
Введение в класс std::string_view
В качестве следующего примера возьмем окно в вашем доме и автомобиль, стоящий на улице неподалеку. Вы можете посмотреть через окно и увидеть машину, но при этом вы не можете дотронуться до машины или передвинуть её. Ваше окно лишь обеспечивает вид на автомобиль, который является отдельным независимым от вас объектом.
В стандарте C++17 вводится еще один способ использования строк — с помощью класса std::string_view, который находится в заголовочном файле string_view.
В отличие от объектов класса std::string, которые хранят свою собственную копию строки, класс std::string_view обеспечивает представление (англ. «view») для заданной строки, которая может быть определена где-нибудь в другом месте.
Попробуем переписать код предыдущего примера, заменив каждое вхождение на :
#include <iostream>
#include <string_view>
int main()
{
std::string_view text{ «hello» }; // представление для строки «hello», которое хранится в бинарном виде
std::string_view str{ text }; // представление этой же строки — «hello»
std::string_view more{ str }; // представление этой же строки — «hello»
std::cout << text << ‘ ‘ << str << ‘ ‘ << more << ‘\n’;
return 0;
}
|
1 |
#include <iostream> intmain() { std::string_viewtext{«hello»};// представление для строки «hello», которое хранится в бинарном виде std::string_viewstr{text};// представление этой же строки — «hello» std::string_viewmore{str};// представление этой же строки — «hello» std::cout<<text<<‘ ‘<<str<<‘ ‘<<more<<‘\n’; return; } |
В результате мы получим точно такой же вывод на экран, как и в предыдущем примере, но при этом у нас не будут созданы лишние копии строки . Когда мы копируем объект класса std::string_view, то новый объект std::string_view будет «смотреть» на ту же самую строку, на которую «смотрел» исходный объект. Ко всему прочему, класс std::string_view не только быстр, но и обладает многими функциями, которые мы изучили при работе с классом std::string:
#include <iostream>
#include <string_view>
int main()
{
std::string_view str{ «Trains are fast!» };
std::cout << str.length() << ‘\n’; // 16
std::cout << str.substr(0, str.find(‘ ‘)) << ‘\n’; // Trains
std::cout << (str == «Trains are fast!») << ‘\n’; // 1
// Начиная с C++20
std::cout << str.starts_with(«Boats») << ‘\n’; // 0
std::cout << str.ends_with(«fast!») << ‘\n’; // 1
std::cout << str << ‘\n’; // Trains are fast!
return 0;
}
|
1 |
#include <iostream> intmain() { std::string_viewstr{«Trains are fast!»}; std::cout<<str.length()<<‘\n’;// 16 std::cout<<str.substr(,str.find(‘ ‘))<<‘\n’;// Trains std::cout<<(str==»Trains are fast!»)<<‘\n’;// 1 // Начиная с C++20 std::cout<<str.starts_with(«Boats»)<<‘\n’;// 0 std::cout<<str.ends_with(«fast!»)<<‘\n’;// 1 std::cout<<str<<‘\n’;// Trains are fast! return; } |
Т.к. объект класса std::string_view не создает копии строки, то, изменив исходную строку, мы, тем самым, повлияем и на её представление в связанном с ней объектом std::string_view:
#include <iostream>
#include <string_view>
int main()
{
char arr[]{ «Gold» };
std::string_view str{ arr };
std::cout << str << ‘\n’; // Gold
// Изменяем ‘d’ на ‘f’ в arr
arr = ‘f’;
std::cout << str << ‘\n’; // Golf
return 0;
}
|
1 |
#include <iostream> intmain() { chararr{«Gold»}; std::string_viewstr{arr}; std::cout<<str<<‘\n’;// Gold // Изменяем ‘d’ на ‘f’ в arr arr3=’f’; std::cout<<str<<‘\n’;// Golf return; } |
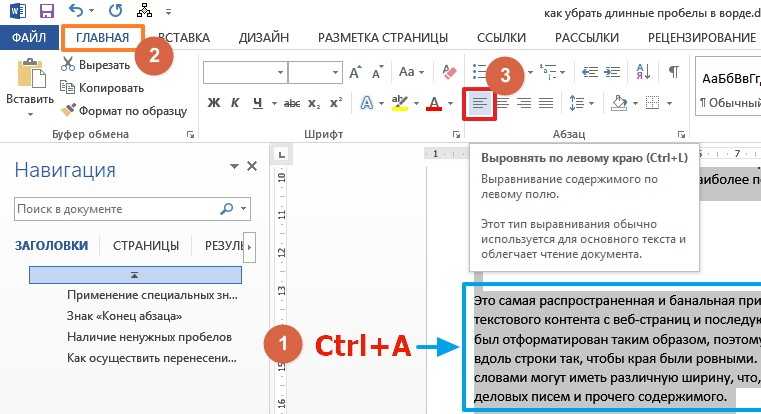
Изменяя , можно видеть, как изменяется и . Это происходит из-за того, что исходная строка является общей для этих переменных. Стоит отметить, что при использовании объектов класса std::string_view лучше избегать модифицирования исходной строки, пока существуют связанные с ней объекты класса std::string_view, так как в противном случае, это может привести к путанице и ошибкам.
Совет: Используйте std::string_view вместо строк C-style. Для строк, которые не планируете изменять в дальнейшем, предпочтительнее использовать класс std::string_view вместо std::string.
12 ответов
-
0 рейтинг
От gamedev
ответ дан rupello, с репутацией 6802, 17.09.2008
-
0 рейтинг
ответ дан Arno, с репутацией 1467, 17.09.2008
-
0 рейтинг
использовать его:
ответ дан SudoBash, с репутацией 81, 27.04.2012
-
0 рейтинг
Можете ли вы использовать Boost String Algo?
ответ дан Nemanja Trifunovic, с репутацией 22115, 17.09.2008
-
0 рейтинг
Для обрезки используйте алгоритмов бустерной строки :
ответ дан Roman, с репутацией 181, 18.11.2009
-
0 рейтинг
Боюсь, это лучшее решение, которое я могу придумать. Но вы можете использовать reserve () для предварительного выделения минимально необходимой памяти заранее, чтобы немного ускорить процесс. В итоге вы получите новую строку, которая, вероятно, будет короче, но займет тот же объем памяти, но вы избежите перераспределения.
РЕДАКТИРОВАТЬ: В зависимости от вашей ситуации, это может потребовать меньше накладных расходов, чем жонглирование персонажей вокруг.
Вам следует попробовать разные подходы и посмотреть, что лучше для вас: у вас могут вообще не быть проблем с производительностью.
ответ дан Dave Van den Eynde, с репутацией 12223, 17.09.2008
-
0 рейтинг
ответ дан test c, с репутацией 11, 4.05.2015
-
0 рейтинг
Лучше всего использовать алгоритм и isspace:
Теперь сам алгоритм не может изменить контейнер (только изменить значения), поэтому он фактически тасует значения вокруг и возвращает указатель на то место, где должен быть конец. Поэтому мы должны вызвать string :: erase для фактического изменения длины контейнера:
Также следует отметить, что remove_if сделает максимум одну копию данных. Вот пример реализации:
ответ дан Matt Price, с репутацией 27761, 17.09.2008
-
0 рейтинг
Вы можете использовать это решение для удаления символа:
ответ дан user2281802, с репутацией 111, 15.04.2013
-
0 рейтинг
Если вы хотите сделать это с помощью простого макроса, вот один:
Это предполагает, что вы сделали , конечно.
Назовите это так:
ответ дан Volomike, с репутацией 13336, 30.01.2016
-
0 рейтинг
Привет, ты можешь сделать что-то подобное. Эта функция удаляет все пробелы.
Я сделал еще одну функцию, которая удаляет все ненужные пробелы.
ответ дан ddacot, с репутацией 726, 15.01.2012
-
0 рейтинг
Я использовал приведенный ниже обходной вариант долго — не уверен насчет его сложности.
, когда вы хотите удалить персонажа , а некоторые, например, использовать
аналогично, просто увеличьте , если количество символов, которое вы хотите удалить, не равно 1
, но, как уже упоминалось, идиома удаления стирания также кажется хорошей.
ответ дан Explorer_N, с репутацией 839, 18.04.2016
Источник:
Ссылка взята с этого форума.
- 1 На самом деле это не добавляет ничего большего, чем этот ответ уже есть. Есть ли дополнительные объяснения или подробности, которые вы могли бы добавить, чтобы ваш ответ был более качественным и заслуживающим внимания на этот вопрос?
- Я думаю это больше проще, потому что он делает то же самое в одном утверждении.
- 2 Отлично! Затем представьте это рассуждение как объяснение прямо в вашем ответе. Исходный вопрос более чем Одиннадцать лет, и без обоснования ваш ответ может быть воспринят как шум по сравнению с другими принятыми ответами, получившими высокую оценку. Такое объяснение поможет избежать удаления вашего ответа.
- Это было бы хороший но я не мог понять, как мне поставить что в мой ответ … что мой ответ лучше этого ответа.? Было бы очень приятно, если бы вы могли редактировать мой ответ.
- 2 К сожалению, редактирование вашего ответа для добавления этого содержимого будет противоречить правилам редактирования, и мое изменение, вероятно, будет отклонено или откатано позже. Вы можете использовать первую ссылку в этом комментарии, чтобы отредактировать ответ самостоятельно. Совершенно приемлемо заявить, что вы думаете, что ваш ответ лучше, чем какой-либо другой, и дать ему обоснование. Сообщество решит, правы вы, голосуя за или против.
Удаляет все символы пробелов, такие как табуляция и разрывы строк (C ++ 11):
- Почему вы рекомендуете этот подход вместо принятого ответа @ Matt-Price более десяти лет назад?
- Пусть здесь будут представлены все решения. Может кому понадобится это решение.
- Я не возражаю против этого. Я говорю, что людям будет легче оценивать различные подходы, объясняя различия и сценарии, для которых они могут лучше подходить.
- 2 Возможно, это решение не самое экономичное, но оно позволяет избавиться от всех пробелов «\ s», а не только от пробелов ».
вывод: 2CF4323CB9DE
- 3 Обычно рекомендуется добавлять краткое пояснение к ответам кода.
- 1 @test — возвращает , а не . занимает , а не . Функция, вероятно, завершится ошибкой, если встретятся два последовательных пробела, поскольку индекс всегда увеличивается. Если один пробел удален, цикл будет считываться за пределы строки. Вам, вероятно, следует удалить этот ответ, поскольку он требует серьезной помощи.
Боюсь, это лучшее решение, которое я могу придумать. Но вы можете использовать резерв (), чтобы заранее выделить минимально необходимую память, чтобы немного ускорить работу. В результате вы получите новую строку, которая, вероятно, будет короче, но займет такой же объем памяти, но вы избежите перераспределения.
РЕДАКТИРОВАТЬ: в зависимости от вашей ситуации это может потребовать меньше накладных расходов, чем беспорядочные символы.
Вам следует попробовать разные подходы и посмотреть, что лучше для вас: у вас может вообще не возникнуть проблем с производительностью.
remove_if создает не более одной копии каждого значения. Так что накладных расходов на то, что необходимо сделать, действительно не так уж и много.
Источник:
Ссылка взята с этого форума.
- 1 На самом деле это не добавляет ничего большего, чем этот ответ уже есть. Есть ли дополнительные объяснения или подробности, которые вы могли бы добавить, чтобы ваш ответ был более качественным и заслуживающим внимания на этот вопрос?
- Я думаю это больше проще, потому что он делает то же самое в одном утверждении.
- 2 Отлично! Затем представьте это рассуждение как объяснение прямо в вашем ответе. Исходный вопрос более чем Одиннадцать лет, и без обоснования ваш ответ может быть воспринят как шум по сравнению с другими принятыми ответами, получившими высокую оценку. Такое объяснение поможет избежать удаления вашего ответа.
- Это было бы хорошо но я не мог понять, как мне поставить тот в мой ответ … что мой ответ лучше этого ответа.? Было бы очень приятно, если бы вы могли редактировать мой ответ.
- 2 К сожалению, редактирование вашего ответа для добавления этого содержимого будет противоречить правилам редактирования, и мое изменение, скорее всего, будет отклонено или откатано позже. Вы можете использовать первую ссылку в этом комментарии, чтобы отредактировать ответ самостоятельно. Совершенно приемлемо заявить, что вы думаете, что ваш ответ лучше, чем какой-либо другой, и дать ему обоснование. Сообщество решит, правы вы, голосуя за или против.
Удаляет все символы пробелов, такие как табуляция и разрывы строк (C ++ 11):
- Почему вы рекомендуете этот подход вместо принятого ответа @ Matt-Price более десяти лет назад?
- Пусть здесь будут представлены все решения. Может кому понадобится это решение.
- Я не возражаю против этого. Я говорю, что людям будет легче оценивать различные подходы, объясняя различия и сценарии, для которых они могут лучше подходить.
- 2 Наверное, это не самое экономичное решение, но оно позволяет избавиться от всех пробелов «\ s», а не только от пробелов ».
вывод: 2CF4323CB9DE
Просто для удовольствия, поскольку другие ответы намного лучше, чем этот.
Я создал функцию, которая удаляет пробелы с обоих концов строки. Такие как , будет преобразован в .
Это работает аналогично , и функции, которые часто используются в Python.
- 3 Обычно рекомендуется добавлять краткое пояснение к ответам кода.
- 1 @test — возвращает , а не . занимает , а не . Функция, вероятно, завершится ошибкой, если встретятся два последовательных пробела, поскольку индекс всегда увеличивается. Если один пробел удален, цикл будет считываться за пределы строки. Вам, вероятно, следует удалить этот ответ, поскольку он требует серьезной помощи.
Боюсь, это лучшее решение, которое я могу придумать. Но вы можете использовать Reserve (), чтобы заранее выделить минимально необходимую память, чтобы немного ускорить работу. В результате вы получите новую строку, которая, вероятно, будет короче, но займет такой же объем памяти, но вы избежите перераспределения.
РЕДАКТИРОВАТЬ: в зависимости от вашей ситуации это может потребовать меньше накладных расходов, чем беспорядочные символы.
Вам следует попробовать разные подходы и посмотреть, что лучше для вас: у вас может вообще не возникнуть проблем с производительностью.
remove_if делает не более одной копии каждого значения. Так что накладных расходов на то, что нужно сделать, действительно не так уж и много.
Why remove_if can’t delete from the container
The simple answer: It’s not possible.
The longer answer: The arguments for std::remove_if doesn’t include the container type. It only includes an iterator range and a predicate (or value in the case of std::remove). The method itself doesn’t know about the underlying storage. If and only if remove_if were limited to vector or list, then it would have been possible to actually remove elements. But that is not the case.
It’s possible to create iterators from a regular array, and it’s not possible to resize an array without reallocating memory, thus copying (or moving) elements from the old array to the new array.
That’s why std::remove and std::remove_if doesn’t actually remove elements, it only moves elements to be kept.
One other thing to remember is that removed elements will be destroyed. After remove_if, there may or may not be usable data in the area after the iterator returned by the method.
Using std::find_if function
Another efficient solution is to use std::find_if to remove leading and trailing spaces, as shown below:
|
1 |
#include <iostream> std::string<rim(std::string&s) { auto it=std::find_if(s.begin(),s.end(), (charc){ return!std::isspace<char>(c,std::locale::classic()); }); s.erase(s.begin(),it); returns; } std::string&rtrim(std::string&s) { auto it=std::find_if(s.rbegin(),s.rend(), (charc){ return!std::isspace<char>(c,std::locale::classic()); }); s.erase(it.base(),s.end()); returns; } std::string&trim(std::string&s){ returnltrim(rtrim(s)); } intmain() { std::strings=»\n\t Hello World «; std::cout<<«START::»<<trim(s)<<«::END»; return; } |
Download Run Code
7 ответов
Лучший ответ
Попробуйте использовать Linq , чтобы отфильтровать пробелы:
Результат :
21
Dmitry Bychenko
22 Сен 2017 в 13:04
Ответ на этот вопрос не так прост, как кажется. Проблема не в том, чтобы на самом деле кодировать замену, а в том, чтобы определить, что такое пробел.
Например, в перечислены десятки символов (кодовые точки Unicode), которые имеют Атрибут Unicode , а также множество связанных символов, которые большинство людей считают пустым пространством, но которые не имеют атрибута .
Учитывая это, я никогда не буду полагаться на то, что рассматривает какой-то парсер регулярных выражений , потому что это на самом деле не стандартизировано. Я совершенно уверен, что синтаксический анализатор регулярных выражений в C # не рассматривает такие точки кода, как , как пробел, поэтому они не будут удалены из вашей строки.
Это может или не может быть проблемой для вашего приложения; это зависит от того, как строки, которые вы должны обработать, фильтруются в первую очередь. Но если вы собираетесь обрабатывать строки на иностранных языках (другими словами: строки, содержащие символы вне диапазона ASCII), вам придется подумать об этом.
При этом имейте в виду, что регулярные выражения медленны. Если вам все равно нужно определить собственные замены (по причинам, указанным выше), вам следует использовать более легкую функцию замены (если C # или ее сборки предоставляют такую возможность — я не использую C #, поэтому не знаю).
3
Binarus
22 Сен 2017 в 12:31
Matheus Lacerda
21 Фев 2018 в 19:53
Для тех, кто заходит на эту страницу, есть отличная статья CodeProject, в которой автор сравнивает несколько разных решений этой проблемы. Самым быстрым полностью управляемым решением, которое он придумал, является (по сути) следующее:
Есть, конечно, много предостережений и, возможно, разногласий по поводу правильного набора пробельных символов, но основная информация довольно полезна (например, RegEx был самым медленным на сегодняшний день).
Полная статья здесь: https: // www.codeproject.com/Articles/1014073/Fastest-method-to-remove-all-whitespace-from-Strin
Примечание: я не имею никакого отношения к автору или CodeProject. Я только что нашел эту статью с помощью обычного веб-поиска.
2
Dave Parker
24 Июл 2018 в 18:01
Одним из способов является использование Regex
Взято из: https://codereview.stackexchange.com/questions / 64935 / заменить — каждый — пробельные -в — строка — с — 20
8
Roland Nordborg-Løvstad
22 Сен 2017 в 12:03
Просто передайте строку при вызове метода, она вернет строку без пробелов.
1
Veer Jangid
24 Июл 2018 в 12:24
Это может быть удобно:
franiis
28 Июн 2019 в 07:57
Using std::regex_replace function
With C++11, we can also use std::regex_replace for this. This is demonstrated below:
|
1 |
#include <iostream> std::stringltrim(conststd::string&s){ returnstd::regex_replace(s,std::regex(«^\\s+»),std::string(«»)); } std::stringrtrim(conststd::string&s){ returnstd::regex_replace(s,std::regex(«\\s+$»),std::string(«»)); } std::stringtrim(conststd::string&s){ returnltrim(rtrim(s)); } intmain() { std::strings=» \t\n Hello World «; std::cout<<«START::»<<trim(s)<<«::END»; return; } |
Download Run Code
Зачем нужен std::string?
Мы уже знаем, что строки C-style используют массивы типа char для хранения целой строки. Если вы попытаетесь что-либо сделать со строками C-style, то вы очень быстро обнаружите, что работать с ними трудно, запутаться легко, а проводить отладку сложно.
Строки C-style имеют много недостатков, в первую очередь связанных с тем, что вы должны самостоятельно управлять памятью. Например, если вы захотите поместить строку в буфер, то вам сначала нужно будет динамически выделить буфер правильной длины:
char *strHello = new char;
| 1 | char*strHello=newchar7; |
Не забудьте учесть дополнительный символ для нуль-терминатора! Затем вам нужно будет скопировать значение:
strcpy(strHello, «Hello!»);
| 1 | strcpy(strHello,»Hello!»); |
И здесь вам нельзя прогадать с длиной буфера, иначе произойдет ! И, конечно, поскольку строка выделяется динамически, то вы должны её еще и правильно удалить:
delete[] strHello;
| 1 | deletestrHello; |
Не забудьте использовать форму оператора delete, которая работает с массивами, а не обычную форму оператора delete.
Кроме того, многие из интуитивно понятных операторов, которые предоставляет язык C++ для работы с числами, такие как , , , , , и попросту не работают со строками C-style. Иногда они могут работать без ошибок со стороны компилятора, но результат будет неверным. Например, сравнение двух строк C-style с использованием оператора на самом деле выполнит сравнение указателей, а не строк. Присваивание одной строки C-style другой строке C-style с использованием оператора будет работать, но выполняться будет копирование указателя (), что не всегда то, что нам нужно. Такие вещи могут легко привести к ошибкам и сбоям в программе, а разбираться с ними не так уж и легко (относительно)!
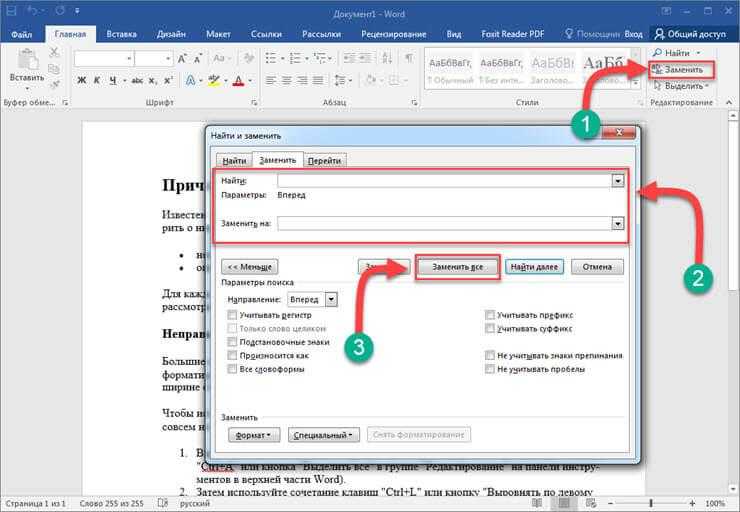
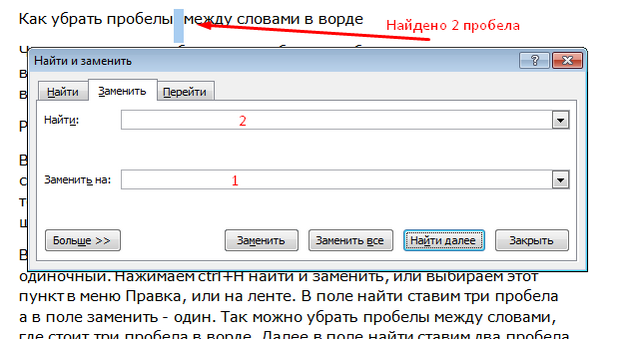
Суть в том, что работая со строками C-style, вам нужно помнить множество придирчивых правил о том, что делать безопасно, а что — нет; запоминать много функций, таких как strcat() и strcmp(), чтобы использовать их вместо интуитивных операторов; а также самостоятельно выполнять управление памятью.
К счастью, язык C++ предоставляет гораздо лучший способ для работы со строками: классы std::string и std::wstring
Используя такие концепции С++, как конструкторы, деструкторы и перегрузку операторов, std::string позволяет создавать и манипулировать строками в интуитивно понятной форме и, что не менее важно, выполнять это безопасно! Никакого управления памятью, запоминания странных названий функций и значительно меньшая вероятность возникновения ошибок/сбоев
Обзор классов строк
Весь строковый функционал стандартной библиотеки находится в заголовочном файле. Чтобы использовать его, просто включите заголовок :
На самом деле в заголовке есть 3 разных класса строк. Первый – это шаблонный базовый класс с именем :
Вы не будете работать с этим классом напрямую, поэтому пока не беспокойтесь о том, что это за и . Значений по умолчанию будет достаточно почти во всех мыслимых случаях.
Стандартная библиотека предоставляет две разновидности :
Это два класса, которые вы непосредственно будете использовать. используется для стандартных строк ASCII и UTF-8. используется для строк с расширенными символами / Unicode (UTF-16). Для строк UTF-32 нет встроенного класса (хотя вы можете расширить из свой собственный класс, если он вам нужен).
Хотя вы будете напрямую использовать и , весь строковый функционал реализован в классе . и могут получить доступ к этому функционалу напрямую благодаря шаблону. Следовательно, все представленные функции будут работать как для , так и для . Однако, поскольку является шаблонным классом, это также означает, что, если вы сделаете что-то синтаксически неверное со или , компилятор выдаст ужасно выглядящие ошибки шаблона. Не пугайтесь этих ошибок; они выглядят намного хуже, чем они есть на самом деле!
Вот список всех функций в строковом классе. Для обработки различных типов входных данных большинство этих функций имеют несколько разновидностей, которые мы рассмотрим более подробно в следующих уроках.
| Функция | Действие |
|---|---|
| Создание и уничтожение | |
| конструктор | Создает или копирует строку |
| деструктор | Уничтожает строку |
| Размер и вместимость | |
| Возвращает количество символов, которые могут храниться без перераспределения памяти | |
| Возвращает логическое значение, указывающее, пуста ли строка | |
| , | Возвращает количество символов в строке |
| Возвращает максимальный размер строки, которая может быть размещена | |
| Увеличить или уменьшить вместимость строки | |
| Доступ к элементам | |
| , | Доступ к символу по определенному индексу |
| Модификация | |
| , | Присваивает новое значение строке |
| , , | Добавляет символы в конец строки |
| Вставляет символы в строку по произвольному индексу | |
| Удаляет все символы в строке | |
| Стирает символы по произвольному индексу в строке | |
| Заменяет символы с произвольным индексом на другие символы | |
| Расширение или сжатие строки (обрезает или добавляет символы в конце строки) | |
| Меняет местами значения двух строк | |
| Ввод и вывод | |
| , | Считывает значения из входного потока в строку |
| Записывает значение строки в выходной поток | |
| Возвращает содержимое строки как строку в стиле C с завершающим нулем | |
| Копирует содержимое (не оканчивающееся нулем) в массив символов | |
| То же, что . Неконстантная перегрузка позволяет выполнять запись в возвращаемую строку | |
| Сравнение строк | |
| , | Сравнивает, равны или неравны две строки (возвращает ) |
| , , , | Сравнивает, являются ли две строки меньше/больше друг друга (возвращает ) |
| Сравнивает, равны или неравны две строки (возвращает -1, 0 или 1) | |
| Подстроки и конкатенация | |
| Объединяет две строки | |
| Возвращает подстроку | |
| Поиск | |
| Найти индекс первого символа/подстроки | |
| Найти индекс первого символа из набора символов | |
| Найти индекс первого символа, не входящего в набор символов | |
| Найти индекс последнего символа из набора символов | |
| Найти индекс последнего символа, не входящего в набор символов | |
| Найти индекс последнего символа/подстроки | |
| Поддержка итераторов и распределителей памяти (аллокаторов) | |
| , | Поддержка итератора прямого направления для начала/конца строки |
| Возвращает распределитель | |
| , | Поддержка итератора обратного направления для начала/конца строки |
Хотя строковые классы библиотеки STL предоставляют множество функций, есть несколько заметных упущений:
- поддержка регулярных выражений;
- конструкторы для создания строк из чисел;
- функции изменения регистра на верхний/нижний;
- сравнение без учета регистра;
- разбиение строки на массив;
- простые функции для получения левой или правой части строки;
- обрезка пробелов в начале и конце строки;
- форматирование строки в стиле ;
- преобразование из UTF-8 в UTF-16 или наоборот.
Для большинства из них вам придется либо написать свои собственные функции, либо преобразовать вашу строку в строку в стиле C (используя ) и использовать функции C, которые предлагают эту функциональность.
В следующих уроках мы более подробно рассмотрим различные функции класса . Хотя в наших примерах мы будем использовать , всё в равной степени применимо и к .
Practical use for remove_if
The most practical use for remove and remove_if is to remove elements from a range.
With some collections counting millions of elements, it’s not feasible to remove one element at a time. With a logical deleted tag, it’s possible to remove all elements with linear complexity, also known as O(n).
The rationale of using std::remove_if is simple. If you’re deleting 10000 elements from a vector containing 1 million elements, you will, in the worst case scenario, move or copy most elements 10000 times. With 1 million elements, it will be close to 10 billion copies or moves.
Here is one example. Widget is an example struct for some user supplied type.
The data will look like this in the vector.
After std::remove_if, the vector will still have the same size, but notice how the move operator have actually moved the string names from the end of the vector to the beginning of the vector. This is most apparent with W5 and W8. The corresponding value after is an empty string.
Original ‘W1’=true ‘W2’=true ‘W3’=false ‘W4’=true ‘W5’=false ‘W6’=true ‘W7’=true ‘W8’=false After remove_if ‘W3’=false ‘W5’=false ‘W8’=false ‘W4’=true ”=false ‘W6’=true ‘W7’=true ”=false After erase, the vector have been resized to contain only non-deleted elements.
Original ‘W1’=true ‘W2’=true ‘W3’=false ‘W4’=true ‘W5’=false ‘W6’=true ‘W7’=true ‘W8’=false After remove_if ‘W3’=false ‘W5’=false ‘W8’=false ‘W4’=true ”=false ‘W6’=true ‘W7’=true ”=false After erase ‘W3’=false ‘W5’=false ‘W8’=false
«`
std::remove_if и лямбда
Пришло время разобраться, как использовать remove_if с лямбда-функцией в качестве предиката (который должен вернуть true, если данный элемент следует удалить).
Будем выполнять операции над динамическим массивом целых чисел.
- С помощью remove_if мы отфильтруем все числа больше 3
- После фильтрации мы получим итератор, указывающий на первый элемент после последнего уцелевшего элемента
- Размер массива пока ещё не изменился, поэтому у нас есть итератор на начало удаляемой области диапазона
- С помощью метода erase мы удалим все элементы от первого элемента удаляемой области до последнего элемента массива
Если скомпилировать и запустить пример, вы получите вывод четырёх чисел, больших числа 3
Как это произошло? Разберём подробнее
With a vector of ints, we can inspect the vector before and after the two steps.
At this step, the contents of the vector looks like this.
Original vector 1 1 2 3 4 5 6 Then we decide we want to filter out some values, say any value less than 3 must be removed. For this we can use std::remove_if. It will do what you asked for, except you must combine it with an explicit erase of the container. Why will be explained later.
The lambda expression looks like this. It has the same argument as the vector value type (int).
Call std::remove_if with the lambda as predicate.
After remove_if, the vector will look like this.
Original vector 1 1 2 3 4 5 6 After remove_if 3 4 5 6 4 5 6 Red numbers are removed, green are kept, while gray numbers are surplus.
To remove the elements, we will have to call erase on the vector.
The arguments for erase is a range of elements to be removed.
Original vector 1 1 2 3 4 5 6 After remove_if 3 4 5 6 4 5 6 After erase 3 4 5 6
Функционал std::string
Создание и удаление:
конструктор — создает или копирует строку;
деструктор — уничтожает строку.
Размер и ёмкость:
capacity() — возвращает количество символов, которое строка может хранить без дополнительного перевыделения памяти;
empty() — возвращает логическое значение, указывающее, является ли строка пустой;
length(), size() — возвращают количество символов в строке;
max_size() — возвращает максимальный размер строки, который может быть выделен;
reserve() — расширяет или уменьшает ёмкость строки.
Доступ к элементам:
, at() — доступ к элементу по заданному индексу.
Изменение:
, assign() — присваивают новое значение строке;
, append(), push_back() — добавляют символы к концу строки;
insert() — вставляет символы в произвольный индекс строки;
clear() — удаляет все символы строки;
erase() — удаляет символы по произвольному индексу строки;
replace() — заменяет символы произвольных индексов строки другими символами;
resize() — расширяет или уменьшает строку (удаляет или добавляет символы в конце строки);
swap() — меняет местами значения двух строк.
Ввод/вывод:
, getline() — считывают значения из входного потока в строку;
— записывает значение строки в выходной поток;
c_str() — конвертирует строку в строку C-style с нуль-терминатором в конце;
copy() — копирует содержимое строки (которое без нуль-терминатора) в массив типа char;
data() — возвращает содержимое строки в виде массива типа char, который не заканчивается нуль-терминатором.
Сравнение строк:
, — сравнивают, являются ли две строки равными/неравными (возвращают значение типа bool);
, , , — сравнивают, являются ли две строки меньше или больше друг друга (возвращают значение типа bool);
compare() — сравнивает, являются ли две строки равными/неравными (возвращает , или ).
Подстроки и конкатенация:
— соединяет две строки;
substr() — возвращает подстроку.
Поиск:
find — ищет индекс первого символа/подстроки;
find_first_of — ищет индекс первого символа из набора символов;
find_first_not_of — ищет индекс первого символа НЕ из набора символов;
find_last_of — ищет индекс последнего символа из набора символов;
find_last_not_of — ищет индекс последнего символа НЕ из набора символов;
rfind — ищет индекс последнего символа/подстроки.
Поддержка итераторов и распределителей (allocators):
begin(), end() — возвращают «прямой» итератор, указывающий на первый и последний (элемент, который идет за последним) элементы строки;
get_allocator() — возвращает распределитель;
rbegin(), rend() — возвращают «обратный» итератор, указывающий на последний (т.е. «обратное» начало) и первый (элемент, который предшествует первому элементу строки — «обратный» конец) элементы строки. Отличие от begin() и end() в том, что движение итераторов происходит в обратную сторону.
Using find_first_not_of() with find_last_not_of() function
We can use a combination of string’s find_first_not_of() and find_last_not_of() functions to remove leading and trailing spaces from a string in C++ by finding the index of the first and last non-whitespace character and pass the index to functions to trim the string.
|
1 |
#include <iostream> conststd::stringWHITESPACE=» \n\r\t\f\v»; std::stringltrim(conststd::string&s) { size_t start=s.find_first_not_of(WHITESPACE); return(start==std::string::npos)?»»s.substr(start); } std::stringrtrim(conststd::string&s) { size_t end=s.find_last_not_of(WHITESPACE); return(end==std::string::npos)?»»s.substr(,end+1); } std::stringtrim(conststd::string&s){ returnrtrim(ltrim(s)); } intmain() { std::strings=»\n\tHello World \r\n»; std::cout<<«START::»<<trim(s)<<«::END»; return; } |
Download Run Code





