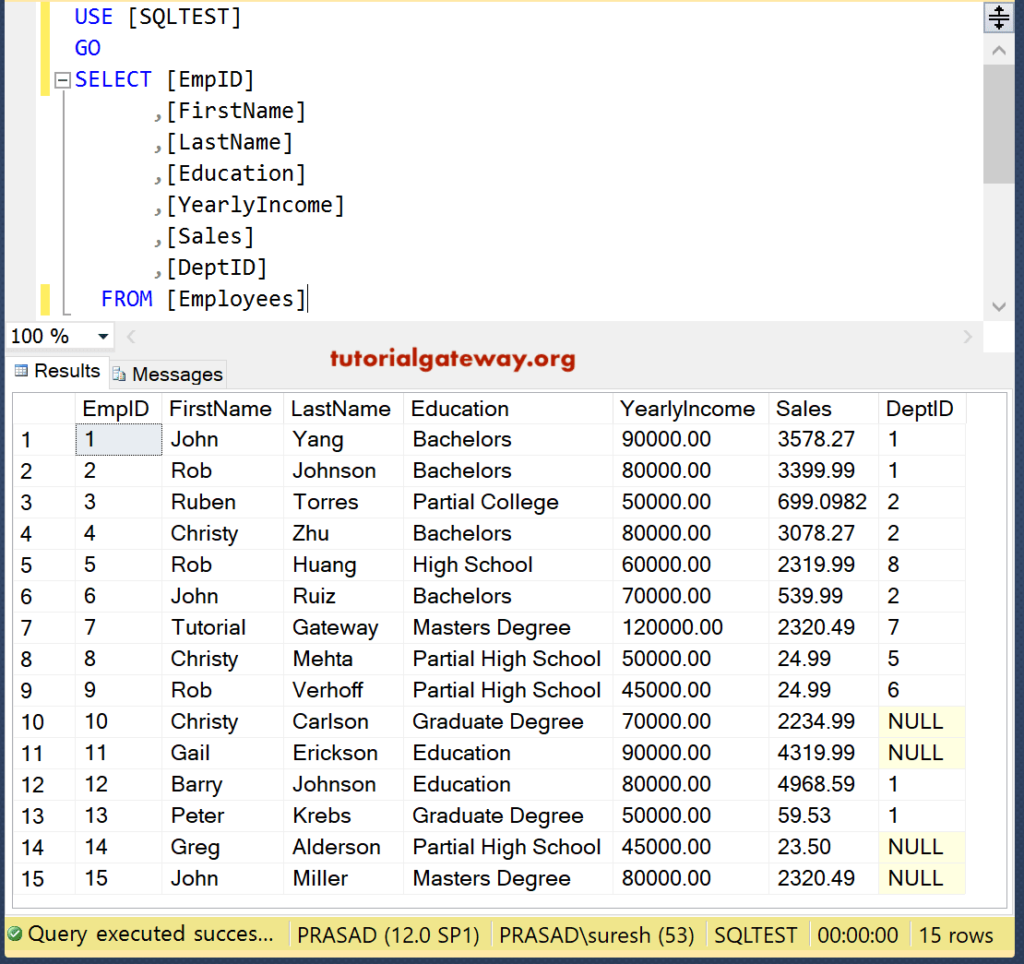
Преобразование типов
Разные типы данных могут представлять одно значение по-разному, например, значение типа int и значение типа float хранятся как совершенно разные двоичные шаблоны.
И как вы думаете, что произойдет, если сделать следующее:
float f = 4; // инициализация переменной типа с плавающей точкой целым числом 4
| 1 | floatf=4;// инициализация переменной типа с плавающей точкой целым числом 4 |
Здесь компилятор не сможет просто скопировать биты из значения типа int и переместить их в переменную типа float. Вместо этого ему нужно будет преобразовать целое число в число типа с плавающей точкой, которое затем можно будет присвоить переменной .
Процесс конвертации значений из одного типа данных в другой называется преобразованием типов. Преобразование типов может выполняться в следующих случаях:
Случай №1: Присваивание или инициализация переменной значением другого типа данных:
double k(4); // инициализация переменной типа double целым числом 4
k = 7; // присваиваем переменной типа double целое число 7
|
1 |
doublek(4);// инициализация переменной типа double целым числом 4 k=7;// присваиваем переменной типа double целое число 7 |
Случай №2: Передача значения в функцию, где тип параметра — другой:
void doSomething(long l)
{
}
doSomething(4); // передача числа 4 (тип int) в функцию с параметром типа long
|
1 |
voiddoSomething(longl) { doSomething(4);// передача числа 4 (тип int) в функцию с параметром типа long |
Случай №3: Возврат из функции, где тип возвращаемого значения — другой:
float doSomething()
{
return 4.0; // передача значения 4.0 (тип double) из функции, которая возвращает float
}
|
1 |
floatdoSomething() { return4.0;// передача значения 4.0 (тип double) из функции, которая возвращает float } |
Случай №4: Использование с операндами разных типов:
double division = 5.0 / 4; // операция деления со значениями типов double и int
| 1 | doubledivision=5.04;// операция деления со значениями типов double и int |
Во всех этих случаях (и во многих других) C++ будет использовать преобразование типов.
Есть 2 основных способа преобразования типов:
Неявное преобразование типов, когда компилятор автоматически конвертирует один фундаментальный тип данных в другой.
Явное преобразование типов, когда разработчик использует один из операторов явного преобразования для выполнения конвертации объекта из одного типа данных в другой.
Удалённые возможности
Удаление триграфов
В старые времена для работы на необычных системах, где не было некоторых символов ASCII, были введены триграфы. Например:
- цепочку компилятор воспринимал как
- цепочку компилятор воспринимал как
Все триграфы начинались с символа . Начиная с C++17 триграфов больше не существует.
Однако, диграфы пока ещё сохранились:
- компилятор воспринимает как
- компилятор воспринимает как
- компилятор воспринимает как
- компилятор воспринимает как
- компилятор воспринимает как
Удаление ключевого слова register
Ключевое слово больше не используется как спецификатор переменной. Оно зарезервировано для применения в будущем в других целях.
Запрет спецификации типов исключений
Больше нельзя указывать, какие именно исключения выбрасывает функция. Можно использовать только , но лучше писать . Пример кода, который больше не скомпилируется, приведён ниже:
Удаление auto_ptr
Класс удалён в пользу . Проблемой auto_ptr был странный “конструктор копирования”, который принимал другой объект по изменяемой ссылке и вместо копирования принимал изъятие внутренних данных.
Если вы используете компилятор MSVC с флагом , то при использовании auto_ptr вы получите ошибку:
Зачем нужен std::string?
Мы уже знаем, что строки C-style используют массивы типа char для хранения целой строки. Если вы попытаетесь что-либо сделать со строками C-style, то вы очень быстро обнаружите, что работать с ними трудно, запутаться легко, а проводить отладку сложно.
Строки C-style имеют много недостатков, в первую очередь связанных с тем, что вы должны самостоятельно управлять памятью. Например, если вы захотите поместить строку в буфер, то вам сначала нужно будет динамически выделить буфер правильной длины:
char *strHello = new char;
| 1 | char*strHello=newchar7; |
Не забудьте учесть дополнительный символ для нуль-терминатора! Затем вам нужно будет скопировать значение:
strcpy(strHello, «Hello!»);
| 1 | strcpy(strHello,»Hello!»); |
И здесь вам нельзя прогадать с длиной буфера, иначе произойдет ! И, конечно, поскольку строка выделяется динамически, то вы должны её еще и правильно удалить:
delete[] strHello;
| 1 | deletestrHello; |
Не забудьте использовать форму оператора delete, которая работает с массивами, а не обычную форму оператора delete.
Кроме того, многие из интуитивно понятных операторов, которые предоставляет язык C++ для работы с числами, такие как , , , , , и попросту не работают со строками C-style. Иногда они могут работать без ошибок со стороны компилятора, но результат будет неверным. Например, сравнение двух строк C-style с использованием оператора на самом деле выполнит сравнение указателей, а не строк. Присваивание одной строки C-style другой строке C-style с использованием оператора будет работать, но выполняться будет копирование указателя (), что не всегда то, что нам нужно. Такие вещи могут легко привести к ошибкам и сбоям в программе, а разбираться с ними не так уж и легко (относительно)!
Суть в том, что работая со строками C-style, вам нужно помнить множество придирчивых правил о том, что делать безопасно, а что — нет; запоминать много функций, таких как strcat() и strcmp(), чтобы использовать их вместо интуитивных операторов; а также самостоятельно выполнять управление памятью.
К счастью, язык C++ предоставляет гораздо лучший способ для работы со строками: классы std::string и std::wstring
Используя такие концепции С++, как конструкторы, деструкторы и перегрузку операторов, std::string позволяет создавать и манипулировать строками в интуитивно понятной форме и, что не менее важно, выполнять это безопасно! Никакого управления памятью, запоминания странных названий функций и значительно меньшая вероятность возникновения ошибок/сбоев
Создание строки
Строковые классы имеют ряд конструкторов, которые можно использовать для создания строк. Здесь мы рассмотрим каждого из них.
Примечание: преобразуется в , который является тем же целочисленным типом без знака, который возвращается оператором . Его фактический размер зависит от среды. Для целей этого руководства представьте его как .
Конструктор по умолчанию. Создает пустую строку.
Пример кода:
Вывод:
Конструктор копирования. Этот конструктор создает новую строку как копию .




Пример кода:
Вывод:
Этот конструктор создает новую строку, содержащую не более символов из , начиная с индекса .
- Если встречается , копирование строки завершится, даже если значение не было достигнуто.
- Если значение не указано, будут использоваться все символы, начиная с .
- Если значение больше размера строки, будет выброшено исключение .
Пример кода:
Вывод:
Этот конструктор создает новую строку из строки в стиле C, но не включая завершающий ноль.
- Если результирующий размер превышает максимальную длину строки, будет сгенерировано исключение .
- Предупреждение: не должна быть равна .
Пример кода:
Вывод:
Этот конструктор создает новую строку из первых символов из строки в стиле C.
- Если результирующий размер превышает максимальную длину строки, будет сгенерировано исключение .
- Предупреждение: только для этой функции нули в не обрабатываются как символы конца строки! Это означает, что можно выйти за конец строки, если значение слишком велико. Будьте осторожны, чтобы не переполнить строковый буфер!
Пример кода:
Вывод:
Этот конструктор создает новую строку, инициализированную вхождениями символа .
Если результирующий размер превышает максимальную длину строки, будет сгенерировано исключение length_error.
Пример кода:
Вывод:
Этот конструктор создает новую строку, инициализированную символами диапазона [, ).
Если результирующий размер превышает максимальную длину строки, будет сгенерировано исключение length_error.
Здесь нет примера, поскольку это достаточно запутанный способ создания строки, и вы вряд ли когда-то им не воспользуетесь.
Инструкции и поток управления
switch-case и fallthrough
В C++17 появился атрибут fallthrough, способный помочь с вечными проблемами case/break:
- обычно в конце case происходит break, return или throw, что завершает выполнение блока кода
- если в конце case ничего нет, в C++17 надо поставить — атрибут для следующего case
- если компилятор не увидит , в C++17 он должен выдать предупреждение о неожиданном переходе к следующей метке case
Гарантированное устранение копирования (guaranteed copy elision)
В C++17 вы можете полагаться на устранение копирований и перемещений и смело писать код как в примере ниже, не оглядываясь на конструкторы копирования и перемещения:
Декомпозиция в объявлениях переменных
В C++17 появилась декомпозиция пользовательских структур, std::tuple, std::pair и std::array в объявлении переменных:
if и switch с инициализатором
В C++17 условие if и switch может состоять из двух секций:
Это может упростить работу с итераторами или некоторыми указателями:
Отметим, что в C++ и раньше можно было в некоторых случаях выполнять присваивание с проверкой:
Вывод типов при конструировании шаблонных классов
Вызовы функций make_pair, make_tuple и т.п. можно заменить на прямое конструирование:
Эта фишка упрощает работу с std::array:
Новые гарантии порядка вычислений
- постфиксные выражения, в том числе вызовы и обращения к элементу, вычисляются слева направо
- присваивания вычисляются справа налево, включая составные присваивания
- операнды в операторах смещения и вычисляются слева направо
Данные гарантии нужны для будущих версий стандартной библиотеки.
Атрибут nodiscard
Используйте атрибут `nodiscard` для пометки функции, если отсутствие обработки возвращаемого функцией значения скорее всего является ошибкой. Примером служат функции-конструкторы, которые возвращают unique_ptr или shared_ptr без побочных эффектов.
constexpr if
В C++17 появились constexpr if, которые широко применимы в метапрограммировании, но также полезны и в повседневном коде внутри полиморфных лямбда-функций:
Явное и неявное преобразование
Преобразование типов данных бывает явным и неявным.
Неявное преобразование скрыто от пользователя. SQL Server автоматически преобразует данные из одного типа в другой. Например, если smallint сравнивается с int, то перед сравнением smallint неявно преобразуется в int.
GETDATE() выполняет неявное преобразование в стиль даты 0. SYSDATETIME() выполняет неявное преобразование в стиль даты 21.
Явное преобразование выполняется с помощью функций CAST и CONVERT.
Функции CAST и CONVERT преобразуют значение (локальную переменную, столбец или выражение) из одного типа данных в другой. Например, приведенная ниже функция преобразует числовое значение в строку символов :
Если программный код Transact-SQL должен соответствовать требованиям ISO, используйте функцию CAST вместо CONVERT. Использование функции CONVERT вместо CAST дает преимущество в дополнительной функциональности.
На следующей иллюстрации показаны все явные и неявные преобразования типов данных, допустимые для системных типов данных SQL Server. Это могут быть типы xml, bigint и sql_variant. При присваивании неявного преобразования из типа sql_variant не происходит, но неявное преобразование в тип sql_variant производится.
Хотя на приведенной выше диаграмме показаны все явные и неявные преобразования, которые допускаются в SQL Server, в ней не указан результирующий тип данных. Когда SQL Server выполняет явное преобразование, сам оператор определяет результирующий тип данных. Для неявных преобразований операторы назначения, такие как установка значения переменной или вставка значения в столбец, дают в результате тип данных, определенный в объявлении переменной или в определении столбца. Для операторов сравнения или других выражений результирующий тип данных зависит от правил приоритета типов данных.
Например, следующий сценарий определяет переменную типа , присваивает переменной значение типа , а затем выбирает объединение переменной со строкой.
Значение преобразуется в , поэтому оператор возвращает значение .
В следующем примере показан похожий сценарий с переменной :
В этом случае оператор выдает следующую ошибку:
Чтобы вычислить выражение , SQL Server следует правилам приоритета типов данных для выполнения неявного преобразования перед вычислением результата выражения. Поскольку имеет более высокий приоритет, чем , SQL Server пытается преобразовать строку в целое число, и операция завершается ошибкой, так как эта строка не может быть преобразована в целое число. Если выражение содержит строку, которую можно преобразовать, работа оператора завершается успешно, как показано в следующем примере:


В этом случае строка может быть преобразована в целочисленное значение , поэтому оператор возвращает значение
Обратите внимание, что оператор выполняет сложение, а не объединение, если предоставленные типы данных являются целыми числами
Обзор классов строк
Весь строковый функционал стандартной библиотеки находится в заголовочном файле. Чтобы использовать его, просто включите заголовок :
На самом деле в заголовке есть 3 разных класса строк. Первый – это шаблонный базовый класс с именем :
Вы не будете работать с этим классом напрямую, поэтому пока не беспокойтесь о том, что это за и . Значений по умолчанию будет достаточно почти во всех мыслимых случаях.
Стандартная библиотека предоставляет две разновидности :
Это два класса, которые вы непосредственно будете использовать. используется для стандартных строк ASCII и UTF-8. используется для строк с расширенными символами / Unicode (UTF-16). Для строк UTF-32 нет встроенного класса (хотя вы можете расширить из свой собственный класс, если он вам нужен).
Хотя вы будете напрямую использовать и , весь строковый функционал реализован в классе . и могут получить доступ к этому функционалу напрямую благодаря шаблону. Следовательно, все представленные функции будут работать как для , так и для . Однако, поскольку является шаблонным классом, это также означает, что, если вы сделаете что-то синтаксически неверное со или , компилятор выдаст ужасно выглядящие ошибки шаблона. Не пугайтесь этих ошибок; они выглядят намного хуже, чем они есть на самом деле!
Вот список всех функций в строковом классе. Для обработки различных типов входных данных большинство этих функций имеют несколько разновидностей, которые мы рассмотрим более подробно в следующих уроках.
| Функция | Действие |
|---|---|
| Создание и уничтожение | |
| конструктор | Создает или копирует строку |
| деструктор | Уничтожает строку |
| Размер и вместимость | |
| Возвращает количество символов, которые могут храниться без перераспределения памяти | |
| Возвращает логическое значение, указывающее, пуста ли строка | |
| , | Возвращает количество символов в строке |
| Возвращает максимальный размер строки, которая может быть размещена | |
| Увеличить или уменьшить вместимость строки | |
| Доступ к элементам | |
| , | Доступ к символу по определенному индексу |
| Модификация | |
| , | Присваивает новое значение строке |
| , , | Добавляет символы в конец строки |
| Вставляет символы в строку по произвольному индексу | |
| Удаляет все символы в строке | |
| Стирает символы по произвольному индексу в строке | |
| Заменяет символы с произвольным индексом на другие символы | |
| Расширение или сжатие строки (обрезает или добавляет символы в конце строки) | |
| Меняет местами значения двух строк | |
| Ввод и вывод | |
| , | Считывает значения из входного потока в строку |
| Записывает значение строки в выходной поток | |
| Возвращает содержимое строки как строку в стиле C с завершающим нулем | |
| Копирует содержимое (не оканчивающееся нулем) в массив символов | |
| То же, что . Неконстантная перегрузка позволяет выполнять запись в возвращаемую строку | |
| Сравнение строк | |
| , | Сравнивает, равны или неравны две строки (возвращает ) |
| , , , | Сравнивает, являются ли две строки меньше/больше друг друга (возвращает ) |
| Сравнивает, равны или неравны две строки (возвращает -1, 0 или 1) | |
| Подстроки и конкатенация | |
| Объединяет две строки | |
| Возвращает подстроку | |
| Поиск | |
| Найти индекс первого символа/подстроки | |
| Найти индекс первого символа из набора символов | |
| Найти индекс первого символа, не входящего в набор символов | |
| Найти индекс последнего символа из набора символов | |
| Найти индекс последнего символа, не входящего в набор символов | |
| Найти индекс последнего символа/подстроки | |
| Поддержка итераторов и распределителей памяти (аллокаторов) | |
| , | Поддержка итератора прямого направления для начала/конца строки |
| Возвращает распределитель | |
| , | Поддержка итератора обратного направления для начала/конца строки |
Хотя строковые классы библиотеки STL предоставляют множество функций, есть несколько заметных упущений:
- поддержка регулярных выражений;
- конструкторы для создания строк из чисел;
- функции изменения регистра на верхний/нижний;
- сравнение без учета регистра;
- разбиение строки на массив;
- простые функции для получения левой или правой части строки;
- обрезка пробелов в начале и конце строки;
- форматирование строки в стиле ;
- преобразование из UTF-8 в UTF-16 или наоборот.
Для большинства из них вам придется либо написать свои собственные функции, либо преобразовать вашу строку в строку в стиле C (используя ) и использовать функции C, которые предлагают эту функциональность.
В следующих уроках мы более подробно рассмотрим различные функции класса . Хотя в наших примерах мы будем использовать , всё в равной степени применимо и к .
Извлечение и пробелы
Важный момент: оператор извлечения работает с «отформатированными» данными, т.е. он игнорирует все пробелы, символы табуляции и символ новой строки. Например:
#include <iostream>
int main()
{
char ch;
while (std::cin >> ch)
std::cout << ch;
return 0;
}
|
1 |
#include <iostream> intmain() { charch; while(std::cin>>ch) std::cout<<ch; return; } |
Если пользователь введет следующее:
То оператор извлечения пропустит все пробелы и символы новой строки. Следовательно, результат выполнения программы:
Часто пользовательский ввод все же нужен со всеми его пробелами. Для этого класс предоставляет множество функций. Одной из наиболее полезных является фунция get(), которая извлекает символ из входного потока. Вот вышеприведенная программа, но уже с использованием функции get():
#include <iostream>
int main()
{
char ch;
while (std::cin.get(ch))
std::cout << ch;
return 0;
}
|
1 |
#include <iostream> intmain() { charch; while(std::cin.get(ch)) std::cout<<ch; return; } |
Теперь, если мы введем следующее:
То получим:
Функция get() также имеет строковую версию, в которой можно указать максимальное количество символов для извлечения. Например:
#include <iostream>
int main()
{
char strBuf;
std::cin.get(strBuf, 12);
std::cout << strBuf << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { charstrBuf12; std::cin.get(strBuf,12); std::cout<<strBuf<<std::endl; return; } |
Если мы введем следующее:
То получим:
Обратите внимание, программа считывает только первые 11 символов (+ нуль-терминатор). Остальные символы остаются во входном потоке
Один важный нюанс: функция get() не считывает символ новой строки! Например:
#include <iostream>
int main()
{
char strBuf;
// Считываем первые 11 символов
std::cin.get(strBuf, 12);
std::cout << strBuf << std::endl;
// Считываем дополнительно еще 11 символов
std::cin.get(strBuf, 12);
std::cout << strBuf << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { charstrBuf12; // Считываем первые 11 символов std::cin.get(strBuf,12); std::cout<<strBuf<<std::endl; // Считываем дополнительно еще 11 символов std::cin.get(strBuf,12); std::cout<<strBuf<<std::endl; return; } |
Если пользователь введет следующее:
То получит:
И программа сразу же завершит свое выполнение! Почему так? Почему не срабатывает второй ввод данных? Дело в том, что первый get() считывает символы до символа новой строки, а затем останавливается. Второй get() видит, что во входном потоке все еще есть данные и пытается их извлечь. Но первый символ, на который он натыкается — символ новой строки, поэтому происходит второй «Стоп!».





Для решения данной проблемы класс предоставляет функцию getline(), которая работает точно так же, как и функция get(), но при этом может считывать символы новой строки:
#include <iostream>
int main()
{
char strBuf;
// Считываем 11 символов
std::cin.getline(strBuf, 12);
std::cout << strBuf << std::endl;
// Считываем дополнительно еще 11 символов
std::cin.getline(strBuf, 12);
std::cout << strBuf << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { charstrBuf12; // Считываем 11 символов std::cin.getline(strBuf,12); std::cout<<strBuf<<std::endl; // Считываем дополнительно еще 11 символов std::cin.getline(strBuf,12); std::cout<<strBuf<<std::endl; return; } |
Этот код работает точно так, как ожидается, даже если пользователь введет строку с символом новой строки.
Если вам нужно узнать количество символов, извлеченных последним getline(), используйте функцию gcount():
#include <iostream>
int main()
{
char strBuf;
std::cin.getline(strBuf, 100);
std::cout << strBuf << std::endl;
std::cout << std::cin.gcount() << » characters were read» << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { charstrBuf100; std::cin.getline(strBuf,100); std::cout<<strBuf<<std::endl; std::cout<<std::cin.gcount()<<» characters were read»<<std::endl; return; } |
Результат:
Строка Python в Int
Собственно, во многих случаях это необходимо. Например, вы читаете некоторые данные из файла, тогда они будут в формате String, и вам нужно будет преобразовать String в int.
Теперь перейдем к коду. Если вы хотите преобразовать число, представленное в строке, в int, вы должны использовать для этого функцию int(). Смотрите следующий пример:
num = '123' # string data
# print the type
print('Type of num is :', type(num))
# convert using int()
num = int(num)
# print the type again
print('Now, type of num is :', type(num))
Результатом следующего кода будет:
Type of num is : <class 'str'> Now, type of num is : <class 'int'>
Использование функции stoi ()
Функция atoi () используется для возврата числа путем преобразования строкового значения в целое число. Первый аргумент этой функции является обязательным, а остальные аргументы — необязательными. Синтаксис этой функции приведен ниже.
Синтаксис:
Создайте файл C ++ со следующим кодом для преобразования строки в целое число с помощью функции stoi (). После выполнения кода входное значение, полученное от пользователя, будет преобразовано в число и распечатано, если входное значение является допустимым числом. Если входное значение содержит какой-либо алфавитный или нечисловой символ, будет сгенерировано исключение invalid_argument и будет напечатано сообщение об ошибке.
Выход:
Следующий вывод появится, если после выполнения кода в качестве входных данных будет выбрано 4577.
Следующий вывод появится, если после выполнения кода будет принято приветствие в качестве ввода.
Новый модуль std::filesystem
Знаменитая библиотека Boost.Filesystem мигрировала в стандарт, и теперь будет реализована производителями компиляторов в пространстве имён std::filesystem. Это радует, потому что Boost.Filesystem имеет известные проблемы внутренней архитектуры:
- внутри Boost.Filesystem присутствуют места с неопределённым поведением, например, разыменование нулевых указателей и передача их в виде ссылки, а затем повторное получение указателя
- на Windows в некоторых случаях, например внутри функции exist, используются конвертации в 8-битные кодировки, что приводит к проблемам при работе с путями, содержащими определённые символы Unicode