
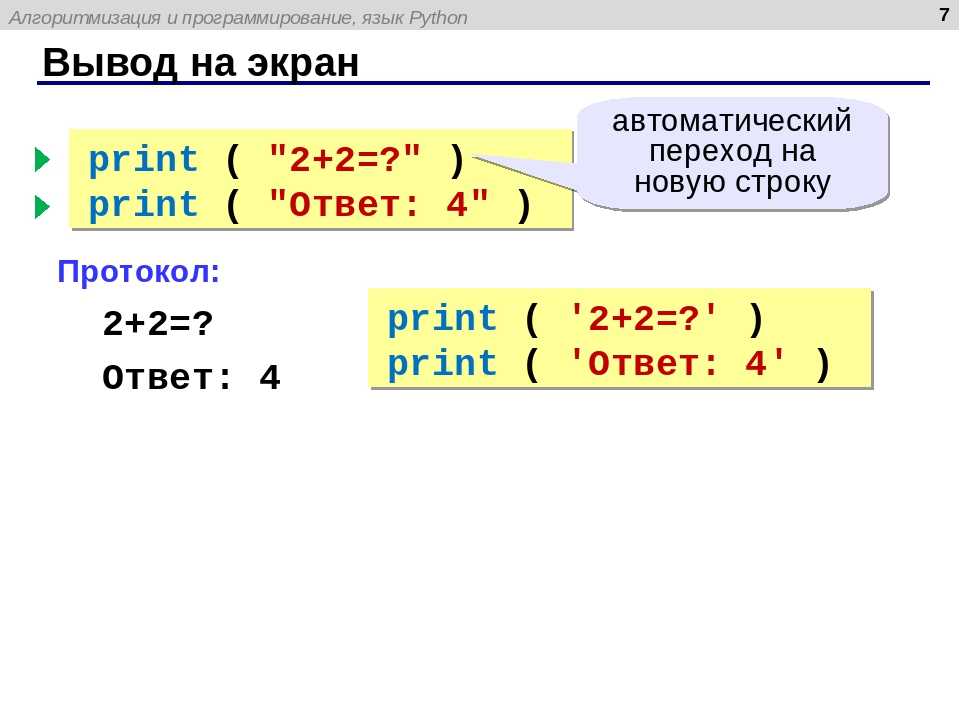
Разделение строк
Также мы можем вызвать ряд символов из строки. Допустим, мы хотим вывести слово . Для этого мы можем создать срез, представляющий собой последовательность символов в исходной строке. С помощью срезов мы можем вызывать несколько значений символов, создавая диапазоны символов, разделенные двоеточием :
При построении среза, такого как , первый индекс соответствует началу среза (включительно), а второй — окончанию среза (не включительно). Поэтому в нашем примере конец диапазона обозначается индексом позиции сразу после конца строки.
При разделении строк на срезы мы создаем подстроки, то есть, строки внутри других строк. Вызывая , мы вызываем подстроку , существующую в строке .
Если мы хотим включить любой конец строки, мы можем пропустить одно из чисел в синтаксисе . Например, если нам нужно вывести первое слово строки — “Sammy”, мы можем сделать это так:
Мы пропустили индекс перед двоеточием в синтаксисе среза и указали только индекс после двоеточия, обозначающий конец подстроки.
Чтобы вывести подстроку, начинающуюся в середине строки и идущую до конца строки, мы можем указать только индекс перед двоеточием:
Если мы укажем только индекс перед двоеточием и не укажем второй индекс, подстрока будет идти от соответствующего первому индексу символа до конца строки.
Для создания срезов также можно использовать отрицательные индексы. Как мы уже говорили раньше, отрицательные индексы строки начинаются с -1 и отсчитываются далее к началу строки. При использовании отрицательных индексов, мы начинаем с меньшего числа, потому что соответствующий ему символ идет раньше.
Давайте используем два отрицательных индекса для создания среза строки :
Подстрока “ark” выводится из строки “Sammy Shark!”, потому что символ “a” соответствует индексу -4, а символ “k” находится перед позицией индекса -1.
Что такое подстрока в Python?
Подстрока в Python – это последовательный сегмент символов в строке. Другими словами: «часть строки является подстрокой. Строка Python определяет несколько методов построения подстроки, проверки, включает ли строка подстроку, индекс подстроки и т. д.»
Например, подстрока «the better of» – «It was the better of times». А, «Itwastimes» – это серия «It was the better of times», а не подстрока.
Создание подстроки
Мы можем построить подстроку с помощью нарезки строки. Мы должны использовать метод split() для создания массива подстрок на основе указанного разделителя.
Синтаксис создания строки в Python приведен ниже:
S = 'Welcome to the python world' name = s // substring creation with the help of slice print A1 = s.split() Print(A1) // Array of substring with the help of split() method
Здесь индекс начинается с 0.
Пример:
>>> s = 'Welcome to the python world' >>> s 'python' >>> s.split() >>>
Выход:
После успешного выполнения кода мы получили то, что видим ниже на экране.
Проверяем, нашли ли мы подстроку
Мы можем использовать метод find() или оператор in, чтобы оценить, доступна ли подстрока в последовательности или нет.
Синтаксис:
s = 'Welcome to the python world'
if 'Name' in s: // Checking substring with the help of in operator
print('Substring found')
if s.find('Name') != -1: // Checking substring with the help of find()
print('Substring found')
Здесь метод find() возвращает индекс позиции подстроки, если он совпадает, иначе он вернет -1.
Пример кода:
>>> s = 'Welcome to the python world'
>>>
>>> if 'name' in s:
Print('Substring found')
...
Substring found
>>>
>>> if s.find('name') ! = -1:
Print('Substring found')
...
Substring found
>>>
Проверка наличия подстроки
Мы можем определить количество итераций подстроки в массиве с помощью метода count().
Синтаксис проверки наличия подстроки:
s = ' Welcome to the python world '
print('Substring count =', s.count('c'))
s = 'Python is a best language'
print('Substring count =', s.count('Py'))
Пример кода
>>> s = ' Welcome to the python world '
>>> print('Substring count =', s.count('c'))
>>> s = 'Python is a best language'
>>> print('Substring count =', s.count('Py'))
>>>
Выход
После выполнения вышеуказанного кода мы получили следующий результат:
Поиск всех индексов в подстроке
В языке Python нет встроенной функции для получения массива всех значений индекса подстроки. В конце концов, используя метод find(), мы можем просто добиться этого.
Синтаксис поиска всех индексов подстроки приведен ниже:
def find_all_indexes(input_str, substring): s = 'Python is the best programming language' print(find_all_indexes(s, 'Py'))
Пример кода:
>>> def find_all_indexes(input_str, substring): ? L2 = [] ? length = Len(input_str) ? index = 0 ? while index < Length: ? i = input_str.find(substring, index) ? if i == -1: ? return L2 ? L2.append(i) ? index = i + 1 ? return L2 ? >>> s = ' Python is the best programming language ' >>> print(find_all_indexes(s, 'Py'))
Выход:
После успешного выполнения вышеуказанного программного кода мы получили следующий результат:
Нарезка с помощью start-index без end-index
Это возвращает нарезанную строку, начиная с позиции 5 массива до последней из последовательности Python.
Синтаксис:
s = s
Пример:
// Substring or slicing with the help of start index without end index >>> s = 'It is to demonstrate substring functionality in python.' >>> s
Выход:
Нарезка с помощью end-index без start-index
Это возвращает нарезанную строку от начала до конца index-1.
Синтаксис:
s = s
Пример:
// Substring or slicing with the help of end index without start index >>> s = 'Python is a powerful programming language' >>> s
Выход:
Нарезка целой строкой
Это поможет вам получить на выходе всю строку.
Синтаксис для нарезки всей подстроки показан ниже:
s = s
Пример кода:
// Substring or slicing of complete string >>> s = 'Python is a robust programming language.' >>> s
Выход:
Вырезание одного символа из строки
Это возвращает один символ подстроки из строки.
Синтаксис для выделения одного символа из строки показан ниже:
s = s
Пример кода:
// Substring or slicing of a single character >>> s = 'Python is a widely used language.' >>> s
Выход
После успешного выполнения вышеуказанного кода мы получили следующий результат:
Переворот строки с помощью отрицательного(-) шага
Это поможет вам вернуть строку в обратном порядке.
Синтаксис:
s = s
Пример кода:
// Reversing of a string with the help of Substring or slicing through negative step >>> s = 'Python language supports the string concept.' >>> s
Выход
После успешного выполнения вышеуказанного программного кода мы получили следующий результат:
Использование функции rstrip для удаления последнего символа из строки в Python
Строковый метод rstrip используется для удаления символов из правой части заданной ему строки. Поэтому мы будем использовать его для удаления или удаления последнего символа строки. Это можно сделать только в одной строке кода и простым методом удалить последний символ из строки.
Давайте рассмотрим пример для лучшего понимания концепции:
#taking input from the user
str = input("Enter the string : ")
remaining_string = str.rstrip(str)
print("String : ",remaining_string)
Выход:
Enter the string : Latracal solutionss String : Latracal solution
Объяснение:
Здесь, во-первых, мы взяли входные данные от пользователя в виде строки. Во-вторых, мы использовали функцию rstrip в данной строке и использовали ее для удаления последнего символа из строки. Наконец-то мы напечатали результат. Следовательно, мы видели, что нежелательный персонаж был удален.
Как разделить строку в Python
Разделение струны на более мелкие части – это очень распространенная задача. Для этого мы используем Метод в Python.
Давайте посмотрим некоторые примеры о том, как это сделать.
Пример 1: используйте пробелы в качестве разделителей
В этом примере мы разделяем фразу на пробеле, создавая список с именем my_words с пятью элементами, соответствующими каждому слову в фразе.
my_phrase = "let's go to the beach"
my_words = my_phrase.split(" ")
for word in my_words:
print(word)
#output:
#let's
#go
#to
#the
#beach
print(my_words)
#output:
#
Обратите внимание, что по умолчанию Метод использует любое последовательное количество пробелов в качестве разделителей. Мы можем изменить код выше:
my_phrase = "let's go to the beach"
my_words = my_phrase.split()
for word in my_words:
print(word)
#output:
#let's
#go
#to
#the
#beach
Выход то же самое, так как у нас есть только один пробел между каждым словом.
Пример 2: пройти разные аргументы в качестве разделителей
При работе с данными очень часто читают некоторые файлы CSV для извлечения информации от них.
Таким образом, вам может потребоваться сохранить некоторые конкретные данные из определенного столбца.
Файлы CSV обычно имеют поля, разделенные с запятой «;» или запятая »,”.
В этом примере мы собираемся использовать метод, проходящий в качестве аргумента конкретный разделитель, «;» в таком случае.
my_csv = "mary;32;australia;mary@email.com"
my_data = my_csv.split(";")
for data in my_data:
print(data)
#output:
#mary
#32
#australia
#mary@email.com
print(my_data)
#output:
# mary@email.com
Специальные символы
Пользоваться тройными кавычками для форматирования строк не всегда удобно, так как это порой занимает слишком много места в коде. Чтобы задать собственное форматирование текста, достаточно применять специальные управляющие символы с обратным слэшем, как это показано в следующем примере. Здесь используется символ табуляции \t, а также знак перехода на новую строку \n. Метод print демонстрирует вывод нового объекта на экран.
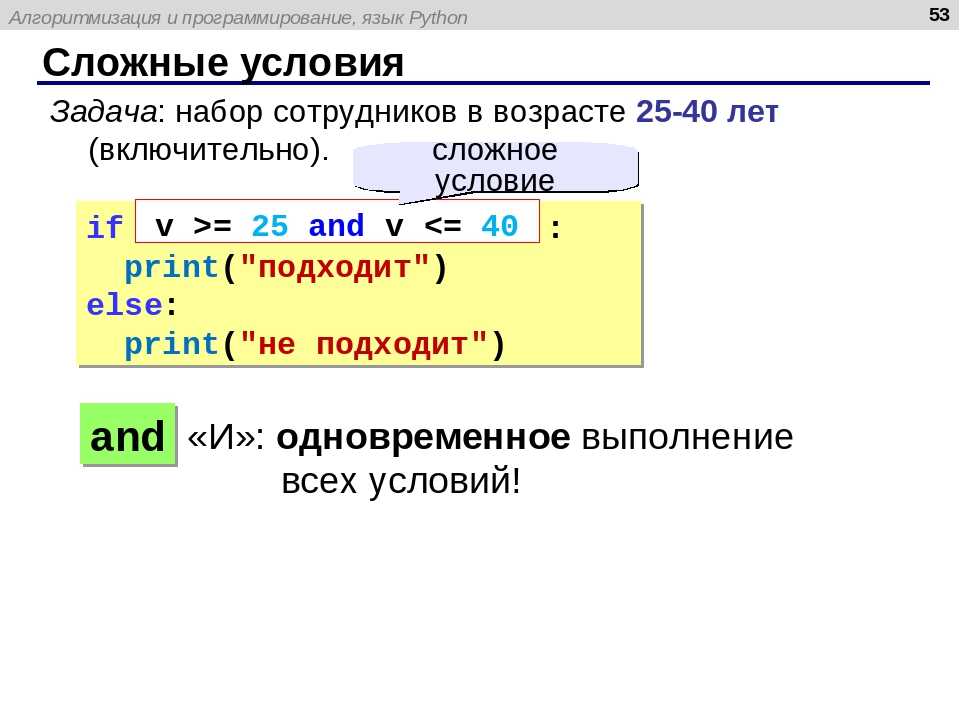


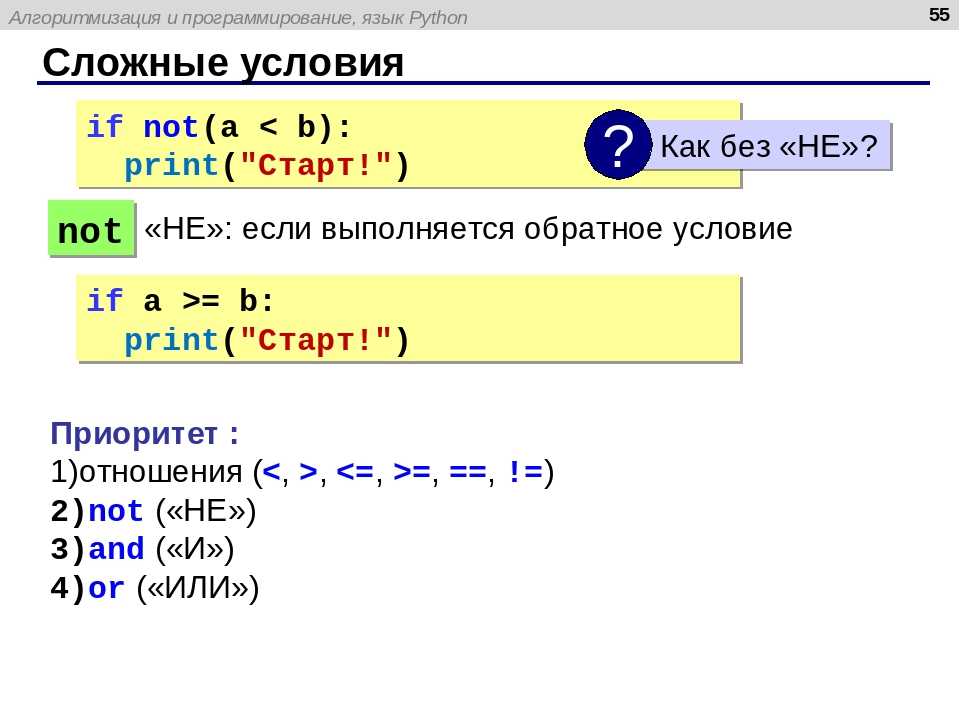
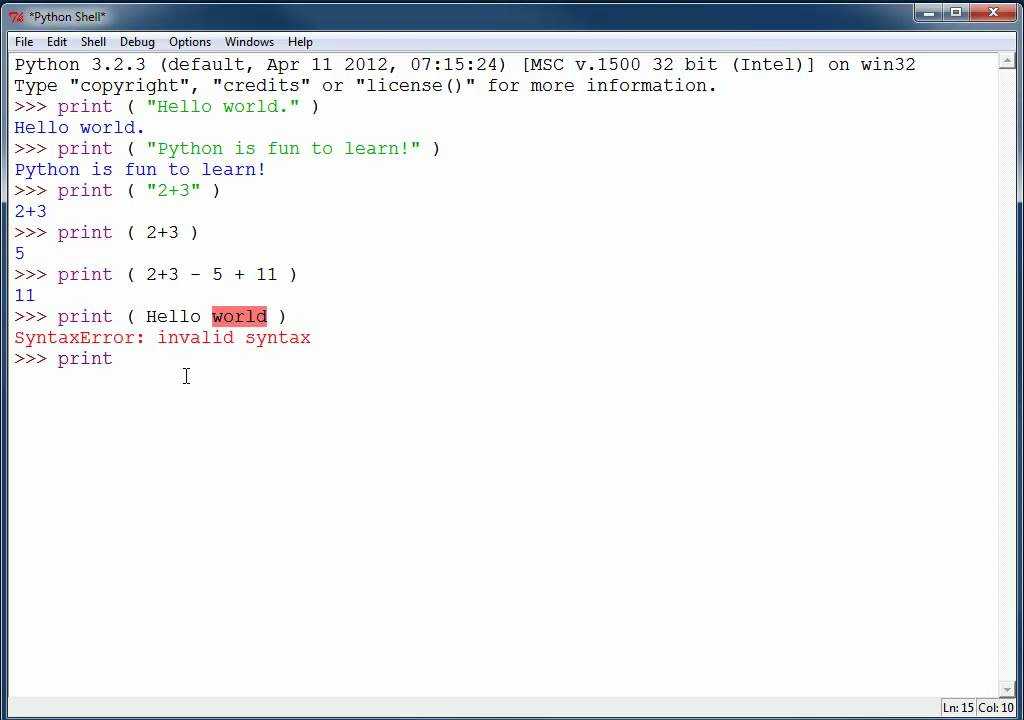
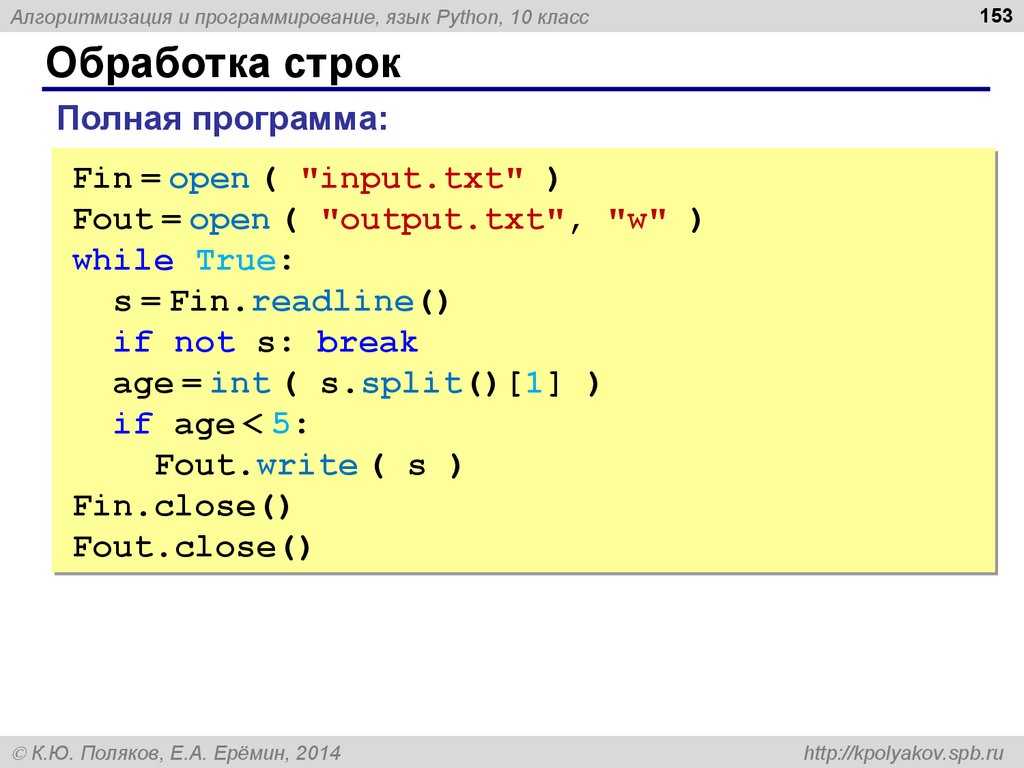
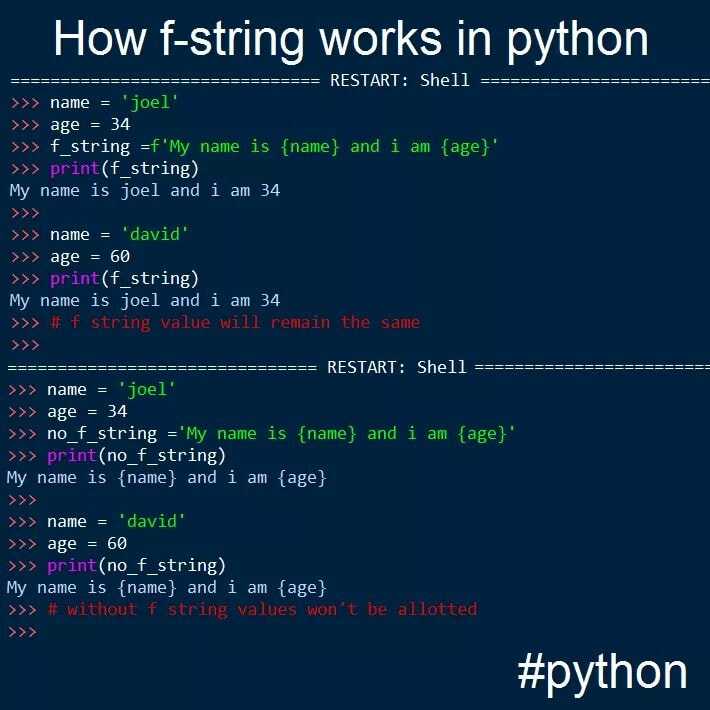

string = "some\ttext\nnew line here" print(string) some text new line here
Служебные символы для форматирования строк выполняют свои функции автоматически, но иногда это мешает, к примеру, когда требуется сохранить путь к файлу на диске. Чтобы их отключить, необходимо применить специальный префикс r перед первой кавычкой литерала. Таким образом, обратные слэши будут игнорироваться программой во время ее запуска.
string = r"D:\dir\new"
Следующая таблица демонстрирует перечень всех используемых в языке Python служебных символов для форматирования строк. Как правило, большинство из них позволяют менять положение каретки для выполнения перевода строки, табуляции или возврата каретки.
| Символ | Назначение |
| \n | Перевод каретки на новую строку |
| \b | Возврат каретки на один символ назад |
| \f | Перевод каретки на новую страницу |
| \r | Возврат каретки на начало строки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \a | Подача звукового сигнала |
| \N | Идентификатор базы данных |
| \u, \U | 16-битовый и 32-битовый символ Unicode |
| \x | Символ в 16-ричной системе исчисления |
| \o | Символ в 8-ричной системе исчисления |
| \0 | Символ Null |
Очень часто испльзуется \n. С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
print('first\nsecond')
first
second
lstrip () vs readleprefix () и rstrip () vs removeuffix ()
Это вызывает путаницу для многих людей.
Легко посмотреть на и И удивляйтесь, какая реальная разница между ними.
При использовании Аргумент – это набор ведущих персонажей, которые будут удалены столько раз, сколько они возникают:
>>> word = 'hubbubbubboo'
>>> word.lstrip('hub')
'oo'
В то время как Удалю только точное совпадение:
>>> word = 'hubbubbubboo'
>>> word.removeprefix('hub')
'bubbubboo'
Вы можете использовать ту же обоснование, чтобы различать и Отказ
>>> word = 'peekeeneenee'
>>> word.rstrip('nee')
'peek'
>>> word = 'peekeeneenee'
>>> word.removesuffix('nee')
'peekeenee'
И как бонус, на всякий случай, если вы никогда не работали с регулярными выражениями раньше, будьте благодарны, что у вас есть Обрезать наборы символов из строки вместо регулярного выражения:
>>> import re
>>> word = 'amazonia'
>>> word.strip('ami')
'zon'
>>> re.search('^*(.*?)*$', word).group(1)
'zon'
Пример 1
В Python встроенная функция sub () присутствует в модуле регулярного выражения для удаления чисел из строки Python. Метод sub () заменяет все существования данного порядка в строке, используя заменяющую строку. Если вы не можете найти порядок в строке, то результирующая строка будет такой же.
Чтобы понять концепцию функции sub (), все, что вам нужно сделать, это открыть файл программы и реализовать код. Итак, в нашем первом программном коде мы сначала импортируем модуль регулярного выражения Python, а затем создаем строку, содержащую число и символы. Затем мы можем определить шаблон, который удаляет числа от 0 до 9. После этого мы вызываем команду sub (), которая принимает в качестве параметра три аргумента, то есть строку, пустую строку, шаблон. Функция сначала выполняет итерацию по строке, удаляет число от 0 до 9 и меняет их местами на пустую строку. Затем он печатает новую отфильтрованную строку. Здесь написан программный код, который объясняется.
Сохраните и выполните программный код, чтобы увидеть, как функция sub () удаляет числа из строки. На экране консоли отображается результат.
![]()
Использование регулярного выражения для удаления знаков препинания из строки в Python
Python дает нам библиотеку регулярных выражений для управления всеми видами регулярных выражений , а также для управления ими и манипулирования ими. Если вы не знаете, что такое регулярное выражение, позвольте мне сказать вам: Регулярное выражение-это последовательность символов, которые задают шаблон поиска. Обычно эти паттерны используются алгоритмами поиска строк для операций «найти» или» найти и заменить» над строками или для входного сигнала. Это стратегия, разработанная в теоретической информатике и теории формального языка.
Примечание: Нам нужно импортировать библиотеку re для работы с регулярным выражением.
Регулярное выражение в python поставляется с функцией sub-strong, и мы будем использовать эту функцию. Чтобы удалить знаки препинания из строки в python.
Синтаксис re.sub
- шаблон: знаки препинания(шаблон), которые мы хотим заменить.
- замена: Строка замены шаблона (в основном пустая строка).
- original_string: Исходная строка, из которой нам нужно удалить знаки препинания(шаблон).
Давайте посмотрим на работу на примере:
Пример удаления знаков препинания из строки в Python с помощью регулярного выражения
import re
__cf_email__" href="/cdn-cgi/l/email-protection"> P)(*y&tho.n"
.sub(r'','',my_string)
print('String with Punctuation: ', my_string)
print('String without Punctuation: ', op_string)
Выход:
Объяснение
В приведенном выше примере нам нужно импортировать библиотеку регулярных выражений, поскольку мы используем функцию, доступную в библиотеке регулярных выражений. Затем у нас есть входная строка с пунктуациями в ней. И мы сохранили его в переменной my_string. Впоследствии, с помощью функции re.sub, которую мы имеем, мы удалили все знаки препинания. Здесь, в параметрах ‘re.sub’, вам может быть интересно, что такое r’. Итак, в основном, r’ — это шаблон для выбора символов и чисел.
Я предпочитаю использовать регулярные выражения, хотя они просты в обслуживании, а также легче понять (если кто-то другой читает ваш код).
Форматирование строки Python
Управляющая последовательность
Предположим, нам нужно написать текст – They said, “Hello what’s going on?” – данный оператор может быть записан в одинарные или двойные кавычки, но он вызовет ошибку SyntaxError, поскольку он содержит как одинарные, так и двойные кавычки.
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
str = "They said, "Hello what's going on?"" print(str)
Выход:
SyntaxError: invalid syntax
Мы можем использовать тройные кавычки для решения этой проблемы, но Python предоставляет escape-последовательность.
Символ обратной косой черты(/) обозначает escape-последовательность. За обратной косой чертой может следовать специальный символ, который интерпретируется по-разному. Одиночные кавычки внутри строки должны быть экранированы. Мы можем применить то же самое, что и в двойных кавычках.
Пример –
# using triple quotes
print('''''They said, "What's there?"''')
# escaping single quotes
print('They said, "What\'s going on?"')
# escaping double quotes
print("They said, \"What's going on?\"")
Выход:
They said, "What's there?" They said, "What's going on?" They said, "What's going on?"
Список escape-последовательностей приведен ниже:
| Номер | Последовательность | Описание | Пример |
|---|---|---|---|
| 1. | \newline | Игнорирует новую строку |
print("Python1 \
Python2 \
Python3")
Output: Python1 Python2 Python3 |
| 2. | \\ | Косая черта |
print("\\")
Output: \ |
| 3. | \’ | одиночные кавычки |
print('\'')
Output: ' |
| 4. | \\” | Двойные кавычки |
print("\"")
Output: " |
| 5. | \a | ASCII Bell |
print("\a")
|
| 6. | \b | ASCII клавиша Backspace |
print("Hello \b World")
Output: Hello World |
| 7. | \f | ASCII Formfeed |
print("Hello \f World!")
Hello World!
|
| 8. | \n | ASCII Linefeed |
print("Hello \n World!")
Output: Hello World! |
| 9. | \r | ASCII Carriege Return(CR) |
print("Hello \r World!")
Output: World! |
| 10. | \t | ASCII горизонтальный tab |
print("Hello \t World!")
Output: Hello World! |
| 11. | \v | ASCII вертикальный Tab |
print("Hello \v World!")
Output: Hello World! |
| 12. | \ooo | Символ с восьмеричным значением |
print("\110\145\154\154\157")
Output: Hello |
| 13 | \xHH | Символ с шестнадцатеричным значением |
print("\x48\x65\x6c\x6c\x6f")
Output: Hello |
Вот простой пример escape-последовательности.
print("C:\\Users\\DEVANSH SHARMA\\Python32\\Lib")
print("This is the \n multiline quotes")
print("This is \x48\x45\x58 representation")
Выход:
C:\Users\DEVANSH SHARMA\Python32\Lib This is the multiline quotes This is HEX representation
Мы можем игнорировать escape-последовательность из данной строки, используя необработанную строку. Мы можем сделать это, написав r или R перед строкой. Рассмотрим следующий пример.
print(r"C:\\Users\\DEVANSH SHARMA\\Python32")
Выход:
C:\\Users\\DEVANSH SHARMA\\Python32
Использование цикла for для удаления последнего символа из строки в Python
Мы также можем использовать цикл for для удаления или удаления последнего символа из строки. Мы выведем длину строки из функции len (). Тогда мы возьмем пустую строку. После этого мы запустим цикл от 0 до l2 и добавим строку в пустую строку. Наконец, мы напечатаем вывод в виде оставшейся строки.
Давайте рассмотрим пример для лучшего понимания концепции:
#sample string
str = "Latracal Solutionss"
#length of the string
l = len(str)
#empty string
Final_string = ""
#using loop
#add the string character by character
for i in range(0,l-2):
Final_string = Final_string + str
print("Final String : ",Final_string)
Выход:
Final String : Latracal Solution
Объяснение:
Здесь, во-первых, мы взяли образец str = ” Latracal Решения.” Во-вторых, мы вычислили длину строки с помощью функции len (). В-третьих, мы взяли пустую строку, чтобы добавить строку, чтобы сформировать новую строку. В-четвертых, мы использовали цикл for от 0-го индекса до l2 и на каждой итерации добавляли символ в пустую строку. Наконец, мы напечатали последнюю сформированную строку. Следовательно, мы видели, что нежелательный персонаж был удален.
Табуляция и разрыв строк в Python.
В программировании термином пропуск ( whitespace ) называются такие непечатаемые символы, как пробелы, табуляции и символы конца строки. Пропуски структурируют текст, чтобы пользователю было удобнее читать его.
В таблице приведены наиболее часто встречаемые комбинации символов.
|
Последовательность символов |
Описание |
|---|---|
| \t | Вставляет символ горизонтальной табуляции |
| \n | Вставляет в строку символ новой строки |
| \\ | Вставляет символ обратного слеша |
| \» | Вставляет символ двойной кавычки |
| \’ | Вставляет символ одиночной кавычки |
Для добавления в текст табуляции используется комбинация символов \t. Разрыв строки добавляется с помощью комбинации символов \n.
>>> print(«Python»)Python
>>> print(«\tPython»)
Python
>>> print(«Языки программирования:\nPython\nJava\nC»)Языки программирования:
Python
Java
C
Табуляция и разрыв строк могут сочетаться в тексте. В следующем примере происходит вывод одного сообщения с разбиением на строки с отступами.
>>> print(«Языки программирования:\n\tPython\n\tJava\n\tC»)Языки программирования:
Python
Java
C
Задание определенной точности
Иногда нам нужно указать количество знаков после запятой в числе. В такой ситуации мы используем все ту же функцию float(), а после нее — функцию format(), чтобы определить количество десятичных знаков в нашем числе.
В данном примере мы работаем со строкой . Нам нужно преобразовать эту строку в число с плавающей запятой и оставить только 4 цифры после запятой.
str = '6.759104'
number = float(str)
result = '{:.4f}'.format(number)
print(result)
# Output:
# 6.7591
Здесь метод format() используется для определения количества десятичных знаков в числе с плавающей запятой. В данном случае в исходном числе после запятой больше знаков, чем четыре, поэтому происходит округление. Однако если бы вдруг знаков оказалось меньше, то в конец просто бы добавились нули.
Таким образом, после применения функции format() мы получим .
Используем методы split() и join()
Следующий пример – это комбинация split() и join() — двух строковых методов Python. Функция split() разделяет строку по указанному разделителю и возвращает разделенные элементы исходной строки в виде списка. Общий синтаксис функции split() выглядит следующим образом:
variableName.split(separator, count)
Итак, давайте разбираться. – это переменная, содержащая исходную строку.
Аргумент определяет разделитель, который будет использоваться для разделения исходной строки. Этот аргумент необязателен. Значение по умолчанию – пробел.
Счетчик определяет количество разделений, которое необходимо сделать. Это также необязательный аргумент. Его значение по умолчанию – это все вхождения. То есть сколько раз разделитель встречается, столько раз мы и дробим строку.
Кроме того, есть обратная функция — join(), которая принимает итерируемый объект и возвращает все его элементы, объединенные в одну строку. Ниже приведен синтаксис функции join():
variableName.join(iterable)
Рассмотрим, что здесь есть. Аргумент представляет собой итерируемый объект, содержащий элементы, которые будут возвращены в виде одной строки. Этот аргумент обязателен.
– это строка, которая служит сепаратором. Когда элементы будут объединены, этот сепаратор будет вставлен между ними. Если указать как пустую строку (), объединяемые элементы будут просто идти друг за другом, без разделителей.
Используем методы split() и join(), чтобы удалить пробелы из строки :
>>> PyString = 'This is Python String \n\t' >>> "".join(PyString.split()) 'ThisisPythonString'
В результате мы получили то, что хотели – все пробелы удалены. Также мы удалили символы .
Как удалить Знаки препинания Из файла в Python
При выполнении некоторых проектов и некоторых математических задач возникает необходимость иметь чистый и понятный текстовый файл для работы. В которой нет знаков препинания. Таким образом, мы можем легко выполнять математические вычисления.
Оригинальный Текстовый файл с пунктуацией
./#$%^&*_~'''
for ele in string:
if ele in punc:
.replace(ele, "")
return string
try:
with) as f:
.read()
with) as f:
f.write(remove_punc(data))
print("Removed punctuations from the file", filename)
except FileNotFoundError:
print("File not found")
(«enter>
Выход:
Очистите текстовый файл после удаления знаков препинания с помощью Python
Объяснение:
Чтение и запись файлов является неотъемлемой частью кода python, и каждый программист должен знать, как это сделать. Чтобы сделать то же самое, мы использовали метод open() для чтения и записи файлов.
Во-первых, мы объявляем пользовательскую входную переменную, которая просит пользователя ввести имя файла. Затем мы создали настраиваемую функцию для удаления всех строковых знаков препинания. Затем мы читаем файл с помощью оператора open (). Чтобы избежать ошибки «Файл не найден», мы использовали метод try-catch для информирования конечного пользователя о недопустимости имени файла. Затем мы используем remove_punch (), чтобы удалить все знаки препинания и переписать файл с помощью метода open ().
Строковые функции в Python
Python предоставляет различные встроенные функции, которые используются для работы со строками.
| Метод | Описание |
|---|---|
| Выводит первый символ строки заглавными буквами. Эта функция устарела в python3 | |
| Возвращает версию строки, пригодную для сравнений без регистра. | |
| Возвращает строку, заполненную пробелами, причем исходная строка центрируется с равным количеством пробелов слева и справа. | |
| Подсчитывает количество вхождений подстроки в строку между начальным и конечным индексом. | |
| Декодирует строку. | |
| Кодирование строки. Кодировка по умолчанию — . | |
| Возвращает булево значение, если строка заканчивается заданным суффиксом между begin и end. | |
| Определяет табуляцию в строке до нескольких пробелов. По умолчанию количество пробела равно 8. | |
| Возвращает значение индекса строки, в которой найдена подстрока между начальным и конечным индексами. | |
| Возвращает форматированную версию строки, используя переданное значение. | |
| Выбрасывает исключение, если строка не найдена. Работает так же, как и метод . | |
| Возвращает true, если символы в строке являются буквенно-цифровыми, т.е. алфавитами или цифрами, и в ней есть хотя бы один символ. В противном случае возвращается . | |
| Возвращает , если все символы являются алфавитными и есть хотя бы один символ, иначе . | |
| Возвращает , если все символы строки являются десятичными. | |
| Возвращает , если все символы являются цифрами и есть хотя бы один символ, иначе . | |
| Возвращает , если строка является действительным идентификатором. | |
| Возвращает , если символы строки находятся в нижнем регистре, иначе . | |
| Возвращает , если строка содержит только числовые символы. | |
| Возвращает , если все символы строки являются печатными или строка пустая, в противном случае возвращает . | |
| Возвращает , если символы строки находятся в верхнем регистре, иначе . | |
| Возвращает , если символы строки являются пробелами, иначе . | |
| Возвращает , если строка имеет правильный заголовок, и в противном случае. Заголовок строки — это строка, в которой первый символ в верхнем регистре, а остальные символы в нижнем регистре. | |
| Он объединяет строковое представление заданной последовательности. | |
| Возвращает длину строки. | |
| Возвращает строки, заполненные пробелами, с исходной строкой, выровненной по левому краю до заданной ширины. | |
| Он преобразует все символы строки в нижний регистр. | |
| Удаляет все пробелы в строке, а также может быть использован для удаления определенного символа из строки. | |
| Он ищет разделитель в строке и возвращает часть перед ним, сам разделитель и часть после него. Если разделитель не найден, возвращается кортеж в виде переданной строка и двух пустых строк. | |
| Возвращает таблицу перевода для использования в функции . | |
| Заменяет старую последовательность символов на новую. Если задано значение , то заменяются все вхождения. | |
| Похож на , но обходит строку в обратном направлении. | |
| Это то же самое, что и , но обходит строку в обратном направлении. | |
| Возвращает строку с пробелами, исходная строка которой выровнена по правому краю на указанное количество символов. | |
| Он удаляет все пробелы в строке, а также может быть использован для удаления определенного символа. | |
| Он аналогичен функции , но обрабатывает строку в обратном направлении. Возвращает список слов в строке. Если разделитель не указан, то строка разделяется в соответствии с пробелами. | |
| Разделяет строку в соответствии с разделителем . Строка разделяется по пробелу, если разделитель не указан. Возвращает список подстрок, скомпонованных с разделителем. | |
| Он возвращает список строк в каждой строке с удаленной строкой. | |
| Возвращает булево значение, если строка начинается с заданной строки между и . | |
| Он используется для выполнения функций и над строкой. | |
| Он инвертирует регистр всех символов в строке. | |
| Он используется для преобразования строки в заглавный регистр, т.е. строка будет преобразована в . | |
| Он переводит строку в соответствии с таблицей перевода, переданной в функцию . | |
| Он преобразует все символы строки в верхний регистр. | |
| Возвращает исходную строку, дополненную нулями минимального количества символов (параметр ); предназначена для чисел, сохраняет любой заданный знак (за вычетом одного нуля). | |
| Ищет последнее вхождение указанной строки и разбивает строку на кортеж, содержащий три элемента (часть перед указанной строкой, саму строку и часть после нее). |
Способы использования возврата каретки
Мы покажем все типы, с помощью которых мы можем использовать ‘\r’ в python.
1. Использование только возврата каретки в Python
В этом примере мы будем использовать только возврат каретки в программе между строками.
string = 'My website is Latracal \rSolution' print(string)
Выход:
Solutionte is Latracal
Объяснение:
- Во-первых, мы взяли входную строку как строку.
- мы применили \r между строками.
- \r переместил курсор в начало, и “решение” содержит 8 букв. С самого начала 8 букв будут стерты, а на их месте будет напечатан раствор.
- Вы можете увидеть результат для лучшего понимания.
2. Использование возврата каретки в Python с символом новой строки
В этом примере мы будем использовать ‘\r’ с новым символом строки(\n) в строковой программе.
string = 'My website is Latracal \r\nSolution' print(string) string = 'My website is Latracal \n\rSolution' print(string) string = 'My web\nsite is Latracal \rSolution' print(string)
Выход:
My website is Latracal Solution My website is Latracal Solution My web SolutionLatracal
Объяснение:
- Во-первых, мы взяли входную строку как строку.
- Затем мы применили \n и \r в нескольких местах строки.
- \n – это для новой строки.
- В первых двух строках мы поместили \n до и после \r. Таким образом, выходные данные печатаются в новой строке.
- В последней строке \n стоит первым после ‘site is’, который содержит 8 букв в качестве решения, поэтому они заменяются.
- Следовательно, вы можете видеть результат.
3. Использование возврата каретки в python с пробелом табуляции
В этом примере мы будем использовать каретку или \r с комбинацией табуляции или \t в программе между строками.
str = ('\tLatracal \rsolution')
print(str)
Выход:
solutionLatracal
Объяснение:
- Во – первых, мы приняли вход как str.
- Затем мы применили пробел табуляции в начале строки, который даст 8 пробелов в начале.
- Затем мы применили \r. После \r есть 8 букв решения.
- В выходных данных буква решения заполнит пробелы табуляции, поскольку они равны.
- Вы можете увидеть результат для лучшего понимания.
4. Использование возврата каретки в python, табуляции и символа новой строки
В этом примере мы будем смешивать все символы, такие как возврат каретки(\r), пробел табуляции(\t) и символ новой строки(\n) в данной строке, и видеть выходные данные, чтобы мы могли более четко понять использование \r.
str = ('\tlatracal\rsolution\n\tis a\rwebsite\n')
print(str)
Выход:
solutionlatracal website is a
Объяснение:
- Во – первых, мы взяли входную строку как str.
- Затем мы применили все символы, такие как \t для пространства табуляции, \namebroker для новой строки и \r для возврата каретки.
- Следовательно, вы можете видеть результат.
Методы строк
join(str) — Соединение строк из последовательности str через разделитель, заданный строкой
s="hello" s1="-".join(s) s1 # 'h-e-l-l-o' |
s1.count(s) — количество вхождений подстроки в строку . Результатом является число. Можно указать позицию начала поиска i и окончания поиска j:



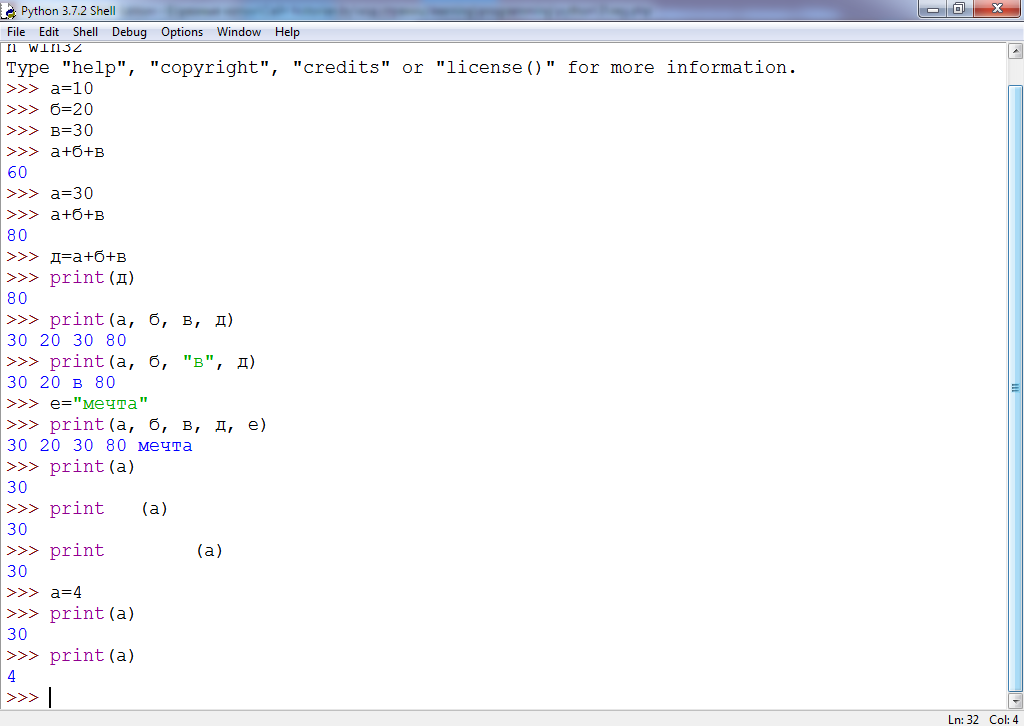
s1="abrakadabra"; s1.count('ab') # 2
s1.count('ab',1) # 1
s1.count('ab',1,-3) # 0 , т.к. s1='brakada'
|
s1.find(s) — определяется позиция первого (считая слева) вхождения подстроки в строку . Результатом является число. и определяют начало и конец области поиска:
s1="abrakadabra"; s1.find('br') # 1
|
s1.replace(s2,s3) — создаётся новая строка, в которой фрагмент (подстрока) исходной строки заменяется на фрагмент . Необязательный аргумент указывает количество замен:
s1="breKeKeKeKs"; ss=s1.replace('Ke','XoXo',2)
ss # breXoXoXoXoKeKs
|
Задание Python 5_5: Преобразовать дату в «компьютерном» представлении (системную дату: 2016-03-26) в «российский» формат, т. е. день/месяц/год (например, 26/03/2016). Известно, что на год выделено всегда 4 цифры, а на день и месяц – всегда 2 цифры.
Примечание:
- Использовать строковые функции языка и срезы.
- Функциями работы с датами и временем «заведует» в Python datetime модуль, а непосредственно для работы с датами используется объект date и его методы.
Подсказка:
from datetime import date # Получаем текущую дату d1=date.today() # Преобразуем результат в строку ds=str(d1) |
Задание Python 5_6:
Ввести адрес файла и «разобрать» его на части, разделенные знаком ‘/’. Каждую часть вывести в отдельной строке.
Например: c:/изображения/2018/1.jpg
Результат:
c: изображения 2018 1.jpg
Задание Python 5_7:
Ввести строку, в которой записана сумма натуральных чисел, например, ‘1+25+3’. Вычислите это выражение. Использовать строковые функции языка.
Задание Python 5_8: Определить, является ли введённая строка палиндромом («перевёртышем») типа ABBA, kazak и пр.
Примечание:
если , то
Для решения используйте алгоритм, изображенный на блок-схеме:
![]()





