
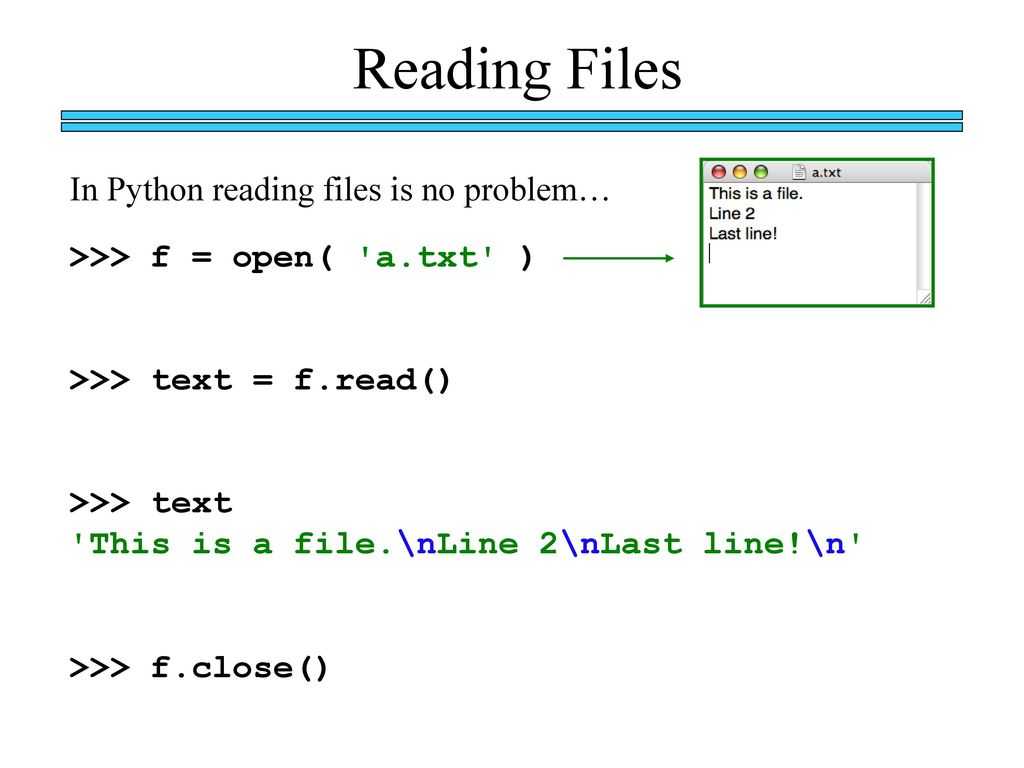
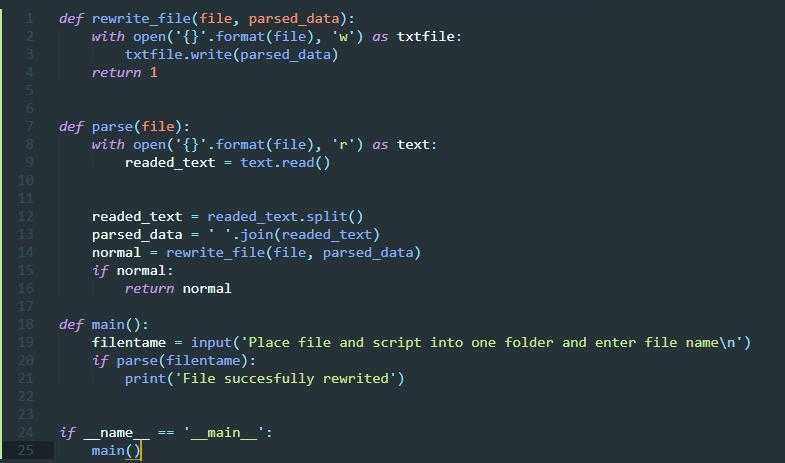
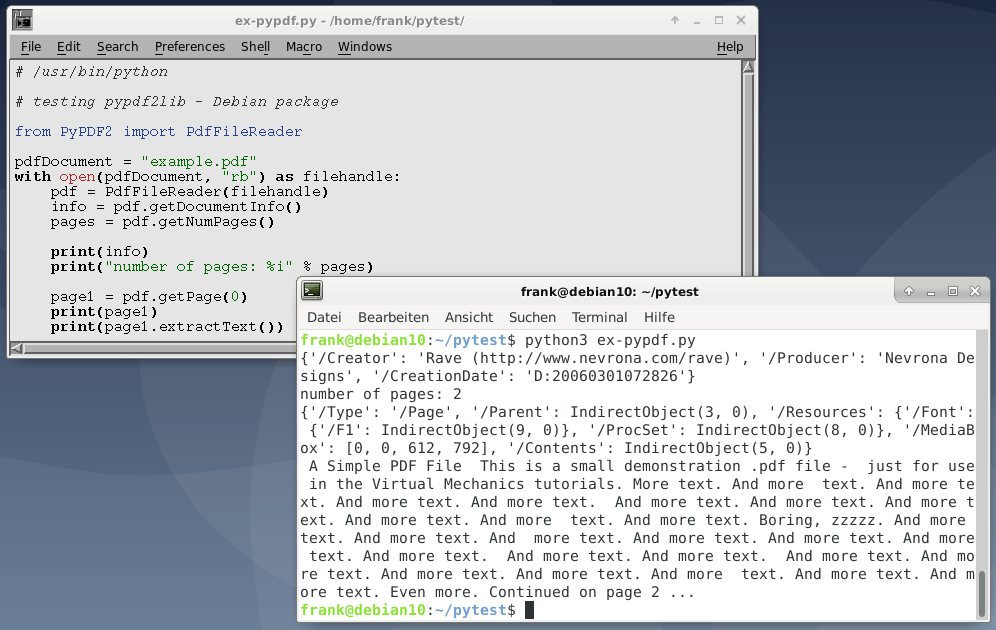
Чтение построчно
Прочитать содержимое текстового файла построчно в языке Python очень просто, поскольку в этом прекрасно помогает цикл for. Но для начала все же необходимо открыть документ, как и в предыдущем случае, при помощи open и with as. Однако на этот раз следует указать другой режим обработки файла, выбрав для него “r” для получения доступа к чтению данных.
with open(r"D:\test.txt", "r") as file:
for line in file:
print(line)
В этом примере показывается открытие файла test.txt, в котором уже содержится небольшой массив строк, записанный ранее. Построчное чтение информации из файла производится в цикле for. Каждая итерация выводит сведения из новой строки (line) при помощи функции print. Все элементы отображаются на экране построчно, как и были ранее помещены в test.txt.
Создание переменных
Вам нужно будет передать несколько аргументов вашему скрипту, если вы хотите, чтобы он был достаточно гибким, чтобы обрабатывать большинство сценариев, для которых вы будете использовать FFMPEG. Для этого вам понадобится немало переменных. Конечно, вы можете использовать ввод, но это будет намного сложнее.
srcExt=$1 destExt=$2 srcDir=$3 destDir=$4 opts=$5
Всего у вас пять переменных; исходное расширение, конечное расширение, исходный каталог, целевой каталог и ваши параметры. Параметры — это любые опции, которые вы хотите использовать в команде FFMPEG. Есть и другие способы сделать это, но проще передать их как строку.
Concatenation of files with different codecs
In many cases, input files will have different codecs or different codec properties, which makes it impossible to use any of the above methods.
Concat filter
See the for more info. The filter works on segments of synchronized video and audio streams. All segments must have the same number of streams of each type, and that will also be the number of streams at output.
Note: Filters are incompatible with ; you can’t use with this method. Since you have to re-encode the video and audio stream(s), and since re-encoding may introduce compression artifacts, make sure to add proper target bitrate or quality settings. See the encoding guides for more info.
For the concat filter to work, the inputs have to be of the same frame dimensions (e.g., 1920⨉1080 pixels) and should have the same framerate. Therefore, you may at least have to add a or filter before concatenating videos. A handful of other attributes have to match as well, like the stream aspect ratio. Refer to the documentation of the filter for more info.
Instructions
Let’s say we have three files that we want to concatenate – each of them with one video and audio stream. The concat filter command would look like this:
ffmpeg -i input1.mp4 -i input2.webm -i input3.mov \ -filter_complex "concat=n=3:v=1:a=1" \ -map "" -map "" output.mkv
Now, let’s dissect that command. We first specify all the input files, then instantiate a filtergraph – this is needed instead of because it has multiple inputs and outputs.
The following line:
tells ffmpeg which streams to take from the input files and send as input to the concat filter. In this case, video stream 0 and audio stream 0 from input 0 ( in this example), and video stream 0 and audio stream 0 from input 1 (), etc.
concat=n=3:v=1:a=1'
This is the concat filter itself. is telling the filter that there are three input segments; is telling it that there will be one video stream per segment; is telling it that there will be one audio stream per segment. The filter then concatenates these segments and produces two output streams. and are names for these output streams. Note that the quotes around the filter section are required.
The following image shows the stream mapping to and from the filter in the above example:
![]()
You can then either re-use these streams in other filters, or map them to the output file:
-map "" -map "" output.mkv
This tells ffmpeg to use the results of the concat filter rather than the streams directly from the input files.
There is a Bash script called mmcat which was useful for older versions of ffmpeg that did not include the filter.
Небольшое лирическое отступление о вреде перфекционизма
Здесь я решил сделать небольшое признание. При написании этой статьи мне впервые пришлось столкнуться с работой FFmpeg. Пришлось изучать мануалы и достаточно долго гуглить. В итоге, я нагуглил сочетание ключей программы FFmpeg для скриншаринга со звуком, на основании документации добавил ключи для передачи скриншаринга в поток на WCS сервере, успешно протестировал публикацию через FFMpeg и воспроизведение по WebRTC в среде Windows и Linux и начал писать эту статью-инструкцию.
На этапе тестирования команда для FFmpeg скриншаринга показалась мне достаточно хаотичной. Поэтому, работая над текстом статьи я решил ее «причесать» — собрал все что относится к захвату и кодированию видео в начале команды, потом собрал ключи для захвата и кодирования звука и завершил команду ключами для передачи данных на сервер и формирования потока.
Внимание! НЕ используйте эту команду!
ffmpeg.exe -f gdigrab -i desktop -draw_mouse 1 -rtbufsize 100M -framerate 30 -probesize 10M -c:v libx264 -r 30 -preset ultrafast -tune zerolatency -crf 25 -pix_fmt yuv420p -f dshow -i audio="@device_cm_{33D9A762-90C8-11D0-BD43-00A0C911CE86}\wave_{F585B65B-4690-4433-8109-F16C6389C066}" -acodec aac -f flv rtmp://demo.flashphoner.com:1935/live/rtmp_stream
Перед публикацией статьи в блоге я проверил получившуюся команду и, к своему разочарованию, получил полное отсутствие в потоке и аудио, и видео составляющих.
![]()
Пришлось вернуться к мануалам и Google.
Я вновь и вновь проверял ключи, с которыми запускается FFmpeg. Я даже нашел альтернативный способ захвата системного звука для Windows (о чем обязательно расскажу далее). Я тестировал с разными драйверами в Windows и разными версиями рабочих столов в Ubuntu, но все мои действия приводили к одному:
На WCS сервере формировался пустой поток.
В одном из мануалов мне попалась фраза, которая прочно засела в моей голове: «Не смешивайте ключи для аудио и видео!». Вот я старательно и раскладывал ключи по полочкам. Сначала связанное с аудио, потом связанное с видео, потом передача в поток.
В какой-то момент, я запустил исходную команду, которая на первый взгляд выглядела хаотичным набором ключей. И, о чудо! В плеере был поток скриншаринга со звуком. Тогда я внимательно присмотрелся к ключам, и, наконец-то, понял свою ошибку. Нельзя смешивать ключи для аудио и видео и ключи для разных действий!
Опытным путем мне удалось выяснить, что структура команды должна быть такой:
ключи для захвата аудио + ключи для захвата видео + ключи для кодирования аудио + ключи для кодирования видео + ключи для отправки данных в поток на сервере
К сожалению, FFmpeg не поддерживает каких-либо служебных ключей для разделения секций команды, поэтому неопытному пользователю бывает сложно сориентироваться. Далее по тексту, в описаниях ключей я уточню, какие ключи к какому действию относятся.
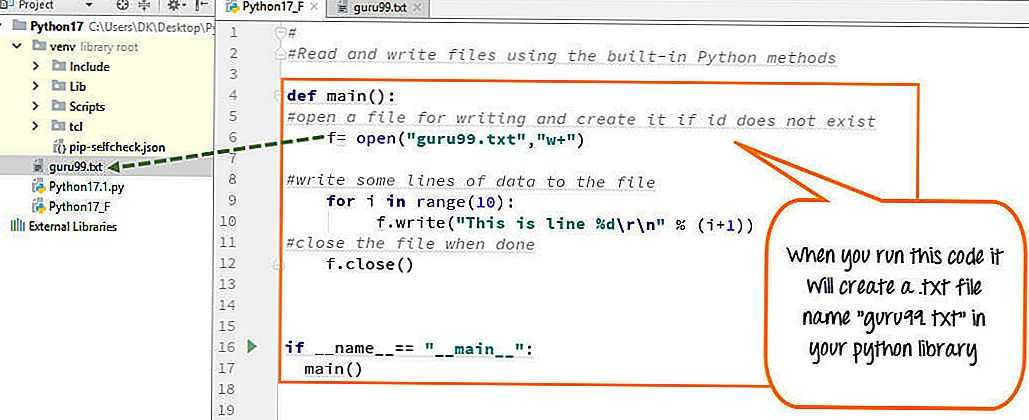
Чтение текстового файла
Следующий код использует класс для открытия, чтения и закрытия текстового файла. Вы можете передать путь текстового файла конструктору, чтобы открыть его автоматически. Метод читает каждую строку текста и приращение указателя файла к следующей строке по мере чтения. Когда метод достигает конца файла, он возвращает ссылку null. Дополнительные сведения см. в группе StreamReader Class.
-
Создайте пример текстового файла в Блокнот. Выполните приведенные ниже действия.
- Вклеить текст hello world в Блокнот.
- Сохраните файл как Sample.txt.
-
Начните Microsoft Visual Studio.
-
В меню File указать на New, а затем выбрать Project.
-
Выберите visual C# проектов в Project типов, а затем выберите консольное приложение в шаблонах.
-
Добавьте следующий код в начале файла Class1.cs:
-
Добавьте в метод следующий код:
-
В меню Отлаговка выберите Пуск для компиляции и запуска приложения. Нажмите КНОПКУ ВВОД, чтобы закрыть окно консоли. В окне Консоли отображается содержимое файла Sample.txt:
4 ответа
5
Если входной файл не имеет допустимой частоты кадров, вам может потребоваться явно указать его
2
Я мог только получить измененную частоту кадров, чтобы вступить в силу, если входной файл был классифицирован как «сырой» файл:
Без указания он по умолчанию будет 25 кадров в секунду, и он не может быть изменен. По-видимому, это связано с тем, что в потоке не было никакой информации о частоте кадров, и это частота кадров ffmpeg по умолчанию.
По-видимому, когда вы используете в качестве опции вывода, он дублирует или опускает кадры, чтобы видео воспроизводилось с одинаковой скоростью — в этом случае , а не то, что вы хотите! Но изменение входной частоты кадров, как указано выше, приведет к ускорению или замедлению видео, без потери или дублирования кадров.
2
Я знаю, что это старый вопрос, но ни один из текущих ответов больше не рекомендуется. Это руководство от ffmpeg вики
Обратите внимание, что для всех этих параметров требуется повторное кодирование видео
Ускорение /замедление видео
Вы можете изменить скорость видеопотока, используя фильтр видеопотоков
Обратите внимание, что в следующих примерах аудиопоток не изменяется, поэтому в идеале он должен быть отключен с помощью -an
Чтобы удвоить скорость видео, вы можете использовать:
Фильтр работает, изменяя временную метку представления (PTS) каждого видеокадра. Например, если на временных отметках 1 и 2 показаны два последовательных кадра, и вы хотите ускорить видео, эти метки времени должны стать 0.5 и 1 соответственно. Таким образом, мы должны умножить их на 0,5.







Обратите внимание, что этот метод будет отбрасывать кадры для достижения желаемой скорости. Вы можете избежать сброшенных кадров, указав более высокую скорость выходного кадра, чем вход
Например, чтобы перейти от входа 4 FPS к одному, который ускорен до 4x, что (16 FPS):
Чтобы замедлить ваше видео, вам необходимо использовать множитель, превышающий 1:
Гладкие
Вы можете сгладить медленное /быстрое видео с помощью фильтра фильтра minterpolate. Это также известно как «интерполяция движения» или «оптический поток».
Другие варианты включают slowmoVideo и Butterflow.
Ускорение /замедление звука
Вы можете ускорить или замедлить звук с помощью звукового фильтра atempo. Чтобы удвоить скорость звука:
Фильтр atempo ограничен использованием значений от 0,5 до 2,0 (поэтому он может замедлить его до не менее половины первоначальной скорости и ускорить до двух раз больше входного сигнала). Если вам нужно, вы можете обойти это ограничение, объединив несколько фильтров atempo. Следующие с четырехкратной скоростью звука:
Используя сложный фильтр, вы можете одновременно ускорить видео и аудио:
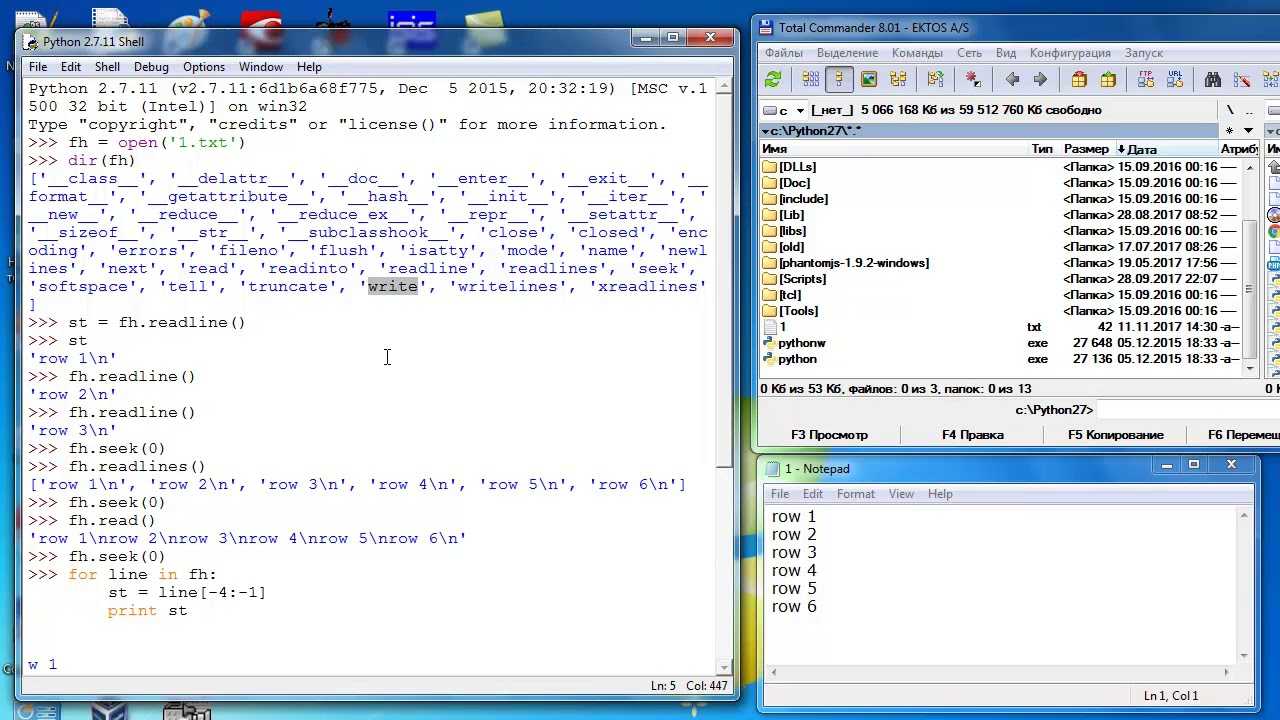
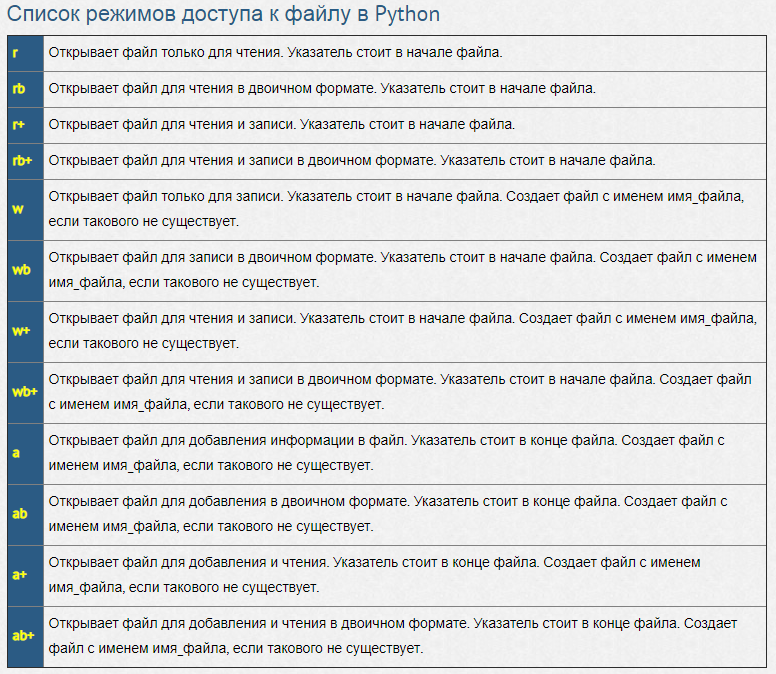
Методы файла в Python
| закрывает открытый файл | |
| возвращает целочисленный дескриптор файла | |
| очищает внутренний буфер | |
| возвращает True, если файл привязан к терминалу | |
| возвращает следующую строку файла | |
| чтение первых n символов файла | |
| читает одну строчку строки или файла | |
| читает и возвращает список всех строк в файле | |
| file.seek(offset) | устанавливает текущую позицию в файле |
| проверяет, поддерживает ли файл случайный доступ. Возвращает , если да | |
| возвращает текущую позицию в файле | |
| уменьшает размер файл. Если n указала, то файл обрезается до n байт, если нет — до текущей позиции | |
| добавляет строку в файл | |
| добавляет последовательность строк в файл |
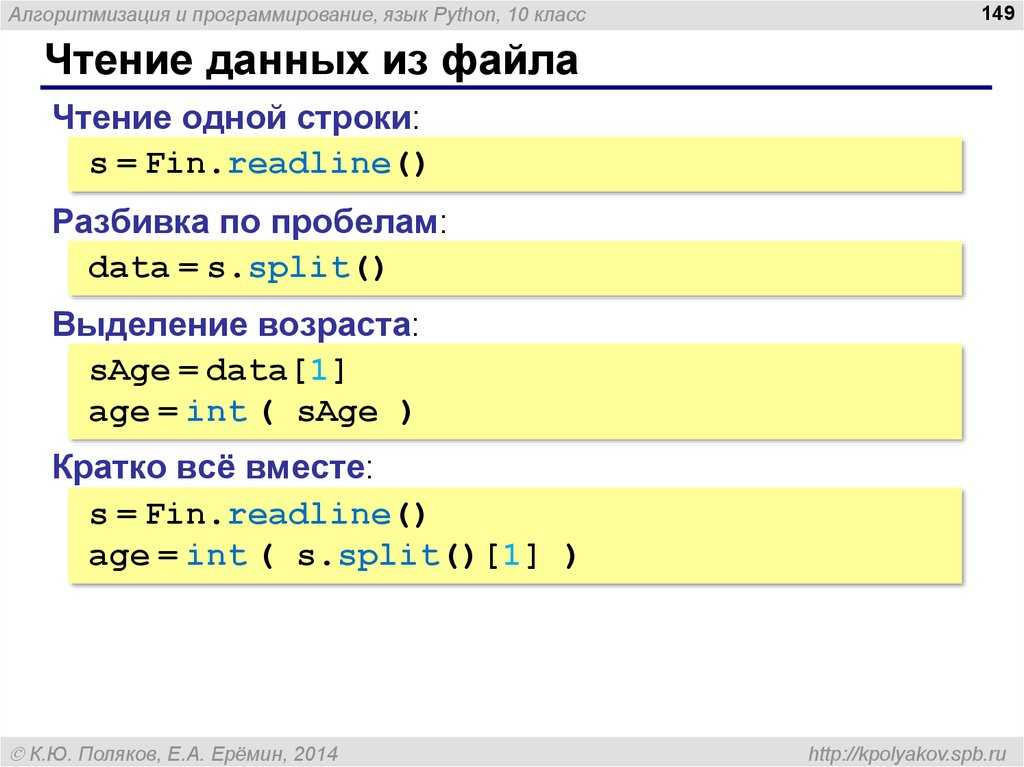
Текстовые файлы в паскале: процедуры работы
Текстовый файл в Паскале — это совокупность строк произвольной длины, которые разделены между собой метками конца строки, а весь файл заканчивается меткой конца файла.
Важно: Если быть точными, то каждая строка текстового файла завершается специальной комбинацией, называемой «конец строки».
Комбинация «конец строки» состоит из двух символов: перевод каретки () и перевод строки (). Завершается текстовый файл символом конец файла ().. Возможные расширения файлов:
*.txt, *.log,
*.htm, *.html
Возможные расширения файлов:
*.txt, *.log,
*.htm, *.html
Метод работы с текстовым файлом в Паскале предусматривает лишь последовательный доступ к каждой строке файла. Это означает, что начинать всегда возможно только с первой строки, затем проходя по каждой строке, дойти постепенно до необходимой. Т.е. можно сказать, что чтение (или запись) из файла (в файл) ведутся байт за байтом от начала к концу.
Предусмотрены два режима работы: режим для записи в файл информации и для чтения ее из файла. Одновременная запись и чтение запрещены.
Открытие файла (классический Pascal)
Допустим, мы в программе описали переменную для работы с текстовым файлом:
var f text; |
Рассмотрим дальнейшую последовательность работы с ним, и рассмотрим процедуры, необходимые для работы с текстовым файлом в Паскале:
![]()
Чтение из файла (классический Pascal)
- чтение осуществляется с той позиции, где в данный момент стоит курсор;
- после чтения курсор сдвигается к первому непрочитанному символу.
![]()
- Чтение до конца файла: оператор .
- Чтение до конца строки: оператор .
![]()
Для возврата в начало файла:
close ( f );
reset ( f ); { начинаем с начала }
|
Запись в текстовый файл (классический Pascal)
Процедуры работы с файлом и закрытие файла
Важно: Таким образом, работа с файлом осуществляется через три основных шага:
- Процедура assign.
- Процедура reset или rewrite.
- Процедура close.
Рассмотрим пример работы с файлами в паскале:
Пример 1: В файле text.txt записаны строки. Вывести первую и третью из них на экран.
(предварительно создать text.txt с тремя строками)
Решение:
| Паскаль | PascalAbc.NET | ||||
|---|---|---|---|---|---|
|
|
Как пользоваться ffmpeg
Как я уже сказал, утилита ffmpeg поддерживает большинство аудио и видео форматов. Чтобы проверить какие форматы поддерживаются вы можете выполнить:
Если вы новичок в использовании этого инструмента, то вот некоторые команды, которые могут вам очень сильно помочь. Дальше вы узнаете как пользоваться ffmpeg.
1. Получить информацию о видео
Чтобы получить доступную информацию о видео, достаточно просто указать файл источника. Выполните такую команду:
Опция -hide_banner указывает программе, что не нужно показывать информацию о себе, опции сборки и так далее. Вы можете выполнить команду без этой опции, тогда получите всю информацию, в том числе и об ffmpeg:
2. Разбить видео на кадры
Чтобы разбить видео на изображения подойдет такая команда:
Утилита сгенерирует изображения с именами image1.jpg, image2.jpg, image3.jpg и так далее. После завершения вы найдете очень большое количество изображений в папке с видео.
3. Собрать видео из изображений
Вы можете взять полученный набор картинок и собрать все обратно в видео. Для этого выполните:
Опция -f задает формат входного файла, вы можете использовать jpeg, png, jpg и другие картинки. И вы уже знаете как посмотреть поддерживаемые форматы ffmpeg.
4. Вытянуть звук из видео
Чтобы конвертировать видео в mp3 выполните команду:
Вот описание новых опций:
- -vn — не обрабатывать видео, вся видео информация будет отброшена;
- -ar — частота дискретизации, измеряется в герцах, чем больше, тем лучше качество звука;
- -ab — устанавливает битрейт аудио;
- -ac — устанавливает количество каналов;
- -f — указывает формат полученного файла.
6. Преобразовать видео в gif
Таким же самым образом можно переделать видео в анимированную gif картинку:
Мы не указываем кодеки ffmpeg и формат, потому что программа может их сама определить по расширению.
Чтобы конвертировать видео mpg в flv выполните:
Здесь мы уже задали битрейт и формат.
8. Преобразовать avi в mpeg
Для этого выполните команду:
Использованные опции:
- -target pal-dvd — формат исходящего файла;
- -ps 2000000000 — максимальный размер полученного файла;
- -aspect 16:9 — соотношение сторон экрана.
9. Конвертировать видео в CD или DVD формат
Чтобы выполнить конвертирование ffmpeg видео в формат DVD, нужно задать ваш формат с помощью опции -target. Доступны такие форматы: vcd, svcd, dvd, dv, pal-vcd или ntsc-svcd. Чтобы создать VCD выполните:




11. Увеличить/уменьшить скорость видео
Чтобы увеличить скорость воспроизведения видео мы будем использовать фильтры, с помощью опции -vf. За скорость отвечает фильтр setpts. Например:
А так можно уменьшить скорость:
12. Вырезать прямоугольник из видео
Для того чтобы вырезать определенный участок кадра из видео тоже используются фильтры. На этот раз фильтр crop:
- out_w — ширина нужного прямоугольника;
- out_h — высота нужного прямоугольника;
- x,y — задают координаты прямоугольника от начала видео.
Например, обрежем прямоугольник размером 80х60 от позиции 100х200:
Кроме этих опций, здесь можно задавать кодеки ffmpeg и форматы, чтобы параллельно выполнить кодирование ffmpeg.
13. Обрезать видео
Тут уже фильтры нам не помогут, но зато мы можем указать опциями из какого момента нужно начать и где завершить, например:
Начинаем от минуты и пишем еще минуту:
- -ss задает время на видео, из которого стоит начать запись;
- -t задает время когда запись нужно завершить относительно ss;
- -с задает кодеки для аудио и видео, в нашем случае просто копировать файлы, ничего не перекодируя.
15. Проиграть видео
Вы можете быстро проиграть видео, чтобы оценить его качество, для этого есть команда:
Программа открывает и видео, и аудио.
16. Фото-баннер для аудио
Вы можете добавить фото баннер к вашей аудио записи с помощью следующей команды:
Рассмотрим опции:
- -loop — задает, что нужно всегда повторять оду и ту же картинку;
- -i — задают входящие файлы, картинку и аудиофайл;
- -с:v — задает видеокодек, эквивалентно -vc;
- -c:a — задает аудиокодек, эквивалентно -ac;
- -b:a — задает битрейт аудио, эквивалентно -ab;
- -strict experimental — кодек aac для ffmpeg экспериментальный, поэтому чтобы его использовать нужна эта опция.
17. Добавить субтитры к видео
Если у вас есть отдельный файл субтитров, например с именем subtutle.srt, вы можете использовать такую команду, чтобы добавить его к видео:
ЗаписьТекста
Для последовательной записи текста используется следующий алгоритм:
- Создается объект ЗаписьТекста.
- У данного объекта вызывается метод Открыть, первым параметром нужно указать путь к файлу.
- Для записи каждой строки вызывается метод ЗаписатьСтроку, которому параметром передается записываемая строка.
- Для закрытия текстового файла вызывается метод Закрыть.
ПутьКФайлу = «F:\Текст док.txt»;
Запись = Новый ЗаписьТекста;
Запись.Открыть(ПутьКФайлу);
Запись.ЗаписатьСтроку(«Первая строка»);
Запись.ЗаписатьСтроку(«Вторая строка»);
Запись.ЗаписатьСтроку(«Третья строка»);
Запись.Закрыть();
|
1 |
ПутьКФайлу= «F:\Текст док.txt»; Запись= Новый ЗаписьТекста; Запись.Открыть(ПутьКФайлу); Запись.ЗаписатьСтроку(«Первая строка»); Запись.ЗаписатьСтроку(«Вторая строка»); Запись.ЗаписатьСтроку(«Третья строка»); Запись.Закрыть(); |
В результате будет записан следующий текстовый файл:
Если такого файла на диске еще не было, то он будет создан. Если в файле уже что-то было, то он будет перезаписан.
Можно не использовать метод Открыть, а указать путь к файлу в конструкторе объекта ЗаписьТекста:
Запись = Новый ЗаписьТекста(ПутьКФайлу);
| 1 | Запись= Новый ЗаписьТекста(ПутьКФайлу); |
Кодировку текста можно указать вторым параметром или в конструкторе объекта ЗаписьТекста или в методе Открыть:
Кодировка = «UTF-16LE»;
Запись = Новый ЗаписьТекста(ПутьКФайлу, Кодировка);
|
1 |
Кодировка= «UTF-16LE»; Запись= Новый ЗаписьТекста(ПутьКФайлу,Кодировка); |
Если кодировка не указана, то используется UTF-8.
Третьим параметром можно переопределить разделитель строк (по умолчанию используется Символы.ПС, LF). Например, можно указать символ процента:
Разделитель = «%»;
Запись = Новый ЗаписьТекста(ПутьКФайлу,, Разделитель);
|
1 |
Разделитель= «%»; Запись= Новый ЗаписьТекста(ПутьКФайлу,,Разделитель); |
В этом случае текстовый файл будет выглядеть так:
![]()
Также разделитель строк можно указать вторым параметром в методе ЗаписатьСтроку:
Запись.ЗаписатьСтроку(«Первая строка», «%»);
| 1 | Запись.ЗаписатьСтроку(«Первая строка»,»%»); |
В этом случае можно использовать разные разделители после записи каждой строки.
Можно вообще не записывать разделитель строк после записанной строки. В этом случае вместо метода ЗаписатьСтроку нужно использовать метод Записать:
Запись.Записать(«Первая строка»);
| 1 | Запись.Записать(«Первая строка»); |
В этом случае можно сформировать текст файла отдельно, а потом записать его методом Записать:
ПутьКФайлу = «F:\Текст док.txt»;
Текст = «Первая строка» + Символы.ПС +
«Вторая строка» + Символы.ПС +
«Третья строка» + Символы.ПС;
Запись = Новый ЗаписьТекста(ПутьКФайлу);
Запись.Записать(Текст);
Запись.Закрыть();
|
1 |
ПутьКФайлу= «F:\Текст док.txt»; Текст= «Первая строка»+Символы.ПС+ «Вторая строка»+Символы.ПС+ «Третья строка»+Символы.ПС; Запись.Записать(Текст); Запись.Закрыть(); |
Если нужно добавить что-то к уже существующему файлу, то четвертым параметром нужно указать Истина:
Запись = Новый ЗаписьТекста(ПутьКФайлу,,, Истина);
| 1 | Запись= Новый ЗаписьТекста(ПутьКФайлу,,,Истина); |
В этом случае, если дважды записать в один файл, то будет получен следующий текстовый файл:
Запись построчно
Чтобы быстро записать информацию в текстовый файл, достаточно открыть его в программе, написанной на языке Python, после чего воспользоваться функцией write через переменную, которая ссылается на документ.
В Python запись в файл построчно осуществляется с помощью записи нужной строки с последующей записью символа перевода строки ‘\n’. Рассмотрим пример записи списка поэлементно. Каждый элемент будет записан в новой строке:
lines =
with open(r"D:\test.txt", "w") as file:
for line in lines:
file.write(line + '\n')
Приведенный выше пример небольшой программы показывает создание небольшого массива lines, который содержит три строковых элемента: “first”, “second” и “third”. За счет функции open и связки операторов with as происходит открытие текстового файла test.txt в корневом каталоге жесткого диска D. В цикле мы проходим по всем элементам списка и с помощью команды write их записываем. Чтобы каждая запись была с новой строки, добавляем символ перевода строки.
Так же можно воспользоваться функцией writelines. Если мы передадим в качестве ее параметра список, то она запишет элементы друг за другом в одну строку. Но можно поступить следующим образом: в качестве параметра передать генератор следующим образом.
lines =
with open(r"D:\test.txt", "w") as file:
file.writelines("%s\n" % line for line in lines)
Этот пример отличается от предыдущего тем, что вызывается метод writelines, который принимает в качестве аргумента генератор. Для разделения элементов последовательности тут применяется “\n”, благодаря чему каждое слово в документе будет находиться в отдельной строке.
Контрольные вопросы
2. Что такое поток?
Последовательность инструкций, которая может выполняться пареллельно с другими потоками. Поток в Java представлен в виде экземпляра класса java.lang.Thread
3. Что такое буферизация?
Буферизация — метод организации обмена, в частности, ввода и вывода данных в компьютерах и других вычислительных устройствах, который подразумевает использование буфера для временного хранения данных
4. На базе каких абстрактных классов построена система ввода-вывода Java?
В основе всех классов, управляющих потоками байтов, находятся два абстрактных класса: InputStream (представляющий потоки ввода) и OutputStream (представляющий потоки вывода). Но поскольку работать с байтами не очень удобно, то для работы с потоками символов были добавлены абстрактные классы Reader (для чтения потоков символов) и Writer (для записи потоков символов)
5. Как реализуется доступ к произвольной позиции в файле?
Эта возможность обеспечивается следующими методами:
- — возвращает текущее смещение (в байтах) от начала файла
- — Устанавливает файловый указатель в заданную позицию (в байтах). Следующий считанный или записанный байт будет иметь смещение
- — возвращает длину файла
6. Для чего служит метод close() и когда его нужно использовать?
— закрывает входной поток. Метод должен вызываться для освобождения любых ресурсов (например, файловых дескрипторов), связанных с потоком. Если не сделать это, то ресурсы будут считаться занятыми, пока сборщик мусора не вызовет метод finalize данного потока


7. Как осуществить перекодировку содержимого файлов?
Например, чтобы перевести текстовый файл в кодировке в Unicode, необходимо сделать следующее:
FileInputStream fis = new FileInputStream("test.txt");
InputStreamReader isr = new InputStreamReader(fis, "UTF8");
8. Как в Java осуществляется работа с конфигурационными файлами?
В Java можно использовать как распространенный формат конфигурационного файла ini (.ini), так и собственный формат файла свойств properties (.properties)
Для работы с конфигурационными файлами обоих типов в Java можно использовать класс java.util.Properties, метод load которого загружает пары ключ=значение из конфигурационного файла в ассоциативный массив
Вырезаем фрагмент видео
Флагом указываем с какого момента исходного видео обрезаем, — продолжительность. На выходе мы получим двадцати секундное видео, которое начнется с десятой секунды исходного. Запись пригодится для указания более точного промежутка времени. До версии 2.1 FFmpeg в обоих случаях обрезал видео по ближайшему ключевому кадру. В новых версиях итоговое видео максимально близко к указанному интервалу.
Мы добавили , чтобы сохранить кодеки исходного видео. Иначе ffmpeg перекодировал бы их в кодеки по умолчанию. Сейчас видео не перекодируется и команда выполнится быстро. Дальше упростим эту запись флагом .
Если расположить флаги и после входящего видео, то итоговое видео будет таким же, но команда будет выполняться дольше. Флаги будут относиться к итоговому видео и FFmpeg будет декодировать фрагмент видео до . В первом случае эта часть будет проигнорирована.
Флаг можно заменить на , указав вместо продолжительности конечную точку. Этот флаг нельзя применить к входящему видео:
Команда дала нам другой результат: тридцати секундное видео с десятой секунды исходного. Это произошло, потому что использовал временную шкалу , тридцатая секунда на котором равна сороковой секунде . Чтобы использовать исходную шкалу добавим флаг . Так мы получим такое же видео, как от первой команды:
Чтение информации из текстового файла
Для того чтобы прочитать информацию из текстового файла, необходимо описать переменную типа ifstream. После этого нужно открыть файл для чтения с помощью оператора open. Если переменную назвать F, то первые два оператора будут такими:
|
1 2 |
ifstream F; |
После открытия файла в режиме чтения из него можно считывать информацию точно так же, как и с клавиатуры, только вместо cin нужно указать имя потока, из которого будет происходить чтение данных.
Например, для чтения данных из потока F в переменную a, оператор ввода будет выглядеть так:
F>>a;
Два числа в текстовом редакторе считаются разделенными, если между ними есть хотя бы один из символов: пробел, табуляция, символ конца строки. Хорошо, когда программисту заранее известно, сколько и какие значения хранятся в текстовом файле. Однако часто известен лишь тип значений, хранящихся в файле, при этом их количество может быть различным. Для решения данной проблемы необходимо считывать значения из файла поочередно, а перед каждым считыванием проверять, достигнут ли конец файла. А поможет сделать это функция F.eof(). Здесь F — имя потока функция возвращает логическое значение: true или false, в зависимости от того достигнут ли конец файла.
Следовательно, цикл для чтения содержимого всего файла можно записать так:
|
1 2 3 4 5 6 7 8 9 |
//организуем для чтения значений из файла, выполнение//цикла прервется, когда достигнем конец файла,//в этом случае F.eof() вернет истинуwhile (!F.eof()){//чтение очередного значения из потока F в переменную a |
Для лучшего усвоения материала рассмотрим задачу.
Задача 2
В текстовом файле D:\\game\\accounts.txt хранятся вещественные числа, вывести их на экран и вычислить их количество.
Решение
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#include «stdafx.h»#include <iostream>#include <fstream>#include <iomanip>#include <stdlib.h>using namespace std;int main(){ |
На этом относительно объемный урок по текстовым файлам закончен. В следующей статье будут рассмотрены методы манипуляции, при помощи которых в C++ обрабатываются двоичные файлы.
Чтение файла построчно
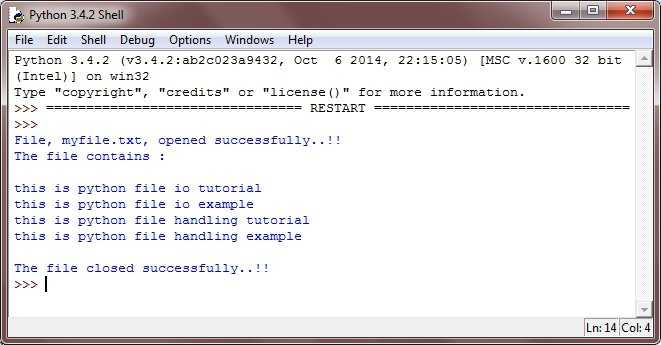
Python упрощает чтение файла построчно с помощью метода readline(). Метод readline() читает строки файла с самого начала, т. е. если мы используем его два раза, мы можем получить первые две строки файла.
Рассмотрим следующий пример, который содержит функцию readline(), которая читает первую строку нашего файла «file2.txt», содержащую три строки.
Пример 1: чтение строк с помощью функции readline()
#open the file.txt in read mode. causes error if no such file exists. fileptr = open("file2.txt","r"); #stores all the data of the file into the variable content content = fileptr.readline() content1 = fileptr.readline() #prints the content of the file print(content) print(content1) #closes the opened file fileptr.close()
Выход:
Python is the modern day language. It makes things so simple.
Мы вызывали функцию readline() два раза, поэтому она считывает две строки из файла.
Python также предоставляет метод readlines(), который используется для чтения строк. Возвращает список строк до конца файла(EOF).
Пример 2: чтение строк с помощью функции readlines()
#open the file.txt in read mode. causes error if no such file exists.
fileptr = open("file2.txt","r");
#stores all the data of the file into the variable content
content = fileptr.readlines()
#prints the content of the file
print(content)
#closes the opened file
fileptr.close()
Выход:





