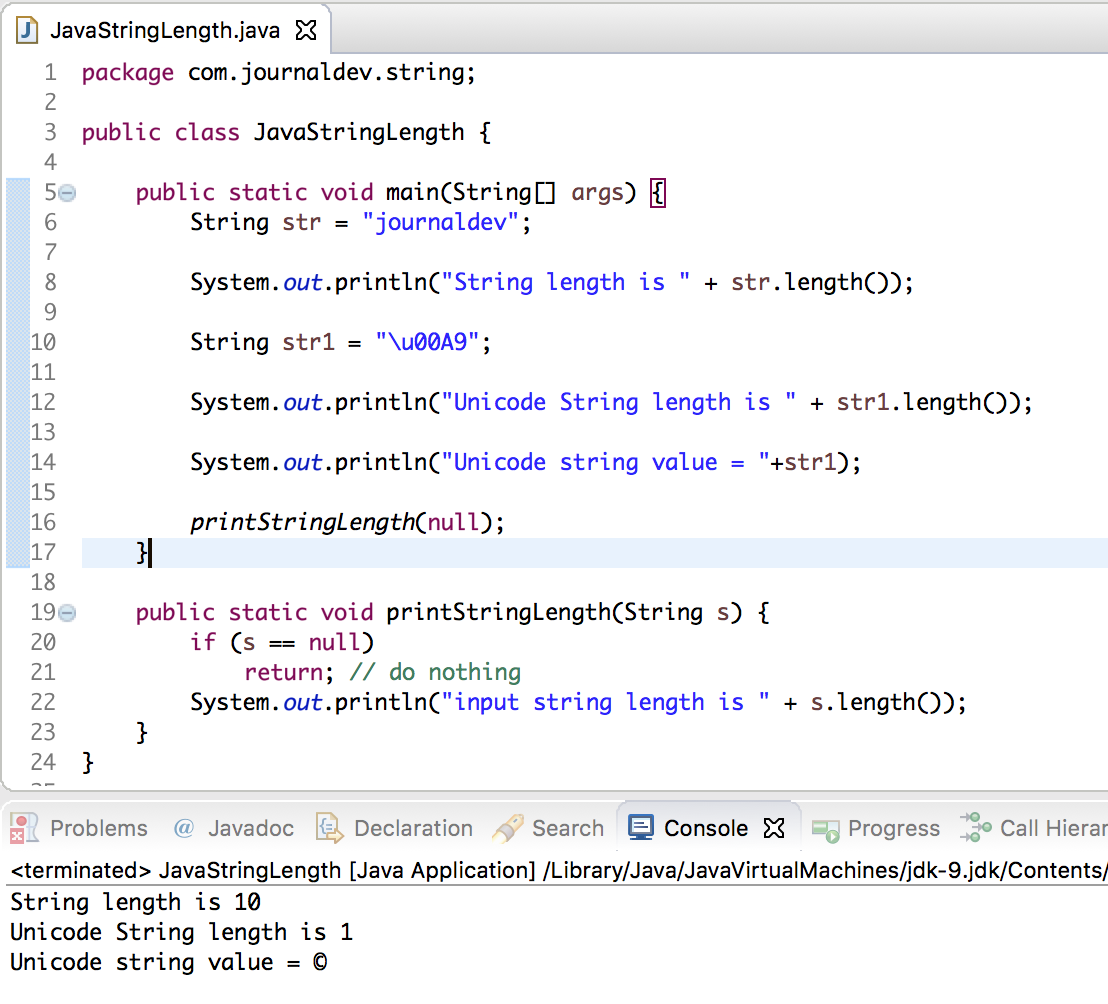
Давайте начнем с удаления дубликатов из вашей строки с помощью метода distinct , представленного в Java 8.
Ниже мы получаем экземпляр Int S stream из данного строкового объекта. Затем мы используем метод distinct для удаления дубликатов. Наконец, мы вызываем метод forEach , чтобы перебрать отдельные символы и добавить их в наш StringBuilder :
StringBuilder sb = new StringBuilder(); str.chars().distinct().forEach(c -> sb.append((char) c));
Временная сложность: O(n) – время выполнения цикла прямо пропорционально размеру входной строки
Вспомогательное пространство: |/O(n) – поскольку distinct использует LinkedHashSet внутренне, и мы также храним полученную строку в объекте StringBuilder
Поддерживает порядок: Да – так как LinkedHashSet поддерживает порядок своих элементов
И хотя приятно, что Java 8 так хорошо справляется с этой задачей, давайте сравним ее с усилиями по созданию нашей собственной.
LPAD, RPAD
Эти функции используются, чтобы дополнить строку
какими-либо символами до определенной длины.
(left padding) используется для дополнения строки символами слева,
а (right padding) — для дополнения справа.
select lpad('1', 5, '0') n1,
lpad('10', 5, '0') n2,
lpad('some_str', 10) n2_1,
rpad('38', 5, '0') n3,
rpad('3', 5, '0') n4
from dual
Первый параметр в этой функции — строка, которую нужно дополнить,
второй — длина строки, которую мы хотим получить, а третий — символы, которыми
будем дополнять строку. Третий параметр не обязателен, и если его не указывать,
то строка будет дополняться пробелами, как в колонке .
Класс StringUtils
Другим методом, который мы рассмотрим, является библиотека Apache Commons.
Во-первых, давайте добавим необходимую зависимость к нашему проекту:
org.apache.commonscommons-lang33.11
Последнюю версию библиотеки можно найти
СтрингУтилс класс имеет методы замены подразрядки Струнные :
String master = "Hello World Baeldung!"; String target = "Baeldung"; String replacement = "Java"; String processed = StringUtils.replace(master, target, replacement); assertTrue(processed.contains(replacement));
Существует перегруженный вариант заменить () что занимает более интегративную макс параметр, который определяет количество возникновений для замены. Мы также можем использовать заменитьИгнорКейс () если чувствительность к делу не является проблемой :
String master2 = "Hello World Baeldung!"; String target2 = "baeldung"; String processed2 = StringUtils.replaceIgnoreCase(master2, target2, replacement); assertFalse(processed2.contains(target));
7 ответов
Лучший ответ
Попробуйте использовать Linq , чтобы отфильтровать пробелы:
Результат :
21
Dmitry Bychenko
22 Сен 2017 в 13:04
Ответ на этот вопрос не так прост, как кажется. Проблема не в том, чтобы на самом деле кодировать замену, а в том, чтобы определить, что такое пробел.

Например, в перечислены десятки символов (кодовые точки Unicode), которые имеют Атрибут Unicode , а также множество связанных символов, которые большинство людей считают пустым пространством, но которые не имеют атрибута .
Учитывая это, я никогда не буду полагаться на то, что рассматривает какой-то парсер регулярных выражений , потому что это на самом деле не стандартизировано. Я совершенно уверен, что синтаксический анализатор регулярных выражений в C # не рассматривает такие точки кода, как , как пробел, поэтому они не будут удалены из вашей строки.
Это может или не может быть проблемой для вашего приложения; это зависит от того, как строки, которые вы должны обработать, фильтруются в первую очередь. Но если вы собираетесь обрабатывать строки на иностранных языках (другими словами: строки, содержащие символы вне диапазона ASCII), вам придется подумать об этом.
При этом имейте в виду, что регулярные выражения медленны. Если вам все равно нужно определить собственные замены (по причинам, указанным выше), вам следует использовать более легкую функцию замены (если C # или ее сборки предоставляют такую возможность — я не использую C #, поэтому не знаю).
3
Binarus
22 Сен 2017 в 12:31
Matheus Lacerda
21 Фев 2018 в 19:53
Для тех, кто заходит на эту страницу, есть отличная статья CodeProject, в которой автор сравнивает несколько разных решений этой проблемы. Самым быстрым полностью управляемым решением, которое он придумал, является (по сути) следующее:
Есть, конечно, много предостережений и, возможно, разногласий по поводу правильного набора пробельных символов, но основная информация довольно полезна (например, RegEx был самым медленным на сегодняшний день).
Полная статья здесь: https: // www.codeproject.com/Articles/1014073/Fastest-method-to-remove-all-whitespace-from-Strin
Примечание: я не имею никакого отношения к автору или CodeProject. Я только что нашел эту статью с помощью обычного веб-поиска.
2
Dave Parker
24 Июл 2018 в 18:01
Одним из способов является использование Regex
Взято из: https://codereview.stackexchange.com/questions / 64935 / заменить — каждый — пробельные -в — строка — с — 20
8
Roland Nordborg-Løvstad
22 Сен 2017 в 12:03
Просто передайте строку при вызове метода, она вернет строку без пробелов.
1
Veer Jangid
24 Июл 2018 в 12:24
Это может быть удобно:
franiis
28 Июн 2019 в 07:57
11 ответов
Лучший ответ
См.
Без какого-либо внутреннего метода используйте регулярное выражение, например
Или
Или просто используйте паттерн в чистом виде
31
Nishant
2 Фев 2012 в 08:17
Хотя метод @xehpuk хорош, если вы не хотите использовать регулярное выражение, но он имеет временную сложность O (n ^ 2). Следующее решение также избегает регулярных выражений, но O (n):
Это подсчитывает количество конечных пробелов в начале и конце строки, пока либо «левый» и «правый» индексы, полученные из подсчета пробелов, не встретятся, либо оба индекса не достигнут непробельного символа. После этого мы либо возвращаем подстроку, полученную с использованием подсчета пробелов, либо пустую строку, если результатом является пробел (необходимо для учета строк, состоящих только из пробелов с нечетным числом символов).
-1
Cody-G-G
31 Май 2017 в 15:33
Поскольку класс Java 11 String имеет метод strip () , который используется для возврата строки, значением которой является эта строка, с удалением всех начальных и конечных пробелов . Это вводится для решения проблемы метода обрезки.
Документы:
Примере:
В классе Java 11+ String есть еще два полезных метода:
-
: возвращает строку, значением которой является эта строка, с удалением всех начальных пробелов.
-
: возвращает строку, значением которой является эта строка, с удалением всех конечных пробелов.
Shivang Agarwal
15 Янв 2020 в 02:32
hage
2 Фев 2012 в 07:54
Почему вы не хотите использовать предопределенные методы? Обычно они наиболее эффективны.
Tarandeep Gill
2 Фев 2012 в 07:54
String.trim () отвечает на вопрос, но для меня это не вариант. Как указано здесь:
Я работаю с японским, где у нас есть символы полной ширины Like this, пространство во всю ширину не будет обрезано String.trim ().
Поэтому я создал функцию, которая, как и фрагмент кода xehpuk, использует Character.isWhitespace (). Однако эта версия не использует StringBuilder и вместо удаления символов находит 2 индекса, которые необходимы для извлечения обрезанной подстроки из исходной String.
1
Community
20 Июн 2020 в 09:12
Просто используйте trim () . Он устраняет только начальные и конечные лишние пробелы в строке.
String fav = «Я люблю яблоко»;
Вывод: мне нравится яблоко // без лишних пробелов в начале и в конце строки
1
Community
20 Июн 2020 в 09:12
Я предпочитаю не использовать регулярные выражения для решения тривиальных задач. Это был бы простой вариант:
1
xehpuk
2 Фев 2012 в 12:14
1
Ariful Islam
2 Фев 2012 в 08:02
Используйте метод обрезки класса String. Он удалит все начальные и конечные пробелы.
1
T.Ho
2 Фев 2012 в 07:54
3
Zala Janaksinh
8 Апр 2014 в 09:15
PATINDEX
С помощью функции PATINDEX можно искать часть подстроки по определенному шаблону. Допустим, что нам надо найти все фамилии, в которых есть две буквы «о», между которыми может находиться любой символ. Эту задачу можно решить с помощью следующего запроса:
SELECT vcFamil, PATINDEX('%О_О%', vcFamil)
FROM tbPeoples
Если посмотреть на функцию, то пока не понятно, чем она отличается от LIKE с шаблоном? Все очень просто – LIKE используется для создания ограничений в секции WHERE, а PATINDEX возвращает индекс символа, начиная с которого идет указанный шаблон в строке. Если бы мы использовали LIKE, то сервер вернул бы нам только те строки, где найден шаблон:
SELECT vcFamil FROM tbPeoples WHERE vcFamil LIKE '%О_О%'
Если использовать функцию PATINDEX, то в результат попадут все строки (мы не ограничиваем вывод в секции WHERE), но там где в фамилии нет шаблона, в соответствующей строке будет стоять ноль, а там где есть, будет стоять 1. Посмотрим на пример результата выполнения запроса с использованием функции PATINDEX:
vcFamil Ind ----------------------------------------------- ПОЧЕЧКИН 0 ПЕТРОВ 0 СИДОРОВ 4 КОНОНОВ 2 СЕРГЕЕВ 0
В данном примере шаблон ‘%О_О%’ присутствует в фамилии Сидоров. Начиная с четвертого символа идут буквы «оро».
SPACE
С помощью функции SPACE можно создавать пробелы. В качестве единственного параметра нужно указать число, которое определяет количество возвращаемых пробелов. Работа функции идентична REPLICATE, если в качестве клонируемого символа указать пробел.
Допустим, что нам нужно вывести на экран поля фамилию и имя, разделенные 5-ю пробелами. Можно сделать так:
SELECT vcFamil+' '+vcName FROM tbPeoples
А можно воспользоваться функцией SPACE:
SELECT vcFamil+SPACE(5)+vcName FROM tbPeoples
Зачем нужна функция, когда можно воспользоваться без нее? Допустим, что вам нужно использовать 5 пробелов в нескольких местах большого сценария. Все легко решается без функций, но в последствии оказалось, что количество пробелов должно быть не 5, а 10. Придется пересматривать весь сценарий и корректировать пробелы. А если бы мы использовали SPACE в сочетании с переменными, то проблема решилась бы намного проще.
Рассмотрим пример, в котором множественные пробелы используются дважды и для задания количества используется переменная:
DECLARE @sp int SET @sp=10 SELECT vcFamil+SPACE(@sp)+vcName+SPACE(@sp)+vcSurName FROM tbPeoples
Теперь, достаточно только изменить значение переменной, и количество пробелов изменено во всем сценарии. А главное – что количество пробелов может быть определено динамически, на основе запросов к таблице.
Формулы для удаления начальных и концевых пробелов.
В некоторых ситуациях вы можете вводить двойные или даже тройные интервалы между словами, чтобы ваши данные были более удобочитаемыми. Однако вам нужно избавиться от ведущих пробелов (находящихся в начале), например:
![]()
Как вы уже знаете, функция СЖПРОБЕЛЫ удаляет лишние интервалы в середине текстовых строк, чего мы в данном случае не хотим. Чтобы сохранить их нетронутыми, мы будем использовать немного более сложную конструкцию:
Это выражение в начале вычисляет позицию первого знака в строке. Затем вы передаете это число другой функции ПСТР, чтобы она возвращала всю текстовую строку (длина строки рассчитывается с помощью ДЛСТР), начиная с позиции первого знака.
Вы видите, что все ведущие пробелы исчезли, хотя несколько интервалов между словами всё же остались.В качестве последнего штриха замените исходный текст полученными значениями, как это было описано выше.
Если же нужно удалить только пробелы в конце каждой ячейки, то формула будет немного сложнее:
![]()
И обратите снимание, что ее нужно вводить как формулу массива (с ). В столбце A выровнять по правому краю получилось плохо из-за разного количества концевых пробелов в каждой ячейке. В столбце B эта проблема решена, и можно красиво расположить текст.
Как убрать все пробелы в конце ячеек при помощи «Найти и заменить»
Этот метод можно использовать в некоторых ситуациях, потому что для него характерна особая быстрота и простота.
Удаление двойных интервалов
Если в начале или конце ячейки стоит пробел, не рекомендуется пользоваться этим способом. Все потому, что один из них все равно будет. Тем не менее, рассмотрим, как пользоваться этим методом для того, чтобы убрать двойные пробелы:
- Сделайте клик по ячейке, в которой нужно убрать ненужные пробелы. Также можно выделить целый диапазон значений.
- Откройте главное меню. Там есть группа инструментов «Редактирование» и там нужно нажать на кнопку «Найти и выделить». После этого появится небольшая менюшка, в которой нужно выбрать «Заменить». Также возможно использование комбинации горячих клавиш CTRL+H.
- В появившемся окне нужно ввести в поле «Найти» двойной пробел и заменить его на одинарный.
После того, как мы введем все необходимые данные, нужно просто нажать на кнопку «Заменить все». А вот нажимать на кнопку «Заменить» не рекомендуется, потому что она заменяет только одну ошибку, и ее нужно нажимать много раз для исправления.
Бывают и более сложные ситуации. Например, у пользователя в ячейке три интервала, поэтому при выполнении в точности всех описанных выше действий останется два, поскольку описанный ранее метод убирает лишь один пропуск. Поэтому рекомендуется выполнить эту операцию несколько раз, чтобы оставшиеся пробелы были убраны.
Вы можете сами понять недостатки этого метода. Перед некоторыми словами начальный пробел остается. Точно так же некоторые конечные пробелы остались видны, просто их нельзя увидеть на глаз. Поэтому если выражение текстовое в ячейке, использовать этот способ нежелательно.
Удаление всех пробелов в тексте
Может понадобиться и удаление всех пробелов. Если это надо сделать, то нужно выполнить такие шаги:
- Выделить ячейки, с которыми мы будем выполнять эту операцию.
- Открываем вкладку «Главная», и там нажимаем на кнопку «Заменить» так, как мы это делали в предыдущем примере. Сочетание клавиш то же самое.
- В окне вводим следующие данные:
- Найти: одинарный пробел.
- Поле «Заменить» не заполняем.
- После этого нажимаем на «Заменить все».
Этот способ позволяет удалить все пробелы, которые есть в ячейке. Недостаток также понятен. С помощью данного метода можно удалить и нужные пробелы, которые ставятся между словами. Поэтому перед тем, как его использовать, нужно удостовериться, что все ячейки в диапазоне содержат не больше одного слова. По этой причине данный метод лучше всего подходит для числовых операций.
В ряде случаев могут возникать ненужные пробелы между разрядами. Очень часто это происходит, когда пользователь пытается импортировать информацию из другой программы. Также ячейка может быть в текстовом формате. На данном этапе это не является проблемой, а потом мы разберемся, что делать для того, чтобы изменить формат на числовой.
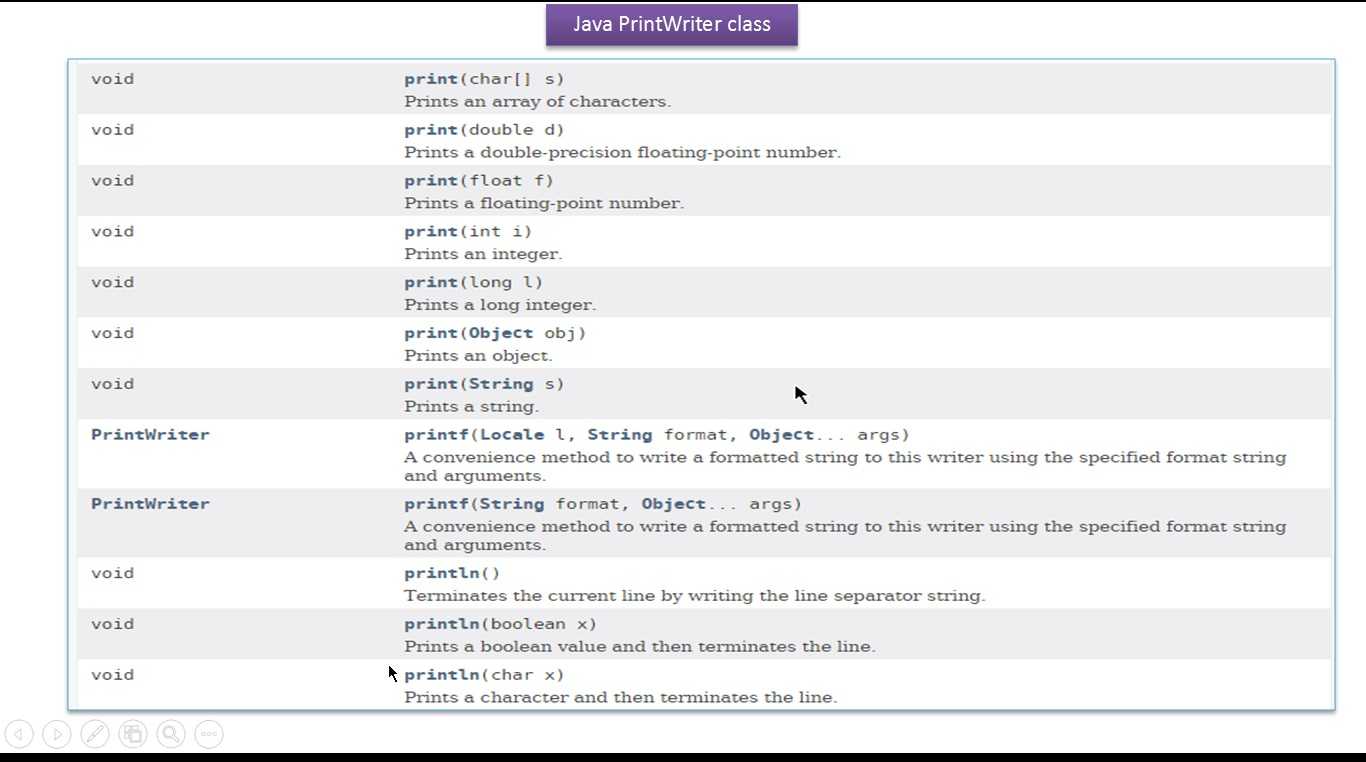
Строка API
Одним из самых простых и простых методов замены подразрядки является использование заменить, заменитьВсе или заменитьПервый из Струнный класс.
заменить () метод принимает два аргумента – целевой и замены текста:
String master = "Hello World Baeldung!"; String target = "Baeldung"; String replacement = "Java"; String processed = master.replace(target, replacement); assertTrue(processed.contains(replacement)); assertFalse(processed.contains(target));
Вышеупомянутый фрагмент даст этот вывод:
Hello World Java!
Если при выборе цели требуется регулярное выражение, то заменитьВсе () или заменитьПервый () должен быть метод выбора. Как следует из их названия, заменитьВсе () заменит каждое совпадение, в то время как заменитьПервый () заменит первое совпадение:
String master2 = "Welcome to Baeldung, Hello World Baeldung";
String regexTarget = "(Baeldung)$";
String processed2 = master2.replaceAll(regexTarget, replacement);
assertTrue(processed2.endsWith("Java"));
Значение обработано2 будет:
Welcome to Baeldung, Hello World Java
Это потому, что regex поставляется как regexTarget будет соответствовать только последнему появлению Бэлдунг. Во всех примерах, приведенных выше, мы можем использовать пустую замену, и это будет эффективно удалить целевые из мастер .