
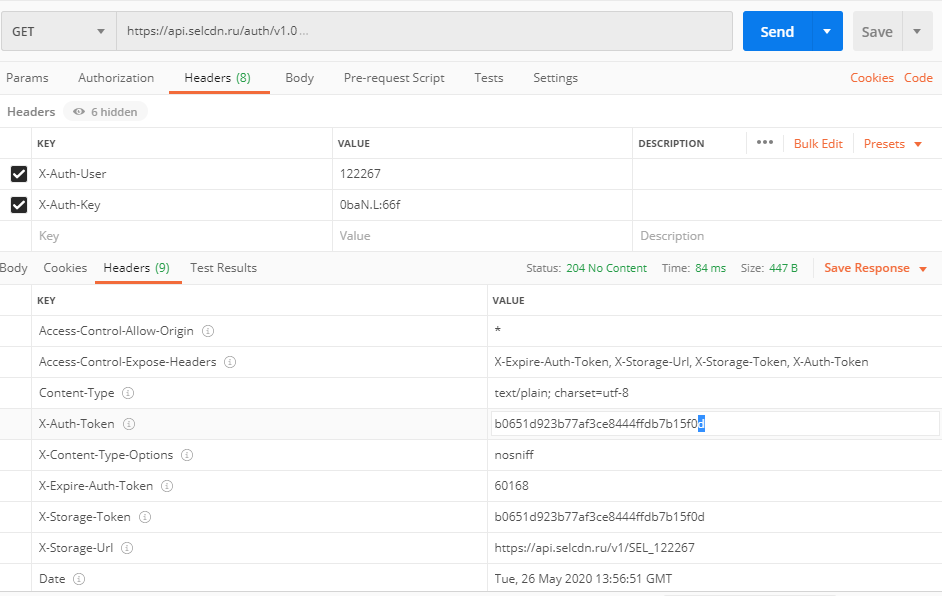
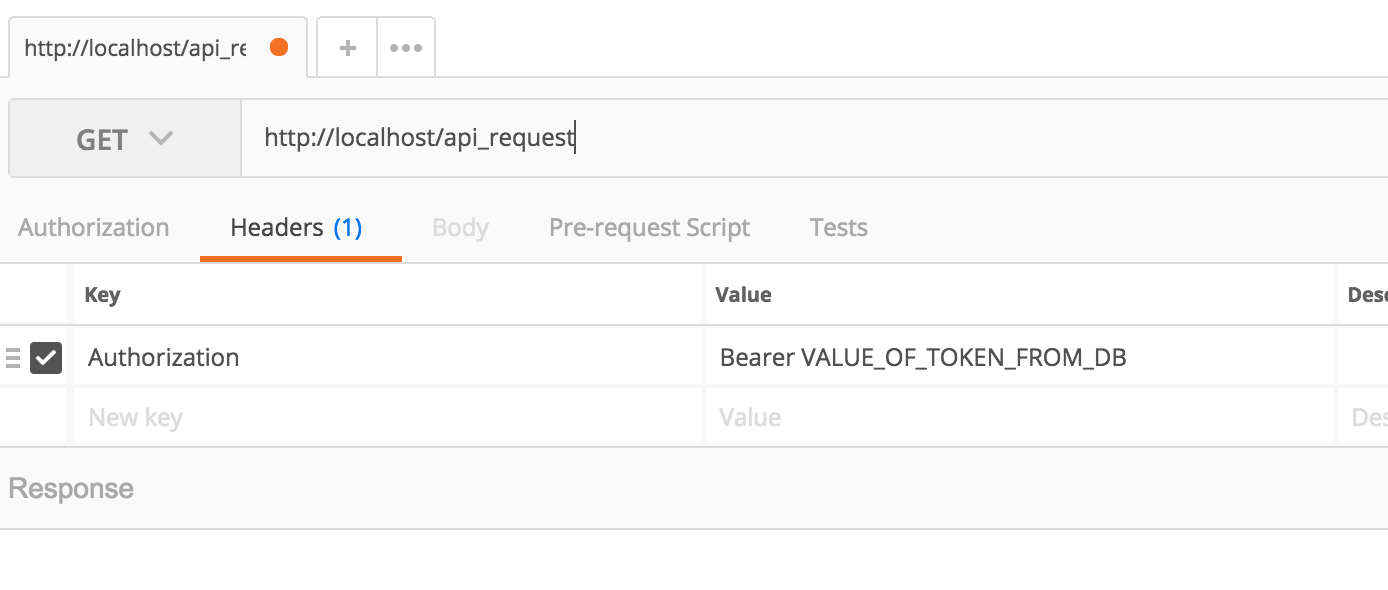
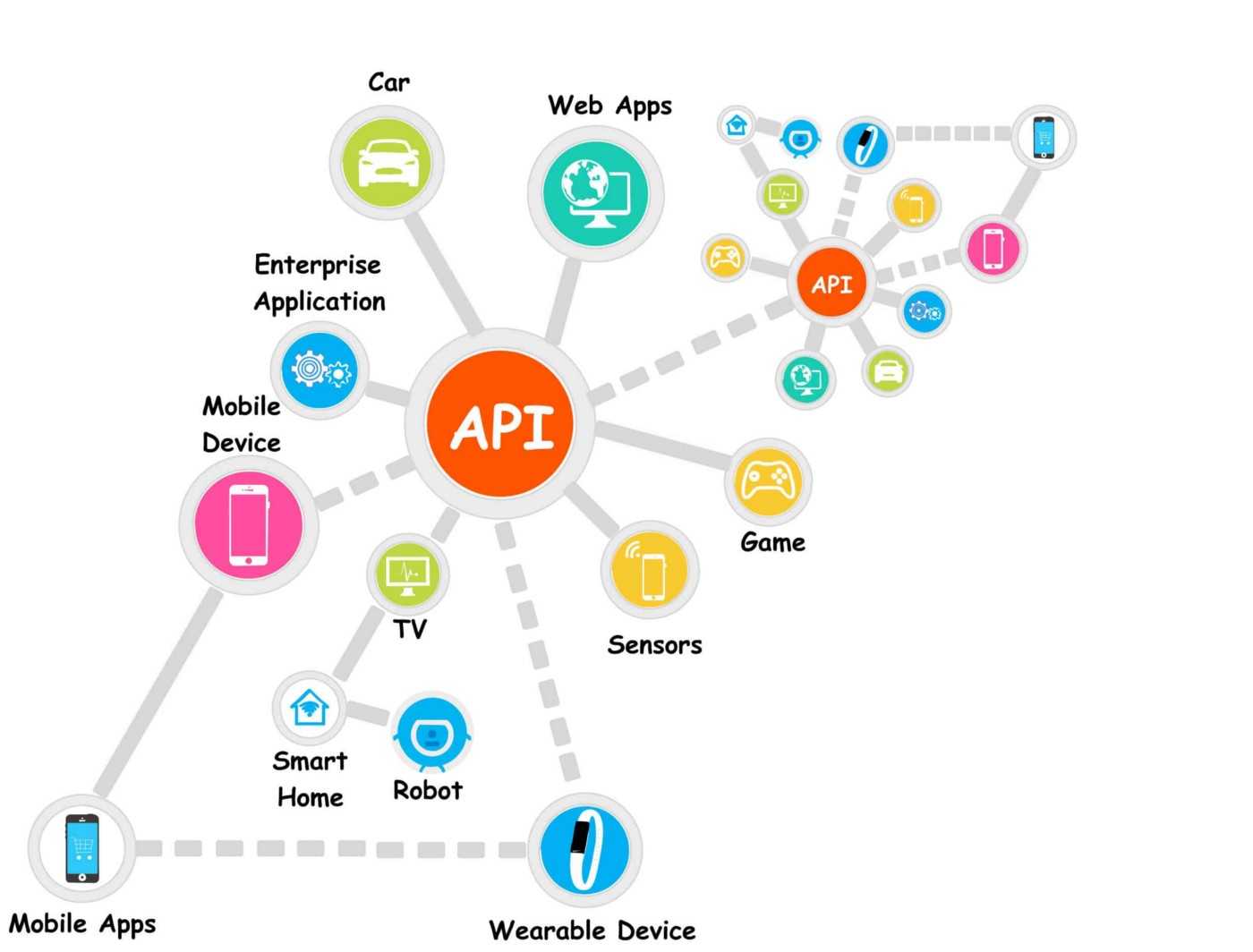
Отправка файлов
Для того, чтобы отправить файлы на сервер, мы просто заполняем поля POST запроса, указывая там специальный класс CURLFile. На сервере вы можете получить отправленные файлы, при помощи суперглобального массива $_FILES.
$url = 'https://phpstack.ru/';
$postFields = [
'photo1' => new \CURLFile( __DIR__ . '/img1.jpg' ),
'photo2' => new \CURLFile( __DIR__ . '/img2.jpg' ),
];
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $postFields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
Несколько примеров на Guzzle
GET запросы на Guzzle
// Создаем клиента с базовым URL
$client = new GuzzleHttp\Client(['base_uri' => 'https://foo.com/api/']);
// Посылаем запрос на https://foo.com/api/test
$response = $client->request('GET', 'test');
// Посылаем запрос на https://foo.com/root
$response = $client->request('GET', '/root');
Разные типы запросов на Guzzle
$response = $client->get('http://httpbin.org/get');
$response = $client->delete('http://httpbin.org/delete');
$response = $client->head('http://httpbin.org/get');
$response = $client->options('http://httpbin.org/get');
$response = $client->patch('http://httpbin.org/patch');
$response = $client->post('http://httpbin.org/post');
$response = $client->put('http://httpbin.org/put');
Асинхронные запросы на Guzzle
$promise = $client->getAsync('http://httpbin.org/get');
$promise = $client->deleteAsync('http://httpbin.org/delete');
$promise = $client->headAsync('http://httpbin.org/get');
$promise = $client->optionsAsync('http://httpbin.org/get');
$promise = $client->patchAsync('http://httpbin.org/patch');
$promise = $client->postAsync('http://httpbin.org/post');
$promise = $client->putAsync('http://httpbin.org/put');
Если интересно, то читайте: Guzzle Quick Start
Пишите комментарии, если что-то осталось непонятно.
Помогла ли Вам эта статья?
Да
Нет
👨💻 Опрос
Проверьте свою внимательность. Что означают следующие параметры?
Tip: Использование curl в Терминале или iTerm OS Mac обеспечивают намного более простую работу, чем использование командной строки в Windows. Если серьезно относиться к документации API, работая на ПК, стоит подумать о переходе с OS Windows. Будет много утилит, которые мы установим при помощи Терминала, который просто работает на Mac. Кроме того, находясь в Силиконовой долине, и используя ПК вместо Mac можно показаться старомодным для окружающих (см. Почему большинство стартапов покупают MacBook для своих сотрудников).
Для более подробного изучения curl в документировании REST API можно посмотреть REST-esting with curl.
Примеры команд wget
Как скачать файл и сохранить с другим названием
Параметр устанавливает имя выходного файла. Если файл называется , и вы хотите сохранить его непосредственно в , вы должны использовать такую команду:
Как установить скорость загрузки
Вы можете установить скорость загрузки при скачивании большого файла, чтобы он не использовал всю доступную пропускную способность. Скорость загрузки определяется в килобайтах (k) и мегабайтах (m). Используйте команду:
Как продолжить загрузку после прерывания
Вместо того, чтобы начинать с нуля, wget может возобновить загрузку с того места, где она была остановлена до прерывания. Это полезная функция, если при загрузке файла происходит потеря соединения.
Как скачать несколько файлов
- Сначала создайте и откройте файл с именем MultipleDownloads.txt (или другим именем по вашему выбору) с помощью текстового редактора.:
- В редакторе добавьте URL-адреса, которые вы хотите загрузить, по одному в каждой строке.
- Сохраните и выйдите из файла.
- Выполните следующую команду wget в окне терминала:
Как загрузить зеркало веб-страницы
С помощью wget вы можете загрузить весь веб-сайт из Интернета, используя параметр . Он предлагает wget создать зеркало указанной веб-страницы. Основная команда для этого:
Как увеличить число попыток повтора
По умолчанию количество повторных попыток установлено на 20.
Вы также можете установить число на бесконечность со значениями 0 или inf, как в следующем примере:
Как пропустить проверку сертификата
По умолчанию wget проверяет, есть ли у сервера действительный сертификат SSL / TLS. Если он не идентифицирует подлинный сертификат, он отказывается от загрузки.
Параметр используется, чтобы отменить проверку сертификата. Однако используйте его только в том случае, если вы уверены в надежности веб-сайта или не беспокоитесь о проблемах безопасности, которые он может вызвать.
Как изменить User Agent
При загрузке веб-страницы wget по сути эмулирует браузер. В некоторых случаях в выводе может быть указано, что у вас нет разрешения на доступ к серверу или что соединение запрещено. Это может быть связано с тем, что веб-сайт блокирует клиентские браузеры с определенным «User-Agent».
«User-Agent» — это поле заголовка, которое браузер отправляет на сервер, к которому он хочет получить доступ. Поэтому для загрузки с сервера, который отказывается подключаться, попробуйте его изменить.
Найдите базу данных всех пользовательских агентов в сети, найдите тот, который вам нужен, и выполните команду:
Параметры рекурсивной загрузки
- -r
- —recursive
- Включить рекурсивную загрузку.
- -l depth
- —level=depth
- Максимальная глубина рекурсивной загрузки depth. По умолчанию ее значение равно 5.
- —delete-after
-
Удалять каждую страницу (локально) после ее загрузки. Используется для сохранения новых версий часто запрашиваемых страниц на прокси. Например:
wget -r -nd --delete-after http://whatever.com/~popular/page/
Параметр -r включает загрузку по умолчанию, параметр -nd отключает создание папок.
При указанном параметре —delete-after будет игнорироваться параметр —convert-links.
- -k
- —convert-links
- После завершения загрузки конвертировать ссылки в документе для просмотра в автономном режиме. Это касается не только видимых ссылок на другие документы, а ссылок на все внешние локальные файлы.
Каждая ссылка изменяется одним из двух способов:
-
- *
- Ссылки на файлы, загруженные Wget изменяются на соответствующие относительные ссылки.
Например: если загруженный файл /foo/doc.html, то ссылка на также загруженный файл /bar/img.gif будет выглядеть, как ../bar/img.gif. Этот способ работает, если есть видимое соотношение между папками одного и другого файла.
- *
- Ссылки на файлы, не загруженные Wget будут изменены на абсолютные адреса этих файлов на удаленном сервере.
Например: если загруженный файл /foo/doc.html содержит ссылку на /bar/img.gif (или на ../bar/img.gif), то ссылка в файле doc.html изменится на http://host/bar/img.gif.
-
Благодаря этому, возможен автономный просмотр сайта и файлов: если загружен файл, на который есть ссылка, то ссылка будет указывать на него, если нет — то ссылка будет указывать на его адрес в интернет (если такой существует). При конвертировании используются относительные ссылки, значит вы сможете переносить загруженный сайт в другую папку, не меняя его структуру.
Только после завершения загрузки Wget знает, какие файлы были загружены. Следовательно, при параметре -k конвертация произойдет только по завершении загрузки.
-
- -K
- —backup-converted
- Конвертировать ссылки обратно — убирать расширение .orig. Изменяет поведение опции -N.
- -m
- —mirror
- Включить параметры для зеркального хранения сайтов. Этот параметр равен нескольким параметрам: -r -N -l inf -nr. Для неприхотливого хранения зеркальных копий сайтов вы можете использовать данный параметр.
- -p
- —page-requisites
- Загружать все файлы, которые нужны для отображения страниц HTML. Например: рисунки, звук, каскадные стили.
По умолчанию такие файлы не загружаются. Параметры -r и -l, указанные вместе могут помочь, но т.к. Wget не различает внешние и внутренние документы, то нет гарантии, что загрузится все требуемое.
Например, 1.html содержит тег "", со ссылкой на 1.gif, и тег "", ссылающийся на внешний документ 2.html. Страница 2.html аналогична, но ее рисунок — 2.gif и ссылается она на 3.html. Скажем, это продолжается до определенного числа.
wget -r -l 2 http://I/1.html
то 1.html, 1.gif, 2.html, 2.gif и 3.html загрузятся. Как видим, 3.html без 3.gif, т.к. Wget просто считает число прыжков, по которым он перешел, доходит до 2 и останавливается. А при параметрах:
wget -r -l 2 -p http://I/1.html
Все файлы и рисунок 3.gif страницы 3.html загрузятся. Аналогично
wget -r -l 1 -p http://I/1.html
приведет к загрузке 1.html, 1.gif, 2.html и 2.gif. Чтобы загрузить одну указанную страницу HTML со всеми ее элементами, просто не указывайте -r и -l:
wget -p http://I/1.html
При этом Wget будет себя вести, как при параметре -r, но будут загружены страница и ее вспомогательные файлы. Если вы хотите, чтобы вспомогательные файлы на других серверах (т.е. через абсолютные ссылки) были загружены, используйте:
wget -E -H -k -K -p http://I/I
И в завершении, нужно сказать, что для Wget внешняя ссылка — это URL, указанный в тегах "", "" и " ", кроме " ".
Обнаружение перенаправления в зависимости от браузера
В этом первом примере мы напишем код, который сможет обнаружить перенаправления URL, основанные на различных настройках браузера. Например, некоторые веб-сайты перенаправляют браузеры сотового телефона, или любого другого устройства.
Мы собираемся использовать опцию CURLOPT_HTTPHEADER для того, чтобы определить наши исходящие HTTP заголовки, включая название браузера пользователя и доступные языки. В конечном итоге мы сможем определить, какие сайты перенаправляют нас к разным URL.
// тестируем URL
$urls = array(
"http://www.cnn.com",
"http://www.mozilla.com",
"http://www.facebook.com"
);
// тестируем браузеры
$browsers = array(
"standard" => array (
"user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 (.NET CLR 3.5.30729)",
"language" => "en-us,en;q=0.5"
),
"iphone" => array (
"user_agent" => "Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1A537a Safari/419.3",
"language" => "en"
),
"french" => array (
"user_agent" => "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)",
"language" => "fr,fr-FR;q=0.5"
)
);
foreach ($urls as $url) {
echo "URL: $url\n";
foreach ($browsers as $test_name => $browser) {
$ch = curl_init();
// указываем url
curl_setopt($ch, CURLOPT_URL, $url);
// указываем заголовки для браузера
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"User-Agent: {$browser}",
"Accept-Language: {$browser}"
));
// нам не нужно содержание страницы
curl_setopt($ch, CURLOPT_NOBODY, 1);
// нам необходимо получить HTTP заголовки
curl_setopt($ch, CURLOPT_HEADER, 1);
// возвращаем результаты вместо вывода
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
// был ли HTTP редирект?
if (preg_match("!Location: (.*)!", $output, $matches)) {
echo "$test_name: redirects to $matches\n";
} else {
echo "$test_name: no redirection\n";
}
}
echo "\n\n";
}
Сначала мы указываем список URL сайтов, которые будем проверять. Точнее, нам понадобятся адреса данных сайтов. Далее нам необходимо определить настройки браузера, чтобы протестировать каждый из этих URL. После этого мы воспользуемся циклом, в котором пробежимся по всем полученным результатам.
Приём, который мы используем в этом примере для того, чтобы задать настройки cURL, позволит нам получить не содержание страницы, а только HTTP-заголовки (сохраненные в $output). Далее, воспользовавшись простым regex, мы можем определить, присутствовала ли строка “Location:” в полученных заголовках.
Когда вы запустите данный код, то должны будете получить примерно следующий результат:
![]()
Параметры HTTP
- -E
- —html-extension
- Если тип загруженного файла text/html и его адрес не оканчивается на .?, при использовании данного параметра к его имени будет добавлено .html. Это может быть полезно при зеркальном хранении страниц .asp, если вы не хотите, чтобы они вмешивались в работу вашего сервера Apache. Другой случай применения этого парамера — это загрузка страниц-ответов CGI скриптов. Страница с URL вида http://site.com/article.cgi?25 будет сохранена, как article.cgi?25.html.
Примечание: при обновлении или другой перезагрузке страниц с данным параметром последние будут загружаться заново в любом случае, т.к. Wget не может узнать, имеет ли отношение локальный файл X.html к загружаемому с URL X. Чтобы избежать лишней перезагрузки, используйте опции -k и -K. При этом оригинальные версии файлов будут также сохранены как X.orig.
- —http-user=user
- —http-passwd=password
- Имя пользователя user и пароль password для сервера HTTP. В зависимости от типа отклика, Wget будет использовать "basic" (небезопасную) или "digest" (защищенную) авторизацию.
Можно также указывать имя пользователя и пароль и в самом URL.
- -C on/off
- —cache=on/off
- Включает или выключает кеширование со стороны сервера. При этом Wget посылает соответствующих запрос (Pragma: no-cache). Также используется для быстрого обновления файлов на прокси-сервере.
По умолчанию кеширование разрешено.
- —cookies=on/off
- Включает или выключает использование cookie. Сервер отправляет клиенту cookie, используя заголовок "Set-Cookie" и клиент отвечает таким же cookie. Благодаря этому сервер может вести статистику посетителей. По умолчанию cookie используются, но запись их на диск выключена.
- —load-cookies file
- Загружать cookie из file перед первой загрузкой HTTP. file имеет текстовый формат, как cookies.txt у Netscape.
Этот параметр используется при зеркалировании. Для этого Wget отправляет те же cookies, которые отправляет ваш браузер при соединении с сервером HTTP. Это включается данным параметром — просто укажите Wget путь к cookies.txt. Разные браузеры хранят cookie в разных папках:
-
- Netscape 4.x.
- Файл находится в ~/.netscape/cookies.txt.
- Mozilla и Netscape 6.x.
- Mozilla хранит cookies в cookies.txt, расположенном где-то в ~/.mozilla, в папке вашего профиля. Полный путь обычно заканчивается чем-то вроде ~/.mozilla/default/some-weird-string/cookies.txt.
- Internet Explorer.
- Чтобы экспортировать cookie для Wget, выберите «Файл», «Импорт и Экспорт», в мастере выберите «Экспорт файлов cookie». Проверено в Internet Explorer 5; возможно не будет работать в ранних версиях.
- Другие обозреватели.
- Параметр —load-cookies будет работать с cookie в формате Netscape, который поддерживается Wget.
-
Если вы не можете использовать параметр —load-cookies, то все равно есть выход. Если ваш обозреватель поддерживает Запишите имя и значение cookie и вручную укажите Wget отправку этих cookie:
wget --cookies=off --header "Cookie: I=I"
-
- —save-cookies file
- Сохранить cookie из file в конце сессии. Устаревшие cookie не сохраняются.
- —ignore-length
- Некоторые серверы HTTP (точнее, скрипты CGI) отправляют заголовки "Content-Length", которые указывают Wget, что загружено еще не все. И Wget загружает один документ несколько раз.
С этим параметром, Wget будет игнорировать заголовки "Content-Length".
- —header=additional-header
- Определяет additional-header, отправляемый серверу HTTP. Он должен содержать и символы после него.
Вы можете определить несколько дополнительных заголовков через использование —header несколько раз.
wget --header='Accept-Charset: iso-8859-2' --header='Accept-Language: hr' http://fly.srk.fer.hr/
Указание пустой строки в значении заголовка очистит все определенные пользователем до этого заголовки.
- —proxy-user=user
- —proxy-passwd=password
- Определяет имя пользователя user и пароль password для авторизации сервере прокси. Будет использован тип авторизации "basic".
- —referer=url
- Добавляет заголовок `Referer: url‘ в запрос HTTP. Используется при загрузке страниц, которые передаются правильно только если сервер знает, с какой страницы вы пришли.
- -s
- —save-headers
- Сохранять заголовки, отправляемые серверам HTTP.
- -U agent-string
- —user-agent=agent-string
- Идентифицироваться, как agent-string при запросе на HTTP сервер.
Протокол HTTP позволяет определять себя использованием заголовка агента. Wget по умолчанию идентифицируется, как Wget/version, где version — это версия Wget.
Некоторые серверы выдают требуемую информацию только для обозревателей, идентифицирующихся как "Mozilla" или Microsoft "Internet Explorer". Этот параметр позволяет обмануть такие серверы.
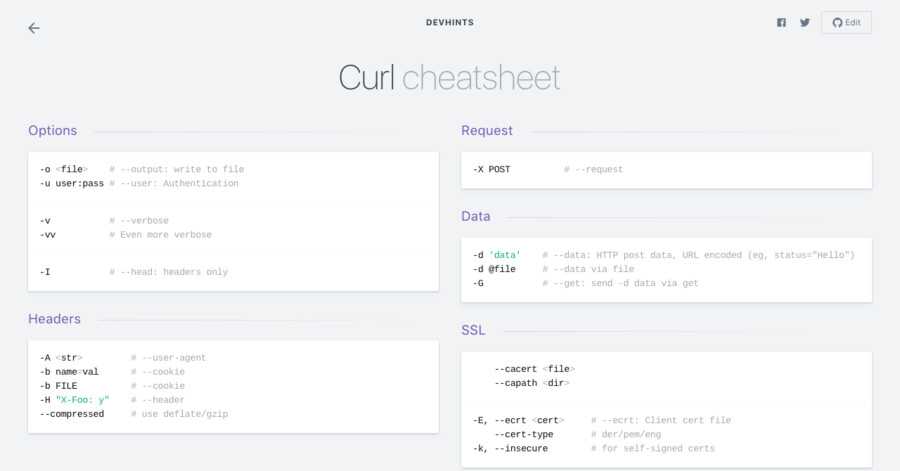

Что такое curl?
На самом деле, curl — это больше чем просто утилита командной строки для Linux или Windows. Это набор библиотек, в которых реализуются базовые возможности работы с URL страницами и передачи файлов. Библиотека поддерживает работу с протоколами: FTP, FTPS, HTTP, HTTPS, TFTP, SCP, SFTP, Telnet, DICT, LDAP, а также POP3, IMAP и SMTP. Она отлично подходит для имитации действий пользователя на страницах и других операций с URL адресами.
Поддержка библиотеки curl была добавлена в множество различных языков программирования и платформ. Утилита curl — это независимая обвертка для этой библиотеки. Именно на этой утилите мы и остановимся в этой статье.
Следовать за редиректами
Сервер Google сообщил нам, что страница перемещена (301 Moved Permanently), и теперь надо запрашивать страницу . С помощью опции укажем CURL следовать редиректам:
> curl -L google.com <!doctype html> <html itemscope="" itemtype="http://schema.org/WebPage" lang="ru"> <head> <meta content="Поиск информации в интернете: веб страницы, картинки, видео и многое другое." name="description"> <meta content="noodp" name="robots"> <meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"> <meta content="origin" name="referrer"> <title>Google</title> ..........
Запросы и ответы содержат заголовки
При вводе адреса веб-сайта мы видим только текст ответа. Но на самом деле происходит гораздо больше процессов. Когда мы делаем запрос, мы отправляем заголовок запроса, который содержит информацию о запросе. Ответ также содержит заголовок ответа.
Для того чтобы увидеть заголовок ответа в запрос curl, добавим ключ :
Заголовок будет включен над телом ответа:
Чтобы в ответе получить только заголовок, используем ключ
Заголовок содержит метаданные ответа. Вся эта информация передается в браузер при запросе URL в нашем браузере (например, при просмотре веб-страницы в Интернете), но браузер не отображает эту информацию. Можно просмотреть информацию заголовка с помощью консоли Chrome Developer Tools, перейдя на вкладку .
Теперь давайте уточним метод. Метод GET (чтение) подразумевается по умолчанию, когда не указан другой метод, но мы сделаем это здесь явно с параметром -X:
При посещении веб-сайта мы отправляем запрос, используя метод GET. Существуют и другие методы HTTP, которые можно использовать при взаимодействии с REST API. Вот общие методы, используемые при работе с конечными точками REST:
| HTTP метод | Описание |
|---|---|
| POST | Создание ресурса |
| GET | Чтение (получение) ресурса |
| PUT | Обновление ресурса |
| DELETE | Удаление ресурса |
Note: Метод GET используется по умолчанию в запросах curl. При использовании curl для выполнения запросов HTTP, отличных от GET, необходимо указывать нужный метод HTTP.
Иммитация браузера с помощью cURL
Иногда сайт, к которому мы обращаемся может фильтровать запросы, защищаясь от парсинга. Если для этого используются упрощенные способы защиты, например проверка User-Agent, то мы можем легко притвориться, что являемся реальным польователем, который взаимодействует с сайтом через браузер, мы можем послать заголовки и cookie, которые обычно посылает браузер.
В данном примере установлены заголовки, которые посылает Chrome.
$url = 'https://phpstack.ru/';
$headers = [
'Connection: keep-alive',
'Upgrade-Insecure-Requests: 1',
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding: gzip, deflate',
'Accept-Language: ru,en-US;q=0.9,en;q=0.8',
];
$cookieFile = __DIR__ . '/cookie.txt';
$curl = curl_init(); // создаем экземпляр curl
curl_setopt($curl, CURLOPT_HTTPHEADER, $headers);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_VERBOSE, 1);
curl_setopt($curl, CURLOPT_COOKIEFILE, $cookieFile);
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookieFile);
curl_setopt($curl, CURLOPT_POST, false); //
curl_setopt($curl, CURLOPT_URL, $url);
$result = curl_exec($curl);
В простых ситуациях этого хватает. Но если используется защита при помощи javascript или что-то более продвинутое, то здесь cURL бессилен, и следует использовать либо BAS либо Zennoposter. Либо если вы хотите попытать счастье с PHP, то Selenium.
Не используйте эти знания в противоправных целях.
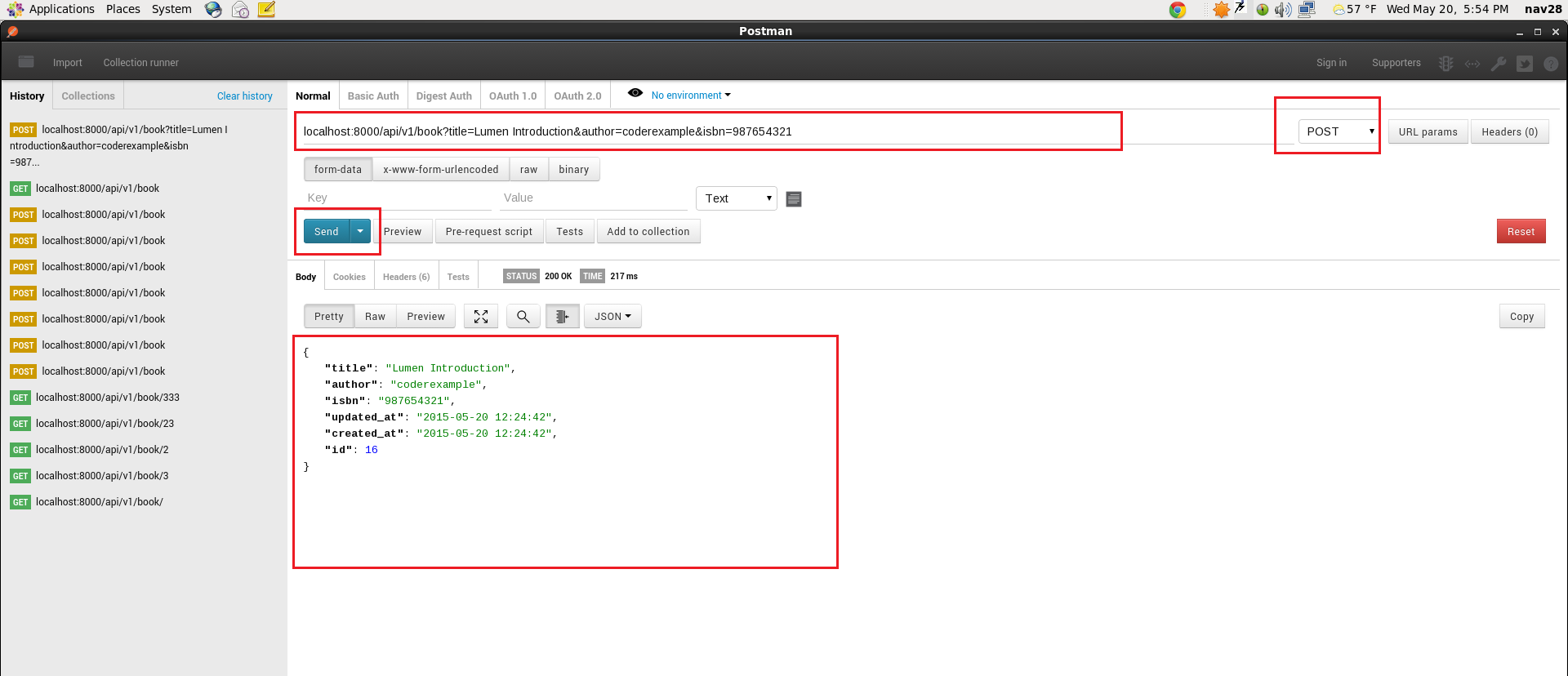
👨💻 Создаем запрос к OpenWeatherAPI с помощью curl
- Предположим, что практическое занятие раздела выполнено, возвращаемся в Postman.
- В любом запросе кликаем на кнопку под кнопкой
- В диалоговом окне “Generate Code Snippets” выбираем cURL из выпадающего списка и нажимаем на кнопку
Код Postman для запроса прогноза погоды OpenWeatherMap выглядит в формате cURL следующим образом:
Postman добавил свою информацию о хедере (обозначено -Н) Тэги добавленного заголовка можно удалить. Также можно удалить знаки “», они добавлены для читаемости текста.
Кроме того, обратите внимание, что в Windows нужно изменить одинарные кавычки на двойные, потому что одинарные кавычки не поддерживаются в терминале Windows по умолчанию. Вот запрос curl с удаленными символами -H и обратной косой чертой, а одинарные кавычки преобразованы в двойные кавычки:
Вот запрос curl с удаленными символами -H и обратной косой чертой, а одинарные кавычки преобразованы в двойные кавычки:
- Curl доступен на MacOS по умолчанию. Если на Windows curl еще не установлен, то инструкции по установке по , нужно выбрать одну из бесплатных версий с правами Администратора.
- Открываем терминал
- на OS Windows нажимаем и вводим команду , Правой кнопкой мыши вызываем меню и выбираем для вставки запроса.
- на MacOS открываем iTerm или терминал, нажимая и вводим команду Вставляем запрос в командную строку и жмем кнопку .
Ответ от OpenWeatherMap на наш запрос будет выглядеть так:
Этот запрос минимизирован. Вы можете развернуть его, например на сайте JSON pretty print или, на MacOS с установленным Python добавив в конец cURL запроса, чтобы минимизировать JSON в ответе (Для подробностей можно посмотреть ветку на Stack Overflow по этой теме).
Самостоятельно сделаем curl запрос на 5-дневный прогноз, сохраненный в Postman. И третий API запрос OpenWeatherMap? сохраненный в Postman тоже выполняем в curl
Сохранение списка URL в файл
Вы можете сохранять список отсканированных URL, а также URL в очереди без данных по ним в текстовом формате на своём устройстве.
7.1. Для того, чтобы сохранить список отсканированных URL:
7.1.1. Откройте нужную таблицу.
7.1.2. Кликните на «Список URL» → «Сохранить список URL в файл» или воспользуйтесь комбинацией Alt+S, находясь в главном окне программы.
7.1.3. Выберите папку для сохранения и определите имя файла (или оставьте автоматически сгенерированное).
7.2. Для того, чтобы сохранить список URL в очереди:
7.2.1. Поставьте сканирование на паузу.
7.2.2. Кликните на «Экспорт» → «Ссылки в очереди».
7.2.3. Выберите папку для сохранения файла и задайте ему имя (или оставьте автоматически сгенерированное).
Обратите внимание: в текстовом документе будет содержаться лишь список всех URL, а не отчёты по ним.
Как пользоваться curl?
Мы рассмотрели все, что касается теории работы с утилитой curl, теперь пришло время перейти к практике, и рассмотреть примеры команды curl.
Загрузка файлов
Самая частая задача — это загрузка файлов linux. Скачать файл очень просто. Для этого достаточно передать утилите в параметрах имя файла или html страницы:

![]()
Но тут вас ждет одна неожиданность, все содержимое файла будет отправлено на стандартный вывод. Чтобы записать его в какой-либо файл используйте:
![]()
А если вы хотите, чтобы полученный файл назывался так же, как и файл на сервере, используйте опцию -O:
![]()
Если загрузка была неожиданно прервана, вы можете ее возобновить:
![]()
Если нужно, одной командой можно скачать несколько файлов:
![]()
Еще одна вещь, которая может быть полезной администратору — это загрузка файла, только если он был изменен:
Данная команда скачает файл, только если он был изменен после 21 декабря 2017.
Ограничение скорости
Вы можете ограничить скорость загрузки до необходимого предела, чтобы не перегружать сеть с помощью опции -Y:
![]()
Здесь нужно указать количество килобайт в секунду, которые можно загружать. Также вы можете разорвать соединение если скорости недостаточно, для этого используйте опцию -Y:
Передача файлов
Загрузка файлов, это достаточно просто, но утилита позволяет выполнять и другие действия, например, отправку файлов на ftp сервер. Для этого существует опция -T:
![]()
Или проверим отправку файла по HTTP, для этого существует специальный сервис:
![]()
В ответе утилита сообщит где вы можете найти загруженный файл.
Отправка данных POST
Вы можете отправлять не только файлы, но и любые данные методом POST. Напомню, что этот метод используется для отправки данных различных форм. Для отправки такого запроса используйте опцию -d. Для тестирования будем пользоваться тем же сервисом:
![]()
Если вас не устраивает такой вариант отправки, вы можете сделать вид, что отправили форму. Для этого есть опция -F:
![]()
Здесь мы передаем формой поле password, с типом обычный текст, точно так же вы можете передать несколько параметров.
Передача и прием куки
Куки или Cookie используются сайтами для хранения некой информации на стороне пользователя. Это может быть необходимо, например, для аутентификации. Вы можете принимать и передавать Cookie с помощью curl. Чтобы сохранить полученные Cookie в файл используйте опцию -c:
Затем можно отправить cookie curl обратно:
Передача и анализ заголовков
Не всегда нам обязательно нужно содержимое страницы. Иногда могут быть интересны только заголовки. Чтобы вывести только их есть опция -I:
![]()
А опция -H позволяет отправить нужный заголовок или несколько на сервер, например, можно передать заголовок If-Modified-Since чтобы страница возвращалась только если она была изменена:
![]()
Аутентификация curl
Если на сервере требуется аутентификация одного из распространенных типов, например, HTTP Basic или FTP, то curl очень просто может справиться с такой задачей. Для указания данных аутентификации просто укажите их через двоеточие в опции -u:
Точно так же будет выполняться аутентификация на серверах HTTP.
Использование прокси
Если вам нужно использовать прокси сервер для загрузки файлов, то это тоже очень просто. Достаточно задать адрес прокси сервера в опции -x:
Использование wget Linux
Команда wget linux, обычно поставляется по умолчанию в большинстве дистрибутивов, но если нет, ее можно очень просто установить. Например установка с помощью yum будет выглядеть следующим образом:
А в дистрибутивах основанных на Debian:
Теперь перейдем непосредственно к примерам:
1. Загрузка файла
Команда wget linux скачает один файл и сохранит его в текущей директории. Во время загрузки мы увидим прогресс, размер файла, дату его последнего изменения, а также скорость загрузки:
Опция -О позволяет задать имя сохраняемому файлу, например, скачать файл wget с именем wget.zip:
Вы можете скачать несколько файлов одной командой даже по разным протоколам, просто указав их URL:
4. Взять URL из файла
Вы можете сохранить несколько URL в файл, а затем загрузить их все, передав файл опции -i. Например создадим файл tmp.txt, со ссылками для загрузки wget, а затем скачаем его:

5. Продолжить загрузку
Утилита wget linux рассчитана на работу в медленных и нестабильных сетях. Поэтому если вы загружали большой файл, и во время загрузки было потеряно соединение, то вы можете скачать файл wget с помощью опции -c.
6. Загрузка файлов в фоне
Опция -b заставляет программу работать в фоновом режиме, весь вывод будет записан в лог файл, для настройки лог файла используются специальные ключи wget:
7. Ограничение скорости загрузки
Команда wget linux позволяет не только продолжать загрузку файлов, но и ограничивать скорость загрузки. Для этого есть опция —limit-rate. Например ограничим скорость до 100 килобит:
Здесь доступны, как и в других подобных командах индексы для указания скорости — k — килобит, m — мегабит, g — гигабит, и так далее.
8. Подключение по логину и паролю
Некоторые ресурсы требуют аутентификации, для загрузки их файлов. С помощью опций —http-user=username, –http-password=password и —ftp-user=username, —ftp-password=password вы можете задать имя пользователя и пароль для HTTP или FTP ресурсов.
Или:
9. Загрузить и выполнить
Вы, наверное, уже видели такие команды. wget позволяет сразу же выполнять скачанные скрипты:
Если опции -O не передать аргументов, то скачанный файл будет выведен в стандартный вывод, затем мы его можем перенаправить с интерпретатор bash, как показано выше.
По умолчанию wget сохраняет файл в текущую папку, но это поведение очень легко изменить с помощью опции -P:
11. Передать информацию о браузере
Некоторые сайты фильтруют ботов, но мы можем передать фальшивую информацию о нашем браузере (user-agent) и страницу с которой мы пришли (http-referer).
12. Количество попыток загрузки
По умолчанию wget пытается повторить загрузку 20 раз, перед тем как завершить работу с ошибкой. Количество раз можно изменить с помощью опции —tries:
13. Квота загрузки
Если вам доступно только ограниченное количество трафика, вы можете указать утилите, какое количество информации можно скачивать, например разрешим скачать файлов из списка только на десять мегабайт:
Здесь работают те же индексы для указания размера — k, m, g, и т д.
14. Скачать сайт
Wget позволяет не только скачивать одиночные файлы, но и целые сайты, чтобы вы могли их потом просматривать в офлайне. Использование wget, чтобы скачать сайт в linux выглядит вот так:
![Как исправить ошибку pip, которая не распознается в командной строке windows? [новости minitool]](http://fuzeservers.ru/wp-content/uploads/7/5/a/75afde9ba94fdc07f978fe568f1c430f.png)




