Хвостовая рекурсия — как не надо делать
Хвостовая рекурсия — частный случай рекурсии, при котором любой рекурсивный вызов является последней операцией перед возвратом из функции.
Вот пример обратного отсчета, написанного с использованием хвостовой рекурсии:
Любое вычисление, которое может быть выполнено с использованием итерации, также может быть выполнено с использованием рекурсии. Вот версия find_max, написанная с использованием хвостовой рекурсии:
Хвостовую рекурсию лучше не использовать, поскольку компилятор Python не обрабатывает оптимизацию для хвостовых рекурсивных вызовов. В таких случаях рекурсивное решение использует больше системных ресурсов, чем итеративное.
Продолжение прохождения стиля с исключениями
Вот более общая функция; он способен обрабатывать все хвостовые рекурсивные функции, включая те, которые возвращают другие функции. Рекурсивные вызовы распознаются из других возвращаемых значений с помощью исключений. Это решение медленнее, чем предыдущее; более быстрый код, вероятно, можно было бы написать, используя некоторые специальные значения в качестве «флагов», обнаруживаемых в основном цикле, но мне не нравится идея использования специальных значений или внутренних ключевых слов. Существует некоторая забавная интерпретация использования исключений: если Python не любит хвостовые рекурсивные вызовы, то должно возникать исключение, когда происходит хвостовой рекурсивный вызов, и питонский способ будет заключаться в том, чтобы перехватить исключение, чтобы найти некоторые чистые решение, которое на самом деле то, что происходит здесь …
Теперь все функции могут быть использованы. В следующем примере оценивается как Тождественная функция для любого положительного значения n:
Конечно, можно утверждать, что исключения не предназначены для преднамеренного использования. перенаправление интерпретатора (как своего рода выражение или, скорее, своего рода продолжение прохождения стиля), который я должен признать. Но опять же Я нахожу забавной идею использования с одной строкой, являющейся выражением : мы пытаемся вернуть что-то (нормальное поведение), но мы не можем сделать это из-за рекурсивного вызова (исключение).
Первоначальный ответ (2013-08-29).
Я написал очень маленький плагин для обработки хвостовой рекурсии. Вы можете найти его с моими объяснениями там:
Он может встроить лямбда-функцию, написанную в стиле хвостовой рекурсии, в другую функцию, которая будет оценивать ее как цикл.
Самая интересная особенность этой маленькой функции, по моему скромному мнению, заключается в том, что эта функция основана не на грязном программировании, а на простом лямбда-исчислении: поведение функции изменяется на другое при вставке в другую лямбда-функцию, которая выглядит очень похоже на Y-комбинатор.
С уважением.
продолжение прохождения стиля с исключениями
вот более общая функция; она способна обрабатывать все хвостовые рекурсивные функции,
в том числе возвращающих другие функции. Рекурсивные вызовы распознаются из
другие возвращаемые значения с помощью исключений. Это решение медленнее, чем
предыдущий; более быстрый код, вероятно, может быть написана с помощью специальных
значения как «флаги» обнаруживаются в основном цикле, но мне не нравится идея
с помощью специальные значения или внутренние ключевые слова. Есть какая-то забавная интерпретация
об использовании исключений: если Python не любит хвостовые рекурсивные вызовы, исключение
должен быть поднят, когда происходит хвост-рекурсивный вызов, и питонический способ будет
чтобы поймать исключение, чтобы найти какое-то чистое решение, которое на самом деле
происходить здесь…
теперь можно использовать все функции. В следующем примере, оценивается в
функция идентификации для любого положительного значения n:
конечно, можно утверждать, что исключения не предназначены для использования намеренно
перенаправление интерпретатора (как своего рода заявление или, скорее, своего рода
продолжение прохождения стиля), что я должен признать. Но, опять же,
Я нахожу забавной идею использования С одной строкой, являющейся заявление: мы пытаемся вернуться
что-то (нормальное поведение), но мы не можем этого сделать из-за рекурсивного вызова (исключение.)
первоначальный ответ (2013-08-29).
я написал очень маленький плагин для обработки хвостовая рекурсия. Вы можете найти его с моими объяснениями там:
он может встроить лямбда-функцию, написанную в стиле хвостовой рекурсии, в другую функцию, которая будет оценивать ее как цикл.
самая интересная особенность в этом небольшом функция, по моему скромному мнению, заключается в том, что функция не полагается на какой-то грязный программный хак, а на простое лямбда-исчисление: поведение функции изменяется на другое при вставке в другую лямбда-функцию, которая очень похожа на Y-комбинатор.
С уважением.
Рекурсивные операции с пересборкой дерева
При рекурсивной пересборке дерева мы не нуждаемся в указателе на родителя. Родитель «при нас», это текущий элемент, так что мы можем контролировать дельнейшие действия.
Определение узла и функции, которая возвращает новый узел.
typedef int T;
#define CMP_EQ(a, b) ((a) == (b))
#define CMP_LT(a, b) ((a) < (b))
#define CMP_GT(a, b) ((a) > (b))
typedef struct Node {
T data;
struct Node *left;
struct Node *right;
} Node;
Node *getNode(T value) {
Node* tmp = (Node*) malloc(sizeof(Node));
tmp->left = tmp->right = NULL;
tmp->data = value;
return tmp;
}
Функция вставки нового элемента возвращает новое дерево. Это дерево построено из старого, в которое добавлен новый узел. Причём процесс пересборки в тоже время производит поиск места, в которое нужно произвести вставку.
Если функция получает NULL в качестве аргумента, то она возвращает новый узел. Если узел больше значения, которое мы хотим вставить, то левой ветви присваиваем значение, которое возвращает наша же функция insert, то есть она «дособирает» левую ветвь. Аналогично, если значение узла меньше, то мы «дособираем» правую ветвь и возвращаем узел.
Node* insert(Node* root, T value) {
if (root == NULL) {
return getNode(value);
}
if (CMP_GT(root->data, value)) {
root->left = insert(root->left, value);
return root;
} else if (CMP_LT(root->data, value)) {
root->right = insert(root->right, value);
return root;
} else {
exit(3);
}
}
Удаление элемента состоит из пересборки дерева, во время которого мы пропускаем добавление удаляемого узла. При этом сам процесс является ещё и нахождением нужного нам узла (того, который мы хотим удалить).
Когда мы доходим до конца дерева, то логично закончить работу и вернуть NULL.
if (root == NULL) {
return NULL;
}
Теперь проверяем, если текущий узел не равен удаляемому значению, то продолжаем сборку левой и правой ветвей.
if (CMP_GT(root->data, value)) {
root->left = deleteNode(root->left, value);
return root;
} else if (CMP_LT(root->data, value)) {
root->right = deleteNode(root->right, value);
return root;
} else {
//Магия здесь
}
}
Если же мы наткнулись на узел, который хотим удалить, то есть несколько ситуаций.
if (root->left && root->right) {
//Заменить значение текущего узла на максимум левой подветви
//Удалить максимум левой подветви
//Вернуть собранное значение
} else if (root->left) {
//Удалить узел и вернуть его левую подветвь
} else if (root->right) {
//Удалить узел и вернуть его правую подветвь
} else {
//Удалить узел и вернуть NULL
}
Полный код
Node* deleteNode(Node* root, T value) {
if (root == NULL) {
return NULL;
}
if (CMP_GT(root->data, value)) {
root->left = deleteNode(root->left, value);
return root;
} else if (CMP_LT(root->data, value)) {
root->right = deleteNode(root->right, value);
return root;
} else {
if (root->left && root->right) {
Node* locMax = findMaxNode(root->left);
root->data = locMax->data;
root->left = deleteNode(root->left, locMax->data);
return root;
} else if (root->left) {
Node *tmp = root->left;
free(root);
return tmp;
} else if (root->right) {
Node *tmp = root->right;
free(root);
return tmp;
} else {
free(root);
return NULL;
}
}
}
Функции нахождения узла, максимум и минимума не изменятся.
Q&A
Всё ещё не понятно? – пиши вопросы на ящик
Рекурсивные функции
Рекурсивная функция — это та, которая вызывает сама себя.
В качестве простейшего примера рассмотрите следующий код:
Копировать
Вызывая рекурсивную функцию здесь и передавая ей целое число, вы получаете факториал этого числа (n!).
Вкратце о факториалах
Факториал числа — это число, умноженное на каждое предыдущее число вплоть до 1.
Вывести факториал числа можно с помощью функции:
Копировать
Эта функция выведет: «Факториал 3 это 6». Еще раз рассмотрим эту рекурсивную функцию:
По аналогии с обычной функцией имя рекурсивной указывается после , а в скобках обозначается параметр :
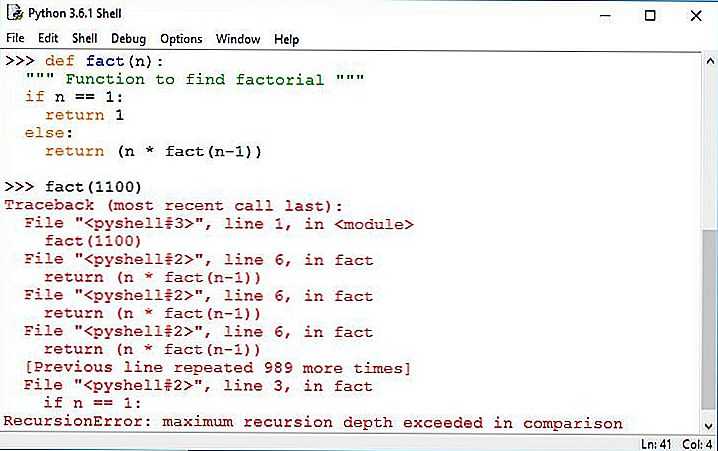
Благодаря условной конструкции переменная вернется только в том случае, если ее значение будет равно 1. Это еще называют условием завершения. Рекурсия останавливается в момент удовлетворения условиям.
В коде выше выделен фрагмент самой рекурсии. В блоке условной конструкции возвращается произведение и значения этой же функции с параметром .
Это и есть рекурсия. В нашем примере это так сработало:
Детали работы рекурсивной функции
Чтобы еще лучше понять, как это работает, разобьем на этапы процесс выполнения функции с параметром 3.
Для этого ниже представим каждый экземпляр с реальными числами. Это поможет «отследить», что происходит при вызове одной функции со значением 3 в качестве аргумента:
Копировать
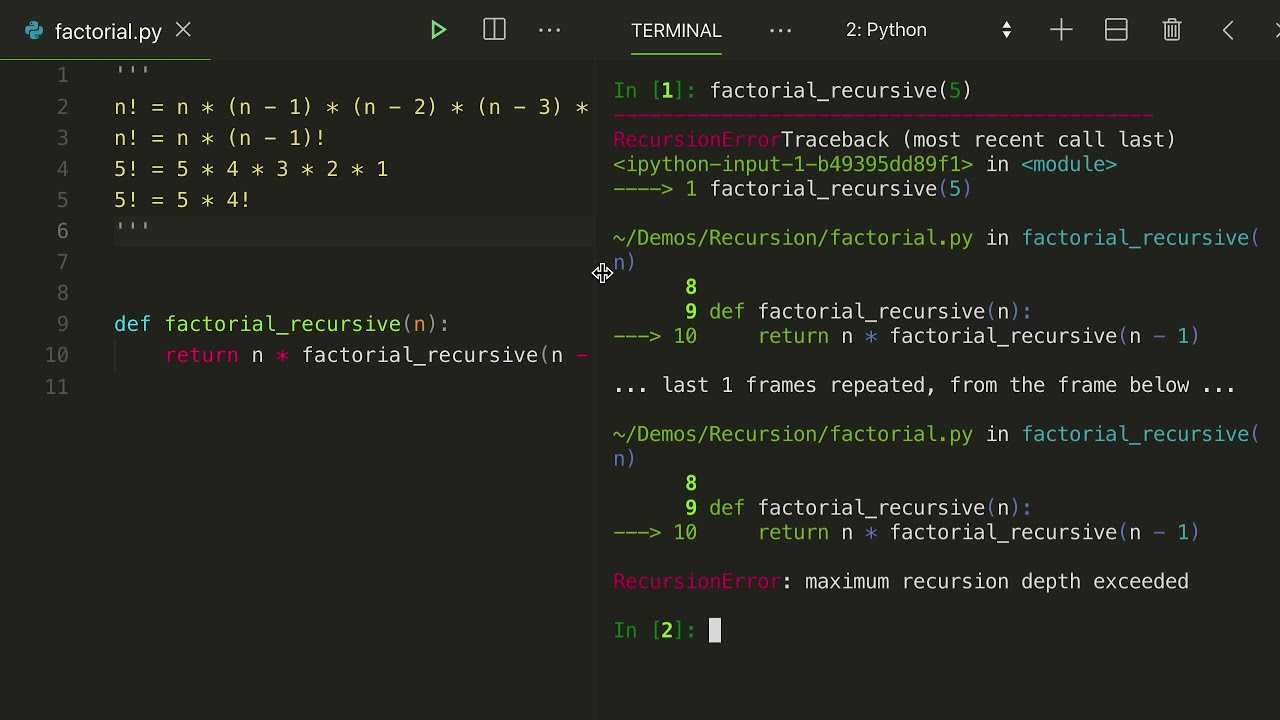
Рекурсивная функция не знает ответа для выражения , поэтому она добавляет в стек еще один вызов.
4 ответа
Лучший ответ
Похоже, ваш реальный вопрос: «Почему глубина рекурсии короче при использовании потоков»? Я постараюсь ответить на этот вопрос.
Во-первых, фон. Каждый уровень рекурсии хранится в области памяти, известной как стек. К сожалению, система должна заранее выделить место в стеке и не знает заранее, сколько места в стеке может понадобиться вашей программе. Вот почему слишком большая рекурсия вызывает ошибку «максимальной глубины рекурсии»: ваша программа израсходовала все это пространство стека.
Каждый поток нуждается в своем собственном стеке для хранения списка функций, которые в данный момент выполняются в этом потоке. В однопоточной программе система может предоставить большой кусок памяти в стек для этого одного потока. В многопоточной программе система должна быть немного более консервативной, и она дает только небольшой стек каждому потоку. В противном случае программа со многими потоками может быстро использовать всю системную память только с использованием стека (большая часть которого не будет использоваться).
Все это выполняется операционной системой и / или библиотекой C, поверх которой работает Python (точнее, CPython). Python изо всех сил пытается помешать вам использовать весь стек C, потому что это вызовет серьезный сбой, а не просто исключение. Вы можете указать Python, как вести себя с функцией , но это не меняет фактический объем доступного стекового пространства.
В unix-системе с оболочкой bash вы можете изменить размер стека с помощью команды . Введите в командной строке bash для получения дополнительной информации.
7
Daniel Stutzbach
26 Апр 2010 в 04:36
Вот итерационный код для быстрой сортировки
Anantha Krishnan
14 Фев 2012 в 08:36
Почему вы пишете свою собственную процедуру быстрой сортировки? Это домашнее задание?
Если нет, я бы предложил использовать встроенные механизмы сортировки; они довольно хороши для подавляющего большинства случаев и не страдают от проблемы глубины рекурсии. Если вы смотрите на очень большие наборы данных, я бы посоветовал взглянуть на различные контейнеры и алгоритмы, доступные от scipy и numpy.






1
Jeffrey Blake
16 Сен 2011 в 15:37
Проблема, с которой вы сталкиваетесь, заключается в том, что рекурсивная функция использует память, и при большом количестве элементов и, следовательно, большом количестве рекурсий у вас не хватает памяти. Это объясняет, почему повышение предела рекурсии приводит к сбою вашей программы — вы запрашиваете больше памяти, чем имеете.
Если вы действительно хотите реализовать быструю сортировку для большого количества элементов, прочитайте статья в Википедии об использовании памяти, особенно с использованием быстрой сортировки. В противном случае, как предложил Натан, в Python уже есть встроенная функция . Если это не домашняя работа или любопытство, я очень рекомендую использовать это.
Mike Graham
26 Апр 2010 в 04:41
5 ответов
Лучший ответ
Да. Gunicorn может служить вашей статики тоже.
Если ничего не помогает, пусть django сделает это за вас (хотя, сделайте это в крайнем случае перед разочарованием). Чтобы сделать это, вам просто нужно добавить еще один шаблон URL, как показано ниже:
Хотя django обслуживает статические файлы лучше, чем не обслуживает их вообще, стоит делегировать это серверам, оптимизированным для того же типа, что и nginx.
Я бы порекомендовал запустить nginx на другом порту и изменить настройку django STATIC_URL для включения порта (после того, как вы подтвердите, что порт обслуживает статические данные). — Сделать это так же просто, как сделать симлинк на MEDIA_ROOT из папки nginx.
И если вы все равно используете nginx, также хорошо проксировать все запросы, использующие его, и передавать запрос django только оружейному кукурузу. Все это требует добавления файла, который сообщает nginx соответственно.
Я вижу, как это может сбить с толку тех, кто начинает и пытается сделать все (запросы прокси, обслуживать статические, настраивать nginx) одновременно. Попробуйте это один за другим. Получите СМИ от Gunicorn; Затем подайте его из nginx, а затем, в конце концов, получите и прокси nginx. Но сделайте это все до того, как ваше приложение будет запущено в производство. Этот подход, я видел, увеличивает понимание и уменьшает разочарование.
11
Lakshman Prasad
2 Июн 2012 в 19:25
Я рекомендую использовать Nginx по нескольким причинам:
- Страница обслуживания или внутренней ошибки сервера может быть легко реализована, когда Gunicorn не работает. Это означает, что у вас всегда будет что ответить, если ваш сервер приложений не работает.
- Как предполагает Gunicorn doc, атаки http, такие как DOS, не обнаруживаются.
- Вы можете захотеть реализовать свою собственную стратегию распределения нагрузки позже. Это станет более важным для разработки релизов по мере масштабирования вашего проекта. Лично я нашел AWS ELB немного ненадежным, и я думаю об этом.
Обновление :
Также, пожалуйста, посмотрите хорошо написанный ответ разработчика Gunicorn:
4
yasc
29 Май 2017 в 09:58
Я сделал с помощью промежуточного программного обеспечения Werkzeug. Это не красиво и не так эффективно, как при использовании сервера nginx, но делает работу:
Установите STATIC_ROOT на settings.py
Чем сказать Werkzeug обслуживать файлы из этой папки
Когда DEBUG = True, Django обслуживает файлы. Когда DEBUG = False, Werkzeug обслуживает файлы из статически собранной папки. Вам нужно запустить collectstatic на сервере, который использует DEBUG = False, чтобы это работало.
Obs: По какой-то причине Werkzeug дает 500 за не найденные файлы, а не 404. Это странно, но все еще работает. Если вы знаете, почему, пожалуйста, прокомментируйте.
2
alanjds
11 Июн 2013 в 20:14
В документации Gunicorn отмечается, что без посреднической буферизации медленных клиентов работник по умолчанию подвержен атаке типа «отказ в обслуживании»: http://gunicorn.org/ deploy.html
Это может быть не так при использовании одного из асинхронных рабочих, таких как gevent или tornado.
10
Mark Lavin
2 Июн 2012 в 13:53
Если вы уже используете веб-сервисы amazon, вы можете использовать s3-контейнеры для размещения статического контента и развернуть свое приложение на ec2 с помощью gunicorn (или чего угодно). Таким образом, вам не нужно беспокоиться о настройке собственного статического файлового сервера.
6
Andbdrew
2 Июн 2012 в 13:46
Что такое рекурсия? ↑
Слово «рекурсия» происходит от латинского слова «recurrere», что означает «бегать или спешить назад, возвращаться, возвращаться или повторяться». Вот несколько онлайн-определений рекурсии:
- Dictionary.com: акт или процесс возвращения или бегства назад
- Викисловарь: определение объекта (обычно функции) в терминах самого этого объекта.
- Свободный словарь: метод определения последовательности объектов, таких как выражение, функция или набор, где задано некоторое количество начальных объектов, и каждый последующий объект определяется в терминах предыдущих объектов.
Рекурсивное определение — это определение, в котором определенный термин появляется в самом определении. Себя-ссылочные ситуации часто возникают в реальной жизни, даже если они не сразу распознаются как таковые. Например, предположим, что вы хотите описать группу людей, из которых состоят ваши предки. Вы могли бы описать их так:
Мои предки = (Мои родители) + (Мои родители’предки)
Обратите внимание, как определяемая концепция, , проявляется в ее собственном определении. Это рекурсивное определение
В программировании рекурсия имеет очень точное значение. Это относится к методике кодирования, при которой функция вызывает сама себя.
PyPy и его особенности
Исторически PyPy имел в виду две вещи:
- Среда динамического языка для создания интерпретаторов для динамических языков;
- Реализация Python с использованием этих рамок;
Вы уже видели второе значение в действии, установив PyPy и запустив с ним небольшой скрипт. Реализация Python, которую вы использовали, была написана с использованием динамической языковой среды под названием RPython, точно так же, как CPython был написан на C, а Jython был написан на Java.
Вам не говорили, что PyPy написан на Python? Причина, по которой PyPy стал известен как интерпретатор Python, написанный на Python (а не на RPython), заключается в том, что RPython использует тот же синтаксис, что и Python.
Чтобы все прояснить, вот как создается PyPy:
- Исходный код написан на RPython.
- Инструменты RPython (translation toolchain) применяются к коду, делая его более эффективным. Они компилируют код в машинный, поэтому под Mac, Windows и Linux необходимы разные версии;
- Создается двоичный исполняемый файл. Это интерпретатор Python, который вы использовали для запуска своего небольшого скрипта.
Вам не нужно проходить все эти шаги, чтобы использовать PyPy, так как исполняемый файл уже доступен для установки.
Поскольку очень сложно использовать одно и то же слово для обозначения фреймворка и реализации, команда, стоящая за PyPy, решила отойти от этого двойного использования. Теперь PyPy относится только к реализации Python. Фреймворк называется набором инструментов перевода RPython.
Далее вы узнаете о функциях, которые в некоторых случаях делают PyPy лучше и быстрее, чем Python.
Начало работы: обратный отсчет до нуля ↑
Первый пример — это функция с именем , которая принимает положительное число в качестве аргумента и печатает числа от указанного аргумента до нуля:
>>> def countdown(n): ... print(n) ... if n == 0: ... return # Завершить рекурсию ... else: ... countdown(n - 1) # Рекурсивный вызов ... >>> countdown(5) 5 4 3 2 1 0
Обратите внимание, как соответствует парадигме рекурсивного алгоритма, описанного выше:
- Базовый случай возникает, когда равно нулю, и в этот момент рекурсия прекращается.
- В рекурсивном вызове аргумент на единицу меньше текущего значения , поэтому каждая рекурсия приближается к базовому случаю.
Показанная выше версия четко выделяет базовый случай и рекурсивный вызов, но есть более краткий способ выразить это:
def countdown(n):
print(n)
if n > 0:
countdown(n - 1)
Вот для сравнения одна из возможных нерекурсивных реализаций:
>>> def countdown(n): ... while n >= 0: ... print(n) ... n -= 1 ... >>> countdown(5) 5 4 3 2 1 0
Это тот случай, когда нерекурсивное решение, по крайней мере, так же ясно и интуитивно понятно, как рекурсивное, а, возможно, даже больше.
Проверка нашего стека
Надеемся, вы не только читали статью, но и параллельно писали этот код. Но в таком случае вы, вероятно, заметили, что при его запуске ничего не происходит.
Как уже было сказано, классы — это своего рода шаблоны объектов. Мы создали шаблон. Теперь давайте проверим его, создав объект. Вы можете это сделать или в оболочке Python, или внизу вашего файла stack.py. Для простоты назовем стек .
>>> s = Stack()
Теперь давайте протестируем наш прекрасный метод , добавив в стек несколько чисел.
>>> s.push(1) >>> s.push(2) >>> s.push(3)
Если мы выведем наш , мы получим . Отлично. Давайте теперь проверим метод .
>>> s.pop()
Если мы теперь выведем , мы получим
Обратите внимание, что удалился только последний элемент, при этом вернулось значение 3. Но что будет, если мы продолжим удалять элементы? Нам нужно увидеть, вернет ли наш метод
Для этого мы повторим ту же команду несколько раз, а затем выведем значение .
>>> s.pop() >>> s.pop() >>> print(s.pop())
Итак, вы реализовали свой первый стек на Python. Можно сказать, изучили свою первую структуру данных.


Создаем стек на Python
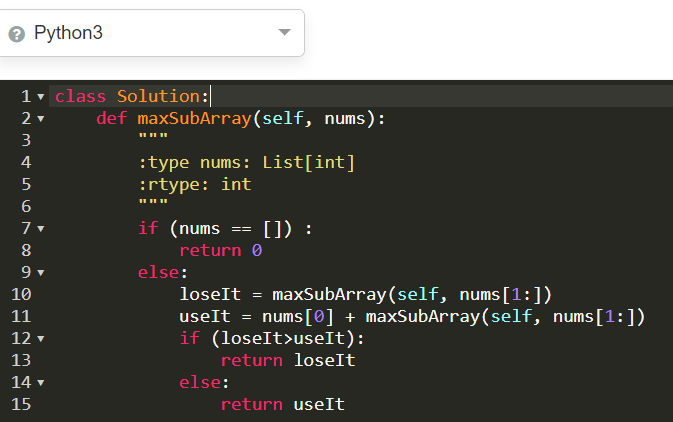
Итак, давайте рассмотрим упрощенный пример задачи, которую вам могут дать на техническом собеседовании. Советуем параллельно с чтением писать этот код в своем редакторе.
Задача начинается со слова «Реализуйте». Это намекает на то, что от вас ожидается создание класса. Если вы не привыкли еще работать с классами, можете считать их чем-то вроде шаблона объекта. При инициации нового объекта класса Stack он будет иметь все свойства и методы, которые мы определим для этого класса.
Начнем с определения класса, а затем добавим метод . Кроме того мы добавим пустые методы и . Ключевое слово нужно только для того, чтобы Python не ругался на наличие пустых методов.
class Stack:
def __init__():
pass
def pop():
pass
def push():
pass
Отлично, теперь у нас есть класс . Давайте определим метод , который будет устанавливать все свойства стека при инициализации. То есть, при рождении каждого нового стека мы будем наделять его кое-чем. Есть идеи, чем именно?
Стек по сути своей — список (в Python массивы называются списками) с особыми свойствами: вы можете добавлять или удалять только самый недавний элемент. Исходя из этого, мы представим стек как список и назовем его . Чтобы определить свойство класса, в Python используется ключевое слово . Для доступа к этому ключевому слову его нужно передать в качестве аргумента в метод.
def __init__(self):
self.stack = []
Хорошо, теперь давайте перейдем к методу . Он тоже будет принимать в качестве аргумента, чтобы мы могли иметь доступ к только что определенной переменной . Кроме того, он будет принимать — элемент, который мы хотим добавить на вершину стека.
def push(self, item):
pass
При добавлении и удалении элементов из стека его вершиной будем считать конец списка. В Python это все облегчает, поскольку мы можем использовать метод для добавления элемента в конец списка:
def push(self, item):
self.stack.append(item)
Метод будет аналогичным. В Python есть метод , удаляющий последний элемент списка. Очень удобно! Этот метод возвращает удаляемый элемент. Мы будем сохранять этот элемент в переменную , а затем возвращать переменную.
def pop(self):
removed = self.stack.pop()
return removed
Но погодите! У нас есть проблема. Что, если в стеке не останется элементов для удаления? К счастью, в условии задачи нам напомнили о такой ситуации:
Все, что нам нужно сделать, это добавить условное выражение для проверки этого крайнего случая. Для этого перед запуском мы добавим предложение , проверяющее, не пуст ли стек. Единственный тип null в Python — это , так что его мы и вернем, если стек все же пуст.
def pop(self):
if len(self.stack) == 0:
return None
removed = self.stack.pop()
return removed
Вот и все! Повторим:
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
def pop(self):
if len(self.stack) == 0:
return None
removed = self.stack.pop()
return removed
Есть еще одна вещь, на которую следует обратить внимание. Все наши методы должны иметь постоянную временную сложность —
Это означает, что их работа должна занимать одинаковое время, независимо от длины стека. Если бы нам пришлось, к примеру, перебирать список в цикле, временная сложность была бы , где — длина списка. Но нам ничего такого делать не пришлось, так что все в порядке.
Заключение
PyPy – это быстрая и эффективная альтернатива CPython. Запустив свой скрипт с его помощью, вы можете получить значительное улучшение скорости, не внося ни одного изменения в код. У него есть ограничения, и вам нужно будет протестировать программу, чтобы проанализировать целесообразность использования альтернативного интерпретатора.
В этом уроке вы узнали:
- Что такое PyPy;
- Как установить PyPy и запустить с ним свой скрипт;
- Как PyPy сравнивается с CPython с точки зрения скорости;
- Какие функции имеет PyPy и как он повышает скорость ваших программ;
- Какие ограничения PyPy могут сделать его непригодным для некоторых случаев.
Если вашему скрипту Python нужно немного увеличить скорость, попробуйте PyPy. В зависимости от сложности вашей программы, вы можете получить заметное улучшение скорости!
Заключение ↑
На этом ваше путешествие по рекурсии — технике программирования, при которой функция вызывает себя, заканчивается. Рекурсия подходит не для каждой задачи. Но некоторые проблемы программирования практически требуют этого. В таких ситуациях это отличный метод.
В этом уроке вы узнали:
- Что означает рекурсивный вызов функции
- Как дизайн функций Python поддерживает рекурсию
- Какие факторы следует учитывать при выборе решения проблемы рекурсивно или нет
- Как реализовать рекурсивную функцию в Python
Вы также увидели несколько примеров рекурсивных алгоритмов и сравнивали их с соответствующими не-рекурсивные решения.
Теперь вы должны быть в состоянии распознать, когда требуется рекурсия, и быть готовым уверенно использовать ее, когда это необходимо! Если вы хотите узнать больше о рекурсии в Python, посмотрите «Рекурсивное мышление в Python».
По мотивам Recursion in Python: An Introduction