
Интерфейс командной строки
unittest может быть использован из командной строки для запуска модулей с тестами, классов или даже отдельных методов:
python -m unittest test_module1 test_module2 python -m unittest test_module.TestClass python -m unittest test_module.TestClass.test_method
Можно также указывать путь к файлу:
python -m unittest tests/test_something.py
С помощью флага -v можно получить более детальный отчёт:
python -m unittest -v test_module
Для нашего примера подробный отчёт будет таким:
test_isupper (__main__.TestStringMethods) ... ok test_split (__main__.TestStringMethods) ... ok test_upper (__main__.TestStringMethods) ... ok ---------------------------------------------------------------------- Ran 3 tests in 0.001s OK
-b (--buffer) — вывод программы при провале теста будет показан, а не скрыт, как обычно.
-c (--catch) — Ctrl+C во время выполнения теста ожидает завершения текущего теста и затем сообщает результаты на данный момент. Второе нажатие Ctrl+C вызывает обычное исключение KeyboardInterrupt.
-f (--failfast) — выход после первого же неудачного теста.
Функция match
Эта функция ищет в и поддерживает настройки с помощью дополнительного . Ниже можно увидеть синтаксис данной функции:
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения () |
| 2 | string — строка, в которой мы будем искать соответствие с шаблоном в начале строки () |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция возвращает объект при успешном завершении, или при ошибке. Мы используем функцию или объекта для получения результатов поиска.
| № | Метод совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — этот метод возвращает полное совпадение (или совпадение конкретной подгруппы) |
| 2 | groups() — этот метод возвращает все найденные подгруппы в tuple |
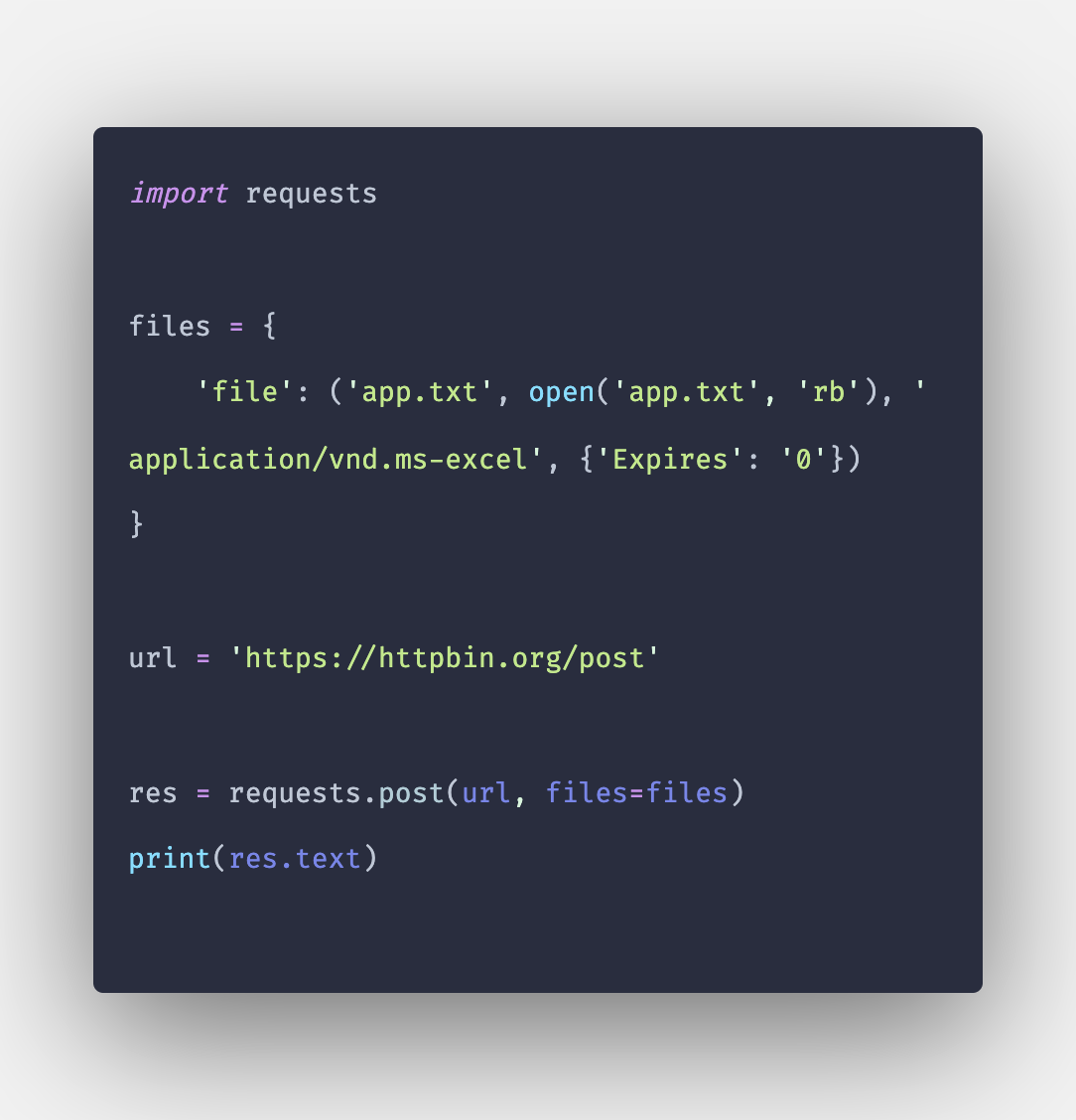
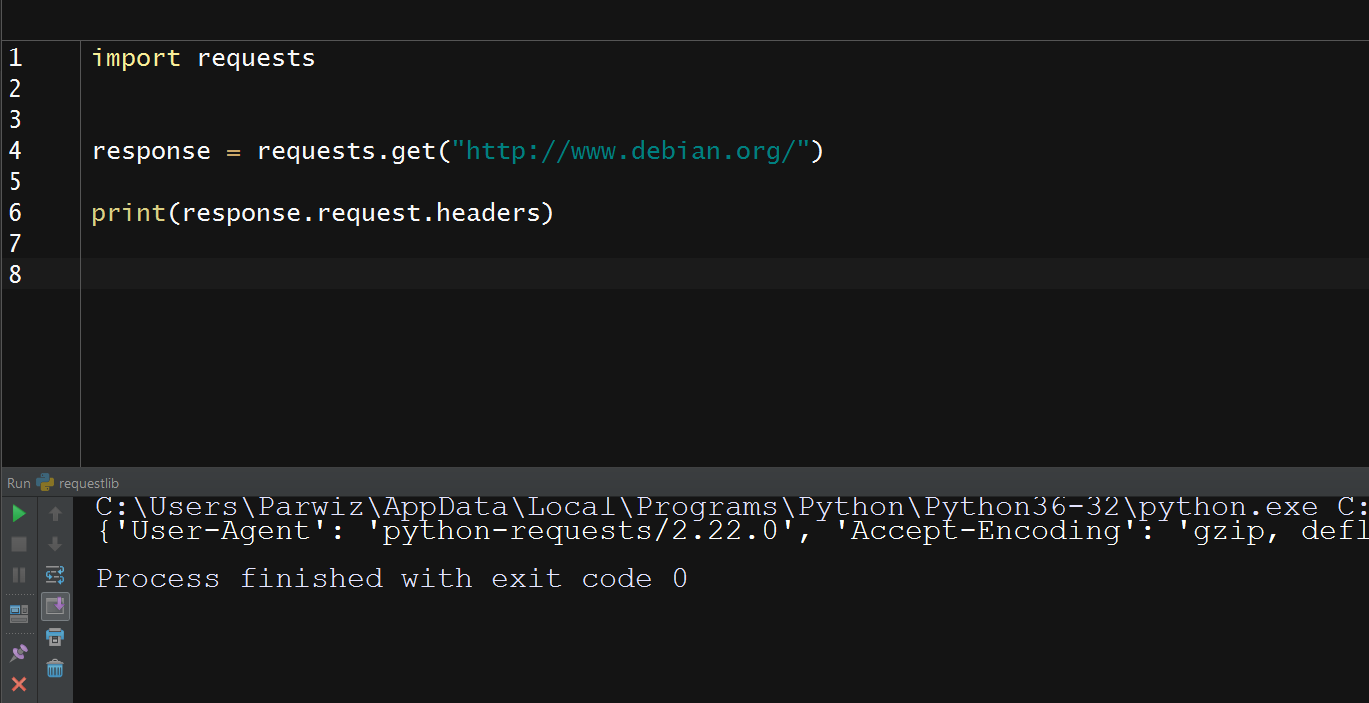
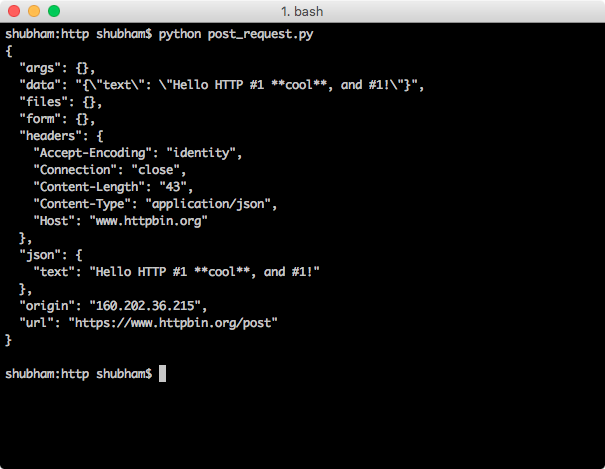
Что же умеет requests?
Для начала хочется показать как выглядит код работы с http, используя модули из стандартной библиотеки Python и код при работе с requests. В качестве мишени для стрельбы http запросами будет использоваться очень удобный сервис httpbin.org
Кстати, urllib.request это надстройка над «низкоуровневой» библиотекой httplib о которой я писал выше.
В простых методах запросов значительных отличий у них не имеется. Но давайте взглянем на работы с Basic Auth:
А теперь чувствуется разница между pythonic и non-pythonic? Я думаю разница на лицо. И несмотря на тот факт, что requests ничто иное как обёртка над urllib3, а последняя является надстройкой над стандартными средствами Python, удобство написания кода в большинстве случаев является приоритетом номер один.
В requests имеется:
- Множество методов http аутентификации
- Сессии с куками
- Полноценная поддержка SSL
- Различные методы-плюшки вроде .json(), которые вернут данные в нужном формате
- Проксирование
- Грамотная и логичная работа с исключениями
О последнем пункте мне бы хотелось поговорить чуточку подробнее.
Обнаружение тестов
unittest поддерживает простое обнаружение тестов. Для совместимости с обнаружением тестов, все файлы тестов должны быть модулями или пакетами, импортируемыми из директории верхнего уровня проекта (см. подробнее о ).
Обнаружение тестов реализовано в TestLoader.discover(), но может быть использовано из командной строки:
cd project_directory python -m unittest discover
-v (--verbose) — подробный вывод.
-s (--start-directory) directory_name — директория начала обнаружения тестов (текущая по умолчанию).
-p (--pattern) pattern — шаблон названия файлов с тестами (по умолчанию test*.py).
Чтение данных
Чтение данных нашей базы данных осуществляется при помощи оператора SQL под названием SELECT:
Python
SELECT name, make, model
FROM table_name;
|
1 2 |
SELECTname,make,model FROMtable_name; |
Так мы возвращаем все строчки из нашей базы данных, но результат будет содержать только три части данных: название, создание и модель. Если вы хотите охватить все данные в базе данных, вы можете выполнить следующее:
Python
SELECT * FROM table_name;
| 1 | SELECT*FROMtable_name; |
Звездочка в данном случае это подстановка, которая говорит SQL, что вы хотите охватить все столбцы. Если вы хотите ограничить выбранный вами охват, вы можете добавить команду WHERE в вашем запросе:
Python
SELECT name, make, model
FROM table_name
WHERE year >= ‘2000-01-01’ AND
year <= ‘2006-01-01’;
|
1 2 3 4 |
SELECTname,make,model FROMtable_name WHERE year>=’2000-01-01’AND year<=’2006-01-01′; |
Так мы получим информацию о названии, создании и модели для 2000-2006 годов. Существует ряд других команд SQL, которые помогут вам в работе с запросами. Убедитесь, что ознакомитесь с такими командами как BETWEEN, LIKE, ORDER BY, DISTINCT и JOIN.
Итерация по Списку в Python с Помощью цикла While
Второй способ перебора списка в python-это использование цикла while. В while loop способе итерации списка мы будем следовать аналогичному подходу, как мы наблюдали в нашем первом способе, то есть методу for-loop. Мы должны просто найти длину списка в качестве дополнительного шага.
Пример
# Program to loop through the list using while loop list = # Finding length of the list(list) # While Loop to iterate through list while i < length: print(list) i
Объяснение
В приведенном выше примере программы мы сначала инициализировали и создали список с именем list. Список содержит шесть элементов, которые являются соответственно
После этого мы должны найти длину списка, найти длину списка в цикле while важно, потому что мы должны проверить условия. Как вы, возможно, уже знаете, цикл while проходит только в том случае, если условия истинны
Вот почему нам нужно найти длину списка, в данном случае длина равна шести, поэтому цикл будет повторяться шесть раз. И мы также объявили и инициализировали переменную ‘i’ с начальным значением ‘0’.
Переходя к циклу while, мы впервые проверили условие, которое истинно. Как и изначально, значение ‘i’ равно ‘0’, а длина списка равна ‘6’. Таким образом, он проверяет ‘0 < 6’ , что является истинным, поэтому он войдет в цикл while и выполнит оператор. Здесь оператор, который должен быть выполнен, состоит в том, чтобы напечатать первый элемент списка. После выполнения оператора он перейдет к выражению updation и выполнит необходимый шаг инкрементирования на ‘1’.
Цикл while будет повторяться до тех пор, пока условие не станет ложным. И мы, наконец, достигнем итерации списка в python.
Аннотация функций обратного вызова typing.Callable.
Платформы, ожидающие функций обратного вызова для определенных сигнатур, могут создать аннотацию типа с помощью .
Например:
from collections.abc import Callable
def feeder(get_next_item Callable, str]) -> None
# тело функции
def async_query(on_success Callable, None],
on_error Callable, None]) -> None
# тело функции
Можно объявить возвращаемый тип вызываемого объекта без указания сигнатуры вызова, подставив буквальное многоточие вместо списка аргументов в аннотации типа: .
Вызываемые объекты, которые принимают другие вызываемые объекты в качестве аргументов, могут указывать на то, что их типы параметров зависят друг от друга с помощью . Кроме того, если этот вызываемый объект добавляет или удаляет аргументы из других вызываемых объектов, то может использоваться оператор . Они принимают форму и соответственно.
Изменено в версии 3.10: теперь поддерживает и .
Также документацию для и ]typing.Concatenate, в которой приведены примеры использования в .
Объект сеанса
Объект сеанса в основном используется для сохранения определенных параметров, например файлов cookie, в различных HTTP-запросах. Объект сеанса может использовать одно TCP-соединение для обработки нескольких сетевых запросов и ответов, что приводит к повышению производительности.
import requests
first_session = requests.Session()
second_session = requests.Session()
first_session.get('http://httpbin.org/cookies/set/cookieone/111')
r = first_session.get('http://httpbin.org/cookies')
print(r.text)
second_session.get('http://httpbin.org/cookies/set/cookietwo/222')
r = second_session.get('http://httpbin.org/cookies')
print(r.text)
r = first_session.get('http://httpbin.org/anything')
print(r.text)
Вывод:
{"cookies":{"cookieone":"111"}}
{"cookies":{"cookietwo":"222"}}
{"args":{},"data":"","files":{},"form":{},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Cookie":"cookieone=111","Host":"httpbin.org","User-Agent":"python-requests/2.9.1"},"json":null,"method":"GET","origin":"103.9.74.222","url":"http://httpbin.org/anything"}
Путь httpbin/cookies/set /{имя}/{значение} установит файл cookie с именем и значением. Здесь мы устанавливаем разные значения cookie для объектов first_session и second_session. Вы можете видеть, что один и тот же файл cookie возвращается во всех будущих сетевых запросах для определенного сеанса.
Точно так же мы можем использовать объект сеанса для сохранения определенных параметров для всех запросов.
import requests
first_session = requests.Session()
first_session.cookies.update({'default_cookie': 'default'})
r = first_session.get('http://httpbin.org/cookies', cookies={'first-cookie': '111'})
print(r.text)
r = first_session.get('http://httpbin.org/cookies')
print(r.text)
Вывод:
{"cookies":{"default_cookie":"default","first-cookie":"111"}}
{"cookies":{"default_cookie":"default"}}
Как видите, default_cookie отправляется с каждым запросом сеанса. Если мы добавим какой-либо дополнительный параметр к объекту cookie, он добавится к файлу default_cookie. «first-cookie»: «111» добавляется к cookie по умолчанию «default_cookie»:»default».
Объекты OpenerDirector¶
Экземпляры имеют следующие методы:
(handler)
handler должен быть экземпляром
Следующие методы
ищутся и добавляются к возможным цепочкам (обратите внимание, что ошибки
HTTP — это особый случай). Обратите внимание, что в дальнейшем protocol
следует заменить фактическим протоколом для обработки, например
будет обработчиком ответа протокола HTTP
Также type
следует заменить фактическим кодом HTTP, например
будет обрабатывать ошибки HTTP 404.
— сигнализирует о том, что обработчик знает, как
открывать URL-адреса protocol.
См. для получения дополнительной информации.
— сигнализирует о том, что обработчик знает,
как обрабатывать ошибки HTTP с кодом ошибки HTTP type.
См. для получения дополнительной информации.
— сигнализирует, что обработчик знает, как
обрабатывать ошибки из (не ) protocol.
— сигнализирует, что обработчик знает, как
предварительно обрабатывать запросы protocol.
См. для получения дополнительной информации.
— сигнализирует о том, что обработчик знает,
как постобработать ответы protocol.
См. для получения дополнительной информации.
- (url, data=None, timeout)
-
Открыть данный url (который может быть объектом запроса или строкой), при
необходимости передавая данный data. Аргументы, возвращаемые значения и
возникшие исключения такие же, как и для (который просто
вызывает метод для установленного в настоящее время глобального
). Необязательный параметр timeout указывает тайм-
аут в секундах для блокирующих операций, таких как попытка подключения (если
не указан, будет использоваться глобальная настройка тайм-аута по
умолчанию). Функция тайм-аута фактически работает только для соединений
HTTP, HTTPS и FTP).
- (proto, *args)
-
Обработать ошибку данного протокола. Это вызовет зарегистрированные
обработчики ошибок для данного протокола с заданными аргументами (которые
зависят от протокола). Протокол HTTP — это особый случай, который
использует код ответа HTTP для определения конкретного обработчика ошибок;
обратитесь к методам классов обработчиков.Возвращаемые значения и возникшие исключения такие же, как и для
.
Объекты OpenerDirector открывают URL-адреса в три этапа:
Порядок, в котором эти методы вызываются на каждом этапе, определяется
сортировкой экземпляров обработчика.
Различение итераций теста с помощью подтестов
Когда некоторые тесты имеют лишь незначительные отличия, например некоторые параметры, unittest позволяет различать их внутри одного тестового метода, используя менеджер контекста subTest().
Например, следующий тест:
class NumbersTest(unittest.TestCase):
def test_even(self):
"""
Test that numbers between 0 and 5 are all even.
"""
for i in range(, 6):
with self.subTest(i=i):
self.assertEqual(i % 2, )
даст следующий отчёт:
======================================================================
FAIL test_even (__main__.NumbersTest) (i=1)
----------------------------------------------------------------------
Traceback (most recent call last):
File "subtests.py", line 32, in test_even
self.assertEqual(i % 2, )
AssertionError 1 !=
======================================================================
FAIL test_even (__main__.NumbersTest) (i=3)
----------------------------------------------------------------------
Traceback (most recent call last):
File "subtests.py", line 32, in test_even
self.assertEqual(i % 2, )
AssertionError 1 !=
======================================================================
FAIL test_even (__main__.NumbersTest) (i=5)
----------------------------------------------------------------------
Traceback (most recent call last):
File "subtests.py", line 32, in test_even
self.assertEqual(i % 2, )
AssertionError 1 !=
Без использования подтестов, выполнение будет остановлено после первой ошибки, и ошибку будет сложнее диагностировать, потому что значение i не будет показано:
BaseHandler Objects¶
objects provide a couple of methods that are directly
useful, and others that are meant to be used by derived classes. These are
intended for direct use:
- (director)
-
Add a director as parent.
- ()
-
Remove any parents.
The following attribute and methods should only be used by classes derived from
.
Note
The convention has been adopted that subclasses defining
or methods are named
; all others are named .
-
A valid , which can be used to open using a different
protocol, or handle errors.
- (req)
-
This method is not defined in , but subclasses should
define it if they want to catch all URLs.This method, if implemented, will be called by the parent
. It should return a file-like object as described in
the return value of the of , or .
It should raise , unless a truly exceptional
thing happens (for example, should not be mapped to
).This method will be called before any protocol-specific open method.
-
This method is not defined in , but subclasses should
define it if they want to handle URLs with the given protocol.This method, if defined, will be called by the parent .
Return values should be the same as for .
- (req)
-
This method is not defined in , but subclasses should
define it if they want to catch all URLs with no specific registered handler to
open it.This method, if implemented, will be called by the
. Return values should be the same as for
.
- (req, fp, code, msg, hdrs)
-
This method is not defined in , but subclasses should
override it if they intend to provide a catch-all for otherwise unhandled HTTP
errors. It will be called automatically by the getting
the error, and should not normally be called in other circumstances.req will be a object, fp will be a file-like object with
the HTTP error body, code will be the three-digit code of the error, msg
will be the user-visible explanation of the code and hdrs will be a mapping
object with the headers of the error.Return values and exceptions raised should be the same as those of
.
-
nnn should be a three-digit HTTP error code. This method is also not defined
in , but will be called, if it exists, on an instance of a
subclass, when an HTTP error with code nnn occurs.Subclasses should override this method to handle specific HTTP errors.
Arguments, return values and exceptions raised should be the same as for
.
-
This method is not defined in , but subclasses should
define it if they want to pre-process requests of the given protocol.This method, if defined, will be called by the parent .
req will be a object. The return value should be a
object.
Создание таблицы
Первое что вам нужно для базы данных – это таблица. Это место, где ваши данные будут организованы и храниться. Большую часть времени вам будут нужны несколько таблиц, в каждой из которых будут храниться поднастройки ваших данных. Создание таблицы в SQL это просто. Все что вам нужно сделать, это следующее:
MySQL
CREATE TABLE table_name (
id INTEGER,
name VARCHAR,
make VARCHAR
model VARCHAR,
year DATE,
PRIMARY KEY (id)
);
|
1 2 3 4 5 6 7 8 |
CREATETABLEtable_name( idINTEGER, nameVARCHAR, makeVARCHAR modelVARCHAR, yearDATE, PRIMARY KEY(id) |
Это довольно обобщенный код, но он работает в большей части случаев
Первое, на что стоит обратить внимание – куча слов прописанных заглавными буквами. Это команды SQL
Их не всегда нужно вписывать через капс, но мы сделали это, чтобы помочь вам увидеть их. Я также хочу обратить внимание на то, что каждая база данных поддерживает слегка отличающиеся команды. Большинство будет содержать CREATE TABLE, но типы столбцов баз данных могут быть разными. Обратите внимание на то, что в этом примере у нас есть базы данных INTEGER, VARCHAR и DATE.
DATE может вызывать много разных штук, как и VARCHAR. Проконсультируйтесь с документацией на тему того, что вам нужно делать. В любом случае, в этом примере мы создаем базу данных с пятью столбцами. Первый – это id, который мы настраиваем в качестве нашего основного ключа. Он не должен быть NULL, но мы и не указываем, что в нем, так как еще раз, каждый бекенд базы данных выполняет работу по-разному, или делает это автоматически для нас. Остальные столбцы говорят сами за себя
GET и POST запросы с использованием Python
Существует два метода запросов HTTP (протокол передачи гипертекста): запросы GET и POST в Python.
Что такое HTTP/HTTPS?
HTTP — это набор протоколов, предназначенных для обеспечения связи между клиентами и серверами. Он работает как протокол запроса-ответа между клиентом и сервером.


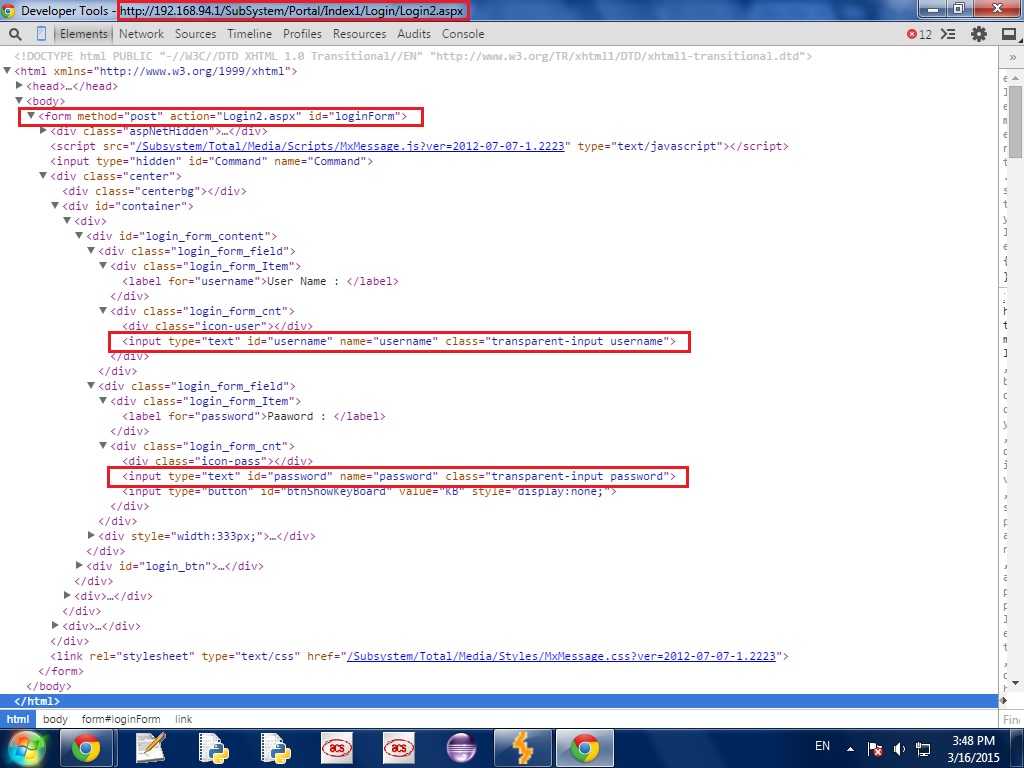
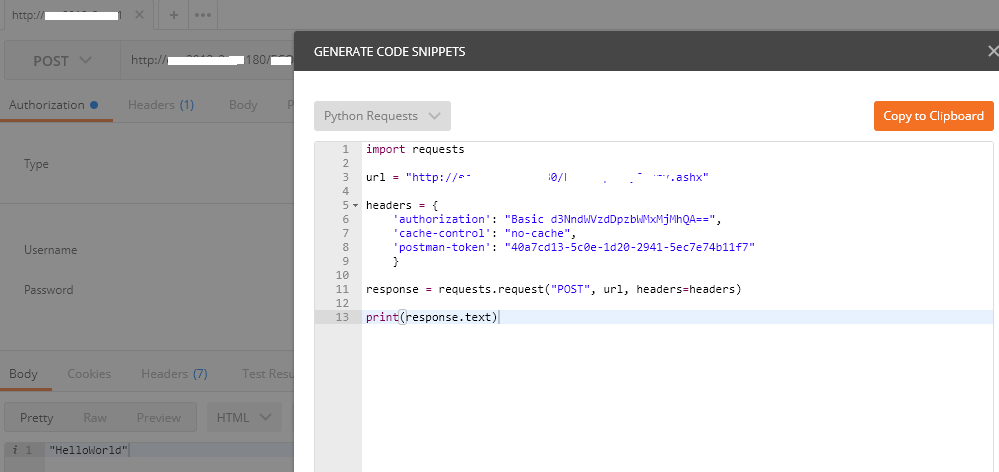
Веб-браузер может быть клиентом, а приложение на компьютере, на котором размещен веб-сайт, может быть сервером.
Итак, чтобы запросить ответ у сервера, в основном используют два метода:
- GET: запросить данные с сервера. Т.е. мы отправляем только URL (HTTP) запрос без данных. Метод HTTP GET предназначен для получения информации от сервера. В рамках GET-запроса некоторые данные могут быть переданы в строке запроса URI в формате параметров (например, условия поиска, диапазоны дат, ID Объекта, номер счетчика и т.д.).
- POST: отправить данные для обработки на сервер (и получить ответ от сервера). Мы отправляем набор информации, набор параметров для API. Метод запроса POST предназначен для запроса, при котором веб-сервер принимает данные, заключённые в тело сообщения POST запроса.
Чтобы сделать HTTP-запросы в python, мы можем использовать несколько HTTP-библиотек, таких как:
- HTTPLIB
- URLLIB
- REQUESTS
Самая элегантная и простая из перечисленных выше библиотек — это Requests. Библиотека запросов не является частью стандартной библиотеки Python, поэтому вам нужно установить ее, чтобы начать работать с ней.
Если вы используете pip для управления вашими пакетами Python, вы можете устанавливать запросы, используя следующую команду:
pip install requests
Если вы используете conda, вам понадобится следующая команда:
conda install requests
После того, как вы установили библиотеку, вам нужно будет ее импортировать
Давайте начнем с этого важного шага:
import requests
Синтаксис / структура получения данных через GET/POST запросы к API
Есть много разных типов запросов. Наиболее часто используемый, GET запрос, используется для получения данных.
Когда мы делаем запрос, ответ от API сопровождается кодом ответа, который сообщает нам, был ли наш запрос успешным. Коды ответов важны, потому что они немедленно сообщают нам, если что-то пошло не так.
Чтобы сделать запрос «GET», мы будем использовать функцию.
Метод используется, когда вы хотите отправить некоторые данные на сервер.
Ниже приведена подборка различных примеров использования запросов GET и POST через библиотеку REQUESTS. Безусловно, существует еще больше разных случаев. Всегда прежде чем, писать запрос, необходимо обратиться к официальной документации API (например, у Yandex есть документация к API различных сервисов, у Bitrix24 есть документация к API, у AmoCRM есть дока по API, у сервисов Google есть дока по API и т.д.). Вы смотрите какие методы есть у API, какие запросы API принимает, какие данные нужны для API, чтобы он мог выдать информацию в соответствии с запросом. Как авторизоваться, как обновлять ключи доступа (access_token). Все эти моменты могут быть реализованы по разному и всегда нужно ответ искать в официальной документации у поставщика API.
#GET запрос без параметров
response = requests.get('https://api-server-name.com/methodname_get')
#GET запрос с параметрами в URL
response = requests.get("https://api-server-name.com/methodname_get?param1=ford¶m2=-234¶m3=8267")
# URL запроса преобразуется в формат https://api-server-name.com/methodname_get?key2=value2&key1=value1
param_request = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api-server-name.com/methodname_get', params=param_request)
#GET запрос с заголовком
url = 'https://api-server-name.com/methodname_get'
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url, headers=headers)
#POST запрос с параметрами в запросе
response = requests.post('https://api-server-name.com/methodname_post', data = {'key':'value'})
#POST запрос с параметрами через кортеж
param_tuples =
response = requests.post('https://api-server-name.com/methodname_post', data=param_tuples)
#POST запрос с параметрами через словарь
param_dict = {'param': }
response = requests.post('https://api-server-name.com/methodname_post', data=payload_dict)
#POST запрос с параметрами в формате JSON
import json
url = 'https://api-server-name.com/methodname_post'
param_dict = {'param': 'data'}
response = requests.post(url, data=json.dumps(param_dict))
Объекты запроса¶
Следующие методы описывают открытый интерфейс , поэтому все они
могут быть переопределены в подклассах. Он также определяет несколько
общедоступных атрибутов, которые могут использоваться клиентами для проверки
проанализированного запроса.
-
Исходный URL-адрес, переданный конструктору.
Изменено в версии 3.4.
Request.full_url — это свойство с установщиком, получателем и удалителем.
Получение возвращает исходный URL-адрес запроса с
фрагментом, если он присутствовал.
-
Схема URI.
-
Полномочия URI, обычно это хост, но также могут содержать порт, разделенный
двоеточием.
-
Исходный хост для запроса, без порта.
-
Путь URI. Если использует прокси, то селектором будет
полный URL, который передается прокси.
-
Тело объекта запроса или , если не указано.
Изменено в версии 3.4: При изменении значения теперь удаляется заголовок
Content-Length, если он был ранее установлен или рассчитан.
-
Используемый метод HTTP-запроса. По умолчанию его значение —
, что означает, что выполнит
обычное вычисление используемого метода. Его значение можно установить
(таким образом, переопределив вычисление по умолчанию в
), либо предоставив значение по умолчанию,
установив его на уровне класса в подклассе , либо передав
значение в конструктор через аргумент method.Добавлено в версии 3.3.
Изменено в версии 3.4: Теперь в подклассах можно установить значение по умолчанию; раньше его
можно было установить только с помощью аргумента конструктора.
- ()
-
Возвращает строку, указывающую метод HTTP-запроса. Если
не , возвращает его значение, в противном
случае возвращает , если — это , или
, если это не так. Это имеет значение только для HTTP-запросов.Изменено в версии 3.3: get_method теперь смотрит на значение .
(key, val)
Добавить к запросу ещё один заголовок. Заголовки в настоящее время
игнорируются всеми обработчиками, кроме обработчиков HTTP, где они
добавляются в список заголовков, отправляемых на сервер
Обратите внимание,
что не может быть более одного заголовка с одним и тем же именем, и более
поздние вызовы будут перезаписывать предыдущие вызовы в случае конфликта
key. В настоящее время это не потеря функциональности HTTP, поскольку все
заголовки, которые имеют значение при многократном использовании, имеют
(зависящий от заголовка) способ получения той же функциональности с
использованием только одного заголовка.
- (key, header)
-
Добавить заголовок, который не будет добавлен в перенаправленный запрос.
- (header)
-
Возвращает, имеет ли экземпляр названный заголовок (проверяет как обычный,
так и не перенаправленный).
- (header)
-
Удалить именованный заголовок из экземпляра запроса (как из обычных, так и
из не перенаправленных заголовков).Добавлено в версии 3.4.
- ()
-
Возвращает URL-адрес, указанный в конструкторе.
Изменено в версии 3.4.
Возвращает
- (host, type)
-
Подготовить запрос, подключившись к прокси-серверу. host и type заменят
те из экземпляра, а селектор экземпляра будет исходным URL-адресом,
указанным в конструкторе.
- (header_name, default=None)
-
Возвращает значение данного заголовка. Если заголовок отсутствует,
возвращает значение по умолчанию.
- ()
-
Возвращает список кортежей (header_name, header_value) заголовков запроса.
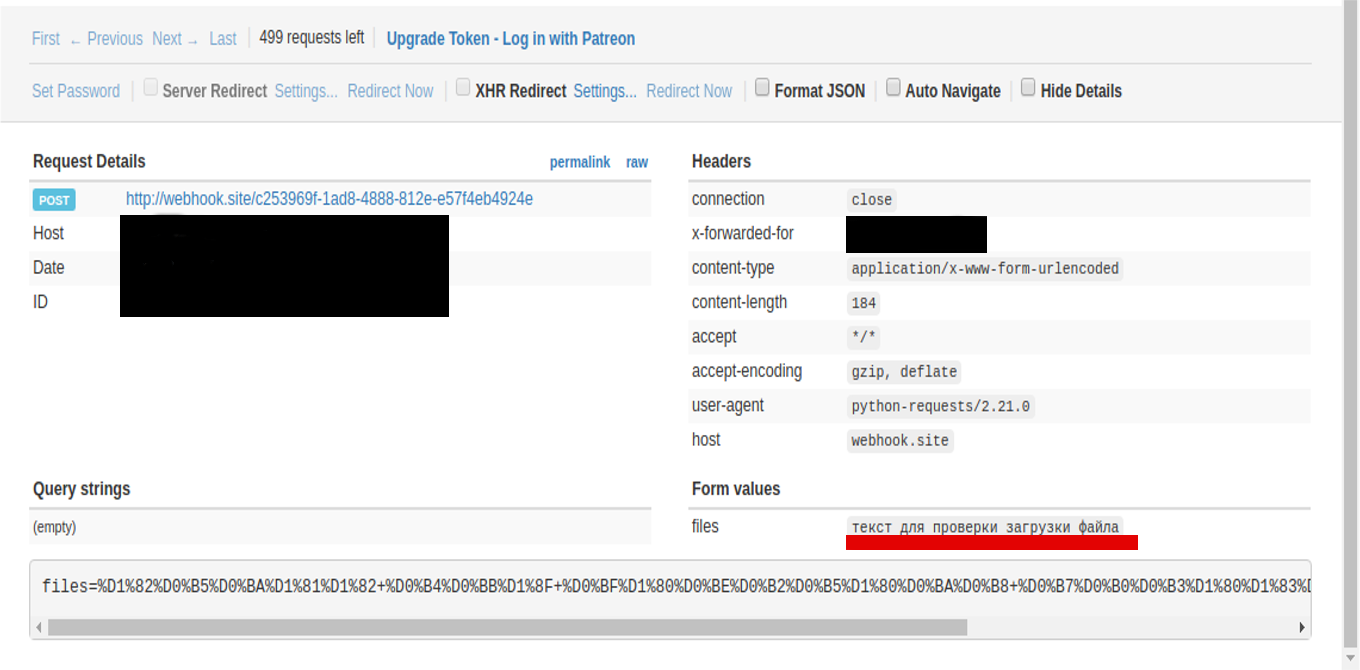
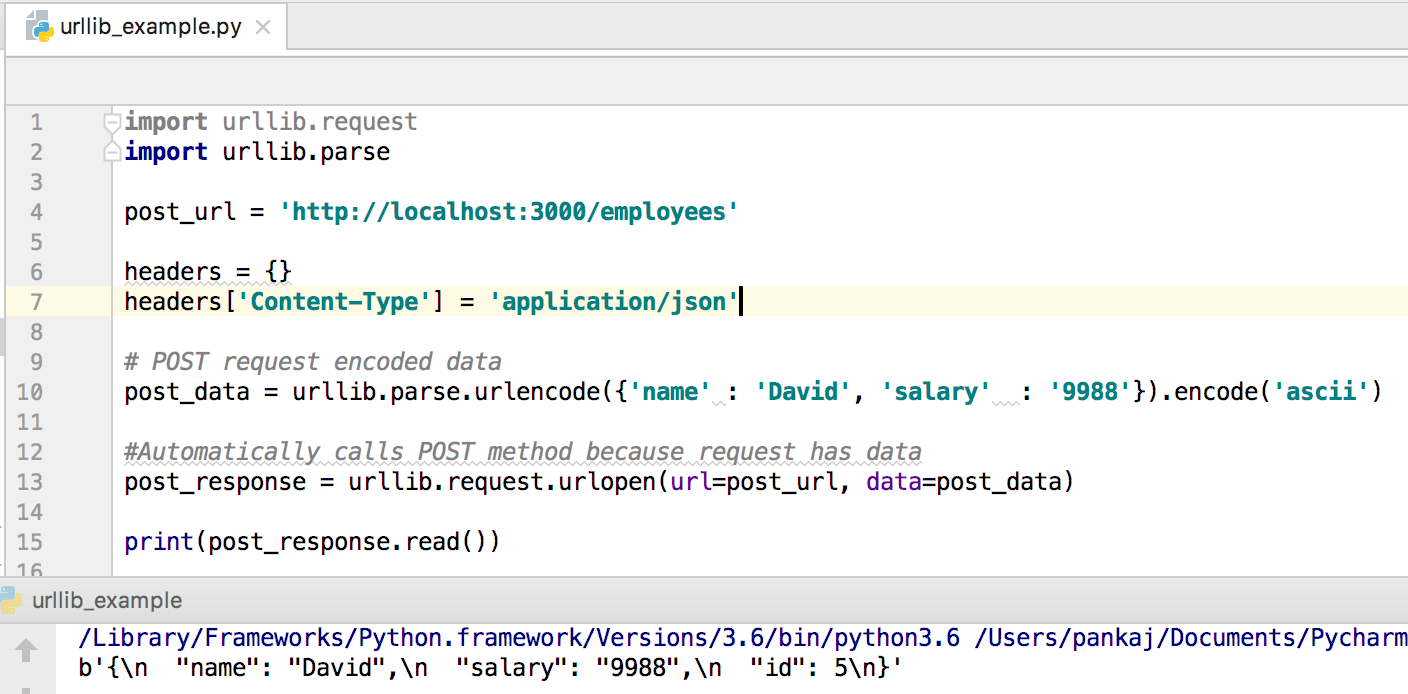
Почему и зачем использовать веб-парсинг?
Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
Динамический мониторинг цен
Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
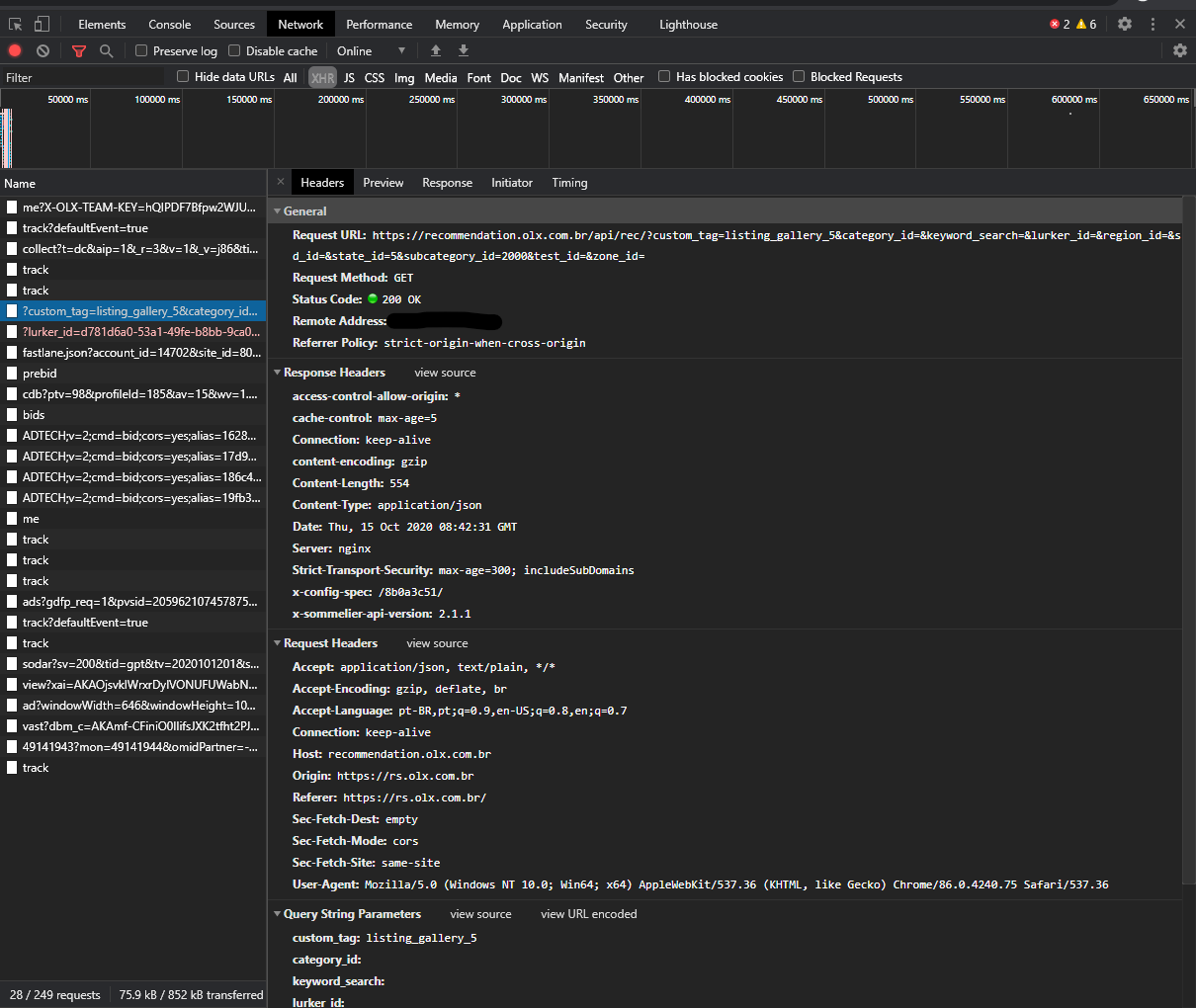
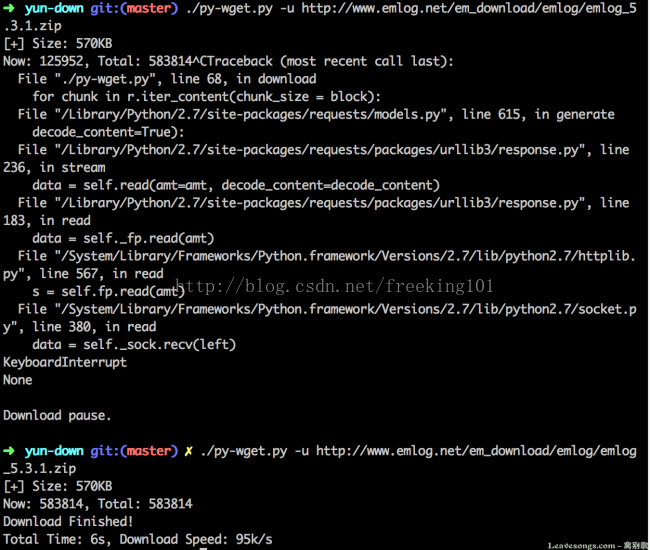
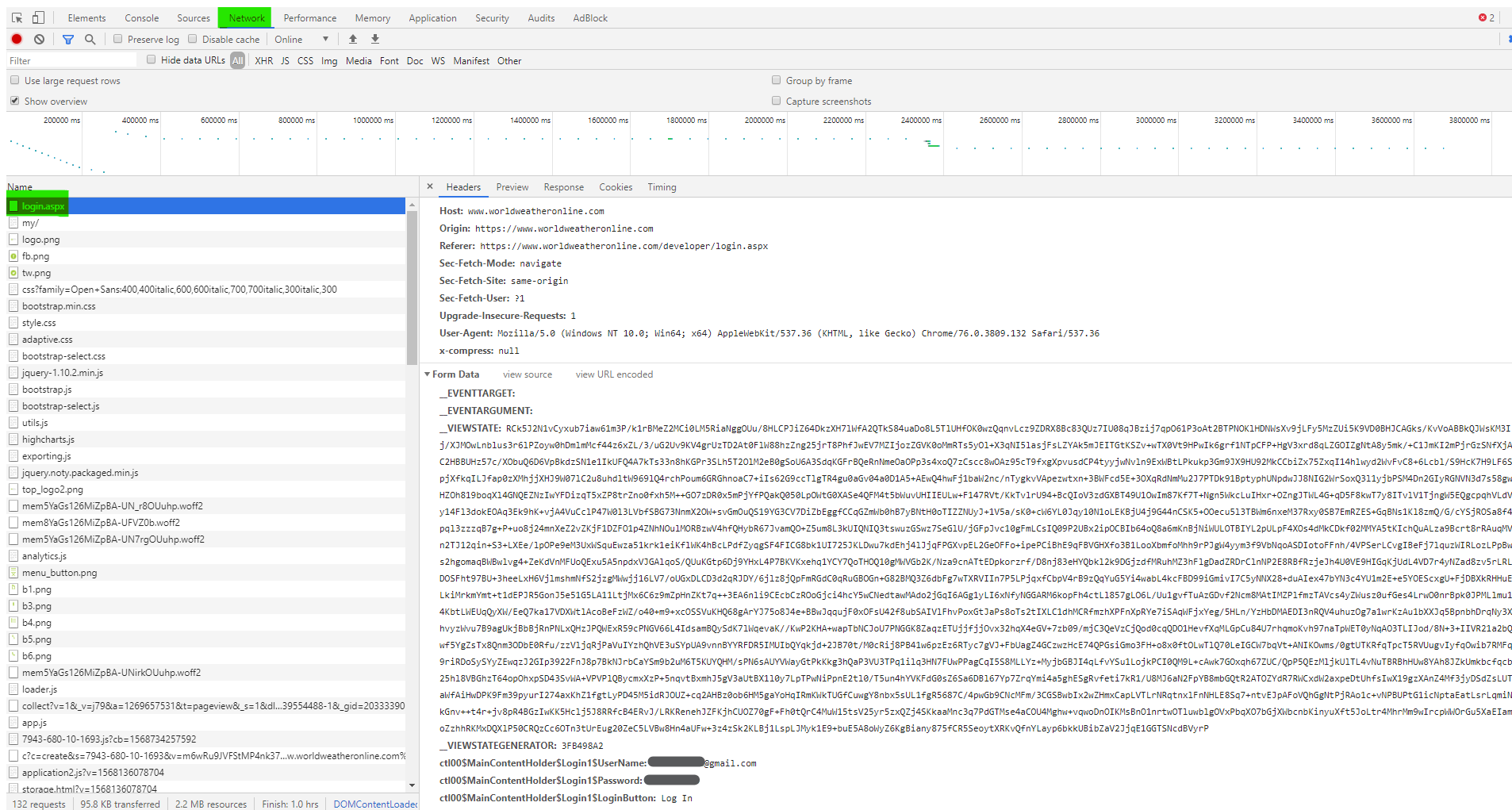
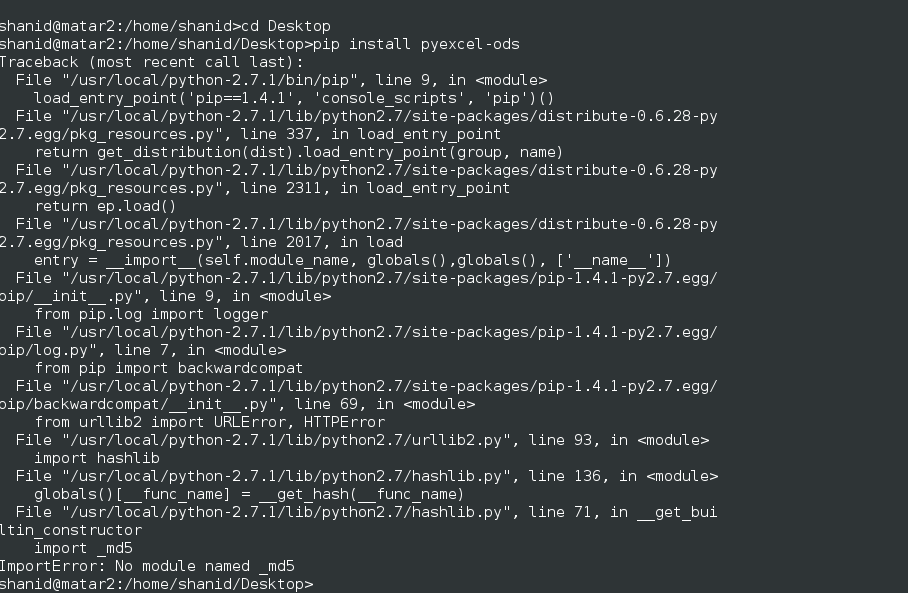
Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
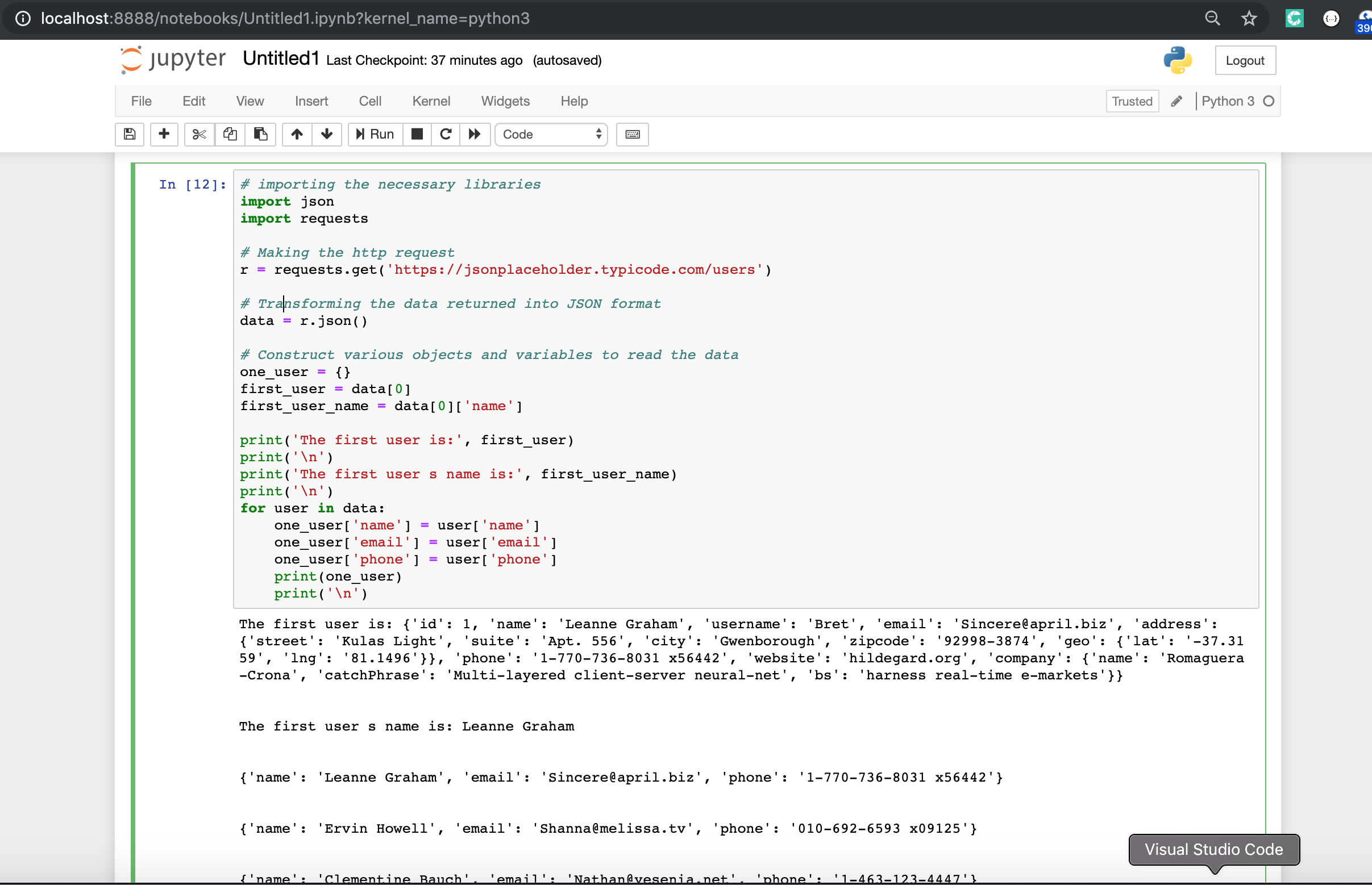
Работа с данными JSON в Python
JSON (JavaScript Object Notation) — это язык API. JSON — это способ кодирования структур данных, который простоту чтения данных машинами. JSON — это основной формат, в котором данные передаются туда и обратно в API, и большинство серверов API отправляют свои ответы в формате JSON.
JSON выглядит так, как будто он содержит словари, списки, строки и целые числа Python. Вы можете думать о JSON как о комбинации этих объектов, представленных в виде строк.
Рассмотрим пример:
Python имеет отличный инструментарий для работы с данными в формате JSON (пакет json — является частью стандартной библиотеки). Мы можем конвертировать списки и словари в JSON, а также конвертировать строки в списки и словари.
Библиотека JSON имеет две основные функции:
- — принимает объект Python и преобразует его в строку.
- — принимает строку JSON и преобразует (загружает) ее в объект Python.
Функция особенно полезна, поскольку мы можем использовать ее для печати отформатированной строки, которая облегчает понимание вывода JSON.
Рассмотрим пример:
# Импорт библиотеки requests
import requests
# Запрос GET (Отправка только URL без параметров)
response = requests.get("http://api.open-notify.org/astros.json")
# Вывод кода
print(response.status_code)
# Вывод ответа, полученного от сервера API
print(response.json())
Результат:
200
{'people': , 'message': 'success', 'number': 3}
Теперь попробуем применить функцию dump() — структура данных станет более наглядна:
# Импорт библиотеки requests
import requests
# Импорт библиотеки json
import json
def jprint(obj):
# create a formatted string of the Python JSON object
text = json.dumps(obj, sort_keys=True, indent=4)
print(text)
# Запрос GET (Отправка только URL без параметров)
response = requests.get("http://api.open-notify.org/astros.json")
# Вывод ответа, через пользовательскую функцию jprint
jprint(response.json())
Результат:
{
"message": "success",
"number": 3,
"people":
}
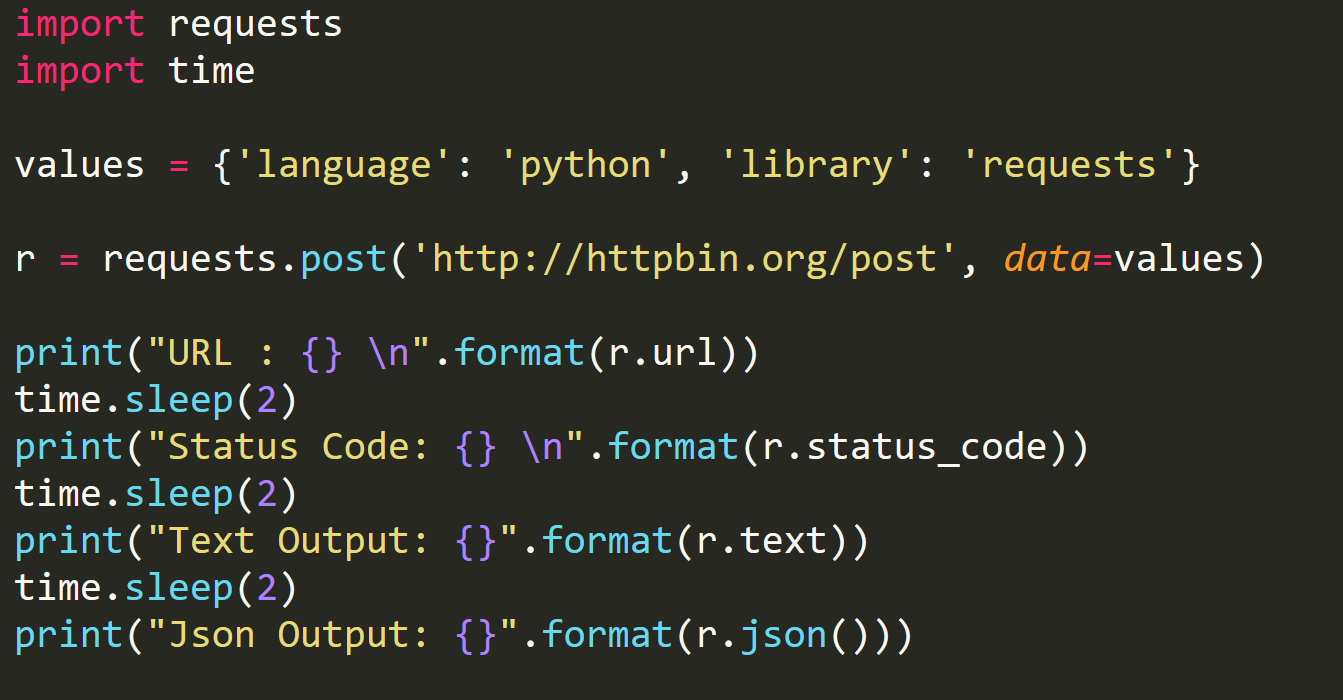
Дополнительные команды для просмотра параметров Response библиотеки Requests Python
Пример скрипта Python:
# Импорт библиотеки requests
import requests
# Запрос GET (Отправка только URL без параметров)
response = requests.get("http://api.open-notify.org/iss-pass.json?lat=40.71&lon=-74")
# Вывод ответа, через пользовательскую функцию jprint
print("response:\n{}\n\n".format(response))
print("response.url:\n{}\n\n".format(response.url)) #Посмотреть формат URL (с параметрами)
print("response.headers:\n{}\n\n".format(response.headers)) #Header of the request
print("response.status_code:\n{}\n\n".format(response.status_code)) #Получить код ответа
print("response.text:\n{}\n\n".format(response.text)) #Text Output
print("response.encoding:\n{}\n\n".format(response.encoding)) #Узнать, какую кодировку использует Requests
print("response.content:\n{}\n\n".format(response.content)) #В бинарном виде
print("response.json():\n{}\n\n".format(response.json())) #JSON Output
Результат:
response:
<Response >
response.url:
http://api.open-notify.org/iss-pass.json?lat=40.71&lon=-74
response.headers:
{'Server': 'nginx/1.10.3', 'Date': 'Tue, 07 Apr 2020 05:44:13 GMT', 'Content-Type': 'application/json', 'Content-Length': '519', 'Connection': 'keep-alive', 'Via': '1.1 vegur'}
response.status_code:
200
response.text:
{
"message": "success",
"request": {
"altitude": 100,
"datetime": 1586237266,
"latitude": 40.71,
"longitude": -74.0,
"passes": 5
},
"response":
}
response.encoding:
None
response.content:
b'{\n "message": "success", \n "request": {\n "altitude": 100, \n "datetime": 1586237266, \n "latitude": 40.71, \n "longitude": -74.0, \n "passes": 5\n }, \n "response": \n}\n'
response.json():
{'message': 'success', 'request': {'altitude': 100, 'datetime': 1586237266, 'latitude': 40.71, 'longitude': -74.0, 'passes': 5}, 'response': }





