
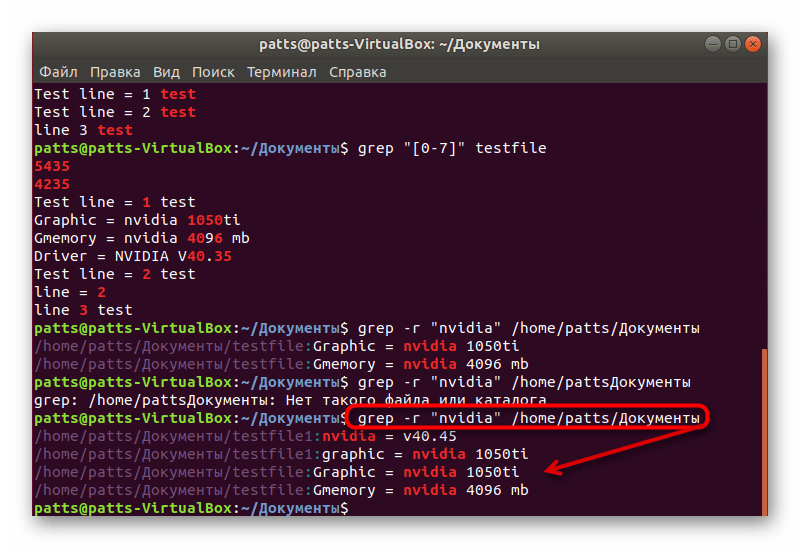
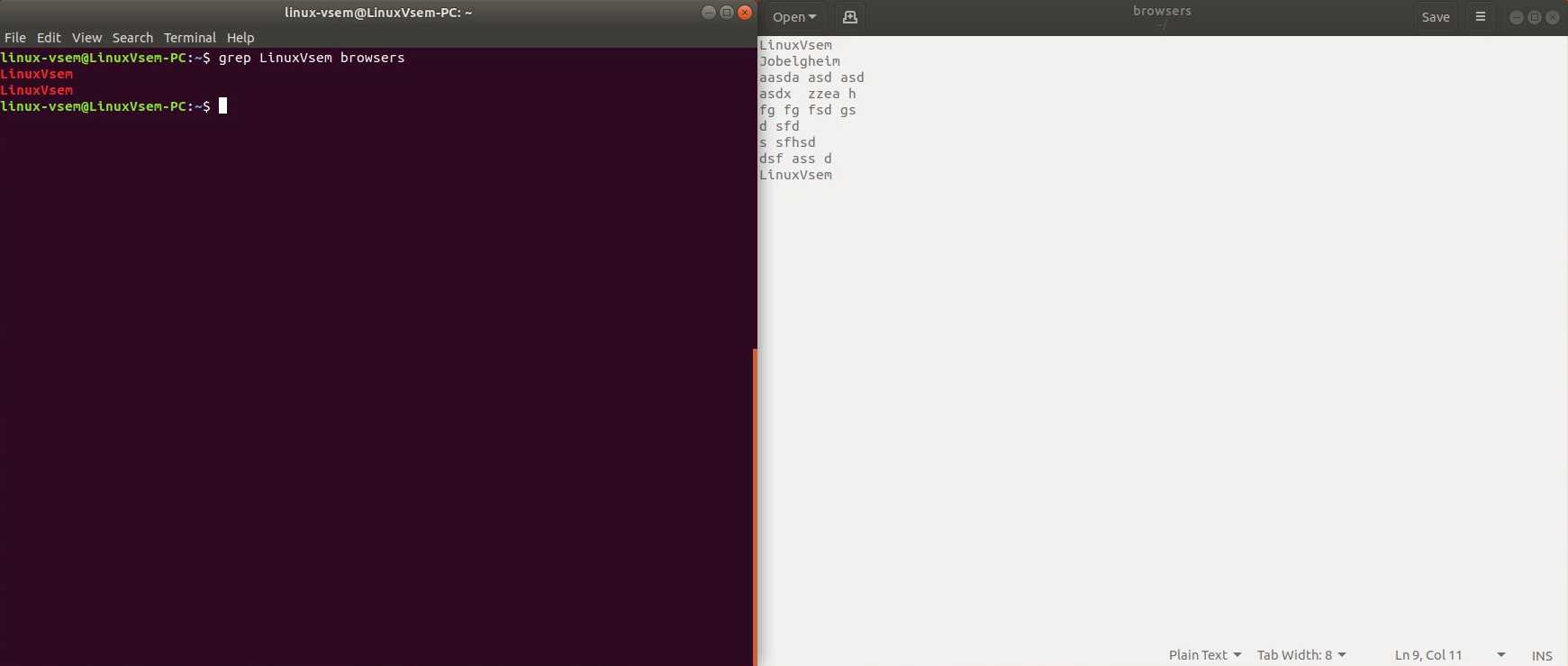
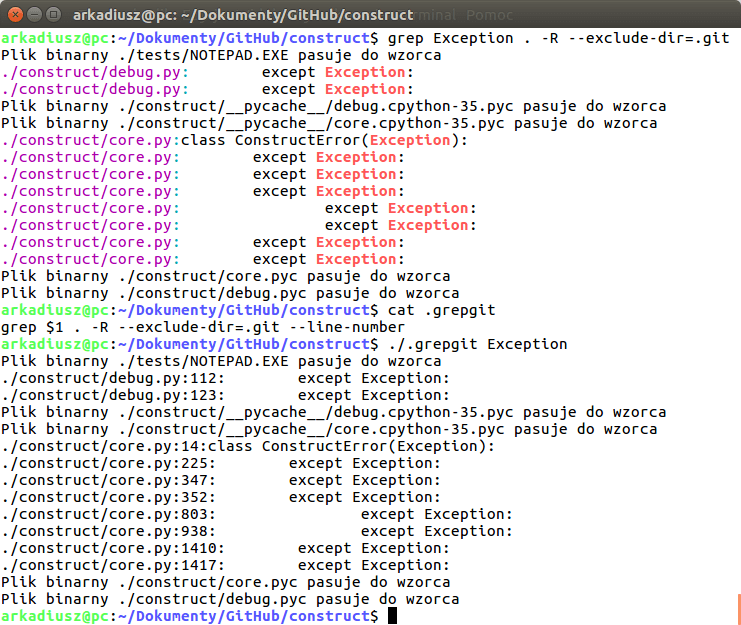
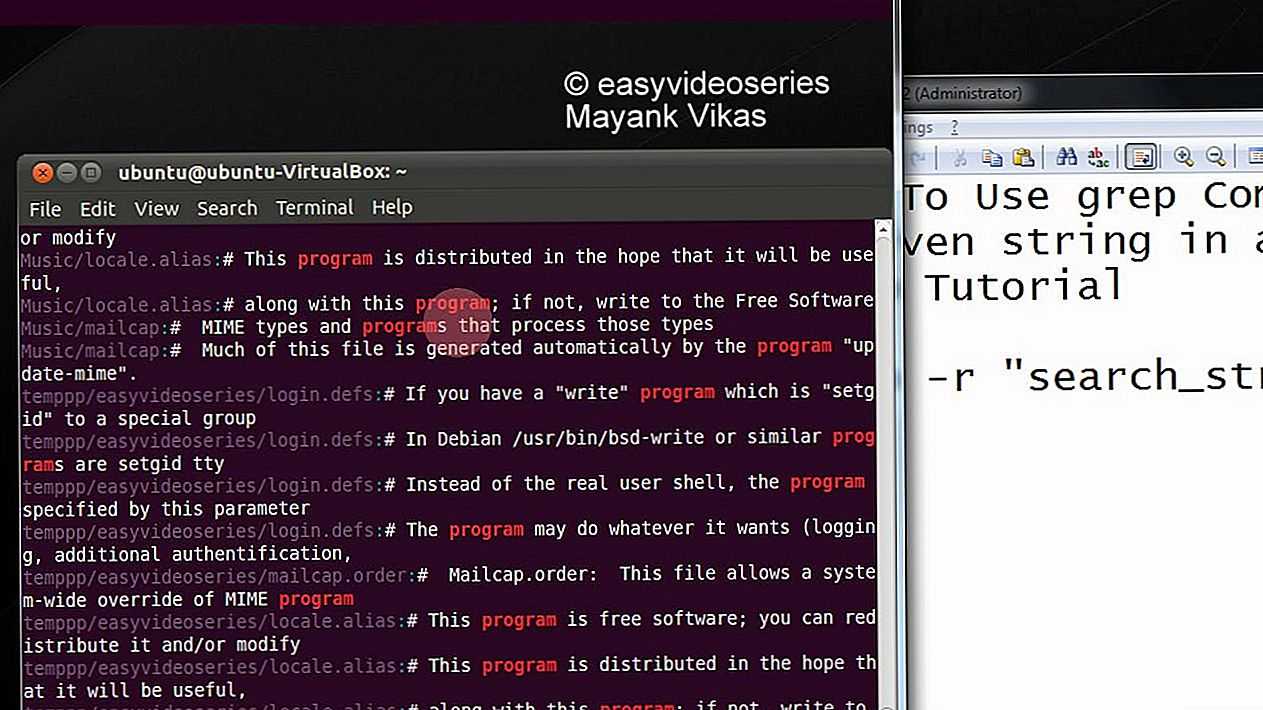
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите с параметром (или ). Когда используется этот параметр, будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо используйте параметр (или ).
Вот пример, показывающий, как искать строку во всех файлах внутри каталога :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию , будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда вызывается с потому что файлы внутри каталога с Nginx являются символическими ссылками на файлы конфигурации внутри каталога с
Команда tail в Linux
Перед тем как мы будем рассматривать примеры tail linux, давайте разберем ее синтаксис и опции. А синтаксис очень прост:
$ tail опции файл
По умолчанию утилита выводит десять последних строк из файла, но ее поведение можно настроить с помощью опций:
- -c — выводить указанное количество байт с конца файла;
- -f — обновлять информацию по мере появления новых строк в файле;
- -n — выводить указанное количество строк из конца файла;
- —pid — используется с опцией -f, позволяет завершить работу утилиты, когда завершится указанный процесс;
- -q — не выводить имена файлов;
- —retry — повторять попытки открыть файл, если он недоступен;
- -v — выводить подробную информацию о файле;
В качестве значения параметра -c можно использовать число с приставкой b, kB, K, MB, M, GB, G T, P, E, Z, Y. Еще есть одно замечание по поводу имен файлов. По умолчанию утилита не отслеживает изменение имен, но вы можете указать что нужно отслеживать файл по дескриптору, подробнее в примерах.
systemd и journald
systemd — это подсистема инициализации и управления службами в Linux, фактически вытеснившая в 2010-е годы традиционную подсистему init. В связке с ней работает и journald — демон сбора логов, являющийся частью systemd. Он собирает логи со всей системы и хранит их в бинарном виде в каталоге var/log/journal. Для того чтобы их просмотреть, создана специальная утилита journalctl. Рассмотрим несколько примеров её применения.
Чтобы просмотреть последние 10 строк логов всех запусков системы, достаточно выполнить следующую команду:
![]()
Видите столбец, который я обвел красным? Цифрой в нем обозначена текущая загрузка системы, цифрой — предыдущая и т.д. Если вы хотите просмотреть логи какой-то конкретной загрузки, например, позапрошлой, то достаточно ввести:
![]()
Также можно просмотреть информацию по выбранной службе, например, по NetworkManager:
![]()
Или же вывести сообщения ядра ОС:
![]()
Для получения своих, каких-то более конкретных результатов, допускается комбинировать опции и параметры команды :
![]()
Для вывода информации только по нескольким последним записям, применяется опция , задающая их количество:
![]()
![]()
С помощью параметра можно увидеть, сколько времени понадобилось для загрузки каждой конкретной службы (при этом сверху отобразятся самые медленные):
![]()
Использование регулярных выражений
Истинная сила grep заключается в возможности применения для поиска соответствий регулярным выражениям. В регулярных выражениях в аргументе ШАБЛОН используются специальные символы для охвата более широкого диапазона строк. Рассмотрим простой пример.
Допустим, требуется найти каждое появление фразы, похожей на «our products», которая всегда должна начинаться с «our» и заканчиваться на «products». Для этого нужно указать такой шаблон: «our.*products».
В регулярных выражениях точка («.») интерпретируется как маска для одного символа. Она означает «подойдет любой символ на этом месте». Звездочка («*») означает «подойдет предыдущий символ в количестве от нуля и более». Таким образом, комбинация «.*» означает, что подойдет любой символ в любом количестве. Например, «our amazing products», «ours, the best-ever products» и даже «ourproducts» будут соответствовать выражению. А так как указана опция –i, ему будут соответствовать также «OUR PRODUCTS» и «OuRpRoDuCtS». При запуске команды с этим регулярным выражением мы получим дополнительные совпадения:
$ grep –-color –n -i «our.*products» *.html product-details.html:27:<p><b>OUR PRODUCTS</b></p> product-details.html:59:<p class=”products-searchbox”>To search a comprehensive list of our products type your search term in the box below and click the magnifying glass</p> product-replacement.html:58:<p>If you experience dissatisfaction with any of our fine products, do not hesitate to contact us using the form below.</p> $
Была найдена фраза «our fine products».
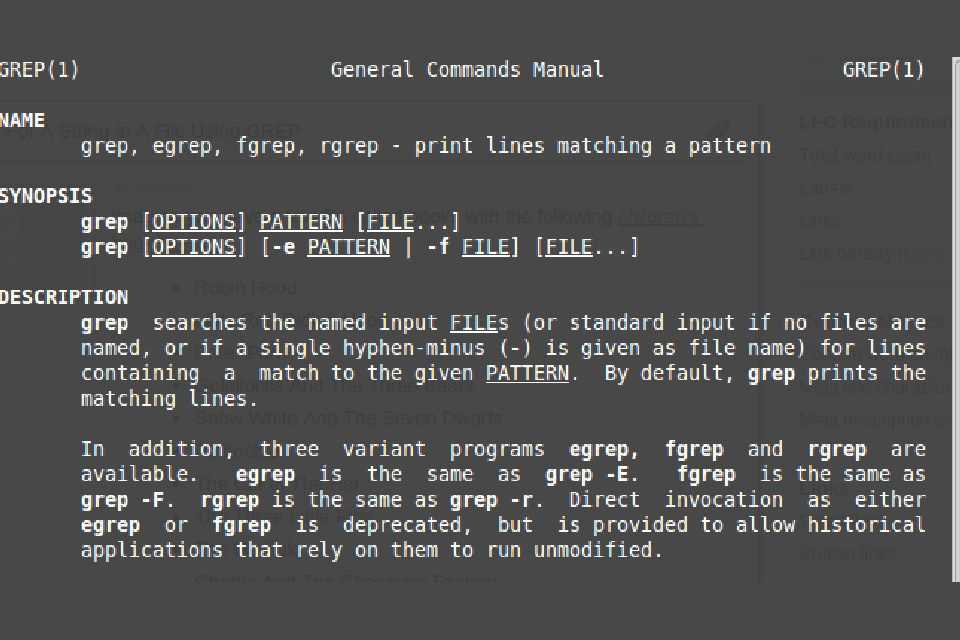
Grep – мощный инструмент работы с текстовыми файлами. При умелом использовании регулярных выражений он предоставляет еще более широкие возможности. Здесь рассмотрены наиболее типичные примеры использования команды. Другие опции командной строки можно узнать, запустив команду с опцией —help.
Основные логи
В основных логах, необходимых для работы Linux, содержится наиболее значительный объем информации о текущем состоянии системы. Их можно условно разделить на четыре категории:
системные лог-файлы;
лог-файлы событий;
лог-файлы служб;
лог-файлы приложений.
Многие из этих лог-файлов располагаются в каталоге var/log. Наиболее распространенными логами являются:
/var/log/boot.log — журнал загрузки системы (в нем хранится вся информация, связанная с этапами загрузки ОС);
/var/log/kern.log — журнал ядра (в нем хранятся сообщения и предупреждения, поступающие непосредственно из );
/var/log/syslog или /var/log/messages — журналы, в которых хранится информация об общей активности в системе (включая сообщения этапа загрузки);
/var/log/auth.log или /var/log/secure — журналы аутентификации и безопасности (в них хранятся записи обо всех попытках входа в систему, включая как успешные, так и неудачные);
/var/log/debug — журнал отладки (в нем хранится подробная отладочная информация системы и приложений);
/var/log/daemon.log — журнал демонов (содержит информацию о событиях, связанных с различными запущенными в системе демонами/службами);
/var/log/maillog или /var/log/mail.log — журналы почтовых серверов (в них хранится информация, относящаяся к почтовым серверам и архивированию электронных писем);
/var/log/cron — журнал, в котором хранится информация о запланированных задачах (заданиях cron);
/var/log/faillog — информация о неудачных входах в систему. Журнал полезен для изучения потенциальных нарушений безопасности, таких как: взломы учетных записей, попытки перебора паролей и пр.;
/var/log/dmesg — журнал сообщений драйверов устройств. Просмотреть содержимое данного журнала можно с помощью команды . Стоит заметить, что при достижении своего предела, старые сообщения перезаписываются более новыми.
/var/log/Xorg.x.log — журнал сообщений X-сервера.
В зависимости от выбранного дистрибутива, вы можете встретить следующие лог-файлы менеджеров пакетов:
/var/log/dpkg.log — журнал пакетов, установленных через утилиту dpkg в системах на основе .
/var/log/yum.log — журнал пакетов, установленных через утилиту yum в системах на основе .


/var/log/emerge.log — журнал пакетов (ebuild), установленных через утилиту emerge в Gentoo Linux.
Не все журналы разработаны в удобочитаемом виде. Некоторые из них предназначены только для чтения системными приложениями и представлены в бинарном формате данных:
/var/log/utmp и /var/log/utmp — журналы учета входов пользователей в систему. Для просмотра сообщений применяется команда , например:
![]()
/var/log/lastlog — журнал с информацией о последних входах пользователей. Для просмотра сообщений применяется команда :
![]()
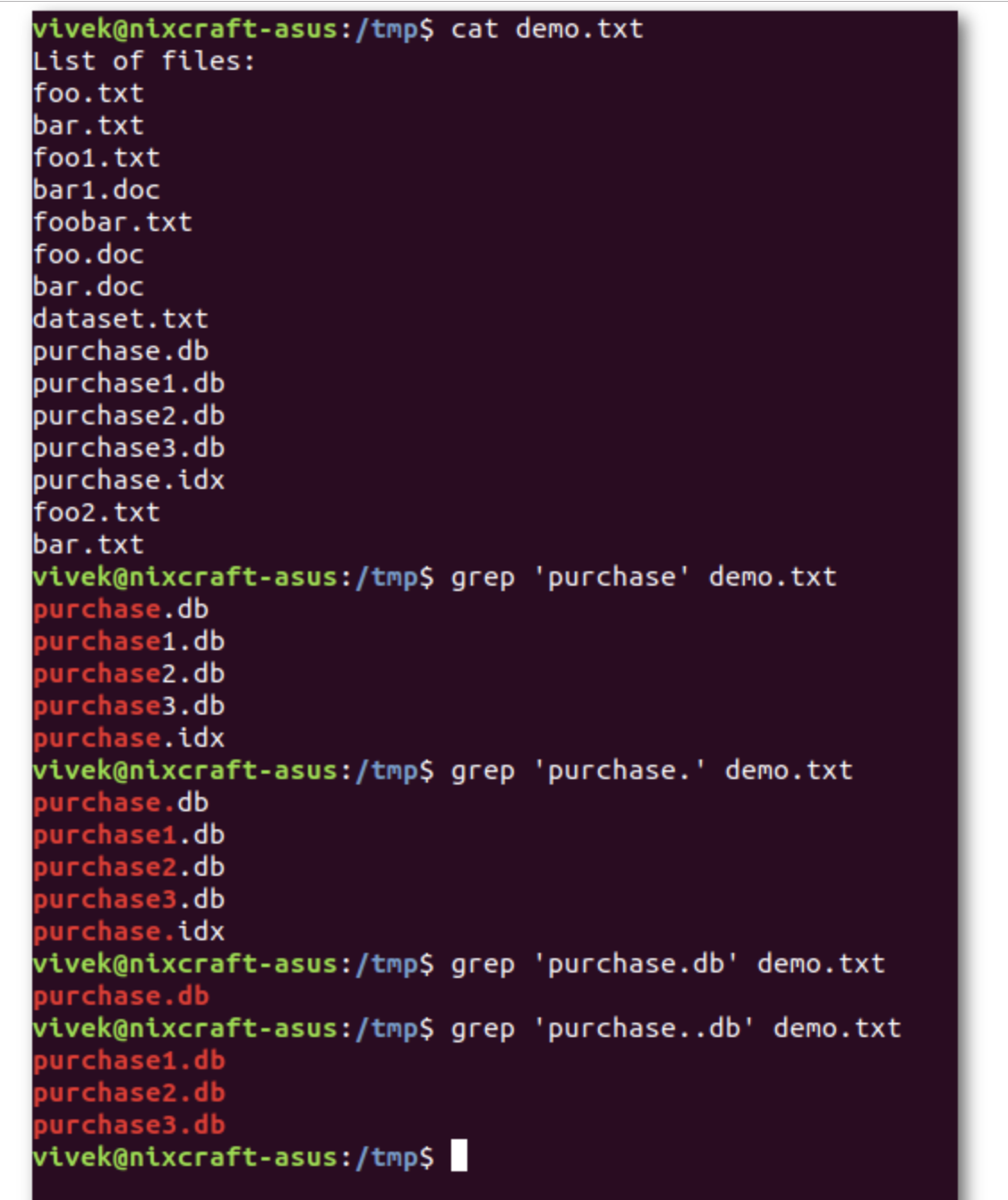
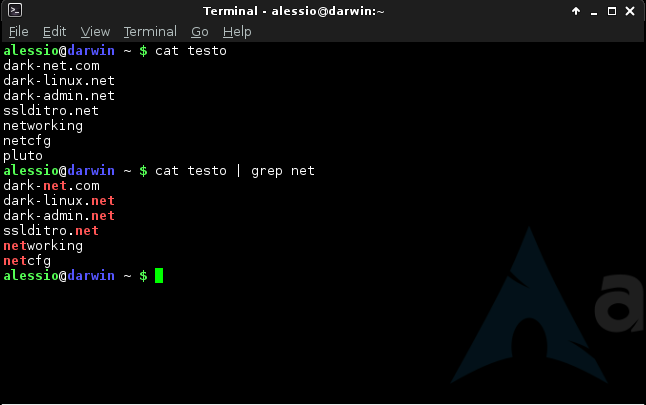
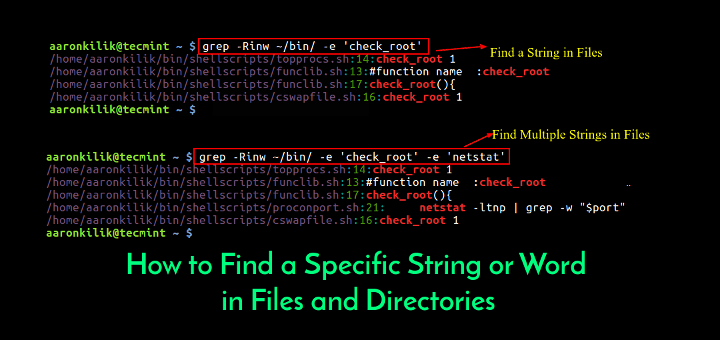
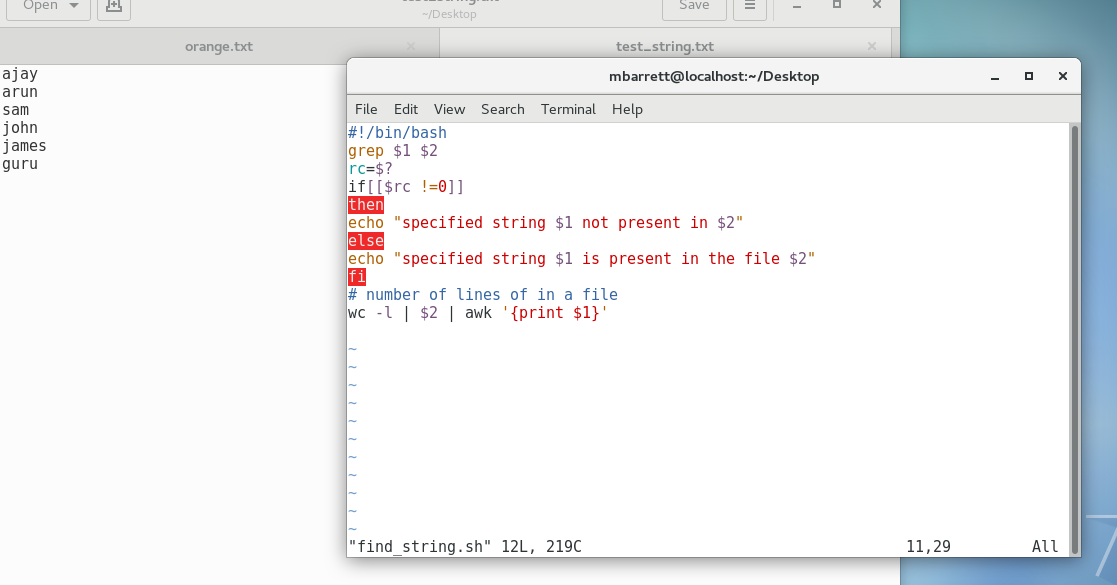
Checking for the given string in multiple files.
Syntax: grep "string" FILE_PATTERN
This is also a basic usage of grep command. For this example, let us copy the demo_file to demo_file1. The grep output will also include the file name in front of the line that matched the specific pattern as shown below. When the Linux shell sees the meta character, it does the expansion and gives all the files as input to grep.
$ cp demo_file demo_file1 $ grep "this" demo_* demo_file:this line is the 1st lower case line in this file. demo_file:Two lines above this line is empty. demo_file:And this is the last line. demo_file1:this line is the 1st lower case line in this file. demo_file1:Two lines above this line is empty. demo_file1:And this is the last line.
Invert match using grep -v
You had different options to show the lines matched, to show the lines before match, and to show the lines after match, and to highlight match. So definitely You’d also want the option -v to do invert match.
When you want to display the lines which does not matches the given string/pattern, use the option -v as shown below. This example will display all the lines that did not match the word «go».
$ grep -v "go" demo_text 4. Vim Word Navigation You may want to do several navigation in relation to the words, such as: WORD - WORD consists of a sequence of non-blank characters, separated with white space. word - word consists of a sequence of letters, digits and underscores. Example to show the difference between WORD and word * 192.168.1.1 - single WORD * 192.168.1.1 - seven words.
Grep. Несколько шаблонов
grep в GNU поддерживает три синтаксиса регулярных выражений: Basic, Extended и Perl-совместимый. Если тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор or (чередование).
Оператор чередования |(конвейер) позволяет указывать различные возможные совпадения, которые могут быть литеральными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис для поиска нескольких шаблонов с использованием grep основных регулярных выражений выглядит следующим образом:
grep 'pattern1\|pattern2' file...
Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквенные символы. Чтобы сохранить специальные значения метасимволов, их необходимо экранировать обратной косой чертой (\). Вот почему мы избегаем оператора or (|) с косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите команду grep с параметром -E (или –extended-regexp). При использовании расширенного регулярного выражения не экранируйте оператор |:
grep -E 'pattern1|pattern2' file...
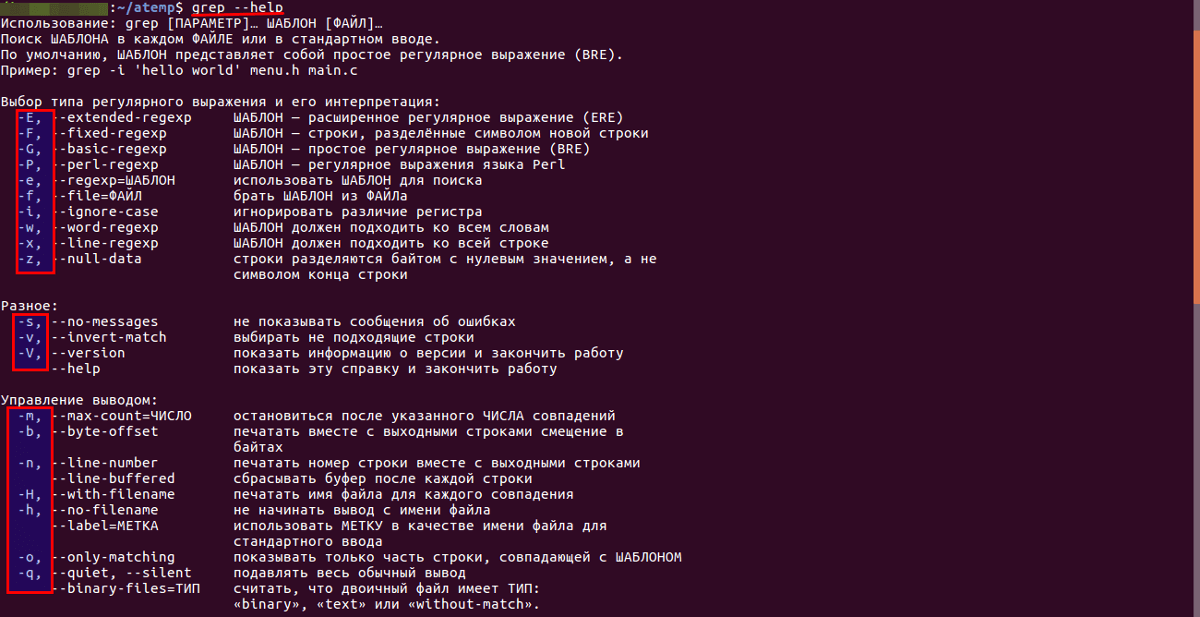
Параметры grep
Опция -r
—recursive
Еще больше увеличит зону поисков опция -r, которая заставит команду grep рекурсивно обследовать все дерево указанной директории, то есть субдиректории, субдиректории субдиректорий, и так далее вплоть до файлов. Например:
grep -r menu /boot /boot/grub/grub.txt:Highlight the menu entry you want to edit and press 'e', then
/boot/grub/grub.txt:Press the key to return to the GRUB menu.
/boot/grub/menu.lst:# GRUB configuration file ‘/boot/grub/menu.lst’.
/boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Опция -i
—ignore-case
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Опция -c
—count
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
grep -c root /etc/group 8
То есть в восьми строках файла /etc/group встречается сочетание символов root.
—line-number
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
Опция -v
—invert-match
Выполняет работу, обратную обычной — выводит строки, в которых ОБРАЗЕЦ не встречается:
grep -v print /etc/printcap # # # for you (at least initially), such as apsfilter # (/usr/share/apsfilter/SETUP, used in conjunction with the # LPRng lpd daemon), or with the web interface provided by the # (if you use CUPS).
Опция -w
—word-regexp
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
grep -w "длинная ко" example/*
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
grep -w "длинная коса" example/* example/alice.txt:длинная коса!
находит точное соответствие в файле alice.txt.
Опция -x
—line-regexp
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
grep -x "1234" example/* example/123.txt:1234
Внимание: Мне попадались (на собственном компьютере) версии grep (например, GNU 2.5), в которых опция -x работала неадекватно. В то же время, другие версии (GNU 2.5.1) работали прекрасно
Если что-то не ладится с этой опцией, попробуйте другую версию, или обновите свою.
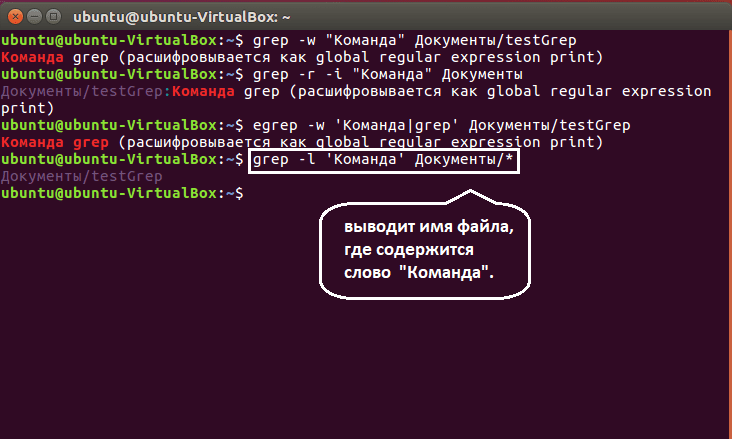
Опция -l
—files-with-matches
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
grep -l 'Алиса' example/* example/alice.txt
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Опция -L
—files-without-match
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
grep -L 'Алиса' example/* example/123.txt example/ast.txt
Как мы имели случай заметить, команда grep, в поисках соответствия ОБРАЗЦУ, просматривает только содержимое файлов, но не их имена. А так часто нужно найти файл по его имени или другим параметрам, например времени модификации! Тут нам придет на помощь простейший программный канал (pipe). При помощи знака программного канала — вертикальной черты (|) мы можем направить вывод команды ls, то есть список файлов в текущей директории, на ввод команды grep, не забыв указать, что мы, собственно, ищем (ОБРАЗЕЦ). Например:
ls | grep grep grep/ grep-ru.txt
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
Если мы хотим искать по другим параметрам файла, а не по его имени, то следует применить команду ls -l, которая выводит файлы со всеми параметрами:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 123.txt drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 example/ -rw-r--r-- 1 ya users 11931 2008-12-30 14:59 grep-ru.txt
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
dmesg | grep -i usb
Опция -i необходима, так как usb часто пишется заглавными буквами. Проделайте этот пример самостоятельно — у него длинный вывод, который не укладывается в рамки данной статьи.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
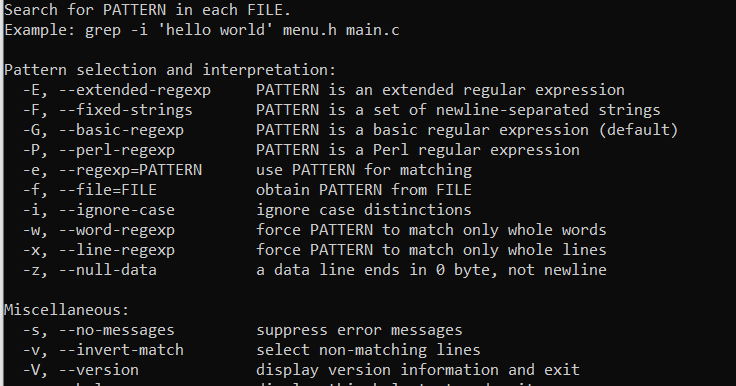
Основные параметры:
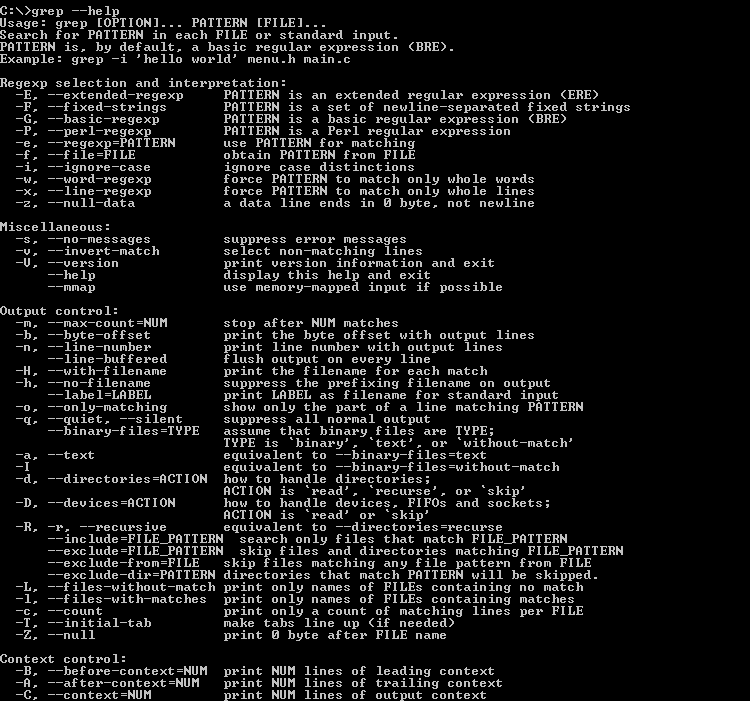
—help. Вывести справочную информацию.
![Gnu grep [айти бубен]](https://fuzeservers.ru/wp-content/uploads/9/1/2/912b0abebf9d58a582f6f916f43895d2.png)
![15 практических примеров использования команды grep в linux [rtfm.wiki]](https://fuzeservers.ru/wp-content/uploads/9/1/2/912f30dcdb074b1e23ccab0ea4c2206a.jpeg)
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
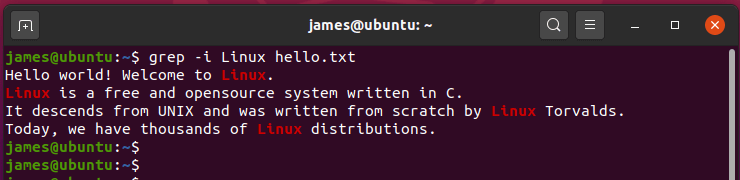
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
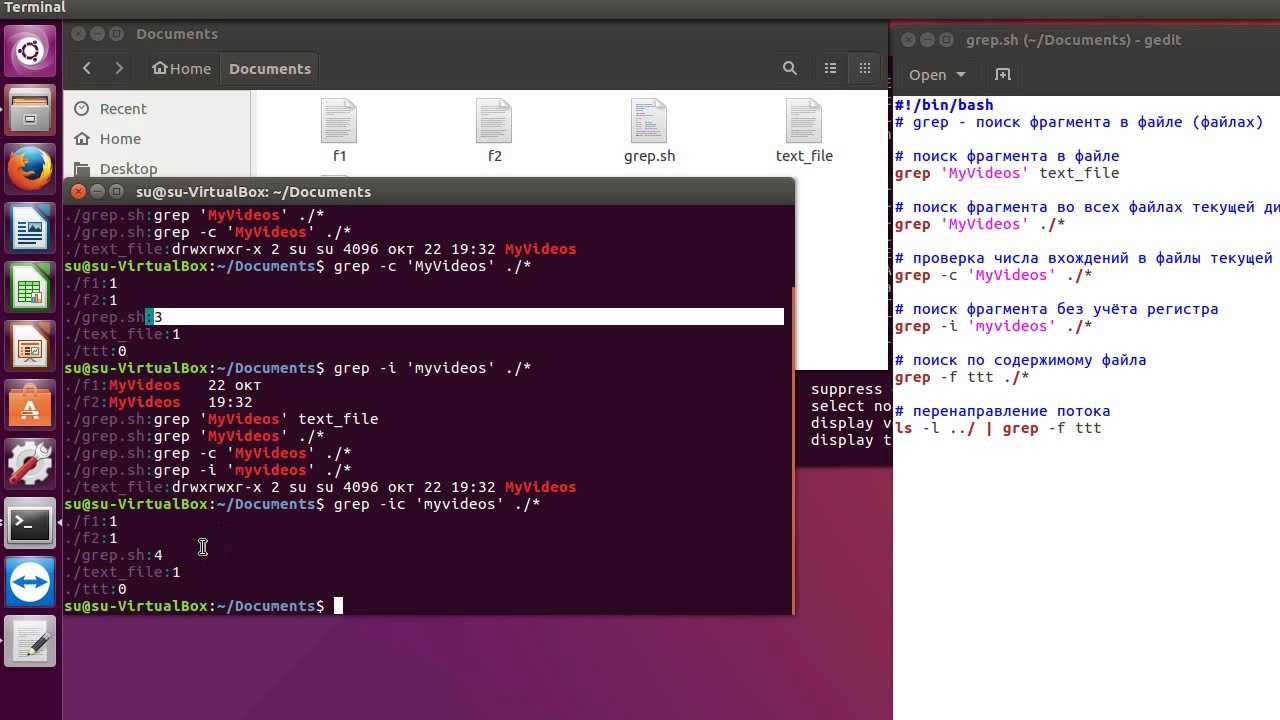
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили
CentOS Linux
и хотите посмотреть все установленные пакеты в названии которых есть слово
kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel
: нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
Например
grep server /etc/ntp.conf
# Use public servers from the pool.ntp.org project.
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#broadcast 192.168.1.255 autokey # broadcast server
#broadcast 224.0.1.1 autokey # multicast server
#manycastserver 239.255.254.254 # manycast server
grep ‘\bkernel\b’ huge_file
Где \b
это word boundary — границы слова
huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово
kernel
в середине, а только те, которые начинаются с
kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
Вывести всё, что заканчивается на определённый набор символов
Для работы со следующими примерами установите words
sudo yum -y install words
cp /usr/share/dict/words huge_file
grep -E ‘ion$’ huge_file
…
Cynoscion
cytodifferentiation
Czechization
dactylion
Daedalion
…
Найти слова по первым и последним буквам
Допустим вы знаете только начало и конец слова
grep -E ‘^ha..ed$’ huge_file
…
handed
hanged
hanked
hanted
happed
harked
…
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘{5}’ /usr/share/dict/words
cadiueio
Chaouia
cooeeing
euouae
Guauaenok
miaoued
miaouing
Pauiie
queueing
Поиск слова в файле с помощью grep
Пожалуй, самый простой пример использования команды grep –
это поиск подстроки в файле:
– выведет строки, в которых grep нашёл точное совпадение. Однако, в этом
списке строк сложно ориентироваться. Предлагаю немного апгрейдить нашу команду,
чтобы и номера строк выводила, да ещё и контекст добавляла:
Пробежимся по ключам:
-
– игнорирование регистра – grep будет находить, даже если строчные
буквы в подстроке оказались заглавными и наоборот. В случае с «Безуховым»
это не так критично, но если бы мы искали «Граф», то в начале предложения
оно таким и было бы, а вот внутри могло быть и с маленькой буквы. -
– вывод номера строки, где было найдено вхождение нашей подстроки.
Согласитесь, так приятнее и искать, да и представлять, на сколько
подстрока разбросана по файлу, легче. -
– выводим по 3 строки до найденой строки и после – полезно понимать,
в каком контексте была произнесена та или иная фраза. Для удобства
каждая находка отделяется от других строкой из «—«.
В итоге мы получим нечто следующее:
Grep. Несколько строк
Литеральные строки – самые основные образцы.
В следующем примере мы ищем все вхождения слов fatal, error и critical в журнале файла ошибки Nginx:
grep 'fatal\|error\|critical' /var/log/nginx/error.log
Если искомая строка содержит пробелы, заключите ее в двойные кавычки.
Вот тот же пример, использующий расширенное регулярное выражение, которое устраняет необходимость экранирования оператора |
grep -E 'fatal|error|critical' /var/log/nginx/error.log
По умолчанию учитывается регистр grep. Это означает, что прописные и строчные символы рассматриваются как разные.
Для того, чтобы игнорировать регистр при поиске, призовите grep with с параметром -i (или –ignore-case):
grep -i 'fatal\|error\|critical' /var/log/nginx/error.log
При поиске строки grep будет отображаться все строки, в которых строка встроена в более крупные строки. Так что, если вы искали «error», grep также напечатает строки, в которых «error» встроена в более крупные слова, такие как «errorless» или «antiterrorists».
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр -w (или –word-regexp):
grep -w 'fatal\|error\|critical' /var/log/nginx/error.log
Символы в слове включают буквенно-цифровые символы (az, AZ и 0-9) и подчеркивания (_). Все остальные символы рассматриваются как несловесные символы.
Для более подробной информации о параметрах grep, посетите нашу статью Команда Grep.
Ротация лог-файлов
Если учесть, что информация в лог-файлы поступает регулярно и по любому поводу, то в скором времени они должны были бы стать просто гигантскими, занимая при этом огромную кучу места на диске. А работать с ними было бы просто невозможно. Но этого не происходит благодаря ротации лог-файлов.
Цель ротации заключается в сжатии устаревших лог-файлов, которые занимают много места. Лог-файлы, в конце имен которых добавлены нули, являются ротируемыми (их имена были автоматически изменены системой). Ротацию лог-файлов можно выполнить с помощью команды logrotate, например:
Настройки ротации лог-файлов хранятся в соответствующем файле конфигурации /etc/logrotate.conf:
Разберем детально каждую строку вышеприведенного фрагмента:
— указывает команде не выводить ошибку, если лог-файл отсутствует.
— если лог-файл пуст, то ротации не будет.
— лог-файл необходимо сжать.
— гарантирует, что лог-файл не превышает заданного размера, в противном случае производится его ротация.
— ротация лог-файлов по ежедневному расписанию. Также можно задавать ежечасный (), еженедельный (), ежемесячный () или ежегодный () график.
— создает экземпляр лог-файла, владельцем и группой которого является root.
Теперь, разобравшись с тем, что означает каждый параметр, можно каждому лог-файлу задавать соответствующий индивидуальный параметр ротации.
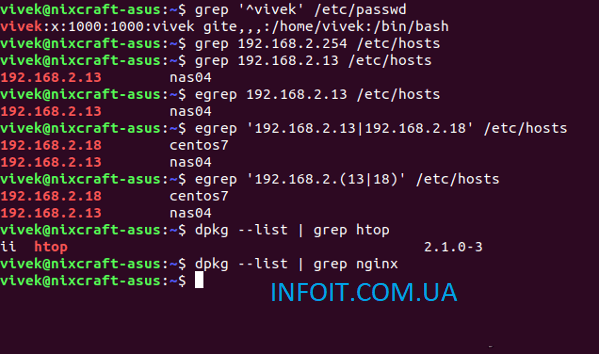
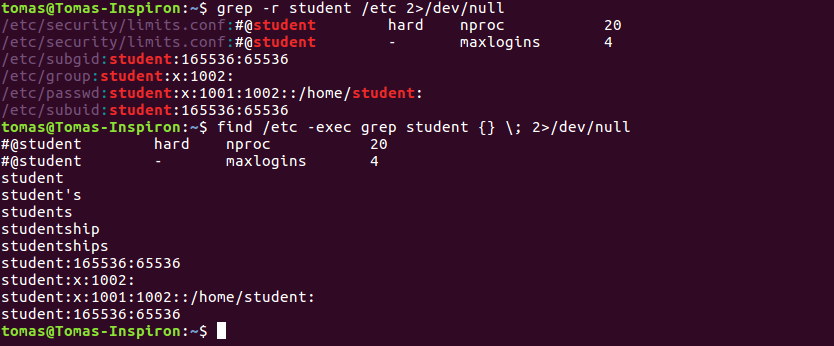
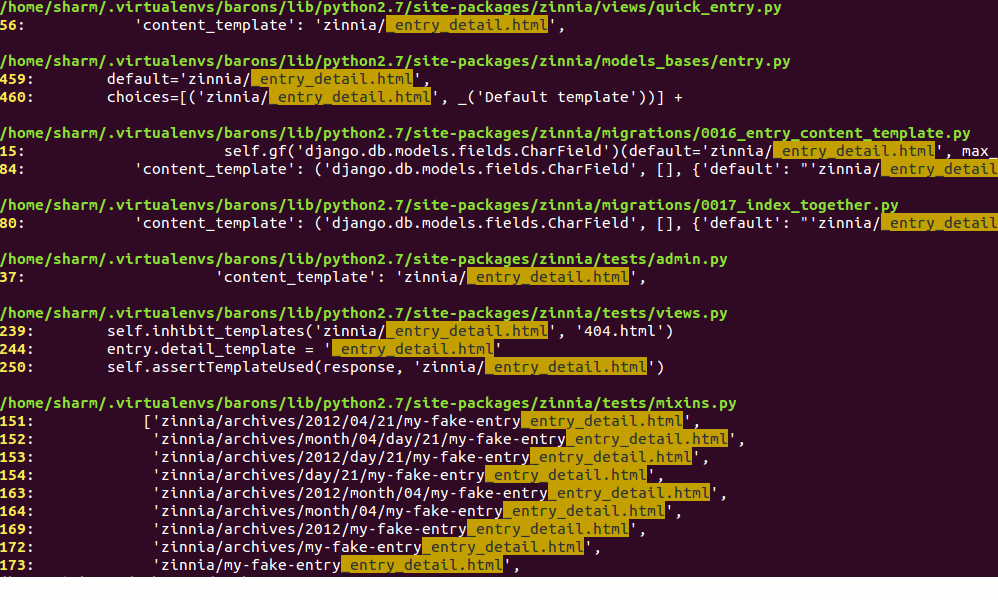
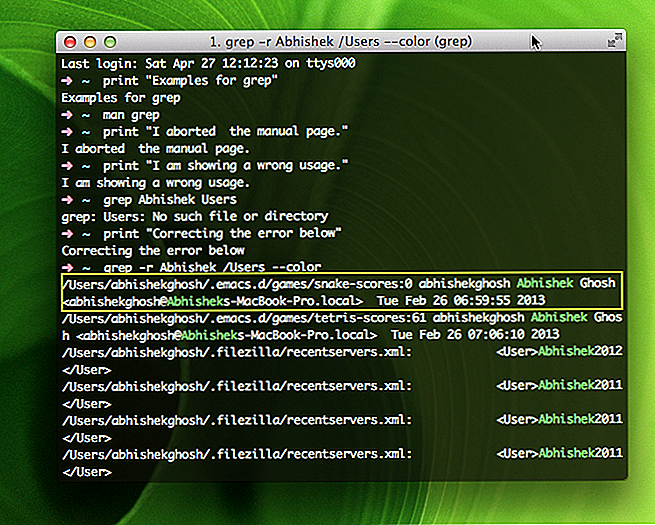
Как использовать grep рекурсивно
Вы можете выполнять поиск рекурсивно, т.е. читать все файлы в каждом каталоге по строке “192.168.1.5”
ИЛИ
Примеры выходных данных:
/etc/ppp/options:# ms-wins 192.168.1.50 /etc/ppp/options:# ms-wins 192.168.1.51 /etc/NetworkManager/system-connections/Wired connection 1:addresses1=192.168.1.5;24;192.168.1.2;
Вы увидите результат для 192.168.1.5 в отдельной строке, перед которой будет указано имя файла (например /etc/ppp/options) в котором он был найден. Включение имен файлов в выходные данные можно подавить, используя -h следующее:
ИЛИ
Примеры выходных данных:
# ms-wins 192.168.1.50 # ms-wins 192.168.1.51 addresses1=192.168.1.5;24;192.168.1.2;





