
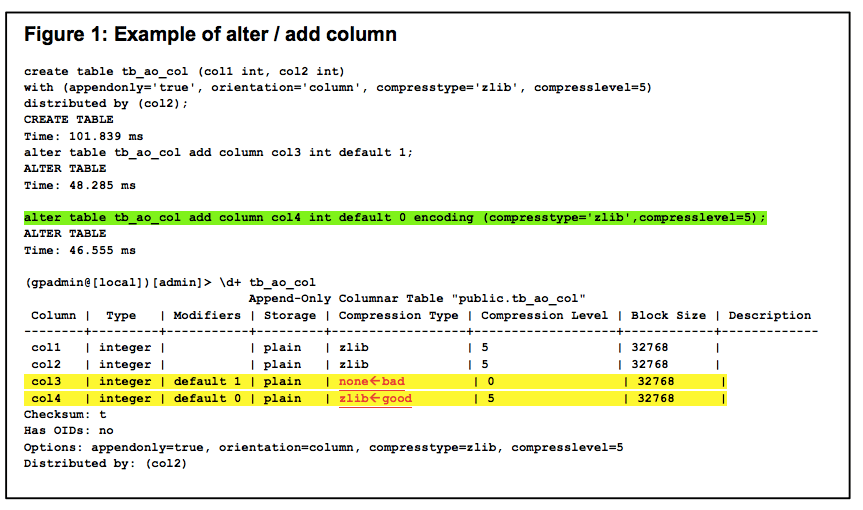
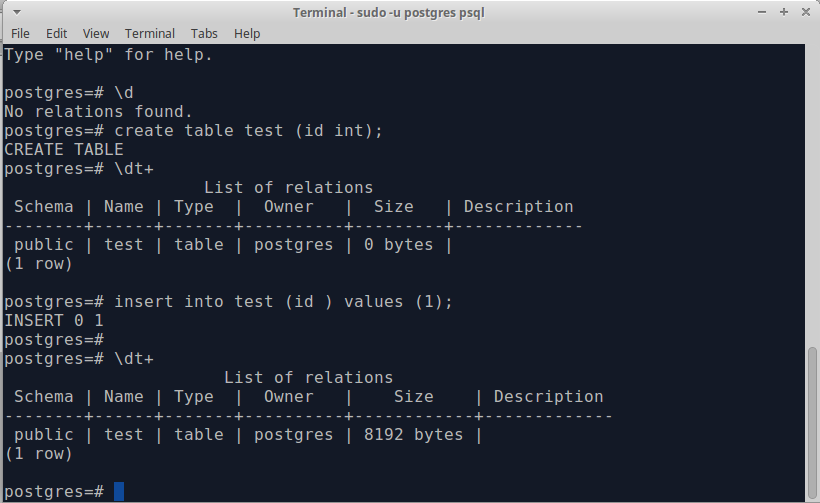
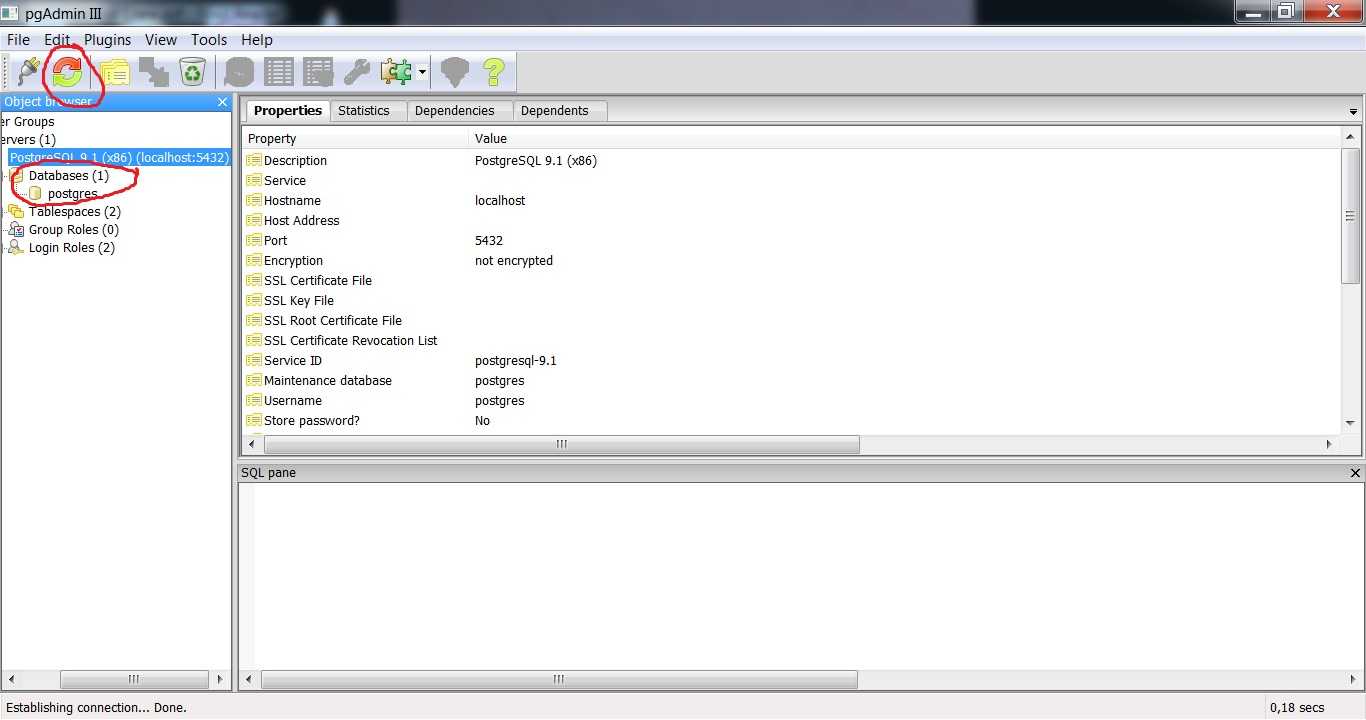
Клонирование базы данных
Время от времени приходится создавать миграции для баз данных. Процесс разработки такой миграции полон боли и ошибок, а это значит, что я создаю их итерационно, проверяя каждую написанную команду. Я накатываю и откатываю миграцию много раз, убеждаясь что ничего не ломается.
Локальная база данных, на которой я тренируюсь, обычно заполнена вручную или восстановлена из дампа с прода. Т.к. я гоняю преобразование схемы много раз, то обязательно случается, что данные приходят в некорректное состояние. В таком случае я восстанавливаю базу из дампа, что может отнимать достаточно много времени.
В данном случае проще будет воспользоваться клонированием базы данных, а если что-то пойдёт не так, то восстановить из бэкапа. Благо это делается в пару строчек. Для копирования достаточно указать существующую в качестве шаблона.
Для восстановления удалим существующую и склонируем обратно.
Роли и методы аутентификации PostgreSQL
Разрешения на доступ к базе данных в PostgreSQL обрабатываются с помощью концепции ролей. Роль может представлять пользователя базы данных или группу пользователей базы данных.
- Доверие — с помощью этого метода роль может подключаться без пароля, если соблюдаются критерии, определенные в .
- Пароль — роль может подключиться, указав пароль. Пароли могут быть сохранены как и (открытый текст).
- Ident — этот метод поддерживается только для соединений TCP / IP. Он работает путем получения имени пользователя операционной системы клиента с дополнительным отображением имени пользователя.
- Peer — То же, что и Ident, но поддерживается только для локальных подключений.
Аутентификация клиента PostgreSQL определяется в файле конфигурации с именем . По умолчанию для локальных подключений PostgreSQL настроен на использование метода одноранговой аутентификации.
Пользователь создается автоматически при установке PostgreSQL. Этот пользователь является суперпользователем для экземпляра PostgreSQL и эквивалентен корневому пользователю MySQL.
Чтобы войти на сервер PostgreSQL в качестве пользователя postgres, сначала вам нужно переключиться на пользователя postgres, а затем получить доступ к приглашению PostgreSQL с помощью утилиты :
Отсюда вы можете взаимодействовать со своим экземпляром PostgreSQL. Чтобы выйти из оболочки PostgreSQL, введите:
Вы также можете получить доступ к командной строке PostgreSQL, не переключая пользователей, с помощью команды :
Пользователь обычно используется только с локального хоста, и не рекомендуется устанавливать пароль для этого пользователя.
Если вы установили PostgreSQL версии 10 из официальных репозиториев PostgreSQL, вам нужно будет использовать полный путь к двоичному файлу есть .
Установите PostgreSQL из репозиториев CentOS
На момент написания этой статьи последней версией PostgreSQL, доступной в репозиториях CentOS, была PostgreSQL версии 9.2.23.
Чтобы установить PostgreSQL на ваш сервер CentOS, выполните следующие действия:
-
Установка PostgreSQL
Чтобы установить сервер PostgreSQL вместе с пакетом PostgreSQL contrib, который предоставляет несколько дополнительных функций для базы данных PostgreSQL, просто введите:
-
Инициализация базы данных
Инициализируйте базу данных PostgreSQL с помощью следующей команды:
-
Запуск PostgreSQL
Чтобы запустить службу PostgreSQL и разрешить ей запускаться при загрузке, просто введите:
-
Проверка установки PostgreSQL
Чтобы проверить установку, мы попытаемся подключиться к серверу базы данных PostgreSQL с помощью инструмента и распечатать версию сервера :
Psql — это интерактивная утилита командной строки, которая позволяет нам взаимодействовать с сервером PostgreSQL.
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
Основные настройки
Конфигурационный файл отвечающий за настройки аутентификации – pg_hba.conf. Он находится в каталоге PGDATA:
postgres@s-pg13:~$ ls -l $PGDATA/pg_hba.conf -rw------- 1 postgres postgres 4760 июн 21 15:15 /usr/local/pgsql/data/pg_hba.conf
Его местоположение можно изменить задав параметр hba_file в конфигурационном файле postgresql.conf:
postgres@s-pg13:~$ cat $PGDATA/postgresql.conf | grep hba #hba_file = 'ConfigDir/pg_hba.conf' # host-based authentication file
При изменении этого файла конфигурацию сервера нужно перечитать, выполнив:
- – из операционной системы;
- – если вы подключены к СУБД.
Если вы подключены к СУБД, то узнать местоположение файла можно таким способом:
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SHOW hba_file;
hba_file
-----------------------------------
/usr/local/pgsql/data/pg_hba.conf
(1 row)
Time: 0,740 ms
Файл pg_hba.conf состоит из строк, а строки состоят из следующих полей:
- тип подключения;
- имя БД;
- имя пользователя;
- адрес узла;
- метод аутентификации;
- необязательные дополнительные параметры в виде имя=значение. Эти параметры нужны некоторым методам аутентификации.
Эти строки обрабатываются сверху вниз и применяется первая найденная строка. Таким образом если тип подключения, имя БД, имя пользователя и адрес сервера совпали, то применяется определённый метод аутентификации.
pg_hba – если-то
При подключении выполняется аутентификация и проверяется привилегия CONNECT. Если результат отрицательный, доступ запрещается и строки ниже не рассматриваются. Если ни одна запись не подошла, доступ запрещается. Таким образом записи должны идти сверху вниз от частного к общему.
Вот пример файла pg_hba.conf, который создаётся при сборке из исходников:
# TYPE DATABASE USER ADDRESS METHOD local all all trust host all all 127.0.0.1/32 trust host all all ::1/128 trust local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust
Первая строчка это тип подключения local, в котором используется локальный unix сокет, и не задействована сеть. При таком подключении все пользователи (all) могут подключаться методом trust. О методах поговорим позже.
Третья и четвёртая строки относятся к tcp подключениям (host). При таком подключении все пользователи могут подключаться только из локального хоста (127.0.0.1/32 или ::1/128) используя метод trust.
Последние три строки относятся к репликации. Репликация возможна по сокету (local) и по сети (host) но только с локального хоста (127.0.0.1/32 или ::1/128). Здесь тоже используется метод trust.
Если вы подключены к СУБД, то сможете посмотреть содержимое файла pg_hba.conf с помощью представления pg_hba_file_rules:
postgres@postgres=# SELECT * FROM pg_hba_file_rules;
line_number | type | database | user_name | address | netmask | auth_method | options | error
-------------+-------+---------------+-----------+-----------+-----------------------------------------+-------------+---------+-------
88 | local | {all} | {all} | | | trust | |
90 | host | {all} | {all} | 127.0.0.1 | 255.255.255.255 | trust | |
92 | host | {all} | {all} | ::1 | ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff | trust | |
95 | local | {replication} | {all} | | | trust | |
96 | host | {replication} | {all} | 127.0.0.1 | 255.255.255.255 | trust | |
97 | host | {replication} | {all} | ::1 | ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff | trust | |
(6 rows)
Time: 2,006 ms
Если в строке допущена ошибка, то это представление в поле error покажет ошибку.
Установка PostgreSQL 9.4
Начнем мы с проверки, какая версия PostgreSQL есть в стандартных репозиториях CentOS 7.1
yum list | grep postgresql
![]()
Мы видим, что там присутствует только версия 9.2, поэтому давайте подключим дополнительный репозиторий
rpm -Uvh http://yum.postgresql.org/9.4/redhat/rhel-7-x86_64/pgdg-centos94-9.4-1.noarch.rpm
![]()
И еще раз проверим, появилась ли нужная нам версия
yum list | grep postgresql
![]()
Как видим, она появилась.
Переходим непосредственно к установке, выполняем команду
yum -y install postgresql94-server postgresql94
![]()
Для инициализации базы данных выполним
/usr/pgsql-9.4/bin/postgresql94-setup initdb
![]()
COLUMNS
Содержит столбцы, которые считываются из системной таблицы system.columns, и столбцы, которые не поддерживаются в ClickHouse или не имеют смысла (всегда имеют значение ), но должны быть по стандарту.
Столбцы:
- (String) — имя базы данных, в которой находится таблица.
- (String) — имя базы данных, в которой находится таблица.
- (String) — имя таблицы.
- (String) — имя столбца.
- (UInt64) — порядковый номер столбца в таблице (нумерация начинается с 1).
- (String) — выражение для значения по умолчанию или пустая строка.
- (UInt8) — флаг, показывающий является ли столбец типа .
- (String) — тип столбца.
- (Nullable(UInt64)) — максимальная длина в байтах для двоичных данных, символьных данных или текстовых данных и изображений. В ClickHouse имеет смысл только для типа данных . Иначе возвращается значение .
- (Nullable(UInt64)) — максимальная длина в байтах для двоичных данных, символьных данных или текстовых данных и изображений. В ClickHouse имеет смысл только для типа данных . Иначе возвращается значение .
- (Nullable(UInt64)) — точность приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse это разрядность для целочисленных типов и десятичная точность для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — основание системы счисления точности приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse значение столбца равно 2 для целочисленных типов и 10 — для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — масштаб приблизительных числовых данных, точных числовых данных, целочисленных данных или денежных данных. В ClickHouse имеет смысл только для типов . Иначе возвращается значение .
- (Nullable(UInt64)) — десятичная точность для данных типа . Для других типов данных возвращается значение .
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
- (Nullable(String)) — , не поддерживается.
Пример
Запрос:
Результат:
Псевдо роль public
Псевдо роль public не видна, но про неё следует знать. Это групповая роль, в которую включены все остальные роли. Это означает, что все роли по умолчанию будут иметь привилегии наследуемые от public. Поэтому иногда у public отбирают некоторые привилегии, чтобы отнять их у всех пользователей.
Роль public по умолчанию имеет следующие привилегии:
-
для всех баз данных:
- CONNECT – это означает что любая созданная роль сможет подключаться к базам данных, но не путайте с привилегией LOGIN;
- TEMPORARY – любая созданная роль сможет создавать временные объекты во всех база данных и объекты эти могут быть любого размера;
-
для схемы public:
- CREATE (создание объектов) – любая роль может создавать объекты в этой схеме;
- USAGE (доступ к объектам) – любая роль может использовать объекты в этой схеме;
-
для схемы pg_catalog и information_schema
USAGE (доступ к объектам) – любая роль может обращаться к таблицам системного каталога;
:
-
для всех функций
EXECUTE (выполнение) – любая роль может выполнять любую функцию. Ещё нужны ещё права USAGE на ту схему, в которой функция находится, и права к объектам к которым обращается функция.
:
-

Это сделано для удобства, но снижает безопасность сервера баз данных.
Команды PostgreSQL (Шпаргалка по PostgreSQL)
Доступ к серверу PostgreSQL через psql с определенным пользователем:
psql -U ;
Например, следующая команда использует пользователя postgres для доступа к серверу базы данных PostgreSQL:
psql -U postgres
Подключение к определенной базе данных:
\c database_name;
Подключение к базе данных dvdrental:
\c dvdrental; You are now connected to database "dvdrental" as user "postgres".
Чтобы выйти из psql:
\q
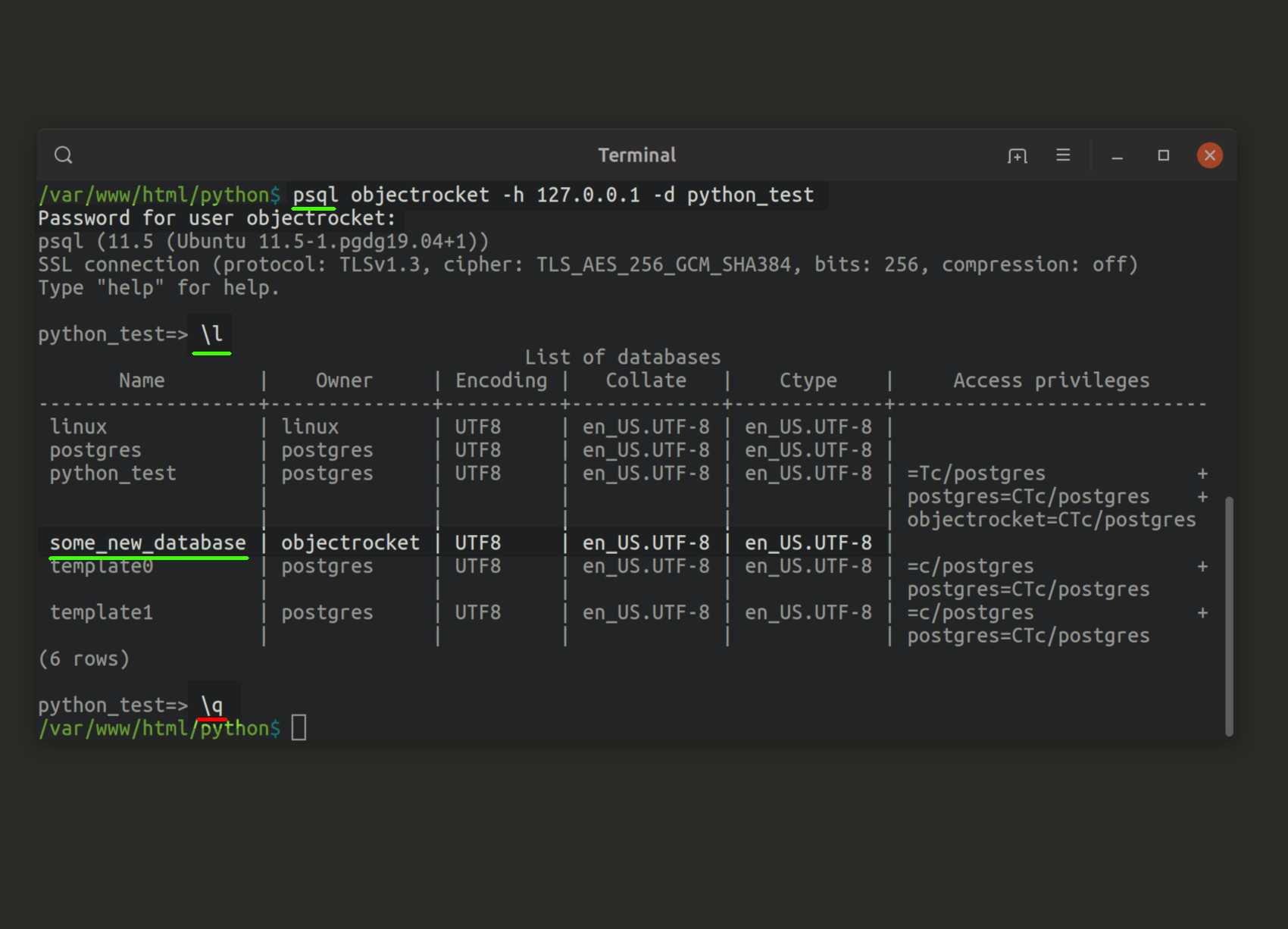
Список всех баз данных на сервере PostgreSQL
\l
Список всех схем:
\dn
Список всех хранимых процедур и функций:
\df
Список всех представлений
\dv
Список всех таблиц в текущей базе данных.
\dt
Или для получения дополнительной информации о таблицах в текущей базе данных:
\dt+
Получение подробной информации о таблице.
\d+ table_name
Показывает хранимую процедуру или код функции:
\df+ function_name
Показывает вывод запроса в красивом формате:
\x
Список всех пользователей:
\du
Создает новую роль:
CREATE ROLE role_name;
Создает новую роль с: и :
CREATE ROLE username NOINHERIT LOGIN PASSWORD password;
Изменяет роль для текущей сессии на :
SET ROLE new_role;
Разрешить установить свою роль как :
GRANT role_2 TO role_1;
Создание и настройка пользователей в PostgreSQL 9.4
И для начала давайте зададим пароль для пользователя postgres, так как по умолчанию он создается без пароля, для этого переключимся на пользователя postgres и запустим утилиту psql
su - postgres psql
Меняем пароль пользователя postgres
\password postgres
Теперь давайте создадим нового пользователя, пишем команду (просто, для того чтобы уметь это делать)
CREATE ROLE testuser WITH PASSWORD '123456' LOGIN;
Где, testuser это логин пользователя, а 123456 его пароль.
Для выхода из psql и переключения обратно под root нажимаем два раза сочетание клавиш CTRL+D.
Перезапускаем PostgreSQL
systemctl restart postgresql-9.4
![]()
Ректальное администрирование: Основы для практикующих системных АДминистраторов
Одной из самых популярных и зарекомендовавших себя методологий системного администрирования является так называемое ректальное. Редкий случай сопровождения и обслуживания информационных систем, инфраструктуры организации обходится без его использования. Зачастую без знания данной методологии сисадминам даже бывает сложно найти работу в сфере ИТ, потому что работодатели, особенно всякие аутсорсинговые ИТ фирмы, в основном отдают предпочтение классическим, зарекомендовавшим себя методикам, а не новомодным заграничным веяниям: практикам ITIL, нормальным ITSM и прочей ерунде.
Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Входим в систему под пользователем postgres:
su — postgres
Создаем нового пользователя для репликации:
createuser —replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
exit
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su — postgres -c «psql -c ‘SHOW config_file;'»
В моем случае система вернула строку:
/etc/postgresql/9.6/main/postgresql.conf
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
vi /etc/postgresql/9.6/main/postgresql.conf
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.10’
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
vi /etc/postgresql/9.6/main/pg_hba.conf
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться
Установка сервера 1С:Предприятие
1) Установка сервера 1С:Предприятие из пакетов.
Как оговаривалось в начале статьи, предполагается что у нас уже есть дистрибутив сервера 1С для RPM-based Linux-систем. Он из себя представляет архив с именем rpm64.tar.gz. После разархивирования мы получим список файлов:
![Psql интерактивный терминал postgresql [айти бубен]](https://fuzeservers.ru/wp-content/uploads/c/1/6/c16ea53f3b08240accc438512f056465.jpeg)
1C_Enterprise83-common-8.3.9-1818.x86_64.rpm 1C_Enterprise83-server-8.3.9-1818.x86_64.rpm 1C_Enterprise83-ws-8.3.9-1818.x86_64.rpm 1C_Enterprise83-common-nls-8.3.9-1818.x86_64.rpm 1C_Enterprise83-server-nls-8.3.9-1818.x86_64.rpm 1C_Enterprise83-ws-nls-8.3.9-1818.x86_64.rpm
Находясь в каталоге с этими файлами, мы их устанавливаем командой:
yum localinstall *.rpm
2) Запуск сервера 1С.
systemctl enable srv1cv83 systemctl start srv1cv83 systemctl status srv1cv83
Высока вероятность, что сервер не запустится с первого раза, и при попытке запуска Вы получите ошибку вида:
Failed at step EXEC spawning /etc/rc.d/init.d/srv1cv83: Exec format error
Чтобы устранить эту ошибку, необходимо в скрипте инициализации сервера указать интерпретатор (например shell или bash), для этого необходимо добавить в начало файла /etc/init.d/srv1cv83 строку:
#!/bin/bash
Затем надо перезагрузить systemd для поиска новых или измененных юнитов:
systemctl daemon-reload
И снова попытаться запустить сервер 1С:Предприятие
systemctl restart srv1cv83.service
3) Установка необходимых пакетов для корректной работы сервера 1С.
В документации сервера 1С:Предприятия описана утилита config_system, которая необходима для анализа готовности системы к запуску сервера 1С, в частности она помогает обнаружить отсутствующие необходимые пакеты для корректной работы сервера 1С. К сожалению, анализ rmp пакетов (rmp -ql) показал отсутствие данной утилиты в составе дистрибутива сервера 1С версии 8.3.9.1818.
Необходимость данных пакетов выяснилась опытным путем:
yum install fontconfig-devel yum install ImageMagick
4) Рестарт сервера 1С.
systemctl stop srv1cv83 systemctl start srv1cv83 systemctl status srv1cv83
Шаг 9 — Добавление и удаление столбцов из таблицы
После создания таблицы вы можете изменить ее и добавить или удалить столбцы. Добавьте столбец для отображения даты последнего технического обслуживания для каждого элемента оборудования, введя следующую команду:
Если вы снова просмотрите данные таблицы, то увидите, что новый столбец был добавлен (но не были добавлены данные):
Вы увидите следующее:
Удаление столбца является таким же простым. Если вы обнаружите, что ваши работники используют отдельный инструмент для отслеживания истории обслуживания, то можете удалить столбец, введя следующую команду:
Эта команда удаляет столбец и любые значения внутри него, но оставляет все другие данные нетронутыми.
После добавления и удаления столбцов вы можете попробовать обновить существующие данные на заключительном шаге.
Утилиты (программы) PosgreSQL:
- createdb и dropdb – создание и удаление базы данных (соответственно)
- createuser и dropuser – создание и пользователя (соответственно)
- pg_ctl – программа предназначенная для решения общих задач управления (запуск, останов, настройка параметров и т.д.)
- postmaster – многопользовательский серверный модуль PostgreSQL (настройка уровней отладки, портов, каталогов данных)
- initdb – создание новых кластеров PostgreSQL
- initlocation – программа для создания каталогов для вторичного хранения баз данных
- vacuumdb – физическое и аналитическое сопровождение БД
- pg_dump – архивация и восстановление данных
- pg_dumpall – резервное копирование всего кластера PostgreSQL
- pg_restore – восстановление БД из архивов (.tar, .tar.gz)
Примеры создания резервных копий:
Создание бекапа базы mydb, в сжатом виде
pg_dump -h localhost -p 5440 -U someuser -F c -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в виде обычного текстового файла, включая команду для создания БД
pg_dump -h localhost -p 5432 -U someuser -C -F p -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в сжатом виде, с таблицами которые содержат в имени payments
pg_dump -h localhost -p 5432 -U someuser -F c -b -v -t *payments* -f payment_tables.backup mydb
Дамп данных только одной, конкретной таблицы. Если нужно создать резервную копию нескольких таблиц, то имена этих таблиц перечисляются с помощью ключа -t для каждой таблицы.
pg_dump -a -t table_name -f file_name database_name
Создание резервной копии с сжатием в gz
pg_dump -h localhost -O -F p -c -U postgres mydb | gzip -c > mydb.gz
Список наиболее часто используемых опций:
- -h host — хост, если не указан то используется localhost или значение из переменной окружения PGHOST.
- -p port — порт, если не указан то используется 5432 или значение из переменной окружения PGPORT.
- -u — пользователь, если не указан то используется текущий пользователь, также значение можно указать в переменной окружения PGUSER.
- -a, —data-only — дамп только данных, по-умолчанию сохраняются данные и схема.
- -b — включать в дамп большие объекты (blog’и).
- -s, —schema-only — дамп только схемы.
- -C, —create — добавляет команду для создания БД.
- -c — добавляет команды для удаления (drop) объектов (таблиц, видов и т.д.).
- -O — не добавлять команды для установки владельца объекта (таблиц, видов и т.д.).
- -F, —format {c|t|p} — выходной формат дампа, custom, tar, или plain text.
- -t, —table=TABLE — указываем определенную таблицу для дампа.
- -v, —verbose — вывод подробной информации.
- -D, —attribute-inserts — дамп используя команду INSERT с списком имен свойств.
Бекап всех баз данных используя команду pg_dumpall.
pg_dumpall > all.sql
Восстановление таблиц из резервных копий (бэкапов):
psql — восстановление бекапов, которые хранятся в обычном текстовом файле (plain text);
pg_restore — восстановление сжатых бекапов (tar);
Восстановление всего бекапа с игнорированием ошибок
psql -h localhost -U someuser -d dbname -f mydb.sql
Восстановление всего бекапа с остановкой на первой ошибке
psql -h localhost -U someuser —set ON_ERROR_STOP=on -f mydb.sql
Для восстановления из tar-арихива нам понадобиться сначала создать базу с помощью CREATE DATABASE mydb; (если при создании бекапа не была указана опция -C) и восстановить
pg_restore —dbname=mydb —jobs=4 —verbose mydb.backup
Восстановление резервной копии БД, сжатой gz
gunzip mydb.gz psql -U postgres -d mydb -f mydb
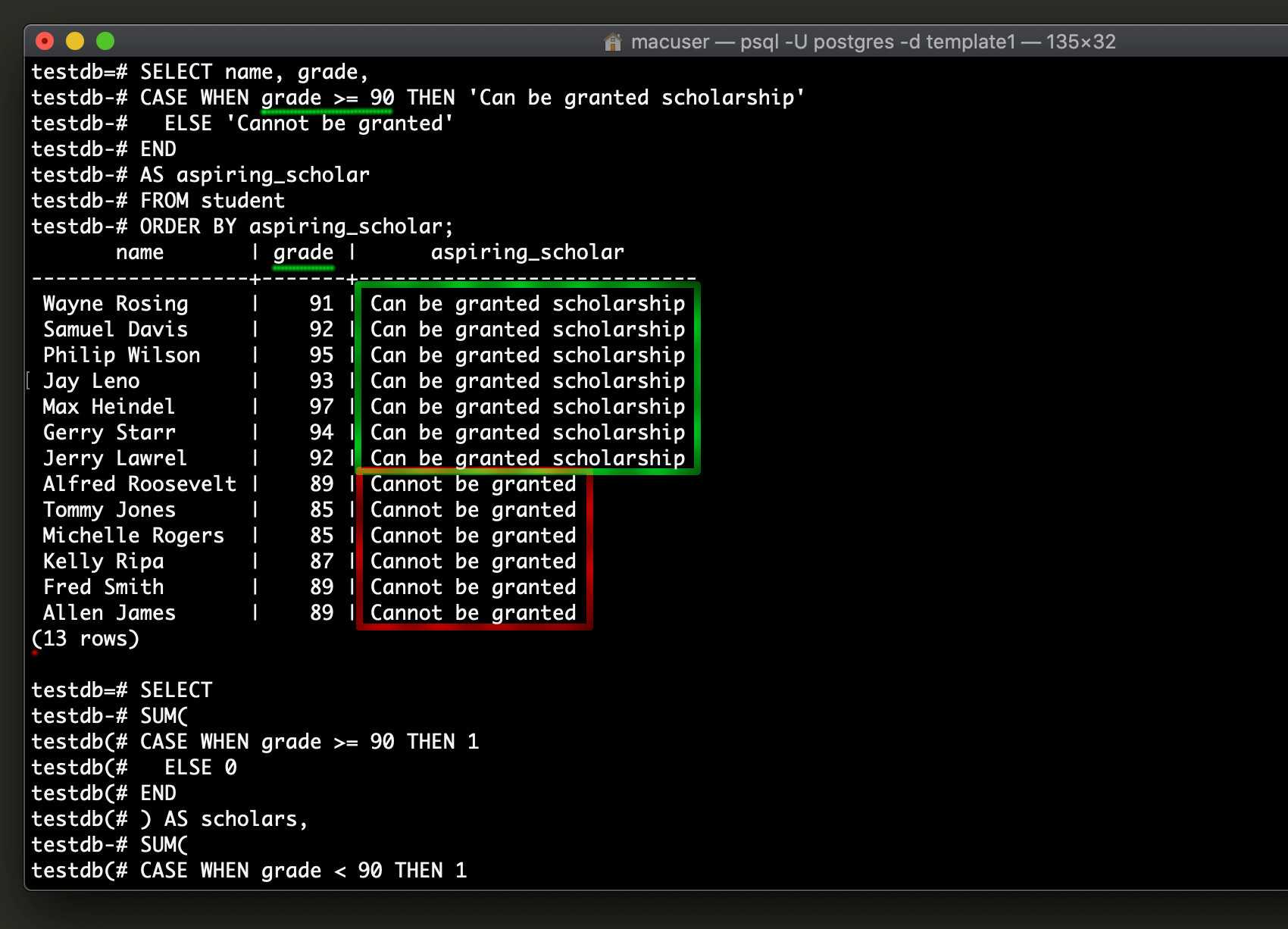
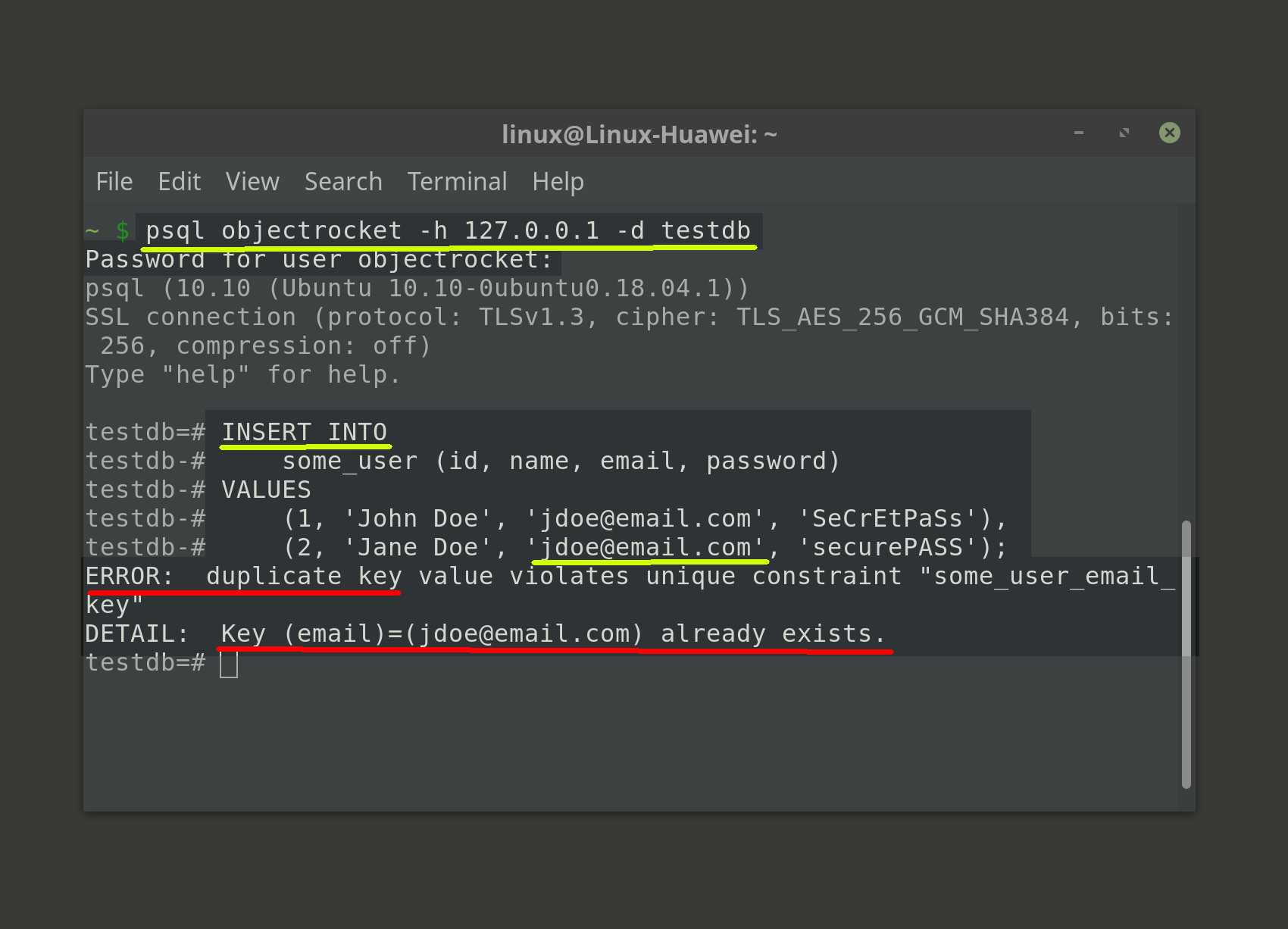
Шаг 3 — Использование ролей и баз данных PostgreSQL
PostgreSQL использует концепцию ролей для выполнения аутентификации и авторизации клиента. В некоторых аспектах они напоминают обычные учетные записи в Unix, однако Postgres не делает различий между пользователями и группами и предпочитает использовать более гибкий термин — роль.
После установки Postgres настроена на использование аутентификации ident, что значит, что выполняется привязка ролей Postgres с соответствующей системной учетной записью Unix/Linux. Если роль существует внутри Postgres, пользователь Unix/Linux с тем же именем может выполнить вход в качестве этой роли.
В ходе установки была создана учетную запись пользователя postgres, которая связана с используемой по умолчанию ролью . Чтобы использовать PostgreSQL, вы можете войти в эту учетную запись.
Существует несколько способов использования этой учетной записи для доступа к командной строке PostgreSQL.
Переключение на учетную запись postgres
Вы можете переключиться на учетную запись postgres на вашем сервере с помощью следующей команды:
Теперь вы можете немедленно получить доступ к командной строке Postgres с помощью следующей команды:
В результате вы можете получить доступ к командной строке PostgreSQL, а уже отсюда свободно взаимодействовать с системой управления базами данных.
Закройте командную строку PostgreSQL с помощью следующей команды:
В результате вы вернетесь в командную строку Linux для учетной записи postgres. Теперь вернитесь к первоначальной учетной записи следующим образом:
Доступ к командной строке Postgres без переключения учетных записей
Также вы можете запускать команды с помощью учетной записи postgres напрямую, используя .
Например, в последнем примере от вас требовалось перейти в командную строку Postgres с помощью переключения на пользователя postgres и последующего запуска , чтобы открыть командную строку Postgres. Вы можете сделать это в один прием с помощью отдельной команды , используя пользователя postgres с следующим образом:
Это позволит выполнить вход в Postgres без необходимости использования промежуточной командной строки .
Вы снова сможете выйти из интерактивного сеанса Postgres с помощью следующей команды:
На этом шаге мы использовали учетную запись postgres для получения доступа к командной строке . Многие варианты использования требуют использования сразу нескольких ролей Postgres. Ниже вы узнаете, как выполнить настройку новых ролей.
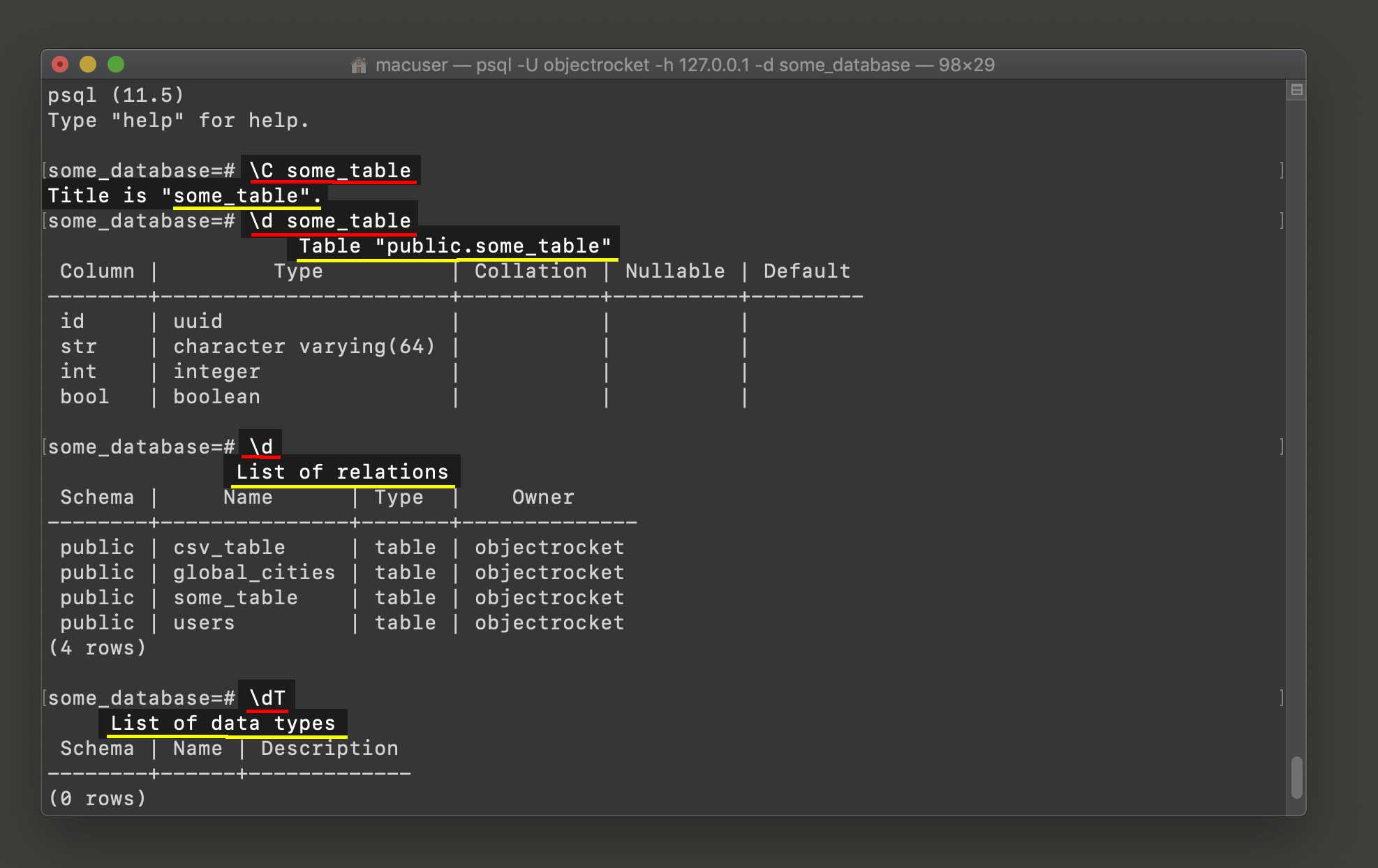
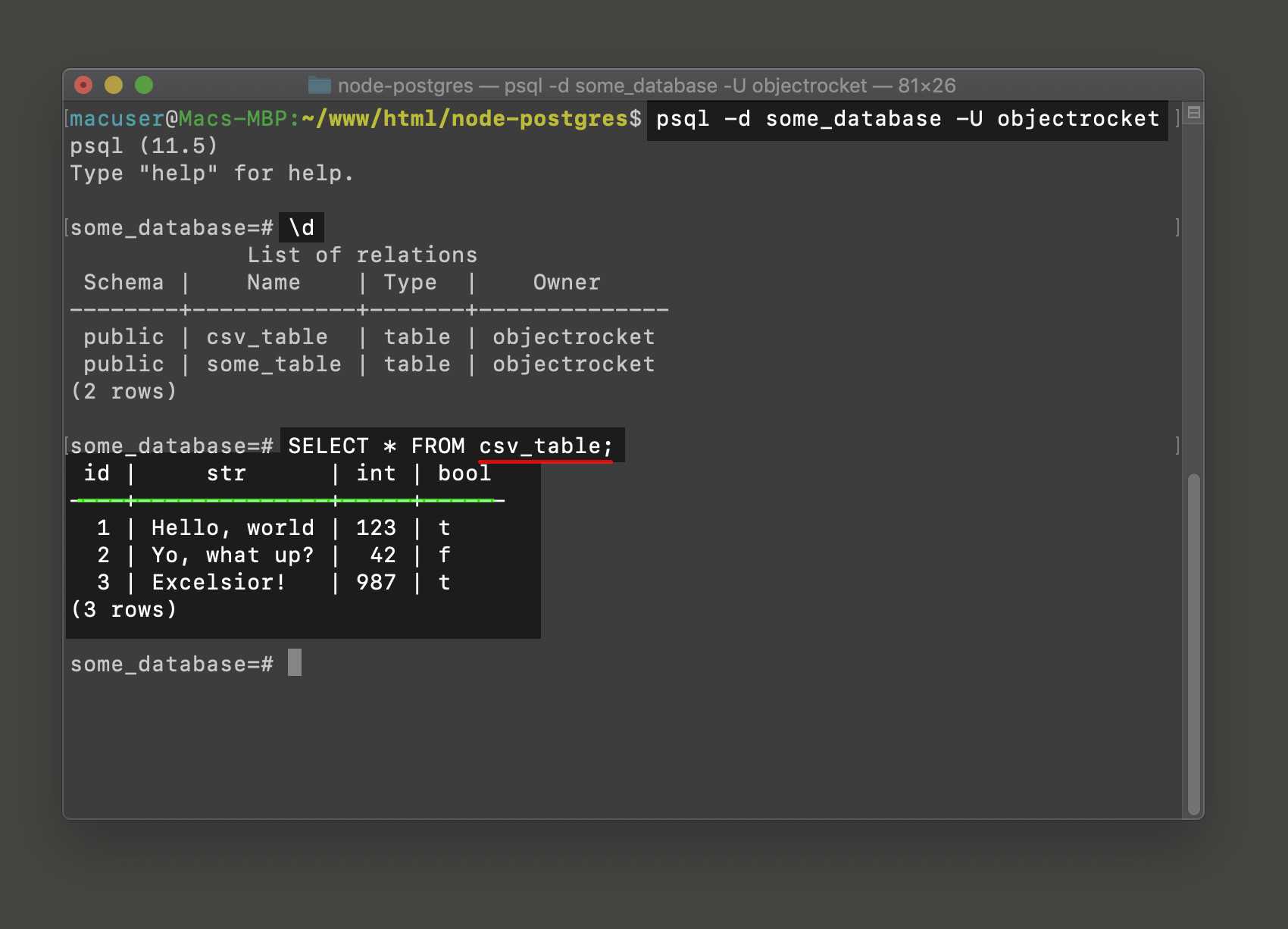
Описание таблицы
Если таблица создана какое-то время назад. Вы могли уже забыть, какие конкретно столбцы она содержит.
Для описания таблицы используется команда \d
\d booking_sites
Table «public.booking_sites»
Column | Type | Collation | Nullable | Default
—————-+————————+————+———-+——————————————-
id | bigint | | not null | nextval(‘booking_sites_id_seq’::regclass)
company_name | character varying(50) | | not null |
origin_country | character varying(50) | | not null |
age | character varying(3) | | not null |
date_of_birth | date | | not null |
website_url | character varying(50) | | |
Indexes:
«booking_sites_pkey» PRIMARY KEY, btree (id)
Шаг 8 — Добавление, запрос и удаление данных в таблице
Теперь, когда у вас есть таблица, вы можете ввести в нее данные.
В качестве примера добавьте строги swing (качели) и slide (горка), вызвав таблицу, куда вы хотите добавить данные, указав столбцы и предоставив данные для каждого столбца:
Вы должны быть внимательны при вводе данных, чтобы не допустить нескольких общих проблем. Во-первых, оборачивайте в кавычки не названия столбцов, а значения в столбцах.
Еще один момент, который необходимо учитывать, состоит в том, что вы не должны указывать значения для столбца . Это вызвано тем, что оно автоматически генерируется при создании новой строки в таблице.
Получите добавленную вами информацию, введя следующую команду:
Результат будет выглядеть следующим образом:
Вы можете убедиться, что столбец уже заполнен успешно, а все другие данные были организованы корректно.
Если же строка slide в таблице разрывается, вы можете удалить строку из таблицы, использовав следующую команду:
Запросите таблицу еще раз:
Вы увидите следующее:
Вы видите, что ваша горка уже не является частью таблицы.
Теперь, когда вы добавили и удалили элементы в таблице, вы можете попробовать добавить и удалить столбцы.
Построение запросов
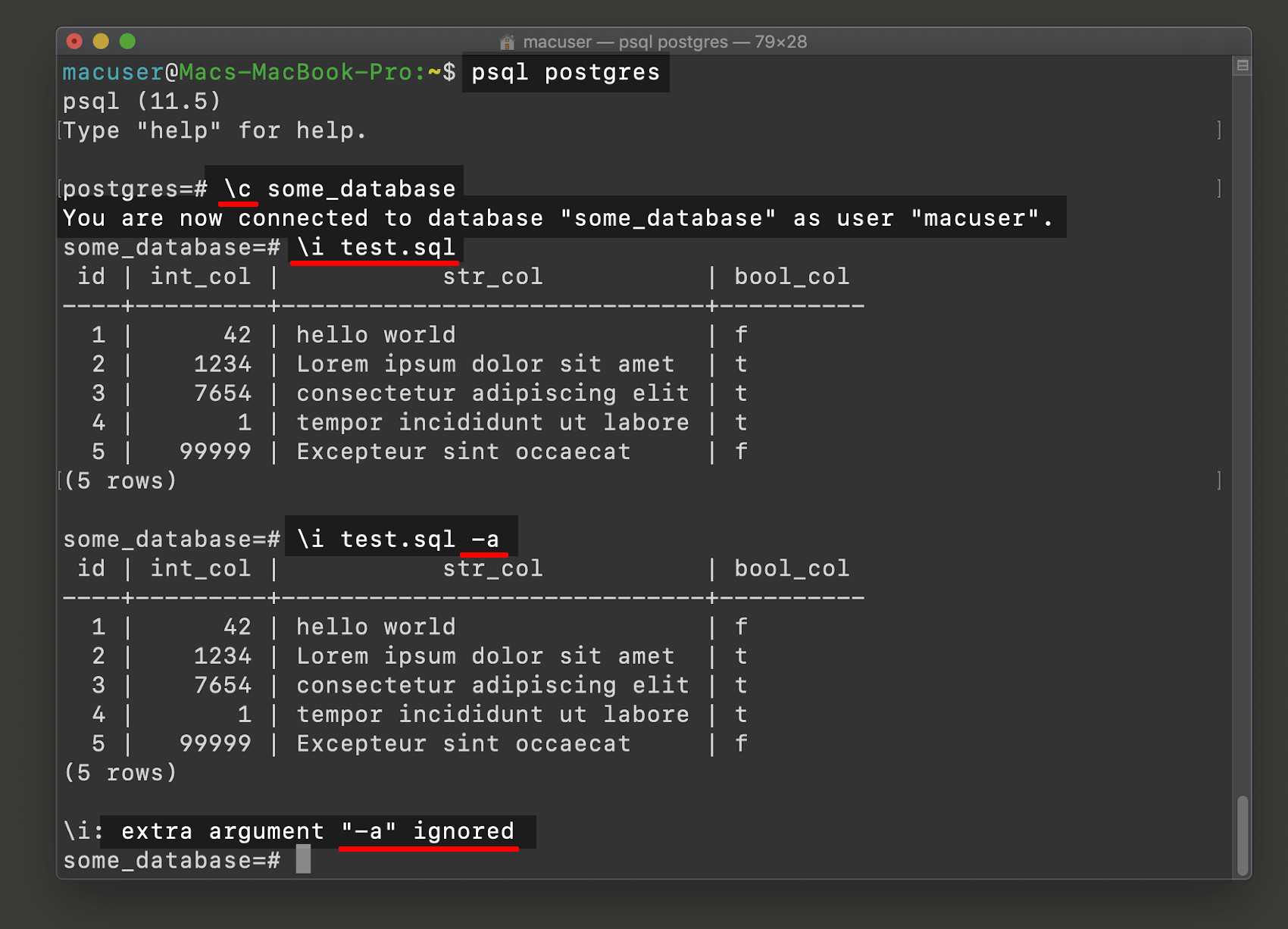
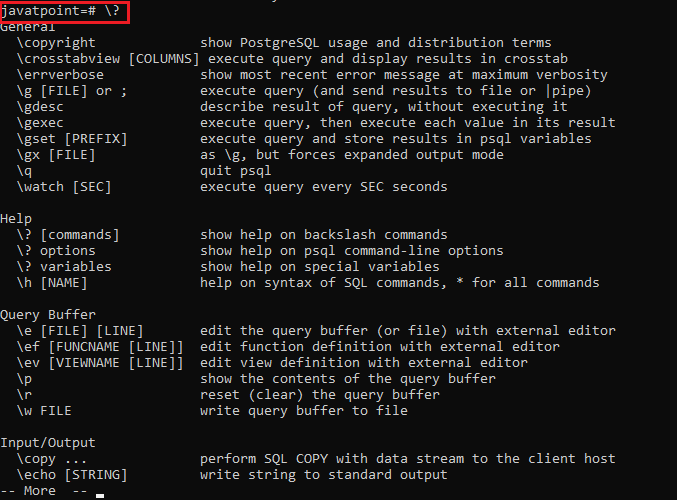
psql превосходно подходит для построения небольших запросов, однако для многострочных и вложенных надо использовать более адекватный инструмент. Например, — она открывает последний запрос в вашем любимом редакторе, который может уже обеспечить и подсветку синтаксиса, и автодополнение, и прочие полезные вещи. Для выполнения достаточно сохранить этот псевдо-файл и выйти (ну прям как с git). удобно использовать для итеративного построения большого запроса.
В режиме такого редактирования можно также сохранить запрос в какой-нибудь отдельный файл на диске. Открыть же его можно с помощью команды . psql прочитает запрос из filename.sql и выполнит его.
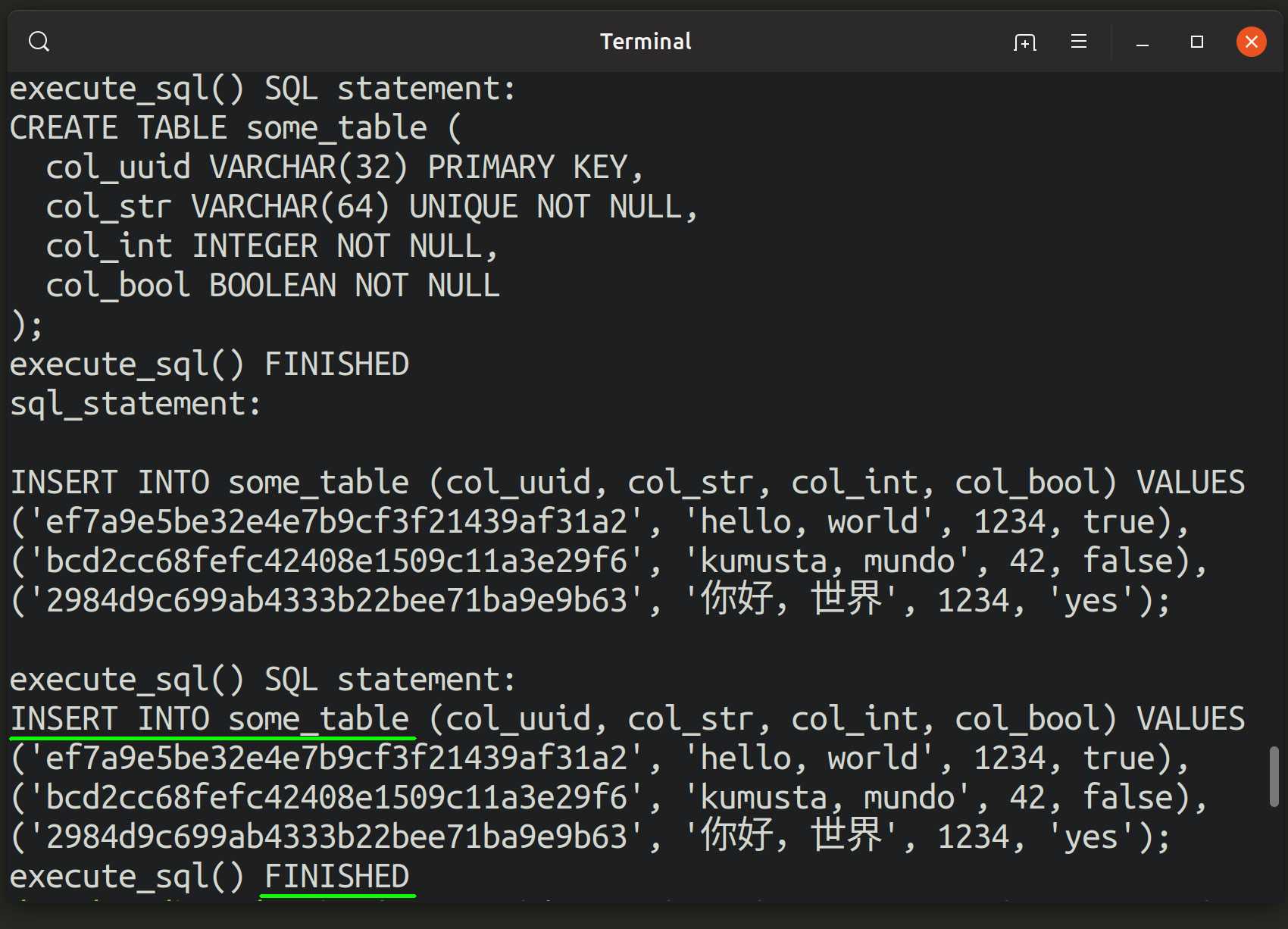
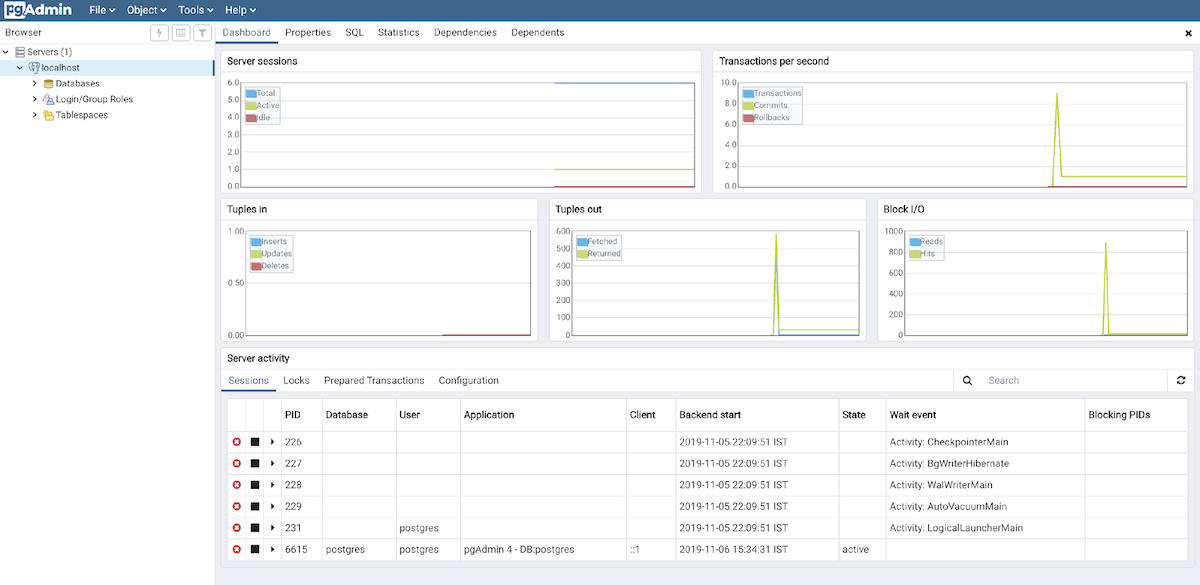
работает только с уже существующими файлами. Передавая имя в качестве аргумента, вы откроете файл в текстовом редакторе и выполните содержимое при выходе. Но как быть когда вы только начинаете писать новый запрос? Выходить из psql, создавать файл и возвращаться обратно слишком сложно. Можно выполнить команду оболочки прямо из psql с помощью , например, .
и существенно упрощают работу над сложными sql запросами. Лично у меня открыто 2 окна side-by-side: один с vim, а другой с psql, где я выполняю только . Переключаюсь — правлю, переключаюсь — выполняю. Прошли те времена, когда я копипастил из java-приложений с помощью незнакомых сочетаний горячих клавиш.
Установите PostgreSQL из репозиториев PostgreSQL
Выполните следующие действия, чтобы установить последнюю версию PostgreSQL на свой сервер CentOS:
-
Включение репозитория PostgreSQL
Чтобы включить репозиторий PostgreSQL, просто установите файл репозитория:
-
Установка PostgreSQL
После включения репозитория установите сервер PostgreSQL и пакеты Contrib PostgreSQL с помощью:
-
Инициализация базы данных
Чтобы инициализировать тип базы данных PostgreSQL:
-
Запуск PostgreSQL
Чтобы запустить службу PostgreSQL и разрешить ей запускаться при загрузке, введите:
-
Проверка установки PostgreSQL
Чтобы проверить установку, мы попытаемся подключиться к серверу базы данных PostgreSQL с помощью инструмента и распечатать версию сервера:
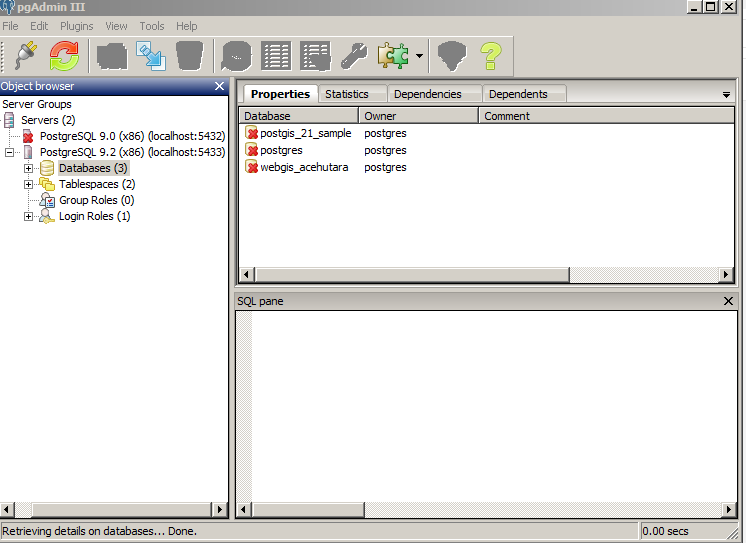
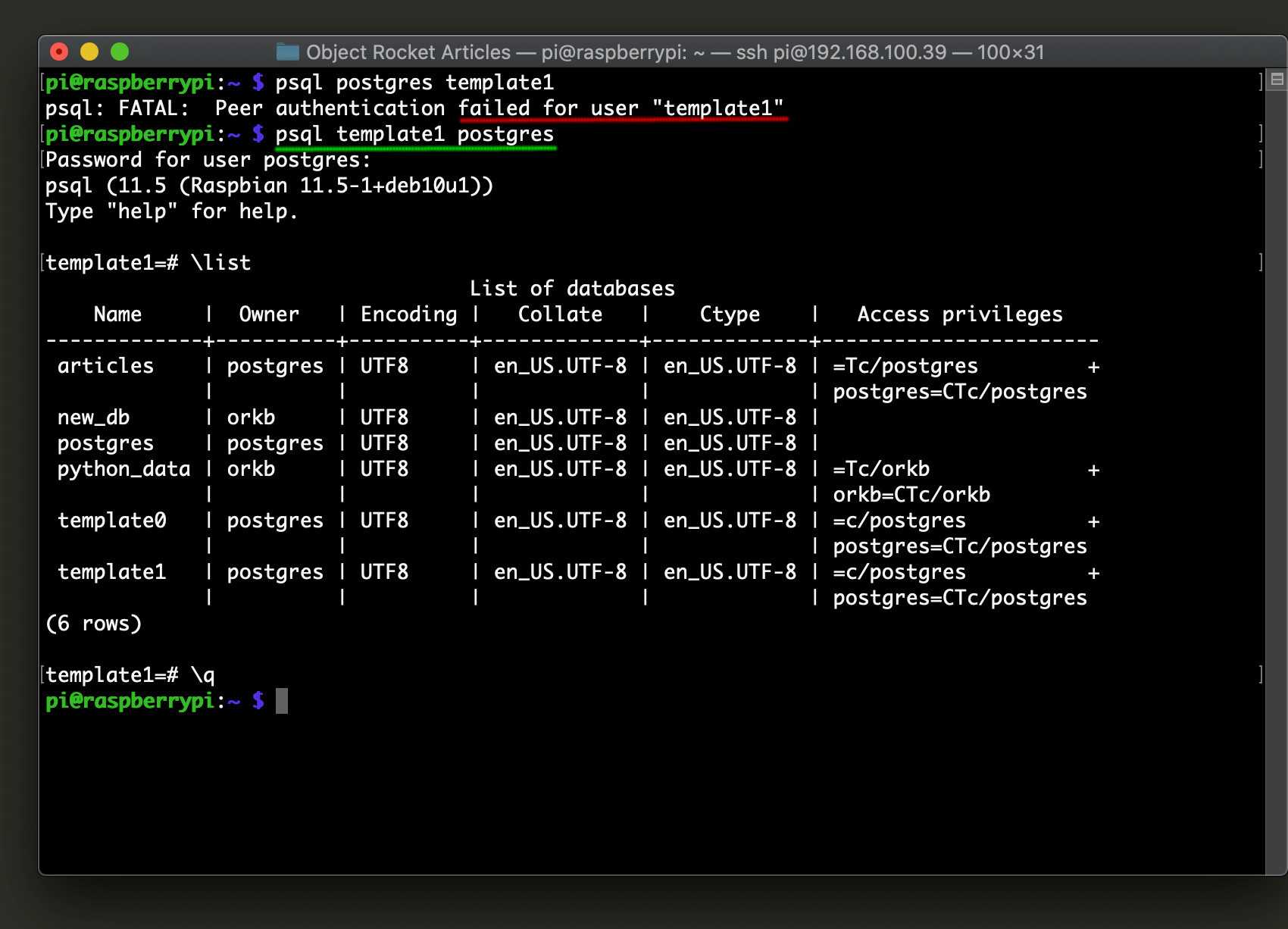
Работа с шаблонами баз данных
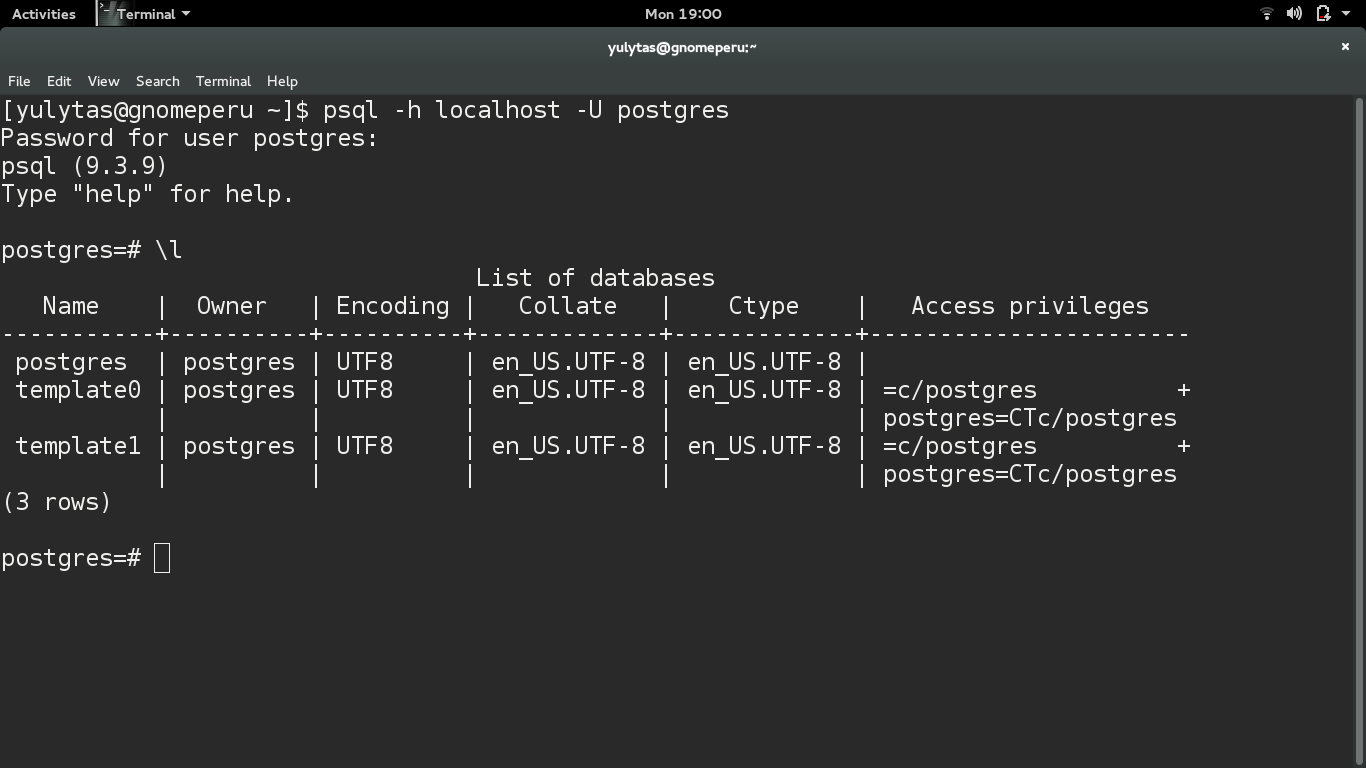
При установке PostgreSQL по умолчанию создаются три базы данных: postgres, template0, template1.
Template0 и template1 — это шаблоны баз данных, из которых в дальнейшем будут создаваться пользовательские БД.
Фактически, когда вы выполняете команду CREATE DATABASE, Postgres создает клон базы template1. Если внести изменения в template1, они будут наследоваться всеми новыми создаваемыми базами. Это позволяет, например, добавить в template1 необходимые вам таблицы с данными или установить расширения, после чего не потребуется добавлять их для каждой новой базы.
Обратите внимание, что для установки расширений необходимо подключиться к template1 от суперпользователя (postgres или другой роли, имеющей данные привилегии). Подключитесь к шаблону template1:
Подключитесь к шаблону template1:
\c template1
И установите расширение:
CREATE EXTENSION название_расширения;
Например, если вы установите в template1 расширение pgcrypto, то в дальнейшем, при выполнении CREATE DATABASE, новые базы будут создаваться с уже установленным pgrypto.
Template0 — это исходная база, которая используется, когда нужно создать новую базу без каких-либо изменений, внесенных в шаблон template1, или же вернуть template1 в его изначальное состояние.
Чтобы создать «чистую» базу на основе template0, нужно выполнить:
CREATE DATABASE имя_базы TEMPLATE template0;
Также template0 необходима, если вам нужно внести изменения в кодировку или локаль создаваемой базы данных. По умолчанию (при использовании template1) эти изменения невозможны.
В этом случае нужно при создании базы указать template0 в качестве шаблона и указать требуемую кодировку и/или локаль, например:
CREATE DATABASE имя_базы TEMPLATE template0 ENCODING 'SQL_ASCII';
Пересоздание template1
С помощью template0 вы также можете вернуть базу template1 в исходный вид: для этого потребуется ее удалить, а после создать заново, на основе шаблона template0.
Сначала необходимо указать, что template1 не является шаблоном, чтобы удаление стало возможно:
UPDATE pg_database SET datistemplate = false WHERE datname = 'template1';
Далее удалить template1:
DROP DATABASE template1;
И создать базу template1 заново, указав, что она будет являться шаблоном:
CREATE DATABASE template1 OWNER postgres TEMPLATE template0 is_template true;





