
Увеличение строки ++
С числами все довольно просто, но что будет если инкрементить строки?
$a = 'fact_2'; echo ++$a; //> fact_3 $a = '2nd_fact'; echo ++$a; //> 2nd_facu $a = 'a_fact'; echo ++$a; //> a_facu $a = 'a_fact?'; echo ++$a; //> a_fact? $a = 'Привет'; echo ++$a; //> Привет
При инкременте строки, PHP изменяет последний символ на символ следующий по алфавиту. Так при инкременте, если в конце строки 2, то эта 2-ка изменится на 3. После t следует u. Однако эта операция не имеет никакого смысла в случае, когда строка заканчивается на не буквенно-численный символ (в примере выше это символ кириллицы).
Этот момент хорошо описан в официальной документации по операциям инкремента/декремента, однако многие не читали этот материал, потому что не ожидали встретить там ничего особенного.
Сравнение строк по алфавиту на Bash
Задача усложняется при попытке определить, является ли строка предшественницей другой строки в последовательности сортировки по возрастанию. Люди, пишущие сценарии на языке командного интерпретатора bash, нередко сталкиваются с двумя проблемами, касающимися операций “больше” и “меньше” относительно сравнения строк Linux, у которых достаточно простые решения:
Во-первых, символы “больше” и “меньше” нужно экранировать, добавив перед ними обратный слэш (), потому что в противном случае в командном интерпретаторе они будут расцениваться как символы перенаправления, а строки — как имена файлов. Это один из тех случаев, когда отследить ошибку достаточно сложно.
Пример:
#!/bin/bash# неправильное использование операторов сравнения строкval1=baseballval2=hockeyif thenecho “$val1 больше, чем $val2”elseecho “$val1 меньше, чем $val2”fi
Что получится, если сравнить строки bash:
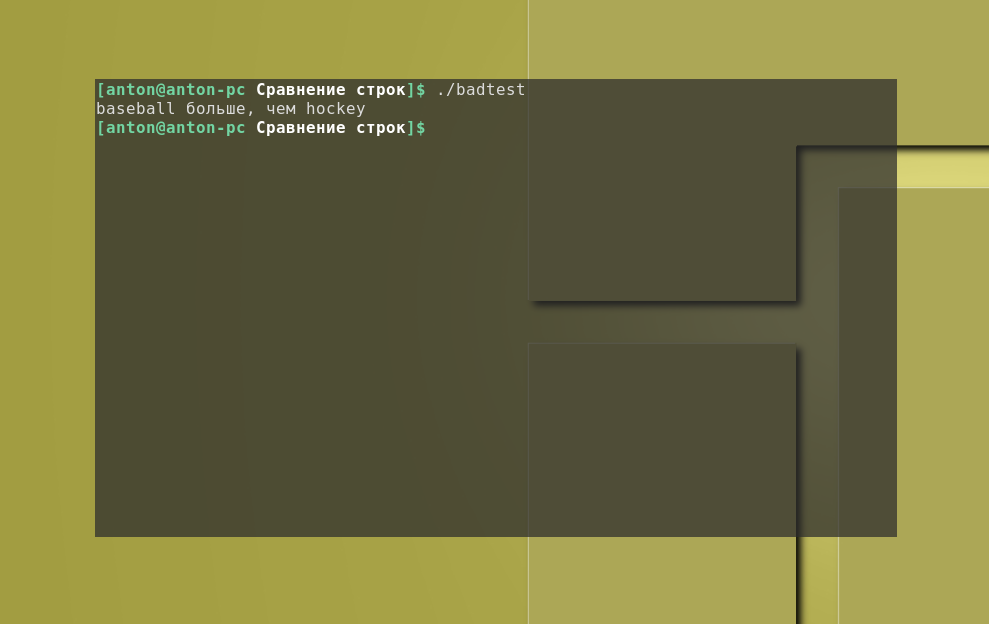
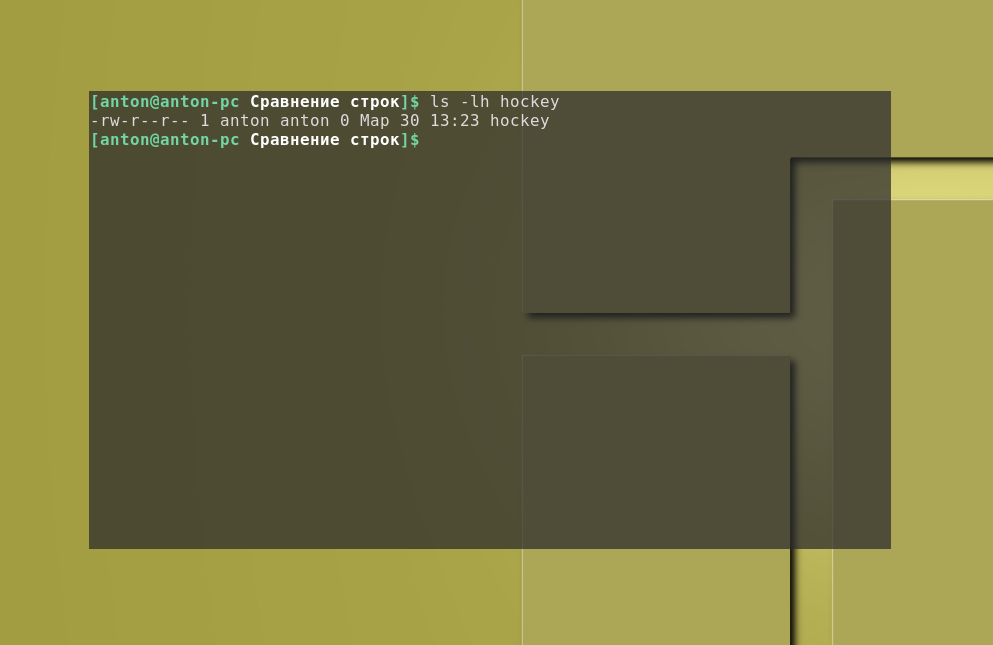
Как видно, один лишь символ “больше” в своём непосредственном виде привёл к неправильным результатам, хотя и не было сформировано никаких ошибок. В данном случае этот символ привёл к перенаправлению потока вывода, поэтому никаких синтаксических ошибок не было обнаружено и, как результат, был создан файл с именем hockey:
Для устранения этой ошибки нужно экранировать символ “>”, чтобы условие выглядело следующим образом:
…if …
Тогда результат работы программы будет правильным:
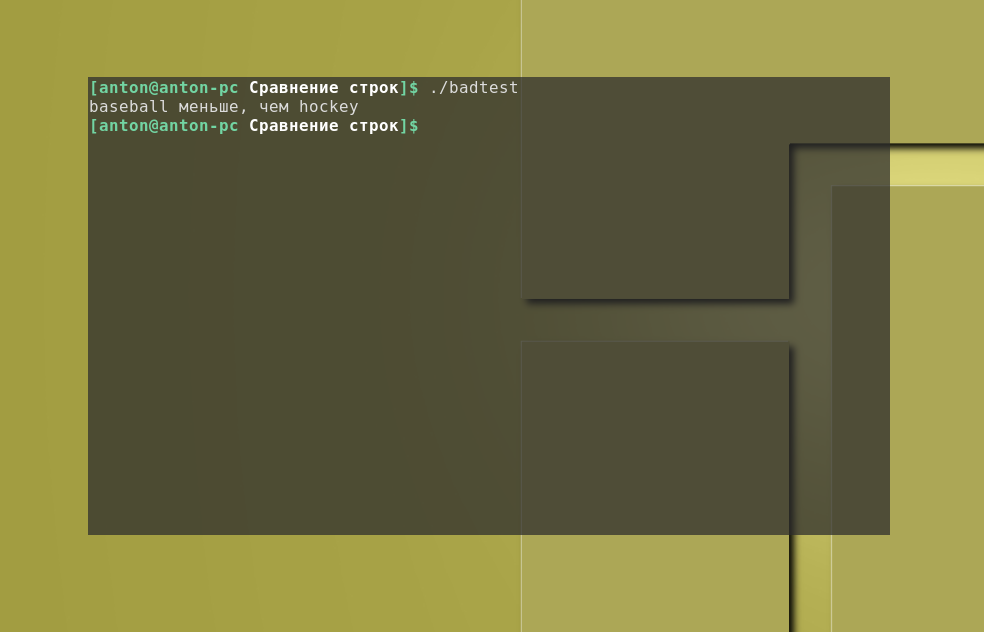
Во-вторых, упорядочиваемые с помощью операторов “больше” и “меньше” строки располагаются иначе, чем это происходит с командой sort. Здесь проблемы сложнее поддаются распознаванию, и с ними вообще можно не столкнуться, если при сравнении не будет учитываться регистр букв. В команде sort и test сравнение происходит по разному:
#!/bin/bashval1=Testingval2=testingif thenecho “$val1 больше, чем $val2”elseecho “$val1 меньше, чем $val2”fi
Результат работы кода:
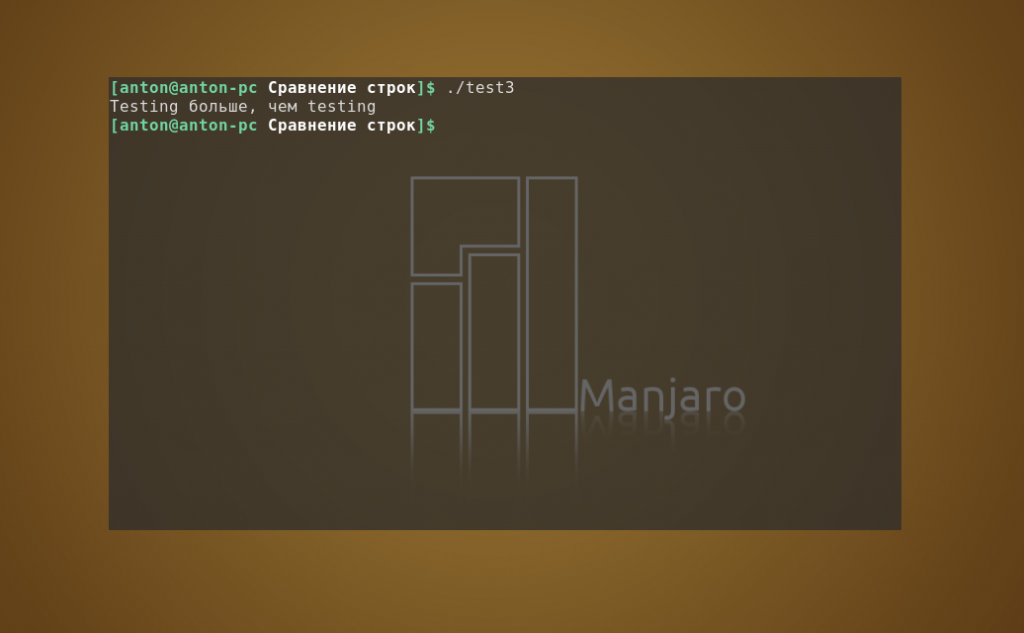
В команде test строки с прописными буквами вначале будут предшествовать строкам со строчными буквами. Но если эти же данные записать в файл, к которому потом применить команду sort, то строки со строчными буквами будут идти раньше:

Разница их работы заключается в том, что в test для определения порядка сортировки за основу взято расположение символов по таблице ASCII. В sort же используется порядок сортировки, указанный для параметров языка региональных установок.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство «=»: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность «==»: возвращается «TRUE», если первая строка эквивалентна второй (дом == дом).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность str1 !== str2: «TRUE», если одна строковая переменная не равна другой по смысловому значению (дерево !== огонь).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, дерево > огонь, поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 < str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, «огонь < дерево», поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 «-z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения «-n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test.
- Далее необходимо открыть терминал и запустить test на выполнение командой:
./test
- Предварительно необходимо дать файлу право на исполнение командой:
chmod +x test
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.

in_array() нас обманывает
Вы мастер массивов в PHP. Вы уже знаете все о создании, редактировании и удалении массивов. Тем не менее, следующий пример может вас удивить.
Часто при работаете с массивами приходится в них что-либо искать с помощью in_array().
$array = array( false, true, 1 );
if( in_array( 'строка', $array ) ){
echo 'Неужто нашлось';
}
Как думаете выведет этот пример надпись «Неужто нашлось»? После такого вопроса, вы наверняка решили что условие сработает, но при написании кода, скорее всего было бы наоборот — и вы бы решили что условие не сработает На самом деле, это условие сработает и код выведет надпись «Неужто нашлось».
Так происходит, потому что PHP язык бестиповой и in_array() в данном случае сравнивает значения, но не учитывает тип, т.е. использует оператор ==, а не ===. А даст нам true. Вот и получается что in_array() лжёт!
Чтобы избежать такого «обмана», нужно указать true в третий параметр в in_array(), так все сравнения будут проходить с учетом типа значения.
$array = array( false, true, 1 ); if( in_array( 'строка', $array, true ) ) echo 'Неужто нашлось'; else echo 'Не найдено'; // сработает этот вариант условия
Closure::call — вызов анонимной функции с указанием контекста
Это не столько неожиданность, сколько интересная особенность, о которой мало кто знает.
PHP замыкания (анонимные функции) можно вызывать передавая в них контекст (объект). В результате замыкание можно использовать как метод переданного объекта.
Для этого в объекте замыкания есть метод:
call( $that, ...$params )
- $that(object)
- Объект для привязки к замыканию на время его вызова.
- …$params
- Сколько угодно параметров, которые передаются в замыкание.
Пример того как это использовать
class Value {
protected $value;
function __construct( $value ){
$this->value = $value;
}
function get_value(){
return $this->value;
}
}
$three = new Value( 3 );
$four = new Value( 4 );
$closure = function( $delta ){
echo $this->get_value() + $delta;
};
$closure->call( $three, 4 ); // 7
$closure->call( $four, 4 ); // 8
Что мы видим? При вызове одного и того же замыкания мы получаем разный результат, который зависит от контекста вызова (от того какой объект передается и используется в замыкании).
Примеры
Здесь мы создадим пять переменных. Формат заключается в вводе имени, знака равенства и значения
Обратите внимание, что нет пробела до или после знака равенства. Присвоение переменной значения часто называется присвоением значения переменной
Мы создадим четыре строковые переменные и одну числовую переменную
меня = Dave
my_boost = Linux
он = Popeye
his_boost = шпинат
this_year = 2019
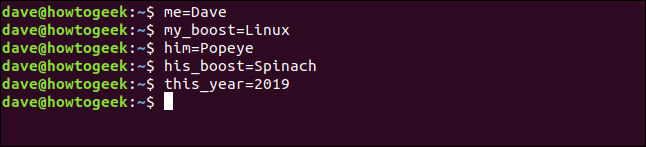
Чтобы увидеть значение в переменной, используйте команду . Имя переменной должно предшествовать знаку доллара каждый раз, когда вы ссылаетесь на содержащееся в нем значение, как показано ниже:
echo $ my_name
echo $ my_boost
echo $ this_year
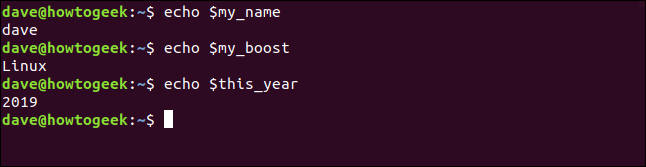
Давайте использовать все наши переменные одновременно:
echo "$ my_boost для $ меня, как $ his_boost для $ него (с) $ this_year"

Значения переменных заменяют их имена. Вы также можете изменить значения переменных. Чтобы назначить новое значение переменной , вы просто повторяете то, что делали, когда присваивали первое значение, например:
my_boost = Текила

Если вы повторно запустите предыдущую команду, вы получите другой результат:
echo "$ my_boost для $ меня, как $ his_boost для $ него (с) $ this_year"

Таким образом, вы можете использовать одну и ту же команду, которая ссылается на одни и те же переменные и получить разные результаты, если вы измените значения, содержащиеся в переменных.
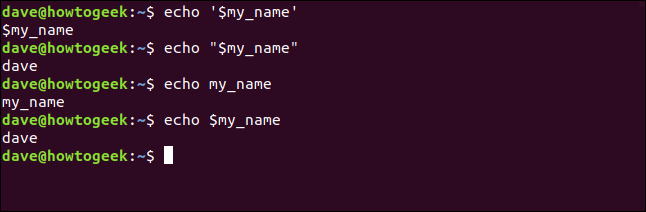
Мы поговорим о цитировании переменных позже. На данный момент вот некоторые вещи, которые нужно запомнить:
- Переменная в одинарных кавычках обрабатывается как буквенная строка, а не как переменная.
- Переменные в кавычках рассматриваются как переменные.
- Чтобы получить значение, хранящееся в переменной, необходимо указать знак доллара .
- Переменная без знака доллара предоставляет только имя переменной.
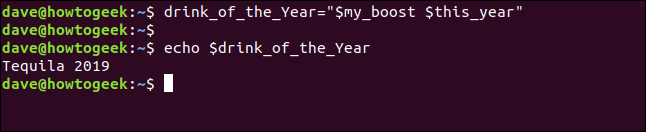
Вы также можете создать переменную, которая берет свое значение из существующей переменной или числа переменных. Следующая команда определяет новую переменную с именем и присваивает ей объединенные значения переменных и :
drink_of-the_Year = "$ my_boost $ this_year"
эхо напиток года
Точное сравнение: 0 == ‘строка’
PHP язык без строгой типизации и потому иногда могут возникать неожиданные результаты при сравнении (проверке) разных значений…
if( 0 == 'строка' ) echo 'Неужели?'; // увидим: 'Неужели?' // строка превращается в число при сравнении и становится 0: var_dump( 0 == 'строка' ); //> bool(true) // но var_dump( '0' == 'строка' ); //> bool(false)
Происходит так очевидно, потому что превращается в ноль: , а это true, разумеется…
Так например можно пропустить переменную запроса:
// $_GET может быть любой строкой и проверка всегда будет срабатывать...
if( $_GET == 0 ){
echo $_GET;
}
// поэтому по возможности ставьте проверку строго по типу
if( $_GET === '0' ){
echo $_GET;
}
Все следующие значения одинаковы, при сравнении через (не строгий оператор сравнения):
0 == false == "" == "0" == null == array()
Ну и так:
1 == '1нечто' == true true == array(111)
4 ответа
Я бы попробовал это так:
(* ПРИМЕЧАНИЕ: мне все равно, я люблю иногда начинать с cat для удобства чтения.)
Сначала мы вводим ввод с помощью cat, затем обрезаем поле перед разделителем ‘]’, затем из оставшегося бита мы вырезаем после ‘[‘. Наконец, мы добавляем строку sed для удаления пустых строк, возвращаемых нулевыми результатами операций вырезания.
*Редактировать:
После сканирования вашего осиротевшего комментария в теме здесь … кажется, что вы, возможно, хотите сохранить скобки. Было бы полезно в будущем показать желаемый результат imho. может быть, это будет работать нормально?
Сначала мы читаем в файле … затем вырезаем для после «=», затем с помощью sed удаляем все результаты с пустыми скобками. и, наконец, еще один sed для удаления пустых строк из результатов.
william_n
8 Апр 2020 в 02:00
Это должно быть простым сравнением их со строкой «[]»
Обратите внимание: поскольку все, что содержит и , выглядит для оболочки как подстановочное выражение для имени файла, вам нужно использовать соответствующие кавычки, чтобы не «услужливо» превратить их в списки совпадающих имен файлов. Это означает двойные кавычки вокруг ссылок на переменные и, возможно, одинарные кавычки вокруг литералов
Кроме того, я рекомендую использовать имена переменных в нижнем или смешанном регистре, чтобы избежать конфликтов со многими именами всех заглавных букв, которые имеют специальные значения / функции. Так что-то вроде этого:
1
Gordon Davisson
8 Апр 2020 в 01:36
Нет, я не хочу использовать круглые скобки, так как я должен передать их в квадратных скобках для своего дальнейшего развертывания в kubernetes. Есть ли способ, которым я могу сделать это с этим форматом?
Shoaib Ahmed Nasir
8 Апр 2020 в 00:52
Здесь есть два вопроса. Похоже, вы хотите определить массивы. Это сделано так:
После того, как они были определены, вы можете проверить, являются ли ВСЕ из этих массивов пустыми, например:
Если вы запустите выше, вы получите: непустой массив, так как ADMINS не пустой.
Однако, если вы закомментируете вторую строку ADMINS и раскомментируете первую строку ADMINS, вы получите: все пустые массивы.
Надеюсь это поможет.
Mamun
8 Апр 2020 в 00:18
Ответ 2
В Bash, когда вы не заботитесь о переносимости для оболочки, которые его не поддерживают, вы всегда должны использовать синтаксис двойных скобок:
Например:
if ]
if ]
if ]
if ]
При использовании двойных квадратных скобок кавычки не нужны. Тест для переменной, которая содержит значение, можно упростить:
if ]
Этот синтаксис совместим с ksh (по крайней мере, с ksh93). Он не работает в чистом POSIX или старых оболочках Bourne, таких как sh или dash.
Также можно проверить, не установлена ли конкретная переменная:
if ]
где «х» произвольное значение.
Если вы хотите узнать, является ли переменная нулевой, и не отключенной:
if ]
Проверьте, существует ли файл
При проверке существования файла наиболее часто используются операторы FILE и . Первый проверит, существует ли файл независимо от типа, а второй вернет истину, только если ФАЙЛ является обычным файлом (а не каталогом или устройством).
Наиболее удобочитаемый вариант при проверке существования файла — использование команды в сочетании с оператором . Любой из приведенных ниже фрагментов проверит, существует ли файл :
Если вы хотите выполнить другое действие в зависимости от того, существует файл или нет, просто используйте конструкцию if / then:
Всегда используйте двойные кавычки, чтобы избежать проблем при работе с файлами, в именах которых есть пробелы.
Вы также можете использовать команду test без оператора if. Команда после оператора будет выполнена только в том случае, если статус выхода тестовой команды — истина,
Если вы хотите запустить серию команд после оператора просто заключите команды в фигурные скобки, разделенные или :
Напротив , оператор после Оператор будет выполняться только в том случае, если статус выхода тестовой команды .
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep. Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep pattern (где options— дополнительные параметры для указания настроек поиска и вывода результата; pattern— шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; file_name1 file_name2 file_nameN— имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep pattern (где instruction — команда интерпретатора bash, options— дополнительные параметры для указания настроек поиска и вывода результата, pattern— шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
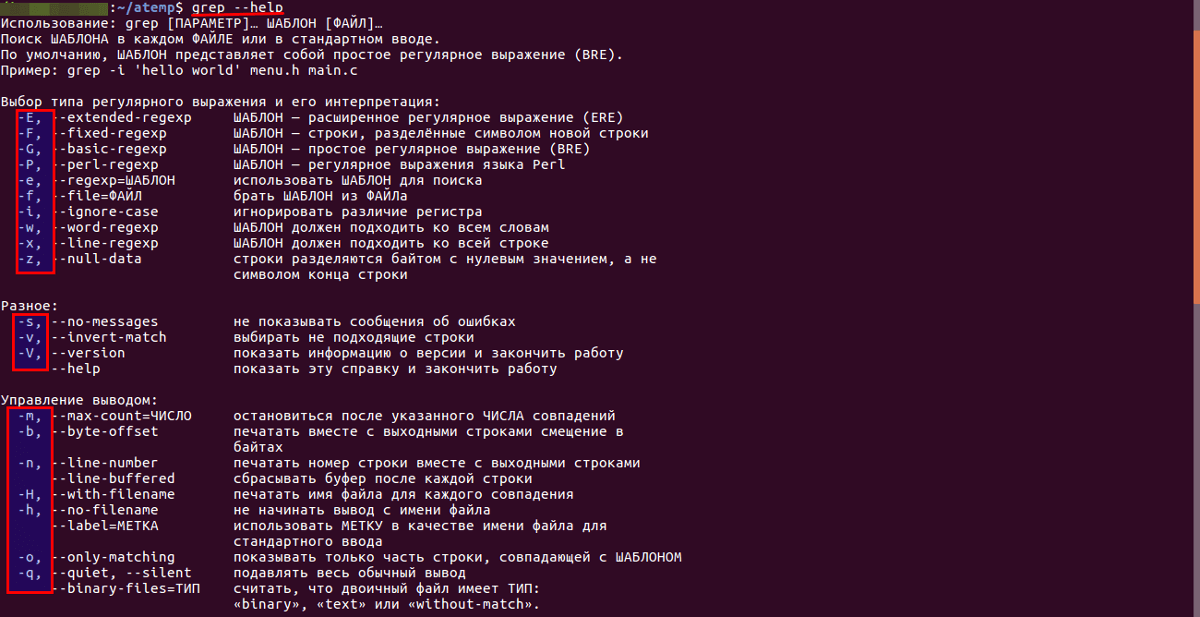
Основные опции
- Отобразить в консоли номер блока перед строкой — -b.
- Число вхождений шаблона строки — -с.
- Не выводить имя файла в результатах поиска — -h.
- Без учета регистра — -i.
- Отобразить только имена файлов с совпадением строки — -l.
- Показать номер строки — -n.
- Игнорировать сообщения об ошибках — -s.
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v.
- Слово, окруженное пробелами, — -w.
- Включить регулярные выражения при поиске — -e.
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn.
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
grep Bourne firstfile.txt
- Без учета регистра:
grep -i "Bourne"txt
Вывод нескольких строк
- Строка с вхождением и две после нее:
grep -A2 "Bourne"txt
- Строка с вхождением и три до нее:
grep -B3 "Bourne"txt
- Строка, содержащая вхождение, и одну до и после нее:
grep -C1 "Bourne"txt
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».В регулярных выражения для обозначения начала строки используется специальный символ «^».
grep "^Фамилия" firstfile.txt
Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep "^Ф" firstfile.txt
- Конец строки, заканчивающийся словом «оболочка». Для обозначения конца строки используется мета-символ «$».grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкциюgrep «а.$» firstfile.txt. В этом случае будут выведены все строки, заканчивающиеся на литеру «а».
- Строки, содержащие числа.
grep -C1 "Bourne"txt
Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
grep ""txt
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
grep -r "оболочка$"
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
grep -h -r "оболочка$"
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ «w»
grep -w "и" firstfile.txt
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
grep -w "и | но" firstfile.txt
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
grep -с "Bourne"txt
- Номера строк с совпадениями:
grep -n "Bourne"txt
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
grep -v "Unix" firstfile.txt
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
grep -I "Unix" *.txt
Использование sed
Потоковый текстовый редактор «sed» встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed instructions (где options— ключи-опции для указания метода обработки текста, instructions— команда, совершаемая над найденным фрагментом текста, file_name— имя файла, над которым совершаются действия).
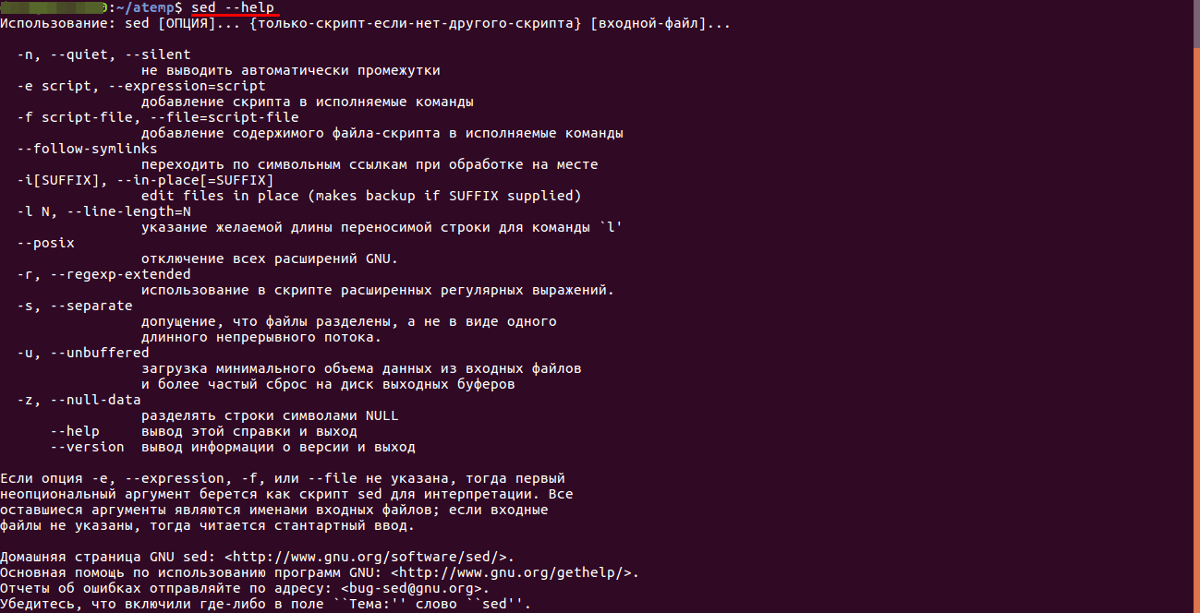
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
sed --help
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
sed 's/команды/инструкции/' firstfile.txt
- Для всех вхождений (используется параметр инструкции — g):
sed 's/команды/инструкции/g' firstfile.txt
- Замена подстроки с несколькими условиями (используется ключ — -e):
sed -e 's/команды/инструкции/g' -e 's/команд/инструкций/g' firstfile.txt
- Заменить часть строки, если она содержит определенный набор символов (например, POSIX):
sed '/POSIX/s/Bash/оболочка/g' firstfile.txt
- Выполнить замену во всех строках, начинающихся на Bash
sed '/^Bash/s/Bash/оболочка/g' firstfile.txt
- Произвести замену только в строках, которые заканчиваются на Bash:
sed '/команды/s/Bash/оболочка/g' firstfile.txt
- Заменить слово с пробелом на слово с тире:
sed 's/Bash\ /оболочка-/g' firstfile.txt
- Заменить символ переноса строки на пробел
sed 's/\n/ /g' firstfile.txt
- Перенос строки обозначается символом — \n.
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i:
sed -i 's/команды/инструкции/' firstfile.txt
После выполнения команды произойдет замена слова командынаинструкциис последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
sed -i '1d' firstfile.txt
- Удалить строку из файла, содержащую слово окне»:
sed '/окне/d' firstfile.txt
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
- Удалить пустые строки:
sed '/^$/d' firstfile.txt
- Убрать пробелы в конце строки:
sed 's/ *$//' firstfile.txt
-
Табуляция удаляется при помощи конструкции:
sed 's/\t*$//' firstfile.txt
- Удалить последний символ в строке:
sed 's/ ;$//' firstfile.txt
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
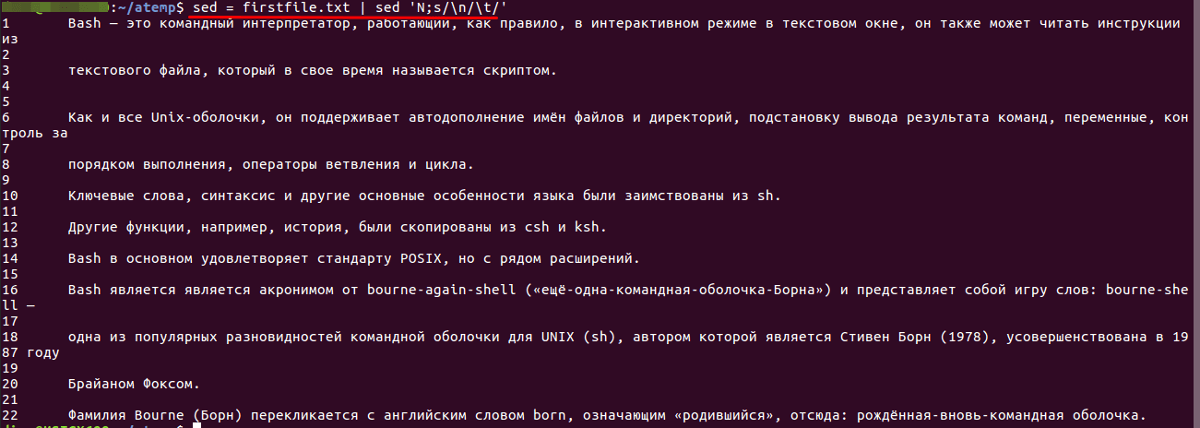
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования
sed = firstfile.txt | sed 'N;s/\n/\t/'
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду «y»:
sed 'y/1978/1977/g' firstfile.txt
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
sed '3s/директорий/папок' firstfile.txt
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
sed '3,4s/директорий/папок' firstfile.txt
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:sed ‘5r input_file.txt’ firstfile.txt (где 5r— 5 строка, input_file.txt— исходный файл и firstfile.txt— файл, в который требуется вставить массив текста).
How to Compare Strings in Bash
17 Мая 2020
|
Терминал
Это руководство описывает, как сравнивать строки в Bash.

При написании сценариев Bash вам часто нужно сравнивать две строки, чтобы проверить, равны они или нет. Две строки равны, если они имеют одинаковую длину и содержат одинаковую последовательность символов.
Операторы сравнения
Операторы сравнения — это операторы, которые сравнивают значения и возвращают true или false. При сравнении строк в Bash вы можете использовать следующие операторы:
-
и — Оператор равенства возвращает true, если операнды равны.
- Используйте оператор с командой.
- Используйте оператор с командой для сопоставления с образцом.
- — Оператор неравенства возвращает true, если операнды не равны.
- — Оператор регулярного выражения возвращает true, если левый операнд соответствует расширенному регулярному выражению справа.
- — Оператор «больше чем» возвращает истину, если левый операнд больше правого, отсортированного по лексикографическому (алфавитному) порядку.
- — Оператор less than возвращает true, если правый операнд больше правого, отсортированного по лексикографическому (алфавитному) порядку.
- — Истина, если длина строки равна нулю.
- — Истина, если длина строки не равна нулю.
Ниже следует отметить несколько моментов при сравнении строк:
- Пустое пространство должно быть использовано между бинарным оператором и операндами.
- Всегда используйте двойные кавычки вокруг имен переменных, чтобы избежать каких-либо проблем с разделением слов или смещениями
- Bash не разделяет переменные по «типу», переменные обрабатываются как целое число или строка в зависимости от контекста.
Проверьте, равны ли две строки
В большинстве случаев при сравнении строк вы хотите проверить, равны ли строки или нет.
Следующий скрипт использует оператор if и команду test, чтобы проверить, совпадают ли строки с оператором:
Когда скрипт выполняется, он напечатает следующий вывод.
Вот еще один скрипт, который принимает входные данные от пользователя и сравнивает заданные строки. В этом примере мы будем использовать команду и оператор.
Запустите скрипт и введите строки при появлении запроса:
Вы также можете использовать логические и и или для сравнения строк:
Проверьте, содержит ли строка подстроку
Есть несколько способов проверить, содержит ли строка подстроку.
Один из подходов заключается в использовании подстроки с символами звездочки, что означает совпадение всех символов.
Скрипт отобразит следующее:
Другой вариант — использовать оператор регулярного выражения, как показано ниже:
Точка, за которой следует звездочка, соответствует нулю или большему количеству вхождений любого символа, кроме символа новой строки.
Проверьте, пуста ли строка
Довольно часто вам также необходимо проверить, является ли переменная пустой строкой или нет. Вы можете сделать это, используя и оператор.
Лексикографическое сравнение
Лексикографическое сравнение — это операция, в которой две строки сравниваются в алфавитном порядке путем сравнения символов в строке последовательно слева направо. Этот вид сравнения используется редко.
Следующие сценарии сравнивают две строки лексикографически:
Скрипт выведет следующее:
Сравнение строк — одна из самых основных и часто используемых операций в сценариях Bash. Прочитав этот урок, вы должны хорошо понимать, как сравнивать строки в Bash. Вы также можете проверить наше руководство о конкатенации строк .
