
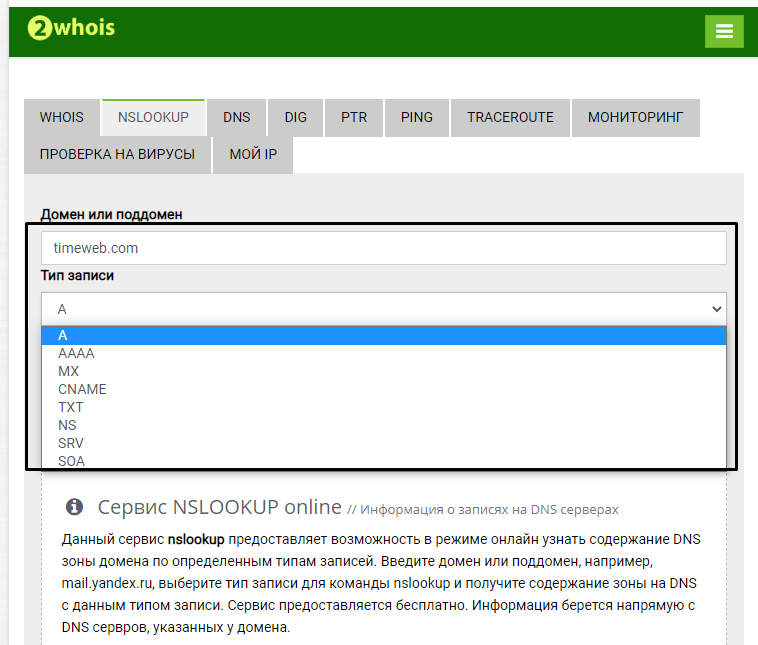
Что такое история запросов и посещений в Яндексе
Просмотр любой страницы в браузере фиксируется и добавляется запись об этом действии в специальное хранилище программы на жестком диске компьютера. Благодаря этому, вы можете, когда угодно посмотреть историю поиска Яндекса и посещенных сайтов. Сохраняются данные как для мобильной версии браузера в телефоне, так и на компьютере.
Благодаря этому в результатах выдачи по искомому запросу, посещенные вами сайты подсвечиваются другим цветом. Смотрите пример ниже:
![]()
Посмотреть историю в Яндексе можно двумя способами:
- найти ее в специальном разделе настроек браузера;
- с помощью другой программы открыть файл истории, который хранится на компьютере.
Сейчас разберем, что такое список поисковых запросов. Если говорить простым языком — это набор слов и словосочетаний, которые вы вводили в поисковую строку, чтобы найти ответ на тот или иной интересующий вас вопрос.
Вот пример на картинке:
![]()
Как видите там подсвечены фиолетовым цветом фразы, которые уже искали, а также поисковик предлагает подсказки искомого запроса, по которым ищут информацию другие пользователи.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
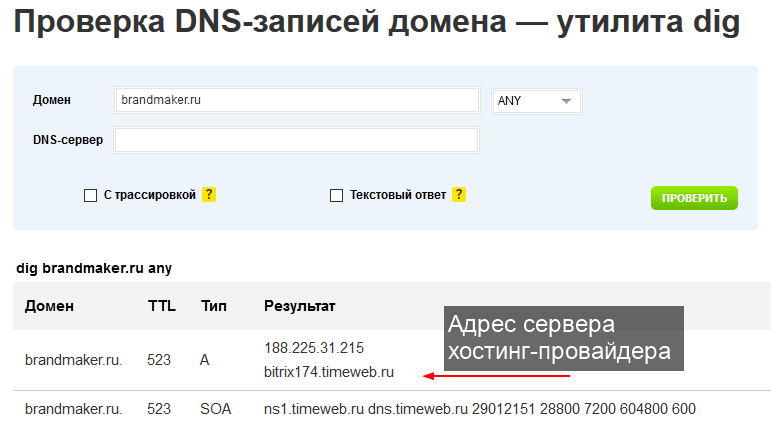
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.
![]()
Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).
![]()
Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
![]()
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
![]()
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
![]()
Запретить вредные службы с помощью консоли services.msc.
![]()
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
![]()
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
![]()
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
![]()
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
![]()
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
![]()
Очистить корзину, временные файлы, кэш браузеров.
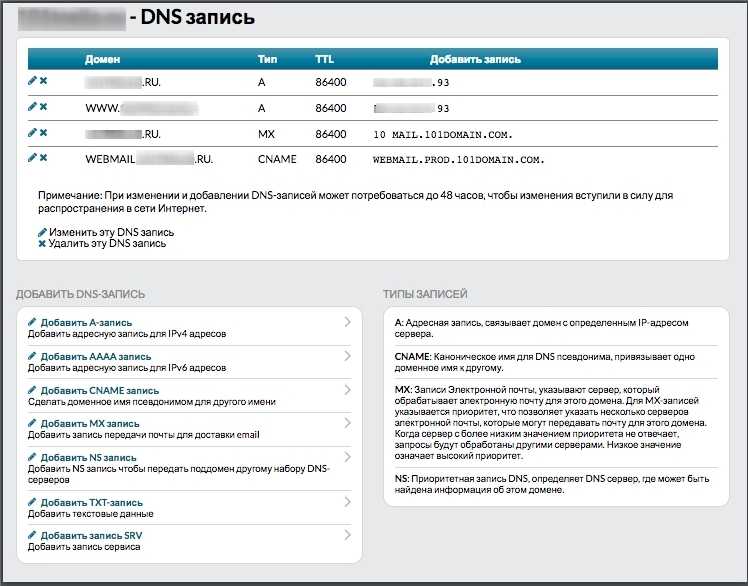
Работа с шаблонами цитирования [ править ]
` citation ` , и все шаблоны Citation Style 1 поддерживают параметр (обратите внимание, что параметр также является обязательным). Другие шаблоны цитирования также могут поддерживать — см
Их документацию.
- → «Главная страница Википедии» . Архивировано из оригинала на 2002-09-30 . Проверено 6 июля 2005 .
- Если на заархивированном ресурсе указана исходная дата публикации, используйте вместо .
- При добавлении URL-адреса архива к любой ссылке, где исходный URL-адрес ресурса все еще работает, полезно добавить параметр. При щелчке по заголовку в сноске вызывается исходный (действующий) URL-адрес, при нажатии кнопки «Архивные» открывается архивная копия. В противном случае заголовок вызывает заархивированную страницу, «Оригинал» вызывает (мертвую, если она не была восстановлена) исходную ссылку: → «Главная страница Википедии» . Архивировано 30 сентября 2002 года . Проверено 6 июля 2005 .Если исходный URL-адрес перестает работать, можно просто изменить его или удалить параметр.
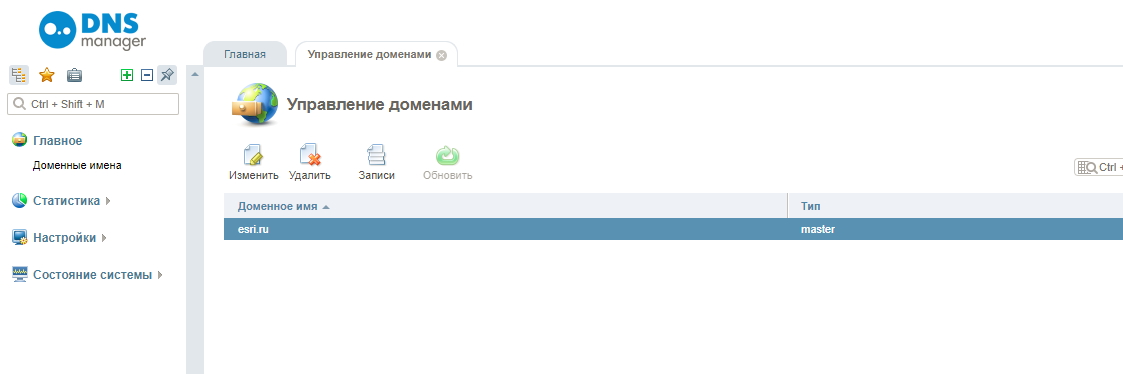
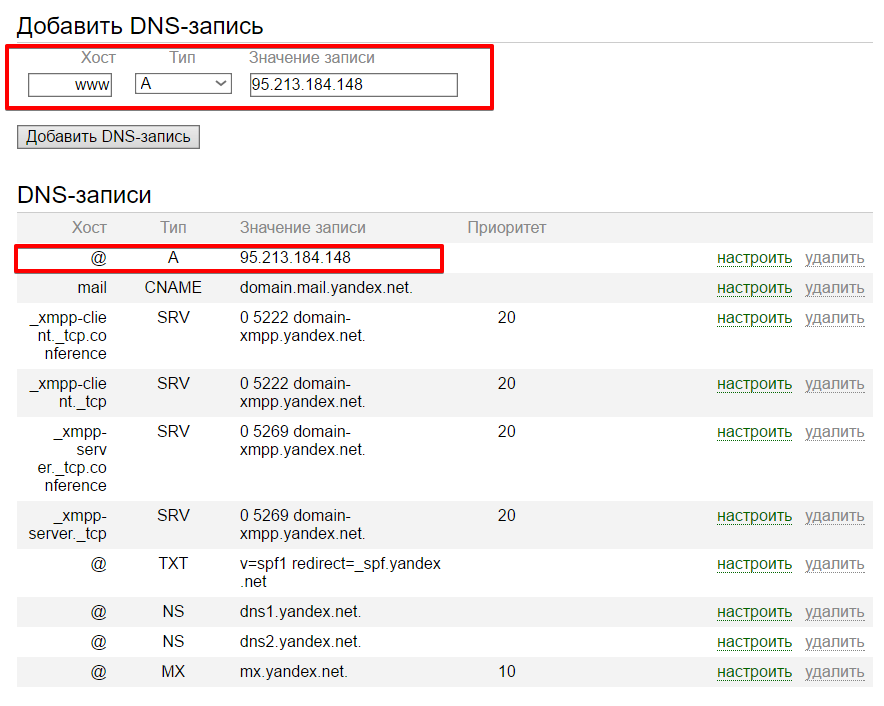
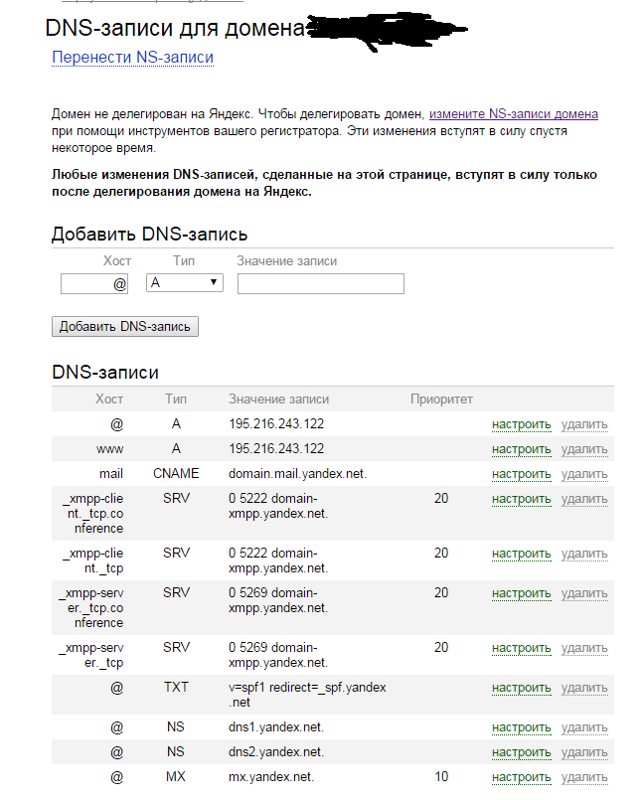
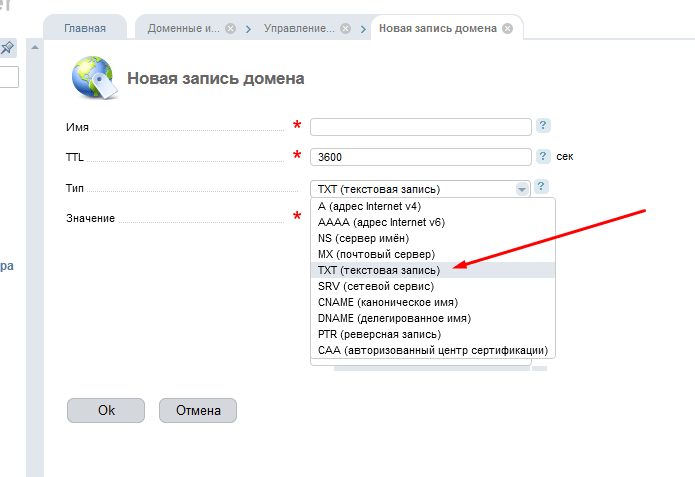
REG.COM
REG.COM является российским регистратором доменных имен. Он предоставляет сервис поиска истории WHOIS, который можно найти в разделе веб-инструментов. В отличие от DomainTools, REG.COM не предоставляет общую статистику истории домена до покупки. Один запрос истории WHOIS домена будет стоить 165 рублей, что составляет около 2,80$. После успешной оплаты войдите в систему, нажмите на вкладку «Все», расположенную в правом верхнем углу, и выберите «Моя история WHOIS»:
![]()
Можно нажать на «Показать результат», чтобы открыть историю WHOIS домена в новой вкладке. А также кнопку «Электронная почта», чтобы отправить отчет на ваш адрес электронной почты. Из теста мы видим, что результат истории WHOIS от REG.COM простой, без каких-либо фильтров или временной шкалы:
![]()
Также мы обнаружили, что REG.COM предлагает больше результатов истории, чем DomainTools. Но после изучения результатов и их сравнения с DomainTools оказалось, что записи истории WHOIS от REG.COM – это те же самые записи из DomainTools. А что касается дополнительных записей в REG.COM, они просто являются дублирующейся информацией следующей более ранней или поздней записи.
Мы считаем, что записи истории WHOIS в REG.COM извлекаются из DomainTools, а потом они добавляют еще несколько дублирующих записей, чтобы их результаты не выглядели точно так же, как в DomainTools.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
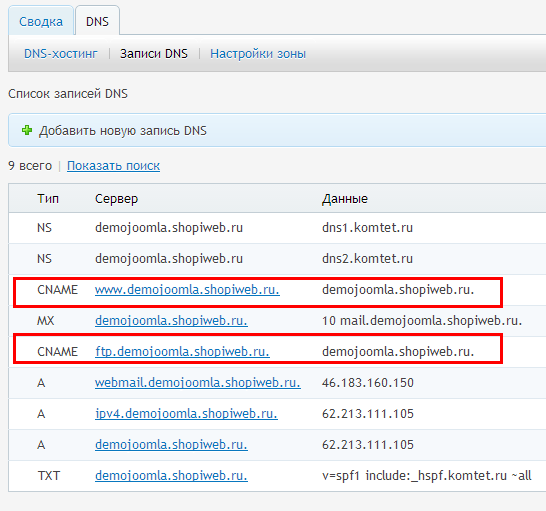
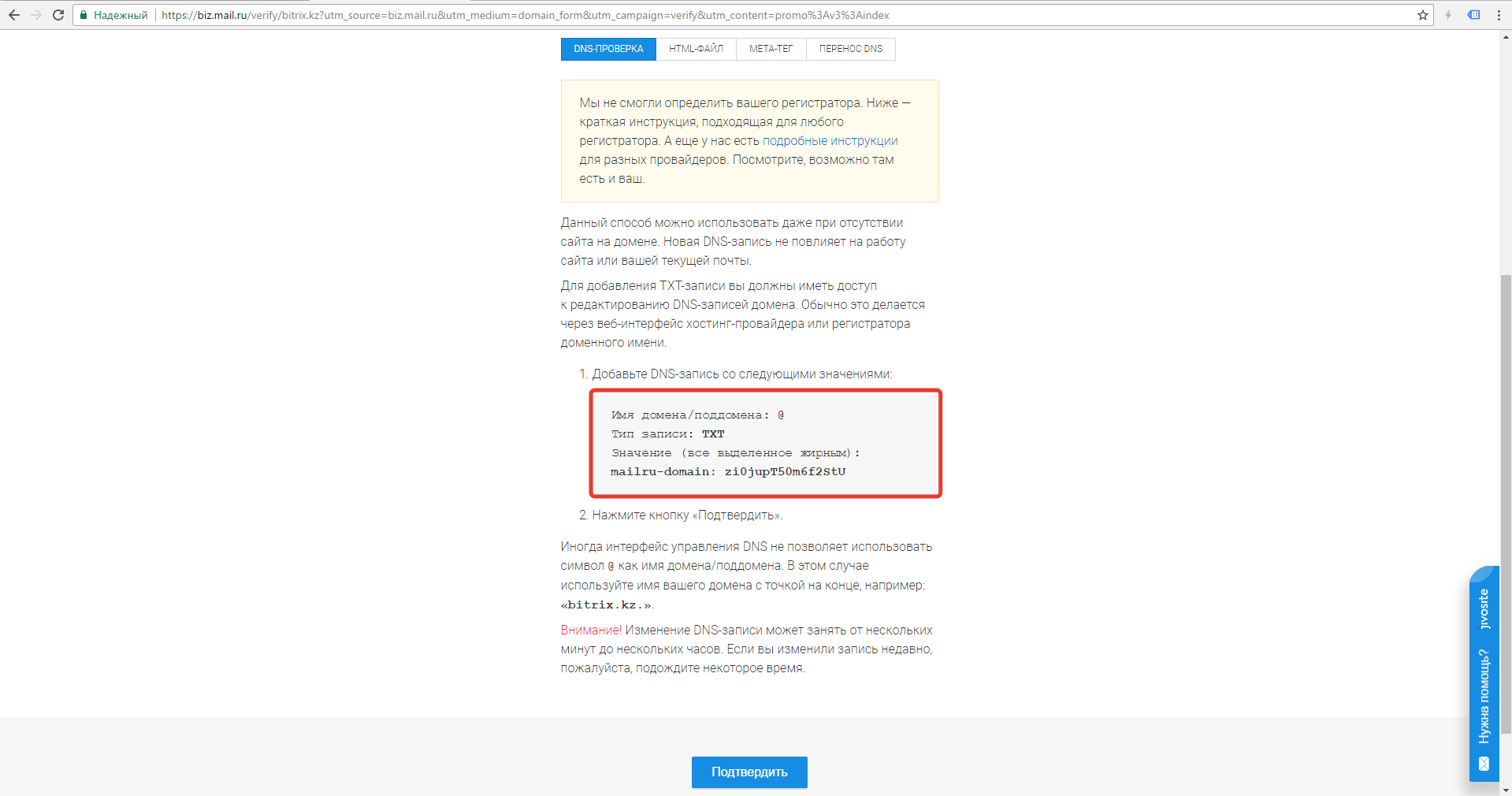
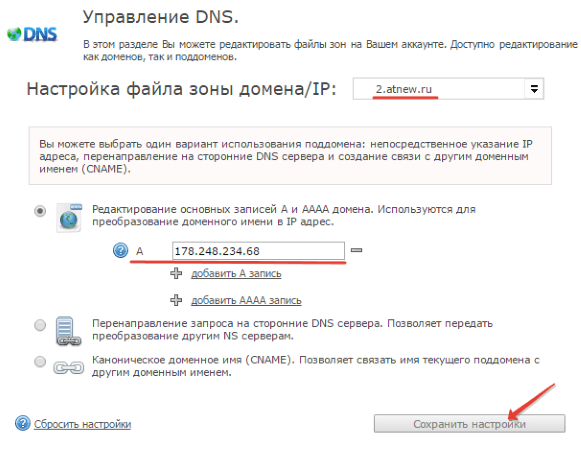
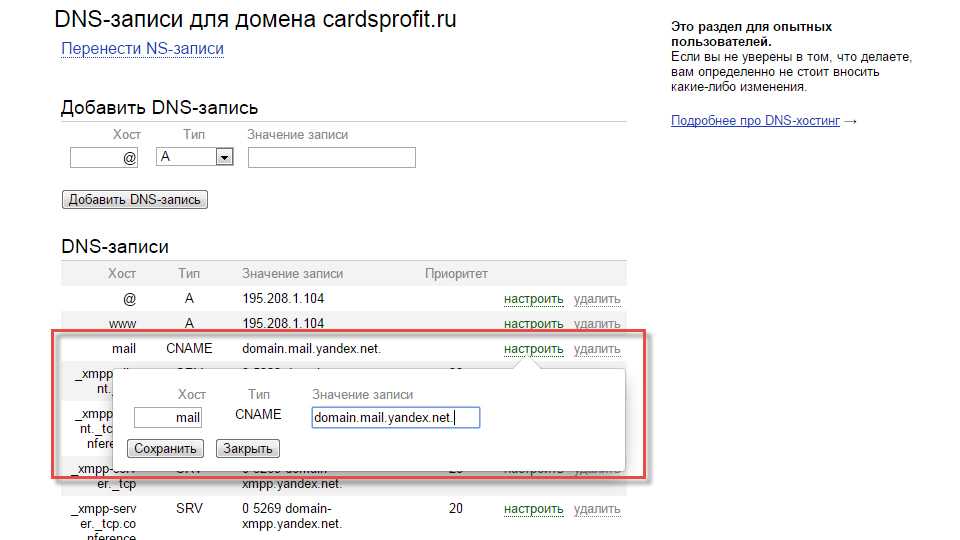
Как посмотреть историю посещения сайтов? Как очистить историю во всех браузерах?
Доброго времени суток.
Оказывается еще далеко не все пользователи знают, что по умолчанию любой браузер запоминает историю посещенных вами страничек. И даже если прошло несколько недель, а может и месяцев, открыв журнал учета посещений браузера — можно найти заветную страничку (если конечно, вы не очищали историю посещений…).
Вообще, опция эта довольно полезна: можно найти ранее посещенный сайт (если забыли добавить его в избранное), или посмотреть чем интересуются другие пользователи, сидящие за данным ПК. В этой небольшой статье я хочу показать как можно посмотреть историю в популярных браузерах, а так же как ее быстро и легко очистить. И так…
Как посмотреть историю посещения сайтов в браузере…
Google Chrome
В Chrome в правом верхнем углу окна есть «кнопка со списком», при нажатии на которую открывается контекстное меню: в нем нужно выбрать пункт «История«. Кстати, поддерживаются и так называемые быстрые клавиши: Ctrl+H (см. рис. 1).
![]()
Рис. 1 Google Chrome
Сама история представляет из себя обычный список адресов интернет страничек, которые отсортированы в зависимости от даты посещения. Довольно легко найти сайты, которые посещал, например, вчера (см. рис. 2).
![]()
Рис. 2 История в Chrome
Firefox
Второй по популярности (после Chrome) браузер на начало 2020г. Чтобы зайти в журнал можно нажать быстрые кнопки (Ctrl+Shift+H), а можно открыть меню «Журнал» и из контекстного меню выбрать пункт «Показать весь журнал«.
Кстати, если у вас нет верхнего меню (файл, правка, вид, журнал…) — просто нажмите левую кнопку «ALT» на клавиатуре (см. рис. 3).
![]()
Рис. 3 открытие журнала в Firefox
Кстати, на мой взгляд в Firefox самая удобная библиотека посещения: можно выбирать ссылки хоть вчерашние, хоть за последние 7 дней, хоть за последний месяц. Очень удобно при поиске!
![]()
Рис. 4 Библиотека посещения в Firefox
Opera
В браузере Opera просмотреть историю очень просто: щелкаете по одноименному значку в левом верхнем углу и из контекстного меню выбираете пункт «История» (кстати, поддерживаются и быстрые клавиши Ctrl+H).
![]()
Рис. 5 Просмотр истории в Opera
Яндекс-браузер
Яндекс-браузер очень сильно напоминает Chrome, поэтому здесь практически все так же: щелкаете в правом верхнем углу экрана по значку «списка» и выбираете пункт «История/Менеджер истории» (или нажмите просто кнопки Ctrl+H, см. рис. 6).
![]()
Рис. 6 просмотр истории посещения в Yandex-браузере
Internet Explorer
Ну и последний браузер, который не мог просто не включить в обзор. Чтобы посмотреть в нем историю — достаточно щелкнуть по значку «звездочка» на панели инструментов: далее должно появиться боковое меню в котором просто выбираете раздел «Журнал».
Кстати, на мой взгляд не совсем логично прятать историю посещения под «звездочку», которая у большинства пользователей ассоциируется с избранным…
![]()
Рис. 7 Internet Explorer…
Как очистить историю во всех браузерах сразу
Можно, конечно, вручную все удалять из журнала, если вы не хотите, чтобы кто-то мог просмотреть вашу историю. А можно просто использовать специальные утилиты, которые за считанные секунды (иногда минуты) очистят всю историю во всех браузерах!
Пользоваться утилитой очень просто: запустили утилиту, нажали кнопку анализа, затем поставили галочки где нужно и нажали кнопку очистки (кстати, история браузера — это Internet History).
![]()
Рис. 8 CCleaner — чистка истории.
В данном обзоре не мог не упомянуть и еще одну утилиту, которая порой показывает еще лучшие результаты по очистке диска — Wise Disk Cleaner.
Пользоваться утилитой так же просто (к тому же она поддерживает русский язык) — сначала нужно нажать кнопку анализа, затем согласиться с теми пунктами по очистке, которая назначила программа, а затем нажать кнопку очистки.
![]()
Рис. 9 Wise Disk Cleaner 8
На этом у меня все, всем удачи!
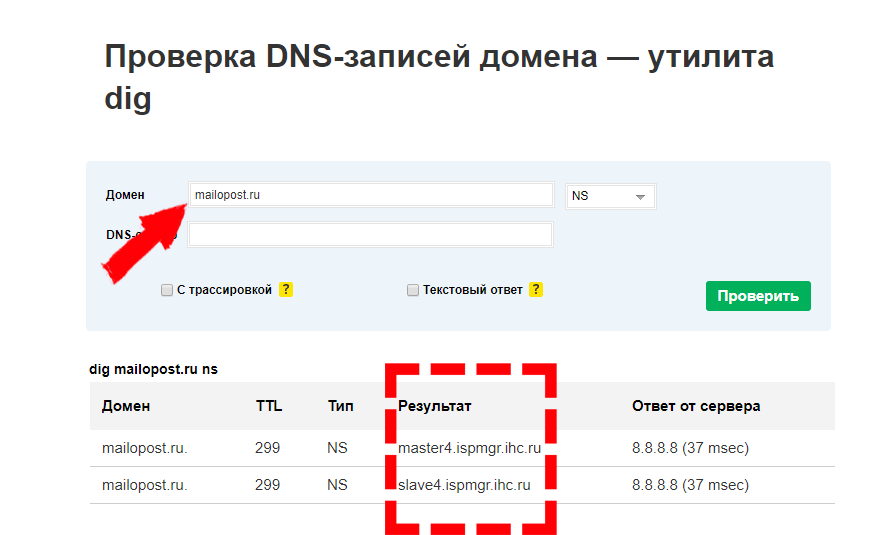
Просмотр истории посещения в браузере:
Chrome
Вариант №1
Нажать простое сочетание кнопок Ctrl+H — должно автоматически открыться окно с историей (прим.: H — History).
![Архив сайтов internet archive wayback machine. интернет-разведка [руководство к действию]](https://fuzeservers.ru/wp-content/uploads/d/d/2/dd203bce5e0c93817a6ddf3e50e48ccb.png)
Вариант №2
Достаточно скопировать адрес: chrome://history/ и вставить его в адресную строку браузера. Просто и легко!
Вариант №3
В правом верхнем углу окна браузера нужно нажать значок с «тремя точками» — в открывшемся списке выбрать вкладку «История» (см. скриншот ниже).
Далее пред вами откроется полный список всех посещений: по датам, времени (см. пример ниже). Также можно искать нужно страничку по ее названию (верхнее меню).
В общем-то, довольно быстро можно найти те сайты, на которые вы заходили…
Opera
Вариант №1
Зажать одновременно кнопки Ctrl+H (также, как и в Chrome).
Вариант №2
Нажать в левом верхнем углу «Меню» и выбрать вкладку «История». Далее у вас будет возможность:
- открыть журнал (историю посещений);
- очистить историю посещений (кстати, для этого также можно зажать кнопки Ctrl+Shift+Del);
- либо просмотреть несколько последних просмотренных страничек (пример ниже).
Кстати, сам журнал, на мой взгляд, даже поудобнее чем в Chrome. Здесь также можно искать в истории по определенному названию странички, сбоку есть удобный рубрикатор по датам: сегодня/вчера/старые.
Firefox
Вариант №1
Для вызова окна журнала посещений необходимо нажать сочетание кнопок Ctrl+Shift+H.
Вариант №2
Также вызвать журнал можно обратившись к меню: в правом верхнем углу нужно на значок с «тремя линиями» — в открывшемся под-окне выбрать «Журнал» (см. скрин ниже).
Кстати, в Firefox журнал посещений (см. скрин ниже), на мой взгляд, выполнен почти идеально: можно смотреть сегодняшнюю историю, вчерашнюю, за последние 7 дней, за этот месяц и пр.
Можно сделать резервную копию, или экспортировать/импортировать записи. В общем-то, все что нужно — под рукой!
Edge
Вариант №1
Нажать сочетание кнопок на клавиатуре Ctrl+H — в правом верхнем окне программы откроется небольшое боковое меню с журналом (пример на скрине ниже).
Вариант №2
Нажать по меню «Центр» (находится в правом верхнем углу программы), затем переключить вкладку с избранного на журнал (см. цифру-2 на скрине ниже).
Собственно, здесь можно и узнать всю необходимую информацию (кстати, здесь же можно очистить историю посещений).
Что входит в историю
Для удобства пользователей браузер накапливает историю, в которую в дальнейшем можно посмотреть, а впоследствии очистить. В нее входят следующие элементы:
- Журнал загрузок и посещений — перечень ресурсов, на которых бывал человек с момента последней чистки.
- Журнал форм и поиска. Сюда входят сведения, которые вводились в поля для заполнения на сайтах (для форм) и информация, введенная в поисковые строки (поиска).
- Куки — сведения о посещенных страницах, а именно внесенные настройки, статус логина и т. д. Злоумышленник может зайти в историю браузера, получить эту информацию и использовать ее против пользователя. Вот почему эти сведения рекомендуется удалять. Деинсталляцию желательно осуществлять на обновленной версии браузера.
- Кэш — временные файлы (картинки, текст, видео и другие данные), которые загружены с Интернета. Они хранятся для ускорения загрузки посещенных ранее страниц. Периодически рекомендуем Вам чистить кэш.
- Активные сеансы. Если человек вошел в профиль, а последствии почистил историю, придется логинится заново.
- Настройки интернет-ресурса. Сюда входит кодировка текста, масштаб, разрешение.
- Информация об автономных сайтах. При наличии разрешения ресурс может сохранять файлы на вашем ПК, чтобы в дальнейшем использовать из без подключения к Сети.
![]()
Все эти данные можно посмотреть в истории посещений. В зависимости от типа браузера конфигурация может отличаться.
Где расположена история в Яндекс браузере на Android
История в мобильной версии Яндекс браузера также содержится на отдельной вкладке, где её можем изучить в любое время. Тут появляются все ссылки сайтов, просмотренных в браузере, а также ссылки с синхронизированных устройств. Мобильная версия Яндекс браузера не даёт возможность перейти к истории через файлик, так что просмотр вкладки – единственный путь.
Рассмотрим, где в Yandex browser на телефоне находится история:
- Открываем веб-обозреватель и переходим на абсолютно любую страницу.
- Нажимаем по значку с цифрой, обведённой в квадрате.
- Клацаем на значок с часами в нижнем меню навигации.
- Попадаем на страницу, где и располагается история в мобильном Яндекс браузере.
Даже перейдя на страницу «Закладки» или «Другие устройства» (располагаются по обе стороны от значка истории), мы сможем увидеть историю Яндекс веб-обозревателя на Андроид. Между этими тремя вкладками легко переходить, навигация на Андроид-устройствах располагается в верхней части окна.
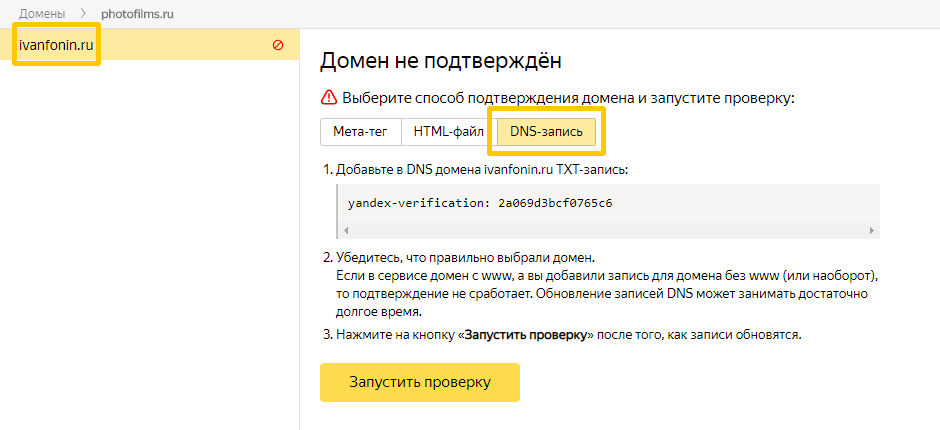
Как отправить страницу на Wayback Machine
Вы можете добавить страницу в Wayback Machine в любое время. Чтобы заархивировать конкретную страницу в том виде, в каком она есть на данный момент, будь то законная ссылка или просто личная ссылка, перейдите в область « Сохранить страницу сейчас» на сайте и вставьте ссылку в текстовое поле.
![]()
На этой странице есть несколько других опций, которые вы можете включить, если хотите:
- Сохранение ссылок : Экономьте время, и Wayback Machine сохраняет даже ссылки, на которые указывает страница.
- Сохранить страницы ошибок (HTTP Status = 4xx, 5xx) : Сохранить страницы, даже если они возвращают ошибку кода состояния HTTP .
- Сохранить снимок экрана : сохранить версию изображения страницы в дополнение к обычному снимку с переходом по клику.
- Сохраните также в моем веб-архиве : если вы вошли в систему, вы увидите эту опцию, которая хранит ссылку на архив в вашей учетной записи для быстрого доступа позже.
Еще один способ использовать Wayback Machine для архивирования веб-страницы — использовать букмарклет. Используйте приведенный ниже код JavaScript в качестве местоположения новой закладки / избранного в вашем браузере и выберите его на любой веб-странице, чтобы мгновенно отправить его на Wayback Machine для архивирования.
Другой вариант отправки страниц на Wayback Machine — расширение Chrome Wayback Machine ; есть и Firefox . Это расширение на самом деле делает гораздо больше, чем просто сохраняет страницы на своем веб-сайте — вы можете использовать его для просмотра страницы на Wayback Machine и автоматической загрузки заархивированной страницы, если открытая страница не работает.
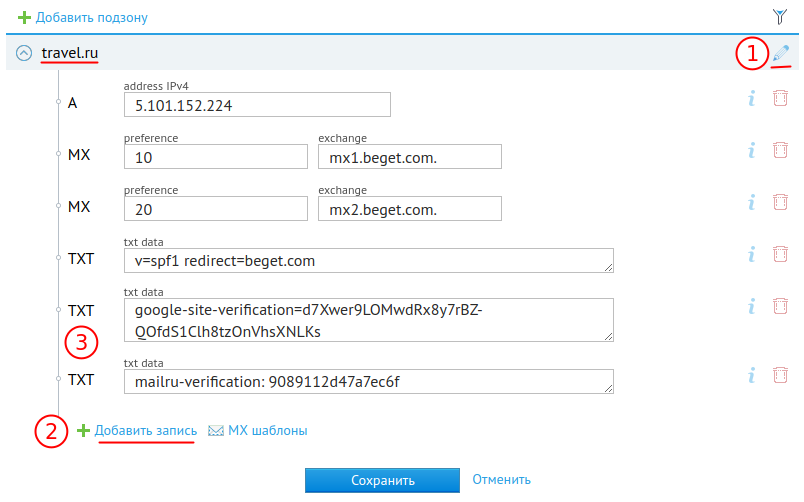
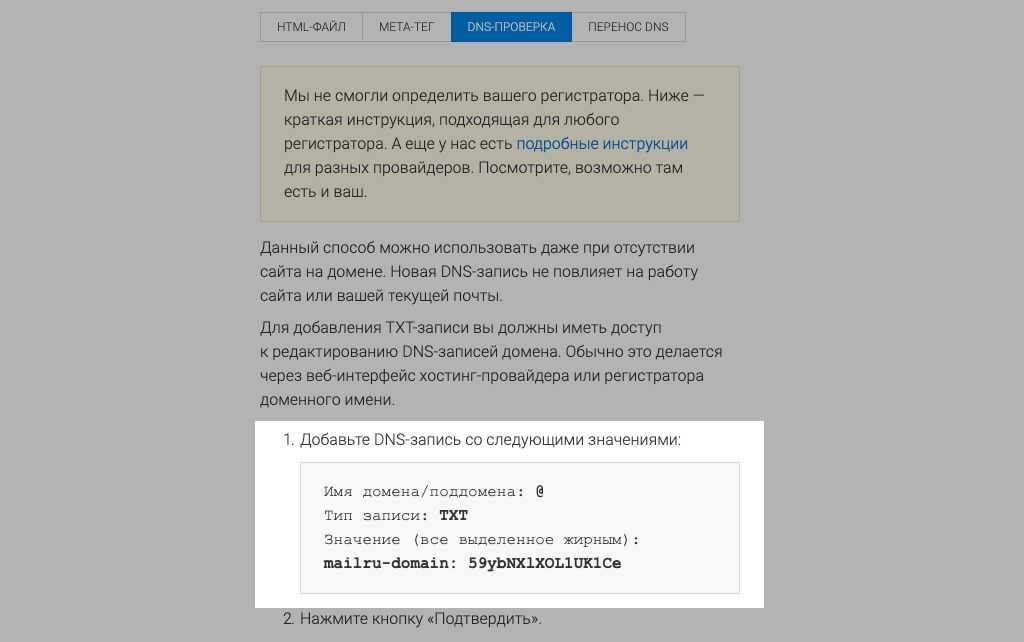
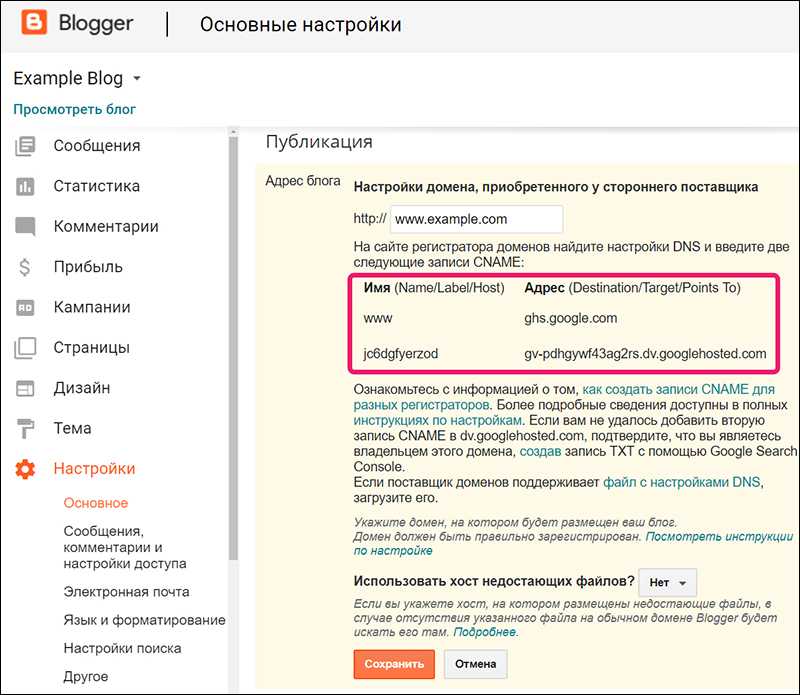
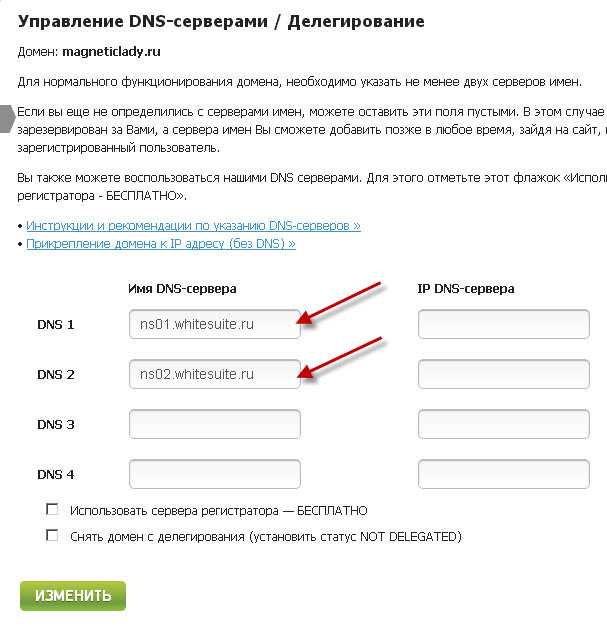
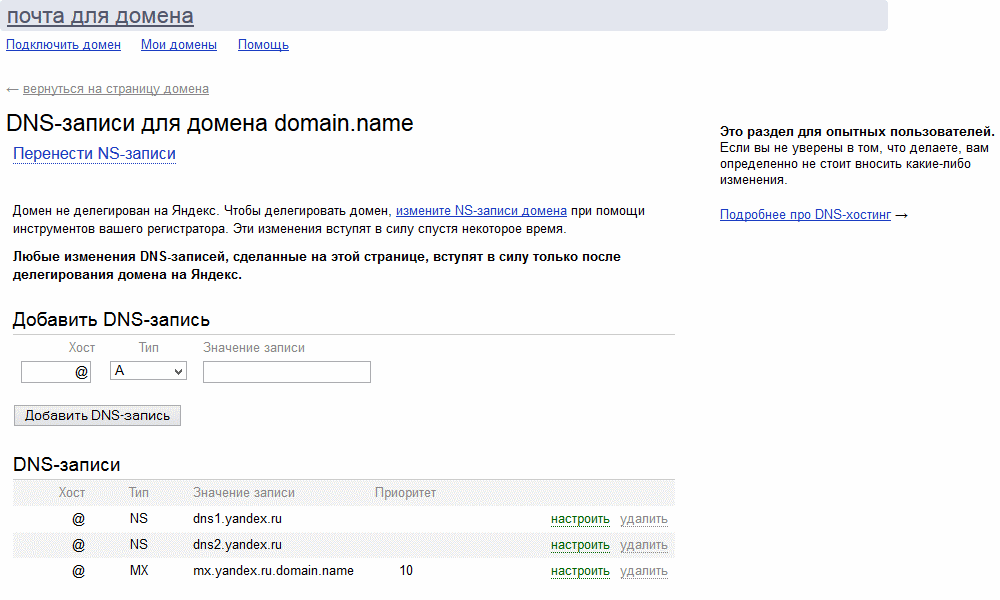
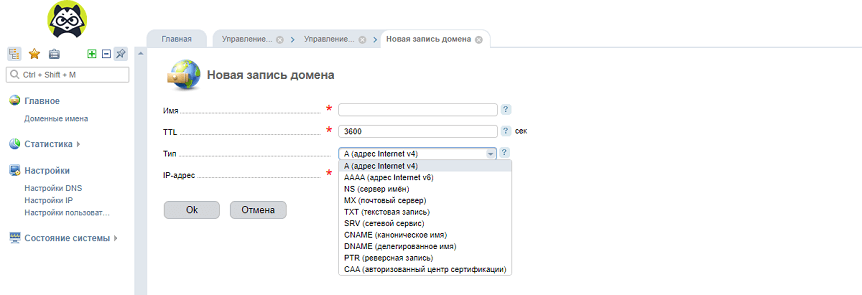
![]()
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.





