Что такое семантика?
Слово семантическое — это прилагательное, которое можно в общих чертах определить как «имеющее отношение к значению». Из этого определения ясно, что семантика подчеркивает значение значения слов, словосочетаний и т. Д. В лингвистике мы особо выделяем значение семантического правила. Вот почему существует особая область исследования, известная как семантика. Семантика относится к изучению значений слов.
Значения слов играют ключевую роль в общении. Вот почему в каждом языке есть определенные определения или значения слов, чтобы не было путаницы в их значении.Представьте себе контекст, в котором одно слово имеет несколько значений. Это сделало бы общение чрезвычайно трудным, потому что люди не понимали, какое именно значение имеет в виду говорящий.
Давайте возьмем пример, чтобы понять значение смысла в общении.
Вы его убили.
Это может просто обозначать, что человек убил что-то, например животное. Но поместите то же предложение в контексте музыкального представления. Здесь человек может сказать «вы его убили», чтобы подчеркнуть, что этот человек работает очень хорошо.
Понимание того, как компилятор видит код
Обычно синтаксический и семантический анализ кода выполняется во «внешней» части компилятора.
-
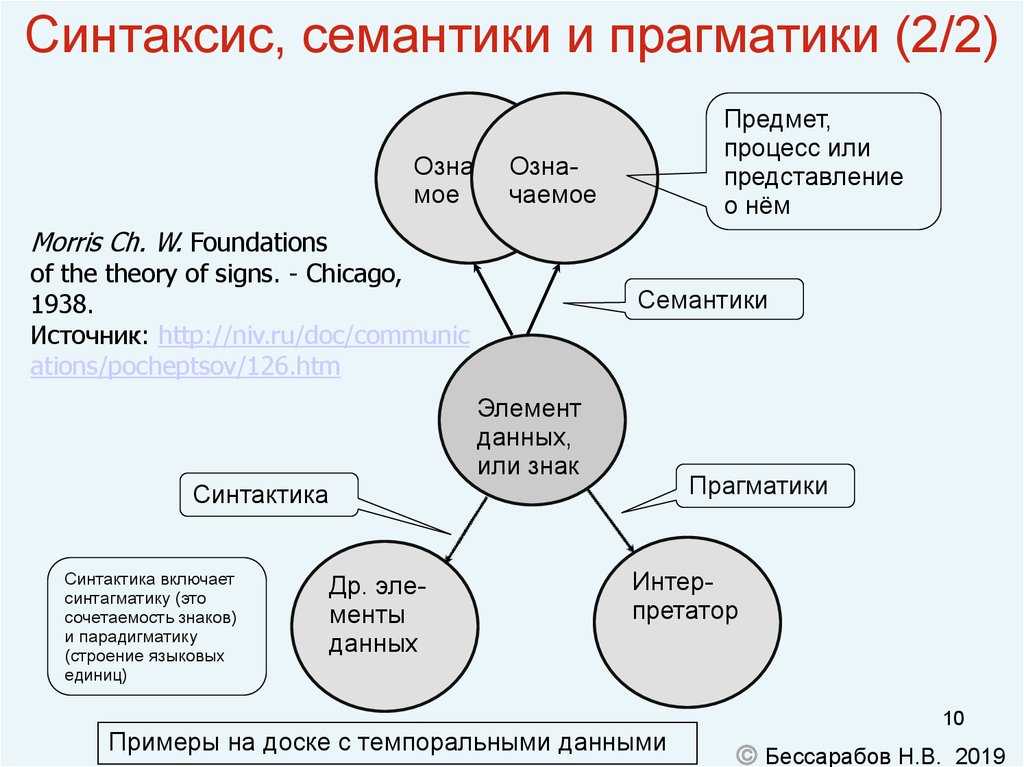
Синтаксис: Компилятор генерирует токены для каждого ключевого слова и символов: токен содержит информационный тип ключевого слова и его расположение в коде. Используя эти токены, создается и анализируется AST (сокращение от Abstract Syntax Tree). Что компилятор здесь на самом деле проверяет, так это то, является ли код лексически значимым, т.е. соответствует ли «последовательность ключевых слов» правилам языка? Как было предложено в предыдущих ответах, вы можете рассматривать это как грамматику языка (а не смысл / значение кода). Боковое примечание: на этом этапе сообщается об ошибках синтаксиса. (Возвращает в систему токены с типом ошибки)
-
Семантика: теперь компилятор проверит, «имеет ли смысл» ваши операции с кодом. например Если язык поддерживает вывод типа, будет сообщаться о сематической ошибке, если вы попытаетесь назначить строку для числа с плавающей точкой. ИЛИ дважды объявить одну и ту же переменную. Это ошибки, которые «грамматически» / синтаксически правильны, но не имеют смысла во время операции. Боковое примечание: для проверки того, объявляется ли одна и та же переменная дважды, компилятор управляет таблицей символов
Итак, результатом этих двух фаз внешнего интерфейса является аннотированный AST (с типами данных) и таблица символов.
Базовые языковые конструкции
PHP обычно следует синтаксису C с исключениями и улучшениями для его основного использования в веб-разработке , в котором интенсивно используются манипуляции со строками . Переменные PHP должны иметь префикс » «. Это позволяет PHP выполнять интерполяцию строк в строках с двойными кавычками , где обратная косая черта поддерживается как escape-символ . Для строк, разделенных одинарными кавычками, не выполняется экранирование или интерполяция . PHP также поддерживает функцию sprintf, подобную C. Код может быть разделен на функции, определенные с помощью ключевого слова . PHP поддерживает необязательный объектно-ориентированный стиль кодирования с классами, обозначенными ключевым словом. Функции, определенные внутри классов, иногда называют методами . Управляющие структуры включают в себя: , , , , , и . Операторы заканчиваются точкой с запятой, а не окончанием строки.
Разделители
Процессор PHP анализирует код только в пределах его разделителей . Все, что находится за пределами его разделителей, отправляется прямо на вывод и не анализируется PHP. PSR-1 допускает только открывающие / закрывающие ограничители » » и » » или и .
Назначение тегов-разделителей — отделить код PHP от данных, не относящихся к PHP (в основном HTML). Хотя на практике это редко, PHP выполняет код, встроенный в любой файл, переданный его интерпретатору, включая двоичные файлы, такие как файлы PDF или JPEG, или в файлы журнала сервера. Все, что находится за пределами разделителей, игнорируется анализатором PHP и передается как вывод.
Эти рекомендуемые разделители создают правильно сформированные XHTML и другие XML- документы. Это может быть полезно, если документы с исходным кодом когда-либо нужно обрабатывать другими способами в течение срока службы программного обеспечения.
Если правильная проверка XML не является проблемой, и файл содержит только код PHP, предпочтительно опустить тег закрытия PHP ( ) в конце файла.
Нерекомендуемые теги
На некоторых серверах можно использовать и другие разделители, хотя большинство из них больше не поддерживаются. Примеры:
- » » и » » (удалено в PHP7)
- Короткие открывающие теги ( ) (настраиваются в настройках ini)
- Теги стиля ASP ( или ) (удалены в PHP7)
Переменные имеют префикс в виде символа доллара, и тип не нужно указывать заранее. В отличие от имен функций и классов, имена переменных чувствительны к регистру. И строки в двойных кавычках ( ), и строки heredoc позволяют вставлять значение переменной в строку. Как и в C, переменные могут быть приведены к определенному типу, добавив к типу префикса в круглых скобках. PHP обрабатывает символы новой строки как пробелы , как в языке произвольной формы . Оператор конкатенации — (точка). Доступ к элементам массива осуществляется с помощью квадратных скобок как в ассоциативных массивах, так и в индексированных массивах. Фигурные скобки можно использовать для доступа к элементам массива, но нельзя их назначать.
В PHP есть три типа : который используется в качестве блочных комментариев, а также который используется для встроенных комментариев. Во многих примерах вместо функции эха используется функция печати . Обе функции почти идентичны; Основное отличие состоит в том, что печать выполняется медленнее, чем эхо, потому что первая вернет статус, указывающий, была ли она успешной или нет, в дополнение к тексту для вывода, тогда как последняя не возвращает статус, а возвращает только текст для вывода.
Простейшая программа
Обычный пример кода » Hello World » для PHP:
<?php echo "Hello World!\n"; ?>
В приведенном выше примере выводится следующее:
Hello World!
Вместо использования и оператора необязательным «ярлыком» является использование вместо, которое неявно отображает данные. Например:
<!DOCTYPE html>
<html>
<head>
<title>PHP "Hello, World!" program</title>
</head>
<body>
<p><?="Hello World!"?></p>
</body>
</html>
Приведенный выше пример также показывает, что текст, не содержащийся во включенных тегах PHP, будет выводиться напрямую.
Определение синтаксиса
![]()
Дерево синтаксического анализа кода Python со вставкой токенизации
Синтаксис текстовых языков программирования обычно определяется с помощью комбинации регулярных выражений (для лексической структуры) и формы Бэкуса – Наура (для грамматической структуры) для индуктивного определения синтаксических категорий (нетерминалов) и терминальных символов. Синтаксические категории определяются правилами, называемыми продукцией , которые определяют значения, принадлежащие определенной синтаксической категории. Терминальные символы — это конкретные символы или строки символов (например, ключевые слова, такие как define , if , let или void ), из которых создаются синтаксически допустимые программы.
В языке могут быть разные эквивалентные грамматики, такие как эквивалентные регулярные выражения (на лексических уровнях) или разные правила фраз, которые генерируют один и тот же язык. Использование более широкой категории грамматик, таких как грамматики LR, может позволить использовать более короткие или более простые грамматики по сравнению с более ограниченными категориями, такими как грамматика LL, для которых могут потребоваться более длинные грамматики с большим количеством правил. Различные, но эквивалентные грамматики фраз дают разные деревья синтаксического анализа, хотя основной язык (набор действительных документов) тот же.








Пример: S-выражения Лиспа
Ниже приводится простая грамматика, определенная с использованием обозначений регулярных выражений и расширенной формы Бэкуса – Наура . Он описывает синтаксис S-выражений , синтаксис данных языка программирования Lisp , который определяет продукцию для выражения синтаксических категорий , атома , числа , символа и списка :
expression = atom | list
atom = number | symbol
number = +-?'0'-'9'+
symbol = 'A'-'Z']['A'-'Z''0'-'9'*
list = '(', expression*, ')'
Эта грамматика определяет следующее:
- выражение является либо атом или список ;
- атом является либо число или символ ;
- номер представляет собой непрерывную последовательность из одной или более десятичных цифр, необязательно предшествует знак плюс или минус;
- символ является буквой с нуля или более любых символов ( за исключением пробела); а также
- список является согласованной парой скобок, с нулем или более выражений внутри него.
Здесь десятичные цифры, символы верхнего и нижнего регистра и круглые скобки являются терминальными символами.
Ниже приведены примеры правильно сформированных последовательностей лексем в этой грамматике: ‘ ‘, ‘ ‘, ‘ ‘
Сложные грамматики
Грамматика, необходимая для определения языка программирования, может быть классифицирована по ее положению в иерархии Хомского . Фразовая грамматика большинства языков программирования может быть указана с использованием грамматики Типа 2, т. Е. Они являются контекстно-независимыми грамматиками , хотя общий синтаксис является контекстно-зависимым (из-за объявлений переменных и вложенных областей видимости), следовательно, Тип 1. Однако есть исключения, и для некоторых языков грамматика фраз — это тип 0 (полный по Тьюрингу).
В некоторых языках, таких как Perl и Lisp, спецификация (или реализация) языка допускает конструкции, которые выполняются на этапе синтаксического анализа. Кроме того, в этих языках есть конструкции, которые позволяют программисту изменять поведение анализатора. Эта комбинация эффективно стирает различие между синтаксическим анализом и выполнением и делает анализ синтаксиса неразрешимой проблемой для этих языков, а это означает, что фаза синтаксического анализа может не завершиться. Например, в Perl можно выполнять код во время синтаксического анализа с помощью оператора, а прототипы функций Perl могут изменять синтаксическую интерпретацию и, возможно, даже синтаксическую достоверность оставшегося кода. В просторечии это называется «только Perl может анализировать Perl» (потому что код должен выполняться во время синтаксического анализа и может изменять грамматику) или, что более строго, «даже Perl не может анализировать Perl» (потому что это неразрешимо). Точно так же макросы Lisp, представленные синтаксисом, также выполняются во время синтаксического анализа, что означает, что компилятор Lisp должен иметь всю систему времени выполнения Lisp. Напротив, макросы C представляют собой просто замену строк и не требуют выполнения кода.
Типы данных
Пролог имеет динамическую типизацию . Он имеет один тип данных , термин , который имеет несколько подтипов: атомы , числа , переменные и составные термины .
Атом представляет собой имя общего назначения, без внутреннего смысла. Он состоит из последовательности символов, которая анализируется средством чтения Prolog как единое целое. Атомы обычно представляют собой голые слова в коде Пролога, написанные без специального синтаксиса. Однако атомы, содержащие пробелы или некоторые другие специальные символы, должны быть заключены в одинарные кавычки. Атомы, начинающиеся с заглавной буквы, также должны быть заключены в кавычки, чтобы отличать их от переменных. Написанный пустой список также является атомом. Другие примеры включают в себя атомы , , , и .
Числа могут быть числами с плавающей запятой или целыми . Многие реализации Prolog также предоставляют неограниченные целые и рациональные числа .
Переменные обозначаются строкой, состоящей из букв, цифр и символов подчеркивания и начинающейся с заглавной буквы или символа подчеркивания. Переменные очень похожи на переменные по логике в том смысле, что они заменяют произвольные термины. Переменная может стать экземпляром (привязанной к определенному члену) посредством унификации . Одиночный символ подчеркивания ( ) обозначает анонимную переменную и означает «любой термин». В отличие от других переменных, подчеркивание не означает одно и то же значение везде, где оно встречается в определении предиката.
Соединение Термин состоит из атома называется «функтор» и ряд «аргументов», которые снова термины. Составные термины обычно записываются как функтор, за которым следует список терминов аргументов, разделенных запятыми, который содержится в круглых скобках. Количество аргументов называется арностью термина . Атом можно рассматривать как составной термин с нулевой арностью .
Примеры составных терминов: и . Сложные термины с функторами, объявленными как операторы, могут быть записаны в префиксной или инфиксной нотации. Например, термины , и также могут быть записаны как , и соответственно. Пользователи могут объявлять произвольные функторы как операторы с разным приоритетом, что позволяет использовать нотации, специфичные для предметной области. Обозначение f / n обычно используется для обозначения термина с функтором f и арностью n .
Частные случаи сложных терминов:
- Списки определяются индуктивно: атом — это список. Составной терм с функтором (точкой) и арностью 2, второй аргумент которого является списком, сам является списком. Для обозначения списков существует специальный синтаксис: эквивалентен . Например, список также можно записать как или еще более компактно как .
- Строки : последовательность символов, заключенная в кавычки, эквивалентна списку (числовых) кодов символов, обычно в локальной кодировке символов или Unicode, если система поддерживает Unicode.
Разница между синтаксисом и семантикой
Определение
Синтаксис: Суб-дисциплина лингвистическая, которая изучает структуру предложения.
Семантика: Поддисциплина языкознания, которая изучает значение слов и предложений.
районы
Синтаксис:Порядок слов, части речи, типы предложений и т. Д. Изучаются в синтаксисе.
Семантика:Такие элементы, как неоднозначность, отношения между словами и предложениями, основанные на значении, изучаются на языке.
Значимые предложения
Синтаксис:Синтаксически правильное предложение не обязательно является осмысленным предложением.
Семантика:Значимое предложение должно быть синтаксически правильным.
Изображение предоставлено:
«Синтаксическое дерево» Аарона Ротенберга — собственная работа.
Отрицание
Встроенный предикат Пролога обеспечивает отрицание как сбой , что позволяет немонотонно рассуждать. Цель в правиле
legal(X) :- \+ illegal(X).
оценивается следующим образом: Пролог пытается доказать, что . Если доказательство для этой цели может быть найдено, исходная цель (т. Е.) Не выполняется. Если не найти доказательств, первоначальная цель достигнута. Поэтому префиксный оператор называется «недоказуемым» оператором, поскольку запрос завершается успешно, если цель недоказуема. Этот вид отрицания является правильным, если его аргумент «заземлен» (т.е. не содержит переменных). Разумность теряется, если аргумент содержит переменные. В частности, запрос теперь нельзя использовать для перечисления всего, что разрешено законом.
Пролог программы
Программы на языке Prolog описывают отношения, определяемые с помощью предложений. Чистый Пролог ограничен предложениями Хорна , полным по Тьюрингу подмножеством логики предикатов первого порядка . Есть два типа статей: факты и правила. Правило имеет форму
Head :- Body.
и читается как «Голова истинна, если тело истинно». Тело правила состоит из вызовов предикатов, которые называются целями правила . Встроенный предикат (то есть оператор 2-арности с именем ) обозначает соединение целей и обозначает дизъюнкцию . Соединения и разъединения могут появляться только в теле, а не в голове правила.









Пункты с пустыми телами называются фактами . Пример факта:
cat(tom).
что эквивалентно правилу:
cat(tom) :- true.
другой пример:
X is 3+2.
и когда вы запустите его, результат будет
X=5 Yes.
Встроенный предикат всегда истинен.
Типы данных
Скалярные типы
PHP поддерживает четыре скалярных типов: , , , .
Логический
PHP имеет собственный логический тип с именем » «, аналогичный собственным логическим типам в Java и C ++ . Используя правила преобразования логического типа, ненулевые значения интерпретируются как, а нулевые как , как в Perl . Обе константы и нечувствительны к регистру.
Целое число
PHP хранит целые числа в диапазоне, зависящем от платформы. Обычно это диапазон 32-разрядных или 64-разрядных целых чисел со знаком. Целочисленные переменные могут быть присвоены в десятичном (положительном и отрицательном), восьмеричном и шестнадцатеричном форматах.
$a = 1234; // decimal number $b = 0321; // octal number (equivalent to 209 decimal) $c = 0x1B; // hexadecimal number (equivalent to 27 decimal) $d = b11; // binary number (equivalent to 3 decimal) $e = 1_234_567; // decimal number (as of PHP 7.4.0)
Плавать
Реальные числа также хранятся в диапазоне, зависящем от платформы. Они могут быть указаны с использованием нотации с плавающей запятой или двух форм экспоненциальной нотации .
$a = 1.234; $b = 1.2e3; // 1200 $c = 7E-5; // 0.00007 $d = 1_234.567; // as of PHP 7.4.0
Нить
PHP поддерживает синтаксис , который можно использовать с одинарными кавычками, двойными кавычками, nowdoc или heredoc .
Строки в двойных кавычках поддерживают интерполяцию переменных:
$age = '23'; echo "John is $age years old"; // John is 23 years old
Синтаксис фигурных скобок:
$f = "sqrt";
$x = 25;
echo "a$xc\n"; // Warning: Undefined variable $xc
echo "a{$x}c\n"; // prints a25c
echo "a${x}c\n"; // also prints a25c
echo "$f($x) is {$f($x)}\n"; // prints sqrt(25) is 5
Особые типы
PHP поддерживает два специальных типа: , . Тип данных представляет собой переменную, не имеющую значения. Единственное значение в типе данных — NULL . Константа NULL не чувствительна к регистру. Переменные типа » » представляют собой ссылки на ресурсы из внешних источников. Обычно они создаются функциями из определенного расширения и могут обрабатываться только функциями из того же расширения. Примеры включают файлы, изображения и ресурсы базы данных.
Составные типы
PHP поддерживает четыре составных типов: , , , .
Множество
Массивы могут содержать смешанные элементы любого типа, включая ресурсы, объекты. Многомерные массивы создаются путем назначения массивов в качестве элементов массива. PHP не имеет истинного типа массива. Массивы PHP изначально разрежены и ассоциативны . Индексированные массивы — это просто хеши, использующие целые числа в качестве ключей.
Индексированный массив:
$season = "Autumn", "Winter", "Spring", "Summer"]; echo $season2]; // Spring
Ассоциативный массив:
$salary = "Alex" => 34000, "Bill" => 43000, "Jim" => 28000]; echo $salary"Bill"]; // 43000
Многомерный массив:
$mark =
"Alex" =>
"biology" => 73,
"history" => 85
],
"Jim" =>
"biology" => 86,
"history" => 92
];
echo $mark"Jim"]; // 92
Объект
Тип данных — это комбинация переменных, функций и структур данных в парадигме объектно-ориентированного программирования .
class Person
{
//...
}
$person = new Person();
Вызываемый
Начиная с версии 5.3 PHP имеет первоклассные функции, которые можно использовать, например, в качестве аргумента для другой функции.
function runner(callable $function, mixed ...$args)
{
return $function(...$args);
}
$f = fn($x, $y) => $x ** $y;
function sum(int|float ...$args)
{
return array_sum($args);
}
echo runner(fn($x) => $x ** 2, 2); // prints 4
echo runner($f, 2, 3); // prints 8
echo runner('sum', 1, 2, 3, 4); // prints 10
Итерабельный
type указывает, что переменная может использоваться с циклом. Это может быть любой объект или или объект, реализующий специальный внутренний интерфейс.
function printSquares(iterable $data)
{
foreach ($data as $value) {
echo ($value ** 2) . " ";
}
echo "\n";
}
// array
$array = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// generator
$generator = function () Generator {
for ($i = 1; $i <= 10; $i++) {
yield $i;
}
};
// object
$arrayIterator = new ArrayIterator();
printSquares($array); // 1 4 9 16 25 36 49 64 81 100
printSquares($generator()); // 1 4 9 16 25 36 49 64 81 100
printSquares($arrayIterator); // 1 4 9 16 25 36 49 64 81 100
function foo(string|int $foo) string|int {}
использованная литература
- Chierchia, G. (1999) , стр. 824-826, в: , под редакцией Кейла и Уилсона (1999) Кембридж, Массачусетс: The MIT Press.
- Хакл, М. (2013) . Lingua, 130, 66-87.
- Хайм, Ирэн ; Кратцер, Анжелика (1998). Семантика в генеративной грамматике . Оксфорд: Уайли Блэквелл. С. 194–198.
- Левин Б. и Пинкер С. (1992) Введение в Бет Левин и Стивен Пинкер (1992, ред.) Лексическая и концептуальная семантика. (Специальный выпуск Cognition) Кембридж, Массачусетс и Оксфорд: Блэквелл, 1991. Стр. 244.
- Левин Б. и Раппапорт Ховав М. (1995). . Кембридж, Массачусетс: MIT Press
- Пинкер, С. (1989) обучаемость и познание: приобретение структуры аргументов . Новое редактирование в 2013 г .: обучаемость и познание, новое издание: «Приобретение структуры аргументов» . Пресса MIT.
- Тенни, К. (1994). Аспектные роли и интерфейс синтаксис-семантика (Том 52). Дордрехт: Клувер.
- Ван Валин, Р.Д. мл. И ЛаПолла, Р.Дж. (1997) Синтаксис: структура, значение и функция . Издательство Кембриджского университета.
- Ван Валин-младший, Р. Д. (2003) Функциональная лингвистика , гл. 13 в , стр. 319-336.
- Ван Валин, Р. Д. мл. (2005). , Cambridge University Press.
- Вендлер, З. (1957) Глаголы и время в The Philosophical Review 66 (2): 143–160. Перепечатано как гл. 4 по лингвистике и философии , Итака, штат Нью-Йорк: издательство Корнельского университета, 1967, стр. 97-121.
Оценка
Выполнение программы на Прологе инициируется публикацией пользователем единственной цели, называемой запросом. Логично, что механизм Prolog пытается найти опровержение разрешения отрицательного запроса. Метод разрешения, используемый Prolog, называется разрешением SLD . Если отрицательный запрос может быть опровергнут, это означает, что запрос с соответствующими привязками переменных является логическим следствием программы. В этом случае пользователю сообщается обо всех сгенерированных привязках переменных, и считается, что запрос выполнен успешно. С функциональной точки зрения стратегию выполнения Пролога можно рассматривать как обобщение вызовов функций на других языках, с одним отличием в том, что несколько заголовков предложений могут соответствовать заданному вызову. В этом случае система создает точку выбора, объединяет цель с заголовком предложения первой альтернативы и продолжает цели этой первой альтернативы. Если какая-либо цель терпит неудачу в ходе выполнения программы, все привязки переменных, которые были сделаны с момента создания самой последней точки выбора, отменяются, и выполнение продолжается со следующей альтернативой этой точки выбора. Эта стратегия исполнения называется хронологическим возвратом . Например:
mother_child(trude, sally). father_child(tom, sally). father_child(tom, erica). father_child(mike, tom). sibling(X, Y) :- parent_child(Z, X), parent_child(Z, Y). parent_child(X, Y) :- father_child(X, Y). parent_child(X, Y) :- mother_child(X, Y).
Это приводит к тому, что следующий запрос оценивается как истинный:
?- sibling(sally, erica). Yes
Это получается следующим образом: Первоначально единственным совпадающим заголовком предложения для запроса является первое, поэтому доказательство запроса эквивалентно доказательству тела этого предложения с соответствующими привязками переменных на месте, т. Е. Конъюнкцией . Следующая цель доказать это крайний левый один из этой совокупности, то есть . Этой цели соответствуют две главы статьи. Система создает точку выбора и пробует первую альтернативу, тело которой находится . Эта цель может быть доказана , используя тот факт , поэтому связывание генерируется, и следующая целью доказать это вторая часть выше комбинаций: . Опять же, это подтверждается соответствующим фактом. Поскольку все цели могут быть доказаны, запрос выполняется. Поскольку запрос не содержит переменных, пользователю не сообщается о привязках. Запрос с переменными, например:
?- father_child(Father, Child).
перечисляет все действительные ответы при возврате.
Обратите внимание, что с указанным выше кодом запрос также выполняется успешно. При желании можно было бы вставить дополнительные цели для описания соответствующих ограничений.
Различные стороны определения языка в компьютерных науках
Для создания, проверки и преобразования программ, построения систем программирования, а также для многих других нужд нам необходимо если не определение, то хотя бы описание алгоритмического языка. При этом требуются точные описания как текстов, так и их интерпретации. Рассмотрим существующие варианты.





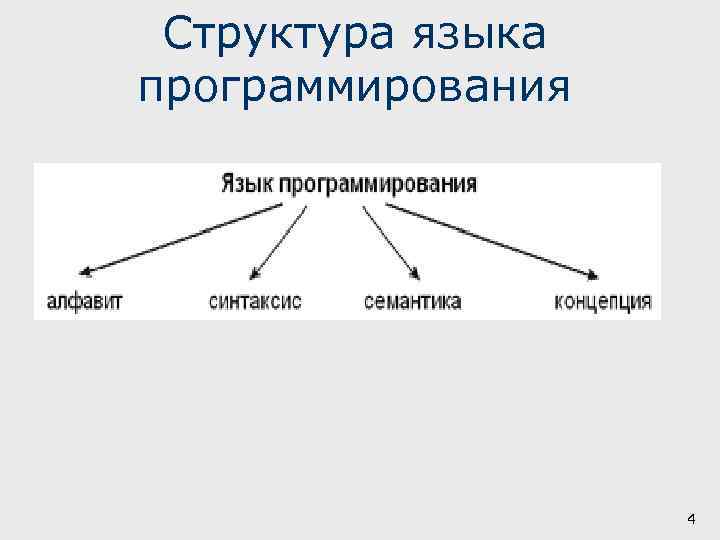
-
Сама программа-транслятор считается описанием языка. Тут сразу точно описаны и тексты (правильная программа — та, на которой транслятор не выдает ), и их интерпретация (интерпретация программы — то, как исполняется ее текст после перевода транслятором).
Именно так пытались поступать на заре программирования, когда, скажем, легендарный язык FORTRAN создавался одновременно с первым транслятором с данного языка.
- Определением языка считается формальная лингвистическая система (грамматика). Впервые этот подход был последовательно применен в Алголе. Встречавшиеся вам при изучении языков синтаксические диаграммы являются непосредственными потомками того, что было сделано в Алголе.
- Определением языка считается соответствие между структурными единицами текста и правилами интерпретации. Этот вариант был полностью реализован при определении языка Алгол 68.
Первый вариант — совершенно неудовлетворительный путь, поскольку всякое изменение в программе-трансляторе может полностью изменить смысл некоторых конструкций языка со всеми вытекающими отсюда последствиями.
Второй вариант соответствует взгляду на язык как на множество правильно построенных последовательностей символов. Если последовательность символов принадлежит языку, то она считается синтаксически правильной. Для программы это означает, чтотранслятор на ней не выдает ошибки. Но синтаксическая правильность не гарантирует даже осмысленности программы. Таким образом, здесь определяется лишь одна сторона языка.
Третий вариант работает только вместе со вторым, поскольку структурные единицы должны соединиться в синтаксически правильную систему. Он раскрывает еще одну сторону языка.
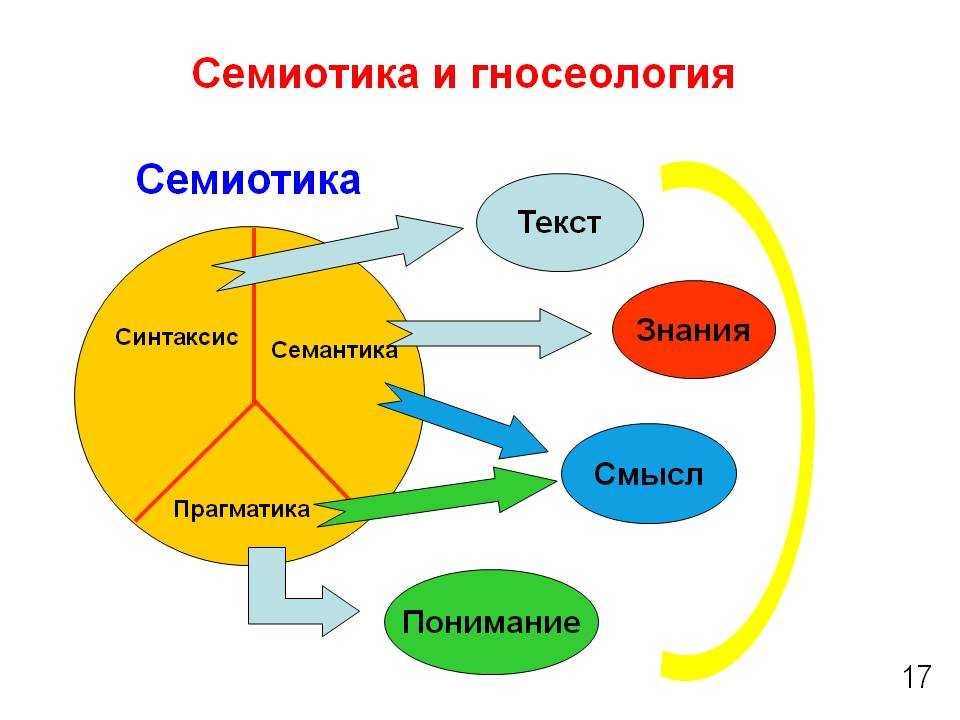
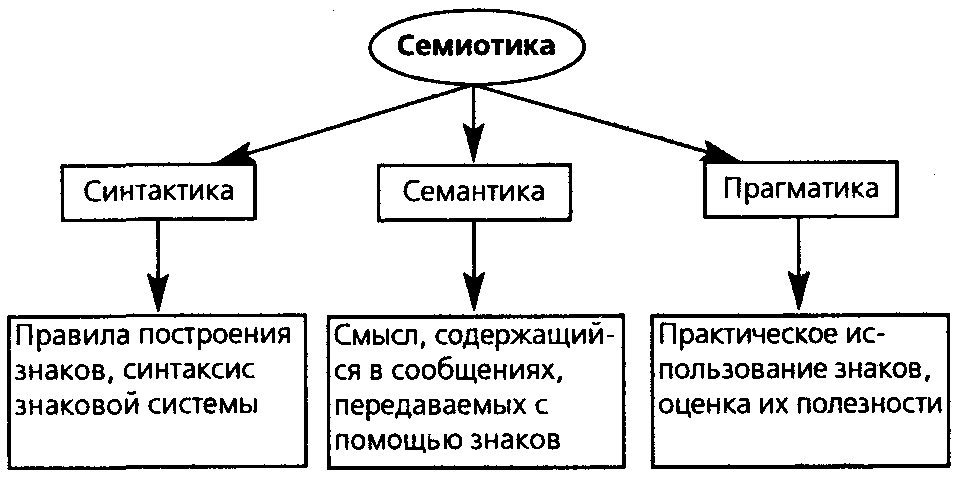
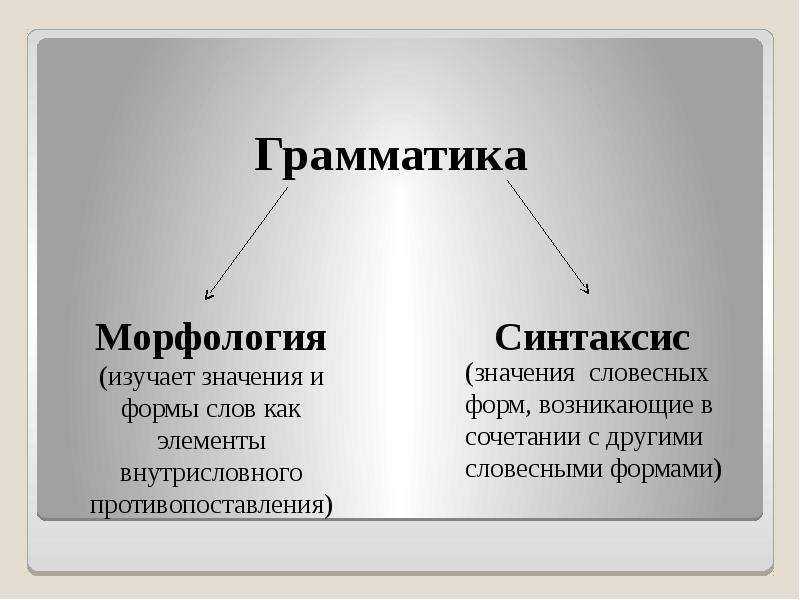
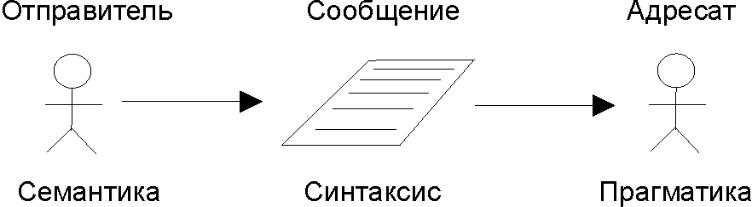
Таким образом, мы видим, что каждый язык имеет три стороны: синтаксис (второй вариант), семантика (третий вариант), прагматика(первый вариант).
Синтаксис алгоритмического языка — совокупность правил, позволяющая:
- формально проверить текст программы (выделив множество синтаксически правильных программ);
- разбить эти программы на составляющие конструкции и в конце концов на лексемы.
Семантика алгоритмического языка — соответствие между синтаксически правильными программами и действиями абстрактного исполнителя, позволяющее определить, какие последовательности действий абстрактного исполнителя будут правильны в случае, если мы имеем данную программу и данное ее внешнее окружение.
Под внешним окружением понимаются характеристики машины, на которой исполняется программа (точность представления данных, объем памяти, другие программы, которые можно использовать при выполнении данной, и т. д.), и входных данных, поступающие в программу в ходе ее исполнения.
Прагматика алгоритмического языка — то, что связывает программу с ее конкретной реализацией. При этом, в частности, происходит следующее.
- Все определения становятся явными (изгоняются такие понятия, как «не определено», «определяется реализацией» и т. п.) 2.
- Появляются дополнительные конструкции, описатели и др., обусловленные реализацией. Они обязательно учитывают:
- особенности вычислительной машины и среды вычислений;
- особенности принятой схемы реализации языка;
- обеспечение эффективности вычислений;
- ориентацию на специфику пользователей.
Прагматика иногда предписывается стандартом языка, иногда нет. Это зависит от того, для каких целей предназначены язык и его реализация.
Описание языка требует точного задания синтаксиса и семантики. На практике, однако, чем точнее и чем лучше для построения транслятора описан язык, тем, как правило, такое описание более громоздко и менее понятно для обычного человека, и поэтому точные описания существуют не для всех реальных языков программирования. Даже если они имеются, то в виде стандартов, к которым обращаются лишь в крайних случаях.