Перед началом работы[]
Выявление фрагментации
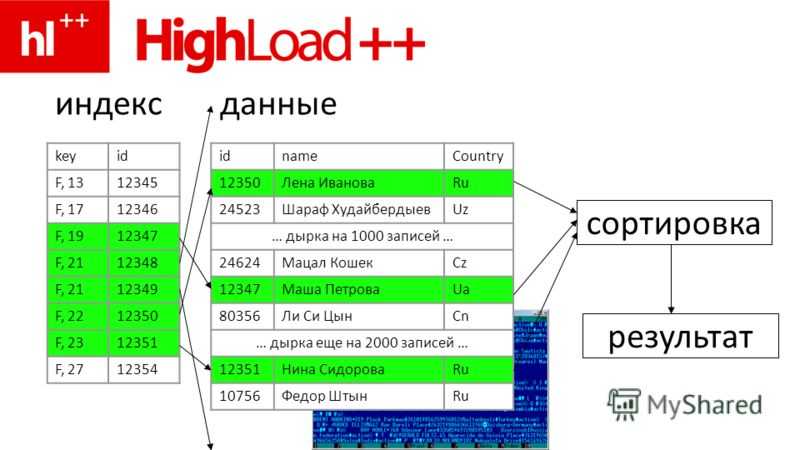
Системная функция sys.dm_db_index_physical_stats позволяет выявить фрагментацию конкретного индекса, всех индексов в таблице или индексированном представлении, всех индексов в базе данных или всех индексов во всех базах данных. Для секционированных индексов sys.dm_db_index_physical_stats также предоставляет сведения о фрагментации каждой секции.
Результирующий набор, возвращаемый функцией sys.dm_db_index_physical_stats, включает следующие столбцы:
|
Столбец |
Описание |
|---|---|
| avg_fragmentation_in_percent | Процентная доля логической фрагментации (неупорядоченные страницы в индексе). |
| fragment_count | Число фрагментов (физически последовательные конечные страницы) в индексе. |
| avg_fragment_size_in_pages | Среднее число страниц в одном фрагменте индекса. |
Выяснив степень фрагментации, используйте нижеследующую таблицу для определения наиболее подходящего метода устранения фрагментации.
|
Корректирующая инструкция |
|
|---|---|
| > 5 % и <= 30 % | ALTER INDEX REORGANIZE |
| > 30% | ALTER INDEX REBUILD WITH (ONLINE = ON)* |
Реорганизация индекса всегда выполняется в режиме в сети. Чтобы добиться доступности, подобной варианту с реорганизацией, следует перестраивать индексы в режиме в сети.
Однако фактические значения могут различаться в каждом конкретном случае. Важно определить наилучшее пороговое значение для используемой среды экспериментальным путем.При очень низких уровнях фрагментации (менее 5 %) эти команды использоваться не должны, так как выгода от дефрагментации столь низкого уровня почти всегда в достаточной степени компенсируется за счет реорганизации или перестроения индекса.
| Примечание |
|---|
| Страницы индексов малого размера хранятся в смешанных экстентах. Смешанные экстенты могут совместно использоваться восемью объектами, поэтому фрагментация в небольшом индексе может не сократиться после реорганизации или перестроения индекса. |
Ограничения
- На этапе логического перестроения существующие единицы распределения, используемые индексом, помечаются для освобождения, строки данных копируются и сортируются, а затем перемещаются в новые единицы распределения, созданные для хранения перестроенного индекса. На этапе физического перестроения единицы распределения, ранее помеченные для освобождения, физически удаляются посредством выполняемых в режиме в сети коротких транзакций, и многочисленные блокировки для этого не требуются.
- Параметры индекса не могут быть указаны при реорганизации индекса.
Разрешения
Пользователь должен быть членом предопределенной роли сервера sysadmin или предопределенных ролей базы данных db_ddladmin и db_owner.
Большинство методов поддерживают «thisArg»
Почти все методы массива, которые вызывают функции – такие как , , , за исключением метода , принимают необязательный параметр .
Этот параметр не объяснялся выше, так как очень редко используется, но для наиболее полного понимания темы мы обязаны его рассмотреть.
Вот полный синтаксис этих методов:
Значение параметра становится для .
Например, вот тут мы используем метод объекта как фильтр, и передаёт ему контекст:
Если бы мы в примере выше использовали просто , то вызов был бы в режиме отдельной функции, с . Это тут же привело бы к ошибке.
Вызов можно заменить на , который делает то же самое. Последняя запись используется даже чаще, так как функция-стрелка более наглядна.
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
- SSMS (MSSQL Management Studio);
- специальный язык Transact-SQL (T-SQL, поддерживающий Paging Queries).
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать соответствующую таблицу.
- Остановившись на пункте «Индексы» кликнуть мышкой.
- Выбрать «Создать индекс» и соответствующий тип (выбираем «Кластеризованный»).
- В новом окне появится форма «Новый индекс». Здесь потребуется вписать наименование нового создаваемого индекса (в рамках одной таблицы требуется, чтобы оно было уникальным). Поставить галочку, что он уникальный.
- Выбрать столбец, который будет являться ключом индекса. Он ляжет в основу создаваемого Clustered index. Провести сортировку строк табличных данных кнопкой «Добавить».
- После ввода всех необходимых параметров кликнуть «ОК».
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать требуемую таблицу и щелкнуть мышкой по пункту «Индексы».
- Выбрать «Создать индекс», а затем «Некластеризованный» (не ставить галочку на уникальности).
- В открывшейся форме «Новый индекс» вписать наименование нового индекса, добавить один или несколько ключевых столбцов, воспользовавшись кнопкой «Добавить».
- Перейти во вкладку «Включено столбцы». Добавить все столбцы, которые должны быть включены в индекс, воспользовавшись кнопкой «Добавить».
- Когда введены все нужные параметры кликнуть «ОК».
Все готово!
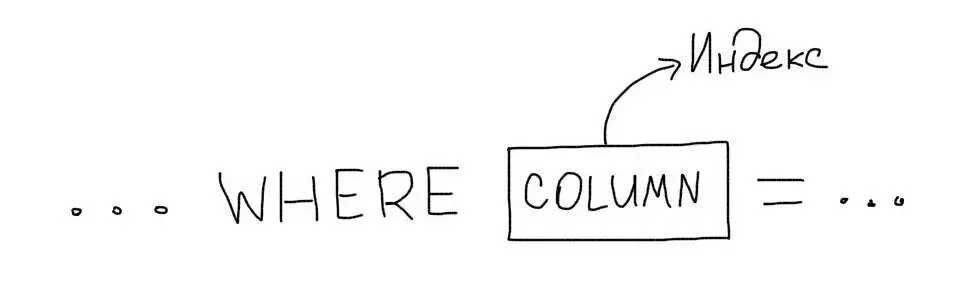
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Базы данных
Как сказано выше, производительность системы напрямую зависит от индексов. При поступлении запроса они могут увеличивать ее, обеспечивая быстрый поиск данных либо снижать, т.к. при каждой операции с данными будут изменяться и они, дабы отражать действия, производимые над данными







И не важно, что происходит с ними – добавление, удаление или обновление
Потому, при разработке плана стратегии по индексированию, необходимо придерживаться советов специалистов:
- Если предполагается частое обновление данных в таблице, то для нее нужно применять минимум индексов.
- Для таблицы со значительным количеством данных, которые предположительно будут редко изменяться, можно использовать то число индексов, которое улучшит производительность запросов. Но для таблиц небольшого объема не всегда целесообразно вообще их использовать. Такой поиск может выполняться дольше, чем обычное сканирование таблицы.
- Для Clustered indexes используйте самые короткие поля, которые только допустимы. Лучше всего их применять на столбцах с уникальными значениями и в которых не допускается использование NULL. По этой причине чаще всего PRIMARY KEY выступает в роли Clustered index.
- Производительность индекса напрямую зависит от того, насколько уникальны значения в столбце. Она снижается с увеличением дублей если в столбце и растет с уменьшением. Потому, при каждой возможности следует использовать уникальный индекс.
- Если используется составной индекс, то в нем нужно учитывать порядок столбцов. Первыми идут те, в которых в выражениях используется WHERE. За ними – столбцы с наивысшими показателями уникальных значений. Остальные выстраиваются по мере понижения этого показателя.
- Допускается использование индекса на вычисляемых столбцах таблицы, но лишь при условии соблюдения определенных требований (для вычисления значений такого столбца могут использоваться только детерминистические выражения, т.е. результат для определенного набора входящих параметров всегда должен быть одинаковым).
Что такое индексы в sql server
Разберемся в понятии индексов (indexes) – это особые таблицы, используемые поисковыми системами для поиска данных. Их активное использование играет важнейшую роль в повышении производительности sql серверов.
Словно указатель в грамотно составленной книге, индекс помогает быстро получить доступ к строкам требуемых данных в таблице, соответствующих запросу. Таким образом, их использование позволяет ускорить выполнение требуемого запроса.
К примеру, для получения всех страниц в книге, касающихся выбранной тематики, сначала нужно обратиться к перечню тем, а затем выбрать нужные страницы. Для этого следует создать индекс по выбранной теме. На ее основе и будут выбираться ссылки на страницы книги по затронутой теме. Используя значения, заданные первичным ключом, sql server найдет нужный индекс и с его помощью быстро выберет все строки с необходимыми данными. Если не использовать индекс, то для поиска информации будет произведено сканирование каждой строки таблицы. Это значительно понизит производительность и увеличит время поиска.
Благодаря индексу процесс поиска данных сокращается за счет их упорядочивания как физического, так и логического. Таким образом, он выглядит как набор ссылок на данные, которые упорядочены по выбранному столбцу таблицы. Такой столбец называется индексированным. Индексы находятся в таблице и по сути выступают полезными внутренними механизмами системы sql-сервера, которые помогают сделать доступ к данным наиболее оптимальным.
Создать стандартный индекс можно на всех столбцах данных, кроме:
- столбцов, которые используются для хранения данных объектов, имеющих большие размеры, (LOB): TEXT, IMAGE, VARCHAR (MAX);
- представленных в XML. Для работы с данными, представлены в таком формате используются xml-index, которые отличаются от стандартных. О них рассказано ниже.
Запросы к базе данных
При проектировании вторым важным пунктом является понимание и учет того, какие выполняются запросы к базе данных. Необходимо учитывать частоту изменения данных, а также требуется соблюдение определенных принципов:
- Предпочтительнее, чтобы один запрос содержал наибольшее число строк, нежели разбивать их на соответствующее число отдельных запросов.
- На столбцах, используемых в запросах с WHERE чаще всего, предпочтительнее создавать Nonclustered index в качестве условия поиска и соединения в JOIN.
- Следует воспользоваться возможностями индексирования столбцов, используемых в поисковых запросах на соответствие конкретным значениям.
Как создать строку из массива
Могут быть ситуации, когда вы просто хотите создать строку, объединив элементы массива. Для этого вы можете использовать метод join(). Этот метод принимает необязательный параметр, который является строкой-разделителем, которая добавляется между каждым элементом. Если вы опустите разделитель, то JavaScript будет использовать запятую (,) по умолчанию. В следующем примере показано, как это работает:
var colors = ;
document.write(colors.join()); // Результат: Red,Green,Blue
document.write(colors.join("")); // Результат: RedGreenBlue
document.write(colors.join("-")); // Результат: Red-Green-Blue
document.write(colors.join(", ")); // Результат: Red, Green, Blue
Вы также можете преобразовать массив в строку через запятую, используя toString(). Этот метод не принимает параметр разделителя, как это делает join(). Пример работы метода toString():
var colors = ; document.write(colors.toString()); // Результат: Red,Green,Blue
Объект как ассоциативный массив
В качестве ассоциативного массива можно использовать обычный объект.
Создание пустого ассоциативного массива через объект:
Заполнение ассоциативный массив значениями на этапе его создания:
Добавление нового элемента (пары «ключ-значение»):
Добавление нового элемента будет выполняться только в том случае, если данного ключа в нём нет. Если данный ключ уже существует, то указанное значение просто изменит существующее.
В качестве значения можно использовать не только примитивные типы данных, но и ссылочные.
В JavaScript для обращения к ключу можно использовать не только квадратные скобки, но и выполнять это через точку. Но это доступно только для ключей, имена которых отвечают правилам именования переменных.
Получение значения ключа:
Получить количество ключей (длину) можно так:
Удаление ключа выполняется с помощью оператора :
Выполнить проверку (наличия) ключа можно так:
Перебор ключей с помощью цикла :
Преобразовать объект, используем в качестве ассоциативного массива, в JSON и обратно можно так:
Внутреннее устройство массива
Массив – это особый подвид объектов. Квадратные скобки, используемые для того, чтобы получить доступ к свойству – это по сути обычный синтаксис доступа по ключу, как , где в роли у нас , а в качестве ключа – числовой индекс.
Массивы расширяют объекты, так как предусматривают специальные методы для работы с упорядоченными коллекциями данных, а также свойство . Но в основе всё равно лежит объект.
Следует помнить, что в JavaScript существует 8 основных типов данных. Массив является объектом и, следовательно, ведёт себя как объект.
…Но то, что действительно делает массивы особенными – это их внутреннее представление. Движок JavaScript старается хранить элементы массива в непрерывной области памяти, один за другим, так, как это показано на иллюстрациях к этой главе. Существуют и другие способы оптимизации, благодаря которым массивы работают очень быстро.
Но все они утратят эффективность, если мы перестанем работать с массивом как с «упорядоченной коллекцией данных» и начнём использовать его как обычный объект.
Например, технически мы можем сделать следующее:
Это возможно, потому что в основе массива лежит объект. Мы можем присвоить ему любые свойства.
Но движок поймёт, что мы работаем с массивом, как с обычным объектом. Способы оптимизации, используемые для массивов, в этом случае не подходят, поэтому они будут отключены и никакой выгоды не принесут.




Варианты неправильного применения массива:
- Добавление нечислового свойства, например: .
- Создание «дыр», например: добавление , затем (между ними ничего нет).
- Заполнение массива в обратном порядке, например: , и т.д.
Массив следует считать особой структурой, позволяющей работать с упорядоченными данными. Для этого массивы предоставляют специальные методы. Массивы тщательно настроены в движках JavaScript для работы с однотипными упорядоченными данными, поэтому, пожалуйста, используйте их именно в таких случаях. Если вам нужны произвольные ключи, вполне возможно, лучше подойдёт обычный объект .
Вступление
Благодаря индексам мы можем делать более эффективные запросы в базу. Без индексирования MongoDB при запросе должен выполнить сканирование всей коллекции, то есть обойти каждый документ, чтобы выбрать документ, который подходит под ваш запрос. Если для запроса существует индекс, то он может ограничить количество документов, которое должен обойти MongoDB. Индексы — это специальный тип данных, которые хранят небольшую часть набора данных коллекций в форме удобной для обхода. Индекс хранит значение определенного поля или набора полей, упорядоченных по значению поля. Упорядочение записей индекса поддерживает эффективное сопоставление и запросы на основе диапазоне. Также индексы могут возвращать отсортированный результат, используя порядок в индексе.
Фундаментально индексы в MongoDB аналогичны индексам в других базах данных. MongoDB определяет индексы на уровне коллекций и поддерживает индексы в любом поле документов в коллекции MongoDB.
Эффективность индексов
Хотя индексы и позволяют повысить поиск, но с каждым индексом связаны дополнительные накладные расходы. Каждый раз когда в коллекцию добавляется документ, его также нужно добавить во все индексы связанные с этой коллекцией. Получается если над коллекцией построено 10 индексов, то при добавлении документа, нужно изменить 10 разных структур данных. И это относится к любой операции записи, добавления, удаления, обновления полей документа, которые проиндексированы. Для приложений ориентированных на чтение, затраты на индексы почти всегда оправданы. Следите за тем, чтобы индексы которые есть использовались, а если не используются то удаляйте их.
Чтобы удалить индекс пользуйтесь командой:
db.collection.dropIndex("catIdx");
Где это название индекса. Чтобы посмотреть все индексы которые относятся к коллекции, нужно воспользоваться командой:
db.collection.getIndexes();// В ответе мы получим следующее
Также мы можем удалить все индексы сразу:
MySQL Advanced —- Оптимизация индекса (1): Анализ индекса
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>style=»clear:both;»>
Во-первых, одна таблица
1, структура таблицы
2. Анализ случая
Информация Информация Отображение таблицы: Показать индекс от имени
Исследователь: все еще использует сортировку файлов, поскольку запросы диапазона комментариев могут привести к сбою индекса
После того, как состояние где изменяется на комментарии = 1, результаты анализа следующие: он эквивалентен двум столбам в данном индексе комбинации и может быть получен с помощью индекса.
Информация Информация Отображение таблицы: Показать индекс от имени
Результат анализа: сортировка не используется в этом дополнительном
Во-вторых, две таблицы
1, структура таблицы
2. Анализ случая (Неистемный индекс)
2.1 Левое соединение
Решение: добавьте индекс, ноВопрос в том, какая таблица индекса построена? ? Давай попробуем.
в заключении
Вывод: индекс построен на карте левой таблицы. Тип, используемый запросом: индекс, который гораздо больше, чем Ref; и эта ситуация в рядах 20, 20, более эффективна, чем предыдущие строки 1, 20 Эффективность
2.2 Правильное соединение:
Нет индекса
Добавьте индекс в левую таблицу Class.Card Поле (Индекс правого подключения добавляется в левую таблицу, указатель левого соединения добавляется вправо)
Три, три листа
1, структура таблицы
Добавьте новую таблицу на основе двух таблиц
2. Анализ случая
Три таблицы оставили
Построить индекс
ринализатор
Интеллектуальная рекомендация
19.03.21 Я загрузил комплексные обучающие видеоуроки Photoshop CC 2015 и обучающие видеоуроки по новым функциям PS CC 2015. Я просмотрел несколько видео, но мне кажется, что они в основном объясняют н…
…
проверка данных весеннего mvc Два способа проверки данных Spring MVC: 1.JSR303 2.Hibernate Validator Второй метод является дополнением к первому методу Шаги для проверки данных с использованием Hibern…
Существует два способа вызова между сервисами Springcloud: RestTemplate и Feign. Здесь мы представляем сервисы вызова RestTemplate. 1. Что такое RestTemplate RestTemplate — это структура веб-запросов …
1. Понимать предварительный, средний, последующий порядок и иерархическую последовательность бинарных деревьев; Свяжите язык C со структурой данных двоичного дерева; Освойте с…
Вам также может понравиться
Последнее обучение, как использовать Kaldi, чтобы проснуться без использования WSTF, поэтому вам нужно глубоко пойти в Kaldi для обучения. Временное состояние обучения. Три изображения представляют со…
Во время простоя некоторые веб-страницы, которые мы создали, не были завершены, но не хотят, чтобы другие видели, вы можете создать простой эффект шифрования страницы на странице этой веб-страницы, ан…
Расширенные статьи серии Zookeeper 1. NIO, ZAB соглашение, 2PC представления концепции 2. Лидер выборов 3. Рукописный распределенный замок, центр настройки ==================================== 1. NIO,…
Посмотрите на конечный эффект первым DemoPreview.gif SETP1 эффект капли воды Первая реакция на эффект капли воды — нарисовать замкнутую кривую. С помощью события MotionEvent измените радиус во время п…
…
Удаление узлов
Удалить узел из DOM можно в JavaScript с помощью методов (считается устаревшим) и .
removeChild
Синтаксис :
parent.removeChild(node)
Для удаления узла необходимо вызвать метод у родительского элемента и передать ему в качестве аргумента его сам ().
Например, удалим второй в :
<ol id="devices">
<li>Смартфон</li>
<li>Планшет</li>
<li>Ноутбук</li>
</ol>
<script>
const $liSecond = document.querySelector('#devices li:nth-child(2)');
// вызываем у родительского элемента метод removeChild и передаём ему в качестве аргумента узел который нужно удалить
$liSecond.parentNode.removeChild($liSecond);
</script>
В качестве результата метод возвращает удалённый узел.
Например, удалим элемент, а затем вставим его в другое место:
<div id="message-1">
<p>...</p>
</div>
<div id="message-2"></div>
<script>
const $p = document.querySelector('#message-1>p');
// удалим элемент p
const result = $p.parentElement.removeChild($p);
// вставим удалённый элемент p в #message-2
document.querySelector('#message-2').append(result);
</script>
remove
Ещё один способ удалить узел – это использовать метод .
Синтаксис :
node.remove()
Например, удалим элемент при нажатии на него:
<button>Кнопка</button>
<script>
document.querySelector('button').onclick = function() {
// удалим элемент
this.remove();
}
</script>
Когда мы вставляем элементы, они удаляются со старых мест.
Вывод массива объектов с использованием цикла for … in
Предположим, что нам нужно вывести ряд html-элементов, например, абзацев, с различным css-форматированием, причем набор правил и текст мы получаем в виде массива объектов. Чаще всего каждый объект в таком массиве имеет набор полей, которые идут в строго определенном порядке, но, предположим, наш массив формировал неопытный студент вручную, поэтому в объектах поля следуют по-разному.




Если посмотреть на названия свойств (полей), то можно заметить, что только свойство text не относится к css-свойствам. Все же остальные и по названию свойства, и по значению относятся к правилам css. Поэтому проще всего собрать css-свойства в одну строку, которая в приведенном ниже скрипте является переменной , а затем добавить ее в качестве значения атрибута style для абзаца. С этим нам поможет справится замечательный цикл for…in. Есть только одно но — нам нельзя в css-свойства записать свойство text объекта, поэтому напишем для этой ситуации проверку с помощью и пропустим добавление текста к с помощью оператора циклов .
Вывод отформатированных абзацев
JavaScript
const data = ;
data.forEach(item =>{
let styleStr = »;
for(key in item){
if(key == ‘text’) continue;
styleStr+= key+’:’+item+’;’;
}
//document.write(`<p style=»color: ${item.color};font-weight: ${item}; padding: ${item}; border: ${item.border} «>${item.text}</p>`);
document.write(`<p style=»${styleStr}»>${item.text}</p>`);
})
|
1 24 |
constdata= { color’green’, ‘font-weight»bold’, padding’10px’, border’4px dashed #50e690′, text’Lorem ipsum dolor sit amet, consectetur adipisicing elit. Amet, libero. Dolor porro, ipsum reprehenderit. ‘ }, { color’#1c3dc7′, text’Ducimus temporibus laboriosam tempora dolorem laborum eligendi cumque adipisci in, vel, quaerat repellat necessitatibus explicabo.’, ‘font-weight»normal’, padding’15px’, border’3px double #57abff’, }, ; data.forEach(item=>{ let styleStr=»; for(key initem){ if(key==’text’)continue; styleStr+=key+’:’+itemkey+’;’; } document.write(`<pstyle=»${styleStr}»>${item.text}<p>`); }) |
Обратите внимание, насколько длиннее строка 23, в которой мы записали все свойства без использования цикла и подумайте, насколько больше шансов допустить в ней ошибку по сравнению с использованием цикла. Результат работы скрипта:
Результат работы скрипта: