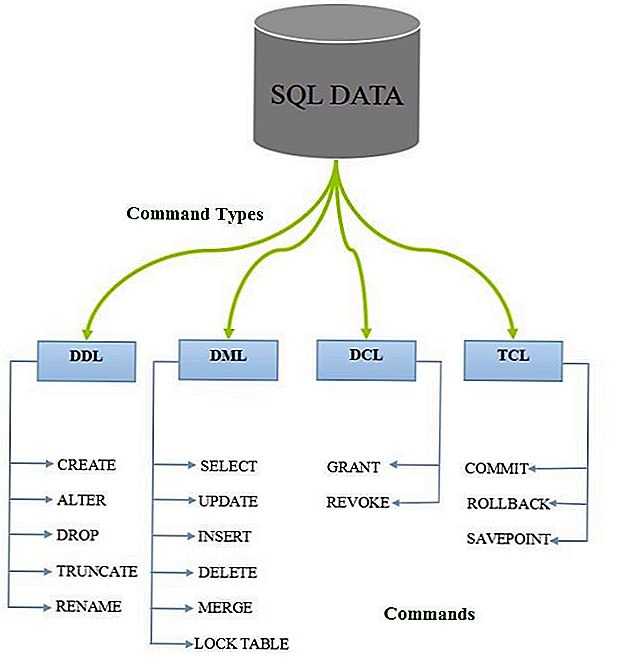
Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
- Создание таблиц в Microsoft SQL Server (CREATE TABLE);
- Добавление данных в таблицы Microsoft SQL Server (INSERT INTO).
--Создание таблицы Goods
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_ProductId PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
GO
--Добавление строк в таблицу Goods
INSERT INTO Goods(ProductName, Price)
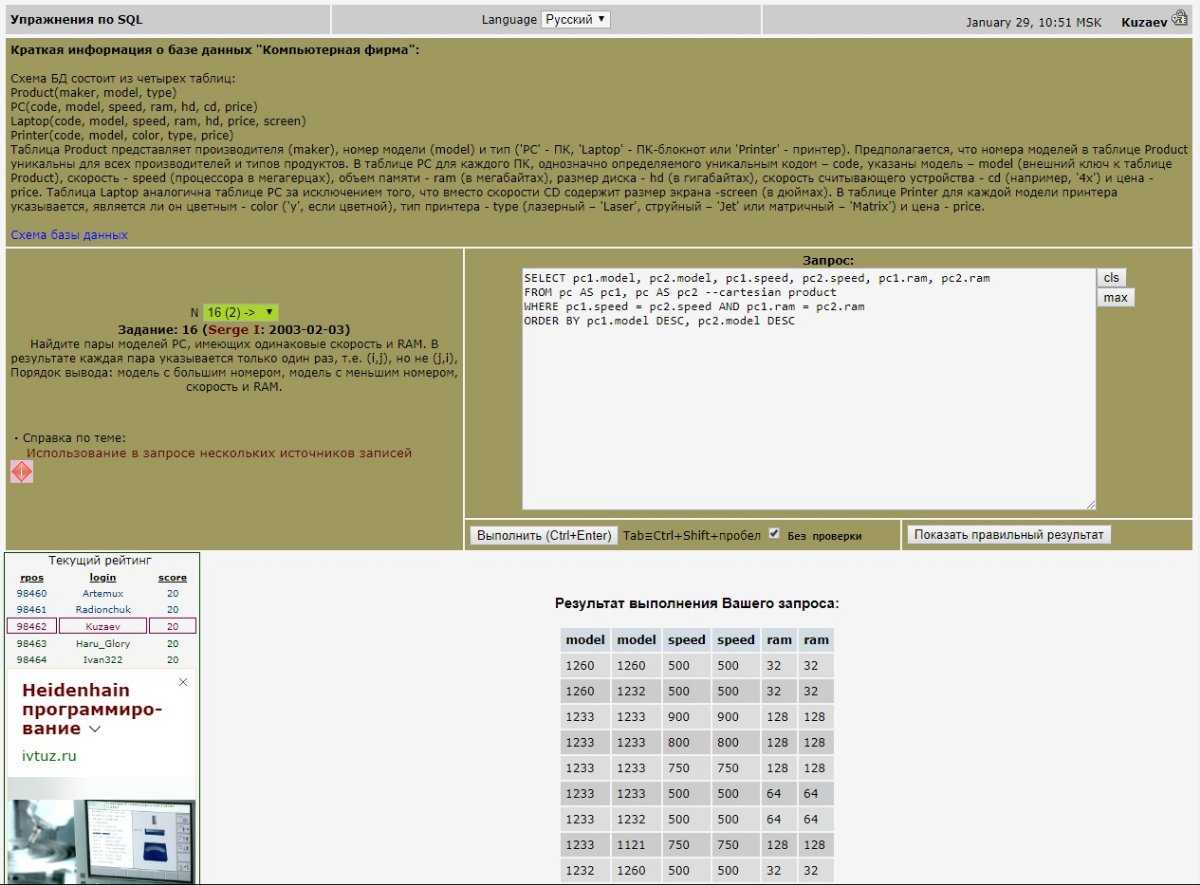
VALUES ('Системный блок', 100),
('Монитор', 200),
('Сканер', 150),
('Принтер', 200),
('Клавиатура', 50),
('Смартфон', 300),
('Мышь', 20),
('Планшет', 300),
('Процессор', 200);
GO
--Выборка данных
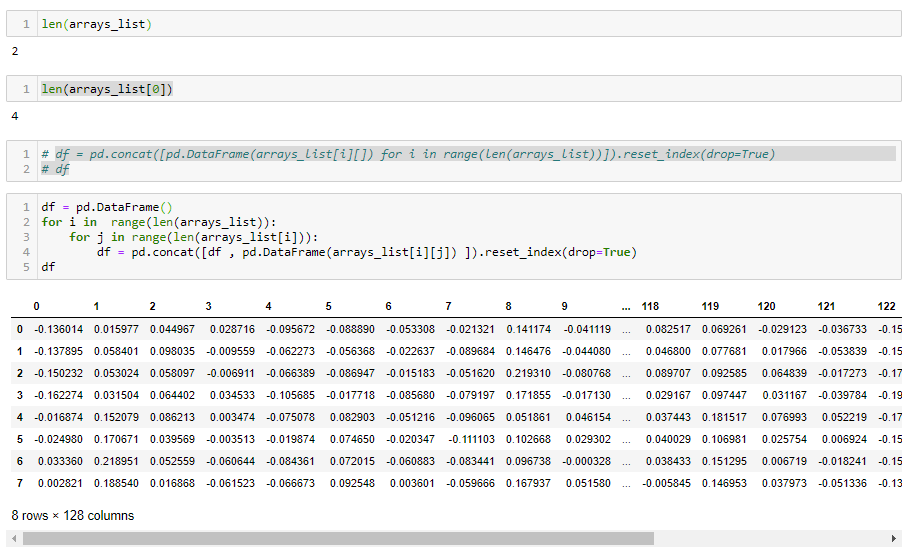
SELECT ProductId, ProductName, Price
FROM Goods;
![]()
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT)
> SELECT GROUP_CONCAT(DISTINCT CONVERT(id USING ‘utf8’) SEPARATOR ‘, ‘) as ids FROM users
* из таблицы users извлекаются данные по полю id, все они помещаются в одну строку, значения разделяются запятыми.
2. Группировка данных по двум и более полям
> SELECT * FROM users GROUP BY CONCAT(title, ‘::’, birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth. Перед группировкой мы делаем объединение полей в одну строку с разделителем ::.
3. Объединение результатов из двух таблиц (UNION)
> (SELECT id, fio, address, ‘Пользователи’ as type FROM users)
UNION
(SELECT id, fio, address, ‘Покупатели’ as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers.
4. Выборка средних значений, сгруппированных за каждый час
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’) as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’)
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
5. Использование операторов IF и CASE
Данные операторы позволяют определять исход запроса исходя из условия.
а) выбрать пол мужской или женский:
SELECT IF(sex = ‘m’, ‘мужчина’, ‘женщина’) as sex FROM people
* в данном примере мы возвращаем слово «мужчина», если поле sex равно ‘m’, иначе — «женщина».
б) заменяем идентификатор времени года более понятным человеку значением:
SELECT CASE season_id WHEN 1 THEN ‘зима’ WHEN 2 THEN ‘весна’ WHEN 3 THEN ‘лето’ WHEN 4 THEN ‘осень’ ELSE ‘неправильный идентификатор времени года’ END as season FROM ` seasons
* в данном примере мы используем оператор CASE. Если 1, то вернем слово «зима», если 2 — «весна» и так далее.
Использование запросов в PHP
Подключаемся к базе данных:
mysql_connect (‘localhost’, ‘login’, ‘password’) or die («MySQL connect error»);
mysql_select_db (‘db_name’);
mysql_query(«SET NAMES ‘utf8′»);
* где подключение выполняется к базе на локальном сервере (localhost); учетные данные для подключения — login и password (соответственно, логин и пароль); в качестве базы используется db_name; используемая кодировка UTF-8.
Также можно создать постоянное подключение:
mysql_pconnect (‘localhost’, ‘login’, ‘password’) or die («MySQL connect error»);
* однако есть вероятность достигнуть максимально разрешенного лимита хостинга. Данным способом стоит пользоваться на собственных серверах, где мы сами можем контролировать ситуацию.
Завершить подключение:
mysql_close();
* в PHP выполняется автоматически, кроме постоянных подключений (mysql_pconnect).
Запрос к MySQL (Mariadb) в PHP делается функцией mysql_query(), а извлечение данных из запроса — mysql_fetch_array():
$result = mysql_query(«SELECT * FROM users»);
while ($mass = mysql_fetch_array($result)) {
echo $mass . ‘<br>’;
}
* в данном примере выполнен запрос к таблице users. Результат запроса помещен в переменную $result. Далее используется цикл while, каждая итерация которого извлекает массив данных и помещает его в переменную $mass — в каждой итерации мы работаем с одной строкой базы данных.
Используемая функция mysql_fetch_array() возвращает ассоциативный массив, с которым удобно работать, но есть еще альтернатива — mysql_fetch_row(), которая возвращает обычный нумерованный массив.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Искать дубликаты в нескольких столбцах
Синтаксис запроса для проверки или подсчета дубликатов для нескольких столбцов следующий:
>> SELECT col1, COUNT(col1), col2, COUNT(col2) FROM table GROUP BY col1, col2 HAVING COUNT(col1) > 1 AND COUNT(col2) > 1;
Вот объяснение вышеуказанного запроса:
- col1, col2: имя проверяемых столбцов.
- COUNT(): функция, используемая для подсчета нескольких повторяющихся значений.
- GROUP BY: предложение, используемое для группировки всех строк в соответствии с этим конкретным столбцом.
Мы использовали ту же таблицу под названием «животные» с повторяющимися значениями. Мы получили приведенный ниже результат, используя указанный выше запрос для проверки повторяющихся значений в нескольких столбцах. Мы проверяли и подсчитывали повторяющиеся значения для столбцов «Gender» и «Price», сгруппированные по столбцу «Price». Он покажет пол домашних животных и их цены, которые находятся в таблице, как дубликаты не более 5.
>> SELECT Gender, COUNT(Gender), Price, COUNT(Price) FROM data.animals GROUP BY Price HAVING COUNT(Price) < 5 AND COUNT(Gender) < 5;
Поиск дубликатов в одной таблице с помощью INNER JOIN
Вот основной синтаксис для поиска дубликатов в одной таблице:
>> SELECT col1, col2, table.col FROM table INNER JOIN(SELECT col FROM table GROUP BY col HAVING COUNT(col1) > 1) temp ON table.col= temp.col;
Вот описание служебного запроса:
- Col: имя столбца, который нужно проверить и выбрать для дублирования.
- Temp: ключевое слово для применения внутреннего соединения к столбцу.
- Таблица: имя проверяемой таблицы.
У нас есть новая таблица order2 с повторяющимися значениями в столбце OrderNo, как показано ниже.
>> SELECT * FROM data.order2;
Мы выбираем три столбца: Item, Sales, OrderNo, которые будут отображаться в выводе. В то время как столбец OrderNo используется для проверки дубликатов. Внутреннее соединение выберет значения или строки, имеющие значения элементов более одного в таблице. После выполнения мы получим следующие результаты.
>> SELECT Item, Sales, order2.OrderNo FROM data.order2 INNER JOIN(SELECT OrderNo FROM data.order2 GROUP BY OrderNo HAVING COUNT(Item) > 1) temp ON order2.OrderNo= temp.OrderNo;
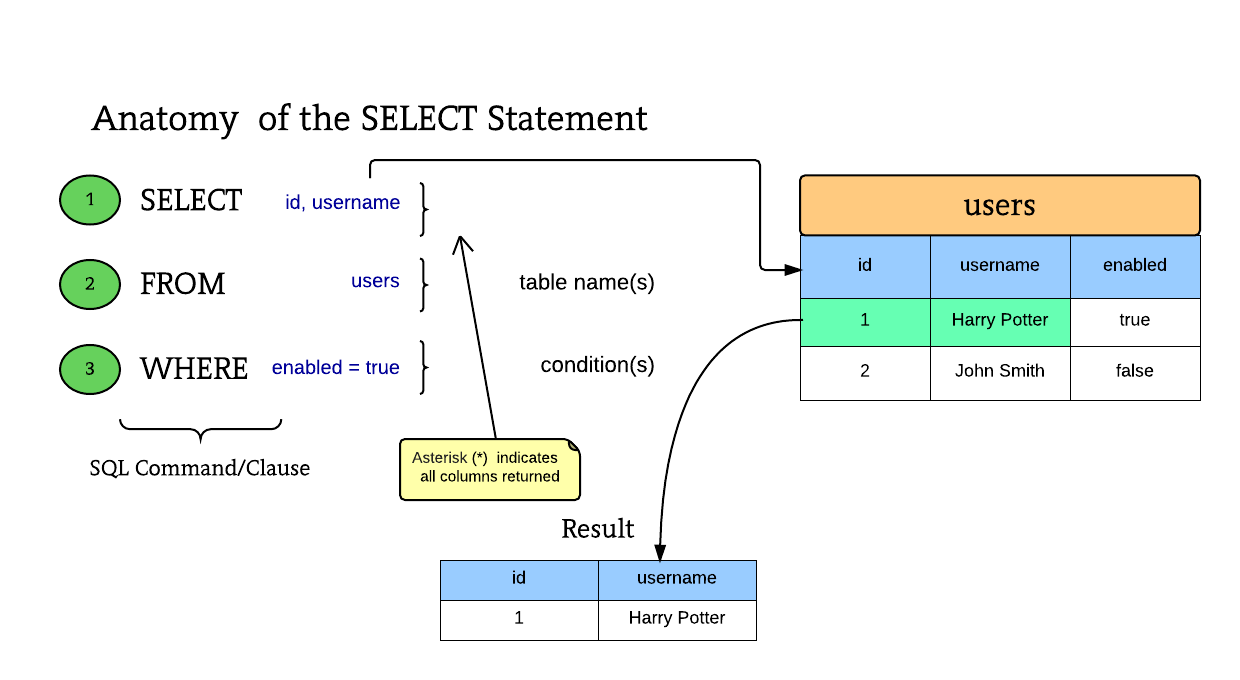
Оператор SELECT sql
SQL-запрос Select предназначен для обычной выборки из базы данных. Т.е. если нам необходимо просто получить данные, не делая с ними никакой обработки и не внося изменений в базу данных, то можно смело использовать данный запмагарос.
Синтаксис оператора SELECT
Рассмотрим примеры sql запросов select:
Пример : если вы создали локальную базу данных и заполнили таблицы, как в рассмотренном ранее уроке (или же воспользовались сервисом sqlFiddle), то выполним следующий пример.
Необходимо выбрать все записи из таблицы
SELECT * FROM teachers; |
Задание 1_1. . Вывести все поля из таблицы Группы.
SELECT name, zarplata FROM teachers; |
Выберет все значения полей и в том же порядке (сначала , затем )
Задание 1_2. . Получить информацию только о фамилии и годе рождения из таблицы
Сортировка в SQL
SELECT name, zarplata, premia FROM teachers ORDER BY name; |
Выберет значения полей , , и отсортирует по полю (по алфавиту)
Пример: БД «Компьютерный магазин». Выбрать данные о скорости и памяти компьютеров. Требуется упорядочить результирующий набор по скорости процессора в порядке возрастания.
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC |
Или
SELECT `Скорость`,`Память` FROM `pc` ORDER BY 1 ASC |
Результат:
Сортировку можно выполнять по двум полям:
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC, `Память` ASC |
Задание sql select 1_1. База данных : Получить информацию только о скорости процессора и объеме оперативной памяти компьютеров.
Задание sql select 1_2. База данных : Требуется упорядочить результирующий набор по объему оперативной памяти в порядке убывания.
SELECT name, zarplata, premia FROM teachers ORDER BY name DESC; |
Выберет значения полей , , и отсортирует по полю по убыванию
Задание 1_3. . Вывести информацию о фамилиях и годах рождения. Упорядочить результирующий набор по году рождения в порядке убывания.
Удаление повторяющихся значений в SQL
Пример БД «Институт»: требуется узнать возможные варианты размера премий. Если не использовать , в результате будет выдаваться два одинаковых значения. Удалить в sql повторяющиеся значения можно при введении — в результате дублирующиеся значения не повторяются.
-
SELECT premia FROM teachers;
-
SELECT DISTINCT premia FROM teachers;
Рассмотрим другой пример из базы данных «Компьютерный магазин»:
Пример: База данных «Компьютерный магазин»: требуется получить информацию только о скорости процессора и объеме оперативной памяти компьютеров
SELECT Скорость, Память FROM PC; |
Результат:
В таблице первичным ключом является поле . Поскольку это поле отсутствует в запросе, в приведенном выше результирующем наборе имеются дубликаты строк.
Когда требуется получить уникальные строки (например, нас интересуют только различные комбинации скорости процессора и объема памяти, а не характеристики всех имеющихся компьютеров), то нужно использовать :
SELECT DISTINCT Скорость, Память FROM PC; |
Результат:
Задание sql select 1_3. База данных : Из таблицы выбрать различные страны-производители.
Задание sql select 1_1. БД «Институт» Выполните запрос на выборку и из таблицы учителей. Отсортируйте фамилии учителей по убыванию
Задание sql select 1_2. БД «Институт» Выведите возможные варианты длины курсов () из таблицы курсов (), удалив повторяющиеся значения
Задание 1_4. . Из таблицы личные данные вывести поля и . Получить уникальные строки
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Создание образца базы данных
Прежде чем мы сможем начать делать запросы в SQL, мы сначала создадим базу данных и пару таблиц, а затем заполним эти таблицы некоторыми примерами данных. Это позволит вам получить практический опыт, когда вы начнете делать запросы позже.
Для примера базы данных, которую мы будем использовать в этом руководстве, представьте следующий сценарий:
Вы и несколько ваших друзей празднуете свои дни рождения друг с другом. В каждом случае члены группы направляются в местный боулинг, участвуют в дружеском турнире, а затем все направляются к вам, где вы готовите любимое блюдо для именинника.
Теперь, что эта традиция продолжается некоторое время, вы решили начать отслеживать записи с этих турниров. Кроме того, чтобы упростить планирование обедов, вы решаете создать запись о днях рождения ваших друзей и их любимых блюдах, сторонах и десертах. Вместо того чтобы хранить эту информацию в физической книге, вы решаете использовать свои навыки работы с базами данных, записав ее в базу данных MySQL.
Если вы создали сервер в NetAngels на основе образа Ubuntu 18.04 Bionic LAMP, то откройте приглашение MySQL выполнив от пользователя root команду:
mysql
Примечание: Если зайти в MySQL таким образом не удается, то для аутентификации с использованием пароля используйте команду:
mysql -u root -p
Затем создайте базу данных, запустив:
Затем выберите эту базу данных, набрав:
Затем создайте две таблицы в этой базе данных. Мы будем использовать первую таблицу, чтобы отслеживать записи ваших друзей в боулинге. Следующая команда создаст таблицу под названием «tourneys» со столбцами для «name» каждого из ваших друзей, количества турниров, которые они выиграли («wins»), их лучший результат за все время и каков размер обувь для боулинга, которую они носят ():
Как только вы запустите команду и заполните ее заголовками столбцов, вы получите следующий вывод:
Заполните таблицу ‘tourneys’ некоторыми примерами данных:
Вы получите такой вывод:
После этого создайте еще одну таблицу в той же базе данных, которую мы будем использовать для хранения информации о любимых блюдах ваших друзей на день рождения. Следующая команда создает таблицу с именем dinners и столбцами для«имя» каждого из ваших друзей, их «дата рождения», их любимое «блюдо», их любимое «гарнир» и их любимый «десерт»:
Аналогично для этой таблицы вы получите отзыв, подтверждающий успешное выполнение команды:
Заполните эту таблицу также некоторыми примерами данных:
Как только эта команда завершится успешно, вы закончили настройку базы данных. Далее мы рассмотрим основную структуру команд запросов SELECT.

Составные индексы
Рассмотрим такой запрос:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
Нам следует создать составной индекс на обе колонки:
CREATE INDEX age_gender ON users(age, gender);
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значения всех входящих колонок сразу. Для таблицы с такими данными:
id | name | age | gender 1 | Den | 29 | male 2 | Alyona | 15 | female 3 | Putin | 89 | tsar 4 | Petro | 12 | male
значения составного индекса будут такими:
age_gender 12male 15female 29male 89tsar
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
SELECT * FROM users WHERE age <= 29 AND gender = 'male'
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
age_gender 12male 15female 29male 89tsar
Сначала будут отфильтрованы все данные, которые подходят под условие age <= 29. Затем, поиск по значению “male” будет произведен без использования индекса.
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
SELECT * FROM users WHERE gender = 'male' ORDER BY age
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
CREATE INDEX gender_age ON users(gender, age);
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
SELECT * FROM users WHERE gender = 'male' AND country = 'UA' ORDER BY age, register_time
В этом случае следует создать такой индекс:
CREATE INDEX gender_country_age_register ON users(gender, country, age, register_time);
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с и , можно ненадолго снова вернуться к .
Агрегатные функции
В операторе можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде:
Пользователю доступны следующие агрегатные функции:
- ‑ вычисляет сумму множества значений указанного столбца;
- ‑ вычисляет количество значений указанного столбца;
- / ‑ определяет минимальное/максимальное значение в указанном столбце;
- ‑ вычисляет среднее арифметическое значение множества значений столбца;
- / ‑ определяет первое/последнее значение в указанном столбце.
Пример 15.Определить общий объем поставляемых деталей.
| Expr1000 |
|---|
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все -значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции возможен особый вариант использования — . Его назначение состоит в подсчете всех строк в результирующей таблице, включая -значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: `MAX(SUM(VOLUME))`
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция . Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
| Sum |
|---|
| 2000 |
Пример 16.Определить количество поставщиков, которые поставляют детали в настоящее время.
| Count |
|---|
| 6 |
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6
Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения
Операция
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово .
| Count |
|---|
| 3 |
можно задать только один раз для одного предложения .
Противоположностью является операция . Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
Агрегатные функции
Часто при работе с данными необязательно просматривать сами данные. Скорее, вам нужна информация о данных. Синтаксис SQL включает в себя ряд функций, которые позволяют интерпретировать или выполнять вычисления для ваших данных, просто выполнив запрос «SELECT». Они известны как aggregate functions.
Функция считает и возвращает количество строк, соответствующих определенным критериям. Например, если вы хотите узнать, сколько ваших друзей предпочитают тофу для своего дня рождения, вы можете выполнить этот запрос:
Функция возвращает среднее (среднее) значение столбца. Используя наш пример таблицы, вы можете найти средний лучший результат среди ваших друзей с помощью этого запроса:
используется для поиска общей суммы данного столбца. Например, если вы хотите посмотреть, сколько игр вы и ваши друзья играли в боулинг за эти годы, вы можете выполнить этот запрос:
Обратите внимание, что функции и будут работать правильно только при использовании с числовыми данными. Если вы попытаетесь использовать их для нечисловых данных, это приведет к ошибке или просто к «0», в зависимости от того, какую СУБД вы используете:. MIN используется для поиска наименьшего значения в указанном столбце
Вы можете использовать этот запрос, чтобы увидеть, какой худший общий рекорд в боулинге (с точки зрения количества побед):
MIN используется для поиска наименьшего значения в указанном столбце. Вы можете использовать этот запрос, чтобы увидеть, какой худший общий рекорд в боулинге (с точки зрения количества побед):
Аналогично, используется для поиска наибольшего числового значения в данном столбце. Следующий запрос покажет лучший общий результат в боулинге:
В отличие от и, функции и могут использоваться как для числовых, так и для буквенных типов данных. При запуске в столбце, содержащем строковые значения, функция MIN будет отображать первое значение в алфавитном порядке:
Аналогично, при запуске в столбце, содержащем строковые значения, функция покажет последнее значение в алфавитном порядке:
Агрегатные функции умеют больше того, что было описано в этом разделе. Они особенно полезны при использовании с предложением , которое рассматривается в следующем разделе, а также с несколькими другими предложениями запроса, которые влияют на сортировку наборов результатов.

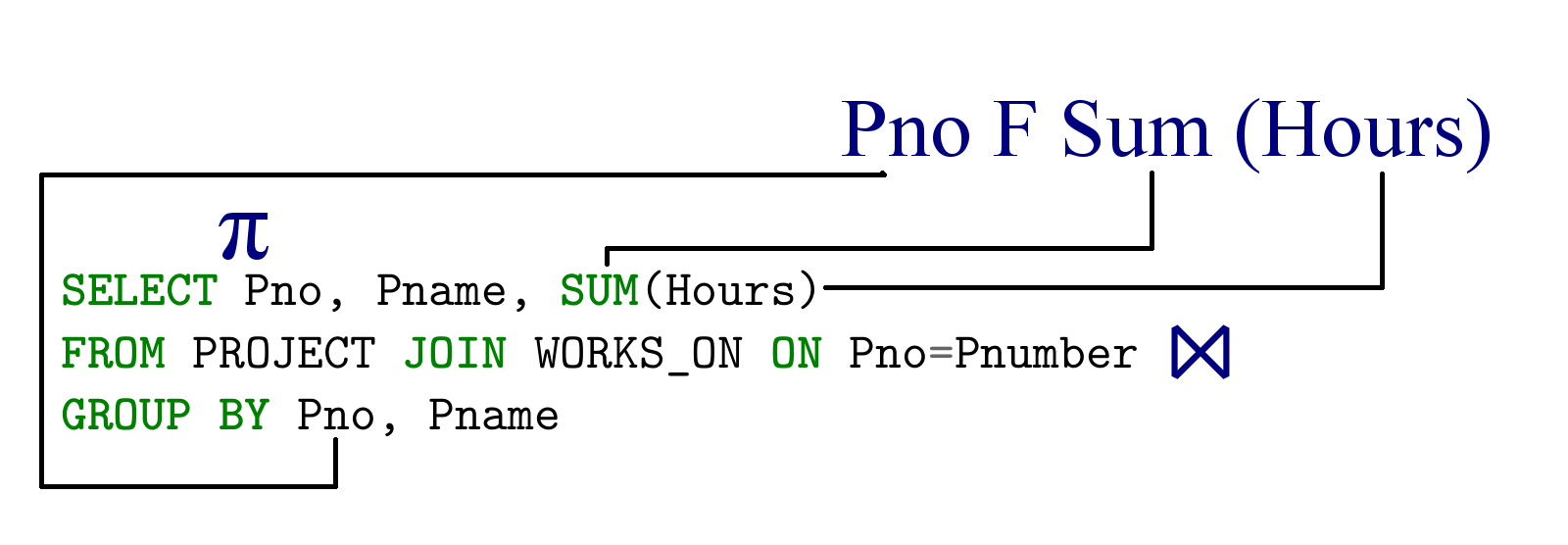
Раздел FROM
Этот раздел является обязательным и позволяет: → Указать имена исходных таблиц В разделе FROM указываются имена таблиц и/или представлений, из которых будут извлекаться данные. Причем одна и та же таблица может несколько раз входить в этот раздел. Примечание: В СУБД Oracle можно выбирать строки и из снимков (Snapshot).
→ Указать псевдонимы таблиц Под псевдонимом таблицы понимается дополнительный, обычно краткий идентификатор, указываемый через пробел после имени таблицы/представления. Пример: Customer C
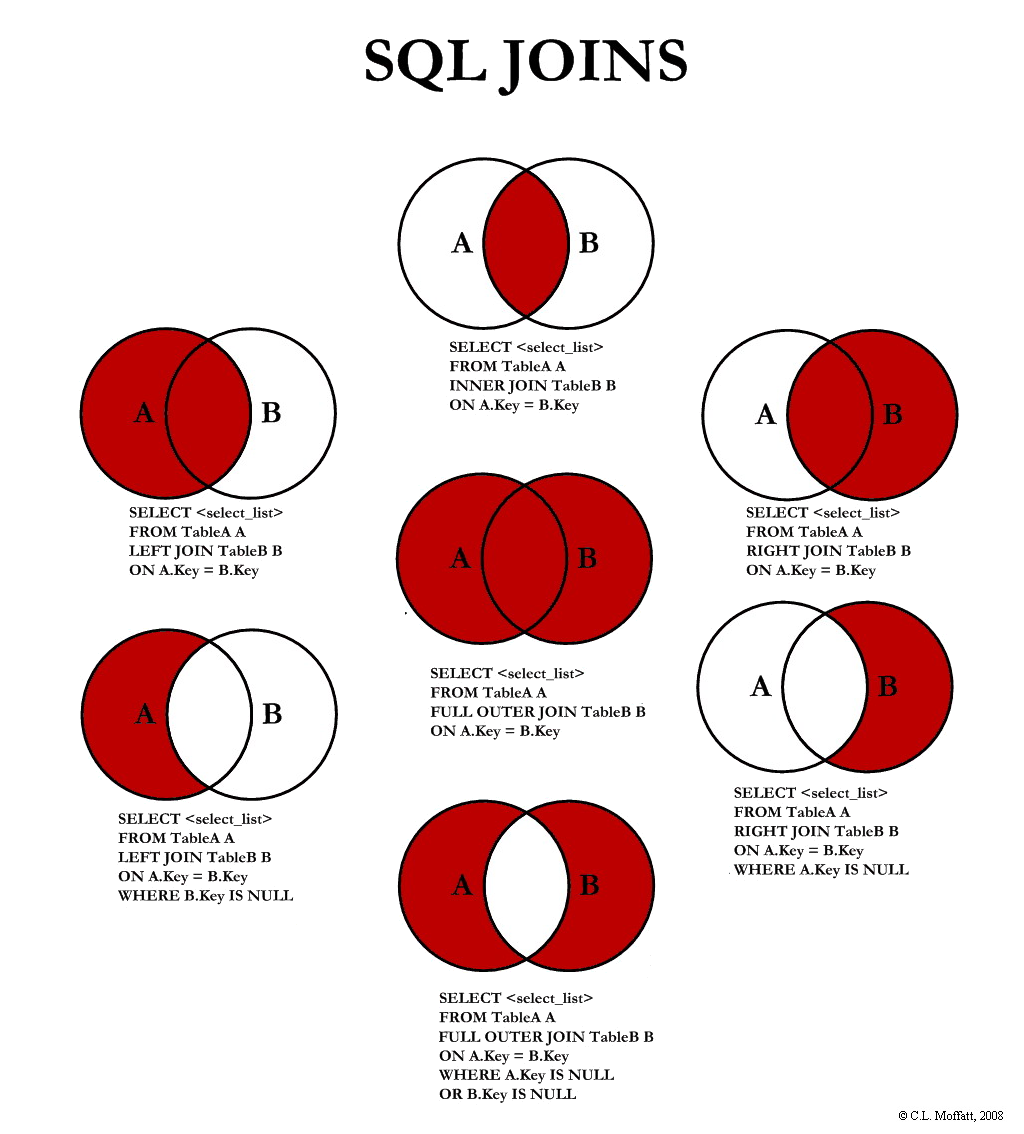
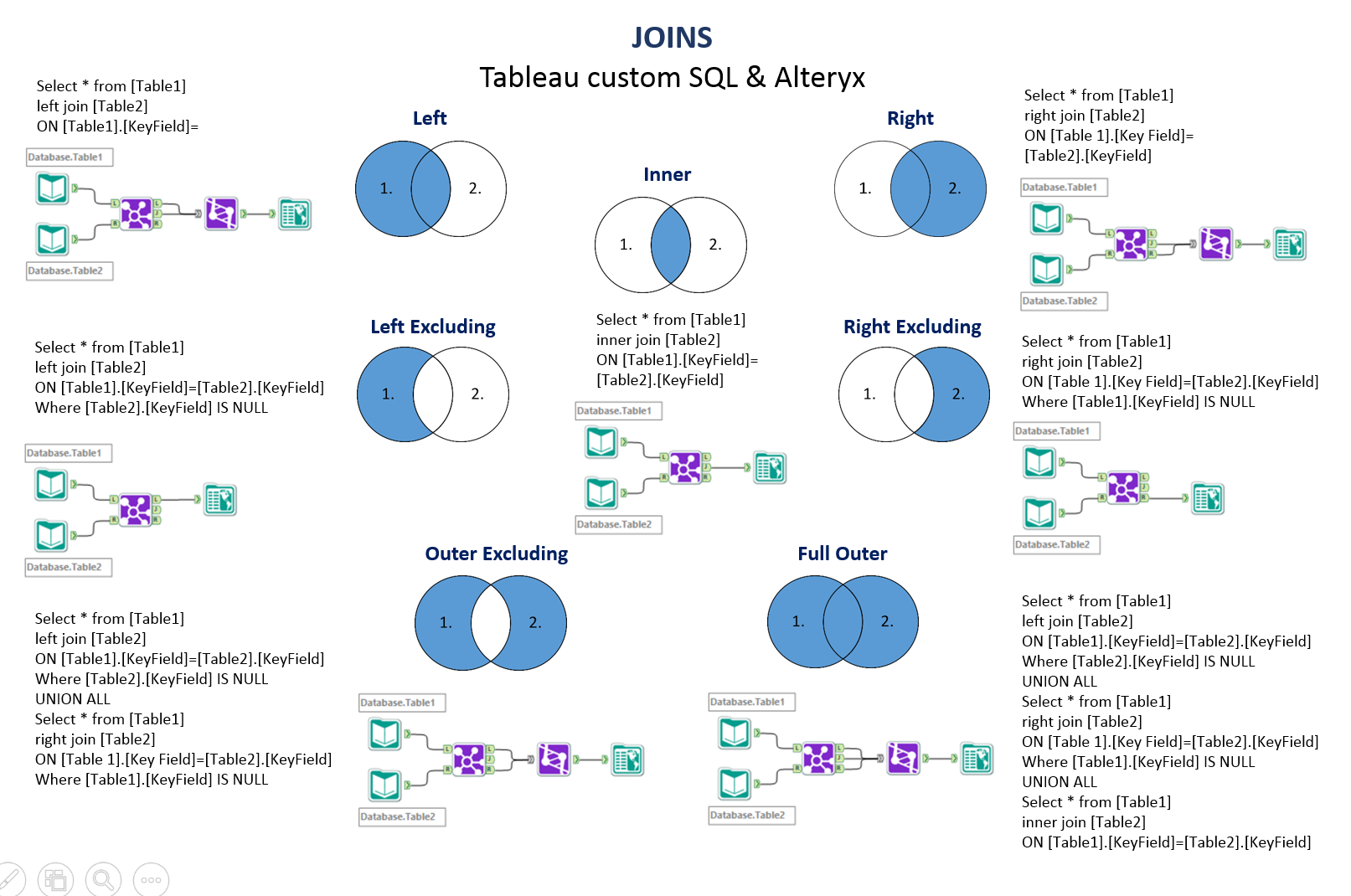
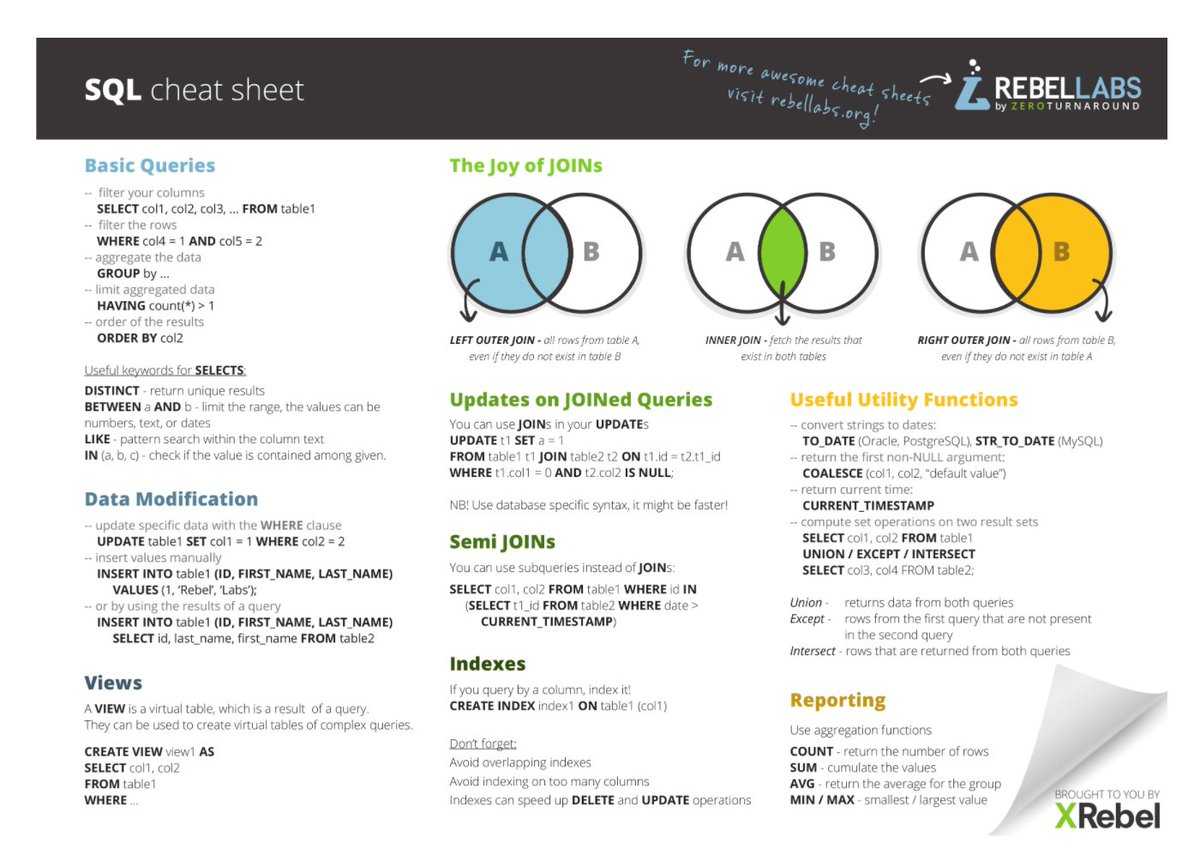
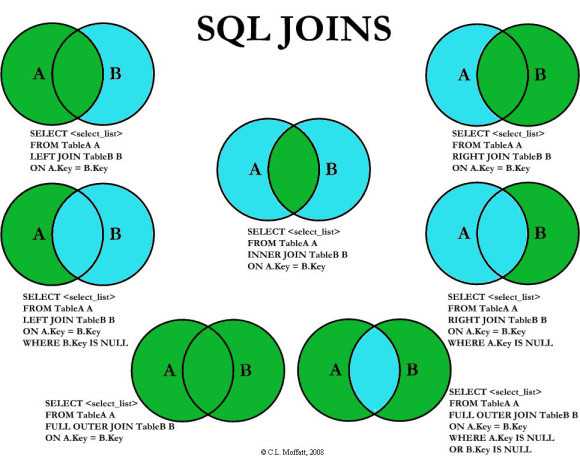
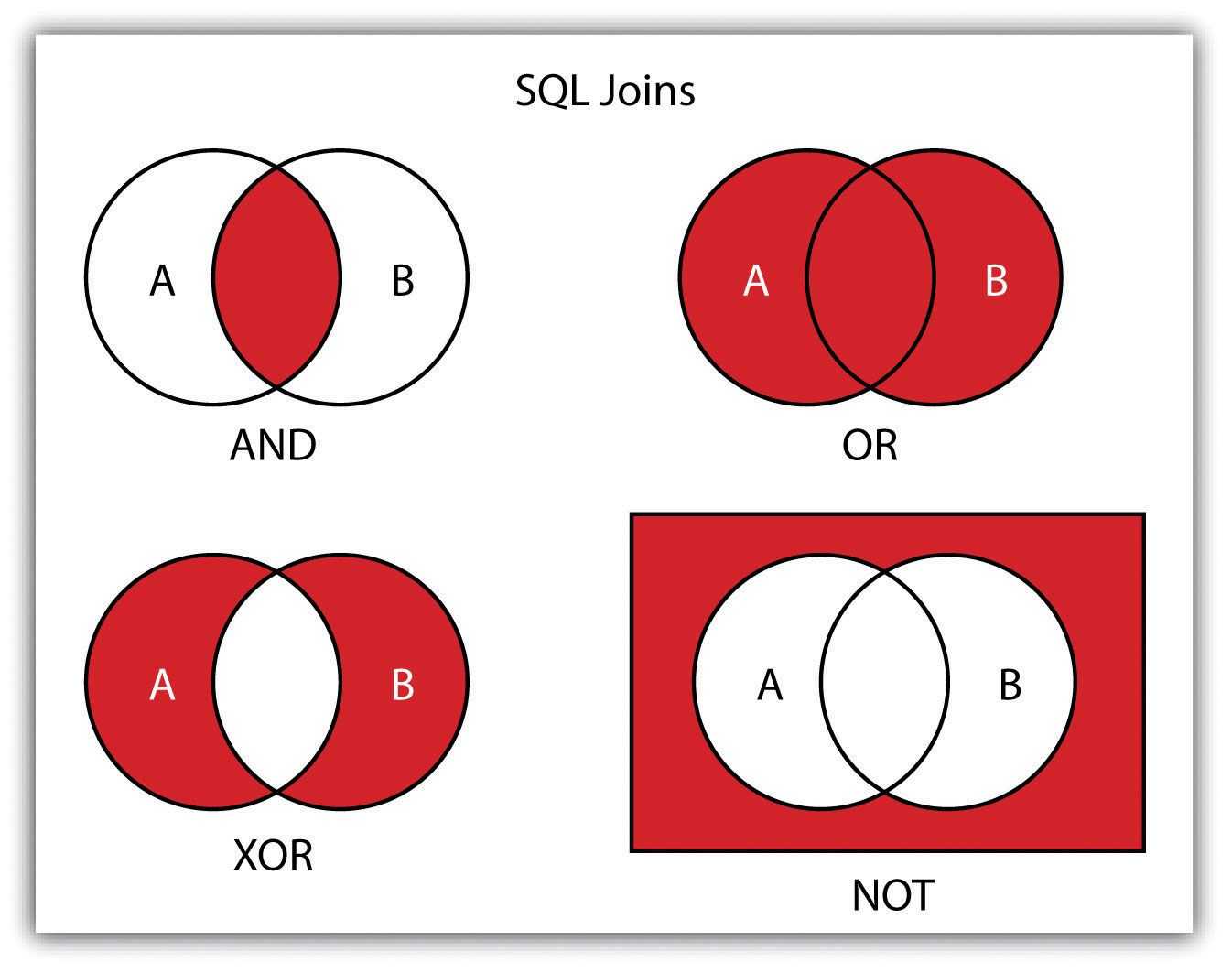
→ Указать вариант внешнего объединения таблиц Если в разделе FROM указано несколько таблиц, то все они неявно считаются внешними соединениями. В стандарте предусмотрены следующие основные виды соединений таблиц:
1) Перекрестное соединение CROSS JOIN — определяются все возможные сочетания пар строк по одной для каждой строки каждой из объединяемых таблиц. Эквивалентно картезианскому соединению. Иногда называет декартовым произведением.
2) Естественное соединение [] JOIN — определяются только те строки таблиц А и B, в которых значения столбцов одинаковы. Называют не совсем полноценным эквисоединением. Это автоматическое соединение по нескольким столбцам со всеми одинаковыми именами (join over).
3) Соединение объединением UNION JOIN — определяются только те строки каждой из таблиц, для которых совпадения не были установлены. Столбцы из другой таблицы заполняются значениями NULL. Отметим, что соединение UNION и оператор UNIUN – это не одно и то же. Соединение противоположно соединению типа INNER.
4) Объединение посредством предиката [] JOIN ON — фильтрует строки. Предикат может содержать подзапросы.
5) Объединение посредством имен столбцов [] JOIN USING() – определяет соединение только по указанным столбцам, в то время как NATURAL – автоматически по всем одноименным.
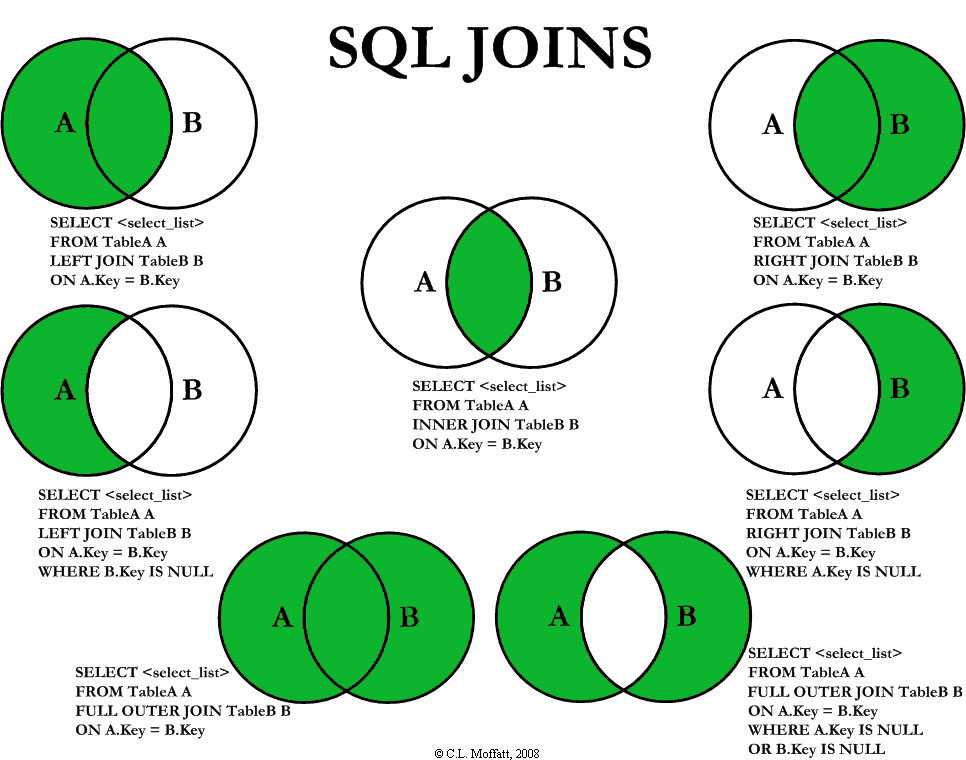
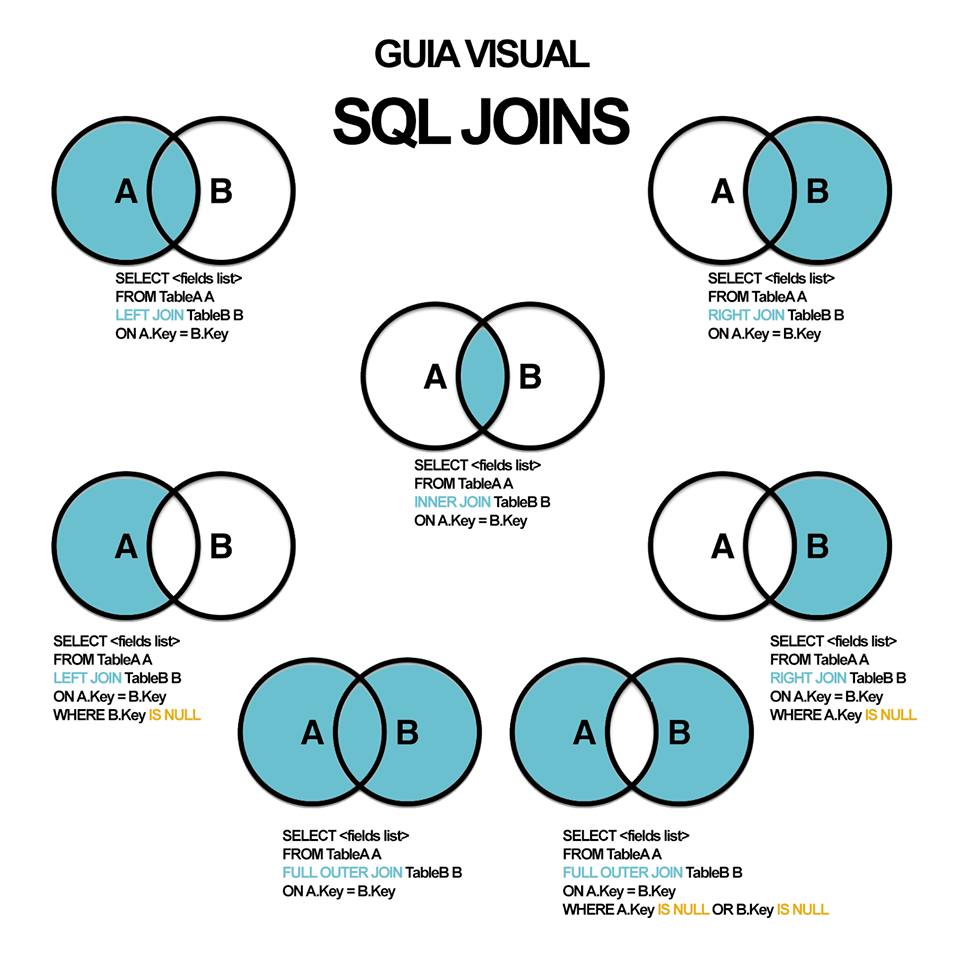
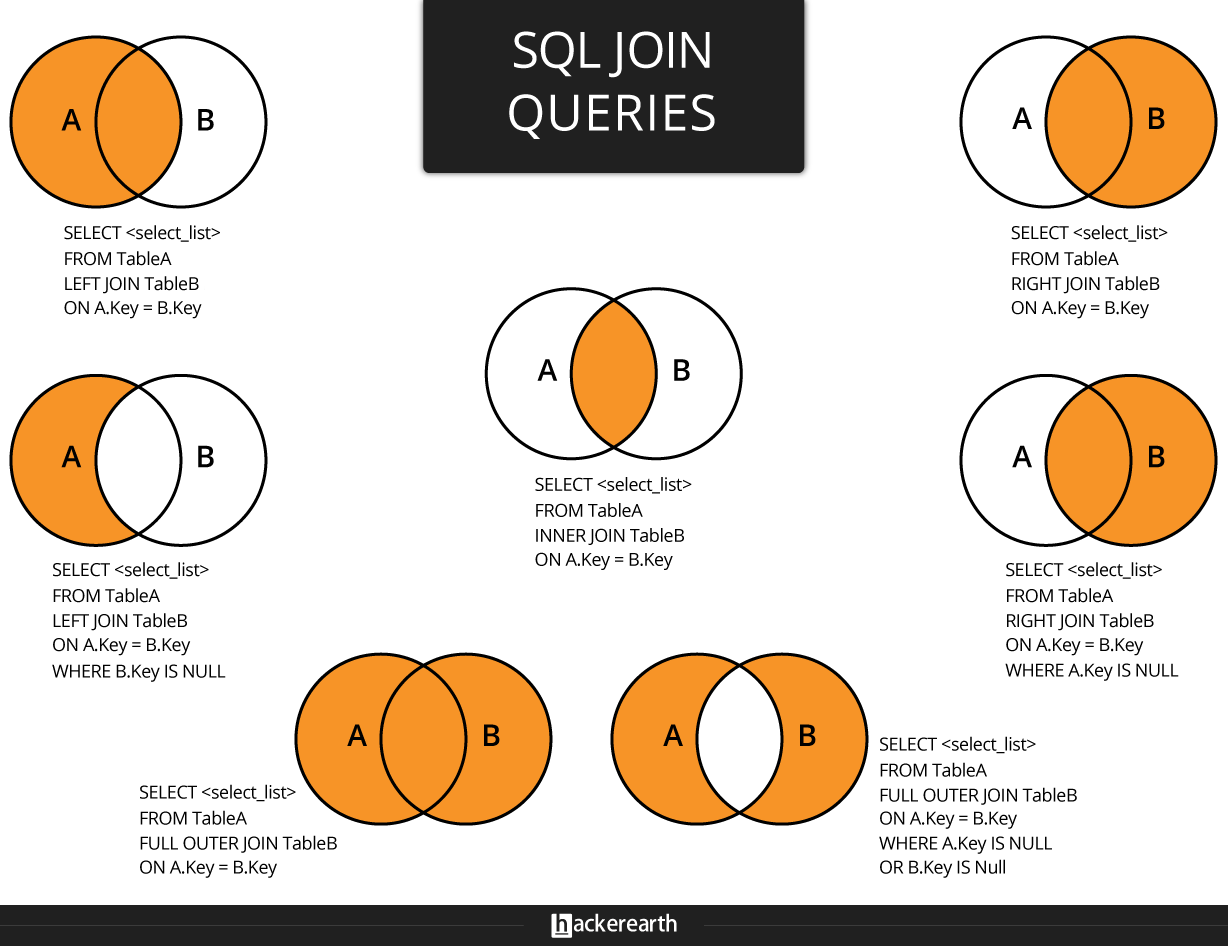
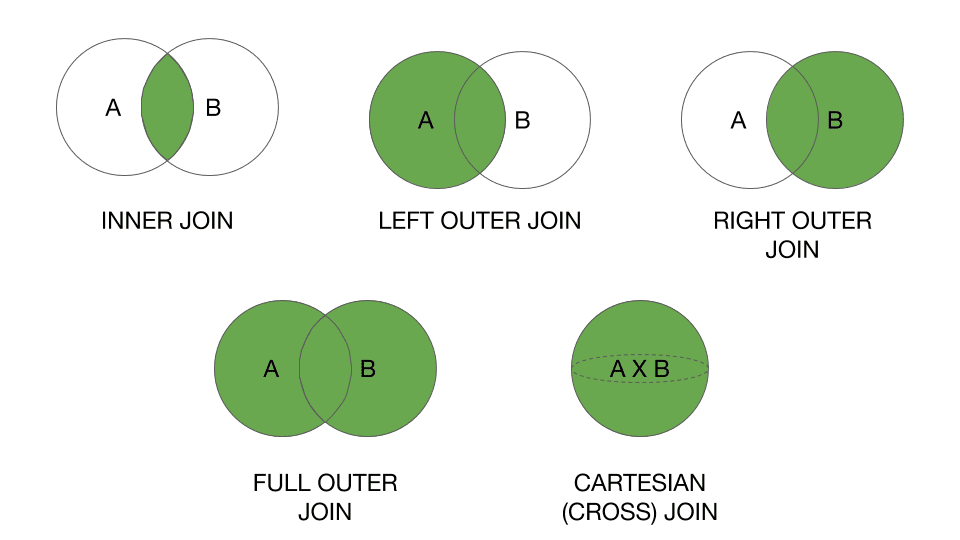
Типы соединений
представляет собой один из аргументов: INNER|{LEFT|RIGHT|FULL} • INNER – включает строки, в которых есть столбцы с совпадающими данными объединяемых таблиц. Используется по умолчанию. • LEFT – включает все строки таблицы А (левая таблица) и все совпадающие значения из таблицы B. Столбцы несовпадающих строки заполняются NULL-значениями. • RIGHT – включает все строки таблицы B (правая таблица) и все совпадающие значения таблицы А. обратный вариант для левого объединения. • FULL – включает все строки обеих таблиц. Столбцы совпадающих строк заполнены реальными значениями, а несовпадающих строк – NULL-значениями. • OUTER (внешний) – уточняющее слово, означающее, что несовпадающие строки из ведущей таблицы включаются вместе с совпадающими.
Примеры на внешнее объединение:
Картезианские соединения и самообъединения • Если при включении нескольких таблиц не используются те или иные варианты соединения таблиц, то такие соединения называются картезианскими. Они используются для получения строк из двух различных таблиц. Тогда например, при соединении двух таблиц, каждая из которых содержит по 20 строк, итоговая таблица будет содержать 100 строк – каждая из строк одной таблицы с каждой из строк другой таблицы. SELECT * FROM Customer, Orders. • Соединения одинаковых таблиц называют самообъединением (self-join).