
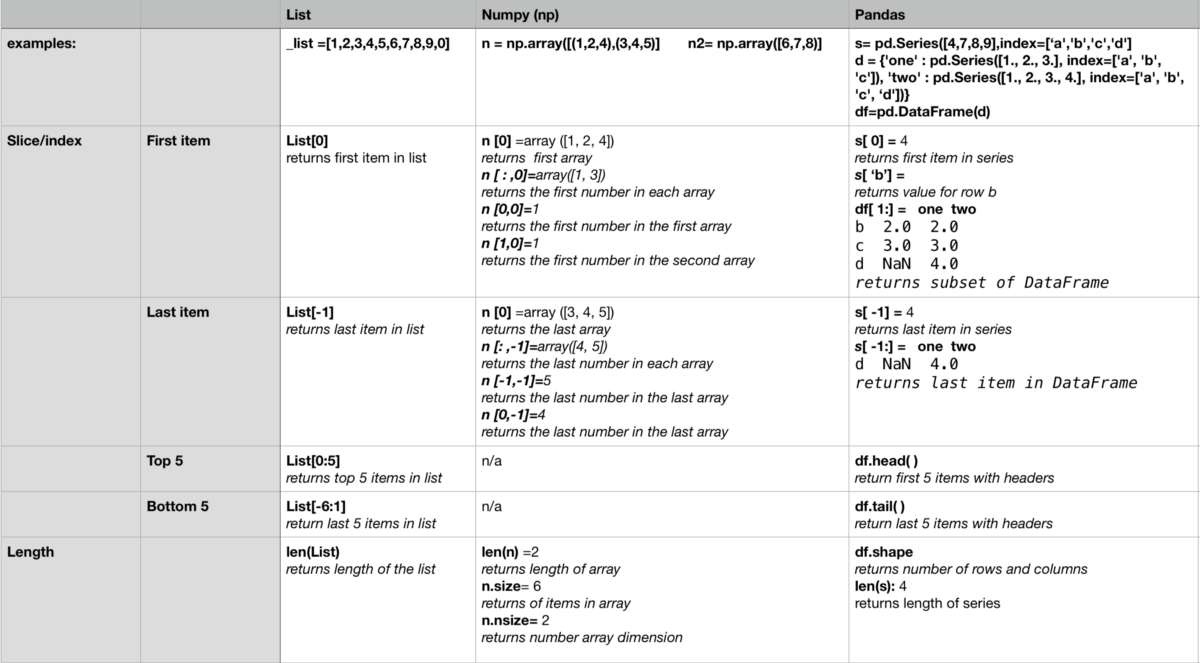
Очистка всего набора данных с помощью функции applymap
В определенных ситуациях вы увидите, что «грязь» не локализована в одном столбце, а более разбросана. В некоторых случаях было бы полезно применить настраиваемую функцию к каждой ячейке или элементу DataFrame. Метод Pandas .applymap() похож на метод in-построил функцию map() и просто применяет функцию ко всем элементам в DataFrame. Давайте посмотрим на пример. Мы создадим DataFrame из ранее добавленного в проект файла «university_towns.txt»:
$ head Datasets/univerisity_towns.txt Alabama Auburn (Auburn University) Florence (University of North Alabama) Jacksonville (Jacksonville State University) Livingston (University of West Alabama) Montevallo (University of Montevallo) Troy (Troy University) Tuscaloosa (University of Alabama, Stillman College, Shelton State) Tuskegee (Tuskegee University) Alaska
Мы видим, что у нас есть периодические названия штатов, за которыми следуют университетские города в этом штате: StateA TownA1 TownA2 StateB TownB1 TownB2 …. Если мы посмотрим на то, как названия штатов записаны в файле, мы увидим, что все они имеют в них подстрока . Мы можем воспользоваться этим шаблоном, создав список (state, city) кортежи и обертывание этого списка в DataFrame:
university_towns = []
with open('Datasets/university_towns.txt') as file:
for line in file:
if '' in line:
state = line
else:
university_towns.append((state, line))
print('Вывод созданного списка, преобразованного в DataFrame:')
print(university_towns)
Результат:
Мы можем обернуть этот список в DataFrame и установить столбцы как «State» и «RegionName». Pandas возьмет каждый элемент в списке и установит State на левое значение, а RegionName — на правое значение:
towns_df = pd.DataFrame(university_towns,
columns=)
print('Вывод результирующего DataFrame:')
print(towns_df.head())
Результат:
Хотя мы могли бы очистить эти строки в цикле for выше, Pandas упрощает это. Нам нужно только название штата и название города, а все остальное можно удалить. Хотя здесь мы могли бы снова использовать методы Pandas .str(), мы также могли бы использовать applymap() для сопоставления вызываемого Python с каждым элементом DataFrame.
Переименование столбцов и пропуск строк
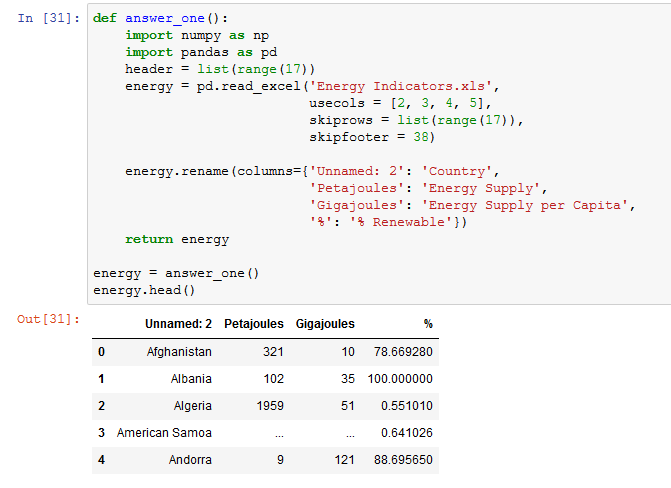
Часто наборы данных, с которыми вы будете работать, будут иметь либо имена столбцов, которые непросто понять, либо неважную информацию в первых нескольких и/или последних строках, такую как определения терминов в наборе данных или сноски. В этом случае, мы хотели бы переименовать столбцы и пропустить определенные строки, чтобы можно было перейти к необходимой информации с помощью правильных и понятных меток. Чтобы продемонстрировать, как это сделать, давайте сначала взглянем на первые пять строк все также ранее добавленного набора данных olympics.csv:
$ head -n 5 Datasets/olympics.csv 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 ,? Summer,01 !,02 !,03 !,Total,? Winter,01 !,02 !,03 !,Total,? Games,01 !,02 !,03 !,Combined total Afghanistan (AFG),13,0,0,2,2,0,0,0,0,0,13,0,0,2,2 Algeria (ALG),12,5,2,8,15,3,0,0,0,0,15,5,2,8,15 Argentina (ARG),23,18,24,28,70,18,0,0,0,0,41,18,24,28,70
Теперь мы прочитаем его в DataFrame Pandas:
olympics_df = pd.read_csv('Datasets/olympics.csv')
print('Вывод olympics.csv:')
print(olympics_df.head())
Результат:
Это действительно грязно! Поэтому, мы должны пропустить одну строку и установить заголовок как первую (с нулевым индексом) строку и переименовать столбцы. Для того, чтобы удалить 0-ю строку мы используем:
olympics_df = pd.read_csv('Datasets/olympics.csv', header=1)
print('Вывод olympics.csv без 0 строки:')
print(olympics_df.head())
Результат:
Теперь у нас есть правильная строка, установленная в качестве заголовка, и все ненужные строки удалены
Обратите внимание на то, как Pandas изменил имя столбца, содержащего названия стран, с NaN на Unnamed: 0. Чтобы переименовать столбцы, мы будем использовать метод rename() DataFrame, который позволяет вам изменить метку оси на основе сопоставления (в данном случае dict)
Начнем с определения словаря, который сопоставляет текущие имена столбцов (как ключи) с более удобными (значениями словаря):
new_names = {'Unnamed: 0': 'Country',
'? Summer': 'Summer Olympics',
'01 !': 'Gold',
'02 !': 'Silver',
'03 !': 'Bronze',
'? Winter': 'Winter Olympics',
'01 !.1': 'Gold.1',
'02 !.1': 'Silver.1',
'03 !.1': 'Bronze.1',
'? Games': '# Games',
'01 !.2': 'Gold.2',
'02 !.2': 'Silver.2',
'03 !.2': 'Bronze.2'}
Далее вызываем функцию rename() для нашего объекта:
olympics_df.rename(columns=new_names, inplace=True)
Установка inplace в True указывает, что наши изменения будут внесены непосредственно в объект. Результат:
Pandas DataFrame – Удалить столбцы (ы)
Вы можете удалить одну или несколько столбцов DataFrame.
Чтобы удалить или удалить только один столбец из Pandas DataFrame, вы можете использовать либо ключевое слово, Функция или Функция на dataframe.
Чтобы удалить несколько столбцов из PandaS DataFrame, используйте Функция на dataframe.
Пример 1: Удалить столбец с помощью ключевого слова
В этом примере мы создадим dataframe, а затем удалите указанный столбец, используя ключевое слово del. Столбец выбран для удаления, используя метку столбца.
Python Program
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete a column
del df_marks
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Выход
Original DataFrame -------------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 DataFrame after deleting column -------------- names physics algebra 0 Somu 68 78 1 Kiku 74 88 2 Amol 77 82 3 Lini 78 87
Мы удалили Химия столбец из DataFrame.
Пример 2: Удалить столбец с помощью функции POP ()
В этом примере мы создадим dataframe, а затем использовать функцию POP () в DataFrame, чтобы удалить определенный столбец. Столбец выбран для удаления, используя метку столбца.
Python Program
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete column
df_marks.pop('chemistry')
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Выход
Original DataFrame -------------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 DataFrame after deleting column -------------- names physics algebra 0 Somu 68 78 1 Kiku 74 88 2 Amol 77 82 3 Lini 78 87
Мы удалили Химия столбец из DataFrame.
Пример 3: Удалить столбец, используя функцию Drop ()
В этом примере мы будем использовать функцию drop () на dataframe, чтобы удалить определенный столбец. Мы используем метку столбцов, чтобы выбрать столбец для удаления.
Python Program
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete column
df_marks = df_marks.drop(, axis=1)
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Выход
Пример 4: Удалить несколько столбцов, используя функцию Drop ()
В этом примере мы будем использовать функцию drop () на dataframe, чтобы удалить несколько столбцов. Мы используем массив меток столбцов, чтобы выбрать столбцы для удаления.
Python Program
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete columns
df_marks = df_marks.drop(, axis=1)
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Выход
Резюме
В этом уроке Pandas мы узнали, как удалить столбец из Pandas DataFrame с использованием метода DEL ключевого слова, POP () и Drop (), с помощью хорошо подробных примеров Python.
Получаем данные из датафреймов
Данные из датафреймов можно получать по-разному: указав номера колонок и строк, использовав условные операторы или язык запросов. Расскажу подробнее о каждом способе.
Указываем нужные строки и колонки
Обратите внимание, результат команды — новый датафрейм с таким же индексом. Если нужно вывести несколько столбцов, в квадратные скобки нужно вставить список с их названиями: orders]
Будьте внимательны: квадратные скобки стали двойными. Первые — от датафрейма, вторые — от списка:
Если нужно вывести несколько столбцов, в квадратные скобки нужно вставить список с их названиями: orders] . Будьте внимательны: квадратные скобки стали двойными. Первые — от датафрейма, вторые — от списка:
Перейдем к строкам. Их можно фильтровать по индексу и по порядку. Например, мы хотим вывести только заказы 100363, 100391 и 100706, для этого есть команда .loc[] :
А в другой раз бывает нужно достать просто заказы с 1 по 3 по порядку, вне зависимости от их номеров в таблицемы. Тогда используют команду .iloc[] :
Можно фильтровать датафреймы по колонкам и столбцам одновременно:
Часто вы не знаете заранее номеров заказов, которые вам нужны. Например, если задача — получить заказы, стоимостью более 1000 рублей. Эту задачу удобно решать с помощью условных операторов.
Если — то. Условные операторы
Задача: нужно узнать, откуда приходят самые большие заказы. Начнем с того, что достанем все покупки стоимостью более 1000 долларов:
Помните, в начале статьи я упоминал, что в сериях все операции применяются по-элементно? Так вот, операция orders > 1000 идет по каждому элементу серии и, если условие выполняется, возвращает True . Если не выполняется — False . Получившуюся серию мы сохраняем в переменную filter_large .
Вторая команда фильтрует строки датафрейма с помощью серии. Если элемент filter_large равен True , заказ отобразится, если False — нет. Результат — датафрейм с заказами, стоимостью более 1000 долларов.
Интересно, сколько дорогих заказов было доставлено первым классом? Добавим в фильтр ещё одно условие:
Логика не изменилась. В переменную filter_large сохранили серию, удовлетворяющую условию orders > 1000 . В filter_first_class — серию, удовлетворяющую orders == ‘First’ .
Затем объединили обе серии с помощью логического ‘И’: filter_first_class & filter_first_class . Получили новую серию той же длины, в элементах которой True только у заказов, стоимостью больше 1000, доставленных первым классом. Таких условий может быть сколько угодно.
Язык запросов
Еще один способ решить предыдущую задачу — использовать язык запросов. Все условия пишем одной строкой ‘sales > 1000 & ship_mode == ‘First’ и передаем ее в метод .query() . Запрос получается компактнее.
Отдельный кайф: значения для фильтров можно сохранить в переменной, а в запросе сослаться на нее с помощью символа @: sales > @sales_filter .
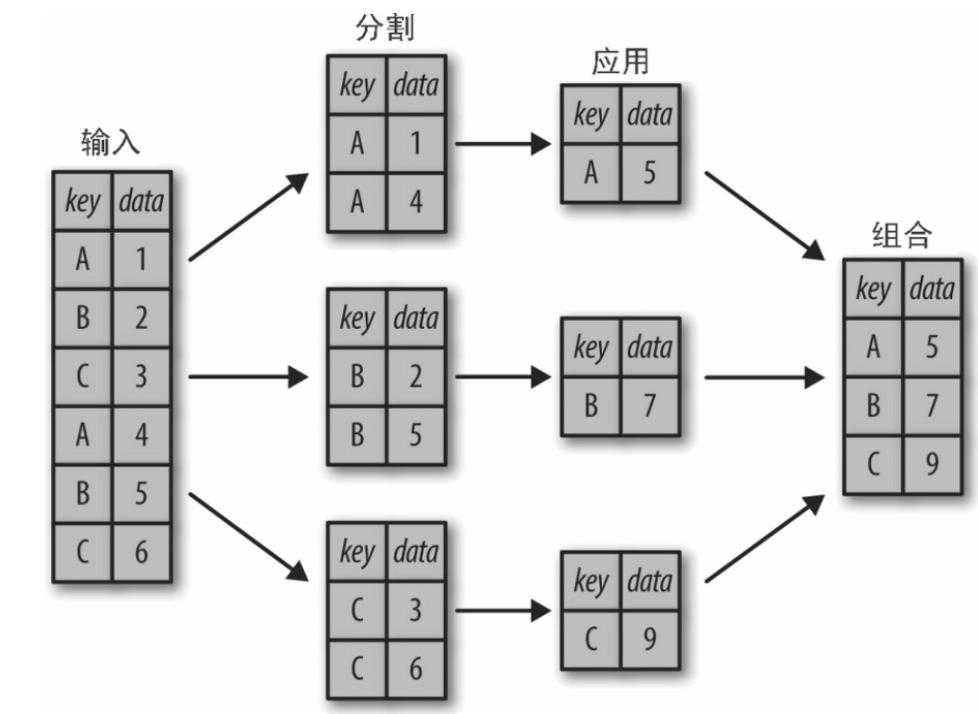
Разобравшись, как получать куски данных из датафрейма, перейдем к тому, как считать агрегированные метрики: количество заказов, суммарную выручку, средний чек, конверсию.
Удаление столбцов или строк мультииндекса
Теперь, в случае, если мы хотим удалить столбцы C2 второго уровня, использование того, что было объяснено до сих пор, приведет к ошибке.
Чтобы избежать этого, необходимо указать через свойство level функции drop(), что вы хотите удалить столбец второго уровня.
То есть, присвоив свойству значение 1, как показано ниже.
На самом деле, в этом есть большой смысл, поскольку в случае, когда один и тот же тег используется в двух разных уровнях, Pandas не может знать, какой из них удалить. Поэтому необходимо указать уровень, на котором вы хотите его применить, если он не первый.
В случае с рядами процесс аналогичен предыдущему.
Как и для индексов первого уровня, также возможно удаление строк и столбцов с помощью одной инструкции. Однако они должны быть одного уровня.
16th Century Warband Mod Gameplay Let’s Play Part 8 (ИНФИЛЬТРАЦИЯ! ИСТОРИЧЕСКИЙ МОД СПЕЦИАЛЬНАЯ ОСОБЕННОСТЬ)
https://youtube.com/watch?v=I8uiTrpFbsM
у меня есть это было создано путем анализа некоторых электронных таблиц Excel. Столбец, в котором есть пустые ячейки. Например, ниже приведены выходные данные для частоты этого столбца, 32320 записей имеют пропущенные значения для Арендатор.
Однако я пытаюсь удалить строки, в которых отсутствует Tenant опция не распознает отсутствующие значения.
Столбец имеет тип данных «Объект». Что в этом случае происходит? Как мне сбросить записи куда Арендатор пропал, отсутствует?
Pandas распознает значение как null, если это объект, который будет напечатан как в DataFrame. Ваши отсутствующие значения, вероятно, являются пустыми строками, которые Pandas не распознает как null. Чтобы исправить это, вы можете преобразовать пустые жала (или все, что находится в ваших пустых ячейках) в объекты, использующие , а затем позвоните в вашем DataFrame, чтобы удалить строки с нулевыми арендаторами.
Чтобы продемонстрировать, мы создаем DataFrame с некоторыми случайными значениями и некоторыми пустыми строками в столбец:
Теперь заменим все пустые строки в столбец с объекты, например:
Теперь мы можем отбросить нулевые значения:
- Большое спасибо, я попробую и вернусь!
- 2 @mcmath, немного любопытно. Почему вы импортируете numpy и используете когда ты сможешь сделать ?
- 3 @ propjk007, как и во многих других делах в жизни, есть много способов делать много вещей
- Из моих тестов кажется, что (при условии отсутствия пробельных символов — только пустая строка) Быстрее чем
Pythonic + Pandorable:
Пустые строки являются ложными, что означает, что вы можете фильтровать значения типа bool следующим образом:
Если ваша цель — удалить не только пустые строки, но и строки, содержащие только пробелы, используйте заранее:
Быстрее, чем вы думаете
является векторизованной операцией, это быстрее, чем все варианты, представленные до сих пор. По крайней мере, из моих тестов. YMMV.
Вот сравнение времени, я добавил несколько других методов, которые я мог придумать.
![]()
Код тестирования, для справки:
value_counts по умолчанию опускает NaN, поэтому вы, скорее всего, имеете дело с «».
Так что вы можете просто отфильтровать их, как
- 1 решение @Bobs у меня не сработало. df.dropna (subset = [’tenant’], inplace = True) работает.
- 1 Сожалею об этом. Я думал, ты имеешь дело с «» с. Вы должны опубликовать свое решение в качестве ответа
Есть ситуация, когда в ячейке есть белое пространство, вы его не видите, используйте
чтобы заменить пробел на NaN, затем
Вы можете использовать этот вариант:
Это выведет (** — выделение только желаемых строк):
Итак, чтобы отбросить все, что не имеет значения «образование», используйте приведенный ниже код:
(‘~’ означает НЕ)
Результат:
Создание набора данных
Как обычно, перед изучением работы метода drop() в многоиндексных датафреймах, необходимо создать такой, для чего можно использовать следующий код.
В этом примере данные были созданы с помощью функции np.arange() в сочетании с np.reshape() для получения матрицы 6 на 6.
После этого необходимо создать мультииндексы для столбцов и строк.
Существуют различные способы сделать это, но в примере он был создан из кортежей с помощью функции pd.MultiIndex.from_tuples().
После получения мультииндексных объектов dataframe создается обычным способом, используя эти элементы вместо векторов для индексов строк и столбцов.
Решаем задачу
Закрепим полученный материал, решив задачу. Найдем 5 городов, принесших самую большую выручку в 2016 году.
Для начала отфильтруем заказы из 2016 года:
Город — это атрибут пользователей, а не заказов. Добавим информацию о пользователях:
Cруппируем получившийся датафрейм по городам и посчитаем выручку:
Отсортируем по убыванию продаж и оставим топ-5:
Возьмите данные о заказах и покупателях и посчитайте:
- Сколько заказов, отправлено первым классом за последние 5 лет?
- Сколько в базе клиентов из Калифорнии?
- Сколько заказов они сделали?
- Постройте сводную таблицу средних чеков по всем штатам за каждый год.
Через некоторое время выложу ответы в Телеграме. Подписывайтесь, чтобы не пропустить ответы и новые статьи.
Кстати, большое спасибо Александру Марфицину за то, что помог отредактировать статью.
Пример 1: с помощью ключевого слова del
В этом примере мы создадим DataFrame, а затем удалим указанный столбец с помощью ключевого слова del. Столбец выбирается для удаления с помощью метки столбца.
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete a column
del df_marks
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Вывод:
Original DataFrame -------------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 DataFrame after deleting column -------------- names physics algebra 0 Somu 68 78 1 Kiku 74 88 2 Amol 77 82 3 Lini 78 87
Мы удалили столбец химии из DataFrame.
Пример 2: со значением по умолчанию
В этом примере мы создадим df_marks и добавим новый столбец с именем geometry со значением по умолчанию для каждой строки в DataFrame.
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#add column
df_marks = 65
print('\n\nDataFrame after adding "geometry" column\n--------------')
print(df_marks)
Вывод:
Original DataFrame -------------- names physics chemistry algebra 0 Somu 68 84 78 1 Kiku 74 56 88 2 Amol 77 73 82 3 Lini 78 69 87 DataFrame after adding "geometry" column -------------- names physics chemistry algebra geometry 0 Somu 68 84 78 65 1 Kiku 74 56 88 65 2 Amol 77 73 82 65 3 Lini 78 69 87 65
Столбец добавляется в DataFrame с указанным значением в качестве значения столбца по умолчанию.
Пример 2
В этом примере мы попытаемся удалить столбец, которого нет в DataFrame.
Когда вы пытаетесь удалить несуществующий столбец с помощью pop(), функция выдает ошибку KeyError.
import pandas as pd
mydictionary = {'names': ,
'physics': ,
'chemistry': ,
'algebra': }
#create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n--------------')
print(df_marks)
#delete column that is not present
df_marks.pop('geometry')
print('\n\nDataFrame after deleting column\n--------------')
print(df_marks)
Вывод:
В этом руководстве на примерах Python мы узнали, как удалить столбец из DataFrame с помощью pop() с помощью хорошо подробных примеров программ.
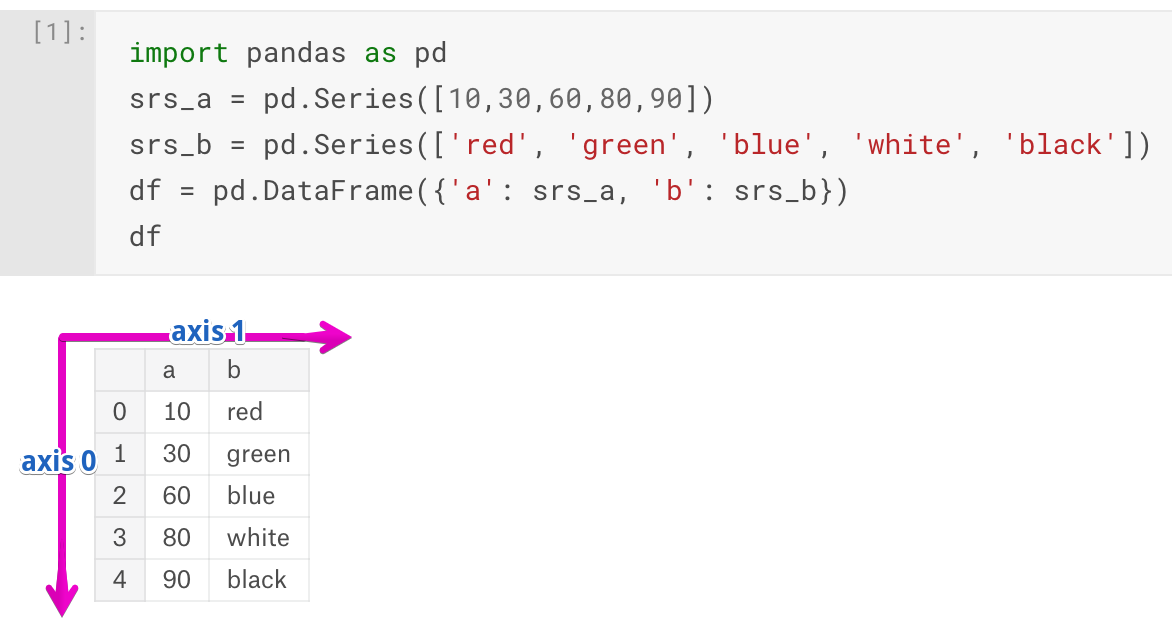
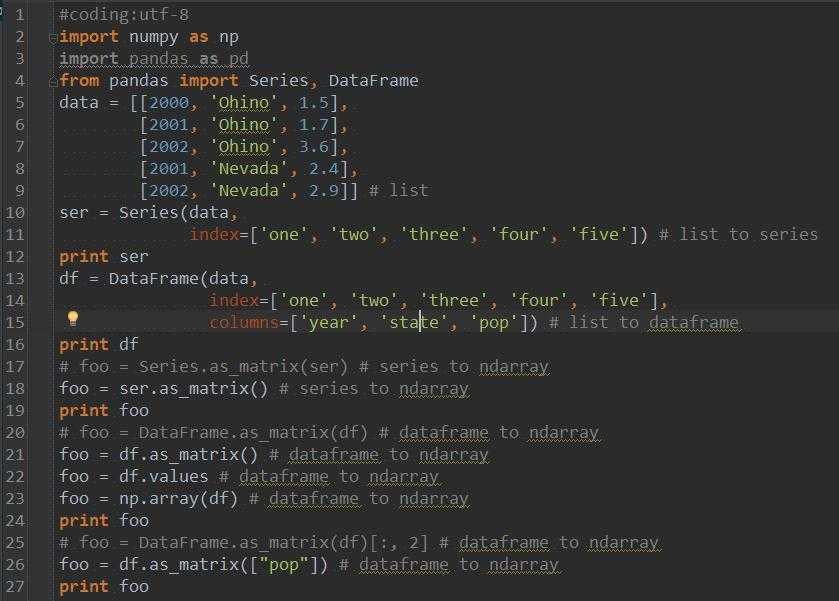
Структуры данных: серии и датафреймы
Серии — одномерные массивы данных. Они очень похожи на списки, но отличаются по поведению — например, операции применяются к списку целиком, а в сериях — поэлементно.
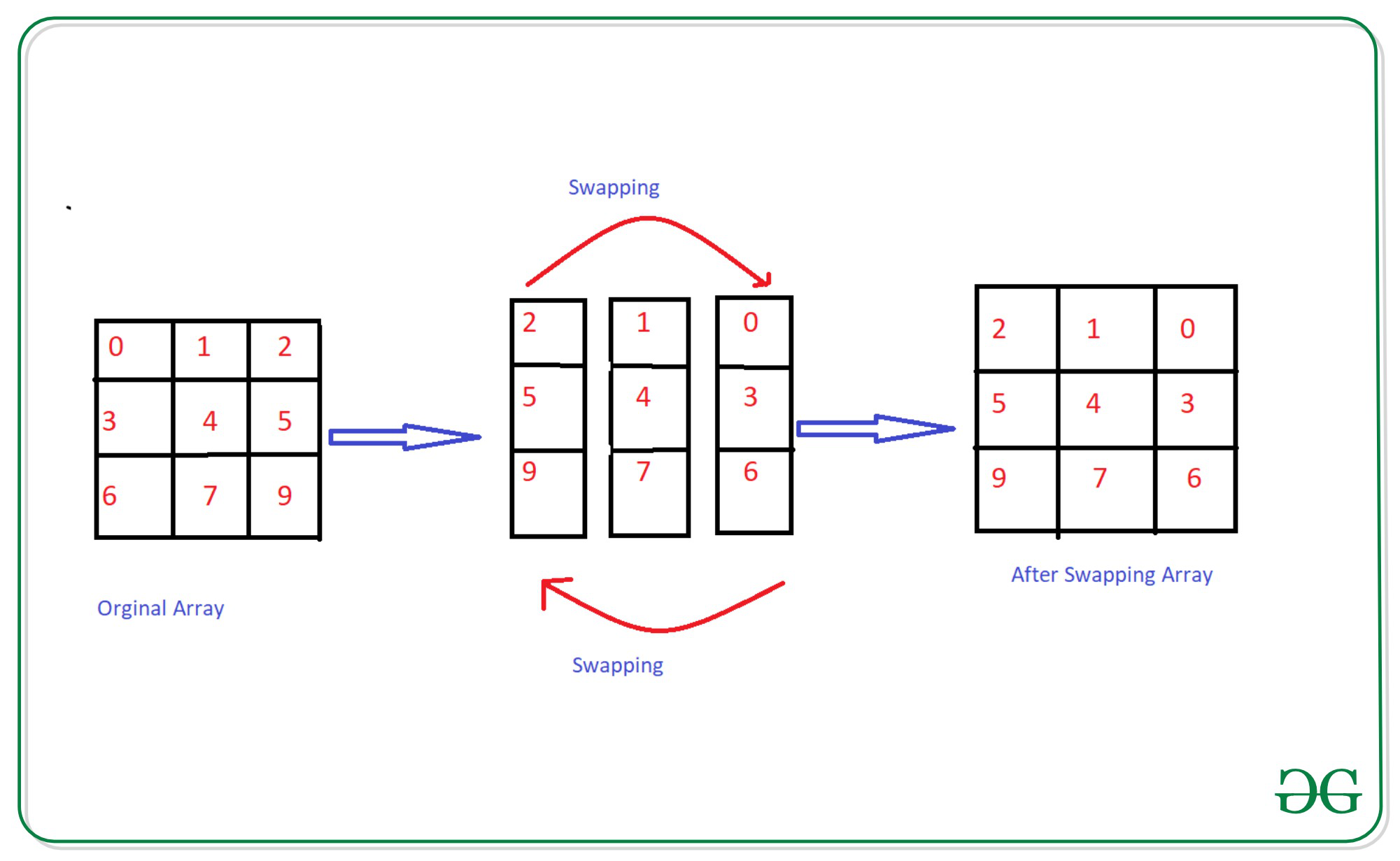
То есть, если список умножить на 2, получите тот же список, повторенный 2 раза.
А если умножить серию, ее длина не изменится, а вот элементы удвоятся.
Обратите внимание на первый столбик вывода. Это индекс, в котором хранятся адреса каждого элемента серии
Каждый элемент потом можно получать, обратившись по нужному адресу.
Еще одно отличие серий от списков — в качестве индексов можно использовать произвольные значения, это делает данные нагляднее. Представим, что мы анализируем помесячные продажи. Используем в качестве индексов названия месяцев, значениями будет выручка:
Теперь можем получать значения каждого месяца:
Так как серии — одномерный массив данных, в них удобно хранить измерения по одному. На практике удобнее группировать данные вместе. Например, если мы анализируем помесячные продажи, полезно видеть не только выручку, но и количество проданных товаров, количество новых клиентов и средний чек. Для этого отлично подходят датафреймы.
Датафреймы — это таблицы. У их есть строки, колонки и ячейки.
Технически, колонки датафреймов — это серии. Поскольку в колонках обычно описывают одни и те же объекты, то все колонки делят один и тот же индекс:
Объясню, как создавать датафреймы и загружать в них данные.
Объединяем несколько датафреймов
Мы знаем тип клиента, место его проживания, его имя и имя контактного лица. У каждого клиента есть уникальный номер id . Этот же номер лежит в колонке customer_id таблицы orders . Значит мы можем найти, какие заказы сделал каждый клиент. Например, посмотрим, заказы пользователя CG-12520 :
Вернемся к задаче из предыдущего раздела: узнать, что за клиенты, которые сделали 18 марта заказы со стандартной доставкой. Для этого объединим таблицы с клиентами и заказами. Датафреймы объединяют с помощью методов .concat() , .merge() и .join() . Все они делают одно и то же, но отличаются синтаксисом — на практике достаточно уметь пользоваться одним из них.
Покажу на примере .merge() :
В .merge() я сначала указал названия датафреймов, которые хочу объединить. Затем уточнил, как именно их объединить и какие колонки использовать в качестве ключа.
Ключ — это колонка, связывающая оба датафрейма. В нашем случае — номер клиента. В таблице с заказами он в колонке customer_id , а таблице с клиентами — в индексе. Поэтому в команде мы пишем: left_on=’customer_ >.
Что такое Pandas и зачем он нужен
Pandas — это библиотека для работы с данными на Python. Она упрощает жизнь аналитикам: где раньше использовалось 10 строк кода теперь хватит одной.
Например, чтобы прочитать данные из csv, в стандартном Python надо сначала решить, как хранить данные, затем открыть файл, прочитать его построчно, отделить значения друг от друга и очистить данные от специальных символов.
В Pandas всё проще. Во-первых, не нужно думать, как будут храниться данные — они лежат в датафрейме. Во-вторых, достаточно написать одну команду:
Pandas добавляет в Python новые структуры данных — серии и датафреймы. Расскажу, что это такое.
7 ответов
Лучший ответ
Другой способ — использовать :
2
sophocles
19 Мар 2021 в 14:05
Использовать
См. подтверждение регулярного выражения.
ПОЯСНЕНИЕ
Ryszard Czech
19 Мар 2021 в 22:57
Вы можете сопоставить либо точку в начале строки, либо сопоставить в конце. Затем используйте пустую строку для замены.
Например
Выход
1
The fourth bird
19 Мар 2021 в 18:15
Я хочу объяснить, почему вы получили такой результат. Это связано с тем, что имеет особое значение при использовании в шаблоне, re docs a> список специальных символов начинается с
Поэтому, когда вы имеете в виду literal , вам нужно его избежать, рассмотрим следующий пример
Выход
Обратите внимание, что здесь я использовал так называемую необработанную строку, которая позволяет более читаемую форму экранирования символов со специальным значением в шаблоне (без необработанной строки мне пришлось бы написать , обратитесь к документации для получения дополнительной информации ). Если вам сложно использовать шаблон регулярного выражения, я предлагаю использовать regex101.com, чтобы получить его объяснение
1
Daweo
19 Мар 2021 в 14:03
Сведения о регулярном выражении .
- : подтвердить позицию в начале строки
- : группа без захвата, соответствующая символу
- : соответствует предыдущей группе без захвата ноль или один раз
- : группа захвата, которая соответствует любому символу, кроме терминаторов строки, ноль или более раз, но как можно меньшее количество раз ()
- : группа без захвата, которая соответствует
- : соответствует предыдущей группе без захвата ноль или один раз
- : утверждает позицию в конце строки
См.
2
Shubham Sharma
19 Мар 2021 в 14:40
Вы также можете использовать :
2
Mayank Porwal
19 Мар 2021 в 14:18
Вы должны уметь делать то, что хотите, с помощью якорей и так называемого позитивного просмотра назад.
В регулярных выражениях есть специальные символы, которые увеличивают функциональность. Здесь «$» означает, что заканчивается на. Так что, если вы хотите просто воздействовать на укусы, оканчивающиеся на ‘.T’, вы должны добавить это в конец. Часть выражения, которая является ретроспективной, — ‘(?
Я действительно не знаю, как это объяснить, кроме того, что это похоже на то, как работают классы CSS, что на самом деле не очень хороший пример.
Знак ‘?
Чтобы заменить слова, начинающиеся с «.» очень просто. Это просто противоположный якорь,
https://regex101.com/ — отличный веб-сайт, помогающий создавать регулярные выражения. Это также объяснит, что делает ваше регулярное выражение.
2
vip-evan
19 Мар 2021 в 14:17
Исследуем загруженные данные
Расскажу о четырех атрибутах, которые есть у любого датафрейма: .shape , .columns , .index и .dtypes .
.shape показывает, сколько в датафрейме строк и колонок. Он возвращает пару значений (n_rows, n_columns) . Сначала идут строки, потом колонки.
В датафрейме 5009 строк и 5 колонок.
Окей, масштаб оценили. Теперь посмотрим, какая информация содержится в каждой колонке. С помощью .columns узнаем названия колонок:
Теперь видим, что в таблице есть дата заказа, метод доставки, номер клиента и выручка.
С помощью .dtypes узнаем типы данных, находящихся в каждой колонке и поймем, надо ли их обрабатывать. Бывает, что числа загружаются в виде текста. Если мы попробуем сложить две текстовых значения ‘1’ + ‘1’ , то получим не число 2, а строку ’11’ :
Тип object — это текст, float64 — это дробное число типа 3,14.
C помощью атрибута .index посмотрим, как называются строки:
Ожидаемо, в индексе датафрейма номера заказов: 100762, 100860 и так далее.
В колонке sales хранится стоимость каждого проданного товара. Чтобы узнать разброс значений, среднюю стоимость и медиану, используем метод .describe() :
Наконец, чтобы посмотреть на несколько примеров записей датафрейма, используем команды .head() и .sample() . Первая возвращает 6 записей из начала датафрейма. Вторая — 6 случайных записей:
Получив первое представление о датафреймах, теперь обсудим, как доставать из него данные.
Библиотека Pandas
Python в целом отлично подходит для анализа данных: с помощь него можно решать задачи автоматизации сбора и обработки данных и реализовать на работе новые подходы к анализу, например решать задачи с помощью обучения нейросетей.
В Pandas можно работать с данными трех структур:
- последовательности (Series) — одномерные массивы данных;
- фреймы (Data Frames) — объединение нескольких одномерных массивов в двумерный, то есть привычная таблица из строк и столбцов. Этот формат чаще всего используют аналитики;
- панели (Panels) — трехмерная структура из нескольких фреймов.
Библиотека пригодится всем, кто работает с данными, особенно аналитикам. С помощью Pandas можно группировать таблицы, очищать и изменять данные, вычислять параметры и делать выборки.
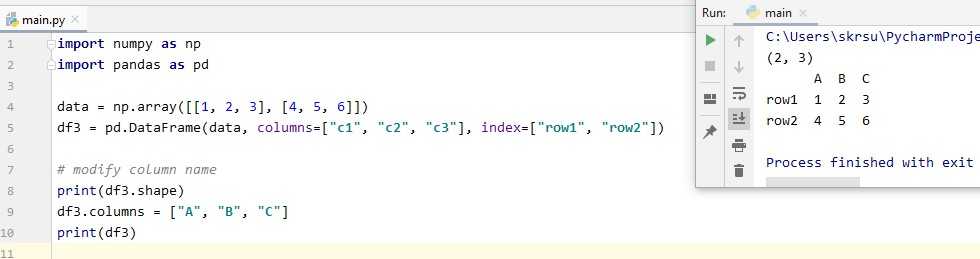
Изменение индекса фрейма данных
Индекс Pandas расширяет функциональность массивов NumPy, чтобы обеспечить более гибкое нарезание и маркировку. Во многих случаях полезно использовать однозначное идентифицирующее поле данных в качестве индекса. Давайте заменим существующий индекс в BL-Flickr-Images-Book.csv столбцом Identifier, используя set_index:
df = df.set_index('Identifier')
print(' Замена существующего индекса столбцом Identifier:')
print(df.head())
Результат:
Кроме этого, мы можем получить доступ к каждой записи простым способом с помощью loc[]. Хотя loc[] может не иметь всего этого интуитивно понятного имени, он позволяет нам выполнять индексацию на основе меток, которая представляет собой маркировку строки или записи независимо от ее положения:
print('Получение доступа к каждой записи:')
print(df.loc)
Результат:
Другими словами, 206 — это первая метка индекса. Ранее нашим индексом был RangeIndex: целые числа, начинающиеся с 0, аналог встроенного диапазона Python. Передав имя столбца в set_index, мы изменили индекс на значения в Identifier.





