
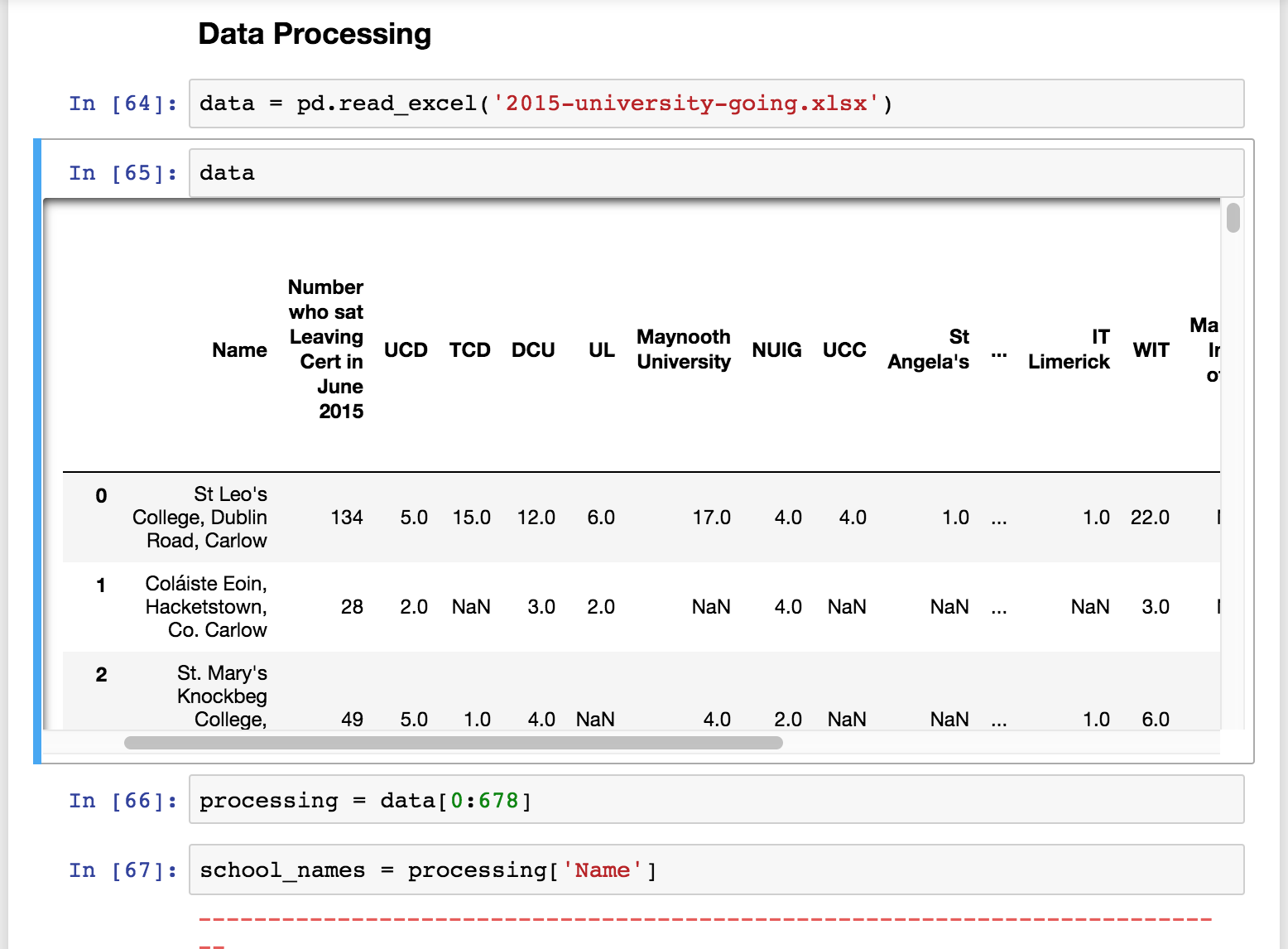
Западайте NAN и сброс индекс
Проблема : Что происходит с индексами после сброса определенных рядов?
import pandas as pd
df = pd.read_csv("Cars.csv")
# Dataframe "df"
# ----------
# make fuel aspiration body-style price engine-size
# 0 audi gas turbo sedan 30000 2.0
# 1 dodge gas std sedan 17000 1.8
# 2 mazda diesel std sedan 17000 NaN
# 3 porsche gas turbo convertible 120000 6.0
# 4 volvo diesel std sedan 25000 2.0
# ----------
df.drop(, inplace=True)
df.reset_index(inplace=True)
result = df.index.to_list()
print(result)
#
Метод На DataFrame удаляет строки или столбцы по индексу. Вы можете пройти одно значение или список значений.
По умолчанию Параметр установлен на Так что модификации не повлияют на исходный объект dataframe. Вместо этого метод возвращает модифицированную копию датафарама. В головоломке вы набор к Таким образом, делеции выполняются непосредственно на DataFrame.
После удаления первых трех строк первые два метки индекса являются 3 и 4. Вы можете сбросить индексацию по умолчанию, вызывая метод На DataFrame, чтобы индекс снова запускается в 0. Поскольку в DataFrame осталось только два ряда строк, результат – Отказ
Статистические методы в Pandas
Для того, чтобы из DataFrame отдельно извлечь статистические параметры в Pandas используются и другие методы:
|
Метод |
Действие |
|---|---|
|
.max() |
Максимальное значение |
|
.min() |
Минимальное значение |
|
.mean() |
Среднее значение |
|
.sum() |
Сумма |
|
.count() |
Количество непустых значений |
|
.std() |
Стандартное отклонение |
|
.median() |
Медианное значение |
|
.quantile() |
Квантиль: в скобках указывается параметр: 0.25, 0.5 (то же, что и медиана) или 0.75 |
Давайте попробуем получить максимальную выручку. Для того, чтобы сделать это, необходимо применить метод .max() к столбцу “выручка”.
Если применить любой из этих статистических методов к конкретной колонке — в результате мы получим число, например, максимальное значение. А если ко всему датафрейму — получим объект типа Series.
Кстати, в каждый из статистических методов можно передать параметр, например, применить метод к строке (axis=0) или столбцу (axis=1) или определить, что делать вычисления нужно только по числовым столбцам или строкам (numeric_only=True).
Официальная документация по методам в pandas.
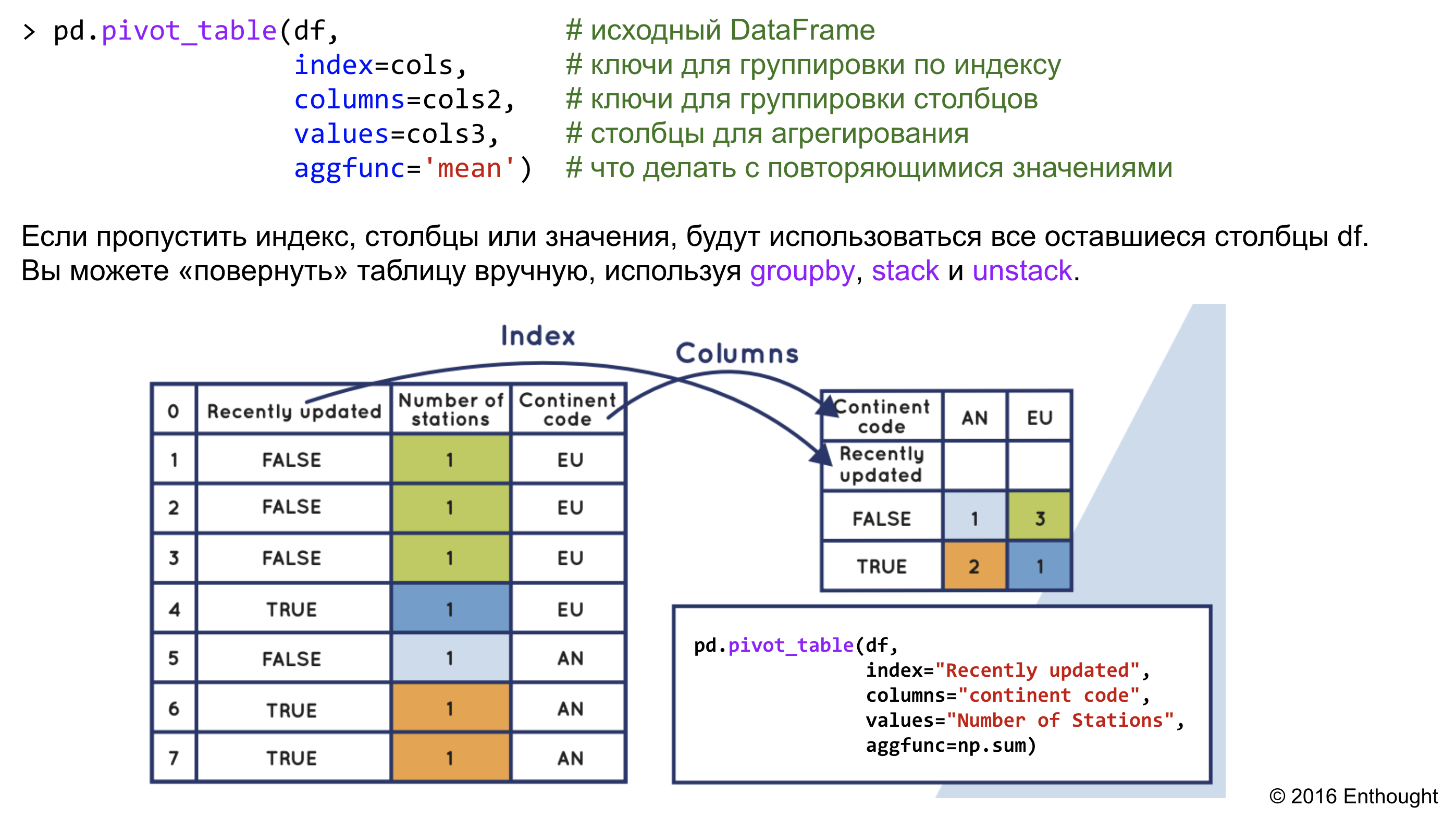
Сортировка фрейма данных по одному столбцу ↑
Для сортировки DataFrame по значениям в одном столбце используем . По умолчанию получим новый DataFrame, отсортированный в порядке возрастания. Исходный DataFrame не изменяется.
Сортировка по столбцу в порядке возрастания
Для использования передадим один аргумент методу, содержащий имя столбца, по которому необходимо выполнить сортировку. В этом примере сортируем DataFrame по столбцу , который представляет город MPG для автомобилей, работающих только на топливе:
>>> df.sort_values("city08")
city08 cylinders fuelType ... mpgData trany year
99 9 8 Premium ... N Automatic 4-spd 1993
1 9 12 Regular ... N Manual 5-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
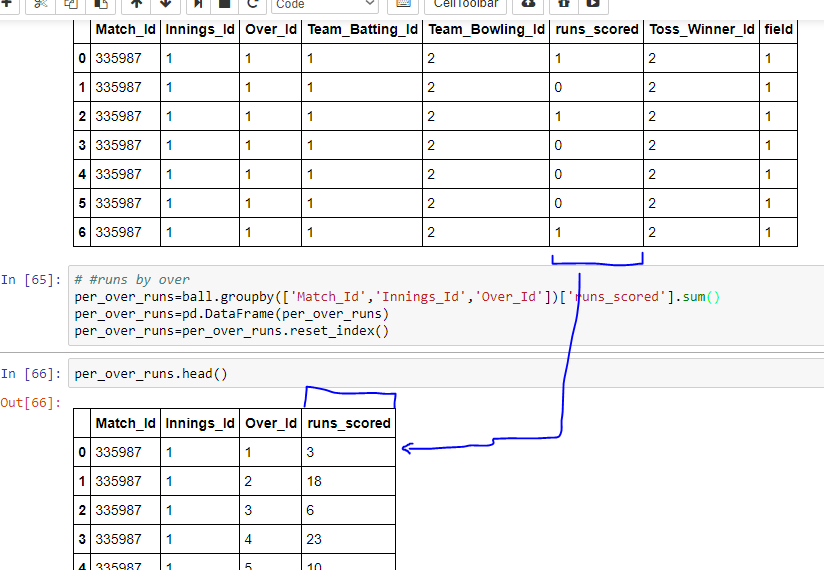
3 10 8 Regular ... N Automatic 3-spd 1985
.. ... ... ... ... ... ... ...
9 23 4 Regular ... Y Automatic 4-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
7 23 4 Regular ... Y Automatic 3-spd 1993
76 23 4 Regular ... Y Manual 5-spd 1993
2 23 4 Regular ... Y Manual 5-spd 1985
Сортирует DataFrame с использованием значений из столбца , показывая сначала автомобили с самым низким MPG. По умолчанию сортирует данные в порядке возрастания. Хотя имя аргумента, переданного в , не указано, фактически использован параметр , который увидим в следующем примере.
Изменение порядка сортировки
Другой параметр — . По умолчанию имеет значение True, т.е. сортировка по возрастанию. Если вы хотите изменить порядок сортировки DataFrame на обратный, то можно передать значение этому параметру:
>>> df.sort_values(
... by="city08",
... ascending=False
... )
city08 cylinders fuelType ... mpgData trany year
9 23 4 Regular ... Y Automatic 4-spd 1993
2 23 4 Regular ... Y Manual 5-spd 1985
7 23 4 Regular ... Y Automatic 3-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
76 23 4 Regular ... Y Manual 5-spd 1993
.. ... ... ... ... ... ... ...
58 10 8 Regular ... N Automatic 3-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
99 9 8 Premium ... N Automatic 4-spd 1993
Передавая для , меняется порядок сортировки. Теперь DataFrame отсортирован в порядке убывания по средней MPG, измеренной в городских условиях. Транспортные средства с наибольшим значением MPG находятся в начале.
Выбор алгоритма сортировки
>>> df.sort_values(
... by="city08",
... ascending=False,
... kind="mergesort"
... )
city08 cylinders fuelType ... mpgData trany year
2 23 4 Regular ... Y Manual 5-spd 1985
7 23 4 Regular ... Y Automatic 3-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
9 23 4 Regular ... Y Automatic 4-spd 1993
10 23 4 Regular ... Y Manual 5-spd 1993
.. ... ... ... ... ... ... ...
69 10 8 Regular ... N Automatic 3-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
99 9 8 Premium ... N Automatic 4-spd 1993
Когда вы сортируете несколько записей с одним и тем же ключом, стабильный алгоритм сортировки сохранит исходный порядок этих записей после сортировки. По этой причине использование стабильного алгоритма сортировки необходимо, если вы планируете выполнять несколько сортировок.
Метод 1: использование astype()
DataFrame.astype() приводит этот DataFrame к указанному типу данных. Ниже приводится синтаксис метода.
astype(dtype, copy=True, errors='raise', **kwargs)
Нас интересует только первый аргумент dtype – это тип данных или dict имени столбца.
Итак, давайте использовать метод astype() с аргументом dtype, чтобы изменить тип данных одного или нескольких столбцов DataFrame.
Как изменить тип данных одного столбца?
Давайте сначала начнем с изменения типа данных только для одного столбца.
В следующей программе мы изменим тип данных столбца a на float.
import pandas as pd
import numpy as np
#initialize a dataframe
df = pd.DataFrame(
,
,
,
],
columns=)
print('Previous Datatypes\n', df.dtypes, sep='')
#change datatype of column
df = df.astype({'a': np.float})
#print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
Вывод:
Previous Datatypes
a int64
b int64
c int64
dtype: object
New Datatypes
a float64
b int64
c int64
dtype: object
DataFrame
a b c
0 21.0 72 67
1 23.0 78 62
2 32.0 74 54
3 52.0 54 76
Как изменить тип данных нескольких столбцов?
Теперь давайте изменим тип данных более чем для одного столбца. Все, что нам нужно сделать, это предоставить больше пар column_name: datatype key:value в аргументе метода astype().

В следующей программе мы изменим тип данных столбца a на float, а b на int8.
import pandas as pd
import numpy as np
#initialize a dataframe
df = pd.DataFrame(
,
,
,
],
columns=)
print('Previous Datatypes\n', df.dtypes, sep='')
#change datatype of column
df = df.astype({'a': np.float, 'b': np.int8})
#print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
Вывод:
Previous Datatypes
a int64
b int64
c int64
dtype: object
New Datatypes
a float64
b int8
c int64
dtype: object
DataFrame
a b c
0 21.0 72 67
1 23.0 78 62
2 32.0 74 54
3 52.0 54 76
Как изменить тип данных всех столбцов?
Если вы хотите изменить тип данных всех столбцов DataFrame, вы можете просто передать этот тип данных в качестве аргумента методу astype() без словаря.
В следующей программе мы изменим тип данных всех столбцов на float.
import pandas as pd
import numpy as np
#initialize a dataframe
df = pd.DataFrame(
,
,
,
],
columns=)
print('Previous Datatypes\n', df.dtypes, sep='')
#change datatype of column
df = df.astype(np.float)
#print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
Вывод:
Previous Datatypes
a int64
b int64
c int64
dtype: object
New Datatypes
a float64
b float64
c float64
dtype: object
DataFrame
a b c
0 21.0 72.0 67.0
1 23.0 78.0 62.0
2 32.0 74.0 54.0
3 52.0 54.0 76.0
Создание новых признаков в Pandas
Сбор, подготовка и очистка данных — большая часть анализа. В реальных условиях от аналитика данных часто требуется не только привести данных в порядок, но и собрать дополнительную информацию, которая может быть полезной при исследованиях, например, выявлении закономерностей или аномалий.
Приведем практический пример: крупная компания, занимающаяся недвижимостью строит новый жилой комплекс. Для того, чтобы цена за жилье была оправданной, необходимо проанализировать много очевидно важных факторов: стоимость материалов, площадь квартир, вид отделки. Но есть и те факторы, которые влияют косвенно, например, инфраструктура, наличие школ и детских садов. Такие данные часто приходится собирать отдельно.
Представим, что дополнительные данные мы уже собрали, но хранятся они отдельно, да еще и в разных форматах. Существует много метода объединения данных, но сейчас мы поговорим только о том, как добавить новый признак или столбец уже имеющемуся датасету.
Создадим датафрейм с двумя колонками рандомных чисел:
Для того, чтобы создать новую колонку в dataframe, необходимо указать название датафрейма и название новой колонки в квадратных скобках и присвоить ей значение. Создадим новую колонку ‘fird_col’ с 10 случайными числами и добавим ее к dataframe:
Теперь датасет выглядит так:
Сортировка столбцов фрейма данных ↑
Кроме того, можно использовать метки столбцов DataFrame для сортировки значений в строках. Использование с необязательным параметром , установленной на 1, отсортирует DataFrame по меткам столбцов. Алгоритм сортировки применяется к меткам осей, а не к фактическим данным. Это может быть полезно для визуального осмотра DataFrame.
Работа с осью DataFrame
Когда вы используете без явных аргументов, в качестве аргумента по умолчанию используется . Ось DataFrame относится либо к индексу (), либо к столбцам (). Вы можете использовать обе оси для индексации и выбора данных в DataFrame, а также для сортировки данных.
Использование меток столбцов для сортировки
Вы также можете использовать метки столбцов DataFrame в качестве ключа сортировки для . Установка в 1 сортирует столбцы вашего DataFrame на основе меток столбцов:
>>> df.sort_index(axis=1)
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Y Automatic 3-spd 1993
96 17 6 Regular ... N Automatic 4-spd 1993
97 15 6 Regular ... N Automatic 4-spd 1993
98 15 6 Regular ... N Manual 5-spd 1993
99 9 8 Premium ... N Automatic 4-spd 1993
Столбцы вашего DataFrame сортируются слева направо в возрастающем алфавитном порядке. Если вы хотите отсортировать столбцы в порядке убывания, вы можете использовать :
>>> df.sort_index(axis=1, ascending=False)
year trany mpgData ... fuelType cylinders city08
0 1985 Manual 5-spd Y ... Regular 4 19
1 1985 Manual 5-spd N ... Regular 12 9
2 1985 Manual 5-spd Y ... Regular 4 23
3 1985 Automatic 3-spd N ... Regular 8 10
4 1993 Manual 5-spd N ... Premium 4 17
.. ... ... ... ... ... ... ...
95 1993 Automatic 3-spd Y ... Regular 6 17
96 1993 Automatic 4-spd N ... Regular 6 17
97 1993 Automatic 4-spd N ... Regular 6 15
98 1993 Manual 5-spd N ... Regular 6 15
99 1993 Automatic 4-spd N ... Premium 8 9
Используя в , вы отсортировали столбцы вашего DataFrame как по возрастанию, так и по убыванию. Это может быть более полезно в других наборах данных, например, в тех, в которых метки столбцов соответствуют месяцам в году. В этом случае имеет смысл расположить данные по месяцам в порядке возрастания или убывания.
Равен () против сравнения NAN
Проблема:
import pandas as pd
df = pd.read_csv("Cars.csv")
# Dataframe "df"
# ----------
# make fuel aspiration body-style price engine-size
# 0 audi gas turbo sedan 30000 2.0
# 1 dodge gas std sedan 17000 1.8
# 2 mazda diesel std sedan 17000 NaN
# 3 porsche gas turbo convertible 120000 6.0
# 4 volvo diesel std sedan 25000 2.0
# ----------
df = df
check1 = (df == df).all()
check2 = df.equals(df)
print(check1 == check2)
# False
Этот фрагмент кода показывает, как сравнивать столбцы или целые дата данных относительно формы и элементов.
Сравнение с использованием оператора Возвращает Для нашего датафарама, потому что сравнение -Валены с всегда дает Отказ
С другой стороны, позволяет сравнивать две серии или данных данных. В этом случае -Валены в том же месте считаются равными.
Заголовки столбцов не должны иметь один и тот же тип, но элементы внутри столбцов должны быть одинакового Отказ
С результата это и результат Урожайность Окончательный выход – Отказ
Перестановка
Операции перестановки (случайного изменения порядка) в объекте или строках можно выполнить с помощью функции .
Для этого примера создайте с числами в порядке возрастания.
Теперь создайте массив из пяти чисел от 0 до 4 в случайном порядке с функцией . Этот массив будет новым порядком, в котором потребуется разместить и значения строк из .
Теперь примените его ко всем строкам с помощью функции .
Как видите, порядок строк поменялся, а индексы соответствуют порядку в массиве .
Перестановку можно произвести и для отдельной части . Это сгенерирует массив с последовательностью, ограниченной конкретным диапазоном, например, от 2 до 4.
Дискретизация и биннинг
Более сложный процесс преобразования называется дискретизацией. Он используется для обработки большим объемов данных. Для анализа их необходимо разделять на дискретные категории, например, распределив диапазон значений на меньшие интервалы и посчитав статистику для каждого. Еще один пример — большое количество образцов. Даже здесь необходимо разделять весь диапазон по категориям и внутри них считать вхождения и статистику.
В следующем случае, например, нужно работать с экспериментальными значениями, лежащими в диапазоне от 0 до 100. Эти данные собраны в список.
Вы знаете, что все значения лежат в диапазоне от 0 до 100, а это значит, что их можно разделить на 4 одинаковых части, бины. В первом будут элементы от 0 до 25, во втором — от 26 до 50, в третьем — от 51 до 75, а в последнем — от 75 до 100.
Для этого в pandas сначала нужно определить массив со значениями разделения:
Затем используется специальная функция , которая применяется к массиву. В нее нужно добавить и бины.
Функция возвращает специальный объект типа . Его можно считать массивом строк с названиями бинов. Внутри каждая содержит массив , включающий названия разных внутренних категорий и массив со списком чисел, равных элементам . Число соответствует бину, которому был присвоен соответствующий элемент .
Чтобы узнать число вхождений каждого бина, то есть, результаты для всех категорий, нужно использовать функцию .
У каждого класса есть нижний предел с круглой скобкой и верхний — с квадратной. Такая запись соответствует математической, используемой для записи интервалов. Если скобка квадратная, то число лежит в диапазоне, а если круглая — то нет.
Бинам можно задавать имена, передав их в массив строк, а затем присвоив его параметру в функции , которая используется для создания объекта .
Если функции передать в качестве аргумента целое число, а не границы бина, то диапазон значений будет разделен на указанное количество интервалов.
Пределы будут основаны на минимуме и максимуме данных.
Также в pandas есть еще одна функция для биннинга, . Она делит весь набор на квантили. Так, в зависимости от имеющихся данных обеспечит разное количество данных для каждого бина. А позаботится о том, чтобы количество вхождений было одинаковым. Могут отличаться только границы.


В этом примере видно, что интервалы отличаются от тех, что получились в результате использования функции
Также можно обратить внимание на то, что попыталась стандартизировать вхождения для каждого бина, поэтому в первых двух больше вхождений. Это связано с тем, что количество объектов не делится на 5
Извлечение значений по условиям в Pandas
Иногда нам нужно получить не все данные из DataFrame, а только некоторые, удовлетворяющие каким-то условиям.
Разберем практический пример. У нас есть база сотрудников с информацией об их именах, возрасте и зарплате. Создадим dataframe:
Давайте выведем только тех сотрудников, чей возраст превышает 30 лет:
Вывод:
![]()
Итак, все просто: мы указываем DataFrame, к которому применяем условие, а само условие записывается в квадратных скобках. Подробнее об операторах сравнения.
В качестве условий можно также использовать статистические методы.
Давайте попробуем вывести имена тех сотрудников, чья зарплата выше среднего:
Изменение данных в DataFrame в Pandas
Кроме сбора дополнительных данных, как уже упоминалось, значительную часть времени занимает предобработка и очистка или разведывательный анализ данных.
Датасет представляет собой описание того, как условия жизни учеников, например, образование родителей, наличие отношений и интернета, влияют на их оценки по математике.
Мы не будем проводить целое исследование признаков, скорее рассмотрим как обработать данные: например, привести данные в колонке к одному формату или создать новый признак на основе имеющихся.
![]()
Обратимся к признаку “romantic”, который содержит текстовые данные: “yes”, если учащийся имеет романтические отношения и “no”, если нет.
Бывают случаи, например, в рамках машинного обучения, когда мы можем работать только с числовыми типами данных. Давайте попробуем преобразовать два возможных значения этой колонки в числа (по сути сделать признак бинарным): “1”, в случае наличия отношения и “0” — в обратном.
Есть два способа изменения значений колонки:
1. мы можем написать функцию. Этот способ оптимален в том случае, если нужно изменить данные в несколько шагов, сделать несколько операций или шагов, или применить сразу к нескольким колонкам;
можем воспользоваться lambda-функцией. С помощью нее можно выполнять простые преобразования данных, не создавая функции. Однако если одну и ту же функцию надо применить к нескольким колонкам, удобнее создать обычную функцию.
Рассмотрим первый вариант:
Применить функцию к конкретной колонке в Pandas позволяет метод .apply():
Обновить колонку датафрейма:
2. Второй вариант: изменение значений колонки с помощью lambda-функции в Pandas
В данном случае мы делаем простое преобразование, значит можно воспользоваться безымянной функцией — lambda. Синтаксис довольно простой:
С помощью функции lambda пройдемся по всем значениям (х) колонки, к которой она применена и вернем “1”, если значение (x) — “yes”, в противном случае вернем 0.
Итак, мы рассмотрели базовые манипуляции с данными при помощи библиотеки Pandas.
Падение nan-ценностей
Проблема : Как отбросить все строки, которые содержат Нан Значение в любом из его столбцов – и как ограничить это определенным столбцам?
import pandas as pd
df = pd.read_csv("Cars.csv")
# Dataframe "df"
# ----------
# make fuel aspiration body-style price engine-size
# 0 audi gas turbo sedan 30000 2.0
# 1 dodge gas std sedan 17000 1.8
# 2 mazda diesel std sedan 17000 NaN
# 3 porsche gas turbo convertible 120000 6.0
# 4 volvo diesel std sedan 25000 2.0
# ----------
selection1 = df.dropna(subset=)
selection2 = df.dropna()
print(len(selection1), len(selection2))
# 5 4
DataFrame’s Способ удаляет все строки, которые содержат Значение в любом из его колонн. Но как ограничить столбцы, которые будут отсканированы для значения?
Передав список меток столбца в дополнительный параметр , вы можете определить, какие столбцы вы хотите рассмотреть.
Звонок Без ограничения, капли линии Из-за Значение в столбце Отказ Когда вы ограничиваете колонны только на , никакие ряды не будут сброшены, потому что нет Значение присутствует.
Стоит ли покупать БП 19 Сезона
Боевой Пропуск даёт крайне много бонусов активным игрокам — в нём и В-Баксы получить можно, и большой набор скинов. А если вдруг этого вам недостаточно, то вот полный список бонусов БП:
- Обилие наград (за 950 В-Баксов вам даётся столько предметов, сколько невозможно купить в магазине за эти же 950 В-Баксов)
- Эксклюзивность (награды, выдаваемые в БП, можно получить только в этом же БП)
- Цена (БП стоит 950 В-Баксов, а получить из него можно даже больше, параллельно получая скины. А если у вас есть подписка, то себестоимость БП станет ещё меньше).
- Больше испытаний и наград (некоторые испытания или награды открываются только для владельцев Боевого Пропуска)
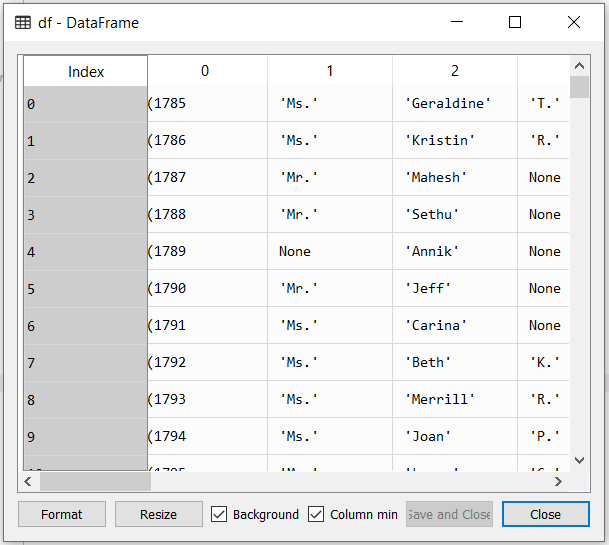
Объекты Index
Зная, что такое и , и понимая как они устроены, проще разобраться со всеми их достоинствами. Главная особенность этих структур — наличие объекта , который в них интегрирован.
Объекты являются метками осей и содержат другие метаданные. Вы уже знаете, как массив с метками превращается в объект , и что для него нужно определить параметр в конструкторе.
В отличие от других элементов в структурах данных pandas ( и ) объекты — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, и — структуры, возвращающие индексы с самым маленьким и большим значениями.
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, с повторяющимися метками.
Если метке соответствует несколько значений, то она вернет не один элемент, а объект .
То же применимо и к . При повторяющихся индексах он возвращает .

В случае с маленькими структурами легко определять любые повторяющиеся индексы, но если структура большая, то растет и сложность этой операции. Для этого в pandas у объектов есть атрибут . Он сообщает, есть ли индексы с повторяющимися метками в структуре ( или ).
Прочие изменения
ГУЛАГЕсли вы выиграете ГУЛАГ в Warzone Pacific Season 1, вы сможете вернуться с оружием, полученным во время дуэли. По сути, любые боеприпасы или оставшееся оборудование переносятся между ГУЛАГом и передислокацией.
Маркеры выпадения снаряженияВам нужно будет купить маркеры сброса снаряжения на станциях покупки и только после того, как событие сброса снаряжения произойдет в матче после закрытия первого круга.
Изменения в противогазеПротивогазы больше не будут прерывать так много действий, как раньше, хотя вы по-прежнему будете в боевом невыгодном положении по сравнению с кем-то, стоящим в круге.
МелководьеОператоры смогут переходить мелководье вброд, что поможет скрыть шаги от тех, у кого есть перк Трекер. Приседание в воде также даст вам преимущество хладнокровного перка, хотя вы не сможете лечь ничком, если вас заметят.
Операции между структурами данных
Теперь когда вы знакомы со структурами данных, и , а также базовыми операциями для работы с ними, стоит рассмотреть операции, включающие две или более структур.
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
Для их вызова нужно использовать другую спецификацию. Например, вместо того чтобы выполнять операцию для двух объектов по примеру + , потребуется следующий формат:
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Результат такой же, как при использовании оператора сложения
Также стоит обратить внимание, что если названия индексов и колонок сильно отличаются, то результатом станет новый объект , состоящий только из значений
Операции между Dataframe и Series
Pandas позволяет выполнять переносы между разными структурами, например, между и . Определить две структуры можно следующим образом.
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 1 | 2 | 3 | |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Они были специально созданы так, чтобы индексы в совпадали с названиями колонок в . В таком случае можно выполнить прямую операцию.
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | ||||
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |
По результату видно, что элементы были вычтены из соответствующих тому же индексу в колонках значений .
Если индекс не представлен ни в одной из структур, то появится новая колонка с этим индексом и значениями .
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| red | NaN | ||||
| blue | 4 | NaN | 4 | 4 | 4 |
| yellow | 8 | NaN | 8 | 8 | 8 |
| white | 12 | NaN | 12 | 12 | 12 |
Работа с отсутствующими данными при сортировке в Pandas ↑
Часто данные реального мира имеют много недостатков. Хотя у pandas есть несколько методов, которые можно использовать для очистки данных перед сортировкой, иногда приятно увидеть, какие данные отсутствуют во время сортировки. Это можно сделать с помощью параметра .
Подмножество данных об экономии топлива, используемое в этом руководстве, не имеет пропущенных значений. Чтобы проиллюстрировать использование , сначала нужно создать некоторые недостающие данные. Следующий фрагмент кода создает новый столбец на основе существующего столбца , сопоставляя , где равно и , где это не так:
>>> df = df.map({"Y": True})
>>> df
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
1 9 12 Regular ... Manual 5-spd 1985 NaN
2 23 4 Regular ... Manual 5-spd 1985 True
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Automatic 3-spd 1993 True
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
Теперь у вас есть новый столбец с именем , который содержит значения и . В этом столбце вы увидите, какой эффект дает при использовании двух методов сортировки. Чтобы узнать больше об использовании , вы можете прочитать Pandas Project: Make Gradebook With Python & Pandas.
Значение параметра na_position в .sort_values()
принимает параметр с именем , который помогает упорядочить недостающие данные в столбце, по которому выполняется сортировка. Если сортируется столбец с отсутствующими данными, то строки с отсутствующими значениями появятся в конце . Это происходит независимо от того, выполнятся ли сортировка по возрастанию или по убыванию.
Вот как выглядит DataFrame при сортировке по столбцу с отсутствующими данными:
>>> df.sort_values(by="mpgData_")
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
55 18 6 Regular ... Automatic 4-spd 1993 True
56 18 6 Regular ... Automatic 4-spd 1993 True
57 16 6 Premium ... Manual 5-spd 1993 True
59 17 6 Regular ... Automatic 4-spd 1993 True
.. ... ... ... ... ... ... ...
94 18 6 Regular ... Automatic 4-spd 1993 NaN
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
Чтобы изменить это поведение и чтобы недостающие данные сначала отображались в DataFrame, надо установить в значение . Параметр принимает только значения , которые являются значениями по умолчанию, или . Вот как использовать в :
>>> df.sort_values(
... by="mpgData_",
... na_position="first"
... )
city08 cylinders fuelType ... trany year mpgData_
1 9 12 Regular ... Manual 5-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
5 21 4 Regular ... Automatic 3-spd 1993 NaN
11 18 4 Regular ... Automatic 4-spd 1993 NaN
.. ... ... ... ... ... ... ...
32 15 8 Premium ... Automatic 4-spd 1993 True
33 15 8 Premium ... Automatic 4-spd 1993 True
37 17 6 Regular ... Automatic 3-spd 1993 True
85 17 6 Regular ... Automatic 4-spd 1993 True
95 17 6 Regular ... Automatic 3-spd 1993 True
Теперь любые недостающие данные из столбцов, которые использовались для сортировки, будут отображаться в верхней части DataFrame. Это особенно полезно при начале анализа своих данные, когда нет уверенности в том, есть ли пропущенные значения.
Описание параметра na_position в .sort_index()
также принимает . Обычно, DataFrame не имеет значений как часть индекса, поэтому этот параметр менее полезен в . Однако полезно знать, что если DataFrame действительно имеет в индексе строки или имени столбца, то можно быстро определить это с помощью и .
По умолчанию для этого параметра установлено значение , что помещает значения в конец отсортированного результата. Чтобы изменить это поведение и сначала сохранить недостающие данные в фрейме данных, установите для параметра значение .





