
Операции со строками в InnoDB
В основном здесь мы извлекли только строковые операции InnoDB, которые выполняют выбор (чтение), удаление, вставку и обновление. Когда количество потоков увеличивается, MySQL 8.0 значительно превосходит MySQL 5.7! Обе версии не имеют каких-либо конкретных изменений конфигурации, но только заметные переменные, которые мы установили. Таким образом, обе версии в значительной степени используют значения по умолчанию.
Интересно, что в отношении заявлений MySQL Server Team о производительности операций чтения и записи в новой версии графики указывают на значительное улучшение производительности, особенно на сервере с высокой нагрузкой. Представьте разницу между MySQL 5.7 и MySQL 8.0 для всех операций с строками InnoDB, есть большая разница, особенно когда количество потоков увеличивается. MySQL 8.0 показывает, что он может работать эффективно независимо от его рабочей нагрузки.
Что такое «нормализация»?
Нормализация — это процесс преобразования отношений базы данных к виду, отвечающему нормальным формам (пошаговый, обратимый процесс замены исходной схемы другой схемой, в которой наборы данных имеют более простую и логичную структуру).
Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную логическую избыточность, и не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма базы данных. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в базе данных информации.
Что такое «реляционная модель данных»?
Реляционная модель данных — это логическая модель данных и прикладная теория построения реляционных баз данных.
Реляционная модель данных включает в себя следующие компоненты:
- Структурный аспект — данные представляют собой набор отношений.
- Аспект целостности — отношения отвечают определенным условиям целостности: уровня домена (типа данных), уровня отношения и уровня базы данных.
- Аспект обработки (манипулирования) — поддержка операторов манипулирования отношениями (реляционная алгебра, реляционное исчисление).
- Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности и определённое как совокупность требований, которым должно удовлетворять отношение.
Что такое «первичный ключ» (primary key)? Каковы критерии его выбора?
Первичный ключ (primary key) в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве основного ключа (ключа по умолчанию).
Если в отношении имеется единственный потенциальный ключ, он является и первичным ключом. Если потенциальных ключей несколько, один из них выбирается в качестве первичного, а другие называют «альтернативными».
В качестве первичного обычно выбирается тот из потенциальных ключей, который наиболее удобен. Поэтому в качестве первичного ключа, как правило, выбирают тот, который имеет наименьший размер (физического хранения) и/или включает наименьшее количество атрибутов. Другой критерий выбора первичного ключа — сохранение его уникальности со временем. Поэтому в качестве первичного ключа стараются выбирать такой потенциальный ключ, который с наибольшей вероятностью никогда не утратит уникальность.
Общие положения
Создать новую базу данных с названием DB_Books с помощью оператора Create Database, создать в ней перечисленные таблицы c помощью
операторов Create table по примеру лабораторной работы №1. Сохранить файл программы с названием ФамилияСтудента_ЛАб_1_DB_Books. В
утилите SQL Server Management Studio с помощью кнопки «Создать запрос» создать отдельные программы по каждому запросу, которые сохранять на диске с названием: ФамилияСтудента_ЛАб_2_№_задания. В сами программы копировать текст задания в виде комментария. Можно сохранять все выполненные запросы в одном файле. Для проверки работы операторов SELECT предварительно создайте программу, которая с помощью операторов INSERT заполнит все таблицы БД DB_Books несколькими записями, сохраните программы с названием ФамилияСтудента_ЛАб_2_Insert.
Оператор Select используется для выбора данных из таблиц.
Для выбора данных из некоторой таблицы нет необходимости знать имена всех ее полей. Звездочка (*) после оператора SELECT означает выбор всех столбцов таблицы. Другими словами, эта команда просто выводит все данные таблицы. Синтаксис:
SELECT * FROM <имя таблицы>
Если необходимо выбрать только определенные столбцы, то нужно их непосредственно указать после слова Select.
Пример. Выбрать сведения о количестве страниц из таблицы Books (поле Pages).
SELECT Pages FROM Books
Пример. Выбрать все данные из таблицы Books.
SELECT * FROM Books
Назовите основные свойства транзакции.
Атомарность (atomicity) гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной.
Согласованность (consistency). Транзакция, достигающая своего нормального завершения и, тем самым, фиксирующая свои результаты, сохраняет согласованность базы данных.
Изолированность (isolation). Во время выполнения транзакции параллельные транзакции не должны оказывать влияние на её результат.
Долговечность (durability). Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу.
Дополнительные задания
Оператор обработки данных Update
- Изменить в таблице Books содержимое поля Pages на 300, если код автора (поле Code_author) =56 и название книги (поле Title_book) =’Мемуары’.
- Изменить в таблице Deliveries содержимое поля Address на ‘нет сведений’, если значение поля является пустым.
- Увеличить в таблице Purchases цену (поле Cost) на 20 процентов, если заказы были оформлены в течение последнего месяца (условие по полю Date_order).
Оператор обработки данных Insert
- Добавить в таблицу Purchases новую запись, причем так, чтобы код покупки (поле Code_purchase) был автоматически увеличен на единицу, а в тип закупки (поле Type_purchase) внести значение ‘опт’.
- Добавить в таблицу Books новую запись, причем вместо ключевого поля поставить код (поле Code_book), автоматически увеличенный на единицу от максимального кода в таблице, вместо названия книги (поле Title_book) написать ‘Наука. Техника. Инновации’.
- Добавить в таблицу Publish_house новую запись, причем вместо ключевого поля поставить код (поле Code_publish), автоматически увеличенный на единицу от максимального кода в таблице, вместо названия города – ‘Москва’ (поле City), вместо издательства – ‘Наука’ (поле Publish).
Оператор обработки данных Delete
- Удалить из таблицы Purchases все записи, у которых количество книг в заказе (поле Amount) = 0.
- Удалить из таблицы Authors все записи, у которых нет имени автора в поле Name_Author.
- Удалить из таблицы Deliveries все записи, у которых не указан ИНН (поле INN пусто)
Создание базы данных
CREATE DATABASE DB_BOOKS
USE DB_BOOKS
CREATE TABLE Authors(
Code_author INT PRIMARY KEY NOT NULL, -- Код автора
Name_author CHAR(30), -- Фамилия автора
Birthday DATETIME -- Дата рождения
)
CREATE TABLE Publishing_house(
Code_publish INT PRIMARY KEY NOT NULL, -- Код издательства
Publish CHAR(30), -- Название издательства
City CHAR(20) -- Город издательства
)
CREATE TABLE Books(
Code_book INT PRIMARY KEY NOT NULL, -- Код книги
Title_book CHAR(40), -- Название книги
Code_author INT FOREIGN KEY REFERENCES Authors(Code_author),
Pages INT,
Code_publish INT FOREIGN KEY REFERENCES Publishing_house(Code_publish)
)
CREATE TABLE Deliveries(
Code_delivery INT PRIMARY KEY NOT NULL, -- Код доставщика
Name_delivery CHAR(30), -- Наименование доставщика
Name_company CHAR(20), -- Наименование компании
Address_company VARCHAR(100), -- Адрес
Phone BIGINT, -- Телефон
INN CHAR(13) -- ИНН
)
CREATE TABLE Purchases(
Code_purchase INT PRIMARY KEY NOT NULL, -- Код продажи
Code_book INT FOREIGN KEY REFERENCES Books(Code_book),
Date_order SMALLDATETIME, -- Дата
Code_delivery INT FOREIGN KEY REFERENCES Deliveries(Code_delivery),
Type_purchase BIT, -- Тип продажи
Cost FLOAT, -- Цена
Amount INT -- Количество
)
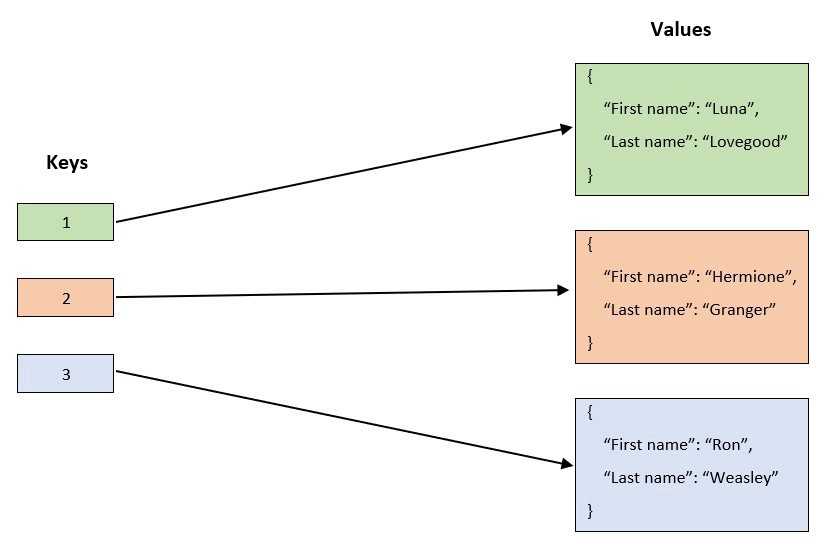
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Ресурсы процессора
Во время этого бенчмаркинга мы решили использовать некоторые аппаратные ресурсы, в частности, загрузку процессора.
Позвольте нам сначала объяснить, как мы используем ресурсы ЦП здесь во время бенчмаркинга. sysbench не включает в себя коллективную статистику для аппаратных ресурсов, использованных или используемых в процессе, когда вы сравниваете базу данных. Из-за этого мы создали флаг, создав файл, подключившись к целевому хосту через SSH, а затем собрав данные из команды top в Linux и проанализировав их во время сна на секунду, а затем собрали снова. После этого возьмите самое значительное увеличение использования ЦП для процесса mysqld, а затем удалите файл флага.
Итак, давайте снова поговорим о графике, кажется, что он показывает, что MySQL 8.0 потребляет много ресурсов процессора. Больше, чем MySQL 5.7. Однако, возможно, придется иметь дело с новыми переменными, добавленными в MySQL 8.0. Например, эти переменные могут повлиять на ваш сервер MySQL 8.0:
- innodb_log_spin_cpu_abs_lwm = 80
- innodb_log_spin_cpu_pct_hwm = 50
- innodb_log_wait_for_flush_spin_hwm = 400
- innodb_parallel_read_threads = 4
Переменные с их значениями оставлены значениями по умолчанию для этого теста. Первые три переменные обрабатывают ЦП для повторного ведения журнала, что в MySQL 8.0 было улучшением из-за перепроектирования того, как InnoDB записывает в журнал REDO. Переменная имеет привязку к процессору, что означает, что она будет игнорировать другие ядра процессора, если mysqld прикреплен только к 4 ядрам, например. Для параллельных потоков чтения в MySQL 8.0 добавлена новая переменная, для которой вы можете настроить количество используемых потоков.
Однако мы не стали углубляться в эту тему. Могут быть способы повышения производительности за счет использования функций, предлагаемых MySQL 8.0.
Поле «ID» не имеет значения по умолчанию в базе данных
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>yle=»margin-bottom:5px;»>Теги: база данных
Я был: когда я был вставлен с MyBatis-Plus, я бы сообщил об ошибке, я узнал, что проблема первичного идентификатора ключа.
1. Первый:
Проверьте, добавлен ли главный ключ в классе объекта.
Авто: автоматическая стратегия роста
2. Ключ (я не в том месте!)
Проверьте, соответствует ли база данных базы данных, проверяется ли первичный ключ и автоматически увеличивается.
(Я забыл проверить это, когда эта таблица была …)
Интеллектуальная рекомендация
1. Для реальных сигналов (для понимания): A (ω) является соотношением амплитуды выходного сигнала и амплитуды входного сигнала, называемого частотой амплитуды. Φ (ω) — это разница межд…
Один. вести Многие люди задавали некоторые вопросы о создании проекта Flex + LCDS (FDS) в сообщениях и группах. Из-за операции ее трудно четко объяснить, поэтому я написал простой учебник (я обещал эт…
package com.example.phonehttp; import android.os.Bundle; import android.os.Handler; import android.app.Activity; import android.widget.ScrollView; import android.widget.TextView; public class MainActi…
Он предназначен для реализации подкласса того же родительского класса с родительским классом. Полиморфизм Один и тот же ссылочный тип использует разные экземпляры для выполнения разных операций; Идея …
тема: Объедините два упорядоченных слоя в новый заказанный список и возврат. Новый список состоит из всех узлов двух связанных списков, данных сплавным. Пример: Анализ: два связанных списка состоит в …
Вам также может понравиться
D. Самая ценная строка Пример ввода 2 2 aa aaa 2 b c Образец вывода aaa c На самом деле, будучи задетым этим вопросом, вы должны быть осторожны. После инвертирования строки, если две строки имеют один…
Given a 2D integer matrix M representing the gray scale of an image, you need to design a smoother to make the gray scale of each cell becomes the average gray scale (rounding down) of all the 8 surro…
calc () может быть очень незнакомым для всех, и трудно поверить, что calc () является частью CSS. Поскольку он выглядит как функция, почему он появляется в CSS, поскольку это функция? Этот момент такж…
Основываясь на дереве регрессии, сформированном CART, а также на предварительной и последующей обрезке дерева, код выглядит следующим образом:…
Откат Обновление в режиме онлайн с версии Centos (CentOS Linux версии 7.3.1611 (Core) до CentOS Linux версии 7.5.1804 (Core)) # ошибка соединения yum-ssh после обновления yexpected key exchange group …
Репликация
Несмотря на то, что репликация может помочь справиться с нагрузкой, ее лучше для этого не применять. Нужно помнить, что наряду с масштабированием у вас всегда будет стоять вопрос доступности. Если реплика, которая помогает обслуживать запросы, выйдет из строя, что случится с системой?
С другой стороны, реплика как раз позволяет обеспечить высокую доступность. Один из подходов выглядит так:
- Использовать master-slave-репликацию для каждого сервера БД.
- Приложение всегда работает только с мастером.
- Если мастер выходит из строя, приложение переключается на слейв.
- Мы в это время поднимаем сломанный сервер и превращаем его в слейв (как это правильно сделать).
Таким образом, в новой схеме мастер и слейв поменялись местами, а приложение (то есть его пользователи) не заметило никаких проблем.
Скорость работы баз данных
Чтобы оптимизация СУБД MySQL дала результат, нужно начать с анализа работы баз данных. Настройки сервиса содержатся в файле /etc/my.cnf.
С помощью настроек можно проверить, какие запросы выполняются медленно и что можно ускорить. Для этого в раздел добавляется следующий запрос:
log-slow-queries=/var/log/mariadb/slow_queries.log long_query_time=5
Информация указана в строчках:
log-slow-queries=/var/log/mariadb//slow_queries.log long_query_time=2
Во второй обозначено минимальное время внесения запроса в лог — 2 секунды.
Чтобы увидеть актуальные данные, сервер перезапускается. Сведения находятся в логе:
# systemctl restart mariadb # tail -f /var/log/mariadb/slow-queries.log
В полученном списке будут представлены все запросы, время выполнения которых превышает указанный показатель. К примеру, больше 10 секунд может выполняться запрос:
SELECT option_name, option_value FROM wp_options WHERE autoload = 'yes'
Если при его выполнении в MySQL операция происходит более 3 секунд, запрос может считаться медленным.
Сайт будет работать корректно при условии, что таких запросов немного. Но если у него постоянная нагрузка, количество необработанных запросов будет постепенно расти. Пропорционально им скорость ответа возрастет до нескольких минут.
Решить эту проблему может оптимизация таблиц или кода. В последнем случае из него убираются все сложные запросы. Это длительный процесс, описать который в рамках одной статьи крайне затруднительно. Поэтому здесь мы подробно рассмотрим именно первый вариант.
Заявление об анализе профиля
Query Profiler — это инструмент диагностического анализа запросов, поставляемый с MySQL. Он может анализировать узкое место производительности оборудования, связанное с оператором SQL. Например, ЦП, ввод-вывод и т. Д., А также время, затрачиваемое на выполнение SQL. Однако этот инструмент реализован только в MySQL 5.0.37 и выше. По умолчанию эта функция MYSQL не включена, и вам нужно вручную запустить ее самостоятельно.
Включите функцию профиля
- Функция Profile управляется переменной сеанса MySQL: profiling, которая по умолчанию отключена.
- Проверьте, включена ли функция профиля:
Включить функцию профиля
Эталонное тестирование OLTP-системы с помощью инструмента sysbench
Эталонное тестирование системы OLTP эмулирует рабочую нагрузку, характерную для обработки транзакций. Приведем пример такого тестирования для таблицы, содержащей 1 миллион строк. В первую очередь нужно подготовить эту таблицу:
Это все, что нужно сделать для подготовки тестовых данных. Затем на 60 секунд запустим эталонный тест в режиме чтения с восьмью конкурентными потоками:
Как и ранее, в полученных результатах содержится очень много информации. Наибольший интерес представляют следующие данные:
- счетчик транзакций;
- количество транзакций в секунду;
- временная статистика (минимальное, среднее, максимальное время и 95-й процентиль);
- татистика равномерности загрузки потоков, которая показывает, насколько справедливо распределялась между ними имитированная нагрузка.
Приводимый пример применим к версии 4 инструмента , которая доступна в предварительно созданных двоичных файлах на SourceForge.net. Но если вы скомпилируете из исходного кода на Launchpad (это легко и просто!), то сможете воспользоваться большим количеством улучшений, внесенных в версию 5. Вы сможете запускать эталонные тесты не для одной таблицы, а для нескольких, через равные интервалы (например, каждые 10 секунд) видеть пропускную способность и время отклика. Эти показатели очень важны для понимания поведения системы.
Какие проблемы могут возникать при параллельном доступе с использованием транзакций?
При параллельном выполнении транзакций возможны следующие проблемы:
- Потерянное обновление (lost update) — при одновременном изменении одного блока данных разными транзакциями одно из изменений теряется;
- «Грязное» чтение (dirty read) — чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится);
- Неповторяющееся чтение (non-repeatable read) — при повторном чтении в рамках одной транзакции ранее прочитанные данные оказываются изменёнными;
-
Фантомное чтение (phantom reads) — одна транзакция в ходе своего выполнения несколько раз выбирает множество записей по одним и тем же критериям. Другая транзакция в интервалах между этими выборками добавляет или удаляет записи или изменяет столбцы некоторых записей, используемых в критериях выборки первой транзакции, и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества записей.
Предположим, имеется две транзакции, открытые различными приложениями, в которых выполнены следующие SQL-операторы:
| Транзакция 1 | Транзакция 2 |
|---|---|
| SELECT SUM(f2) FROM tbl1; | |
| INSERT INTO tbl1 (f1,f2) VALUES (15,20); | |
| COMMIT; | |
| SELECT SUM(f2) FROM tbl1; |
В транзакции 2 выполняется SQL-оператор, использующий все значения поля f2. Затем в транзакции 1 выполняется вставка новой строки, приводящая к тому, что повторное выполнение SQL-оператора в транзакции 2 выдаст другой результат. Такая ситуация называется чтением фантома (фантомным чтением). От неповторяющегося чтения оно отличается тем, что результат повторного обращения к данным изменился не из-за изменения/удаления самих этих данных, а из-за появления новых (фантомных) данных.
Кеш запросов
В кеше запросов (query cache) сохраняются пары запрос-ответ. Когда запрос уже есть в кеше, ответ отдается практически мгновенно. Если данные в таблицах меняются не слишком часто, происходит ощутимый прирост производительности (в противном случае кеш быстро сбрасывается).
По умолчанию кеширование выключено. Включить его можно, добавив в конфигурационный файл my.cnf строчку вида . Через переменную query_cache_size задается размер оперативной памяти, выделяемой под кеш, в данном случае — 64 мегабайта.
Теперь нужно перезапустить MySQL. Сделать это можно из некоторых панелей управления (в ISPmanager: Management tools — Services), либо по SSH из командной строки примерно так:
Всё, кеш включен. Можно попробовать открыть страницу сайта и потом обновить. Во второй раз должна загрузиться быстрее.
Есть еще несколько переменных для настройки кеша:
- query_cache_type задает режим работы кеша, когда query_cache_size установлен больше нуля. Допустимые значения query_cache_type: 0 или OFF — кеширование выключено; 1 или ON — кеширование включено для всех выражений, кроме начинающихся с SELECT SQL_NO_CACHE; 2 или DEMAND — кеширование включено только для запросов, начинающихся с SELECT SQL_CACHE.
- query_cache_limit – максимально допустимый размер, при котором результат выполнения запроса будет сохранен в кеше.
- query_cache_min_res_unit – минимальный размер блоков памяти, выделяемых под кеш. По умолчанию 4 Кб. Если у вас много результатов значительно меньшего объема, query_cache_min_res_unit можно понизить, чтобы память использовалась эффективнее. Подходящее значение можно рассчитать по формуле (query_cache_size — Qcache_free_memory) / Qcache_queries_in_cache.
Пример my.cnf для небольшого VPS:
Посмотреть текущее состояние кеша можно в phpMyAdmin на вкладке Status, либо из командной строки:
# mysql -u root -p Password: ******** mysql> SHOW GLOBAL STATUS LIKE ‘Qcache%’; +----------------------------+------------+ | Variable_name | Value | +----------------------------+------------+ | Qcache_free_blocks | 130 | | Qcache_free_memory | 56705448 | | Qcache_hits | 57092 | | Qcache_inserts | 10412 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 5036 | | Qcache_queries_in_cache | 1023 | | Qcache_total_blocks | 2409 | +----------------------------+------------+ 8 rows in set (0.01 sec)
- Qcache_free_blocks – количество свободных блоков в кеше.
- Qcache_free_memory – объем свободной ОЗУ, отведенной под кеш.
- Qcache_hits – количество запросов, результаты которых были взяты из кеша.
- Qcache_inserts – количество запросов, которые были добавлены в кеш.
- Qcache_lowmem_prunes – количество запросов, которые были удалены из кеша из-за нехватки памяти.
- Qcache_not_cached – количество запросов, которые не были записаны в кеш (с SQL_NO_CACHE или некешируемые по другим причинам).
- Qcache_queries_in_cache – количество запросов, которые находятся в кеше.
- Qcache_total_blocks – общее количество блоков.
Долю закешированных запросов от их общего числа можно посчитать по формуле Qcache_hits / (Com_select + Qcache_hits). Степень использования кеша — Qcache_hits / Qcache_inserts.
О нюансах работы кеша MySQL можно почитать на mysqlperformanceblog.com (англ.)
Скорость работы MySQL
Оптимизация без аналитики бессмысленна. Перед тем как переходить к оптимизации давайте посмотрим как работает база данных сейчас, есть ли запросы, которые выполняются очень медленно. Все настройки вашего сервиса mysql находятся в файле /etc/my.cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию :
Здесь первая строка включает запись лога медленных запросов, вторая указывает, что минимальное время запроса для внесения его в этот лог — две секунды. Еще можно включить в лог запросы, которые не используют индексы:
Но это уже необязательно для проверки скорости и используется больше для отладки кода и правильности создания таблиц. Дальше перезапустите сервер баз данных и посмотрите лог:
Мы можем видеть, что есть запросы, которые выполняются больше, чем 10 секунд. Это, например, запрос
Можно его выполнить отдельно, в консоли mysql:
Здесь тоже измеряется время, и мы видим результат — три секунды. Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями — оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Неверный выбор типа и размера полей
Поскольку размер поля в «правильной» реляционной БД имеет фиксированное значение, он должен быть достаточным (иначе данные могут не поместиться) но не избыточным (лишнее место на диске и в памяти).
Если подумать, то данный параметр должен быть, например, для символьного типа точно равен самой длинной строке генеральной совокупности.
Тип поля должен соответствовать вводимым данным с учетом возможного развития.
В том числе числу записей для идентификаторов.
Ошибка типа — достаточно грубая и примитивная.
Если недостаточный размер поля еще может быть оправдан просто отсутствием достаточного (исчерпывающего) объема информации, то ошибка в выборе типа — следствие слишком поверхностных рассуждений.
Еще один, совсем неочевидный пример. Так как размер поля всегда измеряется в целых байтах, логический тип, теоретически требующий всего одного бита, следует рассматривать как нерациональный.
Да, он будет всегда обрабатываться быстрее, так как может иметь всего от двух до трех вариантов значения (T, F, null).
Но даже банальный интерфейсный флажок, чаще всего используемый для управления полем, может иметь до четырех состояний.
Доступ к этим материалам предоставляется только зарегистрированным пользователям!
….
Прошу обратить особо пристальное внимание на неопределенную информацию, традиционно вносимую для xBase в Memo-поле.
Новые концепции не предусматривают такого типа и придется пользоваться текстовыми полями, дополнительно обдумывая их структуру.
Важно создать среду, когда не будет вывода пользователю, что он превысил объем сохраняемых данных. См. также
также
См. также .
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Статистика базы данных с отбором по подсистемам (кол-во и открытие списков: документов, справочников, регистров) и анализ наличия основных реквизитов: универсальная обработка (два файла — обычный и управляемый режим) Промо
Универсальная обработка для статистики базы данных (документы, справочники, регистры, отчеты) с отбором по подсистемам и с анализом наличия основных реквизитов (организации, контрагенты, договора, номенклатура, сотрудники, физлица, валюта).
Возможность просмотра списка документов или справочников или регистров при активизации в колонке «Документы, справочники, регистры, отчеты» в текущей строке.
Полезная обработка для консультации пользователей, где искать метаданные в каком интерфейсе, т.к. подсистема указывает в каком интерфейсе находятся метаданные (документы, справочники, регистры, отчеты).
При конвертации данных, удобно контролировать статистику загрузки данных в пустую базу приемник при тестировании.
Новое: Оптимизировал вывод результата по скорости при выборе отдельных (не всех) подсистем и добавил возможность отключения анализа реквизитов и анализа подсистем для быстрого вывода результата. Добавил подключение дополнительных реквизитов, если они есть, для документов.
2 стартмани
20.02.2017
22660
59
strelec13
14
Профилирование запроса
Включение профилирования — это доступный способ получить точную оценку времени выполнения запроса. Сначала нужно включить профилирование и вызвать show profiles, чтобы получить время выполнения запроса.
Например, у нас есть следующая операция добавления данных. Предположим, что User1 и Gallery1 уже созданы:
INSERT INTO `homestead`.`images` (`id`, `gallery_id`, `original_filename`, `filename`, `description`) VALUES (1, 1, 'me.jpg', 'me.jpg', 'A photo of me walking down the street'), (2, 1, 'dog.jpg', 'dog.jpg', 'A photo of my dog on the street'), (3, 1, 'cat.jpg', 'cat.jpg', 'A photo of my cat walking down the street'), (4, 1, 'purr.jpg', 'purr.jpg', 'A photo of my cat purring');
Выполнение этого запроса не вызовет проблем. Но рассмотрим следующую команду:
SELECT * FROM `homestead`.`images` AS i WHERE i.description LIKE '%street%';
Этот запрос является подходящим примером того, что может стать причиной проблем в будущем, если мы сделаем выборку из базы данных большого количества изображений.
Чтобы получить точное время выполнения этого запроса, можно использовать следующий SQL-код:
set profiling = 1; SELECT * FROM `homestead`.`images` AS i WHERE i.description LIKE '%street%'; show profiles;
Результат:
| Query_Id | Продолжительность | Запрос |
| 1 | 0.00016950 | SHOW WARNINGS |
| 2 | 0.00039200 | SELECT * FROM homestead.images AS i nWHERE i.description LIKE ’%street%’nLIMIT 0, 1000 |
| 3 | 0.00037600 | SHOW KEYS FROM homestead.images |
| 4 | 0.00034625 | SHOW DATABASES LIKE ’homestead |
| 5 | 0.00027600 | SHOW TABLES FROM homestead LIKE ’images’ |
| 6 | 0.00024950 | SELECT * FROM homestead.images WHERE 0=1 |
| 7 | 0.00104300 | SHOW FULL COLUMNS FROM homestead.images LIKE ’id’ |
Команда show profiles отображает время выполнения не только исходного запроса, но и всех остальных. Таким образом, можно точно профилировать запросы.
Оптимизация на уровне сервера
Оптимизация серверного оборудования
Улучшение аппаратного оборудования, например выбор памяти с максимально возможной частотой (частота не может быть выше поддерживаемой материнской платой), увеличение пропускной способности сети, использование высокоскоростных дисков SSD и повышение производительности ЦП.
Выбор процессора:
Для сценариев, в которых параллелизм базы данных относительно высок, количество процессоров более важно, чем частота.
Для сценариев с интенсивным использованием ЦП и сценариев, в которых часто выполняется сложный SQL, чем выше частота ЦП, тем лучше.
Система CentOS оптимизирована под параметры mysql
Оптимизация конфигурации базы данных MySQL
Файл конфигурации
Сохраните данные в памяти и убедитесь, что данные считываются из памяти.
Установите innodb_buffer_pool_size достаточно большим для чтения данных в память.
Уменьшите количество операций записи на диск
- Для производственной среды не нужно включать многие журналы, например: общий журнал запросов, журнал медленных запросов, журнал ошибок.
- Используйте достаточно большой кеш записи innodb_log_file_size
С чего начать оптимизацию
Итак, вы определили, какие запросы выполняются при генерации страницы. Дальше возможны варианты:
- Есть тяжелые запросы, занимающие сотни миллисекунд.
- Запросов много, но все они выполняются достаточно быстро.
В первом случае можно попробовать оптимизировать отдельные запросы. Здесь поможет SQL-оператор EXPLAIN и знания об индексах. Это решение применимо ко всем сайтам, в том числе размещенным на виртуальном хостинге.
Во втором случае имеет смысл заняться углубленным анализом логов и тонкой настройкой MySQL. На виртуальном хостинге сделать это не получится, только на VPS и выделенных серверах.
Но прежде, чем углубляться в детали, стоит сказать о кеше запросов – быстром и простом способе снять многие проблемы. Возможность включить кеш запросов есть у владельцев VPS и выделенных серверов.
Заключение
Грамотная настройка и оптимизация MySQL позволяет достичь оптимально высоких показателей работы сервера и приложений, развернутых на его основе. Этому процессу способствует запуск скриптов, которые могут быстро обнаружить проблемы, влияющие на производительность базы данных.
Автоматическую оптимизацию с помощью скрипта следует обязательно дополнять настройкой производительности в ручном режиме с помощью регулировки основных параметров СУБД. Для повышения эффективности MySQL не менее важна оптимизация работы с выборкой из нескольких объединенных таблиц.
Оцените материал:
Заключение
Есть множество улучшений, которые присутствуют в MySQL 8.0. Результаты тестирования показывают, что произошло впечатляющее улучшение не только в управлении рабочими нагрузками чтения, но также и в высокой рабочей нагрузке чтения/записи по сравнению с MySQL 5.7.
Переходя к новым функциям MySQL 8.0, похоже, что он использует преимущества самых современных технологий не только в программном обеспечении (например, значительное улучшение для Memcached, удаленное управление для лучшей работы DevOps и т. д.), Но и также в оборудовании. Например, замена latin1 на UTF8MB4 в качестве кодировки символов по умолчанию. Это будет означать, что для этого потребуется больше дискового пространства, поскольку UTF8 требуется 2 байта для символов, не входящих в US-ASCII. Хотя в этом тесте не использовался новый метод аутентификации с , это не повлияет на производительность, если он использует шифрование. После аутентификации он сохраняется в кеше, что означает, что аутентификация выполняется только один раз. Поэтому, если вы используете одного пользователя для своего клиента, это не будет проблемой и будет более безопасным, чем предыдущие версии.
Поскольку MySQL использует самое современное аппаратное и программное обеспечение, он меняет свои переменные по умолчанию.
В целом, MySQL 8.0 эффективно доминирует над MySQL 5.7.