
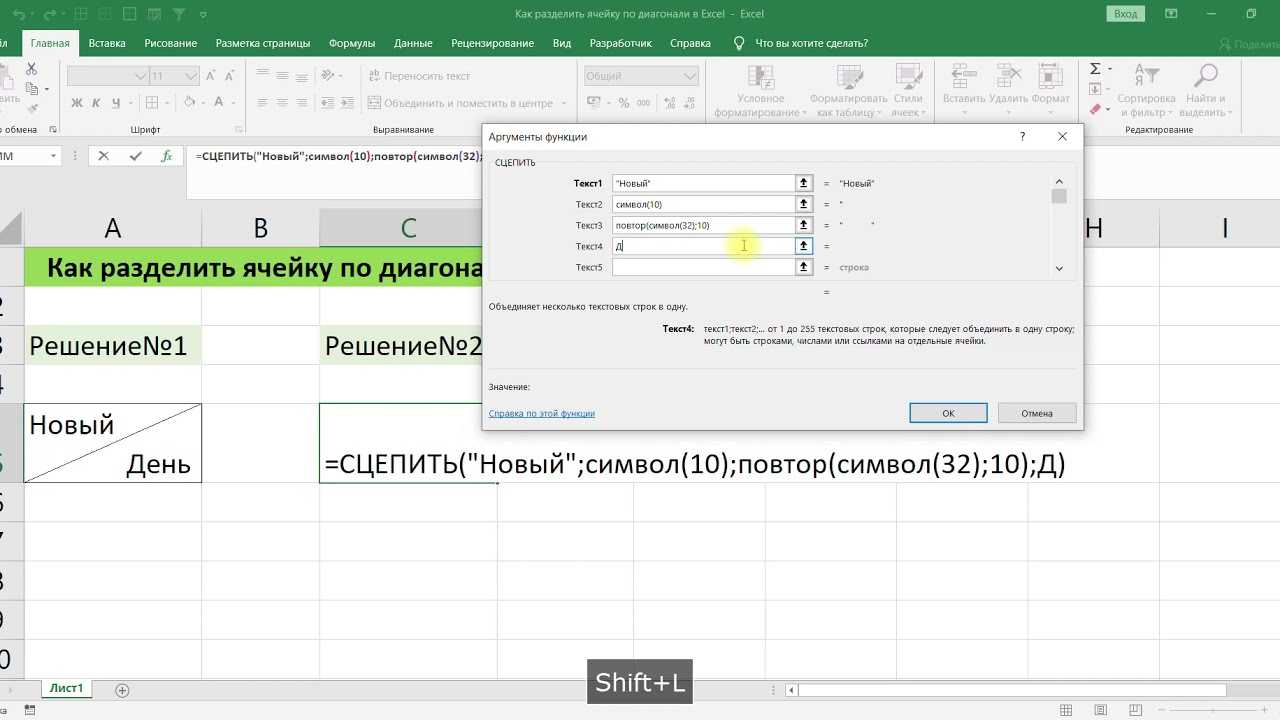
Метод join()
Теперь, когда вы знаете, как разбить строку на подстроки, пора научиться использовать метод join() для формирования строки из подстрок.
Синтаксис метода Python join() следующий:
Здесь – любой итерируемый объект Python, содержащий подстроки. Это может быть, например, список или кортеж. – это разделитель, с помощью которого вы хотите объединить подстроки.
По сути, метод join() объединяет все элементы в , используя в качестве разделителя.
А теперь пора примеров!
Примеры использования метода join() в Python
В предыдущем разделе мы разбивали строку по запятым и получали в итоге список подстрок. Назовем этот список .
Теперь давайте сформируем строку, объединив элементы этого списка при помощи метода join(). Все элементы в – это названия фруктов.
my_list = my_string.split(",")
# после разделения my_string мы получаем my_list:
#
Обратите внимание, что разделитель для присоединения должен быть указан именно в виде строки. В противном случае вы столкнетесь с синтаксическими ошибками
Чтобы объединить элементы в с использованием запятой в качестве разделителя, используйте а не просто . Это показано во фрагменте кода ниже.
", ".join(my_list) # Output: Apples, Oranges, Pears, Bananas, Berries
Здесь элементы объединяются в одну строку с помощью запятых, за которыми следуют пробелы.
Разделитель может быть любым.
Давайте для примера используем в качестве разделителя 3 символа подчеркивания .
"___".join(my_list) # Output: Apples___Oranges___Pears___Bananas___Berries
Элементы в теперь объединены в одну строку и отделены друг от друга тремя подчеркиваниями .
Теперь вы знаете, как сформировать одну строку из нескольких подстрок с помощью метода join().
Как разбить строку в Python
Добавить в избранное
![]()
В этой статье мы поговорим о том, как разбить строку в Python.
Метод .split ()
В Python строки представлены как неизменяемые strобъекты. Класс str приходит с целым рядом строковых методов , которые позволяют манипулировать строку.
Метод .split() возвращает список подстрок , разделенных разделителем. Он имеет следующий синтаксис:
Разделитель может быть символом или последовательностью символов, а не регулярным выражением.
В приведенном ниже примере строка s будет разделена с использованием запятой ,в качестве разделителя.
Результатом будет список строк:
Строковые литералы обычно заключаются в одинарные кавычки, хотя можно использовать и двойные кавычки.
Последовательность символов также может быть использована в качестве разделителя:
Когда maxsplitдано, это ограничит количество расколов. Если не указано или -1, количество разделений не ограничено.
Список результатов будет иметь максимум maxsplit+1 элементов:
Если значение delimне указано или оно есть Null, строка будет разделена с использованием пробела в качестве разделителя. Все последовательные пробелы рассматриваются как один разделитель. Также, если строка содержит конечные и начальные пробелы, результат не будет содержать пустых строк.
Чтобы лучше проиллюстрировать это, давайте рассмотрим следующий пример:
Если разделитель не используется, возвращаемый список не содержит пустых строк. Если в качестве разделителя задано пустое пространство ‘ ‘, начальные, конечные и последовательные пробелы приведут к тому, что результат будет содержать пустые строки.
Заключение
Разделение строк является одной из самых основных операций. Прочитав этот урок, вы должны хорошо понимать, как разбивать строки в Python.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Похожие публикации:
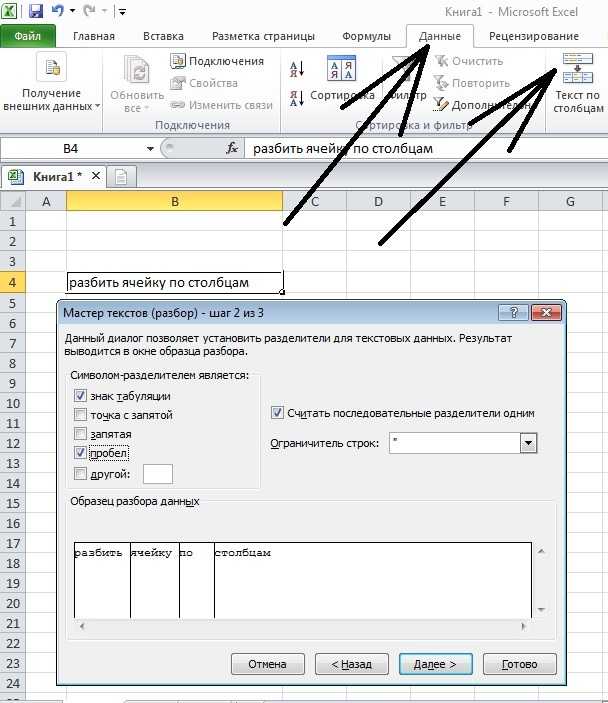
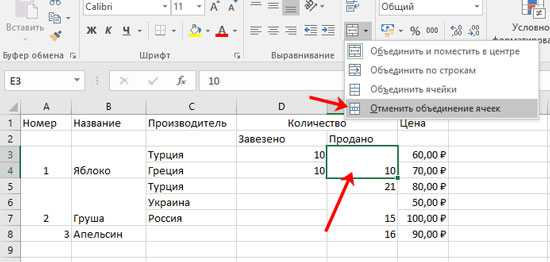
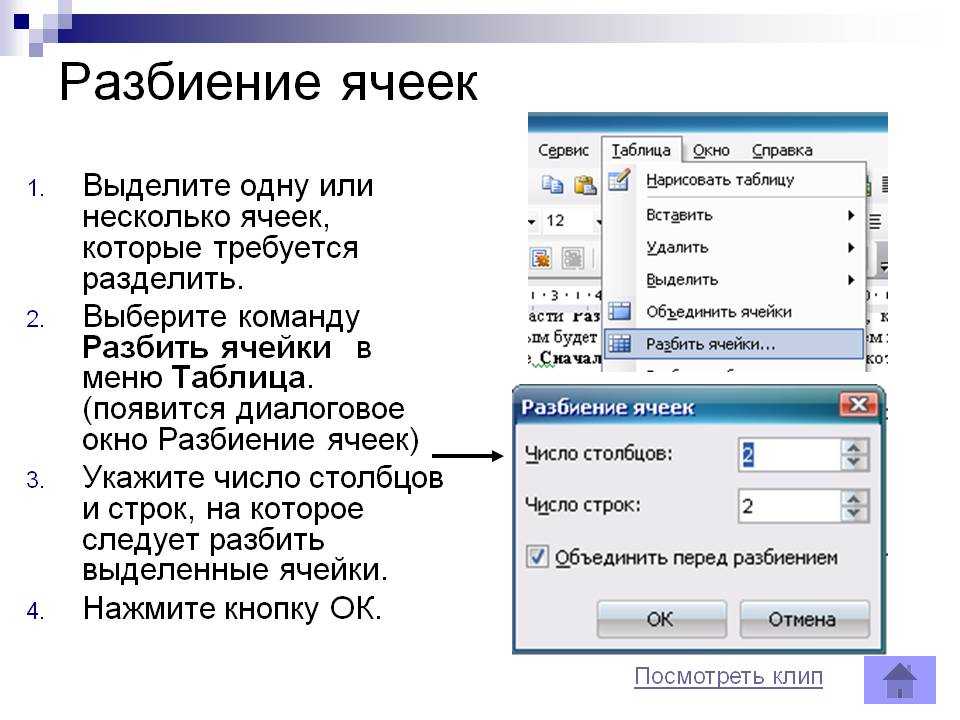
Делим текст вида ФИО по столбцам.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек, который демонстрируется ниже.
В столбце A нашей таблицы записаны Фамилии, имена и отчества сотрудников. Необходимо разделить их на 3 столбца.
Можно сделать это при помощи инструмента «Текст по столбцам». Об этом методе мы достаточно подробно рассказывали, когда рассматривали, как можно разделить ячейку по столбцам.
Кратко напомним:
На ленте «Данные» выбираем «Текст по столбцам» — с разделителями.
Далее в качестве разделителя выбираем пробел.
Обращаем внимание на то, как разделены наши данные в окне образца. В следующем окне определяем формат данных
По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру
В следующем окне определяем формат данных. По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру.
В итоге имеем следующую картину:
При желании можно дать заголовки новым столбцам B,C,D.
А теперь давайте тот же результат получим при помощи формул.
Для многих это удобнее. В том числе и по той причине, что если в таблице появятся новые данные, которые нужно разделить, то нет необходимости повторять всю процедуру с начала, а просто нужно скопировать уже имеющиеся формулы.
Итак, чтобы выделить из нашего ФИО фамилию, будем использовать выражение
В качестве разделителя мы используем пробел. Функция ПОИСК указывает нам, в какой позиции находится первый пробел. А затем именно это количество букв (за минусом 1, чтобы не извлекать сам пробел) мы «отрезаем» слева от нашего ФИО при помощи ЛЕВСИМВ.
Далее будет чуть сложнее.
Нужно извлечь второе слово, то есть имя. Чтобы вырезать кусочек из середины, используем функцию ПСТР.
Как вы, наверное, знаете, функция Excel ПСТР имеет следующий синтаксис:
ПСТР (текст; начальная_позиция; количество_знаков)
Текст извлекается из ячейки A2, а два других аргумента вычисляются с использованием 4 различных функций ПОИСК:
Начальная позиция — это позиция первого пробела плюс 1:
ПОИСК(» «;A2) + 1
Количество знаков для извлечения: разница между положением 2- го и 1- го пробелов, минус 1:
ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) – 1
В итоге имя у нас теперь находится в C.
Осталось отчество. Для него используем выражение:
В этой формуле функция ДЛСТР (LEN) возвращает общую длину строки, из которой вы вычитаете позицию 2- го пробела. Получаем количество символов после 2- го пробела, и функция ПРАВСИМВ их и извлекает.
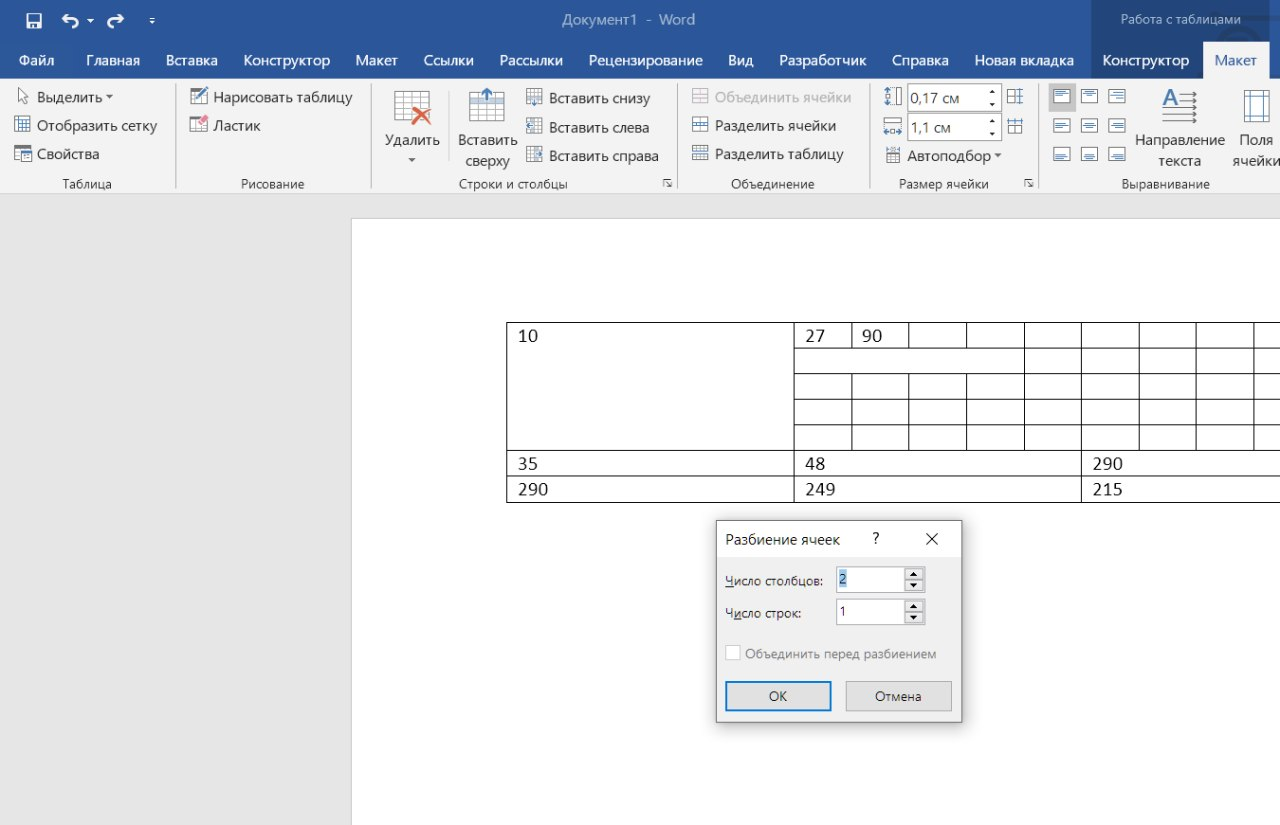

Вот результат нашей работы по разделению фамилии, имени и отчества из одной по отдельным ячейкам.
Как выбрать каждую вторую или n-ю строку в Excel?
Когда мы используем рабочий лист, иногда нам нужно выбрать каждую вторую или n-ю строку листа для форматирования, удаления или копирования. Вы можете выбрать их вручную, но если есть сотни строк, этот метод не лучший выбор. Вот несколько уловок, которые могут вам помочь.
Выберите каждую вторую или n-ю строку с помощью VBA
В этом примере я выберу одну строку с двумя интервалами. С кодом VBA я могу закончить это следующим образом:
1. Выделите диапазон, который вы хотите выделить, каждую вторую или n-ю строку.
2.Click разработчик > Визуальный Бейсик, Новый Microsoft Visual Basic для приложений появится окно, щелкните Вставить > Модуль, и введите в модуль следующий код:
Sub EveryOtherRow()
Dim rng As Range
Dim InputRng As Range
Dim OutRng As Range
Dim xInterval As Integer
xTitleId = "KutoolsforExcel"
Set InputRng = Application.Selection
Set InputRng = Application.InputBox("Range :", xTitleId, InputRng.Address, Type:=8)
xInterval = Application.InputBox("Enter row interval", xTitleId, Type:=1)
For i = 1 To InputRng.Rows.Count Step xInterval + 1
Set rng = InputRng.Cells(i, 1)
If OutRng Is Nothing Then
Set OutRng = rng
Else
Set OutRng = Application.Union(OutRng, rng)
End If
Next
OutRng.EntireRow.Select
End Sub
3. затем нажмите
![]()
4. Нажмите OK, и в этом случае я ввожу 3 в другом всплывающем диалоговом окне в качестве строки интервала. Смотрите скриншот
5. Нажмите OK, и выбрана каждая третья строка. Смотрите скриншот:
![]()
Вы можете изменить интервал по мере необходимости во втором KutoolsforExcel Диалог.
Выберите каждую вторую или n-ю строку с помощью Kutools for Excel
С кодом VBA вы можете выбрать только одну строку с указанными интервалами, если вам нужно выбрать две, три или другие строки с указанными интервалами, Kutools for Excel поможет вам решить эту проблему легко и удобно.
| Kutools for Excel, с более чем 300 удобные функции, облегчающие вашу работу. |
После бесплатная установка Kutools for Excel, сделайте следующее:
1. Нажмите Kutools > Select > Select Interval Rows & Columns…, См. Снимок экрана:
![]()
2. в Select Interval Rows & Columns диалоговое окно, щелкните
RowsColumnsSelect раздел Interval of Rows
![]()
![]()
Ноты: 1. Если вам нужно выбрать все остальные строки в выделенном фрагменте, введите 2 в поле Интервалы ввода и 1 в поле Rows поле ввода.
2. Если вы хотите выделить всю нужную строку, вы можете установить флажок Select entire rows опцию.
![]()
Демо
Затеняйте каждую вторую строку или n-ю строку с помощью Kutools for Excel
Если вы хотите заштриховать диапазоны в каждой второй строке, чтобы данные выглядели более выдающимися, как показано на скриншоте ниже, вы можете применить Kutools for ExcelАвтора Alternate Row/Column Shading функция для быстрого выполнения работы.
|
|
|
|
После бесплатная установка Kutools for Excel, сделайте следующее:
1. Выберите диапазон ячеек, для которых требуется интервал затенения, щелкните Kutools > Format > Alternate Row/Column Shading.
![]()
2. в Alternate Row/Column Shading диалог, выполните следующие действия:
1) Выберите строки или столбцы, которые хотите заштриховать;
2) Выберите Conditional formatting or стандартное форматирование как вам нужно;
3) Укажите интервал штриховки;
4) Выберите цвет штриховки.
![]()
3. Нажмите Ok. Теперь диапазон закрашен в каждой n-й строке.
Если вы хотите убрать затенение, отметьте Удалить существующее затенение альтернативной строки вариант в Альтернативное затенение строки / столбца Диалог.
Демо
Создание и инициализация строки
Так как строка – это массив символов, то объявление и инициализация строки аналогичны подобным операциям с одномерными массивами.
Следующий код иллюстрирует различные способы инициализации строк.
Листинг 1.
char str;
char str1 = {'Y','o','n','g','C','o','d','e','r','\0'};
char str2 = "Hello!";
char str3[] = "Hello!";
Рис.1 Объявление и инициализация строк
В первой строке мы просто объявляем массив из десяти символов. Это даже не совсем строка, т.к. в ней отсутствует нуль-символ \0, пока это просто набор символов.
Вторая строка. Простейший способ инициализации в лоб. Объявляем каждый символ по отдельности. Тут главное не забыть добавить нуль-символ \0.
Третья строка – аналог второй строки
Обратите внимание на картинку. Т.к
символов в строке справа меньше, чем элементов в массиве, остальные элементы заполнятся \0.
Четвёртая строка. Как видите, тут не задан размер. Программа его вычислит автоматически и создаст массив символов нужный длины. При этом последним будет вставлен нуль-символ \0.
Рассоединяем текст с помощью формул
Для этого способа нам понадобятся возможности сочетаний функций ПОИСК и ПСТР. При помощи функции ПОИСК мы будем искать все пробелы, которые есть между словами (например, между фамилией, именем и отчеством). Потом функцией ПСТР выделяем необходимое количество символов для дальнейшего разделения.
И если с первыми двумя словами понятно, что и как разделять, то разделителя для последнего слова нет, а это значит что нужно указать в качестве аргумента условно большое количество символов, как аргумент «число_знаков» для функции ПСТР, например, 100, 200 или больше.
А теперь поэтапно рассмотрим формирование формулы для разделения текста в ячейке:
- Во-первых, нам необходимо найти два пробела, которые разделяют наши слова, для поиска первого пробела нужна формула: =ПОИСК(» «;B2;1), а для второго подойдет: =ПОИСК(» «;B2;C2+1);
- Во-вторых, определяем, сколько символов нужно выделить в строке. Поскольку позиции разделителя мы уже определили, то символов для разделения у нас будет на один меньше. Значит, будем использовать функцию ПСТР для изъятия слов, с ячейки используя как аргумент «количество_знаков» результат работы предыдущей формулы. Для определения первого слова (Фамилии) нужна формула: =ПСТР(B2;1;ПОИСК(» «;B2;1)), для определения второго значения (Имя): =ПСТР(B2;ПОИСК(» «;B2;1)+1;ПОИСК(» «;B2;ПОИСК(» «;B2;1)+1) -ПОИСК(» «;B2;1)), а теперь определим последнее значение (Отчество): =ПСТР(B2;ПОИСК(» «;B2;ПОИСК(» «;B2;1)+1)+1;100).
![]() В результате мы разделили ФИО на три слова, что позволит с ними эффективно работать.
В результате мы разделили ФИО на три слова, что позволит с ними эффективно работать.
Если же значение в ячейке будете делить на две части, то ищете только один пробел (или иной разделитель), а вот чтобы разделить более 4 слов, в формулу добавьте поиск необходимых разделителей.
Регулярные выражения
Если строка соответствует фиксированному шаблону, используйте регулярное выражение для извлечения и обработки ее элементов. Например, если строки имеют форму «номер операнд номер», тогда для извлечения и обработки элементов строки можно использовать регулярное выражение. Пример:
Шаблон регулярного выражения определяется следующим образом:
| Шаблон | Описание |
|---|---|
| Совпадение с одной или несколькими десятичными цифрами. Это первая группа записи. | |
| Совпадение с одним или несколькими пробелами. | |
| Совпадение со знаком арифметического оператора (+, -, *, или /). Это вторая группа записи. | |
| Совпадение с одним или несколькими пробелами. | |
| Совпадение с одной или несколькими десятичными цифрами. Это третья группа записи. |
Вы также можете использовать регулярное выражение для извлечения подстрок из строки на основе шаблона, а не фиксированного набора символов. Это распространенный сценарий, если происходит одно из следующих условий:
-
Один или несколько символов-разделителей не всегда служат разделителями в экземпляре String.
-
Последовательность и количество символов-разделителей являются изменяемыми или неизвестными.
Например, метод Split нельзя использовать для разделения следующей строки, поскольку число символов (новая строка) является изменяемым и они не всегда являются разделителями.
Регулярное выражение может легко разделить эту строку, как показано ниже.
Шаблон регулярного выражения определяется следующим образом:
| Шаблон | Описание |
|---|---|
| Совпадение с открывающей скобой. | |
| Совпадение с любым символом, который не является открывающей или закрывающей скобкой, один или несколько раз. Это первая группа записи. | |
| Совпадение с закрывающей скобкой. |
Метод Regex.Split практически идентичен методу String.Split, за исключением того, что он разделяет строку на основе шаблона регулярного выражения, а не фиксированной кодировки. Например, в следующем примере метод Regex.Split используется для разделения строки, которая содержит подстроки, разделенные с помощью различных сочетаний дефисов и других символов.
Шаблон регулярного выражения определяется следующим образом:
| Шаблон | Описание |
|---|---|
| Совпадение с пробелом, за которым следует дефис. | |
| Совпадение с нулем или одним символом пробела. | |
| Совпадение с нулем или единичное появление символа + или *. | |
| Совпадение с нулем или одним символом пробела. | |
| Совпадение с дефисом, за которым следует пробел. |
Объединение строк Arduino
Объединить две строки в одну можно различными способами. Эта операция также называется конкатенацией. В ее результате получается новый объект String, состоящий из двух соединенных строк. Добавить к строке можно различные символы:
- String3 = string1 + 111; // позволяет прибавить к строке числовую константу. Число должно быть целым.
- String3 = string1 + 111111111; // добавляет к строке длинное целое число
- String3 = string1 + ‘А’; // добавляет символ к строке
- String3 = string1 + “aaa”;// добавляет строковую постоянную.
- String3 = string1 + string2; // объединяет две строки вместе.
Важно осторожно объединять две строки из разных типов данных, так как это может привести к ошибке или неправильному результату
Как разделить строку в Си
19 февраля, 2010 by Сергей Тамкович
Категории:ПрограммированиеРазное
Разделение строки на элементы — стандартная задача при обработке текста. Многие высокоуровневые языки предоставляют удобные операторы для решения этой задачи. Например язык Perl позволяет разбить строку используя в качестве разделителя другую строку или регулярное выражение с помощью функции split. Результат разбиения возвращается в виде массива:
@elements = split(/\s/, "very simple example"); |
В PHP аналогичную роль выполняют функции explode (для деления по текстовому разделителю) и preg_split для деления по регулярному выражению:
$elements1 = explode(" ", "very simple example");
$elements2 = preg_split("/+/", "very simple example");
|
В Си разделение строки несколько сложнее. Многие программисты, в цикле, ищут разделители с помощью таких функций как index или strstr, а затем меняют его на нулевой байт. Данный подход — громоздкий и неудобный. Гораздо проще воспользоваться функцией strtok. Функция strtok позволяет разбить текстовую строку на токены, используя указанные разделители. Пример использования strtok:
/* strtok usage example */
#include <stdio.h>
#include <string.h>
void main () {
char str = "Very simple example,test";
char *token, *last;
printf ("Splitting string \"%s\" into tokens:\n", str);
token = strtok_r(str, " ,", &last);
while (token != NULL) {
printf ("%s\n", token);
token = strtok_r(NULL, " ,.-", &last);
}
}
|
Почему strtok_r, а не strtok и что за третий параметр &last? Функция strtok_r является потоко-безопасной (thread-safe) аналогом функции strtok, третий параметр (**lasts) используется для сохранения текущего положения в оригинальной строке. Поскольку сегодня многопоточные приложения стали нормой, рекомендую использовать именно strtok_r().
char * strtok_r(char *newstring, const char *delimiters, char **save_ptr) |
Функция strtok_r работает следующем образом: В случае если переданный указатель newstring отличен от NULL, считается что передана строка (последовательность ненулевых байт завершающаяся нулевым). При первом вызове функции strtok_r, значение сохранённое в save_ptr — игнорируется. Функция strtok_r, находит в строке newstring первый из разделителей, заменяет его на нулевой байт (‘\0’), сохраняет позицию, следующую за нулевым байтом в save_ptr, и возвращает указатель на найденный токен (для первого вызова функции, указатель на найденный токен будет совпадать с указателем на начало строки). Последующие вызовы выглядят следующим образом:
token = strtok_r(NULL, " ,.-", &last); |
В случае, если указатель newstring равен NULL, обработка строки начинается с указателя сохранённого в save_ptr, в остальном, алгоритм идентичен первому вызову функции.
Finding Tokens in a String
« И ещё про Ванкувер |
ГЛОНАСС »
Категории:ПрограммированиеРазное
Как разбить строку на отдельные символы?
Как её разбить на отдельные символы? Понимаю, что data.split() , но только не понятно, что в split() писать. Заранее спасибо.
![]()
10 ответов 10
data уже является последовательностью ( data работает). Ничего вызывать не надо.
К примеру, чтобы напечатать каждый символ на отдельной строке:
Что можно кратко записать: print(‘\n’.join(text)) . Если нужен именно Питон список, то просто chars = list(text) .
Если вы работаете с текстом, то используйте Unicode. Юникодные строки в Питоне являются неизменямыми последовательностями символов (Unicode code points).
Видимые пользователем буквы (grapheme clusters) могут состоять из нескольких символов, к примеру, ё буква может быть представлена как последовательность двух символов: U+435 U+308 в Unicode— u’\u0435\u0308′ в Питоне:
Каждый символ может быть представлен в различных кодировках одним или несколькими байтами, к примеру, букву я (U+044F) можно закодировать в два байта: 11010001 10001111 в utf-8 кодировке:
Байты/байтовая строка ( bytes тип) это неизменяемая последовательность байт в Питоне.
str тип является bytes в Питоне 2. str является Unicode в Питоне 3.
Кроме того существует понятие code unit (8 бит в utf-8, 16 бит в utf-16). Строки в Javascript можно часто рассматривать как последовательности utf-16 code unit (может иметь значение при переносе функциональности в Питон), к примеру, смайлик 😂 (U+1F602) символ представлен как два code unit: D83D DE02 в utf-16(BE) кодировке:
То есть, если у вас текст, представленный как str в Питоне 3 (Юникод), то вы можете его рассматривать как различные последовательности в зависимости от задачи:
Примитивные строковые типы и String Objects
Для начала мы проясним различие между двумя типами строк. JavaScript различает примитивную строку (неизменяемый тип) и объект String.
Чтобы понять различия между ними, инициализируем примитивную строку и объект-строку.
// Инициализируемпримитивнуюстроку
const stringPrimitive = "A new string.";
// ИнициализируемString Objects
const stringObject = newString("A new string.");
Можно использовать оператор typeof, чтобы определить тип значения. В первом примере мы присвоили переменной строковое значение.
typeof stringPrimitive; Вывод string
Во втором примере мы использовали конструктор new String(), чтобы создать объект-строку и присвоить его переменной.
typeof stringObject; Вывод object
В большинстве случаев вы будете создавать примитивные строки. JavaScript может использовать свойства и методы объекта String без явного приведения примитивной строки к object.
Методы и свойства String Objects доступны для всех строк. Но JavaScript осуществляет конвертацию строки в объект и обратно каждый раз, когда вызывается метод или свойство.
Разделение строк, подстроки (c# string split)
Часто приходится разделять текст (split c#) на фрагменты. Применим метод, который определяет вхождение подстроки по индексу. Предположим, необходимо разделить два предложения, разделенные точкой. В этом случае код будет выглядеть так:
string myString = "Highload.Today"; // исходный текст
int index = myString.IndexOf(".") + 1; // определение индекса подстроки по точке
string fragment_stroki= myString.Substring(index); // создание подстроки
Console.WriteLine(fragment_stroki); // печать подстроки по индексу
Результат выполнения кода C#
Разбиение строк: примеры (split c# пример)
Давайте посмотрим на примеры альтернативного разбиения строк в C#. Метод также может применяться для разделения строк. Он либо просто возвращает текст с обозначенного символа, либо делает это на указанную длину:
using System;
using System.Globalization;
public class cut
{
public static void Main()
{
string fragment1 = "Highload.today!"; // исходный текст
string fragment2 = fragment1.Substring(9,5); // создание строки по индексу и длине
Console.WriteLine(fragment2); // вывод на экран today
}
}
Результат выполнения кода C#
Также можно было использовать:
string fragment1 = "Highload.today!"; // исходный текст string fragment2 = fragment1.Substring(9);
В этом случае второй элемент будет (с восклицательным знаком включительно).
Методом строковые данные преобразуются в массив подстрок:
string text = "И теперь уходим понемногу"; //
string[] slova= text.Split(' '); // Разделение на коллекцию слов
Console.WriteLine(slova); // Печать элемента с индексом 0
Console.WriteLine(slova); // Печать элемента с индексом 3
Результат выполнения кода C#
Распределение текста с разделителями на 3 столбца.
Предположим, у вас есть список одежды вида Наименование-Цвет-Размер, и вы хотите разделить его на 3 отдельных части. Здесь разделитель слов – дефис. С ним и будем работать.
- Чтобы извлечь Наименование товара (все символы до 1-го дефиса), вставьте следующее выражение в B2, а затем скопируйте его вниз по столбцу:
Здесь функция мы сначала определяем позицию первого дефиса («-«) в строке, а ЛЕВСИМВ извлекает все нужные символы начиная с этой позиции. Вы вычитаете 1 из позиции дефиса, потому что вы не хотите извлекать сам дефис.
- Чтобы извлечь цвет (это все буквы между 1-м и 2-м дефисами), запишите в C2, а затем скопируйте ниже:
Логику работы ПСТР мы рассмотрели чуть выше.
- Чтобы извлечь размер (все символы после 3-го дефиса), введите следующее выражение в D2:
Аналогичным образом вы можете в Excel разделить содержимое ячейки в разные ячейки любым другим разделителем. Все, что вам нужно сделать, это заменить «-» на требуемый символ, например пробел (« »), косую черту («/»), двоеточие («:»), точку с запятой («;») и т. д.
Примечание. В приведенных выше формулах +1 и -1 соответствуют количеству знаков в разделителе. В нашем примере это дефис (то есть, 1 знак). Если ваш разделитель состоит из двух знаков, например, запятой и пробела, тогда укажите только запятую («,») в ваших выражениях и используйте +2 и -2 вместо +1 и -1.
Описание
Метод возвращает новый массив.
Если разделитель найден, он удаляется из строки, а подстроки возвращаются в массиве. Если разделитель опущен, массив будет содержать только один элемент, состоящий из всей строки. Если разделитель является пустой строкой, строка будет преобразована в массив символов.
Если разделитель является регулярным выражением, содержащим подгруппы, то каждый раз при сопоставлении с разделителем, результаты (включая те, что не определены) захвата подгруппы будут помещаться внутрь выходного массива. Однако, не все браузеры поддерживают эту возможность.
null
Доступ к символам
Продемонстрируем, как получить доступ к символам и индексам строки How are you?
"How are you?";
Используя квадратные скобки, можно получить доступ к любому символу строки.
"How are you?"; Вывод r
Мы также можем использовать метод charAt(), чтобы вернуть символ, передавая индекс в качестве параметра.
"Howareyou?".charAt(5); Вывод r
Также можно использовать indexOf(), чтобы вернуть индекс первого вхождения символа в строке.
"How are you?".indexOf("o");
Вывод
1
Несмотря на то, что символ «o» появляется в строке How are you? дважды, indexOf() вернёт позицию первого вхождения.
lastIndexOf() используется, чтобы найти последнее вхождение.
"How are you?".lastIndexOf("o");
Вывод
9
Оба метода также можно использовать для поиска нескольких символов в строке. Они вернут индекс первого символа.
"How are you?".indexOf("are");
Вывод
4
А вот метод slice() вернёт символы между двумя индексами.
"How are you?".slice(8, 11); Вывод you
Обратите внимание на то, что 11– это ?, но? не входит в результирующую строку. slice() вернёт всё, что между указанными значениями индекса
Если второй параметр опускается, slice() вернёт всё, начиная от первого параметра до конца строки.
"How are you?".slice(8); Вывод you?
Методы charAt() и slice() помогут получить строковые значения на основании индекса. А indexOf() и lastIndexOf() делают противоположное, возвращая индексы на основании переданной им строки.
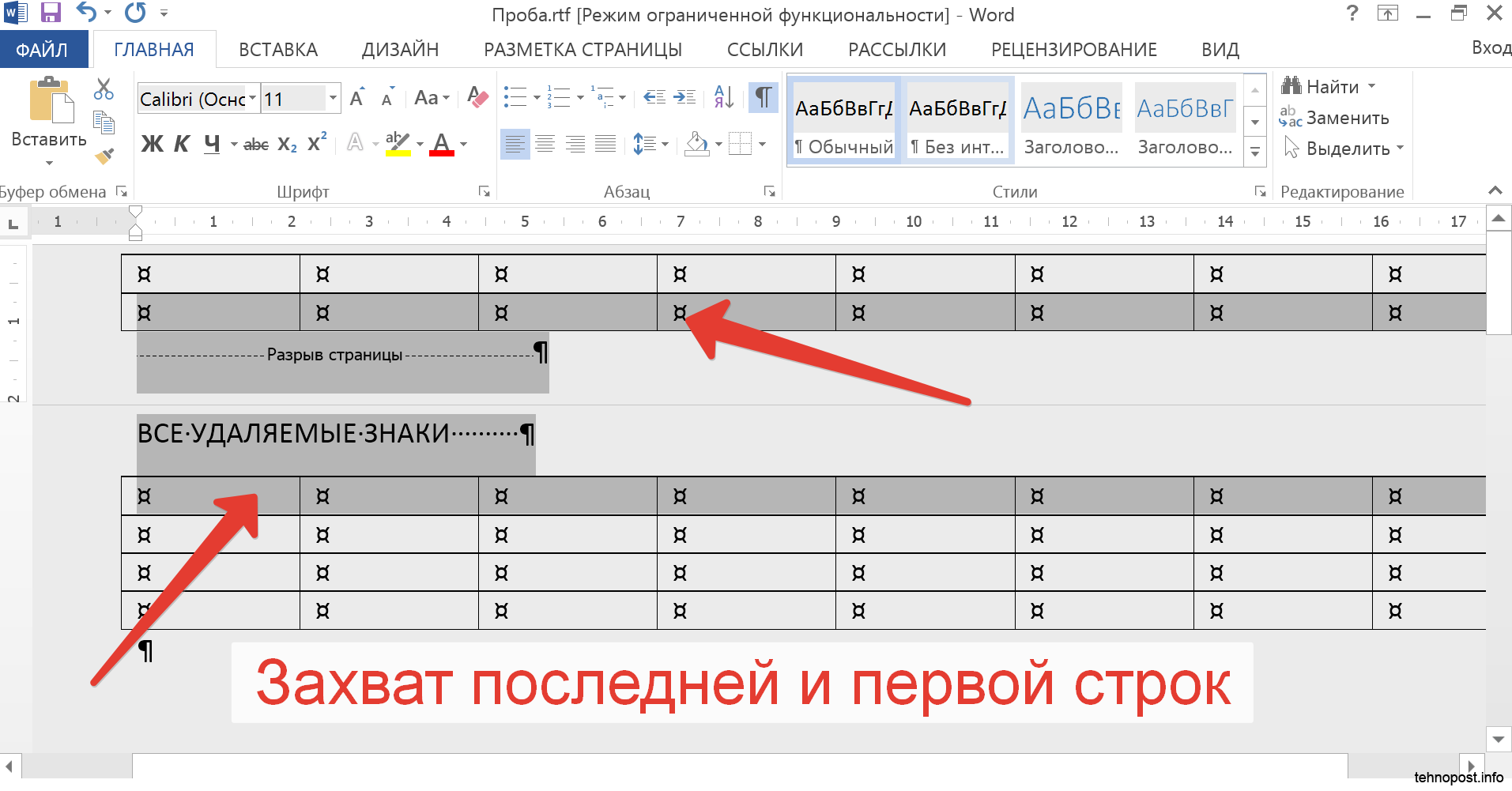
Динамическое выделение переменных
Как статическое, так и автоматическое распределение памяти имеют два общих свойства:
Размер переменной/массива должен быть известен во время компиляции.
Выделение и освобождение памяти происходит автоматически (когда переменная создается/уничтожается).
В большинстве случаев с этим всё ОК. Однако, когда дело доходит до работы с пользовательским вводом, то эти ограничения могут привести к проблемам.
Например, при использовании строки для хранения имени пользователя, мы не знаем наперед насколько длинным оно будет, пока пользователь его не введет. Или нам нужно создать игру с непостоянным количеством монстров (во время игры одни монстры умирают, другие появляются, пытаясь, таким образом, убить игрока).
Если нам нужно объявить размер всех переменных во время компиляции, то самое лучшее, что мы можем сделать — это попытаться угадать их максимальный размер, надеясь, что этого будет достаточно:
char name; // будем надеяться, что пользователь введет имя длиной менее 30 символов!
Monster monster; // 30 монстров максимум
Polygon rendering; // этому 3D-рендерингу лучше состоять из менее чем 40000 полигонов!
|
1 |
charname30;// будем надеяться, что пользователь введет имя длиной менее 30 символов! Monster monster30;// 30 монстров максимум Polygon rendering40000;// этому 3D-рендерингу лучше состоять из менее чем 40000 полигонов! |
Это плохое решение, по крайней мере, по трем причинам:
Во-первых, теряется память, если переменные фактически не используются или используются, но не все. Например, если мы выделим 30 символов для каждого имени, но имена в среднем будут занимать по 15 символов, то потребление памяти получится в два раза больше, чем нам нужно на самом деле. Или рассмотрим массив : если он использует только 20 000 полигонов, то память для других 20 000 полигонов фактически тратится впустую (т.е. не используется)!
Во-вторых, память для большинства обычных переменных (включая фиксированные массивы) выделяется из специального резервуара памяти — стека. Объем памяти стека в программе, как правило, невелик: в Visual Studio он по умолчанию равен 1МБ. Если вы превысите это значение, то произойдет переполнение стека, и операционная система автоматически завершит выполнение вашей программы.
В Visual Studio это можно проверить, запустив следующий фрагмент кода:
int main()
{
int array; // выделяем 1 миллиард целочисленных значений
}
|
1 |
intmain() { intarray1000000000;// выделяем 1 миллиард целочисленных значений } |
Лимит в 1МБ памяти может быть проблематичным для многих программ, особенно где используется графика.
В-третьих, и самое главное, это может привести к искусственным ограничениям и/или переполнению массива. Что произойдет, если пользователь попытается прочесть 500 записей с диска, но мы выделили память максимум для 400? Либо мы выведем пользователю ошибку, что максимальное количество записей — 400, либо (в худшем случае) выполнится переполнение массива и затем что-то очень нехорошее.
К счастью, эти проблемы легко устраняются с помощью динамического выделения памяти. Динамическое выделение памяти — это способ запроса памяти из операционной системы запущенными программами по мере необходимости. Эта память не выделяется из ограниченной памяти стека программы, а выделяется из гораздо большего хранилища, управляемого операционной системой — кучи. На современных компьютерах размер кучи может составлять гигабайты памяти.
Для динамического выделения памяти одной переменной используется оператор new:
new int; // динамически выделяем целочисленную переменную и сразу же отбрасываем результат (так как нигде его не сохраняем)
| 1 | newint;// динамически выделяем целочисленную переменную и сразу же отбрасываем результат (так как нигде его не сохраняем) |
В примере, приведенном выше, мы запрашиваем выделение памяти для целочисленной переменной из операционной системы. Оператор new возвращает указатель, содержащий адрес выделенной памяти.
Для доступа к выделенной памяти создается указатель:
int *ptr = new int; // динамически выделяем целочисленную переменную и присваиваем её адрес ptr, чтобы затем иметь доступ к ней
| 1 | int*ptr=newint;// динамически выделяем целочисленную переменную и присваиваем её адрес ptr, чтобы затем иметь доступ к ней |
Затем мы можем разыменовать указатель для получения значения:
*ptr = 8; // присваиваем значение 8 только что выделенной памяти
| 1 | *ptr=8;// присваиваем значение 8 только что выделенной памяти |
Вот один из случаев, когда указатели полезны. Без указателя с адресом на только что выделенную память у нас не было бы способа получить доступ к ней.
Разделение строки при помощи последовательно идущих разделителей
Если вы для разделения строки используете метод и не указываете разделитель, то разделителем считается пробел. При этом последовательно идущие пробелы трактуются как один разделитель.
Но если вы указываете определенный разделитель, ситуация меняется. При работе метода будет считаться, что последовательно идущие разделители разделяют пустые строки. Например, .
Если вам нужно, чтобы последовательно
идущие разделители все-таки трактовались
как один разделитель, нужно воспользоваться
регулярными выражениями. Разницу можно
видеть в примере:
import re
print('Hello1111World'.split('1'))
print(re.split('1+', 'Hello1111World' ))
Результат:
Когда использовать строковый объект или массив строковых символов
Объект String намного проще в использовании, чем массив строковых символов. Объект имеет встроенные функции, которые могут выполнять ряд операций со строками, которые полностью задокументированы в справочном разделе на веб-сайте Arduino.
Основным недостатком использования объекта String является то, что он использует много памяти и может быстро использовать оперативную память Arduino, что может привести к зависанию, сбою или неожиданному поведению Arduino. Это особенно верно для небольших плат, таких как Arduino Uno.
Если скетч на Arduino небольшой и ограничивает использование объектов, то проблем возникнуть не должно.
Строки символьных массивов сложнее использовать, и вам может потребоваться написать свои собственные функции для работы с этими типами строк. Преимущество состоит в том, что у вас есть контроль над размером создаваемых массивов строк, поэтому вы можете сохранять массивы небольшими для экономии памяти.
Вам нужно убедиться, что вы не пишете через конец границ массива строковыми массивами. У объекта String нет этой проблемы, и он позаботится о границах строки за вас при условии, что у него достаточно памяти. Объект String может попытаться выполнить запись в несуществующую память, когда ему не хватает памяти, но никогда не будет записывать поверх конца строки, с которой он работает.





