
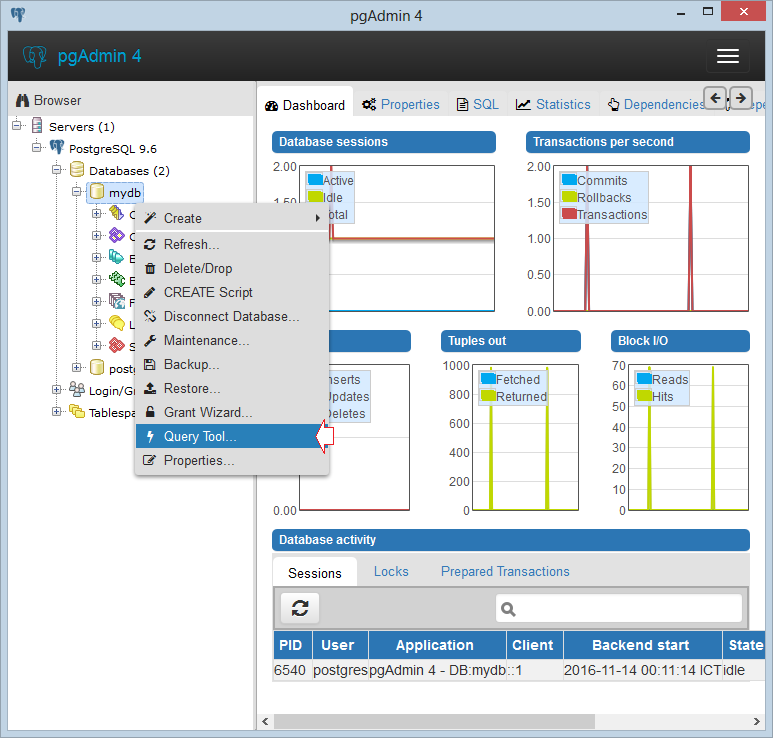
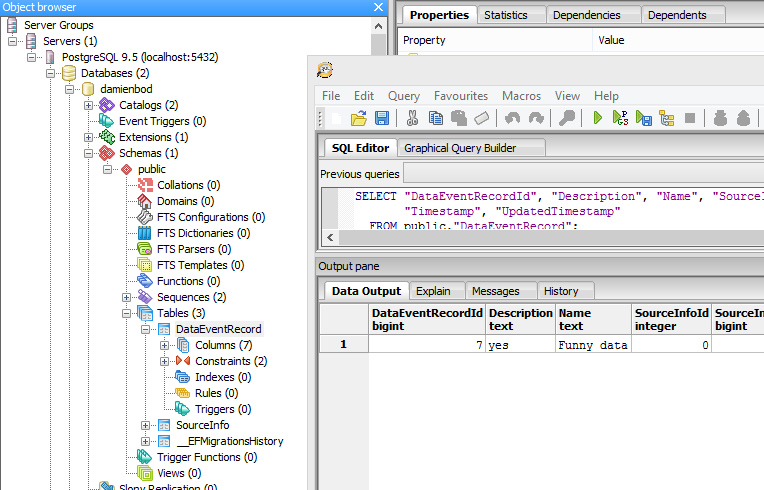
3 ответа
Лучший ответ
Краткий ответ: Добавьте вверху класса :
Больше информации:
Ваша конфигурация мне подходит. Убедитесь, что ваша сущность сканируется. Я имею в виду, что вы, возможно, настроили свой проект так, чтобы ваш класс сущностей не читался. Вот минимальная конфигурация, которую вам нужно иметь:
- Используйте эту зависимость
- Есть в
- Создайте свою сущность (она у вас уже есть)
- Есть ваш класс
И здесь это более чем важно! Если ваш класс сущности отсутствует в подпакете , то вам нужно добавить пользовательскую аннотацию к вашему классу
Подробнее о конфигурации Hibernate
При настройке приложения с использованием JPA, без Spring-boot, вам необходимо указать расположение классов сущностей (а также много другой информации).
Это говорит hibernate сканировать определенные пакеты для поиска ваших сущностей.
С помощью Spring-Boot вам не нужно писать все классы конфигурации. Но если ваши объекты (а это ваш случай) находятся в пакетах, отличных от ваших , вам нужно указать пакеты для сканирования с аннотацией . Действительно, эта аннотация интерпретируется классом для поиска ваших сущностей.
Аннотация здесь, чтобы найти ваши весенние бобы, а не ваши сущности.
Если все хорошо, вы должны увидеть это в своем журнале:
Дайте мне знать.
RUARO Thibault
15 Янв 2020 в 09:54
Попробуйте использовать только создать вместо создания-падение
Jaganath Kamble
14 Янв 2020 в 16:55
Стратегия create-drop будет удалена после закрытия приложения. Попробуйте вместо этого создать .
Рядом с этим: глядя на ваш файл свойств:
С некоторым отступом, похоже, что он не находит вашу конфигурацию jpa, так как он вложен в источник данных.
Пытаться:
JavaBoy
14 Янв 2020 в 16:21
Псевдо роль public
Псевдо роль public не видна, но про неё следует знать. Это групповая роль, в которую включены все остальные роли. Это означает, что все роли по умолчанию будут иметь привилегии наследуемые от public. Поэтому иногда у public отбирают некоторые привилегии, чтобы отнять их у всех пользователей.
Роль public по умолчанию имеет следующие привилегии:
-
для всех баз данных:
- CONNECT – это означает что любая созданная роль сможет подключаться к базам данных, но не путайте с привилегией LOGIN;
- TEMPORARY – любая созданная роль сможет создавать временные объекты во всех база данных и объекты эти могут быть любого размера;
-
для схемы public:
- CREATE (создание объектов) – любая роль может создавать объекты в этой схеме;
- USAGE (доступ к объектам) – любая роль может использовать объекты в этой схеме;
-
для схемы pg_catalog и information_schema
USAGE (доступ к объектам) – любая роль может обращаться к таблицам системного каталога;
:
-
для всех функций
EXECUTE (выполнение) – любая роль может выполнять любую функцию. Ещё нужны ещё права USAGE на ту схему, в которой функция находится, и права к объектам к которым обращается функция.
:
Это сделано для удобства, но снижает безопасность сервера баз данных.
Понимание модели клиент-сервер
Я уже упоминал PostgreSQL Server как важный компонент базы данных. Но что такое сервер в этом контексте и зачем он нам нужен?
Для начала тебе необходимо понимать модель клиент-сервер.
Почти все СУБД (PostgreSQL, MySQL и другие) следуют клиент-серверной модели. В ней база данных находится на сервере, и клиент
отправляет запросы на сервер, который их обрабатывает.
Под клиентом здесь подразумевается бекэнд нашего приложения, а запросы в — это SQL операции, такие как SELECT, INSERT, UPDATE и DELETE.
Для разработки любого бекэнда, тебе нужен локальный сервер для экспериментов и тестирования.
Этот локальный сервер аналогичен удаленному, но работает прямо на твоем компьютере.
С точки зрения клиента удаленный и локальный сервер идентичны. После разработки и тестирования ты можешь заставить свой
продукт взаимодействовать с удаленным сервером вместо локального, просто изменив пару параметров.
Некоторые базы данных не используют эту модель, например SQLite, которая хранит все в простом файле на диске. Это хорошо
работает для небольших приложений, но для большинства реальных приложений тебе понадобится архитектура клиент-сервер.
Значения по умолчанию
В описании столбца, может быть указано выражение для значения по умолчанию, одного из следующих видов:, , .
Пример: .
Если выражение для значения по умолчанию не указано, то в качестве значений по умолчанию будут использоваться нули для чисел, пустые строки для строк, пустые массивы для массивов, а также для дат и для дат с временем. NULL-ы не поддерживаются.
В случае, если указано выражение по умолчанию, то указание типа столбца не обязательно. При отсутствии явно указанного типа, будет использован тип выражения по умолчанию. Пример: — для столбца EventDate будет использован тип Date.
При наличии явно указанного типа данных и выражения по умолчанию, это выражение будет приводиться к указанному типу с использованием функций приведения типа. Пример: — имеет такой же смысл, как .
В качестве выражения для умолчания, может быть указано произвольное выражение от констант и столбцов таблицы. При создании и изменении структуры таблицы, проверяется, что выражения не содержат циклов. При INSERT-е проверяется разрешимость выражений — что все столбцы, из которых их можно вычислить, переданы.
DEFAULT
Обычное значение по умолчанию. Если в запросе INSERT не указан соответствующий столбец, то он будет заполнен путём вычисления соответствующего выражения.
MATERIALIZED
Материализованное выражение. Такой столбец не может быть указан при INSERT, то есть, он всегда вычисляется.
При INSERT без указания списка столбцов, такие столбцы не рассматриваются.
Также этот столбец не подставляется при использовании звёздочки в запросе SELECT. Это необходимо, чтобы сохранить инвариант, что дамп, полученный путём , можно вставить обратно в таблицу INSERT-ом без указания списка столбцов.
ALIAS
Синоним. Такой столбец вообще не хранится в таблице.
Его значения не могут быть вставлены в таблицу, он не подставляется при использовании звёздочки в запросе SELECT.
Он может быть использован в SELECT-ах — в таком случае, во время разбора запроса, алиас раскрывается.
При добавлении новых столбцов с помощью запроса ALTER, старые данные для этих столбцов не записываются. Вместо этого, при чтении старых данных, для которых отсутствуют значения новых столбцов, выполняется вычисление выражений по умолчанию на лету. При этом, если выполнение выражения требует использования других столбцов, не указанных в запросе, то эти столбцы будут дополнительно прочитаны, но только для тех блоков данных, для которых это необходимо.
Если добавить в таблицу новый столбец, а через некоторое время изменить его выражение по умолчанию, то используемые значения для старых данных (для данных, где значения не хранились на диске) поменяются. Также заметим, что при выполнении фоновых слияний, данные для столбцов, отсутствующих в одном из сливаемых кусков, записываются в объединённый кусок.
Отсутствует возможность задать значения по умолчанию для элементов вложенных структур данных.
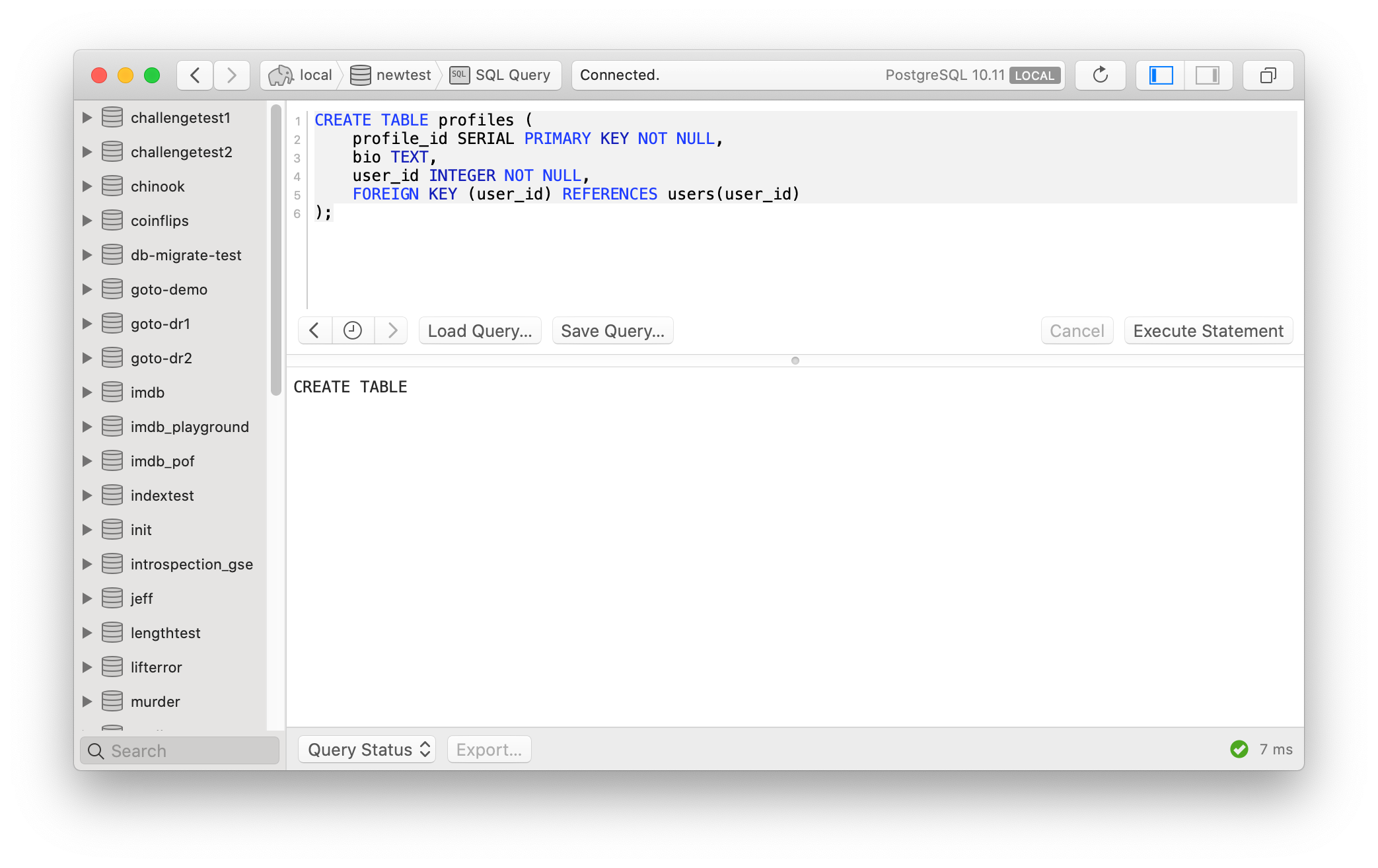
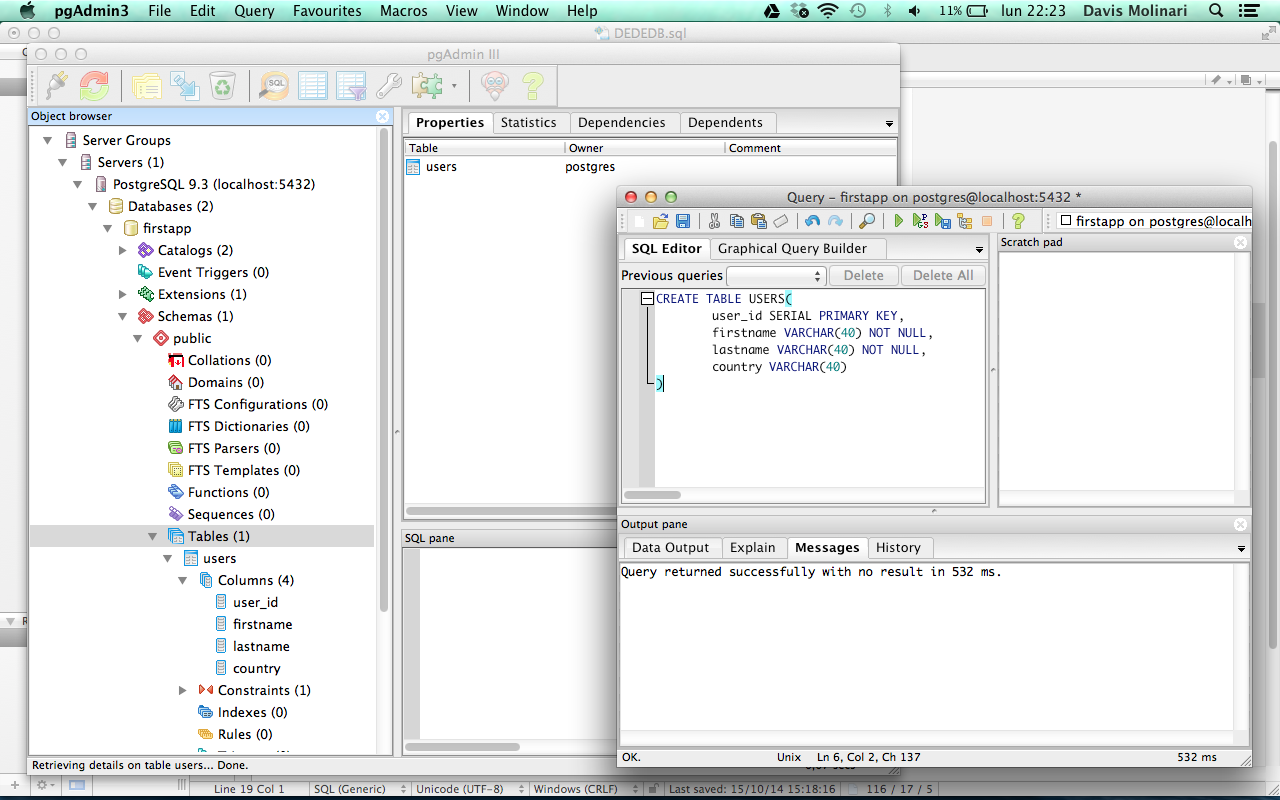
Создание таблицы в PostgreSQL
Попробуйте создать тестовую таблицу. Для примера назовём её pg_equipment и поместим в неё данные о различном оборудовании для детских площадок. Введите следующее определение таблицы:
Чтобы просмотреть таблицу, введите в командную строку \d.
Эта команда выведет на экран таблицу и создаст последовательность согласно типу данных serial.
Изменение таблиц в PostgreSQL
Теперь попробуйте внести в таблицу изменения. Для этого используется следующий синтаксис:
К примеру, можно добавить в таблицу pg_equipment новый столбец.
Чтобы просмотреть новый столбец, введите:
Чтобы добавить значение по умолчанию, которое указывает, что оборудование следует рассматривать как рабочее, если не указано иное, используйте следующую команду:
Чтобы указать также, что значение не может быть нулём, используйте:
Чтобы переименовать столбец, введите:
Удалить столбец можно с помощью команды:
Чтобы переименовать всю таблицу, введите:
Удаление таблиц PostgreSQL
Чтобы удалить таблицу PostgreSQL, введите:
Если применить эту команду к таблице, которой не существует, появится следующее сообщение об ошибке:
Чтобы избежать этой ошибки, можно добавить в команду IF EXISTS; тогда таблица будет удалена, если она существует. В любом случае команда будет выполнена успешно.
В этот раз команда сообщает, что заданная таблица не найдена, но не возвращает ошибки.
6 ответов
Лучший ответ
CREATE TABLE AS считается отдельным оператором от обычного СОЗДАТЬ ТАБЛИЦУ и до версии Postgres 9.5 (см. ) не поддерживает пункт . (Обязательно посмотрите правильную версию руководства для той версии, которую вы используете.)
Хотя и не такой гибкий, синтаксис может быть альтернативой в некоторых ситуациях; вместо того, чтобы брать свою структуру (и содержимое) из оператора , он копирует структуру другой таблицы или представления.
Следовательно, вы можете написать что-то вроде этого (непроверено); последняя вставка — довольно беспорядочный способ ничего не делать, если таблица уже заполнена:
В качестве альтернативы, если вы хотите отбросить предыдущие данные (например, заброшенную временную таблицу), вы можете условно удалить старую таблицу и безоговорочно создать новую:
24
IMSoP
14 Окт 2016 в 08:49
был добавлен в Postgres 9.1. Видеть:
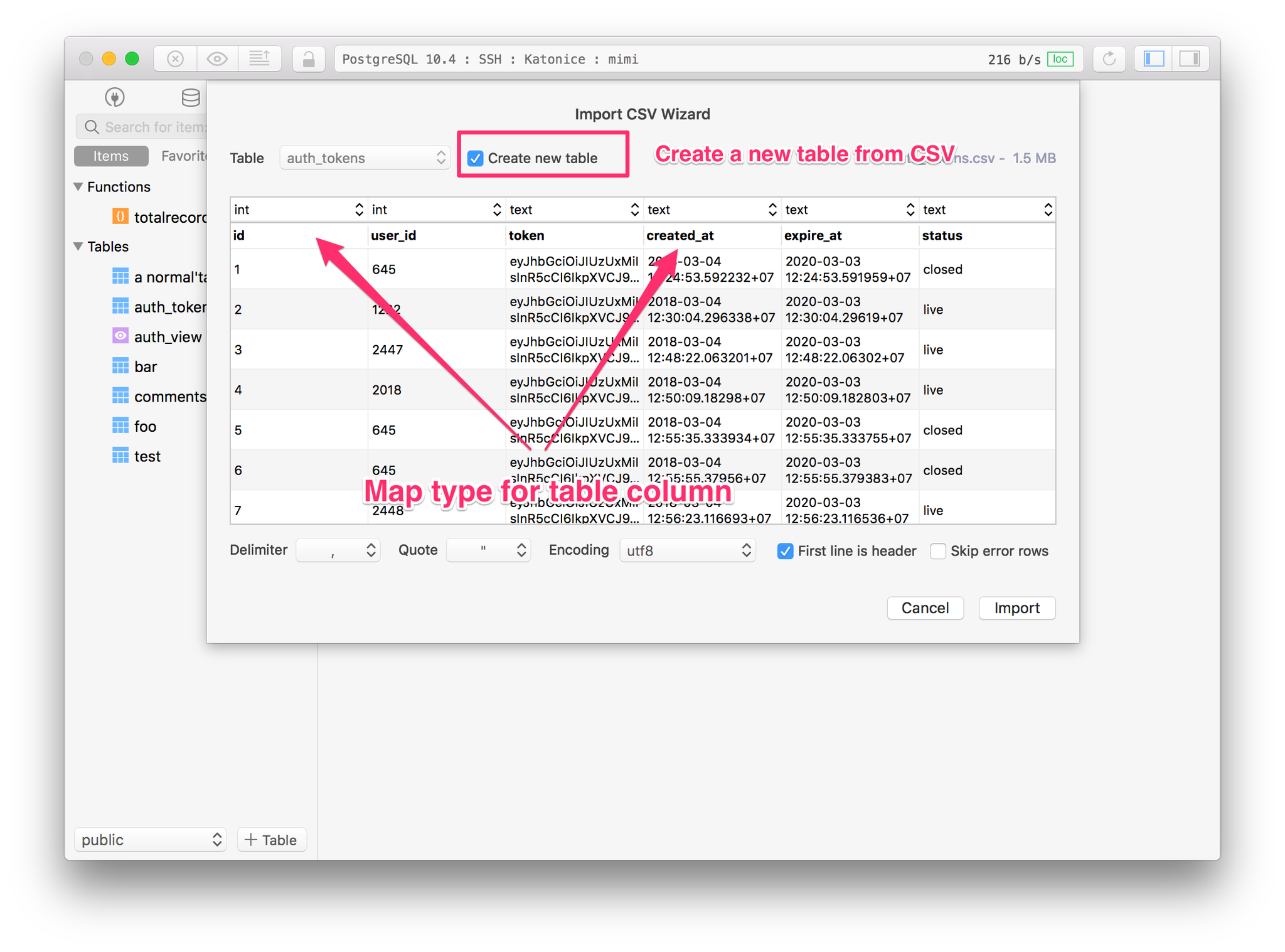
PostgreSQL создает таблицу, если не существует
Postgres 9.0 или старше
Если вы собираетесь написать функцию для этого, основывайте ее на системном каталоге таблица , а не представления в информационная схема или сборщик статистики (которые существуют, только если активированы).
Как проверить, существует ли таблица в данной схеме
Функция принимает имя таблицы и строку запроса, а также, необязательно, схему для создания таблицы (по умолчанию текущая схема ).
Обратите внимание на правильное использование в заголовке функции и в теле функции:
Забытый оператор присваивания «=» и банальный «: =»
Также обратите внимание, как идентификаторы экранируются как идентификаторы. Вы не можете использовать , поскольку таблица еще не существует:. Имя таблицы как параметр функции PostgreSQL
Имя таблицы как параметр функции PostgreSQL
6
Erwin Brandstetter
13 Апр 2021 в 16:37
Попробуй это,
Vivek S.
18 Сен 2014 в 06:07
Это просто:
Eric Aya
25 Дек 2018 в 12:22
Используйте do:
Stéphane Goyet
19 Июн 2019 в 07:57
CTAS (Create Table AS) для варианта REDSHIFT PLPGSQL. Обратитесь к Эрвину Брандштеттеру за корневую идею с использованием чистого синтаксиса PG.
Goran B.
29 Июн 2020 в 00:01
8 ответов
Лучший ответ
Вы должны включить схему, если не общедоступную
Или вы можете изменить схему по умолчанию
Проверьте схему своей таблицы здесь
![]()
Например, если таблица находится в схеме по умолчанию , и то, и другое будет работать нормально.
Но для секторов нужно указать схему
96
Juan Carlos Oropeza
20 Апр 2016 в 19:49
В моем случае в восстановленном файле дампа были эти команды.
Я прокомментировал их и снова восстановил. Проблема решена
samsri
30 Окт 2020 в 12:03
Я использовал pgAdmin для создания своих таблиц, и хотя я не использовал зарезервированные слова, сгенерированная таблица имела кавычки в имени, а в нескольких столбцах были кавычки. Вот пример сгенерированного SQL.
Все эти цитаты были вставлены наугад. Мне просто нужно было отбросить и заново создать таблицу без кавычек.
Проверено на pgAdmin 4.26
Chewy
9 Окт 2020 в 14:05
Ошибка может быть вызвана ограничениями доступа. Решение:
2
Marcel
1 Окт 2020 в 00:47
У меня была та же проблема, которая возникла после восстановления данных из db, сброшенного postgres.
В моем файле дампа была команда ниже, откуда все пошло на юг.
Решения:
- Вероятно, удалите его или замените на .
- Создайте частную схему, которая будет использоваться для доступа ко всем таблицам.
Приведенная выше команда просто деактивирует все общедоступные схемы.
Дополнительную информацию о документации можно найти здесь: https://www.postgresql.org/docs /9.3/ecpg-connect.html
3
dmigwi
17 Сен 2019 в 16:51
Пришлось заключить имя таблицы в двойные кавычки.
???
Двойные кавычки:
Много-много двойных кавычек:
Это postgres 11. Операторы CREATE TABLE из этого дампа также имеют двойные кавычки:
11
dfrankow
26 Сен 2019 в 21:57
Можешь попробовать:
Не забывайте двойные кавычки рядом с my_table.
23
Shree
3 Сен 2019 в 03:20
Я столкнулся с этой ошибкой, и оказалось, что моя строка подключения указывала на другую базу данных, очевидно, что таблицы там не было.
Я потратил на это несколько часов, и никто больше не упомянул о том, чтобы дважды проверить строку подключения .
Jeremy Thompson
13 Ноя 2020 в 02:29
Ответ 3
Вот функция PHP, которая вставит строку, только если все указанные значения столбцов еще не существуют в таблице.
-
Если один из столбцов отличается, строка будет добавлена.
-
Если таблица пуста, строка будет добавлена.
-
Если существует строка, в которой все указанные столбцы имеют указанные значения, строка не будет добавлена.
function insert_unique($table, $vars) {
if (count($vars)) {
$table = mysql_real_escape_string($table);
$vars = array_map(‘mysql_real_escape_string’, $vars);
$req = «INSERT INTO `$table` (`». join(‘`, `’, array_keys($vars)) .»`) «;
$req .= «SELECT ‘». join(«‘, ‘», $vars) .»‘ FROM DUAL «;
$req .= «WHERE NOT EXISTS (SELECT 1 FROM `$table` WHERE «;
foreach ($vars AS $col => $val)
$req .= «`$col`=’$val’ AND «;
$req = substr($req, 0, -5) . «) LIMIT 1»;
$res = mysql_query($req) OR die();
return mysql_insert_id();
}
return False;
}
Пример использования:
<?php
insert_unique(‘mytable’, array(
‘mycolumn1’ => ‘myvalue1’,
‘mycolumn2’ => ‘myvalue2’,
‘mycolumn3’ => ‘myvalue3’
)
);
?>
REPLACE TABLE
Запрос позволяет частично изменить таблицу (структуру или данные).
Замечание
Такие запросы поддерживаются только движком БД Atomic.
Чтобы удалить часть данных из таблицы, вы можете создать новую таблицу, добавить в нее данные из старой таблицы, которые вы хотите оставить (отобрав их с помощью запроса ), затем удалить старую таблицу и переименовать новую таблицу так как старую:
Вместо перечисленных выше операций можно использовать один запрос:
Синтаксис
{CREATE |REPLACE} TABLE table_name
Для данного запроса можно использовать любые варианты синтаксиса запроса . Запрос для несуществующей таблицы вызовет ошибку.
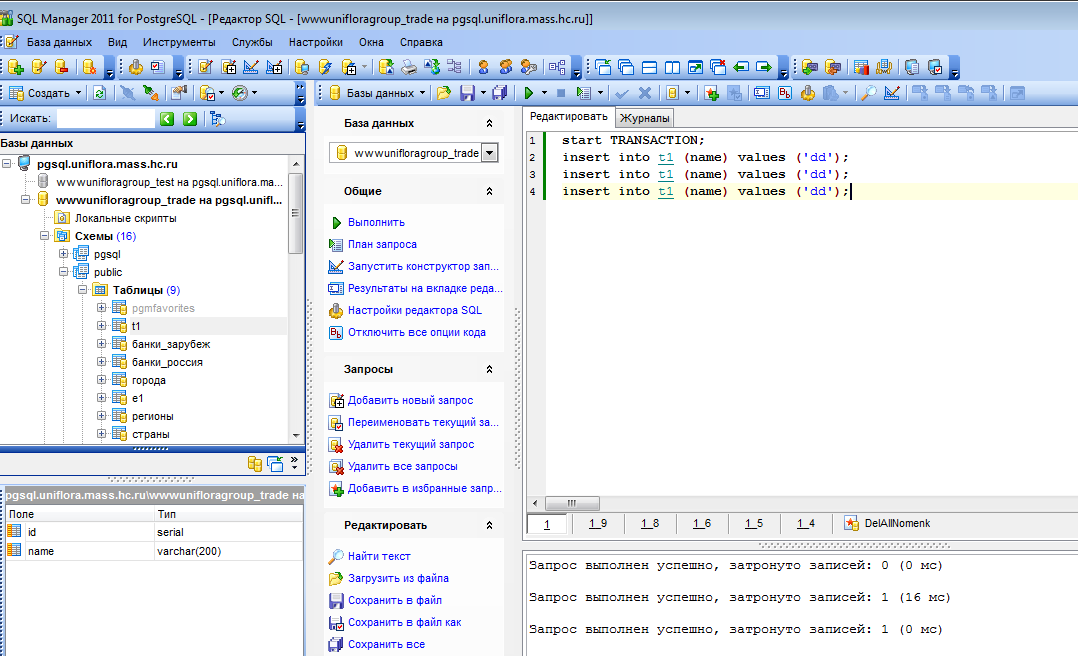
Примеры:
Рассмотрим таблицу:
Используем запрос для удаления всех данных:
Используем запрос для изменения структуры таблицы:
Типы данных PostgreSQL
Символьные значения
- char: хранит один символ
- char (#): содержит # количество символов; свободные места будут заполнены пробелами.
- varchar (#): хранит данные переменной длины (не в Юникоде); параметр # определяет длину строки.
Целые значения
- smallint: целое число между -32768 и 32767.
- int: целое число между -214783648 и 214783647.
- serial: целое число с автоувеличением.
Числа с плавающей точкой
- float (#): число с плавающей точкой, где # – количество битов.
- real: 8-битное число с плавающей точкой.
- numeric (#,after_dec): число с # количеством цифр, где after_dec – количество цифр после десятичного знака
Дата и время
- date: дата
- time: время
- timestamp: дата и время
- timestamptz: дата, время и часовой пояс
- interval: разница между двумя значениями timestamp
Геометрические типы
- point: хранит пару координат определённой точки.
- line: набор точек, определяющих линию.
- lseg: набор данных, определяющий сегмент линии.
- box: набор данных, который определяет прямоугольник.
- polygon: набор данных, определяющий любое закрытое пространство
Базы данных и шаблоны
Когда мы создаём новые кластер командой у нас создается 3 одинаковые базы данных:
- postgres
- template0
- template1
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
База postgres используется, чтобы по умолчанию к ней подключаться. Принципиально она не нужна, но есть приложения которым она может понадобится, поэтому лучше её не удалять.
Две дополнительные базы template0 и template1 – это шаблоны. Новая база всегда создается путём копирования из другой шаблонной базы. По умолчанию для шаблона используется база template1. Поэтому, если у вас есть расширения, которыми вы пользуетесь, можете их заранее создать в template1.
Основная задача базы template0 заключается в том, что бы она никогда не менялась. Она используется, например при загрузке базы из дампа. Вначале вы создаёте базу из template0, а затем туда заливаете сохранённый дамп. Также база template0 позволяет создавать базы с использованием категорий локалей не по умолчанию (LC_COLLATE, LC_CTYPE).
Слои
Каждый файл занимает не больше 1 GB и кратен 8 KB. Поэтому если таблица больше 1 GB, то она хранится в нескольких файлах. Файлы состоят из 8 KB страниц, которые в случае необходимости помещаются в буферный кэш.
Существуют следующие слои:
- Основной слой (main) – сами данные. Этот слой существует у всех объектов;
- Слой инициализации (init) – существует только для нежурналируемых таблиц. Содержит пустую копию таблицы. В случае сбоя PostgreSQL не пытается восстановить нежурналируемую таблицу, а перезаписывает её пустой таблицей из этого слоя. Поэтому после сбоя нежурналируемые таблицы окажутся пустыми.
- Карта свободного пространства (fsm) – хранит информацию о том, где внутри файлов есть свободное пространство.
- Карта видимости (vm) – отмечает страницы, в которых все версии строк видны. Другими словами VACUUM уже их почистил от неактуальных версий строк. Такой слой существует только для таблиц. Он нужен для оптимизации, чтобы VACUUM знал, какие страницы чистить уже не нужно.
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд.
Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Всем мета-командам предшествует обратная косая черта , за которой следует фактическая команда.
Список всех баз данных
Чтобы получить список всех баз данных на сервере, ты можешь использовать команду .
Ввод этой мета-команды в оболочке Postgres выведет:
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
На данный момент мы пока ничего не создали, а базы данных которые ты видишь на экране — создаются по умолчанию при установке Postgres.
- postgres — это просто пустая база данных.
- «template0» и «template1» — это служебные базы данных, которые служат шаблоном для создания новых баз.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы).
Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.
Когда ты находишься внутри оболочки (shell), то можешь использовать команду (или ), за которой следует имя
базы данных. Если бы у тебя была другая база данных под названием , то подключиться к ней можно было бы так:
Полностью в терминале у тебя получится что-то такое:
Обрати внимание, что приглашение оболочки изменилось с на. Это значит, что теперь ты
подключен к базе данных , а не
Получить список всех таблиц в базе данных
Как и в случае со списком существующих баз данных, ты можешь получить список таблиц внутри конкретной базы данных
с помощью команды .
Перед выполнением этой команды вам необходимо войти в базу данных.
Предположим, ты уже находишься внутри базы , и в ней есть таблица с именем. Набрав , ты
получишь следующее:
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных
руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
Список пользователей и ролей
Как ты уже знаешь, при установке Postgres создается суперпользователь с именем .
Список всех пользователей базы данных можно вывести на экран используя команду .
Обрати внимание, что первый столбец называется — роль (role name).
И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей. В PostgreSQL пользователи и роли практически
одинаковы
В PostgreSQL пользователи и роли практически
одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание
других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно.
Вместо этого создают другие роли с меньшими привилегиями.
Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
Загрузка и установка PostgreSQL
PostgreSQL поддерживает все основные операционные системы. Процесс установки прост, поэтому я постараюсь рассказать
о нем как можно быстрее.
Для Windows и Mac ты можешь загрузить установщик
с
веб-сайта EDB
.
EDB больше не предоставляет пакеты для систем GNU/Linux. Вместо этого они рекомендуют вам использовать диспетчер
пакетов твоего дистрибутива.
Установщики включают в себя разные компоненты.
Вот самые важные из них:
- Сервер PostgreSQL (очевидно)
- pgAdmin, графический инструмент для управления базами данных
- Менеджер пакетов для загрузки и установки дополнительных инструментов и драйверов
Windows
Скачав установщик, запусти его как любой другой исполняемый файл. Процесс довольно прямолинеен,
но некоторые вещи все же заслуживают внимания.
Диалоговое окно «Выбрать компоненты» позволяет выборочно устанавливать компоненты.
Если у тебя нет веской причины что-то менять — оставляй все как есть.
По умолчанию PostgreSQL создает суперпользователя с именем (воспринимай его как учетную запись
администратора сервера базы данных).
Во время установки тебе нужно будет указать пароль для суперпользователя (root).
Позже ты сможешь создать других пользователей и назначать им отдельные доступы и роли.
Мы вернемся к этому позже, а сейчас тебе понадобится учетная запись суперпользователя, чтобы начать использовать СУБД.
Чтобы запустить сервер разработки на твоем компьютере или , необходимо
назначить ему порт.
Порт по умолчанию — 5432. Если ты устанавливаешь PostgreSQL впервые, то он скорее всего свободен.
Если окажется, что этот порт уже занят другим экземпляром PostgreSQL, ты можешь указать другое значение, например 5433.
После завершения установки ты сможешь запустить SQL Shell, поставляемый с Postgres.
Шаг за шагом ты выберешь сервер, какую базу данных использовать, порт, имя пользователя и пароль.
Используй данные, которые ты вводил на предыдущих шагах.
Поздравляю! Настройка для Windows завершена, и скоро мы начнем писать первые SQL запросы.
Ниже список вариантов установки для других операционных систем.
macOS
Для macOS у тебя есть разные варианты. Можно скачать установщик с сайта EDB и запустить его.
Кроме того, можно использовать , простое приложение для macOS.
После запуска у тебя появится сервер PostgreSQL, готовый к использованию.
Завершить работу сервера можно просто закрыв приложение.
Кроме того, ты также можете использовать , менеджер пакетов для macOS.
GNU/Linux
Ты можешь найти PostgreSQL в репозиториях большинства дистрибутивов Linux. Установить его можно одним щелчком мыши
из выбранного графического диспетчера пакетов.
Альтернативно, можно использовать установку через терминал.
Ты можешь обратиться к документации твоего дистрибутива для получения дополнительных сведений.
Arch
Запуск оболочки PostgreSQL
После установки PostgreSQL, нужно запустить оболочку(shell), с помощью которой ты получишь возможность управлять базой данных.
Открой терминал и введи:
— это оболочка Postgres, аргумент используется для указания пользователя.
Поскольку ты еще не создавал других
пользователей, ты войдешь в систему как суперпользователь .
После этого нужно будет ввести пароль
суперпользователя, который ты выбрал во время установки.
Как только пароль установлен, база данных PostgreSQL готова к работе!
Если сервер PostgreSQL по какой-то причине не запускается, можешь попробовать запустить его вручную.
Кодеки сжатия столбцов
По умолчанию, ClickHouse применяет к столбцу метод сжатия, определённый в конфигурации сервера. Кроме этого, можно задать метод сжатия для каждого отдельного столбца в запросе .
Если кодек задан для столбца, используется сжатие по умолчанию, которое может зависеть от различных настроек (и свойств данных) во время выполнения.
Пример: — то же самое, что не указать кодек.
Также можно подменить кодек столбца сжатием по умолчанию, определенным в config.xml:
Кодеки можно последовательно комбинировать, например, .
Предупреждение
Нельзя распаковать базу данных ClickHouse с помощью сторонних утилит наподобие . Необходимо использовать специальную утилиту clickhouse-compressor.
Сжатие поддерживается для следующих движков таблиц:
- MergeTree family
- Log family
- Set
- Join
ClickHouse поддерживает кодеки общего назначения и специализированные кодеки.
Кодеки общего назначения
Кодеки:
- — без сжатия.
- — алгоритм сжатия без потерь используемый по умолчанию. Применяет быстрое сжатие LZ4.
- — алгоритм LZ4 HC (high compression) с настраиваемым уровнем сжатия. Уровень по умолчанию — 9. Настройка устанавливает уровень сжания по умолчанию. Возможные уровни сжатия: . Рекомендуемый диапазон уровней: .
- — алгоритм сжатия ZSTD с настраиваемым уровнем сжатия . Возможные уровни сжатия: . Уровень сжатия по умолчанию: 1.
Высокие уровни сжатия полезны для ассимметричных сценариев, подобных «один раз сжал, много раз распаковал». Они подразумевают лучшее сжатие, но большее использование CPU.
Специализированные кодеки
Эти кодеки разработаны для того, чтобы, используя особенности данных сделать сжатие более эффективным. Некоторые из этих кодеков не сжимают данные самостоятельно. Они готовят данные для кодеков общего назначения, которые сжимают подготовленные данные эффективнее, чем неподготовленные.
Специализированные кодеки:
- — Метод, в котором исходные значения заменяются разностью двух соседних значений, за исключением первого значения, которое остаётся неизменным. Для хранения разниц используется до , т.е. — это максимальный размер исходных данных. Возможные значения : 1, 2, 4, 8. Значение по умолчанию для равно , если результат 1, 2, 4, or 8. Во всех других случаях — 1.
- — Вычисляется разницу от разниц и сохраняет её в компакном бинарном виде. Оптимальная степень сжатия достигается для монотонных последовательностей с постоянным шагом, наподобие временных рядов. Можно использовать с любым типом данных фиксированного размера. Реализует алгоритм, используемый в TSDB Gorilla, поддерживает 64-битные типы данных. Использует 1 дополнительный бит для 32-байтовых значений: 5-битные префиксы вместо 4-битных префиксов. Подробнее читайте в разделе «Compressing Time Stamps» документа Gorilla: A Fast, Scalable, In-Memory Time Series Database.
- — Вычисляет XOR между текущим и предыдущим значением и записывает результат в компактной бинарной форме. Еффективно сохраняет ряды медленно изменяющихся чисел с плавающей запятой, поскольку наилучший коэффициент сжатия достигается, если соседние значения одинаковые. Реализует алгоритм, используемый в TSDB Gorilla, адаптируя его для работы с 64-битными значениями. Подробнее читайте в разделе «Compressing Values» документа Gorilla: A Fast, Scalable, In-Memory Time Series Database.
- — Метод сжатия который обрезает неиспользуемые старшие биты целочисленных значений (включая , и ). На каждом шаге алгоритма, кодек помещает блок из 64 значений в матрицу 64✕64, транспонирует её, обрезает неиспользуемые биты, а то, что осталось возвращает в виде последовательности. Неиспользуемые биты, это биты, которые не изменяются от минимального к максимальному на всём диапазоне значений куска данных.
Кодеки и используются в TSDB Gorilla как компоненты алгоритма сжатия. Подход Gorilla эффективен в сценариях, когда данные представляют собой медленно изменяющиеся во времени величины. Метки времени эффективно сжимаются кодеком , а значения кодеком . Например, чтобы создать эффективно хранящуюся таблицу, используйте следующую конфигурацию:





