
3 ответа
Лучший ответ
Нет. Это нарушает правило одного определения:
Если вам нужны разные определения классов, они должны быть разных типов. Одно из возможных решений — это пространство имен с уникальным именем, а анонимное пространство имен — это гарантированный способ получить уникальное (для единицы перевода) пространство имен.
14
Remy Lebeau
17 Авг 2020 в 19:21
Укороченная версия
Ну, нет … C ++ основан на предположении, что каждое имя в пространстве имен уникально. Если вы нарушите это предположение, у вас будет 0 гарантий, что оно будет работать.
Например, если у вас есть методы с одинаковыми именами в двух единицах перевода (файлы ). Компоновщик не знает, какой из них использовать для данного вызова, поэтому он просто вернет ошибку.
Длинная версия
… но на самом деле да!
На самом деле существует довольно много ситуаций, когда вы можете обойтись классами / методами с тем же именем.
На самом деле не используйте ни один из этих приемов в своих программах! Компиляторы могут делать практически все, что угодно, если они думают, что оптимизируют полученную программу, так что любое из приведенных ниже предположений может нарушиться.
Занятия самые легкие. Возьмем какой-нибудь класс только с нестатическими членами и без функций. Это даже не оставляет следов в скомпилированной программе. Классы / структуры — это всего лишь инструменты для программиста для организации данных, поэтому нет необходимости иметь дело с пулами памяти и смещениями. Так что в основном, если у вас есть два класса с одинаковым именем в разных единицах компиляции, это должно работать. После того, как компилятор закончит с ними работать, они будут состоять всего из нескольких инструкций о том, на сколько переместить указатель в памяти для доступа к определенному полю. Здесь нет ничего, что могло бы смутить компоновщика.
Функции и переменные (включая переменные статического класса) сложнее, потому что компилятор часто создает для них символы в файле . Если вам повезет, компоновщик может игнорировать их, если такая функция / переменная не используется, но я бы даже не стал на это рассчитывать. Однако есть способы не создавать для них символы. Статические глобальные элементы или элементы в анонимных пространствах имен не видны за пределами своих единиц перевода, поэтому компоновщик не должен на них жаловаться. Кроме того, встроенные функции не существуют как отдельные сущности, поэтому они также не имеют символов, что особенно актуально здесь, поскольку функции, определенные внутри классов, встроены по умолчанию. Если символа нет, компоновщик не увидит конфликта, и все должно скомпилироваться.
Шаблоны также используют некоторые грязные уловки, потому что они компилируются по запросу в каждой единице компиляции, которая их использует, но в конечном итоге они остаются единственной копией в окончательных программах. Я не думаю, что это тот же случай, что и несколько разных вещей с одним и тем же именем, поэтому давайте оставим эту тему.
В заключение, если у ваших классов нет статических членов и они не определяют функции вне своих тел, возможно, у вас будет два класса с одинаковым именем, если вы не включите их в один и тот же файл. Однако это чрезвычайно хрупко. Даже если он работает прямо сейчас, новая версия компилятора может содержать исправление / оптимизацию / изменение, которое сломало бы такую программу. Не говоря уже о том, что включение имеет тенденцию в значительной степени переплетаться в более крупных проектах, поэтому есть большая вероятность, что в какой-то момент вам потребуется включить оба файла в одно и то же место.
1
NO_NAME
17 Авг 2020 в 23:02
Вы должны понимать, что классы определяются пользователем и, следовательно, должны быть уникальными. Таким образом, вы не можете использовать два класса с одинаковым именем. Используйте пространства имен.
Dsouzax
17 Авг 2020 в 19:16
Объяснение
Возможны следующие причины возникновения этой ошибки запроса.
-
Имя столбца неправильно указано, либо столбец не существует ни в одной указанной таблице.
-
Параметры сортировки базы данных учитывают регистр, а регистр имени столбца, указанный в запросе, не совпадает с регистром столбца, определенного в таблице. Например, если столбец определен в таблице как LastName, а для базы данных используются параметры сортировки с учетом регистра, при выполнении запросов, в которых для этого столбца указано имя Lastname или lastname, возникнет ошибка 207, так как имена столбцов не совпадают.
-
Псевдоним столбца, определенный в предложении SELECT, упоминается в другом предложении, например WHERE или GROUP BY. Например, следующий запрос определяет псевдоним столбца в предложении SELECT и упоминает его в предложении GROUP BY.
Порядок логической обработки предложений запросов вызывает возвращение ошибки 207. Далее приводится порядок обработки.
-
FROM
-
ON
-
JOIN
-
WHERE
-
GROUP BY
-
WITH CUBE или WITH ROLLUP
-
HAVING
-
SELECT
-
DISTINCT
-
ORDER BY
-
В начало
Поскольку псевдоним столбца не определяется до обработки предложения SELECT, псевдоним неизвестен при обработке предложения GROUP BY.
-
-
Инструкция MERGE выдает эту ошибку, когда исходная таблица в предложении WHEN NOT MATCHED BY SOURCE не возвращает строк, а предложение <merge_matched> ссылается на столбцы в исходной таблице. Данная ошибка возникает из-за того, что невозможно обратиться к столбцам в исходной таблице, если запрос не возвратил строк. Например, предложение может стать причиной ошибки инструкции из-за недоступности столбца в исходной таблице.
Роли
Когда нескольким пользователям нужно выполнить похожие действия с отдельной базой данных (и для них нет соответствующей группы Windows), можно добавить роль базы данных, которая задает группу пользователей базы данных, имеющих доступ к одним и тем же объектам базы данных.
Участниками роли базы данных могут быть любые следующие представители:
- группы Windows и учетные записи пользователей Windows
- учетные записи SQL Server
- другие роли
Архитектура безопасности в Database Engine включает несколько систем ролей, которые имеют специальные неявные полномочия. Существуют два типа предварительно определенных ролей (в дополнение к ролям, определенным пользователям):
- фиксированные серверные роли
- фиксированные роли базы данных
Помимо этих двух в следующих разделах также описываются такие типы ролей:
- роли приложений
- роли, определенные пользователем
Фиксированные серверные роли
Фиксированные серверные роли определены на уровне сервера и поэтому существуют вне баз данных, принадлежащих базам данных сервера. Ниже перечислены следующие серверные роли:
- sysadmin – выполняет любые действия в системе баз данных
- serveradmin – конфигурирует серверные установки
- setupadmin – инсталлирует репликацию и управляет расширенными процедурами
- securityadmin – управляет учетными записями и полномочиями CREATE DATABASE, проверяет отчетность
- processadmin – управляет системными процессами
- dbcreator – создает и изменяет базы данных
- diskadmin – управляет дисковыми файлами
Системные процедуры sp_addsrvrolemember и sp_dropsrvrolemember используются, соответственно, для добавления членов и удаления членов из фиксированных серверных ролей. При этом сами серверные роли удалить нельзя. Дополнительно к этому только члены фиксированных серверных ролей могут выполнять системные процедуры для добавления или удаления учетных записей из ролей.
Каждая фиксированная серверная роль имеет собственные неявные полномочия к системной базе данных. Можно просмотреть полномочия у каждой фиксированной серверной роли, используя системную процедуру sp_srvrolepermission. Для получения более полной информации о фиксированных серверных ролях, лучше всего обратиться к BOL.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.

Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
Объяснение
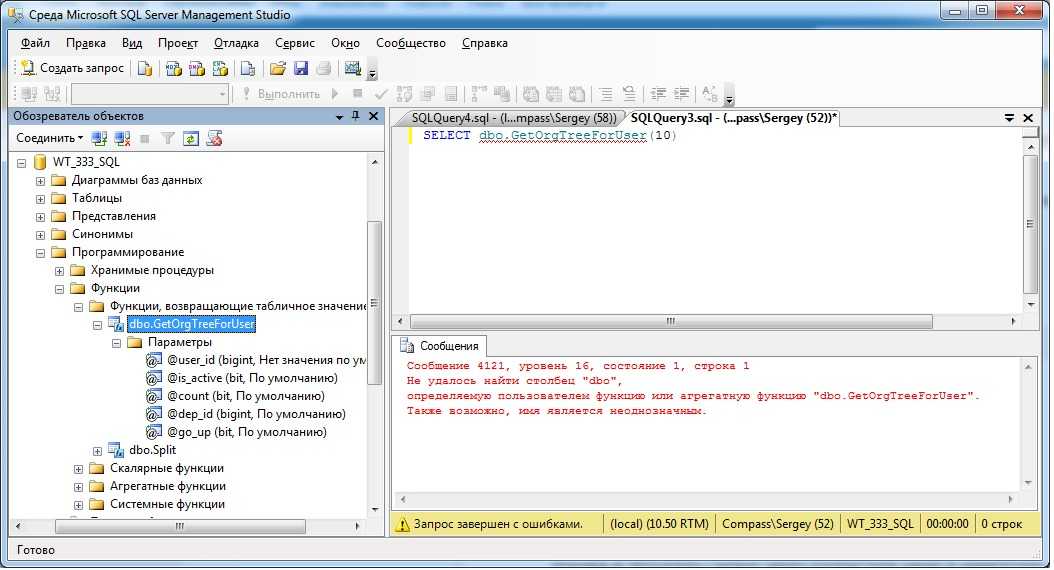
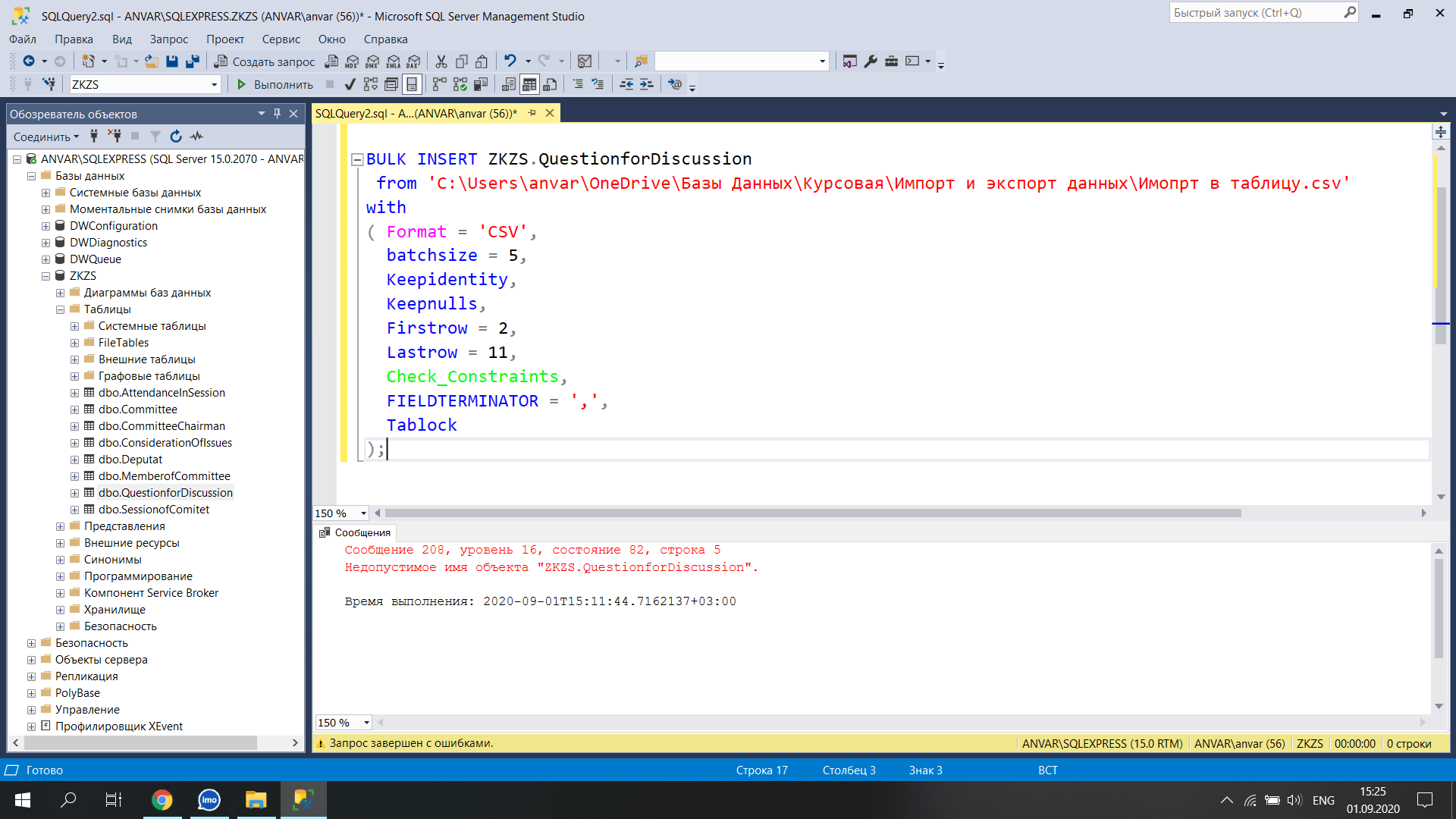
Имя сущности в SQL Server определяется ее идентификатором. Идентификаторы используются, например, всегда при ссылках на сущности путем указания в запросе имен столбца и таблицы. Составной идентификатор содержит один или несколько квалификаторов, являющихся префиксом для идентификатора. Например, перед идентификатором таблицы можно указывать такие квалификаторы, как имя базы данных и имя схемы, в которых содержится таблица, а перед идентификатором столбца могут находиться такие квалификаторы, как имя таблицы или псевдоним таблицы.
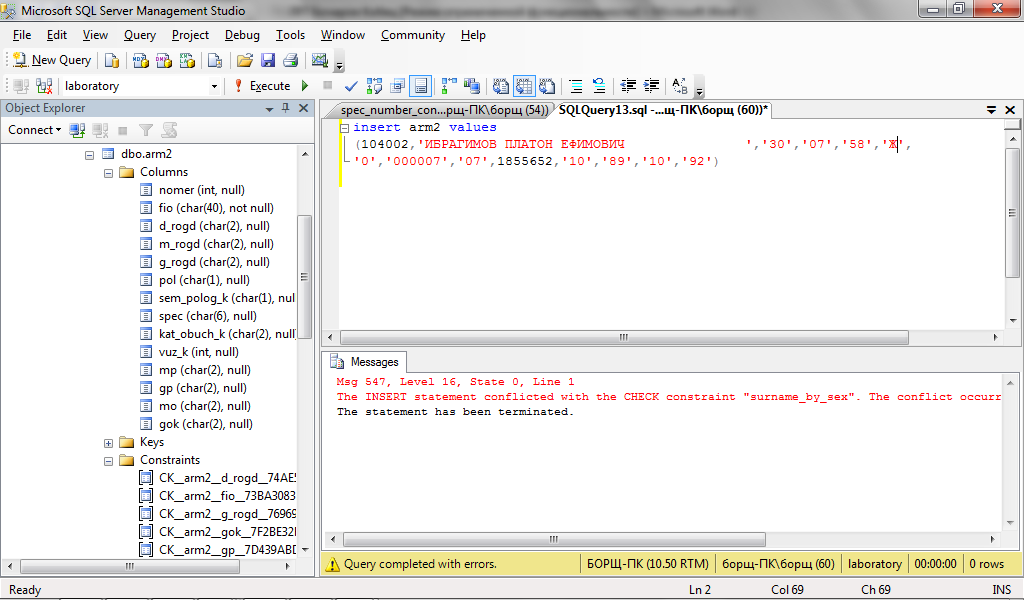
Ошибка 4104 указывает, что заданный составной идентификатор не может быть сопоставлен существующей сущности. Эта ошибка может быть возвращена при следующих условиях.
-
Квалификатор, заданный в качестве префикса для имени столбца, не совпадает ни с одним именем таблицы или псевдонима, используемым в запросе.
Например, в следующей инструкции псевдоним таблицы () используется как префикс столбца, но в предложении FROM нет ссылки на псевдоним таблицы.
В следующих инструкциях составной идентификатор столбца задан в предложении WHERE как часть условия JOIN между двумя таблицами, но в запросе нет явной ссылки на таблицу .
-
Имя псевдонима для таблицы указывается в предложении FROM, но квалификатор, указанный для столбца, является именем таблицы. Например, в следующей инструкции имя таблицы () используется как префикс столбца; но у таблицы есть псевдоним (), ссылка на который содержится в предложении FROM.
Когда используется псевдоним, имя таблицы не может использоваться в других частях инструкции.
-
SQL Server не может определить, указывает ли составной идентификатор на столбец, предваряемый таблицей, или на определяемый пользователем тип данных CLR, предваряемый столбцом. Это происходит потому, что ссылка на свойства столбцов определяемых пользователем типов задается с использованием точки (.) в качестве разделителя между именем столбца и именем свойства, так же как имя столбца предваряется именем таблицы. В следующем примере создается две таблицы, и . Таблица содержит столбец , в котором в качестве типа данных используется определяемый пользователем тип данных CLR . Инструкция SELECT содержит составной идентификатор .
Если определяемый пользователем тип данных не имеет свойства с именем , SQL Server не сможет определить, указывает ли идентификатор на столбец в таблице или на столбец , свойство в таблице .
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.
Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):
В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми
То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
На скриншоте ниже вы видите эту формулу в деле.
Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально
Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:
Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Действие пользователя
-
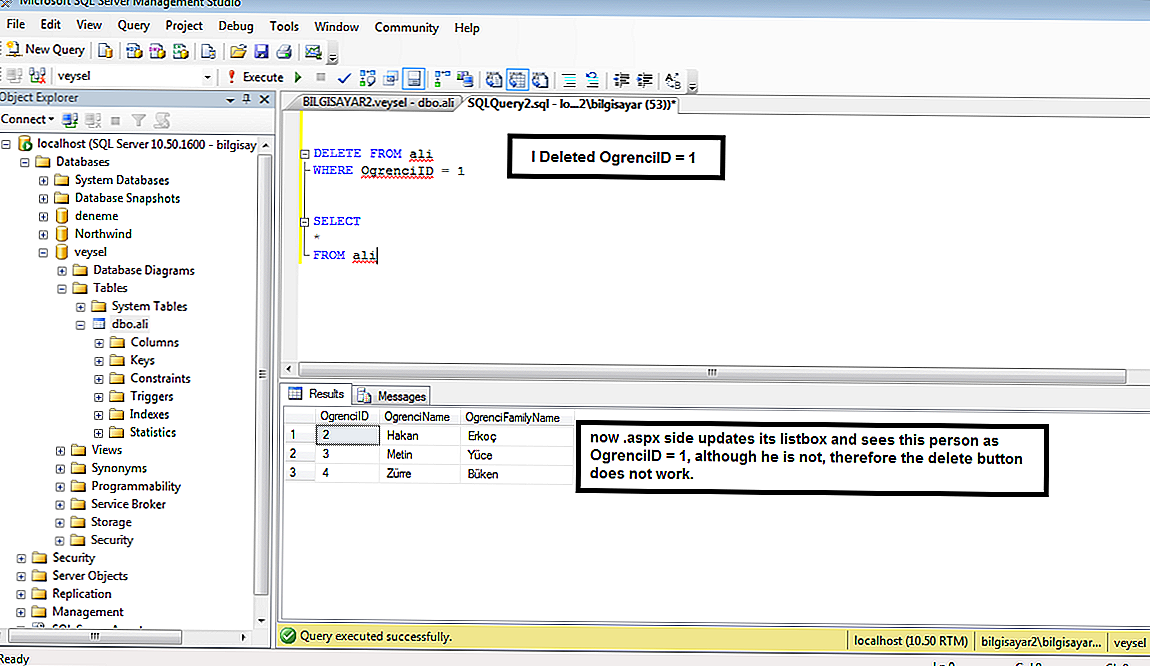
Префиксы столбцов должны быть согласованы с именами таблиц или псевдонимами, указанными в предложении FROM запроса. Если псевдоним определен для имени таблицы в предложении FROM, то псевдоним можно использовать только как квалификатор для столбцов, связанных с этой таблицей.
Приведенные выше инструкции, которые содержат ссылки на таблицу , можно исправить следующим образом:
-
Проверьте, что все таблицы указаны в запросе и условия JOIN между таблицами заданы верно. Инструкция DELETE выше может быть исправлена следующим образом:
Приведенная выше инструкция SELECT для таблицы может быть исправлена следующим образом:
или диспетчер конфигурации служб
-
Используйте для идентификаторов уникальные, понятные имена. В результате будет проще читать и исправлять исходный текст, и снижается опасность неоднозначных ссылок на несколько сущностей.
-

![Sql исключает столбец, используя select * [кроме columna] from tablea? – 35 ответов](https://fuzeservers.ru/wp-content/uploads/c/6/f/c6fdec85d2bd65c0f31f11c746cf6d0a.bmp)
![Sql исключает столбец, используя select * [кроме columna] from tablea?](https://fuzeservers.ru/wp-content/uploads/9/8/7/9876722776a2e3baaa9349651ee7fb09.jpeg)
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Рекомендации по выбору данных из набора столбцов
Следует учитывать следующие рекомендации при выборе данных из набора столбцов.
-
Фактически, набор столбцов — это тип обновляемого, вычисляемого XML-столбца, в котором набор базовых реляционных столбцов собирается в единое XML-представление. Набор столбцов поддерживает только свойство ALL_SPARSE_COLUMNS. Это свойство используется для агрегирования всех значений, отличных от значения NULL, из всех разреженных столбцов в определенной строке.
-
В редакторе таблиц среды SQL Server Management Studio наборы столбцов отображаются как изменяемые XML-поля. Наборы столбцов определяются с помощью следующего формата:
Далее приводятся примеры значений набора столбцов:
-
Разреженные столбцы, содержащие значения NULL, не включаются в XML-представление набора столбцов.
Предупреждение
Добавление набора столбцов изменяет поведение запросов . Запрос будет возвращать набор столбцов как XML-столбец, а не как отдельные разреженные столбцы. Разработчики схем и приложений должны учитывать это, чтобы не нарушить работу существующих приложений. Отдельные разреженные столбцы по-прежнему можно запрашивать по имени в инструкции SELECT.
ВПР по нескольким критериям с применением массивов — способ 2.
Выше мы уже рассматривали, как при помощи формулы массива можно организовать поиск ВПР с несколькими условиями. Предлагаем еще один способ.
Условия возьмем те же, что и в предыдущем примере.
Формулу в С4 введем такую:
Естественно, не забываем нажать CTRL+Shift+Enter.
Теперь давайте пошагово разберем, как это работает.
Наше задача здесь – также создать дополнительный столбец для работы функции ВПР. Только теперь мы создаем его не на листе рабочей книги Excel, а виртуально.
Как и в предыдущем примере, мы ищем текст из объединенных в одно целое условий поиска.
Далее определяем данные, среди которых будем искать.
Конструкция вида A7:A20&B7:B20&C7:C20;D7:D20 создает 2 элемента. Первый – это объединение колонок A, B и C из исходных данных. Если помните, то же самое мы делали в нашем дополнительном столбце. Второй D7:D20 – это значения, одно из которых нужно в итоге выбрать.
Функция ВЫБОР позволяет из этих элементов создать массив. {1,2} как раз и означает, что нужно взять сначала первый элемент, затем второй, и объединить их в виртуальную таблицу – массив.
В первой колонке этой виртуальной таблицы мы будем искать, а из второй – извлекать результат.
Таким образом, для работы функции ВПР с несколькими условиями мы вновь используем дополнительный столбец. Только создаем его не реально, а виртуально.
Примеры
В следующих примерах в таблице документа содержится обычный набор столбцов и . Производственной группе необходимы столбцы и для всех рабочих документов. Группе сбыта необходим столбец для документов сбыта.
A. Создание таблицы с набором столбцов
В следующем примере создается таблица, в которой используются разреженные столбцы и содержится набор столбцов . В этом примере в таблицу вставляются две строки, а затем из таблицы выбираются данные.
Примечание
Эта таблица насчитывает лишь пять столбцов, что упрощает ее отображение и чтение.
Б. Вставка данных в таблицу с использованием имен разреженных столбцов
В следующих примерах в таблицу, созданную в примере А, вставляются две строки. В примерах используются имена разреженных столбцов; набор столбцов не упоминается.
В. Вставка данных в таблицу с использованием имени набора столбцов
В следующем примере в таблицу, созданную в примере А, вставляется третья строка. В этот раз имена разреженных столбцов не используются. Вместо этого используется имя набора столбцов, а операция вставки предоставляет значения для двух из четырех разреженных столбцов в формате XML.
Г. Рассмотрение результатов для набора столбцов при выполнении инструкции SELECT *
В следующем примере из таблицы, содержащей набор столбцов, выбираются все столбцы. Возвращается XML-столбец, содержащий сочетание значений разреженных столбцов. Разреженные столбцы не возвращаются индивидуально.
Результирующий набор:
Д. Рассмотрение результатов выбора набора столбцов с использованием его имени
Поскольку производственному отделу не нужны маркетинговые данные, в этом примере для ограничения выходных данных добавляется предложение . В этом примере используется имя набора столбцов.
Результирующий набор:
Е. Рассмотрение результатов выбора разреженных столбцов с использованием их имен
Несмотря на то, что таблица содержит набор столбцов, можно выполнять запросы из таблицы с использованием имен отдельных столбцов. Это показано в следующем примере.
Результирующий набор:
Ж. Обновление таблицы с помощью набора столбцов
В следующем примере третья запись обновляется новыми значениями для обоих разреженных столбцов, использующихся в этой строке.
Важно!
Инструкция UPDATE, использующая набор столбцов, обновляет все разреженные столбцы в таблице. Для всех разреженных столбцов, которые не были упомянуты, устанавливается значение NULL.


В следующем примере обновляется третья запись, однако значение указывается только для одного из двух заполненных столбцов. Второй столбец, , не включен в инструкцию , и для него устанавливается значение NULL.
Безопасность
Модель безопасности набора столбцов работает схожим образом с моделью безопасности между таблицами и столбцами. Наборы столбцов могут быть визуализированы как мини-таблица; операции выбора для данной мини-таблицы имеют вид . Однако связь между набором столбцов и разреженными столбцами — это связь группирования, а не просто контейнер. Модель безопасности проверяет безопасность столбцов в наборе столбцов и выполняет операции DENY над базовыми разреженными столбцами. Далее приводятся дополнительные характеристики модели безопасности.
-
Права доступа могут быть предоставлены и отменены на столбец в наборе столбцов так же, как и на любой другой столбец в таблице.
-
Выполнение инструкции GRANT или REVOKE для разрешений SELECT, INSERT, UPDATE, DELETE и REFERENCES для столбца в наборе столбцов не распространяется на базовые столбцы-участники этого набора. Оно применяется только к столбцу в наборе столбцов. Разрешение DENY для набора столбцов распространяется на базовые разреженные столбцы таблицы.
-
Чтобы выполнять инструкции SELECT, INSERT, UPDATE и DELETE над столбцами в наборе столбцов, пользователь должен иметь необходимые разрешения на столбец набора столбцов, а также соответствующее разрешение на все разреженные столбцы в таблице. Поскольку набор столбцов представляет все разреженные столбцы в таблице, пользователь должен обладать разрешением на все разреженные столбцы, включая и те, которые не будут изменены.
-
Выполнение инструкции REVOKE над разреженным столбцом или набором столбцов устанавливает для него параметры безопасности, заданные по умолчанию для его родительского объекта.
Имя столбца не начинается с символа @ и содержит косую черту (/)
Если имя столбца не начинается с символа @, но содержит косую черту (/), оно является признаком иерархии XML. Например, если имя столбца «Name1/Name2/Name3…/Namen _ «, каждое имя Name_ i _ представляет имя элемента, вложенного в элемент текущей записи (для i=1), или находящегося в элементе с именем Name_ i-1 . Если имя Namen* _ начинается с «@», оно сопоставляется с атрибутом элемента Name_ n-1 *.
Например, следующий запрос возвращает идентификатор работника и имя, представленное сложным элементом EmpName, который включает в себя имя, отчество и фамилию работника.
Имена столбцов используются в качестве пути при построении XML-документа в режиме PATH. Имя столбца, содержащего значения идентификатора работника, начинается с символа @. Поэтому атрибут EmpID добавляется к элементу . Имена всех других столбцов содержат символ косой черты (/), являющийся признаком иерархии. В итоговом XML-документе будет присутствовать дочерний элемент внутри элемента , а элемент будет, в свою очередь, содержать дочерние элементы , и .
Отчество работника имеет значение NULL, которое по умолчанию сопоставляется с отсутствием элемента или атрибута. Если необходимо сформировать элементы для значений NULL, укажите директиву ELEMENTS с ключевым словом XSINIL, как показано в данном запросе.
Результат:
По умолчанию в режиме PATH формируется элементно-ориентированный XML-документ. Поэтому указание директивы ELEMENTS в режиме PATH не имеет никакого смысла. Однако как показано в предыдущем примере, директива ELEMENTS с ключевым словом XSINIL может быть полезна при формировании элементов для значений NULL.
Следующий запрос кроме идентификатора и имени возвращает еще и адрес работника. В соответствии с путем, указанным в именах столбцов адресов, дочерний элемент добавляется к элементу , а подробные сведения об адресе добавляются в качестве дочерних элементов к элементу .
Результат:
Схемы баз данных по умолчанию
Каждая база данных в системе имеет следующие схемы базы данных по умолчанию:
- guest (гость)
- dbo
- INFORMATION_SCHEMA
- sys
Database Engine дает возможность пользователям, не имеющим учетной записи пользователя получить доступ к базе данных с использованием схемы guest (после создания каждая база данных имеет такую схему). Можно назначать привилегии схеме guest теми же способами, что и любым другим схемам. Можно также удалять и добавлять схему guest в любой базе данных за исключением системных баз данных master и tempdb.
Каждый объект базы данных может принадлежать одной и только одной схеме, которая является схемой по умолчанию для этого объекта. Схема по умолчанию может быть объявлена явно или неявно. Если схема по умолчанию не была объявлена явно в процессе создания объекта, то этот объект будет принадлежать схеме dbo. Логин, который является владельцем базы данных, всегда имеет специальное имя dbo при использовании базы данных, которой он владеет.
Схема INFORMATION_SCHEMA содержит всю информацию о представлениях схемы. Схема sys содержит системные объекты, такие как представления просмотра каталогов.
Разделение пользователей и схем
Схема является коллекцией объектов базы данных, которыми владеет один человек, и множество форм одного пространства имен (две таблицы в одной схеме не могут иметь одинаковых имен). Начиная с SQL Server 2005, жесткая связь между пользователями и схемами была отменена. Теперь Database Engine поддерживает именованные схемы, используя понятие принципала (администратора доступа), который имеет право доступа к объектам.
Принципал может быть:
- индивидуальным
- групповым.
Индивидуальный принципал представляет одного пользователя, например, в виде учетной записи (логин) или учетной записи пользователя Windows. Принципалы являются владельцами схем, однако владение схемой может быть передано другому принципалу без изменения имени схемы.
Отделение пользователей базы данных от схем дает большие преимущества, например, такие:
- один принципал может владеть несколькими схемами;
- несколько индивидуальных принципалов могут владеть одной схемой через их членство в роли или группе Windows.
- удаление пользователя базы данных не требует переименования объектов, содержащихся в схеме этого пользователя.
Каждая база данных содержит схему по умолчанию, используемую для разрешения имен объектов, на которые осуществляются ссылки без указания их полностью квалифицированных имен. Схема по умолчанию указывает первую схему, которая будет отыскиваться сервером базы данных, когда он разрешает имена объектов. Схема по умолчанию может быть установлена и изменена с использованием опции DEFAULT_SCHEMA оператора CREATE USER или ALTER USER. Если схема по умолчанию DEFAULT_SCHEMA оставлена необъявленной, пользователю базы данных будет предоставлена схема dbo в качестве его схемы по умолчанию.





