
10 ответов
Лучший ответ
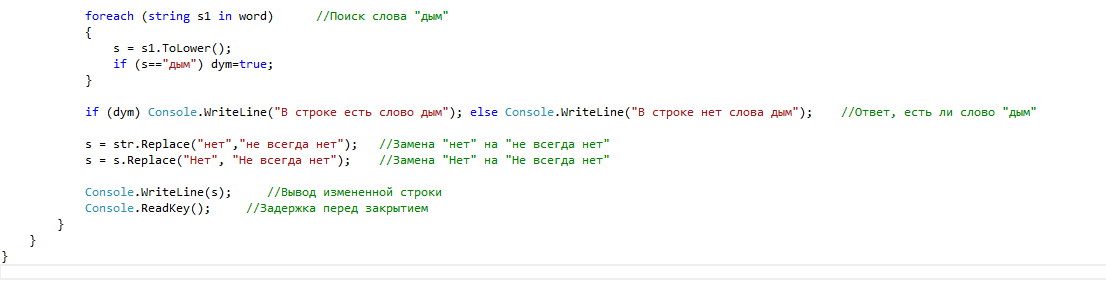
Вы должны использовать функцию замены строки с одним регулярным выражением. Предполагая специальными символами, вы имеете в виду все, что не является буквой, вот решение:
326
SiddAjmera
11 Янв 2020 в 04:51
Я попробовал очень креативное решение Seagul, но обнаружил, что оно рассматривает числа также как специальные символы, которые не соответствуют моим потребностям. Итак, вот мой (отказоустойчивый) твик решения Seagul …
8
Community
26 Дек 2017 в 16:14
Первое решение не работает для любого алфавита UTF-8. (Это будет вырезать текст, такой как Привіт). Мне удалось создать функцию, которая не использует RegExp и использует хорошую поддержку UTF-8 в движке JavaScript. Идея проста, если символ равен в верхнем и нижнем регистре, это специальный символ. Единственное исключение сделано для пробелов.
Обновление
Обратите внимание, что это решение работает только для языков, в которых есть строчные и заглавные буквы. На таких языках, как китайский, это не сработает
Обновление 2 . Я пришел к исходному решению, когда работал над нечетким поиском. Если вы также пытаетесь удалить специальные символы для реализации функции поиска, есть лучший подход. Используйте любую библиотеку транслитерации, в которой вы получите строку только из латинских символов, а затем простой Regexp сделает все магия удаления специальных символов. (Это будет работать и для китайцев, и вы также получите дополнительные преимущества, сделав == ).
29
Seagull
26 Апр 2019 в 17:07
Искать не все (символы слова || пробел):
6
dovid
24 Янв 2018 в 19:12
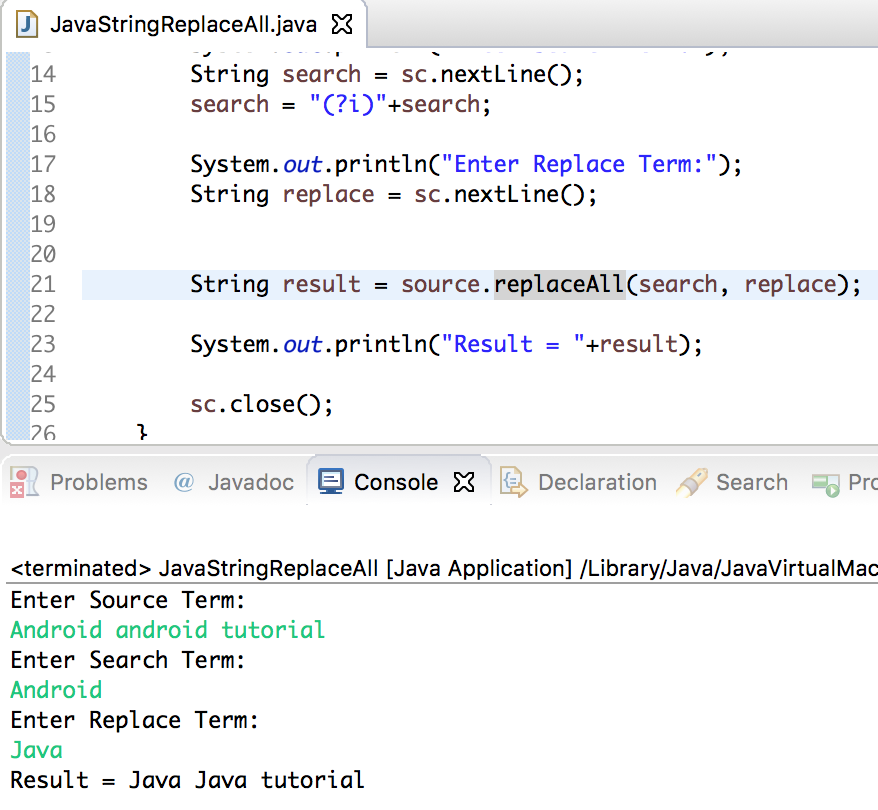
Попробуйте использовать этот
Здесь ^ карат для отрицания \ w для символов слова и \ s для пробела / [] / gi для глобального
Shrinivasan
18 Ноя 2019 в 15:26
Вы можете сделать это, указав символы, которые хотите удалить:
В качестве альтернативы, чтобы изменить все символы, кроме цифр и букв, попробуйте:
115
Pere
28 Фев 2014 в 16:49
sudheer nunna
16 Янв 2020 в 10:10
Точка (.) не может считаться особенной. Я добавил условие ИЛИ в ответ Mozfet & Seagull:
hassanf1
11 Дек 2017 в 07:54
Чьи специальные символы вы хотите удалить из строки, подготовьте их список, а затем пользовательская функция замены javascript для удаления всех специальных символов.
Или вы можете запустить цикл для всей строки, сравнить один-единственный символ с кодом ASCII и создать новую строку.
-11
Gaurav Agrawal
2 Июл 2011 в 04:58
Я не знаю JavaScript, но разве это невозможно с помощью регулярных выражений?
Нечто подобное будет соответствовать чему угодно, кроме цифр, символов и пробелов. Было бы просто вопросом найти синтаксис в JavaScript.
10
Jon
2 Июл 2011 в 18:23
8 ответов
Лучший ответ
Я использую этот простой и надежный подход:
По сути, все, что вам действительно нужно, это ASCII-символы 0-127, поэтому просто перестроите строку char в char. Если это хороший полукок, оставьте его, если нет — бросьте его. Довольно крепкий, и если ваша цель — санитария, она достаточно быстрая (на самом деле она очень быстрая).
28
Ali
7 Ноя 2013 в 05:54
Если вы пытаетесь удалить «недопустимый символ» — � — из строк javascript, то вы можете избавиться от них следующим образом:
8
Dan Mantyla
13 Фев 2017 в 16:19
Я столкнулся с этой проблемой с поистине странным результатом, полученным из данных Date Taken для цифрового изображения. Мой сценарий, по общему признанию, уникален — с использованием хоста сценариев Windows (wsh) и объекта activex Shell.Application, который позволяет получить объект пространства имен папки и вызвать функцию GetDetailsOf, чтобы по существу возвращать данные exif после того, как они были проанализированы ОС.
В Windows Vista и 7 результат выглядит следующим образом:
Итак, мой подход был следующим:
Результатом, конечно же, является строка, которая исключает эти знаки вопроса.
Я знаю, что вы пошли с другим решением в целом, но я подумал, что опубликую свое решение на тот случай, если у кого-то еще возникнут проблемы с ним, и он не сможет использовать языковой подход на стороне сервера.
2
Marcus Pope
29 Янв 2012 в 05:11
Такие языки, как испанский и французский, имеют акцентированные символы, такие как «é», а коды находятся в диапазоне 160-255 см. https: //www.ascii.cl/htmlcodes.htm
3
O’Neill
21 Авг 2019 в 14:13
Строки JavaScript изначально являются Unicode. Они содержат последовательности символов *, а не последовательности байтов, поэтому невозможно содержать недопустимую последовательность байтов.
(Технически они на самом деле содержат последовательности кодовых блоков UTF-16, что не совсем то же самое, но, вероятно, сейчас вам не о чем беспокоиться.)
Вы можете, если вам нужно по какой-то причине, создать строку, содержащую символы, используемые в качестве заполнителей для байтов. то есть . используя символ (‘\ x80’) для обозначения байта 0x80. Это то, что вы получили бы, если бы вы кодировали символы в байты с использованием UTF-8, а затем по ошибке декодировали их обратно в символы с использованием ISO-8859-1. Для этого есть специальная идиома JavaScript:
И снова вернуться от псевдобайт UTF-8 к символам:
(Примечательно, что это единственный случай, когда функции / следует использовать. Их существование в любой другой программе почти всегда является ошибкой.)
, поскольку он ведет себя как декодер UTF-8, вызовет ошибку, если последовательность введенных в него блоков кода не будет принята как байты UTF-8.
Вам очень редко приходится работать с такими байтовыми строками в JavaScript. Лучше продолжать работать в Unicode на стороне клиента. Браузер позаботится о UTF-8-кодировании строки на проводе (при отправке формы или XMLHttpRequest).
20
bobince
19 Апр 2010 в 19:45
Простая ошибка, большой эффект:
Без «глобального» флага замена происходит только для первого совпадения.
Примечание: чтобы удалить любой символ, который не выполняет какое-либо сложное условие, например попадание в набор определенных диапазонов символов Юникода, вы можете использовать отрицательный прогноз:
Где читается как
(?! # negative look-ahead: a position *not followed by*:
# any allowed character range from above
) # end lookahead
. # match this character (only if previous condition is met!)
8
Tomalak
19 Апр 2010 в 19:57
Я использовал решение @ Ali, чтобы не только очистить мою строку, но и заменить недопустимые символы на html-замену:
barbsan
17 Июл 2019 в 11:14
Я собрал некоторые решения, предложенные выше, чтобы избежать ошибок
loretoparisi
31 Май 2019 в 13:46
Строка в качестве второго параметра
Если вы указываете строку как второй параметр — она может включать в себя следующие специальные шаблоны замены:
| Шаблон | Замена |
| Вставляет символ доллара «$». | |
| Вставляет всё найденное совпадение. | |
| Вставляет часть строки до совпадения. | |
| Вставляет часть строки после совпадения. | |
| n-ная группа захвата, где n – значение от О до 9. Например, $1 – это первая группа захвата, $2 – вторая, и т. д. Если захвата нет, используется пустая строка. | |
| nn-ная группа захвата, где nn – значение от О1 до 91. Например, $01 – это первая группа захвата, $02 – вторая, и т. д. Если захвата нет, используется пустая строка. |
Пример использования скобок и $1, $2:
Выполнить код »
Скрыть результаты
Пример, с использованием подстроки, совпадающей со всем шаблоном $&:
Выполнить код »
Скрыть результаты
Сравнение строк
В JavaScript для сравнения строк можно использовать операторы меньше и больше:
В JavaScript строки сравниваются посимвольно в алфавитном порядке. Сначала сравниваются первые символы строк, затем вторые, третьи… И как только какой-то символ оказывается меньше, строка считается меньше, даже если в строке больше символов. Если у какой-то строки заканчиваются символы, то она считается меньше, а если символы закончились у обоих строк одновременно – они одинаковые.
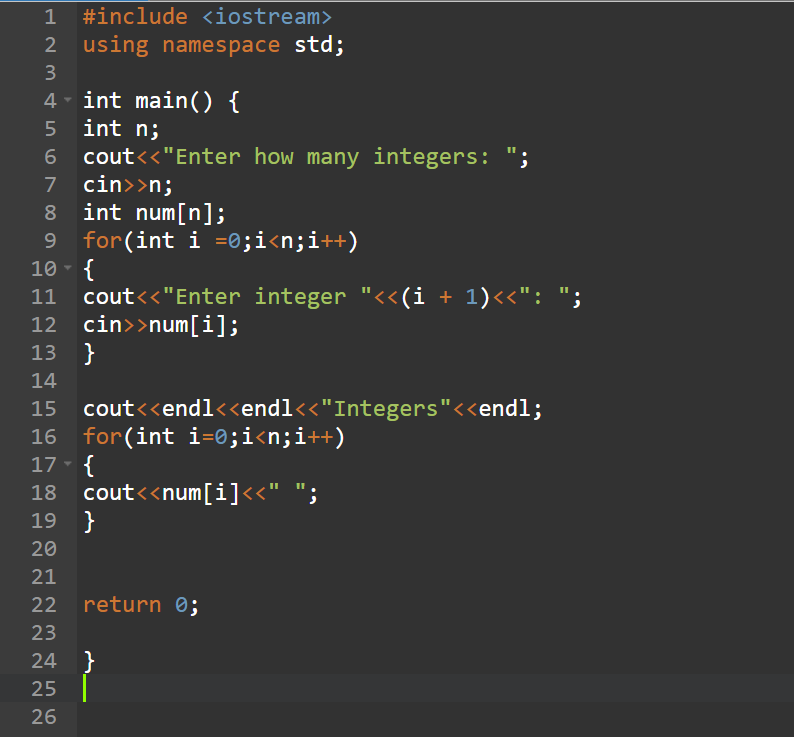

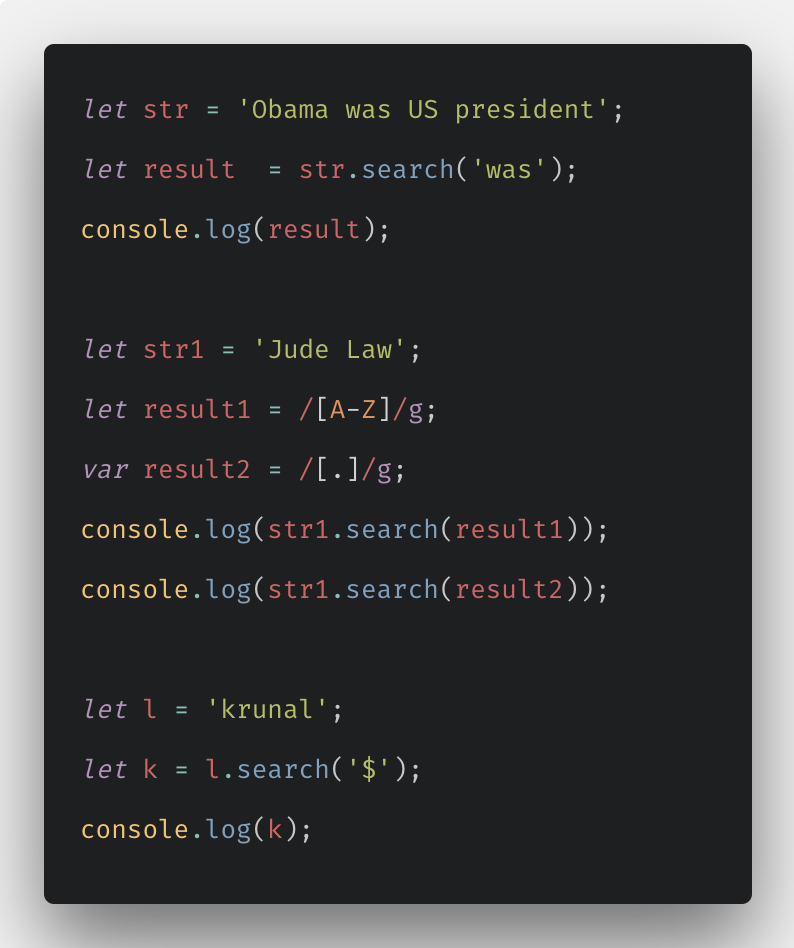
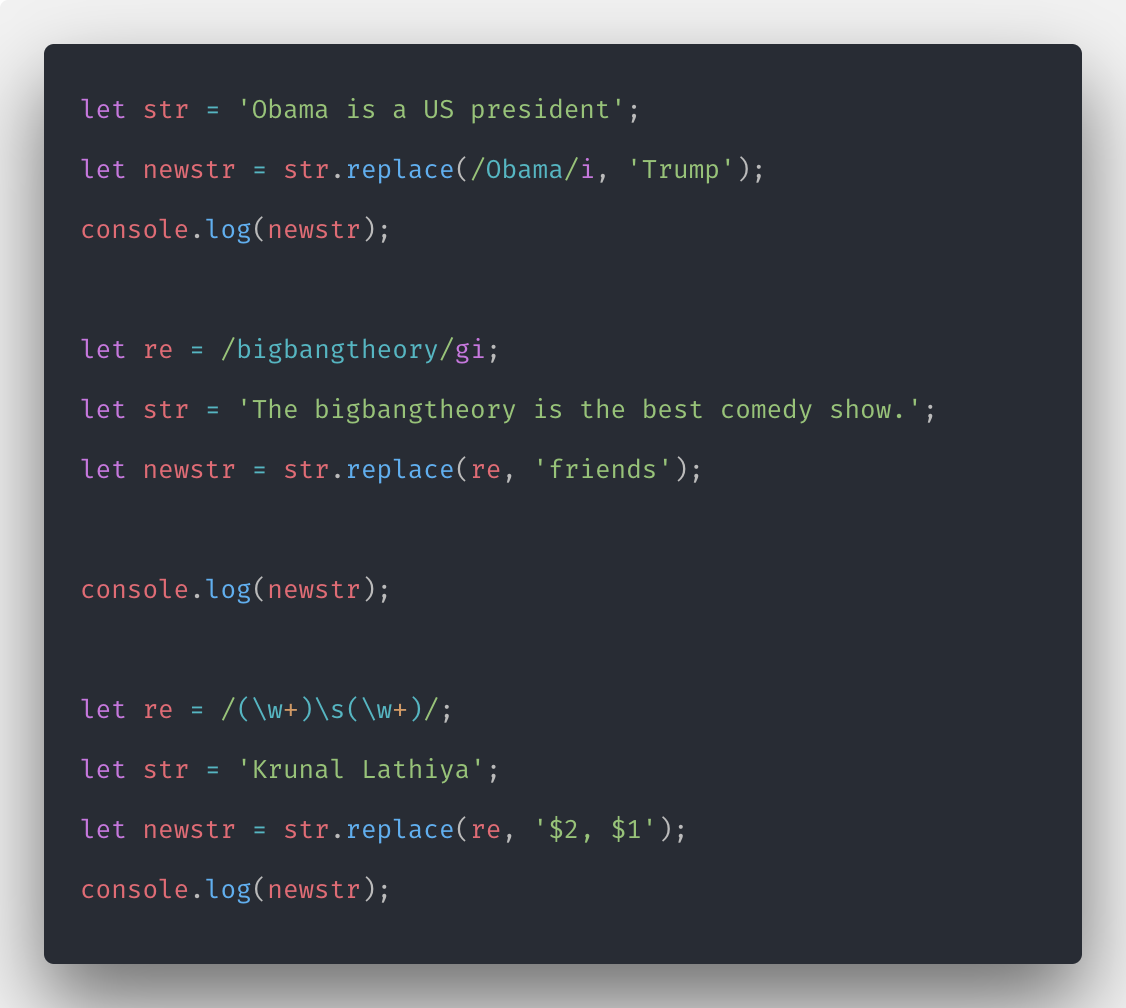
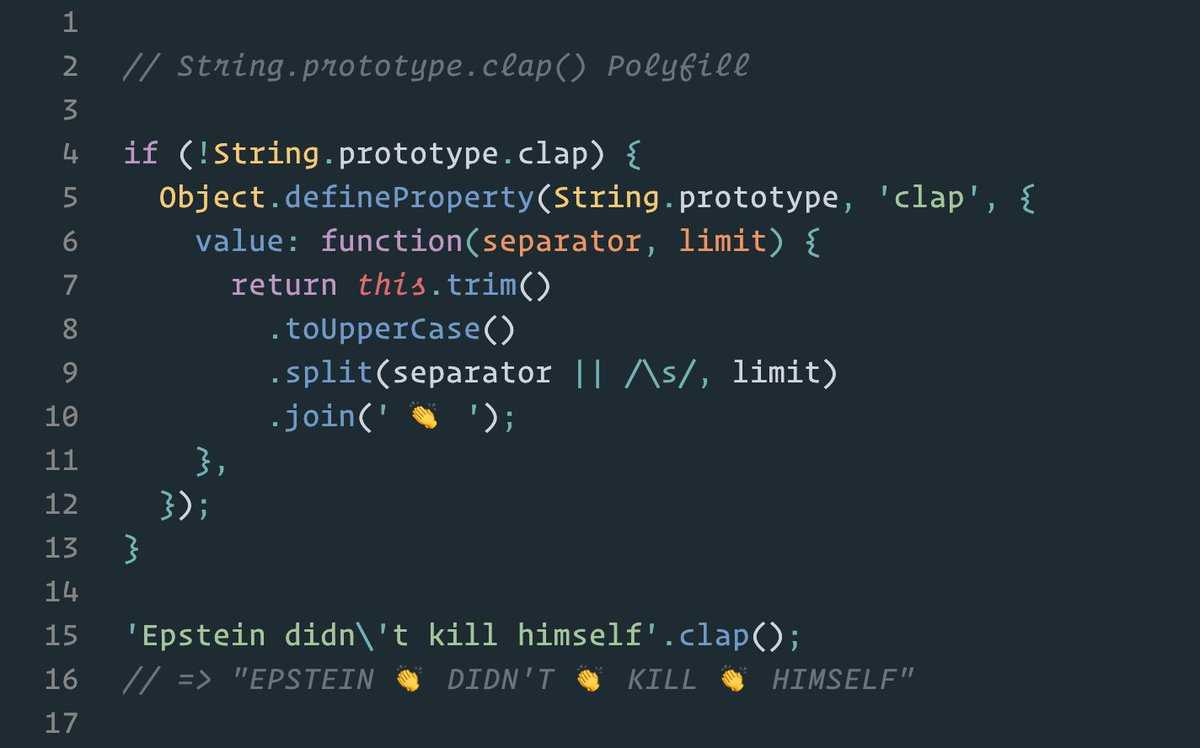
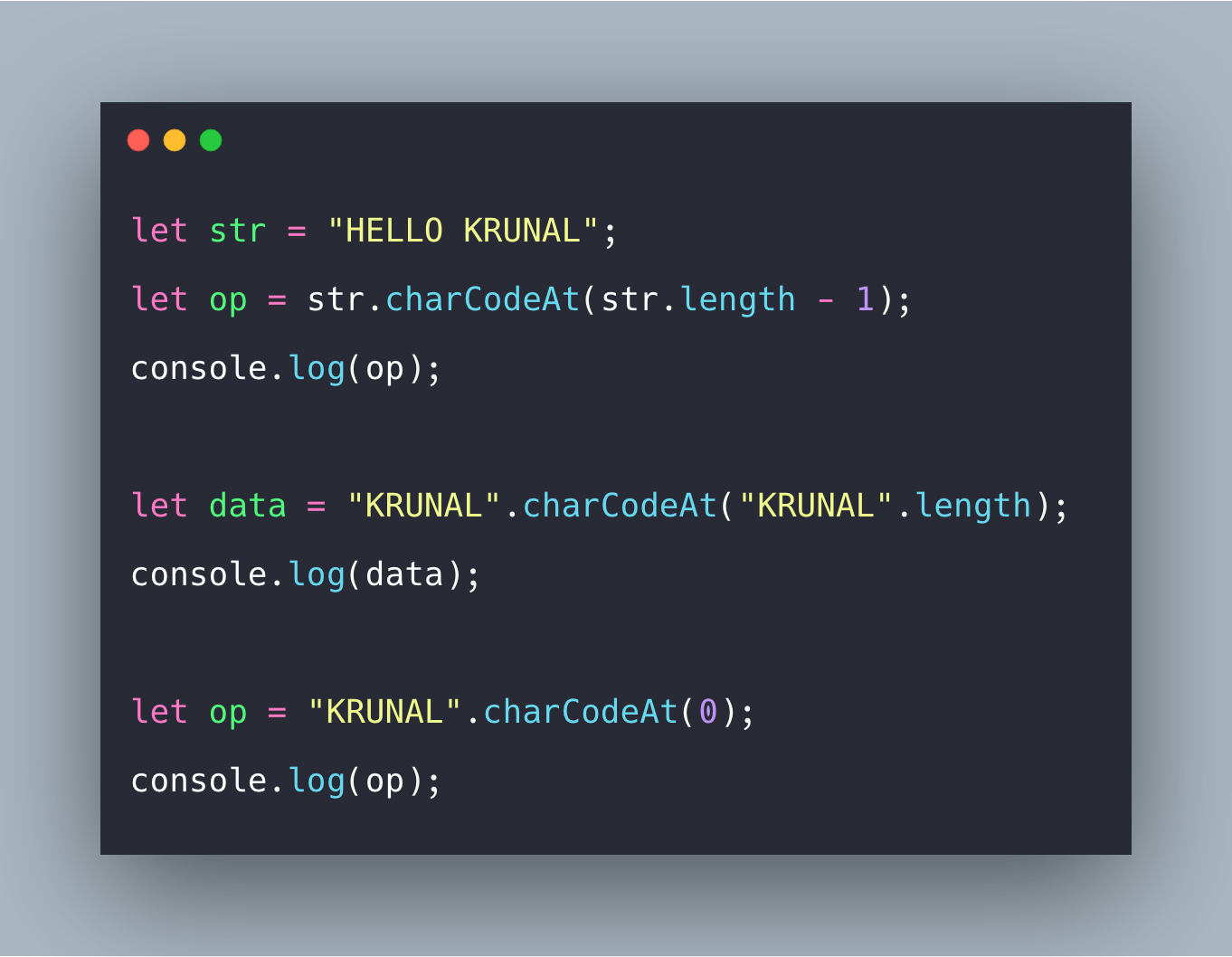

Но стоит отметить, что строки имеют внутреннюю кодировку Юникод – каждому символу соответствует свой числовой код.
Есть метод для получения символа по его коду String.fromCharCode():
Выполнить код »
Скрыть результаты
А вот метод charCodeAt() наоборот возвращает числовое значение Unicode символа, индекс которого был передан методу в качестве аргумента:
Выполнить код »
Скрыть результаты
А теперь давайте выведем интервал символов Unicode с кодами от 1025 до 1105:
Выполнить код »
Скрыть результаты
Как видите, не все символы в Юникоде соответствуют их месту в алфавите. Есть некоторые исключения. Строчные буквы идут после заглавных, поэтому они всегда больше. А буква ‘ё’, имеет код, больший чем ‘я’, поэтому ‘ё’(код 1105) > ‘я’(код 1103).
Для правильного сравнения строк используйте метод str1.localeCompare(str2), который сравнивает одну строку с другой и возвращает одно из трех значений:
- Если строка str1 должна располагаться по алфавиту перед str2, возвращается -1.
- Если строка str1 равна str2, возвращается .
- Если строка str1 должна располагаться по алфавиту после str2, возвращается 1.
7 ответов
Лучший ответ
Этот?
Примере
Обновление: на основе этого вопроса это
Это лучшее решение. Он дает тот же результат, но делает это быстрее.
The Regex
— это регулярное выражение для «пробела», а — «глобальный» флаг, означающий соответствие ВСЕ (пробелы).
Отличное объяснение можно найти здесь .
Как примечание, вы можете заменить содержимое между одинарными кавычками на что угодно, поэтому вы можете заменить пробел любой другой строкой.
1170
Jonathan
10 Июл 2017 в 13:41
Хотя есть способы использовать регулярные выражения для удаления пробелов, есть простая функция, которая может удалить все пробелы, называемые :
-5
Eric Xue
30 Мар 2019 в 01:13
Следующий ответ @rsplak: на самом деле использование пути split / join быстрее, чем использование regexp. Ознакомьтесь с тестовым примером.
Так
Работает быстрее чем
Для небольших текстов это не актуально, но для случаев, когда важно время, например, в анализаторах текста, особенно при взаимодействии с пользователями, это важно. С другой стороны, обрабатывает широкий спектр пробелов
Среди и он также совпадает с символом , и это то, во что включается при получении текста с помощью
С другой стороны, обрабатывает широкий спектр пробелов. Среди и он также совпадает с символом , и это то, во что включается при получении текста с помощью .
Поэтому я думаю, что здесь можно сделать следующий вывод: если вам нужно только заменить пробелы , используйте split / join. Если в классе символов могут быть разные символы — используйте
24
Minstel
1 Фев 2017 в 18:50
Хотя регулярные выражения могут быть медленнее, во многих случаях разработчик манипулирует только несколькими строками одновременно, поэтому скорость не имеет значения. Хотя / / быстрее, чем / \ s /, наличие символа \ s объясняет, что происходит с другим разработчиком, возможно, более четко.
Использование Split + Join позволяет в дальнейшем манипулировать цепочкой.
SoEzPz
14 Июн 2019 в 14:33
Два способа сделать это!
71
vsync
14 Июн 2018 в 10:06
Примечание. Хотя вы используете «g» или «gi» для удаления пробелов, оба ведут себя одинаково.
Если мы используем ‘g’ в функции замены, она проверит точное совпадение. но если мы используем ‘gi’, он игнорирует чувствительность к регистру.
2
Raveendra007
28 Авг 2015 в 11:52
8
Muhammad Tahir
5 Июн 2015 в 12:09
Доступ к символам
Конкретный символ в строке можно получить с помощью метода charAt(). Он принимает в качестве аргумента целое число, указывающее позицию в строке для символа, который следует возвратить. Ввиду того что в JavaScript нет различия между отдельными символами и строками, метод возвращает строку, состоящую из выбранного символа:
Выполнить код »
Скрыть результаты
Другим способом (введённым в ECMAScript 5) является рассмотрение строки как массива, в котором символы имеют соответствующие числовые индексы. Для доступа к символу нужно указать его индекс в квадратных скобках:
Выполнить код »
Скрыть результаты
При доступе к символам через квадратные скобки, попытка удалить символ, или присвоить другое значение числовому индексу в строке закончится неудачей, поскольку эти свойства являются незаписываемыми и ненастраиваемыми.
Вообще содержимое строки в JavaScript нельзя поменять. Можно создать новую строку и присвоить в туже переменную вместо старой, например:
Выполнить код »
Скрыть результаты
Примечание: Разница между доступом к символам строки посредством нотации с квадратными скобками и методом заключается в том, что если на месте искомой позиции символа нет – выдает пустую строку , а скобки – .
Функция в качестве второго параметра
Если вы указываете функцию в качестве второго параметра, то она вызывается при каждом совпадении. При наличии одного совпадения в нее передаются три аргумента: совпадение, позиция совпадения в строке и вся строка. Если групп захвата несколько, каждая совпавшая строка передается в функцию как аргумент, при этом двумя последними аргументами являются позиция совпадения с шаблоном в строке и оригинальная строка. Результат вызова функции (её возвращаемое значение) будет использоваться в качестве строки замены.
Функция принимает следующие аргументы:
- – найденное совпадение, (cоответствует шаблону замены $&, описанному выше).
- – содержимое скобок (если есть), из объекта RegExp в первом параметре метода replace() (cоответствует шаблонам замены $1, $2 и так далее, описанным выше). Например, если в качестве шаблона передано регулярное выражение /(\a+)(\b+)/, параметр p1 будет значение сопоставления с подгруппой \a+, а параметр p2 — с подгруппой \b+.
- – позиция, на которой найдено совпадение (например, если вся строка равна ‘abcd’, а сопоставившаяся подстрока равна ‘bc’, то этот аргумент будет равен 1).
- – исходная строка.
Если скобок в регулярном выражении нет, то у функции всегда будет ровно 3 аргумента: replacer(match, offset, string).
Пример, с использованием функции, выводящей полную информацию о совпадениях:
Выполнить код »
Скрыть результаты
При наличии в регулярном выражении двух скобок функция принимает уже 5 аргументов:
Выполнить код »
Скрыть результаты
← предыдущая
следующая →
Как это работает?
Конструктор регулярных выражений (RegExp) применяет следующую грамматику к входному шаблону String. Ошибка возникает, если грамматика не может интерпретировать String как расширение Pattern.
В паттерне (Pattern) можно использовать Утверждения ():
![]() Assertion — RegExp — JavaScript
Assertion — RegExp — JavaScript
В нашем случае мы использовали конструкцию Утверждения
То есть мы сопоставляем то, что находится слева от круглой скобки с тем, что находится внутри круглых скобок. Дизъюнкция (Disjunction) — это разъединение, разделение. Нашим символом разделения будет являться буква «а«. В качестве сопоставления мы указали на букву «а» перед Утверждением (слева от круглой скобки). То есть, мы имеем как-бы две буквы «а». Цветами отмечены для лучшего понимания:
а+(?=а)g
Мы добавили квантификатор «+» к сопоставляемой букве «а«, чтобы отловить множественные появления последовательностей буквы «а» в строке. Внутри утверждения мы ищем границы, где буква «а» соседствует с такой же буквой «а» (символьное равенство).
Затем мы использовали флаг «g» для регулярных выражений, который говорит нам о том, что условие Утверждения будет проверено «глобально» по всей строке. То есть при помощи флага «g» мы отловим все возможные варианты последовательностей букв с квантификатором «а+«. В этом случае флаг «g» выходит за границу регулярного выражения / / и размещается справа.




Когда мы отловили все варианты последовательностей буквы «а» (где «а» соседствует с «а«) по всей строке, то теперь можем воспользоваться методом замены replace() для объектов-прототипов String. Искомые значения (первый параметр) мы будем заменять на пустую строку (второй параметр). Почему на пустую строку, а не на букву «а«. Потому что Утверждение находит только границы между одной последней буквы «а» в последовательности возможных.
Примеры: а|a, аа|a, ааа|a, и так далее.
Когда начнётся замена, тогда все вариации (что слева от Границы Утверждения) будут заменены на пустую строку, а значит останется только один символ «а«, который по факту является последним в цепочке однотипных последовательностей. Напомню, что сопоставление ведётся по левой стороне Утверждения — слева у нас «а+«.
![]() Схема работы метода replace со строкой, регулярным выражением, вкантификатором и Утверждением — JavaScript
Схема работы метода replace со строкой, регулярным выражением, вкантификатором и Утверждением — JavaScript
В этом Утверждении соответствие символов велось по «началу» последовательности букв «а».
Но мы можем решить задачу другой конструкцией регулярных выражений и вести соответствие последовательности по «концу»:
var stroka = "Маагаааааазин" var stroka2 = stroka.replace((?<=а)а+g,'')
![]() Удалили все повторяющиеся последовательности букв а — через утверждение по концу — JavaScript
Удалили все повторяющиеся последовательности букв а — через утверждение по концу — JavaScript
11 ответов
Лучший ответ
Можете ли вы использовать prototype.js? Если это так, вы можете использовать String.gsub, как
Это также будет принимать регулярные выражения. Для меня это один из самых элегантных способов ее решения. документация prototypejs gsub
-16
Heat Miser
12 Фев 2009 в 18:35
Регулярные выражения намного медленнее, чем поиск строк. Таким образом, создание регулярного выражения с экранированной строкой поиска не является оптимальным способом. Даже зацикливание строки будет быстрее, но я предлагаю использовать встроенные предварительно скомпилированные методы.
Вот быстрый и чистый способ сделать быструю глобальную замену строки:
Вот и все.
38
Lex
15 Янв 2014 в 21:04
Это регулярное выражение, а не строка. Используйте конструктор для объекта RegExp для динамического создания регулярного выражения.
3
Alex Wayne
12 Фев 2009 в 16:56
Пытаться:
2
Crescent Fresh
12 Фев 2009 в 16:55
Вы можете использовать следующее решение для глобальной замены строки с переменной внутри ‘/’ и ‘/ g’:
3
Grant Miller
29 Авг 2018 в 01:25
Вы можете сделать, используя следующий метод
Увидеть эту функцию:
Синтаксис :
Где
- g — глобальная замена с учетом регистра
- giis глобальная замена без учета регистра
Вы можете проверить эту ссылку JSBIN
Fahad
2 Дек 2015 в 15:19
Для регулярных выражений . НО. Если «find» содержит символы, которые являются специальными в регулярном выражении, они будут иметь свое регулярное значение. Так что, если вы пытались заменить «.» в ‘abc.def’ с ‘x’ вы получите ‘xxxxxxx’ — упс.
Если все, что вам нужно, это простая замена строки, вам не нужны регулярные выражения! Вот простая строка заменить идиома:
79
bobince
12 Фев 2009 в 18:20
Если вы хотите, чтобы переменные интерполировались, вам нужно использовать объект RegExp
Примере:
1
Philip Reynolds
12 Фев 2009 в 16:57
Если вам нужно это в функцию
189
Mauricio Gracia Gutierrez
10 Дек 2018 в 19:16
Динамическая глобальная замена
Я пришел в эту ветку в поисках немного более сложного решения, на которое здесь нет ответа. Теперь я нашел ответ, поэтому я опубликую его на тот случай, если кто-нибудь еще посчитает его полезным.
Я хотел сделать динамическую глобальную замену, где строки замены основаны на исходных совпадениях.
Например, чтобы заглавная буква всех слов (например, «cat sat mat» была превращена в «Cat Sat Mat») с помощью глобальной команды find replace. Вот как это сделать.
1
Robin Winslow
14 Июн 2011 в 01:33
16
Community
23 Май 2017 в 12:34
Создание строкового объекта
С помощью конструктора создается объект, в который «упакована» текстовая строка. Для создания строкового объекта используется выражение следующего вида:
Здесь имя переменной (val) выполняет роль ссылки на строковый объект. Аргументом (string) конструктору обычно передается текстовое значение (базового типа): любая последовательность Unicode символов, которую необходимо преобразовать в строку.
Однако можно создать строковый объект и с помощью строковых литералов:
Обратите внимание, что JavaScript различает строковые литералы, заданные через кавычки (и называемые «примитивными» строками) от объектов String, созданных с помощью оператора new:
Выполнить код »
Скрыть результаты
Примечание: Интерпретатор JavaScript неявно использует объект String в качестве объекта обертки, поэтому строковой литерал интерпретируется так, как будто был создан с помощью оператора new, так что на строковых примитивах возможно использовать свойства и методы объекта String.
Решение № 1 — Через метод slice()
Воспользуемся методом , который наследуется нашим экземпляром строки от объекта -прототипа String.
String.prototype.slice ( start, end )
Метод принимает два аргумента, start и end, и возвращает подстроку результата преобразования этого объекта в String, начиная с начала индекса start и до конца индекса end, но не включая его (или до конца String, если end является undefined). Если start отрицательный, он обрабатывается как sourceLength + start, где sourceLength — длина строки. Если end отрицательный, он обрабатывается как sourceLength + end, где sourceLength — длина строки. Результатом является значение String, а не объект String.
Команда по удалению последнего символа строки:
stroka.slice(, -1)
Мы передали два параметра в метод . В первый параметр start мы передали числовое значение «» — это индекс первого элемента строки с которого мы начнём нарезание на кусочки («кусочничать»). Во второй параметр end мы передали числовое значение «-1«.
Удалили последний элемент из строки — JavaScript
Так как второй параметр end отрицательный, то применилось правило (sourceLength + end).
В нашем случае (stroka.length + (-1)). Это (7 — 1) = 6. Таким образом второй параметр end стал равен 6.
Символ косой линии на конце строки — JavaScript
Под индексом 6 в нашей исходной строке находится косая линия, но метод не включит её в итоговую строку. Индекс 6 не попадёт в итоговый результат по правилу работы метода .
ВАЖНО! Метод возвращает новую строку. Это значит, что оригинальная строка на которой вызывается метод не изменяется
10 ответов
Лучший ответ
Для всех случаев, которые будут отброшены, используйте:
PS: функция replace возвращает новую строку и оставляет исходную строку без изменений, поэтому используйте возвращаемое значение функции после вызова replace ().
1098
Community
28 Фев 2020 в 09:20
Достаточно простого старого JavaScript — jQuery не нужен для такой простой задачи:
См. документы по MDN для дополнительная информация и использование.


22
James Hill
1 Май 2012 в 14:14
Эта маленькая функция, которую я сделал, всегда работала для меня ![]()
Я знаю, что это не самое лучшее, но у меня всегда получалось ![]()
9
user8142790user8142790
31 Июл 2017 в 02:18
Использование и для возврата переменной :
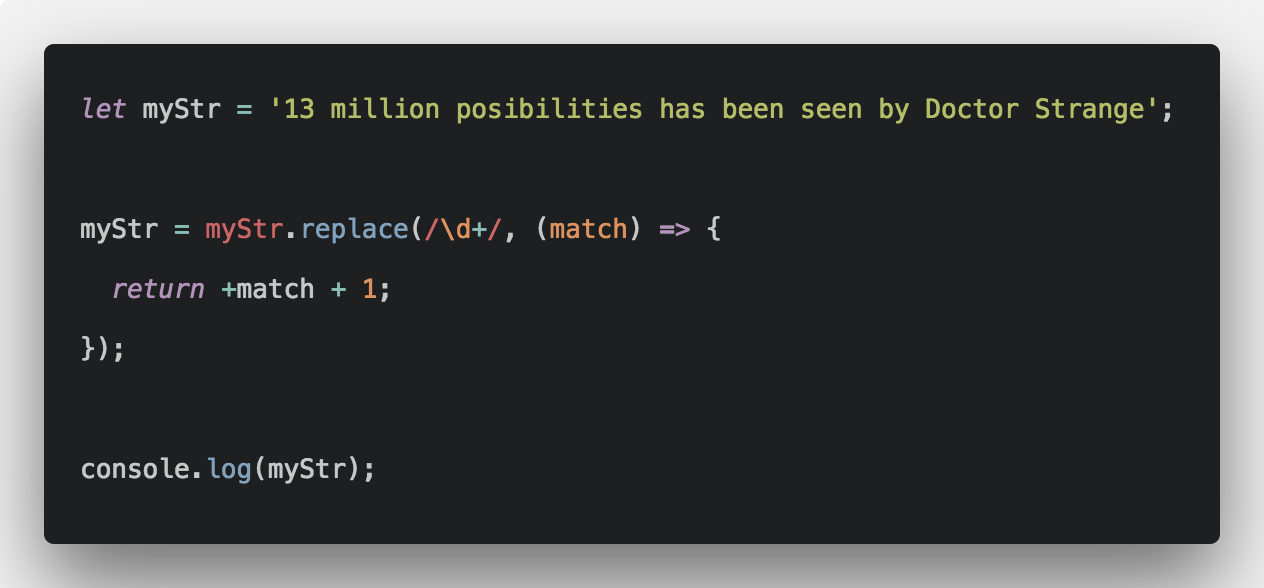
Вот что делает вышеприведенное утверждение … работая посредине:
- — возвращает массив, содержащий совпадения с любой длиной чисел в конце . В этом случае он возвращает массив, содержащий один строковый элемент .
- — преобразует его в числовой тип. Поскольку массив, возвращенный из , содержит единственный элемент, вернет число.
8
Brett DeWoody
16 Апр 2016 в 15:44
Вы можете использовать slice (), он возвращает символы от начала до конца (включая конечную точку)
Вот несколько примеров, чтобы показать, как это работает:
28
m.r shojaei
24 Ноя 2014 в 17:29
Это заменит все вхождения этой конкретной строки из исходной строки.
8
ARC
16 Апр 2018 в 12:30
Я привык к методу C # (Sharp) String.Remove. В Javascript нет функции удаления для строки, но есть функция substr. Вы можете использовать функцию substr один или два раза, чтобы удалить символы из строки. Вы можете сделать следующую функцию, чтобы удалить символы в начале индекса до конца строки, так же, как метод c # сначала перегружает String.Remove (int startIndex):
И / или вы также можете сделать следующую функцию, чтобы удалить символы при начальном индексе и числе, точно так же, как вторая перегрузка метода c # String.Remove (int startIndex, int count):
И тогда вы можете использовать эти две функции или одну из них для ваших нужд!
Пример:
Результат: 123
10
20 Апр 2014 в 12:36
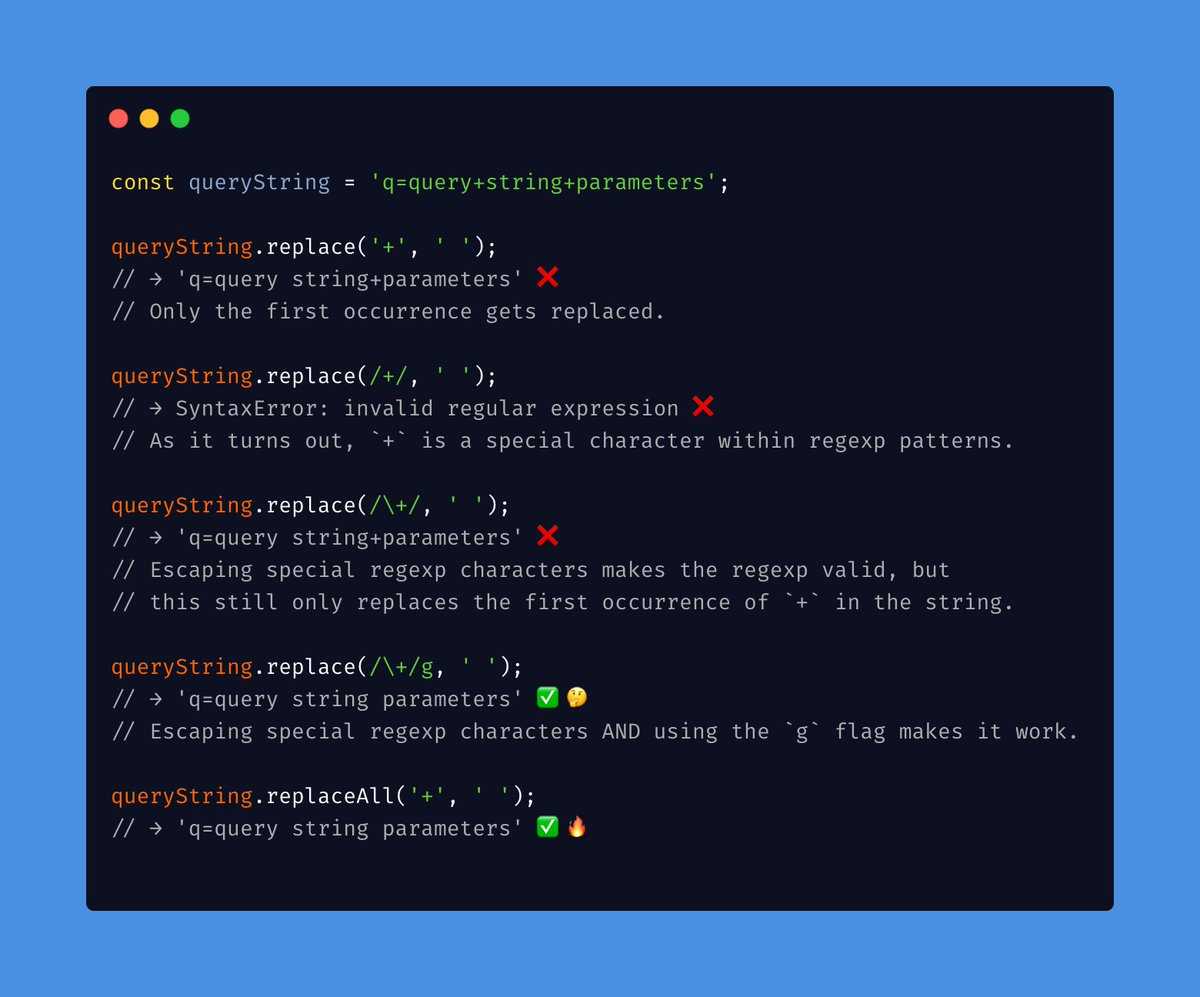
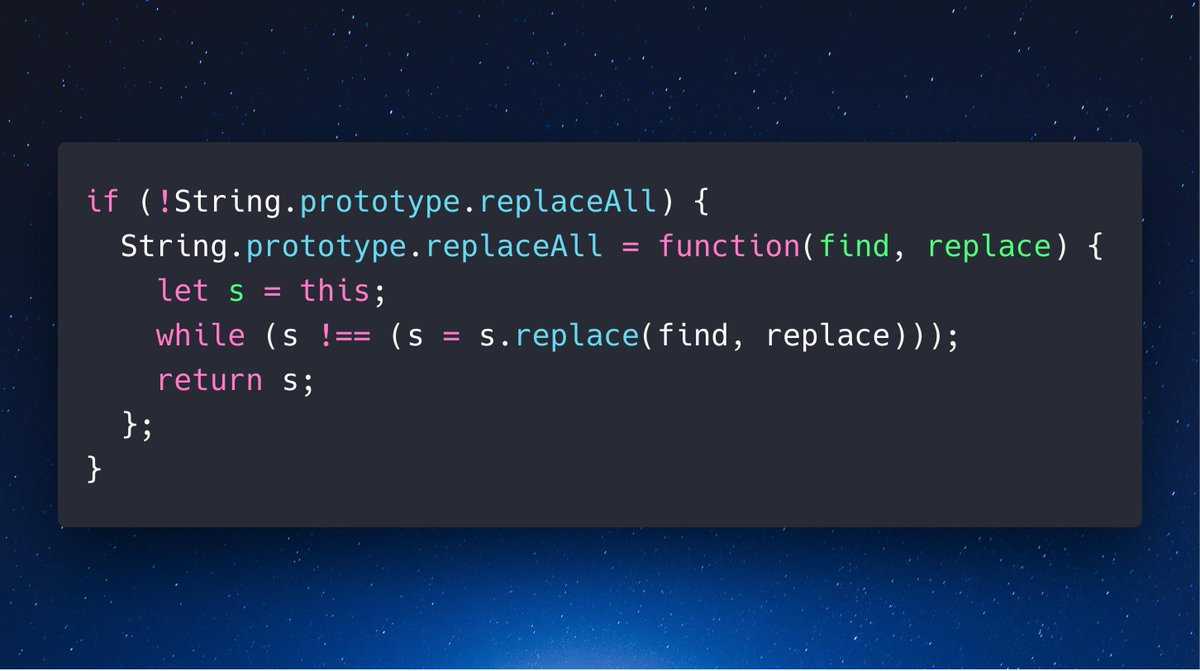
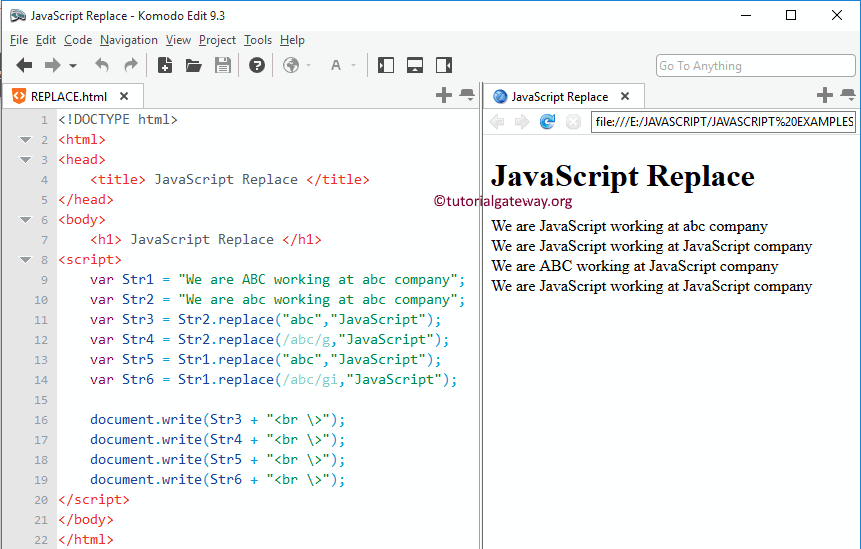
Вы можете использовать , как уже упоминалось, но поскольку заменяет только FIRST экземпляр соответствующего текста, если ваша строка была чем-то вроде , тогда
Заменит только первый соответствующий текст. И ваш вывод будет
Поэтому, если вы хотите заменить все совпадения текста в строке, вы должны использовать регулярное выражение с флагом :
И ваш вывод будет
55
laaposto
8 Май 2014 в 10:21
Это не имеет ничего общего с jQuery. Вы можете использовать функцию JavaScript для этого:
Вы также можете передать регулярное выражение этой функции. В следующем примере он заменит все, кроме чисел:
122
Meetai.com
21 Янв 2015 в 07:57
Ex : —
Надеюсь, это сработает для вас.
16
Ajitej Kaushik
9 Авг 2016 в 10:25
Методы String
| Метод | Описание |
|---|---|
| charAt() | Возвращает символ строки с указанным индексом (позицией). |
| charCodeAt() | Возвращает числовое значение Unicode символа, индекс которого был передан методу в качестве аргумента. |
| concat() | Возвращает строку, содержащую результат объединения двух и более предоставленных строк. |
| fromCharCode() | Возвращает строку, созданную с помощью указанной последовательности значений символов Unicode. |
| indexOf() | Возвращает позицию первого символа первого вхождения указанной подстроки в строке. |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения подстроки или -1, если подстрока не найдена. |
| localeCompare() | Возвращает значение, указывающее, эквивалентны ли две строки в текущем языковом стандарте. |
| match() | Ищет строку, используя предоставленный шаблон регулярного выражения, и возвращает результат в виде массива. Если совпадений не найдено, метод возвращает значение null. |
| replace() | Ищет строку для указанного значения или регулярного выражения и возвращает новую строку, где указанные значения будут заменены. Метод не изменяет строку, для которой он вызывается. |
| search() | Возвращает позицию первого соответствия указанной подстроки или регулярного выражения в строке. |
| slice() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй необязательный аргумент указывает позицию, на которой должно остановиться извлечение. Если второй аргумент не указан, то извлечено будет все с той позиции, которую указывает первый аргумент, и до конца строки. |
| split() | Разбивает строку на подстроки, возвращая массив подстрок. В качестве аргумента можно передать символ разделитель (например запятую), используемый для разбора строки на подстроки. |
| substr() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй аргумент указывает количество символов, которое нужно извлечь. |
| substring() | Извлекает символы из строки между двух указанных индексов, если указан только один аргумент, то извлекаются символы от первого индекса и до конца строки. |
| toLocaleLowerCase() | Преобразует символы строки в нижний регистр с учетом текущего языкового стандарта. |
| toLocaleUpperCase() | Преобразует символы строки в верхний регистр с учетом текущего языкового стандарта. |
| toLowerCase() | Конвертирует все символы строки в нижний регистр и возвращает измененную строку. |
| toString() | Возвращает строковое представление объекта. |
| toUpperCase() | Конвертирует все символы строки в верхний регистр и возвращает измененную строку. |
| trim() | Удаляет пробелы в начале и конце строки и возвращает измененную строку. |
| valueOf() | Возвращает примитивное значение объекта. |
Синтаксис
regexp
Объект регулярного выражения . Сопоставление заменяется возвращаемым значением второго параметра.
substr
Строка, которая должна быть заменена на
Обратите внимание, будет заменено только первое вхождение искомой строки.
newSubStr
Строка, которая заменяет подстроку, полученную из первого параметра. Поддерживает несколько специальных шаблонов замены.
function
Функция, вызываемая для создания новой подстроки, размещаемой вместо подстроки из первого параметра.
flags
Строка, содержащая любую комбинацию флагов : g – глобальное соответствие, i – игнорировать регистр, m – соответствие по нескольким строкам
Этот параметр используется, только если первый параметр является строкой.





