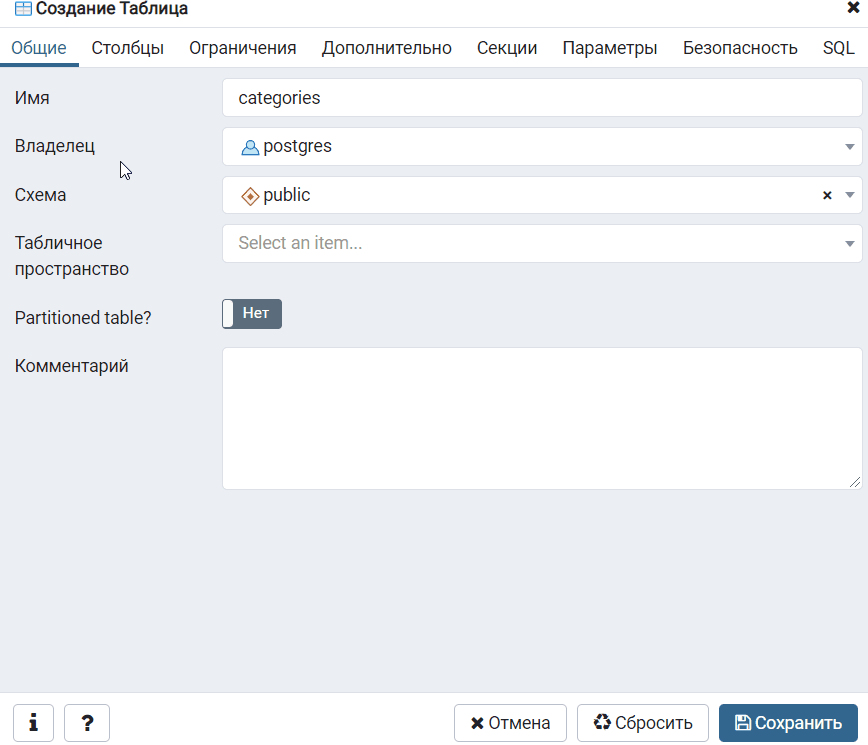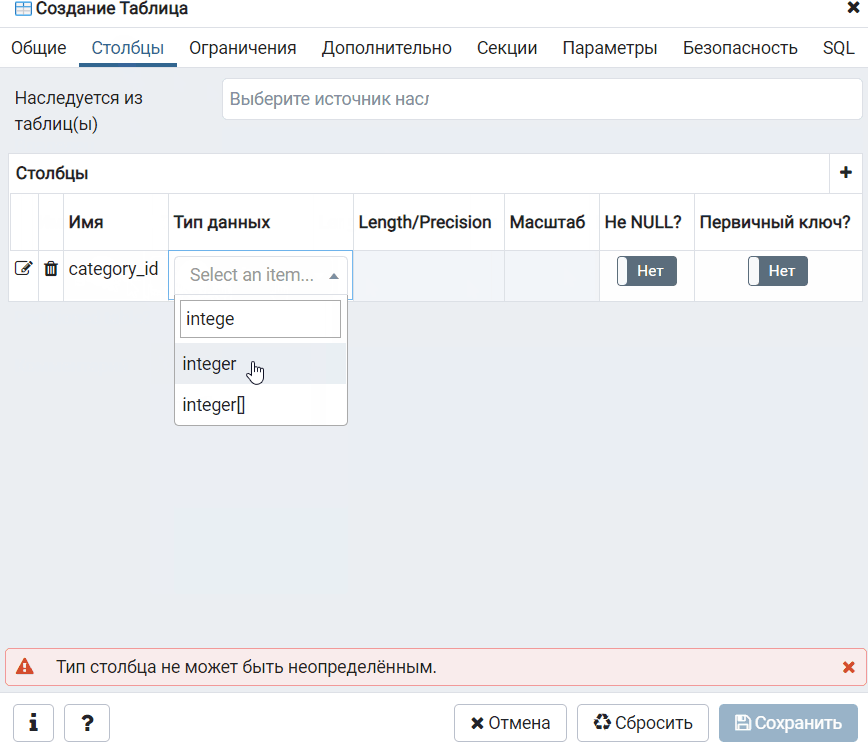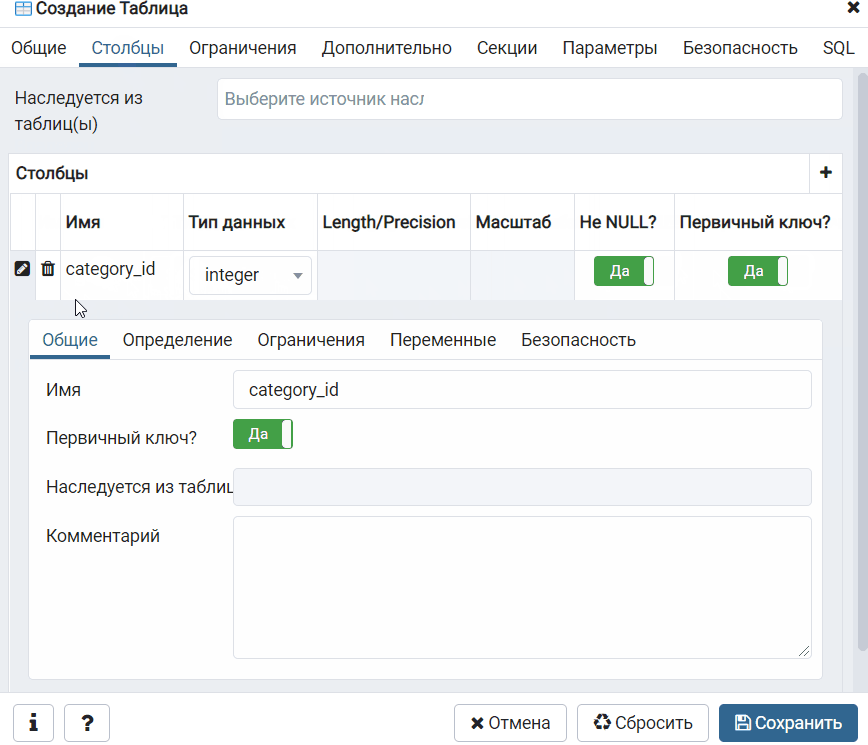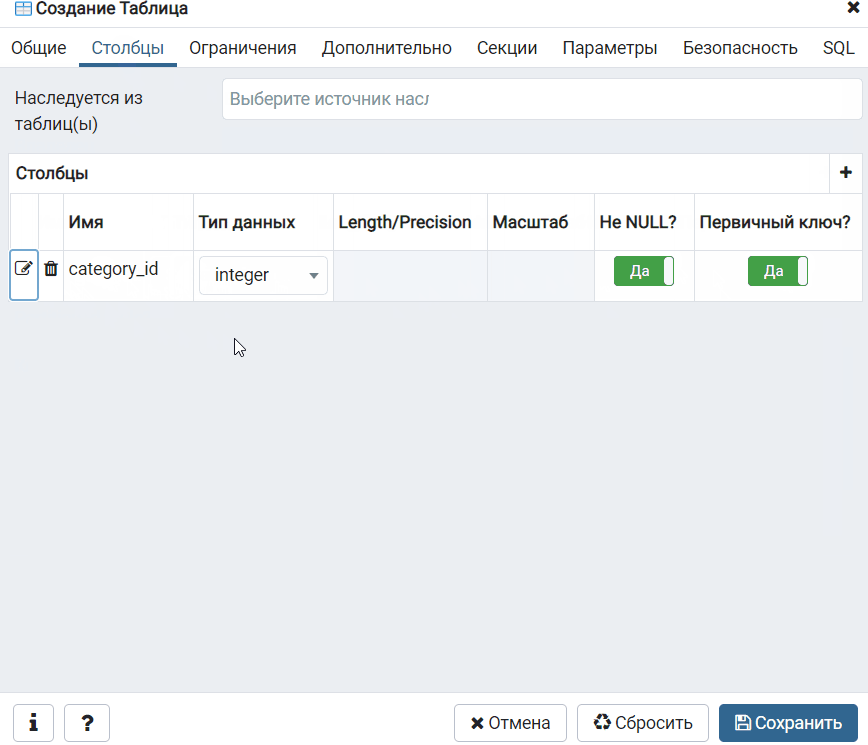
Specifying the File Format
The Format option in Schema.ini specifies the format of the text file. The Text IISAM can read the format automatically from most character-delimited files. You can use any single character as a delimiter in the file except the double quotation mark («). The Format setting in Schema.ini overrides the setting in the Windows Registry, file by file. The following table lists the valid values for the Format option.
| Format specifier | Table format | Schema.ini Format statement |
|---|---|---|
| Tab Delimited | Fields in the file are delimited by tabs. | Format=TabDelimited |
| CSV Delimited | Fields in the file are delimited by commas (comma-separated values). | Format=CSVDelimited |
| Custom Delimited | Fields in the file are delimited by any character you choose to input into the dialog box. All except the double quotation marks («) are allowed, including blank. | Format=Delimited(custom character) -or- With no delimiter specified: Format=Delimited( ) |
| Fixed Length | Fields in the file are of a fixed length. | Format=FixedLength |
Полномочия
Каждый пользователь MySQL имеет право получить доступ к этим таблицам, но может видеть только строки в таблицах,
которые соответствуют объектам, для которых у пользователя есть надлежащие права доступа. В некоторых случаях
(например, столбец в таблица), пользователи, у которых есть
недостаточные полномочия, видят . Эти ограничения не просят таблицы; можно видеть их с только полномочие.
Те же самые полномочия применяются к выбору информации от и
просмотр той же самой информации через
операторы. В любом случае у Вас должно быть некоторое полномочие на объекте видеть информацию об этом.
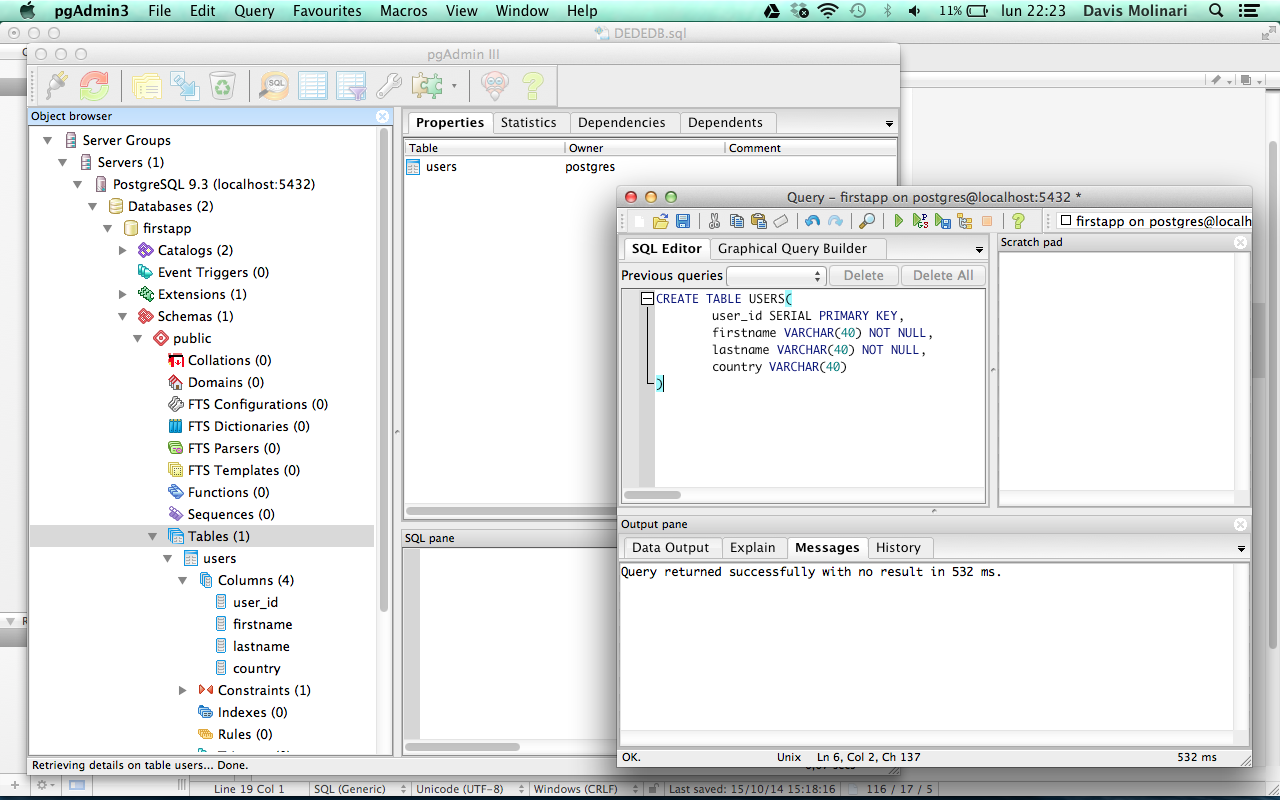
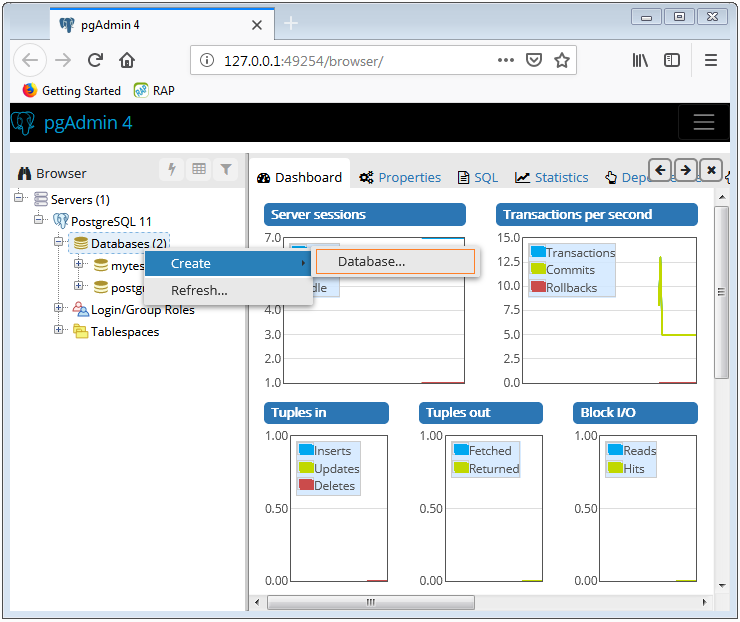
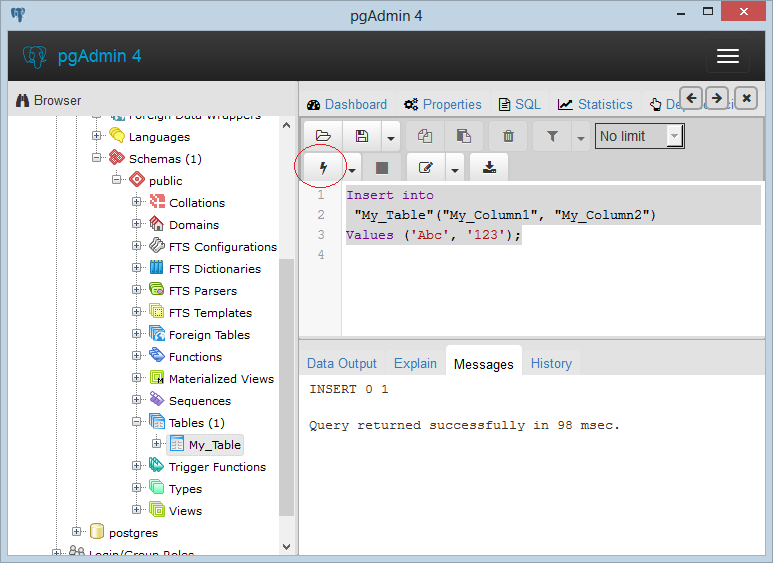
Using INFORMATION_SCHEMA to Access Tables Data
Since this database is an ANSI standard, the following queries should work in other DBMS systems as well. We’ll list all tables in the database we’ve selected and also all constraints. To do that, we’ll use the following queries:
|
1 |
USEour_first_database; SELECT* FROMINFORMATION_SCHEMA.TABLES; — list of all constraints in the selected database SELECT* FROMINFORMATION_SCHEMA.TABLE_CONSTRAINTS; |
![]()
The first important thing is that, after the keyword USE, we should define the database we want to run queries on.
The result is expected. The first query lists all tables from our database, while the second query returns all constraints, we’ve defined when we created our database. In both of these, besides their name and the database schema they belong to, we can see many other details.
It’s important to notice that in constraints we also have the TABLE_NAME column, which tells us which table this
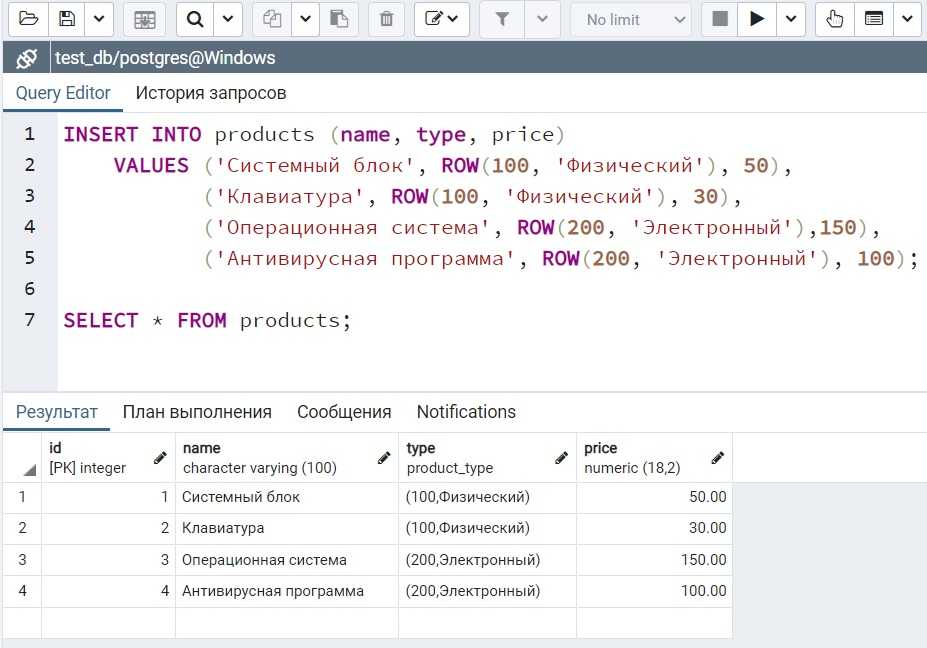
constraint is related to. We’ll use that fact to relate tables INFORMATION_SCHEMA.TABLES and INFORMATION_SCHEMA.TABLE_CONSTRAINTS to create our custom query. Let’s take a look at the query as well as its’
result.
|
1 |
USEour_first_database; —join tables andconstraints data SELECT INFORMATION_SCHEMA.TABLES.TABLE_NAME, INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_NAME, INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLES INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS ON INFORMATION_SCHEMA.TABLES.TABLE_NAME=INFORMATION_SCHEMA.TABLE_CONSTRAINTS.TABLE_NAME ORDER BY INFORMATION_SCHEMA.TABLES.TABLE_NAME ASC, INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE DESC; |
![]()
No doubt this query looks cool. Still, let’s comment on a few things. With this query, we’ve:
-
Again, we’ve pointed out which database we are using. This could have been avoided if you write
<database_name> each time before INFORMATION_SCHEMA, e.g.
our_first_database.INFORMATION_SCHEMA.TABLES.TABLE_NAME. I don’t prefer it that way -
Joined two tables, in the same manner, we would join two “regular” database tables. This is good to know, but,
as we’ll see later, you can join many things (system tables, subqueries) and not only “regular” tables - We have also ordered our result so we can easily notice all the constraints on each table
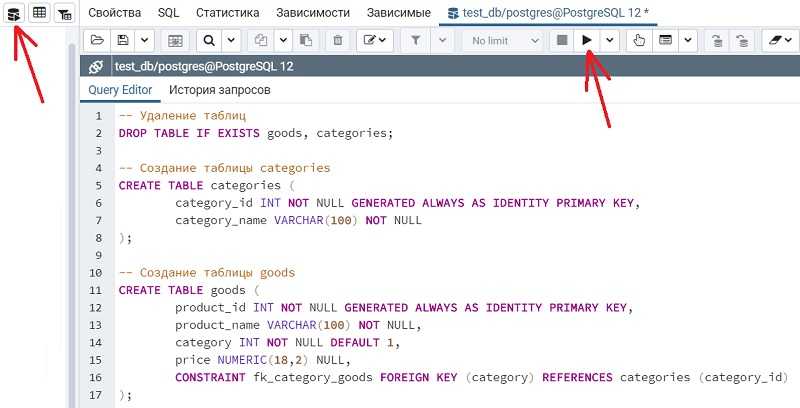
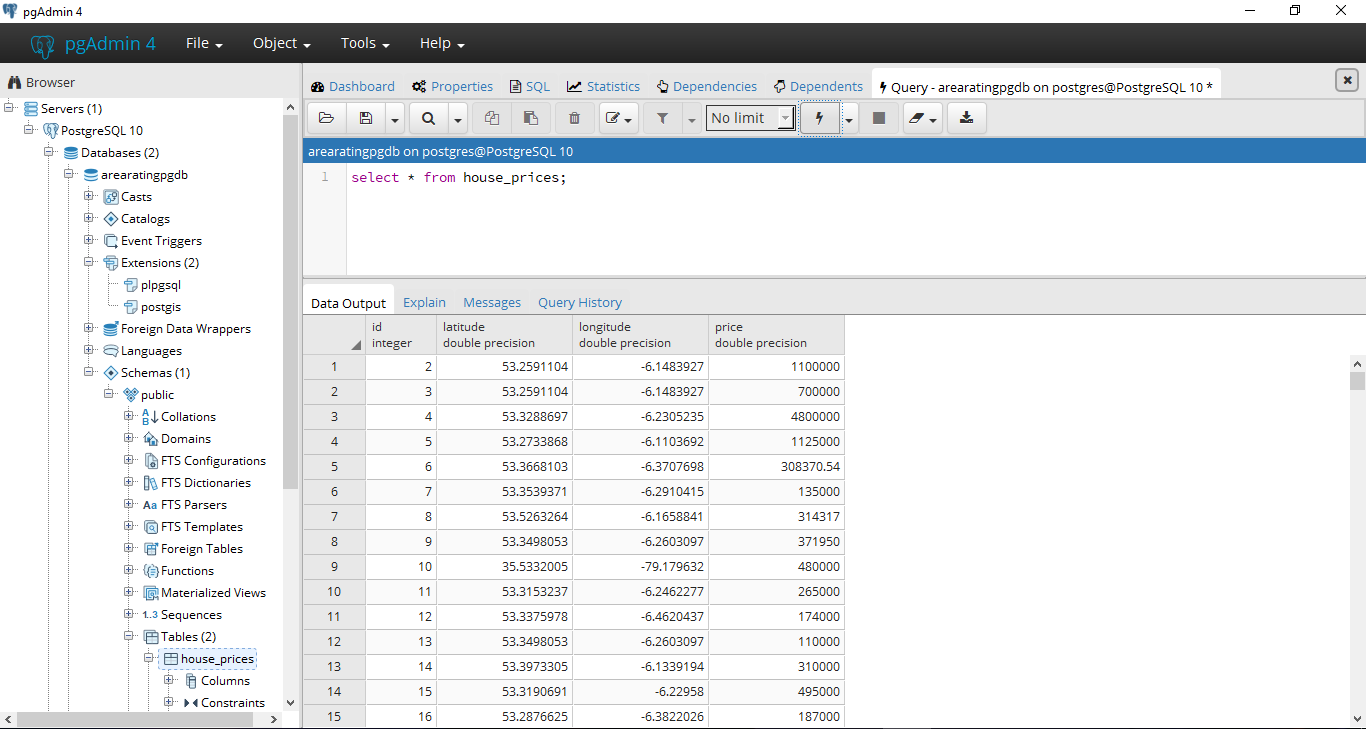
Maybe you’re asking yourself why would you do something like this. Well, with minor modifications to this query, you can easily count a number of keys in each table. Let’s do that.
|
1 |
USEour_first_database; —join tables andconstraints data SELECT INFORMATION_SCHEMA.TABLES.TABLE_NAME, SUM(CASEWHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE=’PRIMARY KEY’THEN1ELSEEND)ASpk, SUM(CASEWHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE=’UNIQUE’THEN1ELSEEND)ASuni, SUM(CASEWHEN INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE=’FOREIGN KEY’THEN1ELSEEND)ASfk FROM INFORMATION_SCHEMA.TABLES LEFT JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS ON INFORMATION_SCHEMA.TABLES.TABLE_NAME=INFORMATION_SCHEMA.TABLE_CONSTRAINTS.TABLE_NAME GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME ORDER BY INFORMATION_SCHEMA.TABLES.TABLE_NAME ASC; |
![]()
From the result, we can now easily notice the number of keys/constraints in all tables. This way we could find
tables:
- Without a primary key. This could be the result of an error in the design process
-
Without foreign keys. Tables without foreign keys should be only dictionaries or some kind of reporting table.
In all other cases, we should have a foreign key -
While UNIQUE shouldn’t be related to errors, in most cases we can expect that the table will have only 0 or 1
UNIQUE values. In case there is more, we could check why is that
Queries like this one could be a part of controls checking is everything ok with your database. You could complicate
things even more and use this query as a subquery for a more complex query that will automatically test predefined
errors/alerts/warnings.
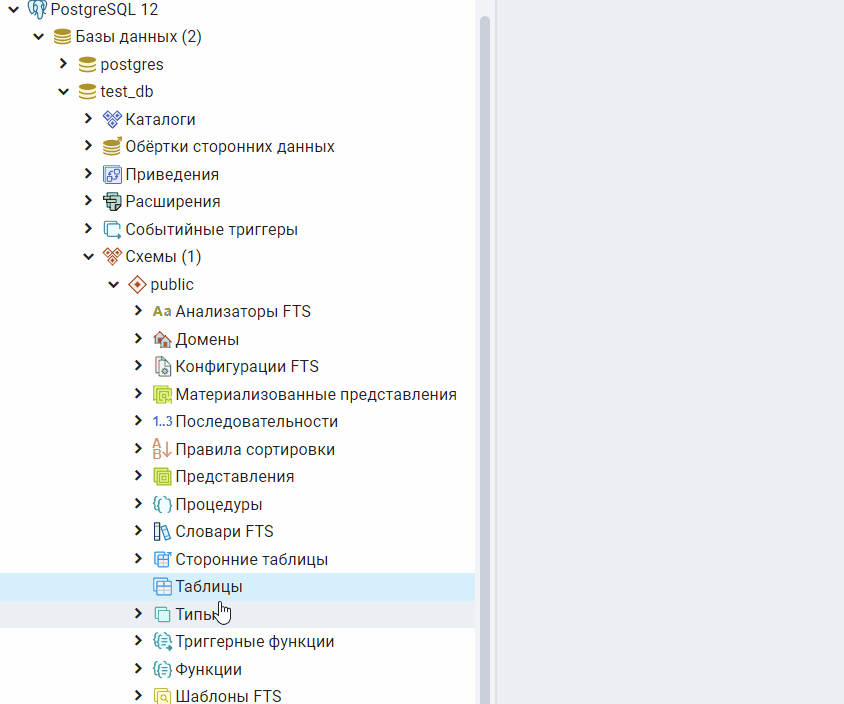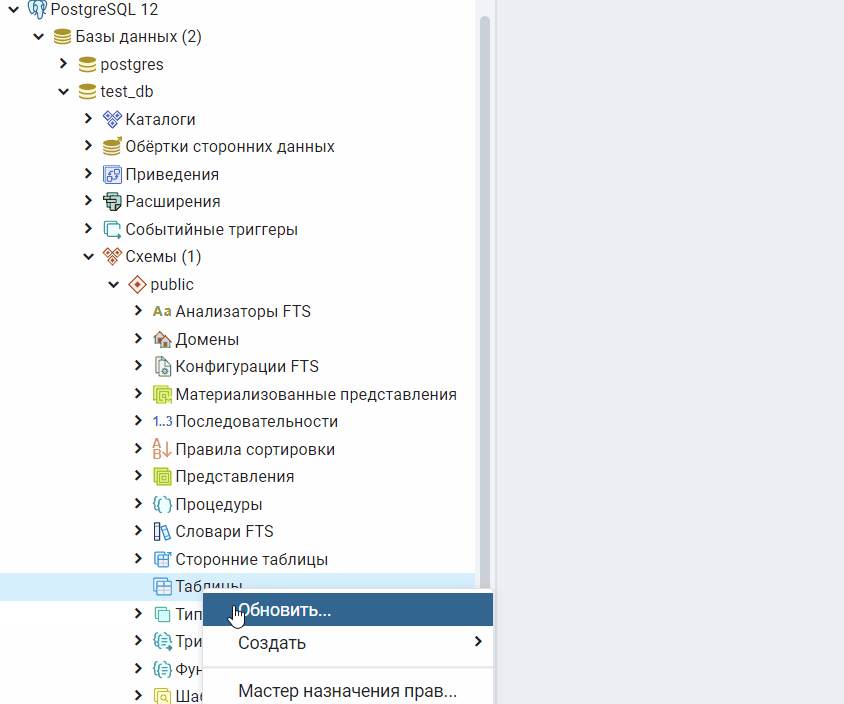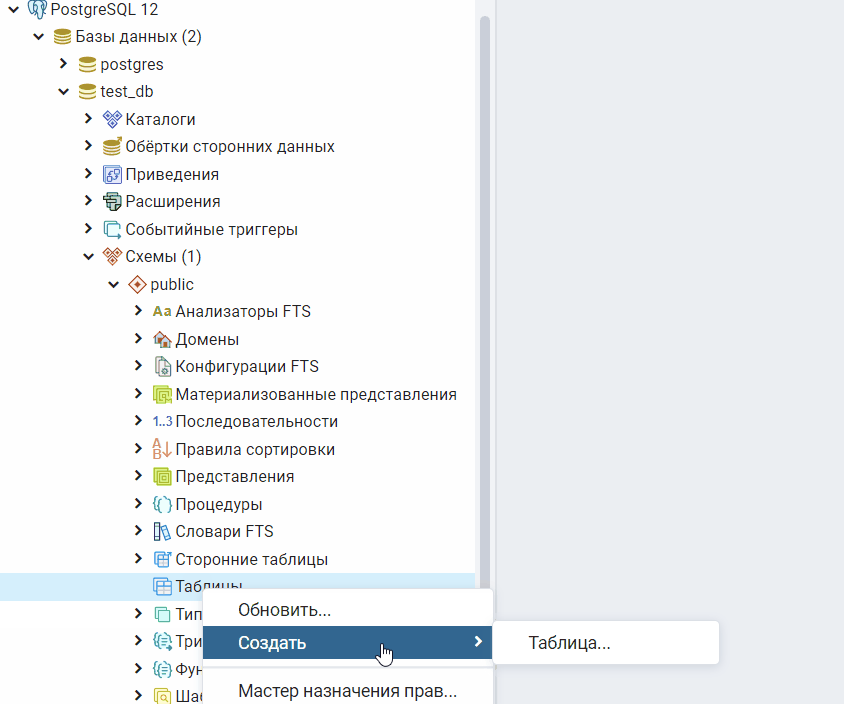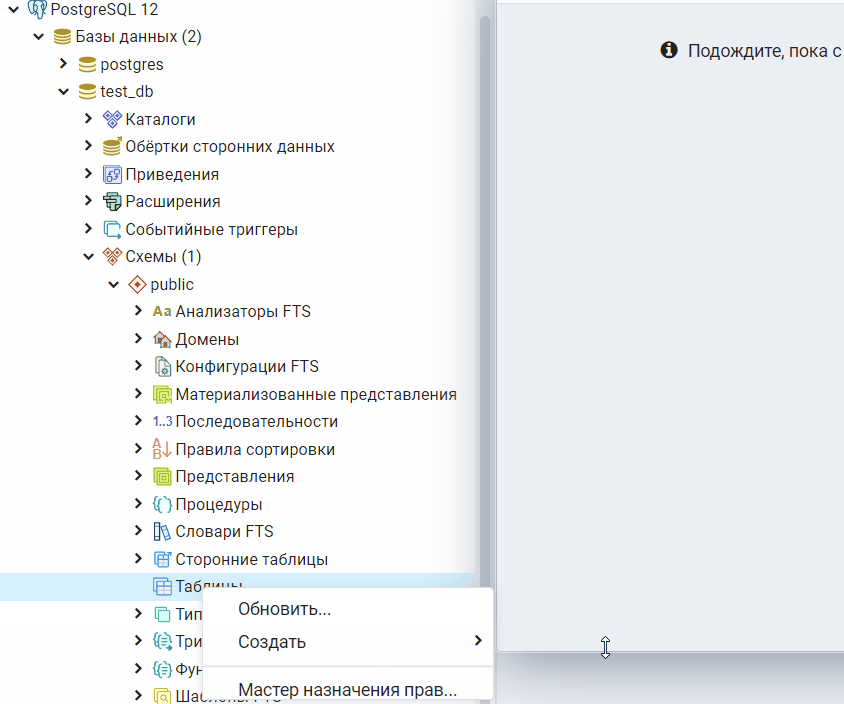
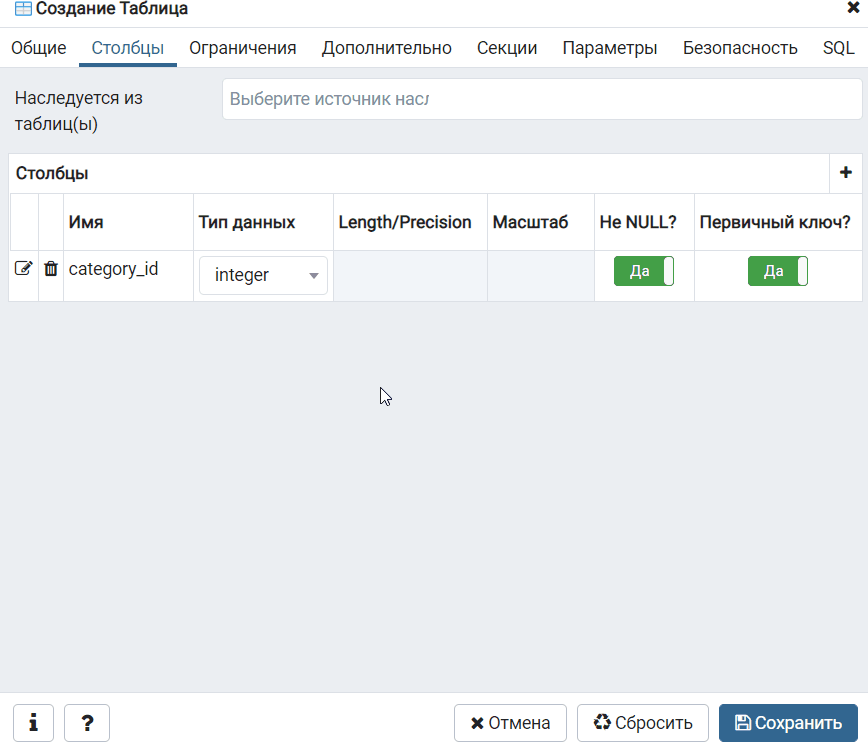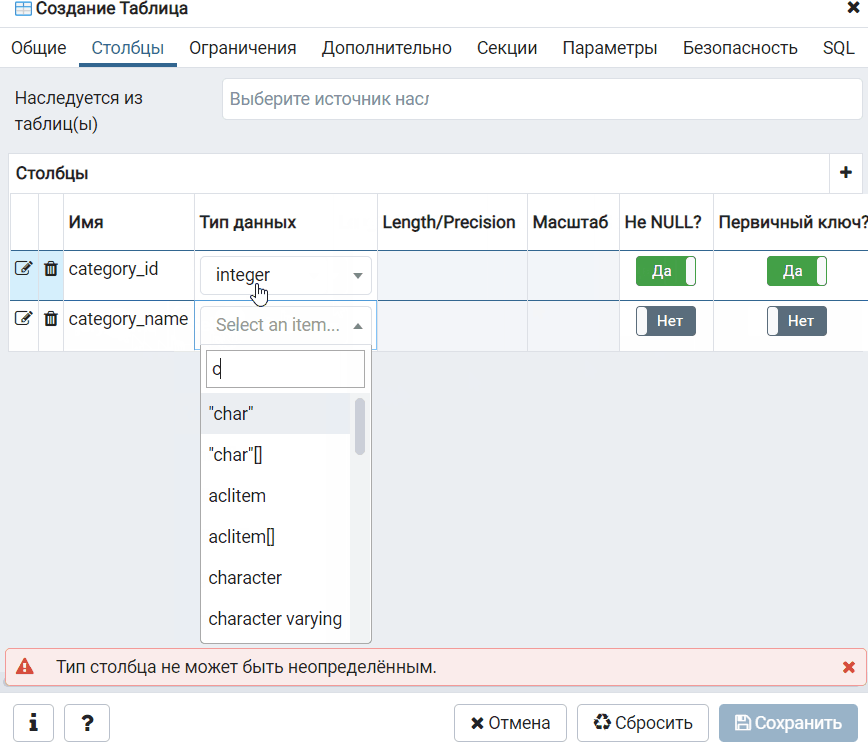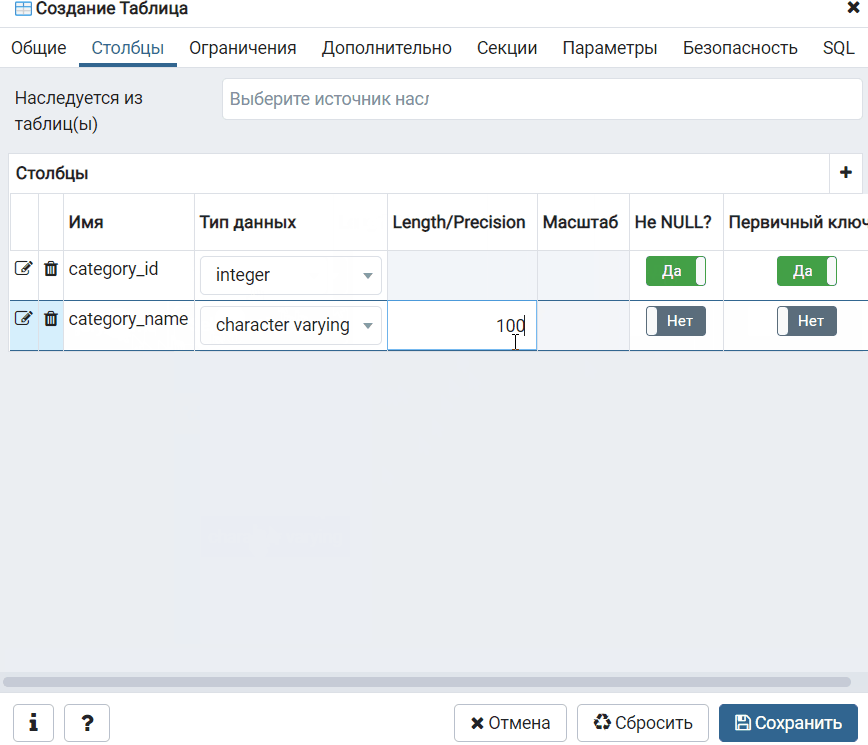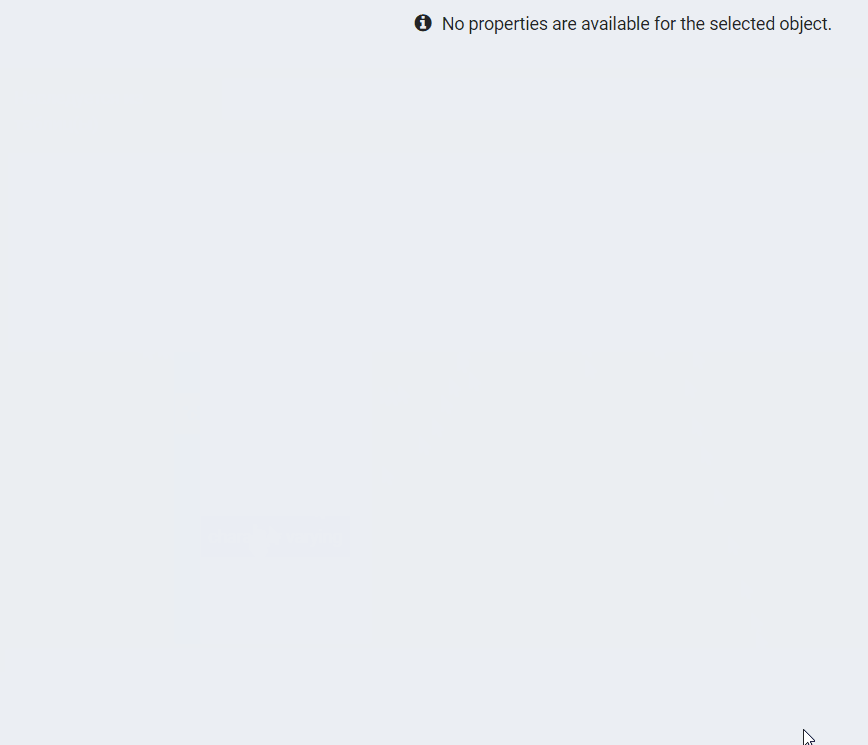
Добавление новой колонки к сущности
Перейдя на , увидим такой код:
import {Entity, PrimaryGeneratedColumn, Column} from "typeorm";@Entity()export class User { @PrimaryGeneratedColumn() id: number; @Column() firstName: string; @Column() lastName: string; @Column() age: number;}
Добавим к сущности новую колонку , копируя и вставляя вот это:
Сохраняем. Перезагружаем локальный сервер и видим, как в таблице появилась колонка .
![]()
![]()
Сравните до и после: новая колонка в красном прямоугольнике.
Вот и всё. Теперь вы видите, как легко в базу данных добавляется новая колонка с помощью в TypeORM.
Используя аналогичный подход, можно даже создать новую таблицу.
Запускаем
npm start
А теперь проясним кое-что важное для понимания материала, изложенного далее:
Объектно-реляционное отображение (ORM) — это мост между API и базой данных
![]()
Сущность, называющаяся также моделью данных, представляет собой класс TypeORM, который хранит в базе данных состояние объекта. Её изменение обновит схему во время синхронизации или миграции.
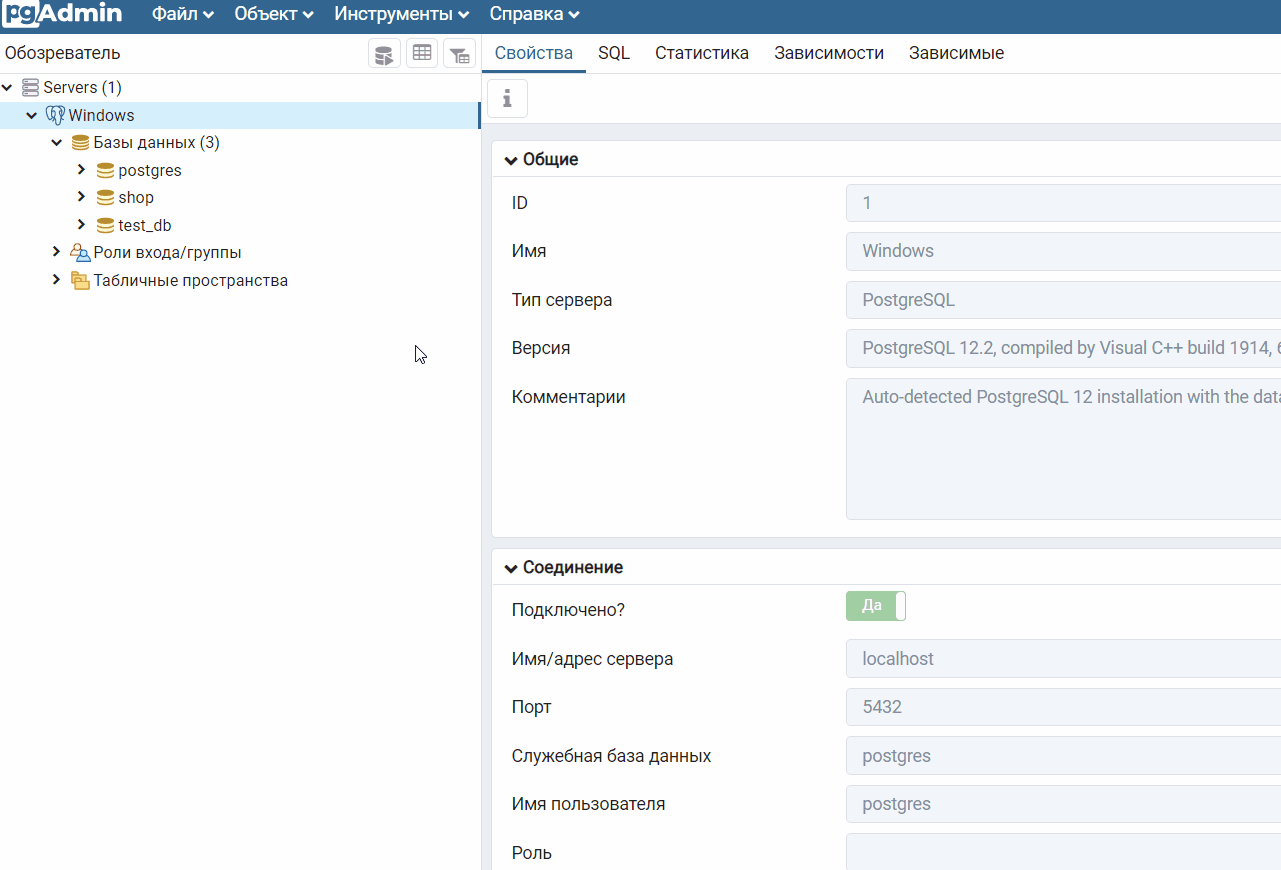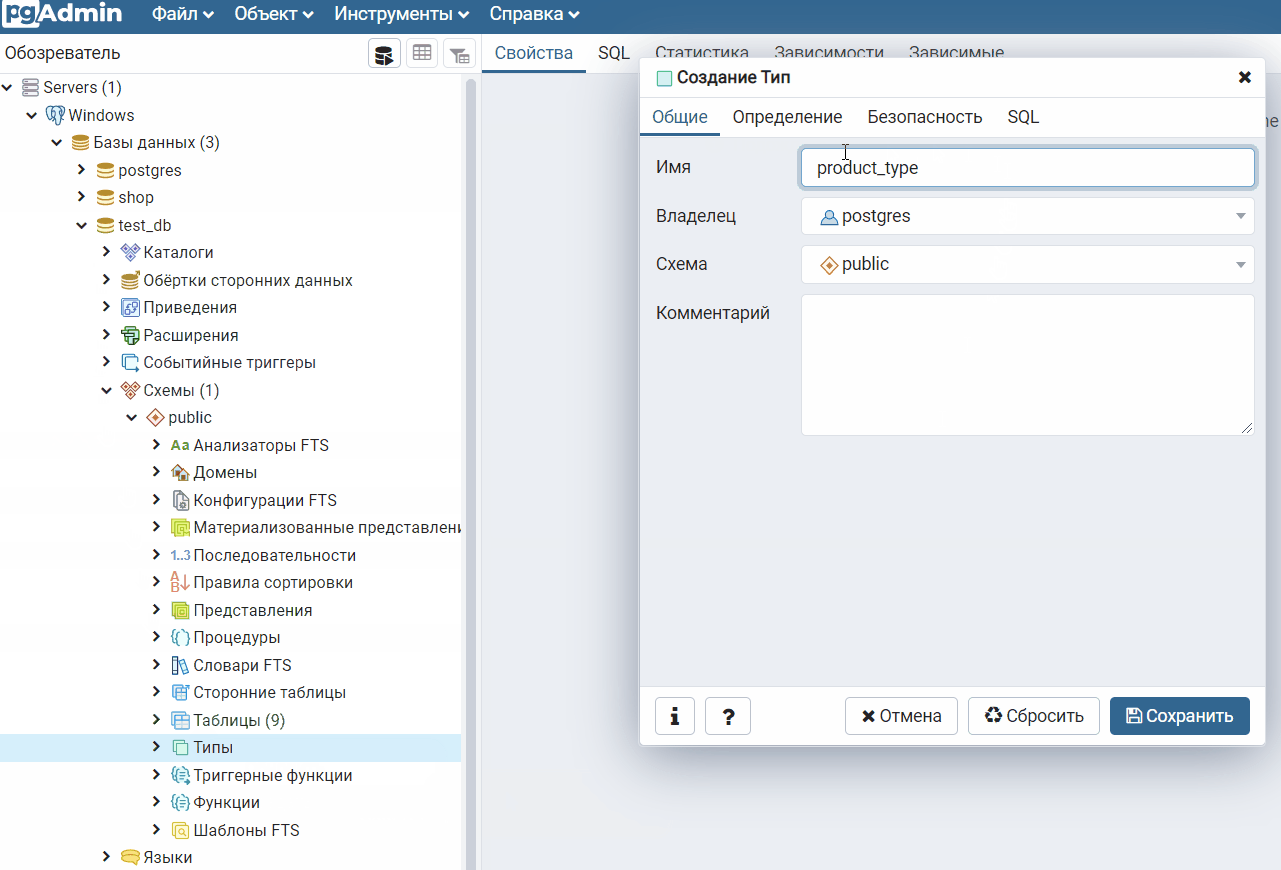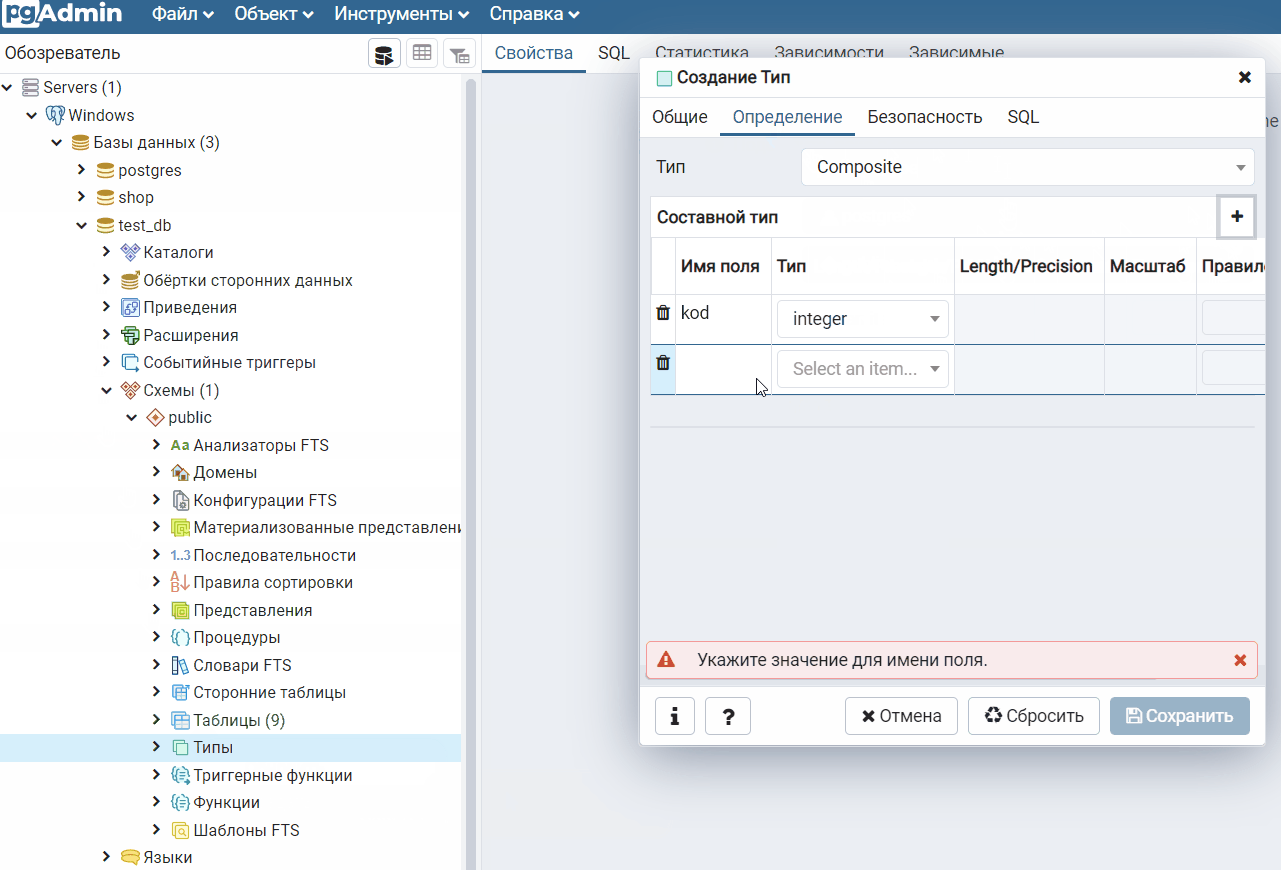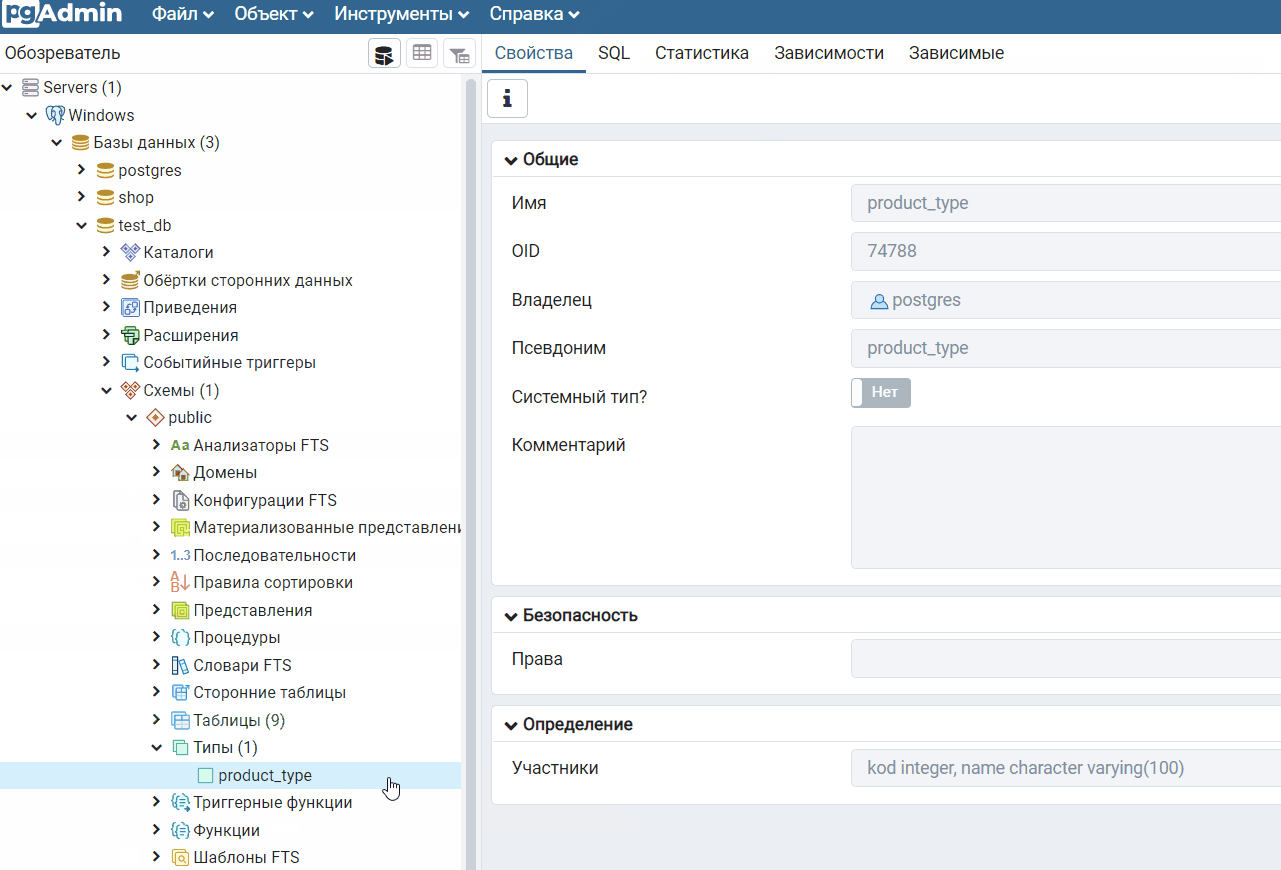
Замечание: в статье я ссылаюсь на MySQL, вы же можете использовать другие базы данных.
Synchronize
Прежде чем переходить к обсуждению миграций в TypeORM, сначала надо пару слов сказать о . Начнём с файла конфигурации , который генерируется при инициализации нового TypeORM-проекта с .
{ "type": "mysql", "host": "localhost", "port": 3306, "username": "test", "password": "test", "database": "test", "synchronize": true, "logging": false, "entities": [ "src/entity/**/*.ts" ], "migrations": [ "src/migration/**/*.ts" ], "subscribers": [ "src/subscriber/**/*.ts" ], "cli": { "entitiesDir": "src/entity", "migrationsDir": "src/migration", "subscribersDir": "src/subscriber" }}
Заметим, что . Это значение по умолчанию, но что конкретно под ним подразумевается? И как оно связано с миграциями? В файле TypeORM README.md сказано:
Другими словами, как только вы вносите изменения в сущность, автоматически происходит обновление изменений схемы с базой данных, привязанной к приложению.
Дальше рассмотрим три сценария синхронизации:
- Добавление новой колонки к сущности.
- Создание новой таблицы на основе новой сущности.
- Удаление колонки и/или таблицы через изменение сущности.
Посмотрим, что у нас получается в каждом из сценариев.
Table of contents
| Learn SQL: CREATE DATABASE & CREATE TABLE Operations | |
| Learn SQL: INSERT INTO TABLE | |
| Learn SQL: Primary Key | |
| Learn SQL: Foreign Key | |
| Learn SQL: SELECT statement | |
| Learn SQL: INNER JOIN vs LEFT JOIN | |
| Learn SQL: SQL Scripts | |
| Learn SQL: Types of relations | |
| Learn SQL: Join multiple tables | |
| Learn SQL: Aggregate Functions | |
| Learn SQL: How to Write a Complex SELECT Query? | |
| Learn SQL: The INFORMATION_SCHEMA Database | |
| Learn SQL: SQL Data Types | |
| Learn SQL: Set Theory | |
| Learn SQL: User-Defined Functions | |
| Learn SQL: User-Defined Stored Procedures | |
| Learn SQL: SQL Views | |
| Learn SQL: SQL Triggers | |
| Learn SQL: Practice SQL Queries | |
| Learn SQL: SQL Query examples | |
| Learn SQL: Create a report manually using SQL queries | |
| Learn SQL: SQL Server date and time functions | |
| Learn SQL: Create SQL Server reports using date and time functions | |
| Learn SQL: SQL Server Pivot Tables | |
| Learn SQL: SQL Server export to Excel | |
| Learn SQL: Intro to SQL Server loops | |
| Learn SQL: SQL Server Cursors | |
| Learn SQL: SQL Best Practices for Deleting and Updating data | |
| Learn SQL: Naming Conventions | |
| Learn SQL: SQL-Related Jobs | |
| Learn SQL: Non-Equi Joins in SQL Server | |
| Learn SQL: SQL Injection | |
| Learn SQL: Dynamic SQL | |
| Learn SQL: How to prevent SQL Injection attacks |
Изменение данных
Добавляет новую строку в таблицу:
INSERT INTO table(column1,column2,...) VALUES(value_1,value_2,...);
Добавляет несколько строк в таблицу:
INSERT INTO table_name(column1,column2,...)
VALUES(value_1,value_2,...),
(value_1,value_2,...),
(value_1,value_2,...)...
Обновление данных для всех строк:
UPDATE table_name
SET column_1 = value_1,
...;
Обновление данных для набора строк, заданных условием в предложении
UPDATE table
SET column_1 = value_1,
...
WHERE condition;
Удаление всех строк таблицы:
DELETE FROM table_name;
Удаление определенных строк на основе условия:
DELETE FROM table_name WHERE condition;
Управление представлениями
Создаем представление:
CREATE OR REPLACE view_name AS query;
Создаем рекурсивное представление:
CREATE RECURSIVE VIEW view_name(column_list) AS SELECT column_list;
Создайте детализированное представление:
CREATE MATERIALIZED VIEW view_name AS query WITH DATA;
Обновление детализированного представления:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;
Удаление существующего представления.
DROP VIEW view_name;
Удаление детализированного представления:
DROP MATERIALIZED VIEW view_name;
Переименование представления:
ALTER VIEW view_name RENAME TO new_name;
5.7.6. Примеры использования
Схемы могут быть использованы для организации ваших данных во
многих случаях. Существует несколько рекомендуемых вариантов
использования схем, которые поддерживаются в конфигурации по
умолчанию:
-
Если вы не создаёте никаких схем, то все пользователи
неявно получают доступ к схеме public. Это симулирует
ситуацию, когда схемы недоступны никому. Такая стратегия
рекомендуется в основном, когда в базе данных работает
только один пользователь или группа скооперированных
пользователей. Также данная стратегия позволяет смягчить
переход из СУБД, где нет схем. -
-
Вы можете создавать схему для каждого пользователя с именем,
таким же как и у пользователя. Вспомните, что по умолчанию
путь поиска начинается с элемента $user,
который означает имя текущего пользоватля. Следовательно,
если каждый пользователь имеет отдельную схему, то он
по умолчанию получает доступ к своей схеме.Если вы используете такую стратегию, то вы можете также
захотеть отобрать доступ к схеме public (или вообще удалить
её), так что пользователи будут ограничены только своими
схемами. -
Чтобы установить разделяемые приложения (где таблицы должны
использоваться любым пользователем или в случае дополнительных
функций от сторонних разработчиков и т.д.), поместите их
в отдельные схемы. Помните, что необходимо предоставить
соответствующие привилегии, чтобы разрешить доступ к ним
другим пользователям. Пользователи могут затем ссылаться на
дополнительные объекты через указания полных имен (со схемой)
или они могут поместить нужные схемы в свой путь поиска, как
им больше понравится.

The INFORMATION_SCHEMA Tables
It would be hard to try out every single table and show what it returns. At least, that would be hard to put into one readable article. I strongly encourage you to play with the INFORMATION_SCHEMA database and explore what is where. The only thing I’ll do here is to list all the tables (views) you have at disposal. They are:
- CHECK_CONSTRAINTS – details related to each CHECK constraint
- COLUMN_DOMAIN_USAGE – details related to columns that have an alias data type
- COLUMN_PRIVILEGES – columns privileges granted to or granted by the current user
- COLUMNS – columns from the current database
- CONSTRAINT_COLUMN_USAGE – details about column-related constraints
- CONSTRAINT_TABLE_USAGE – details about table-related constraints
- DOMAIN_CONSTRAINTS – details related to alias data types and rules related to them (accessible by this user)
- DOMAINS – alias data type details (accessible by this user)
- KEY_COLUMN_USAGE – details returned if the column is related with keys or not
-
PARAMETERS – details related to each parameter related to user-defined functions and procedures accessible by
this user - REFERENTIAL_CONSTRAINTS – details about foreign keys
- ROUTINES –details related to routines (functions & procedures) stored in the database
- ROUTINE_COLUMNS – one row for each column returned by the table-valued function
- SCHEMATA – details related to schemas in the current database
- TABLE_CONSTRAINTS – details related to table constraints in the current database
- TABLE_PRIVILEGES –table privileges granted to or granted by the current user
- TABLES –details related to tables stored in the database
- VIEW_COLUMN_USAGE – details about columns used in the view definition
- VIEW_TABLE_USAGE – details about the tables used in the view definition
- VIEWS – details related to views stored in the database
SQL
Поскольку стандарт языка SQL меняется со временем, и многие поставщики RDB предлагают разные версии SQL, это означает, что используемая нами реализация SQL может отличаться от стандарта ANSI.
Для обеспечения совместимости между базами данных большинство пользователей предпочитают писать команды SQL с использованием стандартного синтаксиса ANSI. Базовые команды SQL DML (INSERT, UPDATE и DELETE) и большинство команд DDL (CREATE DATABASE, CREATE TABLE) будут одинаковыми во всех реализациях. Однако каждая система реляционной базы данных может поддерживать разные типы данных и функции.
COLUMNS
Содержит столбцы, которые считываются из системной таблицы system.columns, и столбцы, которые не поддерживаются в ClickHouse или не имеют смысла (всегда имеют значение ), но должны быть по стандарту.
Столбцы:
- (String) — имя базы данных, в которой находится таблица.
- (String) — имя базы данных, в которой находится таблица.
- (String) — имя таблицы.
- (String) — имя столбца.
- (UInt64) — порядковый номер столбца в таблице (нумерация начинается с 1).
- (String) — выражение для значения по умолчанию или пустая строка.
- (UInt8) — флаг, показывающий является ли столбец типа .
- (String) — тип столбца.
- (Nullable(UInt64)) — максимальная длина в байтах для двоичных данных, символьных данных или текстовых данных и изображений. В ClickHouse имеет смысл только для типа данных . Иначе возвращается значение .
- (Nullable(UInt64)) — максимальная длина в байтах для двоичных данных, символьных данных или текстовых данных и изображений. В ClickHouse имеет смысл только для типа данных . Иначе возвращается значение .
- (Nullable(UInt64)) — точность приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse это разрядность для целочисленных типов и десятичная точность для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — основание системы счисления точности приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse значение столбца равно 2 для целочисленных типов и 10 — для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — масштаб приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse имеет смысл только для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — десятичная точность для данных типа . Для других типов данных возвращается значение .
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
Пример
Запрос:
Результат:
Пример 3. Получаем список и описание всех параметров хранимой процедуры в SQL сервере
Сейчас давайте рассмотрим случай, когда Вам необходимо получить список параметров процедуры, включая их тип данных. В этом случае можно использовать представление информационной схемы PARAMETERS (TestProcedure, как помните, имя моей тестовой процедуры).
SELECT SPECIFIC_NAME AS ,
ORDINAL_POSITION AS ,
PARAMETER_NAME AS ,
DATA_TYPE AS
FROM INFORMATION_SCHEMA.PARAMETERS
WHERE SPECIFIC_NAME = 'TestProcedure'
В данном случае, также можно использовать альтернативный вариант, а именно системное представление sys.parameters, только в данном случае потребуется дополнительное объединение с системным представлением sys.types и вызов функции OBJECT_NAME.
SELECT OBJECT_NAME(object_id) AS ,
P.parameter_id AS ,
P.name AS ,
T.name AS
FROM sys.parameters P
LEFT JOIN sys.types T ON P.user_type_id = T.user_type_id
WHERE OBJECT_ID = OBJECT_ID('TestProcedure')
![]()
На этом у меня все, надеюсь, статья была Вам полезной, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, пока!
Нравится4Не нравится1
Пример
В следующем примере поясняется стандарт ANSI для синтаксиса соединения SQL. ANSI вводит стандарты для синтаксиса соединения в 1992 году (известный как синтаксис соединения ANSI-92). Объединение определяется явно в синтаксисе с использованием соответствующего ключевого слова для каждого типа объединений. Эти ключевые слова:
- CROSS JOIN
- JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
Синтаксис неявного соединения (старый стиль)
В неявном внутреннем синтаксисе все объединяемые таблицы перечислены в предложении FROM, а условие объединения указано в предложении WHERE.
SELECT ProductName, CategoryName FROM Product, Category WHERE Product.CategoryID = Category.ID