
Проверка позиций и зависимостей
Если нужно найти слово рядом с другим, то мы можем это сделать с помощью специальных символов:
- (?=Слово) — поиск слова слева;
- (?<=Слово) — поиск слова справа;
- (?!Слово) — не совпадает со словом слева;
- (?<!Слово) — не совпадает со словом слева.
Для примера мы знаем, что после слова ‘зарплату’ будут идти числа и мы хотим узнать их:
Шаблон выше обозначает:
- (?<=зарплата) — поиск слова справа от ‘зарплата’;
- \s — затем содержится символ пробела;
- \w+ — содержится число или буква один или множество раз;
- \b — слово закачивается.
Аналогичное можно сделать и со словом ‘руб’:
В этом шаблоне:
- \d+ — говорит, что у нас есть число повторяющееся один или более раз;
- \s — после числа следует пробел;
- (?=руб) — после пробела находится слово ‘руб’.
Остальные варианты нужны, когда вам нужно исключить совпадения по определенному значению.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Пример сопоставления нескольких альтернатив.
Следующий пример, который мы рассмотрим, включает использование | шаблон. | шаблон используется как «ИЛИ», чтобы указать несколько альтернатив.
Например:
Oracle PL/SQL
SELECT REGEXP_REPLACE (‘AeroSmith’, ‘a|e|i|o|u’, ‘R’)
FROM dual;
—Результат: ARrRSmRth
|
1 |
SELECTREGEXP_REPLACE(‘AeroSmith’,’a|e|i|o|u’,’R’) FROMdual; |
Этот пример вернет ‘ARrRSmRth’, потому что он ищет первую гласную (a, e, i, o или u) в строке. Поскольку мы не указали значение match_parameter, функция REGEXP_REPLACE будет выполнять поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ не будет сопоставляться.
Мы могли бы изменить наш запрос, чтобы выполнить поиск без учета регистра следующим образом:
Oracle PL/SQL
SELECT REGEXP_REPLACE (‘AeroSmith’, ‘a|e|i|o|u’, ‘R’, 1, 0, ‘i’)
FROM dual;
—Результат: RRrRSmRth
|
1 |
SELECTREGEXP_REPLACE(‘AeroSmith’,’a|e|i|o|u’,’R’,1,0,’i’) FROMdual; |
Теперь, поскольку мы указали match_parameter = ‘i’, запрос заменит ‘A’ в строке. На этот раз ‘A’ в ‘AeroSmith’ сопоставится с шаблоном. Заметим также, что мы указали 5-й параметр как 0, чтобы были заменены все вхождения.
Теперь рассмотри, как вы будете использовать эту функцию со столбцом.
Итак, допустим, у нас есть таблица contact со следующими данными:
| contact_id | last_name |
|---|---|
| 1000 | AeroSmith |
| 2000 | Joy |
| 3000 | Scorpions |
Теперь давайте запустим следующий запрос:
Oracle PL/SQL
SELECT contact_id, last_name, REGEXP_REPLACE (last_name, ‘a|e|i|o|u’, ‘R’, 1, 0, ‘i’) AS «New Name»
FROM contacts;
|
1 |
SELECTcontact_id,last_name,REGEXP_REPLACE(last_name,’a|e|i|o|u’,’R’,1,0,’i’)AS»New Name» FROMcontacts; |
Запрос вернет следующие результаты:
| contact_id | last_name | New Name |
|---|---|---|
| 1000 | AeroSmith | RRrRSmRth |
| 2000 | Joy | JRy |
| 3000 | Scorpions | ScRrpRRns |
Сокращение шаблонов с квантификаторами
В regex есть понятие квантификаторов, который указывает количество повторений символа слева. Квантификаторы помещаются в фигурные скобки {}. В зависимости от ситуации квантификаторы могут работать по разному:
- {1,3} — значение повторяется от 1 до 3 раз;
- {2} — значение слева повторяется два раза;
- {2,} — повторяется минимум 2 раза.
Можно сократить один из шаблонов, который был написан выше до этого:
Обратите внимание, что в следующем сценарии у нас вернутся все значения т.к. во всех них есть 3 цифры:
Кроме квантификаторов вы можете использовать другие метасимволы:
- + эквивалентен {1,} , что значит повторение более одного раза;
- * эквивалентно {0,} , повторение неограниченного количества раз;
- ? тоже что и {0,1} , повторение или отсутствие символа.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.87 от 02.12.2021
3 стартмани
Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста
- удаление пунктуации
- всех символов, кроме букв и цифр
Но бывают случаи, когда необходима реальная замена — например, когда нужно заменить буквы с хвостиками/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:
Диакритические символы и их английские эквиваленты
Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка, она как раз и обозначает любой символ
Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
А так будет выглядеть процесс на практике:
Разбиваем текст на цифры и нецифровые символы (буквы и знаки препинания) с помощью регулярного выражения
Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры:
Эту задачу можно решить также с помощью функции ПОДСТАВИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению. В отличие от обычной процедуры замены, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:
Заменяем первый пробел с помощью замены по регулярному выражению
Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в 2 клика готовой процедурой в меню «Изменить слова«, но можно воспользоваться и несложным выражением для замены:
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое «ИЛИ».
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — «удалить лишние пробелы» или «Удалить символы в начале / конце ячейки«.
Вставка символа после каждого слова с помощью регулярного выражения
Альтернативы¶
Выражения в списке альтернатив разделяются .
Таким образом, будет соответствовать любому из , или (также как и ).
Первое выражение включает в себя все от последнего разделителя шаблона (, или начало шаблона) до первого , а последнее выражение содержит все от последнего к следующему разделителю шаблона.
Звучит сложно, поэтому обычной практикой является заключение списка альтернатив в скобки, чтобы минимизировать путаницу относительно того, где он начинается и заканчивается.
Выражения в списке альтернатив пробуются слева направо, принимается первое же совпадение.
Например, регулярное выражение в строке будет соответствовать — первое же совпадение.
Также помните, что в квадратных скобках воспринимается просто как символ, поэтому, если вы напишите , это тоже самое что .
Свойства объектов Match и Matches Collection
Метод Execute объекта RegExp возвращает агрегатный объект Matches Collection, который содержит коллекцию объектов Match, представляющих все совпадения, найденные механизмом регулярных выражений, в том порядке, в котором они присутствуют в исходной строке. Если совпадений нет, метод возвращает объект Matches Collection без членов.
Свойства объекта Matches Collection
| Свойство | Описание |
|---|---|
| Count | Количество объектов Match, содержащихся в объекте Matches Collection |
| Item | Индекс члена коллекции от нуля до значения свойства Count минус 1 |
Свойства объекта Matches Collection доступны только для чтения.
Свойства объекта Match
| Свойство | Описание |
|---|---|
| FirstIndex | Позиция в исходной строке, где произошло совпадение, причем первая позиция в строке равна нулю |
| Length | Длина совпавшей подстроки |
| Value | Найденная подстрока (является свойством по умолчанию) |
Свойства объекта Match доступны только для чтения.
Примеры
В следующем примере регулярное выражение включает флаги для глобального поиска и игнорирования регистра, которые позволяют методу заменить все вхождения слова «яблоки» в строке на слово «апельсины».
В следующем примере в метод передаётся регулярное выражение вместе с флагом игнорирования регистра.
Пример выведет строку ‘Twas the night before Christmas…’
Следующий скрипт меняет местами слова в строке. В качестве текста замены он использует шаблоны замены и .
Пример выведет строку ‘Смит, Джон’.
В этом примере все входящие в строку (латинские) буквы в верхнем регистре преобразуются в нижний регистр, а перед самой буквой вставляется дефис
Здесь важно то, что прежде чем элемент вставится в качестве замены, над ним нужно провести дополнительные преобразования
Функция замены своим параметром принимает сопоставившийся кусок и перед возвратом использует его для преобразования регистра и соединения с дефисом.
Вызов вернёт строку ‘border-top’.
Поскольку мы хотим провести дополнительные преобразования результата сопоставления до того, как будет использована окончательная подстановка, мы должны использовать функцию. Это заставляет нас принудительно вычислить сопоставление перед использование метода . Если бы мы попытались использовать сопоставление без функции, метод не сработал бы.
Происходит это потому, что сначала часть вычисляется в строковый литерал (результат по-прежнему равен ), а только потом его символы используются в качестве шаблона.
В следующем примере градусы по Фаренгейту заменяются на эквивалентные градусы по Цельсию. Градусы по Фаренгейту должны быть числом, оканчивающимся на букву F. Функция возвращает количество градусов по Цельсию, оканчивающиеся на букву C. Например, если входное число равняется 212F, функция вернёт 100C. Если число равняется 0F, функция вернёт -17.77777777777778C.
Регулярное выражение сопоставляется с любым числом, оканчивающимся на букву F. Количество градусов по Фаренгейту передаётся в функцию через её второй параметр, . Функция переводит градусы по Фаренгейту, переданные в виде строки в функцию code>f2c(), в градусы по Цельсию. Затем функция возвращает количество градусов по Цельсию. Эта функция работает примерно так же, как и флаг в Perl.
Следующий пример принимает строку шаблона и преобразует её в массив объектов.
Входные данные:
Строка, состоящая из символов , и
x-x_ x---x---x---x--- x-xxx-xx-x- x_x_x___x___x___
Выходные данные:
Массив объектов. Символ означает состояние , символ (дефис) означает состояние , а символ (нижнее подчёркивание) означает продолжительность состояния .
Код:
Этот код сгенерирует массив из трёх объектов в описанном формате без использования цикла .
Метод str.replace(reg, str|func)
А это своего рода швейцарский нож для работы со строками, для поиска и замены строки любого уровня сложности.
Его самое простейшее применение – поиск и замена подстроки в строке, вот так:
// заменить дефис на двоеточие
alert('22-54-66'.replace("-", ":")) // 22:54:66
При вызове без флага g со строкой замены replace всегда заменяет только первое совпадение.
Если вы хотите заменить все совпадения, то следует использовать для поиска не строку «-«, а регулярку /-/g, причём именно обязательно с флагом g:
// заменим дефис на двоеточие alert( '22-54-66'.replace( /-/g, ":" ) ) // 22:54:66
В строке для замены также можно использовать и специальные символы:
| Спецсимволы | Действие в строке замены |
|---|---|
| $$ | Вставит «$». |
| $& | Вставит всё найденное совпадение. |
| $` | Вставит часть строки до совпадения. |
| $’ | Вставит часть строки после совпадения. |
| $*n* | где n — двузначное число, которое обозначает n-ю по счёту скобку, если считать слева-направо. |
Вот пример использования скобок и $1, $2:
var str = "Василий Чапаев"; alert(str.replace(/(Василий) (Чапаев)/, '$2, $1')) // Чапаев, Василий
Ещё один пример, с использованием $&:
var str = "Василий Чапаев"; alert(str.replace(/Василий Чапаев/, 'Великий $&!')) // Великий Василий Чапаев!
А вот для ситуаций, которые требуют «умной» замены, в качестве 2-го аргумента предусмотрена функция.
Она будет вызвана для совпадений, и её результат будет вставлен в качестве замены.
Например:
let i = 0;
// заменить каждое вхождение "ой" на результат вызова функции
alert("АЙ-Ай-ай".replace(/ай/gi, function() {
return ++i;
})); // 1-2-3
В примере функция просто возвратила числа по очереди, но как правило она основывается на поиске.
Эта функция получает следующие аргументы:
- str – совпадение,
- p1, p2, …, pn – содержимое скобок,
- offset – позиция, на которой было найдено совпадение,
- s – исходная строка.
Если скобок в регулярном выражении нет, то у функции всегда будет ровно три аргумента: replacer(str, offset, s).
Давайте используем это, чтобы вывести полную информацию о совпадениях:
// вывести и заменить все совпадения
function replacer(str, offset, s) {
alert( "Найдено: " + str + " на такой позиции: " + offset + " в строке: " + s );
return str.toLowerCase();
}
var result = "АЙ-Ай-ай".replace(/ай/gi, replacer);
alert( 'Результат: ' + result ); // Результат: ай-ай-ай
А если с двумя скобочными выражениями – аргументов уже пять:
function replacer(str, name, surname, offset, s) {
return surname + ", " + name;
}
var str = "Василий Чапаев";
alert(str.replace(/(Василий) (Чапаев)/, replacer)) // Пупкин, Василий
Функция – это есть самый мощный инструмент для замены.
Создание объекта RegExp
Ранняя привязка
Обычно рекомендуется использовать объекты с ранней привязкой, так как у них выше быстродействие, а также при написании и редактировании кода доступны подсказки в виде листа свойств-методов, появляющегося автоматически или вызываемого, при необходимости, сочетанием клавиш Ctrl+Пробел.
Раннее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, уже объявленной, как переменная определенного типа (в нашем случае, как RegExp).
Для осуществления ранней привязки необходимо подключить к проекту VBA ссылку на библиотеку «Microsoft VBScript Regular Expression», для чего в редакторе VBA выбираем Tools — References…
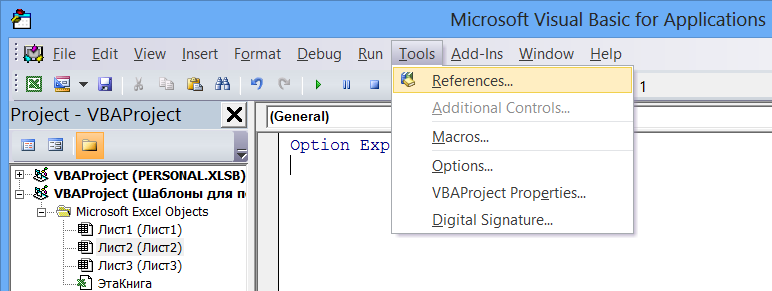
В открывшемся окне «References» находим строку «Microsoft VBScript Regular Expression 5.5» (если у вас ее нет, то строку «Microsoft VBScript Regular Expression 1.0»), отмечаем ее галочкой и нажимаем «ОК».
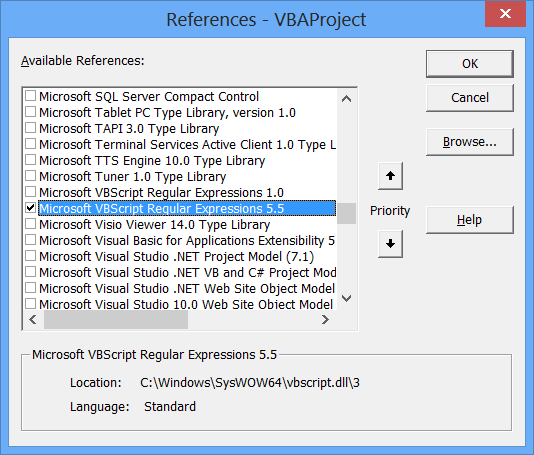
Готово — ссылка добавлена.
Создание объекта RegExp с ранней привязкой:
|
1 |
‘Вариант 1 DimmyRegExp AsRegExp SetmyRegExp=NewRegExp ‘————————- DimmyRegExp AsNewRegExp |
Поздняя привязка
Позднее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, объявленной как Object, с помощью функции CreateObject.
Создание объекта RegExp с поздней привязкой:
|
1 |
DimmyRegExp AsObject SetmyRegExp=CreateObject(«VBScript.RegExp») |
Поиск совпадения
Функция используется для поиска совпадений шаблона в строке. Общий синтаксис :
REGEXP_INSTR (исходная_строка, шаблон ]]]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; номер — порядковый номер совпадения (1 = первое, 2 = второе и т. д.); флаг_возвращаемого_значения — 0 для начальной позиции или 1 для конечной позиции совпадения; модификаторы — один или несколько модификаторов, управляющих процессом поиска (например, i для поиска без учета регистра). Начиная с Oracle11g, также можно задать параметр подвыражение (1 = первое, 2 = второе и т. д.), чтобы функция возвращала начальную позицию заданного подвыражения (части шаблона, заключенной в круглые скобки).
Например, чтобы найти первое вхождение имени, начинающегося с буквы A и завершающегося согласной буквой, можно использовать следующее выражение:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; names_adjusted VARCHAR2(61); comma_delimited BOOLEAN; j_location NUMBER; BEGIN -- Поиск по шаблону comma_delimited := REGEXP_LIKE(names,'^(*,)+(*)$', 'i'); -- Продолжить, только если действительно был обнаружен список, -- разделенный запятыми. IF comma_delimited THEN j_location := REGEXP_INSTR(names, 'A*,|A*$'); DBMS_OUTPUT.PUT_LINE( J_location); END IF; END;
При выполнении этого фрагмента выясняется, что имя на букву A, завершающееся согласной (Andrew), начинается в позиции 22. А вот как проходило построение шаблона:
- Совпадение начинается с буквы A. Беспокоиться о запятых не нужно — на этой стадии мы уже знаем, что работаем со списком, разделенным запятыми.
- За буквой A следует некоторое количество букв или пробелов. Квантификатор * указывает, что за буквой A следует ноль или более таких символов.
- В выражение включается компонент [], чтобы имя могло заканчиваться любым символом, кроме гласной. Знак ^ инвертирует содержимое квадратных скобок —совпадает любой символ, кроме гласной буквы. Так как квантификатор не указан, требуется присутствие ровно одного такого символа.
- Совпадение должно завершаться запятой; в противном случае шаблон найдет совпадение для подстроки «An» в имени «Anna». Хотя добавление запятой решает эту проблему, тут же возникает другая: шаблон не найдет совпадение для имени «Aaron» в конце строки.
- В выражении появляется вертикальная черта (|), обозначение альтернативы: общее совпадение находится при совпадении любого из вариантов. Первый вариант завершается запятой, второй — нет. Второй вариант учитывает возможность того, что текущее имя стоит на последнем месте в списке, поэтому он привязывается к концу строки метасимволом .
Регулярные выражения — далеко не простая тема! Новички часто сталкиваются с нюансами обработки регулярных выражений, которые часто преподносят неприятные сюрпризы. Я потратил некоторое время на работу над этим примером и несколько раз зашел в тупик, прежде чем выйти на правильный путь. Не отчаивайтесь — с опытом писать регулярные выражения становится проще.
Функция приносит пользу в некоторых ситуациях, но обычно нас больше интересует текст совпадения, а не информация о его положении в строке.
get RegExp.prototype.flags
— это , функция которого не определена (является undefined). Его функция доступа get выполняет следующие шаги:
1. Пусть R будет значением this. 2. Если Тип (R) не является Объектом, выбросить исключение TypeError. 3. Пусть результатом result будет пустая Строка. 4. Пусть global будет ! (? (R, "global")). 5. Если global является true (истинно), добавьте кодовую единицу 0x0067 (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G) в качестве последней кодовой единицы результата result. 6. Пусть ignoreCase будет ! (? (R, "ignoreCase")). 7. Если ignoreCase является true (истинно), добавьте кодовую единицу 0x0069 (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I) в качестве последней единицы кода результата result. 8. Пусть multiline будет ! (? (R, "multiline")). 9. Если multiline является true (истинно), добавьте кодовую единицу 0x006D (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M) как последняя кодовая единица результата result. 10. Пусть dotAll будет ! (? (R, "dotAll")). 11. Если dotAll является true (истинно), добавьте кодовую единицу 0x0073 (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S) в качестве последней единицы кода результата result. 12. Да unicode будет ! (? (R, "unicode")). 13. Если unicode является true (истинно), добавьте кодовую единицу 0x0075 (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U) в качестве последней единицы кода результата result. 14. Пусть sticky будет ! (? (R, "sticky")). 15. Если sticky является true (истинно), добавьте кодовую единицу 0x0079 (СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y) в качестве последней единицы кода результата result. 16. Вернуть результат result.