
Mysql
Оптимизация всех таблиц mysql
#!/bin/sh
p="MYSQL_PASSWORD"
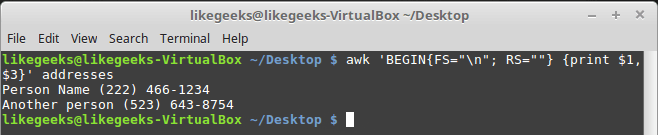
echo "show databases;" | mysql -u root --password="$p" | grep -v "^Database" | awk '{print ("use "$0" ; show tables;")}' \
| mysql -u root --password="$p" \
| awk 'BEGIN {FS="_"}{if ($1 == "Tables") {if ($2 =="in" ) {printf "USE \`"$3; for (i = 4; i < 10; i++) {if ($i != "") printf ("_"$i)}; print ("\`;")} else {print ("OPTIMIZE TABLE \`"$0"\`;")}} else {print ("OPTIMIZE TABLE \`"$0"\`;")}}' \
|mysql -u root --password="$p" > result_optimize.txt
Ремонт всех баз данных mysql кроме некоторых
#!/bin/sh
#Скрипт ремонтирует все базы mysql кроме HTTPD_LOGS и выводит только ошибки восстановления
p="пароль_mysql"
echo "show databases;" | mysql -u root --password="$p" | grep -v "^Database" | grep -v "HTTPD_LOGS" \
| awk -v p="$p" '{system ("mysqlcheck -u root --password=\""p"\" -e --auto-repair --databases "$0)}' | grep -v "OK"
Ввод данных в awk
awk
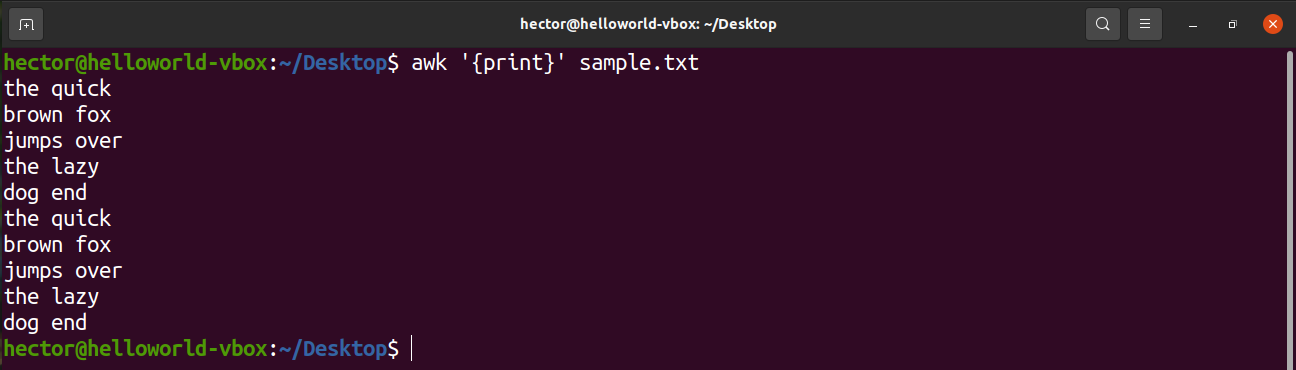
В строке вызова awk можно указать несколько файлов данных,
awk будет последовательно их обрабатывать.
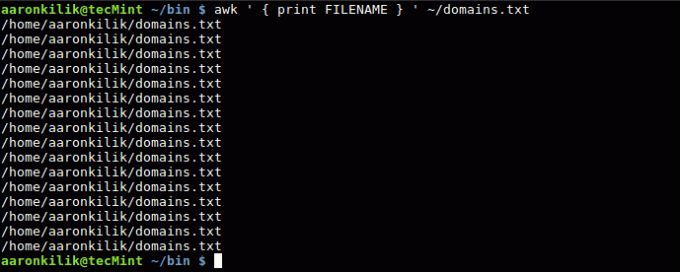
Имя текущего файла ввода
доступно как значение переменной FILENAME.
Эти базовые возможности awk по вводу данных могут быть существенно
расширены использованием функции (или команды) getline.
Использованная без аргументов, getline просто читает очередную
запись из текущего файла ввода. Это позволяет, например, специальным
образом обработать следующую строку, если вы, например, обнаружили во
входных данных сообщение типа:
TOP SECRET! NEXT LINE TO BE BURNED BEFORE READING!
После выполнения команды getline awk продолжает нормальный цикл
своей деятельности, применяя к этой записи последующие пары
образец — действие.
Команда getline может быть использована для ввода значения
строковой переменной:
getline message
Никаких побочных эффектов при этом не происходит, за исключением того,
что изменяется счетчик записей NR.
Команда getline может читать из поименованного файла, используя
технику перенаправления:
getline < file
Выражение file может быть произвольным строковым выражением,
которые
интерпретируются как имя файла в данной операционной системе.
Если getline не встретила каких-либо проблем при исполнении, она
возвращает значение 1.
Если при исполнении обнаружен конец файла,
то возвращается ,
если обнаружена ошибка, то возвращается -1.
В последнем случае причину ошибки можно найти, проанализировав
значение переменной ERRNO.
Строковые функции
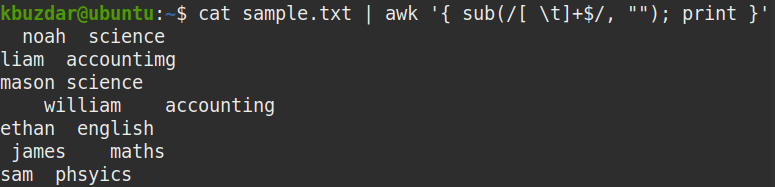
Функция split() помещает поля в массив fld и возвращает число полей.
Если аргумент sep равен пробелу, то пробелы в начале и в конце строки убираются, а разделителем считается произвольная последовательность, состоящая из пробелов и табуляций. Если sep отличен от пробела, то разделителем считается одиночный символ, содержащийся в строке sep, пробелы не удаляются, а выделенные поля могут содержать пробелы или вообще оказаться пустыми.
Функция match() производит инициализацию следующих переменных:
| RLENGTH | длина найденной строки или -1, если строка не найдена |
| RSTART | позиция найденной строки или 0, если строка не найдена |
Функции sub() и gsub() возвращают число сделанных замен (0 или 1 в случае sub()). В аргументе repl можно использовать специальный символ «&», который заменяется на подстроку строки str, совпавшую с регулярным выражением. Символ «&» экранируется с помощью обратной косой черты (backslash).
Часть седьмая: AWK и оболочки (sh/ksh/bash/csh)
Иногда функционала AWK может быть недостаточно. В этом случае можно интегрировать awk в скрипт оболочки. Далее несколько примеров как это можно сделать.
Простой вывод
Иногда хочется использовать awk просто как программу форматирования, и сбрасывать вывод прямо пользователю Следующий скрипт принимает в качества аргумента имя пользователя и использует awk для дампа информации о нём из /etc/passwd.
Примечание: обратите внимание, что в скрипте одинарные кавычки раскрываются (а не являются вложенными) и между двумя раскрытыми парами одинарных кавычек стоит переменная $1 (вторая), которая в данном случае является аргументом скрипта, в то время как $1 является частью синтаксиса $1 (означает первое поле в строке).
#!/bin/sh
while ; do
awk -F: '$1 == "'$1'" { print $1,$3} ' /etc/passwd
shift
done
Присвоение переменным оболочки вывода awk
Иногда мы хотим использовать awk просто для быстрого способа установить значение переменной. Используя тему passwd, у нас есть способ узнать шелл для пользователя и увидеть, входит ли он в список официальных оболочек.
И опять, обратите внимание, как происходит закрытие одинарных кавычек в выражении awk, После закрытой (второй) кавычки, $1 является переменной, в которую передано значение первого аргумента скрипта, а не частью синтаксиса awk.
#!/bin/sh
user="$1"
if ; then echo ERROR: need a username ; exit ; fi
usershell=`awk -F: '$1 == "'$1'" { print $7} ' /etc/passwd`
grep -l $usershell /etc/shells
if ; then
echo ERROR: shell $usershell for user $user not in /etc/shells
fi
Другие альтернативы:
# Смотрите "man regex"
usershell=`awk -F: '/^'$1':/ { print $7} ' /etc/passwd`
echo $usershell;
# Только современные awk принимают -v. Вам может понадобиться использовать "nawk" или "gawk"
usershell2=`awk -F: -v user=$1 '$1 == user { print $7} ' /etc/passwd`
echo $usershell2;
Объяснение дополнительных вышеприведённых методов остаётся домашним заданием читателю
Передача данных в awk по трубе
Иногда хочется поместить awk в качестве фильтра данных, в большую программу или команду в одной строке, вводимую в запрос оболочки. Пример такой команды в скрипте (в качестве аргументов скрипта передаётся список файлов логов веб-сервера, поскольку запись в журнал настраивается и логи могут иметь различную структуру, для работоспособности в конкретных случаях может понадобиться подправить команды):
#!/bin/sh
grep -h ' /index.html' $* | awk -F\" '{print $4}' | sort -u
Contents
- Contents
Что такое строковый процессор awk
Подобные задания с одной стороны могут быть слишком трудоемки
для обычного текстового редактора,
так как могут требовать просмотра тысяч строк текста,
а с другой стороны — неунифицируемыми, так как информация
не структурирована в том виде, как это имеет место в базах
данных или электронных таблицах.
Для эффективной работы в этой »серой» области давно предложен и с успехом
применяется строковый процессор awk.
Это процессор рассматривает входной поток данных
как состоящий из записей,
разделенными специальными символами (RS).
По умолчанию таким символом является символ перехода
на новую строку (»).
Запись считается разделенной ( символами FS)
на поля
и строковый процессор awk автоматически выделяет эти поля
и дает возможность производить
с ними различные операции.
По сути дела, это единственное предположение,
которое делает awk относительно структуры входных данных.
Задание процесса обработки некоторого файла с помощью программы awk состоит
в описании действий, которые нужно произвести с записями и полями.
Для этого awk предоставляет в распоряжение программиста
развитый язык программирования, напоминающий популярный язык программирования
C.
Это и не удивительно, так как авторы awk (Альфред В. Ахо ( Alfred V. Aho — a),
Питер Дж. Вайнбергер ( Peter J. Weinberger — w ) и
Брайан У. Кернихан ( Brian W. Kernighan — k)
известны как родоначальники языка C и
операционной системы UNIX.
Входной язык процессора awk является в определенном смысле
»упрощенным» C и не содержит таких типов данных как
указатели и структуры.
Отсутствуют в нем и другие элементы языка C,
такие, напримерa, как команды препроцессора, битовые операции,
локализация переменных и пр.
Однако, в отличие от C
awk предоставляет удобный операционный синтаксис для строковых
операций, автоматическое преобразование строка-число,
автоматический лексический разбор входного потока и т.п.,
что делает его исключительно удобным средством
выполнения простых, но трудоемких операций
c текстовыми файлами больших размеров.
Кроме этого,
awk является интерпретирующим языком, что существенно
упрощает процесс разработки awk-приложений.
Все это делает awk весьма эффективным и полезным инструментом,
умело владеть которым должен каждый грамотный программист.
Структура awk-файла
awk
образец действие.
awkобразцу действие
Программа на awk может содержать определения
функций, которые можно считать также имеющими форму
образец — действие со специальным видом образца.
Подробнее задание функций описано в разделе []
Действие описывается операторами языка awk,
которые подробнее рассматриваются далее.
Чтобы отделить условие от действия,
последнее обычно заключается в фигурные скобки .
Ислючение составляет лишь случай пустого действия,
которое в этом случае приводит к выводу на печать входной записи.
Выбираем «Да/Нет» из Меню в Bash
Еще один легкий способ — с помощью команды select (источник) :
echo "Do you wish to install this program?"
select yn in "Yes" "No"
case $yn in
Yes ) make install;;
No ) exit;;
esac
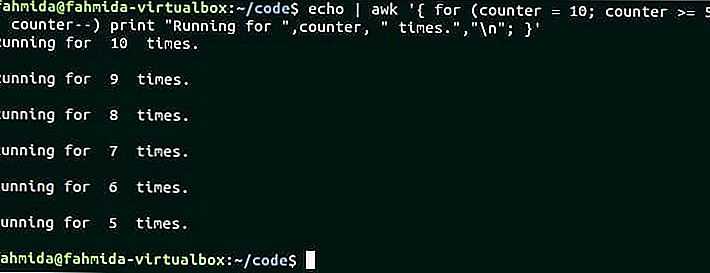
Выполнить и Повторить Команду N Раз в Bash
Иногда возникает необходимость несколько раз выполнить одну и ту же команду из командной строки в Linux.
В Bash существует простая конструкция, с помощью которой команду можно прописать один раз, но сделать так, чтобы она была выполнена N раз.
Из этой небольшой заметки вы узнаете, что лучший способ чтобы выполнить одну и ту же команду N раз подряд — это использовать цикл FOR в Bash.
9.5.3 Арифметические функции
В awk имеются арифметические функции.
- atan2(y, x)
-
Возвращает значение arctan(y/x) в радианнах.
- cos(expr)
-
Возвращает значение cos(expr) в радианнах.
- exp(expr)
-
Возвращает значение экспоненциальной функции.
- int(expr)
-
Возвращает целое от expr.
- log(expr)
-
Возвращает значение натурального логарифма от expr.
- rand()
-
Возвращает случайное значение в интервале .
- sin(expr)
-
Возвращает значение sin(expr).
- sqrt(expr)
-
Возвращает значение sqrt(expr) (квадратный корень из expr).
- srand()
-
Устанавливает новое исходное значение для генератора случайных чисел.
Возвращает предыдущее исходное значение. Если
expr опущено, то используется текущее время в секундах. Таким
образом, если вы
желаете, чтобы у вас при каждом новом запуске awk,
генерировалась
новая псевдослучайная последовательность в функции rand(), то вам
полезно вызвать функцию srand() перед циклом обращений к функции
rand(). -





Разбор строки
Прочитанная строка обрабатывается и производится инициализация следующих предопределенных переменных:
| переменная | значение |
|---|---|
| FILENAME | имя текущего входного файла |
| NR | номер текущей строки |
| FNR | номер текущей строки в текущем входном файле |
| NF | число полей в текущей строке |
| $0 | вся прочитанная строка |
| $n | поле с номером n (n — число, переменная или выражение) |
Из входного потока последовательно выбираются строки. Разделитель строк задается в переменной RS.
Обработка строки состоит в разбиении ее на поля. По умолчанию считается, что поля отделены друг от друга одним или несколькими пробельными символами (пробелами или символами табуляции). В общем случае строка разбивается на поля, отделенные друг от друга разделителем полей. Разделитель полей задается переменной FS. Значение этой переменной может быть присвоено в секции BEGIN. Также можно использовать опцию ‘-F’ в которой задается значение разделителя полей. Разелитель полей может быть регулярным выраженем. Разделитель полей, состощий только из пробельных символов, интерпретируется специальным образом — в этом случае разделителем полей считается любая последовательность пробельных символов. Во всех остальных случаях разделителем полей считается подстрока, удовлетворяющая регулярному выражению (в это правило также попадает случай, когда разделитель полей содержит только обычные символы, как минимум один из которых отличен от пробела). Если разделитель полей равен пустой строке, то происходит посимвольное разделение входной строки на односимвольные поля.
| переменная | интерпретация |
|---|---|
| RS | разделитель строк при разборе входного потока |
| FS | разделитель полей при разборе входной строки |
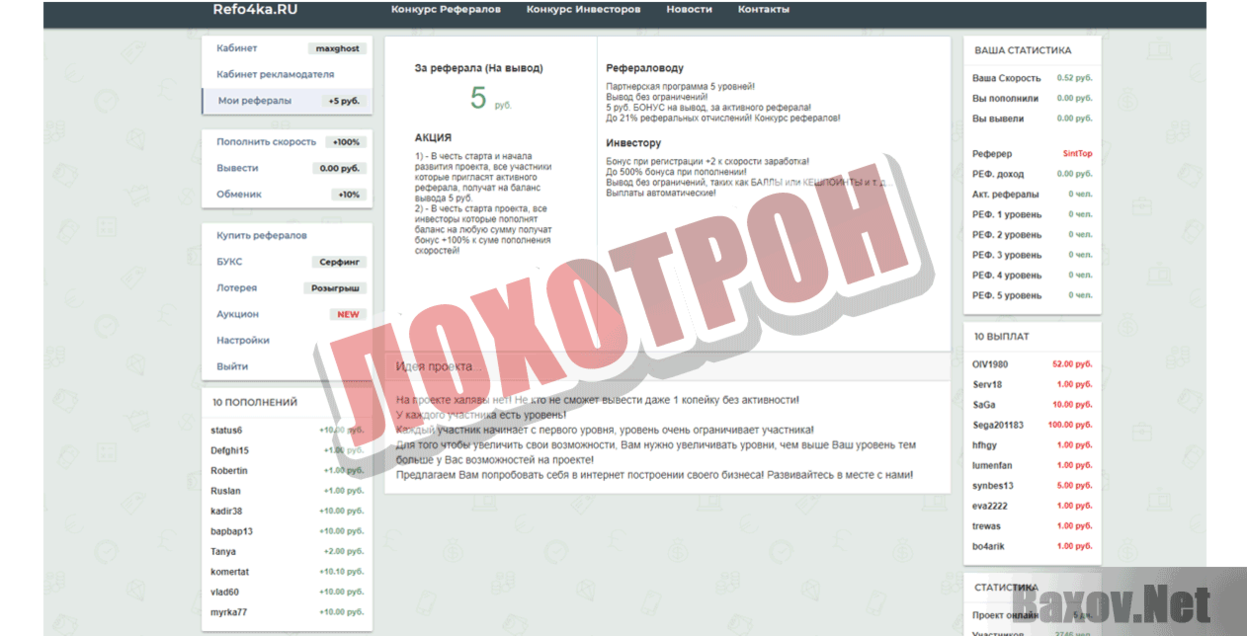
Примеры решения задач с помощью awk
Задача 1.
Есть файл вот с таким содержимым:
ОРГАНИЗАЦИЯ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| ОРГАНИЗАЦИЯ НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| ОРГАНИЗАЦИЯ НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| ОРГАНИЗАЦИЯ НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| ОРГАНИЗАЦИЯ НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| ОРГАНИЗАЦИЯ НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ| НАЧИСЛЕНИЕ|
Таких строк может быть любое количество, как в меньшую, так и в большую сторону. После слов «ОРГАНИЗАЦИЯ» строка продолжается наименованием и реквизитами организации.
После слов «НАЧИСЛЕНИЕ» строка продолжается суммой начисления и прочими данными.
Разделителем является труба: |
Задача такая — с помощью awk найти слово «ОРГАНИЗАЦИЯ», скопировать содержимое этой строки и привязанные к ней строки «НАЧИСЛЕНИЕ».
Т.е. первую строку «ОРГАНИЗАЦИЯ» и две строки ниже со словом «НАЧИСЛЕНИЕ». Вывести эти 3 строки в отдельный файл. Количество строк может быть любым.
Найти следующие строки по такому же принципу и опять в отдельный файл.
По этому примеру должно быть 6 файлов и каждый со своей организацией и начислениями.
Решение 1. Работает в awk под Linux
awk -v y=0 '/ОРГАНИЗАЦИЯ/{if(x) print x>y; x=$0 ;y++} !/ОРГАНИЗАЦИЯ/{x=x"\r\n"$0} END {print x>y}' test.txt
Решение 2. Работает в awk под Windows
awk.exe -v y=0 "/ОРГАНИЗАЦИЯ/{y++; print $0>y\".txt\";} !/ОРГАНИЗАЦИЯ/{print $0>y\".txt\"}" test.txt
Входные данные в файле test.txt. Тестировалась в cmd (а не в PowerShell).
Скриншот:
Содержимое первых четырёх файлов:
Задача 2.
Как добавить в существующий файл строку с нужными мне данными?
Т.е. есть файл, например, с 6 строками и я хочу добавить сроку перед 1 строкой или добавить строку во все .txt файлы в определённой папке.
Решение 1. Работает в awk под Linux
Итак, следующий пример считывает все файлы из текущего каталога (*). Если нужно, чтобы считывал только файлы с определённым разрешением, то вместо звёздочки можно записать, например, так *.txt.
Для каждого обрабатываемого файла в самое начало добавляется строка «СТРОКА» — замените на нужную. Новые файлы сохраняются в эту же папку, с такими же именами, но перед именем добавляется префикс «new_» — при желании, его можно удалить или заменить на другой (в двух местах команды!).
Собственно команда:
awk -v 'OLD_FILENAME=""' '{if(OLD_FILENAME!=FILENAME) print "СТРОКА" > "new_"FILENAME; OLD_FILENAME=FILENAME} {print > "new_"FILENAME;}' *
Логика работы:
- при запуске awk инициализируется переменная OLD_FILENAME — которой в качестве значения присваивается пустая строка
- при обработке каждой строки, значение переменной OLD_FILENAME сравнивается со значением встроенной переменной FILENAME в которой (сюрприз!) содержится имя текущего файла. Если эти значения НЕ равны, то в файлы печатается строка «СТРОКА» И переменной OLD_FILENAME присваивается значение, которое содержит FILENAME.
- следующая часть {print > «new_»FILENAME;} просто печатает очередную строку в новый файл
- при последующих прохождениях (вторая строка, третья строка и т. д.) значения OLD_FILENAME и FILENAME будут одинаковыми. Вплоть до момента, пока обрабатываемый файл не сменится на новый. В этот момент OLD_FILENAME и FILENAME становятся не равны и в новый файл первой печатается строка «СТРОКА» и переменной OLD_FILENAME присваивается значение FILENAME
- всё продолжается, пока все строки во всех файлах не кончатся
Решение 2. Работает в awk под Windows
Для Windows (cmd, а не PowerShell):
awk.exe -v OLD_FILENAME="" "{if(OLD_FILENAME!=FILENAME) print \"СТРОКА\" > \"new_\"FILENAME; OLD_FILENAME=FILENAME} {print > \"new_\"FILENAME;}" *.txt
4 ответа
Лучший ответ
Это будет работать:
напечатает первую строку, а напечатает последнюю строку.
В качестве предложения ознакомьтесь с info sed, а не только . Вы можете найти несколько примеров по вашему вопросу в пункте 2.1.
1
Francesco Lucianò
8 Июл 2020 в 07:35
Исходя из вашего нового требования ничего не выводить, если входной файл занимает всего 1 строку (см. Как найти только первую и последнюю строку файла с помощью sed ):
Оригинальный ответ:
Это одна из тех вещей, которые вы можете, на первый взгляд, достаточно легко сделать в sed:
Но то, как обрабатывать крайние случаи, такие как одна строка ввода, неочевидно, например это действительно правильный вывод:
Или правильный вывод просто:
И если последнее, как вы настраиваете эту команду sed для получения этого вывода? @potong предложил команду GNU sed:
Которая работает, но может быть только GNU (idk) и, что более важно, не очень похожа на команду, с которой мы начали, поэтому самое незначительное изменение требований означало полное переписывание с использованием различных конструкций. А как насчет того, чтобы улучшить его, скажем, только для печати первой и последней строки, если файл содержал ? Я ожидаю, что это будет еще одно сложное упражнение с sed и, вероятно, будет включать также непереносимые конструкции
А как насчет того, чтобы улучшить его, скажем, только для печати первой и последней строки, если файл содержал ? Я ожидаю, что это будет еще одно сложное упражнение с sed и, вероятно, будет включать также непереносимые конструкции.
Просто бессмысленно учиться делать это с помощью sed, когда вы можете использовать другой инструмент, такой как awk, и делать все что угодно в простом, согласованном, переносимом синтаксисе:
Заметь:
- Каждая команда выглядит как любая другая команда.
- Незначительное изменение требований приводит к незначительному изменению кода, а не к полной перезаписи.
- Как только вы научитесь делать любую заданную вещь A, как делать подобные вещи B, C, D и т. Д. Просто на основе уже использованного вами синтаксиса, вам не придется изучать совершенно другой синтаксис.
- Каждая из этих команд будет работать с использованием любого awk в любой оболочке на каждом компьютере UNIX.
А как насчет того, если вы хотите сделать это для нескольких файлов, которые будут созданы с помощью следующих команд?
С помощью awk вы можете просто сохранить строки в массиве для печати в END:
Или с помощью GNU awk вы можете распечатать их из ENDFILE:
С седом? Упражнение оставлено для читателя.
1
Ed Morton
8 Июл 2020 в 19:57
Это может работать для вас (GNU sed):
Все команды sed могут начинаться с адреса или с помощью регулярного выражения. Адрес — это либо номер строки, либо , представляющий последнюю строку. Если ни адрес, ни регулярное выражение отсутствуют, следующая команда применяется ко всем другим строкам.




Нормальный цикл sed представляет каждую строку ввода (за исключением ее новой строки) в пространстве шаблона. Затем применяются команды sed, и последним действием цикла является повторное присоединение новой строки и вывод результата.
Команда управляет потоком команд; если он сам по себе выпрыгивает из следующих команд sed к последнему действию цикла, то есть когда новая строка присоединяется и выводится результат.
Команда удаляет пространство шаблона, и, поскольку ничего не нужно печатать, дальнейшая обработка не выполняется (включая повторное присоединение новой строки и печать результата).
Таким образом, решение выше печатает первую строку и последнюю и удаляет остальные.
У Sed есть несколько параметров командной строки, один из которых включает неявную печать результата пространства шаблона . Команда печатает текущее состояние пространства шаблона. Таким образом, двойственное из вышеуказанного решения:
Нотабене Если входной файл содержит только одну строку, первое решение напечатает только одну строку, тогда как второе решение напечатает одну и ту же строку дважды. Кроме того, если вводится более одного файла, оба решения будут печатать первую строку первого файла и последнюю строку последнего файла, если не установлена опция , и в этом случае каждый файл будет изменен. Параметр реплицирует это без внесения поправок в каждый файл, но передает результаты в стандартный вывод, как если бы каждый файл обрабатывался отдельно.
1
potong
9 Июл 2020 в 07:20
Первая строка:
Последняя линия:
1
Necklondon
8 Июл 2020 в 06:31
Работа со строками в awk
Как вы могли убедиться, обладает неплохим набором функций для фильтрации строк текста. Однако для этих строк еще можно выполнять различные преобразования. Команды для работы со строками должны быть обернуты в фигурные скобки . Код в скобках последовательно вызывается для каждой строки обрабатываемого текста.
В имеется прямой аналог функции языка . В качестве примера выведем в начале каждой строки ее номер:
Вот что получили:
Кроме есть в и другие функции. Например, и :
Соответствующий результат:
Условные конструкции
В -программах доступны операторы . Например, следующий код выводит без изменения строки, у которых на 1-ой позиции стоит , а на последней — , иначе на консоль отправляется :
Выполнение кода приводит к выводу следующего:
Переменные
Доступны в -программах и переменные, которые не требуется предварительно объявлять. Следующий код для подсчета количества строк и слов в тексте поместим в файл :
Тогда его вызов осуществляется следующим образом:
Результат выполнения:
Фильтр указывает, что код в скобках после него должен выполняться только после прохода всех строк. Доступен в и фильтр , поэтому в более общем случае программа принимает вид:
Обратите внимание, что посчитать строки и слова в тексте намного проще с помощью :
Циклы
В -программах вам также доступны циклы и в стиле . Для примера выведем все строки в обратном порядке. Создадим файл следующего содержимого:
Вызовем программу следующий образом:
В результате слова в каждой строке будут выведены в обратном порядке:
Нестандартный разделитель слов
По умолчанию в качестве разделителя слов использует пробельные символы, однако такое поведение можно изменить. Для этого воспользуйтесь ключом , после которого укажите строку, определяющую разделитель. Например, следующая программа выводит название группы и ее пользователей (если в группе есть пользователи) из файла , применяя в качестве разделителя символ двоеточия:
Комбинирование фильтров и команд печати
Все рассмотренные ранее фильтры можно использовать совместно с командами обработки строк. Достаточно записать ограничения перед фигурными скобками. Ниже представлен пример для вывода первых 9 строк вывода команды , содержащей информацию о пользователе, идентификаторе процесса и имени команды:
После запуска увидим:
Использование Операторов «Grep ИЛИ / Grep И / Grep НЕ» в BASH
Оператор Grep ‘OR’
Находим все строки в файле, которые содержат какие-либо из перечисленных шаблонов.
Используя команду GREP :
grep "pattern1\|pattern2" file.txt grep -E "pattern1|pattern2" file.txt grep -e pattern1 -e pattern2 file.txt egrep "pattern1|pattern2" file.txt
Используя команду AWK :
awk '/pattern1|pattern2/' file.txt
Используя команду SED :
sed -e '/pattern1/b' -e '/pattern2/b' -e d file.txt
Оператор Grep ‘AND’
Находим и печатаем строки содержащие все перечисленные паттерны.
Используя команду GREP :
grep -E 'pattern1.*pattern2' file.txt # в такой последовательности grep -E 'pattern1.*pattern2|pattern2.*pattern1' file.txt # в любой последовательности grep 'pattern1' file.txt | grep 'pattern2' # в любой последовательности
Используя команду AWK :
awk '/pattern1.*pattern2/' file.txt # в такой последовательности awk '/pattern1/ && /pattern2/' file.txt # в любой последовательности
Используя команду SED :
sed '/pattern1.*pattern2/!d' file.txt # в такой последовательности sed '/pattern1/!d; /pattern2/!d' file.txt # в любой последовательности
Оператор Grep ‘NOT’
Находим и печатаем строки, которые не содержат указанный паттерн.
Используя команду GREP :
grep -v 'pattern1' file.txt
Используя команду AWK :
awk '!/pattern1/' file.txt
Используя команду SED :
sed -n '/pattern1/!p' file.txt
Парсинг CSV
По умолчанию в качестве разделителя используются пробел и табуляция. Чтобы определить иной разделитель, например запятую, нужно использовать FS=’,’ или опцию «-F». В качестве параметра может быть задано регулярное выражение, например:
FS='^ *| *, *| *$'
Но для разбора CSV это не подойдет, так как пробелы могут присутствовать и внутри строк, поэтому проще вырезать лидирующие пробелы перед и после запятой:
FS=','
for(i=1;i<=NF;i++){
gsub(/^ *| *$/,"",$i);
print "Field " i " is " $i;
}
Если в CSV данные помещены в кавычки, например «field1″,»field2», то подойдет такой скрипт:
FS=','
for(i=1;i<=NF;i++){
gsub(/^ *"|" *$/,"",$i);
print "Field " i " is " $i;
}
Но скрипт придется усовершенствовать для разбора полей вида:
field1, «field2,with,commas» , field3 , «field4,foo»
$0=$0",";
while($0) {
match($0,/*,| *"*" *,/);
sf=f=substr($0,RSTART,RLENGTH);
gsub(/^ *"?|"? *,$/,"",f);
print "Field " ++c " is " f;
sub(sf,"");
}
Перенос части выражения на новую строку
Деление длинного оператора на части улучшит его читаемость, сделает код процедуры более наглядным и компактным, не позволит ему уходить за пределы видимого экрана справа.
Переносимые на новые строки части кода одного выражения разделяются символом нижнего подчеркивания (_), который ставится обязательно после пробела. Этот символ указывает компилятору VBA Excel, что ниже идет продолжение текущей строки.


Пример 1
Процедуры без переноса и с переносом части кода операторов:
|
1 |
‘Процедура без переноса SubPrimer_1_1() DimaAsLong,bAsLong a=12*7-155+36 b=a+25+36*15-5 MsgBoxb EndSub ‘Процедура с переносом SubPrimer_1_2() DimaAsLong,_ bAsLong a=12*7-15_ 5+36 b=a+25+36_ *15-5 MsgBoxb EndSub |
Вы можете скопировать код Примера 1 и проверить его работоспособность. В обоих случаях информационное окно MsgBox покажет одинаковый результат.
Иногда пишут, что для переноса кода добавляется пробел с символом подчеркивания. Так легче запомнить и не забыть, что перед знаком подчеркивания обязательно должен быть пробел. Но на самом деле, как видите из примера выше, пробелы уже есть в исходном коде, и мы добавили только символы подчеркивания.
Объединение операторов в одной строке
Множество коротких выражений в коде VBA Excel можно объединить в одной строке. Для этого используется символ двоеточия с пробелом «: », который указывает компилятору, что за ним идет следующий оператор.
Пример 2
Процедуры без объединения и с объединением операторов:
|
1 |
‘Процедура без объединения SubPrimer_2_1() DimaAsLong,bAsLong,cAsLong a=12 b=a+25 c=a*b MsgBoxc EndSub ‘Процедура с объединением SubPrimer_2_2() DimaAsLong,bAsLong,cAsLong a=12b=a+25c=a*bMsgBoxc EndSub |
Во втором примере, как и в первом, информационное окно MsgBox покажет одинаковый результат.




![Папка продолжает возвращаться только для чтения [решено] - gadgetshelp,com](http://fuzeservers.ru/wp-content/uploads/2/d/3/2d310fee7eca4e8c0d505d2b78421c8c.jpeg)
