16 ответов
-
97 рейтинг
Проще говоря:
Итак, внутри строки замените каждую кавычку на две из них.
или
Escape it =)
ответ дан Rob, с репутацией 36172, 20.05.2009
-
9 рейтинг
См. Мой ответ на
В любой библиотеке, которую вы используете для общения с MySQL, будет встроена функция экранирования, т.е. г. в PHP вы можете использовать mysqli_real_escape_string или PDO :: цитата
ответ дан Paul Dixon, с репутацией 234700, 20.05.2009
-
8 рейтинг
‘является escape-символом. Итак, ваша строка должна быть: Это перо Ашока
Редактировать:
Если вы используете какой-либо интерфейсный код, перед отправкой данных в SP необходимо выполнить замену строки.
Например, в C # вы можете сделать
, а затем передать значение в SP.
ответ дан Rashmi Pandit, с репутацией 15757, 20.05.2009
-
7 рейтинг
Если вы используете подготовленные операторы, драйвер будет обрабатывать любое экранирование. Например (Java):
ответ дан hd1, с репутацией 23363, 23.05.2013
-
5 рейтинг
Вы должны экранировать специальные символы, используя символ .
Становится:
ответ дан simon622, с репутацией 1983, 20.05.2009
-
4 рейтинг
Это действительно старый вопрос, но есть другой способ сделать это, который может быть или не быть более безопасным, в зависимости от вашей точки зрения. Требуется MySQL 5. 6 или позднее из-за использования определенной строковой функции: .
Допустим, у вас есть это сообщение, которое вы хотите вставить:
Эта цитата содержит кучу одинарных и двойных кавычек, и ее будет очень сложно вставить в MySQL. Если вы вставляете это из программы, легко избежать кавычек и т. Д. Но если вам нужно вставить это в скрипт SQL, вам придется редактировать текст (чтобы избежать кавычек), который может быть подвержен ошибкам или чувствителен к переносу слов и т. Д.
Вместо этого вы можете base64-кодировать текст, поэтому у вас есть «чистая» строка:
Некоторые заметки о base64-кодировке:
- base64-encoding — это двоичная кодировка , поэтому вам лучше убедиться, что вы правильно установили свой набор символов при кодировании, потому что MySQL собирается декодировать строку в кодировке base64 в байты, а затем интерпретировать их. Убедитесь, что и MySQL согласны с кодировкой символов (я рекомендую UTF-8).
- Я обернул строку в 50 столбцов для удобства чтения на SO. Вы можете обернуть его в любое количество столбцов, которые вы хотите (или не обернуть вообще), и он все равно будет работать.
Теперь, чтобы загрузить это в MySQL:
Это вставит без каких-либо жалоб, и вам не пришлось вручную экранировать любой текст внутри строки.
ответ дан Christopher Schultz, с репутацией 13529, 16.02.2017
-
4 рейтинг
Используйте этот код:
Это решит вашу проблему, потому что база данных не может обнаружить специальный символ строки.
ответ дан user3818708, с репутацией 65, 12.07.2014
-
3 рейтинг
Вы можете использовать этот код
, если mysqli_real_escape_string не работает
ответ дан Parkhya developer, с репутацией 161, 10.03.2017
-
2 рейтинг
В PHP используйте mysqli_real_escape_string. ,
Пример из руководства по PHP:
ответ дан Marcel Verwey, с репутацией 333, 6.11.2013
-
1 рейтинг
ответ дан Michael Temitayo Adeyanju, с репутацией 11, 22.11.2016
-
0 рейтинг
, если вы используете php, просто используйте функцию addlashes ()
ответ дан Sonu, с репутацией 21, 27.11.2013
-
0 рейтинг
В Perl DBI, например, вы можете использовать:
ответ дан Elle Fie, с репутацией 83, 22.05.2013
-
0 рейтинг
Может быть, вы могли бы взглянуть на функцию Quote в руководстве Mysql.
ответ дан Julian, с репутацией 1255, 4.12.2015
-
0 рейтинг
Как я делаю, используя Delphi:
TheString для «побега»:
Решение:
Результат:
Эта функция заменит все символы Char (39) на «\», что позволяет без проблем вставлять или обновлять текстовые поля в MySQL.
Подобные функции есть во всех прог-языках!
ответ дан user7276516, с репутацией 1, 10.12.2016
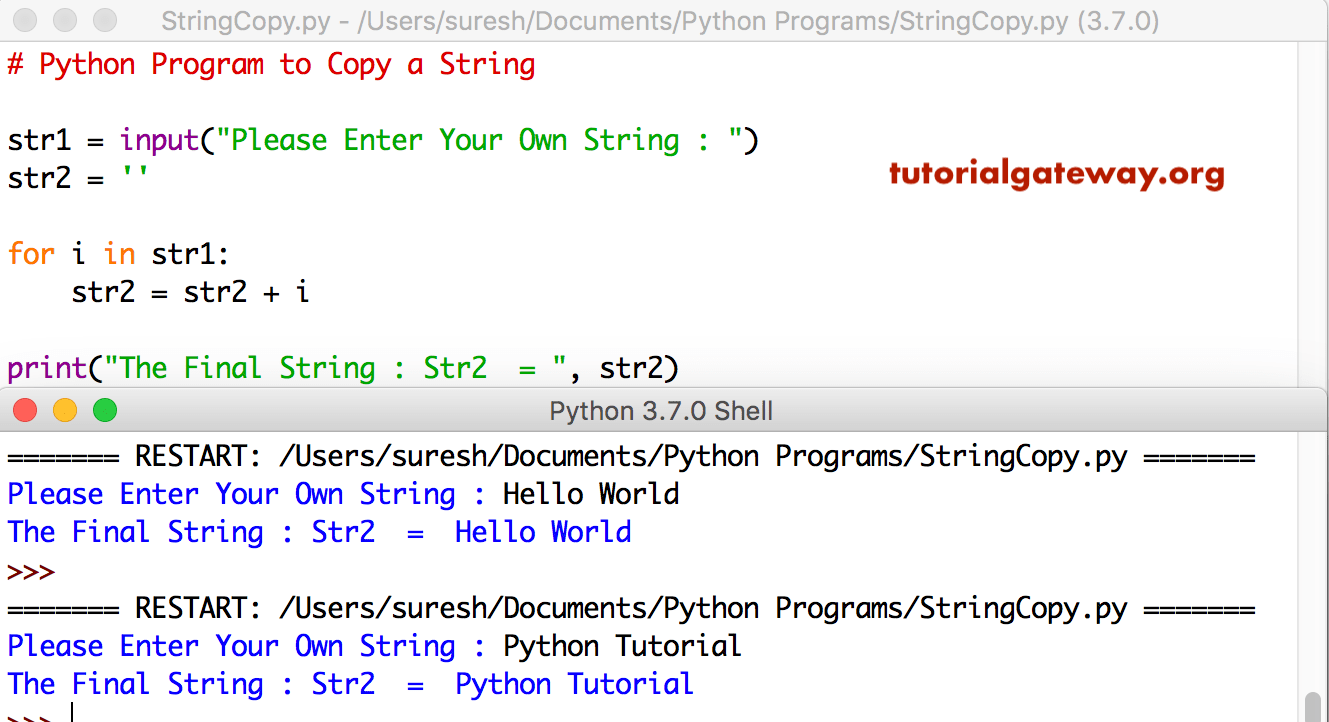
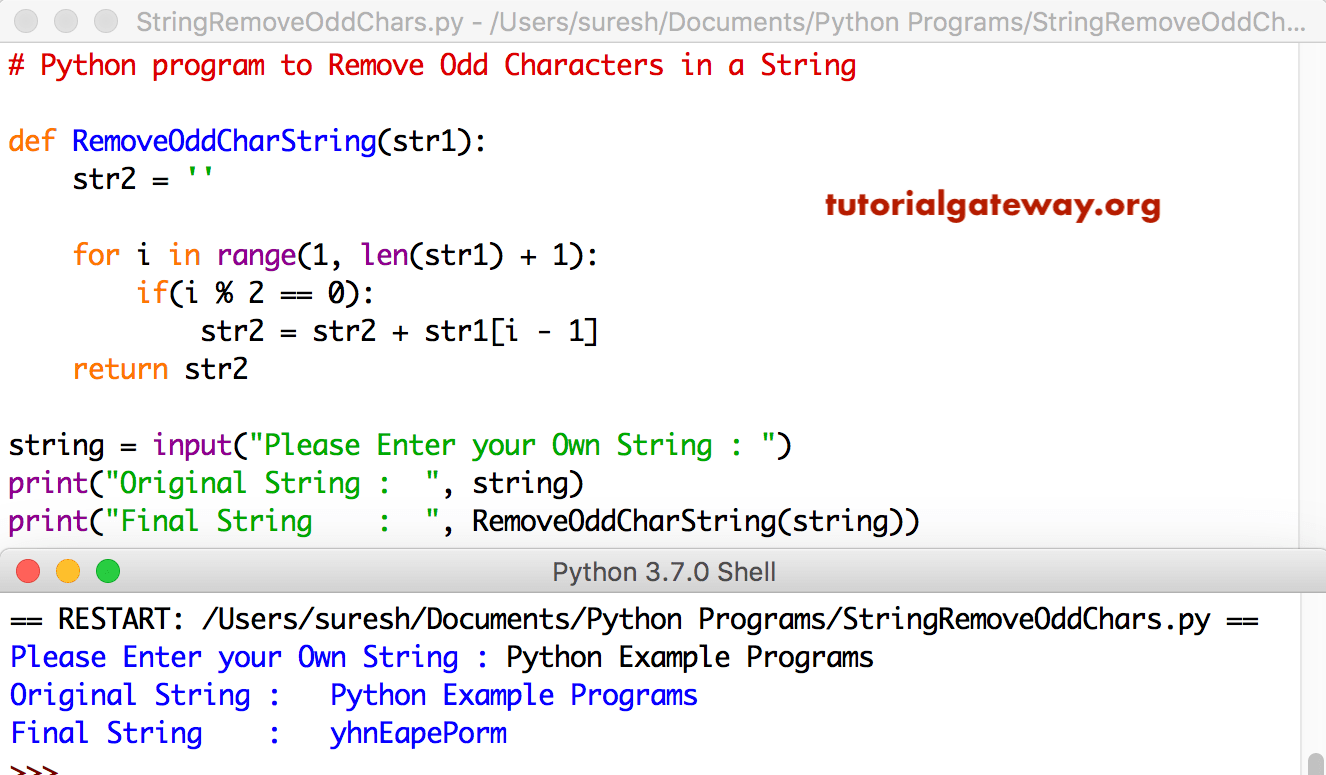
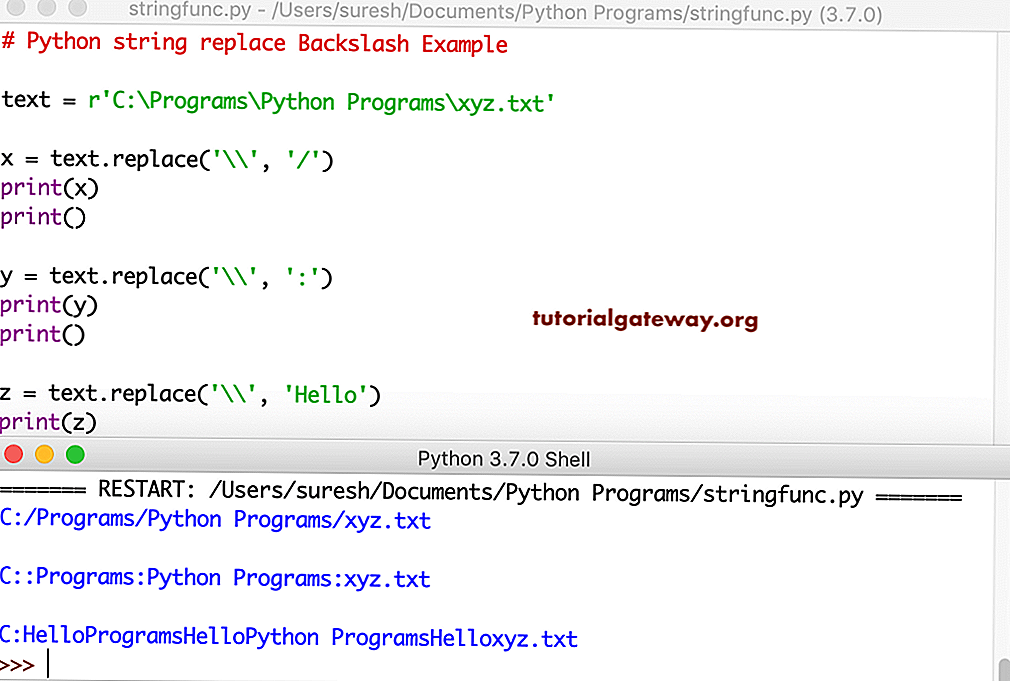
Строковые функции в Python
Python предоставляет различные встроенные функции, которые используются для работы со строками.
| Метод | Описание |
|---|---|
| Выводит первый символ строки заглавными буквами. Эта функция устарела в python3 | |
| Возвращает версию строки, пригодную для сравнений без регистра. | |
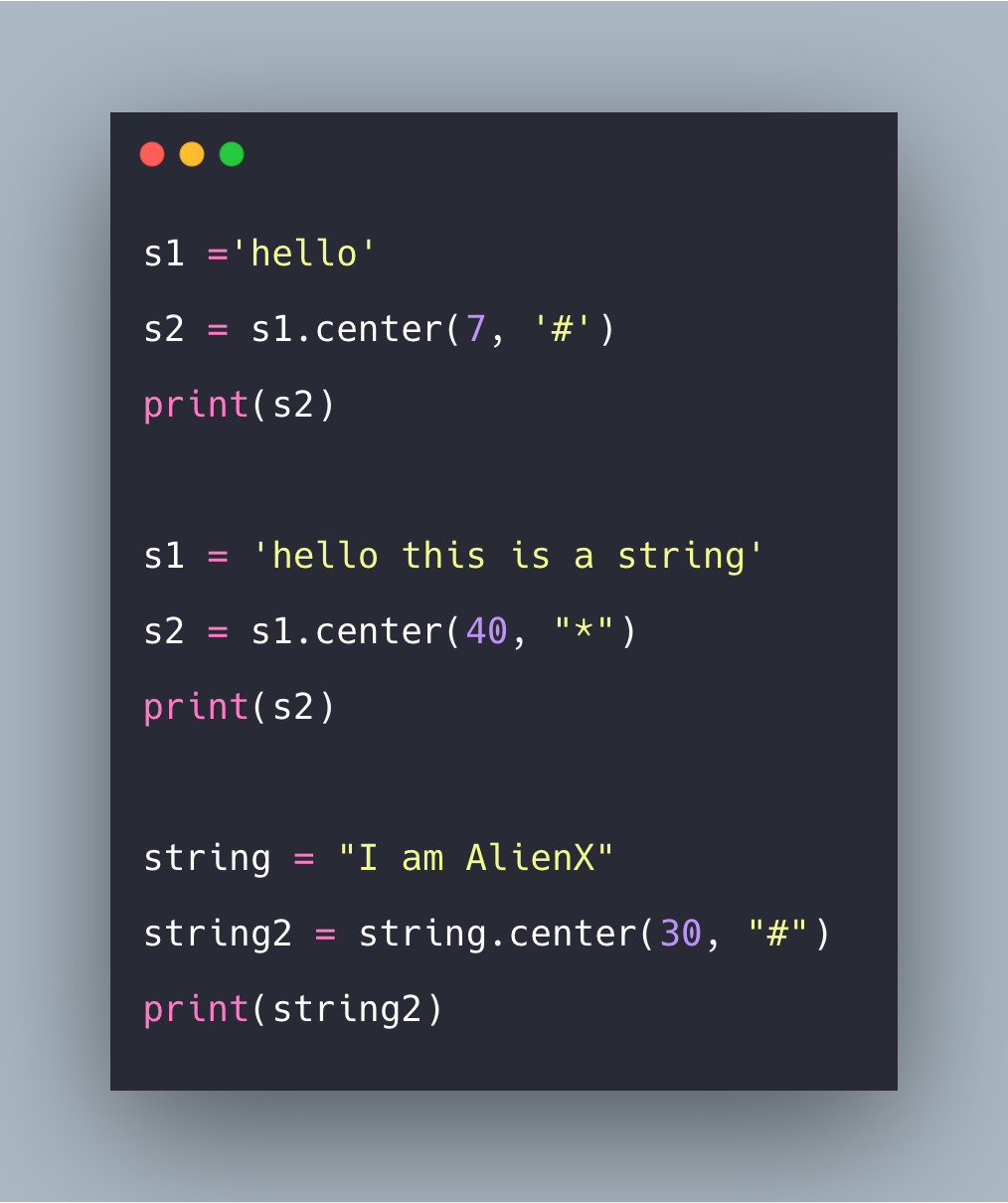
| Возвращает строку, заполненную пробелами, причем исходная строка центрируется с равным количеством пробелов слева и справа. | |
| Подсчитывает количество вхождений подстроки в строку между начальным и конечным индексом. | |
| Декодирует строку. | |
| Кодирование строки. Кодировка по умолчанию — . | |
| Возвращает булево значение, если строка заканчивается заданным суффиксом между begin и end. | |
| Определяет табуляцию в строке до нескольких пробелов. По умолчанию количество пробела равно 8. | |
| Возвращает значение индекса строки, в которой найдена подстрока между начальным и конечным индексами. | |
| Возвращает форматированную версию строки, используя переданное значение. | |
| Выбрасывает исключение, если строка не найдена. Работает так же, как и метод . | |
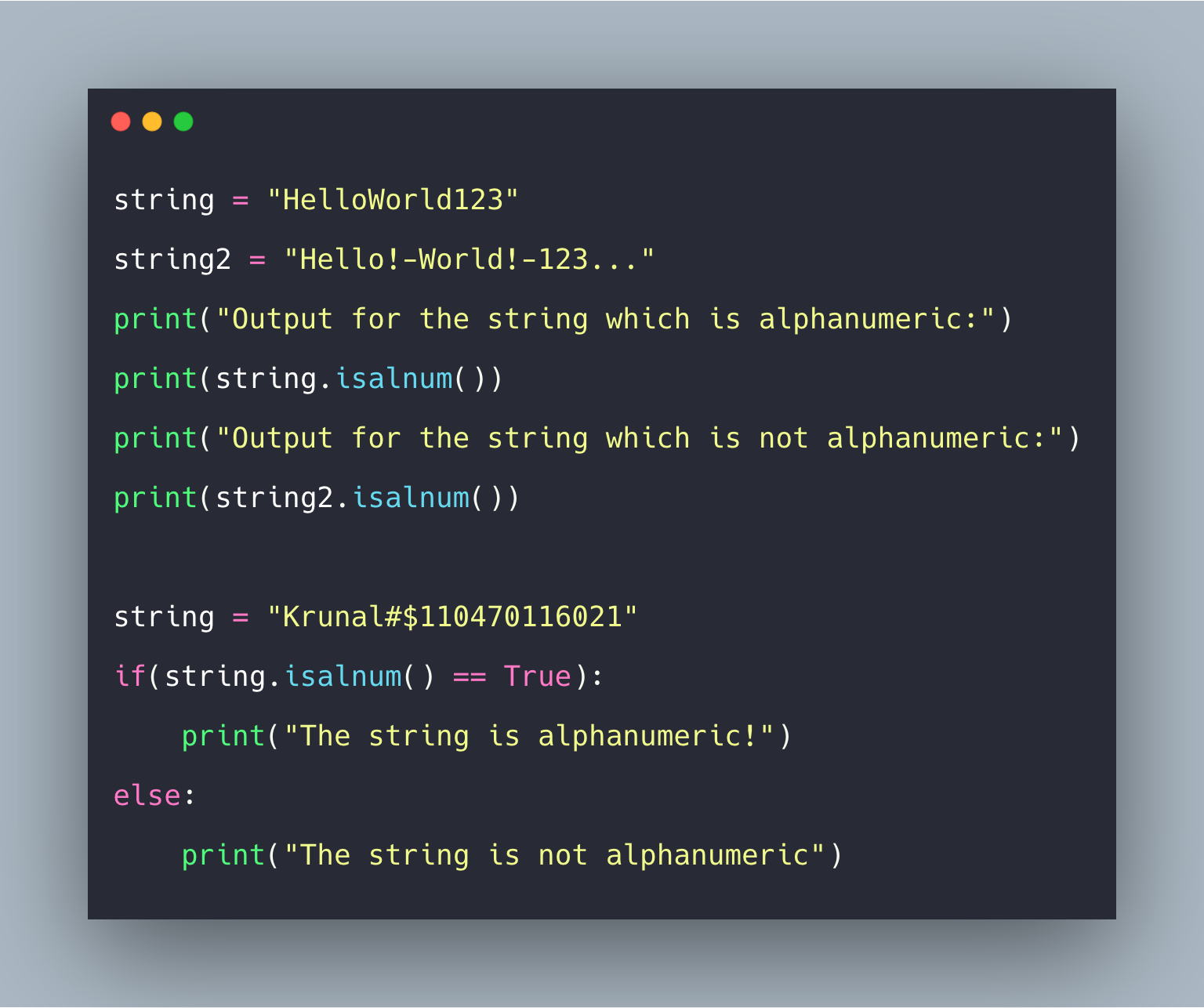
| Возвращает true, если символы в строке являются буквенно-цифровыми, т.е. алфавитами или цифрами, и в ней есть хотя бы один символ. В противном случае возвращается . | |
| Возвращает , если все символы являются алфавитными и есть хотя бы один символ, иначе . | |
| Возвращает , если все символы строки являются десятичными. | |
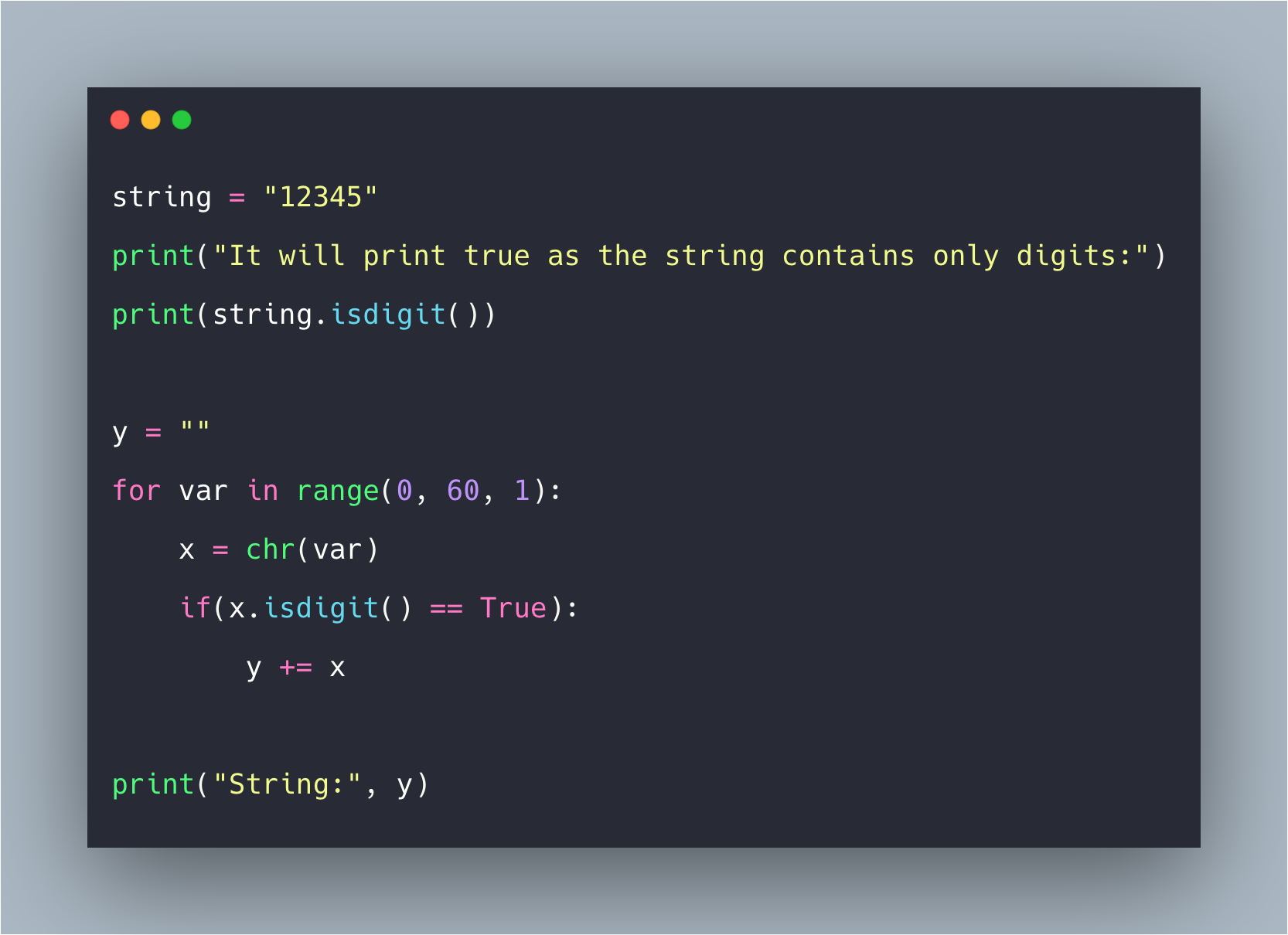
| Возвращает , если все символы являются цифрами и есть хотя бы один символ, иначе . | |
| Возвращает , если строка является действительным идентификатором. | |
| Возвращает , если символы строки находятся в нижнем регистре, иначе . | |
| Возвращает , если строка содержит только числовые символы. | |
| Возвращает , если все символы строки являются печатными или строка пустая, в противном случае возвращает . | |
| Возвращает , если символы строки находятся в верхнем регистре, иначе . | |
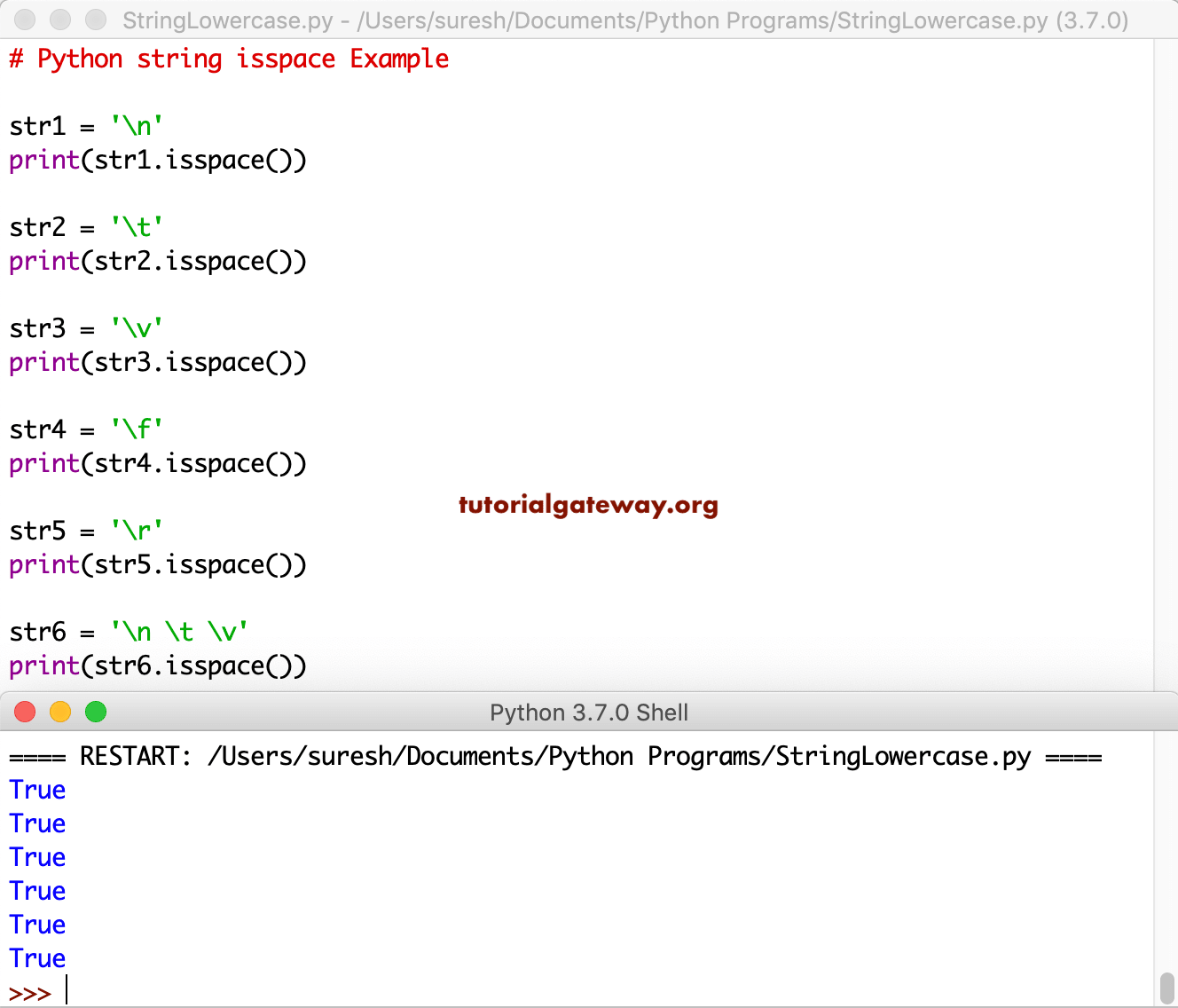
| Возвращает , если символы строки являются пробелами, иначе . | |
| Возвращает , если строка имеет правильный заголовок, и в противном случае. Заголовок строки — это строка, в которой первый символ в верхнем регистре, а остальные символы в нижнем регистре. | |
| Он объединяет строковое представление заданной последовательности. | |
| Возвращает длину строки. | |
| Возвращает строки, заполненные пробелами, с исходной строкой, выровненной по левому краю до заданной ширины. | |
| Он преобразует все символы строки в нижний регистр. | |
| Удаляет все пробелы в строке, а также может быть использован для удаления определенного символа из строки. | |
| Он ищет разделитель в строке и возвращает часть перед ним, сам разделитель и часть после него. Если разделитель не найден, возвращается кортеж в виде переданной строка и двух пустых строк. | |
| Возвращает таблицу перевода для использования в функции . | |
| Заменяет старую последовательность символов на новую. Если задано значение , то заменяются все вхождения. | |
| Похож на , но обходит строку в обратном направлении. | |
| Это то же самое, что и , но обходит строку в обратном направлении. | |
| Возвращает строку с пробелами, исходная строка которой выровнена по правому краю на указанное количество символов. | |
| Он удаляет все пробелы в строке, а также может быть использован для удаления определенного символа. | |
| Он аналогичен функции , но обрабатывает строку в обратном направлении. Возвращает список слов в строке. Если разделитель не указан, то строка разделяется в соответствии с пробелами. | |
| Разделяет строку в соответствии с разделителем . Строка разделяется по пробелу, если разделитель не указан. Возвращает список подстрок, скомпонованных с разделителем. | |
| Он возвращает список строк в каждой строке с удаленной строкой. | |
| Возвращает булево значение, если строка начинается с заданной строки между и . | |
| Он используется для выполнения функций и над строкой. | |
| Он инвертирует регистр всех символов в строке. | |
| Он используется для преобразования строки в заглавный регистр, т.е. строка будет преобразована в . | |
| Он переводит строку в соответствии с таблицей перевода, переданной в функцию . | |
| Он преобразует все символы строки в верхний регистр. | |
| Возвращает исходную строку, дополненную нулями минимального количества символов (параметр ); предназначена для чисел, сохраняет любой заданный знак (за вычетом одного нуля). | |
| Ищет последнее вхождение указанной строки и разбивает строку на кортеж, содержащий три элемента (часть перед указанной строкой, саму строку и часть после нее). |
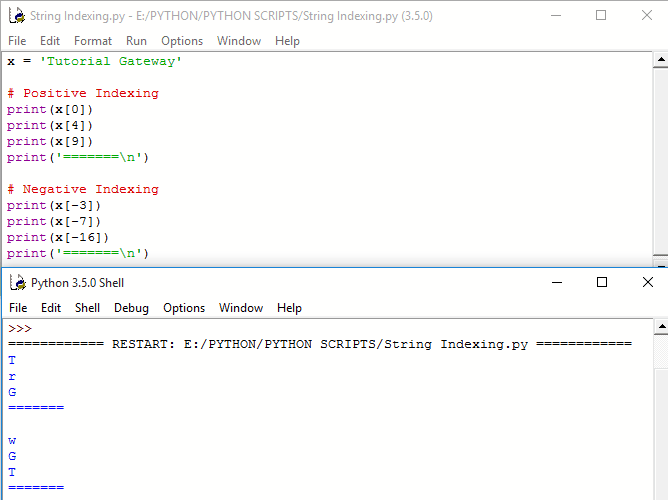
substring(int beginIndex, int endIndex)
Этот метод вернет новый объект String, содержащий подстроку данной строки от указанного startIndex до endIndex. И получит часть String, начиная с данного beginIndex и до указанного endIndex.
public String substring(int beginIndex, int endIndex)
где beginIndex – индекс, с которого нужно начать извлечение возвращаемой подстроки. (включительно) endIndex – индекс, с которого нужно закончить извлечение возвращаемой подстроки. (эксклюзив)
Смысл в том, что мы можем указать, где начинать и заканчивать копирование символов из исходной строки.
public class SubstringTest {
public static void main(String[] args) {
String testString = "ABCDEFGHIJ";
System.out.println(testString.substring(0,5));
System.out.println(testString.substring(1,5));
System.out.println(testString.substring(2,5));
System.out.println(testString.substring(0,6));
System.out.println(testString.substring(1,6));
System.out.println(testString.substring(2,6));
System.out.println(testString.substring(0,7));
System.out.println(testString.substring(1,7));
System.out.println(testString.substring(2,7));
}
}
Вывод
ABCDE BCDE CDE ABCDEF BCDEF CDEF ABCDEFG BCDEFG CDEFG
Вот пример программы, которая примет строку и распечатает все возможные подстроки.
import java.util.Scanner;
public class PrintAllSubstring {
public static void main(String[] args) {
System.out.println("Enter a string:");
Scanner in = new Scanner(System.in);
String inputString = in.nextLine();
for (int beginIndex = 0; beginIndex < inputString.length(); beginIndex++) {
for (int endIndex = beginIndex + 1; endIndex <= inputString.length(); endIndex++) {
System.out.println(inputString.substring(beginIndex, endIndex));
}
}
}
}
И вот результат, предполагающий, что была введена строка wxyz.
Enter a string: wxyz w wx wxy wxyz x xy xyz y yz z
Вот пример того, как получить середину строки с помощью метода substring в алгоритме.
public class MiddleStrTest {
public static void main(String[] args) {
System.out.println("A --> " + getMiddleString("A"));
System.out.println("AB --> " + getMiddleString("AB"));
System.out.println("ABC --> " + getMiddleString("ABC"));
System.out.println("ABCD --> " + getMiddleString("ABCD"));
System.out.println("ABCDE --> " + getMiddleString("ABCDE"));
System.out.println("ABCDEF --> " + getMiddleString("ABCDEF"));
System.out.println("ABCDEFG --> " + getMiddleString("ABCDEFG"));
}
private static String getMiddleString(String str) {
if (str.length() <= 2) {
return str;
}
int beginIndex = (str.length() - 1) / 2;
int endIndex = beginIndex + 2 - (str.length() % 2);
return str.substring(beginIndex, endIndex);
}
}
Вывод
A --> A AB --> AB ABC --> B ABCD --> BC ABCDE --> C ABCDEF --> CD ABCDEFG --> D
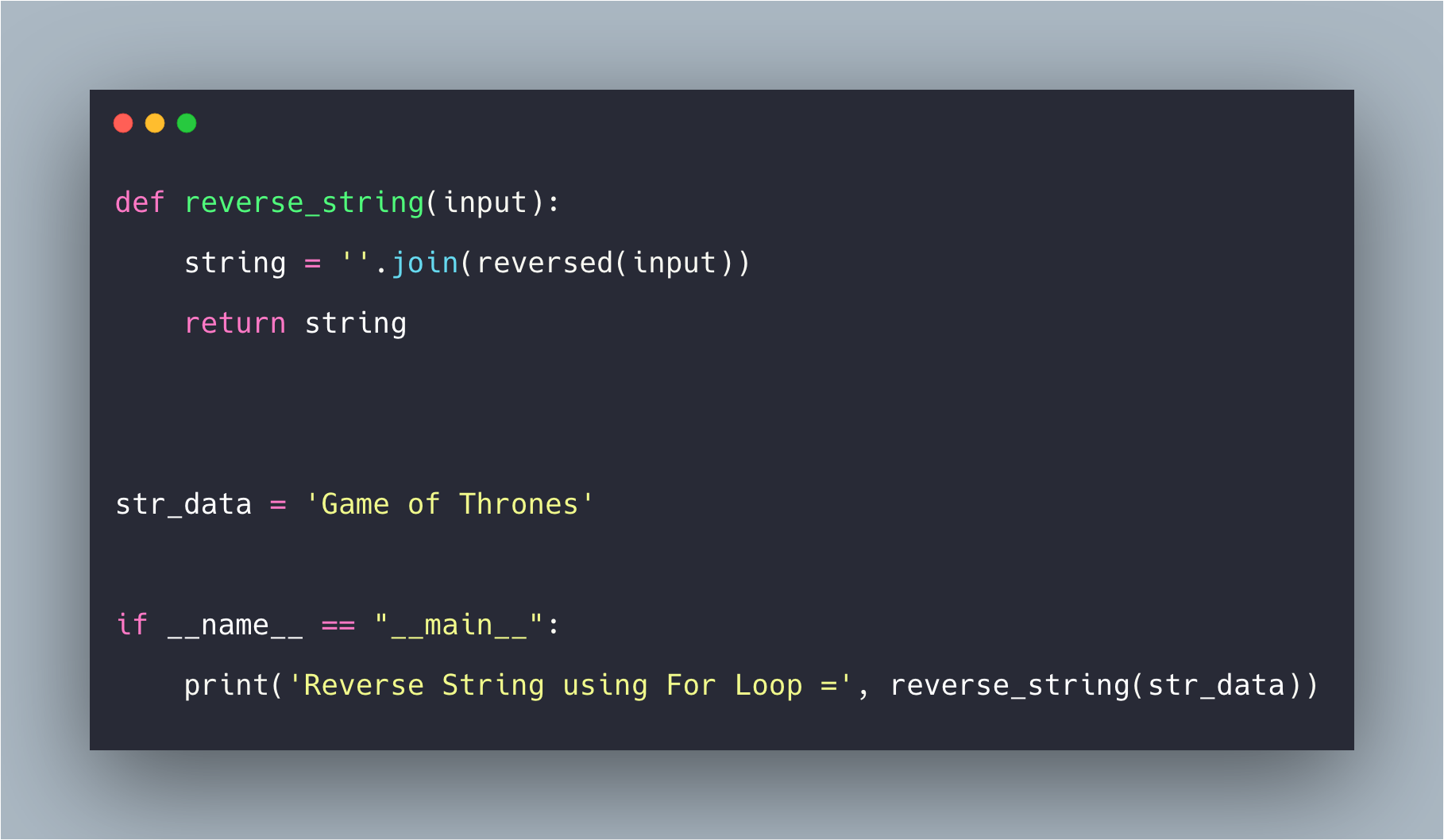
Вот пример программы, которая перевернет строку.
public class ReverseTest {
public static void main(String[] args) {
System.out.println(reverse("ABCDEFG"));
}
private static String reverse(String str) {
if (str.length() <= 1) {
return str;
}
return reverse(str.substring(1)) + str.substring(0, 1);
}
}
Это выведет обратную строку ABCDEFG: Вот пример программы, которая проверит, является ли строка палиндромом или нет.
public class PalTest {
public static void main(String[] args) {
System.out.println(palindrome("ABCBA"));
System.out.println(palindrome("ABCCBA"));
System.out.println(palindrome("ABCCXA"));
System.out.println(palindrome("ABCDEFG"));
}
private static boolean palindrome(String str) {
if (str.length() <= 1) {
return true;
}
String first = str.substring(0, 1);
String last = str.substring(str.length() - 1);
return first.equals(last)
&& palindrome(str.substring(1, str.length() - 1));
}
}
Вывод
true true false false
Оцени статью
Оценить
Средняя оценка / 5. Количество голосов:
Видим, что вы не нашли ответ на свой вопрос.
Помогите улучшить статью.
Спасибо за ваши отзыв!
Часть третья: Специальные переменные
Мы уже сказали про обычный синтаксис awk. Сейчас давайте начнём рассматривать модные штуки.

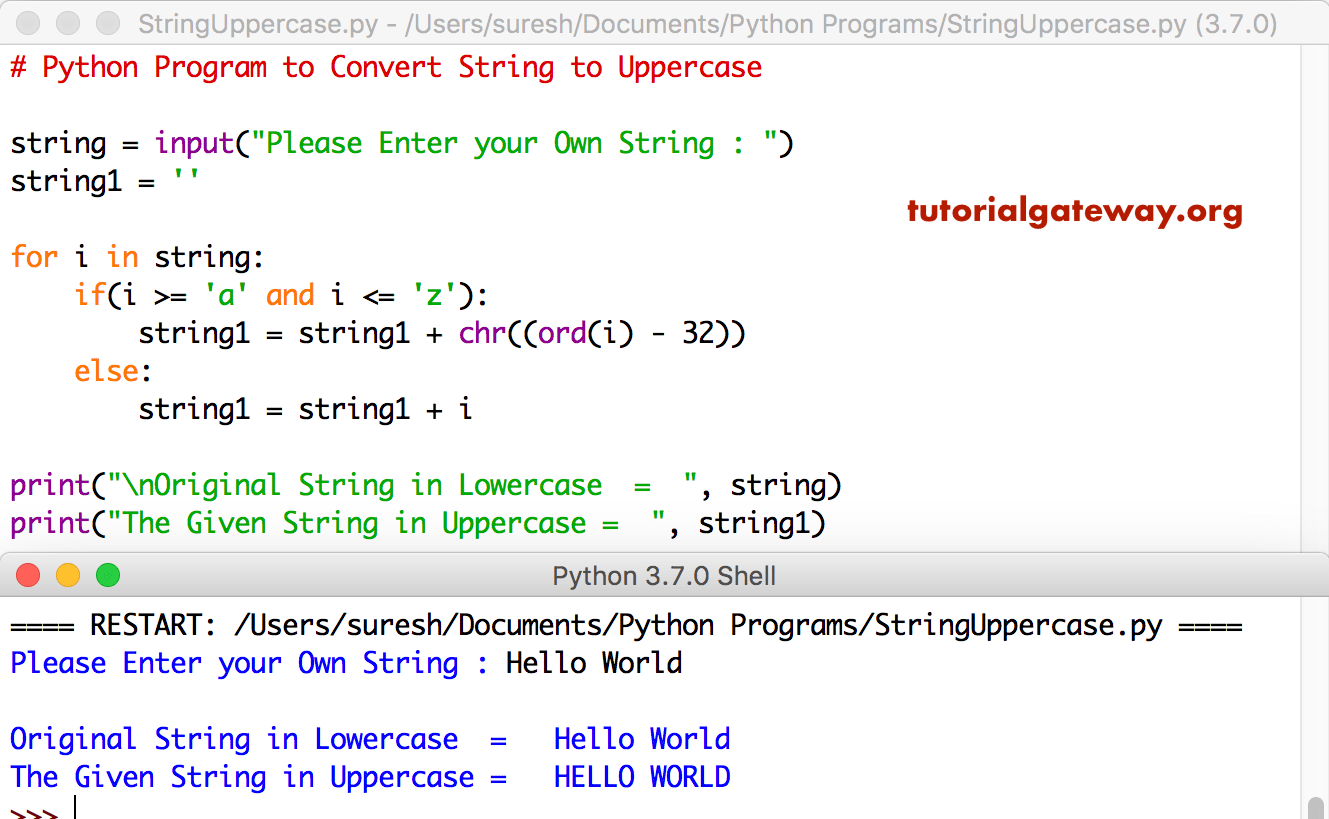
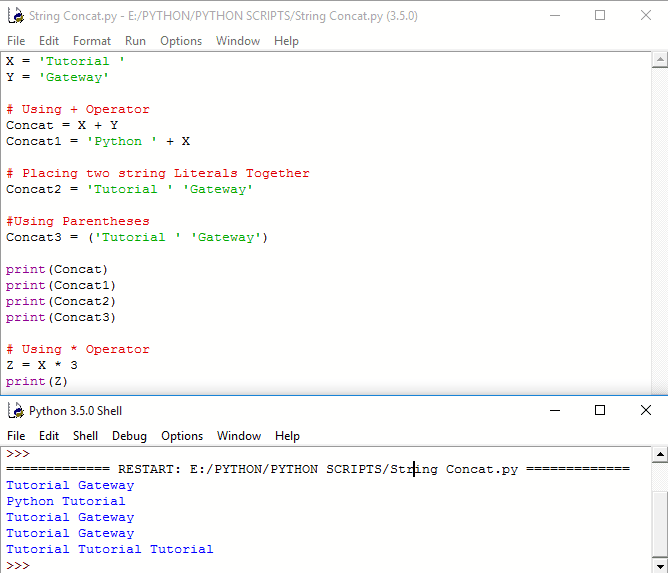
awk имеет «специальные» строки соответствия: «BEGIN» и «END»
Директива BEGIN вызывается однажды перед чтением каких-либо строк из данных, никогда снова.
Директива END вызывается после прочтения всех строк. Если дано несколько файлов, то она вызывается только после завершения самого последнего файла.
Обычно вы будете использовать BEGIN для различной инициализации, а END для подведения итогов или очистки.
Пример:
BEGIN { maxerrors=3 ; logfile=/var/log/something ; tmpfile=/tmp/blah}
... { blah blah blah }
/^header/ { headercount += 1 }
END { printf("всего подсчитано заголовков=%d\n", headercount);
Этот пример посчитает количество раз, которое встречается «header» в файле ввода и напечатает общее количество только после завершения обработки всего файла.
AWK также имеет множество других специальных величин, которые вы можете использовать в секции { }. Например,
print NF
даст вам общее количество колонок (Number of Fields – Количество полей) в текущей строке. FILENAME будет текущим именем файла, подразумевается, что имя файла было передано в awk, а не использована труба.
Вы НЕ МОЖЕТЕ ИЗМЕНИТЬ NF самостоятельно.
Аналогично с переменной NR, которая говорит, как много строк вы обработали. («Number of Records» – Количество записей)
Есть и другие специальные переменные, вы даже такие, которые вы МОЖЕТЕ изменить в середине программы.
10 ответов
Лучший ответ
Документация MySQL, которую вы цитируете, на самом деле говорит немного больше, чем вы упоминаете. В нем также говорится:
(Кроме того, вы связались с , а текущая версия — 5.6, но текущая выглядят очень похоже.)
Думаю, что является информативным:
Это говорит мне, что использование удвоенного символа одинарной кавычки — лучший общий и долгосрочный выбор, чем использование обратной косой черты для выхода из одинарной кавычки.
Теперь, если вы также хотите добавить в уравнение выбор языка, выбор базы данных SQL и ее нестандартные особенности, а также выбор структуры запросов, тогда вы можете получить другой выбор. Вы не даете много информации о своих ограничениях.
211
Jonathan Leffler
23 Сен 2013 в 00:27
Я считаю, что user2087510 имел в виду:
Я тоже использовал это с успехом.
13
user3169788
29 Янв 2014 в 21:06
Стандартный SQL использует двойные кавычки; MySQL должен принять это, чтобы быть достаточно совместимым.
48
Jonathan Leffler
7 Мар 2012 в 06:14
В PHP мне нравится использовать mysqli_real_escape_string (), который экранирует специальные символы в строке для использования в операторе SQL.
См. https://www.php.net/manual/en /mysqli.real-escape-string.php
-1
will
19 Авг 2019 в 12:58
Возможно, не по теме, но, возможно, вы пришли сюда в поисках способа дезинфицировать ввод текста из HTML-формы, чтобы, когда пользователь вводит символ апострофа, он не выдавал ошибку при попытке записать текст в SQL таблица в БД. Есть несколько способов сделать это, и вы также можете прочитать о SQL-инъекции. Вот пример использования подготовленных операторов и связанных параметров в PHP:
Grindlay
3 Фев 2021 в 16:37
Я думаю, что если у вас есть точка данных с апострофом, вы можете добавить один апостроф перед апострофом
Например. ‘Это дом Джона’
Здесь MYSQL предполагает два предложения: «Это место Джона»
Вы можете указать «Это дом Джона». Я думаю, так должно работать.
Priyanka Pandhi
6 Окт 2017 в 14:41
Замените строку
Где значение — это ваша строка, которая будет храниться в вашей базе данных.
Ashutosh Jha
19 Сен 2017 в 12:06
Просто напишите вместо то есть дважды
6
SimonSimCity
14 Окт 2016 в 11:51
Вот пример:
Просто используйте двойные кавычки, чтобы заключить одинарные кавычки.
Если вы настаиваете на использовании одинарных кавычек (и необходимости экранировать символ):
6
Overkillica
7 Мар 2012 в 06:20
Я знаю три способа. Первый не самый красивый, а второй — распространенный способ в большинстве языков программирования:
- Используйте другую одинарную кавычку:
- Используйте escape-символ перед одиночной кавычкой :
- Вместо одинарных кавычек используйте двойные кавычки, чтобы заключить строку:
8
Robert Rocha
7 Май 2017 в 18:31
15 ответов
Лучший ответ
Проще говоря:
Итак, внутри строки замените каждую одиночную кавычку двумя из них.
Или же:
Избежать этого =)
138
Rob
27 Окт 2012 в 22:10
‘- это escape-символ. Итак, ваша строка должна быть:
Если вы используете какой-либо интерфейсный код, вам необходимо выполнить замену строки перед отправкой данных в хранимую процедуру.
Например, в C # вы можете сделать
А затем передать значение хранимой процедуре.
11
Peter Mortensen
15 Июл 2019 в 15:28
См. Мой ответ на
Какая бы библиотека вы ни использовали для общения с MySQL, она будет иметь встроенную функцию экранирования, например в PHP вы можете использовать mysqli_real_escape_string или PDO :: quote
9
Paul Dixon
3 Май 2018 в 22:05
Если вы используете подготовленные операторы, драйвер обработает любое экранирование. Например (Java):
7
hd1
23 Май 2013 в 09:56
Используйте этот код:
Это решит вашу проблему, потому что база данных не может обнаружить специальные символы строки.
7
Peter Mortensen
15 Июл 2019 в 19:20
Вы должны экранировать специальные символы, используя символ .
Становится :
5
Chris Seymour
23 Май 2013 в 09:51
Вы можете использовать этот код,
Если mysqli_real_escape_string () не работает.
3
Peter Mortensen
15 Июл 2019 в 19:15
В PHP используйте mysqli_real_escape_string.
Пример из руководства PHP:
3
Kos
1 Сен 2019 в 10:37
Если вы хотите сохранить апостроф в базе данных, используйте следующий код:
можно хранить в базе данных.
3
frianH
12 Окт 2020 в 09:11
1
FelixSFD
22 Ноя 2016 в 11:27
Если вы используете PHP, просто используйте функцию addlashes ().
1
Peter Mortensen
15 Июл 2019 в 19:21
Например, в Perl DBI вы можете использовать:
Elle Fie
22 Май 2013 в 23:40
Используйте addlahes () или mysql_real_escape_string ().
Peter Mortensen
15 Июл 2019 в 19:13
Как я это делаю, используя Delphi:
Строка для «побега»:
Решение:
Результат:
Эта функция заменит все Char (39) на «\», что позволит вам без проблем вставлять или обновлять текстовые поля в MySQL.
Подобные функции есть во всех языках программирования!
Peter Mortensen
15 Июл 2019 в 19:18
Возможно, вам стоит взглянуть на функцию в руководстве по MySQL.
Peter Mortensen
15 Июл 2019 в 19:19
Что мне делать, если строка содержит одинарные или двойные кавычки в базе данных mysql?
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>style=»clear:both;»>
По скриншоты и код напрямую
Вы также можете обратиться кЭта почта
Метод обработки
1. Используйте экранирование
2. Если строка содержит одинарные кавычки, поместите слой двойных кавычек за пределами строки; если строка содержит двойные кавычки, поместите слой одинарных кавычек за пределами строки.
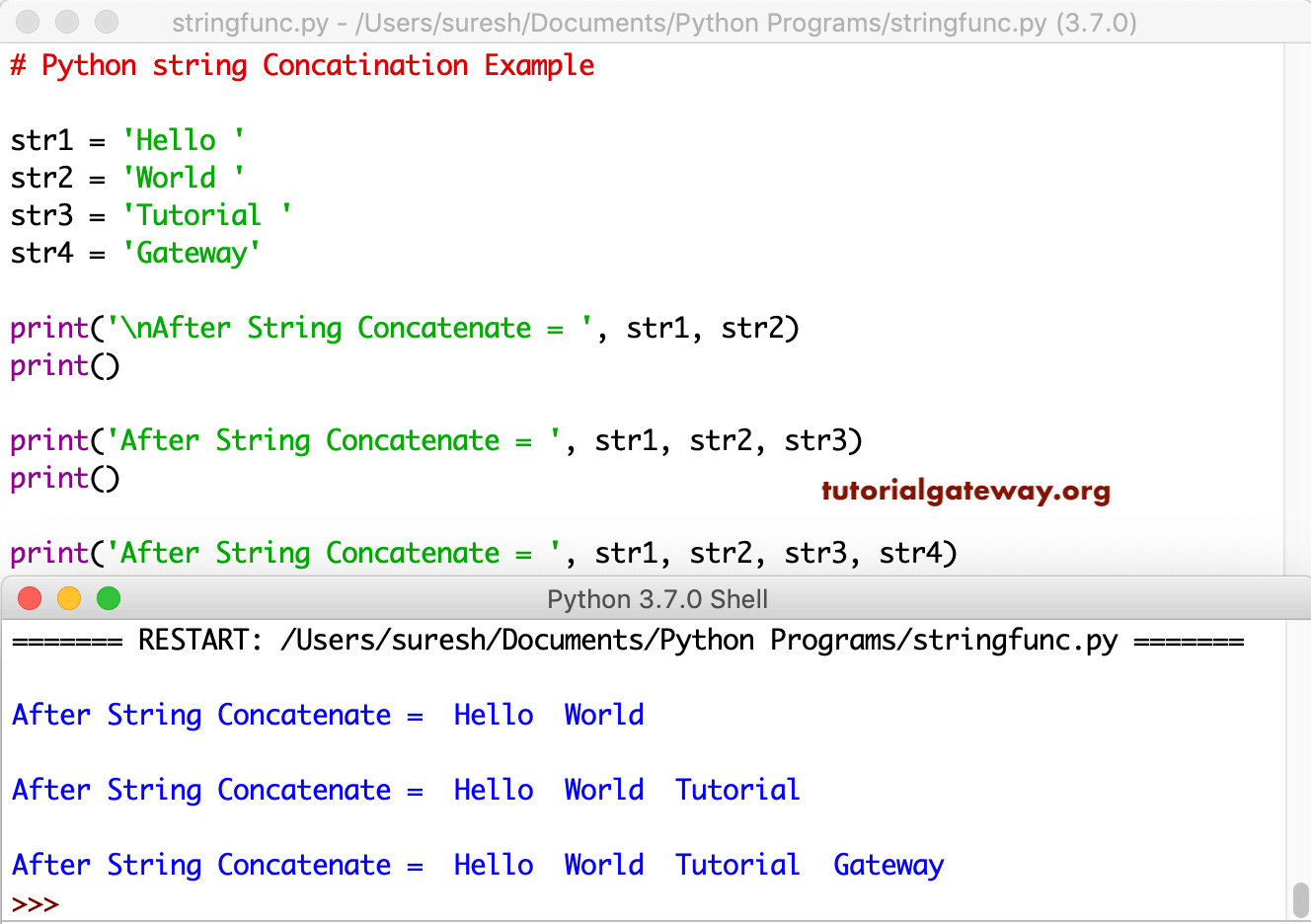
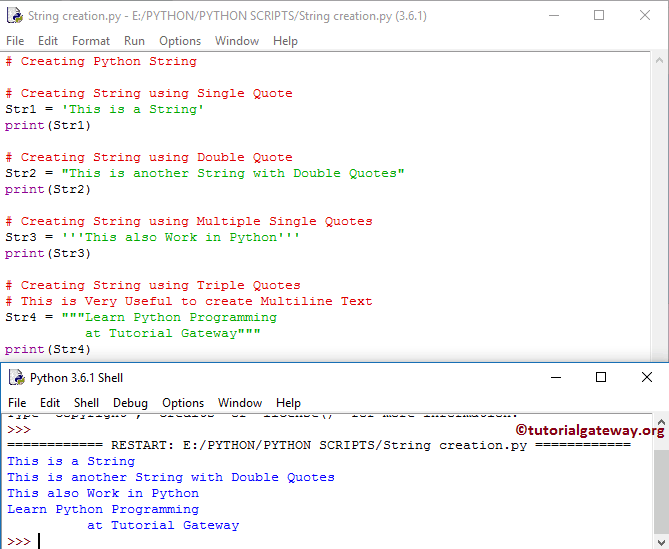



3. Если строка содержит одинарные кавычки, добавьте одинарную кавычку рядом с одинарной кавычкой, а затем оберните слой одинарных кавычек за пределами строки, если строка содержит двойные кавычки, добавьте рядом с ней другие кавычки. Двойные кавычки, а затем слой двойных кавычек за пределами строки.
С помощью следующих двух снимков экрана каждый также должен понять.
Интеллектуальная рекомендация
1. Для реальных сигналов (для понимания): A (ω) является соотношением амплитуды выходного сигнала и амплитуды входного сигнала, называемого частотой амплитуды. Φ (ω) — это разница межд…
Один. вести Многие люди задавали некоторые вопросы о создании проекта Flex + LCDS (FDS) в сообщениях и группах. Из-за операции ее трудно четко объяснить, поэтому я написал простой учебник (я обещал эт…
package com.example.phonehttp; import android.os.Bundle; import android.os.Handler; import android.app.Activity; import android.widget.ScrollView; import android.widget.TextView; public class MainActi…
Он предназначен для реализации подкласса того же родительского класса с родительским классом. Полиморфизм Один и тот же ссылочный тип использует разные экземпляры для выполнения разных операций; Идея …
тема: Объедините два упорядоченных слоя в новый заказанный список и возврат. Новый список состоит из всех узлов двух связанных списков, данных сплавным. Пример: Анализ: два связанных списка состоит в …
Вам также может понравиться
D. Самая ценная строка Пример ввода 2 2 aa aaa 2 b c Образец вывода aaa c На самом деле, будучи задетым этим вопросом, вы должны быть осторожны. После инвертирования строки, если две строки имеют один…
Given a 2D integer matrix M representing the gray scale of an image, you need to design a smoother to make the gray scale of each cell becomes the average gray scale (rounding down) of all the 8 surro…
calc () может быть очень незнакомым для всех, и трудно поверить, что calc () является частью CSS. Поскольку он выглядит как функция, почему он появляется в CSS, поскольку это функция? Этот момент такж…
Основываясь на дереве регрессии, сформированном CART, а также на предварительной и последующей обрезке дерева, код выглядит следующим образом:…
Откат Обновление в режиме онлайн с версии Centos (CentOS Linux версии 7.3.1611 (Core) до CentOS Linux версии 7.5.1804 (Core)) # ошибка соединения yum-ssh после обновления yexpected key exchange group …
Причины ошибки EOL При сканировании строкового литерала
Существуют известные причины ошибки EOL в Python. Как только вы узнаете их все, вы сможете легко отлаживать свой код и исправлять его. Хотя эти причины не обязательно являются единственными известными причинами ошибки. Некоторые другие ошибки также могут привести к возникновению ошибки EOL. Давайте сразу перейдем ко всем причинам –
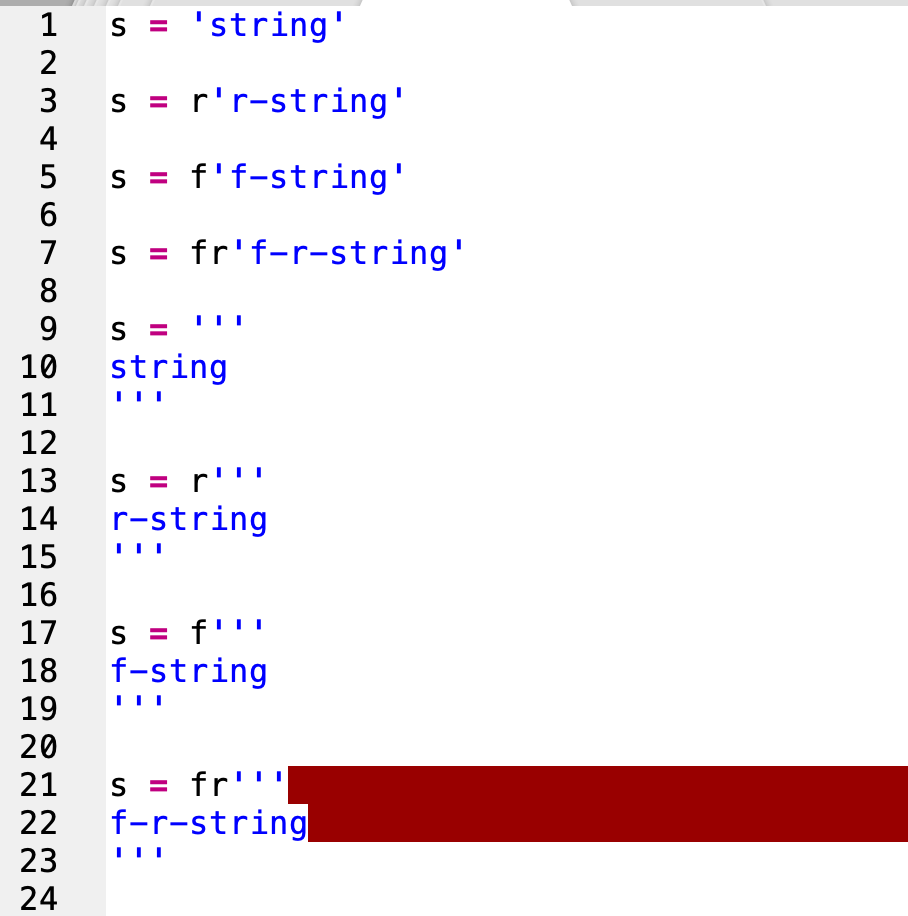
Причина 1: Незамкнутые Одинарные кавычки
Строковые литералы в python могут быть объявлены с помощью одинарных кавычек в вашей программе. Эти литералы должны быть закрыты в пределах двух одинарных кавычек знака (‘ ‘). Если вам не удалось заключить строку между этими двумя кавычками, она выдаст EOL При сканировании строкового литерала с ошибкой. Более того, если вы дадите дополнительную одинарную кавычку в своей строке, она также выдаст ту же ошибку. Следующие примеры помогут вам понять –
Пример 1 –
example1 = 'Single Quotes String"Triple Quotes String""" example1 # will print S
В этом примере в строке 1 отсутствует конечная одинарная кавычка. Эта пропущенная цитата заставляет интерпретатор анализировать следующие строки как неверные. Добавление одной кавычки в конце строки 1 может решить эту проблему.
Пример 2 –
x = 'This is a String print(x)
В этом примере в конце строки 1 отсутствует одинарная кавычка.
Пример 3 –
В этом специальном примере в первой строке есть три одиночные кавычки. Согласно python, строка для переменной x заканчивается в конце одинарной кавычки. Следующая часть будет рассматриваться как часть другого кода, а не как строка. Это приводит к появлению синтаксической ошибки на экране.
Причина 2: Незамкнутые Двойные кавычки
Строковые литералы также могут быть объявлены с помощью двойных кавычек. В большинстве языков программирования двойные кавычки-это способ объявления строки по умолчанию. Таким образом, если вы не заключите строку в двойные кавычки, она вызовет SyntaxError. Более того, если вы использовали нечетное количество кавычек («) в своей строке, она также выдаст эту ошибку из-за пропущенной кавычки. Следующий пример поможет вам понять –
Пример 1 –
«»triple>
В этом примере в конце второй строки отсутствует двойная кавычка. Эта пропущенная цитата заставляет интерпретатор анализировать все следующие коды как часть строки для переменной пример 2. В конце концов, он выдает ошибку EOL, когда достигает конца файла.
Пример 2 –
x = "This is a String print(x)
Аналогично, в конце строки 1 отсутствует двойная кавычка.
Пример 3 –
В этом специальном примере в первой строке есть три двойные кавычки. Согласно python, строка для переменной x заканчивается в конце одинарной кавычки. Следующая часть будет рассматриваться как часть другого кода, а не как строка. Это приводит к появлению синтаксической ошибки на экране.
В Python существует специальный способ объявления строк с использованием трех двойных кавычек («»»). Этот способ чрезвычайно часто используется, когда вам приходится включать двойные и одинарные кавычки в вашу строку. С помощью этого типа объявления вы можете включить в строку любой символ. Итак, если вы не закрыли эту тройную цитату, я брошу ошибку EOL. Следующие примеры помогут вам понять –
Пример 1 –
В строке 3 примера отсутствует цитата из набора тройных кавычек. В результате интерпретатор python будет рассматривать все следующие строки как часть переменной string for example 3. В конце концов, поскольку нет окончательных тройных кавычек, это вызовет ошибку EOL.
«triple>
Пример 2 –
Как и в примере 1, в строке 1 отсутствуют две кавычки.
«this>
Причина 4: Нечетное число обратных косых черт в необработанной строке
Обратные косые черты используются в строке для включения в нее специальных символов. Например, если вы хотите добавить двойные кавычки в строку с двойными кавычками, вы можете использовать\», чтобы добавить ее. Каждый символ после обратной косой черты имеет свое значение для python. Таким образом, если вы не предоставите соответствующий следующий символ после обратной косой черты (\), вы получите EOL При сканировании строкового литерала Ошибки. Следующие примеры помогут вам понять это –
Пример 1 –
Следующая строка недопустима, так как после обратной косой черты нет следующего символа. В настоящее время python обрабатывает строки так же, как и стандартный C. Чтобы избежать этой ошибки, поставьте «r» или «R» перед вашей строкой.
Пример 2 –
Следующий пример содержит нечетное число обратных косых черт без следующих символов. Это приводит к возникновению ошибки EOL, поскольку интерпретация ожидает следующего символа.
Пример 3 –
Последняя обратная косая черта в строке не имеет следующего символа. Это приводит к тому, что компилятор выдает ошибку.
SQL-Ex blog
Одной из моих любимых команд SQL являлась QUOTENAME. При программировании генерации кода обычно возникает необходимость заключать строковое значение в кавычки и экранировать любые символы, совпадающие с теми, которыми вы ограничиваете строку, их удвоением. (А если у вас пара таких символов в строке, вам их потребуется уже четыре.) Например, чтобы взять следующую строку в одинарные кавычки (‘):
Чтобы иметь возможность использовать её в динамическом операторе или объявлении переменной, потребуется удвоить одинарную кавычку в строке:
Или, если вы Rob Volk (@sql_r на Twitter), и хотите создать раздражающую базу данных на вашем лучшем заклятом SQL Server, то, чтобы включить скобки в имя базы типа:
вам придется сделать так:
Удваивается закрывающая скобка, но не открывающая. Для экранирования можно использовать QUOTENAME. Параметрами этой функции являются строка и разделитель. По умолчанию удваивается скобка как у большинства имён SQL Server, хотя вы можете использовать любой символ для удвоения. Так для нашей строки:
Этот код вернет
| objectName | string |
|---|
Mr. O’Malley
‘Mr. O»Malley’
Кажется, работает отлично, поэтому вы чувствуете, что, если вам потребуется нагенерировать некоторый код, вы сможете поступить так:
Выполните этот запрос в Management Studio. Вы увидите на вкладке результата строку, начинающуюся с приведенного выше текста. Проблема состоит в том, что QUOTENAME предназначена для закавычивания значений имен SQL Server, а поскольку в SQL Server имена не могут быть длиннее, чем 128 символов. на входе должно быть не более 128 символов (ниже покажем, что может быть и больше). Итак:
Когда вход превышает 128 символов, возвращается NULL без каких либо предупреждений. Это, мягко говоря, не то, что вы хотели. В моем случае я разработал генератор скрипта расширенных свойств, который принимает значение типа sql_variant и преобразует его к nvarchar(max). Я не тестировал входы, превышающие 128 символов, но коллега любезно предоставил мне строку размером порядка 8000 символов. К счастью, это не был рабочий сервер, где бы безостановочно звонил телефон поддержки.
Итак, я могу предложить использование QUOTENAME в рабочем коде только для квотирования реальных имен операторов SQL, и использовать более неуклюжий метод для других целей:
Этот код демонстирует один и тот же результат для обоих вариантов.
Следует заметить, что это (как и любая простая повторно исполняемая скалярная функция) просится для использования в качестве пользовательской функции. В версиях, предшествующих 2019, всегда однозначно советовали избегать их, т.к. они, мягко говоря, ограничивали производительность. В одних случаях падение производительности было незначительным, в других — существенными провалами. В SQL Server 2019 Microsoft изменила механизм выполнения некоторых скалярных функций, который будет «встраивать» код функции в план запроса, использующего эту функцию. В результате производительность, полученная для перекодируемого оператора и при использовании функции соизмеримы (даже для довольно сложных функций!).
Построим, например, в базе данных WideWorldImporters следующую функцию:
Выполнить функцию можно так:
И вы можете проверить, встраивается ли она, таким образом:
Этот запрос для нашей новой функции возвращает 1.
Встраиваемая или нет, вы не увидите каких либо изменений в этом простом примере — я просто хотел указать на это как на более ценную возможность в будущем. Подробнее о встраиваемых функциях смотрите в публикации Brent Ozar’а.


Наконец, давайте взглянем на немного туповатый трюк, который в целом полезен для определения того, наколько длинной может быть заковыченная строка. Меня интересует, какого максимального размера может быть вывод функции QUOTENAME. Если вы выполните следующий оператор:
вернет []]]]], что на 2 символа больше, чем исходная строка. Если у нас 128 символов ], мы должны получить SELECT 127*2+4 или 258 символов, которые должен вывести следующий оператор.
Мы могли бы это просто прочитать в документации о QUOTENAME, где говорится о результате nvarchar(258)! Следовательно, вот какого размера должна быть переменная/столбец, чтобы ее можно было обработать с помощью функции EscapeString:
Здесь максимальная длина — это не 2 миллиарда как у varchar(max), а максимальная длина, которую может иметь ваш источник данных. Конечно, когда вы используете это значение со всеми экранированными строками, оно будет выглядеть больше, чем результирующее значение, но просто потому, что нам требуется пространство для 258 символов на имя, что не означает, что нам требуется именно 258 символов. Это просто еще одно препятствие, с которым вы столкнетесь, строя пуленепробиваемый генератор кода.
Переменная интерполяция
Шаблоны кавычек для переменных не меняются, хотя, если вы намереваетесь интерполировать переменные непосредственно в строку, в PHP они должны быть заключены в двойные кавычки. Просто убедитесь, что вы правильно экранировали переменные для использования в SQL. (Вместо этого рекомендуется использовать API, поддерживающий подготовленные операторы, в качестве защиты от внедрения SQL).
// То же самое с некоторыми заменами переменных // Здесь имя таблицы переменных $ table заключено в обратные кавычки, а переменные // в списке VALUES заключены в одинарные кавычки $ query = "INSERT INTO `$ table` (`id`,` col1`, `col2`,` date`) VALUES (NULL, '$ val1', '$ val2', "$ дата")';
Символы, требующие использования обратных кавычек в идентификаторах:
Согласно документации MySQL, вам не нужно заключать в кавычки (обратные апострофы) идентификаторы, используя следующий набор символов:
Вы можете использовать символы, выходящие за рамки этого набора, в качестве идентификаторов таблицы или столбца, включая, например, пробелы, но тогда вы должен цитировать (обратный апостроф) их.
Кроме того, хотя числа являются допустимыми символами для идентификаторов, идентификаторы не могут состоять только из чисел. Если они это сделают, они должны быть завернуты в обратные кавычки.
- 45 ‘но одинарные кавычки более широко принимаются другими СУБД«- использование одинарных кавычек для строковых литералов определено (и требуется) стандартом SQL.
- 3 это неправда: «MySQL также ожидает, что буквальные значения DATE и DATETIME будут заключены в одинарные кавычки в виде строк, таких как ‘2001-01-01 00:00:00′»
- 3 @evilReiko MySQL docs, похоже, не совсем четко рассматривает цитирование псевдонимов. Он будет принимать одинарные, двойные или обратные кавычки для псевдонимов, но это может зависеть от различных режимов ANSI SQL. Я не уверен, что спецификация SQL требует для псевдонимов кавычек — Личные предпочтения: для согласованности я цитирую их так же, как идентификаторы столбцов, то есть я либо делаю обратные ссылки, если необходимо, либо оставляю их без кавычек, если нет. Я не использую одинарные или двойные кавычки для псевдонимов.
- 2 @GuneyOzsan Да, очень уязвима. Никогда не используйте переменную для имени таблицы, если она не была проверена на соответствие списку допустимых имен таблиц — создайте массив допустимых имен и проверьте, что переменная совпадает с чем-то в списке, чтобы ее можно было безопасно использовать. В противном случае вы не сможете безопасно избежать использования переменной имени таблицы.
- +1 Майкл теперь все разобрал спасибо. Могу я предложить отредактировать диаграмму, чтобы добавить связанные переменные. Это абсолютно великолепно, и если бы еще одна бедняжка пришла проверять это было бы еще прекраснее. ATB Стив
В MySQL есть два типа кавычек:
- для включения строковых литералов
- для включения идентификаторов, таких как имена таблиц и столбцов
А потом есть что является частным случаем. Его можно использовать для один вышеупомянутых целей за раз в зависимости от сервера MySQL :
- По умолчанию в символ может использоваться для включения строковых литералов, как и
- В режим символ может использоваться для обозначения идентификаторов, как и