
Что такое ошибка сегментации?
Ошибка сегментации, Segmentation fault, или Segfault, или SIGSEGV в Ubuntu и других Unix подобных дистрибутивах, означает ошибку работы с памятью. Когда вы получаете эту ошибку, это значит, что срабатывает системный механизм защиты памяти, потому что программа попыталась получить доступ или записать данные в ту часть памяти, к которой у нее нет прав обращаться.
Чтобы понять почему так происходит, давайте рассмотрим как устроена работа с памятью в Linux, я попытаюсь все упростить, но приблизительно так оно и работает.
Допустим, в вашей системе есть 6 Гигабайт оперативной памяти, каждой программе нужно выделить определенную область, куда будет записана она сама, ее данные и новые данные, которые она будет создавать. Чтобы дать возможность каждой из запущенных программ использовать все шесть гигабайт памяти был придуман механизм виртуального адресного пространства. Создается виртуальное пространство очень большого размера, а из него уже выделяется по 6 Гб для каждой программы. Если интересно, это адресное пространство можно найти в файле /proc/kcore, только не вздумайте никуда его копировать.
Выделенное адресное пространство для программы называется сегментом. Как только программа попытается записать или прочитать данные не из своего сегмента, ядро отправит ей сигнал SIGSEGV и программа завершится с нашей ошибкой. Более того, каждый сегмент поделен на секции, в некоторые из них запись невозможна, другие нельзя выполнять, если программа и тут попытается сделать что-то запрещенное, мы опять получим ошибку сегментации Ubuntu.
Испанский Lexico: Hasta la vista, baby
Ещё один учебный язык. Lexico — объектно-ориентированный и работает на платформе .NET от Microsoft. Придумали Lexico в Laboratorios Riosur.net E U ещё в 1985 году. Цель ставили простую: надо было облегчить жизнь благородных идальго — студентов и преподавателей ООП. Интересно, что Lexico постоянно развивался, вплоть до 2010-х: новые спецификации языка выходили в 1992, 2002 и 2009 годах. Синтаксически он напоминает С# и поставляется с компилятором и простой «фирменной» IDE.
На Lexico удобно писать простые алгоритмы, логические схемы и структуры. Все объекты основаны на двух классах — количестве и характере, а вместо оператора присваивания используется ключевое слово copie.
Lexico работает только на платформе от Microsoft, поэтому пользователи Linux и других ОС в пролёте. Именно в этом главный недостаток языка и причина его невысокой популярности в реальной разработке. А вы думали, всё дело в неанглийских словах? Да ладно вам, какой серьёзный девелопер не мечтает писать страстные и кровавые программы на испанском! Да ведь их можно петь под гитару вместо серенад. Послушайте, как звучит: «Привадос! Эль обхэкто валорес ун карактер!» Ах, ну что за прекрасная музыка — мы уже на всё согласные!
Вот и пример кода на Lexico — создание графического окна:
Автоматическая генерация файла OpenAPI из аннотаций кода
Вместо того, чтобы кодировать документ в спецификации OpenAPI вручную, также можно автоматически сгенерировать его из аннотаций в программном коде. Этот подход, ориентированный на разработчиков, имеет смысл, если есть большое количество API-интерфейсов или если для технических писателей нецелесообразно создавать эту документацию.
Swagger предлагает множество библиотек, которые можно добавлять в свой программный код для создания документа в спецификации. Эти библиотеки Swagger анализируют аннотации, которые добавляют разработчики, и генерируют документ в спецификации OpenAPI. Эти библиотеки считаются частью проекта Swagger Codegen. Методы аннотации различаются в зависимости от языка программирования. Например, вот справочник по аннотированию кода с помощью Swagger для Scalatra. Для получения дополнительной информации о Codegen см. Сравнение инструментов автоматического генерирования кода API для Swagger по API Evangelist. Дополнительные инструменты и библиотеки см. В разделах «Интеграции и инструменты Swagger» и «Интеграция с открытым исходным кодом».
Хотя этот подход и «автоматизирует» генерацию спецификации, нужно еще понимать, какие аннотации добавить и как их добавить (этот процесс не слишком отличается от комментариев и аннотаций Javadoc). Затем нужно написать контент для каждого из значений аннотации (описывая конечную точку, параметры и т. Д.).
Короче говоря, поработать все нужно — автоматизированная часть заставляет библиотеки Codegen генерировать определения модели и действительный документ, который соответствует схеме OpenAPI. Тем не менее, многие разработчики взволнованы этим подходом, потому что он предлагает способ генерировать документацию из аннотаций кода, что разработчики годами делали с другими языками программирования, такими как Java (используя Javadoc) или C ++ (используя Doxygen). Они обычно считают, что генерация документации из кода приводит к меньшему отклонению документации. Документы, будут оставаться актуальными, если будут тесно связан с кодом.
Если идти по этому пути, нужно убедиться, что есть доступ к исходному коду для внесения изменений в аннотации. В противном случае разработчики будут писать документацию (что может и хорошо, но часто приводит к плохим результатам).
Подключение источника ПО
urpmi не будет работать, если предварительно не подключить какой-либо источник ПО. Обычно, стандартная процедура установки Mageia предусматривает подключение заранее заданного набора источников ПО, который соответствует выбранному вами методу установки: это может быть установочный CD, или сервер HTTP или FTP, если вы выбрали установку с сетевого зеркала, и так далее. Но вы можете пожелать подключить свой собственный набор источников ПО. Для этого предназначена программа urpmi.addmedia. Её синтаксис таков:
urpmi.addmedia <имя источника> <url>
Поддерживаются следующие URL:
- http://
- ftp://
- rsync://
- ssh:// (с использованием rsync)
- file://
- cdrom://
Если источник ПО требует идентификации, следует использовать обычный синтаксис URL:
<scheme>://<login>:<pass>@host/path
Введённые параметры не сохраняются ни в каком текстовом файле. В некоторых случаях, если ваш источник ПО находится на внешнем HTTP или FTP сервере, можно подключаться к нему через proxy. Для этого предназначены параметры —proxy и —proxy-user; последний на случай, если ваш proxy требует идентификации.
Создание собственного источника ПО
Простейший способ создать собственный источник ПО — воспользоваться утилитой urpmi.addmedia. Учтите, что она предназначена для небольшого количества файлов RPM, находящихся на диске или на подмонтированном коллективном сетевом диске NFS. Если ваши RPM-файлы находятся в каталоге /var/my-rpms, просто введите команду:
urpmi.addmedia my-media /var/my-rpms
Если же необходимо создать источник ПО, содержащий большое количество RPM или он должен быть размещён на коллективном сервере, необходимо воспользоваться утилитой gendistrib из пакета rpmtools. Эта утилита способна сгенерировать зеркальное дерево для одного или нескольких источников ПО.
Типичный репозиторий в каталоге суперпользователя /ROOT/ имеет следующую структуру (здесь два источника ПО обозначены именами «first» и «second»):
ROOT/ - media/
|- first/
| `- media_info/
|- second/
| `- media_info/
`- media_info/
RPM-файлы размещаются в подкаталогах first и second. Метаданные репозитория находятся в каталоге media_info верхнего уровня. Метаданные источников ПО находятся в подкаталогах first/media_info и second/media_info.
Метаданные источника ПО состоят из сжатого программой gzip файла hdlist.cz со списком заголовков RPM-файлов источника ПО; из файла synthesis.hdlist.cz, намного меньшего, чем hdlist, в котором содержится информация, нужная только urpmi для разрешения зависимостей и иногда, если RPM-файлы подписаны, из файла pubkey (таким образом urpmi может проверить, имеет ли загружаемый RPM ключ к этому источнику ПО).
Перед использованием gendistrib, необходимо создать файл media_info/media.cfg, в котором дать описание этого репозитория. Синтакс этого файла знаком вам по файлам .ini. Он содержит по одной секции на каждый источник ПО. Например,
hdlist=hdlist_first.cz
name=First supplementary media
Здесь
- first — имя каталога
- hdlist_first.cz — имя файла hdlist, который будет в результате создан (имя должно заканчиваться на «.cz»)
- «name=» описание источника ПО в произвольной форме
После этого можно запускать gendistrib с /ROOT/ каталогом в качестве параметра. Программа сгенерирует все необходимые файлы для полной функциональности репозитория.
Более полную информацию см. man gendistrib(1).
Якоря и псевдоним YAML
Якоря и псевдонимы — это конструкции YAML, которые позволяют сократить синтаксис повторения и расширить существующие узлы данных. Вы можете разместить Anchors ( &) на объекте, чтобы отметить многострочный раздел. Затем вы можете использовать *вызов Alias ( ), который будет привязан позже в документе, для ссылки на этот раздел. Якоря и псевдонимы очень полезны для больших проектов, поскольку они устраняют визуальный беспорядок, вызванный лишними линиями.
Псевдоним, по сути, действует как команда «см. Выше», которая заставляет программу приостанавливать стандартный обход, возвращаться к точке привязки, а затем возобновлять стандартный обход после завершения закрепленной части. Если вы знакомы с конструкциями объектно-ориентированного программирования, с Anchors вы будете чувствовать себя как дома.
Ниже build-testякорь начинается в строке 3 и вызывается псевдонимами в строках 13 и 15.
Возможные ошибки
Рассмотрим примеры ошибко, с которыми мы можем столкнуться.
Installed (but unpackaged) file(s) found
Ошибка появляется в конце процесса сборки пакета.
Причина: обнаружены файлы, которые были установлены с помощью make install, но которые не были перечислены в %files. Таким образом, сборщик пакета не знает, что с ними делать.
Решение: секция %files должна содержать все файлы, необходимые для работы приложения. Их нужно перечислить.
Но если у нас есть полная уверенность, что мы перечислили все необходимое, а оставшиеся файлы нам ни к чему, то добавляем в файл spec:
%define _unpackaged_files_terminate_build 0
* в верхнюю часть.
hunk FAILED — saving rejects
Данная ошибка означает, что один из патчей (какой именно — указано в выводе rpmbuild) не может быть применен без изменений к новой версии программы. Обычно это означает, что патч необходимо переделать (предварительно определив — нужен ли он еще), что требует определенной квалификации. Однако иногда такая ошибка возникает из-за «строгости» rpmbuild при применении патчей и проблемный патч может быть исправлен в автоматическом режиме с помощью утилиты rediff_patch.
Для этого достаточно склонировать себе Git-репозиторий, перейти в склонированную папку, поместить туда архив с исходным кодом новой версии и запустит rediff_patch, передав ей нужный патч к качестве аргумента:
Если все сложится удачно, то радом со старым патчем «some_patch_to_rediff» появится новый — «some_patch_to_rediff.new» Если же что-то пойдет не так, то в текущей директории останутся папка «rediff_patch» с подпапками вида «myproject.orig» и «myproject» — содержащие соответсвенно оригинальный исходный код и исходный код, получившийся после попытки применить
патч. Во второй папке вы найдете файлы с расширениями *rej — это куски патчей, которые применить не удалось.
Подход: разработка по спецификации
Можно сгенерировать свою спецификацию из аннотаций кода, но говорят, что автоматическая генерация — не лучший подход. Майкл Стоу (Michael Stowe) в статье Беспрепятственный REST: руководство по проектированию Perfect API рекомендует группам вручную реализовать спецификацию, а затем обрабатывать документ спецификации как документ, который разработчики используют при выполнении реального кодирования. Этот подход часто упоминается как «spec-first development».
![]() Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Другими словами, разработчики обращаются к спецификации, чтобы увидеть, как должны называться имена параметров, каковы должны быть ответы и так далее. После того, как этот «контракт» или «план» был принят, Стоу говорит, можно поместить аннотации в свой код (при желании), чтобы сгенерировать документ спецификации более автоматизированным способом. Но не стоит кодировать без предварительной спецификации.
Слишком часто команды разработчиков быстро переходят к кодированию конечных точек API, параметров и ответов, без пользовательского тестирования или исследования, соответствует ли API тому, что хотят пользователи. Поскольку управление версиями API-интерфейсов чрезвычайно сложно (необходимо поддерживать каждую новую версию в дальнейшем с полной обратной совместимостью с предыдущими версиями), есть желание избежать подхода «быстрый сбой», который так часто отмечают agile энтузиасты. Нет ничего хуже, чем выпустить новую версию вашего API, которая делает недействительными конечные точки или параметры, используемые в предыдущих выпусках. Постоянное версионирование в API может стать кошмаром документации.
Компания Smartbear, которая делает SwaggerHub (платформу для совместной работы команд над спецификациями API Swagger), говорит, что теперь для команд чаще встречается ручное написание спецификации, а не встраивание аннотаций исходного кода в программный код для автоматической генерации. Подход “spec-first development” в первую очередь помогает работать документации среди большего количества членов команды, нежели только инженеров. Определение спецификации перед кодированием также помогает командам создавать лучшие API.
Даже до создания API спецификация может генерировать , добавляя определения ответа в спецификацию. Мок-сервер генерирует ответ, который выглядит так, как будто он исходит от реального сервера, но это просто предопределенный ответ в коде, и кажется динамичным для пользователя.
File not found
Ошибка означает, что в новой версии пакета отсутсвуют некоторые файлы, присутствувавшие ранее. Причин для этого может быть несколько:
- в новой версии действительно нет таких файлов — в этом случае надо просто убрать их описание из секции %files
- в новой версии файлы переименованы либо перемещены в другое место. В этом случае вы также увидите ошибку «Installed (but unpackaged) file(s) found», как в случае с библиотеками (см. выше). В случае с библиотеками для исправления сразу обеих ошибок необходимо изменить значение переменной major в начале spec-файла. В общем же случае необходимо исправить секцию %files, чтобы она соответсвовала новым реалиям.
- отсутсвующие файлы собираются или не собираются в зависимости от параметров окружения и сборки — опций компиляции или установленных в сборочной среде пакетов (описанных в BuildRequires). Возможно, в новой версии пакета надо использовать какие-то новые опции сборки либо добавить дополнительные сборочные зависимости для получения этих файлов. Выявить такие ситуации можно на основе анализа журналов сборки и вывода команд наподобие configure или cmake, которые сообщают, какие опцилнальные возможности будут включены при сборке, а какие — нет. Например, squid может собираться с поддержкой аутентификации SASL и без нее. В первом случае в пакете будет присутсвовать файл basic_sasl_auth, во втором его не будет. Для ключения/отключения SASL необходимо добавить/удалить значение SASL из параметра —enable-auth-basic команды configure, а также добавить сборочную зависимость (BuildRequires) от sasl-devel.
Помните, что при добавлении файлов в секции %files принято заменять некоторые стандартные пути макросами, а также что при описании файлов в секции %files могут использоваться символы ‘?’ и ‘*’ (означающие один произвольный символ и любое количество
произвольных символов соответсвенно).
Проверка
При проверке пакета сравнивается информация о файлах, установленных из пакета, с информацией в оригинальном пакете. Помимо остального, при такой проверке проверяется размер, сумма MD5, разрешения, тип, владелец и группа владельца каждого файла.
Команда rpm -V выполняет проверку пакета. Вы можете использовать любой из перечисленных Параметров выбора пакета, для указания пакетов, которые вы хотите проверить. Простым примером выполнения проверки является команда rpm -V foo, которая проверяет, что все в файлы в пакете foo находятся там, куда они были первоначально установлены. Например:
-
Чтобы проверить пакет, содержащий конкретный файл, выполните:
rpm -Vf /bin/vi
-
Чтобы проверить ВСЕ установленные пакеты:
rpm -Va
-
Чтобы сравнить установленный пакет с файлом пакета RPM:
rpm -Vp foo-1.0-1.i386.rpm
Эта команда может быть полезно, если вы сомневаетесь в целостности баз данных RPM.
Если проверка проходит успешно, никакие сообщения на экране не появятся. В случае обнаружения каких-либо нарушений, вы увидите сообщения об этом. Для каждого несоответствия на экран будет выведена строка из восьми символов ( c обозначает файл конфигурации), а затем имя файла. Каждый из восьми символов обозначает результат сравнения одного атрибута файла со значением атрибута, записанного в базе данных RPM. Одна . (точка) означает, что тест пройден. Следующие символы обозначают ошибки при выполнении определённых проверок:
-
5 — контрольная сумма MD5
-
S — размер
-
L — символическая ссылка
-
T — дата изменения файла
-
D — устройство
-
U — пользователь
-
G — группа
-
M — режим (включая разрешения и тип файла)
-
? — файл не удалось прочитать
Если вы увидели такие сообщения, вы должны решить, будете ли вы удалять или переустанавливать пакет или исправлять проблему другим способом.
Схемы YAML
Схемы — это наборы правил в YAML 1.2, которые сообщают загрузчику / парсеру, что каждая часть вашего файла YAML преобразуется в фактические команды. По сути, они представляют собой набор операторов if / then для обработки удобочитаемых тегов YAML. Например, в схеме YAML Core указано, что оба !!str my stringи my stringэквивалентны и должны анализироваться для одного и того же действия.
Существует схема по умолчанию для YAML общего назначения и множество схем специального использования, каждая из которых подходит для определенных нишевых сценариев. Вы даже можете создавать свои собственные пользовательские схемы или загружать схемы других пользователей в JSON Schema Store.
Настраиваемые схемы полезны, когда файлы конфигурации включают настраиваемые объекты или если вы хотите создать сериализацию объектов для конкретного языка.
Для YAML есть три схемы по умолчанию:
- Failsafe Schema: минималистичная схема, которая поддерживает только теги String ( !!str), Map ( !!map) и Sequence ( !!seq). Failsafe гарантированно работает с любым документом YAML из-за его простоты, но он не поддерживает никаких сложных тегов.
- Схема JSON: базовая схема, предназначенная для надежного синтаксического анализа эквивалентных файлов YAML и JSON для получения одного и того же конечного результата. Это наиболее часто используемая схема и отправная точка для большинства схем. Он поддерживает все отказоустойчивые теги, а также Boolean ( !!bool), null ( !!null), Integer ( !!int) и Float ( !!float).
- Базовая схема: схема YAML по умолчанию, которая расширяет критерии соответствия на стороне YAML. По сути, это менее самоуверенная версия схемы JSON. Например, JSON принимает логические значения, соответствующие критерию «Соответствие: true| false». Для сравнения, вот логический критерий Core: » true| True| TRUE| false| False| FALSE«.
Что такое RPM?
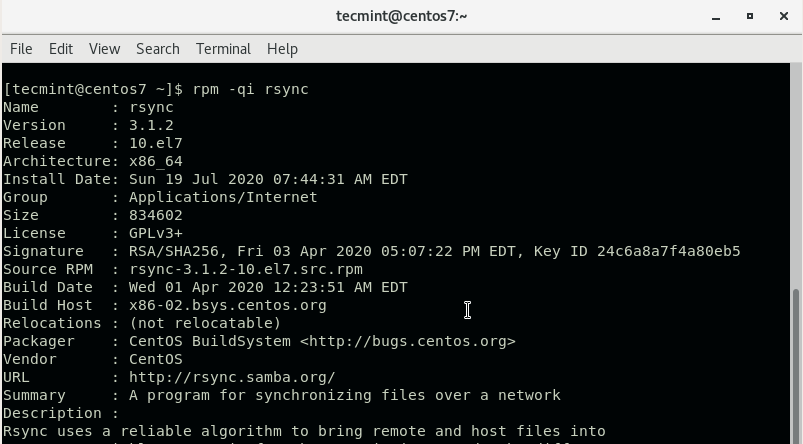
RPM или RPM Package Manager — это пакетный менеджер, используемый в дистрибутивах Linux, основанных на Red Hat. Такое же название имеет формат файлов этого пакетного менеджера.
Этот формат не очень сильно отличается от того же самого Deb. Вы можете посмотреть их детальное сравнение в статье что лучше *.deb или *.rpm. Здесь же, только отмечу, что файл rpm — это обычный cpio архив, в котором содержатся сами файлы программы, а также метаданные, описывающие куда их нужно устанавливать. База всех установленных пакетов находится в каталоге /var/lib/rpm. Из особенностей можно отметить, что rpm не поддерживает рекомендованные пакеты, а также зависимости формата или-или.
Для управления пакетами, так же как и в Debian-системах, здесь существует консольная, низкоуровневая утилита с одноименным названием — rpm. Ее мы и будем рассматривать дальше в статье. В разных системах используются разные пакетные менеджеры, например в Red Hat используется Yum, в Fedora — DNF, а в OpenSUSE — zypper, но во всех этих системах будет работать утилита rpm.
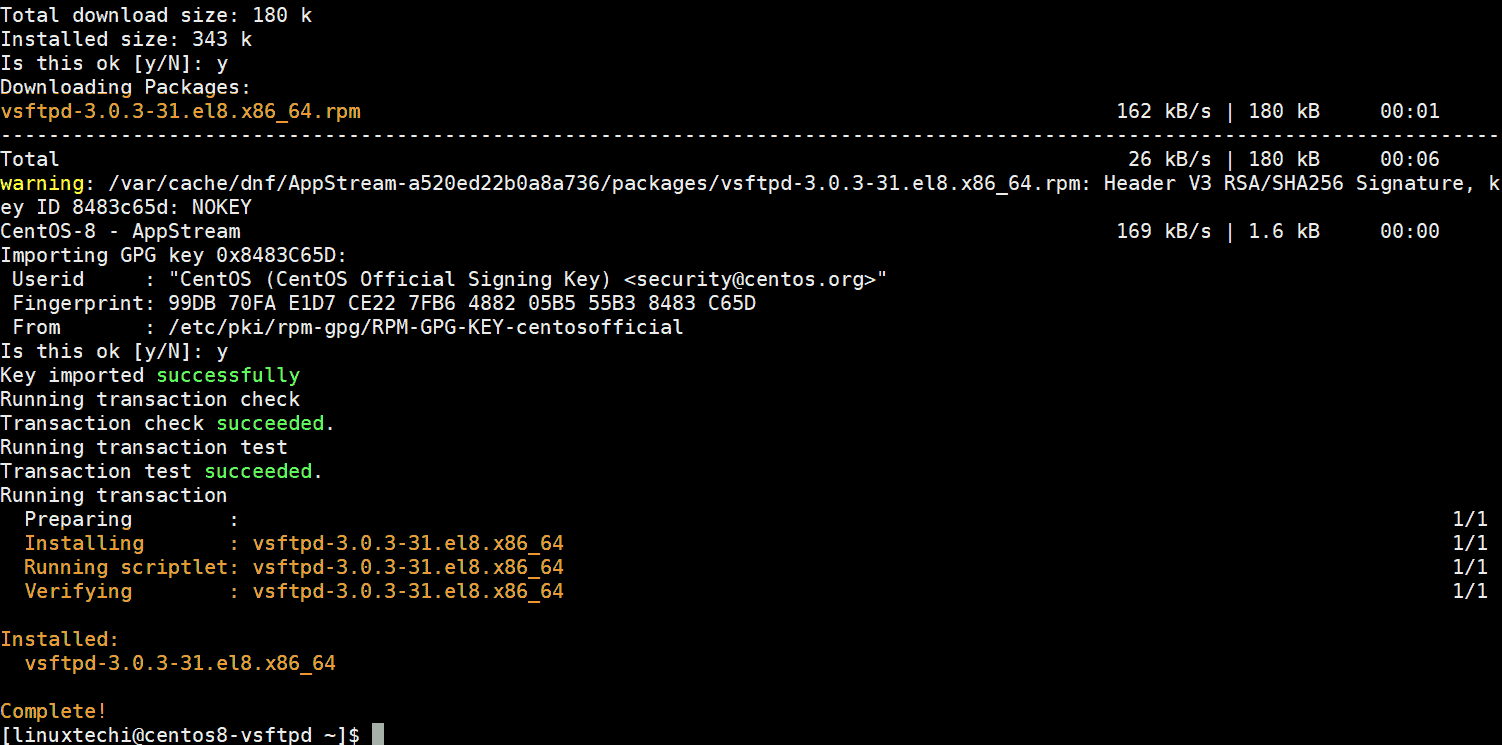
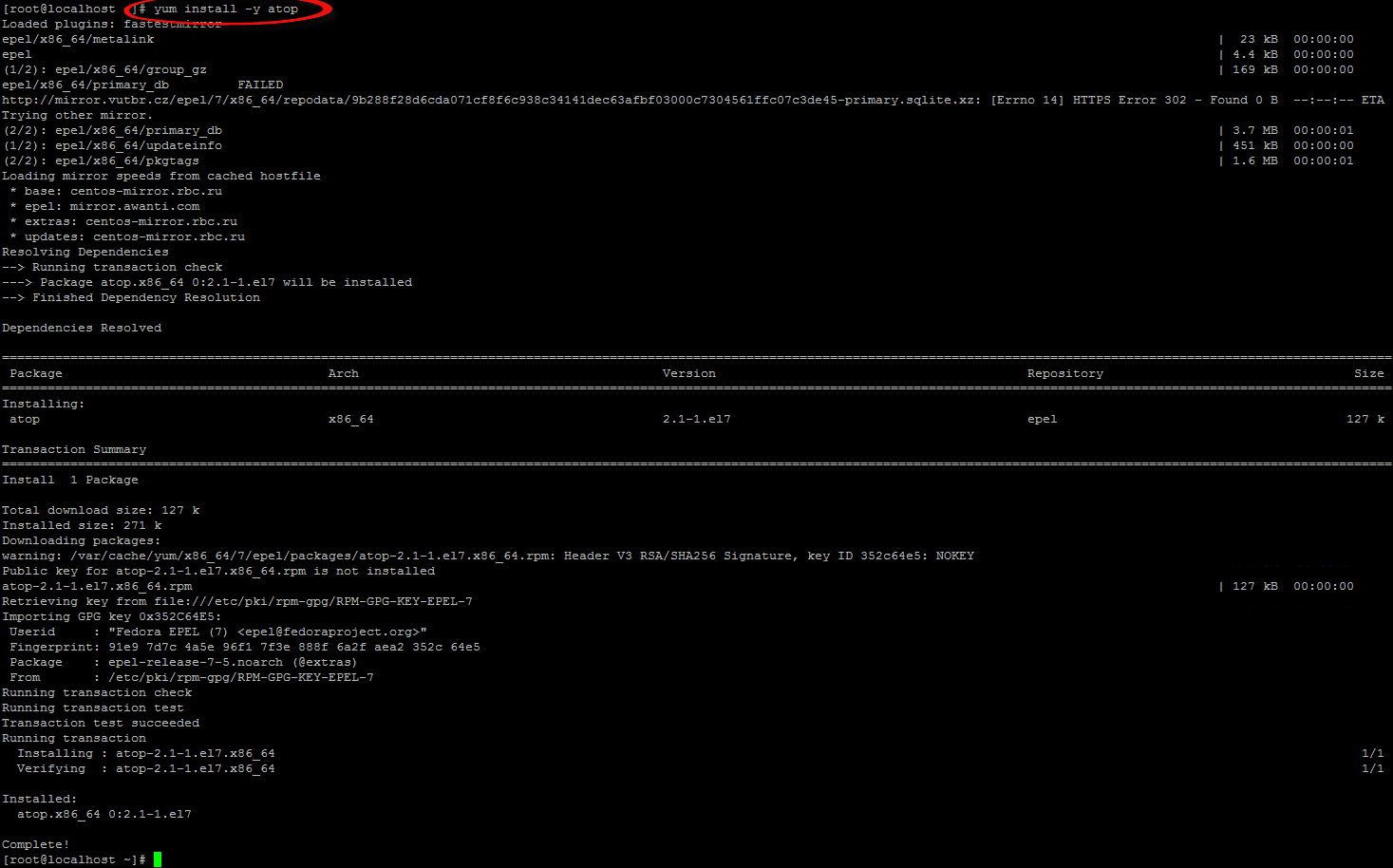
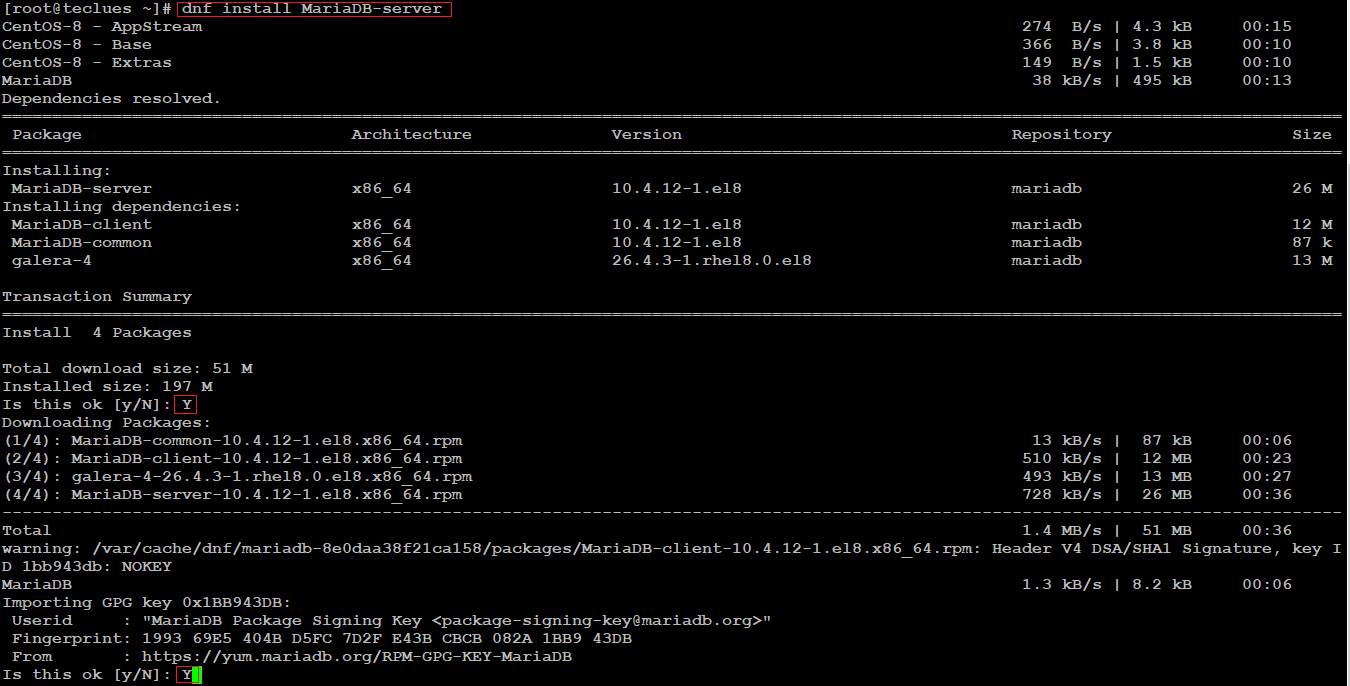
15.2.2. Установка
Обычно файлы, содержащие пакеты RPM, имеют имена вроде foo-1.0-1.i386.rpm. Имя файла включает название пакета (foo), версию (1.0), выпуск (1) и архитектуру (i386). Чтобы установить пакет, войдите в систему под именем root и введите в приглашении оболочки следующую команду:
rpm -Uvh foo-1.0-1.i386.rpm |
Если установка пройдёт успешно, на экране появится следующее:
Preparing... ########################################### 1:foo ########################################### |
Как вы видите, RPM выводит имя пакета, а затем, по мере установки пакета, последовательность символов «решётка», отражающую процесс установки.
При установке или обновлении пакета автоматически проверяется подпись пакета. Эта подпись подтверждает то, что пакет был подписан разработчиком и не был изменён. Например, если при проверке подписи происходит ошибка, вы получите примерно следующее сообщение:
error: V3 DSA signature: BAD, key ID 0352860f |
Если это новая подпись только для заголовка появляется такое сообщение:
error: Header V3 DSA signature: BAD, key ID 0352860f |
Если у вас не установлен ключ, подходящий для проверки подписи, сообщение об ошибке содержит слово NOKEY, например:
warning: V3 DSA signature: NOKEY, key ID 0352860f |
За дополнительными сведениями о проверке подписи пакета обратитесь к разделу 15.3 Проверка подписи пакета.
| Предупреждение | |
|---|---|
|
Если вы устанавливаете пакет ядра, вместо этой команды следует использовать rpm -ivh. За подробностями обратитесь к главе 37 Обновление ядра вручную. |
Установка пакетов должна выполняться просто, но иногда вы можете встретить ошибки:
15.2.2.1. Пакет уже установлен
Если пакет той же версии уже установлен, вы увидите:
Preparing... ########################################### package foo-1.0-1 is already installed |
Если версия пакета, который вы пытаетесь установить, совпадает с версией уже установленного, но вы, тем не менее, хотите установить пакет, вы можете указать параметр --replacepkgs и RPM проигнорирует эту ошибку:
rpm -ivh --replacepkgs foo-1.0-1.i386.rpm |
Этот параметр полезен, если файлы, установленные из пакета RPM, были удалены или вы не хотите, чтобы были установлены оригинальные файлы конфигурации RPM.
15.2.2.2. Конфликтующие файлы
Если вы пытаетесь установить пакет, который содержит файл, установленный другим пакетом или более ранней версий того же пакета, на экране появляется сообщение:
Preparing... ########################################### file /usr/bin/foo from install of foo-1.0-1 conflicts with file from package bar-2.0.20 |
Чтобы RPM игнорировал эту ошибку, укажите параметр --replacefiles:
rpm -ivh --replacefiles foo-1.0-1.i386.rpm |
Исландский Fjölnir: Рейкьявик-Рейкьявик
Fjölnir (читается как Фьёльнир») — это язык программирования на исландском. Его используют для обработки списков (как семейство Лиспов) и модульного программирования. Отличительная черта языка — взаимосвязи, благодаря которым имена при импорте не перечисляются «внутри» каждого модуля, а задаются «снаружи» — как выражения над модулями.
Вот так выглядит промозглый исландский «Hello, World!»:
Fjölnir придумал профессор информатики Исландского университета Снорри Агнарссон ещё в восьмидесятые. И он был довольно популярен среди местных программистов. Если вам вдруг попадётся файл с расширением fjo или sma — знайте, это Fjölnir.
Advanced Placement, что это?
Advanced Placement (AP) в США и Канаде – программа предуниверситетской подготовки старшеклассников. Ученикам 11-12 классов (High School) предлагается выбрать несколько предметов для углубленного изучения, отдавая предпочтение дисциплинам, тесно связанным с будущей специальностью. В конце обучения, студентам предлагается сдать экзамены, однако это элективная, а не обязательная опция. AP проходит не только в средних школах Канады и США. Благодаря высокому качеству получаемого учениками образования программа предлагается в международных частных учебных заведениях, расположенных в Швейцарии, Италии и других странах.
Прохождение программы AP позволяет:
- изучить профилирующие предметы вузовской программы, соответствующие 1-2 семестру
- подготовиться к обучению в университете
- получить кредитные баллы, которые учитываются не только при зачислении, но и во время учебы в вузе
- сдать экзамены по всем изучаемым дисциплинам, результаты принимаются 90% вузов США, Канады, Великобритании и более 50 стран мира и засчитываются в качестве вступительных (в некоторых случаях)
С 2014 года наряду с программой AP проходит AP Capstone, которая направлена на развитие у учеников навыков проведения исследований, общения и умения работать в команде. Сегодня курс доступен в более 650 государственных и частных школах в США и Канаде, а также учебных заведениях по всему миру. Программа AP Capstone включает семинары (AP Seminar) и исследовательскую деятельность (AP Research), в ходе которых старшеклассники получают передовые знания по сложным дисциплинам университетского уровня.
Программа Advanced Placement предоставляет возможность углубленного изучения 38 предметов. Однако окончательный список зависит от каждой конкретной школы, т.е. одна предлагает ученикам на выбор все 38 дисциплин, а другая только часть.
AP предметы
- История искусства
- Биология
- Химия
- Компьютерные науки (в том числе «Принципы информатики»)
- Английский язык
- Английская литература
- Иностранные языки и культура (включая французский, немецкий, китайский, итальянский, японский, испанский)
- История (в том числе европейская, американская (США), мировая)
- Экономика (макроэкономика, микроэкономика)
- Физика
- Философия
- Исследования (в рамках AP Capstone)
- Семинары (в рамках AP Capstone)
- Латынь
- География
- Математика
- Теория музыки
- Статистика
- Искусство (включая рисование, 2D-дизайн, 3D-дизайн)
- Испанская литература и культура
- Правительство и политика
- Науки об окружающей среде
Помимо вышеперечисленных, частные школы в Америке и других частях света предлагают более узкопрофильные дисциплины, привлекая студентов с особыми планами на будущую карьеру. Обучение по каждому рассчитано на 1 академический год, при этом занятия проходят по насыщенному расписанию, иногда, на 1 предмет выделяется 8 часов в неделю. По окончании изучения дисциплины сдается письменный экзамен АР.
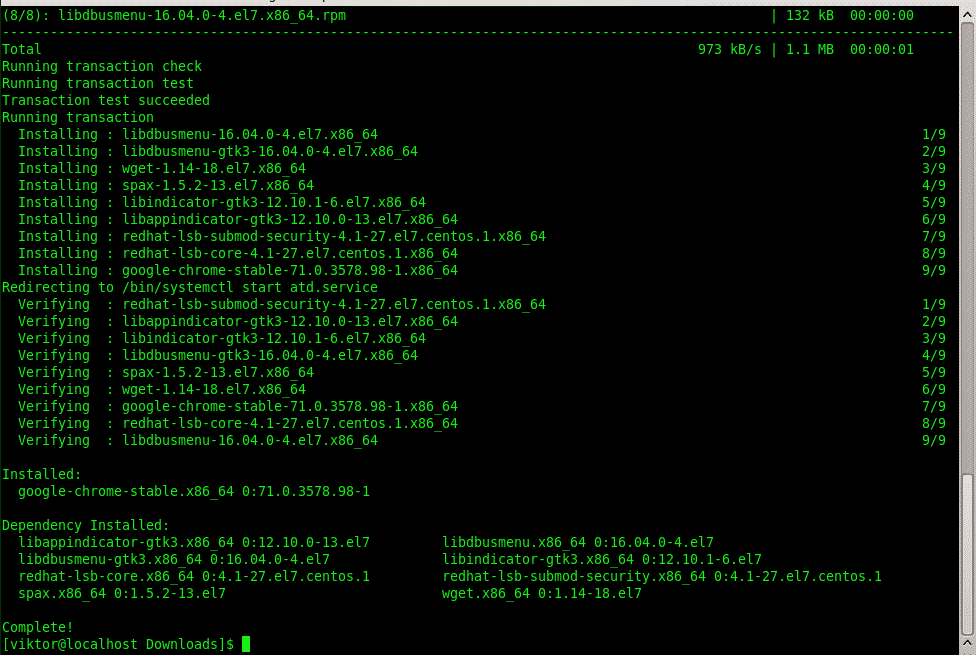
Пакет RPM в системе Ubuntu / Debian
Изначально система управления пакетами RPM была создана для Red Hat Linux. Позже он стал популярным и доступен для Fedora, SuSE Linux и других дистрибутивов Linux на основе Red Hat. Поскольку Red Hat и Debian — это разные системы Linux и обе имеют свой репозиторий пакетов, вы должны быть осторожны при установке пакетов RPM в Ubuntu Linux, чтобы избежать ошибок зависимости. В этом посте будет показано, как вы можете установить пакеты RPM в Ubuntu и других дистрибутивах Debian Linux.
Шаг 1. Установите пакет Alien в системе Debian
В Linux приложение Alien представляет собой конвертер пакетов дистрибутива для Debian Linux. Он может конвертировать пакеты RPM в формат Debian. Вы можете запустить следующую команду в терминальной оболочке Ubuntu с правами суперпользователя, чтобы установить пакет Alien в вашей системе Debian.
sudo apt install alien
Шаг 2. Загрузите пакет RPM
Инструмент Alien позволит установить пакет RPM в вашей системе Ubuntu. Но вы не можете использовать команды YUM или DNF для установки пакетов RPM через репозиторий Red Hat; вам необходимо преобразовать пакет RPM в формат Debian.
Во-первых, вы должны загрузить желаемый RPM-пакет в свою систему. Давайте загрузим пакет RPM и преобразуем его в RPM. Здесь я загружу RPM-пакет Google Chrome, чтобы продемонстрировать процесс. Вы также можете выбрать другие пакеты RPM. Щелкните здесь, чтобы загрузить RPM-пакет Google Chrome.
Шаг 3. Установите RPM-пакеты в Debian Linux
Есть два метода установки пакета RPM в системе Ubuntu. Вы можете преобразовать пакет .rpm в пакет .deb или установить пакет RPM прямо в систему Debian с помощью инструмента Alien. Здесь мы рассмотрим оба способа установки пакета RPM в системе Debian Linux.
Метод 1: преобразование и установка пакета RPM в Ubuntu
После установки инструмента Alien в Debian Linux вы можете преобразовать пакет rpm, который вы скачали ранее. Вы можете выполнить приведенный ниже процесс, чтобы преобразовать пакет. Выполните следующую команду в оболочке терминала, чтобы преобразовать пакет RPM в формат Debian. Не забудьте заменить путь и имя пакета своими.
sudo alien google-chrome-stable_current_x86_64.rpm
Хотя преобразование прошло успешно, теперь вы можете запустить команду dpkg или команду apt install в оболочке терминала, чтобы установить пакет RPM в Ubuntu Linux.
Команда Dpkg для установки пакета в Ubuntu.
sudo dpkg -i google-chrome-stable_88.0.4324.96-2_amd64.deb
Команда apt для установки пакета в Ubuntu.
sudo apt install ./google-chrome-stable_88.0.4324.96-2_amd64.deb
Метод 2: установить пакет RPM непосредственно в Ubuntu
Это простой процесс установки пакета rpm на рабочий стол ubuntu. Сначала откройте каталог, в который вы загрузили пакет .rpm, затем выполните следующую команду Alien в оболочке терминала, чтобы установить пакет непосредственно в Ubuntu или других дистрибутивах Linux на основе Debian.
sudo alien -i google-chrome-stable_current_x86_64.rpm
Степень починки[править]
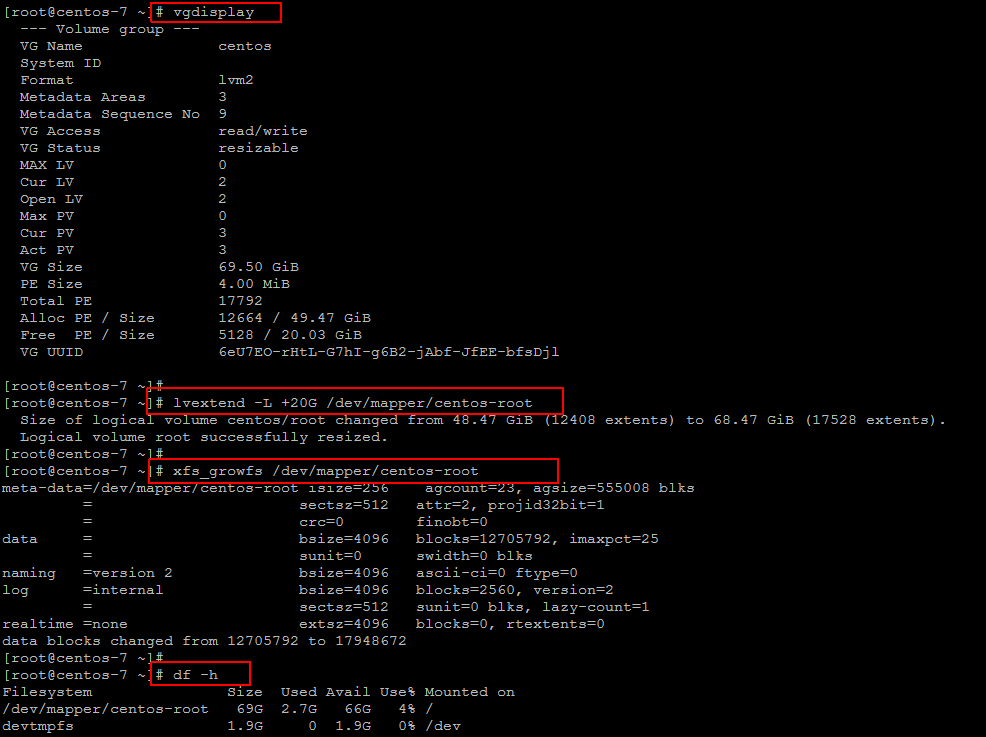
rpmrepair —nodeps без дополнительных манипуляций практически гарантированно создаст RPM, который можно будет установить в систему. Конечно не факт, что упакованное ПО при этом заработает. Если же рабочий RPM получается с использованием rpmrepair —repair —scripts без дополнительных манипуляций, это намного лучше. Ключ —repair включает все стандартные очень жёсткие проверки альтовой сборочницы, включается максимальный поиск зависимостей и провайдсов, отделяются отладочные символы. Пробуйте разные варианты с индивидуальной RPM’кой, если не хотите вдаваться в детали.
Типы данных
Типы данных в порядке увеличения приоритета:
- Логические (logical)
- Целочисленные (integer)
- Вещественные числа (numeric)
- Комлексные числа (complex)
- Текстовые (character)
- Списки (list)
Векторы и типы данных
Вектор может содержать данные только одного типа.
Логические:
Целочисленные:
Текстовые:
Какой класс будет иметь вектор?
Factors
Factor — представляет номинальную или ранговую шкалу.
Используется для представления Y в классификационных моделях.
Data.frames
Data.frame — двумерный набор данных (таблица). В отличие от матриц, колонки в data.frame могут содержать данные различного типа. Однако тип данных внутри каждой колонки может быть только один. Это объясняется тем, что data.frame это список векторов (колонок). Поэтому к data.frame могут быть применены различные функции применимые к спискам.
Формулы
Формулы — специальная форма выражения отношений между переменными в уравнении. Формулы используются при построении моделей для определения функциональной зависимости между параметрами.
Линейная комбинация (+):
Линейная комбинация с отсутствующим свободным членом (+0)
Функция идентичности I(), при этом выражение в скобках рассматривается как обычное математическое.
Формулы могут содержать математические функции
Символ точки (.) подставляет все имеющиеся переменные. Функция зависимости y от всех остальных переменных, которые будут передаваться в функцию выглядит так
| Синтаксис | Модель | Пояснение |
|---|---|---|
| Y ~ A | \( Y = \beta_{0} + \beta_{1}A \) | Уравнение регрессии с неявно заданным свободным членом |
| Y ~ A + 0 | \( Y = \beta_{1}A \) | Уравнение регрессии без свободного члена |
| Y ~ A + B | \( Y = \beta_{0} + \beta_{1}A + \beta_{2}B \) | Уравнеие модели первого порядка |
| Y ~ A + I(A^2) | \( Y = \beta_{0} + \beta_{1}A + \beta_{2}A^2 \) | Уравнеие модели второго порядка с одной переменной |
| Y ~ A:B | \( Y = \beta_{0} + \beta_{1}AB \) | Уравнение модели первого порядка, в которое входят только произведения переменных |
| Y ~ A*B | \( Y = \beta_{0} + \beta_{1}A + \beta_{2}B + \beta_{3}AB \) | Полное уравнение модели первого порядка, аналогично Y ~ A + B + A:B |
| Y ~ (A + B + C)^2 | \( Y = \beta_{0} + \beta_{1}A + \beta_{2}B + \beta_{3}C + \beta_{4}AB + \beta_{5}AC + \beta_{6}BC \) | Модель первого порядка включающая все произведения до порядка n, аналогично Y ~ A*B*C — A:B:C |
Списки
Списки содержат упорядоченный набор элементов, каждый из которых может являться вектором, матрицей, массивом, списком и т.д.
Как правило в виде списков удобно хранить либо какие-то однотипные данные соответствующие разным итерациям, например, множество моделей. Или хранить разнородные данные, которые имеют смысловую связь, например, различные статистические характеристики отдельной модели.
Заключение
Хорошая работа над продвинутым синтаксисом YAML. Хотя YAML может показаться нишевым навыком, это необходимое условие для многих рабочих мест на рынке. Однако большинство собеседований по кодированию не будут включать YAML. Лучший способ продемонстрировать свои знания YAML — использовать их в проекте портфолио или иметь возможность продемонстрировать прошлый опыт работы с этой технологией.
Чтобы помочь вам поразить рекрутеров своими навыками YAML, Educative создал Introduction to YAML. Этот курс охватывает синтаксис и методы на уровне от новичка до эксперта в сжатом практическом формате. К концу курса вы сможете уверенно использовать YAML и будете иметь собственный сертификат YAML, который можно будет разместить в своем резюме.





