
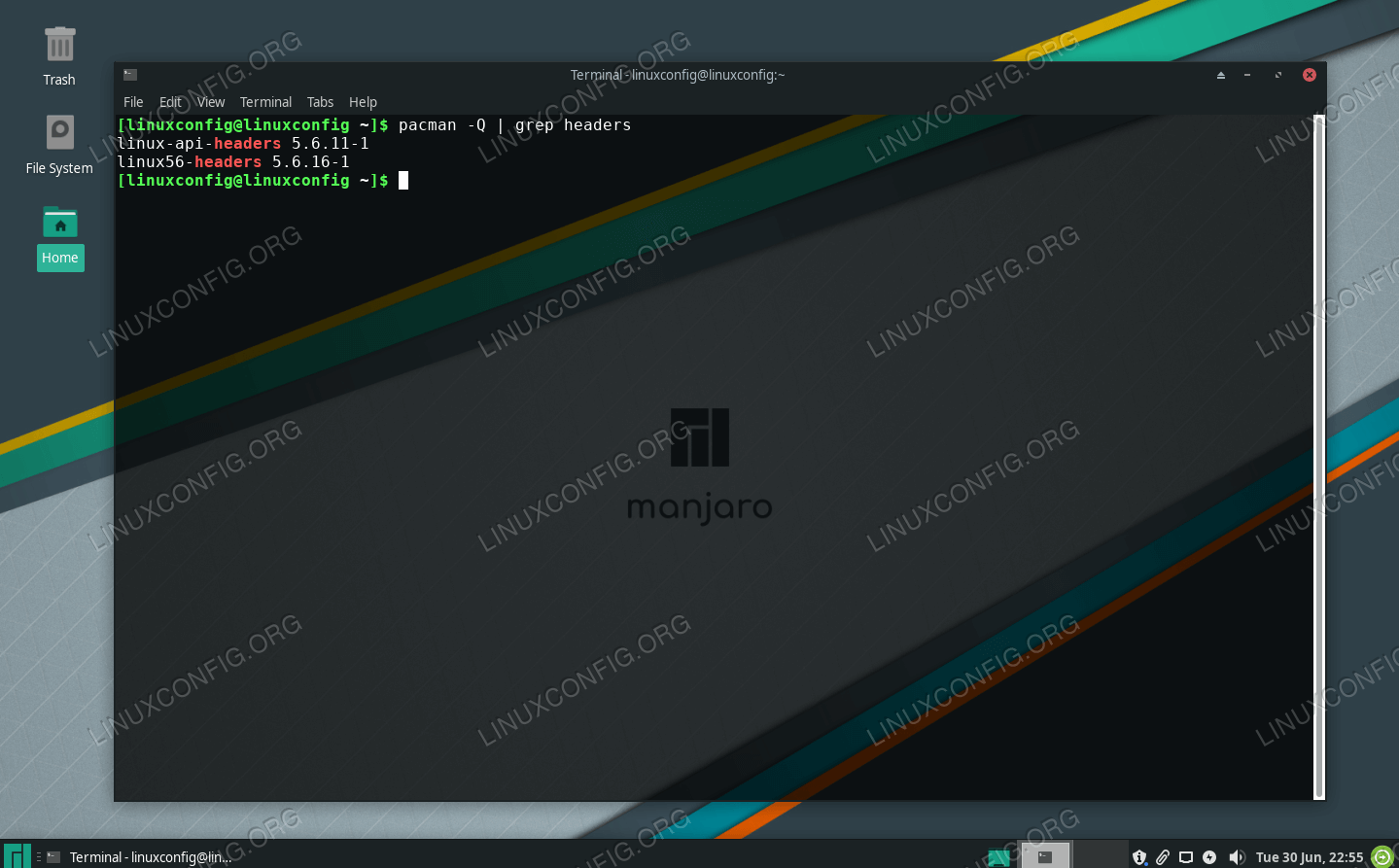
PID
Идентификатор процесса (process identifier, PID) — уникальный номер (идентификатор) процесса в многозадачной операционной системе (ОС).
Как правило, PID’ы выдаются последовательно от 0. По достижении лимита счёт снова начинается с 300 (в Mac OS X — со 100). Это сделано отчасти для ускорения, потому что малые PID часто заняты системными процессами.
Часто имеется два специальных значения PID: swapper или sched — процесс с номером 0 (часто не отображается в списке), отвечает за выгрузку страниц и является частью ядра операционной системы. Процесс 1 — обычно является процессом init, ответственным за запуск и остановку системы.
C
В C-коде: тип данных (на самом деле определён как ).
#include <unistd.h> pid_t getpid(void);
Приятно, обрабатывать ошибочный код возврата не нужно. «These functions are always successful.»
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t p = getpid();
printf("My PID is %d\n", p);
return ;
}
Во-вторых, ограничения ресурсов Linux
1. Ограничения пользовательских ресурсов
В Bash есть команда ulimit, которая обеспечивает управление доступными ресурсами оболочки и процессами, запускаемыми оболочкой. В основном это количество открытых файловых дескрипторов, максимальное количество процессов пользователя, размер файла coredump и т. Д.
Конфигурацию ограничений ресурсов можно настроить в файле подконфигурации в /etc/security/limits.conf или /etc/security/limits.d/. Система сначала загружает limits.conf, а затем загружает каталог limits.d в алфавитном порядке. После загрузки файла конфигурации он перезапишет предыдущую конфигурацию. Формат конфигурации следующий:
soft — значение предупреждения, hard — максимальное значение, * означает соответствие всем пользователям
Просмотр ограничений пользовательских ресурсов для входа в текущую оболочку
2. ограничение ресурса обслуживания
Мы всегда упоминали оболочку выше, поэтому для тех пользователей, которые не вошли в систему через аутентификацию PAM, таких как mysql, nginx и т. Д., Вышеуказанная конфигурация не эффективна;
Поскольку в системе CentOS 7 / RHEL 7 вместо предыдущего SysV используется Systemd, область конфигурации файла /etc/security/limits.conf сокращается. Конфигурация в limits.conf применима только для аутентификации PAM. Ограничение ресурсов вошедшего в систему пользователя, оно не влияет на ограничение ресурсов службы systemd.
Его нужно настроить с помощью файлов /etc/systemd/system.conf и /etc/systemd/user.conf. Точно так же все файлы .conf в двух соответствующих каталогах /etc/systemd/system.conf.d/* .conf и /etc/systemd/user.conf.d/*.conf.
Среди них system.conf используется экземплярами системы, а user.conf — экземплярами пользователей. Для общих служб используйте конфигурацию в system.conf. Конфигурация в system.conf.d / *. Conf переопределит system.conf.
Формат конфигурации следующий:
= Тип ресурса слева, размер справа
Просмотр лимита ресурсов службы
cat /proc/YOUR-PID/limits
Например, проверьте влияние конфигурации службы nginx:
3. Лимит системных ресурсов
Для пользователя и службы ранее были выделены ресурсы, но каково общее количество ресурсов в системе? Сюда входят параметры ядра. Существует много параметров ядра. Нам нужно только знать, как изменить наиболее часто используемые, такие как количество процессов и количество дескрипторов.
Большой опыт в поиске многолетних уязвимостей
Компания Qualys была основана в 1999 г. За 22 года своего существования она многократно находила в Linux и других системах уязвимости, существовавшие годами.
Например, в начале 2013 г. ее эксперты выловили брешь, позволявшую исполнять любой нужный хакерам код на веб-серверах, почтовых серверах и других серверных системах. Они обнаружили ее в библиотеке GNU C (glibc), в которой содержатся стандартные функции, используемые программами, написанными на языках C и C++.
Рассказать миру об уязвимости, промаркированной как CVE-2015-0235, Qualys решила лишь в конце января 2015 г., то есть спустя два года с момента ее обнаружения. Разработчикам Qualys поведала о ней без промедления, однако далее через два года большинство версий Linux, используемых в сервером оборудовании, так и не были обновлены.
По утверждению специалистов Qualys, CVE-2015-0235 появилась в Linux еще в 2000 г., когда вышла библиотека glibc версии 2.2. В список «дырявых» дистрибутивов Linux вошли Debian 7, CentOS 6 и 7? RHEL 6 и 7, а также Ubuntu 12.04.
В-четвертых, ограничение количества ручек
1. Ограничьте количество пользовательских дескрипторов
Лимит пользователя для входа, как упоминалось выше, можно настроить с помощью файла подконфигурации в /etc/security/limits.conf или /etc/security/limits.d/ следующим образом:
Примечание: изменение файла конфигурации не повлияет на ограничение дескриптора текущего пользователя, вошедшего в систему.
2. Предел обработки обслуживания
Примечание. Изменение файла конфигурации не приведет к изменению ограничения дескриптора запущенной в данный момент службы.
3. Общее количество системных дескрипторов.
Количество процессов, которые могут быть открыты каждым пользователем, и количество дескрипторов, которые могут быть открыты каждым процессом, указаны выше; есть также файл, который устанавливает общее количество дескрипторов, которые могут быть открыты всеми процессами в системе, то есть этот параметр является системным.
Измените максимальное количество системных дескрипторов, метод следующий (действителен после настройки):
Просмотрите общее количество дескрипторов, используемых в настоящее время в системе:
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
runlevels
Пример файла /etc/inittab:
id:5:initdefault: si::sysinit:/etc/rc.d/rc.sysinit l0:0:wait:/etc/rc.d/rc 0 l1:1:wait:/etc/rc.d/rc 1 l2:2:wait:/etc/rc.d/rc 2 l3:3:wait:/etc/rc.d/rc 3 l4:4:wait:/etc/rc.d/rc 4 l5:5:wait:/etc/rc.d/rc 5 l6:6:wait:/etc/rc.d/rc 6 1:2345:respawn:/sbin/mingetty tty1 2:2345:respawn:/sbin/mingetty tty2 3:2345:respawn:/sbin/mingetty tty3 4:2345:respawn:/sbin/mingetty tty4 5:2345:respawn:/sbin/mingetty tty5 6:2345:respawn:/sbin/mingetty tty6 x:5:respawn:/etc/X11/prefdm -nodaemon
По умолчанию в системе использовано 7 уровней инициализации:
- 0 — остановка системы
- 1 — загрузка в однопользовательском режиме
- 2 — загрузка в многопользовательском режиме без поддержки сети
- 3 — загрузка в многопользовательском режиме с поддержкой сети
- 4 — не используется
- 5 — загрузка в многопользовательском режиме с поддержкой сети и графического входа в систему
- 6 — перезагрузка
Вы можете подумать, речь идёт о каких-то уровнях, через которые система проходит в процессе загрузки. Это не так. Представляйте себе уровень запуска как некую точку, в которую переходит система, загружаясь.
В большинстве Unix/Linux систем, узнать текущий уровень инициализации можно командами:
Набрав init n в терминале (с правами суперпользователя), где n — номер уровня инициализации, можно переключиться в любой из вышеперечисленных уровней.
Стартовые скрипты для каждого уровня находятся в каталогах с /etc/rc0.d до /etc/rc6.d, где цифра после rc соответствует номеру уровня инициализации.





$ ls /etc/rc5.d/ README S02acpid S02irqbalance S02thermald S04cups-browsed S01apport S02anacron S02kerneloops S02whoopsie S04saned S01binfmt-support S02atd S02nginx S03avahi-daemon S05grub-common S01php7.0-fpm S02atop S02rsync S03bluetooth S05ondemand S01rsyslog S02cron S02speech-dispatcher S03lightdm S05plymouth S01uuidd S02dbus S02sysstat S04cups S05rc.local
Обычно скрипты не дублируются для каждого уровня. В каталогах rcX просто ставятся симлинки на скрипты в /etc/init.d.
$ ls -l /etc/rc5.d/S02nginx lrwxrwxrwx 1 root root 15 Nov 28 19:56 /etc/rc5.d/S02nginx -> ../init.d/nginx
Сами скрипты в /etc/init.d обычно пишутся по шаблону и должны уметь принимать параметр start|stop|restart.
В именовании используется такая логика.
- S — скрипты для запуска (start)
- K — скрипты для остановки (stop)
- Номер задаёт порядок выполнения: чем меньше номер, тем раньше запускается скрипт.
Для автоматизации создания этих линков с правильными именами есть специальные утилиты. Например, в RedHat и Fedora используется программа chkconfig, в Debian — update-rc.d.
Есть также специальный скрипт /etc/rc.local, который выполняется во всех многопользовательских уровнях.
Настройка UTF-8 в Gentoo Linux
Поиск или создание локалей UTF-8
Теперь, когда принципы лежащие в основе Unicode были изложены, начнем использовать UTF-8 на локальной системе!
Пользователям, которым нужна более детальная информация, могут найти ее в статье Руководство по локализации Gentoo.
Далее, нужно определить, доступна ли локаль UTF-8 для нашего языка или придется создать её.
en_GB en_GB.utf8
На выходе этой команды мы должны получить хотя бы одну строку, содержащую суффикс . Если таковых нет, то нам придётся создать локаль, совместимую с UTF-8.
ЗаметкаЗапускайте следующую команду, если в система не имеет UTF-8 локали для выбранного языка.
Замените «en_GB», если нужна какая-то другая локаль:
Другим способом включить локаль UTF-8 является добавление её в файл /etc/locale.gen и генерация нужных локалей, используя команду locale-gen. Локали будут записаны в архив локалей /usr/lib/locale/locale-archive.
Код Строка в /etc/locale.gen
en_GB.UTF-8 UTF-8
* Generating 1 locales (this might take a while) with 1 jobs * (1/1) Generating en_GB.UTF-8 ... * Generation complete
Настройка локали
Есть одна переменная среда, которую необходимо настроить, чтобы использовать UTF-8 локали: LC_CTYPE (также, можно изменить переменную LANG, чтобы изменить системный язык). Есть множество способов сделать это. Некоторые системные администраторы предпочитают использовать UTF-8 только для определенного пользователя, поэтому они устанавливают эту переменную в своём ~/.profile (/bin/sh> для пользователей Bourne shell), ~/.bash_profile или ~/.bashrc (/bin/bash для пользователей Bourne again shell). Больше информации, а также наилучшие способы локализации можно найти в Руководстве по локализации.
Другие же предпочитают установить локаль глобально. Есть по крайней один весомый аргумент в пользу этого подхода — при использовании /etc/init.d/xdm, так как init-скрипт запускают диспетчер окон до того, как будут загружены конфигурационные файлы командной оболочки. Другими словами, это выполняется до того момента, как какие-либо переменные попадут в окружение пользователя.
Настройка локали глобально делается с помощью файла /etc/env.d/02locale. Он должен выглядеть следующим образом:
Файл Демонстрация для en_GB.utf8
## (Как обычно, замените "en_GB.utf8" соответствующее значение локали; каждый язык имеет своё значение!) LANG="en_GB.utf8"
Далее, следует обновить среду переменных, запустив следующую команду:
>>> Regenerating /etc/ld.so.cache...
Теперь запустите locale без аргументов, чтобы увидеть, что верные переменные были загружены в окружающую среду переменных:
LANG=en_GB.utf8 LC_CTYPE="en_GB.utf8" LC_NUMERIC="en_GB.utf8" LC_TIME="en_GB.utf8" LC_COLLATE="en_GB.utf8" LC_MONETARY="en_GB.utf8" LC_MESSAGES="en_GB.utf8" LC_PAPER="en_GB.utf8" LC_NAME="en_GB.utf8" LC_ADDRESS="en_GB.utf8" LC_TELEPHONE="en_GB.utf8" LC_MEASUREMENT="en_GB.utf8" LC_IDENTIFICATION="en_GB.utf8" LC_ALL=
Альтернативный метод: использование eselect для настройки локали
То, что было написано выше, достаточно, чтобы хорошо настроить систему, можно также проверить правильность настройки локали с помощью утилиты eselect.
Используйте команду eselect, чтобы получить список доступных локалей в системе:
C POSIX * en_GB.utf8 (free form)
Утилита eselect выводит список локалей. После того, как нужная локаль была определена, активируйте ее:
Setting LANG to en_GB.utf8 ...
Проверим результат:
C POSIX en_GB.utf8 * (free form)
В случае предпочтения использовать заместо в /etc/env.d/02locale, запустите соответствующую команду eselect:
Setting LANG to en_GB.UTF-8 ...
C POSIX en_GB.utf8 en_GB.UTF-8 * (free form)
Запуск следующей команды обновит переменное окружение для shell:
>>> Regenerating /etc/ld.so.cache...
Вот и всё. Теперь система использует локаль UTF-8. Следующим этапом будет настройка повседневно используемых приложений.
Первоначальные преимущества Unix
Деннис Ритчи и Кен Томпсон выпустили первый релиз операционной системы Unix 3 ноября 1971 года. Когда историки обсуждают, что особенного было в Unix в то время, они обычно подчеркивают, что Unix поддерживала возможность одновременной работы нескольких пользователей, в то время как в других операционных системах того времени одно задание выполнялось от начала и до конца без возможности прерывания. Я думаю, что более важным отличием Unix была портируемость системы. В те года большинство операционных систем были привязаны к конкретной архитектуре процессора. С помощью Unix вы могли обновлять свой компьютер годами и десятилетиями и по-прежнему использовать одну и ту же операционную систему, и приложения. Это дало большой толчок в развитии вычислительной техники.
Если бы Unix была привязана к компьютеру PDP-11, на котором велась её первоначальная разработка, то данная ОС вряд ли бы оставила сколь-нибудь заметный след в истории. Свойство переносимости системы позволило Unix пережить эволюцию компьютерного оборудования и, в конечном счете, занять лидирующие позиции среди других ОС. Как гласит официальная временная шкала Unix: «В 1973 году система была переписана на язык программирования Си. Это сделало её переносимой и сильно повлияло на историю развития ОС в целом».
![]()
Сегодня переносимость Unix и её утилит в полной мере присутствует и в Linux: изначально разрабатываемая под процессоры Intel, система работает на нескольких различных архитектурах. Когда ядро Linux совершило скачок от процессоров Intel к архитектуре ARM, тем самым сделав доступным использование Linux на небольших (появившихся в 1990-х годах) мобильных устройствах, то это событие вызвало всеобщее волнение в Linux-сообществе и открыло новые перспективы развития вычислительной техники.
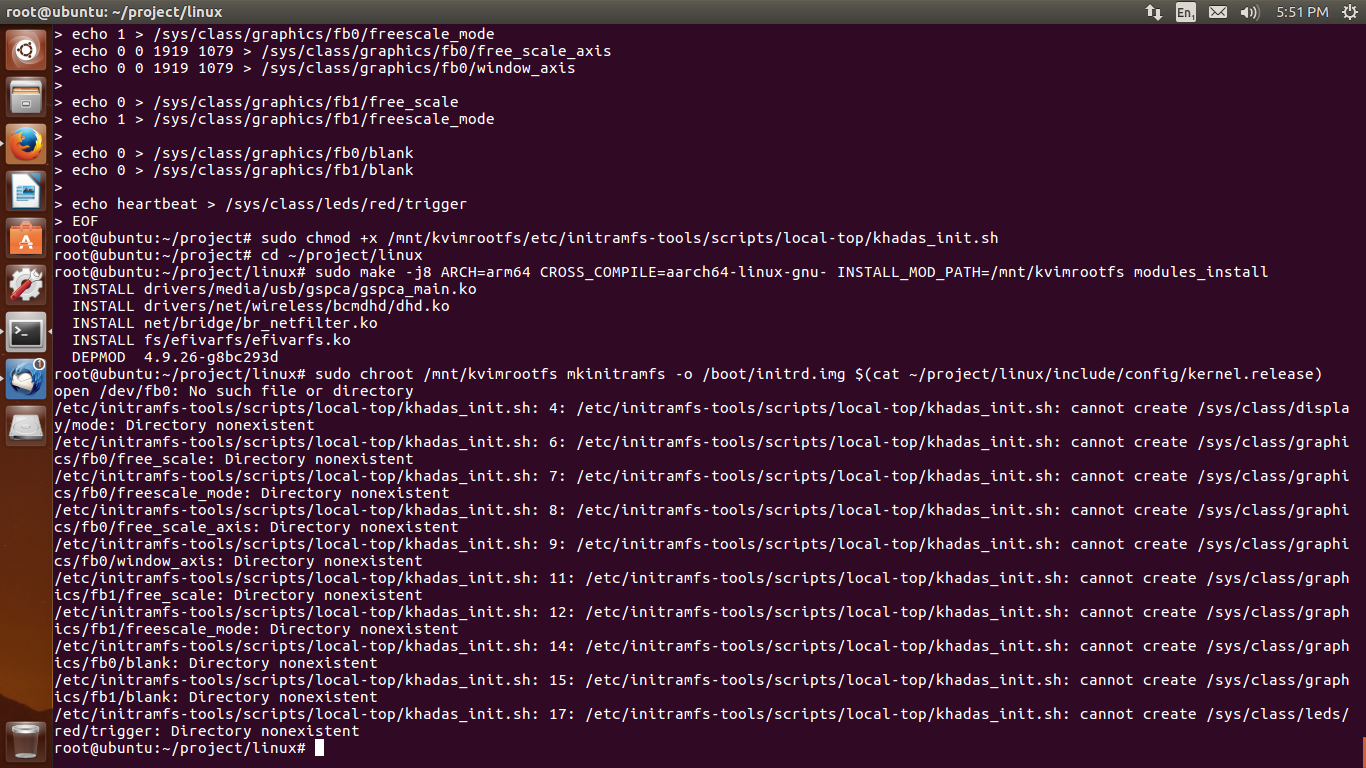
Установка ядра
# make modules_install
Разместит *.ko-файлы в /lib/modules.
# make install
Разместит файлы в /boot/.
188K config-4.4.0-57-generic 196K config-4.9.0BSU 35M initrd.img-4.4.0-57-generic 309M initrd.img-4.9.0BSU 3,7M System.map-4.4.0-57-generic 3,9M System.map-4.9.0BSU 6,8M vmlinuz-4.4.0-57-generic 7,0M vmlinuz-4.9.0BSU
Ужас, рамдиск получился огромный! Оказывается, надо было при установке передавать опцию INSTALL_MOD_STRIP=1.
35M initrd.img-4.4.0-57-generic 34M initrd.img-4.9.0BSU
$ uname -a Linux sobols-VirtualBox 4.9.0BSU #1 SMP Thu Dec 22 03:09:25 +03 2016 x86_64 x86_64 x86_64 GNU/Linux
Информация о дисковом носителе
1. df
Команда выдает информацию о подмонтированных разделах и объемах, занимаемых ими:
df -h
Пример ответа:
Файловая система Размер Использовано Дост Использовано% Cмонтировано в
/dev/mapper/sys-root 25G 11G 15G 41% /
devtmpfs 1,9G 0 1,9G 0% /dev
tmpfs 1,9G 4,0K 1,9G 1% /dev/shm
tmpfs 1,9G 193M 1,7G 11% /run
tmpfs 1,9G 0 1,9G 0% /sys/fs/cgroup
/dev/sda1 1014M 186M 829M 19% /boot
2. fdisk
Подробная информация о диске и его разделах:
fdisk /dev/sda -l
Ответ:
Disk /dev/sda: 32.2 GB, 32212254720 bytes, 62914560 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000d5e55
Устр-во Загр Начало Конец Блоки Id Система
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 62914559 30407680 8e Linux LVM
3. iotop
Команда позволяем увидеть загруженность дисковой системы. Утилиты может не быть в системе — сначала ее нужно установить.
а) на Ubuntu / Debian:
apt-get install iotop
б) на CentOS / Red Hat:
yum install iotop
После установки утилита запускается командой:
iotop
Вывод похож на top:
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd —swi…
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 %
3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
5 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
1542 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 %
…







4. smartmontools
Утилита позволяет получить SMART дисковых накопителей. По умолчанию, она не установлена — установка выполняется из репозитория.
а) на Ubuntu / Debian:
apt-get install smartmontools
б) на CentOS / Red Hat:
yum install smartmontools
После установки можно использовать:
smartctl -a /dev/sda
* в данном примере мы увидим полный тест для диска sda.
Если нам нужно посмотреть только общее состояние здоровья, то используем опцию H:
smartctl -H /dev/sda
Если мы хотим получить информацию по всем дискам, вводим команды по очереди для каждого или:
find /dev -name ‘sd’ -exec smartctl -a {} \;
Процессы-демоны
![]()
Схематическое изображение демона Максвелла
Демон (daemon, dæmon, божество) — программа в ОС семейства Unix, запускаемая самой системой и работающая в фоновом режиме без прямого взаимодействия с пользователем.
Демоны обычно запускаются во время загрузки системы. Типичные задачи демонов: серверы сетевых протоколов (HTTP, FTP, электронная почта и др.), управление оборудованием, поддержка очередей печати, управление выполнением заданий по расписанию и т.д. В техническом смысле демоном считается процесс, который не имеет управляющего терминала. Чаще всего (но не обязательно) предком демона является init — корневой процесс UNIX.
В системах Windows аналогичный класс программ называется службой (Services).
Название «демон» появилось ещё до Unix, в 1960-x годах в системе Project MAC. Названо в честь демона Максвелла из физики, занимающегося сортировкой молекул в фоновом режиме. Демон также является персонажем греческой мифологии, выполняющим задачи, за которые не хотят браться боги.
Типичным демоном является cron, использующийся для периодического выполнения заданий в определённое время. Регулярные действия описываются инструкциями, помещенными в файлы crontab и в специальные каталоги.
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
� � � �
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
![]()
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
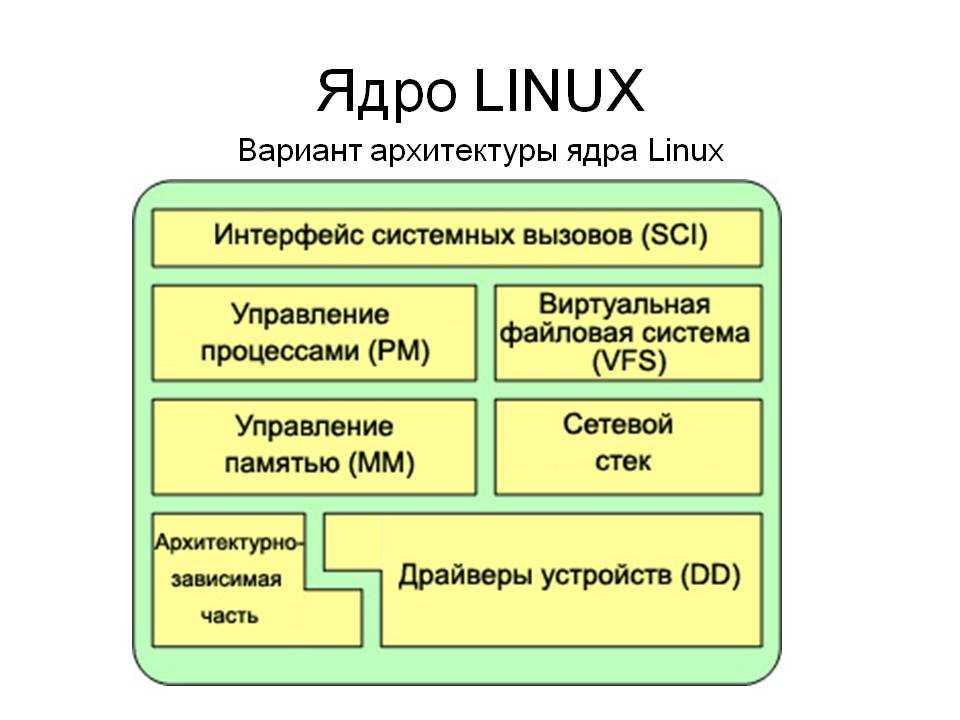
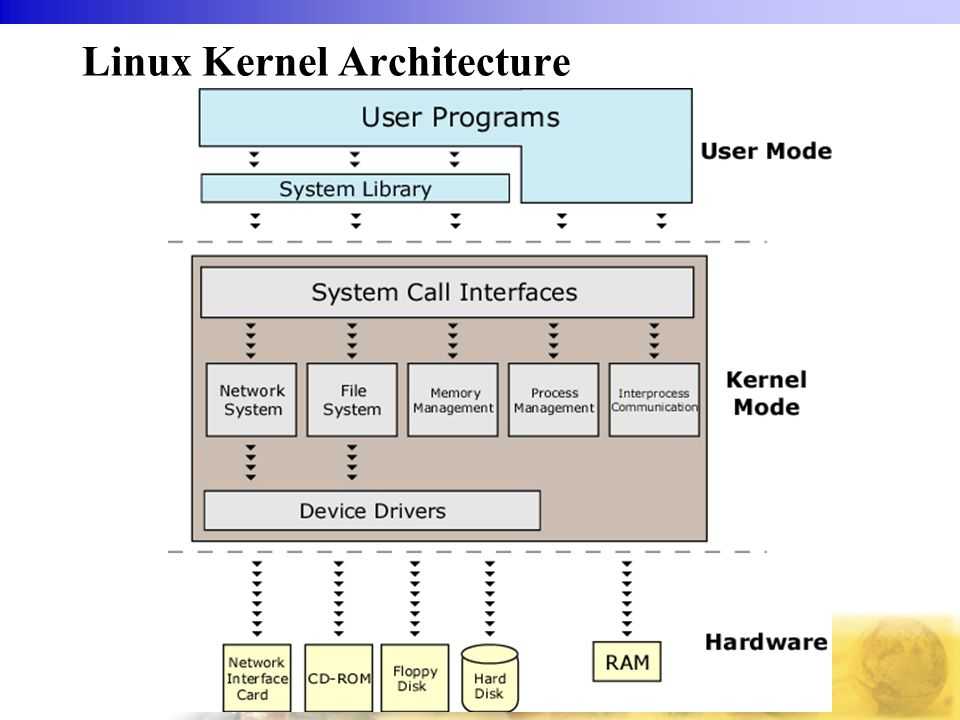
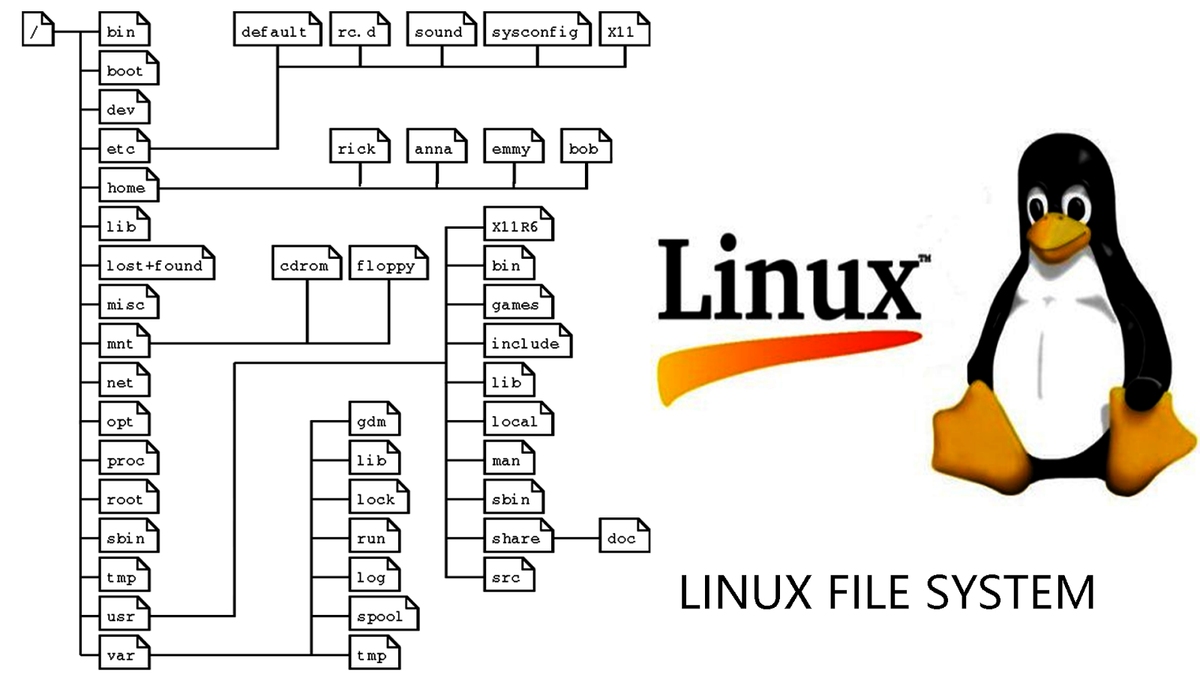
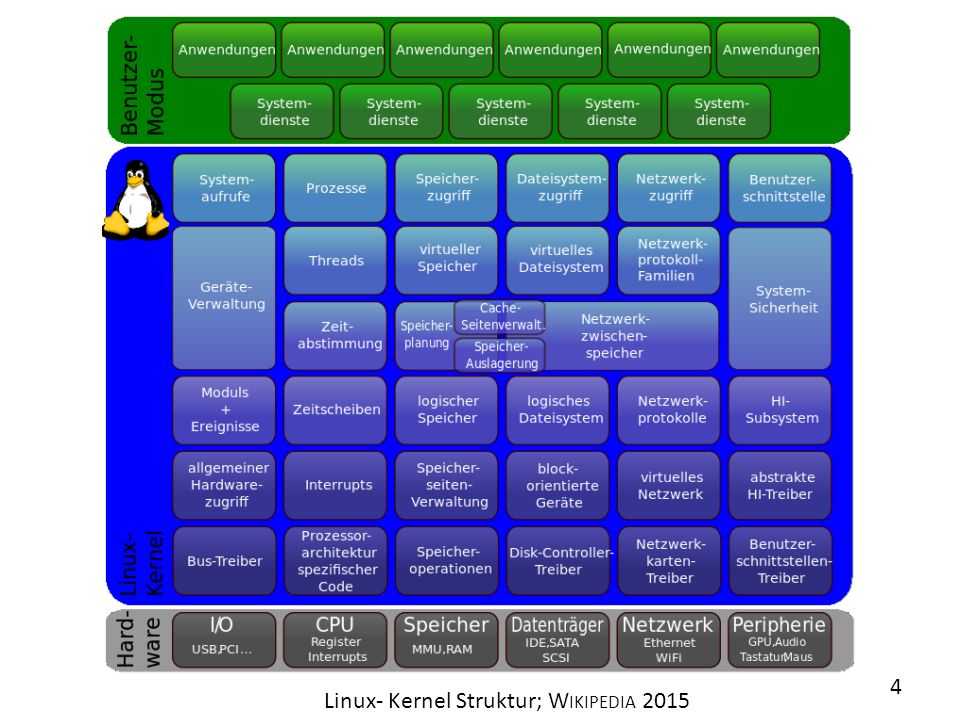
Архитектура ядра Linux
На сегодняшний день Linux — монолитное ядро с поддержкой загружаемых модулей. Драйверы устройств и расширения ядра обычно запускаются в 0-м кольце защиты, с полным доступом к оборудованию. Все драйверы и подсистемы работают в своем адресном пространстве, отделенном от пользовательского.
Сам термин «монолит» говорит о том, что в ядре сконцентрировано всё, и, по логике, ничего не может в него добавляться или удаляться. В отличие от обычных монолитных ядер, драйверы устройств легко собираются в виде модулей и загружаются или выгружаются во время работы системы.
То, что архитектура Linux не является микроядерной, вызвало обширнейшие прения между Торвальдсом и Эндрю Таненбаумом в конференции по Minix в 1992 году.
Характеристика дистрибутивов Linux в WSL
Debian
Debian — популярен как дистрибутив, например, для серверов, так и как основа для других дистрибутивов. Например, на Debian основываются Ubuntu, Kali Linux, Linux Mint (есть версия LMDE, которая основывается непосредственно на Debian, а также «классическая» версия, которая основывается на Ubuntu, которая, в свою очередь, также основывается на Debian).
То есть Debian и производные очень популярна.
Вы сможете использовать полную среду командной строки Debian, содержащую среду полной текущей стабильной версии.
Kali Linux
Kali Linux — это популярнейший дистрибутив для специалистов в информационной безопасности, цифровой криминалистике, хакеров и продвинутых пользователей. Вы можете установить и использовать в родной среде Linux множество специализированных инструментов. Для Kali Linux разработано ПО для упрощённого запуска графического интерфейса (смотрите статью «Как установить Kali Linux с Win-KeX (графический интерфейс) в WSL2 (подсистему Windows для Linux)», а также для инструкций на HackWare.ru взят именно этот дистрибутив, поэтому для него вы найдёте много детаьлных инструкций. По этой причине рекомендуется Kali Linux.
SUSE Linux Enterprise Server
SUSE Linux Enterprise Server — это мультимодальная операционная система, которая открывает путь к трансформации ИТ в эпоху программного обеспечения. Современная модульная ОС помогает упростить мультимодальные ИТ, делает традиционную ИТ-инфраструктуру эффективной и обеспечивает привлекательную платформу для разработчиков. В результате вы можете легко развертывать и переносить критически важные для бизнеса рабочие нагрузки в локальную и общедоступную облачные среды. SUSE Linux Enterprise Server 15 SP1 с его мультимодальным дизайном помогает организациям трансформировать свой ИТ-ландшафт за счет объединения традиционной и программно определяемой инфраструктуры.
Ubuntu
В WSL у дистрибутива Ubuntu также отсутствует графический интерфейс (как по умолчанию у всех других дистрибутивов), поэтому её нельзя назвать более «дружественной» к пользователю. Основана на Debian.
Fedora
Обещают добавить, но пока отсутствует.
Практика
Будем экспериментировать на ОС Ubuntu.
sobols@sobols-VirtualBox:~$ uname -a Linux sobols-VirtualBox 4.4.0-119-generic #143-Ubuntu SMP Mon Apr 2 16:08:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux sobols@sobols-VirtualBox:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.04.1 LTS Release: 16.04 Codename: xenial
Скачиваем свежий ванильный архив с официального сайта:
Скорее всего, нужно будет доустановить некоторые пакеты.
Чтобы воспользоваться консольным конфигуратором, понадобится библиотека для псевдографики:
$ sudo apt-get install libncurses5-dev bison flex
make oldconfig
Берёт существующий конфиг (либо из файла .config в корне исходников ядра, либо из /boot/ для той версии ядра, которая используется в данный момент) и выставляет новые опции (на выбор пользователя или по умолчанию).
# # configuration written to .config #
Если вопросов много и мы не хотим отвечать, можно везде брать значение по умолчанию:
yes "" | make oldconfig
make menuconfig
Имеет псевдографический интерфейс в виде меню. Программа основана на библиотеке ncurses.




Для интереса выставим в General Setup -> Local version значение -bsu.
Поехали!
make -j2
Недолго музыка играла…
HOSTCC scripts/recordmcount HOSTCC scripts/sortextable HOSTCC scripts/asn1_compiler HOSTCC scripts/sign-file scripts/sign-file.c:25:30: fatal error: openssl/opensslv.h: No such file or directory compilation terminated. scripts/Makefile.host:107: recipe for target 'scripts/sign-file' failed make: *** [scripts/sign-file] Error 1
Ищем, какой пакет доустановить.
$ dpkg -S opensslv.h dpkg-query: no path found matching pattern *opensslv.h* $ apt-cache search openssl
$ sudo apt-get install libssl-dev
Возможно, придётся ещё что-то доустановить.
Наконец, всё должно собраться:
$ make CHK include/config/kernel.release CHK include/generated/uapi/linux/version.h CHK include/generated/utsrelease.h CHK include/generated/timeconst.h CHK include/generated/bounds.h CHK include/generated/asm-offsets.h CALL scripts/checksyscalls.sh CHK include/generated/compile.h DATAREL arch/x86/boot/compressed/vmlinux Kernel: arch/x86/boot/bzImage is ready (#1) Building modules, stage 2. MODPOST 4548 modules
Мотивация Кука
Кис Кук объяснил свой призыв к найму большего числа инженеров тем, что из-за сложившейся вокруг ядра Linux ситуации многие уязвимости могут находиться в нем годами. Пока разработчики латают одну брешь, другая теряется в строчках кода.
В словах Кука есть внушительная доля правды. В ядре Linux постоянно обнаруживаются «дыры» в возрасте нескольких лет, многие из которых несут чрезвычайную опасность как для частных пользователей, так и для корпораций.
Кис Кук уверен, что подход к разработке Linux нужно менять полностью
Например, в ноябре 2017 г. CNews рассказывал о том, как россиянин Антон Коновалов всего за несколько месяцев выловил в коде ядра Linux, по меньшей мере, 15 багов в драйверах USB. Он подчеркнул, что такие уязвимости можно использовать для запуска произвольного кода и захвата контроля над пользовательскими системами.
В июле 2021 г. эксперты по информационной безопасности компании Qualys нашли в ядре уязвимости с зашкаливающим уровнем опасности. Они позволяют вызвать крах системы и выполнить произвольный код. И если в случае «дыр», выявленных Антоном Коноваловым их возраст не был установлен, то находкам Qualys совсем недавно исполнилось шесть и семь лет.
Более того, одну из этих уязвимостей они нашли, успешно проэксплуатировав вторую. Из-за них под угрозой оказались пользователи Debian, Ubuntu, Red Hat и целого ряда других популярных дистрибутивов Linux.
Совместимость кодирования
Не существует общего стандарта кодировки для имен файлов.
Имена файлов должны обмениваться между программными средами для сетевой передачи файлов, хранения файловой системы, программного обеспечения для резервного копирования и синхронизации файлов, управления конфигурацией, сжатия и архивирования данных и т. Д
Таким образом, очень важно не потерять информацию об именах файлов между приложениями. Это привело к широкому распространению Unicode в качестве стандарта для кодирования имен файлов, хотя устаревшее программное обеспечение могло не поддерживать Unicode.
Совместимость индикации кодирования
Традиционно имена файлов допускали использование любых символов в именах файлов, если они были безопасными для файловой системы. Хотя это позволяло использовать любую кодировку и, таким образом, позволяло представлять любой локальный текст в любой локальной системе, это вызывало множество проблем с совместимостью.
Имя файла может быть сохранено с использованием разных байтовых строк в разных системах в пределах одной страны, например, если в одной из них используется японская кодировка Shift JIS и другая японская кодировка EUC . Преобразование было невозможно, поскольку большинство систем не отображало описание кодировки, используемой для имени файла, как часть расширенной информации о файле. Это заставляло дорогостоящее угадывать кодировку имени файла при каждом доступе к файлу.
Решением было принять Unicode в качестве кодировки имен файлов.
Однако в классической Mac OS кодировка имени файла сохранялась с атрибутами имени файла.
Совместимость Unicode
Стандарт Unicode решает проблему определения кодировки.
Тем не менее, остаются некоторые ограниченные проблемы совместимости, такие как нормализация (эквивалентность) или используемая версия Unicode. Например, UDF ограничен Unicode 2.0; В файловой системе MacOS HFS + применяется нормализация NFD Unicode и, при необходимости, учитывается регистр (по умолчанию регистр не учитывается). Максимальная длина имени файла нестандартна и может зависеть от размера единицы кода. Хотя это серьезная проблема, в большинстве случаев она носит ограниченный характер.
В Linux это означает, что имени файла недостаточно для открытия файла: кроме того, требуется точное байтовое представление имени файла на устройстве хранения. Это можно решить на уровне приложения с помощью некоторых сложных вызовов нормализации.
Проблема эквивалентности Unicode известна как «коллизия нормализованных имен». Решением является ненормализующая осведомленность о композиции Unicode, используемая в технических сообществах Subversion и Apache. Это решение не нормализует пути в репозитории. Пути нормализованы только для сравнения. Тем не менее, некоторые сообщества запатентовали эту стратегию, запрещая ее использование другими сообществами.
Перспективы
Чтобы ограничить проблемы взаимодействия, некоторые идеи, описанные Sun, заключаются в следующем:
- используйте одну кодировку Unicode (например, UTF-8)
- делать прозрачные преобразования кода для имен файлов
- не хранить нормализованные имена файлов
- проверьте каноническую эквивалентность между именами файлов, чтобы избежать двух канонически эквивалентных имен файлов в одном каталоге.
Эти соображения создают ограничение, не позволяющее переключиться на будущую кодировку, отличную от UTF-8.
Миграция Unicode
Одна из проблем заключалась в переходе на Unicode. С этой целью несколько компаний-разработчиков программного обеспечения предоставили программное обеспечение для перевода имен файлов в новую кодировку Unicode.
- Microsoft предоставила прозрачную для пользователя миграцию в рамках технологии VFAT.
- Apple предоставила «Утилиту восстановления кодировки имен файлов v1.0».
- Сообщество Linux предоставило « convmv ».
Mac OS X 10.3 ознаменовала принятие Apple декомпозиции символов Unicode 3.2, которая заменила использовавшуюся ранее декомпозицию Unicode 2.1. Это изменение вызвало проблемы у разработчиков, пишущих программное обеспечение для Mac OS X.





