Семантические изменения
Если это просто оптимизация времени, она, кажется, не использует достаточные причины. Фактически, AST не основана на оптимизации времени, но для решения проблемы грамматики. Давайте посмотрим на некоторые изменения семантики.
Доходность не нуждается в скобках
В реализации PHP5, если вы используете доход в контексте выражения (например, на правой стороне выражения назначения, вы должны применять кронштейны в доходности:
Такое поведение только из-за ограничений PHP5, в PHP7 скобки больше не нужны. Так что следующее также законно:
Конечно, вы должны следовать сценарию приложений выхода.
Бренд не влияет на поведение
В PHP5, и Значение двух утверждений отличается. На самом деле, предыдущий путь является незаконным, вы получите следующую ошибку:
Но в PHP7 два способа написания указывают на то же значение.
Точно так же, если параметры функции завернуты в скобки, возникает проблема в проверке типа, и эта проблема в PHP7 была решена:
Приведенный выше код не тревоги в PHP5, если только не используется Режим вызова, но в PHP7, независимо от На обеих сторонах нет скобок, чтобы получить следующую ошибку:
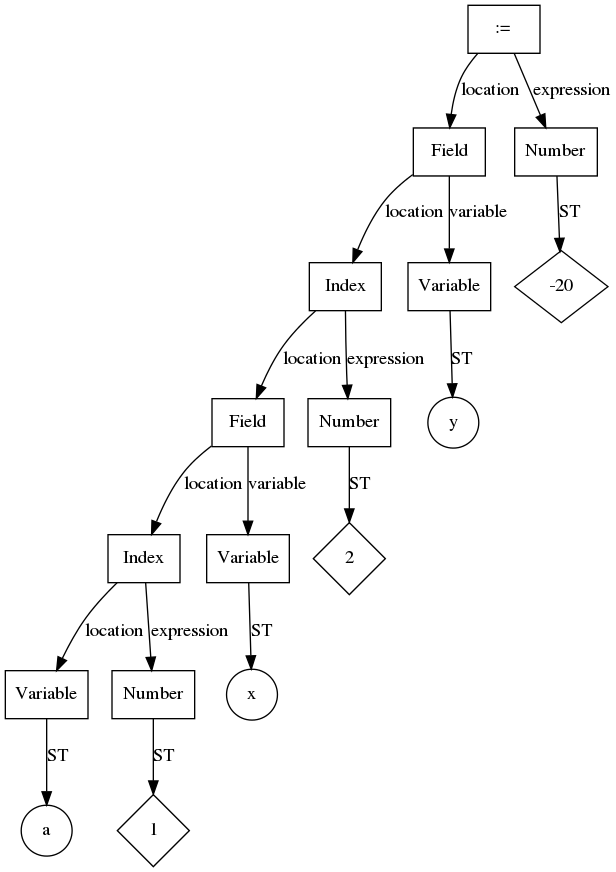
Список () Изменить
Поведение смены ключа списка много изменилось. Список дает порядок переменной (порядок другого знака », справа налево, теперь слева направо:
Причина вышеупомянутого изменения является именно потому, что во время назначения PHP5, Будет сначала заполнен массивом, Наконец, это изменилось в порядке.
Те же изменения:
Это потому, что во время предыдущего процесса назначения Сначала получить,Затем Значение становится,но сейчас Превратите его во имяБольше не массив, так Стал。
Список теперь будет доступ к каждому смещению один раз:
Пустые члены списка теперь все запрещены, прежде чем в некоторых случаях:
__CLONE Способ можно назвать напрямую
Теперь можно использовать его напрямую Писать, чтобы позвонить метод. Это единственный магический метод, который запрещен напрямую от него, вы получите такую ошибку до:
Создать семантический валидатор
Скорее всего, ваш язык допускает синтаксически правильные конструкции, которые могут не иметь смысла в определенных контекстах. Примером является дублирование объявления той же переменной или передача параметра неправильного типа. Валидатор обнаружит такие ошибки, глядя на дерево.
Валидатор также разрешает ссылки на другие модули, написанные на вашем языке, загружает эти другие модули и использует их в процессе проверки. Например, этот шаг будет гарантировать, что число параметров, переданных функции из другого модуля, является правильным.
Опять же, напишите и запустите много тестов. Тривиальные случаи так же необходимы при устранении неполадок, как умные и сложные.
Спорные вопросы
Некоторые сущности трудно отнести к той или иной категории. Например:
- Объявление анонимной функции (лямбды) можно считать объявлением без имени либо выражением
- Объявление переменной можно считать как просто инструкцией, так и полноценным объявлением
Спорные вопросы обычно решаются в сторону удобства для создателя языка или компилятора.
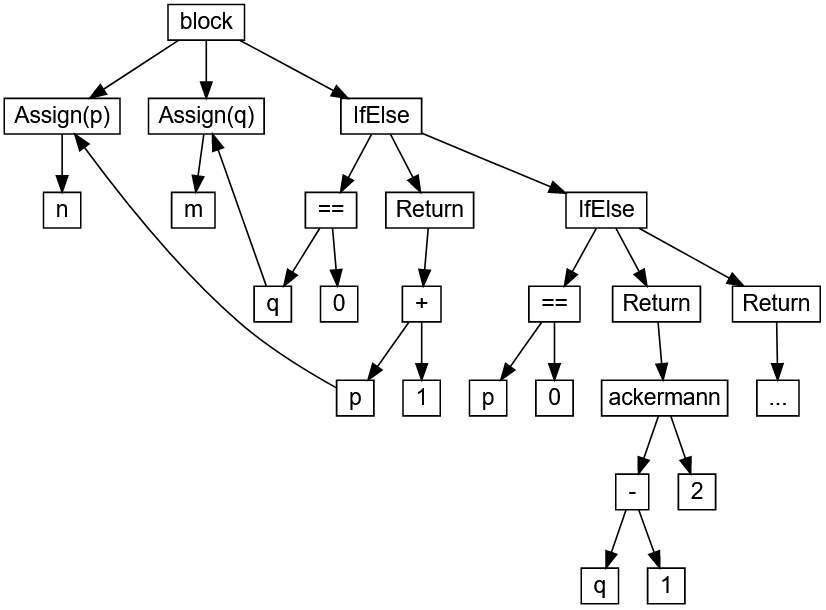
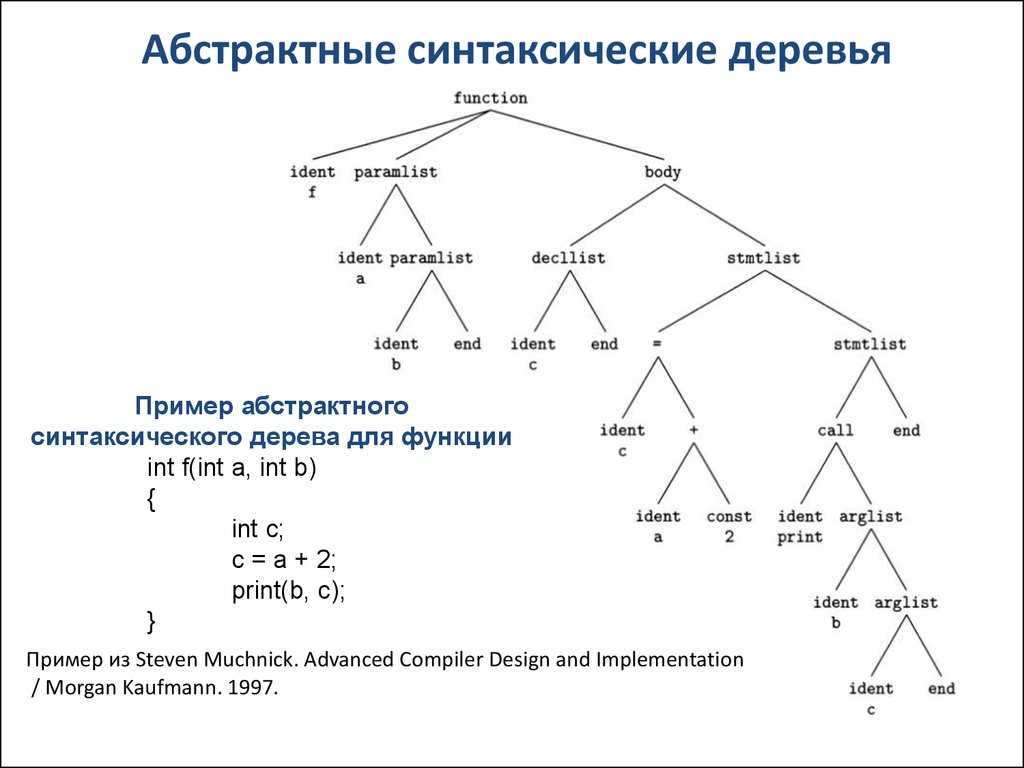
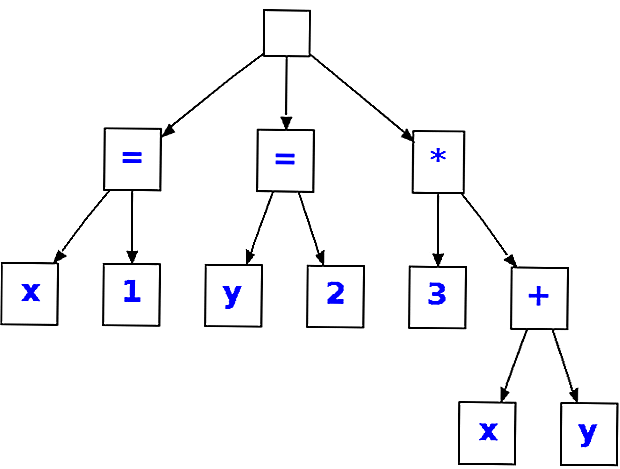
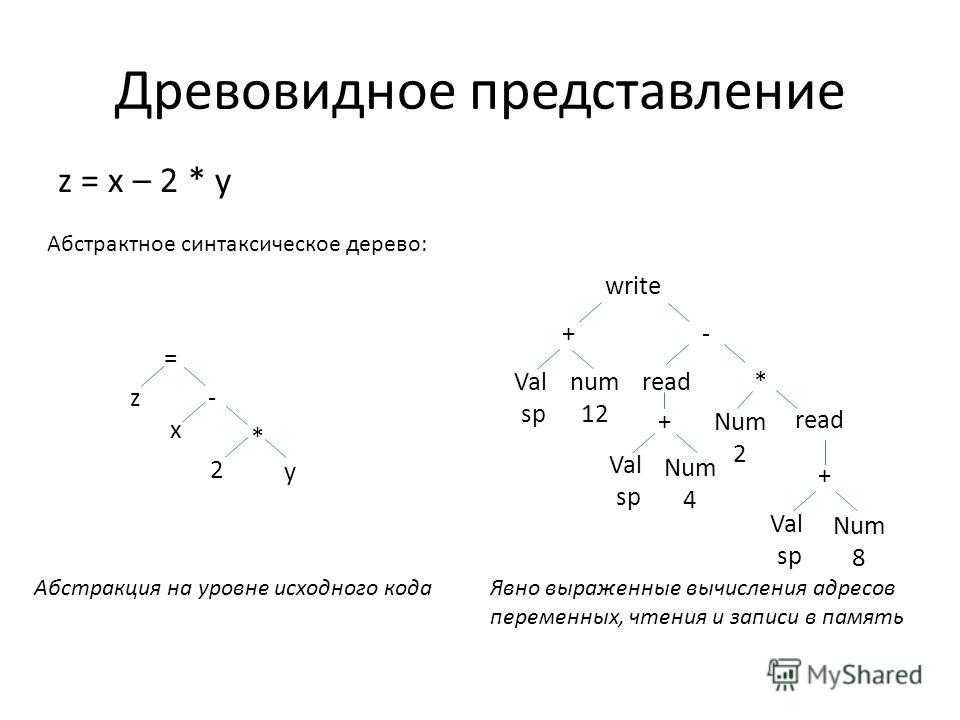
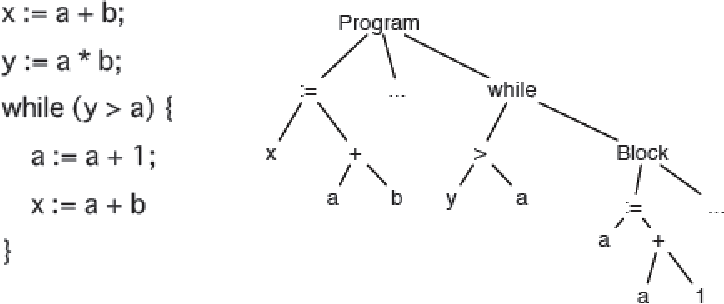
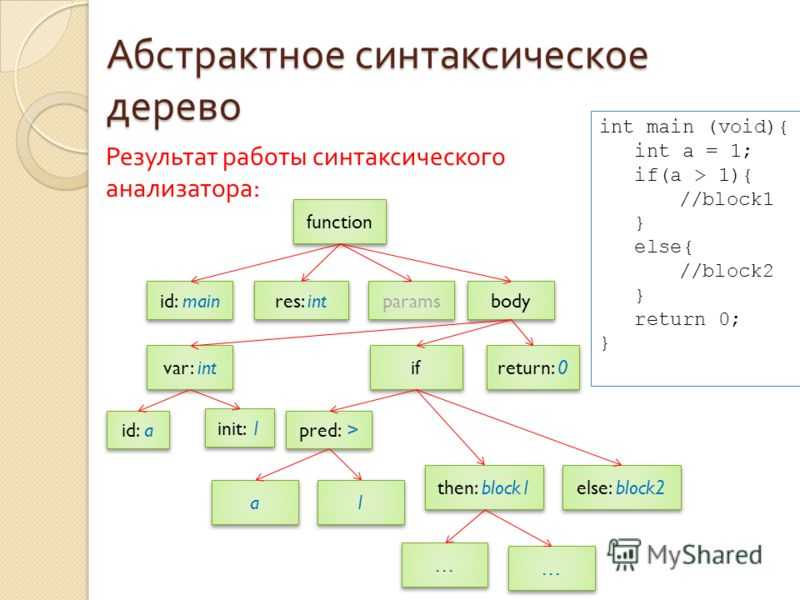
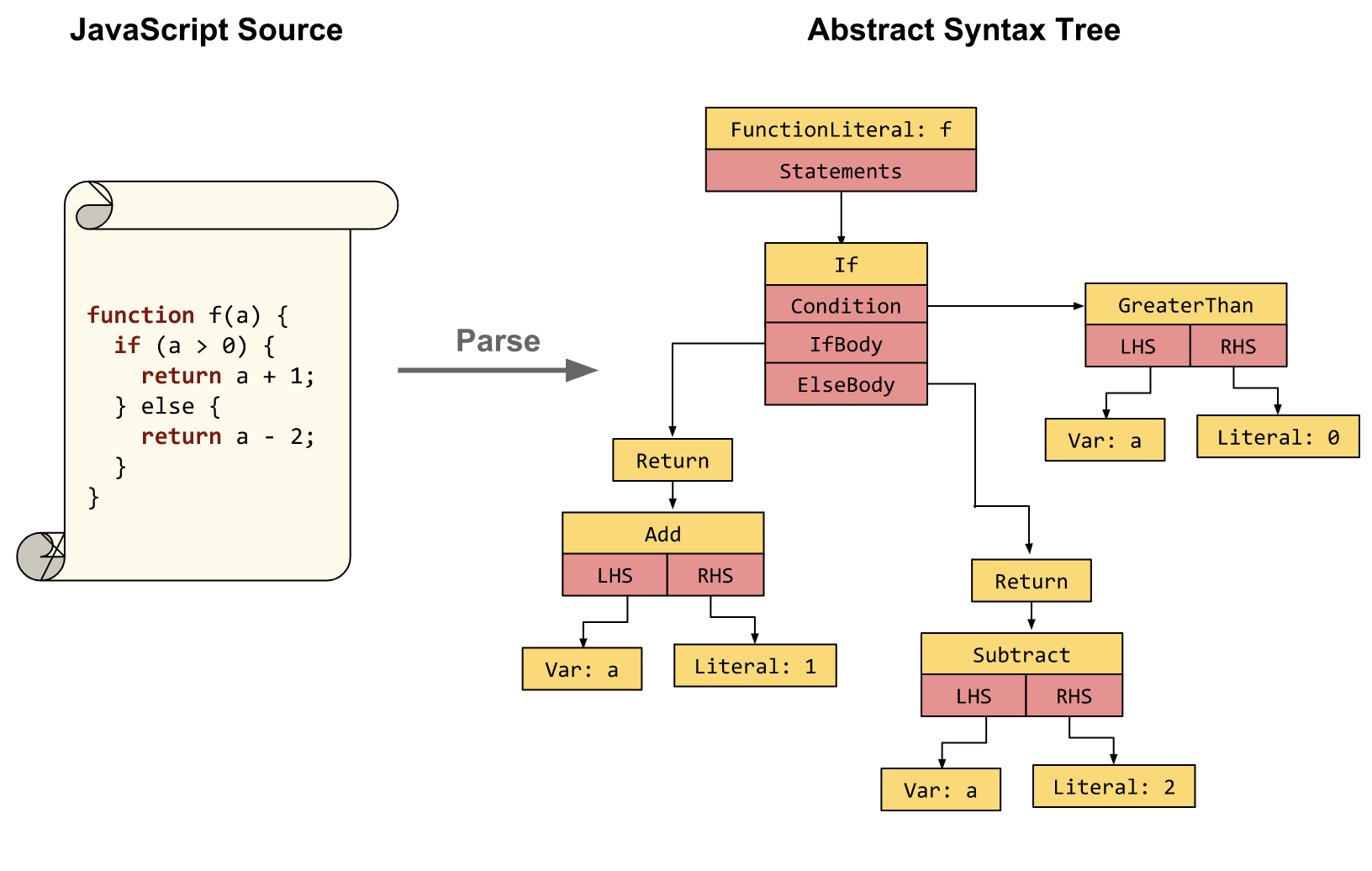
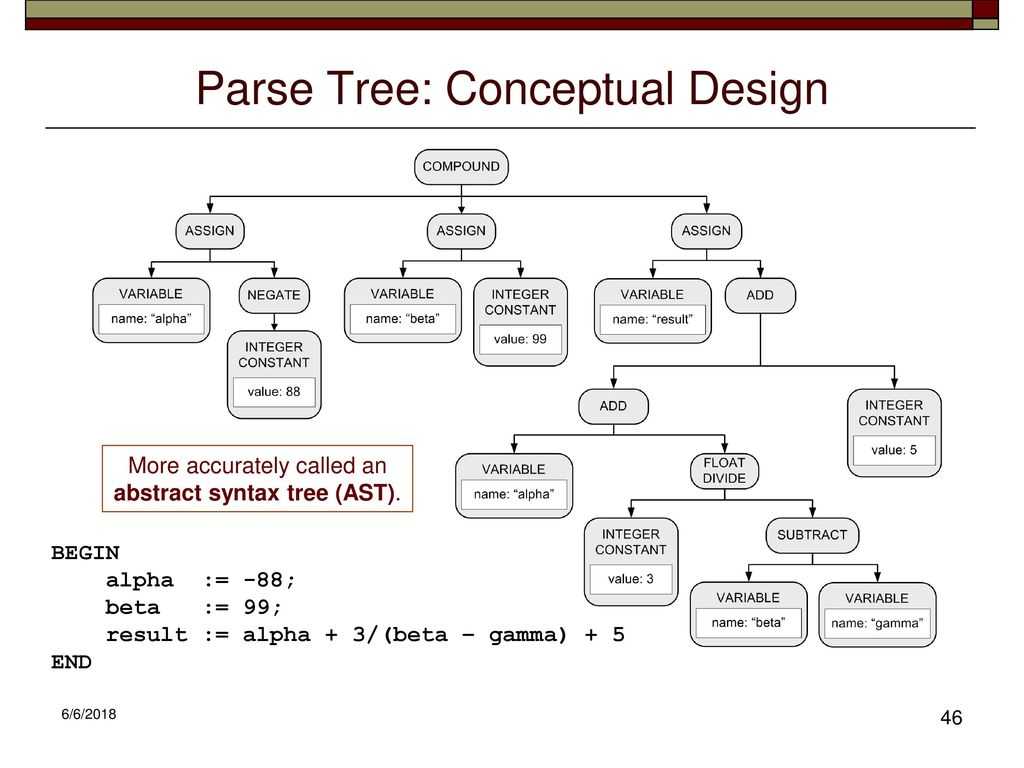
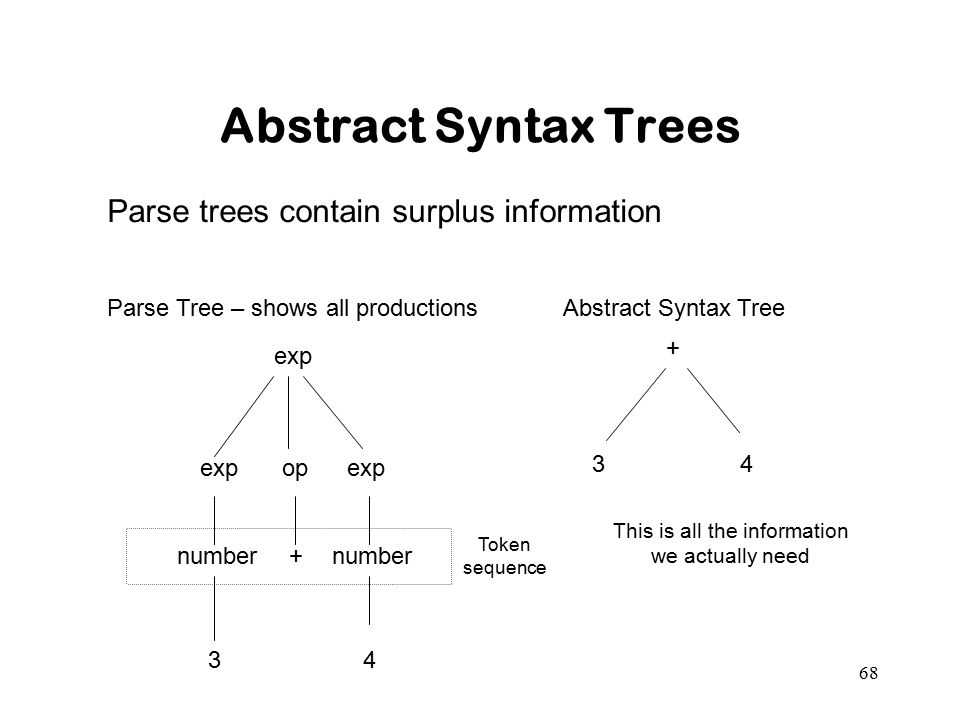
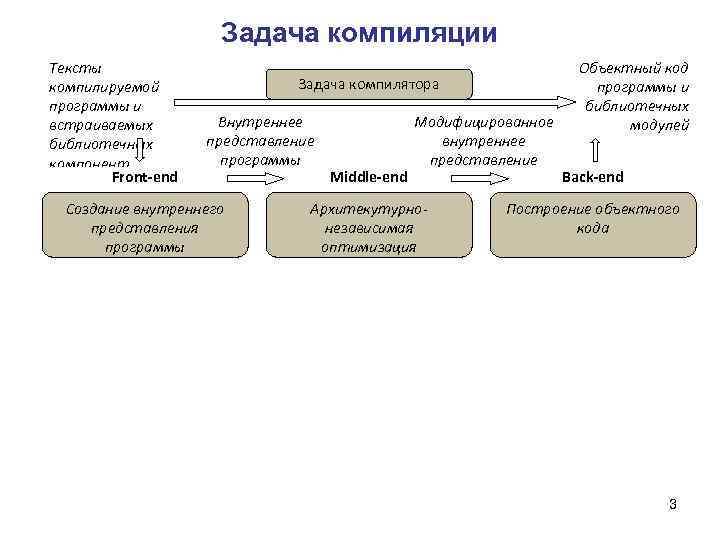
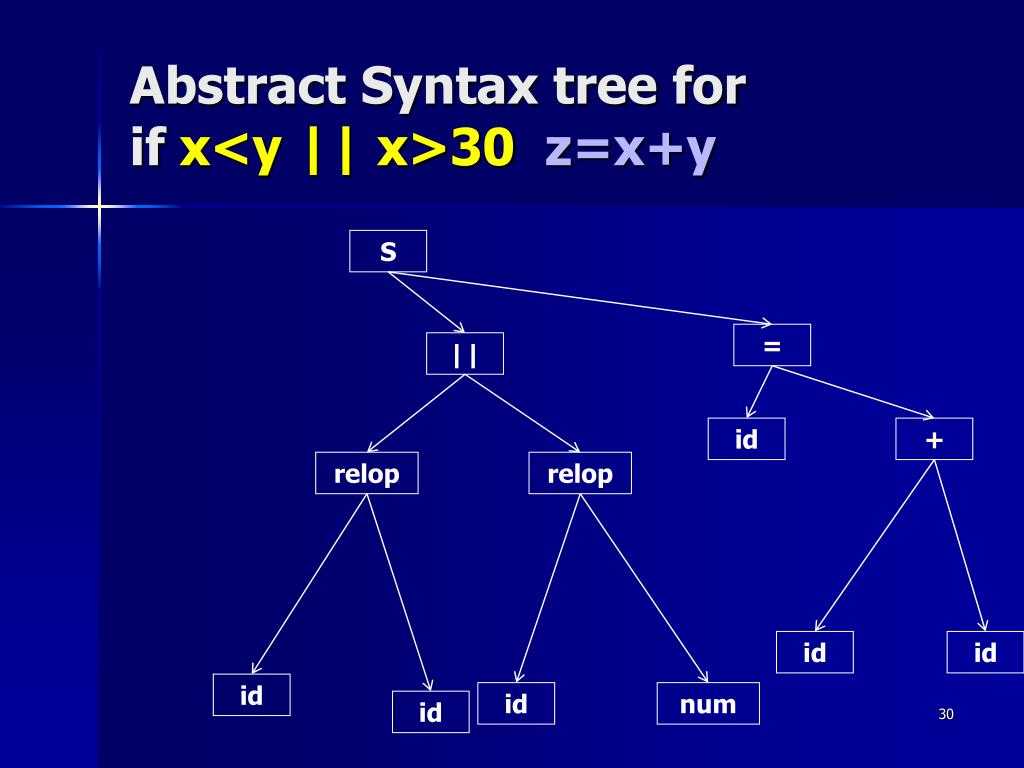
Что такое AST?
AST — это Abstract Syntax Tree, т.е. представление структуры программы в виде дерева объявлений, инструкций и выражений.
- AST не является бинарным деревом: например, у унарного оператора будет один дочерний узел
- AST является гетерогенным деревом, состоящим из узлов разного типа
- В каждом поддереве дочерними узлами становятся лексически вложенные сущности: например, для узла объявления функции дочерними узлами являются инструкции, составляющие тело функции, а также объявления параметров функции (если они выделены в отдельные узлы AST волей автора компилятора)
Удобный способ реализовать AST в коде — это иерархия классов и интерфейсов. Например, можно ввести три базовых интерфейса:
- — интерфейс, который реализуется всеми выражениями
- — интерфейс, который реализуется всеми инструкциями
-
— аналогичный интерфейс для объявлений функций и типов
- В компилируемых языках всю программу целиком можно считать списком , в скриптовых — списком
- Альтернативно, можно ввести специальный узел или
Если в языке нет типов, то можно для удобства превратить в и считать программу списком .
Все остальные классы из иерархии наследуются от базовых интерфейсов и реализуют объявленные ими методы. Какие методы находятся в базовых интерфейсах — решать автору компилятора/интерпретатора. В любом случае, методы должны выстраиваться в единую модель генерации кода или интерпретации.
Суть дерева — в возможности обойти его (слева направо в глубину или другим способом). При обходе можно выполнять осмысленные действия, при этом возникает проблема двойной диспетчеризации: мы должны выбирать действие в зависимости как от алгоритма, которым мы обрабатываем дерево, так и от типа узла дерева, который мы сейчас обходим. Рассмотрим пути решения проблемы:
- Можно избежать проблемы: например, добавляем полиморфный метод в интерфейс и реализуем его по-разному в классах , , , — на выходе получаем возможность вычислить выражение
- Можно решить проблему с помощью шаблона проектирования Visitor (Посетитель)
- Можно решить проблему с помощью сопоставления шаблона (pattern matching) по типу, если язык это поддерживает
- Например, в можно использовать type switch
- В C++ можно было бы использовать , но он не поддерживает рекурсию в собственном определении
Конструирование AST в парсере
Для конструирования узлов AST потребуется выделять память, а затем запоминать указатель в стеке парсера. Напомним, что любой реальный язык содержит рекурсивные синтаксические правила (например, выражения всегда определяются рекурсивно), значит, парсер языка не может быть реализован без стека или без рекурсии (которая эквивалентна стеку). Поэтому способ работы с AST зависит от метода создания парсера.
Какие ошибки может определить компилятор?
Когда компилятор анализирует текст программы, он проверяет, соответствует ли запись оператора стандартам языка. Если найдено несоответствие, то компилятор выводит об этом информацию пользователю в виде ошибки. Когда вся программа разобрана, пользователь видит список ошибок, которые есть в коде, и может их исправить.
Пока программист не исправит ошибки, компилятор не перейдет к следующему этапу — генерации машинного кода для процессора.
Чаще всего компилятор показывает пользователю:
- ошибки объявления переменных или отсутствие их начальных значений
- ошибки несоответствия типов
- ошибки неправильной записи операторов и функций
Иногда компилятор определяет код, который при выполнении дает неправильный результат. Но преобразовать такую программу в машинный код все-таки можно. В этом случае компилятор показывает пользователю предупреждение
Такая реакция компилятора больше похожа на рекомендации, но на них стоит обратить внимание. Программист сам решает оставить код с предупреждением или изменить программу.
Анализируя текст программы, компилятор не только ищет ошибки, но еще и упрощает ее код
Такой процесс называется оптимизацией.
Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Что такое компилятор C++?
Если в двух словах, то это утилита, которая преобразует написанный человеком код в язык, понятный для компьютера.
Если подробнее, то сначала надо обратиться к тому, как работает программный код. Компьютеры понимают только машинный язык (ассемблер), представляющий собой чередующиеся нули и единицы. Других прямых механизмов взаимодействия между компьютеров и человеком не существует.
Программировать, используя только бинарные символы, конечно, можно. Но это займет неприлично много времени и в несколько раз усложнит процесс разработки программного обеспечения любого порядка (разработчики превратятся в вымирающий вид). Поэтому люди придумали языки программирования более высокого класса, чтобы было легче взаимодействовать с ПК.
Ассемблер общается с аппаратным обеспечением напрямую. Языкам в духе C и C++ требуется компилятор, который сможет превратить более очеловеченный код в машинный. Похожим образом работают более «высокие» языки наподобие JavaScript и Python. Только они сначала преобразуются в С++, а потом в ассемблер. Все сводится к одному.
И мы снова возвращаемся к процессорам, которые понимают только нули и единицы. Для них нужен переводчик, который будет низводить до примитивного состояния код С++. Это и есть компилятор.
Язык для операционной системы
Для начала стоит абстрагироваться, ведь программирование – это не только вбивание определенных ключей-слов в машину, это еще и тщательно продуманные действия, связанные с компонентами системы. Изначально был двоичный код, потом программисты создали полумашинный язык программирования – ассемблер, но для чего?
Представьте себе, что вам надо считать на калькуляторе программиста каждый бит, потом правильно его связывать и многое другое. В ассемблере все стало чуточку проще, но все еще очень и очень непросто, если сравнивать с современными языками программирования, например, С++, который называют одним из сложнейших, но про него речь пойдет чуть позже.
![]()
В языке ассемблер все осуществляется благодаря регистрам процессора: деление, умножение, перемещение значения из точки А в точку Б и т. д. Основная его проблема, что он все еще является полумашинным, но все равно поддается прочтению человеку, в отличии от хаотично раскиданных битов. Еще одним минусом было ограниченное количество этих самых регистров.
В 80-х годах решили придумать язык программирования, благодаря которому можно будет легко и просто написать операционную систему. Так появился С и компилятор С GCC от компании GNU. Если вы пользуетесь Linux, то обязательно должны были видеть продукты данной компании. Кстати, ассемблер используется и поныне, ведь некоторые компиляторы создают объектные файлы с двоичным кодом, а другие исполнительные – с кодом на ассемблере. Все зависит от платформы разработчика.
Современный компилятор имеет следующие программы в себе:
- Дебагер – программа, которая отправляет сообщения об ошибке от линковщика, препроцессора, интерпретатора.
- Препроцессор – это программа, главной задачей которой является поиск специальных меток, начинающихся со знака #, и выполнение определенного рода команд. Например, добавления сторонней библиотеки для компиляции проекта.
- Интерпретатор – программа, которая переводит наш более-менее понятный язык программирования в двоичный код или ассемблер.
- Линковщик – программа, благодаря которой недостающие файлы автоматически подключаются.
Также существует 2 типа сборки проекта компилятором: динамическая и статическая. В первой добавляются лишь нужные проекту файлы, несмотря на среду разработки, а во втором случае — все в кучу (подключенные, конечно). Итак, из этого уже можно сказать, что компилятор – это целый список программ для сбора и обработки информации в понятный и логичный для компьютера вид. Дальше мы рассмотрим, с чего все начиналось.
Генерировать код
Используйте самые простые методы, которые вы знаете. Часто можно просто переводить языковую конструкцию (например, оператор ) в слегка параметризованный шаблон кода, в отличие от шаблона HTML.
Опять же, игнорируйте эффективность и сосредоточьтесь на правильности.
Таргетинг на независимую от платформы низкоуровневую виртуальную машину
Я полагаю, что вы игнорируете вещи низкого уровня, если вы не заинтересованы в деталях оборудования. Эти детали кровавы и сложны.
Ваши варианты:
- LLVM: позволяет эффективно генерировать машинный код, обычно для x86 и ARM.
- CLR: предназначен для .NET, в основном для x86/Windows; имеет хороший JIT.
- JVM: target Java world, довольно мультиплатформенный, имеет хороший JIT.
Как работает Babel
Три основных этапа обработки Babel:
Анализировать (анализировать), преобразовывать (преобразовывать), генерировать (генерировать).
Если описать декомпозицию процесса на словах, то это будет так:
Парсинг
Использоватьbabylon Парсер анализирует строку исходного кода и генерирует начальный AST (File.prototype.parse)
Использоватьbabel-traverse Этот автономный пакет выполняет ASTТраверс, И разобрать все деревоpath, Прочтите соответствующую метаинформацию через смонтированный metadataVisitor, этот шаг называется процессом установки AST
Преобразование
процесс преобразования: пройти по дереву AST и применить каждыйtransformers(plugin) Создать преобразованное дерево AST
Ядро Babel — этоbabel-core, Он предоставляет интерфейс babel.transform.
генерировать
Использоватьbabel-generator БудетAST Вывод дерева в виде строки кода после перекодирования
Предварительная компиляция
Как видите, подготовка JS-кода к работе — дело, требующее немалых системных ресурсов. Почему бы не выполнять всё это на сервере? В конце концов, гораздо лучше один раз подготовить программу к выполнению и передавать то, что получилось, клиентам, нежели принуждать каждую клиентскую систему каждый раз обрабатывать исходный код. На самом деле, эта возможность сейчас обсуждается, в частности, вопрос заключается в том, должны ли браузерные JS-движки предлагать механизмы выполнения предварительно скомпилированных скриптов, чтобы освободить браузеры от задач по подготовке кода к выполнению. В целом, идея заключается в том, чтобы у нас был некий серверный инструмент, умеющий генерировать байт-код, который достаточно передать клиенту по сети и выполнить. Это даст значительное сокращение времени подготовки веб-страниц к работе. И хотя выглядит подобный механизм довольно соблазнительно, на самом деле, не всё так просто. Подготовка кода к работе на сервере может произвести обратный эффект, так как объём передаваемых данных, вероятно, возрастёт, может возникнуть необходимость в подписывании кода и в его проверке для целей обеспечения безопасности. Кроме того, JS-движки развиваются в уже сформировавшемся русле, в частности, команда разработчиков V8 работает над внутренними механизмами движка, направленными на то, чтобы избавиться от повторного парсинга. Подобные подходы к оптимизации на стороне клиента могут сделать предварительную компиляцию на сервере уже не столь привлекательной.
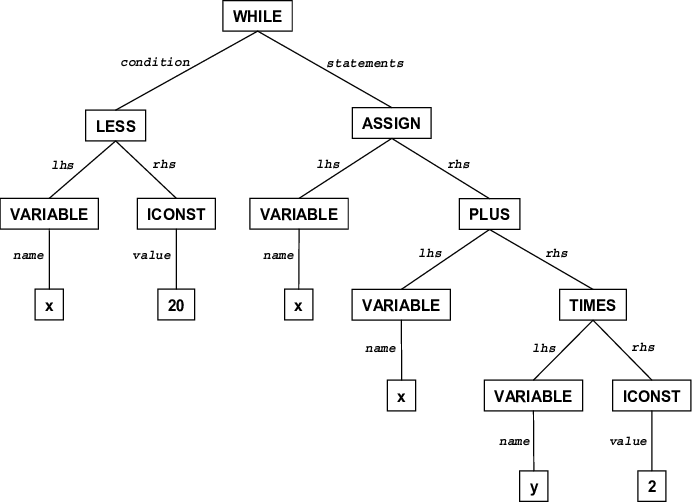
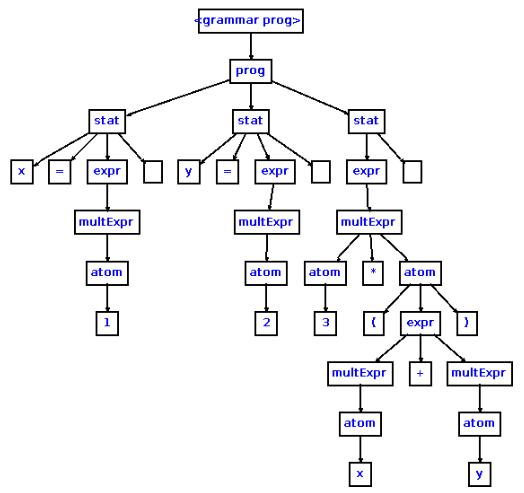
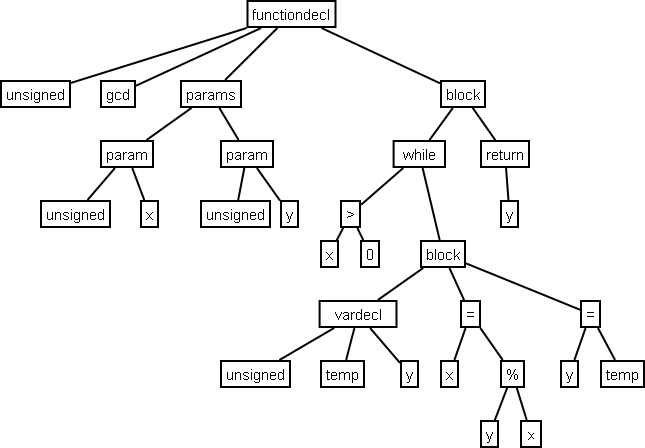
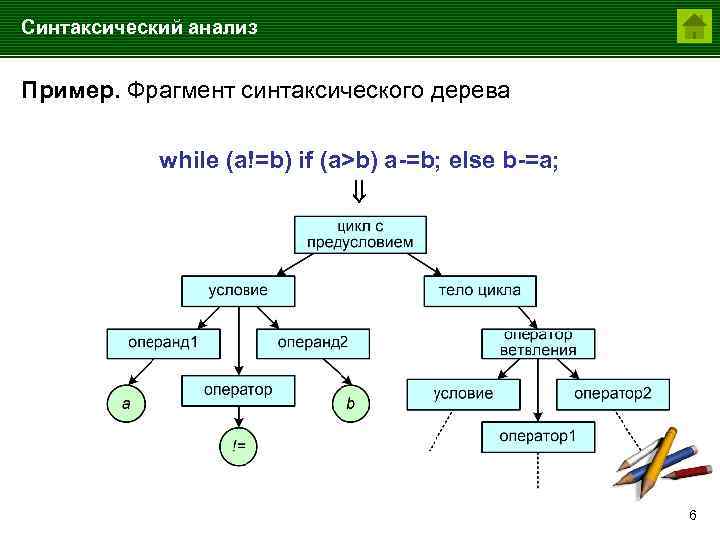
Разбирать деревья
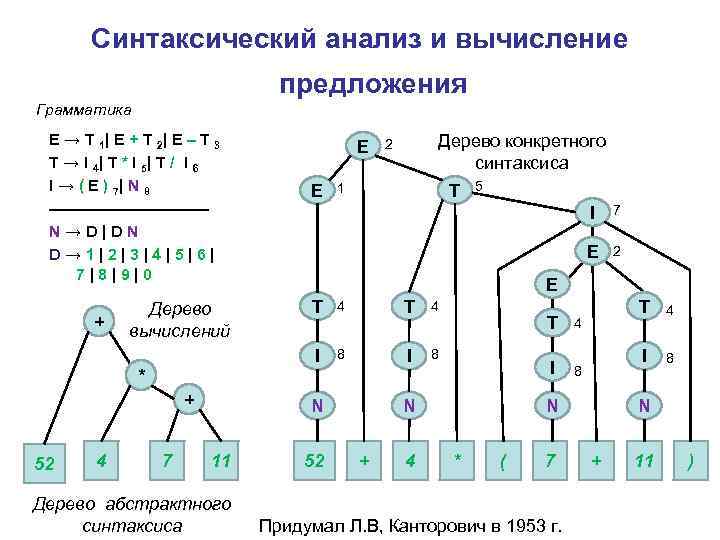
Деревья разбора обычно генерируются в качестве следующего шага после лексического анализа (который превращает исходный код в серию токенов, которые можно рассматривать как значимые единицы, а не просто последовательность символов).
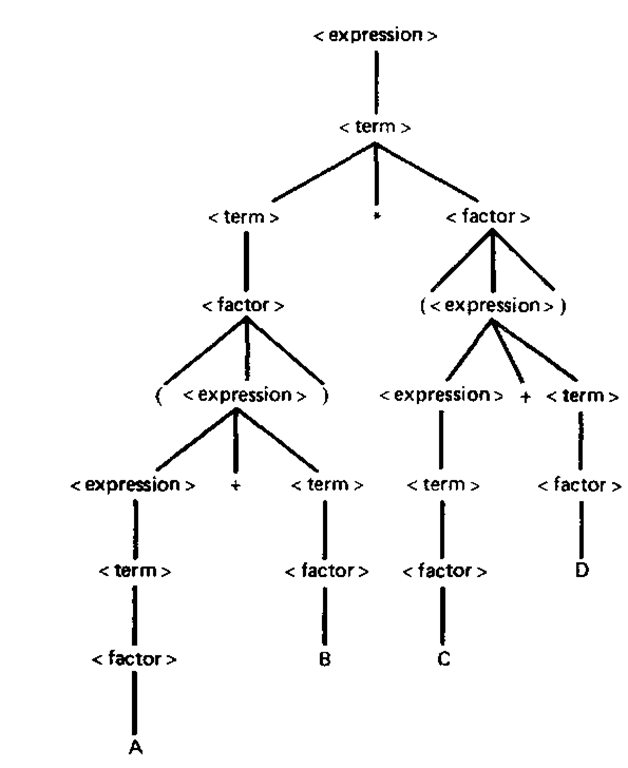
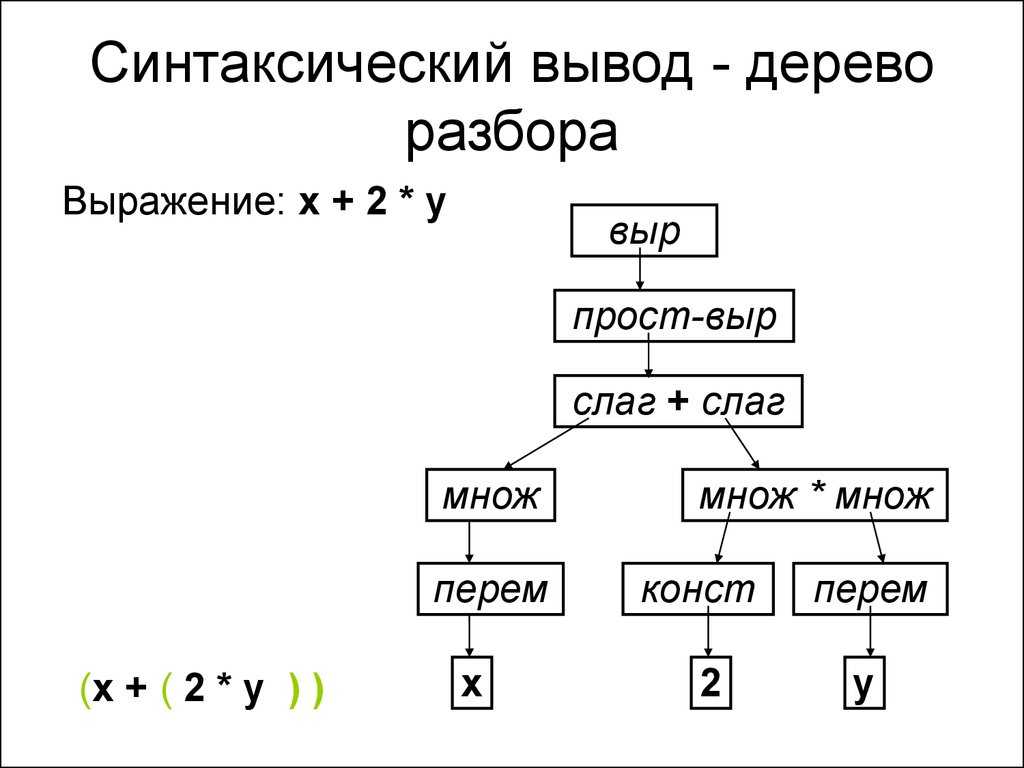
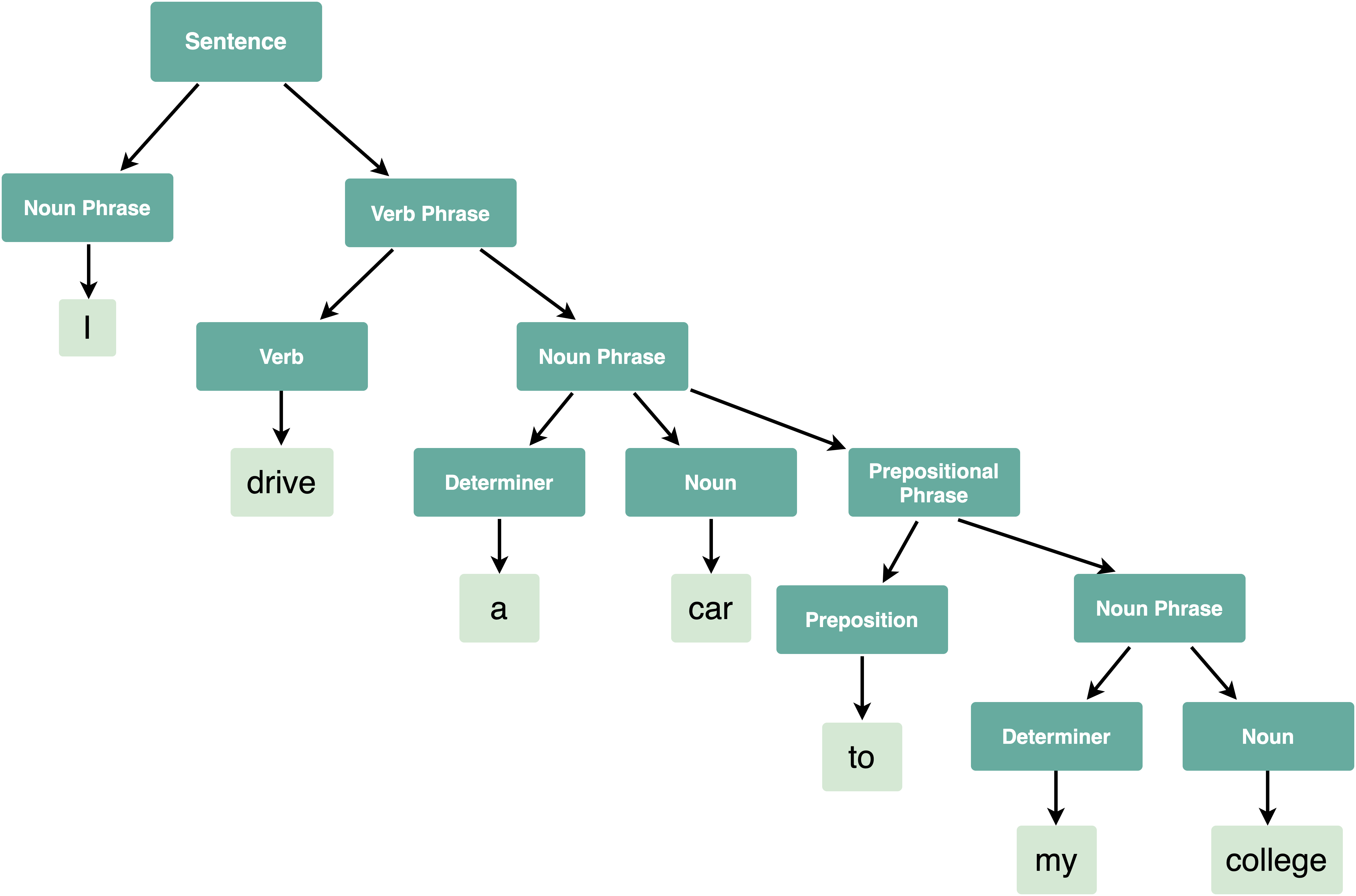
Это древовидные структуры данных, которые показывают, как входная строка терминалов (токенов исходного кода) была сгенерирована грамматикой рассматриваемого языка. Корень дерева разбора является наиболее общим символом грамматики — начальным символом (например, оператор), а внутренние узлы представляют нетерминальные символы, в которые расширяется начальный символ (может включать в себя сам начальный символ) , например, выражение, оператор, термин, вызов функции. Листья являются терминалами грамматики, фактическими символами, которые появляются как идентификаторы, ключевые слова и константы в строке языка/ввода, например, для , 9 , если и т. д.
При синтаксическом анализе компилятор также выполняет различные проверки, чтобы гарантировать правильность синтаксиса — и отчеты о синтаксических ошибках могут быть встроены в код синтаксического анализатора.
Они могут использоваться для синтаксически-ориентированной трансляции через синтаксически-ориентированные определения или схемы перевода для простых задач, таких как преобразование инфиксного выражения в постфиксное.
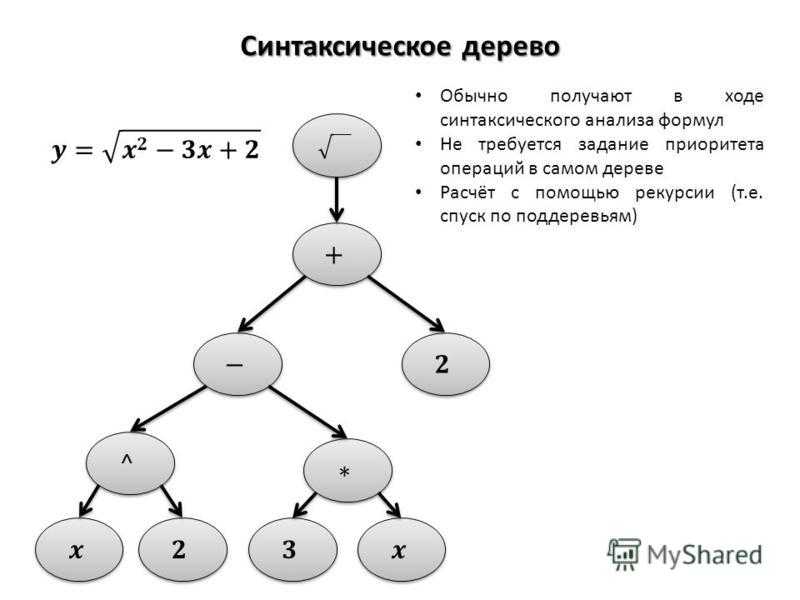
Вот графическое представление дерева разбора для выражения (обратите внимание на расположение терминалов в дереве и фактических символов из строки выражения):
Совет начинающим программистам
Ваш путь будет тернист – это стоит знать прежде всего. Для начала работы с языком, например, если это С, вы обязательно должны будете ознакомиться с компилятором C. А если с ним не подружиться и не понять его логику, то ваши проекты один за одним будут лагать и вылетать.
![]()
Попытайтесь как можно больше читать книг не только про основы программирования, но и про историю создания языков, так вы обязательно начнете понимать саму суть процесса. Старайтесь совмещать практику и новые знания, так все куда быстрее запоминается. Кроме того, постарайтесь довести свой английский хотя бы до среднего уровня, иначе вам будет очень сложно в ориентировании по IDE.
Напишите плагин Babel
Начните с функции, которая получает объект babel в качестве параметра.
Затем он возвращает объект, атрибут посетителя которого является главным посетителем узла этого плагина.
Когда мы вводим зависимости на ежедневной основе, мы будем импортировать весь пакет, в результате чего упакованный код будет слишком избыточным, добавив много ненужных модулей, таких как index.js три строки кода, размер упакованного файла достиг 483 КиБ,
index.js
Итак, наша цель на этот раз —
Преобразовано так, что вводятся только два модуля lodash, что сокращает объем упаковки
Этапы реализации следующие:
- Создайте новую папку в node_module под проектомbabel-plugin-extract
- Создайте новый index.js в babel-plugin-extract
- модифицироватьwebpack.prod.config.jsВ элементе конфигурации babel-loader добавьте собственное имя плагина в плагины
- Запустите webpack.config.js с добавленными настраиваемыми плагинами
Размер файла пакета теперь 21,4 КБ, что значительно меньше, и настраиваемый плагин успешно работает! ~
Каталог файлов плагина
Если вы думаете, что это весело, обратите на это внимание ~ Приветствуем всех, чтобы добавить в закладки и комментировать ~~~
Microsoft Visual Studio Community
Для индивидуальных или начинающих программистов Microsoft Visual Studio Community включает в себя много важных инструментов из коммерческих версий проекта. Вы получите в свое распоряжение IDE, отладчик, оптимизирующий компилятор, редактор, средства отладки и профилирования. С помощью этого пакета можно разрабатывать программы для настольных и мобильных версий Windows, а также Android. Компилятор C++ поддерживает большинство функций ISO C++ 11, некоторые из ISO C++ 14 и C++ 17. В то же время компилятор C уже безнадежно устарел и не имеет даже надлежащей поддержки C99.
Программное обеспечение также поставляется с поддержкой построения программ на C#, Visual Basic, F# и Python. В то время, когда я писал эту статью, на сайте проекта утверждалось, что Visual Studio Community 2015 «бесплатный инструмент для индивидуальных разработчиков, проектов с открытым исходным кодом, научных исследований, образовательных проектов и небольших профессиональных групп».
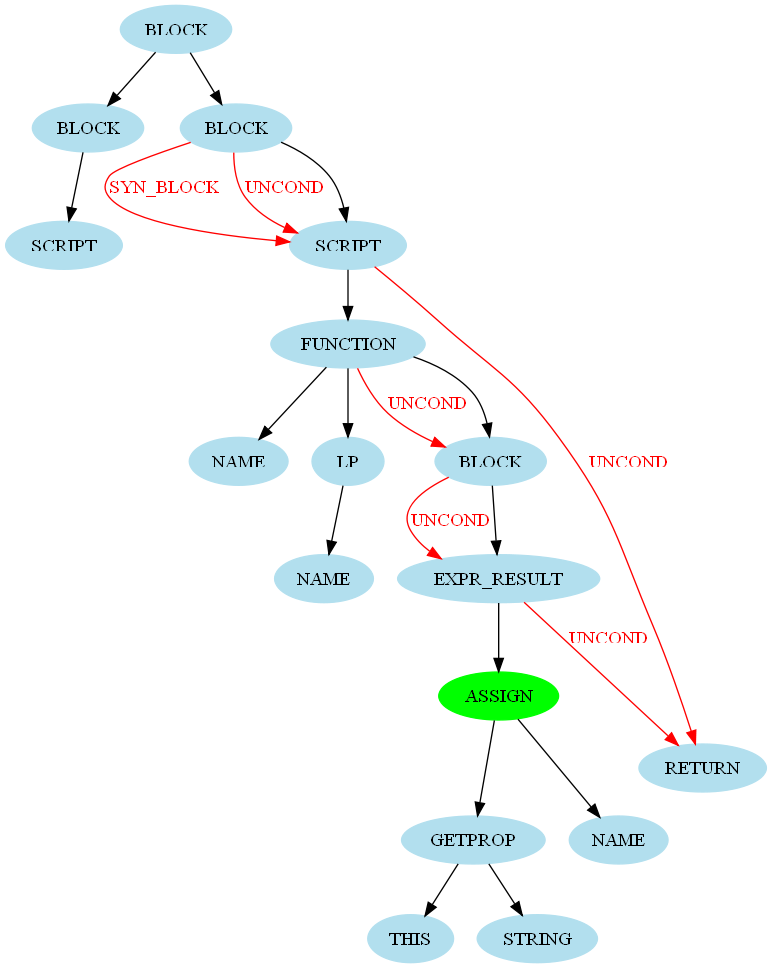
Новый процесс исполнения
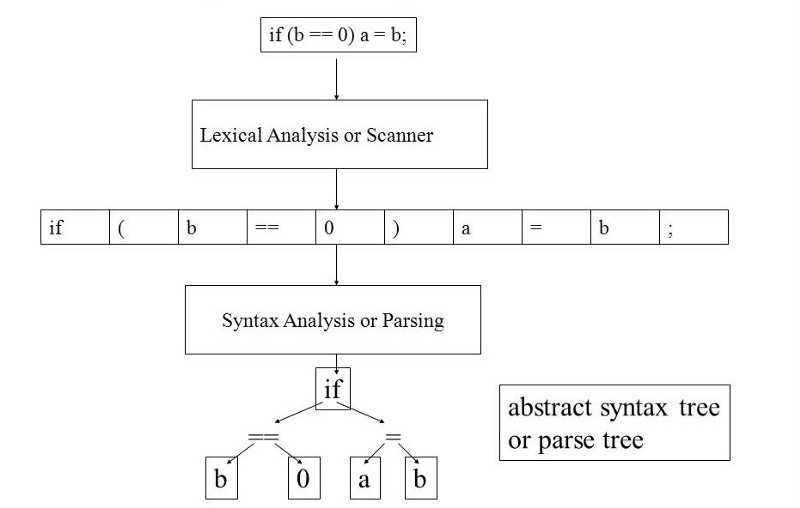
Важным изменением в ядре PHP7 является присоединение к AST. В PHP5 процесс выполнения из скриптов PHP к OPCODES:
-
Lexing: Lexing Analysis, преобразуйте исходный файл в потоковый токен;
-
Пашина: грамматический анализ, генерирует OP массивы на этом этапе.
PHP7 больше не напрямую генерирует OP массивы во время грамматического этапа анализа, но мистер AST, поэтому процесс больше шага:
-
Lexing: Lexing Analysis, преобразуйте исходный файл в потоковый токен;
-
Анализ: грамматический анализ, генерируя абстрактное дерево грамматики из потока токена;
-
Компиляция: генерировать OP массивы от абстрактных синтаксических деревьев.
Используйте свой любимый язык
Полностью нормально писать компилятор в Python или Ruby или на любом другом языке, который вам удобен. Используйте простые алгоритмы, которые вы хорошо понимаете. Первая версия не имеет Быть быстрым, или эффективным, или полным функций. Он должен быть достаточно корректным и легко изменяемым.
Также можно писать разные этапы компилятора на разных языках, если это необходимо.
Приготовьтесь написать много тестов
Весь ваш язык должен быть покрыт тестовыми случаями; фактически он будет определен ими. Познакомьтесь с предпочитаемой платформой тестирования. Пишите тесты с первого дня. Сосредоточьтесь на «положительных» тестах, которые принимают правильный код, в отличие от обнаружения неправильного кода.
Регулярно запускайте все тесты. Исправьте неработающие тесты, прежде чем продолжить. Было бы стыдно получить плохо определенный язык, который не может принимать действительный код.
Руководство по созданию интерпретатора языка Pascal на Python
![]()
Предлагаем вашему вниманию серию статей, опубликованную в блоге Руслана Спивака. В ней автор подробно описывает процесс разработки базового интерпретатора. Серия пополняется, и в этой подборке вы найдете первые части руководства.
Примеры кода приведены на Python, однако подробные пояснения позволят читателю использовать для реализации любой другой удобный язык. В качестве интерпретируемого языка выбран Pascal, однако и здесь вы не будете ограничены — можно обратиться к любому другому языку, с семантикой которого вы хорошо знакомы.
Небольшой ликбез перед прочтением. Компилятор — программа, которая переводит (транслирует) исходный код на языке программирования (высокого уровня) на язык, «более понятный компьютеру» (низкоуровневый). При этом программа сначала полностью транслируется, а затем выполняется. Интерпретатор — такой же транслятор, но выполняющий инструкции «на лету» (пооператорно, построчно), то есть без предварительной компиляции всего кода.
![]()
Различие между компилятором и интерпретатором
Почему вам нужно создать свой интерпретатор:
- Написать компилятор — значит задействовать и/или развить сразу несколько различных технических навыков. Причем навыков, которые окажутся полезными в программировании вообще, а не только при написании трансляторов.
- Вы станете чуть ближе к разгадке тайны, как же все-таки работают компьютеры. Компиляторы и интепретаторы — это магия. И нужно чувствовать себя комфортно при работе с этой магией.
- Вы сможете создать собственный язык программирования, восполняющий видимые вам недостатки существующих. А это, во-первых, сейчас модно, а во-вторых, при достаточном везении вы обретете мировую известность.
- Да ну и чем вам еще сейчас можно заняться? (Кстати, мы уже предлагали вам несколько вариантов на зимние каникулы и лето.)
Что приятно, статьи подробно иллюстрируются. Создается впечатление, что автор перед вами ведет настоящую лекцию. Вот, например, одна из синтаксических диаграмм:
![]()
В конце каждой части руководства дается несколько задач для самостоятельной реализации и список полезных книг для более полного изучения вопроса. Итак, теперь приступайте к чтению:
Часть 1. Основные понятия, разбиение на токены и сложение однозначных чисел.
Часть 2. Обработка пробельных символов, многозначные числа.
Часть 3. Синтаксические диаграммы, одиночные умножение и деление.
Часть 4. Множественные умножения и деления, форма Бэкуса-Наура.
Часть 5. Калькулятор с произвольным числом операций, ассоциативность и порядок выполнения операторов.
Часть 6. Заканчиваем калькулятор: произвольный уровень вложенности.
Часть 7. Базовые используемые структуры данных. Также рекомендуем эту серию статей.
Часть 9. Объявление программы, составные операторы, присваивание, таблицы символов и обработка переменных.
Часть 10. Продолжение предыдущей части руководства. Обработка комментариев.
Серия продолжит пополняться, а пока можете обратиться к одному из пособий, которые рекомендует автор в конце каждой части.
Как скомпилировать С++
Для этого нужна специальная программа. Она считывает код и начинает его трансформировать (переводить с одного языка на другой). Некоторые из них включают в себя текстовый редактор, куда можно вставить код, а некоторые работают в командной строке и взаимодействуют с готовыми скриптами.
Обычно процесс компиляции заключается в введении команды для запуска компилятора и передачи пути до файла-скрипта. Иногда компиляцию удается запустить через графический интерфейс. Все зависит от используемого ПО.
После запуска интерпретатор кода считывает содержимое файла, находит там директивы и флаги, подключает внешние необходимые библиотеки, а потом передает необходимые данные процессору. Ну а тот уже делает то, что нам вздумалось: пролистает страницу на сайте или запустит игру.
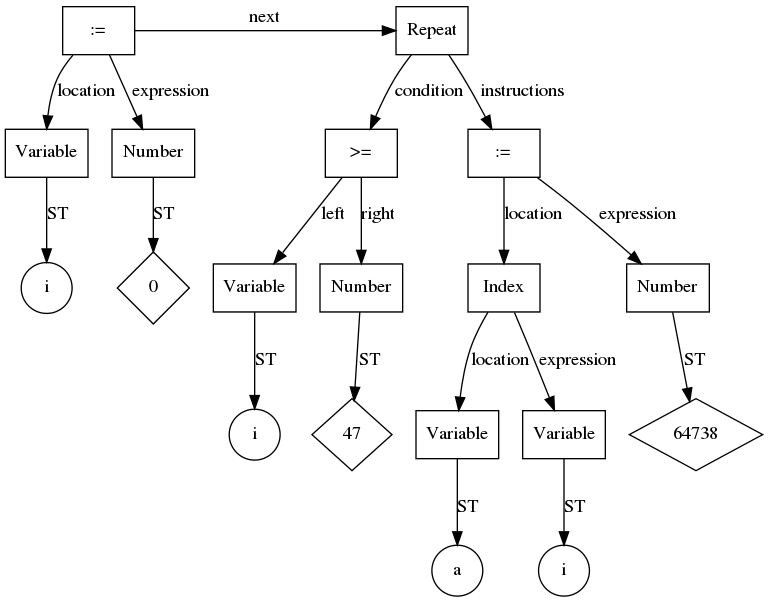
Восходящий разбор методом свёртки (LL, LR, SLR, LALR)
Если вы используете табличный недетерминированный конечный автомат со стеком для восходящего разбора методом свёртки, то вы можете следовать нескольким правилам:
- добавляйте действия по созданию AST в список действий при свёртке в рамках атрибутивной грамматики
- на каждое правило грамматики создавайте узлы AST с помощью оператора
- сохраняйте указатели на узлы в ячейку стека парсера, соответствующую результату свёртки текущего правила
- извлекайте из соответствующих ячеек стека результаты свёртки предыдущих правил
Пример декларативного описания правила грамматики с конструированием AST (для генератора парсеров Lemon):
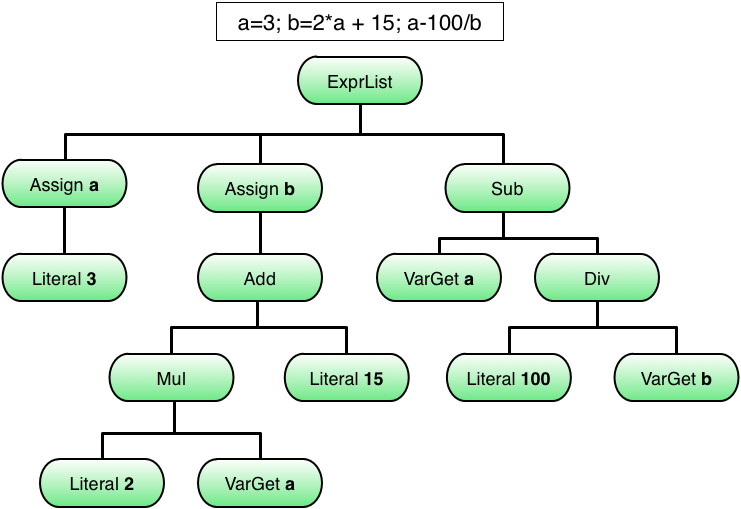
Обработка готового AST
Путём обработки готового AST можно
- во фронтенде компилятора или интерпретатора: проверять семантические правила языка
- в компиляторе: выполнять генерацию промежуточного или машинного кода
- в компиляторе или интерпретаторе: генерировать код виртуальной машины
- в интерпретаторе: выполнять программу непосредственно
- для отладки: печатать AST, полученный из парсера
Что такое компилятор C++?
Итак, давайте начнем с основ. Любой компьютер понимает только машинный код или ассемблер, который состоит из нулей и единиц. Это самый низкий, базовый уровень работы компьютера. Однако программировать таким образом весьма сложно и неудобно. Даже использовать низкоуровневый ассемблер — это то еще удовольствие. Хотя, впрочем, на нем есть даже своя операционная система.
Однако большинство разработчиков предпочитают высокоуровневые языки программирования, такие как C++. «Высокий уровень» означает, что они работают на уровне операционной системы, а не машинных кодов. И вот именно компилятор обеспечивает взаимодействие между кодом на C++ или любом другом высокоуровневом языке, и собственно, машинным кодом. Это утилита-посредник, которая обеспечивает преобразование вот такого кода:
#include <iostream>
int main() {
std::cout << "Hello World!";
return 0;
}
Примерно в такой, понятный процессору:
global _main
extern
extern
extern
section .text
_main:
; DWORD bytes;
mov ebp, esp
sub esp, 4
; hStdOut = GetstdHandle( STD_OUTPUT_HANDLE)
push -11
call
mov ebx, eax
; WriteFile( hstdOut, message, length(message), &bytes, 0);
push 0
lea eax,
push eax
push (message_end - message)
push message
push ebx
call
; ExitProcess(0)
push 0
call
; never here
hlt
message:
db 'Hello, World', 10
message_end:
Подобным образом работают и другие языки, к примеру, Python, JavaScript и так далее. Только они преобразовываются сначала в C++, а уже затем в ассемблерные коды.
И потому важным вопросом был, есть и остается — какой же компилятор C++ самый лучший. Сегодня мы постараемся подробно разобрать эту тему и выяснить ответ.
Создать хороший парсер
Генераторов парсеров много . Выберите то, что вы хотите. Вы также можете написать свой собственный парсер с нуля, но это того стоит, только если синтаксис вашего языка мертв простой.
Парсер должен обнаруживать и сообщать о синтаксических ошибках. Напишите много тестовых случаев, как положительных, так и отрицательных; повторно используйте код, который вы написали при определении языка.
Выход вашего парсера — абстрактное синтаксическое дерево.
Если в вашем языке есть модули, вывод синтаксического анализатора может быть простейшим представлением «объектного кода», который вы генерируете. Существует множество простых способов выгрузить дерево в файл и быстро загрузить его обратно.
Применение абстрактного синтаксического дерева
Используйте абстрактное синтаксическое дерево для реконструкции кода JavaScript
Если у нас возникнет необходимость в рефакторинге JavaScript, они пригодятся.
Рассмотрим такое требование ниже:
мы знаем, Он используется для преобразования строки в целое число, но у него есть второй параметр, что означает, что строка распознается в виде десятичного числа. Если второй параметр не передан, он будет судить сам, например:
Поскольку есть некоторые ситуации, которые отличаются от наших ожиданий, рекомендуется добавить второй параметр в любое время.
Надеюсь, что ниже есть сценарий, просмотрите все Есть ли второй параметр, если нет, добавьте второй параметр 10, что означает, что строка распознается в десятичном виде.
Эту функцию можно выполнить с помощью UglifyJS:
Здесь я использовал ходунки, чтобы найти Там, где он вызывается, проверьте, есть ли второй параметр. Если нет, запишите его. Затем, в соответствии с каждой записью, замените исходное содержимое новым содержимым, содержащим второй параметр, чтобы завершить реконструкцию кода.
Некоторые люди могут спросить, в этом простом случае обычное сопоставление также можно легко заменить, зачем использовать абстрактные синтаксические деревья?
Применение абстрактного синтаксического дерева в Meituan
В команде интерфейса пользователя Meituan мы используем YUI в качестве базовой инфраструктуры интерфейса.Практическая проблема, с которой мы столкнулись ранее, заключается в том, что зависимости между модулями часто пропускаются. Такие как:
Приведенный выше код определяет два модуля, из которых Имитация щелчка Для Элементы реализацииА затем определите метод, И наконец объявили зависимость с участием ; Казнен Метод, определенный в, и Был аннотирован и, наконец, объявлена зависимость с участием 。
Вот Есть две распространенные ошибки, одна из них Да Вышеописанный метод легко забыть объявить зависимости, другой Только некоторые методы нужно полагаться на, Итак, здесь объявлена зависимость; После добавления комментария легко забыть удалить исходную зависимость。
Следовательно, правильные зависимости должны быть следующими:
Чтобы автоматизировать обнаружение зависимостей модулей, мы создали инструмент обнаружения зависимостей модулей, который использует абстрактные синтаксические деревья, чтобы анализировать, какие интерфейсы определены и какие интерфейсы используются, а затем находить, на какие модули должны полагаться эти интерфейсы, а затем находить зависимости модулей. Общий процесс ошибки выглядит следующим образом:
- Найдите определение модуля в коде ()часть
- Проанализируйте определения функций, определения переменных, операторы присваивания и т. Д. В каждом модуле, чтобы выяснить, что отвечает требованиям (с Выходной интерфейс (например, средний)
- Сгенерировать соответствие «интерфейс-модуль»
- Проанализируйте вызовы функций и использование переменных в каждом модуле, чтобы найти интерфейс ввода, который соответствует требованиям (например, средний,,)
- Посредством переписки «интерфейс-модуль» узнайте, на какие еще модули этот модуль должен полагаться.
- Проанализировать, есть ли ошибки в требованиях
Используйте этот инструмент, чтобы гарантировать правильность зависимостей при каждой отправке кода. Он помогает нам автоматизировать обнаружение зависимостей модулей.