
insertAdjacentHTML/Text/Element
С этим может помочь другой, довольно универсальный метод: .
Первый параметр – это специальное слово, указывающее, куда по отношению к производить вставку. Значение должно быть одним из следующих:
- – вставить непосредственно перед ,
- – вставить в начало ,
- – вставить в конец ,
- – вставить непосредственно после .
Второй параметр – это HTML-строка, которая будет вставлена именно «как HTML».
Например:
…Приведёт к:
Так мы можем добавлять произвольный HTML на страницу.
Варианты вставки:
Мы можем легко заметить сходство между этой и предыдущей картинкой. Точки вставки фактически одинаковые, но этот метод вставляет HTML.
У метода есть два брата:
- – такой же синтаксис, но строка вставляется «как текст», вместо HTML,
- – такой же синтаксис, но вставляет элемент .
Они существуют, в основном, чтобы унифицировать синтаксис. На практике часто используется только . Потому что для элементов и текста у нас есть методы – их быстрее написать, и они могут вставлять как узлы, так и текст.
Так что, вот альтернативный вариант показа сообщения:
Внешний вид данных отчета
Выражения позволяют изменять внешний вид данных, отображаемых в отчете. Например, можно отобразить значения двух полей в одном текстовом поле, вывести сведения об отчете или изменить порядок разбиения на страницы.
Верхние и нижние колонтитулы страницы
При конструировании отчета может понадобиться вывести в области нижнего колонтитула имя отчета и номер страницы. Для этого воспользуйтесь следующими выражениями.
-
Следующее выражение выдает имя отчета и время его запуска. Его можно указать в текстовом поле в нижнем колонтитуле или в теле отчета. Время форматируется с помощью строки форматирования .NET Framework для короткой даты:
-
Следующее выражение, если его поместить в текстовое поле в нижнем колонтитуле отчета, выводит номер страницы и общее число страниц, содержащихся в отчете:
В следующих примерах показано, как вывести в верхнем колонтитуле страницы первое и последнее значение на странице, получив результат, похожий на список каталогов. Подразумевается, что в области данных существует текстовое поле .
-
Следующее выражение, помещенное в текстовое поле в левой части верхнего колонтитула, выводит первое значение текстового поля на этой странице.
-
Следующее выражение, помещенное в текстовое поле в правой части верхнего колонтитула, выводит последнее значение текстового поля на этой странице.
В следующем примере показано, как отобразить общее количество страниц. Подразумевается, что в области данных существует текстовое поле .
Следующее выражение, помещенное в верхний или нижний колонтитул, выводит сумму значений в текстовом поле Cost для данной страницы.
=Sum(ReportItems(«Cost»).Value)
Примечание
При ссылке из колонтитула в выражении может быть указан только один элемент отчета. Кроме того, в выражениях верхнего и нижнего колонтитулов можно ссылаться на имя текстового поля, но не использовать выражение фактических данных в текстовом поле.
Разрывы страниц
В некоторых отчетах может понадобиться возможность вставлять разрывы страниц после вывода указанного количества строк вместо или в дополнение к разрывам, вставляемым по группам или элементам отчета. Для этого создайте группу, содержащую необходимые группы или записи сведений, добавьте к группе разрыв страницы, а затем добавьте выражение группы для группирования по указанному числу строк.
Следующее выражение, будучи указанным в качестве выражения группы, назначает номер каждому набору из 25 строк. Если для этой группы определен разрыв страницы, данное выражение будет выводить его через каждые 25 строк.
=Ceiling(RowNumber(Nothing)/25)
Чтобы позволить пользователю устанавливать значение числа строк на странице, создайте параметр с именем RowsPerPage и положите в основу выражения группы этот параметр, как показано в следующем выражении.
=Ceiling(RowNumber(Nothing)/Parameters!RowsPerPage.Value)
Дополнительные сведения об установке разрывов страниц см. в разделе Добавление разрыва страницы (построитель отчетов и службы SSRS).
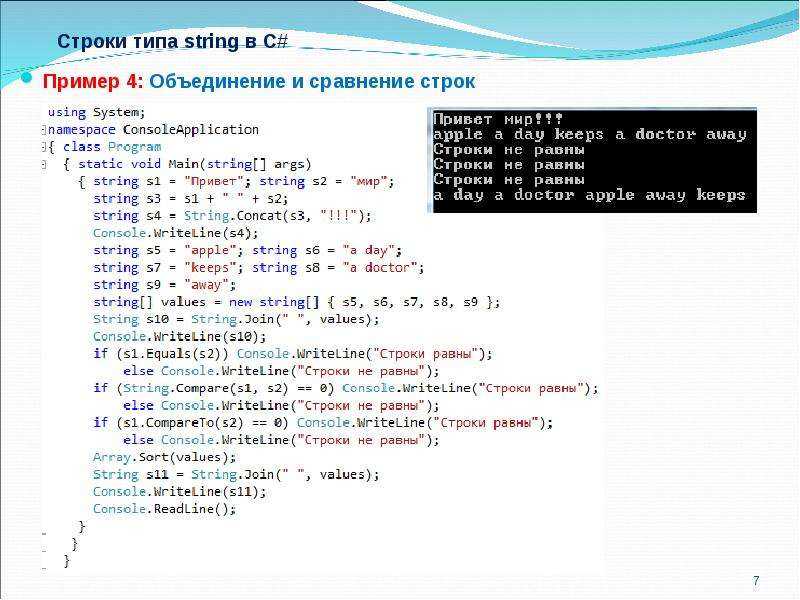
Пример __str__ и __repr__ в Python
Обе эти функции используются при отладке, давайте посмотрим, что произойдет, если мы не определим эти функции для объекта.
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
p = Person('Pankaj', 34)
print(p.__str__())
print(p.__repr__())
Вывод:
<__main__.Person object at 0x10ff22470> <__main__.Person object at 0x10ff22470>
Как видите, реализация по умолчанию бесполезна. Давайте продолжим и реализуем оба этих метода:
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
def __repr__(self):
return {'name':self.name, 'age':self.age}
def __str__(self):
return 'Person(name='+self.name+', age='+str(self.age)+ ')'
Обратите внимание, что мы возвращаем dict для функции __repr__. Посмотрим, что произойдет, если мы воспользуемся этими методами
p = Person('Pankaj', 34)
# __str__() example
print(p)
print(p.__str__())
s = str(p)
print(s)
# __repr__() example
print(p.__repr__())
print(type(p.__repr__()))
print(repr(p))
Вывод:
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
{'name': 'Pankaj', 'age': 34}
<class 'dict'>
File "/Users/pankaj/Documents/PycharmProjects/BasicPython/basic_examples/str_repr_functions.py", line 29, in <module>
print(repr(p))
TypeError: __repr__ returned non-string (type dict)
Обратите внимание, что функция repr() выдает ошибку TypeError, поскольку наша реализация __repr__ возвращает dict, а не строку. Изменим реализацию функции __repr__ следующим образом:
Изменим реализацию функции __repr__ следующим образом:
def __repr__(self):
return '{name:'+self.name+', age:'+str(self.age)+ '}'
Теперь он возвращает String, и новый вывод для вызовов представления объекта будет:
{name:Pankaj, age:34}
<class 'str'>
{name:Pankaj, age:34}
Ранее мы упоминали, что если мы не реализуем функцию __str__, то вызывается функция __repr__. Просто прокомментируйте реализацию функции __str__ из класса Person, и print (p) напечатает {name: Pankaj, age: 34}.
Пример
Например, есть слой с текстом и кнопка при нажатии на которую нужно будет все пробелы в слое удалить.
Во время решения задачи напишем функцию string del_spaces(string string), которая возвращает строку string без пробелов.
Смотреть онлайн пример
<!DOCTYPE HTML><html><head><meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″><title>Удалить все порбелы (JavaScript)</title><script type=”text/javascript”>// Функция удаления пробеловfunction del_spaces(str){ str = str.replace(/s/g, ”); return str;}var lorem = ‘Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmodtempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrudexercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute iruredolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollitanim id est laborum.’;function lorem_del_spaces(){ document.getElementById(‘lorem’).innerHTML = del_spaces(lorem);}</script></head><body><div id=”lorem” style=”width:600px; margin:0 auto;”>Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididuntut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamcolaboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderitin voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecatcupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.</div><div style=”width:600px; margin:20px auto;”><input type=”button” onClick=”lorem_del_spaces()” value=”Удалить пробелы из текста”></div></body></html>
нет оценок
Артём Фёдоров26 февраля 2012
Категории
ПрограммированиеJavaScriptСтроки в JavaScriptСтроки
- Удалить все пробелы (PHP)
- Удалить двойные пробелы (PHP)
- Удалить все теги (PHP)
- str_repeat (JavaScript)
- str_pad (JavaScript)
- Вырезать все кроме цифр (PHP)
- JavaScript md5
- Переменная является строкой (JavaScript)
- Многострочные переменные-строки (JavaScript)
- Первую букву в верхний регистр (JavaScript)
- JavaScript trim
- Как обрезать строку (JavaScript)
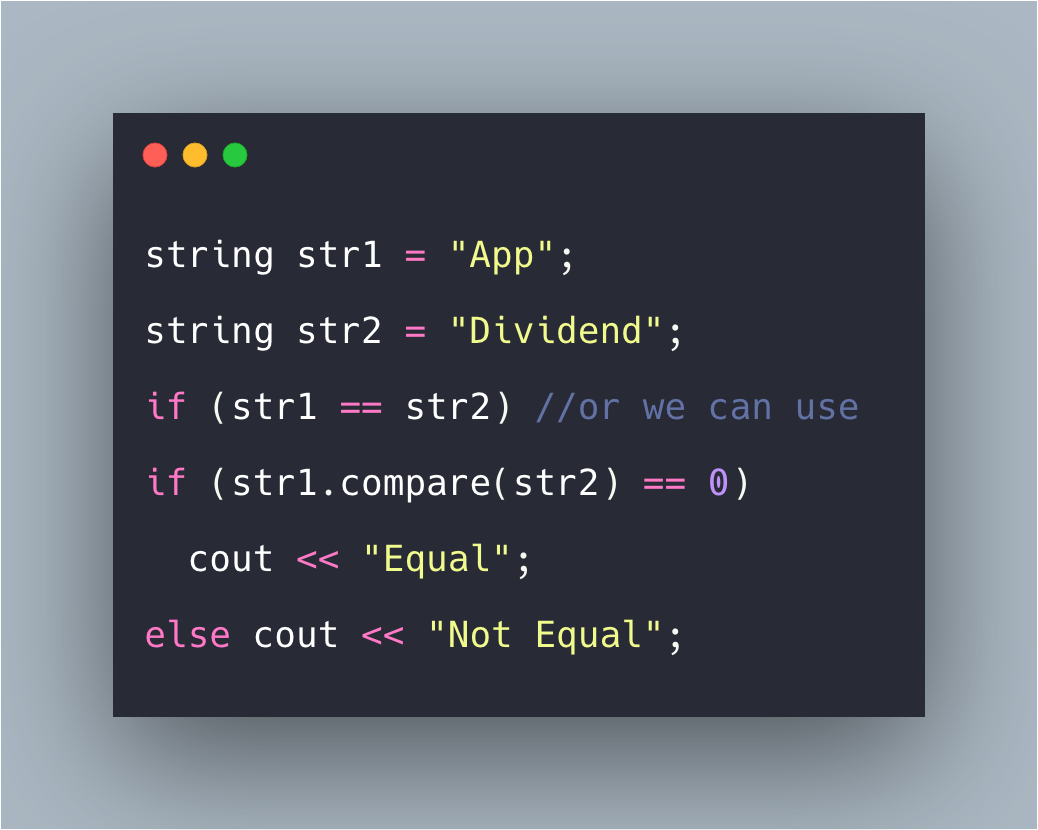
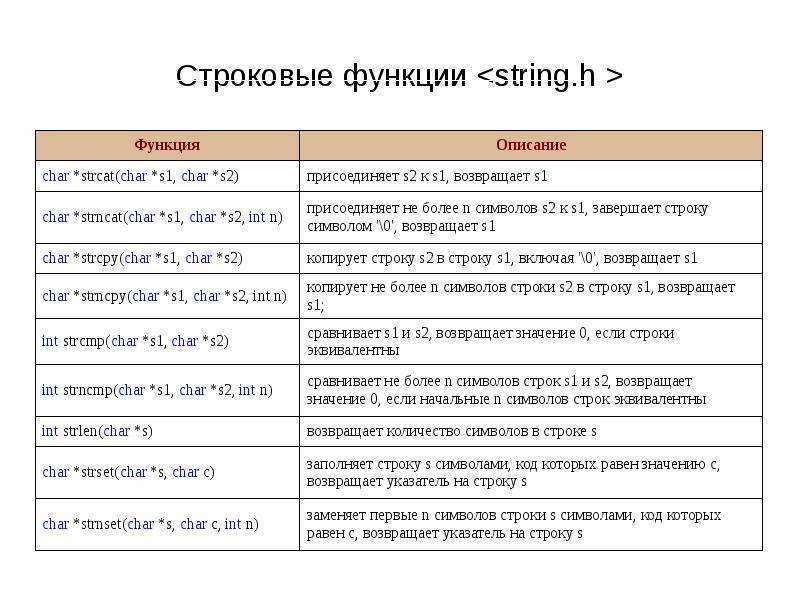
strtok
char* strtok( char* src, const char* seps );
Последовательно разбивает строку src на лексемы
(токены), считая разделителями все символы строки seps.
При каждом вызове возвращается указатель на очередную найденную лексему или NULL, если
достигнут конец строки src. Отметим, что данная функция
модифицирует исходную строку. Пример использования:

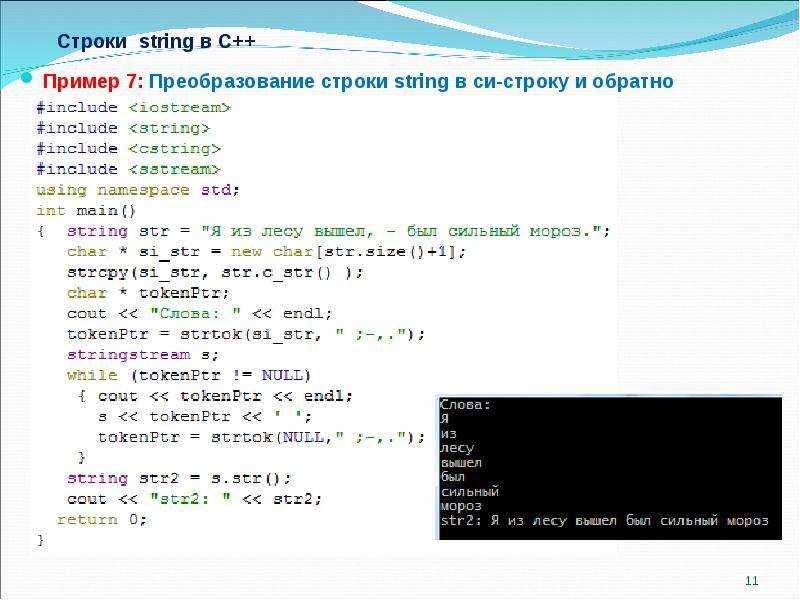




Обратите внимание, что указатель на исходную строку передается только при первом вызове
функции; при последующих вызовах для работы с этой же строкой необходимо в качестве ее
адреса передавать значение NULL. Естественно, что в реальных случаях обработка лексем
выполняется в цикле, завершающемся при достижении конца исходной строки:
Текстовый ввод/вывод
| Заголовочный файл | #include <stdio.h> |
Поскольку нашей основной целью является создание Windows-приложений, взаимодействующих
с пользователем посредством GUI, мы рассмотрим только две функции стандартной библиотеки,
предназначенные для текстового ввода/вывода.
Очистка stringstream для повторного использования
Есть несколько способов очистить буфер stringstream:
Способ №1: Использовать функцию str() с пустой строкой C-style:
#include <iostream>
#include <sstream> // для stringstream
int main()
{
std::stringstream myString;
myString << «Hello «;
myString.str(«»); // очищаем буфер
myString << «World!»;
std::cout << myString.str();
}
|
1 |
#include <iostream> intmain() { std::stringstream myString; myString<<«Hello «; myString.str(«»);// очищаем буфер myString<<«World!»; std::cout<<myString.str(); } |
Способ №2: Использовать функцию str() с пустым объектом std::string:
#include <iostream>
#include <sstream> // для stringstream
int main()
{
std::stringstream myString;
myString << «Hello «;
myString.str(std::string()); // очищаем буфер
myString << «World!»;
std::cout << myString.str();
}
|
1 |
#include <iostream> intmain() { std::stringstream myString; myString<<«Hello «; myString.str(std::string());// очищаем буфер myString<<«World!»; std::cout<<myString.str(); } |
Результат выполнения вышеприведенных программ:
При очистке stringstream неплохой идеей является вызов функции clear():
#include <iostream>
#include <sstream> // для stringstream
int main()
{
std::stringstream myString;
myString << «Hello «;
myString.str(«»); // очищаем буфер
myString.clear(); // сбрасываем все флаги ошибок
myString << «World!»;
std::cout << myString.str();
}
|
1 |
#include <iostream> intmain() { std::stringstream myString; myString<<«Hello «; myString.str(«»);// очищаем буфер myString.clear();// сбрасываем все флаги ошибок myString<<«World!»; std::cout<<myString.str(); } |
Функция clear() сбрасывает все флаги ошибок, которые были ранее установлены, и возвращает поток обратно в его прежнее (без ошибок) состояние. Мы поговорим детально о состояниях потока и флагах ошибок на следующем уроке.
Текстовые файлы в паскале: процедуры работы
Текстовый файл в Паскале — это совокупность строк произвольной длины, которые разделены между собой метками конца строки, а весь файл заканчивается меткой конца файла.
Важно: Если быть точными, то каждая строка текстового файла завершается специальной комбинацией, называемой «конец строки».
Комбинация «конец строки» состоит из двух символов: перевод каретки () и перевод строки (). Завершается текстовый файл символом конец файла ().. Возможные расширения файлов:
*.txt, *.log,
*.htm, *.html
Возможные расширения файлов:
*.txt, *.log,
*.htm, *.html
Метод работы с текстовым файлом в Паскале предусматривает лишь последовательный доступ к каждой строке файла. Это означает, что начинать всегда возможно только с первой строки, затем проходя по каждой строке, дойти постепенно до необходимой. Т.е. можно сказать, что чтение (или запись) из файла (в файл) ведутся байт за байтом от начала к концу.
Предусмотрены два режима работы: режим для записи в файл информации и для чтения ее из файла. Одновременная запись и чтение запрещены.
Открытие файла (классический Pascal)
Допустим, мы в программе описали переменную для работы с текстовым файлом:
var f text; |
Рассмотрим дальнейшую последовательность работы с ним, и рассмотрим процедуры, необходимые для работы с текстовым файлом в Паскале:
Чтение из файла (классический Pascal)
- чтение осуществляется с той позиции, где в данный момент стоит курсор;
- после чтения курсор сдвигается к первому непрочитанному символу.
- Чтение до конца файла: оператор .
- Чтение до конца строки: оператор .
Для возврата в начало файла:
close ( f );
reset ( f ); { начинаем с начала }
|
Запись в текстовый файл (классический Pascal)
Процедуры работы с файлом и закрытие файла
Важно: Таким образом, работа с файлом осуществляется через три основных шага:
- Процедура assign.
- Процедура reset или rewrite.
- Процедура close.
Рассмотрим пример работы с файлами в паскале:
Пример 1: В файле text.txt записаны строки. Вывести первую и третью из них на экран.
(предварительно создать text.txt с тремя строками)
Решение:
| Паскаль | PascalAbc.NET | ||||
|---|---|---|---|---|---|
|
|
Создание строкового объекта
С помощью конструктора создается объект, в который «упакована» текстовая строка. Для создания строкового объекта используется выражение следующего вида:
Здесь имя переменной (val) выполняет роль ссылки на строковый объект. Аргументом (string) конструктору обычно передается текстовое значение (базового типа): любая последовательность Unicode символов, которую необходимо преобразовать в строку.
Однако можно создать строковый объект и с помощью строковых литералов:
Обратите внимание, что JavaScript различает строковые литералы, заданные через кавычки (и называемые «примитивными» строками) от объектов String, созданных с помощью оператора new:
Выполнить код »
Скрыть результаты
Примечание: Интерпретатор JavaScript неявно использует объект String в качестве объекта обертки, поэтому строковой литерал интерпретируется так, как будто был создан с помощью оператора new, так что на строковых примитивах возможно использовать свойства и методы объекта String.
6 ответов
Это?
Пример
Обновление: на основе этого вопроса , это:
является лучшим решением. Он дает тот же результат, но делает это быстрее.







Regex
— это регулярное выражение для «пробела», а — это флаг «global», что означает совпадение с ALL (пробелы).
Отличное объяснение можно найти .
В качестве примечания вы можете заменить содержимое между одинарными кавычками на любое другое, поэтому вы можете заменить пробел любой другой строкой.
Два способа сделать это!
Следующий ответ @rsplak: на самом деле использование пути split /join быстрее, чем использование regexp. См. тестовый пример
Итак,
работает быстрее, чем
Для небольших текстов это не актуально, но для случаев, когда важно время, например, в анализаторах текста, особенно при взаимодействии с пользователями, это важно. С другой стороны, обрабатывает большее количество пробелов
Среди и , также соответствует символу , и именно это включается при получении текста с использованием
С другой стороны, обрабатывает большее количество пробелов. Среди и , также соответствует символу , и именно это включается при получении текста с использованием .
Поэтому я думаю, что здесь можно сделать следующий вывод: если вам нужно только заменить пробелы , используйте split /join. Если в символьном классе могут быть разные символы — используйте
SHORTEST и FASTEST :
Benchmark:
Вот мои результаты — (2018.07.13) MacOs High Sierra 10.13.3 для Chrome 67.0.3396 (64-разрядная версия), Safari 11.0.3 (13604.5.6), Firefox 59.0.2 (64-разрядная версия):
Короткие строки
Короткая строка, похожая на примеры из вопроса OP
Самым быстрым решением для всех браузеров является (regexp1a) — Chrome 17,7M (операция /сек), Safari 10,1M, Firefox 8.8M. Самым медленным для всех браузеров было решение . Измените на или добавьте или для регулярного выражения замедляет обработку.
Длинные строки
Для строки длиной около 3 миллионов символов:
- regexp1a : Safari 50,14 операций в секунду, Firefox 18,57, Chrome 8,95
- regexp2b : Safari 38,39, Firefox 19,45, Chrome 9,26
- split-join : Firefox 26,41, Safari 23,10, Chrome 7,98,
Вы можете запустить его на своем компьютере: https://jsperf.com/remove-string -пространствами /1
Примечание. Хотя вы используете «g» или «gi» для удаления пробелов, оба ведут себя одинаково.
Если мы используем ‘g’ в функции замены, она проверит точное совпадение. но если мы используем ‘gi’, он игнорирует чувствительность к регистру.
7 ответов
этого?
str = str.replace(/s/g, ”);
пример
var str = ‘/var/www/site/Brand new document.docx’;document.write( str.replace(/s/g, ”) );
обновление: на основе этот вопрос это:
str = str.replace(/s+/g, ”);
является лучшим решением. Он дает тот же результат, но делает это быстрее.
Регулярное Выражение
s – это regex для “пробел”, и g является” глобальным ” флагом, что означает match ALL s (пробелы).
многие объяснение + можно найти здесь.
в качестве примечания вы можете заменить содержимое между одинарными кавычками на все, что хотите, чтобы вы могли заменить пробелы любой другой строкой.
var a = b = ” /var/www/site/Brand new document.docx “;console.log( a.split(‘ ‘).join(”) );console.log( b.replace( /s/g, ”) );
два способа сделать это!
следующий ответ @rsplak: на самом деле, использование split/join way быстрее, чем использование regexp. Смотрите представление тест
так
var result = text.split(‘ ‘).join(”)
работает быстрее, чем
var result = text.replace(/s+/g, ”)
на небольших текстах это не актуально, но для случаев, когда важно время, например, в текстовых анализаторах, особенно при взаимодействии с пользователями, это важно. С другой стороны, s+ обрабатывает более широкий спектр символов пространства
Среди с n и t, Он также соответствует u00a0 характер, и это то, что включается при получении текста с помощью textDomNode.nodeValue
С другой стороны, s+ обрабатывает более широкий спектр символов пространства. Среди с n и t, Он также соответствует u00a0 характер, и это то, что включается при получении текста с помощью textDomNode.nodeValue.








поэтому я думаю, что вывод здесь можно сделать следующим образом: если вам нужно только заменить помещения ‘ ‘, используйте split / join. Если могут быть разные символы символ класс – используйте replace(/s+/g, ”)
var input = ‘/var/www/site/Brand new document.docx’;//remove spaceinput = input.replace(/s/g, ”);//make string lowerinput = input.toLowerCase();alert(input);
Нажмите здесь для рабочего примера
вы можете попробовать использовать это:
input.split(‘ ‘).join(”);
var output = ‘/var/www/site/Brand new document.docx’.replace(/ /g, “”); or var output = ‘/var/www/site/Brand new document.docx’.replace(/ /gi,””);
Примечание: хотя вы используете “g” или ” gi ” для удаления пробелов, оба ведут себя одинаково.
Если мы используем ‘g’ в функции replace, он проверит точное соответствие. но если мы используем “gi”, он игнорирует чувствительность к регистру.
для справки нажмите здесь.
Только до конца загрузки
Во время загрузки браузер читает документ и тут же строит из него DOM, по мере получения информации достраивая новые и новые узлы, и тут же отображая их. Этот процесс идёт непрерывным потоком. Вы наверняка видели это, когда заходили на сайты в качестве посетителя – браузер зачастую отображает неполный документ, добавляя его новыми узлами по мере их получения.
Методы и пишут напрямую в текст документа, до того как браузер построит из него DOM, поэтому они могут записать в документ все, что угодно, любые стили и незакрытые теги.
Браузер учтёт их при построении DOM, точно так же, как учитывает очередную порцию HTML-текста.
Технически, вызвать можно в любое время, однако, когда HTML загрузился, и браузер полностью построил DOM, документ становится «закрытым». Попытка дописать что-то в закрытый документ открывает его заново. При этом все текущее содержимое удаляется.
Текущая страница, скорее всего, уже загрузилась, поэтому если вы нажмёте на эту кнопку – её содержимое удалится:
Из-за этой особенности для загруженных документов не используют.
XHTML и
В некоторых современных браузерах при получении страницы с заголовком или включается «XML-режим» чтения документа. Метод при этом не работает.
Это лишь одна из причин, по которой XML-режим обычно не используют.





