
Генерация произвольного количества строк
В postgresql обнаружил прекрасную функцию для генерации любого количества строк, ранее мы создавали дополнительную табличку с чслами для этих целей.
generate_series(start, stop) где start и stop произвольные целые числа, у данной функции существуют ещё две удобные перезагрузки:
generate_series(start, stop, step) первые два параметра анлогичны, а третий размер шага (в том числе и отрицательный).
generate_series(start, stop, step) первые два параметра имеют тип timestamp, а третий размер шага (тип interval), например
generate_series('2008-03-01 00:00'::timestamp,'2008-03-04 12:00', '10 hours').
Создаем дамп базы данных MySQL
Существует несколько способов создания дампов: через консольное окно или с помощью phpMyAdmin. Рассмотрим последовательно каждый из методов, а также попробуем восстановить БД из дампа.
Способ 1: Консольное окно MySQL
Удаленное подключение к хостингу по SSH разрешает работать с информационными хранилищами. Выбор данного протокола обусловлен его высокой безопасностью, так как вся информация передается в зашифрованном виде без возможности перехвата трафика.
Для подключения вы можете воспользоваться такими программами, как PuTTY и WinSCP – они распространяются в бесплатном доступе. Остановимся на первой утилите и посмотрим, как с ее помощью можно сделать дамп базы данных MySQL.
Обратите внимание, что если на компьютере функционирует сервер с БД, то соединение через порт 3306 будет некорректно. В таких случаях рекомендуется использовать другие значения, например, 3307, 3308 и так далее
Теперь мы можем переходить к удаленному администрированию БД: создадим дамп базы данных MySQL. Для этого введем в консоль следующий запрос:
mysqldump -uDataBase -pPASSWRD DataBase_NAME > FileName
- -uDataBase — имя базы в формате типа -u
- -pPasswrd — пароль от базы в формате типа -p
- DataBase_NAME — имя БД
- FileName — название файла
В целях безопасности рекомендуется вообще не использовать логин и пароль. В таком случае команда примет следующий вид:
mysqldump -u -p DataBase_NAME > FileNameToSave
Для понимания можете взглянуть на пример с использованием пользователя и пароля:
mysqldump -uAdmin -p123456789 WordPressDB > WordPressDump.sql
Таким образом будет создан файл WordPressDump.sql, содержащий в себе все нужные данные для точного копирования. Посмотрим, как этот файл импортировать в проект через консоль:
mysql -uUSER -pPASSWRD -f DataBase_NAME < FileNameToEnter
Аналогично подставляем свои данные в команду и в итоге получаем:
mysql -uWordPressDB -p123456789 -f WordPressDB < WordPeressDump.sql
Также при импорте мы можем указать кодировку — для этого достаточно добавить ключ default-character-set. В итоге код преобразуется:
mysql -uAdmin -p123456789 -f --default-character-set=cp1251 WordPressDB < WordPeressDump.sql
Вот такими несложными действиями можно сделать копирование через консольное окно. Теперь давайте «покопаемся» в phpMyAdmin и выполним в нем копирование БД.
Способ 2: Инструмент phpMyAdmin
PhpMyAdmin по умолчанию предустановлен на каждой CMS. Доступ к нему осуществляется через личный кабинет пользователя на хостинге либо через локальный веб-сервер на домашнем ПК.
Подключаемся к phpMyAdmin и экспортируем БД:
- Открываем личный кабинет хостинга, на котором установлен веб-ресурс, и переходим в phpMyAdmin. На Timeweb это выполняется через раздел «База данных MySQL». Если вы используете локальный сервер на OpenServer, то достаточно в панели задач кликнуть правой кнопкой мыши по его иконке, перейти в меню «Дополнительно» и выбрать «PhpMyAdmin».
- Вводим логин и пароль, в результате чего попадаем в систему phpMyAdmin. В левой части выбираем БД для копирования и кликаем по ней левой кнопкой мыши.
- Переходим в раздел «Экспорт» и выбираем метод экспорта. Первый минимизирован – получится обычная БД без особых настроек, второй разрешает вносить важные уточнения. Например, мы можем удалять таблицы, изменять кодировку, добавлять особые параметры формата и многое другое. Перед сохранением файла указываем его формат и только потом нажимаем на кнопку «Вперед».
После этого нам будет предложен выбор места сохранения файла. В последующем мы сможем его использовать через вкладку «Импорт». Для этого достаточно загрузить файл и указать подходящую для него кодировку:![]()
В заключение стоит сказать, что дамп базы данных – это незаменимый файл, без которого не обходится ни один серверный переезд. Используйте его для переноса базы на хостинге или с локальной машины, а также для создания резервных копий. Удачи!
![]()
Получение определенного количества строк
Если таблица содержит тысячи строк, то получение всех из них может занять много времени. Но существует альтернатива в виде .
Вот ее синтаксис:
- — это количество строк, которые требуется получить.
- этот метод делает запрос на определенное количество строк из результата запроса. возвращает список кортежей, содержащих строки.
- возвращает пустой список, если строки не были найдены. Количество строк зависит от аргумента SIZE. Ошибка возникает в том случае, если предыдущий вызов execute() не дал никаких результатов.
вернет меньше строк, если в таблице их меньше, чем было указано в аргументе SIZE.
Пример получения ограниченного количества строк из таблицы PostgreSQL с помощью :
Копировать
Вывод:
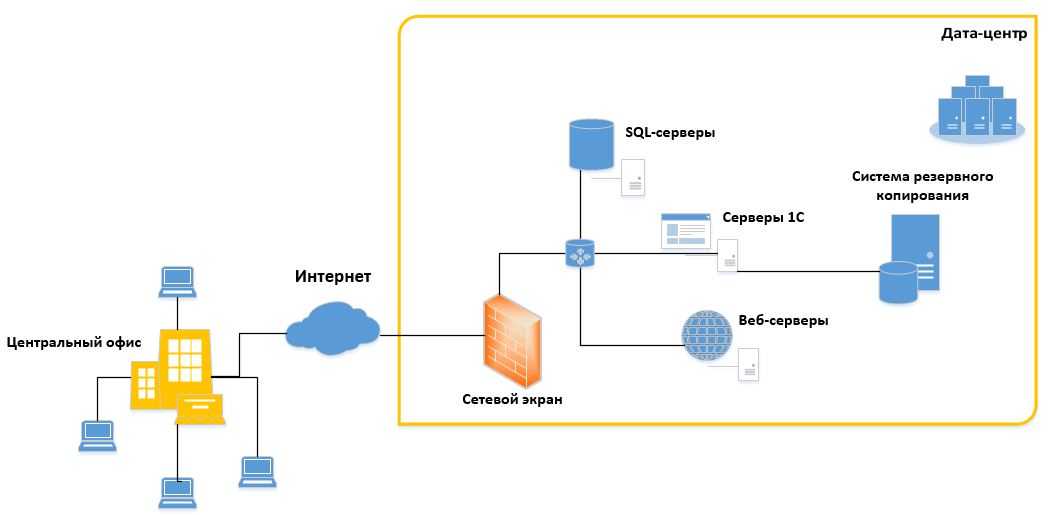
Оптимизация процесса миграции
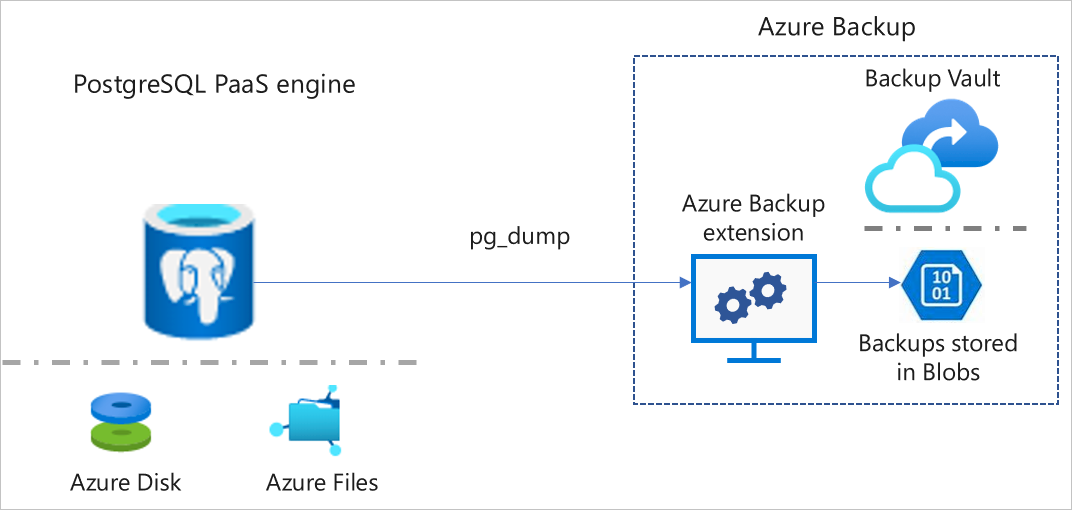
Один из способов миграции существующей базы данных PostgreSQL в службу баз данных Azure для PostgreSQL — это резервное копирование базы данных в источнике и ее восстановление в Azure. Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
Примечание
Подробные сведения о синтаксисе см. в статьях о pg_dump и pg_restore.
Для резервного копирования
Создайте резервную копию с использованием параметра , чтобы можно было выполнять восстановление параллельно. Это позволит ускорить процесс. Пример:
Для восстановления
Переместите файл резервной копии на виртуальную машину Azure в том же регионе, в котором находится сервер базы данных Azure для PostgreSQL, на который выполняется миграция. Выполните из этой виртуальной машины, чтобы снизить задержку в сети. Создание виртуальной машины с ускоренной сетью.
Откройте файл дампа, чтобы убедиться в том, что инструкции создания индекса находятся после вставки данных. Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.
Для параллелизации восстановления необходимо выполнить восстановление с параметрами и (с номером). Указанное вами число — это количество ядер на целевом сервере. Вы также можете попробовать установить вдвое большее количество ядер целевого сервера, чтобы оценить нагрузку.
Ниже приведен пример использования этого для одиночного сервера:
Ниже приведен пример использования этого для гибкого сервера:
Файл дампа также можно отредактировать, добавив в его начале команду , а в конце — команду . Если не включить ее в конце, это может привести к последующей потере данных прежде, чем приложения изменят данные.
Перед восстановлением рассмотрите возможность выполнения следующих действий на целевом сервере Базы данных Azure для PostgreSQL.
Отключите отслеживание производительности запросов. Эти статистические данные не требуются во время миграции. Это можно сделать, установив для параметров , и значение .
Используйте SKU с высоким объемом ресурсов вычисления и памяти, например модель 32 vCore Memory Optimized (32 виртуальных ядра с оптимизацией для операций в памяти), чтобы ускорить миграцию. Вы можете легко вернуться к предпочитаемому SKU после завершения восстановления. Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра в команде .
Увеличьте число операций ввода-вывода в секунду на целевом сервере — это может улучшить производительность восстановления. Вы можете подготовить больше операций ввода-вывода в секунду, увеличив объем хранилища на сервере
Этот параметр необратим, но стоит принять во внимание, будет ли большее количество операций ввода-вывода в секунду полезным для вашей рабочей нагрузки в будущем.
Не забудьте проверить и протестировать эти команды в тестовой среде, прежде чем использовать их в рабочей среде.
Пример 1
В этой таблице, как вы можете видеть на снимке, есть похожие данные в каждом столбце. Чтобы различать необычные значения, мы применим команду «отличные». Этот запрос будет принимать в качестве параметра один столбец, значения которого должны быть извлечены. Мы хотим использовать первый столбец таблицы в качестве входных данных для запроса.
Из выходных данных вы можете видеть, что всего строк составляет 7, тогда как в таблице всего 10 строк, что означает, что некоторые строки вычтены. Все числа в столбце «id», которые были дублированы дважды или более, отображаются только один раз, чтобы отличить результирующую таблицу от других. Все результаты располагаются в порядке возрастания с помощью «предложения порядка».
![]()
Возможные ошибки
Input file appears to be a text format dump. please use psql.
Причина: дамп сделан в текстовом формате, поэтому нельзя использовать утилиту pg_restore.
Решение: восстановить данные можно командой psql <имя базы> < <файл с дампом> или выполнив SQL, открыв файл, скопировав его содержимое и вставив в SQL-редактор.
No matching tables were found
Причина: Таблица, для которой создается дамп не существует. Утилита pg_dump чувствительна к лишним пробелам, порядку ключей и регистру.
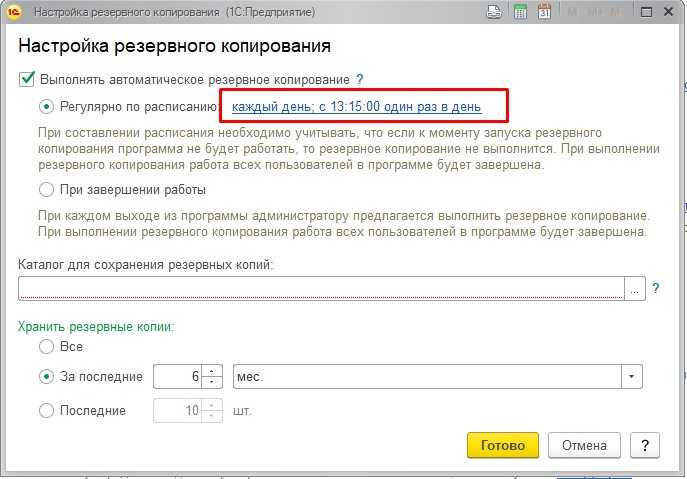
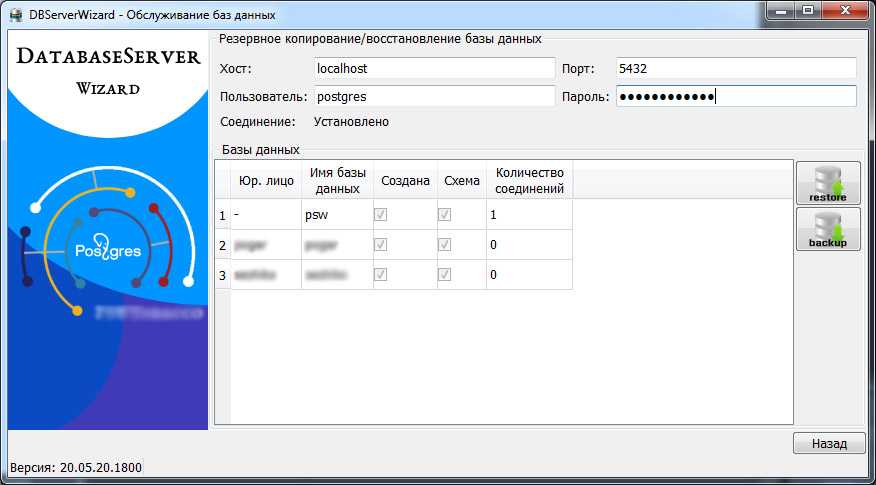
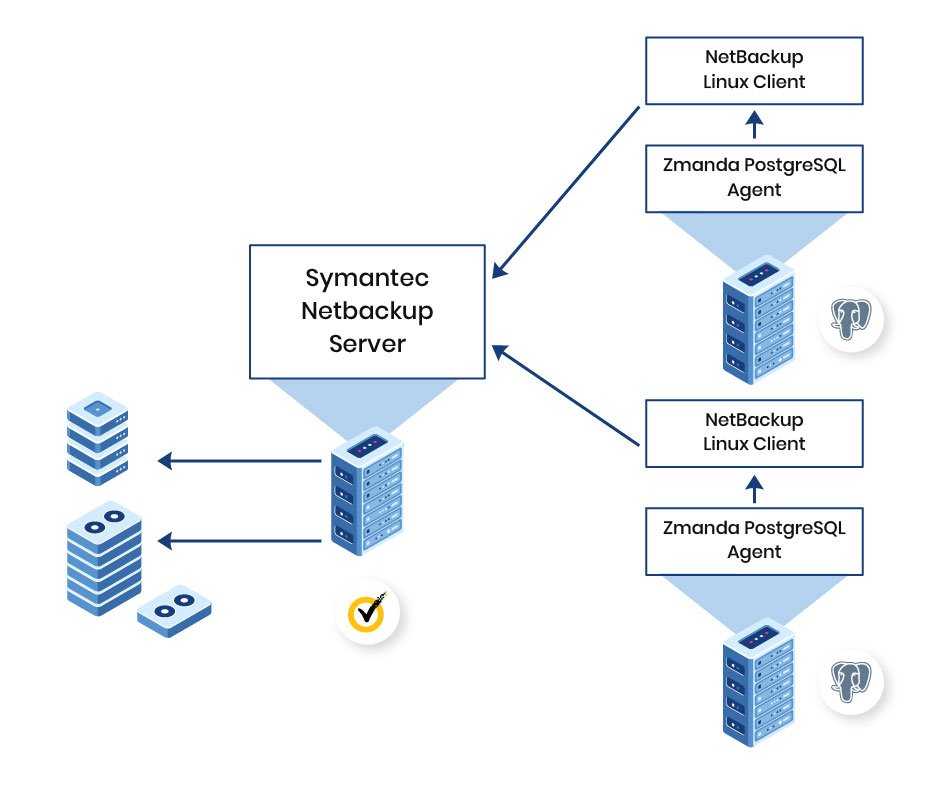
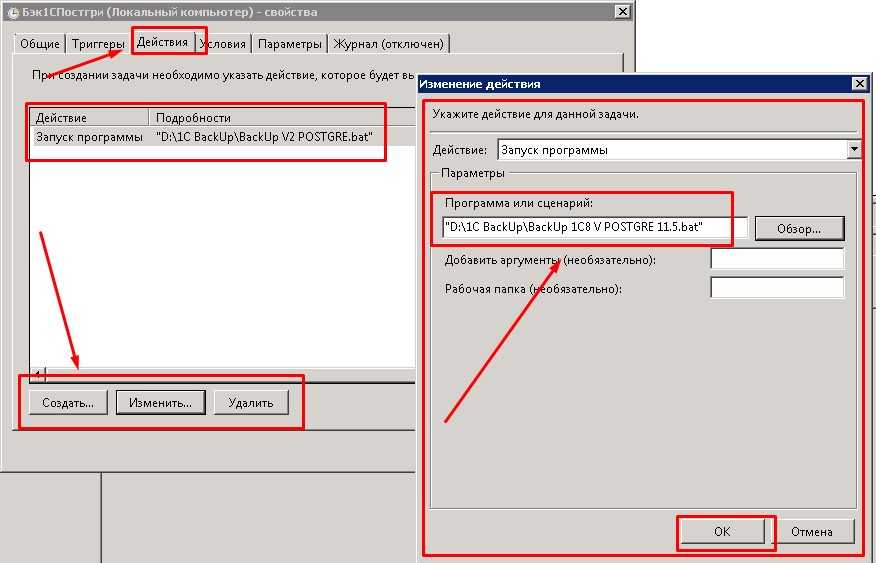
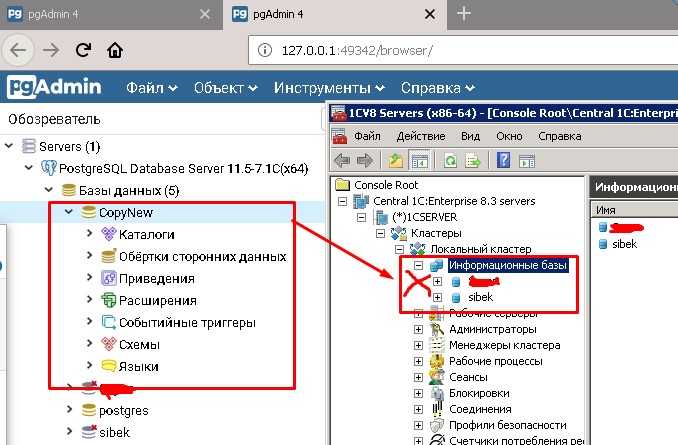
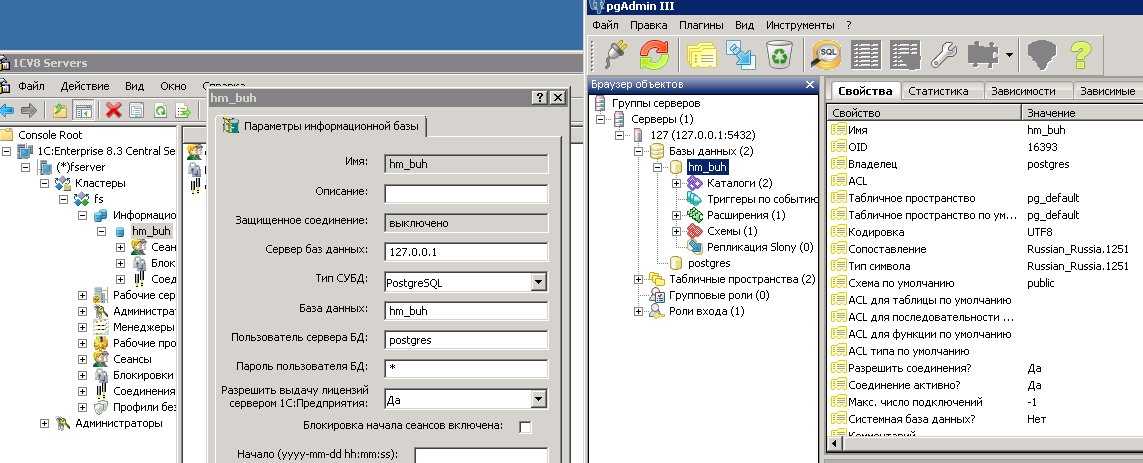
Решение: проверьте, что правильно написано название таблицы и нет лишних пробелов.
Причина: Утилита pg_dump чувствительна к лишним пробелам.
Решение: проверьте, что нет лишних пробелов.
Aborting because of server version mismatch
Причина: несовместимая версия сервера и утилиты pg_dump. Может возникнуть после обновления или при выполнении резервного копирования с удаленной консоли.
Решение: нужная версия утилиты хранится в каталоге /usr/lib/postgresql/<version>/bin/. Необходимо найти нужный каталог, если их несколько и запускать нужную версию. При отсутствии последней, установить.
No password supplied
Причина: нет системной переменной PGPASSWORD или она пустая.
Решение: либо настройте сервер для предоставление доступа без пароля в файле pg_hba.conf либо экспортируйте переменную PGPASSWORD (export PGPASSWORD или set PGPASSWORD).
Неверная команда \
Причина: при выполнении восстановления возникла ошибка, которую СУБД не показывает при стандартных параметрах восстановления.
Решение: запускаем восстановление с опцией -v ON_ERROR_STOP=1, например:
psql -v ON_ERROR_STOP=1 users < /tmp/users.dump
Теперь, когда возникнет ошибка, система прекратит выполнять операцию и выведет сообщение на экран.
Пример 5
Снова рассмотрим ту же таблицу с некоторыми изменениями. Мы добавили новый слой, чтобы применить некоторые ограничения.
В этом примере к двум столбцам используются те же предложения group by и order by. Выбраны Id и order_no, и оба сгруппированы и упорядочены по 1.
Поскольку каждый идентификатор имеет другой порядковый номер, за исключением одного числа, к которому добавлено «10», все другие числа, дважды или более присутствующие в таблице, отображаются одновременно. Например, идентификатор «1» имеет порядковые номера 4 и 8, поэтому оба упомянуты отдельно. Но в случае идентификатора «10» он записывается один раз, потому что оба идентификатора и order_no одинаковы.
Пример 7
В этом примере используются почти все предложения. Например, используются предложение select, group by, has clause, order by и функция count. Используя предложение «имеющий», мы также можем получить повторяющиеся значения, но здесь мы применили условие с функцией подсчета.
Выбран только один столбец. Прежде всего, выбираются значения order_no, отличные от других строк, и к ним применяется функция count. Результат, полученный после функции счета, упорядочен по возрастанию. Затем все значения сравниваются со значением «1». Отображаются значения столбца больше 1. Поэтому из 11 рядов получается всего 4 ряда.
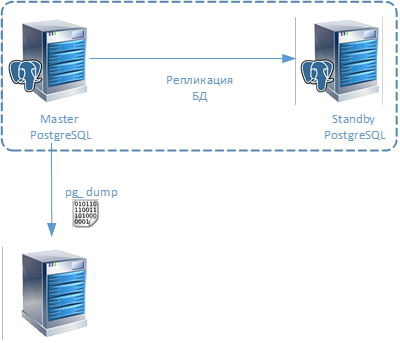
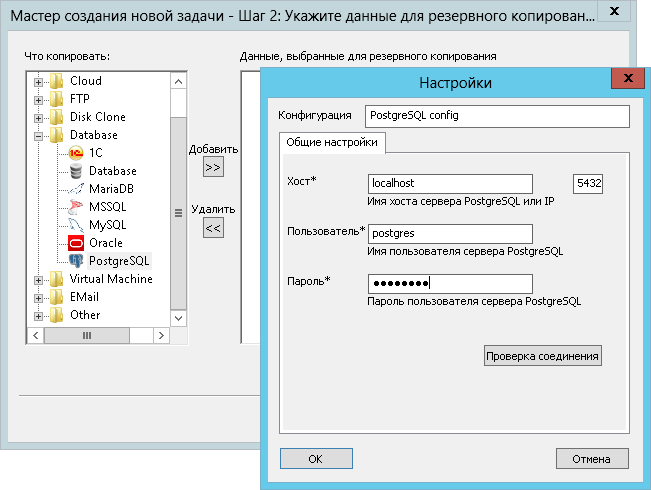
Резервное копирование базы данных
Бэкап одной базы данных
В примере ниже, мы сделаем резервную копию базы данных под названием , принадлежащей пользователю и сохраним её в файл :
pg_dump -U bosha thebosharu -f thebosharu.sql
Если вы работаете с базой данных не под тем же пользователем, под которым работаете в системе, то pg_dump спросит пароль к базе данных и после его успешного ввода создаст указанный файл содержащий SQL команды для создания необходимой структуры и копирования данных.
Вот часть дампа моей базы данных, чтобы вы понимали что в нем находится:
--
-- Name: auth_user; Type: TABLE; Schema: public; Owner: bosha; Tablespace:
--
CREATE TABLE auth_user (
id integer NOT NULL,
username character varying(250) NOT NULL,
password character varying(250),
email character varying(250),
first_name character varying(250),
last_name character varying(250),
middle_name character varying(250),
authenticated boolean,
active boolean,
is_admin boolean
);
ALTER TABLE auth_user OWNER TO bosha;
--
-- Name: auth_user_id_seq; Type: SEQUENCE; Schema: public; Owner: bosha
--
CREATE SEQUENCE auth_user_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE auth_user_id_seq OWNER TO bosha;
--
-- Name: auth_user_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: bosha
--
ALTER SEQUENCE auth_user_id_seq OWNED BY auth_user.id;
--
-- Data for Name: auth_user; Type: TABLE DATA; Schema: public; Owner: bosha
--
COPY auth_user (id, username, password, email, first_name, last_name, middle_name, authenticated, active, is_admin) FROM stdin;
1 test pbkdf2sha1$sfadfadafda$sfadfadf10019sdfadfad0101010dsfadf0202022 \N f f f
\.
Так же можно передать ключ , чтобы pg_dump запаковал базу данных в tar:
pg_dump -U bosha thebosharu --format=t -f thebosharu.sql.tar
Бэкап всех баз данных
Для того, чтобы сделать резервную копию всех баз данных, нужно использовать другую утилиту — pg_dumpall.
Права доступа могут быть настроены у всех по разному, поэтому бэкап всех баз данных лучше делать из под пользователя .
Зайдем под ним:
su - postgres
И выполним:
pg_dumpall > all_databases.sql
Бэкап всех баз данных будет содержаться в файле .
Крайне желательно убедится, что все нужные базы данных были копированы. Для этого все из под того же пользователя postgres посмотрим список всех баз данных:
psql -l
В моем случае было три базы данных:
postgres~$ psql -l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
---------------+----------+----------+-------------+-------------+---------------------------
thebosharu | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | thebosharu=CTcpostgres
testdb1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | testdb1=CTcpostgres
testdb2 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | testdb2=CTcpostgres
(3 rows)
Теперь удостоверимся, что все перечисленные базы попали в дамп:
bash:~$ grep "^connect" all.sql \connect thebosharu \connect testdb1 \connect testdb2
Бэкап определенной таблицы
pg_dump --table auth_user -U bosha thebosharu -f auth_user_table.sql
Для бэкапа определенной таблицы используется параметр и следом за ним названием таблицы. Если в базе данных указанная таблица есть в разных схемах, то её можно указать используя параметр .
Пример 3
Чтобы получить различные значения, мы воспользуемся еще одним методом. Ключевое слово «отличное» используется с функцией count () и предложением «группировать по». Здесь мы выбрали столбец с именем «адрес». Функция count подсчитывает значения из столбца адреса, полученные с помощью отдельной функции. Если мы случайно подумаем о подсчете различных значений, помимо результата запроса, мы получим одно значение для каждого элемента. Поскольку, как видно из названия, отличные будут иметь значения, равные единице, либо они присутствуют в числах. Точно так же функция подсчета будет отображать только одно значение.
Каждый адрес считается одним числом из-за различных значений.
Проверка форматов: число, дата.
Когда возникает необходимость проверки: является ли строка числом или датой, можно воспользоваться следующими функциями:
- isdigit(text)
- isdate(text)
Функции возвращают TRUE или FALSE в зависимости от того, верный ли формат.
Вот скрипты для создания этих функций:
isdigit :
CREATE OR REPLACE FUNCTION public.isdigit(text) RETURNS pg_catalog.bool AS $BODY$ DECLARE inputText ALIAS FOR $1; tempChar text; isNumeric boolean; BEGIN isNumeric = true; FOR i IN 1..length(inputText) LOOP tempChar = substr(inputText, i, 1); IF tempChar ~ '' THEN /* do nothing */ ELSE return FALSE; END IF; END LOOP; return isNumeric; END; $BODY$ LANGUAGE 'plpgsql' VOLATILE COST 100 ; ALTER FUNCTION public.isdigit(text) OWNER TO postgres; isdate CREATE OR REPLACE FUNCTION public.isdate(v text) RETURNS pg_catalog.bool AS $BODY$ BEGIN if v is null then return false; else perform v::date; return true; end if; exception when others then return false; END; $BODY$ LANGUAGE 'plpgsql' VOLATILE COST 100 ; ALTER FUNCTION public.isdate(v text) OWNER TO postgres;
Обновление статистики и реиндексация в postgresql
С бэкапами разобрались, теперь настроим регламентные операции на уровне субд, чтобы поддерживать быстродействие базы данных. Тут особых комментариев не будет, в интернете очень много информации на тему регламентных заданий для баз 1С. Я просто приведу пример того, как это выглядит в postgresql.
Выполняем очистку и анализ базы данных 1С:
# vacuumdb --full --analyze --username postgres --dbname base1c
Реиндексация таблиц базы данных:
# reindexdb --username postgres --dbname base1c
Завернем все это в скрипт с логированием времени выполнения команд:
# cat /root/bin/service-sql.sh
#!/bin/sh # Записываем информацию в лог echo "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuum base1c" >> /var/log/postgresql/service.log # Выполняем очистку и анализ базы данных /usr/bin/vacuumdb --full --analyze --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuum base1c" >> /var/log/postgresql/service.log sleep 2 echo "`date +"%Y-%m-%d_%H-%M-%S"` Start reindex base1c" >> /var/log/postgresql/service.log # Переиндексирвоать базу /usr/bin/reindexdb --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End reindex base1c" >> /var/log/postgresql/service.log
Сохраняем скрипт и добавляем в планировщик. Хотя я для удобства сделал еще один скрипт, который объединяет бэкап и обслуживание и уже его добавил в cron:
# cat all-sql.sh
#!/bin/sh /root/bin/backup-sql.sh sleep 2 /root/bin/service-sql.sh
Добавялем в /etc/crontab:
# Бэкап и обслуживание БД 1 3 * * * root /root/bin/all-sql.sh
Проверяем лог файл и наличие бэкапа. Не забывайте делать проверочное регулярное восстановление бд из архива.
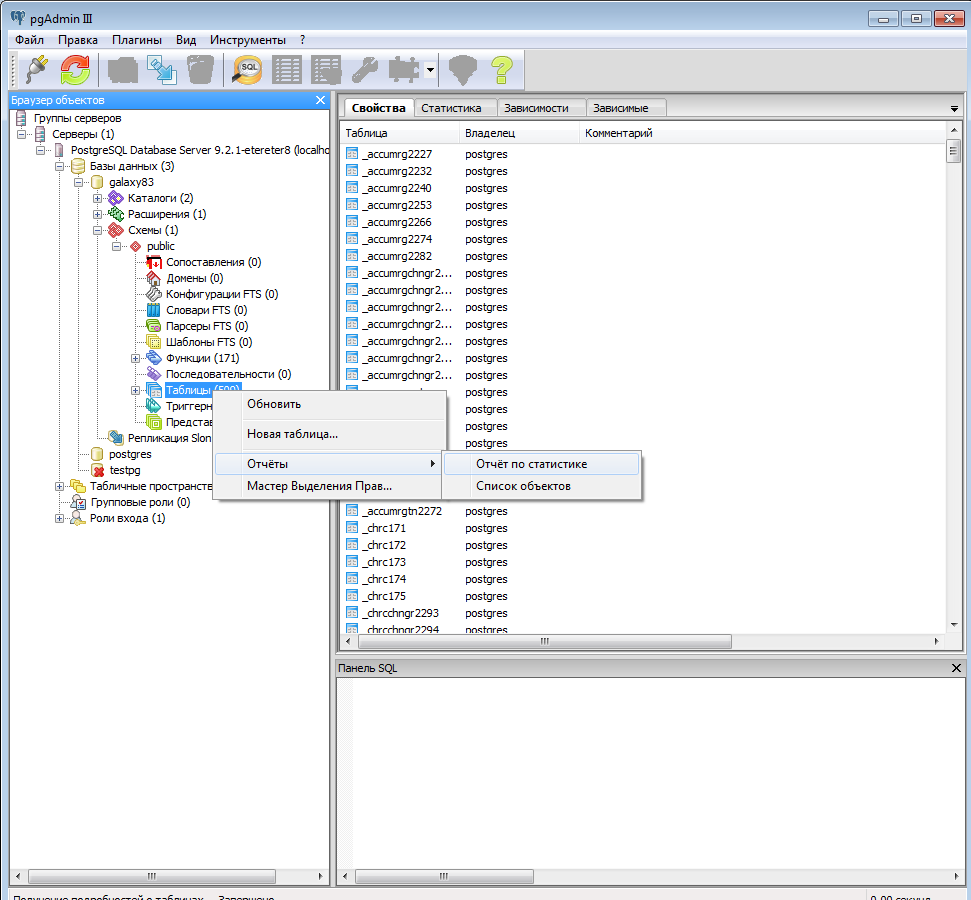
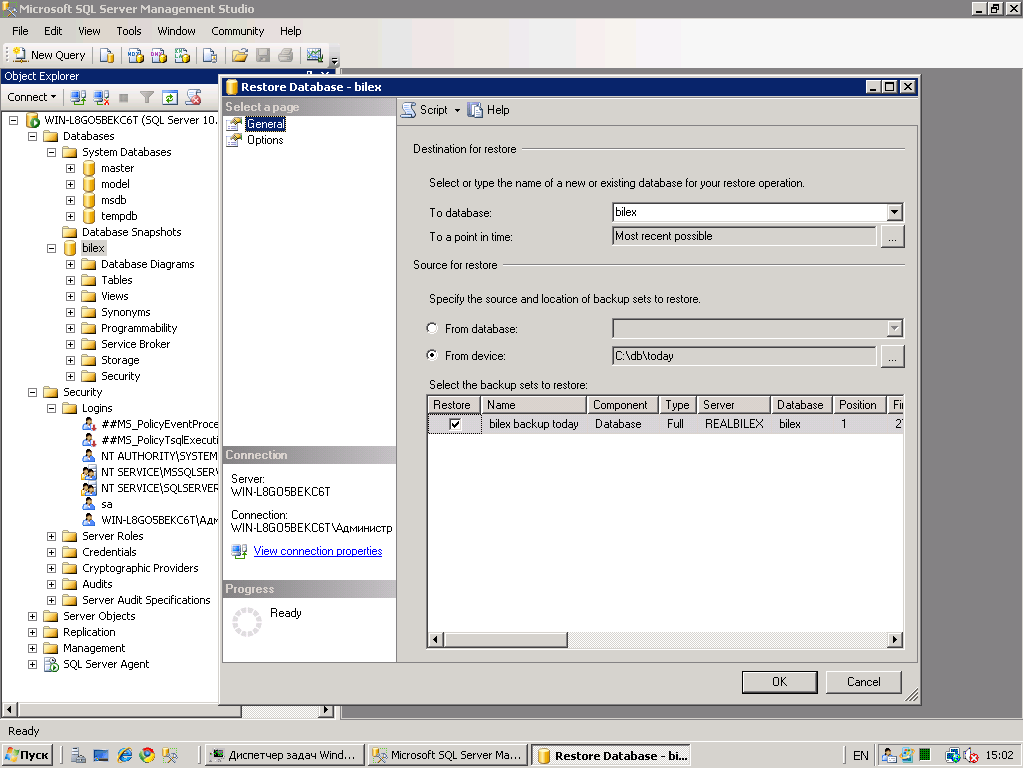
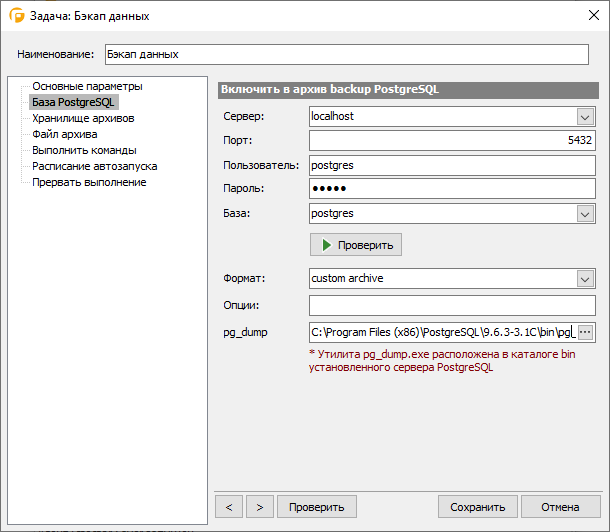
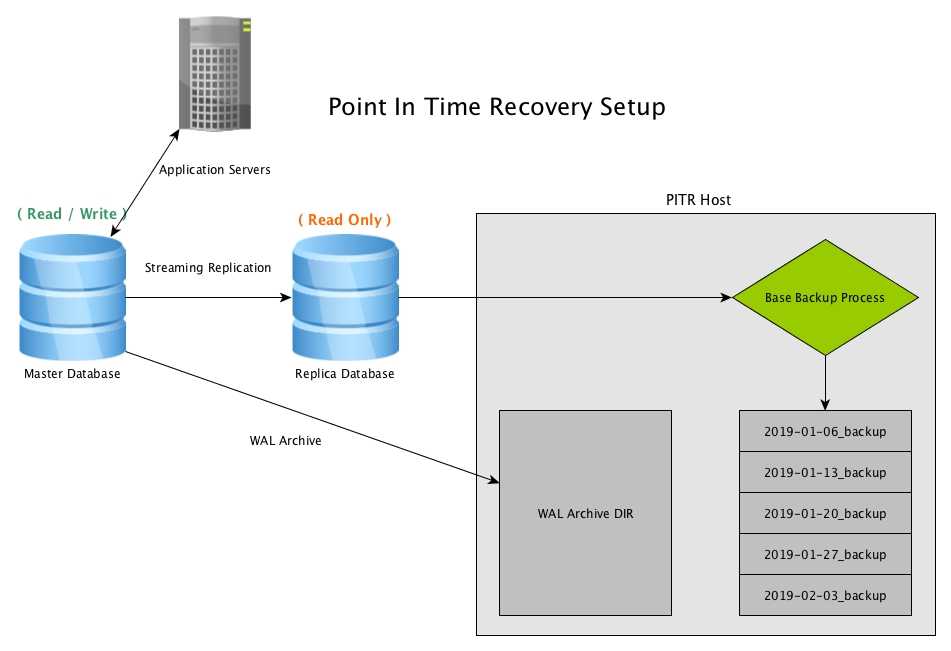
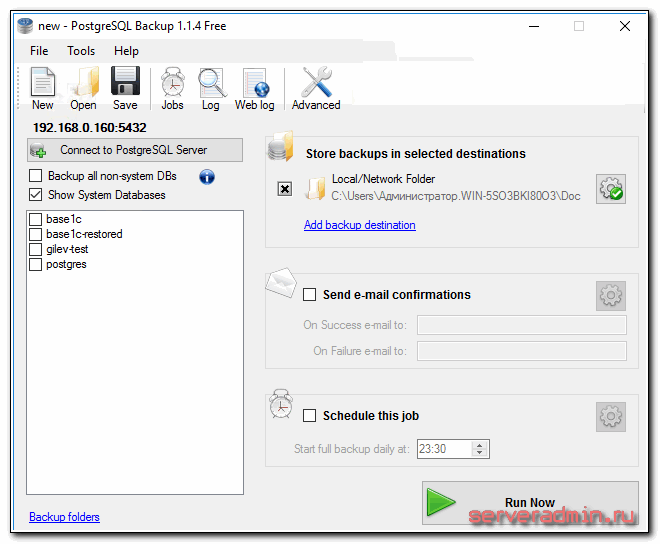
Описанные выше операции очистки и переиндексации можно делать в ручном режиме в программе под windows — pgAdmin. Рекомендую ее установить на всякий случай. Достаточно удобно и быстро можно посмотреть информацию или выполнить какие-то операции с базой данных посгрес.
![]()
Длина названий столбцов и таблиц
В postgres есть ограничение на длину имен столбцов и таблиц. Все имена не должны быть больше 63 символов (63 байта данный параметр в принципе можно изменить при сборке postgres)
Более подробно см. ссылку
postgresql.ru.net/manual/sql-syntax-lexical.html
Но для кириллических символом данное ограничение более существенно, каждый русский символ эквивалентен 2 обычным. Таким образом невозможно создать таблицу у которой столбец имеет полностью русское имя длиннее 31 символа.
При больших длинах идентификаторов (имена столбцом и таблиц являются идентификаторами) текст будет обрезан.
Данное поведение может наблюдаться в showcase при отображении гридов. Из этой ситуации есть 2 более менее простых выхода
- Уменьшить длину идентификатора (универсальный способ)
- Передавать данные для грида через xml (способ для showcase)
Пример 2
Этот пример относится к подзапросу, в котором в подзапросе используется отдельное ключевое слово. Основной запрос выбирает order_no из содержимого, полученного из подзапроса, который является входом для основного запроса.
Подзапрос получит все уникальные номера заказов; даже повторяющиеся отображаются один раз. Тот же столбец order_no снова упорядочивает результат. В конце запроса вы заметили использование «foo». Это действует как заполнитель для хранения значения, которое может изменяться в соответствии с заданным условием. Вы также можете попробовать, не используя его. Но чтобы убедиться в правильности, мы воспользовались этим.
Запрос SQL 2008, который показывает, какие запросы висят и все блочат
SELECT
db.name DBName,
tl.request_session_id,
wt.blocking_session_id,
OBJECT_NAME(p.OBJECT_ID) BlockedObjectName,
tl.resource_type,
h1.TEXT AS RequestingText,
h2.TEXT AS BlockingTest,
tl.request_mode
FROM sys.dm_tran_locks AS tl
INNER JOIN sys.databases db ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.partitions AS p ON p.hobt_id = tl.resource_associated_entity_id
INNER JOIN sys.dm_exec_connections ec1 ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2 ON ec2.session_id = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2
Функция occur. Считает количество вхождений символа в строку.
Сколько раз встречается символ в строке?
Функция occur может быть полезна для создания отступа в иерархическом селекторе
строка — это заранее сформированный сортировочный код (полезно для больших таблиц типа ОКВЕД — ~ 15000 записей, до 7 уровней)
Вызов, например,
select occur('D — DL — 30 — 30.0 — 30.02.000 — 30.02.310 — 30.02.313','-',)
— — —
DECLARE
i int4;
BEGIN
i = position(symbol in string);
IF i > THEN
count = occur(substr(string, i+1), symbol, Coalesce(init_value,) + 1);
ELSE
count = Coalesce(init_value,);
END IF;
END
Parameters: OUT count int4, IN string text, IN symbol varchar, IN init_value int4
Return type: int4
Неточный поиск в ShowCase (БД на postgreSQL)
Иногда бывает нужно найти запись по неточной информации, например, неточно известна фамилия слушателя Факультета Усовершенствования Врачей (ФУВ). Сотрудник деканата ФУВ пытается найти Слушателя: Куманшева Наталья Викторовна, и не находит. На самом деле фамилия слушателя: Кумакшева.
Для этого может быть использована функция похожести similarity(text, text) из расширения postgreSQL, которое подключается командой:
create extension pg_trgm;
select similarity(‘Куманшева’,’Кумакшева’)
— выдает некий коэффициент, в данном случае: 0,538462.
В форме (xForms) делается поле ввода фамилии и кнопка «Найти похожие», по которой вызывается обычный селектор, показывающий записи, удовлетворяющие условию, что этот коэффициент больше определенного порога.
Для практических нужд в селекторе достаточно использовать значение 0,3 (если поиск только по фамилии).
Будут выданы все ФИО с похожей фамилией (их желательно отсортировать по этому коэффициенту — чем выше коэффициент, тем выше в списке запись).
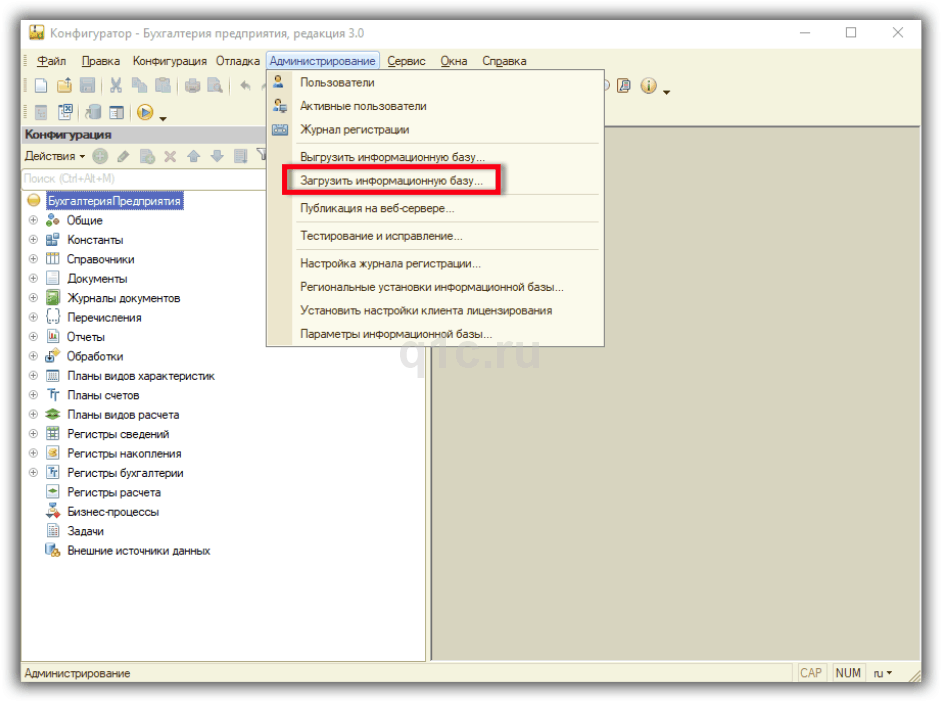
Восстановление
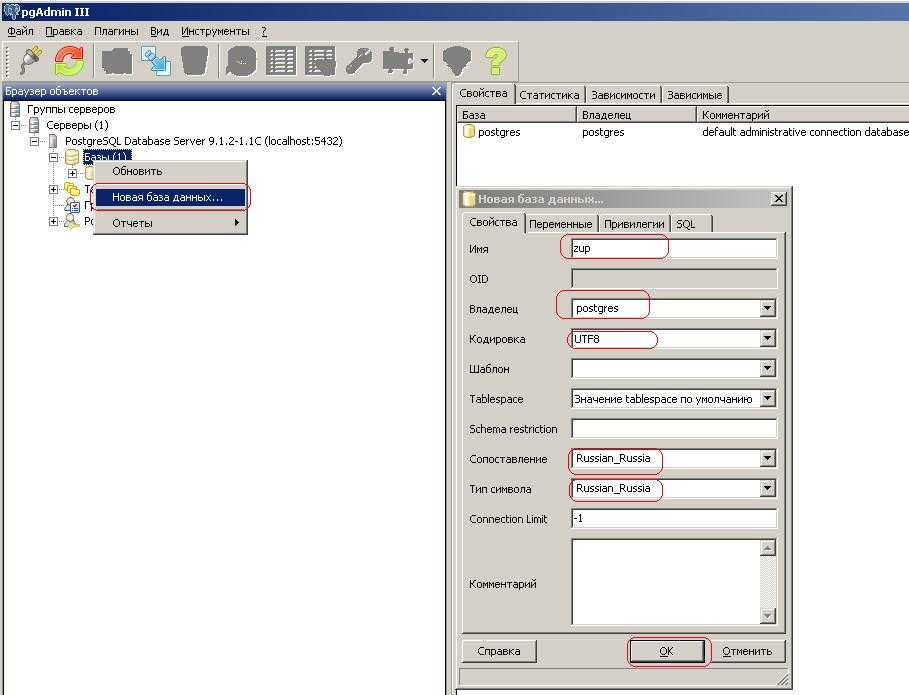
Может понадобиться создать базу данных. Это можно сделать SQL-запросом:
=# CREATE DATABASE users WITH ENCODING=’UTF-8′;
* где users — имя базы; UTF-8 — используемая кодировка.
Если мы получим ошибку:
ERROR: encoding «UTF8» does not match locale «en_US»
DETAIL: The chosen LC_CTYPE setting requires encoding «LATIN1».
Указываем больше параметров при создании базы:
CREATE DATABASE users WITH OWNER ‘postgres’ ENCODING ‘UTF8’ LC_COLLATE = ‘ru_RU.UTF-8’ LC_CTYPE = ‘ru_RU.UTF-8’ TEMPLATE = template0;
Синтаксис:
psql <имя базы> < <файл с дампом>
Пример:
psql users < /tmp/users.dump
С авторизацией
При необходимости авторизоваться при подключении к базе вводим:
psql -U dmosk -W users < /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Из файла gz
Сначала распаковываем файл, затем запускаем восстановление:
gunzip users.dump.gz
psql users < users.dump
Или одной командой:
zcat users.dump.gz | psql users
Определенную базу
Если резервная копия делалась для определенной базы, запускаем восстановление:
psql users < /tmp/database.dump
Если делался полный дамп (всех баз), восстановить определенную можно при помощи утилиты pg_restore с параметром -d:
pg_restore -d users cluster.bak
Определенную таблицу
Если резервная копия делалась для определенной таблицы, можно просто запустить восстановление:
psql users < /tmp/students.dump
Если делался полный дамп, восстановить определенную таблицу можно при помощи утилиты pg_restore с параметром -t:
pg_restore -a -t students users.dump
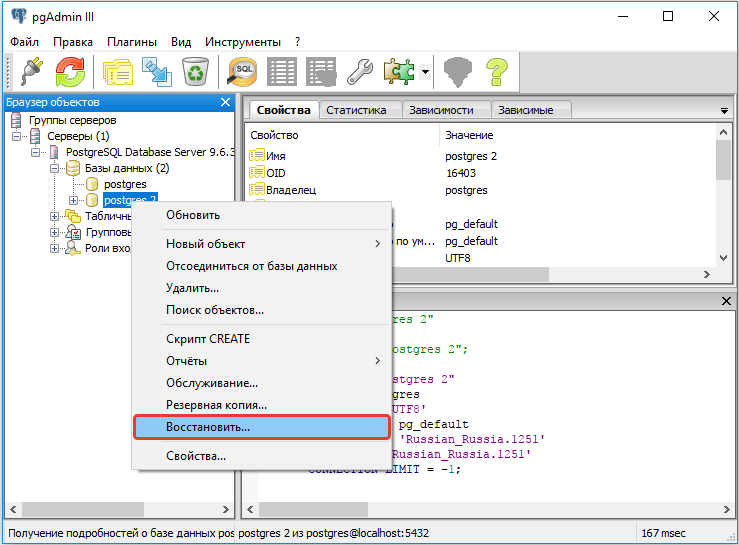
С помощью pgAdmin
Запускаем pgAdmin — подключаемся к серверу — кликаем правой кнопкой мыши по базе, для которой хотим восстановить данные — выбираем Восстановить:
Выбираем наш файл с дампом:
И кликаем по Восстановить:
Использование pg_restore
Данная утилита предназначена для восстановления данных не текстового формата (в одном из примеров создания копий мы тоже делали резервную копию не текстового формата).
Из бинарника:
pg_restore -Fc users.bak
Из тарбола:
pg_restore -Ft users.tar
С создание новой базы:
pg_restore -Ft -C users.tar
Поиск по тексту хранимых процедур postgresq
Чтобы найти вхождение какой-либо строки в тексте хранимых процедур; например для того, чтобы узнать, откуда происходит вызов процедур, либо убедиться, что на таблицу, которую Вы хотите удалить, ничего не ссылается; можно использовать обращение к таблице pg_catalog.pg_proc, содержащей строковые ресурсы хранимых процедур в колонке prosrc.
Найти нужную строчку можно с помощью следующего запроса:
SELECT proname, proargnames, prosrc FROM pg_proc WHERE prosrc ILIKE '%search_string%';
где ILIKE — ключевое слово в Postgresql, которое можно использовать вместо LIKE, чтобы находить нечувствительные к регистру вхождения строки.
Также с помощью таблицы pg_catalog.pg_proc можно заменить идентификатор сразу во всех процедурах.
Подготовка
Перед началом работы нужно убедиться, что у вас есть следующее:
- Имя пользователя и пароль для подключения к PostgreSQL
- Название базы данных, из которой требуется получить данные
В этом материале воспользуемся таблицей «mobile», которая была создана в первом руководстве по работе с PostgreSQL в Python. Если таблицы нет, то ее нужно создать.
Шаги для выполнения запроса SELECT из Python-программы
- Установить psycopg2 с помощью pip.
- Создать соединение с базой данных PostgreSQL.
- Создать инструкцию с запросом SELECT для получения данных из таблицы PostgreSQL.
- Выполнить запрос с помощью и получить результат.
- Выполнить итерацию по объекту с помощью цикла и получить значения всех полей (колонок) базы данных для каждой строки.
- Закрыть объекты cursor и connection.
- Перехватить любые SQL-исключения, которые могут произойти в процессе.
Заключение
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.
Онлайн курс по Linux
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «Administrator Linux. Professional» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Что даст вам этот курс:
- Знание архитектуры Linux.
- Освоение современных методов и инструментов анализа и обработки данных.
- Умение подбирать конфигурацию под необходимые задачи, управлять процессами и обеспечивать безопасность системы.
- Владение основными рабочими инструментами системного администратора.
- Понимание особенностей развертывания, настройки и обслуживания сетей, построенных на базе Linux.
- Способность быстро решать возникающие проблемы и обеспечивать стабильную и бесперебойную работу системы.
Проверьте себя на вступительном тесте и смотрите подробнее программу по .





