
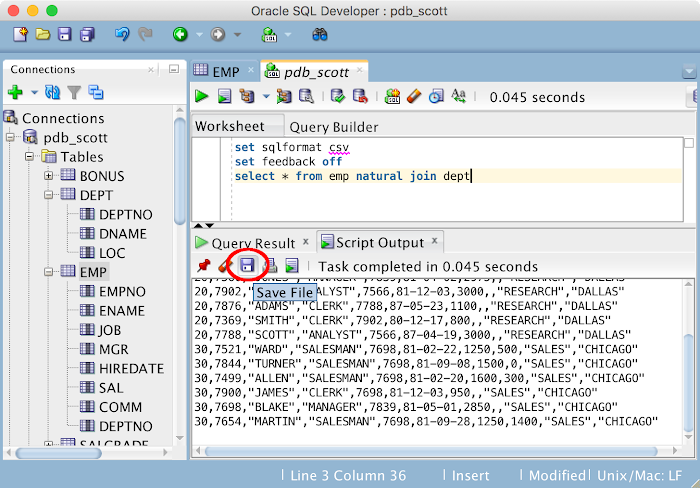
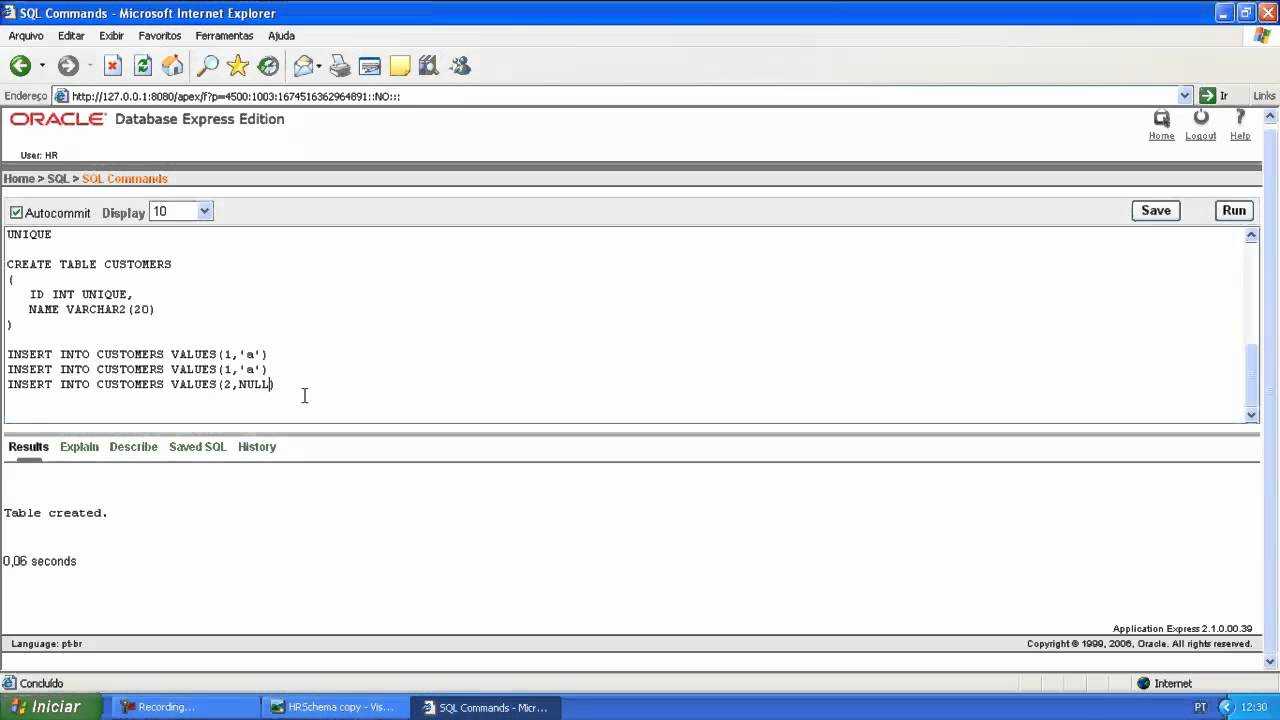
ПОЛНОЕ удаление лишних организаций и связанных с ними данных
Обработка предназначена для удаления лишних организаций и связанных с ними данных (документами, записями в регистрах сведений, подчиненных справочников). Эта обработка является немного переделанной от автора Ант10 (https://infostart.ru/public/696618/), отличатся от оригинальной версии возможностью выбора сразу нескольких организаций. Удобна, когда таких организаций много (в частности, задублированных организаций). Работает только с управляемыми формами, тестировалась в типовой конфигурации 1С: «Бухгалтерии предприятия 3.0» релиз 3.0.88.28. На платформе 1С 8.3.18.1334.
1 стартмани
2.3Кванторы и предикаты с несколькими переменными
Связывание одной переменной
S(x,y)=x2=yxy∃xS(x,y)
Если задать конкретное значение y, например, y=4, получается такая штука:
∃xS(x,4) или попросту
∃xx2=4
4x=2
Однако, можно выбрать другое значение y, например, положить y=−1. Тогда
получается утверждение
∃xx2=−1
x−1
Вернёмся теперь к утверждению ∃xS(x,y). Мы видим, что в это
утверждение вместо y можно подставлять различные числа и получать разные
высказывания — верные и неверные. Значит, перед нами предикат, зависящий от y.
Обозначим его через Q(y). Можно записать:
Q(y):=(∃xS(x,y))
Syx∃xS(x,y)yx
Последовательное применение кванторов
G(n,m)=n>m
Z(m):=(∃nG(n,m))=(∃nn>m).
∀mZ(m)
∀m∃nn>m.(2.3)
mnn>m
Во-первых, нужно заметить. что получившееся утверждение не является предикатом
— мы последовательно связали обе переменные и то, что получилось, уже ни от чего
не зависит, это просто высказывание, которое может быть истинным или ложным.
Является ли оно истинным? Да, является. Действительно, возьмём любое m.
Заметим, что для него предикат Z(m) верен, поскольку существует такое n
(например, можно взять n=m+1), для которого n>m. (Действительно, m+1>m,
каким бы ни было m.)
Словами это высказывание можно было бы записать так: «для всякого натурального
числа найдётся большее его число». Эта формулировка с точки зрения привычного
нам языка выглядит немножко неестественно и может возникнуть искушение сделать
её более привычной, переформулировав таким образом:
«найдется натуральное число, большее любого другого натурального числа». Однако,
то, что в результате получилось — не переформулировка исходного утверждения, а
совсем другое высказывание. Оно формально записывается так:
∃n∀mn>m(2.4)
mnn>mnn>mmnnm=nm=n+1m=n+2n>m
Отрицание и серия кванторов
∀mn>mW(n)
¬(∃nW(n))
¬(∃nW(n))=∀n(¬W(n))=∀n(¬(∀mn>m))=…(2.5)
¬(∃nW(n))=∀n(¬W(n))==∀n(¬(∀mn>m))=…(2.5)
¬(∀mn>m)
…=(∀n∃m¬(n>m))=(∀n∃mn⩽m).
n>mn>mn⩽m
∀n∃mn⩽m.
nmn⩽mm=nm=n+1m=n+100
Пример метода DELETE с Associative Arrays
Следующий пример заполняет Associative Arrays, индексированный строкой, и удаляет все элементы, что освобождает выделенную им память. Затем пример заменяет удаленные элементы, то есть добавляет новые элементы, которые имеют те же индексы, что и удаленные элементы. Новые элементы замены не занимают ту же память, что и соответствующие удаленные элементы. Наконец, пример удаляет один элемент, а затем ряд элементов. Процедура print_aa_str показывает эффекты операций.
Oracle PL/SQL
DECLARE
TYPE aa_type_str IS TABLE OF INTEGER INDEX BY VARCHAR2(10);
aa_str aa_type_str;
PROCEDURE print_aa_str IS
i VARCHAR2(10);
BEGIN
i := aa_str.FIRST;
IF i IS NULL THEN
DBMS_OUTPUT.PUT_LINE(‘aa_str is empty’);
ELSE
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT(‘aa_str.(‘ || i || ‘) = ‘); print(aa_str(i));
i := aa_str.NEXT(i);
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE(‘—‘);
END print_aa_str;
BEGIN
aa_str(‘M’) := 13;
aa_str(‘Z’) := 26;
aa_str(‘C’) := 3;
print_aa_str;
aa_str.DELETE; — Delete all elements
print_aa_str;
aa_str(‘M’) := 13; — Заменит удаленный элемент тем же значением
aa_str(‘Z’) := 260; — Заменит удаленный элемент новым значением
aa_str(‘C’) := 30; — Заменит удаленный элемент новым значением
aa_str(‘W’) := 23; — Добавит новый элемент
aa_str(‘J’) := 10; — Добавит новый элемент
aa_str(‘N’) := 14; — Добавит новый элемент
aa_str(‘P’) := 16; — Добавит новый элемент
aa_str(‘W’) := 23; — Добавит новый элемент
aa_str(‘J’) := 10; — Добавит новый элемент
print_aa_str;
aa_str.DELETE(‘C’); — Удаляет один элемент
print_aa_str;
aa_str.DELETE(‘N’,’W’); — Удаляет диапазон элементов
print_aa_str;
aa_str.DELETE(‘Z’,’M’); — Ничего не делает
print_aa_str;
END;
Результат:
aa_str.(C) = 3
aa_str.(M) = 13
aa_str.(Z) = 26
—
aa_str is empty
—
aa_str.(C) = 30
aa_str.(J) = 10
aa_str.(M) = 13
aa_str.(N) = 14
aa_str.(P) = 16
aa_str.(W) = 23
aa_str.(Z) = 260
—
aa_str.(J) = 10
aa_str.(M) = 13
aa_str.(N) = 14
aa_str.(P) = 16
aa_str.(W) = 23
aa_str.(Z) = 260
—
aa_str.(J) = 10
aa_str.(M) = 13
aa_str.(Z) = 260
—
aa_str.(J) = 10
aa_str.(M) = 13
aa_str.(Z) = 260
—
|
1 |
DECLARE TYPEaa_type_strISTABLEOFINTEGERINDEXBYVARCHAR2(10); aa_straa_type_str; PROCEDUREprint_aa_strIS iVARCHAR2(10); BEGIN i:=aa_str.FIRST; IFiISNULLTHEN DBMS_OUTPUT.PUT_LINE(‘aa_str is empty’); ELSE WHILEiISNOTNULLLOOP DBMS_OUTPUT.PUT(‘aa_str.(‘||i||’) = ‘);print(aa_str(i)); i:=aa_str.NEXT(i); ENDLOOP; ENDIF; DBMS_OUTPUT.PUT_LINE(‘—‘); ENDprint_aa_str; BEGIN aa_str(‘M’):=13; aa_str(‘Z’):=26; aa_str(‘C’):=3; print_aa_str; aa_str.DELETE;— Delete all elements print_aa_str; aa_str(‘M’):=13;— Заменит удаленный элемент тем же значением aa_str(‘Z’):=260;— Заменит удаленный элемент новым значением aa_str(‘C’):=30;— Заменит удаленный элемент новым значением aa_str(‘W’):=23;— Добавит новый элемент aa_str(‘J’):=10;— Добавит новый элемент aa_str(‘N’):=14;— Добавит новый элемент aa_str(‘P’):=16;— Добавит новый элемент aa_str(‘W’):=23;— Добавит новый элемент aa_str(‘J’):=10;— Добавит новый элемент print_aa_str; aa_str.DELETE(‘C’);— Удаляет один элемент print_aa_str; aa_str.DELETE(‘N’,’W’);— Удаляет диапазон элементов print_aa_str; aa_str.DELETE(‘Z’,’M’);— Ничего не делает print_aa_str; END; |
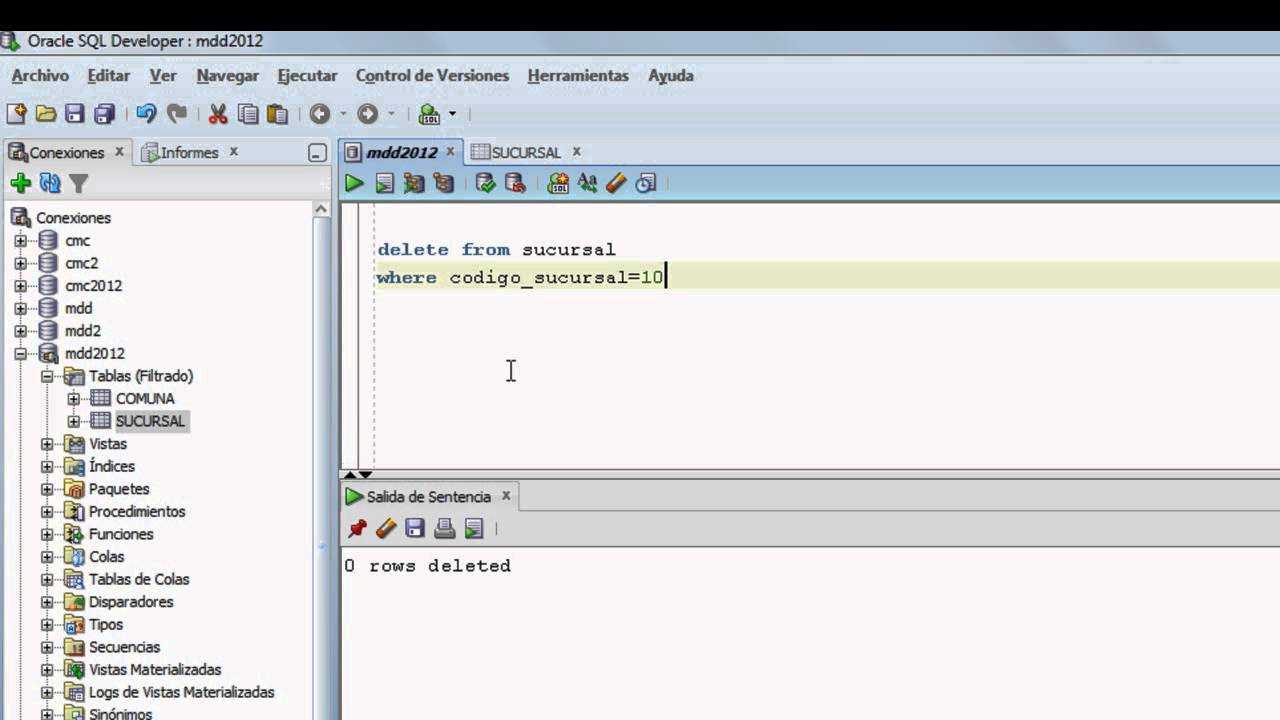
Оператор SQL DELETE и удаление данных с условием
Оператор SQL DELETE предназначен для удаления данных из таблицы. Он имеет следующий синтаксис:
DELETE FROM ИМЯ_ТАБЛИЦЫ
WHERE УСЛОВИЕ
Если не указывать условие, из таблицы будут удалены все строки. Кроме того, следует помнить,
что могут быть удалены лишь строки с первичными ключами, на которые не ссылаются внешние ключи в других
таблицах (более подробно об ограничениях удаления — в ).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
А скрипт для создания базы данных «Портал объявлений 1», её таблицы и заполения таблицы данных —
в файле по этой ссылке.
Пример 1. Итак, есть база портала объявлений. В ней есть таблица Ads, содержащая
данные о объявлениях, поданных за неделю (более подробно — в , пример 7).
Таблица выглядит так:
| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Требуется удалить из таблицы строку, имеющую идентификатор 4. Для этого
пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Id=4
Пример 2. Можно удалить и несколько строк, если в условии применить
оператор сравнения «больше» или «меньше» (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Id>4
В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Пример 3. Аналогично можно удалять строки с заданными значениями
любого столбца. Удалим, например, строки об объявлениях, за которые выручено менее 10000 денежных единиц
(запрос на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Money
В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
Оператор SQL DELETE и удаление всех данных из таблицы
Для удаления всех строк из таблицы применяется оператор SQL DELETE без условий, заданных в секции WHERE и
без любых других ограничей и условий, например, диапазона удаляемых строк. Таким образом, для удаления
всех строк синтаксис оператора DELETE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ИМЯ_ТАБЛИЦЫ
Пример 4. Чтобы удалить все данные из таблицы ADS, достаточно
написать следующий запрос:
DELETE FROM ADS
Если после выполнения этого запроса обратиться к таблице ADS при помощи оператора
SELECT, применяемого для получения выборки данных, то будет выведено сообщение о том, что эта
таблица не содержит данных.
Оператору DELETE без условий и ограничений аналогичен оператор TRUNCATE TABLE. Он
также удаляет из таблицы все строки, но выполняется намного быстрее.
Пример 5. Запрос на удаление всех данных из таблицы ADS
при помощи оператора TRUNCATE TABLE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
TRUNCATE TABLE ADS
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, HAVING и UNION.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Электронное приложение к уроку
Презентация «Элементы алгебры логики» (Open Document Format)
Ссылки на ресурсы ЕК ЦОР
- демонстрация к лекции «Основные понятия математической логики» (128630);http://school-collection.edu.ru/catalog/res/a969e5e4-f2e2-43f0-963b-65199b61416e/?inter
- демонстрация к лекции «Вычисление логических выражений» (128658);http://school-collection.edu.ru/catalog/res/f054fcc2-67a8-4426-81c8-ced80691d7e9/?inter
Федеральный центр информационных образовательных ресурсов:
- информационный модуль «Высказывание. Простые и сложные высказывания. Основные логические операции»; http://fcior.edu.ru/card/12468/vyskazyvanie-prostye-i-slozhnye-vyskazyvaniya-osnovnye-logicheskie-operacii.html
- практический модуль «Высказывание. Простые и сложные высказывания. Основные логические операции»; http://fcior.edu.ru/card/12921/vyskazyvanie-prostye-i-slozhnye-vyskazyvaniya-osnovnye-logicheskie-operacii.html
- информационный модуль «Построение отрицания к простым высказываниям, записанным на русском языке»;http://fcior.edu.ru/card/4059/postroenie-otricaniya-k-prostym-vyskazyvaniyam-zapisannym-na-russkom-yazyke.html
- практический модуль «Построение отрицания к простым высказываниям, записанным на русском языке»;http://fcior.edu.ru/card/7268/postroenie-otricaniya-k-prostym-vyskazyvaniyam-zapisannym-na-russkom-yazyke.html
- контрольный модуль «Построение отрицания к простым высказываниям, записанным на русском языке»; http://fcior.edu.ru/card/7120/postroenie-otricaniya-k-prostym-vyskazyvaniyam-zapisannym-na-russkom-yazyke.html
- информационный модуль «Логические законы и правила преобразования логических выражений»; http://fcior.edu.ru/card/14287/logicheskie-zakony-i-pravila-preobrazovaniya-logicheskih-vyrazheniy.html
- практический модуль «Логические законы и правила преобразования логических выражений»; http://fcior.edu.ru/card/10357/logicheskie-zakony-i-pravila-preobrazovaniya-logicheskih-vyrazheniy.html
- контрольный модуль «Логические законы и правила преобразования логических выражений»; http://fcior.edu.ru/card/3342/logicheskie-zakony-i-pravila-preobrazovaniya-logicheskih-vyrazheniy.html
- информационный модуль «Решение логических задач»; http://fcior.edu.ru/card/9561/reshenie-logicheskih-zadach.html
- практический модуль «Решение логических задач»; http://fcior.edu.ru/card/10836/reshenie-logicheskih-zadach.html
- контрольный модуль «Решение логических задач» http://fcior.edu.ru/card/8052/reshenie-logicheskih-zadach.html
Свободное программное обеспечение:
- демонстрационная версия логической головоломки «Шерлок»http://www.kaser.com
- тренажер «Логика» http://kpolyakov.spb.ru/prog/logic.htm
| Презентации, плакаты, текстовые файлы | Вернуться к материалам урока | Ресурсы ЭОР |
Cкачать материалы урока
ВПР по нескольким критериям с применением массивов — способ 2.
Выше мы уже рассматривали, как при помощи формулы массива можно организовать поиск ВПР с несколькими условиями. Предлагаем еще один способ.
Условия возьмем те же, что и в предыдущем примере.
Формулу в С4 введем такую:
Естественно, не забываем нажать CTRL+Shift+Enter.
Теперь давайте пошагово разберем, как это работает.
Наше задача здесь – также создать дополнительный столбец для работы функции ВПР. Только теперь мы создаем его не на листе рабочей книги Excel, а виртуально.




Как и в предыдущем примере, мы ищем текст из объединенных в одно целое условий поиска.
Далее определяем данные, среди которых будем искать.
Конструкция вида A7:A20&B7:B20&C7:C20;D7:D20 создает 2 элемента. Первый – это объединение колонок A, B и C из исходных данных. Если помните, то же самое мы делали в нашем дополнительном столбце. Второй D7:D20 – это значения, одно из которых нужно в итоге выбрать.
Функция ВЫБОР позволяет из этих элементов создать массив. {1,2} как раз и означает, что нужно взять сначала первый элемент, затем второй, и объединить их в виртуальную таблицу – массив.
В первой колонке этой виртуальной таблицы мы будем искать, а из второй – извлекать результат.
Таким образом, для работы функции ВПР с несколькими условиями мы вновь используем дополнительный столбец. Только создаем его не реально, а виртуально.
Пример оператора DELETE с одним условием
Если вы запустите оператор DELETE без условий в предложении WHERE, все записи из таблицы будут удалены. В результате вы чаще всего будете включать предложение WHERE, по крайней мере с одним условием, в свой оператор DELETE.
Давайте начнем с простого примера запроса DELETE, который имеет одно условие в предложении WHERE.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Moscow |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Введите следующий оператор DELETE:
PgSQL
DELETE FROM suppliers
WHERE supplier_name = ‘Yandex’;
|
1 |
DELETEFROMsuppliers WHEREsupplier_name=’Yandex’; |
Будет удалена 1 запись. Снова выберите данные из таблицы поставщиков:
PgSQL
SELECT * FROM suppliers;
| 1 | SELECT*FROMsuppliers; |
Вот результаты, которые вы должны получить:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
В этом примере удаляются все записи из таблицы suppliers, где supplier_name — Yandex.
Вы можете проверить количество строк, которые будут удалены. Вы можете определить количество строк, которые будут удалены, выполнив следующий запрос SELECT перед выполнением удаления:
PgSQL
SELECT COUNT(*)
FROM suppliers
WHERE supplier_name = ‘Yandex’;
|
1 |
SELECTCOUNT(*) FROMsuppliers WHEREsupplier_name=’Yandex’; |
Этот запрос вернет количество записей, которые будут удалены при выполнении оператора DELETE.
| COUNT(*) |
|---|
| 1 |
Новости теперь и в Telegram-канале
15 декабря 2021 г.
Новые задачи для тренировки 19-21 (А. Рогов).
14 декабря 2021 г.
Новая задача для тренировки 19-21 (И. Осипов).
Новые задачи для тренировки 22 (А. Кабанов).
13 декабря 2021 г.
Исправлен ответ к задаче 17.268.
12 декабря 2021 г.
Новые задачи для тренировки 24, 27 (Л. Шастин).
6 декабря 2021 г.
Исправлен ответ к задаче 10.180.
2 декабря 2021 г.
Новые задачи для тренировки 17.
30 ноября 2021 г.
Исправлена опечатка в условии задачи 15.473.
Исправлены ответы к задачам 17.(224, 230, 231, 239).
28 ноября 2021 г.
Исправлен ответ к задаче 3.67.
Новые задачи для тренировки 6 (П. Волгин).
2.4Импликация
AQ(n)nE(n)n∀nQ(n)E(n)
Вероятно, здесь проще начать с отрицания. Что нам нужно было бы сделать, чтобы
опровергнуть утверждение A? Нужно придумать такое n, чтобы оно делилось на
4, но при этом не делилось на 2. Именно такой контрпример, если бы он
был построен, опроверг бы наше утверждение. Иными словами, нам нужно было бы
предъявить такое n, что Q(n) выполняется, а E(n) нет, то есть верно
утверждение Q(n)∧(¬E(n)). Итак, отрицание к A
выглядит так:
¬A=(∃nQ(n)∧(¬E(n)))
A=(∀n(¬Q(n))∨E(n))(2.6)
n¬Q(n)¬Q(n)E(n)
Это ровно то, что мы хотим сказать.
Вопрос 2. Зачем городить такой огород? Почему нельзя было просто написать
∀nE(n)∧Q(n)?(2.7)
и
эквивалентны.
Неверный ответ.
А вот и нет. Например, утверждение A и формула
являются истинными, а утверждение в формуле
ложно. Действительно, возьмём, например,
n=6. Оно не делится на 4, значит, Q(6) ложно, и значит для
этого значения n конъюнкция ложна, а раз такое n нашлось, то
и всё утверждение ложно. Проверьте, что этот пример не
опровергает утверждение .
Верный ответ.
Так и есть. Например, утверждение A и формула
являются истинными, а утверждение в формуле
ложно. Действительно, возьмём, например,
n=6. Оно не делится на 4, значит, Q(6) ложно, и значит для
этого значения n конъюнкция ложна, а раз такое n нашлось, то
и всё утверждение ложно. Проверьте, что этот пример не
опровергает утверждение .
В общем виде это формулируется так. Пусть есть два высказывания, A и B.
Утверждения «из A следует B» или «A влечёт B» или «если A
истинно, то B тоже истинно», формально записываются так: ¬A∨B. Иными словами, говоря «если A истинно, то B тоже истинно», мы
говорим, что A может и не быть истинным, но нас этот случай, не интересует, мы
про него никаких выводов не делаем (а значит, и ошибаться не можем), но если уж
A истинно, то B обязано быть истинным.
Эта операция с высказываниями A и B настолько важна, что хотя она и
выражается через конъюнкцию, дизъюнкцию и отрицание, у него есть специальное
название — импликация (ср. с английским словом imply, влечёт), и
специальное обозначение: A⇒B. Утверждение A называется
посылкой, а утверждение B — заключением.
Давайте построим таблицу истинности для A⇒B (то есть ¬A∨B).
ABA⇒BИИИИЛЛЛИИЛЛИ
A⇒BABAB
Возвращаясь к примеру, который мы разбирали раньше: «если число n делится на
4, то оно чётное». Рассмотрим число n=6. Для него посылка оказалась ложной
(оно не делится на 4), и хотя заключение оказалось истинным (оно чётно), это
никак не противоречит нашей импликации: она остаётся верна и в этом случае.
В дальнейшем мы будем постоянно пользоваться импликацией в доказательствах.
Начнём прямо со следующей лекции.
ВПР по двум условиям при помощи формулы массива.
У нас есть таблица, в которой записана выручка по каждому магазину за день. Мы хотим быстро найти сумму продаж по конкретному магазину за определенный день.
Для этого в верхней части нашего листа запишем критерии поиска: дата и магазин. В ячейке B3 будем выводить сумму выручки.
Формула в B3 выглядит следующим образом:
Обратите внимание на фигурные скобки, которые означают, что это формула массива. То есть наша функция ВПР работает не с отдельными значениями, а разу с массивами данных
Разберем процесс подробно.
Мы ищем дату, записанную в ячейке B1. Но вот только разыскивать мы ее будем не в нашем исходном диапазоне данных, а в немного видоизмененном. Для этого используем условие
То есть, в том случае, если наименование магазина совпадает с критерием в ячейке B2, мы оставляем исходные значения из нашего диапазона. А если нет – заменяем их на пробелы. И так по каждой строке.
В результате получим вот такой виртуальный массив данных на основе нашей исходной таблицы:
Как видите, строки, в которых ранее был «Магазин 1», заменены на пустые. И теперь искать нужную дату мы будем только среди информации по «Магазин 2». И извлекать значения выручки из третьей колонки.
С такой работой функция ВПР вполне справится.
Такой ход стал возможен путем применения формулы массива
Поэтому обратите особое внимание: круглые скобки в формуле писать руками не нужно! В ячейке B3 вы записываете формулу. И затем нажимаете комбинацию клавиш CTRL+Shift+Enter. При этом Excel поймет, что вы хотите ввести формулу массива и сам подставит скобки
И затем нажимаете комбинацию клавиш CTRL+Shift+Enter. При этом Excel поймет, что вы хотите ввести формулу массива и сам подставит скобки.



Таким образом, функция ВПР поиск по двум столбцам производит в 2 этапа: сначала мы очищаем диапазон данных от строк, не соответствующих одному из условий, при помощи функции ЕСЛИ и формулы массива. А затем уже в этой откорректированной информации производим обычный поиск по одному только второму критерию при помощи ВПР.
Чтобы упростить работу в будущем и застраховать себя от возможных ошибок при добавлении новой информации о продажах, мы рекомендуем использовать «умную» таблицу. Она автоматически подстроит свой размер с учетом добавленных строк, и никакие ссылки в формулах не нужно будет менять.
Вот как это будет выглядеть.
Объединить две таблицы — альтернатива ВПР в Excel без формул.
Если ваши файлы Excel чрезвычайно велики и сложны, а выполнить расчеты нужно быстро, и вы ищете кого-то, кто может протянуть вам руку помощи, то попробуйте Мастер объединения таблиц .
Этот инструмент является простой и наглядной альтернативой функции ВПР в Excel. Работает он следующим образом:
- Выберите свою основную таблицу. Предположим, это таблица с данными о продажах.
- Выберите таблицу поиска. Это может быть список менеджеров, закрепленных за отдельными покупателями.
- Выберите один или несколько общих столбцов в качестве уникальных идентификаторов. В нашем случае это будет наименование заказчика.
Укажите, какие столбцы нужно обновить. В данном случае – ничего. Просто пропускаем этот шаг.
При желании выберите столбцы, которые нужно добавить. Добавим в основную таблицу колонку с фамилиями менеджеров, которые работают с конкретным заказчиком
При этом совершенно не важно, где находятся эти столбцы для добавления — слева или справа от столбца поиска.
- На следующем шаге вы можете указать дополнительные опции объединения – выделение цветом добавленного, добавление несовпадающих значений в конец основной таблицы, вставка столбца статуса и др. Но в нашем случае в этом нет необходимости. Ведь мы просто хотим найти и добавить в основную таблицу фамилии менеджеров. Поэтому просто нажимаем Finish. Теперь дайте Мастеру объединения таблиц несколько секунд для обработки… и наслаждайтесь результатами

Согласитесь, это именно то, что делает функция ВПР — выбирает из таблицы поиска значения, соответствующие данным из основной таблицы. Но в данном случае мы прекрасно обошлись без формул.
Более подробную информацию об инструменте Merge Tables вы можете посмотреть здесь.
Дополнительные материалы о функции ВПР:
Метод DELETE
Метод предназначен для удаления одного, нескольких или всех элементов ассоциативного массива, вложенной таблицы или массива . При вызове без аргументов он удаляет все элементы коллекции. Вызов (i) удаляет i-й элемент вложенной таблицы или ассоциативного массива. А вызов () удаляет все элементы с индексами от до включительно. Если коллекция представляет собой ассоциативный массив, индексируемый строками, и должны быть строковыми значениями; в противном случае они являются целыми числами.
При вызове с аргументами метод резервирует место, занимавшееся «удаленным» элементом, и позднее этому элементу можно присвоить новое значение.
Фактически PL/SQL освобождает память лишь при условии, что программа удаляет количество элементов, достаточное для освобождения целой страницы памяти. (Если же метод вызывается без параметров и очищает всю коллекцию, память освобождается немедленно.)
Применительно к массивам метод может вызываться только без аргументов. Иначе говоря, с помощью указанного метода из этой структуры нельзя удалять отдельные элементы, поскольку в таком случае она станет разреженной, что недопустимо. Единственный способ удалить из один или несколько элементов — воспользоваться методом , предназначенным для удаления группы расположенных рядом элементов, начиная с конца коллекции.
Следующая процедура удаляет из коллекции все элементы, кроме последнего. В ней используются четыре метода: — для получения номера первого удаляемого элемента; — для получения номера последнего удаляемого элемента; — для определения номера предпоследнего элемента; — для удаления всех элементов, кроме последнего:
Несколько дополнительных примеров:
Удаление всех строк из таблицы names:
Удаление 77-й строки из таблицы globals:
Удаление из таблицы temp_reading всех элементов, начиная с индекса –15 000 и до индекса 0 включительно:
Граничные условия
Если значения индексов и/или указывают на несуществующие элементы, пытается «сделать наилучшее» и не генерирует исключение. Например, если таблица содержит три элемента с индексами 1, 2 и 3, то вызов метода (–5,1) удалит только один элемент с индексом 1, а вызов (–5) не изменит состояния коллекции.
Возможные исключения
Вызов метода для неинициализированной вложенной таблицы или массива инициирует исключение .
Двойной ВПР при помощи ИНДЕКС + ПОИСКПОЗ
Далее речь у нас пойдет уже не о функции ВПР, но задачу мы будем решать ту же самую. В качестве критерия поиска нам опять нужно использовать несколько условий.
Существуют, пожалуй, даже более гибкие решения, нежели функция ВПР. Это комбинация функций ИНДЕКС + ПОИСКПОЗ.
Область их применения очень велика, о чем бы также будем рассказывать на сайте mister-office.ru.
А пока вернемся вновь к нашей задаче.
Формула в С4 теперь выглядит так:
И не забываем при вводе нажать CTRL+Shift+Enter! Это формула массива.
Теперь давайте разбираться, как это работает.
Функция ИНДЕКС в нашем случае позволяет извлечь элемент из списка по его порядковому номеру. Список – это диапазон D7:D20, где записаны суммы выручки. А вот порядковый номер, который нужно извлечь, мы определяем при помощи ПОИСКПОЗ.
Синтаксис здесь следующий:
Тип поиска ставим 0, то есть точное совпадение. В нашем случае мы будем искать 1. Далее мы определим массив, в котором будем работать.
Выражение (A7:A20=C1)*(B7:B20=C2)*(C7:C20=C3) позволит создать виртуальную таблицу примерно такого вида:
Как видите, первоначально мы последовательно сравниваем каждое значение с нашим критерием отбора. В столбце А у нас записаны месяцы – сравниваем их с месяцем-критерием из ячейки C1. В случае совпадения получаем ИСТИНА, иначе – ЛОЖЬ. Аналогично последовательно проверяем год и название магазина. А затем просто перемножаем значения. Поскольку логические переменные для Excel – это либо 0, либо 1, то произведение их может быть равно 1 только в том случае, если мы имеем по каждой колонке ИСТИНА (то есть,1). Во всех остальных случаях получаем 0.
Убеждаемся, что цифра 1 встречается только единожды.
При помощи ПОИСКПОЗ определяем, на какой позиции она находится. На какой позиции находится 1, на той же позиции находится в массиве и искомая сумма выручки. В нашем случае это 10-я.
Далее при помощи ИНДЕКС извлекаем 10-ю по счету выручку.
Таким образом мы выбрали значение по нескольким условиям без использования функции ВПР.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.
В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
2.1Высказывания
Примеры высказываний
Как бы определение 1. Высказывание — это утверждение с чётко определенным смыслом, которое может
быть истинным или ложным.
Как обычно, проще привести несколько примеров.
Пример.
- «2+2=5» — пример высказывания. Оно ложно.
- «3>2» — ещё один пример высказывания. Оно истинно.
- «5 — простое число» — ещё одно истинное высказывание.
- «Множество простых чисел конечно» — это ложное высказывание.
- «Если целое число простое и оно больше двух, оно нечётно» —
истинное высказывание. - «Каждое чётное число, большее двух, можно представить в виде суммы
двух простых чисел» — это высказывание, истинность которого в
настоящий момент неизвестна (это так называемая бинарная проблема
Гольдбаха). - «n — чётное число» — это не высказывание, потому что непонятно,
чему равно n (здесь, конечно, под n подразумевается не
собственно буква, а переменная, которая может принимать разные
значения), и поэтому это утверждение не является ни ложным, ни
истинным. С такого типа утверждениями (они называются предикатами)
мы познакомимся чуть позже.
Вместо «истинно» или «ложно» используются и другие синонимичные выражения:
верно (неверно), корректно (некорректно) и т.д.
Операции с высказываниями
AB
Определение 1. Высказывание «верно по крайней мере одно из двух высказываний A или B (или
оба)», называется дизъюнкцией высказываний A и B. Оно
обозначается A∨B. Другой термин для дизъюнкции — логическое
«ИЛИ».
Определение 2. Высказывание «верны оба высказывания A и B» называется
конъюнкцией высказываний A и B. Оно обозначается A∧B.
Другой термин для конъюнкции — логическое «И».
Определение 3. Высказывание «высказывание A неверно» называется отрицанием A.
Обозначается ¬A. Другой термин — логическое «НЕ».
Если про каждое из высказываний A и B известно, является оно истинным или
ложным, легко установить истинность их конъюнкции, дизъюнкции и отрицания.
Например, если A истинно, то ¬A ложно. Если A и B оба истинны, то
A∧B истинно, иначе оно ложно. И так далее. Эту информацию удобно
записывать в виде табличек, которые называются таблицами истинности.
Таблица истинности для отрицания выглядит так:
A¬AИЛЛИ
ABA∨BA∧BИИИИИЛИЛЛИИЛЛЛЛЛ
Раскрытие скобок с отрицанием
AB¬(A∨B)AB
¬(A∨B)=(¬A)∧(¬B)
¬(A∧B)AB
¬(A∧B)=(¬A)∨(¬B)
∨∧
Эти правила преобразования формул в алгебре логики называются законами де
Моргана.
Замечание 1. Законы де Моргана мгновенно обобщаются на случай большего количества
высказываний. Например, ¬(A∧B∧C)=(¬A)∨(¬B)∨(¬C).
Операции
Ниже рассмотрим основные операции, которые применяются в булевой алгебре. Их хватит, чтобы упростить львиную долю всех выражений, которые Вам встретятся.
Конъюнкция
Конъюнкция (булево умножение) — функция, по своему смыслу приближенная к союзу «И». При выполнении конъюнкции результат истинен (равен 1) тогда и только тогда, когда истинны ВСЕ переменные. Если хотя бы одно из высказываний ложно, то ложно и всё выражение (равно 0).
Функция может работать как с двумя операндами (высказываниями), так и с тремя, четырьмя и т.д. В математике обозначается с помощью знаков \( \wedge \) и &. Обозначение в языках программирования AND, &&. Таблица истинности для двух операндов:
Дизъюнкция
Дизъюнкцией называется функция булева сложения. По смыслу дизъюнкция приближена к союзу «ИЛИ». В результате выполнения данной функции результирующие выражение является истинным, когда хотя бы одно из высказываний в этом выражении тоже истинно.
Булево сложение, также как и умножение, может работать с произвольным количеством операндов. В математике обозначается как V, а в программировании с помощью OR или I.
Инверсия
Логическое отрицание – функция, работающая с одним высказыванием, и заменяющая истину на ложь, а ложь на истину. В математике обозначается с помощью черты над значением, а в программирование и информатике с помощью слова NOT.
Импликация
Также называется булевым следованием. В русском языке данной функции соответствует оборот «Если …, то …». Например, если на улице гремит гром, то стоит пасмурная погода.
Результирующее значение будет ложным только тогда, когда из истинного высказывания будет следовать ложное следствие. Имеет обозначение в виде стрелочки \( \Longrightarrow \)
Важно: импликация работает только с двумя операндами
Эквивалентность
Булева тождественность или равенство. На простом языке будет обозначено как «… эквивалентно (равно) …». Результат будет истинным тогда, когда все значения в выражении будут иметь одинаковую истинность.
Обозначается с помощью трех черточек или ⟺.
Удаление помеченных объектов, замена ссылок. Обычное и управляемое приложение. Не монопольно, включая рекурсивные ссылки, с отбором по метаданным и произвольным запросом Промо
Обработка удаления помеченных объектов с расширенным функционалом. Работает в обычном и управляемом приложении. Монопольный и разделенный режим работы. Отображение и отбор по структуре метаданных. Отборы данных произвольными запросами. Копирование и сохранение отборов. Удаление циклических ссылок (рекурсия). Представление циклических в виде дерева с отображением ключевых ссылок, не позволяющих удалить текущий объект информационной базы. Удаление записей связанных независимых регистров сведений. Групповая замена ссылок. Индикатор прогресса при поиске и контроле ссылочности.
10 стартмани





