
Введение
За основу я возьму 2 виртуальные машины на базе Centos 8. Если у вас их еще нет, можете воспользоваться моими статьями на тему установки и базовой настройки Centos 8. Ниже небольшая таблица, чтобы дальше было проще ориентироваться в статье.
| Hostname | IP адрес | Версия OS | Версия Mysql |
| mysql-master | 10.20.1.23 | Centos 8 | Percona Server for MySQL 8.0 |
| mysql-slave | 10.20.1.29 | Centos 8 | Percona Server for MySQL 8.0 |
Начнем настройку репликации с установки Mysql сервера на обе виртуальные машины. Ниже приведу краткий список действий, чтобы сразу было понятно, что мы будем делать.
Краткий список действий
Необходимое время: 1 час.
Настройка master-slave репликации mysql.
-
Установка percona mysql server.
Подключаем репозиторий и устанавливаем необходимые пакеты.
-
Создание или загрузка баз данных для репликации.
Покажу на примере, как загрузить из дампа базу данных, для которой настроим репликацию.
-
Настройка непосредственно репликации.
Подробно расскажу и покажу, как настроить репликацию загруженной базы.
-
Проверка работы репликации.
Приведу пример, как можно убедиться, что репликация работает.
Искусственный интеллект
The AI Summit SILICON VALLEY 2021
Крупнейшее мировое событие в сфере ИИ: более четырёх тысяч участников из 120 стран, в том числе более 100 топ-менеджеров компаний из Fortune 500. Например, Google, IBM, Microsoft, Samsung, Intel, Facebook, Cisco.
AI Super Summit
На саммите обсуждают вопросы искусственного интеллекта. Среди спикеров — директор Facebook AI Research и профессор Нью-Йоркского университета Ян Лекун, профессор компьютерных наук и исследований операций Монреальского университета Йошуа Бенджио, главный научный сотрудник Google Кэсси Козырькова, технический директор Amazon.com д-р Вернер Фогельс, корпоративный вице-президент и технический директор AI Microsoft Джозеф Сирош.
AI & Big Data Expo Europe
Ведущая конференция и выставка по технологиям искусственного интеллекта и Big Data. Ожидается 8000 участников и более 500 докладчиков. Обсудят вопросы ИИ, Big Data и аналитики данных, машинное обучение, чат-боты и виртуальные помощники, RPA и автоматизацию, клиентский опыт, компьютерное зрение, голосовые технологии, NLP, бизнес-аналитику.
Insurance AI and Innovative Tech USA 2021
Это онлайн-мероприятие для страховых компаний, проводимое Reuters. Обсудят применение ИИ и других технологий в страховании.
Tutorials Schedule — Monday 22 April 2013
9:30am to 12:30pm
Innodb Architecture and Performance OptimizationSpeaker(s): Peter ZaitsevBallroom A
MySQL Patterns in Amazon — Make the Cloud Work For YouSpeaker(s): Jay Edwards, Ben BlackBallroom B
Ramp-up tutorial for MySQL Cluster — Scaling with continuous availability (Part 1)Speaker(s): René CannaòBallroom C
Using TokuDB: A Guided Walk Through a TokuDB ImplementationSpeaker(s): Gerardo NarvajaBallroom D
Percona XtraDB Cluster / Galera in Practice (Part 1)Speaker(s): Jay Janssen, Seppo JaakolaBallroom E
Cookbook for Creating INDEXes — All about IndexingSpeaker(s): Rick JamesBallroom F
Operational DBA In A Nutshell! Hands On Tutorial! (Part 1)Speaker(s): Kenny Gryp, Frederic Descamps, Liz van DijkBallroom G
Evaluating MySQL High Availability alternativesSpeaker(s): Henrik IngoBallroom H
1:30pm to 4:30pm
Using Tungsten Replicator to solve replication problemsSpeaker(s): Neil Armitage, Giuseppe MaxiaBallroom A
Advanced query optimizer tuning and analysisSpeaker(s): Sergei Petrunia, Timour KatchaounovBallroom B
Ramp-up tutorial for MySQL Cluster — Scaling with continuous availability (Part 2)Speaker(s): René CannaòBallroom C
From Crash to Testcase: a Debugging PrimerSpeaker(s): Roel Van de PaarBallroom D
Percona XtraDB Cluster / Galera in Practice (Part 2)Speaker(s): Jay Janssen, Seppo JaakolaBallroom E
Percona XtraBackup: old and new featuresSpeaker(s): Vadim TkachenkoBallroom F
Operational DBA In A Nutshell! Hands On Tutorial! (Part 2)Speaker(s): Kenny Gryp, Frederic Descamps, Liz van DijkBallroom G
Full-text search: from scratch to a HA clusterSpeaker(s): Andrew AksyonoffBallroom H
4:30pm to 6:30pm
Welcome Reception (in Expo Hall)
Разработка
Dash 2021
Ежегодная конференция о создании и масштабировании приложений и инфраструктуры. Аудитория — разработчики, поддержка, специалисты по безопасности.
GOTO Copenhagen 2021
О чём пойдёт речь: видеоаналитика, TypeScript, машинное обучение, работа с данными, Kotlin/JS, DevOps. Среди спикеров — специалист по машинному обучению в Cloud Technology Solutions Йован Вельяноски, старший консультант Miles Вагиф Абилов, специалист в области компьютерного зрения, видеоаналитики и глубокого обучения в NVIDIA Екатерина Сиразитдинова.
Mendix World
Конференция для разработчиков, бизнесменов и ИТ-руководителей по технологиям low-code. В программе — экспертные сессии и презентации новинок.
Оптимизация MySQL
Конфигурация MySQL достаточно сложная, но, к счастью, вам не нужно в нее сильно углубляться. Есть специальный скрипт под названием MySQLTunner, который анализирует работу MySQL и дает советы какие параметры нужно изменить и какие значения для них установить. Скрипт поддерживает большинство версий MariaDB, MySQL и Percona XtraDB. Нам понадобится загрузить три файла с помощью wget:
![]()
Первый из них — это сам скрипт, написанный на Perl, второй и третий — база данных простых паролей и уязвимостей. Они позволяют обнаружить проблемы с безопасностью. Дальше можно переходить к тестированию. Я использую сервер с настройками mysql по умолчанию, установленными панелью управления VestaCP.
![]()
Буквально за несколько минут скрипт выдаст полную статистику по работе MySQL. Количеству запросов, занимаемому объему памяти и эффективности работы буферов. Вы можете ознакомиться со всем этим, чтобы лучше понять в чем причина проблем. Проблемные места обозначены красными восклицательными знаками. Например, здесь мы видим, что размер буфера движка таблиц InnoDB (InnoDB buffer pool) намного меньше, чем должен быть для оптимальной работы:
![]()
Кроме того, в самом конце вывода утилита предоставит список рекомендаций как исправить ситуацию. Мы рассмотрим все сообщения утилиты из этого примера и почему нужно использовать именно их, а не другие.






![]()
Все параметры нужно добавлять в /etc/my.cnf. Еще раз замечу, что вы не копируете статью, а смотрите что вам выдала утилита. Начнем с query-cache.
Скрипт рекомендует отключить кэш запросов. Query Cache — это кэш вызовов SELECT. Когда базе данных отправляется запрос, она выполняет его и сохраняет сам запрос и результат в этом кэше. И все бы ничего, но при использовании его вместе с InnoDB при любом изменении совпадающих данных кэш будет перестраиваться, что влечет за собой потерю производительности. И чем больше объем кэша, тем больше потери. Кроме того при обновлении кэша могут возникать блокировки запросов. Таким образом, если данные часто пишутся в базу данных — его надежнее отключить.
Оба параметра устанавливают размер памяти, которая используется для внутренних временных таблиц MySQL. Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64
Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное
Этот параметр отвечает за количество потоков, которые будут закэшированны. После того, как работа с подключением будет завершена, база данных не разорвет его, а закэширует, если количество кэшированных потоков не превышает ограничение. Утилита рекомендует больше четырех, например, 16.
Указывает, что не нужно пытаться определить доменное имя для подключений извне. Ускоряет работу, так как не тратится время на DNS запросы.
Этот параметр определяет размер буфера InnoDB в оперативной памяти, от этого размера очень сильно зависит скорость выполнения запросов. Значение зависит от размера ваших таблиц и количества данных в них. Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.
![]()
Размер файла лога innodb должен составлять 25% от размера буфера. В случае 800 мегабайт это будет 200М. Но тут есть одна проблема. Чтобы изменить размер лога нужно выполнить несколько действий. Поскольку мы изменили все нужные параметры перейдем к перезагрузке сервера. Для нашего лога нужно остановить сервис:
Затем переместите файлы лога в /tmp:
![]()
И запустите сервис:
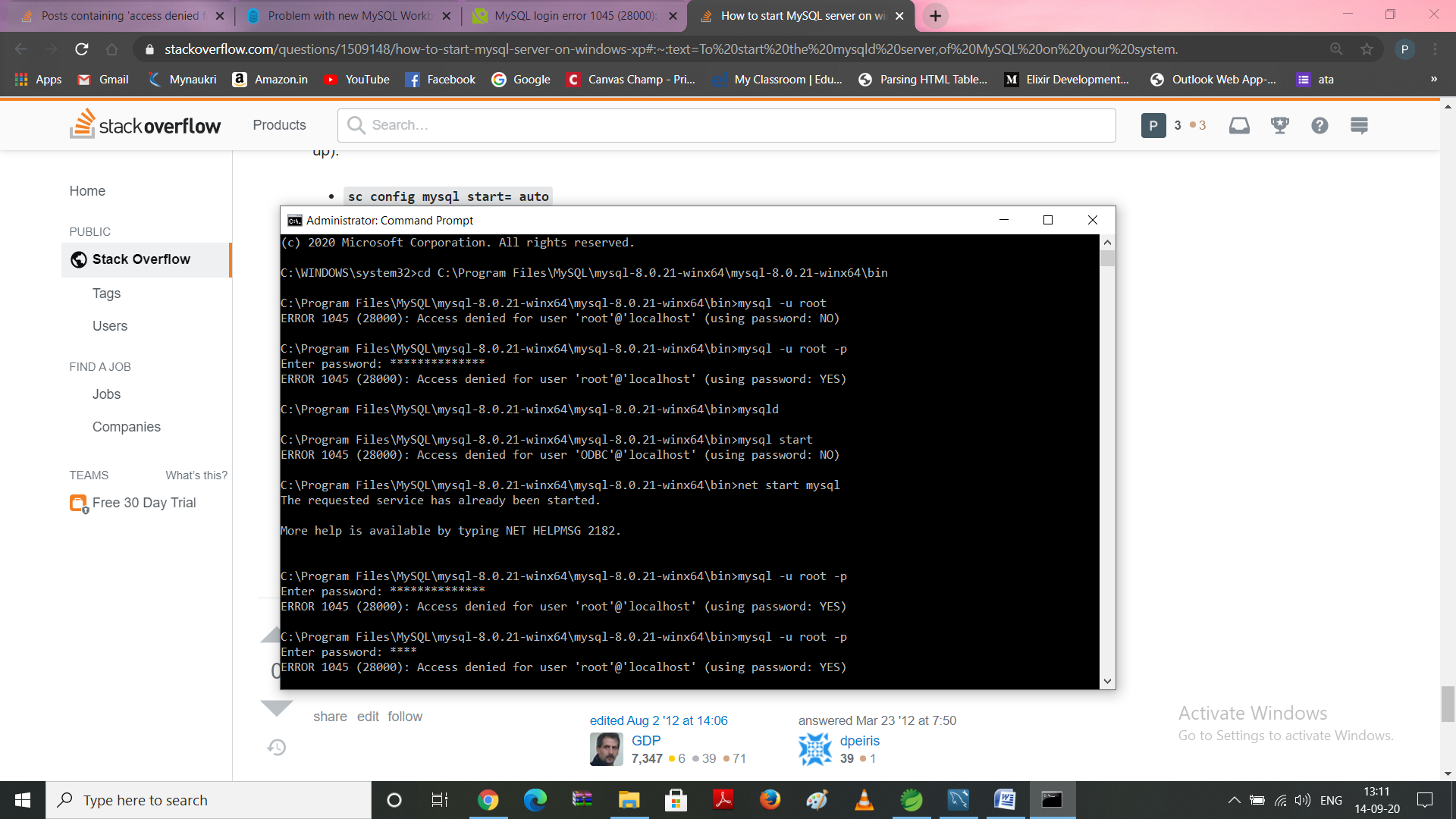
Когда размер лога меняется сервис видит поврежденный лог, выдает ошибку и не запускается. Поэтому сначала нужно удалить старый. После этого смотрите есть ли сообщения об ошибках:
![]()
Категории
1: запросы MySQL
и будет использовать несколько процессоров, при условии, что операционная система их поддерживает. Это также увеличит системные ресурсы при правильной настройке производительности.
Типичная настройка в , которая влияет на производительность потока:
можно увеличить, чтобы повысить производительность, если у вас много новых подключений. Как правило, это не обеспечивает заметного улучшения производительности, если у вас есть хорошая реализация потока. Однако, если ваш сервер видит сотни соединений в секунду, вы должны обычно устанавливать достаточно высокий уровень thread_cache_size, чтобы большинство новых соединений использовали кэшированные потоки
Если вы используете Solaris, тогда вы можете использовать
позволяет приложениям дать системе потоков подсказку о желаемом количестве потоков, которые должны быть запущены одновременно.
Эта переменная устарела с MySQL 5.6.1 и удалена в MySQL 5.7. Вы должны удалить это из файлов конфигурации MySQL всякий раз, когда вы видите это, если они не для Solaris 8 или ранее.
InnoDB::
У вас нет таких ограничений, если вы используете Innodb имеет механизм хранения, потому что он полностью поддерживает параллелизм потоков
Вы также можете посмотреть на и , где по умолчанию установлено значение , и его можно увеличить до в зависимости от аппаратного обеспечения
Другие:
Другие конфигурации, на которые следует обратить внимание, включают в себя , , и т.д., Которые могут привести к повышению производительности
PHP:
В чистом PHP вы можете создать MySQL Worker, где каждый запрос выполняется в отдельных потоках PHP
2. Разбор HTML-контента
Если вы уже знаете проблему, ее легче решить с помощью циклов событий, очереди заданий или потоков.
Работа над одним документом по одному может быть очень, очень медленным и болезненным процессом. @ka однажды взломав свой выход с помощью ajax для вызова нескольких запросов, некоторые творческие умы просто разветвляют процесс, используя pcntl_fork, но если вы используете , то вы не можете воспользоваться из
С , поддерживающим как Windows, так и Unix-системы, у вас нет таких ограничений. Это так же просто, как… Если вам нужно разобрать 100 документов? Spawn 100 Threads… Простой
Сканирование HTML
Выход
Класс используется
Эксперимент
Попробуйте проанализировать файлы, которые имеют ссылки без потоков, и посмотрите, сколько времени это займет.
Лучшая архитектура
Создание слишком большого количества потоков, что не очень разумно делать в производстве. лучше было бы использовать пул. Имейте пул определения рабочих, а затем стека с
Улучшение производительности
Хорошо, приведенный выше пример все еще можно улучшить. Вместо того, чтобы ждать, пока система просканирует все файлы в одном потоке, вы можете использовать несколько потоков для сканирования файлов в моей системе, а затем складывать данные рабочим для обработки
3. Обновление поискового индекса
На первый ответ это было в значительной степени ответом, но есть много способов улучшить производительность. Вы когда-нибудь рассматривали подход, основанный на событиях?
Представляем мероприятие
@rdlowrey Цитата 1:
@rdlowrey Цитата 2:
Почему бы вам не поэкспериментировать с подходом , к вашей проблеме. PHP имеет libevent, чтобы перегружать ваше приложение.





Я знаю, что весь этот вопрос , но если у вас есть время, вы можете посмотреть этот Ядерный реактор, написанный на PHP @igorw
Creating a MySQL User Account to Be Used with PMM
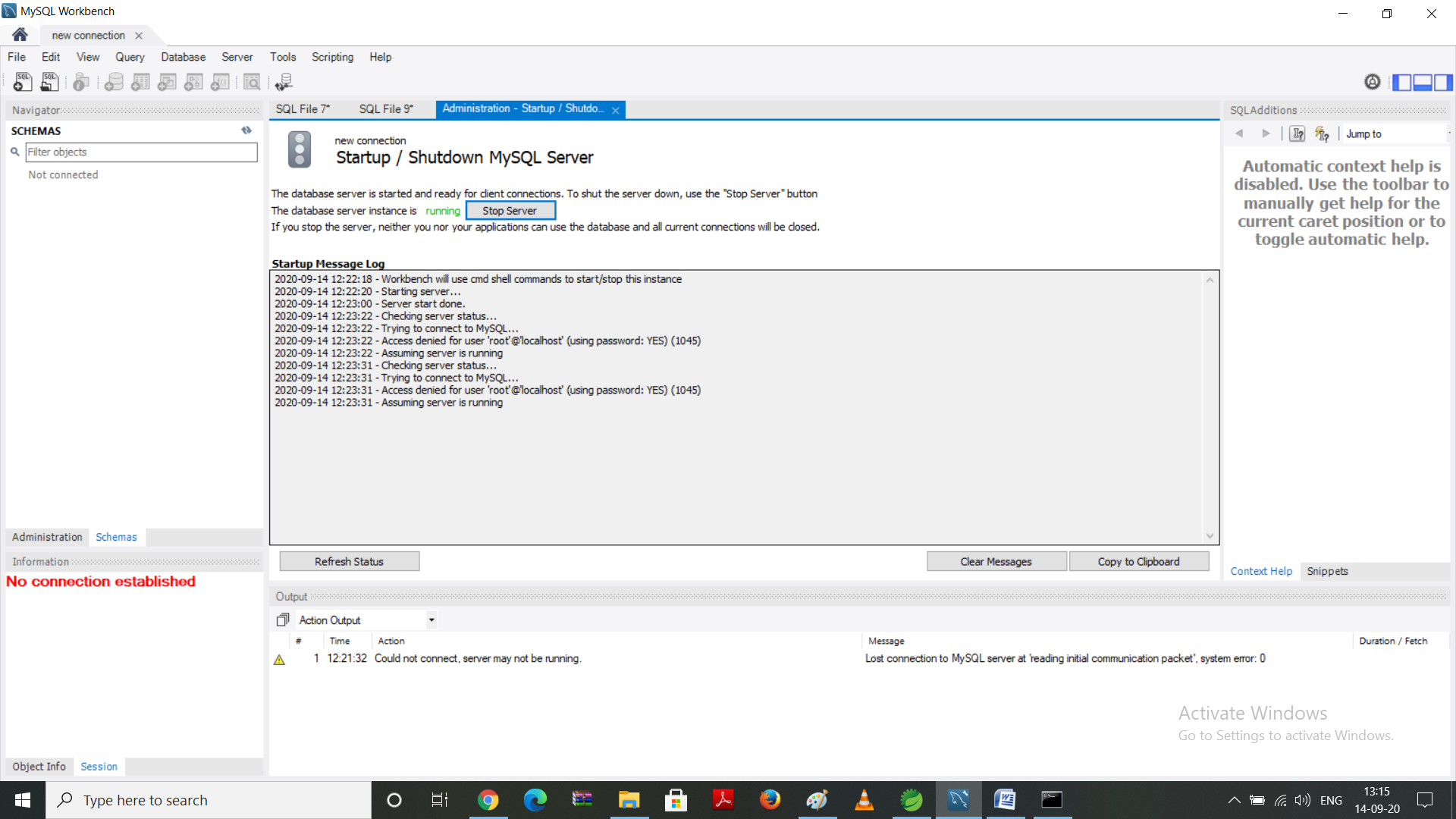
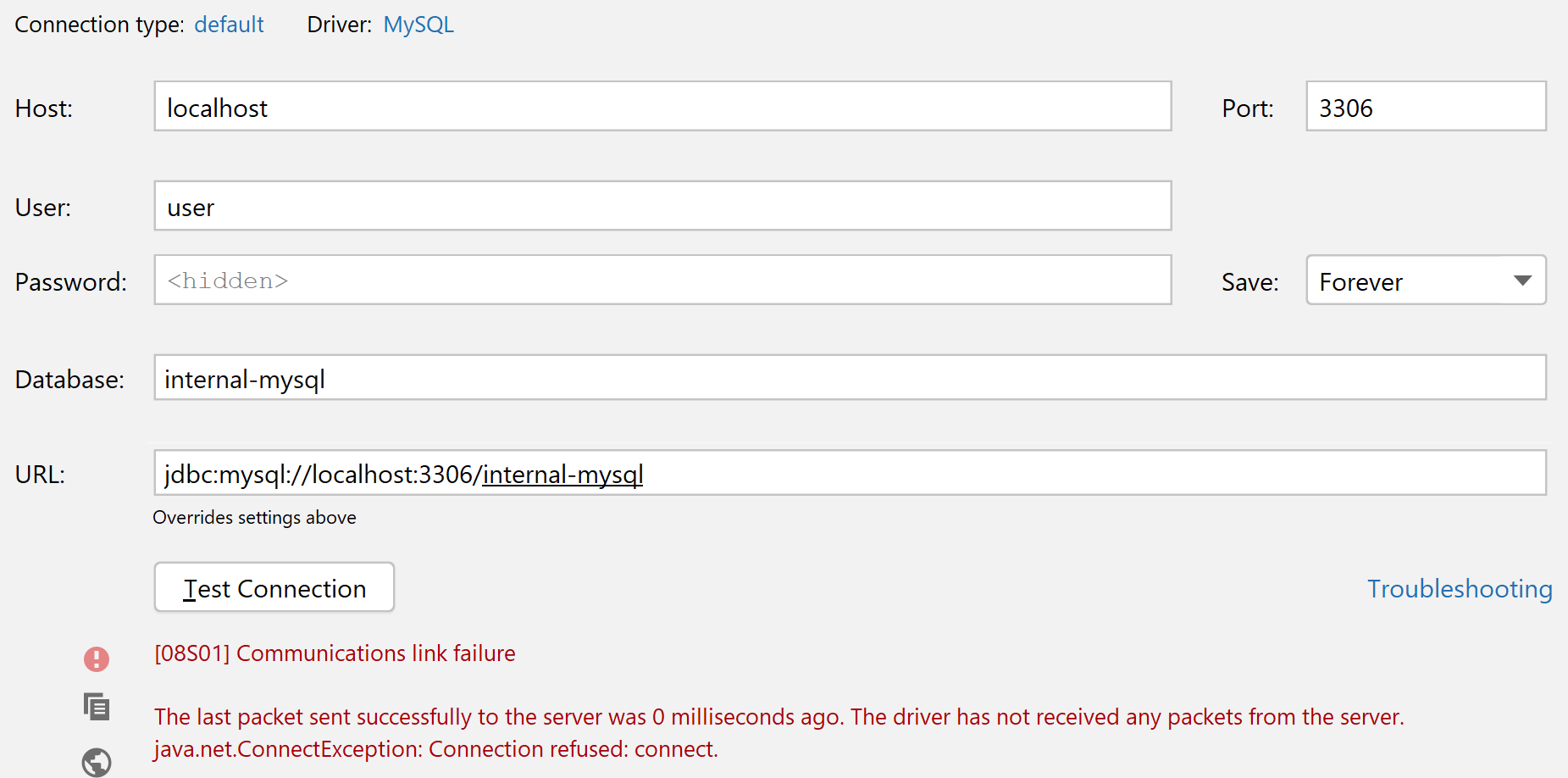
When adding a MySQL instance to monitoring, you can specify the MySQL server superuser account credentials. However, monitoring with the superuser account is not secure. If you also specify the option, it will create a user with only the necessary privileges for collecting data.
You can also set up the user manually with necessary privileges and pass its credentials when adding the instance.
To enable complete MySQL instance monitoring, a command similar to the following is recommended:
The superuser credentials are required only to set up the user with necessary privileges for collecting data. If you want to create this user yourself, the following privileges are required:
If the user already exists, simply pass its credential when you add the instance:
For more information, run as root pmm-admin add .
5 ответов
103
Я узнал что-то удивительное: несмотря на документацию, лучше оставить в 0 (бесконечный параллелизм). Таким образом, InnoDB решает наилучшее количество , чтобы открыть для данной установки экземпляра MySQL.
После того, как вы установили innodb_thread_concurrency в 0, вы можете установить и (оба начиная с MySQL 5.1.38) до максимального значения 64. Это должно включать больше ядер.
24
MySQL будет автоматически использовать несколько ядер, поэтому либо ваша нагрузка 25% будет совпадением 1 , либо потенциальной неправильной конфигурацией на Solaris. Я не буду притворяться, что знаю, как настраивать солярис, но вот статья, в которой описывается информация о настройке солярия .
Настраиваемые страницы InnoDB прошли капитальный ремонт в MySQL 5.5, поэтому есть и хорошая информация. Из подсказок IO для дисководов InnoDB :
Некоторые другие вещи для проверки:
-
Переключение на O_DIRECT стоит проверить , Если это поможет, возможно, вам потребуется подключить файловую систему с помощью опции
-
Измените от 1 до 0 ( если вы не против потери последней секунды при сбое mysql) или 2 (если вы не против потери последней секунды при сбое ОС).
-
Проверьте значение . В этой статье о переменной.
Но в конце раздела есть некоторые оговорки о том, что значит включить переменную (по умолчанию она включена в 5.5).
-
Возможно, что репликация вызывает некоторые проблемы. Я понимаю, что вас не интересует параллелизм, но из описания этого рабочего журнала :
В конечном счете, InnoDB, возможно, не лучший движок для datawarehousing, из-за возникающих на диске операций. Вы могли бы рассмотреть возможность изменения таблиц (ов) данных в виде данных сжатого MyISAM .
1 Посредством совпадения я имею в виду, что есть узкое место, которое предотвращает увеличение вашей нагрузки выше 25%, но не обязательно является принудительной одноядерной проблемой.
12
В одном соединении будет использоваться только одно ядро. (ОК, InnoDB использует другие потоки, следовательно, ядра для некоторой обработки ввода-вывода, но это не имеет значения.)
У вас было 3 ALTERs, поэтому вы не использовали гораздо больше, чем 3 основных достоинства.
Увы, даже PARTITION не использует несколько ядер.
До недавнего времени несколько соединений были максимально удалены после 4-8 ядер. Perl’s Xtradb (входит в состав MariaDB) позволяет лучше использовать несколько ядер, но все равно только один на поток. Максимум составляет около 32 ядер.
6
IMHO и в описанном случае использования вы никогда не будете использовать более одного ядра. Причина в том, что ваша рабочая нагрузка связана с IO, а не с привязкой к ЦП. Поскольку ваши 3 соединения создают новый индекс, каждый из них должен прочитать всю таблицу с диска: это то, что занимает время, а не вычисление индексов.
4
Учтите, что ваше узкое место может быть производительностью IO вашей файловой системы.
В дополнение к настройкам, предложенным @RolandoMySQLDBA, я также устанавливаю параметры монтирования в для раздела, содержащего мой каталог данных mysql ( в моем случае с , установленным на ).
По умолчанию linux записывает время доступа для чтения или записи КАЖДОГО диска, что отрицательно влияет на производительность ввода-вывода, особенно для приложений с высоким IO, таких как базы данных. Это означает, что даже чтение данных из файла вызывает запись на диск … WAT!
Чтобы отключить это, добавьте параметр монтирования в для нужной точки монтирования следующим образом (пример в моем случае):
Затем перемонтируйте раздел:
Это должно повысить производительность чтения /записи приложений с использованием этого раздела. НО … ничего не бьет все ваши данные в памяти.
Общие настройки
max_connections=64 — устанавливаем параметр минимальным возможным при необходимости экономить ресурсы сервера, при возникновении в логе записей вида «Too many connections…» увеличиваем значение. Не следует изменять значение этого параметра на старте. 4000 клиентов является максимумом. Можно довести максимальное количество клиентов до 7000, но для стандартных сборок 4000 является пределом.
open_files_limit = 2048 Устанавливать значение стоит опираясь на существующее количество открытых файлов MySQL:
В конфигурационном файле задается большее значение.
connect_timeout (MySQL pre-5.1.23: default 5, MySQL 5.1.23+: default 10) — количество секунд по прошествии которых сервер баз данных будет выдавать ошибку, при активном веб-сервере значение можно уменьшать чтобы увеличить скорость работы, на медленной машине — можно увеличивать. max_connect_errors (default 10) — максимальное количество единовременных соединений с сервером баз данных с хоста запрос блокируется если он прерывается запросами с того же хоста до момента окончания обработки запроса) блокируются навсегда, очистить можно только из командной оболочки MySQL:
В случае атаки на сервер нужно уменьшать (5) чтобы отсекать попытки соединения, при большой активности веб-сервера можно увеличивать max_allowed_packet (default 1M) — максимальный для буфера соединений и буфера результата при исполнении SQL инструкций. Каждый тред имеет свой буфер. Хорошим значением для начала будет 16М. tmp_table_size (system-specific default) — максимальный размер памяти выделяемой под хранение временных таблиц. 16М — довольно много.
Примеры готовых конфигураций для разных объёмов памяти можно посмотреть здесь.
Чтобы посомореть значения переменных можно воспользоваться SQL запросом:
или для конкретных переменных:
Чтобы проверить мониториг InnoDB, используте:
Чтобы узнать, не свопается ли память, используйте команду и смотрите строку swap:
Сравнение Percona Server и MySQL
Persona Server имеет следующие преимущества по сравнению со стандартным сервером базы данных MySQL:
| Характеристики | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| Open source | Да | Да |
| ACID-совместимость | Да | Да |
| Multi-Version Concurrency Control | Да | Да |
| Блокировка строк | Да | Да |
| Автоматическое восстановление после сбоя | Да | Да |
| Разметка таблиц | Да | Да |
| Просмотры | Да | Да |
| Подзапросы | Да | Да |
| Триггеры | Да | Да |
| Хранимые процедуры | Да | Да |
| Внешние ключи | Да | Да |
| Да | Да |
| Дополнительные функции для разработчиков | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| NoSQL Soket-Level интерфейс | Да | Да |
| Дополнительные хэш\дайджест функции | Да | Нет |
| Дополнительные функции диагностики | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| 75 | 61 | |
| Количество глобальных счетчиков производительности и состояния | 385 | 355 |
| Счетчики производительности таблиц | Да | Нет |
| Счетчики производительности индексов | Да | Нет |
| Счетчики производительности пользователей | Да | Нет |
| Счетчики производительности клиентов | Да | Нет |
| Счетчики производительности потоков | Да | Нет |
| Глобальная статистика времени ответа на запросы | Да | Нет |
| Да | Нет | |
| Откат информации о сегментах | Да | Нет |
| Информация о временных таблицах | Да | Нет |
| Улучшения производительности и масштабируемости | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| Улучшенная масштабируемость за счет разделения мьютексов | Да | Нет |
| Да | Нет | |
| Улучшенная очистка | Да | Нет |
| Дополнительные функции для администраторов и операционистов | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| Настраиваемые размеры страниц | Да | Да |
| Настраиваемое быстрое создание индексов | Да | Нет |
| Отслеживание изменений страницы | Да | Нет |
| PAM-аутентификация | Да | Только в версии Enterprise |
| Пул потоков | Да | Только в версии Enterprise |
| Блокировка до резервного копирования | Да | Нет |
| Да | Нет | |
| Улучшенная система обработки поврежденных таблиц | Да | Нет |
| Возможность аннулирования простаивающих транзакции | Да | Нет |
| Да | Нет |
| Функции для работы с DBaaS (Database-as-a-service) | Percona Server 5.7.10 | MySQL 5.7.10 |
|---|---|---|
| Да | Нет | |
| Расширенные модификаторы программных опций | Да | Нет |
| Да | Нет |
Configuring the slow query log in Percona Server
If you are running Percona Server, a properly configured slow query log will provide the most amount of information with the lowest overhead. In other cases, use Performance Schema if it is supported.






By definition, the slow query log is supposed to capture only slow queries. These are the queries the execution time of which is above a certain threshold. The threshold is defined by the variable.
In heavily loaded applications, frequent fast queries can actually have a much bigger impact on performance than rare slow queries. To ensure comprehensive analysis of your query traffic, set the to so that all queries are captured.
However, capturing all queries can consume I/O bandwidth and cause the slow query log file to quickly grow very large. To limit the amount of queries captured by the slow query log, use the query sampling feature available in Percona Server.
The variable defines the fraction of queries captured by the slow query log. A good rule of thumb is to have approximately 100 queries logged per second. For example, if your Percona Server instance processes 10_000 queries per second, you should set to and capture every 100th query for the slow query log.
Note
When using query sampling, set to so that it applies to queries, rather than sessions.
It is also a good idea to set to so that maximum amount of information about each captured query is stored in the slow query log.
A possible problem with query sampling is that rare slow queries might not get captured at all. To avoid this, use the variable to specify which queries should ignore sampling. That is, queries with longer execution time will always be captured by the slow query log.
By default, slow query log settings apply only to new sessions. If you want to configure the slow query log during runtime and apply these settings to existing connections, set the variable to .
Окончательно
Рассмотрение
Я думаю, вам следует рассмотреть возможность использования и для некоторых ваших задач. Вы можете легко получить сообщение со словами
Затем выполняйте все задачи, отнимающие время, в фоновом режиме. Пожалуйста, посмотрите на то, чтобы сделать большую работу по обработке меньше для аналогичного тематического исследования.
Профилирование
Инструмент профилирования? Нет единого инструмента профиля для веб-приложения от Xdebug до Yslow , все они очень полезны. Например, Xdebug не полезен, когда дело доходит до потоков, потому что он не поддерживается
У меня нет любимого
Заключение
Грамотная настройка и оптимизация MySQL позволяет достичь оптимально высоких показателей работы сервера и приложений, развернутых на его основе. Этому процессу способствует запуск скриптов, которые могут быстро обнаружить проблемы, влияющие на производительность базы данных.
Автоматическую оптимизацию с помощью скрипта следует обязательно дополнять настройкой производительности в ручном режиме с помощью регулировки основных параметров СУБД. Для повышения эффективности MySQL не менее важна оптимизация работы с выборкой из нескольких объединенных таблиц.
Оцените материал:





